Playtesting: What is Beyond Personas
Abstract
Playtesting is an essential step in the game design process. Game designers use the feedback from playtests to refine their designs. Game designers may employ procedural personas to automate the playtesting process. In this paper, we present two approaches to improve automated playtesting. First, we propose developing persona, which allows a persona to progress to different goals. In contrast, the procedural persona is fixed to a single goal. Second, a human playtester knows which paths she has tested before, and during the consequent tests, she may test different paths. However, Reinforcement Learning (RL) agents disregard these previous paths. We propose a novel methodology that we refer to as Alternative Path Finder (APF). We train APF with previous paths and employ APF during the training of an RL agent. APF modulates the reward structure of the environment while preserving the agent’s goal. When evaluated, the agent generates a different trajectory that achieves the same goal. We use the General Video Game Artificial Intelligence (GVG-AI) and VizDoom frameworks to test our proposed methodologies. We use Proximal Policy Optimization (PPO) RL agent during experiments. First, we compare the playtest data generated by developing and procedural persona. Our experiments show that developing persona provides better insight into the game and how different players would play. Second, we present the alternative paths found using APF and argue why traditional RL agents cannot learn those paths.
Index Terms:
Reinforcement Learning, Player Modeling, Automated Playtesting, Play PersonaI Introduction
Game designers envision how a game will work during a play through. As the game develops, it becomes increasingly difficult to predict how players will interact with the game. Playtesters help out this process by providing feedback by playing the game. However, human playtesting introduces latency and additional costs to the process. Therefore, researchers proposed methods to automate the playtesting process [1] [2] [3].
Additionally, the playtesting process may employ players with distinct playstyles. These players will respond to the game differently, and they will generate different play traces. The game designer can use these play traces to shape her game. In order to automate playtesting with different players, researchers replaced these playtesters with procedural personas. A procedural persona describes an archetypal player’s behavior. Researchers used personas to playtest a Role-Playing Game [4] and a Match-3 [5] game. As a result, personas enabled distinct playstyles and helped to playtest a game like distinct players.
In order to realize the personas using RL agents, researchers used a utility function [6] to define the decision model of a persona. This utility function was used as the reward function of the Q-Learning agents. However, this replacement makes the agents bound to the utility function. Since the utility function is tailored for a specific decision model, the behavior of these agents is constant throughout the game. Therefore, the procedural personas approach is not flexible enough to create personas with developing decision models. For example, a player may change her objectives while playing the game. Consequently, the decision model of this player cannot be captured by a utility function.
Bartle [7] presents examples of these changes that a player can undergo while playing a Massively Multiplayer Online Role-Playing Game. We believe that the change in the playstyle occurs after accomplishing a goal. For example, a player may start a game by opening the treasures to find a required item and then killing monsters. This player chooses her actions like a Treasure Collector until she finds the desired item and becomes a Monster Killer. We propose a sequence of goals to model the decision-making mechanism of this player. The sequence-based approach was previously used in automated video game testing agents [8] and was found more practical than non-sequence-based approaches.
The developing persona model consists of multiple goals that are linked. Each goal consists of criteria and a utility function. The utility function serves the same purpose as in procedural personas. The criteria determine until which condition the current goal is active. When the current goal criteria are fulfilled, the next goal becomes active. The agent plays until the last goal criterion is fulfilled or until the end of the game. The game designer sets the criteria and utility functions of each goal. The goal structure enables the creation of dynamic personas. Additionally, this approach gives a more granularized control over a persona. The game designer can create variations of Monster Killer by setting different criteria. In order to playtest a casual Monster Killer, the game designer may set a health threshold as the criterion; and to playtest a hardcore Monster Killer, the game designer may set the percentage of monsters killed as the criterion.
Furthermore, the game designer may envision a game with various endings. In order to playtest her game, she utilizes an agent that behaves like an Exit persona and exercises this agent multiple times. Then, the game designer analyzes the trajectories generated by this agent and sees that all the trajectories provide data for only one of the possible endings. On the other hand, a human playtester would have generated trajectories that cover various endings. Thus, the shortcoming of automated playtests is not caused by the Exit persona but by the inherent nature of RL algorithms. RL algorithms such as Deep Q-Network (DQN) [9], Proximal Policy Optimization (PPO) [10], and Monte Carlo Tree Search (MCTS) [11] disregard the previous trajectories. Consequently, even if we train an agent with any of these algorithms and then evaluate the agent, and repeat this process numerous times, all the generated trajectories would be similar most of the time. However, the trajectories may be different due to the following reasons a) the random initialization of the Neural Network (DQN and PPO) b) -greedy policy of DQN c) stochasticity of MCTS d) the game’s nondeterminism. The critical point is that even if the agent generates a distinct trajectory, this result is not by design but by random chance.
Exploration methods in RL improve the agent’s policy by motivating the agent to explore the environment. As the agent explores an environment, the agent improves its policy. The researchers proposed methods to motivate the agent to explore less visited states [12] [13] [14]. Compared to the traditional exploration methods such as -greedy, where exploration is achieved through randomness, these modern algorithms entice exploration logically. These algorithms learn to distinguish the unvisited states from the visited states, consequently, these algorithms guide the agents to less-visited states. As a result, exploration methods vastly improved the agent’s score, such as Montezuma’s Revenge [12].
On the other hand, APF knows the previous trajectories and guides the agent to learn to play differently from previous ones. For this purpose, APF penalizes the agent when the agent visits a similar state and rewards the agent when the agent visits a different state, compared to the states in the previous trajectories. APF employs the state comparison algorithms used in exploration algorithms. These state comparison algorithms are the backbone of exploration research, and researchers tested these algorithms in multiple games. We show how we build the APF framework to generate new and unique playtests and how APF augments any RL agent.
In this paper, we list the contributions as follows. Our first contribution is the developing persona. The developing persona is more flexible and capable than the current persona models. We show how game designers can utilize the developing persona to empower the playtesting. Our second contribution is the Alternative Path Finder. We present a generic APF framework that can augment every RL agent. We use the GVG-AI [15] and VizDoom [16] environments to demonstrate our proposed methodologies.
This paper is structured as follows: Section II describes the examples and methodologies of related research. We grouped the related research into four subsections: Playtesting, Personas in Playtesting, Automated Playtesting, and Exploration Methods in Reinforcement Learning. The developing persona is based on the first three subsections. Next, APF is founded on the Exploration Methods in Reinforcement Learning. Our proposed methodology that consists of developing persona and APF is presented in Section III. Section IV describes our experimentation setup and Section V presents the results of these experiments. Section VI discusses the outcomes of the strategies used, their contributions and limitations. Lastly, Section VII concludes this paper.
II Related Research
II-A Playtesting
Playtesting is a methodology used in the game design process. Playtesters test a game, and feedback is collected from these playtesters. The game designers use this feedback to improve their game. As this process requires a human effort, researchers proposed methods to automate game playtesting. Powley et al. [1] coupled automated playtesting with a game development application. Gudmundsson et al. [2] trained a convolutional neural network to predict the most humane action in Candy Crush, and they used this network to assess level difficulty. Roohi et al. [3] used RL and a population model to determine level difficulty for Angry Birds Dream Blast. These approaches derive the automated playtesters from an individual player archetype. Nevertheless, during a playtest, there can be various playtesters resembling a different player archetype.
II-B Personas in Playtesting
In playtesting, personas provide game designers information about how different player archetypes would play the game. Persona is a fictional character that represents a user type. Bartle [17] introduces a taxonomy of personas that are identified from a Multi-user Dungeon Game. The author acknowledges these four distinct personas as Socializers, Explorers, Achievers, and Killers. The author introduces a graph with axes that maps the players’ interest in a persona. Bartle [7] extends this research by introducing development sequences for personas. The development sequences reveal how and why a player may change to a different persona. Tychsen and Canossa [18] present a study on collecting game metrics and how different personas can be identified by these metrics. The authors present the personas of the game Hitman Blood Assassin. The game identifies these personas: Mass Murderer, Silent Assassin, Mad Butcher, and The Cleaner. They argue that a persona can be recognized using the metrics collected from a play trace. These approaches focus on identifying different personas in a game.
II-C Automated Playtesting
In order to automate the playtesting, researchers proposed techniques to realize the decision model of a persona. Holmgård et al. [6] used a utility function to realize the decision model of a persona. This utility function is used as the reward function for the Q-Learning agent. The agents are exercised in an environment called MiniDungeons. The agents produced play traces as if they are of a specific persona. Holmgård et al. [19] extended their previous work by substituting the Q-Learning agents with a neural network. The inputs to the neural network were hard-coded, handpicked parameters. The authors used a genetic algorithm to find the weights of this neural network. They called their new method ‘evolved agent’. Evolved agent required less training than the Q-Learning agent and was able to generalize to other levels better. Holmgård et al. [20] upgraded the environment to MiniDungeons 2. In this study, the authors proposed to generate personas using MCTS agents that use their proposed utility function. Their reasoning for using MCTS, especially Vanilla MCTS [11], was to provide faster data to the game designer. In Q-Learning and Evolved agents, these agents have to be trained first. Holmgård et al. [4] extend the MCTS by improving the selection method of MCTS. In their previous study, the authors state that the Mini Dungeons 2 game was too complex for Vanilla MCTS. Therefore, they model a new selection phase that is specifically tailored towards a specific persona. They accomplish this by evolving the UCB formula by a genetic algorithm. The authors crafted the fitness function of each persona. This fitness function also determined the fitness function of the evolutionary algorithm. The evolved UCB formula improved their results among every persona. Silva et al. [21] used personas to playtest the Ticket to Ride board game. The authors designed four different competitive personas to play the board game. The authors handcrafted a set of heuristics for each persona. They showed that personas revealed useful information that the game rules did not provide rules for two situations. Mugrai et al. [5] employed four different personas for Match-3 games. These personas are Max Score, Min Score, Max Moves, and Min Moves. The authors showed that these four personas could give the game designer valuable information about a level.
The main drawback of persona research is the utility function. First, the utility function is static and stays constant throughout the game. Therefore, the game designers cannot model players with development sequences [7]. Second, depending on the level layout, personas can execute a similar sequence [4]. Hence, the synthetic playtesters would provide ineffective feedback. Lastly, synthetic playtesters are realized using RL agents. Since RL agents optimize the total accumulated reward, synthetic playtesters would not test all playable paths.
II-D Exploration Methods in Reinforcement Learning
An RL agent explores the environment to learn which action yields the highest reward in a state. In order to learn this policy, the RL agent has to explore the environment. Intrinsically motivating an RL agent to explore novel states is an exploration problem. The researchers proposed different ways to make agents explore distinct states of the environment. Count-based approaches reward the less-visited states more than frequently visited states. Therefore, the agent becomes inclined to visit the less visited states. The count is formulated using a density model [12], a neural density model [22], a hash table [23], and exemplar models [13]. Another proposed approach is to augment the reward function by measuring the agent’s uncertainty about the environment. Researchers measured the uncertainty using bootstrapped DQN [24], state-space features [14], and error of a neural function [25]. Additionally, researchers proposed approaches that explore the state space by optimizing the state marginal distribution to match a target distribution [26]. These exploration proposals intelligently incite the agent to explore the environment. The goal of exploration is not to find a unique way of playing but to find the best path every time we execute the RL agent. However, these methods can differentiate between similar states and new states. We base our APF proposal based on this accomplishment.
III Methodology
In this paper, we address the shortcomings of the procedural persona with a multi-goal oriented persona, the developing persona. Additionally, we recognize there may be alternative playtests that a persona may produce. We propose APF to discover those playtests.
In the following subsections, first, we introduce the developing persona. Afterward, we present the necessity for an APF and introduce the foundation of APF. Next, we show how we use the techniques in exploration field to implement the APF. Finally, we describe how to use APF with an RL agent.
III-A Developing Persona
A persona reflects an archetypal player’s decision model. In order to realize a persona, first, the persona’s decision model should be translated to game conditions. Second, an actor should play according to this translation. Researchers [4] [5] proposed using a utility function to map the decision model to game conditions. This utility function replaces the reward mechanism of the environment and provides a tailored reward mechanism for each persona. Researchers [4] [5] used RL agents as actors. Consequently, these RL agents are akin to synthetic playtesters that represent the decision model of a persona. These playtesters, procedural personas, represented various personas such as the Monster Killer, Treasure Collector, and Exit personas. In this paper, we extend the procedural persona framework by introducing a multi-goal persona.
We propose a multi-goal persona to generate a more customizable playtester. We have two reasons that a multi-goal persona would be beneficial for game designers. First, the game designer does not have granular control over the personas. For example, the game designer may want to playtest a monster killer persona that kills monsters until its health drops below a certain percent. However, when to cease killing monsters was left to the RL agent, and the game designer had little control over these decisions [27]. Second, the previous approaches do not allow development in persona. Though procedural personas may realize the persona archetypes that Bartle [7] presented, procedural personas cannot realize the development sequences that Bartle also presents. For example, if the goal of the procedural persona is killing monsters, the procedural persona will always be a Monster Killer.
A multi-goal persona is a procedural persona with a linked sequence of goals rather than a single utility function. A goal contains a utility function and a transition to the next goal. If there is a single goal in the sequence, there is no need to define the transition. Hence, a goal-based persona with a single goal is equivalent to a procedural persona. The transition connects the goals, and the transition occurs depending on the criteria. Game designers determine the criteria, and criteria hold conditions related to the game. For example, a criterion can be killing 50% of the monsters or exploring 90% of the game or having health less than 20% or the combination of these conditions. The developing persona maintains knowledge of interactions such as how many Monsters, Treasures have been killed or collected. Next to the interactions, the developing persona knows how much of its health is left. Developing persona uses this knowledge to check whether the current criteria are fulfilled. When all of the criteria of the current goal are fulfilled, the next goal becomes active. When there are no more goals, the training or the evaluation of the goal-based persona ends.
In this section, we have described the “sudden” transitions between goals, the previous goal becomes inactive, and the next goal becomes active immediately. However, this transition could also be “fuzzy”. The current goal and the next goal can be active simultaneously. A possible implementation of fuzzy transition may use the criteria fulfillment percentage. For example, when the criteria are completed at least 50%, the next goal could become active while not deactivating the current goal. The persona would be rewarded from both of the utility functions. Whenever the persona fulfills the current goal completely, the next goal becomes the only active goal. Consequently, a fuzzy transition would create a smoother progression of playstyles.

In Figure 1, we created an example level to demonstrate the goal-based personas. In this example, the Avatar situated at bottom right corner can execute the following actions Pass, Attack, Left, Right, Up, and Down. The direction of the Avatar is shown by a pink triangle. If the direction of the Avatar and the action align, the Avatar moves one space in that direction, else the Avatar changes direction. When Avatar executes Attack, the Avatar slashes towards its direction. The Avatar can slay Monsters by Attacking them. The monsters move randomly and kill the Avatar if they collide with the Avatar. There are also Treasure chests that Avatar can pick up by simply moving over them. Lastly, when the Avatar exits through the Door, the game terminates successfully.
| Goal Names | |||
|---|---|---|---|
| Game Event | Killer | Collector | Exit |
| Death | -1.0 | -1.0 | -1.0 |
| Exit Door | 1.0 | ||
| Monster Killed | 1.0 | ||
| Treasure Collected | 1.0 | ||
A game designer may playtest a Monster Killer persona in the game shown in Figure 1 and generate the following two developing personas. First one kills the Monsters and then collects the Treasure as trophy. Second one collects the Treasure hoping to gain an advantage against the Monsters and then kills the Monsters. In order to realize the aforementioned personas, the game designer designs two developing personas, as seen in Figure 2. Next, she designs the utility functions of the goals, as seen in Table I. In order to realize these personas as playtesters in a game, the game designer can employ any RL agent. When the agent finishes training, the game designer can use the agent for playtesting. The importance of developing personas is that developing personas introduces a framework to formalize how players change their goals over the course of playing a game.

III-B Alternative Path Finder
The actions of an RL agent are motivated based on the feedback received from an environment. As the agent is trained in an environment, the feedback will shape the agent’s policy. When the training is over, the agent will behave according to the learned policy. Additionally, if we train the same agent in the same environment multiple times, the learned policies will be similar. At the end of each training, we can evaluate the trained agent in the same environment to obtain trajectories. These trajectories will be similar as the learned policies were similar. On the other hand, the game designer might be interested in seeing different playstyles.
In order to diversify the learned policies, one has to change the feedback mechanism of the environment. Procedural personas [4] [5] accomplish this by rewiring the feedback mechanism by a utility function. An agent representing a persona will learn a different policy than another agent that represents a different persona. However, when the game designer wants to see different playstyles within the same persona, the procedural persona approach also falls short. For example, the game designer may want to see how different players complete a game with multiple endings. To model these players, she trains an agent that mimics the Exit persona, and she analyzes the trajectory from this agent’s execution. Nevertheless, the resultant trajectory of this persona will be the path to the closest ending. The other endings in the game will be neglected, and the game designer will only have playtest data that corresponds to one possible end of the game. A preliminary solution to this problem is masking the feedback from some of the endings. Thus, the agent will generate a playtest towards a particular ending. However, this solution requires additional tinkering, and there might be additional playtests towards the same ending. Another subpar solution is that the game designer would apply randomness to the agent’s actions or add random noise to the input to diversify the trajectories. However, randomness does not guarantee that the agent will generate different playtests. Therefore, this solution also does not give complete control to the game designer.
On the other hand, with human playtesters, the game designer could have asked a playtester to play differently. The playtester already knows which paths or particular states she has visited before, so she uses this past knowledge to play the game differently. Therefore, the source of this problem is that the current agent does not know what the previous agents did in the prior runs. Every playtester which an RL agent represents generates a playtest anew. In order to solve this problem, we propose Alternative Path Finder.
III-B1 Measuring Similarity
A game can be formulated using a Markov Decision Process (MDP). MDP formulates the interaction between an actor and the environment [28].
Suppose a human player or an agent played a game, and we obtain the trajectory where corresponds to a state, corresponds to an action, and the subscripts denote the state or action at time . We want to train an agent that knows , and we want this agent to generate a trajectory different than . Therefore, we need to calculate a measure to represent the similarity of these two trajectories. We propose two different methods to calculate the similarity. First method is to calculate the recoding probability of a state , . If , then the probability should be high, and if , then the probability should be low. Second method is calculating the prediction error of a dynamics model . If the transition exists in , then the prediction error should be low, and if this transition does not exist in , then the error should be high.
III-B2 From Recoding Probability to Intrinsic Feedback
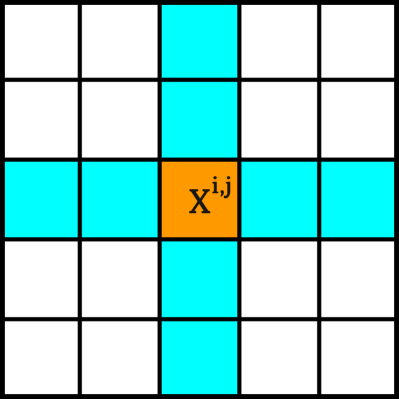
Bellemare et al. [12] used Context Tree Switching (CTS) [29] to intrinsically motivate an RL agent for exploration. CTS uses a filter to evaluate the recoding probability of a pixel. The filter used by the authors and in our experiments is shown in Figure 3(a) and Figure 3(b), respectively. The filter gathers information around a pixel and CTS uses this information to predict this pixel. When this operation is done for every pixel of an image, the recoding probability of an image is calculated.

In order to use the recoding probability to differentiate between the novel frames from similar frames, we need a boundary probability value. We refer to this probability as (see Eq. 1). First, we train a CTS model using all of the frames in trajectories. Then, we calculate the recoding probability of every frame in this trajectory. Next, we set the equal to the minimum of all these recoding probabilities. As CTS is a learning-positive model, every frame from these trained trajectories will have a higher recoding probability than .
| (1) | |||
When an agent or a human player plays the game, the actor will receive a new frame . First, we calculate its recoding probability . If is smaller than , this indicates that this frame provides new information and if is greater than , this indicates that this frame does not provide new information. Next, the magnitude of the information depends on how close is to . We use this difference to calculate the amount of reward or penalty.
| (2) | |||
We use Eq. 2 to calculate the additional reward signal. This formula yields maximum reward when and minimum when . This additional reward signal provides a negative feedback for visiting similar states and positive feedback for visiting novel states. We refer to the APF method that uses CTS internally as APFCTS.
III-B3 From Predicting Dynamics to Intrinsic Feedback
Pathak et al. [14] used the Intrinsic Curiosity Module (ICM) to intrinsically motivate an RL agent for exploration. ICM is a Neural Network (NN) architecture that learns to predict the environment dynamics and uses the prediction error as the intrinsic motivation. ICM has two NNs called as forward model and inverse model. The forward model predicts the next state features using the current state features and current action . The inverse model predicts the current action using the current state features and the next state features . ICM uses Convolutional Neural Network (CNN) to encode the states into state features, . The prediction error is the difference between the predicted next state features and extracted next state features . Therefore, if the agent has seen the transition , the prediciton error will be low, and if not, the prediction error will be high.
In order to use the prediction error to differentiate between the novel frames from similar frames, we need a boundary value. We refer to this value as (see Eq. 3). First, we initialize an empty ICM architecture. Next, we use transfer learning to set the weights of CNN encoders, and then we freeze the weights of CNN. The source can be the CNN layers of the RL agent, or if the agent also used ICM, we can use ICM’s CNN layers. Afterward, we use the previous trajectories to train the forward and inverse models of ICM. At the end of the training, we have an ICM model that has a better prediction towards the transitions that exist in the given trajectories and a worse prediction towards the transitions that do not exist. Lastly, we replay the previous trajectories, gather all of the prediction errors, and calculate the mean of all the prediction errors. We do not calculate the max of all the prediction errors as the ICM may not improve the predictions for every transition or make prediction errors. Therefore, max would be a poor choice for a boundary value.
| (3) | |||
When an agent or a human player plays the game, the actor executes action on frame . As a result, the actor sees a new frame . First, we calculate the prediction error of this transition, . If is greater than , this indicates that this transition is less likely to exist in the previous trajectories. If is less than , this indicates that this transition is likely to exist in the previous trajectories.
| (4) | |||
We use Eq. 4 to calculate the additional reward signal. This formula yields maximum reward when and minimum when . We use this additional feedback signal to reward the novel transitions and to penalize similar transitions. We refer to the APF method that uses ICM internally as APFICM.
III-B4 APF Architecture
We augment the traditional Agent and Environment interaction by adding a new box. This augmented architecture is shown in Figure 4. The APF corresponds to either APFCTS or APFICM. Before we start training an agent, we first train the APF with the previous trajectories as described in Section III-B2 or Section III-B3. At this point, we have an APF module that discerns the states or transitions. Afterward, when a new state and a new reward are observed from the environment during the training, these observations first enter the APF. APF modulates the reward signal by adding a penalty or reward by using the Eq. 2 or Eq. 4.

The one drawback of this approach is that the feedback is unbounded. Since the feedback is infinite, the agent may loop over novel states or get stuck in a novel state [25]. The agent may visit a novel state repeatedly to get a positive reward and forget the actual task in the environment. The second drawback is that some portion of the game may be strict, offering no alternative paths such as Super Mario Bros. [14]. Consequently, APF will penalize this portion of the game, naively thinking there may be alternative paths.
We propose a solution for each of these drawbacks. For the first drawback, we propose to put a cap on the total reward and penalty that APF provides. This solution limits the infinite feedback, and this process operates as follows: if a state is distinct, APF clamps the reward by the positive cap . Then, APF yields this clamped reward and updates the positive cap by subtracting the clamped reward. Once the positive cap is exhausted, the additional reward that APF provides becomes zero. We also apply the same principles for the penalty by providing a negative cap, . This solution limits the agent looping over distinct states or getting stuck in a state like the noisy TV problem [25]. Furthermore, as the total reward and penalty are known beforehand, this solution also simplifies the design of the utility function for personas. For the second drawback, we propose to cut these portions from the collected trajectories. Consequently, APF will not penalize the agent, as APF will be blind for this portion of the path.
We introduced two different APF approaches as each has its advantages and disadvantages. The advantage of APFCTS is that the CTS model can be trained from a trajectory that consists of a few frames. However, APFICM is more data-intensive compared to APFCTS. Furthermore, APFICM requires a previously trained agent for transfer learning, which is not required for APFCTS. Nevertheless, as APFCTS operates directly on pixels, a slight noise in a frame would decrease the recoding probability.
Last but not least, though we presented the APF on top of exploration methods CTS and ICM, APF may also be formulated on other exploration methods such as exemplar models [13]. As APF depends on methods used in exploration, we need to draw a line between exploration and APF. The goal of exploration methods is to increase the agent’s knowledge about its environment during training. So that when we evaluate, this agent delivers top performance in this environment. The goal of APF is to help the agent to discover the different performances without changing the agent’s goal. Therefore during training, APF modulates the reward structure so that the old performances are penalized, and different performances are rewarded.
IV Experiments
In this paper, we used two different environments to test our proposals, GVG-AI [15] and VizDoom [16]. We describe the environments and the experimental setup in this section.
The first testbed game is created using the GVG-AI framework, shown in Figure 5. The game has a grid-size, and consists of an Avatar, Exits, static Monsters, Treasures, and Walls. The human player or an agent controls the Avatar. The game lasts until the Avatar goes to one of the Exits, or gets killed by a Monster, or until 200 timesteps. The action space consists of six actions No-Op, Attack, Left, Right, Up, and Down. GVG-AI framework is extended to run a game with more than one Door. The actor receives distinct feedback for the following interactions killing a Monster, getting killed by a Monster, collecting a Treasure, and colliding with a Door.

The second testbed game is a Doom level, shown in Figure 7. The game has a grid size, and consists of an Avatar, Exit, Monsters, Treasures, and Walls. The human player or an agent controls the Avatar. The game lasts until the Avatar goes to the Door, or gets killed by a Monster, or until 2000 timesteps. The action space consists of seven actions Attack, Move Left, Move Right, Move Up, Move Down, Turn Left, and Turn Right. The actor receives distinct feedback for the following interactions killing a Monster, getting killed by a Monster, collecting a Treasure, and colliding with the Door. Additionally, the actor receives constant negative feedback of for every step taken.


The third testbed game is another Doom level, shown in Figure 8. The game has a grid size, and consists of an Avatar, an Exit, and Walls. The human player or an agent controls the Avatar. The game lasts until the Avatar goes to the Door, or until 2000 timesteps. The action space consists of seven actions Attack, Move Left, Move Right, Move Up, Move Down, Turn Left, and Turn Right. The actor receives feedback if the actor interacts with the Door. Additionally, the actor receives constant negative feedback of for every step taken.

We experiment with the procedural and goal-based personas in the first and second testbed games. We test the APF in the first and third testbed games. We used the same random seed during the APF experiment to properly test the APF method. We use PPO [10] agent in all of the experiments. For the PPO+CTS, PPO+ICM, PPO+APFCTS, and PPO+ICM+APFICM, we change the base PPO implementation slightly. The base PPO implementation is from the Stable-Baselines project [30]. We also tested the proposed persona with other RL agents during the initial experiments, and we found that PPO requires less hyperparameter tuning, so we used PPO in all of our experiments. The hyperparameters of PPO agents are presented in Table XI, and the hyperparameters of APF techniques are shown in Table XII. Lastly, as the first game is deterministic, we evaluated the trained agent once. On the other hand, as the second and the third games are stochastic, we evaluated the trained agent 1000 times. Furthermore, we noticed that our training was more consistent whenever we used an exploration algorithm such as CTS or ICM. Consequently, we had to restart the training in the first game.
GVG-AI environment sends an observation with shape , we downscale this observation to and then convert the observation into grayscale. Afterward, we stack the most recent four observations, and lastly feed the stacked observations to the agent. For CTS used in PPO+CTS and APFCTS, we process the observation into we , 3-bit grayscale image, and calculate the recoding probability of this observation. Doom environment sends the observation with shape , we resize this observation to , and we feed the agent and the APFICM this resized observation.
We created four different procedural personas and five different developing personas. The four procedural personas are Exit, Monster Killer, Treasure Collector, and Completionist. The utility weights of these procedural personas is given in Table II. We chose these procedural personas from [4], and we drew inspiration from these personas to make their developing persona counterparts. The five developing personas are Developing Monster Killer, Developing Treasure Collector, Developing Raider, Developing Completionist, and Developing Casual Completionist. The development sequences of these personas are presented in Table IV, the utility function of the goals are given in Table III, and the criteria of these goals are shown in Table V.
| Personas | ||||
|---|---|---|---|---|
| Game Event | (E) | (MK) | (TC) | (C) |
| Reaching an Exit | 1 | 0.5 | 0.5 | |
| Killing a Monster | 1 | 1 | ||
| Collecting a Treasure | 1 | 1 | ||
| Dying | -1 | -1 | -1 | -1 |
| Goal Names | ||||
|---|---|---|---|---|
| Game Event | (K) | (Col) | (E) | (Com) |
| Death | -1 | -1 | -1 | -1 |
| Exit Door | 1 | |||
| Monster Killed | 1 | 1 | ||
| Treasure Collected | 1 | 1 | ||
| Hyperparameters | Development Sequence |
|---|---|
| Dev. Killer | Killer -> Exit |
| Dev. Collector | Collector -> Exit |
| Dev. Raider | Killer -> Collector -> Exit |
| Dev. Completionist | Completionist -> Exit |
| Dev. Casual Completionist | Casual Completionist -> Exit |
| Goal Names | ||||
|---|---|---|---|---|
| Criterion | (K) | (Col) | (Com) | (Cas. Com.) |
| Monsters Killed | 50% | 100% | ||
| Treasure Collected | 50% | 100% | ||
| Remaining Health | 50% | |||
V Results
In this study, we asked the following research questions.
-
•
How does a goal-based persona perform compared to a procedural persona?
-
–
Diversity of playtests generated by personas
-
–
Agreement between interactions performed and Persona’s decision model
-
–
-
•
Which additional paths can be discovered with APF?
V-A Experiment I: Procedural vs Goal-based personas:
Table VI presents the interactions done by seven different personas. The Exit persona directly goes to the Door, which is four spaces below the Avatar. The other three procedural personas also go to the same Door, but also collecting the Treasure and killing the Monster on the way. The Developing Killer persona defeats all of the Monsters on the upper half of the level. The Developing Collector persona collects four of the Treasures on the upper half of the level. The Developing Raider is a combination of Developing Killer and Developing Collector, consequently kills the Monsters and then collects the Treasures in the upper half of the level. Lastly, the Developing Completionist kills more Monsters and collects more Treasures than every other persona. However, Developing Completionist misses the Monster and the Treasure below the starting position. We see all procedural personas interact with a small region of the level, whereas the developing personas interact with a broader region. Therefore, we conducted the same experiment for procedural personas with PPO + CTS RL agent. Table VI displays the interactions performed by procedural personas when the agent explores the environment. We see that the interactions performed by PPO + CTS RL agent fit better to the persona’s decision model.
| Game Event | |||
|---|---|---|---|
| Personas | Monsters Killed | Treasures Collected | Door |
| Exit | 0 | 0 | 1 |
| Monster Killer | 1 | 1 | 1 |
| Treasure Collector | 1 | 1 | 1 |
| Completionist | 1 | 1 | 1 |
| Dev. Killer | 3 | 0 | 1 |
| Dev. Collector | 1 | 4 | 1 |
| Dev. Raider | 3 | 4 | 1 |
| Dev. Completionist | 5 | 8 | 1 |
| Game Event | |||
|---|---|---|---|
| Personas | Monsters Killed | Treasures Collected | Door |
| Monster Killer | 2 | 0 | 1 |
| Treasure Collector | 0 | 3 | 1 |
| Completionist | 2 | 3 | 1 |
V-B Experiment II: Alternative paths found in GVG-AI:
We used the path found by the Exit persona in Experiment I to train APFCTS (see Path 1 in Figure 9). Then, we trained the PPO + CTS + APFCTS agent in the first testbed game while using the Exit persona’s utility weights. We repeated the experiment for each path obtained from the PPO + CTS + APFCTS agent. First, an APFCTS is trained using one of the obtained paths, and then we use this trained APFCTS to train a PPO + CTS + APFCTS agent. The paths identified at the end of the process are shown in Figure 9. Table LABEL:table:r:e_2_results shows the total discounted rewards—the rewards received from the environment and the APFCTS. The bold values indicate the alternative paths of the trained path. For example, Path 1 has four alternative paths—Paths 2 to 6. Table LABEL:table:r:e_2_results also shows that, when we use APFCTS, we see that the reward of playing the same path decreases by at least , and the reward of space-disjoint paths increases by at least . This reward difference justifies why APF supports finding alternative paths.
Lastly, from Table LABEL:table:r:e_2_results we notice that APFCTS clusters the paths in Experiment II into two equivalence classes, which are and . Therefore, we may interpret that distinct paths refer to paths that are space-disjoint from the one trained on for APFCTS.
| Tested Paths | ||||||
|---|---|---|---|---|---|---|
| Trained Path | 1 | 2 | 3 | 4 | 5 | 6 |
| - | 0.86 | 0.78 | 0.84 | 0.84 | 0.86 | 0.76 |
| 1 | 0.76 | 0.77 | 0.98 | 0.98 | 0.98 | 0.98 |
| 2 | 0.82 | 0.61 | 0.98 | 0.99 | 0.98 | 0.98 |
| 3 | 0.98 | 0.98 | 0.74 | 0.86 | 0.82 | 0.88 |
| 4 | 0.99 | 0.98 | 0.86 | 0.72 | 0.86 | 0.86 |
| 5 | 0.98 | 0.98 | 0.81 | 0.85 | 0.76 | 0.87 |
| 6 | 0.99 | 0.98 | 0.87 | 0.87 | 0.88 | 0.60 |

V-C Experiment III: Personas in Doom:
We experimented with 9 different personas in the second testbed game, a Doom level (see Figure 7). The interaction results are presented in Table IX, and all of the personas behave similarly to their specifications. The Exit persona always finishes the game, and in some of the evaluations, Exit persona kills a Monster but never collects a Treasure. The Monster Killer persona generally kills all of the Monsters, rarely collects a Treasure, and habitually finishes the game. Developing Killer is similar to Monster Killer but kills half of the Monsters and rarely dies. The Treasure Collector and Developing Collector are alike. They both collect a single Treasure, kill the least Monsters and die the most. The Completionist, Developing Completionist, and Developing Casual Completionist personas behave similarly, but minor differences exist. The Developing Casual Completionist always finishes the level but usually cannot collect the second Treasure. The Completionist and Developing Completionist regularly collect the second Treasure, but in doing so, rarely die and cannot finish the level.
| Game Event | ||||
|---|---|---|---|---|
| Personas | Monsters | Treasures | Door | Death |
| Exit | 0.27 0.48 | 0.00 0.00 | 1.00 0.00 | 0.00 0.00 |
| MK | 5.79 0.91 | 0.01 0.07 | 0.98 0.15 | 0.00 0.00 |
| Dev. Killer | 3.54 0.98 | 0.01 0.08 | 0.96 0.19 | 0.01 0.08 |
| TC | 1.94 0.70 | 0.94 0.24 | 0.80 0.40 | 0.19 0.39 |
| Dev. Collector | 2.00 0.65 | 0.95 0.22 | 0.87 0.34 | 0.13 0.34 |
| Dev. Raider | 3.52 0.73 | 0.98 0.15 | 0.97 0.17 | 0.01 0.08 |
| Comp. | 5.76 1.06 | 1.91 0.38 | 0.95 0.22 | 0.01 0.11 |
| Dev. Comp. | 5.81 0.92 | 1.91 0.36 | 0.96 0.19 | 0.01 0.09 |
| Dev. Cas. Comp. | 5.83 0.53 | 0.98 0.13 | 0.98 0.14 | 0.00 0.00 |
V-D Experiment IV: Alternative paths found in Doom:
We trained an Exit persona in the third testbed game using PPO + ICM agent. The first path shown in Figure 10 is the trajectory taken by the Exit persona. We trained an APFICM using this first path, and then we trained a new Exit persona using PPO + ICM + APFICM agent. The new Exit persona played the second path. The total discounted reward obtained by these two Exit personas is shown in Table LABEL:table:r:e_4_results. As the first path consists of 52 steps, whereas the second path consists of 77 steps, the total reward of the first path is higher than the second. However, applying APFICM, we increase the total reward obtained from the second path and decrease the total reward obtained from the first path.

| Tested Paths | ||
|---|---|---|
| Trained Path | 1 | 2 |
| - | 0.80 0.02 | 0.68 0.01 |
| 1 | 0.51 0.02 | 0.78 0.01 |
VI Discussion
In this paper, we presented an advancement for procedural persona, goal-based persona and introduced a method to let RL agents discover different paths, APF. We experimented with these methods in GVG-AI and Doom environments.
Procedural personas and developing personas are two methods used by game designers to automate the playtesting process. One drawback of the procedural personas originates from the utility function. A utility function realizes the decision model of a persona. For example, a Treasure Collector receives positive feedback from finishing the level and collecting a Treasure. However, if the starting position of the agent is close to the Door, the agent may neglect the Treasures. Conversely, if the Door is positioned after the Treasures, the agent is likely to interact with most of the Treasures. We saw this dilemma in Experiment I. Without any exploration technique, the procedural personas Monster Killer, Treasure Collector, and Completionist executed the same set of actions. When we integrated exploration into the agents that realize these personas, the set of actions executed by these personas became different. Furthermore, these new sets of actions were more fitting to their decision model. This problem is also seen in the MCTS agent playtesting the MiniDungeons 2 game [4].
The problem with the utility function is that the utility function is an amalgamation of multiple goals. Hence, depending on the level composition and RL agent’s hyperparameters, the procedural persona represents one of those playstyles. In Experiment I, we believe that the Developing Completionist fits better with the idea of a “Completionist” persona than the procedural Completionist. Developing persona addresses this problem by introducing a sequence of goals. Consequently, a game designer may use the developing persona to choose which playstyle she wants to playtest carefully.
Another advantage of developing personas over procedural personas is that developing personas support playstyles that involve alteration. For example, in Experiment I, the Developing Raider killed the Monsters and then collected the Treasures. The Developing Raider starts the game as a Monster Killer and becomes a different persona —a Treasure Collector— after fulfilling a criterion. These development sequences were mentioned by Bartle [17], but development sequences were impractical while using a single utility function. Consequently, this behavior performed by Developing Raider was missing in procedural personas. On the other hand, another important aspect of playtesting is the ability to generate playtraces as if a human would. In this paper, we used handcrafted utility functions, however, these utility functions could have been extracted from human playtest data by Inverse Reinforcement Learning [28]. This alteration might help the RL agent to generate a playtest that is more human-like [8][31].
In addition to the GVG-AI environment, we conducted experiments on the Doom environment. To the best of our knowledge, this paper is the first study to playtest personas in a 3D environment. In 2D environments, the researchers [4][5] employed MCTS RL agent to realize personas. Nevertheless, MCTS would be an ineffective choice for 3D environments, and MCTS would underrepresent the persona. Consequently, we used the PPO agent in Experiments III and IV, as PPO is a competent agent used by OpenAI [32]. In Experiment III, we see that the PPO agent realized the decision models of personas properly. From the results in Table IX, we interpret that a player has to kill a Monster to finish this level. The level is hardest for Treasure Collector and Developing Collector as they have to kill a Monster to collect the Treasures. We see an interesting fact about the game when we compare the Developing Casual Completionist and the Developing Completionist personas. The former never dies but collects only a single Treasure, whereas the latter seldom dies but collects both of the Treasures. From this data, we understand that collecting the second Treasure causes the death of the player. As the Developing Casual Completionist fears losing her health more, this persona finds collecting the second Treasure risky. Furthermore, comparing the Killer and the Developing Killer personas shows that the latter die more than the former. This comparison unravels another fact about this level. If a player engages in combat to kill Monsters, then this player should kill as much as possible. Otherwise, this player is likely to die, such as the Developing Killer. On the other hand, the Developing Casual Completionist also kills as much Monsters as a Monster Killer. This indifference indicates that the game may not be challenging enough for a hardcore player.
In Experiment II, we prepared a game that consists of five Doors. We found that —without APF— the Exit persona would take either the first or the fifth path shown in Figure 9. The lengths of these paths are the same and shorter than every possible path that ends with a Door. Consequently, in the first row of Table LABEL:table:r:e_2_results, we see that the first and the fifth path share the highest score. Furthermore, in Experiment IV, we saw that —without APF— the Exit persona would take the first path (see Figure 10). Since this path is the closest towards the Door, and therefore, playing this path yields a higher score compared to the other path, shown in Table LABEL:table:r:e_4_results.
We proposed APF to let RL agents discover these additional paths shown in Figure 9 and Figure 10. A human playtester would have played these paths, but without APF, the Exit persona would overlook them as these paths yield a lower score. Hence, the game designer would not have any playtest data for other endings. Table LABEL:table:r:e_2_results and Table LABEL:table:r:e_4_results show insight on how APF achieves this feat. APF modulates the reward signal of the environment. When the agent tries to learn a similar path, the agent is penalized, and when the agent tries to learn a distinct path, the agent is rewarded. This reward modulation is the reason how APF promotes finding distinct paths. The game designer can exercise the APF to get a distinct path and then study this path to improve her game. Afterward, she can exercise the APF to generate as many paths as she needs. However, the game designer might be interested in examining the play traces that could have come from human playtesters. We could employ an auxiliary NN trained to select the best human-like action given an observation [2]. Nevertheless, carefully combining this NN with APF is a topic of another study.
On the other hand, an alternative path is a subjective concept. Every human playtester may think of another way to represent the Exit persona. In Table LABEL:table:r:e_2_results, we see that when we train the APFCTS with the second path, the score of the first path decreases, and the score of the sixth path increases. According to APFCTS, the first and second paths are more similar than the second and sixth paths (see Figure 9). However, one might argue that the first and second paths are distinct as they reach different Doors, and the second and sixth paths are similar as they reach the same Door. Though APFCTS is objective in finding alternative paths, these alternative paths are “subjectively” different for the game designers. The objectivity of APFCTS and APFICM comes from the recoding probability of a frame and the dynamics prediction error, respectively.
Additionally, we found that APFICM is more robust compared to APFCTS. We also experimented with APFCTS in Doom. However, CTS calculated the recoding probability of some frames as . Furthermore, we observed that for our experimentation setup the plus-shaped filter in Figure 3(b) yielded better results than the original CTS filter in Figure 3(a). Lastly, researchers employed curiosity to increase the playtesting coverage of an RL agent [33]. Though we promoted APF to find distinct paths, APF may help game tester agents [8]. Coverage is crucial for testing, and APF increases coverage by finding distinct paths.
Limitations & Challenges: The performance of developing and procedural persona is dependent on the RL algorithms. If the RL algorithm cannot play a game, the game designer could not benefit from these automated playtesters. Furthermore, our APF proposals are based on exploration algorithms. The performance of APF in an environment is linked to how well the exploration algorithm would perform in this environment.
VII Conclusion
This paper focused on the problem of providing additional tools to game designers for playtesting. In this regard, we proposed developing persona, a direct successor to procedural personas. Furthermore, we presented a novel method to help RL agents to discover alternative trajectories, APF. We introduced two APF approaches, APFCTS and APFICM.
Our results show that developing personas are a successor of procedural personas. A game designer can embody various personalities in developing personas to generate unique playtests. Furthermore, our experiments indicate that developing personas provide information to game designers that procedural personas cannot provide. Furthermore, we show that automated playtesting can be extended to 3D environments using state-of-the-art RL algorithms.
We proposed APF to discover alternative paths in an environment. We based APF on exploration research techniques and proposed two methodologies to implement APF, APFCTS, and APFICM. In our experiments in GVG-AI and Doom environments, we found that APF ensures that the same path is not generated again.
In the future, we would like to experiment with different personas using APF. Next, APFICM can be improved by substituting the linear layer with an LSTM layer. This substitution will provide path information rather than state transition information. Lastly, we would like to experiment with other 3D environments such as Minecraft [34].
References
- [1] E. J. Powley, S. Colton, S. Gaudl, R. Saunders, and M. J. Nelson, “Semi-automated level design via auto-playtesting for handheld casual game creation,” in 2016 IEEE Conference on Computational Intelligence and Games (CIG), 2016, pp. 1–8.
- [2] S. Gudmundsson, P. Eisen, E. Poromaa, A. Nodet, S. Purmonen, B. Kozakowski, R. Meurling, and L. Cao, “Human-like playtesting with deep learning,” in 2018 IEEE Conference on Computational Intelligence and Games (CIG), 08 2018, pp. 1–8.
- [3] S. Roohi, A. Relas, J. Takatalo, H. Heiskanen, and P. Hämäläinen, Predicting Game Difficulty and Churn Without Players, ser. CHI PLAY ’20. New York, NY, USA: Association for Computing Machinery, 2020, p. 585–593.
- [4] C. Holmgard, M. C. Green, A. Liapis, and J. Togelius, “Automated playtesting with procedural personas with evolved heuristics,” IEEE Transactions on Games, pp. 1–1, 2018.
- [5] L. Mugrai, F. Silva, C. Holmgård, and J. Togelius, “Automated playtesting of matching tile games,” in 2019 IEEE Conference on Games (CoG). IEEE, 2019, pp. 1–7.
- [6] C. Holmgård, A. Liapis, J. Togelius, and G. N. Yannakakis, “Generative agents for player decision modeling in games,” in Proceedings of the 9th International Conference on the Foundations of Digital Games (FDG), 2014.
- [7] R. Bartle, “Virtual worlds: Why people play,” Massively Multiplayer Game Development 2, vol. 2, pp. 3–18, 01 2005.
- [8] S. Ariyurek, A. Betin-Can, and E. Surer, “Automated video game testing using synthetic and humanlike agents,” IEEE Transactions on Games, vol. 13, no. 1, pp. 50–67, 2021.
- [9] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. A. Riedmiller, A. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nature, vol. 518, pp. 529–533, 2015.
- [10] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” CoRR, vol. abs/1707.06347, 2017.
- [11] C. B. Browne, E. Powley, D. Whitehouse, S. M. Lucas, P. I. Cowling, P. Rohlfshagen, S. Tavener, D. Perez, S. Samothrakis, and S. Colton, “A survey of monte carlo tree search methods,” IEEE Transactions on Computational Intelligence and AI in Games, vol. 4, no. 1, pp. 1–43, March 2012.
- [12] M. G. Bellemare, S. Srinivasan, G. Ostrovski, T. Schaul, D. Saxton, and R. Munos, “Unifying count-based exploration and intrinsic motivation,” in Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain, 2016, pp. 1471–1479.
- [13] J. Fu, J. D. Co-Reyes, and S. Levine, “EX2: exploration with exemplar models for deep reinforcement learning,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, 2017, pp. 2577–2587.
- [14] D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell, “Curiosity-driven exploration by self-supervised prediction,” in Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, 2017, pp. 2778–2787.
- [15] D. Perez-Liebana, J. Liu, A. Khalifa, R. D. Gaina, J. Togelius, and S. M. Lucas, “General video game ai: A multitrack framework for evaluating agents, games, and content generation algorithms,” IEEE Transactions on Games, vol. 11, no. 3, pp. 195–214, 2019.
- [16] M. Kempka, M. Wydmuch, G. Runc, J. Toczek, and W. Jaśkowski, “ViZDoom: A Doom-based AI research platform for visual reinforcement learning,” in IEEE Conference on Computational Intelligence and Games. Santorini, Greece: IEEE, Sep 2016, pp. 341–348, the best paper award.
- [17] R. A. Bartle, “Hearts, clubs, diamonds, spades: Players who suit MUDs,” http://www.mud.co.uk/richard/hcds.htm , 2019.
- [18] A. Tychsen and A. Canossa, “Defining personas in games using metrics,” in Proceedings of the 2008 Conference on Future Play: Research, Play, Share, ser. Future Play ’08. New York, NY, USA: ACM, 2008, pp. 73–80.
- [19] C. Holmgård, A. Liapis, J. Togelius, and G. N. Yannakakis, “Evolving personas for player decision modeling,” in 2014 IEEE Conference on Computational Intelligence and Games. IEEE, 2014, pp. 1–8.
- [20] C. Holmgård, A. Liapis, J. Togelius, and G. N. Yannakakis, “Monte-carlo tree search for persona based player modeling,” in Eleventh Artificial Intelligence and Interactive Digital Entertainment Conference, 2015.
- [21] F. de Mesentier Silva, S. Lee, J. Togelius, and A. Nealen, “Ai-based playtesting of contemporary board games,” in Proceedings of the 12th International Conference on the Foundations of Digital Games. ACM, 2017, p. 13.
- [22] G. Ostrovski, M. G. Bellemare, A. van den Oord, and R. Munos, “Count-based exploration with neural density models,” in Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, 2017, pp. 2721–2730.
- [23] H. Tang, R. Houthooft, D. Foote, A. Stooke, X. Chen, Y. Duan, J. Schulman, F. D. Turck, and P. Abbeel, “#exploration: A study of count-based exploration for deep reinforcement learning,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, 2017, pp. 2753–2762.
- [24] I. Osband, C. Blundell, A. Pritzel, and B. V. Roy, “Deep exploration via bootstrapped DQN,” in Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain, 2016, pp. 4026–4034.
- [25] Y. Burda, H. Edwards, A. J. Storkey, and O. Klimov, “Exploration by random network distillation,” in 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, 2019.
- [26] L. Lee, B. Eysenbach, E. Parisotto, E. P. Xing, S. Levine, and R. Salakhutdinov, “Efficient exploration via state marginal matching,” CoRR, vol. abs/1906.05274, 2019.
- [27] J. A. Brown, “Towards better personas in gaming : Contract based expert systems,” in 2015 IEEE Conference on Computational Intelligence and Games (CIG), 2015, pp. 540–541.
- [28] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018.
- [29] M. G. Bellemare, J. Veness, and E. Talvitie, “Skip context tree switching,” in Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21-26 June 2014, 2014, pp. 1458–1466.
- [30] A. Hill, A. Raffin, M. Ernestus, A. Gleave, A. Kanervisto, R. Traore, P. Dhariwal, C. Hesse, O. Klimov, A. Nichol, M. Plappert, A. Radford, J. Schulman, S. Sidor, and Y. Wu, “Stable baselines,” https://github.com/hill-a/stable-baselines, 2018.
- [31] B. Tastan and G. Sukthankar, “Learning policies for first person shooter games using inverse reinforcement learning,” in Proceedings of the Seventh AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, ser. AIIDE’11. AAAI Press, 2011, pp. 85–90.
- [32] B. Baker, I. Kanitscheider, T. M. Markov, Y. Wu, G. Powell, B. McGrew, and I. Mordatch, “Emergent tool use from multi-agent autocurricula,” in 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020, 2020.
- [33] C. Gordillo, J. Bergdahl, K. Tollmar, and L. Gisslén, “Improving playtesting coverage via curiosity driven reinforcement learning agents,” in 2021 IEEE Conference on Games (CoG), 2021, pp. 1–8.
- [34] M. Johnson, K. Hofmann, T. Hutton, D. Bignell, and K. Hofmann, “The malmo platform for artificial intelligence experimentation,” in 25th International Joint Conference on Artificial Intelligence (IJCAI-16). AAAI - Association for the Advancement of Artificial Intelligence, July 2016.
Appendix A Hyperparameters used in Experiments
| Agents | |||
| Hyperparameters | PPO | PPO+CTS | PPO+ICM |
| Policy | CNN | CNN | CNNLstm |
| Timesteps | 1e8 | 1e8 | 2e8 |
| Horizon | 256 | 256 | 64 |
| Num. Minibatch | 8 | 8 | 8 |
| GAE | 0.95 | 0.95 | 0.99 |
| Discount | 0.99 | 0.99 | 0.999 |
| Learning Rate | |||
| Num. Epochs | 3 | 3 | 4 |
| Entropy Coeff. | 0.01 | 0.01 | 0.001 |
| VF Coeff. | 0.5 | 0.5 | 0.5 |
| Clipping Param. | 0.2 | 0.2 | 0.1 |
| Max Grad. Norm. | 0.5 | 0.5 | 0.5 |
| Num. of Actors | 16 | 16 | 32 |
| CTS Beta | - | 0.05 | - |
| CTS Filter | - | L-shaped | - |
| ICM State Features | - | - | 256 |
| ICM Beta | - | - | 0.2 |
| Hyperparameters | APFCTS | APFICM |
|---|---|---|
| 0.4 | 0.1 | |
| -0.4 | -0.4 | |
| APF Beta | 0.01 | 0.01 |