POAR: Towards Open Vocabulary Pedestrian Attribute Recognition
Abstract.
Pedestrian attribute recognition (PAR) aims to predict the attributes of a target pedestrian. Recent methods often address the PAR problem by training a multi-label classifier with predefined attribute classes, but they can hardly exhaust all possible pedestrian attributes in the real world. To tackle this problem, we propose a novel Pedestrian Open-Attribute Recognition (POAR) approach by formulating the problem as a task of image-text search. Our approach employs a Transformer-based Encoder with a Masking Strategy (TEMS) to focus on the attributes of specific pedestrian parts (e.g., head, upper body, lower body, feet, etc.), and introduces a set of attribute tokens to encode the corresponding attributes into visual embeddings. Each attribute category is described as a natural language sentence and encoded by the text encoder. Then, we compute the similarity between the visual and text embeddings to find the best attribute descriptions for the input images. To handle multiple attributes of a single pedestrian, we propose a Many-To-Many Contrastive (MTMC) loss with masked tokens. In addition, we propose a Grouped Knowledge Distillation (GKD) method to minimize the disparity between visual embeddings and unseen attribute text embeddings. We evaluate our proposed method on three PAR datasets with an open-attribute setting. The results demonstrate the effectiveness of our method as a strong baseline for the POAR task. Our code is available at https://github.com/IvyYZ/POAR.
1. Introduction
Pedestrian attribute recognition (PAR) aims to predict attributes of a target pedestrian, such as gender, age, clothing, accessories, etc. Due to the increasing importance of person search (Zhang et al., 2020; He et al., 2021; Zhang et al., 2022) and scene understanding (Wang et al., 2022a; Chang et al., 2021) in many applications, PAR has emerged as an active research topic in the field of computer vision. Existing methods such as global-local methods (Tang et al., 2019; Guo et al., 2022; Liu et al., 2018), attention methods (Liu et al., 2017, 2018), textual semantic correlations methods (Cheng et al., 2022; Li et al., 2022) address the PAR problem by training a multi-label classifier within a predetermined attribute space. Thus they cannot recognize attributes beyond the predefined classes, such as “cotton” and “long coat” shown in Figure 1. In this work, we explore how to handle new attributes in an open world and examine a new Pedestrian Open-Attribute Recognition (POAR) problem.

Recently, Radford et al. (Radford et al., 2021) proposed a Contrastive Language-Image Pre-training (CLIP) method to model the similarity relationship between images and raw text. CLIP is trained in a task-agnostic setting and can be used to recognize general objects, such as airplane, bird, ocean, and so on. However, it is not yet generalizable on more fine-grained attributes, such as “upper stride”, “lower stripe”, “lower jeans”, in PAR task. For PAR, the challenge is that a pedestrian may have multiple attributes but there are no corresponding location and scale information in the ground truth label set. To address this challenge, part-based (Zhu et al., 2015) and attention-based (Tang et al., 2019) methods have been proposed to localize attributes and learn the attribute-specific features. However, these methods ignore the regional label conflicts, e.g., “long sleeve” and “short sleeve”. Zhao et al. (Zhao et al., 2018) proposed a grouping attribute recognition method by dividing all labels into different groups and localizing regions corresponding to each group attribute based on the detection algorithm. However, the detection algorithm is attribute sensitive. Similarly, we divide the whole attribute classes into multiple groups, and each group corresponds to one visual region, as shown in Figure 1. But contrastingly, we propose a Masking the Irrelevant Patches (MIP) strategy to eliminate insignificant image patches. The appearance of pedestrians can be divided into fixed groups, with certain parts of each group requiring no attention. The proposed strategy does not compromise the ability to identify unseen classes, and it enables accurate localization of regions for improved identification.
Different from the general PAR task that recognizes only the seen attributes in the training set, our POAR task expands beyond the seen attributes to allow new pedestrian attributes based on the application’s needs. To address this challenge, we formulate the POAR problem as an image-text search task, which is trained in a downstream attribute-agnostic manner under the supervision of natural language. Different from CLIP, one image or object has only one class name; our method can use multiple attributes to describe one person in the POAR task. Using Figure 1 as an example, “male and long coat ” are used to describe the pedestrian. To address this problem, we propose multiple attribute tokens ([ATT]) with a masked encoding method in the image encoding step. As shown in Figure 1, we divide the attributes into multiple groups, and each group is encoded with an attribute token. The masking mechanism is introduced to ensure the attribute tokens are independent from one another. The original image is encoded with multiple attribute tokens corresponding to multiple groups. Based on the masking strategy and the many-to-many property, we propose a Many-To-Many Contrastive (MTMC) loss with masked tokens to guide the update of the network parameter.
We propose an end-to-end, Transformer-based Encoder with a Masking Strategy (TEMS) model. During training, we extract visual and text embeddings using the corresponding encoders. The similarity matrix of image-text pairs in a mini-batch is calculated based on these embeddings. Then, the proposed MTMC loss is used to guide the learning of the model. During testing, attribute tokens of unseen attributes such as “cotton” and “long coat” in Figure 1 can be localized based on our MIP strategy. Then, the visual embeddings of unseen attributes are extracted from the localized regions. Meanwhile, text embeddings of these attributes can be extracted using the text encoder. Finally, the attributes of a pedestrian can be recognized based on the similarities of the visual and text embeddings. Considering the potential misalignment between image embeddings and text embeddings of unseen classes, we propose a Grouped Knowledge Distillation (GKD) method by using CLIP model as a teacher network to guide the learning of the embedding space and improve the performance of the proposed TEMS model.
Our contributions can be summarized as follows:
-
•
We formulate the problem of pedestrian open-attribute recognition (POAR) and develop an effective TEMS method as a strong baseline to address it. To the best of our knowledge, this is the first approach to address the POAR problem.
-
•
We propose an effective masking mechanism to address the localization and encoding of multiple attributes in the TEMS model. Furthermore, we devise a many-to-many contrastive loss with masked tokens to train the network.
-
•
We propose a grouped knowledge distillation (GKD) method to minimize the disparity between visual embeddings and unseen attribute text embeddings, so that it can be scaled to address more unseen attributes.
-
•
We evaluate our proposed TEMS method on benchmark datasets with an open-attribute setting, and demonstrate its effectiveness as a strong baseline.
2. Related Work

2.1. Pedestrian Attribute Recognition
Pedestrian attribute recognition (PAR) has received much interest in person recognition (Cao et al., 2018; Hand and Chellappa, 2017; Jia et al., 2021; Liu et al., 2016; Ding et al., 2021; Wang et al., 2022b) and scene understanding (Jia et al., 2021; Liu et al., 2016; Ding et al., 2021). The mainstream methods address this problem by building a multi-label classifier based on CNN. To improve the recognition accuracy, global methods (Li et al., 2015; Liu et al., 2017), local methods (Sarafianos et al., 2018), global-local methods (Sarfraz et al., 2017), attention-based methods (Guo et al., 2022; Liu et al., 2022; Lu et al., 2023), sequential prediction methods (He et al., 2017; Yang et al., 2020), curriculum learning methods (Zhao et al., 2019), Graphic model methods (Tan et al., 2020; Fan et al., 2022), and group based methods (Zhao et al., 2018; Jia et al., 2022) have been proposed. Nikolaos et al. (Sarafianos et al., 2018) proposed an effective method to extract and aggregate visual attention masks across different scales. Tang et al. (Tang et al., 2019) proposed a flexible attribute localization module to learn attribute-specific regional features. These methods focused on domain-specific model designing. To use additional domain-specific guidance, M. Kalayeh et al. (Kalayeh et al., 2017) used semantic segmentation methods to learn attention maps for accurate attribute prediction. Liu et al. (Liu et al., 2016) learned clothing attributes with additional landmark labels. Yang et al. (Yang et al., 2021) proposed a cascaded split-and-aggregate learning to capture both the individuality and commonality for all attributes. Li et al. (Li et al., 2022) proposed an image-conditioned masked language model to learn complex sample-level attribute correlations from the perspective of language modeling. Tang et al. (Tang and Huang, 2022) and Weng et al. (Weng et al., 2023) employed ViT as a feature extractor for its nature of modeling long-range relations of regions. Cheng et al. (Cheng et al., 2022) proposed an additional textual modality to explore the textual semantic correlations from attribute annotations. These methods are trained on a predefined attribute set and used to recognize the same attributes, which limits the attribute capacity of these models. In our work, we build a TEMS model based on the CLIP (Radford et al., 2021) model to recognize pedestrian open-attributes.
2.2. Open-Attributes Recognition
In classification, open-world recognition (OWR) is first proposed by Scheirer (Scheirer et al., 2013), which aims to discriminate known from unknown samples as well as classify known ones. Later, prototype-based method (Saranrittichai et al., 2022; Vaze et al., 2022), knowledge distillation method (Gu et al., 2021), and out of distribution detection method (Esmaeilpour et al., 2022) become popular in image classification and object detection. Definitions and solutions for open-world recognition also differ based on the specific applications. Esmaeilpour et al. (Esmaeilpour et al., 2022) used an extended model to generate candidate unknown class names for each test sample and compute a confidence score based on both the known class names and candidate unknown class names for zero-shot out-of-distribution detection. Oza et al. (Oza and Patel, 2019) proposed the class conditional auto-encoder to tackle open-set recognition, which includes closed-set training and open-set training stages. Gu et al. (Gu et al., 2021) adopted an image-text pre-trained model as a teacher model to supervise student detectors. Zhao et al. (Zhao et al., 2020) unified the label space from the training of multiple datasets to improve the generalization ability of a model. In addition, some methods (Li et al., 2019; Rahman et al., 2020) aligned region features and the pre-trained text embeddings in base categories to realize zero-shot detection. Dan et al. (Dan et al., 2022) enhanced class understanding via prompt-tuning for zero-shot text classification. Du et al. (Du et al., 2022) proposed a detection prompt, to learn continuous prompt representations for open-vocabulary object detection. The CLIP model was proposed by Radford et al. (Radford et al., 2021), which performs task-agnostic training via natural language prompting. CLIP can realize zero-shot image recognition. However, CLIP is usually used to recognize general objects, such as airplane, bird, ocean, and so on. For fine-grained attributes recognition, CLIP will fall short in these situations. Our work addresses the pedestrian open-attribute recognition task by identifying both classes, seen and unseen classes, simultaneously.
3. Method
3.1. Pedestrian Open-Attribute Recognition
| ATTRIBUTES | KEY | PROMPT |
|---|---|---|
| Long, Short | Hair | This person has hair. |
| Male, Female | Gender | This person is . |
| Less15, Less30, Less45, Less60, Larger60 | Age | The age of this person is years old. |
| Backpack, MessengerBag, PlasticBags, Other, Nothing | Carry | This person is carrying . |
| Sunglasses, Hat, Muffler, Nothing | Accessory | This person is accessory . |
| LeatherShoes, Sandals, Sneaker, Shoes | Foot | This person is wearing in foot. |
| Casual, Formal, Jacket, Logo, ShortSleeve, Plaid, Stripe, Tshirt, VNeck, Other | Upperbody | This person is wearing in upper body. |
| Casual, Formal, Trousers, ShortSkirt, Shorts, Plaid, Jeans | Lowerbody | This person is wearing in lower body. |
Pedestrian attribute recognition aims to recognize the fine-grained attributes of a pedestrian (e.g., hairstyle, age, gender, etc.) from the given image. The conventional PAR usually predetermines a set of pedestrian attributes and follows the close-set assumption during the training and test phases. Suppose there are predetermined pedestrian attributes , e.g., “long hair”, “short hair”, etc. Then, given a labeled pedestrian dataset , where each image is annotated with a subset of the existing pedestrian attributes. The main objective of PAR is to learn a model to answer which pedestrian attributes from appear in a given image .
Existing approaches (Tang et al., 2019; Guo et al., 2022; Cheng et al., 2022) usually convert this to a multi-label classification problem. However, the pedestrian attributes in the real world are potentially unlimited. It is difficult to exhaust all the attributes in a predetermined set and collect the corresponding pedestrian images. Unseen attributes are highly possible to exist in real world applications, while existing classification-based methods (Cheng et al., 2022; Li et al., 2022) are inherently incapable of handling such cases. To address this limitation, we formulate a pedestrian open-attribute recognition problem in this work. Let denote a set of extra attributes that are also of interest in the test phase but not included in the predetermined attribute set . In POAR, we expect that the model can recognize not only the seen attributes from but also the unseen attributes from .
3.2. Framework
Overview. As illustrated in Figure 2, the proposed Transformer-based encoder with a masking strategy (TEMS) framework consists of an image encoder and a text encoder . The image encoder processes the input images and derives the visual representation of various pedestrian attributes. Besides, we construct a set of text descriptions (e.g., “this person has long hair.”, “this person is carrying backpack.”, etc, and utilize the text encoder of CLIP to encode these attribute descriptions into text embeddings. Then, we compute the vision-text similarity to find the best-matched pedestrian attributes for the input images. Different from the original CLIP, we assume one pedestrian may have more than one associated attribute, as shown in Figure 3. To train our model, we propose a many-to-many contrastive (MTMC) loss with masked tokens to handle the many-to-many relationships between the images and text descriptions. The details of each part are described below.
Image Encoding. The image encoding process is organized based on token prediction with Transformer. First, the input image is split into a sequence of non-overlapping small patches {, , , }, where and . Then, each patch ([PAT]) is projected into the embedding space as a vector , where denotes the feature dimension. Thus, we can obtain with patch embeddings. Inspired by (Dosovitskiy et al., 2020; Radford et al., 2021), we introduce learnable attribute tokens , where each attribute token shares the same dimension as . For each patch embedding and each class token, we generate a corresponding position encoding , where . The input of the image encoder is the concatenation of class tokens and patch embeddings combined with their positional embeddings , which is denoted as , where , is the concatenate operation, and denotes the element-wise summation notation. The output of the image encoder is the learned embeddings of class tokens, denoted as . The above process can be summarized as follows:
| (1) |
Text Encoding. The text encoding is performed by using the text encoder transferred from the CLIP model. The input of the text encoder is the prompts of pedestrian attributes which are organized as follows. First, the attributes are divided into groups based on the characteristics of pedestrians, as shown in Table 1. Then, we form a prompt template for the attributes of each group. Finally, each prompt sentence in Table 1 is tokenized into an embedding using the Byte-Pair-Encoding method111https://huggingface.co/transformers/v4.8.0/model_doc/clip.html. Suppose that the maximum number of words in any of these sentences is . Then, each sentence is tokenized into a vector . For the -th group, we can obtain sentence vectors corresponding to the prompts in this group, denoted as . The output of the text encoder is the learned text embeddings for the prompts of the -th group. The above process can be defined as:
| (2) |
where .
Many-to-Many Contrastive Loss.

For a mini-batch images , we first extract their token embeddings and text embeddings using (1) and (2), respectively. and are sets of token embeddings and text embeddings in all attribute groups related to the given mini-batch images, respectively. Different from the CLIP model, which has a one-to-one relationship between image and text. In the TEMS model, the image and text are involved in a many-to-many relationship, as shown in Figure 3. To effectively tackle this scenario, a loss function combined with visual-to-text and text-to-visual contrastive learning is proposed. The visual-to-text contrastive learning term is defined as follows:
| (3) |
where is a temperature parameter, is the number of positive text embeddings that have the same attribute label with . and are the total numbers of token embeddings and text embeddings, respectively. , , . and are a positive pair share the same attribute label. Similarly, the text-to-visual contrastive learning term is defined as follows:
| (4) |
where is the number of positive token embeddings that have the same attribute label with . The final loss function is the combination of (3) and (4), defined as:
| (5) |
3.3. Encoder Networks and Masking Strategy
Image Encoder. The image encoder is a stack of multiple Transformer blocks. Each Transformer block is composed of layer norm (LN) layers (Dosovitskiy et al., 2020), a multi-head self-attention (MSA) layer (Dosovitskiy et al., 2020), and a multi-layer perceptron (MLP) network. In the multi-head self-attention layer, the attention weights of each attribute token are automatically calculated among all input tokens. Specifically, the attention weights between the -th attribute token and the others can be computed as
| (6) |
We observe that the first term often dominates the attention, making the module hardly find the true regions of interest from the input image. This shortcut learning often leads to overfitting and inferior results in our experiments. To address this issue, we mask out the self-attentions between the attribute tokens. This allows useful visual information to be extracted from the input image rather than simply relying on the information that has been extracted by the others. Specifically, we calculate the attention weight of the -th attribute token as
| (7) |
In our experiments, we observe that this technique leads to significant performance gain (Table 7).
In the PAR task, one key challenge is that a pedestrian can have multiple attributes, and there is no corresponding location and scale information in the ground truth label set. We propose to mask the irrelevant patches (MIP) to tackle this challenge. Specifically, we divide the whole attribute classes into multiple groups, and each group ([ATT] token) corresponds to one visual region. Then we mask out regions ([PAT] token) that do not need to pay attention to. For example, the “hair” class token pays more attention to the head of the pedestrian, and we block out regions on the lower part of the head region; similarly, the “upper body” class token pays more attention to the top part of the image, and we block out the bottom part of the image, etc. Thus, the final attention can thus be calculated as follows
| (8) |
where is a mask vector with value for the blocked image patches and otherwise. Taking the “hair” class token, for example, the region of the head will be , and the remaining regions will be . The output of the self-attention unit is as follows:
| (9) |
where is the layer index of the self-attention, , . The whole process of a Transformer block can be formulated as:
| (10) |
| (11) |
Contrastive Learning with Masked Tokens. It should be noted that our contrastive loss is computed based on all the token embeddings and attribute embeddings. The embeddings of those masked tokens are also used to compute the loss. This is because the contrastive loss computed with the masked embeddings will lead to more robust embedding learning.
3.4. Open-Attribute Recognition

The knowledge distillation allows for the transfer of knowledge from a complex teacher model to a simpler student model, albeit a slight decrease in performance. The previous paper underscored CLIP’s impressive generalization capabilities. Nevertheless, its accuracy in certain tasks, such as pedestrian attribute recognition, leaves room for improvement. To address this, we propose the grouped knowledge distillation (GKD) method, as shown in Figure 4, which leverages the CLIP model as a teacher model and distills its extensive knowledge into our pedestrian attribute model during training. The objective function is defined as:
| (12) |
The Kullback-Leibler (KL) divergence is computed by each visual token embedding of the student network and the visual embedding of the teacher network. These loss functions introduce a non-linear transformation to the input data, which helps to capture more complex and abstract features of the data. The CLIP model has strong generalization performance and can be used as a teacher network to guide the learning of embedding space, reducing semantic disparities between the image embedding features and the unseen text features, and thereby improving the performance of the TEMS model.
4. Experiments
| Method | Source Domain | Target Domain | |||||
|---|---|---|---|---|---|---|---|
| PETA | PA100K | RAPv1 | |||||
| R@1 | R@2 | R@1 | R@2 | R@1 | R@2 | ||
| CLIP* | – | 50.2 | 75.7 | 43.4 | 65.9 | 33.6 | 56.5 |
| VTB* | PA100K | 31.4 | 62.2 | 26.9 | 62.2 | 24.2 | 50.7 |
| TEMS | PETA | 87.6 | 96.0 | 45.1 | 73.5 | 42.2 | 68.6 |
| TEMS+CLIP | – | – | 44.7 | 74.7 | 42.1 | 69.7 | |
| TEMS (GKD) | 86.5 | 95.7 | 51.9 | 78.5 | 46.2 | 71.2 | |
| TEMS | PA100K | 42.3 | 76.2 | 83.3 | 92.6 | 39.4 | 63.6 |
| TEMS+CLIP | 50.9 | 77.5 | – | – | 39.4 | 64.5 | |
| TEMS (GKD) | 50.8 | 81.4 | 81.3 | 92.8 | 44.1 | 63.7 | |
| TEMS | RAPv1 | 48.8 | 75.0 | 45.1 | 73.1 | 80.6 | 94.4 |
| TEMS+CLIP | 52.9 | 78.8 | 45.5 | 67.2 | – | – | |
| TEMS (GKD) | 55.0 | 76.3 | 50.3 | 74.7 | 77.5 | 92.3 | |
| Source Domain | Target Domain | |||||
|---|---|---|---|---|---|---|
| PETA | PA100K | RAPv1 | ||||
| SN | UN | SN | UN | SN | UN | |
| PETA | 35 | 0 | 8 | 18 | 12 | 39 |
| PA100K | 8 | 27 | 26 | 0 | 8 | 43 |
| RAPv1 | 12 | 23 | 8 | 18 | 51 | 0 |
4.1. Datasets and Experimental Settings
Datasets and Evaluation Metrics. The proposed method is evaluated on three benchmark datasets, i.e., PETA (Deng et al., 2014), RAPv1 (Li et al., 2015), and PA100K (Liu et al., 2017) with an open-attribute setting, meaning the model is trained on one dataset and evaluated on the other two datasets. The classes included in different datasets may not be identical. Recall@K and mA (mean Accuracy) are used to evaluate the performance of our open-attribute recognition model. For the PETA dataset, the “upper body” and “lower body” groups may include two attribute classes. We select R@2 texts to show for attribute groups in “upper body” and “lower body”.
Implementation Details. Our experiments are conducted on the ViT-B/16 backbone networks, which are stacked with 12 Transformer blocks. The input image size is set to 224224. The value of is 16, and is set to be 8, 8, and 11 in PETA, PA100K, and RAPv1, respectively. The learning rate is with a weight decay of 0.2. The temperature in contrastive loss is set as 5. Data augmentation with random horizontal flip and random erasing are used during training.
4.2. Performance Comparison of POAR
We compare the performance of our method with the CLIP (Radford et al., 2021) and VTB (Cheng et al., 2022) methods based on the image-to-text -nearest neighbor retrieval idea, the top-1 and top-2 recall rates are shown in Table 2. In Table 3, SN and UN represent seen and unseen attributes in the different test sets, respectively.
From Table 2, we can see that the Recall@1 (R@1) scores of our method are 1.7% and 8.6% higher than the CLIP method when the model is trained on the PETA dataset and evaluated on the PA100K and RAPv1 datasets, respectively. When the model is trained on the PA100K and evaluated on the PETA dataset, the R@1 score of our method is 7.9% lower than the CLIP model. When the model is trained on the RAPv1 and evaluated on the PETA, the R@1 scores of our method are 1.4% lower than the CLIP model. This is likely due to the fact that the CLIP model is trained on 400 million image-text pairs which have a high probability of containing “age” and “hair” and other attributes; thus, those unseen attributes defined in our experiments can be considered seen in the CLIP model. However, when we fuse the features of our model and the CLIP model, a higher performance for the POAR task can be obtained. When we train the proposed TEMS model with GKD using the CLIP model as the teacher model, the model’s transferred performance to other datasets improves significantly. However, the TEMS model’s performance on its training dataset decreases as compared to the results without distillation. For instance, when the model is trained on the PETA dataset, its performance on the PETA test set decreases by including distillation. Nevertheless, the model exhibits significant improvements on other datasets.
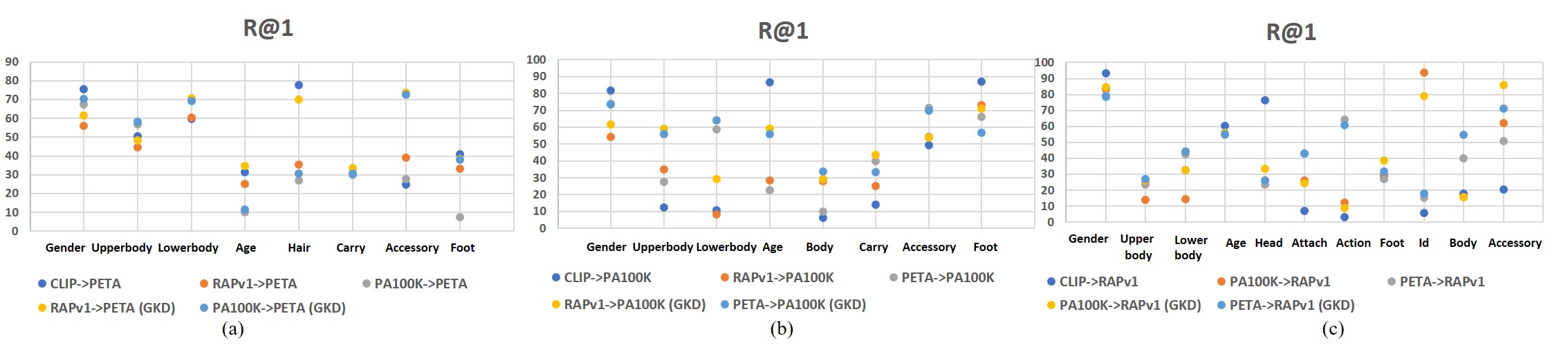
To analyze the details of the POAR performance, we show the performance comparison of each group of the CLIP model and the proposed TEMS model in Figure 5. The results on different datasets and attributes vary between the TEMS method and the CLIP method. However, the model trained through GKD exhibits a significant improvement in the accuracy of various attribute tokens, as evidenced by the comparison between the orange (without GKD) and yellow (with GKD) graphs in Figure 5.

| Source Domain | Target Domain | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | PETA | PA100K | RAPv1 | |||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| TEMS | PETA | 90.3 | 100.0 | 100.0 | 38.5 | 57.7 | 61.5 | 35.3 | 52.9 | 62.8 |
| TEMS | PA100K | 41.9 | 74.2 | 77.4 | 88.5 | 96.2 | 100.0 | 33.3 | 56.9 | 64.7 |
| TEMS | RAPv1 | 35.5 | 58.1 | 71.0 | 34.6 | 61.5 | 69.2 | 96.1 | 100.0 | 100.0 |
| SAT | MAT | MAM | MIP | mA | F1 | R@1 | R@2 |
|---|---|---|---|---|---|---|---|
| 81.1 | 83.0 | 85.7 | 94.7 | ||||
| 80.6 | 82.2 | 86.2 | 95.7 | ||||
| 81.0 | 83.0 | 86.4 | 95.7 | ||||
| 83.1 | 84.4 | 87.6 | 96.0 |
| OTOC | MTMC | mA | F1 | R@1 | R@2 |
|---|---|---|---|---|---|
| 73.0 | 73.4 | 86.3 | 95.8 | ||
| 81.5 | 83.3 | 86.3 | 95.8 | ||
| 83.1 | 84.4 | 87.6 | 96.0 |


Furthermore, we compute the recognition performance of seen and unseen attributes in the PA100K dataset, respectively. Results are shown in Figure 6, the proposed TEMS method has the capability to recognize both seen and unseen categories. For example, when the method is trained on PETA dataset and tested on the PA100K dataset, Figure 6 shows the accuracy of the “Carry” group for seen (blue) and unseen (gray) classes. Moreover, after implementing GKD training, there is a remarkable enhancement in the model’s ability to recognize unseen classes, as evidenced by the comparison of R@1 results for unseen classes in Figure 6 (a) (b) (gray and yellow). This further confirms the effectiveness of the proposed method in identifying unseen classes.
4.3. Text-to-Image Retrieval Results
To examine the generalization ability of our method, we also evaluate the text-to-image retrieval results. The results are reported in Table 4. Compared to the image-to-text retrieve performance of Table 2, we can see that the text-to-image recognition task is more challenging than the image-to-text recognition task. This is mainly due to the fact that the text embedding space is more sparse than the image embedding space.
4.4. Ablation Study
Our ablation study is conducted on the PETA dataset using the close-set and open-set evaluation mechanisms. Table 7 shows the image-to-text retrieval performance of different components in our proposed method, SAT represents a single attribute token. MAT represents multiple attribute tokens. MAM represents multiple attribute tokens with the masking. Table 6 shows the image-to-text retrieval performance for different loss functions, OTOC represents one-to-one contrastive loss. MTMC represents many-to-many contrastive loss. The one-to-one loss function is performed by defining all attributes of one image in a paragraph description as text input. From Table 7, we can see that each component of the proposed method can contribute positively to the final performance gain. From Table 6, we can see that the many-to-many loss function significantly improves the final performance.
4.5. Visualization of the Attention Maps
To illustrate the effectiveness of the proposed masking method, we show the attention map of each attribute token on the PETA dataset in Figure 7. In our method, we proposed a masking strategy to block out distract regions and mask the corresponding attribute tokens. From the attention map, we can see that each attribute token is responsible for a specific part of the body, which shows the effectiveness of the proposed masking method.
4.6. Image-to-Text Retrieval Examples
In Figure 8, we visualize some image-to-text retrieval examples based on embeddings obtained using the CLIP model and our proposed TEMS model. The TEMS model was trained on the PETA dataset. Figure 8 (a) and Figure 8 (b) show examples tested on the PA100K and RAPv1 datasets, respectively. We can see that there are a lot of unseen attributes in the test set, and our model can effectively recognize the unseen attributes. From Figure 8, the CLIP model exhibits a higher rate of errors in recognizing pedestrian attribute categories. In contrast, as illustrated in Figure 8 (a) (i), our proposed model achieves perfect recognition of the pedestrian attributes, while the CLIP model only correctly identifies three attributes for the same pedestrian. In the RAPv1 dataset, there are 39 unseen classes, the recognition accuracy for these classes is much higher by the TEMS model than that of the CLIP model.
5. Conclusions
In this work, we propose a novel method to tackle the problem of pedestrian open-attribute recognition. Our key idea is to formulate the POAR problem as an image-text search problem. Specifically, we propose a TEMS method to encode image patches with attribute tokens. Then, a many-to-many contrastive loss function with masked tokens is developed to train the model. Finally, the knowledge distillation method is employed to improve the recognition of unseen attribution classes. Experimental results on benchmark PAR datasets with an open-attribute setting show the effectiveness of the proposed method. Our proposed POAR task is also promising, as its performance can be further improved by leveraging on the advances in more sophisticated multimodality technologies, like ChatGPT / T5-11B.
Limitations: One limitation of the work is that the text encoder is directly transferred from the CLIP. It is beneficial to examine whether a more effective attribute encoder can be developed in our future work. Another limitation is that the input of the framework is the detected pedestrian; future work could be focused on integrating pedestrian detection and POAR into a unified framework to improve the efficiency of pedestrian open-attribute identification.
Acknowledgements.
This work was supported in part by the National Key R&D Program of China 2021YFE0110500, in part by the National Natural Science Foundation of China under Grant 62202499 and 62062021, in part by the Hunan Provincial Natural Science Foundation of China under Grant 2022JJ40632, in part by the Guiyang scientific plan project contract [2023] 48-11. Corresponding author: Yigang Cen.References
- (1)
- Cao et al. (2018) Jiajiong Cao, Yingming Li, and Zhongfei Zhang. 2018. Partially Shared Multi-Task Convolutional Neural Network With Local Constraint for Face Attribute Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Chang et al. (2021) Xiaojun Chang, Pengzhen Ren, Pengfei Xu, Zhihui Li, Xiaojiang Chen, and Alexander G Hauptmann. 2021. A comprehensive survey of scene graphs: Generation and application. IEEE Transactions on Pattern Analysis and Machine Intelligence (2021).
- Cheng et al. (2022) Xinhua Cheng, Mengxi Jia, Qian Wang, and Jian Zhang. 2022. A Simple Visual-Textual Baseline for Pedestrian Attribute Recognition. IEEE Transactions on Circuits and Systems for Video Technology (2022), 1–1.
- Dan et al. (2022) Yuhao Dan, Jie Zhou, Qin Chen, Qingchun Bai, and Liang He. 2022. Enhancing Class Understanding Via Prompt-Tuning For Zero-Shot Text Classification. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 4303–4307.
- Deng et al. (2014) Yubin Deng, Ping Luo, Chen Change Loy, and Xiaoou Tang. 2014. Pedestrian attribute recognition at far distance. In Proceedings of the 22nd ACM international conference on Multimedia. 789–792.
- Ding et al. (2021) Zefeng Ding, Changxing Ding, Zhiyin Shao, and Dacheng Tao. 2021. Semantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification. CoRR abs/2107.12666 (2021). arXiv:2107.12666 https://arxiv.org/abs/2107.12666
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
- Du et al. (2022) Yu Du, Fangyun Wei, Zihe Zhang, Miaojing Shi, Yue Gao, and Guoqi Li. 2022. Learning to prompt for open-vocabulary object detection with vision-language model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14084–14093.
- Esmaeilpour et al. (2022) Sepideh Esmaeilpour, Bing Liu, Eric Robertson, and Lei Shu. 2022. Zero-Shot Out-of-Distribution Detection Based on the Pretrained Model CLIP. In Proceedings of the AAAI conference on artificial intelligence.
- Fan et al. (2022) Haonan Fan, Hai-Miao Hu, Shuailing Liu, Weiqing Lu, and Shiliang Pu. 2022. Correlation Graph Convolutional Network for Pedestrian Attribute Recognition. IEEE Transactions on Multimedia 24 (2022), 49–60.
- Gu et al. (2021) Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. 2021. Open-vocabulary object detection via vision and language knowledge distillation. arXiv preprint arXiv:2104.13921 (2021).
- Guo et al. (2022) Hao Guo, Xiaochuan Fan, and Song Wang. 2022. Visual Attention Consistency for Human Attribute Recognition. International Journal of Computer Vision 130, 4 (2022), 1088–1106.
- Hand and Chellappa (2017) Emily M. Hand and Rama Chellappa. 2017. Attributes for Improved Attributes: A Multi-Task Network Utilizing Implicit and Explicit Relationships for Facial Attribute Classification. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA, Satinder Singh and Shaul Markovitch (Eds.). AAAI Press, 4068–4074.
- He et al. (2017) Keke He, Zhanxiong Wang, Yanwei Fu, Rui Feng, Yu-Gang Jiang, and Xiangyang Xue. 2017. Adaptively weighted multi-task deep network for person attribute classification. In Proceedings of the 25th ACM international conference on Multimedia. 1636–1644.
- He et al. (2021) Shuting He, Hao Luo, Pichao Wang, Fan Wang, Hao Li, and Wei Jiang. 2021. TransReID: Transformer-Based Object Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 15013–15022.
- Jia et al. (2021) Jian Jia, Xiaotang Chen, and Kaiqi Huang. 2021. Spatial and Semantic Consistency Regularizations for Pedestrian Attribute Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 962–971.
- Jia et al. (2022) Jian Jia, Naiyu Gao, Fei He, Xiaotang Chen, and Kaiqi Huang. 2022. Learning disentangled attribute representations for robust pedestrian attribute recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 1069–1077.
- Kalayeh et al. (2017) Mahdi M. Kalayeh, Boqing Gong, and Mubarak Shah. 2017. Improving Facial Attribute Prediction Using Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Li et al. (2015) Dangwei Li, Xiaotang Chen, and Kaiqi Huang. 2015. Multi-attribute learning for pedestrian attribute recognition in surveillance scenarios. In 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR). 111–115.
- Li et al. (2022) Wanhua Li, Zhexuan Cao, Jianjiang Feng, Jie Zhou, and Jiwen Lu. 2022. Label2Label: A Language Modeling Framework for Multi-Attribute Learning. arXiv e-prints, Article arXiv:2207.08677 (July 2022), arXiv:2207.08677 pages. arXiv:2207.08677 [cs.CV]
- Li et al. (2019) Zhihui Li, Lina Yao, Xiaoqin Zhang, Xianzhi Wang, Salil Kanhere, and Huaxiang Zhang. 2019. Zero-shot object detection with textual descriptions. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 8690–8697.
- Liu et al. (2018) Pengze Liu, Xihui Liu, Junjie Yan, and Jing Shao. 2018. Localization Guided Learning for Pedestrian Attribute Recognition. In British Machine Vision Conference 2018, BMVC 2018.
- Liu et al. (2017) Xihui Liu, Haiyu Zhao, Maoqing Tian, Lu Sheng, Jing Shao, Shuai Yi, Junjie Yan, and Xiaogang Wang. 2017. Hydraplus-net: Attentive deep features for pedestrian analysis. In Proceedings of the IEEE international conference on computer vision. 350–359.
- Liu et al. (2016) Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. 2016. DeepFashion: Powering Robust Clothes Recognition and Retrieval With Rich Annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Liu et al. (2022) Zhenyu Liu, Zhang Zhang, Da Li, Peng Zhang, and Caifeng Shan. 2022. Dual-branch self-attention network for pedestrian attribute recognition. Pattern Recognition Letters 163 (2022), 112–120.
- Lu et al. (2023) Wei-Qing Lu, Hai-Miao Hu, Jinzuo Yu, Yibo Zhou, Hanzi Wang, and Bo Li. 2023. Orientation-Aware Pedestrian Attribute Recognition based on Graph Convolution Network. IEEE Transactions on Multimedia (2023).
- Oza and Patel (2019) Poojan Oza and Vishal M Patel. 2019. C2ae: Class conditioned auto-encoder for open-set recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2307–2316.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning. PMLR, 8748–8763.
- Rahman et al. (2020) Shafin Rahman, Salman Khan, and Nick Barnes. 2020. Improved visual-semantic alignment for zero-shot object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 11932–11939.
- Sarafianos et al. (2018) Nikolaos Sarafianos, Xiang Xu, and Ioannis A. Kakadiaris. 2018. Deep Imbalanced Attribute Classification using Visual Attention Aggregation. In Proceedings of the European Conference on Computer Vision (ECCV).
- Saranrittichai et al. (2022) Piyapat Saranrittichai, Chaithanya Kumar Mummadi, Claudia Blaiotta, Mauricio Munoz, and Volker Fischer. 2022. Multi-attribute Open Set Recognition. In DAGM German Conference on Pattern Recognition. Springer, 101–115.
- Sarfraz et al. (2017) M. Saquib Sarfraz, Arne Schumann, Yan Wang, and Rainer Stiefelhagen. 2017. Deep View-Sensitive Pedestrian Attribute Inference in an end-to-end Model. In British Machine Vision Conference 2017, BMVC 2017, London, UK, September 4-7, 2017. BMVA Press.
- Scheirer et al. (2013) Walter J. Scheirer, Anderson de Rezende Rocha, Archana Sapkota, and Terrance E. Boult. 2013. Toward Open Set Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 35, 7 (2013), 1757–1772.
- Tan et al. (2020) Zichang Tan, Yang Yang, Jun Wan, Guodong Guo, and Stan Z Li. 2020. Relation-aware pedestrian attribute recognition with graph convolutional networks. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 12055–12062.
- Tang et al. (2019) Chufeng Tang, Lu Sheng, Zhaoxiang Zhang, and Xiaolin Hu. 2019. Improving Pedestrian Attribute Recognition With Weakly-Supervised Multi-Scale Attribute-Specific Localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
- Tang and Huang (2022) Zengming Tang and Jun Huang. 2022. DRFormer: Learning dual relations using Transformer for pedestrian attribute recognition. Neurocomputing 497 (2022), 159–169.
- Vaze et al. (2022) Sagar Vaze, Kai Han, Andrea Vedaldi, and Andrew Zisserman. 2022. Open-Set Recognition: a Good Closed-Set Classifier is All You Need?. In International Conference on Learning Representations.
- Wang et al. (2022a) Suchen Wang, Yueqi Duan, Henghui Ding, Yap-Peng Tan, Kim-Hui Yap, and Junsong Yuan. 2022a. Learning Transferable Human-Object Interaction Detector With Natural Language Supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 939–948.
- Wang et al. (2022b) Xiao Wang, Shaofei Zheng, Rui Yang, Aihua Zheng, Zhe Chen, Jin Tang, and Bin Luo. 2022b. Pedestrian attribute recognition: A survey. Pattern Recognition 121 (2022), 108220.
- Weng et al. (2023) Dunfang Weng, Zichang Tan, Liwei Fang, and Guodong Guo. 2023. Exploring attribute localization and correlation for pedestrian attribute recognition. Neurocomputing 531 (2023), 140–150.
- Yang et al. (2020) Jie Yang, Jiarou Fan, Yiru Wang, Yige Wang, Weihao Gan, Lin Liu, and Wei Wu. 2020. Hierarchical Feature Embedding for Attribute Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Yang et al. (2021) Yang Yang, Zichang Tan, Prayag Tiwari, Hari Mohan Pandey, Jun Wan, Zhen Lei, Guodong Guo, and Stan Z Li. 2021. Cascaded split-and-aggregate learning with feature recombination for pedestrian attribute recognition. International Journal of Computer Vision 129 (2021), 2731–2744.
- Zhang et al. (2020) Yue Zhang, Yi Jin, Jianqiang Chen, Shichao Kan, Yigang Cen, and Qi Cao. 2020. PGAN: Part-Based Nondirect Coupling Embedded GAN for Person Reidentification. IEEE MultiMedia 27, 3 (2020), 23–33.
- Zhang et al. (2022) Yue Zhang, Fanghui Zhang, Yi Jin, Yigang Cen, Viacheslav Voronin, and Shaohua Wan. 2022. Local Correlation Ensemble with GCN based on Attention Features for Cross-domain Person Re-ID. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) (2022).
- Zhao et al. (2018) Xin Zhao, Liufang Sang, Guiguang Ding, Yuchen Guo, and Xiaoming Jin. 2018. Grouping attribute recognition for pedestrian with joint recurrent learning.. In IJCAI, Vol. 2018. 27th.
- Zhao et al. (2019) Xin Zhao, Liufang Sang, Guiguang Ding, Jungong Han, Na Di, and Chenggang Yan. 2019. Recurrent attention model for pedestrian attribute recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 9275–9282.
- Zhao et al. (2020) Xiangyun Zhao, Samuel Schulter, Gaurav Sharma, Yi-Hsuan Tsai, Manmohan Chandraker, and Ying Wu. 2020. Object detection with a unified label space from multiple datasets. In European Conference on Computer Vision. Springer, 178–193.
- Zhu et al. (2015) Jianqing Zhu, Shengcai Liao, Dong Yi, Zhen Lei, and Stan Z. Li. 2015. Multi-label CNN based pedestrian attribute learning for soft biometrics. In 2015 International Conference on Biometrics (ICB). 535–540.
Appendix A Supplementary Material
A.1. Datasets and Metrics
We evaluate the proposed TEMS baseline on three large-scale benchmark pedestrian attribute datasets.
PETA dataset. Following the standard settings, 9,500 images are used for training, 1,900 images are used for verification, and 7,600 images are used for testing. The model is evaluated on 35 attributes.
RAPv1 dataset. It is collected from 26 real indoor surveillance cameras and contains 41,585 pedestrians, where 33,268 images are used for training, and 8,317 images are used for testing. The model is evaluated on 51 attributes.
PA100K dataset. It includes 100,000 images, of which 80,000 images are used for training, 10,000 images are used for validation, and 10,000 images are used for testing. Each image is annotated with 26 commonly used attributes.
Metrics. Our model is trained on one dataset and evaluated on the other two datasets. The top-k results are used to evaluate the performance of our open-attribute recognition model.
A.2. Ablation Experiment
Our ablation study is conducted on the RAPv1 dataset using the open-set evaluation mechanisms. Table 7 shows the image-to-text retrieval performance of different components in our proposed method. From Table 7, we can see that each component of the proposed method can contribute positively to the final performance gain.
| SAT | MAT | MAM | MIP | R@1 | R@2 |
|---|---|---|---|---|---|
| 39.9 | 56.1 | ||||
| 41.3 | 61.6 | ||||
| 41.1 | 65.7 | ||||
| 42.2 | 68.6 |
A.3. Text-to-image Retrieval Examples

We also show examples of text-to-image retrieval on three datasets for models trained on the PETA dataset. Specifically, as shown in Figure 9, the first line is the results on the PETA dataset, the second line is the results on the RAPv1 dataset, and the third line is the results on the PA100K dataset. The second and third texts are unseen attributes. Each text corresponds to top-5 results. Figure 9 (a) shows the results of the CLIP method, and Figure 9 (b) shows the results of our proposed TEMS method for POAR task. For the PA100K and RAPv1 datasets, the TEMS model can also retrieve some correct images that belong to the unseen attributes, such as the results of “This person is customer.”.

In addition, we also show examples using all the text descriptions to generate embeddings to search images on the PETA dataset. Results are shown in Figure 10. As can be seen from Figure 10 (a), (b), the results of the top-5 are all correct. The proposed model retrieved correct images based on textual descriptions, which is because the description includes different attributes from different groups. From these examples, we can see that using a paragraph description can also find different images of the same person, which may be helpful for person re-identification applications.
A.4. Image-to-text Retrieval Examples on Complex Scenes
Pedestrian attribute recognition in complex scenes can be effectively achieved through a two-step process involving person detection followed by attribute recognition for each individual. Here we use the WIDERAttribute dataset with 14 human attribute labels and 30 event class labels for testing. Dataset URL http://mmlab.ie.cuhk.edu.hk/projects/WIDERAttribute.
In Figure 11, we present the outcomes of testing our model on the WIDERAttribute dataset, which was trained using the PETA dataset. The test images were entirely new and did not overlap with the training set. Moreover, these images contain multiple pedestrians, often with occlusions, making the recognition task more complex. In some instances, while identifying specific pedestrians, there could be potential influences from other pedestrians’ attribute features. However, overall, our model demonstrates commendable recognition ability even in such challenging scenarios.
