PHALM: Building a Knowledge Graph from Scratch
by Prompting Humans and a Language Model
Abstract
Despite the remarkable progress in natural language understanding with pretrained Transformers, neural language models often do not handle commonsense knowledge well. Toward commonsense-aware models, there have been attempts to obtain knowledge, ranging from automatic acquisition to crowdsourcing. However, it is difficult to obtain a high-quality knowledge base at a low cost, especially from scratch. In this paper, we propose PHALM, a method of building a knowledge graph from scratch, by prompting both crowdworkers and a large language model (LLM). We used this method to build a Japanese event knowledge graph and trained Japanese commonsense generation models. Experimental results revealed the acceptability of the built graph and inferences generated by the trained models. We also report the difference in prompting humans and an LLM. Our code, data, and models are available at github.com/nlp-waseda/comet-atomic-ja.
1 Introduction
Since pretrained models (Radford and Narasimhan, 2018; Devlin et al., 2019; Yang et al., 2019) based on Transformer (Vaswani et al., 2017) appeared, natural language understanding has made remarkable progress. In some benchmarks, the performance of natural language understanding models has already exceeded that of humans. These models are applied to various downstream tasks ranging from translation and question answering to narrative understanding and dialogue response generation. In recent years, the number of parameters in such models has continued to increase (Radford et al., 2019; Brown et al., 2020), and so has their performance.
When we understand or reason, we usually rely on commonsense knowledge. Computers also need such knowledge to answer open-domain questions and to understand narratives and dialogues, for example. However, pretrained models often do not handle commonsense knowledge well (Zhou et al., 2020; Hwang et al., 2021).
There are many knowledge bases for commonsense inference. Some are built by crowdsourcing (Speer et al., 2017; Sap et al., 2019; Hwang et al., 2021), but acquiring a large-scale knowledge base is high-cost. Others are built by automatic acquisition (Zhang et al., 2019, 2020), but it is difficult to acquire high-quality commonsense knowledge. Recently, there have been some methods using large language models (LLMs) for building knowledge bases (Yuan et al., 2021; West et al., 2022; Liu et al., 2022). They often extend existing datasets, but do not build new datasets from scratch. Furthermore, there are not many non-English datasets, although the knowledge that is considered commonsense varies by languages and cultures Lin et al. (2021); Nguyen et al. (2023); Acharya et al. (2021).

In this paper, we propose PHALM111Prompting Humans And a Language Model., a method to build a knowledge graph from scratch with both crowdsourcing and an LLM. Asking humans to describe knowledge using crowdsourcing and generating knowledge using an LLM are essentially the same (as it were, the latter is an analogy of the former), and both can be considered to be prompting. Therefore, we consider prompting for both humans and an LLM and gradually acquire a knowledge graph from a small scale to a large scale. Specifically, we acquire a small-scale knowledge graph by asking crowdworkers to describe knowledge and use them as a few shots for an LLM to generate a large-scale knowledge graph. At each phase, we guarantee the quality of graphs by applying appropriate filtering. In particular, we also propose a low-cost filtering method for the commonsense inferences generated by the LLM.
We built a Japanese knowledge graph on events, considering prompts for both humans and an LLM. With Yahoo! Crowdsourcing222https://crowdsourcing.yahoo.co.jp/ and HyperCLOVA JP, a Japanese variant of the LLMs built by Kim et al. (2021), we obtained a knowledge graph that is not a simple translation, but unique to the culture. Then, we compared inferences collected by crowdsourcing and generated by the LLM. In addition to acquisition, we trained a Japanese commonsense generation model based on the built knowledge graph. With the model, we verified the acceptability of output inferences for unseen events. The resulting knowledge graph and the commonsense model created in this paper will be released to the public.
In summary, our contributions are (1) the proposal of a method to build a large high-quality commonsense knowledge graph from scratch without existing datasets, including a low-cost filtering method, (2) the comparison of prompting for humans and an LLM, and (3) the publication of the resulting Japanese commonsense knowledge graph and commonsense generation models.
2 Related Work


2.1 Commonsense Knowledge Datasets
There are several knowledge bases about commonsense, from what appears in the text to what is tacit but not written in the text. ConceptNet (Speer et al., 2017), for example, is a knowledge graph that connects words and phrases by relations. GenericsKB (Bhakthavatsalam et al., 2020) is a corpus describing knowledge of entities in natural language rather than in graph.
In some datasets, commonsense knowledge is collected in the form of question answering. Roemmele et al. (2011) acquire plausible causes and effects for premises as two-choice questions. Zellers et al. (2018) provide SWAG, acquiring inferences about a situation from video captions as four-choice questions. KUCI (Omura et al., 2020) is a dataset for commonsense inference in Japanese, which is obtained by combining automatic extraction and crowdsourcing. Talmor et al. (2019) build CommonsenseQA, which treats commonsense on ConceptNet’s entities as question answering.
In contrast, we propose a method to construct a structural (not QA form) graph based on events.
2.2 Knowledge Graphs on Events
Regarding commonsense knowledge bases, there are several graphs that focus on events. ATOMIC (Sap et al., 2019) describes the relationship between events, mental states (Rashkin et al., 2018), and personas. Hwang et al. (2021) merge ATOMIC and ConceptNet, proposing ATOMIC-2020.
There are also studies for leveraging context. GLUCOSE (Mostafazadeh et al., 2020) is a commonsense inference knowledge graph for short stories, built by annotating ROCStories (Mostafazadeh et al., 2016). CIDER (Ghosal et al., 2021) and CICERO (Ghosal et al., 2022) are the graphs for dialogues where DailyDialog (Li et al., 2017) and other dialogue corpora are annotated with inferences.
ASER (Zhang et al., 2019) is an event knowledge graph, automatically extracted from text corpora by focusing on discourse. With ASER, TransOMCS (Zhang et al., 2020) aims at bootstrapped knowledge graph acquisition by pattern matching and ranking.
While ConceptNet and ATOMIC are acquired by crowdsourcing, ASER and TransOMCS are automatically built. On one hand, a large-scale graph can be built easily in an automatic way, but it is difficult to obtain knowledge not appearing in the text. On the other hand, crowdsourcing can gather high-quality data, but it is expensive in terms of both money and time.
There is a method that uses crowdsourcing and LLMs together to build an event knowledge graph (West et al., 2022). Although it is possible to acquire a large-scale and high-quality graph, they assume that an initial graph, ATOMIC in this case, has already been available. As stated in Section 1, our proposal is a method to build a commonsense knowledge graph from scratch without such existing graphs.
2.3 Commonsense Generation Models
There have been studies on storing knowledge in a neural form rather than a symbolic form. In particular, methods of considering neural language models as knowledge bases (Petroni et al., 2019; AlKhamissi et al., 2022) have been developed. Bosselut et al. (2019) train COMET by finetuning pretrained Transformers on ATOMIC and ConceptNet, aiming at inference on unseen events and concepts. Gabriel et al. (2021) point out that COMET ignores discourse, introducing recurrent memory for paragraph-level information.
West et al. (2022) propose symbolic knowledge distillation where specific knowledge in a general language model is distilled into a specific language model via a symbolic one. They expand ATOMIC using GPT-3 (Brown et al., 2020), filter the outputs using RoBERTa (Liu et al., 2019), and finetune GPT-2 (Radford et al., 2019) on the filtered ones. Training data for this filtering was created through manual annotation, which is expensive.
3 Prompting Humans and an LLM
We propose a method to build a knowledge graph for commonsense inference from scratch, with both crowdsourcing and an LLM. In our method, we first construct a small-scale knowledge graph by crowdsourcing. Using the small-scale graph for prompts, we then extract commonsense knowledge from an LLM. The flow of our method is shown in Figure 1. Building a knowledge graph from scratch only by crowdsourcing is expensive in terms of both money and time. Hence, the combination of crowdsourcing and an LLM is expected to reduce the cost.
In other words, our method consists of the following two phases: (1) collecting a small-scale graph by crowdsourcing and (2) generating a large-scale graph by an LLM. While crowdsourcing elicits commonsense from people, shots are used to extract knowledge from an LLM. At this point, these phases are intrinsically the same, being considered as prompting (Fig 2). In the two phases, namely, we prompt people and an LLM, respectively.
We build a commonsense inference knowledge graph in Japanese. We focus on an event knowledge graph such as ATOMIC (Sap et al., 2019) and ASER (Zhang et al., 2019). Handling commonsense on events and mental states would facilitate understanding of narratives and dialogues. We use Yahoo! Crowdsourcing in the first phase and HyperCLOVA JP (Kim et al., 2021), an LLM in Japanese, in the second phase. We also propose a method to filter the triplets generated by the LLM at a low cost.
3.1 Acquisition by Crowdsourcing
We first acquire a small-scale high-quality knowledge graph by crowdsourcing. With Yahoo! Crowdsourcing, specifically, we ask crowdworkers to write events and inferences. In a task, we provide them with 10 shots as a prompt for each event and inference. Note that for inferences, the prompts differ for each relation, as mentioned later. We obtain a graph by filtering the collected inferences syntactically and semantically.
Events
We ask crowdworkers to write daily events related to at least one person (PersonX). An example of the crowdsourcing task interface is shown in Figure 5(a). The task provides instructions and 10 examples, and each crowdworker is asked to write at least one event. After all tasks are completed, we remove duplicate events. As a result, 257 events were acquired from 200 crowdworkers. We manually verified that all of the acquired events have sufficient quality.
Inferences
For the events collected above, we ask crowdworkers to write inferences about what happens and how a person feels before and after the events. In this paper, the relations for inference are based on ATOMIC.333The relations are not exactly the same as those of ATOMIC. xIntent in this paper covers xIntent and xWant in ATOMIC, and tails for our xIntent and xReact may contain not mental states but events. The reason for the difference is that English and Japanese have different linguistic characteristics, i.e., it is difficult to collect knowledge in the same structure as the original. The following four are adopted as our target relations.
-
•
xNeed: What would have happened before
-
•
xEffect: What would happen after
-
•
xIntent: What PersonX would have felt before
-
•
xReact: What PersonX would feel after
While xNeed and xEffect are inferences about events, xIntent and xReact are inferences about mental states.
Three crowdworkers are hired per event. Given an instruction and 10 examples, each crowdworker is asked to write one inference. An example of the crowdsourcing task interface is shown in Figure 5(b). We remove duplicate inferences as in the case of events and then apply syntactic filtering444KNP determines if the subject is PersonX, if the tense is present, and if the event is a single sentence. using the Japanese syntactic parser KNP555https://nlp.ist.i.kyoto-u.ac.jp/?KNP.
| Inst # | Val # | Val % | IAA | |
|---|---|---|---|---|
| Event | 257 | - | - | - |
| \hdashlinexNeed | 504 | 402 | 79.76 | 39.85 |
| xEffect | 621 | 554 | 89.21 | 25.00 |
| \hdashlinexIntent | 603 | 519 | 86.07 | 36.11 |
| xReact | 639 | 550 | 86.07 | 31.82 |
| Head | Rel | Tail | Eval |
|---|---|---|---|
| Xが顔を洗う (X washes X’s face) | xNeed | Xが水道で水を出す (X runs water from the tap) | ✓ |
| Xが歯を磨く (X brushes X’s teeth) | |||
| xEffect | Xがタオルを準備する (X prepares a towel) | ✓ | |
| Xが鏡に映った自分の顔に覚えのない傷を見つける (X finds an unrecognizable scar on X’s face in the mirror) | ✓ | ||
| Xが歯磨きをする (X brushes his teeth) | ✓ | ||
| xIntent | スッキリしたい (Want to feel refreshed) | ✓ | |
| 眠いのでしゃきっとしたい (Sleepy and Want to feel refreshed) | ✓ | ||
| xReact | さっぱりして眠気覚ましになる (Feel refreshed and shake off X’s sleepiness) | ✓ | |
| きれいになる (Be clean) | ✓ | ||
| さっぱりした (Felt refreshed) | ✓ |
3.2 Evaluation and Filtering of Crowdsourced Triplets
To examine the qualities of the inferences acquired by crowdsourcing, we crowdsource their evaluation. We ask three crowdworkers whether the inferences are acceptable or not and judge their acceptability by majority voting. The evaluation is crowdsourced independently for each relation. The inferences judged to be unacceptable by majority voting are filtered out.
The inferences collected in Section 3.1 are evaluated and filtered as above. The statistics are listed in the middle two columns of Table 1. We also calculated Fleiss’s 666As a reference, is considered to be “slight” agreement, is “fair”, and is “moderate” Landis and Koch (1977). as an inner-annotator agreement (IAA) in the evaluation, which is shown in the rightmost column of Table 1. The IAAs were “fair” to weak “moderate”. This is because commonsense is subjective and depends on the individual.
There are several tendencies in the inferences filtered out, i.e., judged to be unacceptable. In some inferences, the order is reversed, as in the triplet PersonX sleeps twice, xEffect, PersonX thinks that they are off work today. Others are not plausible, as in PersonX surfs the Internet, xNeed, PersonX gets to the ocean.
3.3 Generation from an LLM
From a small-scale high-quality knowledge graph acquired in Sections 3.1 and 3.2, we generate a large-scale knowledge graph with an LLM. We use the Koya 39B model of HyperCLOVA JP as an LLM. Both events and inferences are generated by providing 10 shots. The shots are randomly chosen from the small-scale graph for each generation.
Events
Inferences
| Rel | Template |
|---|---|
| xNeed | ためには、必要がある。 (To , need to .) |
| xEffect | 。結果として、。 (. As a result, .) |
| \hdashlinexIntent | のは、と思ったから。 ( because felt .) |
| xReact | と、と思う。 ( then feel .) |
As in event generation, the inferences acquired in Sections 3.1 and 3.2 are used as shots. We generate 10 inferences for each event and remove duplicate triplets. While we simply list the shots as a prompt in event generation, different prompts are used for each relation in inference generation. An example prompt for xEffect generation is shown in Figure 6(b). Shots are given in natural language, and tails are extracted by pattern matching. Shot templates for each relation are shown in Table 3. Finally, the syntactic filtering is applied to obtain the graph.
| Inst # | Val % | IAA | |
|---|---|---|---|
| Event | 1,429 | - | - |
| \hdashlinexNeed | 44,269 | 79.95 | 31.79 |
| xEffect | 36,920 | 81.94 | 34.11 |
| \hdashlinexIntent | 52,745 | 84.84 | 31.37 |
| xReact | 60,616 | 89.20 | 19.06 |
| Head | Rel | Tail |
|---|---|---|
| Xがコンビニへ行く (X goes to a convenience store) | xNeed | Xが財布を持っている (X has X’s wallet), Xが外出する (X goes out), Xが外出着に着替える (X changes into going-out clothes), Xが財布を持って出かける (X goes out with X’s wallet), Xが外へ出る (X goes outside) |
| xEffect | Xが買い物をする (X goes shopping), Xが雑誌を立ち読みする (X browses through magazines), XがATMでお金をおろす (X withdraws money from ATM), Xが弁当を買う (X buys lunch), Xがアイスを買う (X buys ice cream) | |
| xIntent | 何か買いたいものがある (Want to buy something), 雑誌を買う (Buy a magazine), 飲み物を買おう (Going to buy a drink), 飲み物や食べ物を買いたい (Want to buy a drink or food), なんでもある (There is everything X wants) | |
| xReact | 何か買いたいものがある (Want to buy something), 何か買う (Buy something), 何か買おう (Going to buy something), 何か買いたくなる (Come to buy something), ついでに何か買ってしまう (Buy something incidentally) |

3.4 Filtering of the Triplets Generated by LLM
Because we use an LLM, some of the generated inferences are invalid. In a previous study, invalid inferences were removed by training and applying a filtering model with RoBERTa. The training data for the filtering model was made by manually annotating a portion of the large graph, which is expensive. In this section, we propose a low-cost filtering method to train filters without human annotation. This is consistent with our claim that a commonsense knowledge graph should be built for each language.
The filtering model is a binary classification model that is given a triplet and outputs whether it is valid or not. Both positive and negative examples are required for training. Since the small-scale graph used as the LLM shots was manually collected, we assume that all triplets in it are valid, and we take them as positive examples. Negative examples are not included, but we create pseudo-negative examples from the triplets in the small graph and adopt them. Details of how to create negative examples are given in Appendix D. The filtering model is constructed by finetuning Japanese RoBERTa777https://huggingface.co/nlp-waseda/roberta-large-japanese on the training data created without human annotation. We use a RoBERTa model finetuned on an NLI task Kurihara et al. (2022) in advance, following the previous study West et al. (2021). See Appendix D for further details on the filtering model.
3.5 The Statistics of the Large Graph
We obtain a large, high-quality commonsense knowledge graph from scratch by the four procedures described in the previous sections: crowdsourcing acquisition, crowdsourcing filtering, LLM scaling, and filtering with RoBERTa. The statistics of events and inferences generated by HyperCLOVA JP are shown in Table 4. The results of the evaluation and the inter-annotator agreement are also shown in Table 4. Since the filtering threshold is a hyperparameter, we present unfiltered statistics here. A comparison with Table 1 indicates that the quality is as good as those written by crowdworkers. Examples of generated inferences are shown in Table 5.
The generated knowledge graph in Japanese reflects the culture of Japan, such as PersonX goes to the office, xNeed, PersonX takes a train and PersonX eats a meal, xNeed, PersonX presses the switch on the rice cooker. This fact indicates the importance of building from scratch for a specific language, rather than translating a similar dataset in a different language, which emphasizes the value of our method proposed in this paper.
4 Analysis on the Built Knowledge Graph
4.1 Effect of Filtering for the Small Graph
In this paper, a small-scale knowledge graph is collected as in Sections 3.1 and 3.2, and a large-scale knowledge graph is generated as in Section 3.3. Here, we examine how effective the filtering for the small graph in Section 3.2 is. As an experiment, we use filtered and unfiltered small-scale graphs as prompts to generate a large-scale graph. Then, we randomly select 500 generated triplets for each relation and evaluate them by crowdsourcing as in Section 3.2. Note that the results for the filtered triplets are the same as Section 3.3.
| xNeed | xEffect | xIntent | xReact | |
|---|---|---|---|---|
| w/o Fltr | 81.62 | 82.42 | 83.84 | 89.29 |
| w/ Fltr | 80.81 | 85.45 | 86.06 | 90.30 |
The ratios of appropriate inferences generated by the LLM with and without filtering for the small graph are shown in Table 6. We experiment with a subset of the graph. For all relations except xNeed, filtering improves the quality of triplets.
4.2 Effect of Filtering for the Large Graph
To evaluate the filtering model in Section 3.4, 500 triplets in the large graph are manually annotated. The results of applying the filter to the test data are shown in the Figure 3. Since setting a high threshold increases the ratio of valid triplets, it can be said that we have constructed an effective filter at a low cost.
4.3 Comparison between Humans and an LLM
In Section 3.1, on one hand, we asked crowdworkers to describe events and inferences. In Section 3.3, on the other hand, we had an LLM generate them. Here, we compare a small-scale knowledge graph by crowdsourcing and a large-scale one from an LLM, i.e., inferences generated by humans and a computer. Because the relationships between events can be largely divided into contingent and temporal relationships (Bethard et al., 2008), we adopt contingency and time interval as metrics for comparison.
Of the four relations, we focus on xEffect as a representative, which is a typical causal relation. For each head of the triplets acquired by crowdsourcing in Sections 3.1 and 3.2, we generate three tails using the LLM in Section 3.3 and compare them with the original tails. From the 554 heads for xEffect in the small-scale graph, we obtained 586 unique inferences.
Contingency
One measure is how likely a given event is to be followed by a subsequent event. Crowdworkers are given a pair of events in an xEffect relation and asked to judge how likely the following event is to happen on a three-point scale: “must happen,” “likely to happen,” and “does not happen.” We ask three crowdworkers per inference and calculate the median of them.
Time Interval
The other measure is the time interval between the occurrence of an event and that of a subsequent event. As in the evaluation of contingency, crowdworkers are given a triplet on xEffect. We ask them to judge the time interval between the two events in five levels: almost simultaneous, seconds to minutes, hours, days to months, and longer. Finally, the median is calculated from the results of three crowdworkers.


The comparison between humans and an LLM for each measure is shown in Figure 4. Figure 4(a) shows that the subsequent events by crowdsourcing, or humans, are slightly more probable. In Figure 4(b), the inferences generated by an LLM have a longer time interval. This result indicates a difference in the results of prompting humans and an LLM; for xEffect, humans infer events that happen relatively soon, while an LLM infers events that happen a bit later.
5 Japanese Commonsense Generation Models
To verify the quality of the graph constructed in Section 4 and to build a neural knowledge base, we train Japanese commonsense generation models. Japanese versions of GPT-2 (Radford et al., 2019) and T5 (Raffel et al., 2020) are finetuned to generate inferences on unseen events. Since our preliminary experiments showed better results with GPT-2 than with T5, we report the full results with GPT-2 in this section. In preliminary experiments, the pretrained models without finetuning performed poorly, which shows that the built graph imparted commonsense reasoning ability to the models. See Appendix E for the results including T5.
5.1 Training
Using the constructed knowledge graph, we finetune pretrained models to construct Japanese commonsense generation models. To evaluate inferences on unseen events, 150 triplets are randomly selected as the test set. For pretrained models, we adopt Japanese GPT-2888https://huggingface.co/nlp-waseda/gpt2-small-japanese of the Hugging Face implementation (Wolf et al., 2020).
As GPT-2 predicts the next word, the head and the relation are given as an input, and the model is trained to output the tail. Since the relations are not included in the vocabulary of the pretrained models, they are added as special tokens.
5.2 Evaluation
We generate inferences for the head events in the test set using the trained Japanese commonsense generation models and evaluate the inferences manually. Examples of the inference results are shown in Appendix E.
Using crowdsourcing, we evaluate how likely the generated inferences are. We ask three crowdworkers how likely each triplet is and decide by majority vote whether each triplet is valid or not. The result is shown in Table 7. Notably, the performance of GPT-2 exceeds that of HyperCLOVA. Comparing Table 7 with Table 4, which can be regarded as the performance of HyperCLOVA’s commonsense generation, GPT-2 performs better for all relations. This represents the quality of the built graphs and the effectiveness of storing commonsense in the neural model.
Furthermore, as shown in Table 7, the ratio of valid triplets of xNeed and xIntent are lower than xEffect and xReact, respectively. Given that xNeed is a relation that infers past events, xEffect is a future event, xIntent is a past mental state, and xReact is a future mental state, this can be attributed to the fact that we used an autoregressive model, which makes it difficult to infer in reverse order of time.
| xNeed | xEffect | xIntent | xReact | Total | |
|---|---|---|---|---|---|
| Val % | 84.00 | 90.00 | 90.00 | 93.33 | 89.33 |
| IAA | 54.56 | 25.00 | 25.59 | 19.52 | - |
6 Conclusion
We proposed a method for building a knowledge graph from scratch with both crowdsourcing and an LLM. Based on our method, we built a knowledge graph on events and mental states in Japanese using Yahoo! Crowdsourcing and HyperCLOVA JP. Since designing tasks for having humans describe commonsense and engineering prompts for having an LLM generate knowledge are similar to each other, we compared their characteristics. We evaluated the graph generated by HyperCLOVA JP and found that it was similar in quality to the graph written by humans.
Furthermore, we trained a commonsense generation model for event inference based on the built knowledge graph. We attempted inference generation for unseen events by finetuning GPT-2 in Japanese on the built graph. The experimental results showed that these models are able to generate acceptable inferences for events and mental states.
We hope that our method for building a knowledge graph from scratch and the acquired knowledge graph lead to further studies on commonsense inference, especially in low-resource languages.
Limitations
For acquiring a small-scale event knowledge graph and analyzing the built graph, we crowdsource several tasks using Yahoo! Crowdsourcing. Specifically, we collect the descriptions of commonsense, filter them, and explore the characteristics of the graph by crowdsourcing. We obtained a consent from crowdworkers on the platform of Yahoo! Crowdsourcing.
The event knowledge graph and the commonsense generation models built in this paper help computers understand commonsense. A commonsense-aware computer, for example, can answer open-domain questions by humans, interpret human statements in detail, and converse with humans naturally. However, such graphs and models may contain incorrect knowledge even with filtering, which leads the applications to harmful behavior.
Acknowledgements
This work was supported by a joint research grant from LINE Corporation.
References
- Acharya et al. (2021) A. Acharya, Kartik Talamadupula, and Mark A. Finlayson. 2021. Toward an atlas of cultural commonsense for machine reasoning. Workshop on Common Sense Knowledge Graphs.
- AlKhamissi et al. (2022) Badr AlKhamissi, Millicent Li, Asli Celikyilmaz, Mona Diab, and Marjan Ghazvininejad. 2022. A review on language models as knowledge bases.
- Bethard et al. (2008) Steven Bethard, William Corvey, Sara Klingenstein, and James H. Martin. 2008. Building a corpus of temporal-causal structure. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08), Marrakech, Morocco. European Language Resources Association (ELRA).
- Bhakthavatsalam et al. (2020) Sumithra Bhakthavatsalam, Chloe Anastasiades, and Peter Clark. 2020. Genericskb: A knowledge base of generic statements.
- Bosselut et al. (2019) Antoine Bosselut, Hannah Rashkin, Maarten Sap, Chaitanya Malaviya, Asli Celikyilmaz, and Yejin Choi. 2019. COMET: Commonsense transformers for automatic knowledge graph construction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4762–4779, Florence, Italy. Association for Computational Linguistics.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Gabriel et al. (2021) Saadia Gabriel, Chandra Bhagavatula, Vered Shwartz, Ronan Le Bras, Maxwell Forbes, and Yejin Choi. 2021. Paragraph-level commonsense transformers with recurrent memory. Proceedings of the AAAI Conference on Artificial Intelligence, 35(14):12857–12865.
- Ghosal et al. (2021) Deepanway Ghosal, Pengfei Hong, Siqi Shen, Navonil Majumder, Rada Mihalcea, and Soujanya Poria. 2021. CIDER: Commonsense inference for dialogue explanation and reasoning. In Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 301–313, Singapore and Online. Association for Computational Linguistics.
- Ghosal et al. (2022) Deepanway Ghosal, Siqi Shen, Navonil Majumder, Rada Mihalcea, and Soujanya Poria. 2022. CICERO: A dataset for contextualized commonsense inference in dialogues. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5010–5028, Dublin, Ireland. Association for Computational Linguistics.
- Hwang et al. (2021) Jena D. Hwang, Chandra Bhagavatula, Ronan Le Bras, Jeff Da, Keisuke Sakaguchi, Antoine Bosselut, and Yejin Choi. 2021. (comet-) atomic 2020: On symbolic and neural commonsense knowledge graphs. Proceedings of the AAAI Conference on Artificial Intelligence, 35(7):6384–6392.
- Kim et al. (2021) Boseop Kim, HyoungSeok Kim, Sang-Woo Lee, Gichang Lee, Donghyun Kwak, Jeon Dong Hyeon, Sunghyun Park, Sungju Kim, Seonhoon Kim, Dongpil Seo, Heungsub Lee, Minyoung Jeong, Sungjae Lee, Minsub Kim, Suk Hyun Ko, Seokhun Kim, Taeyong Park, Jinuk Kim, Soyoung Kang, Na-Hyeon Ryu, Kang Min Yoo, Minsuk Chang, Soobin Suh, Sookyo In, Jinseong Park, Kyungduk Kim, Hiun Kim, Jisu Jeong, Yong Goo Yeo, Donghoon Ham, Dongju Park, Min Young Lee, Jaewook Kang, Inho Kang, Jung-Woo Ha, Woomyoung Park, and Nako Sung. 2021. What changes can large-scale language models bring? intensive study on HyperCLOVA: Billions-scale Korean generative pretrained transformers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3405–3424, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Kurihara et al. (2022) Kentaro Kurihara, Daisuke Kawahara, and Tomohide Shibata. 2022. JGLUE: Japanese general language understanding evaluation. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 2957–2966, Marseille, France. European Language Resources Association.
- Landis and Koch (1977) J. Richard Landis and Gary G. Koch. 1977. The measurement of observer agreement for categorical data. Biometrics, 33(1):159–174.
- Li et al. (2017) Yanran Li, Hui Su, Xiaoyu Shen, Wenjie Li, Ziqiang Cao, and Shuzi Niu. 2017. DailyDialog: A manually labelled multi-turn dialogue dataset. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 986–995, Taipei, Taiwan. Asian Federation of Natural Language Processing.
- Lin et al. (2021) Bill Yuchen Lin, Seyeon Lee, Xiaoyang Qiao, and Xiang Ren. 2021. Common sense beyond English: Evaluating and improving multilingual language models for commonsense reasoning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1274–1287, Online. Association for Computational Linguistics.
- Liu et al. (2022) Alisa Liu, Swabha Swayamdipta, Noah A. Smith, and Yejin Choi. 2022. Wanli: Worker and ai collaboration for natural language inference dataset creation.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.
- Mostafazadeh et al. (2016) Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, and James Allen. 2016. A corpus and cloze evaluation for deeper understanding of commonsense stories. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 839–849, San Diego, California. Association for Computational Linguistics.
- Mostafazadeh et al. (2020) Nasrin Mostafazadeh, Aditya Kalyanpur, Lori Moon, David Buchanan, Lauren Berkowitz, Or Biran, and Jennifer Chu-Carroll. 2020. GLUCOSE: GeneraLized and COntextualized story explanations. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4569–4586, Online. Association for Computational Linguistics.
- Nguyen et al. (2023) Tuan-Phong Nguyen, Simon Razniewski, Aparna Varde, and Gerhard Weikum. 2023. Extracting cultural commonsense knowledge at scale. In Proceedings of the ACM Web Conference 2023, WWW ’23, page 1907–1917, New York, NY, USA. Association for Computing Machinery.
- Omura et al. (2020) Kazumasa Omura, Daisuke Kawahara, and Sadao Kurohashi. 2020. A method for building a commonsense inference dataset based on basic events. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2450–2460, Online. Association for Computational Linguistics.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
- Petroni et al. (2019) Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. Language models as knowledge bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2463–2473, Hong Kong, China. Association for Computational Linguistics.
- Radford and Narasimhan (2018) Alec Radford and Karthik Narasimhan. 2018. Improving language understanding by generative pre-training.
- Radford et al. (2019) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
- Rashkin et al. (2018) Hannah Rashkin, Maarten Sap, Emily Allaway, Noah A. Smith, and Yejin Choi. 2018. Event2Mind: Commonsense inference on events, intents, and reactions. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 463–473, Melbourne, Australia. Association for Computational Linguistics.
- Roemmele et al. (2011) Melissa Roemmele, Cosmin Adrian Bejan, and Andrew S. Gordon. 2011. Choice of plausible alternatives: An evaluation of commonsense causal reasoning. In AAAI Spring Symposium on Logical Formalizations of Commonsense Reasoning, Stanford University.
- Sap et al. (2019) Maarten Sap, Ronan Le Bras, Emily Allaway, Chandra Bhagavatula, Nicholas Lourie, Hannah Rashkin, Brendan Roof, Noah A. Smith, and Yejin Choi. 2019. Atomic: An atlas of machine commonsense for if-then reasoning. Proceedings of the AAAI Conference on Artificial Intelligence, 33(01):3027–3035.
- Speer et al. (2017) Robyn Speer, Joshua Chin, and Catherine Havasi. 2017. Conceptnet 5.5: An open multilingual graph of general knowledge. Proceedings of the AAAI Conference on Artificial Intelligence, 31(1).
- Talmor et al. (2019) Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota. Association for Computational Linguistics.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
- West et al. (2022) Peter West, Chandra Bhagavatula, Jack Hessel, Jena Hwang, Liwei Jiang, Ronan Le Bras, Ximing Lu, Sean Welleck, and Yejin Choi. 2022. Symbolic knowledge distillation: from general language models to commonsense models. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4602–4625, Seattle, United States. Association for Computational Linguistics.
- West et al. (2021) Peter West, Chandra Bhagavatula, Jack Hessel, Jena D. Hwang, Liwei Jiang, Ronan Le Bras, Ximing Lu, Sean Welleck, and Yejin Choi. 2021. Symbolic knowledge distillation: from general language models to commonsense models.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Yang et al. (2019) Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
- Yuan et al. (2021) Ann Yuan, Daphne Ippolito, Vitaly Nikolaev, Chris Callison-Burch, Andy Coenen, and Sebastian Gehrmann. 2021. Synthbio: A case study in faster curation of text datasets. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, volume 1.
- Zellers et al. (2018) Rowan Zellers, Yonatan Bisk, Roy Schwartz, and Yejin Choi. 2018. SWAG: A large-scale adversarial dataset for grounded commonsense inference. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 93–104, Brussels, Belgium. Association for Computational Linguistics.
- Zhang et al. (2020) Hongming Zhang, Daniel Khashabi, Yangqiu Song, and Dan Roth. 2020. Transomcs: From linguistic graphs to commonsense knowledge. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20, pages 4004–4010. International Joint Conferences on Artificial Intelligence Organization. Main track.
- Zhang et al. (2019) Hongming Zhang, Xin Liu, Haojie Pan, Yangqiu Song, and Cane Wing-Ki Leung. 2019. Aser: A large-scale eventuality knowledge graph.
- Zhang* et al. (2020) Tianyi Zhang*, Varsha Kishore*, Felix Wu*, Kilian Q. Weinberger, and Yoav Artzi. 2020. Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations.
- Zhou et al. (2020) Xuhui Zhou, Yue Zhang, Leyang Cui, and Dandan Huang. 2020. Evaluating commonsense in pre-trained language models. Proceedings of the AAAI Conference on Artificial Intelligence, 34(05):9733–9740.
Appendix A Examples of Prompting


Appendix B An Example of Crowdsourced Evaluation

Appendix C Hyperparameter Details
| Max tokens | 32 |
|---|---|
| Temperature | 0.5 |
| Top-P | 0.8 |
| Top-K | 0 |
| Repeat penalty | 5.0 |
| T5 | GPT-2 | |
| Batch size | 64 | 64 |
| Learning rate | 5e-5 | 5e-5 |
| Weight decay | 0.0 | 0.0 |
| Adam betas | (0.9, 0.999) | (0.9, 0.999) |
| Adam epsilon | 1e-8 | 1e-8 |
| Max grad norm | 1.0 | 1.0 |
| Num epochs | 30 | 3 |
| LR scheduler type | Linear | Linear |
| Warmup steps | 0 | 0 |
Appendix D Filtering Model Details
We show the details of the filtering model trained in Section 3.4.
D.1 Training Data
First, how to make negative samples is shown. We collect 1,401 samples for xNeed, 1,750 for xEffect, 1,730 for xIntent, and 1,861 for xReact as training data. Hereafter, represents the small-scale graph.
Negative Sample Type 1
Pseudo-negative samples are adopted by incorrectly ordering the time series. When a valid triplet is given, an inappropriate inference can be obtained by considering . Since the head and tail need to be swapped, it is used only for inference between event pairs.
Negative Sample Type 2
By considering or from two valid triplets of the same relation where , an inappropriate inference can be obtained. Since the context is different between the head and tail, it can be an easy sample during training. For example, it is also possible to consider selecting events with similar contexts by considering the similarity between sentences to make them slightly more difficult.
Negative Sample Type 3
In CSKG, there are relationships that are temporally reversed, such as xIntent and xReact. If we denote the reverse relationship for a relationship as , for two valid triplets with the same head, can be adopted as a negative sample. Unlike Type 2, it is possible to obtain negative samples in the same context.
D.2 Results
The probabilities predicted by the model for each label of the test data are shown in Table 10. The valid triplets yielded higher predictions, again confirming the validity of the filter model.
| Relation | valid(1) | invalid(2) | (1)-(2) |
|---|---|---|---|
| xNeed | 0.8800.295 | 0.6260.450 | +0.254 |
| xEffect | 0.3670.447 | 0.2560.413 | +0.111 |
| xIntent | 0.7810.276 | 0.6430.300 | +0.138 |
| xReact | 0.7590.348 | 0.5190.426 | +0.240 |
Appendix E Commonsense Generation Model Details
E.1 Training Details
To confirm the appropriate model and input format, we construct some commonsense generation models with a subset of the built graph as a preliminary experiment. For pretrained models, we adopt Japanese T5999https://huggingface.co/megagonlabs/t5-base-japanese-web and Japanese GPT-2.
The input format is shown in 11. Since T5 is a seq2seq model, the head and the relation are given in the form of “” as an input, and the tail is given as the correct output. The relation for T5 is changed to a natural language sentence. For example, “xNeed” is rewritten to “What event occurs before this statement?” The instructions to T5 may not be the best; prompt-engineering could improve the results. As GPT-2 predicts the next word, the head and the relation are given as an input, and the model is trained to output the tail. Since the relations are not included in the vocabulary of the pretrained models, they are added as special tokens. In the constructed knowledge graph, the subject of an event is generalized as “X,” but it would be better to change it into a natural expression as the input to the pretrained models. We randomly replace the subject with a personal pronoun during training and inference. To confirm this effect, we also train GPT-2 with the subject represented as “X.” We denote this as GPT-2X.
| Model | Rel | Encoder Input | Decoder Input |
| T5 | xNeed | この文の前に起こるイベントは何ですか?: | |
| (What event occurs before this statement?: ) | |||
| xEffect | このイベントの次に発生する事象は何ですか?: | ||
| (What is the next event to occur after this event?: ) | |||
| xIntent | 次の文の発生した理由は何ですか?: | ||
| (What is the reason for the occurrence of the following statement?: ) | |||
| xReact | 次の文の後に感じることは何ですか?: | ||
| (What will be felt after the following statement?: ) | |||
| GPT-2 | xNeed | - | xNeed |
| xEffect | - | xEffect | |
| xIntent | - | xIntent | |
| xReact | - | xReact |
E.2 Evaluation
Automatic Evaluation
We calculate BLEU (Papineni et al., 2002) and BERTScore (Zhang* et al., 2020) as automatic metrics. Table 12 shows these results. GPT-2X and GPT-2 performed the best in BLEU and BERTScore, respectively. Table 14 shows the average output length and the number of unique words for each model. The average output length of T5 is longer than those of GPT-2s, but GPT-2s have the greater numbers of unique words than T5.
Manual Evaluation
Using crowdsourcing, we evaluate how likely the generated inferences are. Following the previous study (West et al., 2022), we show crowdworkers two events (a head and a tail) and a relation. Then, we ask them to evaluate the appropriateness of the inference by choosing from the following options: “always,” “often,” “sometimes,” and “never.” The choices are displayed with an appropriate verb for each relation (e.g., “always happens” for xEffect). For each inference, the numbers of crowdworkers who choose “never” and other than “never” (i.e., at least “sometimes”) are used to determine the majority vote. The acceptance rate (AR) is the proportion of inferences in which more crowdworkers choose other than “never.” By assigning 0 to 3 points each to “never,” “sometimes,” “often,” and “always,” we also calculate the mean point (MP) as the average score of all the inferences. Table 12 shows these results. AR is higher than 85% for all models, indicating that the inferences for unseen events are almost correct. GPT-2 obtained the highest scores for both AR and MP.
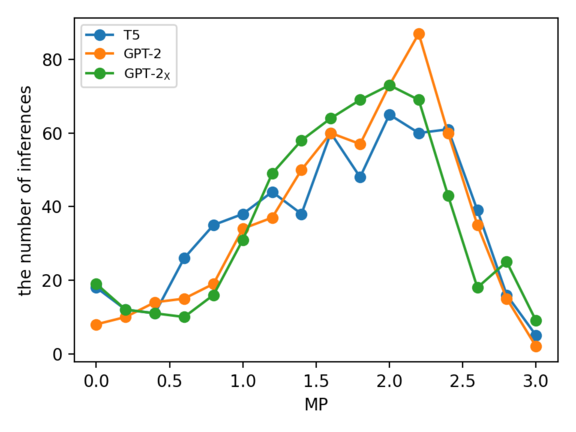
Although the replacement of subjects did not make a difference in AR, there is a difference in the distributions of MP as shown in Figure 8. The number of crowdworkers who chose “never” for the inference of GPT-2 is less than half of that for GPT-2X. This result indicates that it is better for the model to replace subjects “X” with personal pronouns.
Table 15 shows the correlation coefficients between the manual and automatic evaluation metrics. The correlation coefficients between the manual metrics (AR and MP) and BERTScore are positive, while those between the manual metrics and BLEU are negative or have no correlation. It seems that BERTScore, which uses vector representations, can evaluate equivalent sentences with different expressions, but BLEU, which is based on n-gram agreement, cannot correctly judge the equivalence. One of the reasons for the negative correlation in BLEU is that many inferences of the mental state consist of a single word in Japanese, such as “tired” and “bored,” for both the gold answer and the generated result. In this case, BLEU tends to be low because the words are rarely matched, but the shorter the sentences are, the easier it is for the model to generate appropriate results.
Examples of outputs are shown in Table 13. We can see that the obtained outputs are acceptable to humans. The outputs vary for each model.
| Model | AR | MP | BS | BLEU |
|---|---|---|---|---|
| T5 | 87.5 | 1.64 | 90.26 | 18.57 |
| GPT-2 | 91.0 | 1.73 | 92.31 | 18.26 |
| GPT-2X | 91.0 | 1.68 | 92.03 | 18.99 |
| \hdashlineT5freeze | - | - | 68.20 | 3.19 |
| GPT-2freeze | - | - | 69.36 | 7.33 |
| Model | Input | Output |
|---|---|---|
| T5 | この文の前に起こるイベントは何ですか?:あなたが友人たちと旅行に出かける (What event occurs before this statement?: You go on a trip with your friends) | あなたが車を運転する (You drive a car) |
| このイベントの次に発生する事象は何ですか?:あなたが友人たちと旅行に出かける (What is the next event to occur after this event?: You go on a trip with your friends) | あなたが楽しい時間を過ごす (You have a good time) | |
| 次の文の発生した理由は何ですか?:あなたが友人たちと旅行に出かける (What is the reason for the occurrence of the following statement?: You go on a trip with your friends) | 楽しい (Have fun) | |
| 次の文の後に感じることは何ですか?:あなたが友人たちと旅行に出かける (What will be felt after the following statement?: You go on a trip with your friends) | 楽しい (Have fun) | |
| GPT-2 | 僕が友人たちと旅行に出かけるxNeed (I go on a trip with your friends xNeed) | 僕がパスポートを取得する (I get my passport) |
| 僕が友人たちと旅行に出かけるxEffect (I go on a trip with your friends xEffect) | 僕が楽しい時間を過ごす (I have a good time) | |
| 僕が友人たちと旅行に出かけるxIntent (I go on a trip with your friends xIntent) | 楽しいことがしたい (Want to have fun) | |
| 僕が友人たちと旅行に出かけるxReact (I go on a trip with your friends xReact) | 楽しい (Feel fun) |
| Model | Avg Out Len | Uniq Word # |
|---|---|---|
| T5 | 5.29 | 392 |
| GPT-2 | 5.03 | 451 |
| GPT-2X | 5.03 | 436 |
| AR | MP | BS | BLEU | |
|---|---|---|---|---|
| AR | 1.00 | 0.75 | 0.59 | -0.11 |
| MP | - | 1.00 | 0.43 | -0.46 |
| BS | - | - | 1.00 | 0.30 |
| BLEU | - | - | - | 1.00 |