Physics-aware Reduced-order Modeling of Transonic Flow via -Variational Autoencoder
Abstract
Autoencoder-based reduced-order modeling (ROM) has recently attracted significant attention, owing to its ability to capture underlying nonlinear features. However, two critical drawbacks severely undermine its scalability to various physical applications: entangled and therefore uninterpretable latent variables (LVs) and the blindfold determination of latent space dimension. In this regard, this study proposes the physics-aware ROM using only interpretable and information-intensive LVs extracted by -variational autoencoder, which are referred to as physics-aware LVs throughout this paper. To extract these LVs, their independence and information intensity are quantitatively scrutinized in a two-dimensional transonic flow benchmark problem. Then, the physical meanings of the physics-aware LVs are thoroughly investigated and we confirmed that with appropriate hyperparameter , they actually correspond to the generating factors of the training dataset, Mach number and angle of attack. To the best of the authors’ knowledge, our work is the first to practically confirm that -variational autoencoder can automatically extract the physical generating factors in the field of applied physics. Finally, physics-aware ROM, which utilizes only physics-aware LVs, is compared with conventional ROMs, and its validity and efficiency are successfully verified.
1 Introduction
Computational fluid dynamics (CFD) has been widely applied in numerous engineering disciplines. However, high-fidelity CFD simulations are often computationally intensive due to the fine discretization of space and time domains. A practical approach to reduce its computational burden is using a regression model as a cost-efficient alternative to time-consuming flow analysis [1]. Such regression models have been developed extensively, to name a few, cubic spline interpolation [2], the radial basis function [3], and Gaussian process regression (GPR) [4, 5]; however, these models are only suitable for estimating scalar quantities such as lift coefficients of the airfoil. Consequently, when the quantities of interest are high-dimensional vectors, such as pressure or the velocity field, the computational complexity becomes prohibitive owing to “the curse of dimensionality.”
Data-driven reduced-order modeling (ROM) has recently attracted attention for its potential to deal with this problem. It treats a high-fidelity computer simulation as a “black-box function” and generates simplified models in a data-driven manner without any modification of the governing equation. The main purpose of this approach is to reduce the degrees of freedom of the data using the dimensionality reduction (DR) technique (also known as representation learning or manifold learning), which finds the low-dimensional latent representation of high-dimensional original data. Through this technique, the dimensionality of the data can be significantly reduced to a level that is suitable for training the regression models effectively.
One of the most widely used DR techniques is proper orthogonal decomposition (POD) [6], which is also referred to as principal component analysis or the Karhunen-Loève theorem. Given the training data, POD extracts a set of orthogonal bases (also referred to as modes) that maximizes the variance of the projected data. Extracted modes are ranked by their energy content so that the dimensionality can be reduced by truncating non-dominant modes. Specifically, the original high-dimensional data can be represented in a low-dimensional subspace using linear combinations of the dominant modes. However, its linearity makes POD-based ROM suffer from performance degradation in nonlinear problems [7, 8, 9, 10], requiring an excessive number of modes compared to nonlinear DR methods for the same reconstruction accuracy.
In this regard, deep neural networks (DNNs) have become an alternative to POD for their performance on highly nonlinear problems. The most commonly used DNN-based DR technique is the autoencoder (AE), which learns the low-dimensional latent space of the original data in an unsupervised manner [11]. The nonlinear functions between its multiple hidden layers enable it to model nonlinearity, and in this context Hinton et al. referred to AE as a nonlinear generalization of POD [12]. Owing to this property, numerous ROM studies have recently adopted AE as DR model for highly nonlinear problems [13, 14, 15, 16, 17, 18, 19, 20, 21, 22], and they confirmed that AE-based ROM shows higher reconstruction accuracy than the POD-based ROM in various nonlinear problems [13, 14, 15]. Moreover, the flow field reconstruction using AE can be further improved by applying convolutional neural networks (CNNs), which were introduced to train grid-pattern data efficiently [16, 17, 18, 19, 20, 21, 22].
However, there are several issues to be addressed in AE-based ROM. First, AE does not guarantee disentangled latent representation since its training algorithm only aims to reduce the reconstruction error without considering the regularity in latent space. Its irregularity allows multiple features to be entangled in a single latent variable (LV) [23], making it difficult to interpret the physical meanings of LVs. Second, since the model architecture of AE should be predetermined before training, its latent dimension need to be blindly selected large enough to contain the entire information (otherwise, a trial-and-error process should be performed). In POD, it is possible to truncate trivial LVs since it provides the energy contents of LVs (or modes). However, in AE, its algorithm does not treat LVs hierarchically according to their information intensity so that theoretically, the entire information is evenly distributed to each LV. Therefore, all dimensions blindly selected should be used, as truncation of even only one LV can severely compromise its reconstruction accuracy. As a result, the resultant redundancy of the latent dimension will degrade both the physical interpretability of LVs (too many LVs are entangled) and the efficiency of AE-based ROM (too many regression models should be trained).
The introduction of a variational autoencoder (VAE) and its improved understanding has been providing a clue to these problems. While AE only minimizes reconstruction error, VAE also regularizes latent space by minimizing Kullback-Leibler (KL) divergence term [24]. The balance between these two terms in VAE can be adjusted by the hyperparameter , and the corresponding model is referred to as -VAE [23]. It is known that by weighting the KL-divergence term in -VAE, two notable effects can be achieved. First, it learns disentangled latent representations: a single LV encodes only one representation feature of the original dataset and therefore becomes interpretable. This ensures independence between each LV as the POD extracts orthogonal bases. Second, the regularization loss (KL-divergence) encourages learning the most efficient latent representation [23, 25, 26]. Therefore, regardless of the predetermined latent dimension, only necessary LVs are automatically activated to contain the essential information [27]. In summary, unlike AE model, -VAE enables its latent space to be information-intensive without being entangled, indicating its potential to further improve the performance of AE-based ROM.
However, there are few studies related to -VAE in the field of fluid dynamics. Eivazi et al. [27] adopted -VAE to extract interpretable nonlinear modes for time-dependent turbulence flows and proposed a method to rank LVs by measuring their energies. However, their ranking method requires separate post-processing of the reconstructed data after model training, and the energies of LVs are indirectly calculated in the output space rather than in the latent space. Accordingly, the approach is unrelated to KL-divergence which is the main cause of information discrepancies between LVs. Though they finally concluded that their framework successfully extracted interpretable features of turbulent flows, it lacks objectivity since it was based on the visual inspection of the flow fields. Last but not least, their research ended up with nonlinear mode decomposition without showing how interpretable LVs can be efficiently utilized for the ROM process. Indeed, Wang et al. [17] already have applied -VAE to ROM for transonic flow problems and verified its superior performance over POD. Though they extended -VAE to practical application, they only focused on the implementation of -VAE for ROM so that the interpretability of extracted features (main purpose of -VAE) and their effects on ROM performance were not addressed and referred to as their future work.
This study aims to utilize physically interpretable and information-intensive LVs obtained by -VAE, which are referred to as “physics-aware LVs”, for the efficient ROM process. For this purpose, a two-dimensional (2D) transonic flow problem is adopted as benchmark case, and the independence and information intensity of LVs are investigated first to confirm whether they are physics-aware. Herein, it was practically confirmed for the first time in the field of applied physics that -VAE can automatically extract the physical generating factors. Then, “physics-aware ROM”, ROM which utilizes only physics-aware LVs is proposed for its efficiency in that the number of required regression models can be reduced significantly. The presented physics-aware ROM is compared with conventional ROMs, and finally, we successfully verify its validity and efficiency.
The rest of this paper is organized as follows. In Sec. 2, the DNN-based DR techniques are described in detail, and in Sec. 3, the physics-aware ROM is newly proposed. In Sec. 4, the setup of the numerical experiment is presented. In Sec. 5, the process of extracting physics-aware LVs and the discovery of their actual physical meanings are described, and the effectiveness of physics-aware ROM based on them is investigated. And finally, in Sec. 6, the conclusion of this study and future work are presented.
2 Dimensionality reduction techniques
2.1 Autoencoder (AE)
The AE model is a widely used deep learning-based DR technique. The main objective of the AE is to output exactly what is inputted. Its structure consists of two parts: an encoder and a decoder. The input of the AE, x, is entered into the encoder for the compression and exits as LVs, z. Then, z enters the decoder and exits as reconstructed data . The encoder and decoder consist of a multi-layer perceptron (MLP), which makes it possible to model nonlinearity in the reduction and reconstruction processes. Because the objective of training the AE model is to reconstruct similar to the original data x, the loss function is defined by Eq. 1, where denotes the number of data samples. Although its loss function is defined by the mean square error (MSE) in this study, any other error metrics, such as the binary cross entropy between x and , can be used depending on the properties of the data. Note that the adopted MSE is the mean operation over sample-wise, and the summation over element-wise (pixel-wise) directions.
| (1) |
However, this AE model has a obvious limitation: there is no training algorithm for guaranteeing a regularized latent space. Herein, the expression “regularized latent space” means that the latent space is trained to be smooth and continuous; thus, when inputs and are similar (or close), their corresponding mapped latent space, and , should also be similar [28]. In AE model, as the original input x becomes condensed layer-by-layer through the encoder, its representation becomes increasingly abstract [29]. Therefore, the output of the encoder z is not guaranteed to be regularized in the training procedure of the AE. This explains why the decoder part of the AE model cannot be used as a generative model: the trained latent space is irregular and therefore its correlation with the reconstructed data is abstract.
2.2 Variational autoencoder (VAE)
Many studies have focused on the limitations of this unregularized latent space trained by an AE and have alternatively applied VAE in their framework. The structure of the VAE is similar to that of the AE. One major difference is that VAE stochastically extracts the latent space z via random sampling, whereas the AE model obtains its latent space deterministically.
The mathematical formulae for the VAE model are presented below (for further details, please refer to these references [24, 30]). We consider reducing the original dataset (assumed to be independently and identically distributed) to the latent space z using the VAE model. In the inference of z from X, variational inference is adopted due to the intractability of the posterior , where is a parameter of the VAE model (to be more specific, it is intractable owing to the likelihood of ). Therefore, instead of the intractable posterior , the VAE is trained to obtain its substitute, ( is a variational parameter). Then, the log-likelihood of can be expressed as:
| (2) |
where the second term on the right-hand side (RHS) is the KL-divergence of from , , which is always non-negative according to its definition (KL-divergence is a measurement of the statistical distance between two probability distributions). Therefore, the first term on the RHS becomes the lower bound of the log-likelihood and the problem of maximizing the log-likelihood becomes the problem of maximizing the lower bound. This lower bound can be expressed as:
| (3) |
where the first and second terms on the RHS are the reconstruction error and KL-divergence of from , respectively. However, owing to the existence of in the reconstruction error, the back-propagation process cannot be performed, and calculating the gradient of the reconstruction error with respect to is problematic due to the posterior . Therefore, a “reparameterization trick” is adopted, which allows for back-propagation during the sampling process. The concept behind this trick is to sample z from the auxiliary noise variable : this random sampling makes the latent space in the VAE stochastically determined. To be more specific, the LV () is assumed to follow the distribution below:
| (4) |
where denotes Hadamard product (element-wise product). Accordingly, the KL-divergence, the second term on the RHS in Eq. 3 can be rewritten as below when the posterior and prior are assumed to follow the Gaussian distribution and , respectively.
| (5) |
where and represent the mean and standard deviation used during the reparameterization of , and denotes the dimension of the latent space. Herein, as the posterior approximation approaches the prior , the KL-divergence decreases. Finally, the loss function of VAE model can be formulated as in Eq. 6, which consists of the reconstruction error (MSE term) and regularizer (KL-divergence term). Since the KL-divergence term serves to regularize the latent space to be trained, it is also called regularization loss. It induces a sparser latent space [24, 31, 23, 32] just as the L1 regularization term makes the model sparse in the Lasso regression [33].
| (6) |
2.3 -variational autoencoder (-VAE)
Higgins et al. [23] focused on the trade-off relationship between the reconstruction error and KL-divergence in the loss function of the VAE. As the reconstruction accuracy increases, the degree of regularization (or information capacity) in the latent space decreases. To tune the balance between these two performances, Higgins et al. [23] proposed the -VAE, which can control the relative importance of the KL-divergence term using the adjustable hyperparameter . It is a simple modification of the VAE: they have exactly the same structures but slightly different loss functions. The loss function of the -VAE is as follows:
| (7) |
The only difference in the loss functions between the VAE and -VAE is whether the KL-divergence term is weighted by hyperparameter . By introducing this hyperparameter, Higgins et al. [23] achieved quantitative and qualitative improvements in the disentanglement within the latent representations over the traditional VAE model. Finally, they concluded that owing to the disentangling performance of -VAE, the interpretable representations of the independent generating factors of the given dataset can be discovered automatically. In this paper, the terminologies “disentanglement”, “interpretability”, “independence”, and “orthogonality” are used interchangeably to refer to the following property of LVs: single LV stands for a single representation feature without the intervention of other LVs. However, what makes -VAE special is not only in its disentangling performance. The regularization loss (KL-divergence) is known to have sparsification effect to encourage the most efficient representation learning [23]. Burda et al. and Sønderby et al. practically confirmed this effect in that some LVs become inactive during the training process of VAE [25, 34]. In particular, Burda et al. confirmed that inactive LVs have a negligible effect on the reconstruction. This finding indicates that VAE trains its LVs in an efficient manner by selectively activating LVs to contain the only necessary information. Since -VAE model also has regularization term in the loss function and even weighted by the hyperparameter , it can be easily inferred that the sparsification effect in the -VAE model will become more dominant as increases. Taking these two outstanding advantages of -VAE, disentangled and information-intensive latent space, a novel ROM framework is proposed in the next section.
3 Physics-aware reduced-order modeling
The main goal of ROM is to predict the high-dimensional data with low computational cost. As described in Sec. 2, the high-dimensional data can be effectively reconstructed by the low-dimensional LVs through DR techniques. In this context, ROM aims to predict high-dimensional data efficiently by predicting these LVs from input parameters using regression models. Overall structure of ROM is illustrated in Fig. 1. In the reconstruction process (solid arrows), the high-dimensional data is encoded into LVs and reconstructed back into high-dimensional data by the decoder. In the prediction process (dashed arrows), LVs are first predicted from input parameters through regression models (GPR [4, 5] is adopted for regression in this study), and then predicted LVs are decoded into high-dimensional data. Since the high-dimensional data can be repeatedly predicted from input parameters at a very low computational cost, this prediction process is often referred to as the online phase.

Since LVs act as intermediaries in ROM for predicting high-dimensional data, they inevitably affect ROM performance. In this regard, AE model has two critical drawbacks to be applied to ROM. First, it trains the entangled and therefore uninterpretable latent space. Second, its latent dimension need to be blindly selected large enough since the model architecture should be predetermined before the training. Therefore, the AE-based ROM becomes physically uninterpretable and inefficient due to the excessive number of entangled LVs and the regression models to be trained. This study newly proposes physics-aware ROM via -VAE to deal with these issues, considering the following characteristics of -VAE. As stated in Sec. 2.3, the latent space in -VAE is trained to be disentangled and information-intensive. When LVs actually satisfy these two properties simultaneously, they can be regarded as the latent representations which contain both interpretable and necessary information. In that this study uses physical dataset, LVs will correspondingly contain physical information, and accordingly, we refer to those LVs as “physics-aware LVs.” To ease the understanding of physics-aware LVs, the ideal schematic of their extraction with -VAE is shown in Fig. 2: when the dataset is generated through Mach number () and angle of attack (), the ideally extracted physics-aware LVs will be and . Finally, the ROM only utilizing these physics-aware LVs (which refers to “physics-aware ROM”) is proposed for its efficiency that the number of regression models required in the prediction process can be significantly reduced.

In order to extract physics-aware LVs, we first estimate the independence of LVs. In this regard, Eivazi et al.[27] have already measured it using a Pearson correlation matrix and the same approach is applied herein. Then, the information intensity of LVs is quantified. Similar attempt has been made by Eivazi et al.[27], who proposed a strategy to rank LVs by energy percentage, which quantifies the contribution of each LV to the reconstruction quality. However, they ranked LVs not in the latent space which is directly related to them, but in the output space so that there exist two problems. First, its low practicality due to cumbersome post-processing: flow fields should be reconstructed using a forward selection of LVs and then energy percentage is calculated from them. Second, since this method is irrelevant to KL-divergence, which is the main cause of the inactiveness of LVs [25, 34], it cannot be regarded as a fundamental approach for ranking LVs based on their amount of information. Therefore, another ranking criterion should be proposed that estimates the information intensity of each LV without such burdensome post-processing. For this purpose, we propose to apply the KL-divergence (Eq. 5), the immediate cause for the sparser latent space due to its regularization effect. Since the calculation of KL-divergence is performed directly in the latent space, the decoder part of -VAE does not even need to be utilized (no reconstruction required), solving all the limitations of the previous ranking approach.
In physics-aware ROM framework, only physics-aware LVs are utilized so that the number of regression models required in the prediction process can be significantly reduced. For example, suppose that AE-based ROM and -VAE-based ROM are performed where both AE and -VAE has the latent dimension of 16. In the case of AE-based ROM, 16 regression models should be trained because exclusion of just one LV can degrade ROM performance significantly in that all 16 LVs contain information in an entangled manner. However, in -VAE-based ROM, since physics-unaware LVs are judged not to contain any meaningful information, it is sufficient to utilize only the regression models of physics-aware LVs. The overall procedure of physics-aware ROM is summarized in Algorithm 1.
4 Numerical experiments
4.1 Data preparation
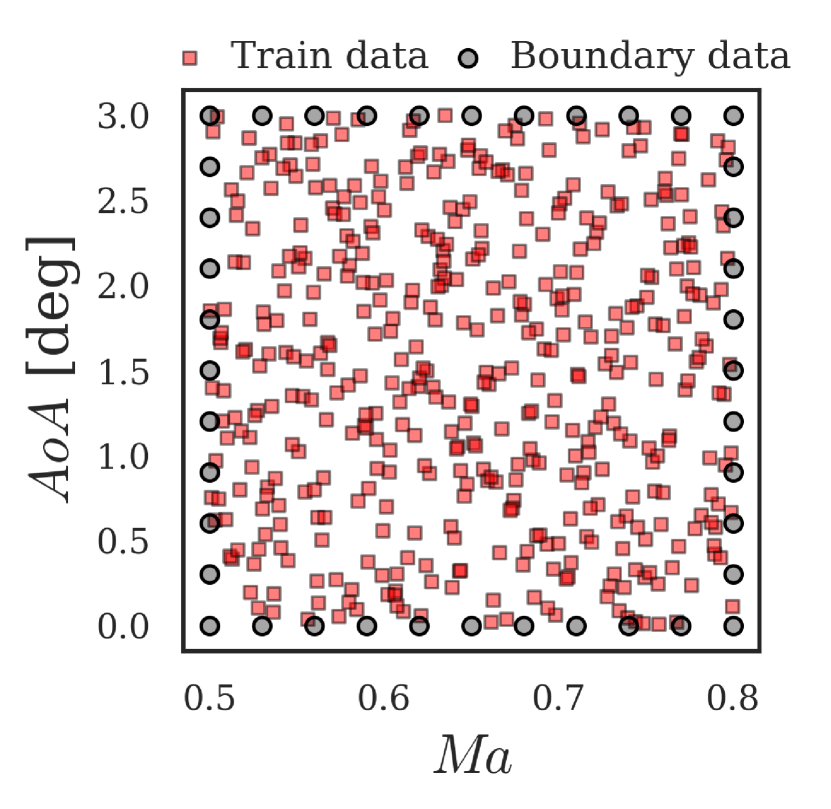
A 2D transonic flow problem, the benchmark case that is widely used in previous ROM studies [9, 10, 8, 17], is adopted for validation of the proposed physics-aware ROM. The transonic flow field is generated by the KFLOW finite-volume-based CFD solver [35, 36]. Specifically, the Reynolds-averaged Navier-Stokes equation is solved coupled with the Spalart-Allmaras turbulence model. RAE 2822 airfoil is selected as the baseline geometry, and a structured O-grid with a shape of (wall-tangential direction wall-normal direction) is generated; the corresponding grid is shown in Fig. 3. The Reynolds number is fixed at , and two physical parameters are chosen: and . The design space of each variable is set to [0.5, 0.8] and [, ], respectively. Latin hypercube design is used to generate 500 sample points in 2D parameter space. A flow analysis of these samples is then conducted and the resultant velocity and pressure fields are normalized by their far-field conditions. As the variations of flow properties far from the airfoil are negligible, only the inner half of the entire grid with respect to the normal direction from the airfoil is used so that the resultant grid becomes . Consequently, a total dataset with a shape of (dataset size flow field components wall-tangential direction grids wall-normal direction grids) is obtained, where the flow-field components are the x-velocity, y-velocity, and pressure. Finally, the dataset size of 500 is split into a ratio of 9:1 so that the size of the training dataset is 450, and that of the test dataset is 50.

4.2 Training details

| Name | Layer type | Filter | Kernel | Stride | Activation | Batch Norm. |
| Up | Max-polling | – | 2 2 | – | – | – |
| Convolution | 64 | 3 3 | 1 | LeakyReLU | o | |
| Down | Upsampling | – | 2 2 | – | – | – |
| Convolution | 64 | 3 3 | 1 | LeakyReLU | o | |
| Conv1_in | Convolution | 64 | 1 1 | 1 | LeakyReLU | o |
| Conv1_out | Convolution | 3 | 1 1 | 1 | – | – |
| FC | Fully Connected | – | – | – | – | – |
| Encoder | Bottleneck | Decoder | |||
|---|---|---|---|---|---|
| Layer | Output size | Layer | Output size | Layer | Output size |
| Input | 3 512 128 | Flatten | 256 | Up1 | 64 8 2 |
| Conv1_in | 64 512 128 | FC1: | 16 | Up2 | 64 16 4 |
| Down1 | 64 256 64 | FC2: | 16 | Up3 | 64 32 8 |
| Down2 | 64 128 32 | Resampling | 16 | Up4 | 64 64 16 |
| Down3 | 64 64 16 | FC3 | 256 | Up5 | 64 128 32 |
| Down4 | 64 32 8 | Unflatten | 64 4 1 | Up6 | 64 256 64 |
| Down5 | 64 16 4 | – | – | Up7 | 64 512 128 |
| Down6 | 64 8 2 | – | – | Conv1_out | 3 512 128 |
| Down7 | 64 4 1 | – | – | Output | 3 512 128 |
In this study, all the models mentioned in Sec. 2, AE, VAE, and -VAE, are trained to investigate their differences in terms of ROM for transonic flow. In particular, several -VAE models are trained () to investigate the effects of the value (technically speaking, -VAE can be regarded as the VAE when has a value of 1). For all models, the dimension of the latent space should be determined blindly before the model training. The selected dimensions should be sufficient for encoding the training data generated from the 2D parameter domain ( and ). In this regard, we adopted the approach suggested by Wang et al. which infers the latent dimension of -VAE considering the accuracy of the POD with the same dimension [17] (their assumption was that POD requires much more dimensions than -VAE for the equivalent reconstruction accuracy, which was also proved in their paper). Finally, dimension of the latent space is determined to be 16 since it conserves 99.18 in terms of energy contents of POD, which is judged to be sufficient.
An appropriate encoder/decoder structure should be selected to effectively compress/reconstruct the data, from dimensions of 3512128 to 16 and vice versa. To determine suitable structures, hyperparameter tuning based on a grid search was conducted. Finally, it was confirmed that the MSE reconstruction error, which represents the overall accuracy of the trained model, does not strongly depend on whether batch normalization, max-pooling, and up-sampling are applied. However, their application significantly affects the smoothness of the reconstructed flow field (it can be inferred that this is due to the effects of batch normalization and max-pooling that prevent overfitting, and the interpolation effect of up-sampling). If an artificial discontinuity (rather than a discontinuity that reflects a physical phenomenon, such as a shock wave) is observed in the reconstructed flow field, the flow field cannot be considered realistic. Finally, the architectures of the selected models, which are considered to be sufficient in terms of MSE error and the smoothness of the reconstructed flow field, are shown in Tables 1 and 2 and Fig. 4. The only difference between the structure of the AE and VAE/-VAE is the bottleneck, and the structures of the VAE and -VAE are exactly the same.
The Adam optimizer is adopted to train selected models. The initial learning rate is set to , and it decays at a rate of 0.1 every 1000 epochs. The maximum epoch should be selected carefully because a model that does not fully converge can make significantly different predictions from a converged model [37]. The maximum number of epochs is set to 3000 since it is verified to guarantee sufficient convergence in terms of the loss function. A mini-batch size of 50 is selected so that nine iterations are performed per epoch (as the size of the training dataset is 450). Using a Tesla P100-PCIE-16GB GPU with Pytorch deep learning library [38], the average training time for each model is calculated to be approximately 3 h.
5 Result and discussion
In this section, the results of physics-aware ROM and physics-unaware ROM are presented in the following order. First, training results of AE/VAE/-VAE are demonstrated to investigate the flow reconstruction accuracy. Next, the methods to measure the independence and information intensity of LVs are presented to determine whether the LVs obtained by AE/VAE/-VAE are physics-aware LVs. At the same time, the validity of the KL-divergence ranking method to measure the information intensity of LVs is confirmed both quantitatively and qualitatively. Then, it is thoroughly investigated with various techniques whether the physics-aware LVs actually have interpretable physical features. In the end, it is verified that the physics-aware ROM based on these physics-aware LVs has equivalent prediction accuracy much more efficiently than physics-unaware ROM.
5.1 Training results
First, the resultant loss functions of the trained models are shown in Fig. 5. More specifically, the loss function is decomposed into the MSE and KL-divergence (as in Eq. 7) to confirm their trade-off relationship. The MSE and KL-divergence of the VAE/-VAE models are indicated by blue and red symbols, respectively. The and KL-divergence values cannot be defined in the AE model; therefore, only its MSE loss is indicated separately by a dashed line. Herein, a clear trade-off relationship between MSE and KL-divergence can be confirmed, as mentioned by Higgins et al. [23]. As increases, KL-divergence decreases, while MSE increases. This is consistent with the concept of the -VAE, which suppresses KL-divergence by increasing . In particular, when , the MSE increases significantly so that an accurate reconstruction of the flow field is no longer possible.

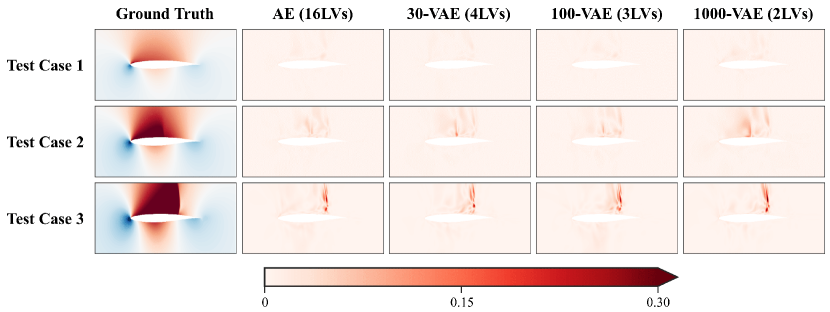
Second, the reconstructed pressure flow fields of the three test cases (which are not used during the training process) are shown in Fig. 6 to compare the trained models more intuitively and visually. The selected test cases are as follows: test case 1 is in the absence of a shock wave ( and ), test case 2 is in the presence of a weak shock wave ( and ), and test case 3 is in the presence of a strong shock wave ( and ). Five models are compared, including the AE, VAE, 30-VAE (-VAE with ), 100-VAE (), and 1000-VAE (). In Fig. 6, it can be confirmed that the reconstructed pressure contours for all three cases and all models do not exhibit any significant difference, indicating all models have been trained to reconstruct the accurate flow fields.

5.2 Independence of LVs
This section is to confirm whether LVs of -VAE are actually trained to be disentangled from each other so that they are interpretable. In Fig. 7, the absolute values of the components in the Pearson correlation matrix are shown from AE to 1000-VAE. Since there is no algorithm in AE model to promote the independence of LVs, it has the largest values. However, in -VAEs, their values decrease as increases, which indicates that the LVs gradually become independent of each other. These results practically prove that the KL-divergence actually encourages the independence of each LV. To measure the degree of correlation within the entire set of LVs, Eivazi et al. computed the determinant of the correlation matrix (when the determinant is 0/1, it indicates that these variables are completely correlated/uncorrelated) [27]. However, given the fact that the KL-divergence term leads to a sparser latent space, which will be discussed in detail in Sec. 5.3, examining the determinant of the whole matrix size of is contradictory. Therefore, the independence of various LV combinations is further analyzed. First, all possible combinations of two to seven LVs are obtained. Then, the determinants of these combinations are calculated and their statistics are summarized in Fig. 8. For any number of LVs used in a combination, the -VAE models have significantly higher determinants than the AE and VAE models. In summary, the results presented in Fig. 7 and 8 consistently show that the -VAE successfully learns uncorrelated LVs compared to AE and VAE models, owing to the KL-divergence, which forces the LVs to be independent.


5.3 Information intensity of LVs
It was verified in Sec. 5.2 that the LVs in -VAE are trained to contain disentangled information. In this section, we tried to rank such disentangled LVs according to their information intensity using KL-divergence. Fig. 9 shows the KL-divergence of each LV in AE/VAE/-VAE. It can be confirmed that both the AE and VAE models do not have any inactive LVs. On the contrary, notable trends are observed in 30-VAE, 100-VAE, and 1000-VAE models: each model has only four (LV index 6, 8, 11, and 15), three (index 8, 11, and 15), and two (index 8 and 11) activated LVs. These results are consistent with those of Eivazi et al. in that the number of activated LVs decreases as beta increases in the -VAE model [27]. In fact, a similar approach was applied by Sønderby et al., who judged whether the LV is activated via the KL-divergence [34]. However, the relationship between the activeness of the LV and KL-divergence was not described clearly. Therefore, we also attempt to clarify it: further investigations are conducted to check whether the LV judged to be more active in terms of the KL-divergence actually has a greater effect on the reconstructed flow field. Sobol sensitivity analysis is utilized for this analysis [39, 40]. A total 18,432 latent vectors are sampled using the Saltelli sampler in the range of , where and each represents estimated mean and standard deviation of LV with respect to the training dataset. The corresponding reconstructed flow fields are obtained through the decoder parts of the AE/VAE/-VAE models. Since Sobol analysis should be conducted on the scalar output, a set of 3512128 pixels of the flow fields is converted to a scalar value. The sum of all pixel components is used in this study, but any scalar value representing the main characteristics of the flow field can be used. Fig. 9 shows the calculated first-order Sobol indices. It can be confirmed that the higher the KL-divergence, the larger the value of the Sobol indices in the VAE/-VAE models (because KL-divergence has nothing to do with the algorithm of the AE model, it does not exhibit a clear trend with the Sobol indices).

Additionally, since the standard deviation represents the dispersion of the variable, which can be regarded as its activeness, values are also investigated. When is low for a specific LV, it can be understood that the corresponding LV remains inactive (or less dispersed) in the latent space during training: a situation where the value of the LV does not change even if the input data changes. In Fig. 10, it can be confirmed again that both AE and VAE models do not have any inactive LVs in that all values are larger than 0.5. However, the most interesting point is that compared to Fig. 9, LVs with high KL-divergence also have high in 30-VAE, 100-VAE, and 1000-VAE models: the LV indices of the activated LVs in terms of KL-divergence exactly match those of . To sum up, we suggest the use of KL-divergence as a criterion for ranking the activeness (information intensity) of LVs for the two reasons. First, it is a regularization loss, which is the direct cause of the information discrepancies between LVs. Second, it does not require any cumbersome post-processing. The justification of this decision-making process is successfully performed through intuitive but quantitative investigations by comparing its ranking with the Sobol indices (Fig. 9) and estimated standard deviations from the training dataset (Fig. 10).

So far, using proposed KL-divergence criterion, the inactiveness within the latent space has been investigated in a quantitative manner, but it does not provide straightforward information on what these activated/inactivated variables actually contain. Accordingly, each LV is visualized via a traversal of itself, which is the most widely adopted approach for this purpose [30, 23]: it shows the traversal of a single LV while other LVs remain fixed so that one can visually understand the features of a specific LV without the intervention of other variables. In this study, a latent traversal plot is applied to identify the physical features of the flow field contained in each LV. Fig. 11 shows the pressure flow fields for two extreme LVs: one is the most dominant LV, which is ranked first by KL-divergence, and the other is the most trivial LV, which is ranked last. In AE, the pressure field changes abruptly as the most dominant LV changes; when the most trivial LV changes, the field changes gradually, but not as significant as that of the most dominant LV. Since the sparsification effect does not occur in AE due to the absence of KL-divergence term in the loss function, all the variables are activated and therefore contain uninterpretable (or entangled) physical features. However, in VAE and 1000-VAE models, the most trivial LVs cause indistinguishable variations in the flow fields. This is because the KL-divergence forces inactiveness in the latent space, so only necessary LVs become activated to contain meaningful physical features: it can be regarded as a virtue of -VAE model. When increases, information is packed into LVs more compactly [27], as observed in the traversal of the most dominant LV in the 1000-VAE model. This LV can be interpreted as containing information on the occurrence of the shock wave, and the variation it arouses is the largest compared to other models.

5.4 Physics-awareness of LVs
The two requirements for physics-aware LVs are investigated so far: whether LVs are disentangled (Sec. 5.2) or information-intensive (Sec. 5.3). In this section, physics-oriented investigations are performed to figure out the physical meanings each physics-aware LV contains.
First, the relationship between the two physical parameters used in this study (whose distributions are shown in Fig. 12a) and the top two ranked LVs by KL-divergence ( LV and LV) is visually investigated as varies. Accordingly, in Fig. 12b, the distributions of the training dataset with respect to those two LVs are shown. For the AE, VAE, 100-VAE, and 1000-VAE models, the plots of the first column are colored by value, and the second column by . Moreover, to confirm that how physical parameter domain can be represented by top two LVs, we also draw the trajectories of the boundary data in Fig. 12b (they are extracted from the boundary of the physical parameter space, as in Fig. 12a). In AE, neither nor have any noticeable trends. In contrast, in VAE, the plot in the first column exhibits a trend that is not clear, but still noticeable: as the / LV increases, / increases. However, the increase in cannot be explained by the increase in the LV alone (the same goes for LV and ). These ambiguous correlations between the two LVs and two physical parameters become more clear in 100-VAE (for this case, as the / LV increases, / increases). Though 100-VAE shows much obvious relationship than AE, the physical parameters cannot be fully represented only by two dominant LVs in that its boundary trajectory does not cover the entire training dataset. Considering the fact that there are three physics-aware LVs in 100-VAE, this may be an expected result. However, it should be noted here that the top two variables sorted by KL-divergence almost succeeded in representing the physical parameters, whereas when the same plot is drawn with the 1st and 3rd dominant LVs, a very irregular pattern is observed. In this regard, the validity of ranking LVs through KL-divergence is confirmed once again. Finally, the 1000-VAE is investigated. Since this model has two physics-aware LVs, in the ideal case one can expect them to correspond to the two physical parameters (this ideal situation was depicted in Fig. 2). And this conjecture is actually happening in 1000-VAE: the correlations between two physical parameters and two LVs become clear, and the latent space of the training dataset is perfectly closed by its boundary trajectory. Here is the key finding of this study: though -VAE has no information about the physical parameters used to generate the training data, it effectively extracts only two LVs out of total 16 LVs (especially when =1000), which correspond to actual physical parameters and . It can be concluded that these marvellous results are owing to the orthogonality effect (makes LVs disentangled) and regularization effect (makes redundant LVs inactive) of the KL-divergence term in -VAE. To make this clear, it should be noted that AE, one of the most widely used nonlinear DR techniques, fails to construct a physics-aware latent space in that it learns all 16 entangled LVs and therefore physically uninterpretable.

As the visual analysis in the previous paragraph is qualitative, a quantitative analysis is performed herein to verify whether or in 1000-VAE corresponds to or (for the sake of brevity, refers to the LV, and refers to the LV, which implies that and are the LVs responsible for and , respectively). Single-variable linear regression (LR) models are trained for this purpose: since the relationships between physical parameters and LVs appear linear in Fig. 12, the LR model is considered to be sufficient. For example, LR model for is trained with the input variable as and the output variable as ,which can be expressed as . The training dataset is the same as in Sec. 4.1 and physical parameters and LVs are standardized before training. If and (or and ) have a linear relationship, the fitted LR models will perform well on the test dataset. The results are shown in Fig. 13. In each subplot, the equation of the trained LR model is also included. For both LR models and , their equations clearly show that and in that the coefficients are approximately 1 and the intercepts are 0. Also, the coefficients of determination () calculated based on the test dataset are 0.950 and 0.969, respectively. It indicates that only one LV is sufficient to accurately represent each physical parameter. In addition, we train two additional LR models with both LVs as input features: one as and the other as . If needs both LVs for its expression, the value of the LR model will be significantly higher than that of . The trained LR models are described as follows:
| (8) |
Herein, there are two notable points. First, the coefficient of is negligible (approximately 0) compared to that of (approximately 1) when modeling , which indicates that is redundant variable for representing (same principal applies when modeling ). The second interesting point is that the values of do not change compared to those of the single-variable LR models. The of LR model only increases 0.001 than , and model has the same as . These two points quantitatively suggest that the extracted physics-aware LVs actually correspond to and in a disentangled (or independent) manner.


Since the physical meanings of and are verified both qualitatively and quantitatively, the latent traversal plots of airfoil surface pressure distributions are shown in Fig. 14 to intuitively check their impact on the flow field. In the traversal of (Fig. 14a), when the LV is in the range of to , there is no shock wave, but as it increases to and , the occurrence of a shock wave is shown. In the traversal of (Fig. 14b), a variation in the location and magnitude of the leading edge suction peak is observed. This visual analysis of the actual effects of and on the pressure distributions also leads to the consistent conclusion that they correspond to and , respectively.
Although the ability of -VAE to extract physics-aware LVs is first observed with simple physical parameters in this study, it has tremendous potential to be utilized to extract generating factors from any dataset in any disciplinary. The scalability of this framework to the real-world engineering dataset which is sparse and noisy can be verified in Appendix B.


5.5 Physics-aware ROM
To summarize the results so far, physics-aware LVs are extracted by estimating the independence and information intensity of each LVs. These physics-aware LVs are strongly correlated to physical parameters which are the generating factor of training dataset, significantly increasing the interpretability. Since LVs act as intermediaries in the prediction process of ROM, their impact on the ROM is bound to be enormous. In this regard, this section investigates the validity and efficiency of physics-aware ROM, which utilizes physics-aware LVs for the prediction of high-dimensional data.
Fig. 15 shows the MSE of the regression models in ROM, ; it is calculated between true LV and predicted LV by regression model (please refer to Fig. 1 for more details about regression models in ROM). In that 16 regression models are required due to 16 LVs, each point represents the MSE of each model, and the symbol o/x indicates whether each LV is physics-aware or physics-unaware. The results show that the values of physics-unaware LVs are considerably higher than those of physics-aware LVs. It is because the correlations between physical parameters and physics-unaware LVs are too trivial to be trained by regression models. Fig. 16 supports this; the distribution of physics-unaware LV (Fig. 16b) is much noisier than that of the physics-aware LV (Fig. 16a). Another interesting point in Fig. 15 is that values of the physics-aware LVs decrease as increases. This implies that the tight coupling between physics-aware LVs and physical parameters is advantageous in terms of regression performance in the ROM process.



Then, the MSE between the ground truth flow fields and those predicted by ROM with the exclusion of LV is calculated, which is denoted as (please note that prediction by ROM means obtaining the flow field from unknown input parameters, as already described in Fig. 1). Specifically, LV is assumed to be constant as , whereas the other LVs are predicted from regression models so that the importance of LV can be investigated. Fig. 17 demonstrates their results, where the x-axis indicates KL-divergence ranking of LVs. An important observation is that the effect of the LV on decreases as the LV ranks down. Likewise, the physics-unaware LVs, those ranked after in 30-VAE, after in 100-VAE, and after in 1000-VAE, have negligible effects on : from the fact that the LV ranked higher by KL-divergence has a greater effect on ROM accuracy, it can be concluded that the proposed ranking approach is also valid in terms of ROM performance. This implies that training regression models of physics-unaware LVs are meaningless with respect to the prediction accuracy of ROM. In other words, it is sufficient enough to train regression models of only physics-aware LVs. In this regard, to examine the necessity of each LV in ROM prediction, Fig. 18 visualizes the values of physics-aware ROM via -VAE, where all physics-unaware LVs are excluded (e.g., only two LVs are used for ROM via 1000-VAE). For the comparison, those of physics-unaware ROM via AE are also shown: herein, utilizing all 16 LVs or 15 LVs with one LV excluded is presented. Although a significantly small number of LVs are used in physics-aware ROM, its accuracy is comparable to that of AE with 16LVs, physics-unaware ROM. Furthermore, even if only one LV is excluded in AE, their ROM accuracy becomes equivalent to or even lower than that of 1000-VAE only with two LVs. This result highlights the inefficiency of ROM through AE, in that it requires all 16 entangled LVs and therefore requires training 16 regression models. Using physics-aware ROM via 30-VAE, the equivalent accuracy can be achieved with only 4 regression models. To visually confirm these results, Fig. 19 shows the pressure contour of physics-aware ROM via -VAE and physics-unaware ROM via AE. Herein, the indiscernible difference between them can be confirmed, indicating their equivalent prediction accuracy.



6 Conclusion
This study proposed the physics-aware ROM based on physics-aware LVs, which are interpretable and information-intensive LVs extracted by -VAE. The proposed framework is validated with the 2D transonic benchmark problem in the following order. First, the extraction process of physics-aware LVs is scrutinized by quantitatively estimating their independence and information intensity. Then, the actual physical meanings of these LVs are thoroughly investigated. Finally, the effectiveness of the proposed physics-aware ROM compared to conventional ROMs are verified. The key contributions of our study can be summarized as follows:
-
1.
The impacts of hyperparameter on the independence of LVs were scrutinized, and its effect on the independence of LVs was practically confirmed in that LVs become disentangled from each other as increases.
-
2.
KL-divergence ranking method was proposed to measure the information intensity of each LV. This approach has two following advantages over the previous ranking method: KL-divergence is the direct cause of the discrepancies in information intensity of LVs and it does not require cumbersome post-processing of reconstructed data. The proposed criterion was confirmed to have a consistent trend with estimated standard deviations and Sobol indices, indicating their validity. Through this ranking method, the effect of on the latent space regularization was practically confirmed in that LVs become information-intensive as increases.
-
3.
The physical meanings contained in physics-aware LVs were thoroughly investigated. The correlation between the physical generating factors of the training dataset and the information physics-aware LVs contain was scrutinized as varies. Finally, it was confirmed quantitatively and qualitatively that the extracted physics-aware LVs in 1000-VAE actually correspond to the generating factors, which were and in this study. To the best of the authors’ knowledge, this is the first study to practically confirm that -VAE can automatically extract the physical generating factors in the field of applied physics.
-
4.
The effects of physics-awareness of LVs on the accuracy of regression and prediction processes in ROM are analyzed and it was confirmed that only physics-aware LVs had a significant effect on their accuracy. Therefore, physics-aware ROM, which utilizes only physics-aware LVs is proposed for its efficiency in that the number of required regression models can be reduced significantly. Finally, compared to the conventional ROMs, its validity and efficiency were successfully verified.
The presented data-driven physics-aware ROM has great potential in two engineering applications. First, extraction process of physics-aware LVs can be applied to discovering generating factors from the given dataset. For example, this application can be extended to identify fault-causing factors in sensor data from manufacturing processes. Second, physics-aware ROM can be an efficient alternative to conventional black-box ROMs in that it utilizes necessary regression models of only physically interpretable and information-intensive LVs, rather than redundant regression models of all uninterpretable LVs. Though the application of this framework was demonstrated via 2D transonic benchmark problem, it can be easily applied and extended to numerous engineering disciplines in that no special assumptions have been made on this specific problem. For future work, a more comprehensive investigation on physics-aware LVs will be conducted, such as their scalability to the temporal dataset or their ability to discern redundant physical parameters.
Acknowledgement
This work was supported by a National Research Foundation of Korea grant funded by the Ministry of Science and ICT (NRF-2017R1A5A1015311).
Author Declarations
Author Contributions
Yu-Eop Kang and Sunwoong Yang contributed equally to this work.
Conflict of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Appendix A POD-based ROM results
While the excellence of AE-based ROM over POD-based ROM has already been conducted by numerous studies [13, 27, 15], it is worth reaffirming from the perspective of this study. Therefore, additional results by POD-based ROM are presented in this section. Fig. 20 shows the same results as in Fig. 14 except it is based on POD. When compared to 1000-VAE in Fig. 14, the discontinuity due to the shock wave is not sharply captured by the top two dominant LVs of POD. Moreover, these two LVs encode two physical characteristics, the presence of the shock wave and the magnitude of the suction peak, in an entangled manner, whereas 1000-VAE successfully separated their information in a disentangled manner. To quantitatively verify the entanglement of POD LVs, the same analysis using LR models with two LVs (as Eq. 8) is repeated, and the results are as follows:
| (9) |
As can be confirmed, both LVs contribute significantly to the prediction of each physical parameter (herein, test dataset values for Ma and AoA are calculated as 0.949 and 0.994), meaning that they cannot solely represent the and as 1000-VAE model. All these results indicate that despite the POD algorithm ensuring orthogonality, the physical interpretability of its latent space cannot be guaranteed.


To inspect the prediction accuracy of POD-based ROM, Fig. 21 shows the pressure contour predicted from POD-based ROM and its absolute error contour. Herein, POD (16LVs) and POD (2LVs) each represents ROM with 16 and 2 LVs (or modes) of POD. When compared to Fig. 19, the error contour of POD with 16LVs is comparable to that of AE/VAE/-VAE. However, when the number of LVs is reduced to 2, which is the number of generating factors of training dataset, the error contour is much more worse. Indeed, of ROM based on POD with 2LVs () is 26 times higher than that of 1000-VAE with 2LVs (). More interestingly, even that of POD with 16LVs () is 1.1 times higher than 1000-VAE with 2LVs. Despite the further increment of the number of LVs used in POD-based ROM to 64, it is confirmed that the of POD () is still higher than that of 1000-VAE. These results confirm that POD-based ROM requires an excessive number of LVs compared to -VAE-based ROM for ensuring the same prediction accuracy.


This section shows the obvious superiority of nonlinear-based DR methods over linear-based DR method (POD) in terms of physical interpretability of latent space and consequent prediction accuracy of ROM, both of which are key factors of this study.
Appendix B Scalability of the framework for extracting physics-aware LVs
In the main text, the framework for extracting physics-aware LVs using -VAE is validated with regularized and well-organized CFD dataset. However, most of the data in real-world engineering is sparse and noisy. Accordingly, in this section, the practical scalability of the proposed framework is verified by utilizing only a small portion of the training dataset and adding artificial noises. For this purpose, the training dataset in the main text (which is the tensor of ) is preprocessed to be a vector with only 35 elements: 32 surface pressure values, lift coefficient (), drag coefficient (), and pitching moment coefficient (). Artificial Gaussian noises are added considering the scale of each element, and the final dataset are shown in Fig. 22. Then, AE and -VAE models () are trained and their top two ranked LVs are visualized in Fig. 23 (which corresponds to Fig. 12 in Sec. 5.4). Again, it can be seen that LVs of AE are highly entangled. On the other hand, LVs of -VAE become more and more disentangled as increases so that eventually in 1-VAE, each LV solely represents and , respectively. It can be concluded that the extraction of physics-aware LVs via -VAE, which is first observed and reported in this study, has the potential to be applied to real-world engineering problems where training datasets are sparse and noisy.





References
- [1] Sunwoong Yang and Kwanjung Yee. Design rule extraction using multi-fidelity surrogate model for unmanned combat aerial vehicles. Journal of Aircraft, pages 1–15, 2022.
- [2] Sky McKinley and Megan Levine. Cubic spline interpolation. College of the Redwoods, 45(1):1049–1060, 1998.
- [3] H-M Gutmann. A radial basis function method for global optimization. Journal of Global Optimization, 19(3):201–227, 2001.
- [4] Carl Edward Rasmussen. Gaussian processes in machine learning. In Summer school on machine learning, pages 63–71. Springer, 2003.
- [5] Eric Schulz, Maarten Speekenbrink, and Andreas Krause. A tutorial on gaussian process regression: Modelling, exploring, and exploiting functions. Journal of Mathematical Psychology, 85:1–16, 2018.
- [6] Lawrence Sirovich. Turbulence and the dynamics of coherent structures. I. Coherent structures. Quarterly of Applied Mathematics, 45(3):561–571, 1987.
- [7] David Amsallem, Matthew J Zahr, and Charbel Farhat. Nonlinear model order reduction based on local reduced-order bases. International Journal for Numerical Methods in Engineering, 92(10):891–916, 2012.
- [8] David J Lucia, Paul I King, and Philip S Beran. Domain decomposition for reduced-order modeling of a flow with moving shocks. AIAA Journal, 40(11):2360–2362, 2002.
- [9] Yu-Eop Kang, Soonho Shon, and Kwanjung Yee. Local non-intrusive reduced order modeling based on soft clustering and classification algorithm. International Journal for Numerical Methods in Engineering, 2022.
- [10] Romain Dupuis, Jean-Christophe Jouhaud, and Pierre Sagaut. Surrogate modeling of aerodynamic simulations for multiple operating conditions using machine learning. AIAA Journal, 56(9):3622–3635, 2018.
- [11] Mark A Kramer. Nonlinear principal component analysis using autoassociative neural networks. AIChE Journal, 37(2):233–243, 1991.
- [12] Geoffrey E Hinton and Ruslan R Salakhutdinov. Reducing the dimensionality of data with neural networks. science, 313(5786):504–507, 2006.
- [13] Michele Milano and Petros Koumoutsakos. Neural network modeling for near wall turbulent flow. Journal of Computational Physics, 182(1):1–26, 2002.
- [14] Hamidreza Eivazi, Hadi Veisi, Mohammad Hossein Naderi, and Vahid Esfahanian. Deep neural networks for nonlinear model order reduction of unsteady flows. Physics of Fluids, 32(10):105104, 2020.
- [15] Jincheng Zhang and Xiaowei Zhao. Machine-learning-based surrogate modeling of aerodynamic flow around distributed structures. AIAA Journal, 59(3):868–879, 2021.
- [16] Kazuto Hasegawa, Kai Fukami, Takaaki Murata, and Koji Fukagata. Machine-learning-based reduced-order modeling for unsteady flows around bluff bodies of various shapes. Theoretical and Computational Fluid Dynamics, 34(4):367–383, 2020.
- [17] Jing Wang, Cheng He, Runze Li, Haixin Chen, Chen Zhai, and Miao Zhang. Flow field prediction of supercritical airfoils via variational autoencoder based deep learning framework. Physics of Fluids, 33(8):086108, 2021.
- [18] Nikolaj T Mücke, Sander M Bohté, and Cornelis W Oosterlee. Reduced order modeling for parameterized time-dependent PDEs using spatially and memory aware deep learning. Journal of Computational Science, 53:101408, 2021.
- [19] Pin Wu, Siquan Gong, Kaikai Pan, Feng Qiu, Weibing Feng, and Christopher Pain. Reduced order model using convolutional auto-encoder with self-attention. Physics of Fluids, 33(7):077107, 2021.
- [20] Romit Maulik, Bethany Lusch, and Prasanna Balaprakash. Reduced-order modeling of advection-dominated systems with recurrent neural networks and convolutional autoencoders. Physics of Fluids, 33(3):037106, 2021.
- [21] Anthony Gruber, Max Gunzburger, Lili Ju, and Zhu Wang. A comparison of neural network architectures for data-driven reduced-order modeling. Computer Methods in Applied Mechanics and Engineering, 393:114764, 2022.
- [22] Teeratorn Kadeethum, Francesco Ballarin, Youngsoo Choi, Daniel O’Malley, Hongkyu Yoon, and Nikolaos Bouklas. Non-intrusive reduced order modeling of natural convection in porous media using convolutional autoencoders: comparison with linear subspace techniques. Advances in Water Resources, page 104098, 2022.
- [23] Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. 2016.
- [24] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- [25] Yuri Burda, Roger Grosse, and Ruslan Salakhutdinov. Importance weighted autoencoders. arXiv preprint arXiv:1509.00519, 2015.
- [26] Christopher P Burgess, Irina Higgins, Arka Pal, Loic Matthey, Nick Watters, Guillaume Desjardins, and Alexander Lerchner. Understanding disentangling in -vae. arXiv preprint arXiv:1804.03599, 2018.
- [27] Hamidreza Eivazi, Soledad Le Clainche, Sergio Hoyas, and Ricardo Vinuesa. Towards extraction of orthogonal and parsimonious non-linear modes from turbulent flows. Expert Systems with Applications, page 117038, 2022.
- [28] Partha Ghosh, Mehdi SM Sajjadi, Antonio Vergari, Michael Black, and Bernhard Schölkopf. From variational to deterministic autoencoders. arXiv preprint arXiv:1903.12436, 2019.
- [29] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine learning, pages 1096–1103, 2008.
- [30] Sunwoong Yang, Sanga Lee, and Kwanjung Yee. Inverse design optimization framework via a two-step deep learning approach: application to a wind turbine airfoil. Engineering with Computers, pages 1–17, 2022.
- [31] Carl Doersch. Tutorial on variational autoencoders. arXiv preprint arXiv:1606.05908, 2016.
- [32] Ashis Pati and Alexander Lerch. Attribute-based regularization of latent spaces for variational auto-encoders. Neural Computing and Applications, 33(9):4429–4444, 2021.
- [33] Robert Tibshirani. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological), 58(1):267–288, 1996.
- [34] Casper Kaae Sønderby, Tapani Raiko, Lars Maaløe, Søren Kaae Sønderby, and Ole Winther. Ladder variational autoencoders. Advances in Neural Information Processing Systems, 29, 2016.
- [35] Soo Hyung Park and Jang Hyuk Kwon. Implementation of kw turbulence models in an implicit multigrid method. AIAA Journal, 42(7):1348–1357, 2004.
- [36] Yoonpyo Hong, Dawoon Lee, Kwanjung Yee, and Soo Hyung Park. Enhanced high-order scheme for high-resolution rotorcraft flowfield analysis. AIAA Journal, 60(1):144–159, 2022.
- [37] Sunwoong Yang and Kwanjung Yee. Comment on “Novel approach for selecting low-fidelity scale factor in multifidelity metamodeling”. AIAA Journal, pages 1–3, 2022.
- [38] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems, 32, 2019.
- [39] Andrea Saltelli, Paola Annoni, Ivano Azzini, Francesca Campolongo, Marco Ratto, and Stefano Tarantola. Variance based sensitivity analysis of model output. design and estimator for the total sensitivity index. Computer Physics Communications, 181(2):259–270, 2010.
- [40] Jon Herman and Will Usher. SALib: An open-source python library for sensitivity analysis. The Journal of Open Source Software, 2(9), jan 2017.