Phase Re-service in Reinforcement Learning Traffic Signal Control
Abstract
This article proposes a novel approach to traffic signal control that combines phase re-service with reinforcement learning (RL). The RL agent directly determines the duration of the next phase in a pre-defined sequence. Before the RL agent’s decision is executed, we use the shock wave theory to estimate queue expansion at the designated movement allowed for re-service and decide if phase re-service is necessary. If necessary, a temporary phase re-service is inserted before the next regular phase. We formulate the RL problem as a semi-Markov decision process (SMDP) and solve it with proximal policy optimization (PPO). We conducted a series of experiments that showed significant improvements thanks to the introduction of phase re-service. Vehicle delays are reduced by up to 29.95% of the average and up to 59.21% of the standard deviation. The number of stops is reduced by 26.05% on average with 45.77% less standard deviation.
I Introduction
Dynamically changing traffic patterns is a core challenge in managing traffic at intersections, and when unaccounted for, they can cause an increase in congestion and travel delay. Adaptive traffic signal control (ATSC) offers a promising solution to mitigate congestion and enhance traffic flow. Significant ATSC deployments including SCOOT [1] and RHODES [2] extract traffic patterns over time and optimize the signal timings accordingly.
Recently, reinforcement learning (RL) has emerged as a promising tool for ATSC, based on its learning and real-time computational capabilities in complex environments [3]. Though potentially promising algorithms have been developed (see [3, 4] for comprehensive surveys), phase starvation and safety concerns are known existing challenges to RL-based ATSC without fixed signal sequences [5]. Additionally, some algorithms experience a performance drop in the presence of heavy traffic demands [6].
The left-turn movement is especially sensitive to high demand profiles because it often conflicts with oncoming traffic flow and has limited capacity. Performing phase re-service [7], which is when the controller serves the same phase twice in one cycle, can be an effective approach to manage left-turn queue lengths [8]. Phase re-service has been successfully deployed in many real-world intersections [9, 10]. While its implementation has been limited to traffic-responsive signal timing optimizations [11], we propose extending re-service to real-time ATSC for enhanced operational flexibility.
The main contribution of this article is that we introduce an approach to augment reinforcement learning-based adaptive traffic signal control to enable phase re-service. The RL agent decides the duration of regular phases, and we use shock wave theory [12, 13, 14, 15, 16] to estimate queue growth and trigger phase re-service. Because the agent selects the phase duration, we model the control problem as a semi-Markov decision process (SMDP) [17]. We test the performance of our approach on two intersection geometries, each with five demand profiles. The simulation results demonstrate that phase re-service significantly reduces vehicle delays and the number of stops overall, and for the protected left turn movement.
The remainder of this article is organized as follows: In Section II, we provide the preliminaries for RL based signal control. Section III presents the technical details of phase re-service determination, RL formulation and algorithm, and the pseudocode summarizing the training process. Experimental settings and result analysis are presented in Section IV. We finally conclude our work in Section V.
II Preliminaries
II-A Traffic signal control setup
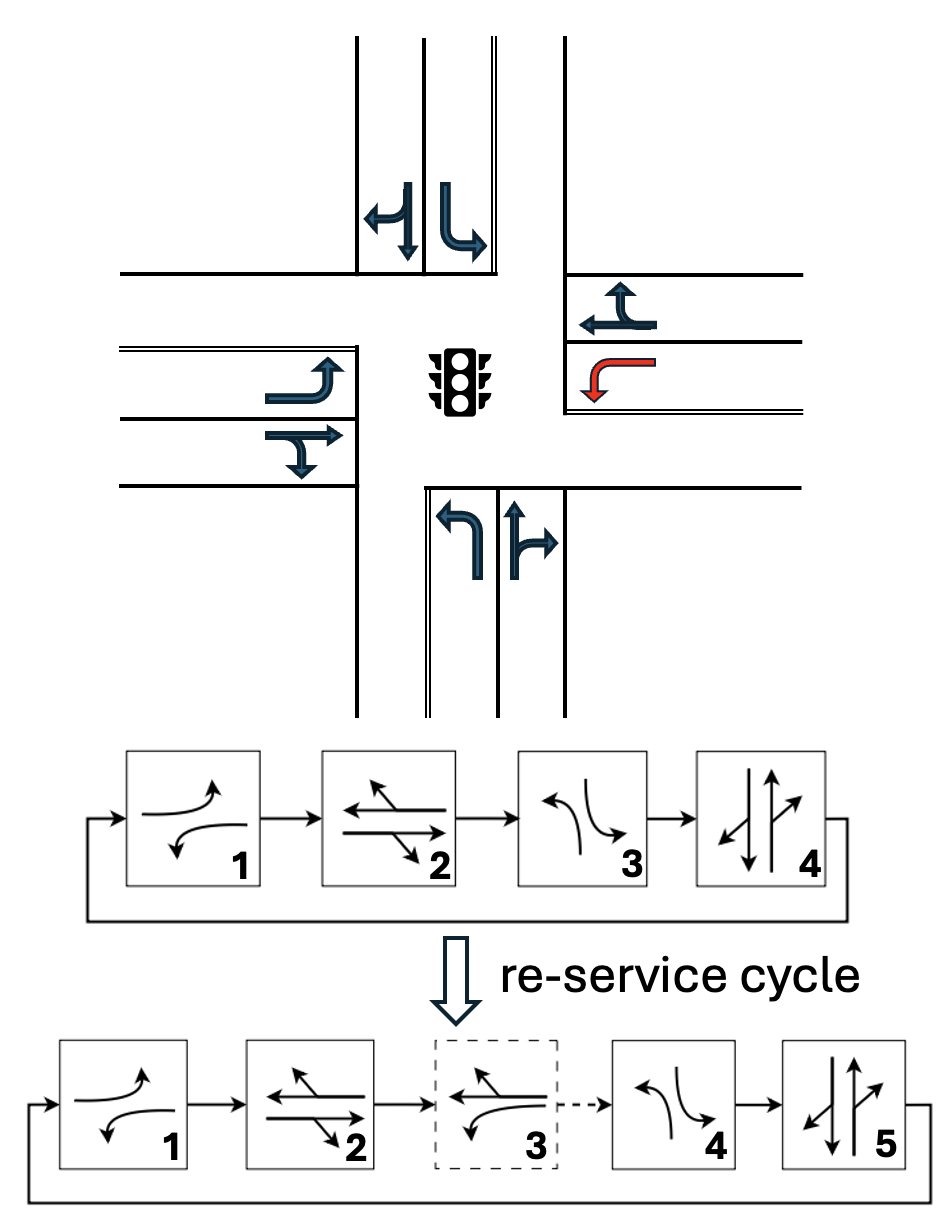
Consider traffic control at a single intersection with multiple incoming and outgoing roadways. Incoming vehicles travel on and are queued on incoming roadway lanes. Queues at signalized intersections are served by phases, each of which groups one or more non-conflicting turning movements. Phases are served with green signals in a pre-defined order known as the phase sequence, and a complete iteration of the sequence is a cycle [7].
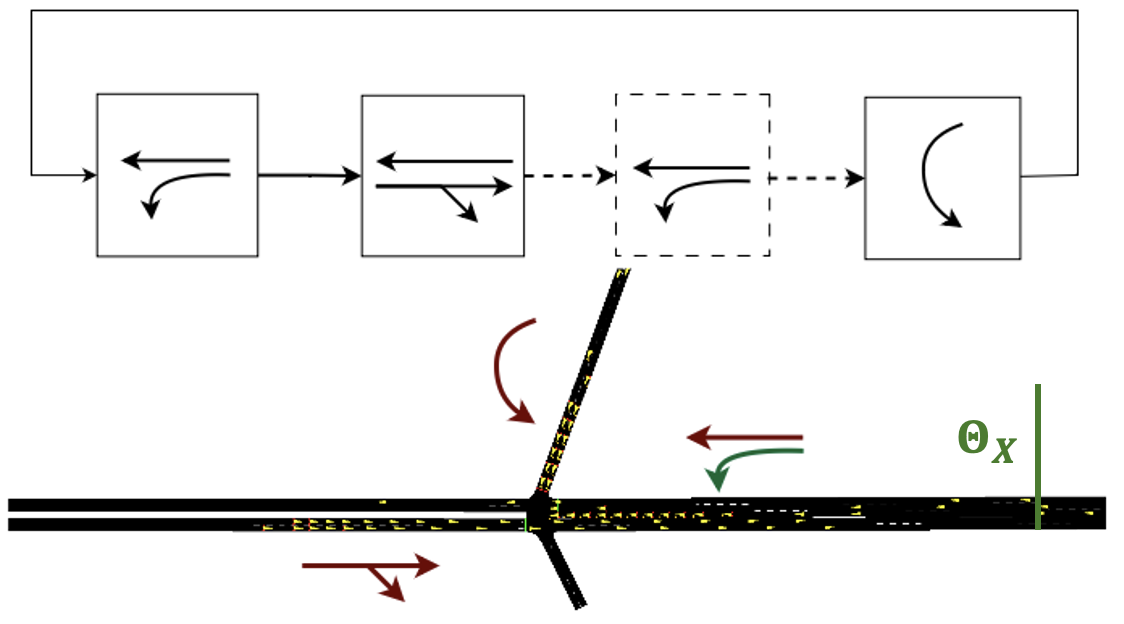
At some intersections, particular left-turn movements face large demands during peak hours, such as the movement marked with red arrow in Fig. 1. Serving a specific left-turn movement such as a protected left turn twice in a cycle can effectively clear excessive left-turn queues. The second service, known as phase re-service, is typically pre-configured to follow the through movement in the same direction. For example, in Fig. 1, the protected movement served in the first phase may be served again in the third phase. Our work considers adding phase re-service into RL based signal controllers.
II-B Semi-Markov decision processes
RL problems for signal control are often formulated as a Markov decision process (MDP), . Here, is the state space of the system in question with dimension , is the space of available actions with dimension , is a reward function, is a probabilistic transition function, and is a discount factor.
Additionally, let be the system state at time , and be the action taken at time . The actions are chosen at each step from a policy parameterized by . RL attempts to maximize the long-term discounted reward by choosing an optimal policy, typically through the selection of optimal policy parameters. Signal control problems in which the action at each timestep is the phase to serve are naturally written as MDPs, which can then be solved with RL.
In this work we formulate a traffic signal control problem as a Semi-MDP, which is an extension of MDP which includes a varying transition time between states. The time between transitions is called the sojourn time, denoted , and we incorporate this into the state transition as , meaning that the transition probability takes both the next state and the transition time to it into account. Signal control problems in which the action is the temporal duration to serve the next phase are naturally written as SMDPs.
II-C Queue dynamics at intersections
Let be an index on signal cycles. A set of important speed properties associated with shock waves at intersections is as follows [16, 14]:
| (2) | ||||
| (3) | ||||
| (4) | ||||
| (5) |
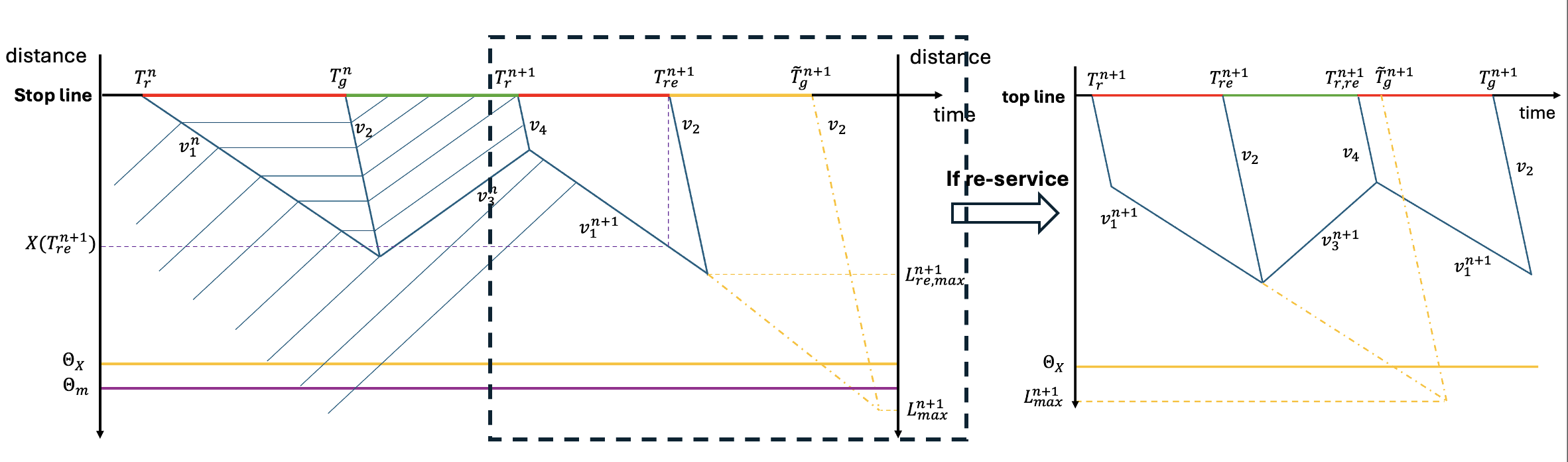
where , , and are critical density, jam density, and saturation flow. Additionally, and are the density and flow for arriving vehicles at each cycle . Modern sensors can directly measure the number of vehicles over a time window as the flow, and the average speed of these counted vehicles. Then the density is obtained from dividing the flow by the average vehicle speed. Let be the queue expansion speed at the red signal, and let be the speed at which the end of queue moves forward to the stop line at the green signal, be the vehicle discharge speed from the queue at the green signal, and be the speed at which the residual of queued vehicles forms a new queue when the green signal ends (only for saturated movements). Fig. 2 shows graphically these different quantities.
III Controller design
In order to handle intersections with high left-turn demand via ATSC, we propose an RL controller design approach combined with phase re-service based on queue length estimation from shockwave theory. We first frame the traffic control problem as an SMDP. Then, we describe how to determine the phase re-service from queue length estimation. Finally, we present a training algorithm.
III-A SMDP formulation
The traffic control problem can be formulated as an SMDP as follows:
State . The state consists of the count of queuing vehicles in each incoming lane, the count of non-stopping vehicles in each incoming lane, as well as the number of phases until service. This information is commonly available from sensor data [4].
Action . The action taken by the RL agent is the duration of the next phase in a predefined cycle. To account for min/max green time constraints, actions are normalized within the range , achieved via a tanh function, and subsequently linearly mapped to actual phase duration as follows:
| (6) |
where and are the actual and normalized duration time for phase , and are the maximum and minimum green time also for . For notational simplicity, we refer to as the actual duration time in the rest of this paper.
Reward . Let be the index of each incoming lane, be the total number of incoming lanes, and be the queue length at timestep for the lane. We define the immediate reward as follows:
| (7) |
where is the maximum distance from the stop line that allows vehicle detection. Queue length is often used as a surrogate reward for vehicle delay [3].
Sojourn time . The sojourn time in this context is the time from applying one phase duration (the action) until the next point of applying another phase duration (the next action). The sojourn time is typically the phase duration plus the yellow signal transition time. However, if reservice is applied, the time when the next action is executed will be delayed by the re-service phase, which extends the sojourn time accordingly.
III-B Queue estimation and phase re-service
Maximum queue estimation. First, we give a maximum queue estimation technique for this problem setup, which is slightly altered form of the queue estimation techniques presented in [19].
We define the following time quantities related to queue length estimation:
-
•
: The start time when the protected movement in the -th cycle is served with a green signal111 is the actual simulation time in seconds. In contrast, is the timestep for the agent’s decision-making..
-
•
: The end time of the protected movement in the -th cycle, which is also the cycle’s start time.
-
•
: The time at which whether to re-service is decided for the -th cycle.
Let refer to the queue length at time . Additionally we define:
as the time between assessing for re-service and the next regular green signal.
At a given , could be used to perform queue length estimation, however it is not known in real-time. Instead, let be a real-time estimate. In this work we estimate at a given by using the running average of the true from prior cycles. In implementation we use 2 prior cycles.
Let be the forecasted maximum queue length in the next cycle, if no re-service is applied. We calculate this as follows:
| (8) |
From , whether or not to apply phase re-service is decided. The different quantities covered here are shown graphically in Fig. 2.
Re-service duration calculation. First, whether or not to execute the re-service is decided via
where is a threshold on queue length.
Next, we calculate the maximum queue length if re-service is applied as follows:
We then calculate the duration of the re-service as follows:
| (9) |
where is the assigned re-service duration, is a coefficient balancing re-service urgency and overall intersection management, and are the min/max re-service durations. A re-service movement has queues analogous to the right-hand side in Fig. 2.
III-C Controller training framework
In Algorithm 1 our proposed training algorithm is presented. The algorithm joins queue estimation based phase re-service with our SMDP formulation and standard policy optimization techniques. In particular, proximal policy optimization with a generalized advantage estimator is used. Minor alterations to the PPO algorithm were made to adapt the algorithm to the SMDP approach.
IV Experimental results
We present the results of a series of numerical experiments conducted in the traffic microsimulation software SUMO [20]. Two different signal control environments are considered, namely a signalized intersection at a freeway ramp and a conventional four-leg intersection.
Three different ATSC algorithms are compared in both environments. We implement our approach of RL with re-service, as well as two other approaches. They are RL without re-service, and the SOTL algorithm [21]. The average vehicle delay, the average number of stops, and total throughput are all measured and compared across a set of different demands.
IV-A Implementation details
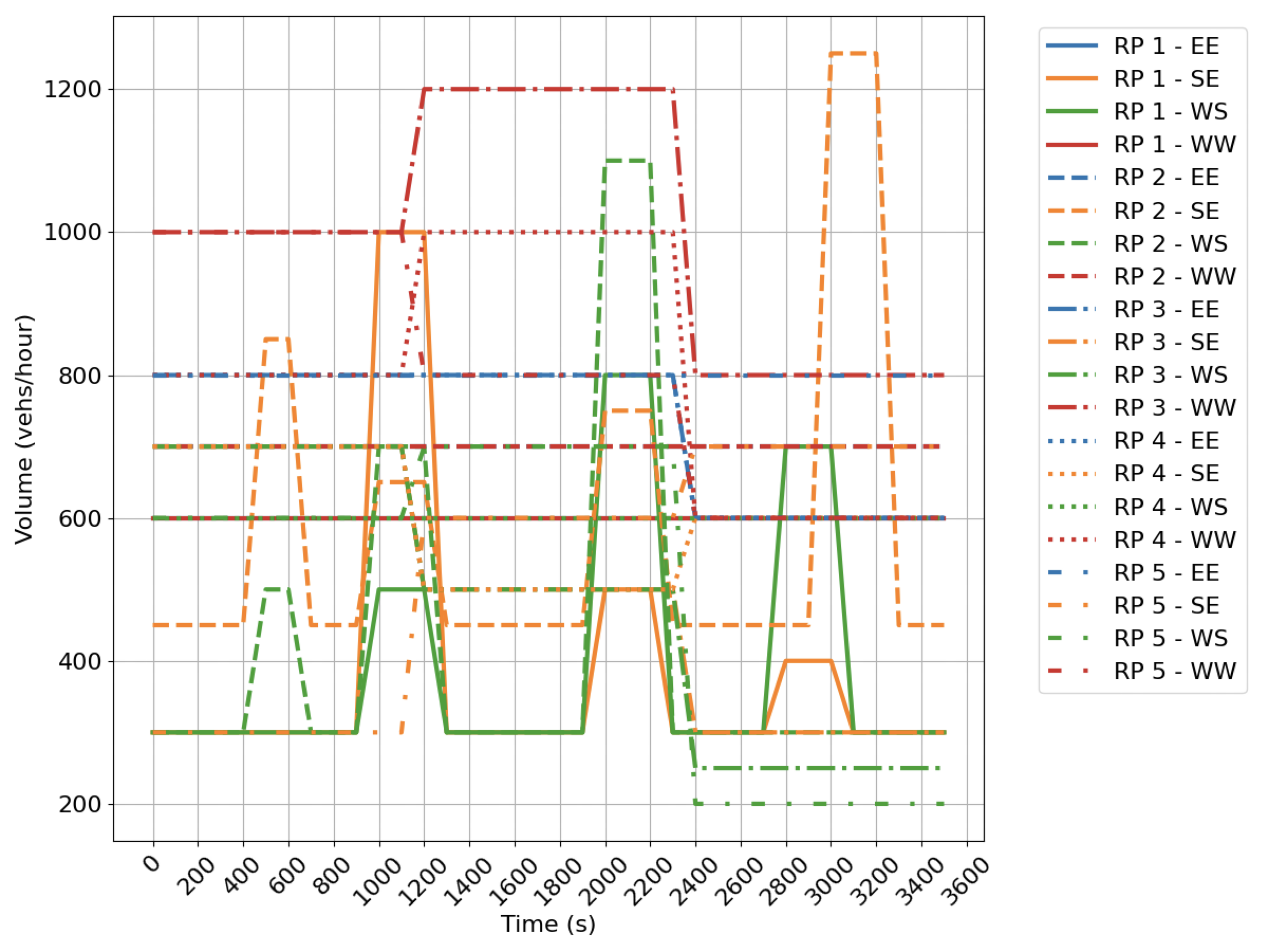
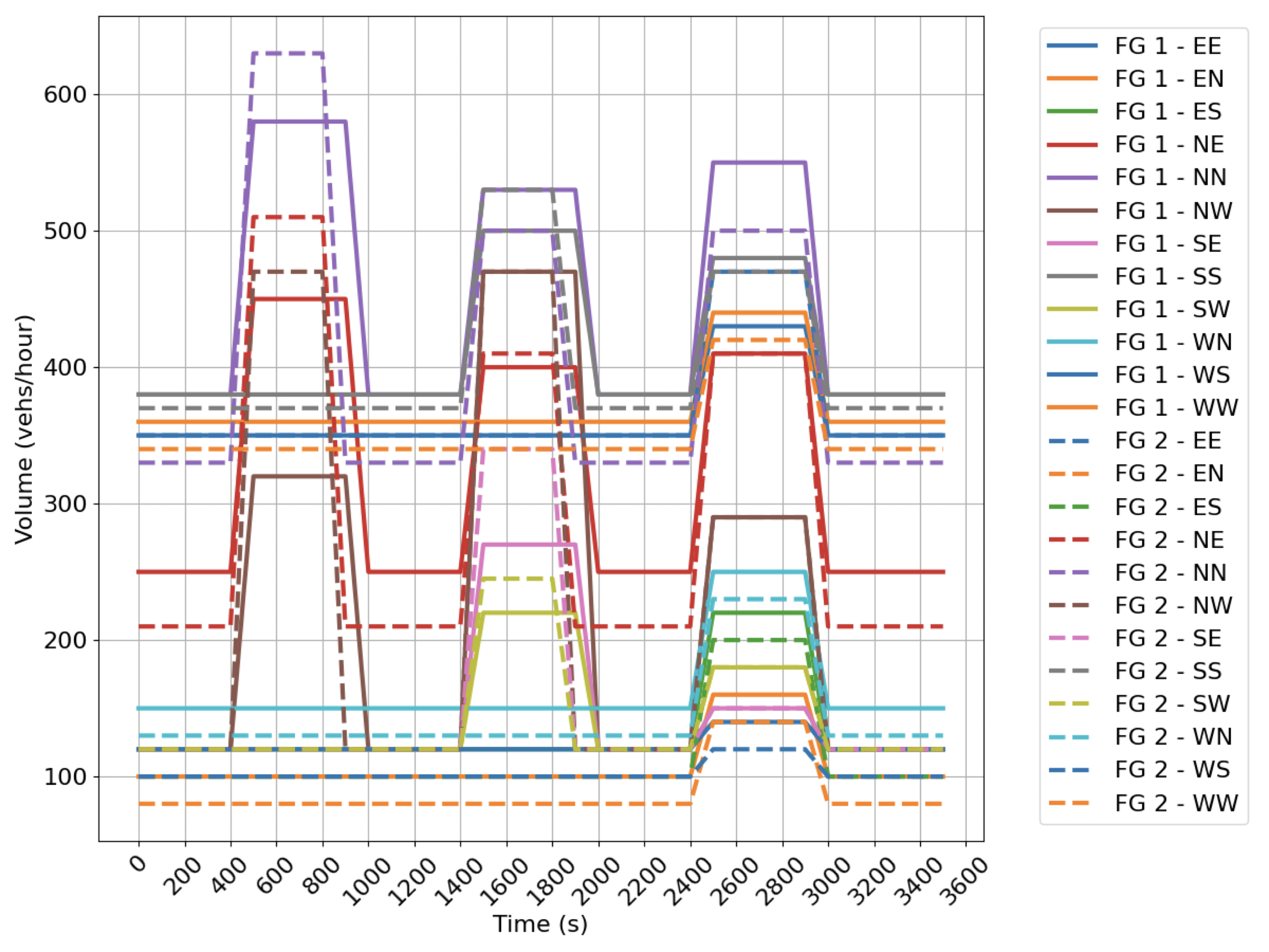
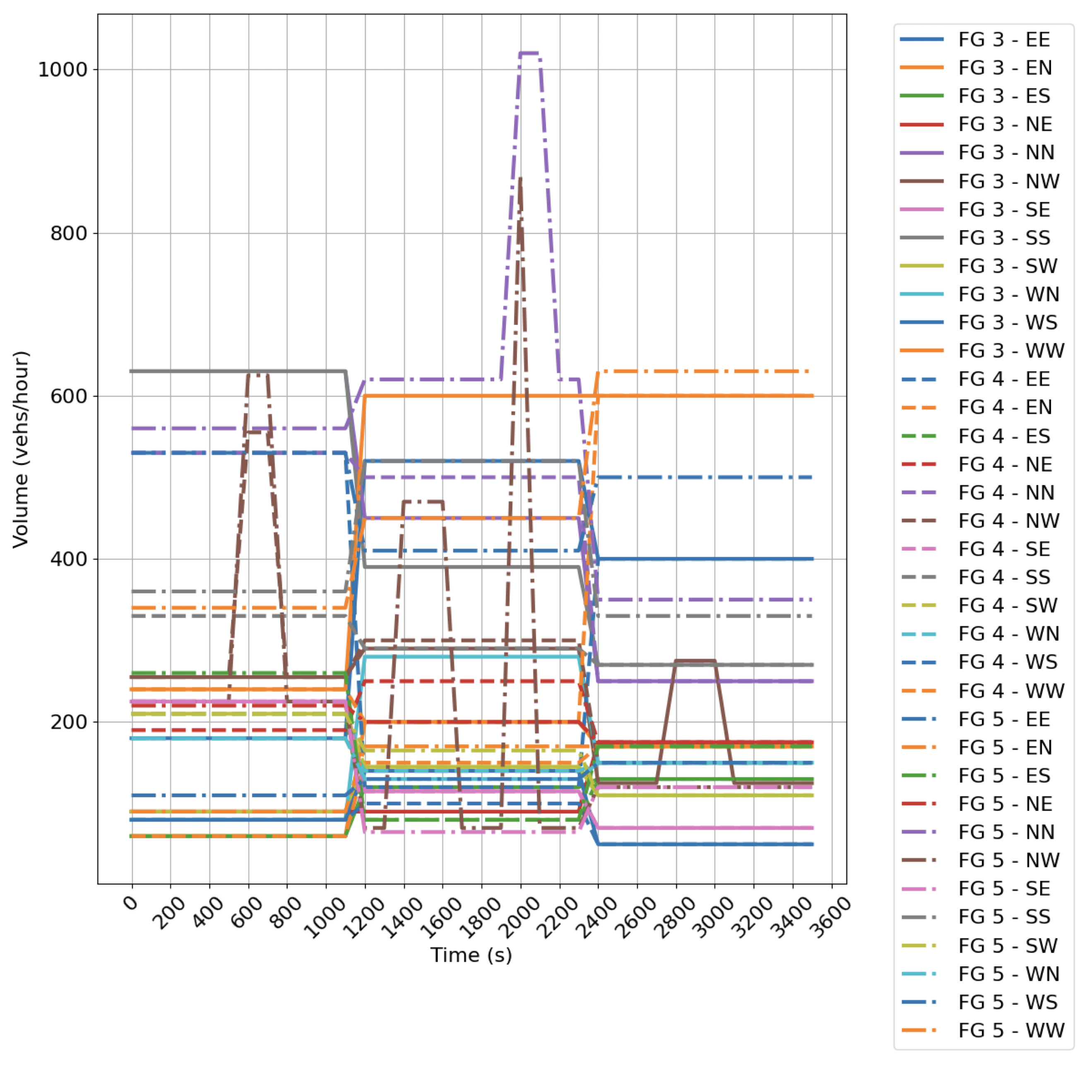
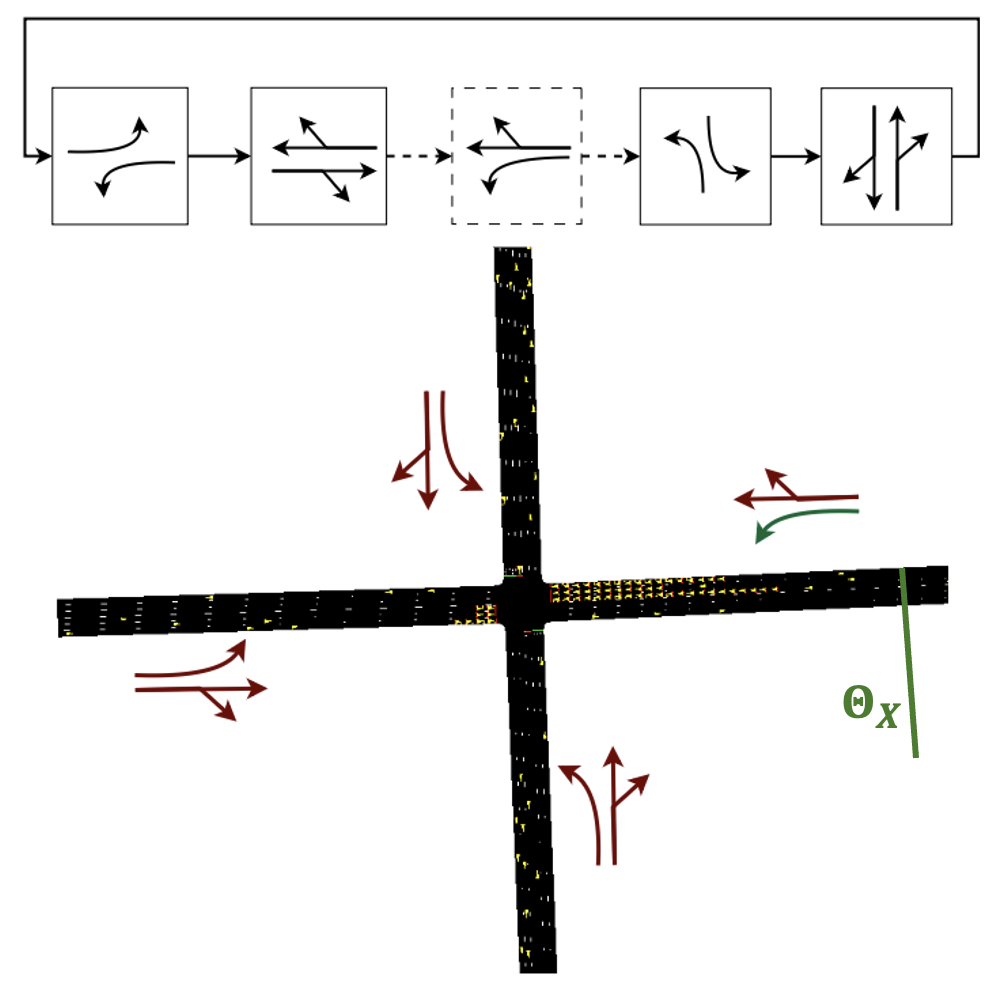
We model the two intersection types in SUMO using the default parameters to control the vehicle dynamics. At each intersection (Fig. 3), we define five time varying demand profiles, which are shown in Appendix A.
The [min, max] green time constraints for each phase are [5, 30], [5, 40], [10, 25], [5, 45] for the freeway ramp intersection, and [5, 25], [5, 70], [5, 25], [5, 25], [5, 70] for the four-leg intersection, all in seconds. Green time constraints for the re-service phases are in Italic. The yellow signal is set at five seconds. The simulation time for all scenarios is one hour. The maximum distance for vehicle detection is set at 250 m, while the threshold for re-service is set at 200 m. The shock wave parameters are estimated from the simulation model parameters as: veh/km, veh/km, and veh/h.
The actor network has a single 128-neuron hidden layer and a tanh activation function for output. Similarly, the critic network also has a hidden layer of 128 neurons but the activation function is ReLU. Both networks are independent, i.e., do not share common neurons. The sampled action value from the actor’s stochastic policy is also activated by tanh. The re-service coefficient is set as . For hyperparameters in PPO, we follow the guidelines in [22] and set the loss clipping hyperparameter , the long-term reward discount factor , the multi-step weighting factor in advantage estimation , the learning rate at 2.5e-4, the minibatch size at 256, the update interval of 1200 transitions, and 20 epochs per update. All agents have the same hyperparameters.
IV-B Training results
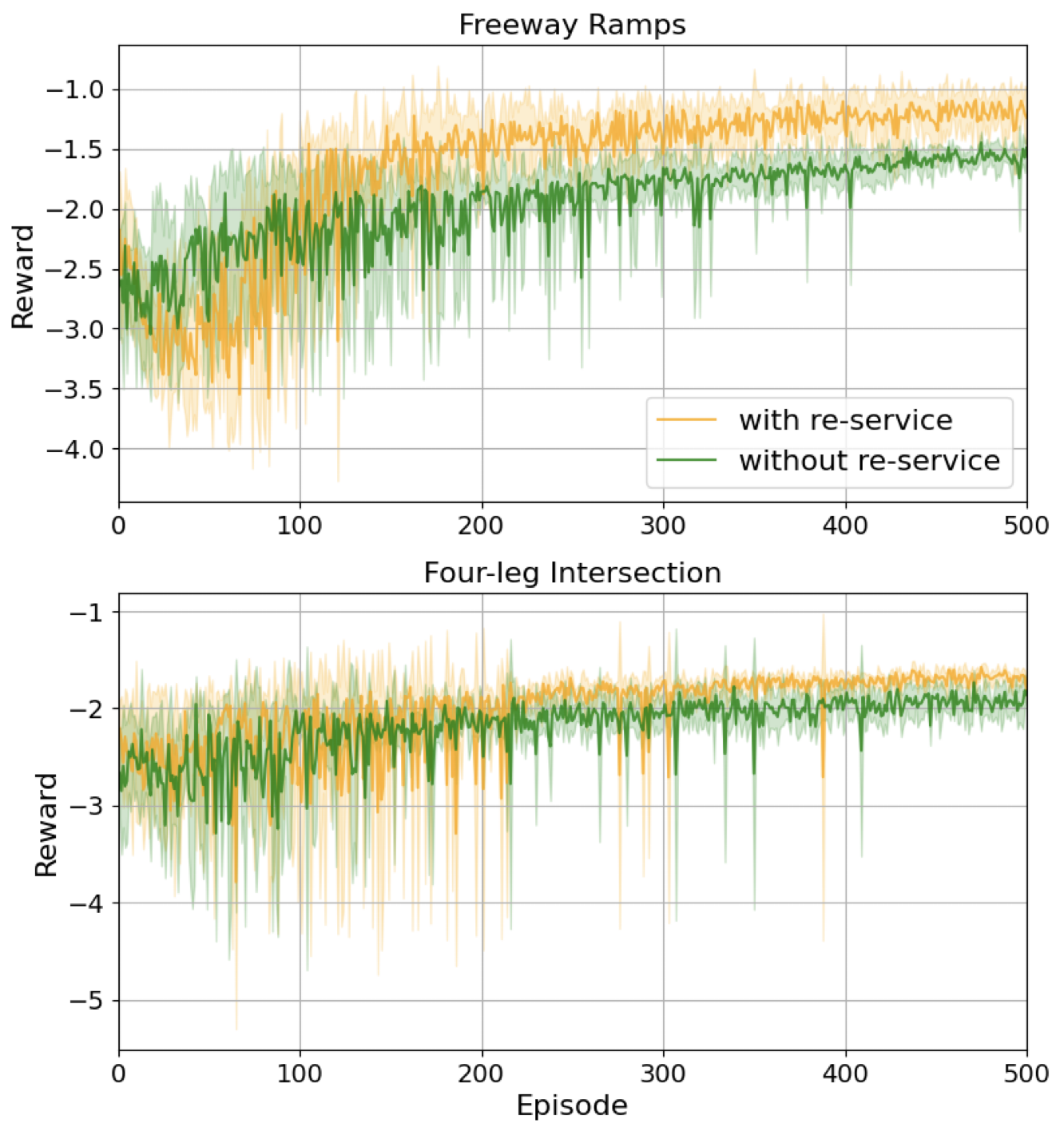
The step-average training results for 500 episodes in two intersections are shown in Fig. 4. Demand 3 of both intersections are training demand profiles. It shows that adding phase re-service as part of the environmental transition does not significantly affect the speed of convergence, and in both intersections, the re-service can further maximize the rewards. The freeway ramps are more benefited from phase re-service probably due to a large percentage of re-serviced vehicles in the total vehicle demands.
| Metric | Algorithm | Demand 1 | Demand 2 | Demand 3 | Demand 4 | Demand 5 |
| Vehicle delay (s) | with re-service | 34.967, 27.853 | 42.813, 36.168 | 48.393, 42.29 | 48.703, 36.119 | 43.019, 35.327 |
| without re-service | 34.62, 30.933 | 44.579, 47.773 | 57.322, 63.986 | 64.876, 69.702 | 61.497, 65.379 | |
| SOTL | 33.167, 35.353 | 57.203, 75.361 | 88.622, 113.092 | 81.864, 102.859 | 70.121, 90.853 | |
| Number of stops | with re-service | 0.681, 0.508 | 0.807, 0.715 | 0.876, 0.772 | 0.897, 0.711 | 0.844, 0.765 |
| without re-service | 0.715, 0.59 | 0.887, 0.898 | 1.12, 1.223 | 1.213, 1.311 | 1.16, 1.225 | |
| SOTL | 0.822, 0.887 | 1.46, 2.059 | 2.394, 3.025 | 2.181, 2.804 | 1.896, 2.608 | |
| % of re-service cycles | with re-service | 6.4 | 15.0 | 23.5 | 45.3 | 26.6 |
| Throughput (veh/h) | with re-service | 1945, 6.59 | 2352, 6.9 | 2694, 8.09 | 2689, 10.06 | 2593, 6.84 |
| without re-service | 1941, 5.3 | 2358, 10.37 | 2690, 7.75 | 2611, 13.59 | 2594, 5.94 | |
| SOTL | 1944, 4.08 | 2314, 13.18 | 2660, 13.36 | 2516, 13.41 | 2510, 13.91 |
| Metric | Algorithm | Demand 1 | Demand 2 | Demand 3 | Demand 4 | Demand 5 |
| Vehicle delay (s) | with re-service | 67.573, 51.672 | 66.355, 51.913 | 65.159, 53.597 | 66.588, 52.591 | 72.759, 55.823 |
| without re-service | 76.605, 77.757 | 72.344, 67.589 | 72.197, 69.815 | 89.74, 128.937 | 80.012, 93.294 | |
| SOTL | 75.689, 80.501 | 80.274, 90.484 | 73.913, 86.785 | 92.121, 149.148 | 83.101, 118.338 | |
| Number of stops | with re-service | 0.841, 0.504 | 0.853, 0.53 | 0.83, 0.509 | 0.856, 0.527 | 0.905, 0.542 |
| without re-service | 0.926, 0.671 | 0.885, 0.597 | 0.878, 0.589 | 1.046, 1.068 | 0.994, 0.831 | |
| SOTL | 0.971, 0.758 | 0.97, 0.78 | 0.959, 0.815 | 1.095, 1.266 | 1.084, 1.11 | |
| % of re-service cycles | with re-service | 4.8 | 11.0 | 4.0 | 13.7 | 14.1 |
| Throughput (veh/h) | with re-service | 2906, 12.6 | 2739, 9.3 | 2782, 13.3 | 2613, 11.9 | 3130, 12.5 |
| without re-service | 2903, 14.9 | 2745, 16.4 | 2771, 11.1 | 2576, 6.3 | 3118, 10.6 | |
| SOTL | 2868, 5.1 | 2701, 3.0 | 2755, 6.4 | 2543, 8.7 | 3116, 7.0 |
IV-C Testing performance
For each intersection, the agent is trained five times with demand profile 3. The best-performing agent in the last episode of the training stage is used for testing. We run each testing scenario (consisting of an intersection and a demand profile) 20 times and report the statistics. Metrics including throughput per hour, vehicle delay per trip, and the number of stops experienced per trip are compared and summarized in Table I and Table II. All metrics are directly calculated within SUMO. A baseline non-RL algorithm called SOTL [21] is evaluated for comparison purposes. SOTL determines phase switching based on the count of arriving vehicles showing excellent performance in previous studies [23]. Below we analyze different traffic performance metrics.
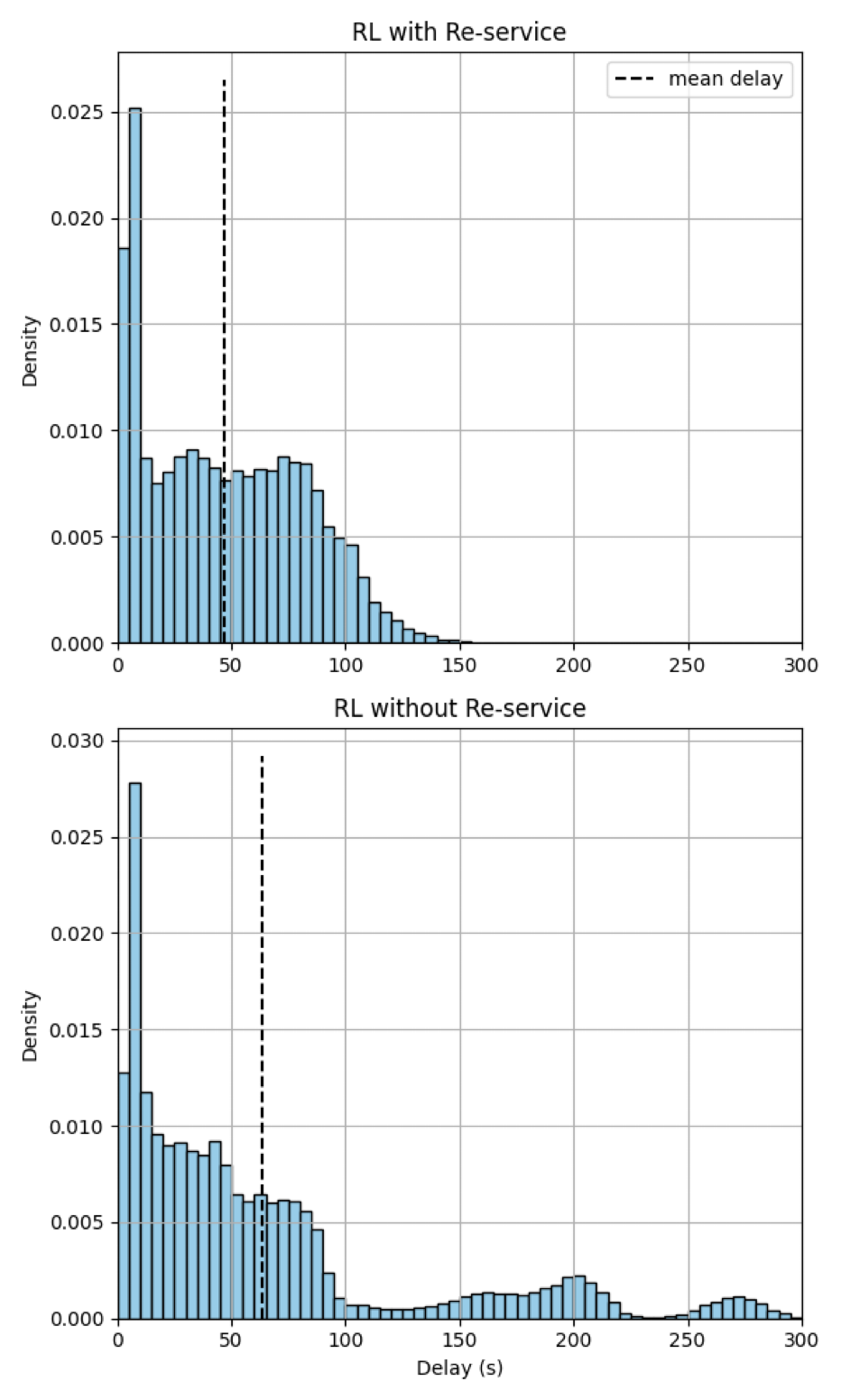
Vehicle delay: We report the average delay per vehicle. In 9 out of 10 scenarios tested, vehicle delay is significantly reduced with re-service compared to scenarios without re-service and to the non-RL baseline. Numerically, compared to RL without re-service, the proposed approach achieves an improvement in terms of the mean and standard deviation of vehicle delay ranging from -1% to 29.95% and 9.95% to 59.21%, respectively. SOTL, in contrast, only exhibits a 4.2% mean vehicle delay improvement with 14.29% higher variance in Table I Demand 1. Further, we present the density histogram of vehicle delays for freeway ramps Demand 4 scenario which benefits most from the phase re-service in Fig. 5. RL with re-service method is able to reshape the distribution with a long tail, i.e., significantly delayed vehicles, back to a more centralized one, leading to a lower average delay and smaller standard deviation.
Number of stops: The average number of vehicle stops is reported as a measure of mobility. The phase re-service significantly reduces the average number of stops and the variance of number of stops over all scenarios. The percentage of improvement reaches as high as 26.05% and 45.77% in terms of the mean and standard deviation (Table I, Demand 4 scenario).
Percentage of re-service cycles: This metric calculates the proportion of cycles incorporating phase re-service in each scenario. The results from Table II Demand 3 suggest that the re-service cycle as low as 4.0% can reduce the average vehicle delay and number of stops by 9.75% and 5.47%, and moreover, lower the variance of both metrics by 23.23% and 13.58%. The highest re-service rate reaches 45.3% (Table I, Demand 4 scenario) which contributes to the largest improvements of both vehicle delay and number of stops.
Throughput: The average throughput is also calculated for each scenario. The RL algorithm with and without phase re-service realizes similar performance in maximizing the throughput, which is also comparable to the baseline.
IV-D Performance metrics by directions
We list the trip-level evaluation metrics by vehicle movements of the RL algorithm with and without phase re-service for the scenarios with the lowest and highest re-service penetration. They are summarized in Table III. Through and right-turn movements are grouped together in the four-leg intersection as they utilize the same phases.
As expected, we observe that movements only in regular phases are delayed and stop more since the phase re-service takes additional time. Nevertheless, the additional delay is mild. EE and SE movements in Table III(a) are on average more delayed by 5.6s and 13.5s; non-protected movements in Table III(b) experience more delays from 3.8s to 14.5s. In contrast, the improvement for the protected movement is substantial: 102.5s less delay and 1.454 fewer stops in Table III(a), 79.98s less delay, and 0.45 fewer stops in Table III(b).
| Metric | Movement | with re-service | without re-service |
|---|---|---|---|
| Vehicle delay (s) | EE | 55.906, 30.871 | 49.572, 27.026 |
| WW | 14.108, 12.629 | 18.604, 15.085 | |
| WS | 71.994, 26.755 | 174.5, 65.297 | |
| SE | 54.07, 31.034 | 40.508, 26.181 | |
| Number of stops | EE | 0.907, 0.389 | 0.862, 0.386 |
| WW | 0.344, 0.477 | 0.508, 0.606 | |
| WS | 1.567, 0.672 | 3.021, 1.635 | |
| SE | 0.855, 0.389 | 0.743, 0.44 |
| Metric | Movement | with re-service | without re-service |
|---|---|---|---|
| Vehicle delay (s) | NN&NE | 47.422, 38.377 | 50.712, 37.564 |
| NW | 134.784, 92.833 | 214.751, 127.958 | |
| WW&WN | 62.366, 41.288 | 55.418, 40.203 | |
| WS | 79.247, 50.538 | 83.084, 46.177 | |
| EE&ES | 56.873, 42.269 | 51.937, 38.735 | |
| EN | 90.578, 51.432 | 95.351, 54.744 | |
| SS&SW | 46.113, 38.467 | 50.441, 37.545 | |
| SE | 75.983, 44.467 | 90.613, 46.752 | |
| Number of stops | NN&NE | 0.694, 0.473 | 0.761, 0.472 |
| NW | 1.382, 0.789 | 1.832, 0.977 | |
| WW&WN | 0.829, 0.428 | 0.754, 0.459 | |
| WS | 0.915, 0.358 | 0.908, 0.309 | |
| EE&ES | 0.77, 0.431 | 0.741, 0.442 | |
| EN | 0.964, 0.365 | 1.038, 0.393 | |
| SS&SW | 0.684, 0.471 | 0.727, 0.452 | |
| SE | 0.896, 0.311 | 0.995, 0.363 |
V Conclusion
In this paper, we propose a method to augment the RL-based ATSC to include temporary phase re-service, aiming to reduce vehicle delays and stops at intersections in high-volume left-turn scenarios. An RL agent determines the duration of the next regular phase, and another rule-based logic incorporating the shock wave theory estimates the queue growth and determines the phase re-service. We formulate the RL problem as SMDP and use PPO to solve it. We test the framework against 2 types of intersections and 10 demand profiles, and demonstrate the general merit of our framework in reducing the vehicle delays and the number of stops overall by up to 29.95% and 26.05% of the average and up to 59.21% and 45.77% of the standard deviation.
References
- [1] P. Hunt, D. Robertson, R. Bretherton, and M. C. Royle, “The scoot on-line traffic signal optimisation technique,” Traffic Engineering & Control, vol. 23, no. 4, 1982.
- [2] P. Mirchandani and L. Head, “A real-time traffic signal control system: architecture, algorithms, and analysis,” Transportation Research Part C: Emerging Technologies, vol. 9, no. 6, pp. 415–432, 2001.
- [3] H. Wei, G. Zheng, V. Gayah, and Z. Li, “Recent advances in reinforcement learning for traffic signal control: A survey of models and evaluation,” ACM SIGKDD Explorations Newsletter, vol. 22, no. 2, pp. 12–18, 2021.
- [4] M. Noaeen, A. Naik, L. Goodman, J. Crebo, T. Abrar, Z. S. H. Abad, A. L. Bazzan, and B. Far, “Reinforcement learning in urban network traffic signal control: A systematic literature review,” Expert Systems with Applications, vol. 199, p. 116830, 2022.
- [5] B. Ibrokhimov, Y.-J. Kim, and S. Kang, “Biased pressure: cyclic reinforcement learning model for intelligent traffic signal control,” Sensors, vol. 22, no. 7, p. 2818, 2022.
- [6] Z. Zhang, M. Quinones-Grueiro, W. Barbour, Y. Zhang, G. Biswas, and D. Work, “Evaluation of traffic signal control at varying demand levels: A comparative study,” in 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2023, pp. 3215–3221.
- [7] T. Urbanik, A. Tanaka, B. Lozner, E. Lindstrom, K. Lee, S. Quayle, S. Beaird, S. Tsoi, P. Ryus, D. Gettman et al., Signal timing manual. Transportation Research Board Washington, DC, 2015, vol. 1.
- [8] A. Wang and Z. Tian, “Leveraging fully actuated signal coordination and phase reservice to facilitate signal timing practices,” Transportation research record, vol. 2677, no. 1, pp. 240–251, 2023.
- [9] J. Corey, X. Xin, Y. Lao, and Y. Wang, “Improving intersection performance with left turn phase reservice strategies,” in 2012 15th International IEEE Conference on Intelligent Transportation Systems. IEEE, 2012, pp. 403–408.
- [10] S. M. Lavrenz, C. M. Day, A. M. Hainen, W. B. Smith, A. L. Stevens, H. Li, and D. M. Bullock, “Characterizing signalized intersection performance using maximum vehicle delay,” Transportation Research Record, 2015.
- [11] F. C. Fang and L. Elefteriadou, “Development of an optimization methodology for adaptive traffic signal control at diamond interchanges,” Journal of Transportation Engineering, vol. 132, no. 8, pp. 629–637, 2006.
- [12] G. Stephanopoulos, P. G. Michalopoulos, and G. Stephanopoulos, “Modelling and analysis of traffic queue dynamics at signalized intersections,” Transportation Research Part A: General, vol. 13, no. 5, pp. 295–307, 1979.
- [13] P. G. Michalopoulos, G. Stephanopoulos, and G. Stephanopoulos, “An application of shock wave theory to traffic signal control,” Transportation Research Part B: Methodological, vol. 15, no. 1, pp. 35–51, 1981.
- [14] Z. Wang, Q. Cai, B. Wu, L. Zheng, and Y. Wang, “Shockwave-based queue estimation approach for undersaturated and oversaturated signalized intersections using multi-source detection data,” Journal of Intelligent Transportation Systems, vol. 21, no. 3, pp. 167–178, 2017.
- [15] Y. Cheng, X. Qin, J. Jin, and B. Ran, “An exploratory shockwave approach to estimating queue length using probe trajectories,” Journal of intelligent transportation systems, vol. 16, no. 1, pp. 12–23, 2012.
- [16] H. X. Liu, X. Wu, W. Ma, and H. Hu, “Real-time queue length estimation for congested signalized intersections,” Transportation research part C: emerging technologies, vol. 17, no. 4, pp. 412–427, 2009.
- [17] A. G. Barto and S. Mahadevan, “Recent advances in hierarchical reinforcement learning,” Discrete event dynamic systems, vol. 13, no. 1-2, pp. 41–77, 2003.
- [18] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018.
- [19] J. Yao, F. Li, K. Tang, and S. Jian, “Sampled trajectory data-driven method of cycle-based volume estimation for signalized intersections by hybridizing shockwave theory and probability distribution,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 6, pp. 2615–2627, 2019.
- [20] D. Krajzewicz, J. Erdmann, M. Behrisch, and L. Bieker, “Recent development and applications of sumo-simulation of urban mobility,” International journal on advances in systems and measurements, vol. 5, no. 3&4, 2012.
- [21] S.-B. Cools, C. Gershenson, and B. D’Hooghe, “Self-organizing traffic lights: A realistic simulation,” Advances in applied self-organizing systems, pp. 45–55, 2013.
- [22] M. Andrychowicz, A. Raichuk, P. Stańczyk, M. Orsini, S. Girgin, R. Marinier, L. Hussenot, M. Geist, O. Pietquin, M. Michalski et al., “What matters for on-policy deep actor-critic methods? a large-scale study,” in International conference on learning representations, 2020.
- [23] G. Zheng, Y. Xiong, X. Zang, J. Feng, H. Wei, H. Zhang, Y. Li, K. Xu, and Z. Li, “Learning phase competition for traffic signal control,” in Proceedings of the 28th ACM international conference on information and knowledge management, 2019, pp. 1963–1972.
-A Demand profiles
We visualize the time varying demand profiles by intersection movement in Fig. 6. Fig. 6(a) provides the ramp (RP) flows for five scenarios. Fig 6(b) and 6(c) show the demand profiles for the four leg intersection (FG).