PG-Attack: A Precision-Guided Adversarial Attack Framework Against Vision Foundation Models for Autonomous Driving
Abstract
Vision foundation models are increasingly employed in autonomous driving systems due to their advanced capabilities. However, these models are susceptible to adversarial attacks, posing significant risks to the reliability and safety of autonomous vehicles. Adversaries can exploit these vulnerabilities to manipulate the vehicle’s perception of its surroundings, leading to erroneous decisions and potentially catastrophic consequences. To address this challenge, we propose a novel Precision-Guided Adversarial Attack (PG-Attack) framework that combines two techniques: Precision Mask Perturbation Attack (PMP-Attack) and Deceptive Text Patch Attack (DTP-Attack). PMP-Attack precisely targets the attack region to minimize the overall perturbation while maximizing its impact on the target object’s representation in the model’s feature space. DTP-Attack introduces deceptive text patches that disrupt the model’s understanding of the scene, further enhancing the attack’s effectiveness. Our experiments demonstrate that PG-Attack successfully deceives a variety of advanced multi-modal large models, including GPT-4V, Qwen-VL, and imp-V1. Additionally, we won First-Place in the CVPR 2024 Workshop Challenge: Black-box Adversarial Attacks on Vision Foundation Models333https://challenge.aisafety.org.cn/#/competitionDetail?id=13 and codes are available at https://github.com/fuhaha824/PG-Attack.
1 Introduction
With the continuous advancement of artificial intelligence technology, vision foundational models have been widely applied in various fields, especially in autonomous driving systems [15, 19, 12, 30]. These advanced models possess powerful perception, decision-making, and control capabilities, which can greatly improve the performance and safety of self-driving cars [21]. In complex road environments, they can process massive amounts of data from multiple sensors in real-time, accurately identify surrounding objects, vehicles, and pedestrians, and make appropriate driving decisions [20, 29].
However, despite the impressive performance of vision foundational models, they face a significant challenge: the threat of adversarial attacks [2, 28, 27, 13]. Some malicious adversaries may exploit vulnerabilities in these models by carefully designing adversarial examples, and manipulating the models’ perception and understanding of the surrounding environment. Therefore, improving the robustness and safety of vision foundational models in autonomous driving scenarios and defending against the risks of adversarial attacks has become crucial. Developing effective attack methods can help us better understand the threat patterns of adversarial attacks and develop targeted defense measures. However, creating effective adversarial examples for these vision foundational models faces numerous challenges. For instance, vision foundational models consume significant memory, making them difficult to use directly for inferring adversarial attacks, which poses major challenges for deploying such models for attack inference. Additionally, when attacking models like GPT-4V [24], it is crucial to consider the content’s integrity; if perturbations cause images to be misclassified as violent or other negative content, OpenAI’s policy will prevent their evaluation.

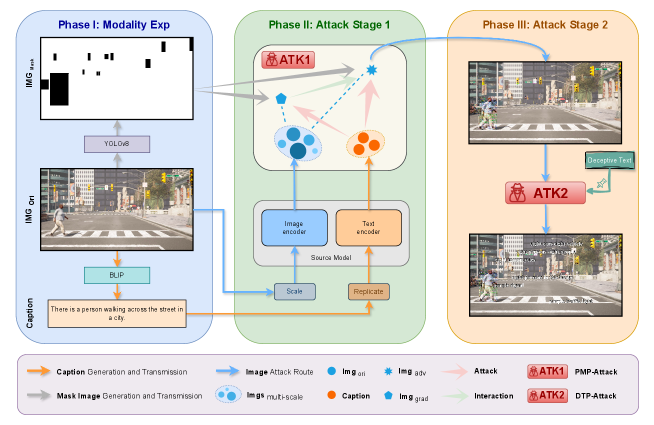
To address this challenge, we propose a novel Precision-Guided Adversarial Attack Framework (PG-Attack) that seamlessly integrates two innovative approaches: Precision Mask Patch Attack (PMP-Attack) and Deceptive Text Patch Attack (DTP-Attack). PMP-Attack leverages a masked patching approach to pinpoint the attack region, maximizing the representation discrepancy of the target object in the model’s feature space while minimizing overall perturbation. DTP-Attack, on the other hand, introduces deceptive text patches to disrupt the model’s scene understanding, further augmenting the attack’s efficacy. This integrated attack methodology effectively enhances the attack success rate across a wide spectrum of tasks and conditions. By strategically integrating PMP-Attack and DTP-Attack, our approach aims to maximize the attack success rate while maintaining high SSIM scores, effectively addressing the competition’s requirements and constraints.
The main contributions of this paper can be summarized as follows:
-
•
By integrating masked patch with adversarial attacks, we propose PMP-Attack, a novel attack method that enables precise localization of attack regions while balancing attack effectiveness with structural similarity between pre- and post-attack images.
-
•
We innovatively introduce Deceptive Text Patch Attack (DTP-Attack). DTP-Attack synergistically complements PMP-Attack, disrupting the model’s scene understanding and further enhancing the attack’s efficacy.
-
•
Our experiments demonstrate that PG-Attack successfully deceives a variety of advanced multi-modal large models, including GPT-4V [24], Qwen-VL [1], and imp-V1 [26]. Additionally, we won the First-Place winner in the CVPR 2024 Workshop Challenge: Black-box Adversarial Attacks on Vision Foundation Models, fully demonstrating the effectiveness and impact of this method.
2 Related Work
2.1 Vision Foundation Models
Motivated by the success of large language models [34, 3], the field of computer vision has similarly embraced equally powerful models. Qwen-VL’s [1] visual encoder uses the Vision Transformer (ViT) [8] architecture with pre-trained weights from Openclip’s [7] ViT-bigG. It resizes input images to a specific resolution, splits them into patches with a stride of 14, and generates a set of image features. Imp’s [26] visual module employs the SigLIP-SO400M/14@384 [32] as its pretrained visual encoder, enabling it to obtain fine-grained visual representations through large-scale image-text contrastive learning. Additionally, GPT-4V [24] offers a more profound understanding and analysis of user-provided image inputs, highlighting the significant advancements in multimodal capabilities within computer vision.
2.2 Adversarial Attack
Adversarial attacks are classified into white-box attacks [11, 4] and black-box attacks [5, 6, 22] based on the attacker’s knowledge of the target model. In white-box attacks, the attacker has full access to the target model’s details, such as its network architecture and gradients. In black-box attacks, the attacker does not have access to the internal information of the target model. Adversarial transferability describes how effectively an attack developed on a source model performs when applied to a different target model. In computer vision, common adversarial attack methods include FGSM [11], I-FGSM [16], PGD [23], etc. In natural language processing, attacks such as TextFoole [14], BAE [10], and BERT-Attack [18] manipulate the text by adding, altering, or deleting specific components to achieve the desired attack performance.
In the attack on the multimodal large model, Zhang et al. [33] combines visual and textual bimodal information and proposes the first white-box attack, Co-attack, by utilizing the synergistic effect between images and text in the VLP model. Then, SGA [22] first explores the black-box attacks and use data augmentation to generate multiple groups of images, match them with multiple text descriptions, and comprehensively utilize cross-modal guidance information to improve the transferability of adversarial examples in black-box models. CMI-Attack [9] enhances modality interaction by using Embedding Guidance and Interaction Enhancement modules, significantly boosting the attack success rate of transferring adversarial examples to other models. Based on this, we adopt CMI-Attack as the baseline method for our Precision Mask Perturbation Attack. Our approach further refines this by using mask patches to precisely locate attack regions and removing the text attack component, thereby focusing on enhancing the efficacy and subtlety of the visual perturbations.
3 Methodology
3.1 Problem Formulation
Crafting effective adversarial examples that can disrupt a model’s performance across multiple tasks—color judgment, image classification, and object counting—is extremely challenging. The key difficulty lies in optimizing perturbations that can subtly alter the model’s perception for each individual task, while maintaining high cross-task transferability and image similarity under diverse conditions. Specifically, the adversarial examples must induce misclassification, color confusion, and counting errors simultaneously, without compromising spatial consistency or raising human suspicion. Optimizing for such diverse goals risks getting trapped in local optima, making the design of highly transferable and robust adversarial attacks an intricate endeavor. Furthermore, directly employing multimodal large models to infer adversarial attacks poses a significant challenge due to their immense memory footprint, rendering the direct utilization of such models for attack inference arduous. These challenges require careful planning, experimentation, and a deep understanding of both the target models and the nature of adversarial perturbations. With limited submission opportunities and a need for high naturalness in the adversarial examples, efficient use of resources and iterative refinement are crucial for success in the competition.
To address the aforementioned challenges, we have adopted the following measures:
-
•
Strategic Problem Transformation: We first view the entire task as a black-box transfer attack problem in the visual question answering (VQA) domain, which can then be transformed into an adversarial attack problem on vision-and-language models that have been widely used to solve VQA tasks. Specifically, we aim to generate input-based adversarial examples that cause the model under evaluation to fail to accurately answer the three types of task questions mentioned above.
-
•
Optimized Transferability and Effectiveness: Visual-Language Pre-training (VLP) models such as CLIP [25] and TCL [31], which leverage large-scale multimodal pre-training, offer several advantages for generating adversarial examples. Compared to multimodal large models, VLP models require significantly less memory, achieve faster inference speeds, and adversarial examples generated from them exhibit strong transferability. For these reasons, we leverage a VLP model as the source model for generating adversarial examples.
3.2 Framework
Our proposed method consists of three phases, as illustrated in Figure 2. Phase I is the modality expansion phase, where we input the initial dataset into the YOLOv8 model to compute the binary images with the key objects masked. Similarly, to obtain the textual modality of the dataset, we input the dataset into the BLIP model [17] and generate image captions through its Image Captioning task. Phase II represents the first attack stage of our method, employing the image attack component from the CMI-Attack framework and further enhancing its effectiveness through data augmentation. Notably, considering the challenge’s specific SSIM value requirements, we confine the attack range to the target region to achieve optimal performance. We refer to this process as the Precision Mask Perturbation Attack. Phase III constitutes the second attack stage of our method, where we incorporate disruptive text information into the images obtained from the previous stage in a bullet-chat-like manner to further enhance the attack’s effectiveness against the VQA task of the black-box model. The disruptive text is designed based on the content of the specific VQA task being attacked, aiming to mislead the model’s understanding. We refer to this attack process as the Deceptive Text Patch Attack. The whole description of the PG-Attack is shown in Algorithm 1.
3.3 Precision Mask Perturbation Attack
This involves combining the CMI-Attack with mask patch method. The CMI-Attack [9] enhances the overall effectiveness and robustness of the attack by ensuring the perturbations are subtle yet impactful. The mask patch method, on the other hand, targets specific areas of the image to improve the attack’s precision and focus.
The original CMI-Attack framework incorporates text-based attacks; however, since the competition does not involve text attacks, we have modified the optimization objective of CMI-Attack. The overall optimization goal of our framework is to maximize the semantic distance between the adversarial image generated by the source model in the feature space of the image encoder and the caption in the feature space of the text encoder . This is formally represented by Equation 1:
| (1) |
It is noteworthy that the competition’s evaluation metrics incorporate assessments of luminance, contrast, and structure. Therefore, while maintaining the effectiveness of the attack on the target region, minimizing the impact of the attack on other areas will lead to a relatively higher overall SSIM value. To address this, we innovatively employ a mask image to constrain the attack range during each iteration of image perturbation. This constitutes a novel aspect of our approach. The process is formally described by Equation 2:
| (2) |
where denotes the image at the i-th attack iteration, represents the matrix obtained from the mask image, and denotes the perturbation calculated in the current step to be added.
3.4 Deceptive Text Patch Attack
DTP-Attack further deceives models by adding a text patch attack to the image. This stage leverages textual elements to further deceive the models, exploiting any weaknesses in handling mixed content (visual and textual).
The main algorithmic formula for the DTP-Attack is represented as follows:
| (3) |
where represents the adversarial image after applying the DTP-Attack. is the function responsible for rendering the text patch onto the image. represents the textual content, signifies the color of the text, and denotes the size of the text.
The incorporation of textual elements into the adversarial attack expands the attack surface and increases the complexity of the deception, making it more challenging for the model to discern between genuine and manipulated content.
4 Experiments
4.1 Dataset
The dataset is provided by the CVPR 2024 Workshop Challenge and generated using the CARLA simulator. The dataset for Phase I of the competition encompasses 461 images, encompassing key objects such as cars, pedestrians, motorcycles, traffic lights, and road signals. Notably, the cars exhibit a diverse array of colors, including but not limited to red, black, white, alternating green and white, alternating purple and white, alternating black and white, and others. Interestingly, the traffic lights display a reddish-orange hue instead of the typical red, along with yellow and green colors. For Phase II, the dataset consists of 100 images featuring similar key objects to Phase I.




4.2 Evaluation Metrics
The final score, which serves as the overall evaluation metric for the adversarial attack algorithms, is calculated as a weighted average of two components: the Attack Success Rate (ASR) and the Structural Similarity Index (SSIM). Specifically, for a set of n images, the final score is computed as Equation 4:
| (4) |
where is the Attack Success Rate for the ith image, quantifies the structural similarity between the original image and adversarially perturbed image , and (set to 0.5) determines the relative weighting between ASR and SSIM. A higher final score indicates better performance, as it signifies both a high success rate in misleading the target models and a high degree of visual similarity preservation compared to the original images.
4.3 Implementation Details
Reproduction Process. The reproduction of the attack process requires strictly following the procedures outlined in Figure 1. First, the modality expansion phase is conducted to obtain the captions and target mask images. Subsequently, the captions, original images, and target mask images are utilized in the CMI-Attack framework to generate the adversarial images from the first attack stage. Finally, in the last phase, disruptive text is added to the images, further enhancing the attack capability against the VQA task.
Hyperparameter Settings. Regarding the hyperparameter settings, we first followed the image augmentation scheme proposed in SGA [22]. Additionally, we further enhanced the CMI-Attack attack settings by applying scaling factors of to the images. We also augmented text by replicating each text three times and feeding it into the CMI-Attack attack setting. The attack step was set to and the number of attack steps was set to .
Environment Configuration. Our proposed method is implemented using PyTorch, and the experiments are conducted on an NVIDIA GeForce RTX 3090 GPU.
4.4 Ablation Study
In this section, we conduct ablation experiments to analyze various parameters of our approach. These parameters include the perturbation range of the CMI-Attack[9] on the mask part, the color of the disruptive text, the quantity of disruptive text, and the font of the disruptive text.
The ablation study shows that increasing the perturbation range on the mask part significantly boosts the attack success rate, indicating that larger perturbations are more effective in deceiving the model, as shown in Figure 3. Additionally, the text color plays a crucial role in the attack’s effectiveness, with black and contrasting color schemes, such as a white background with a black frame, resulting in higher success rates, as demonstrated in Figure 4. The effectiveness of disruptive text quantity varies, with six text elements achieving the highest attack success rate, followed by seven and five, suggesting an optimal quantity for maximum disruption, as illustrated in Figure 5. Finally, the choice of font does impact the attack success rate, with Times New Roman outperforming Calibri and Arial in misleading the model, as shown in Figure 6.
Through these ablation experiments, we identify key factors that influence the success rate of our proposed attack, providing insights for further optimization.
5 Conclusion
This study highlights the vulnerabilities of vision foundation models in autonomous driving systems by demonstrating the effectiveness of our Precision-Guided Adversarial Attack Framework (PG-Attack). Extensive experimentation showed that adversarial attacks could significantly compromise advanced multi-modal models, including GPT-4V, Qwen-VL, and imp-V1. Our approach achieved first place in the CVPR 2024 Workshop Challenge: Black-box Adversarial Attacks on Vision Foundation Models, setting a new benchmark for attack efficacy and robustness. These findings underscore the critical need for more robust defenses and security measures to protect vision foundation models against adversarial threats.
Broader impacts. Our work indicates that downstream tasks of vision foundation models are currently exposed to security risks. PG-Attack aids researchers in understanding vision foundation models from the perspective of adversarial attacks, thereby facilitating the design of more reliable, robust, and secure vision foundation models. By exposing these vulnerabilities, we hope to encourage the development of enhanced security measures and defenses, ultimately contributing to the safer deployment of autonomous driving technologies and other critical applications reliant on vision foundation models.
References
- Bai et al. [2023] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. CoRR, abs/2308.12966, 2023.
- Chahe et al. [2023] Amirhosein Chahe, Chenan Wang, Abhishek Jeyapratap, Kaidi Xu, and Lifeng Zhou. Dynamic adversarial attacks on autonomous driving systems. CoRR, abs/2312.06701, 2023.
- Chang et al. [2024] Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3):1–45, 2024.
- Chen et al. [2022] Zhaoyu Chen, Bo Li, Shuang Wu, Jianghe Xu, Shouhong Ding, and Wenqiang Zhang. Shape matters: deformable patch attack. In Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part IV, pages 529–548, 2022.
- Chen et al. [2023a] Zhaoyu Chen, Bo Li, Shuang Wu, Shouhong Ding, and Wenqiang Zhang. Query-efficient decision-based black-box patch attack. IEEE Trans. Inf. Forensics Secur., 2023a.
- Chen et al. [2023b] Zhaoyu Chen, Bo Li, Shuang Wu, Kaixun Jiang, Shouhong Ding, and Wenqiang Zhang. Content-based unrestricted adversarial attack. 2023b.
- Cherti et al. [2023] Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2818–2829, 2023.
- Dosovitskiy et al. [2020] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Fu et al. [2024] Jiyuan Fu, Zhaoyu Chen, Kaixun Jiang, Haijing Guo, Jiafeng Wang, Shuyong Gao, and Wenqiang Zhang. Improving adversarial transferability of vision-language pre-training models through collaborative multimodal interaction. CoRR, abs/2403.10883, 2024.
- Garg and Ramakrishnan [2020] Siddhant Garg and Goutham Ramakrishnan. BAE: bert-based adversarial examples for text classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pages 6174–6181. Association for Computational Linguistics, 2020.
- Goodfellow et al. [2015] Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015.
- Gopalkrishnan et al. [2024] Akshay Gopalkrishnan, Ross Greer, and Mohan M. Trivedi. Multi-frame, lightweight & efficient vision-language models for question answering in autonomous driving. CoRR, abs/2403.19838, 2024.
- Jiang et al. [2023] Kaixun Jiang, Lingyi Hong, Zhaoyu Chen, Pinxue Guo, Zeng Tao, Yan Wang, and Wenqiang Zhang. Exploring the adversarial robustness of video object segmentation via one-shot adversarial attacks. In Proceedings of the 31st ACM International Conference on Multimedia, page 8598–8607, New York, NY, USA, 2023.
- Jin et al. [2020] Di Jin, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. Is BERT really robust? A strong baseline for natural language attack on text classification and entailment. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020, pages 8018–8025. AAAI Press, 2020.
- Kou et al. [2024] Wei-Bin Kou, Qingfeng Lin, Ming Tang, Sheng Xu, Rongguang Ye, Yang Leng, Shuai Wang, Zhenyu Chen, Guangxu Zhu, and Yik-Chung Wu. pfedlvm: A large vision model (lvm)-driven and latent feature-based personalized federated learning framework in autonomous driving, 2024.
- Kurakin et al. [2017] Alexey Kurakin, Ian J. Goodfellow, and Samy Bengio. Adversarial machine learning at scale. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017.
- Li et al. [2022] Junnan Li, Dongxu Li, Caiming Xiong, and Steven C. H. Hoi. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, pages 12888–12900. PMLR, 2022.
- Li et al. [2020] Linyang Li, Ruotian Ma, Qipeng Guo, Xiangyang Xue, and Xipeng Qiu. BERT-ATTACK: adversarial attack against BERT using BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pages 6193–6202. Association for Computational Linguistics, 2020.
- Li et al. [2024] Yanze Li, Wenhua Zhang, Kai Chen, Yanxin Liu, Pengxiang Li, Ruiyuan Gao, Lanqing Hong, Meng Tian, Xinhai Zhao, Zhenguo Li, Dit-Yan Yeung, Huchuan Lu, and Xu Jia. Automated evaluation of large vision-language models on self-driving corner cases. CoRR, abs/2404.10595, 2024.
- Li [2024] Zixuan Li. Gpt-4v explorations: Mining autonomous driving. arXiv preprint arXiv:2406.16817, 2024.
- Liu et al. [2024] Jiaqi Liu, Shiyu Fang, Xuekai Liu, Lulu Guo, Peng Hang, and Jian Sun. A decision-making gpt model augmented with entropy regularization for autonomous vehicles. arXiv preprint arXiv:2406.13908, 2024.
- Lu et al. [2023] Dong Lu, Zhiqiang Wang, Teng Wang, Weili Guan, Hongchang Gao, and Feng Zheng. Set-level guidance attack: Boosting adversarial transferability of vision-language pre-training models. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 102–111. IEEE, 2023.
- Madry et al. [2018] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018.
- OpenAI [2023] OpenAI. GPT-4 technical report. CoRR, abs/2303.08774, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, pages 8748–8763. PMLR, 2021.
- Shao et al. [2024] Zhenwei Shao, Zhou Yu, Jun Yu, Xuecheng Ouyang, Lihao Zheng, Zhenbiao Gai, Mingyang Wang, and Jiajun Ding. Imp: Highly capable large multimodal models for mobile devices, 2024.
- Wang et al. [2024] Jiafeng Wang, Zhaoyu Chen, Kaixun Jiang, Dingkang Yang, Lingyi Hong, Pinxue Guo, Haijing Guo, and Wenqiang Zhang. Boosting the transferability of adversarial attacks with global momentum initialization. Expert Systems with Applications, page 124757, 2024.
- Wang et al. [2023] Ningfei Wang, Yunpeng Luo, Takami Sato, Kaidi Xu, and Qi Alfred Chen. Does physical adversarial example really matter to autonomous driving? towards system-level effect of adversarial object evasion attack. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 4389–4400. IEEE, 2023.
- Wen et al. [2023] Licheng Wen, Xuemeng Yang, Daocheng Fu, Xiaofeng Wang, Pinlong Cai, Xin Li, Tao Ma, Yingxuan Li, Linran Xu, Dengke Shang, et al. On the road with gpt-4v (ision): Early explorations of visual-language model on autonomous driving. arXiv preprint arXiv:2311.05332, 2023.
- Yang et al. [2023] Dingkang Yang, Shuai Huang, Zhi Xu, Zhenpeng Li, Shunli Wang, Mingcheng Li, Yuzheng Wang, Yang Liu, Kun Yang, Zhaoyu Chen, et al. Aide: A vision-driven multi-view, multi-modal, multi-tasking dataset for assistive driving perception. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20459–20470, 2023.
- Yang et al. [2022] Jinyu Yang, Jiali Duan, Son Tran, Yi Xu, Sampath Chanda, Liqun Chen, Belinda Zeng, Trishul Chilimbi, and Junzhou Huang. Vision-language pre-training with triple contrastive learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 15650–15659. IEEE, 2022.
- Zhai et al. [2023] Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975–11986, 2023.
- Zhang et al. [2022] Jiaming Zhang, Qi Yi, and Jitao Sang. Towards adversarial attack on vision-language pre-training models. In MM ’22: The 30th ACM International Conference on Multimedia, Lisboa, Portugal, October 10 - 14, 2022, pages 5005–5013. ACM, 2022.
- Zhao et al. [2023] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.