PKF: Probabilistic Data Association Kalman Filter for Multi-Object Tracking
Abstract
In this paper, we derive a new Kalman filter with probabilistic data association between measurements and states. We formulate a variational inference problem to approximate the posterior density of the state conditioned on the measurement data. We view the unknown data association as a latent variable and apply Expectation Maximization (EM) to obtain a filter with update step in the same form as the Kalman filter but with expanded measurement vector of all potential associations. We show that the association probabilities can be computed as permanents of matrices with measurement likelihood entries. We also propose an ambiguity check that associates only a subset of ambiguous measurements and states probabilistically, thus reducing the association time and preventing low-probability measurements from harming the estimation accuracy. Experiments in simulation show that our filter achieves lower tracking errors than the well-established joint probabilistic data association filter (JPDAF), while running at comparable rate. We also demonstrate the effectiveness of our filter in multi-object tracking (MOT) on multiple real-world datasets, including MOT17, MOT20, and DanceTrack. We achieve better higher order tracking accuracy (HOTA) than previous Kalman-filter methods and remain real-time. Associating only bounding boxes without deep features or velocities, our method ranks top-10 on both MOT17 and MOT20 in terms of HOTA. Given offline detections, our algorithm tracks at 250+ fps on a single laptop CPU. Code is available at https://github.com/hwcao17/pkf.
1 Introduction
In tasks where ambiguity exists between measurements and variables of interest, probabilistic data association can prevent catastrophic estimation failures. For example, in multi-object tracking (MOT), there can be a lot of occlusions causing high ambiguity in data association. An illustration of how probabilistic data association improves MOT is shown in Figure 1. Methods utilizing the Kalman filter [6, 47, 13] have achieved outstanding performance in MOT but have not considered the impact of probabilistic data association on the tracking process.
We derive a new formulation of the Kalman filter with probabilistic data association. Previous works [3, 12] show that the Kalman filter can be derived using variational inference (VI) by maximizing the evidence lower bound (ELBO) of the input and measurement data likelihood. To deal with ambiguous associations, we approach the VI problem using Expectation-Maximization (EM) with the data association as the latent variable. In the E-step, we show that the association weights can be computed as permanents of matrices with measurement likelihood entries using accelerated permanent algorithms [32, 20]. We also show that the weight computation can be extended to cases with missing detections and clutter. In the M-step, optimizing the EM objective once leads to a Kalman filter with the usual prediction and update steps but with an extended measurement vector and noise covariance matrix capturing all possible data associations. Our formulation is related to the well-known joint probabilistic data association filter (JPDAF) [2]. However, while JPDAF first computes a posterior given each associated measurement, i.e., maximizes the ELBO of each measurement, and then computes the weighted average of the posteriors, our filter directly optimizes the overall ELBO weighted by the data association probabilities. We show that our algorithm achieves lower tracking errors than JPDAF, while running at comparable tracking rates.
We also apply our filter to MOT. We observe that, with accurate detection algorithms [36, 35], binary associations are fast and work well when the ambiguity is not severe and incorporating measurements with low association weights can harm the estimation accuracy. Therefore, we employ a hybrid data association procedure. We first do binary data association (e.g., via [23, 21]) and then perform an ambiguity check which outputs a set of ambiguous measurements and tracks. Then, probabilistic data association is only performed on the ambiguous set, thus reducing the computation time and preventing low-probability measurements from harming the accuracy. We test our algorithm on multiple real-world MOT datasets, including MOT17 [27], MOT20 [15], and DanceTrack [40]. Our method outperforms previous Kalman-filter methods [47, 13] while maintaining almost the same inference speed. We name our probabilistic data association Kalman filter the PKF with P emphasizing both the probabilistic nature of the data association and the matrix permanent computation of the association weights. Our contributions are summarized as follows.
-
•
We formulate state estimation with ambiguous measurements as a VI problem and use EM to derive the PKF, a new Kalman filter with probabilistic data association.
-
•
We show that association probabilities can be computed using matrix permanents and design a hybrid association procedure with an ambiguity check to reduce computation complexity and exclude low-probability associations.
-
•
We demonstrate the effectiveness of the PKF in comparison to the JPDAF and on multiple real-world MOT datasets. PKF ranks top-10 on both MOT17 and MOT20 by associating only bounding boxes and runs at 250+ fps on a single laptop CPU given offline detections.
2 Related work
Probabilistic data association
Data association is a key challenge in estimation problems where measurements need to be related to estimated variables. The most straightforward association approach is by a nearest neighbor rule based on some distance metric, such as Euclidean or Mahalonobis [22]. However, nearest-neighbor associations are prone to mistakes. The joint compatibility branch and bound (JCBB) algorithm [31] computes a joint Mahalonobis distance and performs a joint test for the association event to obtain robust associations. To deal with ambiguity, Bar-Shalom and Tse developed the probabilistic data association filter (PDAF) [1] for tracking single objects in the presence of clutter measurements. In the Kalman filter update step, the innovation terms are computed for each of the possible associations and are averaged weighted by the association probabilities. The performance of PDAF can degrade in the multi-object case because its separate association process can cause multiple tracks to latch onto the same object. The JPDAF [2] extends the PDAF by associating all measurements and tracks jointly. In each association event, a measurement can be associated with at most one track, and vice versa. Musicki et al. [30] develop an integrated probabilistic data association (IPDA) method using a Markov chain modeling probabilistic data association, track initialization, and termination. JIPDA [29] extends IPDA [30] to the multi-object case by performing data association jointly. There are also improvements on the original JPDAF [2] like avoiding coalescence [8] and speeding up the inference [44, 37]. Meyer et al. [26] approach probabilistic data association using a factor graph where the variables (including objects and association events) and functions (motion, observation, et al.) are nodes and the edges model their relationships. The association probabilities can be computed efficiently by message passing in the graph. A survey of data association techniques can be found in [34]. Besides MOT, probabilistic data association is also applied in other estimation tasks like biological data processing [18] and simultaneous localization and mapping [9, 16].
Multi-object tracking State-of-art MOT algorithms are dominated by the tracking-by-detection approach, which consists of two steps: object detection [36, 35] and data association. SORT [6] uses the Hungarian algorithm [23] to associate bounding-box object detections and updates the object tracks using the Kalman filter to achieve real-time online tracking. DeepSORT [42] extends SORT [6] by introducing deep visual features for data association. ByteTrack [47] makes an observation that the detectors can make imperfect predictions in complex scenes and proposes a second round of data association for low-confidence detections. OC-SORT [13] analyzes the limitations of SORT [13], namely sensitivity to state noise and temporal error magnification, and proposes an observation-centric re-update step and object momentum for data association.
A second class of algorithms for MOT performs tracking-by-regression. Feichtenhofer et al. [17] use a correlation function between the feature maps of two frames to predict the transformation of bounding boxes in different frames. Bergmann et al. [4] uses the regression head of Faster-RCNN [36] to predict bounding-box offsets from the previous image to the current image. CenterTrack [49] adopts the same network architecture as CenterNet [48] but takes two consecutive images to predict object offsets between frames. Braso and Leal-Taixe [10] approach MOT with a graph neural network, which stores object features in the nodes and predicts whether two bounding boxes in different frames are the same object by edge features.
A third set of methods performs tracking-by-attention [25] using transformer models [41] for joint detection and tracking based on new object queries and tracked object queries, which solves the creation and association of objects implicitly. Although these methods utilize different techniques for data association, either explicit or implicit, they all consider deterministic data association.
3 Problem formulation
Consider time-varying variables that need to be estimated, denoted as , . We refer to their concatenation into a single vector at time :
| (1) |
as the state of a dynamical system. Suppose that evolves according to a discrete-time linear motion model:
| (2) |
where is the known input and is zero-mean Gaussian noise with covariance .
At each time , a subset of the variables are observed. Let be the number of measurements at time and let be the -th measurement with , which is generated by some according to a linear measurement model:
| (3) |
where is zero-mean Gaussian noise with covariance . We denote the concatenation of all measurements by:
| (4) |
Problem.
Given an estimate of the state at time , an input , and measurements , obtain an estimate of . The association between the measurements and the variables that generated them is unknown.
4 Methodology
We formulate a Kalman filter with probabilistic data association to solve the estimation problem defined in Sec. 3.
4.1 Data association
We define the association between a set of measurements and a set of variables that generated them as follows.
Definition.
The data association of set to set is a function that either associates an element to an element or indicates via that there is no matching element in .
For example, in MOT, is the set of measurements (e.g., features, bounding boxes, or object segmentations), and is the set of tracked objects.
Let be the data association at time , such that measurement is assigned to variable . We denote the set of all possible data association functions at time as and the set of data associations across all times as .
We consider a probabilistic setting, in which we are given a prior probability density of the state , and aim to compute the posterior density of conditioned on the input and the measurements . At each time , we treat the data association as a random variable with a uniform prior independent of . Using Bayes rule and assuming the measurements are mutually independent conditioned on the variables that generated them, the density of conditioned on satisfies:
| (5) |
Let denote the density of a Gaussian distribution with mean and covariance . Since and , we have:
Next, consider the likelihood that is generated by , which we denote by . Using (5), we have:
| (6) |
where is the set of data association functions that assign measurement to variable . We show that can be computed using the permanent of a matrix containing the measurement likelihood as its entries . The permanent of a matrix with is defined as:
| (7) |
where is the set of injective functions .
Proposition 1.
Let be a matrix with elements . The data association weight in (6) can be computed as:
| (8) |
where is the matrix with the -th row and -th column removed.
Proof.
See Supplementary Material Section 7. ∎
Proposition 1 allows us to compute data association weights. Next, we derive a Kalman filter with probabilistic data association.
4.2 Probabilistic data association Kalman filter
To derive a filter, we consider two time steps, namely and , and define a lifted form of the state:
| (9) |
Given the prior density , the input , and the measurement , we aim to find an estimate of the joint posterior . To determine , we use variational inference [7, Ch. 10], which maximizes the ELBO of the evidence with respect to . To save space, we denote by . The evidence can be decomposed as [7, Ch. 10]:
| (10) | ||||
| (11) |
where is the Kullback–Leibler divergence and is the ELBO. Since the evidence is constant for given , the ELBO is maximized when the term is zero.
To account for probabilistic data association, we formulate the optimization inspired by the EM algorithm [7, Ch. 9]. EM determines the maximum likelihood (ML) or maximum a posterior (MAP) in the presence of unobserved variables. It contains an E-step that computes the expectation w.r.t. the unobserved variables and an M-step that maximizes the log-likelihood. Letting the data association be the unobserved variable, we consider the following optimization problem:
| (12) | |||
where the expectation is with respect to . EM splits the optimization in (12) in two steps. The E-step requires computing the data association likelihood . This can be obtained from (5) and Proposition 1. Given the data association weights , the M-step performs the optimization in (12) to determine .
We show that performing the E and M steps for one iteration, with initialization given by the prior state and the predicted state in (2), is equivalent to a Kalman filter with probabilistic data association. We first define an expanded observation model that captures all possible ways of generating the measurements at each time :
| (13) |
where , , is a vector with elements equal to one, is the identity matrix, is the Kronecker product, and is zero-mean Gaussian noise with covariance:
| (14) |
where are the data association weights in (6). Using the expanded measurement model in (13), we obtain a Kalman filter with probabilistic data association.
Proposition 2.
Given prior and input , the predicted Gaussian distribution of computed by the Kalman filter with motion model in (2) has parameters:
| (15) | ||||
Given measurements , the updated Gaussian distribution of conditioned on computed by the Kalman filter with probabilistic data association is obtained from the expanded measurement model in (13) as:
| (16) | ||||
where the Kalman gain is:
| (17) |
Proof.
See Supplementary Material Section 8. ∎
4.3 Comparison with JPDAF
We compare our PKF to the JPDAF [2]. We first show the update scheme difference, then show that the association weights in [2] can be computed using Proposition 1 and compare the tracking errors and speed on simulated data.
4.3.1 Update scheme
Both JPDAF [2] and PKF can be decomposed into two stages. The JPDAF first computes a posterior mean as the normal Kalman filter with each associated measurement, and then averages the posterior means with the association weights and computes the covariance correspondingly. Instead, our PKF first constructs an expanded measurement model and then performs a single update in the same form as the normal Kalman filter but with an expanded measurement vector. The JPDAF maximizes the ELBO with regard to each associated measurement and then averages those estimates, while our PKF maximizes the total weight-averaged ELBO, which does not necessarily maximize each measurement’s individual ELBO but may lead to a higher total ELBO. This difference is underscored by the lower tracking errors in the simulations in Sec. 4.3.3.
Both algorithms can be performed in a coupling or decoupling way. In the coupling way, all the objects are stored in one filter and updated jointly. In the decoupling way, each object is stored and updated separately. Proposition 2 shows the coupling version. In the experiments, we do decoupling updates just like JPDAF. Given measurements and the association weights, the update is the same as Proposition 2 except that there is an estimate of only one object in the state. Regarding the complexity, the Kalman gain in JPDAF is the same as the normal Kalman filter but JPDAF needs all the measurement residuals to update the mean and covariance. In PKF, the complexity of the Kalman gain computation increases due to the expanded measurement model. The original Kalman filter has complexity [28] in terms of the measurement dimension and state dimension . Given the number of associated measurements , the complexity of PKF is . In practice, is usually small because of outlier pruning like validation gating [2] and our ambiguity check in Sec. 5.1. Hence, PKF remains efficient as validated by the experiments in Sec. 4.3.3 and Sec. 5.2.
4.3.2 Weight computation
Following JPDAF [2], we make the assumption that 1) the number of established objects is known and 2) there can be missing or false measurements (clutter) for each object at each time step. Using our notation, the probability of an association event in [2, Eq. 47] can be written as
where is the spatial density of the false measurements Poisson pmf, is the detection probability, is an indicator of whether is associated in the event, i.e. is not treated as clutter, and is an indicator of whether the object is associated. Suppose that the number of clutter points in is , the number of measurements is , and the number of objects is . Since the number of established objects is assumed known, we have . With the number of clutter points fixed, can be simplified as
| (18) | ||||
where is the set of association events that have false measurements. The probability of measurement being assigned to object is computed in [2, Eq. 51] as
| (19) | ||||
where is the set of associations having false measurements and assigning to . Selecting a series of sets of false measurements of size , for each fixed , the second sum on the last line of (19) can be computed via Proposition 1.
4.3.3 Tracking comparison
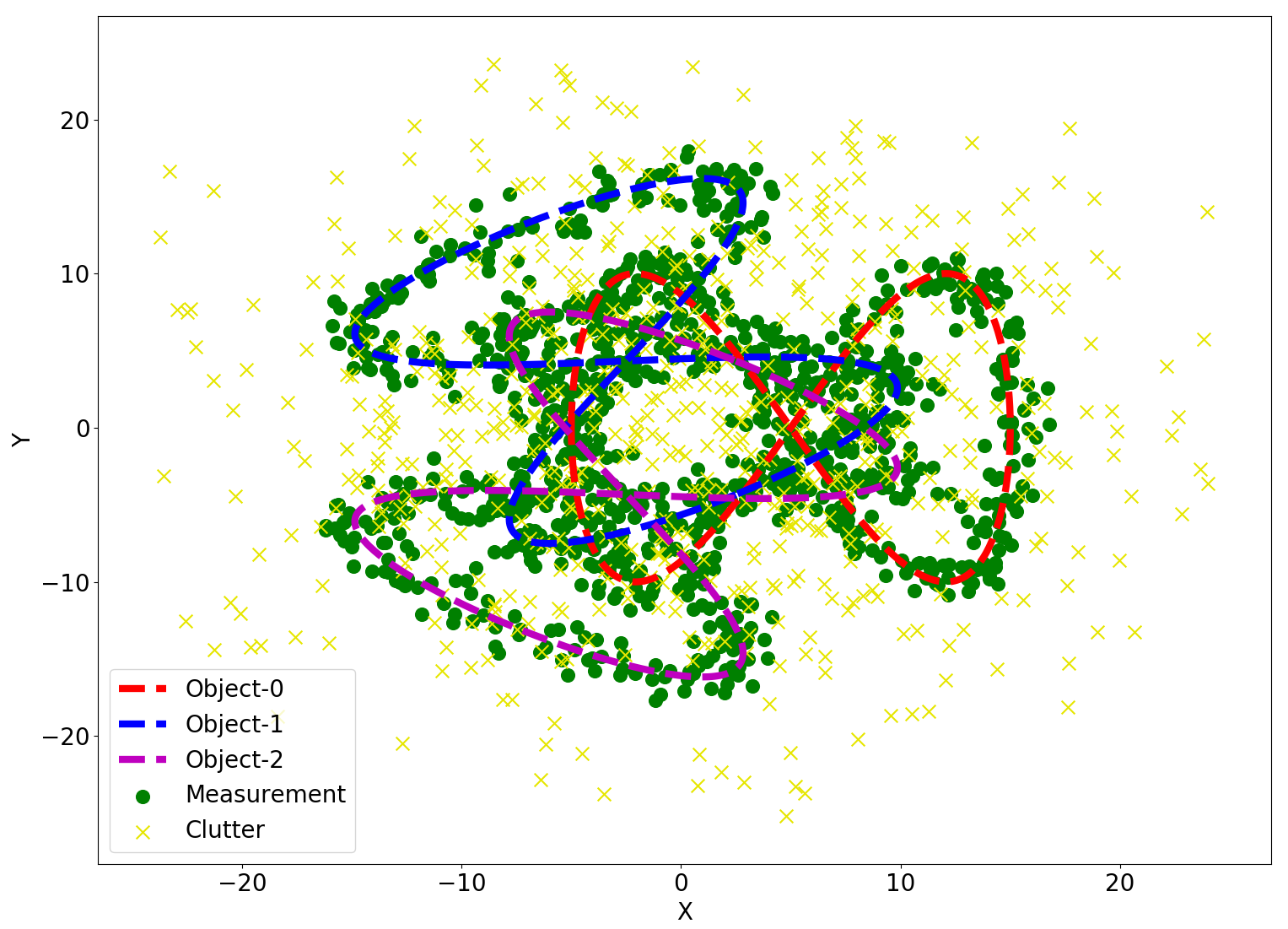
Using the same association weight computation, we compare the performance of JPDAF [2] and our PKF with 2D simulated data. In the simulation, each object is a 2D point and moves along an 8-shape trajectory. The detection probability of each object is , the measurement noise is a zero-mean Gaussian with covariance , and clutter is sampled uniformly in the range of around each ground-truth point. A visualization of 3 simulated objects can be found in Figure 2.
The errors and speed of tracking 3 and 5 objects in simulation are shown in Table 1. PKF achieves lower tracking errors than JPDAF [2] implemented by [19]. Our intuition as to why PKF achieves lower errors is provided in the first paragraph of Sec. 4.3.1. The experiments also show that PKF can track at a comparable speed with JPDAF.
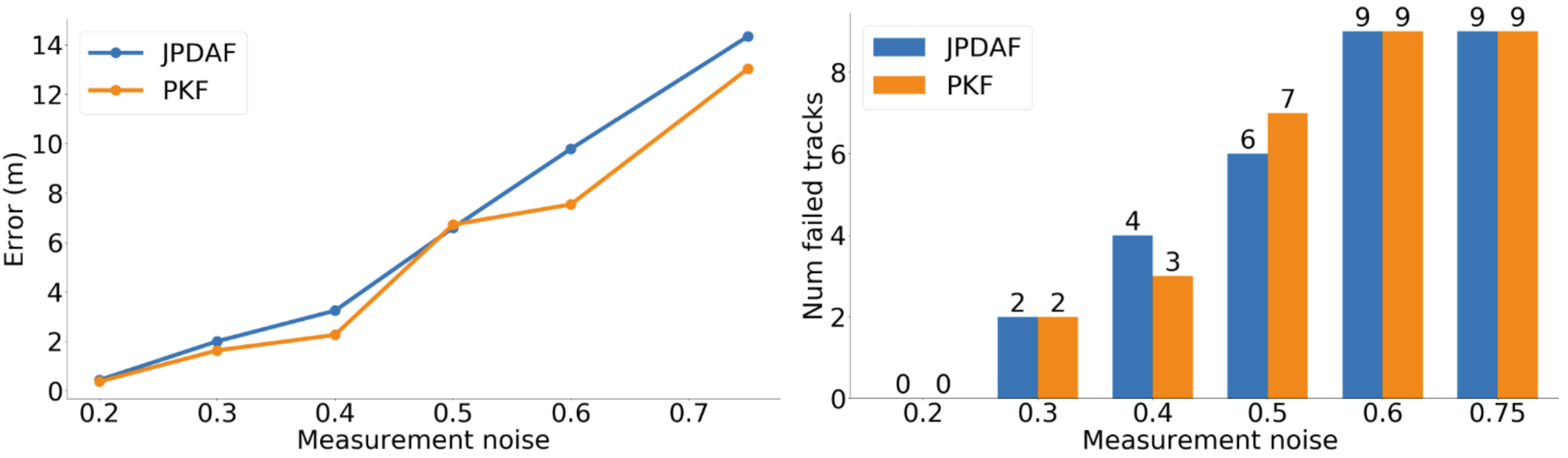
We also compare the two algorithms with a larger number of objects, i.e., 10 objects, under different levels of measurement noises. In this setting, we increase the detection probability to to avoid frequent tracking failures. The clutter generation remains the same and we test with measurement noises from to . The results can be found in Figure 3. We can see that our filter obtains lower tracking errors in most cases. The number of failed tracks is almost the same as JPDAF [2]. The average fps of JPDAF with 10 objects is and that of ours is .
5 Application to multi-object tracking
In this section, we apply our PKF to the MOT task.
5.1 Algorithm design
To make the filter work efficiently in practice, we introduce a hybrid data association scheme that applies probabilistic data association only to a subset of ambiguous measurements. Also, we force the state covariance matrix to be block diagonal so that each track is estimated by a separate filter, although the states are still considered jointly when evaluating the data association probabilities. We follow SORT [6] and model each object’s state as , where and represent the horizontal and vertical pixel location of the center of the object bounding box, while and represent the scale (area) and the aspect ratio of the object’s bounding box respectively. The detections are converted into .
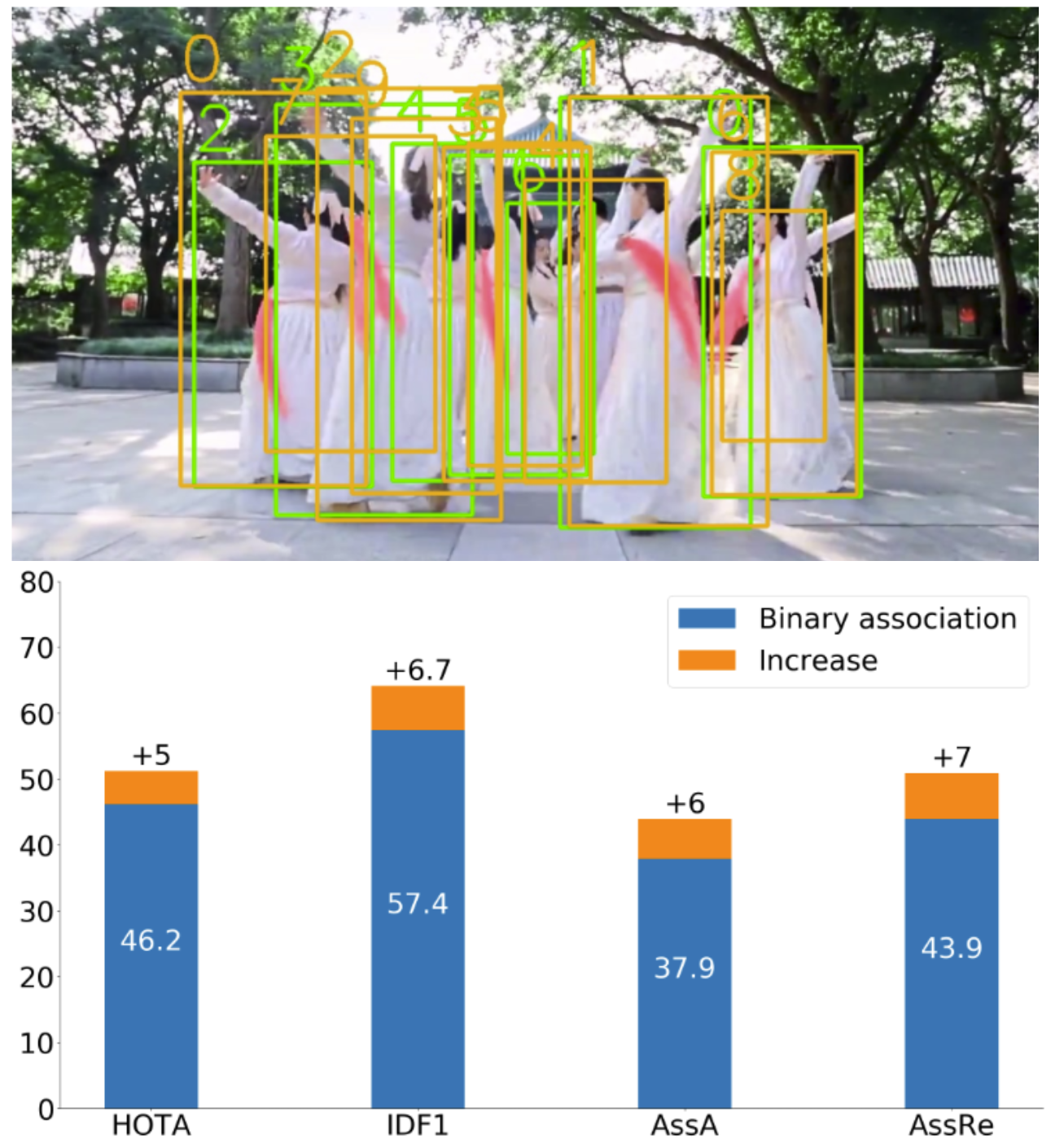
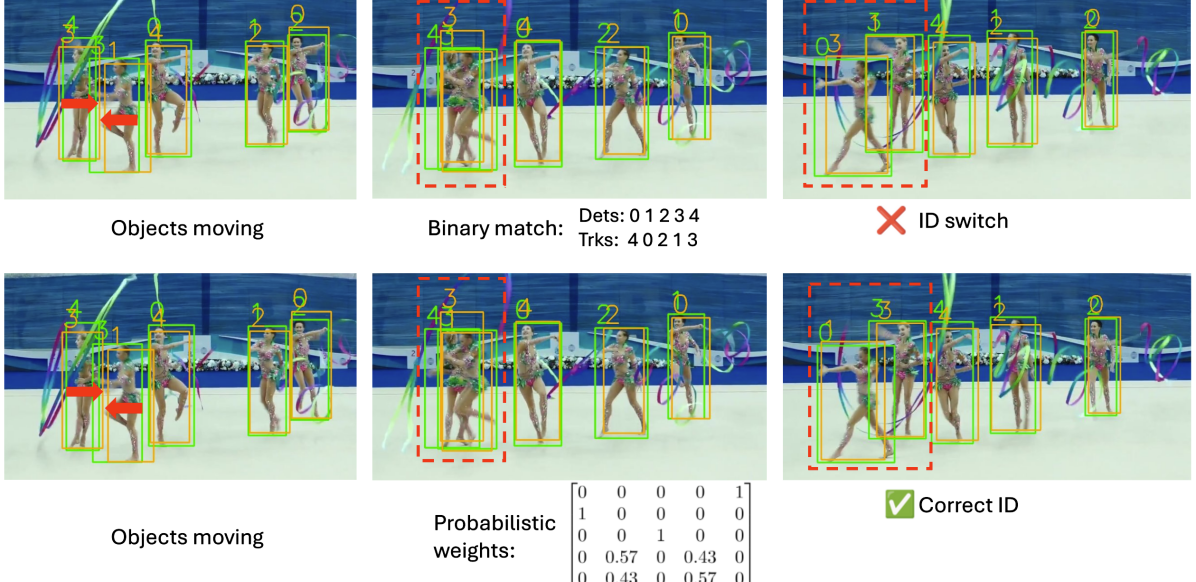
Hybrid data association Constructing a probability matrix using all measurements and states and computing the association weights according to Proposition 1 can be slow and potentially harm the tracking accuracy due to low-probability measurements. A binary matching algorithm, such as the Hungarian [23] or the Jonker-Volgenant [21], is efficient but may make incorrect hard decisions when there is ambiguity. We propose a hybrid association scheme to take advantage of both matching types. Given measurements , and states , , we first compute a score matrix with entries equal to the intersection over union (IoU) for each measurement-object bounding-box pair. A binary matching algorithm is applied to to obtain a binary matching weight matrix. Then, we perform an ambiguity check. For each row of (corresponding to measurement ), we sort the scores from high to low. Supposing the rank is , if object has a score over a threshold , e.g., the score of object , then and are ambiguous objects, and the measurement is an ambiguous measurement. Then, we compare and and so on. We repeat this for all objects and measurements to obtain an ambiguous set. Measurements and objects with their matches marked as ambiguous will also be added to the ambiguous set. Proposition 1 is only applied to the ambiguous set of measurements and objects. Finally, we replace the elements in the initial binary matching weight matrix with the corresponding probabilistic weights. An illustration of how our proposed probabilistic data association Kalman filter benefits the ambiguous case is shown in Figure 4 where binary association causes a wrong ID switch while our proposed association can obtain a correct ID.
Each object as a single filter Instead of storing all objects in the filter state, we create a filter for each new object (which is equivalent to enforcing a block-diagonal covariance matrix). This avoids a large state covariance and observation Jacobian in (17), which speeds up the tracking especially when the number of objects is large. After we get the association weight matrix , each column vector corresponds to a tracked object with measurement association weights. All measurements with a weight larger than a threshold are used to update the tracker by Proposition 2. The thresholding helps exclude potential outliers and achieve stable computation.
5.2 Evaluation
Datasets
We evaluate PKF on multiple MOT datasets, including MOT17 [27], MOT20 [15], and DanceTrack [40]. MOT17 and MOT20 focus on crowded pedestrian tracking in public places. DanceTrack is a dancing-scene dataset, where the objects have similar appearances, move fast, highly non-linearly, and cross over each other frequently, thus imposing a higher requirement on data association.
Metrics We use higher order tracking accuracy (HOTA) [24] as our main metric because it balances between detection accuracy and association accuracy. We also report the AssA [24] and IDF1 [38] metrics which emphasize data association accuracy and the MOTA [5] metric which emphasizes the detection accuracy.
Implementation In performing the data association ambiguity check, we compute the IoU between detections and tracked bounding boxes. To construct the matrix in Proposition 1, we treat as a distance (not an actual distance function mathematically) and compute the conditional probability as , where is a scaling factor. We found to work well in practice. On MOT17 [27] and DanceTrack [40], the ambiguity check threshold was set to . On MOT20, we set since the pedestrians are more crowded. The weight threshold was set at . We used the publicly available YOLOX weights by ByteTrack [47]. Following the common practice of SORT [6], we set the detection confidence threshold at for MOT20 and for other datasets. A new track is created if a detected box has IoU lower than with all the tracks. All experiments were conducted on a laptop with [email protected] CPU, 16 GB RAM, and RTX 3080 GPU.
| Tracker | HOTA | MOTA | IDF1 | FP() | FN() | IDs | Frag | AssA | AssR |
|---|---|---|---|---|---|---|---|---|---|
| FairMOT [46] | 59.3 | 73.7 | 72.3 | 2.75 | 11.7 | 3303 | 8073 | 58.0 | 63.6 |
| QDTrack [33] | 53.9 | 68.7 | 66.3 | 2.66 | 14.7 | 3378 | 8091 | 52.7 | 57.2 |
| MOTR [45] | 57.2 | 71.9 | 68.4 | 2.11 | 13.6 | 2115 | 3897 | 55.8 | 59.2 |
| TransMOT [14] | 61.7 | 76.7 | 75.1 | 3.62 | 9.32 | 2346 | 7719 | 59.9 | 66.5 |
| MeMOT [11] | 56.9 | 72.5 | 69.0 | 2.72 | 11.5 | 2724 | - | 55.2 | - |
| OC-SORT [13] | 63.2 | 78.0 | 77.5 | 1.51 | 10.8 | 1950 | 2040 | 63.2 | 67.5 |
| ByteTrack [47] | 63.1 | 80.3 | 77.3 | 2.55 | 8.37 | 2196 | 2277 | 62.0 | 68.2 |
| PKF | 63.3 | 78.3 | 77.7 | 1.56 | 10.5 | 2130 | 2754 | 63.4 | 67.4 |
5.3 Benchmark results
MOT17 and MOT20
The quantitative results on MOT17 [27] and MOT20 [15] are shown in Table 2 and 3. To get a fair comparison, we use the same detections as ByteTrack [47] and OC-SORT [13] and inherit the linear interpolation. While ByteTrack [47] does multiple rounds of associations and OC-SORT makes use of velocities, does object recovery, and re-updates, PKF only does one round of association using only bounding boxes and performs one single update step. We also do not use the adaptive detection thresholds as in ByteTrack [47] for generalization. We can see that our method is able to achieve comparable results with those two methods [47, 13] and is better in data association as indicated by the higher IDF1 and AssA and achieves higher HOTA results. Note that our method is compatible with techniques used by other methods, like multiple rounds of associations [47], taking into account velocities [13], and doing object recovery [13] but we did not incorporate these to keep the results clear.
| Tracker | HOTA | MOTA | IDF1 | FP() | FN() | IDs | Frag | AssA | AssR |
|---|---|---|---|---|---|---|---|---|---|
| FairMOT [46] | 54.6 | 61.8 | 67.3 | 10.3 | 8.89 | 5243 | 7874 | 54.7 | 60.7 |
| TransMOT [14] | 61.9 | 77.5 | 75.2 | 3.42 | 8.08 | 1615 | 2421 | 60.1 | 66.3 |
| MeMOT [11] | 54.1 | 63.7 | 66.1 | 4.79 | 13.8 | 1938 | - | 55.0 | - |
| OC-SORT [13] | 62.1 | 75.5 | 75.9 | 1.80 | 10.8 | 913 | 1198 | 62.0 | 67.5 |
| ByteTrack [47] | 61.3 | 77.8 | 75.2 | 2.62 | 8.76 | 1223 | 1460 | 59.6 | 66.2 |
| PKF | 62.3 | 75.4 | 76.3 | 1.73 | 10.9 | 980 | 1584 | 62.7 | 67.6 |
| Tracker | HOTA | DetA | AssA | MOTA | IDF1 |
|---|---|---|---|---|---|
| CenterTrack [49] | 41.8 | 78.1 | 22.6 | 86.8 | 35.7 |
| FairMOT [46] | 39.7 | 66.7 | 23.8 | 82.2 | 40.8 |
| QDTrack [33] | 45.7 | 72.1 | 29.2 | 83.0 | 44.8 |
| TraDes [43] | 43.3 | 74.5 | 25.4 | 86.2 | 41.2 |
| MOTR [45] | 54.2 | 73.5 | 40.2 | 79.7 | 51.5 |
| SORT [6] | 47.9 | 72.0 | 31.2 | 91.8 | 50.8 |
| DeepSORT [42] | 45.6 | 71.0 | 29.7 | 87.8 | 47.9 |
| ByteTrack [47] | 47.3 | 71.6 | 31.4 | 89.5 | 52.5 |
| OC-SORT [13] | 54.5 | 80.4 | 37.1 | 89.4 | 54.0 |
| PKF | 51.7 | 79.8 | 33.5 | 89.1 | 50.1 |
| PKF + OCM&OCR | 55.4 | 79.5 | 38.7 | 89.2 | 54.9 |
DanceTrack The results on DanceTrack [40] are shown in Table 4. We can see that PKF achieves better results than SORT [6] and ByteTrack [47]. Since the movement is significant and the number of objects is usually fixed in a dancing scene, we find that OCM (velocity) and OCR (object recovery) proposed in OC-SORT [13] are useful. By incorporating these two components, we can further outperform OC-SORT without ORU (re-update) [13]. In this dataset, there are a lot of occlusions and the dancers can move dramatically. The increase of AssA and IDF1 shows again the advantage of PKF in terms of association. We can see that PKF obtains lower DetA than [13]. This is because the probabilistic data association can incorporate incorrect detections in the update step, making the position estimates slightly worse. However, we can still obtain higher HOTA since at a certain threshold can be decomposed into two parts, a detection accuracy score (DetA) and an association accuracy score (AssA):
| (20) |
The increased HOTA shows the increased association quality can compensate for relatively worse position updates.
| MOT17 | DanceTrack | |||||
|---|---|---|---|---|---|---|
| Metrics | HOTA | IDF1 | (ms) | HOTA | IDF1 | (ms) |
| Binary | 66.4 | 77.8 | 5.9 | 52.6 | 52.2 | 3.4 |
| PKF w/o A.C. | 44.9 | 52.8 | 4970.6 | 44.2 | 45.2 | 121.2 |
| PKF w/o W.T. | 66.6 | 78.1 | 6.3 | 52.0 | 50.4 | 3.8 |
| PKF complete | 66.8 | 78.5 | 6.2 | 53.3 | 53.2 | 3.7 |
Ablation study We study the effect of the ambiguity check and weight thresholding on the validation sets of MOT17 and DanceTrack. The results are shown in Table 5. We observed that associating all measurements and tracks directly not only decreases the association quality, implied by the low HOTA and IDF1, but also makes the tracking slow. Adding weight thresholding can further improve the results as low-probability measurements are usually wrong. Weight thresholding also reduces the time a bit as we use fewer measurements in the update step. The complete PKF algorithm obtains better results than binary association with almost the same tracking speed.
6 Conclusion
We derived a new formulation of the Kalman filter with probabilistic data association by formulating a variational inference problem and introducing data association as a latent variable in the EM algorithm. We showed that, in the E-step, the association probabilities can be computed as matrix permanents, while the M-step led to the usual Kalman filter prediction and update steps but with an extended measurement vector and noise covariance matrix capturing possible data associations. Our experiments demonstrated that our filter can outperform the JPDAF and can achieve top-10 results on MOT benchmarks even without using deep features. Our algorithm is not restricted to the MOT application and can serve as a general method for estimation problems with measurement ambiguity.
References
- Bar-Shalom and Tse [1975] Yaakov Bar-Shalom and Edison Tse. Tracking in a cluttered environment with probabilistic data association. Automatica, 11(5):451–460, 1975.
- Bar-Shalom et al. [2009] Yaakov Bar-Shalom, Fred Daum, and Jim Huang. The probabilistic data association filter. IEEE Control Systems Magazine, 29(6):82–100, 2009.
- Barfoot et al. [2020] Timothy D Barfoot, James R Forbes, and David J Yoon. Exactly sparse gaussian variational inference with application to derivative-free batch nonlinear state estimation. IEEE IJRR, 39(13):1473–1502, 2020.
- Bergmann et al. [2019] Philipp Bergmann, Tim Meinhardt, and Laura Leal-Taixe. Tracking without bells and whistles. In CVPR, pages 941–951, 2019.
- Bernardin and Stiefelhagen [2008] Keni Bernardin and Rainer Stiefelhagen. Evaluating multiple object tracking performance: the clear mot metrics. EURASIP Journal on Image and Video Processing, 2008:1–10, 2008.
- Bewley et al. [2016] Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In ICIP, pages 3464–3468, 2016.
- Bishop [2006] Christopher M Bishop. Pattern Recognition and Machine Learning. Springer, 2006.
- Blom and Bloem [2000] Henk AP Blom and Edwin A Bloem. Probabilistic data association avoiding track coalescence. IEEE TAC, 45(2):247–259, 2000.
- Bowman et al. [2017] Sean L Bowman, Nikolay Atanasov, Kostas Daniilidis, and George J Pappas. Probabilistic data association for semantic slam. In ICRA, pages 1722–1729, 2017.
- Brasó and Leal-Taixé [2020] Guillem Brasó and Laura Leal-Taixé. Learning a neural solver for multiple object tracking. In CVPR, pages 6247–6257, 2020.
- Cai et al. [2022] Jiarui Cai, Mingze Xu, Wei Li, Yuanjun Xiong, Wei Xia, Zhuowen Tu, and Stefano Soatto. MeMOT: Multi-object tracking with memory. In CVPR, pages 8090–8100, 2022.
- Cao et al. [2024] Hanwen Cao, Sriram Shreedharan, and Nikolay Atanasov. Multi-Robot Object SLAM Using Distributed Variational Inference. IEEE Robotics and Automation Letters, 9(10):8722–8729, 2024.
- Cao et al. [2023] Jinkun Cao, Jiangmiao Pang, Xinshuo Weng, Rawal Khirodkar, and Kris Kitani. Observation-centric sort: Rethinking sort for robust multi-object tracking. In CVPR, pages 9686–9696, 2023.
- Chu et al. [2023] Peng Chu, Jiang Wang, Quanzeng You, Haibin Ling, and Zicheng Liu. Transmot: Spatial-temporal graph transformer for multiple object tracking. In WACV, pages 4870–4880, 2023.
- Dendorfer et al. [2020] Patrick Dendorfer, Hamid Rezatofighi, Anton Milan, Javen Shi, Daniel Cremers, Ian Reid, Stefan Roth, Konrad Schindler, and Laura Leal-Taixé. MOT20: A benchmark for multi object tracking in crowded scenes. arXiv preprint arXiv:2003.09003, 2020.
- Doherty et al. [2019] Kevin Doherty, Dehann Fourie, and John Leonard. Multimodal semantic slam with probabilistic data association. In ICRA, pages 2419–2425, 2019.
- Feichtenhofer et al. [2017] Christoph Feichtenhofer, Axel Pinz, and Andrew Zisserman. Detect to track and track to detect. In ICCV, pages 3038–3046, 2017.
- Godinez and Rohr [2014] William J Godinez and Karl Rohr. Tracking multiple particles in fluorescence time-lapse microscopy images via probabilistic data association. IEEE transactions on medical imaging, 34(2):415–432, 2014.
- Hiscocks et al. [2023] Steven Hiscocks, Jordi Barr, Nicola Perree, James Wright, Henry Pritchett, Oliver Rosoman, Michael Harris, Roisín Gorman, Sam Pike, Peter Carniglia, Lyudmil Vladimirov, and Benedict Oakes. Stone Soup: No longer just an appetiser. In International Conference on Information Fusion (FUSION), 2023.
- Huber and Law [2008] Mark Huber and Jenny Law. Fast approximation of the permanent for very dense problems. In Proceedings of the nineteenth annual ACM-SIAM symposium on Discrete algorithms, pages 681–689, 2008.
- Jonker and Volgenant [1988] Roy Jonker and Ton Volgenant. A shortest augmenting path algorithm for dense and sparse linear assignment problems. In DGOR/NSOR: Papers of the 16th Annual Meeting of DGOR in Cooperation with NSOR/Vorträge der 16. Jahrestagung der DGOR zusammen mit der NSOR, pages 622–622, 1988.
- Kaess et al. [2008] Michael Kaess, Ananth Ranganathan, and Frank Dellaert. isam: Incremental smoothing and mapping. IEEE TRO, 24(6):1365–1378, 2008.
- Kuhn [1955] Harold W Kuhn. The hungarian method for the assignment problem. Naval research logistics quarterly, 2(1-2):83–97, 1955.
- Luiten et al. [2021] Jonathon Luiten, Aljosa Osep, Patrick Dendorfer, Philip Torr, Andreas Geiger, Laura Leal-Taixé, and Bastian Leibe. Hota: A higher order metric for evaluating multi-object tracking. IJCV, 129:548–578, 2021.
- Meinhardt et al. [2022] Tim Meinhardt, Alexander Kirillov, Laura Leal-Taixe, and Christoph Feichtenhofer. Trackformer: Multi-object tracking with transformers. In CVPR, pages 8844–8854, 2022.
- Meyer et al. [2018] Florian Meyer, Thomas Kropfreiter, Jason L Williams, Roslyn Lau, Franz Hlawatsch, Paolo Braca, and Moe Z Win. Message passing algorithms for scalable multitarget tracking. Proceedings of the IEEE, 106(2):221–259, 2018.
- Milan et al. [2016] Anton Milan, Laura Leal-Taixé, Ian Reid, Stefan Roth, and Konrad Schindler. MOT16: A benchmark for multi-object tracking. arXiv preprint arXiv:1603.00831, 2016.
- Montella [2011] Corey Montella. The kalman filter and related algorithms: A literature review. Res. Gate, pages 1–17, 2011.
- Musicki and Evans [2004] Darko Musicki and Robin Evans. Joint integrated probabilistic data association: Jipda. IEEE transactions on Aerospace and Electronic Systems, 40(3):1093–1099, 2004.
- Musicki et al. [1994] Darko Musicki, Robin Evans, and Srdjan Stankovic. Integrated probabilistic data association. IEEE TAC, 39(6):1237–1241, 1994.
- Neira and Tardós [2001] José Neira and Juan D Tardós. Data association in stochastic mapping using the joint compatibility test. IEEE Transactions on robotics and automation, 17(6):890–897, 2001.
- Nijenhuis and Wilf [2014] Albert Nijenhuis and Herbert S Wilf. Combinatorial algorithms: for computers and calculators. Elsevier, 2014.
- Pang et al. [2021] Jiangmiao Pang, Linlu Qiu, Xia Li, Haofeng Chen, Qi Li, Trevor Darrell, and Fisher Yu. Quasi-dense similarity learning for multiple object tracking. In CVPR, pages 164–173, 2021.
- Rakai et al. [2022] Lionel Rakai, Huansheng Song, ShiJie Sun, Wentao Zhang, and Yanni Yang. Data association in multiple object tracking: A survey of recent techniques. Expert systems with applications, 192:116300, 2022.
- Redmon et al. [2016] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In NeurIPS, pages 779–788, 2016.
- Ren et al. [2015] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. NeurIPS, 28, 2015.
- Rezatofighi et al. [2015] Seyed Hamid Rezatofighi, Anton Milan, Zhen Zhang, Qinfeng Shi, Anthony Dick, and Ian Reid. Joint probabilistic data association revisited. In ICCV, pages 3047–3055, 2015.
- Ristani et al. [2016] Ergys Ristani, Francesco Solera, Roger Zou, Rita Cucchiara, and Carlo Tomasi. Performance measures and a data set for multi-target, multi-camera tracking. In ECCV, pages 17–35. Springer, 2016.
- Stein [1981] Charles M Stein. Estimation of the mean of a multivariate normal distribution. The Annals of Statistics, pages 1135–1151, 1981.
- Sun et al. [2022] Peize Sun, Jinkun Cao, Yi Jiang, Zehuan Yuan, Song Bai, Kris Kitani, and Ping Luo. Dancetrack: Multi-object tracking in uniform appearance and diverse motion. In CVPR, pages 20993–21002, 2022.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. NeurIPS, 30, 2017.
- Wojke et al. [2017] Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep association metric. In ICIP, pages 3645–3649, 2017.
- Wu et al. [2021] Jialian Wu, Jiale Cao, Liangchen Song, Yu Wang, Ming Yang, and Junsong Yuan. Track to detect and segment: An online multi-object tracker. In CVPR, pages 12352–12361, 2021.
- Yang et al. [2018] Shishan Yang, Kolja Thormann, and Marcus Baum. Linear-time joint probabilistic data association for multiple extended object tracking. In IEEE Sensor Array and Multichannel Signal Processing Workshop (SAM), pages 6–10, 2018.
- Zeng et al. [2022] Fangao Zeng, Bin Dong, Yuang Zhang, Tiancai Wang, Xiangyu Zhang, and Yichen Wei. MOTR: End-to-end multiple-object tracking with transformer. In ECCV, pages 659–675. Springer, 2022.
- Zhang et al. [2021] Yifu Zhang, Chunyu Wang, Xinggang Wang, Wenjun Zeng, and Wenyu Liu. Fairmot: On the fairness of detection and re-identification in multiple object tracking. IJCV, 129:3069–3087, 2021.
- Zhang et al. [2022] Yifu Zhang, Peize Sun, Yi Jiang, Dongdong Yu, Fucheng Weng, Zehuan Yuan, Ping Luo, Wenyu Liu, and Xinggang Wang. Bytetrack: Multi-object tracking by associating every detection box. In ECCV, pages 1–21. Springer, 2022.
- Zhou et al. [2019] Xingyi Zhou, Dequan Wang, and Philipp Krähenbühl. Objects as points. arXiv preprint arXiv:1904.07850, 2019.
- Zhou et al. [2020] Xingyi Zhou, Vladlen Koltun, and Philipp Krähenbühl. Tracking objects as points. In ECCV, pages 474–490. Springer, 2020.
Supplementary Material
7 Proof of Proposition 1
8 Proof of Proposition 2
In this section, we show how optimizing (12) leads to Proposition 2. The objective function in (12) can be rewritten as:
| (22) |
where is some constant unrelated to . To find the maximizer of (12), we take the gradient of w.r.t. and of :
| (23) | ||||
| (24) | ||||
| (25) |
Using (24) and (25), we get the following relationship:
| (26) |
To compute the above derivatives, we use of Stein’s Lemma [39]. With our notation, the Lemma says:
| (27) |
To compute , we first analyze the term :
| (28) | ||||
Focusing on the first term on the right, we get:
| (29) | ||||
where is the subset of all possible data associations that assign measurement to variable . Let , which is the same as (6). The above equation can be rewritten as:
| (30) | ||||
Then, we analyze the second term of (28):
| (31) | ||||
Combining (30) and (31), (28) can be expanded as:
| (32) | ||||
To further simplify the objective, we stack all the known data into a lifted column as
| (33) |
where is an expanded measurement defined as:
| (34) |
where for all , is the number of measurements at time , and is the number of states. Define the following expanded measurement model:
| (35) |
where is defined in (14) (changing to ) and is defined as below
| (36) |
We, then, define the following block-matrix quantities:
| (37) |
Then, (32) can be written in a matrix form as follows:
| (38) |
The derivative is then
| (39) |
Using Stein’s Lemma (27) and (39), the first-order derivative (23) becomes
| (40) |
The second-order derivative is then
| (41) |
To get the minimizer, by setting and using (26), we get
| (42) | ||||
Since we want to obtain the marginal distribution , we need the bottom right block of the inverse of the above matrix. We make use of the following two Lemmas.
Lemma 1.
Let be a block matrix,
| (43) |
If and are invertible, the inverse of is
| (44) | |||
Lemma 2.
Given matrices , , , the inverse of is:
| (45) | ||||
Using Lemma 1 and (42), we get
| (46) | ||||
Then, using Lemma 2, we get
| (47) | ||||
| (48) |
where is the predicted covariance. Setting in (40), we have
| (49) | ||||
| . |
Note that is the mean of conditioned a future measurement , which is not suitable to compute in online filtering. We marginalize it by left-multiplying both sides by
| (50) |
The simplified result is
| (51) | ||||
| . |
While other terms are straightforward to compute, we provide explanation for the two terms marked as and . The term can be obtained in the same way as (46), (47), (48). Then, let us focus on the term, which is the second block of , denoted as . We have
| (52) |
The second term in (52) can be simplified in the same way as (46), (47), (48) into . The first term in (52) can be written as
| (53) |
The term is the predicted mean. Bringing all of the above together, we have the recursive filtering as follows:
| (54a) | ||||
| (54b) | ||||
| (54c) | ||||
| (54d) | ||||
To obtain the canonical form, we first define the Kalman gain as
| (55) |
then we do the following manipulation:
| (56) | ||||
Thus, we obtain the canonical Kalman gain
| (57) |
and rewrite the recursive filter in canonical form:
| predictor: | ||||
| (58a) | ||||
| (58b) | ||||
| corrector: | ||||
| (58c) | ||||
| (58d) | ||||