PM-VIS: High-Performance Box-Supervised Video Instance Segmentation
Abstract
Labeling pixel-wise object masks in videos is a resource-intensive and laborious process. Box-supervised Video Instance Segmentation (VIS) methods have emerged as a viable solution to mitigate the labor-intensive annotation process. However, previous approaches have primarily emphasized a traditional single-step strategy, overlooking the potential of a two-step strategy involving the use of segmentation models to generate pseudo masks, and subsequently leveraging them alongside box annotations for model training. In practical applications, the two-step approach is not only more flexible but also exhibits a higher recognition accuracy. Inspired by the recent success of Segment Anything Model (SAM), we introduce a novel approach that aims at harnessing instance box annotations from multiple perspectives to generate high-quality instance pseudo masks, thus enriching the information contained in instance annotations. We leverage ground-truth boxes to create three types of pseudo masks using the HQ-SAM model, the box-supervised VIS model (IDOL-BoxInst), and the VOS model (DeAOT) separately, along with three corresponding optimization mechanisms. Additionally, we introduce two ground-truth data filtering methods, assisted by high-quality pseudo masks, to further enhance the training dataset quality and improve the performance of fully supervised VIS methods. To fully capitalize on the obtained high-quality Pseudo Masks, we introduce a novel algorithm, PM-VIS, to integrate mask losses into IDOL-BoxInst. Our PM-VIS model, trained with high-quality pseudo mask annotations, demonstrates strong ability in instance mask prediction, achieving state-of-the-art performance on the YouTube-VIS 2019, YouTube-VIS 2021, and OVIS validation sets, notably narrowing the gap between box-supervised and fully supervised VIS methods. Furthermore, the PM-VIS model trained on these filtered ground-truth data shows obvious improvement compared to the baseline algorithm.
Index Terms:
Box-supervised video instance segmentation, Pseudo mask annotations, Weakly-supervised learning.I Introduction
Video Instance Segmentation (VIS) aims to simultaneously detect, segment, and track objects within a video. Although current fully supervised VIS algorithms [1, 2, 3, 4, 5] have demonstrated impressive performance on various benchmarks [6, 7, 8], their practical applications still face significant challenges. A fundamental reason is the substantial cost and difficulty on obtaining pixel-level annotations, in contrast to the less demanding bounding box or point annotations. Moreover, existing datasets often fail to capture the diverse scenarios encountered in real-world applications. Therefore, our approach focuses on training model with bounding box annotations only, enabling low-cost pixel-level instance predictions.
| Method | Sup. | YTVIS2019 | YTVIS2021 | OVIS |
|---|---|---|---|---|
| MaskFreeVIS [9] | Box | 46.6 | 40.9 | 15.7 |
| IDOL-BoxInst | Box | 43.9 | 41.8 | 25.4 |
| PM-VIS | Box | 48.7 | 44.6 | 27.8 |
Building upon the success of box-supervised Image Instance Segmentation (IIS) algorithms [10, 11, 12, 13], the sole box-supervised VIS method [9] has shown promising results. However, prior methods have predominantly favored a traditional single-step strategy, directly employing ground-truth boxes (gtboxes) for model training. This approach overlooks the potential of a two-step strategy, which incorporates segmentation models to generate pseudo masks, subsequently leveraging them in conjunction with box annotations during model training. Expanding upon the single-step method, the two-step approach incorporates more instance information from multiple perspectives, strengthening the algorithm’s recognition capabilities. In practical applications, the two-step approach not only enhances flexibility but also demonstrates superior recognition accuracy, significantly reducing the application costs of VIS and accelerating their development.



Taking inspiration from the success of foundational models such as SAM [14] and HQ-SAM [15] in image segmentation, we propose to utilize high-performance models to generate target-specific pixel-level predictions (pseudo masks) based on object box proposals. Then these pseudo masks are introduced as additional mask annotations of the training set. However, this direct utilization is problematic. Through visualization in Fig. 1, we have identified certain outrageous errors within the generated pseudo-masks. While the SAM model excels in image segmentation, it faces challenges in scenarios where objects share colors with the background, have distinct background features, or exhibit complex color compositions within objects, as shown in Fig. 1 (SAM). Quantitatively, through intersection over union (IoU) calculations between the pseudo masks (SAM-Masks) generated by SAM and the ground-truth masks (gtmasks), as shown in Fig. 2, we observe that the SAM-Masks contain over 64.58% lower-quality data, with an IoU score less than 0.9. Therefore, we believe directly using these noisy data will adversely affect the performance of weakly supervised methods.
To obtain superior-quality pseudo masks and fully harness their potential, our method involves three key components: (i) generating three types of pseudo masks using distinct models, (ii) selecting high-quality pseudo masks from the aforementioned three using SCM, DOOB, and SHQM strategies, and (iii) training the proposed PM-VIS model on the acquired high-quality pseudo masks. While the pseudo masks data has enhanced the performance of weakly supervised algorithms, we believe that there is still untapped useful information within them. Therefore, we introduce an effective approach to fully explore and leverage the hidden information in pseudo mask data: (i) filtering ground-truth data using the obtained high-quality pseudo masks, and (ii) training the proposed PM-VIS model on the filtered ground-truth data.
I-A Pseudo Mask Generation
To effectively leverage information from gtboxes, we propose utilizing three models (HQ-SAM, IDOL-BoxInst, and DeAOT) to generate instance pseudo masks: HQ-SAM-masks, IDOL-BoxInst-masks, and Track-masks.
I-A1 HQ-SAM-masks
In order to mitigate the noise in the generated pseudo masks, we employ HQ-SAM, which incorporates a learnable high-quality output token, to produce these pseudo masks, referred to as HQ-SAM-masks. The HQ-SAM model, as shown in Fig. 1 (HQ-SAM), significantly reduces the number of outrageous errors compared to SAM. Besides, as depicted in Fig. 2, by calculating the IoU between HQ-SAM-masks and gtmasks, we find that HQ-SAM-masks exhibits 6.46% higher high-quality (IoU greater than 0.9) instance count compared to SAM-Masks and has a lower instance count across all intervals of IoU less than 0.9 compared to SAM-Masks.
I-A2 IDOL-BoxInst-masks
We observe that HQ-SAM-masks still exhibits diminished quality in scenarios involving occlusion and rapid motion. Taking into account the effectiveness of the IDOL algorithm in handling occlusion, we introduce IDOL-BoxInst-masks, a set of pseudo masks generated by the box-supervised VIS model IDOL-BoxInst. It combines box-supervised IIS model BoxInst [12] with VIS model IDOL [2] while excluding mask losses [16, 17] from IDOL. This model is trained on the dataset without mask annotations.
I-A3 Track-masks
Despite aforementioned techniques, pseudo masks generated by weakly supervised model still struggle to guarantee the accuracy and completeness of object predictions, especially in scenes with subtle color variations. We observe that within HQ-SAM-masks and IDOL-BoxInst-masks, despite the presence of some subpar segmentations, there are many high-quality instance segmentations that reach the ground-truth level. Subsequently, we employ the semi-supervised Video Object Segmentation (VOS) model DeAOT [18] with initialization of object annotations that comes from the high-quality pseudo masks in IDOL-BoxInst-masks, to track the pseudo masks of the target throughout the entire video, resulting in a novel pseudo mask collection called Track-masks.
I-B Pseudo Mask Selection
To fully leverage the advantages of various pseudo masks, we propose three strategies: SCM, DOOB, and SHQM. These strategies are designed to optimize the quality of pseudo masks and select those of higher quality.
I-B1 SCM
During the inference stage of the IDOL-BoxInst, the model predicts multiple masks for each real instances. However, it is challenging to ascertain the quality of each predicted mask. Using predicted target labels or IDs alone does not uniquely establish the relationship with instance gtboxes. To establish correspondences between predicted masks and gtboxes, we propose a method that utilizes both the IoU between gtboxes and predicted boxes, as well as the IoU between HQ-SAM-masks and predicted masks to determine their associations. Specifically, we utilize HQ-SAM-masks for temporal continuity and object matching, constraining the predicted pseudo masks using our proposed SCM (Scoring Corresponding Mask) confidence scores.
I-B2 DOOB
Upon closer examination of these segmented instances, two distinct issues within the segmented instance annotations appear: (i) overlapping occurs between distinct predicted masks on the same frame, and (ii) the predicted masks extend beyond the boundaries of the corresponding gtbox. To address these concerns, we introduce a pseudo mask optimization strategy, DOOB (Deleting the Overlapping and Out-of-Boundary sections). Specifically, DOOB involves the removal of overlapping portions of pseudo masks from different instances and the removal of parts extending beyond the gtbox boundaries.
I-B3 SHQM
With our multi-keyframes tracking strategy, we obtain a combination of high-quality pseudo masks, named Track-masks-final, selected from the three aforementioned sets (HQ-SAM-masks, IDOL-BoxInst-masks, Track-masks) using SHQM (Selection of High-Quality Masks). Specifically, the SHQM method determines the higher-quality pseudo mask among the three by summing the SCM scores calculated between the target pseudo-mask and the other two pseudo-masks, where a higher SCM score indicates higher quality. As illustrated in Fig. 1 (OURS), Track-masks-final exhibits significantly improved visual quality compared to the previous pseudo masks, closely resembling the gtmasks.
I-C Ground-Truth Data Filtration
We introduce two ground-truth data filtering methods: Missing-Data (Removing Missing Data from ground-truth) and RIA (Removing Instance Annotations with low mask IoU between Track-masks-final and gtmasks). Specifically, we enhance our results through two perspectives. Initially, using the Missing-Data method, we improve the result quality by removing missing data mappings from Track-masks-final in the ground-truth data. We then utilize the problematic pseudo masks from Track-masks-final to further optimize the ground-truth data using the RIA method.
I-D PM-VIS
To fully explore the information from both boxes and Pseudo Masks, we combine IDOL-BoxInst with mask losses from IDOL [2], resulting in the novel VIS algorithm, PM-VIS. Generally, for PM-VIS, the higher the quality of pseudo masks, i.e., the closer they are to manually annotated masks, the better the algorithm performance is expected to be. As shown in Fig. 3, we compute the mask IoU between each type of pseudo masks and the gtmasks, and plot the correlation between mask IoU and algorithm mask AP performance. There is a direct correlation between the mask IoU of pseudo masks and the performance of mask AP. When the mask IoU between datasets containing pseudo masks and ground-truth data increases, the quality of pseudo masks improves, leading to better performance for PM-VIS on datasets with a higher mask IoU. Therefore, training the PM-VIS model with the highest-quality pseudo masks obtained from Track-masks-final will result in the best AP performance.
As indicated in Table I, training the PM-VIS model on the training set containing Track-masks-final, without using gtmasks, results in state-of-the-art (SOTA) AP scores of 48.7%, 44.6%, and 27.8% on the YouTube-VIS 2019 [6], YouTube-VIS 2021 [7], and OVIS [8] validation sets, respectively, with the ResNet-50 backbone. It’s worth noting that the results for MaskFreeVIS [9] are a combination of the Mask2Former [19] baseline on YTVIS2019/2021 and the VITA [3] baseline on OVIS. Meanwhile, we achieve competitive performance when training the fully supervised PM-VIS model with the filtered ground-truth data, surpassing the baseline algorithm (IDOL).
The paper presents the following contributions:
-
•
We introduce three methods for generating pseudo masks. Among these, we propose, for the first time, the use of the box-supervised model (IDOL-BoxInst) to generate pseudo masks for the training set, where IDOL-BoxInst-masks plays a crucial role in producing high-quality pseudo masks.
-
•
We introduce three strategies, SCM, SHQM, and DOOB, for the selection and composition of high-quality pseudo masks from the aforementioned three types of pseudo masks.
-
•
We propose two ground-truth data filtering methods, Missing-Data and RIA, assisted by Track-masks-final, to enhance the quality of ground-truth data through the utilization of pseudo masks.
-
•
Utilizing the box-supervised PM-VIS model with training data incorporating high-quality pseudo masks, we achieve state-of-the-art results across the YTVIS2019, YTVIS2021, and OVIS datasets. Meanwhile, our fully supervised PM-VIS model, trained on meticulously filtered ground-truth data across these three datasets, not only surpasses the baseline (IDOL), but also demonstrates performance on par with strong fully supervised algorithms.
II Related work
II-A Video Instance Segmentation
In the field of VIS, methods can be categorized into two types based on their application modes: offline and online. Offline methods [20, 21, 3, 22, 23, 24] analyze the entirety of a video or a video segment, given the availability of future frames during the inference phase. These techniques are often suitable for tasks involving post-processing and batch analysis, including video editing, content analysis, and offline video comprehension. Early offline methods [22, 23] use instance mask propagation to track the same target across the sequence. With the advent of DETR [25], instance query tracking and matching-based VIS methods [21, 3, 20] have gained popularity due to their remarkable effectiveness. Online methods [5, 26, 2, 6, 27] process instance segmentation and tracking results for each target in video frames by embedding similarity between targets during tracking and optimizing tracking outcomes. These approaches find extensive applications in domains such as video surveillance and autonomous driving. For instance, Mask-Track R-CNN [6], an extension of the IIS model Mask R-CNN [28], associates instances with track heads during inference. Before the introduction of IDOL [2], online methods typically demonstrated lower performance in comparison to offline methods. IDOL enhances conventional techniques through the incorporation of contrastive learning on instance queries across frames and the adoption of heuristic instance matching, building upon Deformable-DETR [29]. MinVIS [26] harnesses the capabilities of the powerful object detector Mask2Former [19] and employs bipartite matching for instance tracking. GenVIS [4] elevates performance through a strategic video-level training approach centered on the Mask2Former [19]. In consideration of algorithm simplicity and robustness, we propose two weakly supervised VIS algorithms, namely, IDOL-BoxInst and PM-VIS, based on the foundation of IDOL.
II-B Video Object Segmentation
VOS methods can be categorized into two types based on how the corresponding object is determined: automatic VOS and semi-automatic (or semi-supervised) VOS. Automatic VOS methods [30, 31, 32] do not require initial object annotations, while semi-supervised VOS methods [33, 34, 18, 35, 36] necessitate providing annotations for the target, typically in the form of annotations in the first frame. Subsequently, the algorithm tracks the corresponding object throughout the entire video. For semi-supervised VOS, AOT [35] proposes to incorporate an identification mechanism to associate multiple objects in a unified embedding space which enables it to handle multiple objects in a single propagation. DeAOT [18] is a semi-supervised VOS method that utilizes an AOT-inspired hierarchical propagation strategy. This strategy incorporates a dual-branch gated propagation module (GPM) to distinctly guide the propagation of visual and identification embeddings. It helps mitigate the potential loss of object-agnostic visual details in deeper layers. Furthermore, DeAOT demonstrates remarkable competence in effectively handling small or dynamically scaled objects. Given its superior performance and robustness, we employ DeAOT as our tracking model to generate pseudo mask annotations for the target throughout the video. This is done by leveraging existing mask annotations provided for the target within the video. It’s important to note that during the process of obtaining instance pseudo masks through tracking, we cannot always guarantee the availability of initial frame information for each instance. Therefore, in this study, we adapt DeAOT to be more flexible, allowing us to initialize instances from various positions within the video and subsequently track them throughout the entire video.
II-C Box-supervised Video Instance Segmentation
As the sole box-supervised VIS algorithm, MaskFreeVIS [9] has been inspired by box-supervised IIS and has incorporated the model [12] into the pixel-supervised VIS baseline. It maintains competitive performance by introducing temporal or spatial correlation losses. Diverging from the aforementioned box-supervised VIS methodology, our contribution, PM-VIS, adopts a more integrative approach to tackle prevailing challenges by synergizing box-supervised IIS algorithm with the VIS task. It employs a training set containing pseudo masks, effectively combines the strengths of these algorithmic paradigms, and achieves promising performance on multiple public benchmarks.
II-D Segment Anything models
SAM [14] is a pioneering model in the field of interactive image segmentation, showcasing remarkable zero-shot generalization capabilities and the ability to generate high-quality masks from just a single foreground point. Extending this innovation to intricate object structures, HQ-SAM [15] supplements SAM by introducing a learnable high-quality output token, thereby enhancing its performance across diverse segmentation contexts. Although both SAM and HQ-SAM excel in image segmentation, their direct application to video segmentation remains limited due to the need for point, box, or polygonal proposals to generate target mask results. Hence, we utilize gtboxes as prompts for HQ-SAM model to facilitate the generation of pixel-level predictions for the target object.


III METHODOLOGY
Firstly, we present the pipelines for high-performance box-supervised VIS and the acquisition of high-quality pseudo masks in Section III-A. Then, in Section III-B, we extend the pixel-supervised VIS method IDOL to the box-supervised VIS (IDOL-BoxInst) baseline and introduce the box-supervised VIS (PM-VIS). Next, in Sections III-C and III-D, we describe several approaches for generating pseudo masks based on box supervision, and strategies for improving the quality of pseudo masks, respectively. Lastly, in Section III-E, we describe two methods for filtering ground-truth data with the help of Track-masks-final.
III-A Pipelines
III-A1 High-performance box-supervised VIS
Fig. 4 illustrates the workflow of high-performance box-supervised VIS, involving a two-step strategy. In Step 1, we obtain a training set with high-quality pseudo masks by leveraging three segmentation models. In Step 2, the PM-VIS model is trained using a combination of box annotations and the aforementioned pseudo masks. Through these procedures, our PM-VIS model achieves SOTA performance.
III-A2 High-quality pseudo masks
The pipeline in Fig. 5 summarizes our method concisely for generating high-quality pseudo masks through two stages. In Stage 1, we employ IDOL-BoxInst and HQ-SAM to process the training dataset under box supervision, yielding two types of pseudo masks: IDOL-BoxInst-masks and HQ-SAM-masks. We establish correspondence between IDOL-BoxInst-masks and gtboxes by calculating SCM scores with the assistance of HQ-SAM-masks and gtboxes. Additionally, the proposed post-processing optimization strategy, DOOB, is applied to both types of pseudo masks obtained in Stage 1, resulting in refined pseudo masks. In Stage 2, we employ VOS model DeAOT to track instances in the video and obtain high-quality pseudo masks. At this stage, there are two points that we need to note specifically. Firstly, we initialize the model using pseudo masks from keyframes and subsequently track the pixel-level prediction information for the targets throughout the entire video. Among these, keyframes are selected from the positions of certain instance pseudo masks in IDOL-BoxInst-masks determined by the SCM scores calculated between IDOL-BoxInst-masks, HQ-SAM-masks, and gtboxes. Secondly, to further enhance pseudo mask quality, we calculate the confidence scores (SHQM) for HQ-SAM-masks, IDOL-BoxInst-masks, and Track-masks. Then, based on these scores, we choose the higher-quality pseudo masks from HQ-SAM-masks or IDOL-BoxInst-masks to substitute for the instance pseudo masks in the original Track-masks.
III-B Modules
III-B1 Projection Loss
The Projection Loss [12] utilizes gtbox annotation to supervise the horizontal and vertical projections of the predicted mask, enhancing the alignment between the predicted mask and the gtbox region. The Projection Loss is formulated as:
| (1) |
| (2) |
where represents the Dice loss defined in BoxInst [12], denotes either the horizontal or vertical axis, is the max operations along with each axis, corresponds to the predicted mask, and signifies the ground-truth box mask.
III-B2 Pairwise Affinity Loss
The Pairwise Affinity Loss [12] supervises pixel-level mask predictions without pixel-wise annotations by considering the color similarity between pixels. Specifically, for two pixels at coordinates and , their color similarity is denoted as . Here, and represent color vectors in the LAB color space, with as a hyper-parameter (default as 2). The color similarity threshold is set at 0.2, labeling the edges with similarity exceeding this threshold as 1. The network predicts as the probability of pixel being part of the foreground. Consequently, the probability for pairwise mask affinity is formulated as . The Pairwise Affinity Loss is defined as:
| (3) |
where is the set of edges containing at least one pixel in the box, and is the number of edges in . The indicator function if , and otherwise.
III-B3 Pseudo mask supervision loss
III-B4 IDOL-BoxInst and PM-VIS
The IDOL-BoxInst algorithm is a box-supervised VIS method that combines the principles of box-supervised losses [12] with the IDOL algorithm [2], effectively eliminating the need for mask annotations and related losses [16, 17]. PM-VIS is trained using a combination of spatio-temporal losses, including BoxInstLoss [12], which comprises Projection Loss and Pairwise Affinity Loss from BoxInst [12], as well as pixel-wise mask supervision losses (Focal loss [17] and Dice loss [16]), referred to as MaskLoss. PM-VIS adopts a weight configuration similar to that of IDOL and BoxInst, setting the weight (W1) for BoxInstLoss to 1 and the weight (W2) for MaskLoss to 0.5.
III-C Pseudo masks
Current VIS training datasets (YTVIS2019 [6], YTVIS2021 [7], and OVIS [8]) for box-supervised VIS include information such as target categories and bounding boxes, yet lacks pixel-level annotations for the designated targets. In the context of VIS, a model trained only with annotations of target bounding boxes typically exhibits diminished recognition capabilities compared to a model trained with mask annotations. Hence, by leveraging three models (HQ-SAM, IDOL-BoxInst, and DeAOT), we generate three types of pseudo masks (HQ-SAM-masks, IDOL-BoxInst-masks, and Track-masks) based on box annotations, further enhancing our VIS performance.
III-C1 HQ-SAM-masks
The HQ-SAM-masks, obtained by processing video frames based on the proposals of gtboxes using the HQ-SAM [15] model, serves as pseudo mask annotations for the training set. In this work, we train the PM-VIS model using pseudo-mask supervision on the mentioned datasets. We observe that the VIS performance is better with the use of pseudo masks compared to without using them. However, due to the limited quality of HQ-SAM-masks, the improvement is constrained.
III-C2 IDOL-BoxInst-masks
As illustrated in Fig. 5 (Stage 1), we generate another type of pseudo masks, namely IDOL-BoxInst-masks, in addition to the pseudo masks generated by the HQ-SAM model. The IDOL-BoxInst model, trained without mask annotations, generates these pseudo masks by predicting the targets in the training set. Nonetheless, the current pseudo masks obtained from this process exhibit several concerns: (i) the predicted masks might exhibit suboptimal quality and inherent errors, (ii) the labels corresponding to the predicted or tracked masks could be inaccurate, and (iii) multiple distinct masks may be independently predicted for the same target, resulting in pixel-level ambiguity and potentially compromising experimental precision. To address these challenges, we introduce an innovative predictive mask allocation and correction strategy called SCM (as described in Section III-D1) that aims at using HQ-SAM-masks to aid in establishing a coherent relationship between the predicted masks and gtboxes for certain instances. Additionally, we conduct an annotation quantity analysis and find that the number of instance annotations for IDOL-BoxInst-masks is relatively lower compared to the ground-truth datasets. Specifically, as shown in Fig. 6, the quantity of IDOL-BoxInst-masks obtained in our experiments is found to be 1.8%, 3.5%, and 7.3% lower than the number of instances annotated in the ground-truth for YTVIS2019, YTVIS2021, and OVIS, respectively.
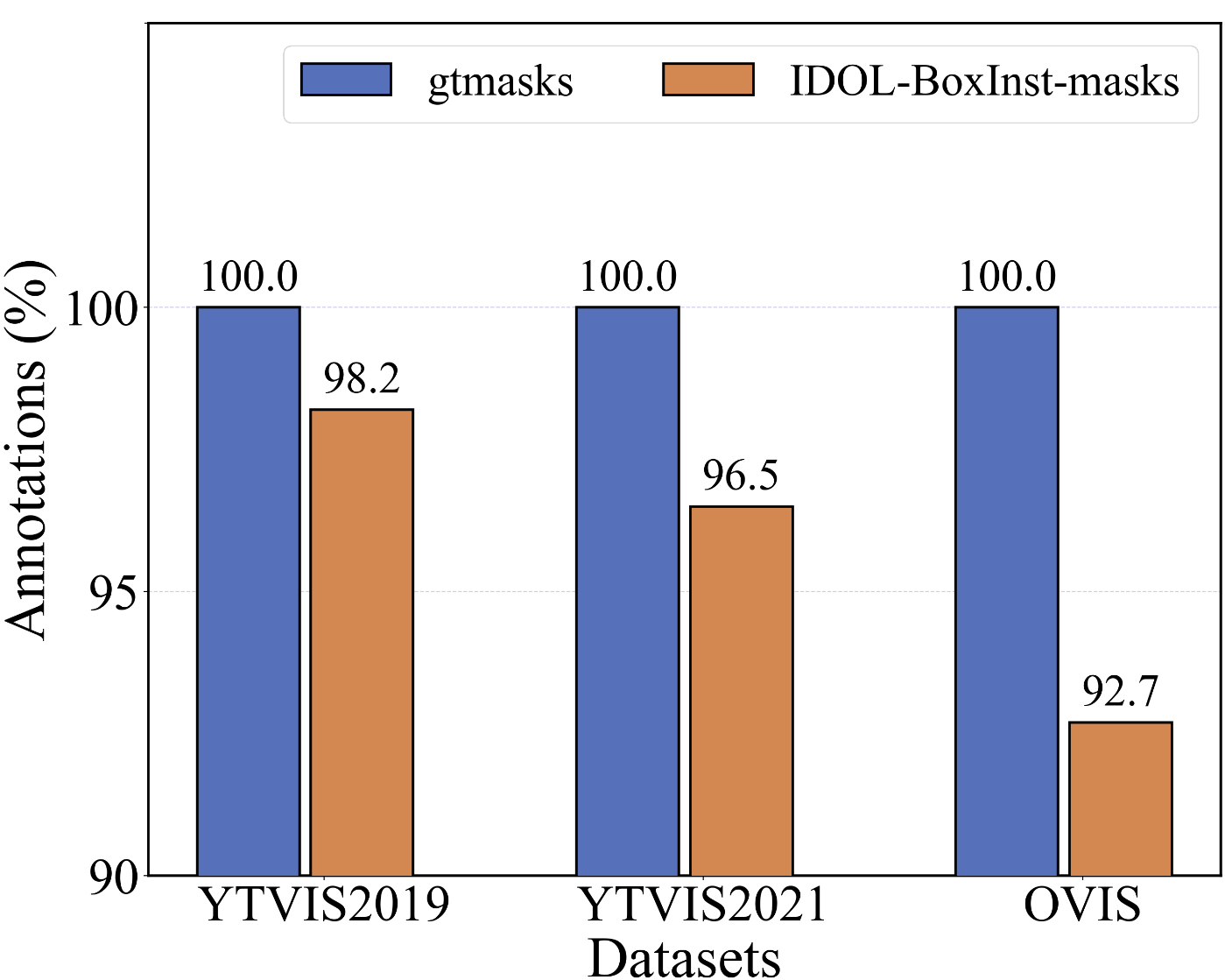
III-C3 Track-masks
As shown in Fig. 5 (Stage 2), Track-masks is a collection of pseudo masks obtained by initializing the semi-supervised VOS model DeAOT with instance mask annotations from IDOL-BoxInst-masks and tracking the instances throughout the entire video. Typically, semi-supervised VOS models require information about the target in the first frame of the video during prediction. However, for our task, the initial frame instance pseudo mask may not be optimal. To overcome this limitation, we propose a mechanism to initiate tracking from various positions in the video, progressing both forwards and backwards until reaching the start and end frames, respectively. Subsequently, the tracked results are amalgamated, and these starting positions are termed keyframes. Specifically, our procedure is as follows: firstly, we employ the SCM method to create a collection of high-quality keyframes from the IDOL-BoxInst-masks. Secondly, we obtain the pseudo mask collection, Track-masks, by feeding the annotations from these keyframes into the DeAOT model for prediction. Finally, we employ two methods to further enhance the quality of Track-masks. These methods involve expanding the keyframes for each instance from one to and selecting high-quality pseudo masks for optimizing Track-masks from both IDOL-Boxlnst-masks and HQ-SAM-masks using the SHQM method. Here, denotes the video length, and we configure as a hyper-parameter, setting it to be 10 for YTVIS2019/YTVIS2021 and 100 for OVIS.
III-D Strategies
As shown in Fig. 5 and Fig. 7, to acquire high-quality pseudo masks, we propose two confidence assessment methods, SCM and SHQM, along with a post-processing technique, DOOB. SCM is employed to identify the most suitable gtboxes for the targets in the frames, assisted by HQ-SAM-masks, both for refining the masks predicted by the IDOL-BoxInst model and for selecting a specific number of keyframes. SHQM serves to choose superior-quality pseudo masks from HQ-SAM-masks, IDOL-BoxInst-masks, and Track-masks, thereby reassembling them into the highest-quality pseudo mask collection, Track-masks-final. Meanwhile, DOOB functions as a post-processing mechanism to rectify erroneous areas within HQ-SAM-masks and IDOL-BoxInst-masks.
III-D1 SCM
We present a methodology to quantify the correlation between pseudo masks, as shown in Eq. (4). Let and denote two distinct types of pseudo masks. We calculate the IoU between these masks and also compute the IoU [37] between the bounding boxes of these masks and the gtbox. The combination of these three factors generates a score, denoted as the Score of Corresponding Mask (SCM), signifying the relationship between the two pseudo masks.
| (4) |
| (5) |
where represents the bounding box of a given pseudo mask, represents the calculation of IoU, while denotes the ground-truth bounding box of the target.
III-D2 SHQM
We introduce another technique called SHQM for Selecting the High-Quality Masks among the three variants: HQ-SAM-masks, IDOL-BoxInst-masks, and Track-masks. This method establishes a composite connection between each pseudo mask and the gtbox, generating confidence scores for every pseudo mask. The pseudo mask attaining the highest score, labeled as , indicates the superior-quality pseudo mask.
| (6) |
| (7) |
| (8) |
This relationship is established through the assessment of the SCM denoted as between different pairs of pseudo masks and , where and are members of the set and are distinct from each other. is equal to here.
III-D3 DOOB
After analyzing the pseudo mask datasets, two significant issues in the predicted masks have become evident: (i) overlapping occurrences between distinct predicted masks within the same frame, and (ii) the expansion of predicted masks beyond the boundaries of the corresponding gtbox, as illustrated in Fig. 7. To address these concerns and enhance the accuracy of the pseudo mask training dataset, we introduce an optimization approach named DOOB, which involves Deleting the Overlapping and Out-of-Boundary sections. Specifically, the strategy ascertains ownership of overlapping regions by computing the bounding rectangle of the overlapping mask and gauging the IoU [37] value with the associated gtbox. Subsequently, it eliminates mask annotations for the current target that exceed a reasonable range determined by the gtbox.

III-E Filter Methods
Evidently, there is a noticeable gap between the current pseudo mask data and the ground-truth data. Through analysis, it has been observed that, in addition to the quality differences in individual instance mask annotations, there is also an issue of instance mask annotations absence, as demonstrated in Fig. 6. This outcome can be attributed to two primary factors. Firstly, the limited recognition capability of the IDOL-BoxInst model makes it unable to fully identify all instances in the video. Secondly, in the process of assigning ownership through IoU calculations between IDOL-BoxInst-masks and predicted masks, instances may be wrongly allocated to other instances due to suboptimal quality in either the predicted masks or HQ-SAM-masks. Therefore, we surmise that these missing annotations might also pose challenges for the algorithm, potentially leading to misleading guidance. Following experimental results demonstrate that these missing instances do have a negative effect on the performance, so we exclude the information about these missing instances from Track-masks. Besides, during the training of the fully supervised model using ground-truth data, we exclude the mapping annotations for these missing instances, and this operation improves Mask Average Precision (AP) of our model.
An undeniable fact is that the quality of pseudo masks exhibits noticeable deficiencies compared to ground truth data, and in weakly supervised tasks, these shortcomings undoubtedly constrain algorithm performance. However, in a fully supervised task, these deficiencies might play a facilitating role. Therefore, to fully harness the potential of pseudo masks, we propose utilizing them to filter the ground truth data.
III-E1 Missing-Data

During the experiments, it becomes apparent that the number of Track-masks is lower than that of the ground-truth data. Upon visualization, as depicted in Fig. 8, we identify several issues with these missing data, including indistinct instance features, low discriminability of instances from surrounding objects or the environment, and severe occlusions. Thus, we propose a filtering method named Missing-Data to remove unnecessary Missing Data from the ground-truth. Specifically, this method leverages our proposed pseudo mask set, Track-masks-final, as a reference to eliminate corresponding discrepancies in the ground-truth data, resulting in a ground-truth dataset of the same size as Track-masks-final.
III-E2 RIA

Our pseudo masks have substantially improved the performance of weakly supervised VIS. However, it’s inevitable that the pseudo mask data we obtained, Track-masks-final, still exhibit disparities in instance segmentation quality compared to the ground-truth, as shown in Fig. 9. Specifically, Track-masks-final tends to struggle with small, complex, and less distinct instances. While this issue poses a challenge in weakly supervised settings, it can be reframed as an optimization problem when considered under fully supervised conditions. Therefore, we propose a method called RIA. This method involves calculating the mask IoU between gtmasks and Track-masks-final data to map and Remove Instance Annotations in the ground-truth with relatively low mask IoU values. As illustrated in Fig. 9 (gtmasks), datasets characterized by lower IoU values frequently encounter challenges, including inconspicuous features and severe occlusions. Consequently, this refinement and optimization process enhances the quality of the ground-truth data, yielding a more compact yet higher-quality dataset.
IV Experiments
IV-A Datasets and Metrics
The proposed approach in this paper involves datasets for two distinct tasks: YTVIS2019 [6], YTVIS2021 [7], and OVIS [8] for VIS, as well as YTVOS18 [38], YTVOS19 [39] and DAVIS [40] for VOS.
IV-A1 VIS
YTVIS2019, a subset of YTVOS18/19, comprises 2883 videos, 40 categories, 4483 objects, and over 130k annotations. YTVIS2021, an improved version of YTVIS2019, has expanded its dataset, refined the 40-category label set, and thus partially overlaps with YTVOS18/19. OVIS, one of the most challenging datasets in the VIS domain, presents significant hurdles. Instances within OVIS exhibit severe occlusion, intricate motion patterns, and rapid deformations. The dataset consists of 607 training videos and 140 validation videos, with notably extended video durations averaging 12.77 seconds. Regarding VIS evaluation, we employ standard metrics such as AP, AP50 (Average Precision at 50% IoU), AP75 (Average Precision at 75% IoU), AR1 (Average Recall at 1), and AR10 (Average Recall at 10).
IV-A2 VOS
YTVOS18/19 and YTVIS2019/2021 represent two distinct datasets utilized for VOS and VIS tasks, respectively. However, in terms of data sources, all data from YTVIS2019 and some data from YTVIS2021 belong to YTVOS18/19. In this paper, we use DeAOT as a tracking model to obtain pseudo masks. To ensure the credibility of our task and avoid the impact of overlapping data, we exclude the overlapping data when retraining DeAOT using data from YTVOS18/19, as shown in Table II. The overlapping data between YTVIS2019/2021 and YTVOS18/19 accounts for 64.5% of the data in YTVOS18/19, while the non-overlapping data accounts for 35.5%. As for VOS evaluation, we adopt the evaluation approach from the DeAOT algorithm, including metrics like the region similarity , the contour accuracy , and their mean value (referred to as ).
| YTVIS2019 | YTVIS2021 | YTVOS18/19 | |
|---|---|---|---|
| YTVIS19 | 2238 / 100.0% | - | - |
| YTVIS21 | 2191 / 73.4% | 2985 / 100.0% | - |
| YTVOS18/19 | 2238 / 64.5% | 2191 / 63.1% | 3471 / 100.0% |
IV-B Implementation Details
For VOS, we fully follow the configuration in the previous DeAOT [18] algorithm. For VIS, unless otherwise stated, we employ the same hyper-parameters as IDOL [2], which is implemented on top of Detectron2 [41]. All our VIS models have been pre-trained on the COCO [42] image instance segmentation dataset with pixel-wise annotations.
Model Settings. Apart from integrating the two box-supervised segmentation loss terms from BoxInst [12], our proposed algorithm only applies necessary adjustments to the weights of mask losses [16, 17] from IDOL. The training and testing details are kept as similar as possible to the original IDOL [2]. Unless specified otherwise, we use ResNet-50 [43] as the backbone.
Training. Our training process has been meticulously aligned with IDOL [2], covering aspects such as the optimizer, weight decay, and the utilization of the COCO pre-trained model provided by IDOL. For YTVIS2019/2021 datasets, we perform downscaling and random cropping on input frames to ensure that the longest side measures no more than 768 pixels. For OVIS, when using the ResNet-50 backbone, we keep the same configuration as training IDOL. When using the Swin Large [44] (Swin-L) backbone, we resize input images to ensure that the shortest side falls within a range of 480 to 736 pixels, and the longest side remains below 736 pixels. Training is conducted on 4 RTX3090 GPUs, each with 24GB of RAM, allocating at least 2 frames per GPU.
Inference. During inference, the input frames are downscaled to 360 pixels for YTVIS2019/2021 following IDOL, and 720 pixels for OVIS, given its videos have a higher resolution. Regarding hyper-parameters, we default to following the specifications outlined in IDOL.
IV-C Ablation study
In our ablation studies on the YTVIS2019 validation set, ResNet-50 is employed as the backbone architecture.
| W1 | AP | AP50 | AP75 | AR1 | AR10 |
|---|---|---|---|---|---|
| 0 | 46.6 | 72.5 | 50.4 | 43.7 | 53.0 |
| 0.5 | 47.3 | 71.9 | 51.0 | 44.2 | 54.9 |
| 1 | 48.7 | 73.4 | 52.4 | 45.2 | 55.3 |
| 1.5 | 46.9 | 71.8 | 50.3 | 44.5 | 55.9 |
| W2 | AP | AP50 | AP75 | AR1 | AR10 |
|---|---|---|---|---|---|
| 0 | 44.8 | 71.2 | 48.3 | 41.8 | 52.9 |
| 0.3 | 47.4 | 72.2 | 51.4 | 43.9 | 54.9 |
| 0.5 | 48.7 | 73.4 | 52.4 | 45.2 | 55.3 |
| 0.8 | 47.9 | 72.8 | 51.6 | 45.5 | 56.6 |
| 1 | 47.0 | 72.1 | 50.5 | 44.7 | 55.2 |
| Method | AP | AP50 | AP75 | AR1 | AR10 |
| HQ-SAM-masks | 46.8 | 72.3 | 49.9 | 45.3 | 55.3 |
| +DOOB | 46.8 | 73.4 | 51.5 | 43.5 | 53.8 |
| IBM+SCM | 45.7 | 72.8 | 47.9 | 43.6 | 53.9 |
| IBM+SCM+DOOB | 46.9 | 73.2 | 49.8 | 45.3 | 55.4 |
| Track-masks | 48.2 | 72.8 | 51.7 | 44.8 | 55.9 |
| +SHQM | 47.4 | 72.9 | 51.6 | 44.2 | 54.8 |
| +multiframe+SHQM | 48.7 | 73.4 | 52.4 | 45.2 | 55.3 |
| Method | Sup. | Pseudo masks | AP |
|---|---|---|---|
| PM-VIS | Pixel | IDOL-BoxInst-masks | 48.7 |
| Track-masks-final | 50.0 |
| Method | Sup. | BoxInstLoss | AP |
|---|---|---|---|
| IDOL† | Pixel | ✗ | 47.7 |
| PM-VIS | ✓ | 50.0 |
| Method | Sup. | Missing-Data | RIA | AP |
|---|---|---|---|---|
| IDOL-BoxInst | Box | ✗ | ✗ | 43.9 |
| ✓ | ✗ | 44.8 | ||
| PM-VIS | Pixel | ✗ | ✗ | 49.1 |
| ✓ | ✗ | 49.3 | ||
| ✓ | ✓ | 50.0 |
| Method | Sup. | AP | |
|---|---|---|---|
| PM-VIS | Pixel | 0 | 49.3 |
| 0.5 | 49.7 | ||
| 0.6 | 50.0 | ||
| 0.7 | 48.2 | ||
| 0.8 | 47.2 |
| Method | Sup. | YTVIS2019 | YTVIS2021 | OVIS | ||||||||||||
| AP | AP50 | AP75 | AR1 | AR10 | AP | AP50 | AP75 | AR1 | AR10 | AP | AP50 | AP75 | AR1 | AR10 | ||
| Mask2Former [1] | Pixel | 47.8 | 69.2 | 52.7 | 46.2 | 56.6 | 40.6 | 60.9 | 41.8 | - | - | 17.3 | 37.3 | 15.1 | 10.5 | 23.5 |
| SeqFormer [21] | Pixel | 47.4 | 69.8 | 51.8 | 45.5 | 54.8 | 40.5 | 62.4 | 43.7 | 36.1 | 48.1 | 15.1 | 31.9 | 13.8 | 10.4 | 27.1 |
| IDOL [2] | Pixel | 49.5 | 74.0 | 52.9 | 47.7 | 58.7 | 43.9 | 68.0 | 49.6 | 38.0 | 50.9 | 30.2 | 51.3 | 30.0 | 15.0 | 37.5 |
| IDOL† [2] | Pixel | 49.0 | 72.2 | 54.8 | 46.4 | 57.3 | 46.6 | 70.2 | 50.6 | 40.5 | 56.0 | 29.4 | 50.6 | 30.9 | 14.9 | 37.7 |
| VITA [3] | Pixel | 49.8 | 72.6 | 54.5 | 49.4 | 61.0 | 45.7 | 67.4 | 49.5 | 40.9 | 53.6 | 19.6 | 41.2 | 17.4 | 11.7 | 26.0 |
| PM-VIS | Pixel | 50.0 | 73.6 | 54.5 | 46.5 | 57.1 | 47.7 | 70.6 | 52.6 | 41.2 | 55.8 | 29.9 | 54.0 | 30.7 | 14.2 | 38.0 |
| MaskFreeVIS [9] | Box | 46.6 | 72.5 | 49.7 | 44.9 | 55.7 | 40.9 | 65.8 | 43.3 | 37.1 | 50.5 | 15.7 | 35.1 | 13.1 | 10.1 | 20.4 |
| IDOL-BoxInst | Box | 43.9 | 71.0 | 47.8 | 42.9 | 52.7 | 41.8 | 67.4 | 43.5 | 36.5 | 50.3 | 25.4 | 47.4 | 23.7 | 12.9 | 32.7 |
| PM-VIS | Box | 48.7 | 73.4 | 52.4 | 45.2 | 55.3 | 44.6 | 69.5 | 49.0 | 38.9 | 52.1 | 27.8 | 48.5 | 27.4 | 13.6 | 36.0 |
| Method | Sup. | YTVIS2019 | YTVIS2021 | OVIS | ||||||||||||
| AP | AP50 | AP75 | AR1 | AR10 | AP | AP50 | AP75 | AR1 | AR10 | AP | AP50 | AP75 | AR1 | AR10 | ||
| Mask2Former [1] | Pixel | 60.4 | 84.4 | 67.0 | - | - | 52.6 | 76.4 | 57.2 | - | - | 26.4 | 50.2 | 26.9 | - | - |
| SeqFormer [21] | Pixel | 59.3 | 82.1 | 66.4 | 51.7 | 64.4 | 51.8 | 74.6 | 58.2 | 42.8 | 58.1 | - | - | - | - | - |
| IDOL [2] | Pixel | 64.3 | 87.5 | 71.0 | 55.6 | 69.1 | 56.1 | 80.8 | 63.5 | 45.0 | 60.1 | 42.6 | 65.7 | 45.2 | 17.9 | 49.6 |
| IDOL† [2] | Pixel | 62.7 | 86.4 | 68.8 | 54.9 | 67.6 | 59.1 | 82.9 | 64.5 | 46.9 | 63.9 | 40.9 | 65.9 | 42.9 | 17.6 | 48.2 |
| PM-VIS | Pixel | 63.0 | 86.9 | 70.0 | 54.5 | 66.9 | 59.2 | 82.3 | 64.9 | 46.5 | 63.0 | 41.0 | 65.6 | 41.7 | 17.6 | 48.3 |
| MaskFreeVIS [9] | Box | 55.3 | 82.5 | 60.8 | 50.7 | 62.2 | - | - | - | - | - | - | - | - | - | - |
| IDOL-BoxInst | Box | 56.5 | 83.3 | 64.1 | 49.7 | 61.3 | 53.2 | 79.7 | 59.6 | 43.0 | 58.1 | 32.2 | 55.7 | 31.9 | 15.8 | 38.5 |
| PM-VIS | Box | 59.7 | 84.8 | 67.7 | 52.3 | 64.3 | 55.8 | 80.6 | 61.8 | 44.4 | 60.2 | 37.5 | 62.6 | 37.5 | 16.8 | 43.9 |
IV-C1 Effect of the BoxInstLoss weight (W1)
Although the pseudo masks we use provide a representation of the target within a specific range, they still exhibit limitations in accurately delineating the target. Issues such as significant pixel color variations across different parts of the target and color similarities among distinct targets pose challenges to the precision of target mask annotations. To address this problem, we introduce BoxInstLoss, a technique that leverages inter-pixel information. On one hand, this approach compensates for the incompleteness in capturing target boundaries. On the other hand, it addresses imprecision in target mask annotation by capitalizing on color similarities between pixels. In Table III, we investigate the impact of the weight W1 of BoxInstLoss on VIS AP when training the model with pseudo masks. The best result is achieved at W1 = 1, while setting W1 = 0 means that the algorithm does not utilize BoxInstLoss. Our algorithm achieves a 2.1% increase in AP, reaching 48.7%, when using BoxInstLoss.
IV-C2 Effect of the MaskLoss weight (W2)
Table IV demonstrates the influence of the weight (W2) assigned to MaskLoss on the algorithm. The optimal result is achieved with W2 = 0.5, whereas setting W2 = 0 means excluding MaskLoss and pseudo masks. The results indicate a noteworthy enhancement in performance with the incorporation of pseudo masks, resulting in a 3.9% increase in AP, elevating it to 48.7%. While BoxInstLoss, built upon bounding boxes, partly simulates real mask effects, this weakly supervised approach lacks object shape information and can be susceptible to object color variations. Consequently, its performance distinctly deviates from ground-truth conditions. Certainly, our proposed pseudo masks, by providing a rough contour of the object, enhance the algorithm’s discernment of object characteristics such as shape, position, and size, thereby contributing to the algorithm’s overall performance.
IV-C3 Effect of pseudo masks for box-supervised VIS
Table V presents a comparison of various pseudo masks under the PM-VIS algorithm. It is evident from the AP performances of the three pseudo masks variants in the PM-VIS algorithm that Track-masks-final exhibits superior quality, achieving 48.7% AP, while HQ-SAM-masks performs less favorably, attaining 46.8% AP. For HQ-SAM-masks and IDOL-BoxInst-masks, we effectively address the issues of overlap and out-of-bounds in the initial pseudo masks using the DOOB strategy. When applied to IDOL-BoxInst-masks, this strategy improves the AP performance by 1.2%, reaching 46.9%. When considering the highest-quality pseudo masks, Track-masks-final, the application of the SHQM method for single-keyframe tracking does not result in an improved algorithm performance. In fact, it leads to a 0.8% decrease in AP. This outcome can be attributed to the predominance of IDOL-BoxInst-masks and HQ-SAM-masks in terms of quantity. The SHQM method, when selecting pseudo masks, appears to be misled by these lower-quality pseudo masks, inadvertently introducing a surplus of unnecessary errors. Conversely, in the context of multi-keyframe tracking, the resultant pseudo masks consist of multiple sets of relatively high-quality masks. When selecting pseudo masks using the SHQM method in this scenario, it introduces a significant number of better-quality tracking masks. This leads to a 0.5% relative increase in AP compared to single-frame scenarios, ultimately reaching an optimal level of 48.7% AP.
IV-C4 Effect of pseudo masks for fully supervised VIS
Among the two types of pseudo masks with an equal number of instance annotations, IDOL-BoxInst-masks and Track-masks-final, the annotation quality of IDOL-BoxInst-masks is observed to be lower than that of Track-masks-final, as evident from the results of weak supervision. In some cases, there are instances that are expected to be recognized or segmented more effectively by weak supervision methods, but the results in IDOL-BoxInst-masks are less satisfactory. On the other hand, Track-masks-final recognizes fewer of these instances. As shown in Table VI, we conduct a comparative analysis of the results obtained when using these two types of pseudo masks as aids in filtering ground-truth data. The results show that training with PM-VIS on ground-truth data filtered with the assistance of Track-masks-final outperforms IDOL-BoxInst-masks by 1.3%, achieving an AP of 50.0%.
IV-C5 Effect of BoxInstLoss for fully supervised VIS
Table VII presents the performance of our PM-VIS algorithm compared to the IDOL algorithm without BoxInstLoss on ground-truth data. The training set used here comprises YTVIS2019 ground-truth data that has undergone two filtering methods: Missing-Data and RIA. These results showcase the algorithm performance on YTVIS2019 VAL. The introduction of BoxInstLoss in our algorithm is primarily motivated by its ability to examine instance segmentation from a pixel similarity perspective. Therefore, we believe that it can still be effective in a fully supervised scenario. As observed, with the inclusion of BoxInstLoss, our algorithm demonstrates a notable 2.3% increase in AP, reaching 50.0%.
IV-C6 Effect of Missing-Data and RIA
Table VIII illustrates the impact of two filtering and optimization methods, Missing-Data and RIA, on algorithm performance. It’s evident that the current algorithms struggle to handle the issues present in the filtered-out data. When training the IDOL-BoxInst model using all ground-truth data without any pixel-level annotations, we notice that the algorithm AP decreases by 0.9% compared to when the missing data is not used. Training the PM-VIS model on ground-truth data filtered only by Missing-Data leads to a slight improvement in AP, with a 0.2% increase compared to using all ground-truth data. Furthermore, when training the PM-VIS model on ground-truth data filtered using both methods, the trained model achieves a significant increase in AP, improving by 0.9% to reach 50.0%.
IV-C7 Effect of various mask IoU thresholds () on the RIA
Table IX presents the impact of different mask IoU thresholds on RIA regarding algorithm performance. These thresholds are determined by calculating mask IoU between Track-masks-final and ground-truth data. When is set to 0, it indicates that this filtering method is not applied, whereas greater than 0 signifies the removal of instance annotations from ground-truth data when their mask IoU values fall below . It is worth to note that the mask IoU is computed between these pseudo masks and ground-truth data because lower mask IoU values correspond to lower mask quality. Despite employing various fusion strategies, enhancing the quality of these instance pseudo masks proves challenging. Consequently, we can conclude that these instances are difficult to identify in certain video frames. Removing them has the potential to improve algorithm performance. In our experiments, setting to 0.6 leads to a 0.7% improvement in the algorithm AP compared to not using this filtering method, achieving a performance level of 50.0%.

IV-D Comparison with SOTA methods
We have compared the PM-VIS model trained without using the gtmasks with SOTA weakly supervised methods using ResNet-50 and Swin Large backbones on YTVIS2019, YTVIS2021, and OVIS datasets. Furthermore, we compare the performance of the PM-VIS model trained using the filtered ground-truth data with other fully supervised VIS algorithms. The results are presented in Table X and Table XI.
IV-D1 ResNet-50 backbone
As shown in Table X, it is apparent that with the ResNet-50 backbone, our basic IDOL-BoxInst model, trained solely on box annotations, underperforms MaskFreeVIS [9] by a margin of 2.7% AP on YTVIS2019. Upon the incorporation of pseudo masks into the PM-VIS algorithm, we observe a noteworthy 4.8% improvement in AP compared to IDOL-BoxInst. Moreover, this enhancement outperforms the performance of the only box-supervised VIS algorithm, MaskFreeVIS, by 2.1%, achieving an outstanding AP of 48.7%. Similarly, on the YTVIS2021 and OVIS datasets, our IDOL-BoxInst algorithm achieves competitive results, surpassing the MaskFreeVIS and even outperforming some fully supervised VIS algorithms. After integrating pseudo masks into the PM-VIS algorithm, we surpass all box-supervised VIS algorithms, outperforming MaskFreeVIS by 3.7% and 12.1%, thus establishing a new SOTA.
Furthermore, training the PM-VIS model using ground-truth data filtered with pseudo masks also yields improved results for three primary reasons. Firstly, the BoxInstLoss enhances mask segmentation precision by extending constraints to both bounding box ranges and pixel similarity. Secondly, a thorough examination, including visual inspection and model performance analysis, demonstrates that the quality of the acquired pseudo masks (Track-masks-final) is approaching that of gtmasks. Thus, the main factor affecting weakly supervised performance appears to be the presence of low-quality instance mask annotations. The application of our proposed filtering methods (Missing-Data and RIA) retains higher-quality, less ambiguous data. Finally, especially for models employing backbone with limited feature extraction capabilities like ResNet-50, the presence of distinct instance features allows the algorithm to efficiently and accurately acquire necessary information, minimizing the need for extensive feature learning and resulting in faster, more precise utilization of the acquired information. When training the PM-VIS model on the filtered ground-truth data, the AP surpasses IDOL† on all three datasets, achieving 50.0%, 47.7%, and 29.9% on each, respectively. It’s evident that our collection of pseudo masks not only enhances the performance of box-supervised VIS but also contributes to an improvement in fully supervised VIS to a certain extent.
IV-D2 Swin Large backbone
As presented in Table XI, we also conduct experiments using Swin-L as the backbone on YTVIS2019, YTVIS2021 and OVIS. The comparison reveals that our algorithm PM-VIS outperforms the basic IDOL-BoxInst by 3.2%, 2.6%, and 5.3% on the respective datasets. Similarly, we also surpass MaskFreeVIS by 4.4% on the YTVIS2019 dataset, establishing a new SOTA for box-supervised VIS algorithms. The outstanding performance significantly narrows the performance gap between fully supervised and weakly supervised VIS methods.
Furthermore, in theory, training the PM-VIS model with filtered ground-truth data will also result in performance exceeding IDOL† with the Swin-L backbone. As our analysis during the training of models with ResNet-50 suggests, stronger backbones, such as Swin-L, possess a greater ability to extract information from ambiguous or low-quality instance segmentation annotations. When utilizing the Swin-L backbone, the model will extract target information from the data more precisely. This implies that by using less data, specifically excluding non-essential data from the dataset, the model can still achieve or even surpass the performance obtained by using the entire dataset. We train the PM-VIS model using Swin-L backbone on the same filtered ground-truth data used for training with ResNet-50 backbone, and the model consistently delivers the expected performance. Specifically, on the YTVIS2019, YTVIS2021, and OVIS datasets, the fully supervised VIS model, PM-VIS, outperforms IDOL† in terms of AP, achieving 63.0%, 59.2%, and 41.0%, respectively. This illustrates that our pseudo masks enhance the performance of weakly supervised algorithms and lead to improvements in fully supervised scenarios, regardless of whether a stronger or weaker backbone is employed.
IV-E Visualization
Fig. 10 illustrates different mask visualization examples. HQ-SAM-masks generated by HQ-SAM shows poor segmentation quality and noticeable errors, making them less effective compared to other pseudo masks. IDOL-BoxInst-masks, assisted by HQ-SAM-masks, demonstrates improved quality and accuracy by aligning with corresponding gtboxes and better capturing target shapes, as shown in the figure. Track-masks-final represents a high-quality pseudo mask collection selected from three sources: HQ-SAM-masks, IDOL-BoxInst-masks, and the original Track-masks. PM-VIS employs pseudo mask information from Track-masks-final, refining it through training to effectively enhance recognition accuracy. It’s worth noting that from the figures, we can observe that the predictions of our weakly supervised algorithm PM-VIS closely resemble those of the gtmasks.
V Conclusion
Despite the substantial performance improvement, contemporary VIS algorithms encounter the constraint of high costs in annotating for instances and inadequate training data for real-world applications. As a result, weakly supervised methods have emerged. While the single-step methods, which solely utilize box annotations for model training, have achieved notable results, there still exists a significant gap compared to fully supervised methods. In this paper, we introduce a novel two-step approach that leverages high-performance models to generate instance pseudo masks and trains the VIS model with these pseudo masks and box annotations. Firstly, we introduce three effective methods for generating target pixel-level mask information utilizing HQ-SAM, IDOL-BoxInst and DeAOT models based on object box annotations. Secondly, we introduce three pseudo mask refinement methods, namely SCM, SHQM, and DOOB, designed to achieve higher-quality pseudo masks based on model characteristics and pseudo mask attributes. Subsequently, utilizing the training dataset improved with these pseudo masks, we train the proposed PM-VIS model without using gtmasks, which demonstrates SOTA performance in YTVIS2019, YTVIS2021 and OVIS. Furthermore, by capitalizing on the characteristics of pseudo masks, we introduce the use of pseudo masks as auxiliary tools for filtering ground-truth data. These filtering methods, named Missing-Data and RIA, are employed to eliminate challenging instance annotations. As a result, when the PM-VIS model is trained on the filtered ground-truth dataset, it exhibits a significant improvement in recognition performance over the baseline. We believe that our contributions and insights will serve as valuable inspiration for future applications and research in both fully supervised and weakly supervised approaches.
References
- [1] B. Cheng, A. Choudhuri, I. Misra, A. Kirillov, R. Girdhar, and A. G. Schwing, “Mask2former for video instance segmentation,” arXiv preprint arXiv:2112.10764, 2021.
- [2] J. Wu, Q. Liu, Y. Jiang, S. Bai, A. Yuille, and X. Bai, “In defense of online models for video instance segmentation,” in European Conference on Computer Vision. Springer, 2022, pp. 588–605.
- [3] M. Heo, S. Hwang, S. W. Oh, J.-Y. Lee, and S. J. Kim, “Vita: Video instance segmentation via object token association,” Advances in Neural Information Processing Systems, vol. 35, pp. 23 109–23 120, 2022.
- [4] M. Heo, S. Hwang, J. Hyun, H. Kim, S. W. Oh, J.-Y. Lee, and S. J. Kim, “A generalized framework for video instance segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 14 623–14 632.
- [5] T. Hannan, R. Koner, M. Bernhard, S. Shit, B. Menze, V. Tresp, M. Schubert, and T. Seidl, “Gratt-vis: Gated residual attention for auto rectifying video instance segmentation,” arXiv preprint arXiv:2305.17096, 2023.
- [6] L. Yang, Y. Fan, and N. Xu, “Video instance segmentation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 5188–5197.
- [7] L. Yang, Y. Fan, Y. Fu, and N. Xu, “The 3rd large-scale video object segmentation challenge - video instance segmentation track,” Jun. 2021.
- [8] J. Qi, Y. Gao, Y. Hu, X. Wang, X. Liu, X. Bai, S. Belongie, A. Yuille, P. H. Torr, and S. Bai, “Occluded video instance segmentation: A benchmark,” International Journal of Computer Vision, vol. 130, no. 8, pp. 2022–2039, 2022.
- [9] L. Ke, M. Danelljan, H. Ding, Y.-W. Tai, C.-K. Tang, and F. Yu, “Mask-free video instance segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 857–22 866.
- [10] T. Cheng, X. Wang, S. Chen, Q. Zhang, and W. Liu, “Boxteacher: Exploring high-quality pseudo labels for weakly supervised instance segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 3145–3154.
- [11] X. Wang, J. Feng, B. Hu, Q. Ding, L. Ran, X. Chen, and W. Liu, “Weakly-supervised instance segmentation via class-agnostic learning with salient images,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10 225–10 235.
- [12] Z. Tian, C. Shen, X. Wang, and H. Chen, “Boxinst: High-performance instance segmentation with box annotations,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 5443–5452.
- [13] S. Lan, Z. Yu, C. Choy, S. Radhakrishnan, G. Liu, Y. Zhu, L. S. Davis, and A. Anandkumar, “Discobox: Weakly supervised instance segmentation and semantic correspondence from box supervision,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3406–3416.
- [14] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” arXiv preprint arXiv:2304.02643, 2023.
- [15] L. Ke, M. Ye, M. Danelljan, Y. Liu, Y.-W. Tai, C.-K. Tang, and F. Yu, “Segment anything in high quality,” arXiv preprint arXiv:2306.01567, 2023.
- [16] F. Milletari, N. Navab, and S.-A. Ahmadi, “V-net: Fully convolutional neural networks for volumetric medical image segmentation,” in 2016 fourth international conference on 3D vision (3DV). Ieee, 2016, pp. 565–571.
- [17] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2980–2988.
- [18] Z. Yang and Y. Yang, “Decoupling features in hierarchical propagation for video object segmentation,” Advances in Neural Information Processing Systems, vol. 35, pp. 36 324–36 336, 2022.
- [19] B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1290–1299.
- [20] X. Li, H. Yuan, W. Zhang, G. Cheng, J. Pang, and C. C. Loy, “Tube-link: A flexible cross tube baseline for universal video segmentation,” arXiv preprint arXiv:2303.12782, 2023.
- [21] J. Wu, Y. Jiang, S. Bai, W. Zhang, and X. Bai, “Seqformer: Sequential transformer for video instance segmentation,” in European Conference on Computer Vision. Springer, 2022, pp. 553–569.
- [22] G. Bertasius and L. Torresani, “Classifying, segmenting, and tracking object instances in video with mask propagation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9739–9748.
- [23] H. Lin, R. Wu, S. Liu, J. Lu, and J. Jia, “Video instance segmentation with a propose-reduce paradigm,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1739–1748.
- [24] X. Li, J. Wang, X. Li, and Y. Lu, “Video instance segmentation by instance flow assembly,” IEEE Transactions on Multimedia, vol. 25, pp. 7469–7479, 2023.
- [25] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision. Springer, 2020, pp. 213–229.
- [26] D.-A. Huang, Z. Yu, and A. Anandkumar, “Minvis: A minimal video instance segmentation framework without video-based training,” Advances in Neural Information Processing Systems, vol. 35, pp. 31 265–31 277, 2022.
- [27] X. Li, H. He, Y. Yang, H. Ding, K. Yang, G. Cheng, Y. Tong, and D. Tao, “Improving video instance segmentation via temporal pyramid routing,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 5, pp. 6594–6601, 2023.
- [28] K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2961–2969.
- [29] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,” arXiv preprint arXiv:2010.04159, 2020.
- [30] T. Zhou, S. Wang, Y. Zhou, Y. Yao, J. Li, and L. Shao, “Motion-attentive transition for zero-shot video object segmentation,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 13 066–13 073.
- [31] M. Siam, R. Karim, H. Zhao, and R. Wildes, “Multiscale memory comparator transformer for few-shot video segmentation,” arXiv preprint arXiv:2307.07812, 2023.
- [32] S. Ren, W. Liu, Y. Liu, H. Chen, G. Han, and S. He, “Reciprocal transformations for unsupervised video object segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 15 455–15 464.
- [33] W. Liu, G. Lin, T. Zhang, and Z. Liu, “Guided co-segmentation network for fast video object segmentation,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 4, pp. 1607–1617, 2021.
- [34] H. K. Cheng and A. G. Schwing, “Xmem: Long-term video object segmentation with an atkinson-shiffrin memory model,” in European Conference on Computer Vision. Springer, 2022, pp. 640–658.
- [35] Z. Yang, Y. Wei, and Y. Yang, “Associating objects with transformers for video object segmentation,” Advances in Neural Information Processing Systems, vol. 34, pp. 2491–2502, 2021.
- [36] Y. Chen, D. Zhang, Y. Zheng, Z.-X. Yang, E. Wu, and H. Zhao, “Boosting video object segmentation via robust and efficient memory network,” IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1, 2023.
- [37] H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, and S. Savarese, “Generalized intersection over union: A metric and a loss for bounding box regression,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 658–666.
- [38] N. Xu, L. Yang, Y. Fan, D. Yue, Y. Liang, J. Yang, and T. Huang, “Youtube-vos: A large-scale video object segmentation benchmark,” arXiv preprint arXiv:1809.03327, 2018.
- [39] L. Yang, Y. Fan, and N. Xu, “The 2nd large-scale video object segmentation challenge - video object segmentation track,” Oct. 2019.
- [40] J. Pont-Tuset, F. Perazzi, S. Caelles, P. Arbeláez, A. Sorkine-Hornung, and L. Van Gool, “The 2017 davis challenge on video object segmentation,” arXiv preprint arXiv:1704.00675, 2017.
- [41] Y. Wu, A. Kirillov, F. Massa, W.-Y. Lo, and R. Girshick, “Detectron2,” https://github.com/facebookresearch/detectron2, 2019.
- [42] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer, 2014, pp. 740–755.
- [43] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [44] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022.