Perturbation-Restrained Sequential Model Editing
Abstract
Model editing is an emerging field that focuses on updating the knowledge embedded within large language models (LLMs) without extensive retraining. However, current model editing methods significantly compromise the general abilities of LLMs as the number of edits increases, and this trade-off poses a substantial challenge to the continual learning of LLMs. In this paper, we first theoretically analyze that the factor affecting the general abilities in sequential model editing lies in the condition number of the edited matrix. The condition number of a matrix represents its numerical sensitivity, and therefore can be used to indicate the extent to which the original knowledge associations stored in LLMs are perturbed after editing. Subsequently, statistical findings demonstrate that the value of this factor becomes larger as the number of edits increases, thereby exacerbating the deterioration of general abilities. To this end, a framework termed Perturbation Restraint on Upper bouNd for Editing (PRUNE) is proposed, which applies the condition number restraints in sequential editing. These restraints can lower the upper bound on perturbation to edited models, thus preserving the general abilities. Systematically, we conduct experiments employing three popular editing methods on three LLMs across four representative downstream tasks. Evaluation results show that PRUNE can preserve considerable general abilities while maintaining the editing performance effectively in sequential model editing. The code and data are available at https://github.com/mjy1111/PRUNE.
1 Introduction
Despite the remarkable capabilities of large language models (LLMs), they encounter challenges such as false or outdated knowledge, and the risk of producing toxic content [65, 46, 29, 28]. Given the prohibitively high cost of retraining LLMs to address these issues, there has been a surge in focus on model editing [12, 41, 43, 44, 42, 39, 64, 27, 40], which aims at updating the knowledge of LLMs cost-effectively. Existing model editing methods can be roughly classified into either parameter-modifying methods [43, 41, 42] that directly modify a small subset of model parameters, or parameter-preserving methods [44, 63] that integrate additional modules without altering the model parameters. In this paper, we study the parameter-modifying editing methods.
Sequential model editing involves making successive edits to the same model over time to continuously update knowledge, as illustrated in Figure 1(a). Recent studies [21, 22, 37] indicate that parameter-modifying editing methods significantly compromise the general abilities of LLMs as the number of edits increases, such as summarization, question answering, and natural language inference. However, these studies neither provide a theoretical analysis of the bottleneck of the general abilities of the edited models, nor propose a solution to preserve these abilities in sequential editing. These affect the scalability of model editing and pose a substantial challenge to the continual learning of LLMs.

In light of the above issues, we first theoretically analyze through matrix perturbation theory [38, 54, 60] to elucidate a crucial factor affecting the general abilities during sequential editing: the condition number [50, 13, 52] of the edited matrix. The condition number of a matrix represents its numerical sensitivity and therefore can be used to indicate the extent to which the original knowledge associations stored in LLMs are perturbed after editing. As shown in Figure 1(b), our statistical findings demonstrate that the condition number of the edited matrix substantially increases as the number of edits increases, thereby exacerbating the perturbation of original knowledge and the deterioration of general abilities. Therefore, we assume that the bottleneck of the general abilities during sequential editing lies in the escalating value of the condition number.
Towards continual and scalable model editing, we propose Perturbation Restraint on Upper bouNd for Editing (PRUNE) based on the above analysis, which applies the condition number restraints in sequential editing to preserve general abilities and maintain new editing knowledge simultaneously. Specifically, the condition number of the edited matrix is restrained by reducing the large singular values [1, 57] of the edit update matrix. Consequently, the upper bound on perturbation to the edited matrix is lowered, thus reducing the perturbation to the original knowledge associations and preserving the general abilities of the edited model, as shown in Figure 1(c). Additionally, we observe that these larger singular values often encapsulate redundant editing overfitting information, so regularizing them will not affect the newly editing knowledge, as shown in Figure 1(d). In this way, the new editing knowledge is embedded into LLMs without affecting their original general abilities. Overall, the proposed editing framework requires only minimal computing resources, and is adaptable to be coupled with multiple existing editing methods.
To validate the effectiveness of the proposed PRUNE, our study comprehensively evaluates the edited LLMs for both general abilities and editing performance in sequential editing scenarios. Extensive empirical research involves three popular editing methods, including MEND [43], ROME [41], and MEMIT [42], which are analyzed based on three representative LLMs including GPT-2 XL (1.5B) [48], LLaMA-2 (7B) [53], and LLaMA-3 (8B). Four representative downstream tasks including reasoning [8], summarization [19], open-domain QA [31], and natural language inference [11] are employed to extensively demonstrate the impact of model editing on the general abilities of LLMs. Experimental results demonstrate that the proposed PRUNE can preserve considerable general abilities and maintain almost all editing performance in sequential editing.
In essence, our research offers three significant contributions: (1) This study theoretically analyzes that the escalating value of the condition number of the edited matrix is the bottleneck of sequential model editing. (2) The PRUNE framework based on the analysis is proposed to preserve the general abilities of the edited model while retaining the editing knowledge. (3) Experimental results including both editing performance and four downstream task performance across three editing methods on three LLMs demonstrate the effectiveness of the proposed method.
2 Related Work
Model Editing Methods
From the perspective of whether the model parameters are modified, existing editing methods can be divided into parameter-modifying [43, 41, 42, 12] and parameter-preserving methods [44, 25, 63]. This paper focuses on the former. Previous works have investigated the role of MLP layers in Transformer, showing that MLP layers store knowledge, which can be located in specific neurons and edited [16, 10, 17]. KE [3] and MEND [43] train a hypernetwork to get gradient changes to update model parameters [43]. Besides, Meng et al. [41] and Meng et al. [42] used Locate-Then-Edit strategy, which first located multi-layer perceptron (MLP) storing factual knowledge, and then edited such knowledge by injecting new key-value pair in the MLP module. Parameter-preserving methods do not modify model weights but store the editing facts with an external memory. For example, Mitchell et al. [44] stored edits in a base model and learned to reason over them to adjust its predictions as needed.
Model Editing Evaluation
Some works investigate the paradigm for model editing evaluation [67, 9, 39, 35, 26, 61, 15, 40]. Cohen et al. [9] introduced the ripple effects of model editing, suggesting that editing a particular fact implies that many other facts need to be updated. Ma et al. [39] constructed a new benchmark to assess the edited model bidirectionally. Besides, Li et al. [35] explored two significant areas of concern: Knowledge Conflict and Knowledge Distortion. These early studies mainly evaluate edited models per edit rather than sequentially, and they focus narrowly on basic factual triples. Recently, some works assess the impact of editing methods on the general abilities of LLMs in sequential editing scenarios. These studies [21, 22, 37] have conducted comprehensive experiments, showing the parameter-modifying methods significantly degrade the model performance on general downstream tasks.
Matrix Perturbation Theory
It plays a crucial role in the field of artificial intelligence (AI) by providing a systematic framework to understand the impact of small changes or perturbations in various AI algorithms and models. Some studies [24, 47, 49] delve into the interpretability of LLMs, revealing how minor alterations in input features or model parameters influence the model’s predictions. This understanding helps uncover significant feature connections within the model architecture. Moreover, it has been instrumental in assessing and enhancing the robustness of models [5, 20, 6]. Furthermore, Bird et al. [2] and Dettmers et al. [14] have employed it for sensitivity analysis to identify critical factors affecting algorithm performance. It also contributes to the development of efficient optimization techniques [34, 7, 30], improving convergence rates and stability of optimization algorithms.
Compared with previous works [41, 42, 62, 21, 22, 37] that are the most relevant, a main difference should be highlighted. They neither theoretically investigate the reasons for general ability degradation, nor propose methods to maintain these abilities during sequential editing. In contrast, our study makes the first attempt to theoretically explore the bottleneck of general abilities in sequential editing and proposes the PRUNE framework to preserve these abilities for continual model editing.
3 Analysis on Bottleneck of Sequential Model Editing
3.1 Preliminary
Model Editing
This task involves modifying the memorized knowledge contained in LMs. Various kinds of complex learned beliefs such as logical, spatial, or numerical knowledge are expected to be edited. In this paper, following previous work [41, 67, 42, 64], we study editing factual knowledge in the form of (subject s, relation r, object o), e.g., (s = United States, r = President of, o = Donald Trump). An LM is expected to recall a memory representing given a natural language prompt such as “The President of the United States is”. Editing a fact is to incorporate a new knowledge triple in place of the current one . An edit is represented as for brevity. Given a set of editing facts and an original model , sequential model editing operationalizes each edit after the last edit111This paper studies editing a single fact at a time and leaves the exploration of batch editing as future work., i.e., , where denotes the model after edits.
Singular Value Decomposition
SVD [1] is a fundamental and effective matrix factorization technique for analyzing matrix structures. Formally, an SVD of a matrix is given by , where , , and . and are the column vectors of and , and constitute an orthonormal basis of and respectively. is a diagonal matrix whose diagonal entries are given by the singular values of in descending order. Additionally, the SVD of could also be formulated as: , where is singular value, and . In the scenario of this paper, is a full-rank matrix, so .
3.2 Matrix Perturbation Theory Analysis
Previous works [16, 41, 23, 59] have analyzed and located that the MLP modules in Transformer [55] store various kinds of knowledge [45, 56]. The MLP module of the -th Transformer layer consists of two projection layers, where the first and second layers are denoted as and respectively. is considered as a linear associative memory which stores knowledge in the form of key-value pairs , and is usually regarded as the editing area [41, 42]. In this paper, is denoted as for brevity. is assumed to store many key-value pairs which satisfies , where and . Assuming in sequential model editing, an edit update matrix is calculated for the edit and added to , which can be formulated as: with calculated from .
Problem Modeling
To explore the reasons for the general ability degradation of edited models, we begin by noting that most of the key-value pairs of correspond to facts unrelated to editing. For the sake of analysis, only the matrix of a single layer is assumed to be modified. We intuitively hypothesize that for the facts that are irrelevant to the editing fact, the cumulative modifications applied during sequential model editing may lead to significant mismatches in the associations between the original key-value pairs . Specifically, consider a key-value pair . After applying an edit that generates and adding it to , if the extracted value remains unchanged, the corresponding key needs to be adjusted with an adjustment denoted as . Mathematically, this can be represented as222As , and we observed in LLMs, so there will be that satisfies this formula. after edits. However, during the editing process, it’s challenging to guarantee such adjustments completely, leading to inaccuracies in the knowledge extracted from the edited model. To delve deeper, let’s analyze how the key changes (i.e., ) when its corresponding value remains unchanged after edits.
Perturbation Analysis of Single Edit
According to matrix perturbation theory [38, 54, 60], the edit update matrix from an edit can be regarded as a perturbation333We obtained some and found , which satisfies the definition of perturbation. for , so we first analyze the situation where is appended with a perturbation . Define is the generalized inverse [51] of , represents 2-norm, and .
Theorem 3.1 Consider , there exists such that satisfies . Let and , and is an acute perturbation of . Then:
| (1) |
where , , and are directly related to . is a monotonically increasing function of and is a function about . , where is square and related to the reduced form of . Each term on the right-hand side involves , which means that the upper bound on the perturbation of the vector is constrained by . Readers can refer to Appendix A.3 for the details and proof of this theorem. However, calculating involves the reduced form of , which incurs unnecessary additional overhead. Therefore, we consider the following theorem and give an alternative estimation.
Theorem 3.2 Let , and suppose that . Then:
| (2) |
According to Theorem 3.2, so . Here is the condition number of , where and are the maximum and minimum singular values of , respectively. Combining Theorem 3.1, we know that the larger is, the greater the upper bound on the perturbation of the vector . Readers can refer to Appendix A for the full theoretical analysis.
3.3 Change Trend of Condition Number
As mentioned above, we have analyzed that the condition number of the edited matrix can be used to indicate the upper bound on the perturbation of the key-value pair associations by a single edit. In order to explore the impact of sequential model editing on these associations, the change trend of the condition number of the edited matrix during sequential editing is illustrated in Figure 2.
Surprisingly, we observed that regardless of the editing methods employed, the condition number of the edited matrix exhibited a rapid increase as the number of edits increased, especially after a large number of edits. According to Theorem 3.1, the adjustment norm corresponding to the -th edit tends to increase as the number of edits increases. It underscores that when the number of edits is relatively large, the upper bound on the perturbation caused by subsequent edits to the key-value pair associations becomes very large, further disrupting the stored original knowledge and exacerbating the deterioration of general abilities.



4 PRUNE: Perturbation Restraint on Upper bouNd for Editing
According to the analysis in Section 3, the bottleneck of the general abilities during sequential editing lies in the escalating value of the condition number. In this section, a framework termed Perturbation Restraint on Upper bouNd for Editing (PRUNE) is proposed, which applies the condition number restraints to preserve general abilities and maintain new editing knowledge simultaneously.
| Edits () | ROME | MEMIT | MEND |
|---|---|---|---|
| 10 | 7.25 | 7.46 | 14.08 |
| 50 | 11.38 | 15.63 | 75.53 |
| 100 | 15.62 | 23.39 | 127.89 |
| 200 | 57.61 | 935 | 191.04 |
Principle
Given an edited matrix with edits, , as shown in Figure 2, its maximum singular value is constantly increasing, while the minimum singular value is basically unchanged as the number of edits increases. This directly leads to the increasing condition number of the edited matrix. Therefore, our motivation is to restrain the maximum singular value of the edited matrix to lower the upper bound on the perturbation. If we directly perform SVD operation on and reduce its singular values, the original will be inevitably destroyed. Consequently, an analysis of the singular values of is conducted, and the results in Table 1 present that its maximum singular value becomes very large when is large. We assume that this is the main reason why the maximum singular value of is large, our method therefore aims to restrain the large singular values of .
Design
Firstly, SVD is operated on the original and respectively as:
| (3) |
This paper considers to be the main part, and any singular value in should be ensured not to obviously exceed the maximum singular value of . Subsequently, if any singular value of is greater than the maximum singular value of , it will be restrained with a function , otherwise it remains unchanged, which could be formulated as:
| (4) |
| (5) |
In the main paper, we use the function in to restrain . Here is a hyperparameter to control the degree of restraints, readers can refer to Appendix B.3 for its details for experiments. Besides, we also provide the definition and results of function in Appendix C.3. Finally, we obtain the restrained edited matrix to replace :
| (6) |
In this way, the condition number of the edited matrix is reduced (see Appendix C.4) and the upper bound on perturbation is significantly restrained.
5 Experiments
In this section, both the downstream task performance and editing performance of three editing methods on three LLMs were evaluated in sequential model editing. The proposed PRUNE was plug-and-play which can be coupled with these editing methods.
5.1 Base LLMs and Editing Methods
Experiments were conducted on three LLMs including GPT-2 XL (1.5B) [48], LLaMA-2 (7B) [53] and LLaMA-3 (8B)444https://llama.meta.com/llama3/. Three popular editing methods were selected as the baselines including MEND [43], ROME [41], and MEMIT [42]. Readers can refer to Appendix B.1 for the details of these editing methods.
5.2 Editing Datasets and Evaluation Metrics
Two popular model editing datasets Zero-Shot Relation Extraction (ZsRE) [33] and CounterFact [41] were adopted in our experiments. ZsRE is a QA dataset using question rephrasings generated by back-translation as the equivalence neighborhood. A key distinction between CounterFact and ZsRE datasets is that ZsRE contains true facts, while CounterFact contains counterfactual examples where the new target has a lower probability when compared to the original answer [22]. Readers can refer to Appendix B.2 for examples of each dataset.
To assess the editing performance of editing methods, following previous works, three fundamental metrics were employed: efficacy, generalization and locality [3, 43, 41, 42]. Given an original model , an edited model with times sequential editing. Each edit has an editing prompt , paraphrase prompts , and locality prompts .
Efficacy validates whether the edited models could recall the editing fact under editing prompt . The assessment is based on Efficacy Score (ES) representing as: , where is the indicator function.
Generalization verifies whether the edited models could recall the editing fact under the paraphrase prompts via Generalization Score (GS): .
Locality verifies whether the output of the edited models for inputs out of editing scope remains unchanged under the locality prompts via Locality Score (LS): , where was the original answer of .
5.3 Downstream Tasks, Datasets and Metrics
To explore the side effects of sequential model editing on the general abilities of LLMs, four representative tasks with corresponding datasets were adopted for assessment, including:
Reasoning on the GSM8K [8], and the results were measured by solve rate.
Summarization on the SAMSum [19], and the results were measured by the average of ROUGE-1, ROUGE-2 and ROUGE-L following Lin [36].
Open-domain QA on the Natural Question [31], and the results were measured by exact match (EM) with the reference answer after minor normalization as in Chen et al. [4] and Lee et al. [32].
Natural language inference (NLI) on the RTE [11], and the results were measured by accuracy of two-way classification.
For each dataset, some examples were randomly sampled for evaluation. Details of prompts for each tasks were shown in Appendix B.4.

5.4 Results of General Abilities
Figure 3 illustrates the downstream task performance of edited models with LLaMA-2 (7B) on the CounterFact dataset. Due to page limitation, results of other LLMs and datasets were put in Appendix C.1. These results were analyzed from the following perspectives.
Current editing methods significantly compromised general abilities. As depicted by the dashed lines of Figure 3, both the ROME and MEMIT methods initially maintained relatively stable performance in downstream tasks when the number of edits was small ( 100). However, as the number of edits surpassed 200, a noticeable decline in performance was observed across all tasks for both methods. Additionally, the MEND method exhibited significant performance degradation after just 20 sequential edits, indicating its inadequacy as a sequential model editing method. Furthermore, when comparing LLMs of different sizes, a general trend emerged: larger models suffered more pronounced compromises in their general abilities when subjected to the same number of edits. For instance, with 300 edits, MEMIT’s performance on GPT2-XL remained largely unchanged, whereas it dwindled to nearly 0 on LLaMA-2 and LLaMA-3.
The performance decline was gradual initially but accelerated with increasing edit count. This trend aligned with the fluctuation observed in the size of the condition number, as depicted in Figure 2. When the number of edits was small, the condition number was small, and each new edit introduced relatively minor perturbations to the model. However, as the number of edits increased, the condition number underwent a substantial increase. Consequently, each subsequent edit exerted a significant perturbation on the model, leading to a pronounced impairment of its general abilities. These results substantiated the analysis presented in Section 3.3.
The proposed PRUNE can preserve considerable general abilities. As shown by the solid lines of Figure 3, when MEMIT was coupled with PRUNE and subjected to 200 edits, its downstream tasks performance remained close to that of the unedited model. However, for the unrestrained MEMIT, downstream task performance had plummeted to nearly 0 by this point. This consistent trend was also observed with ROME and MEND. Nevertheless, for models edited using the unrestrained MEND method, performance degradation was stark after just 20 edits. Even with the addition of PRUNE, preservation could only be extended up to 40 edits. This suggests that while PRUNE effectively preserves general abilities, it does have an upper limit determined by the unrestrained editing method.

5.5 Results of Editing Performance
Figure 4 shows different metrics used for measuring the editing performance of edited models with LLaMA-2 (7B) on the CounterFact dataset. Other results across models and datasets were put in Appendix C.2. Three conclusions can be drawn here.
Previous editing facts were forgotten as the number of edits increased. As shown by the dashed lines of Figure 4, the decline in efficacy and generalization suggests that in sequential editing scenarios, post-edited models gradually forget knowledge acquired from previous edits after a few iterations. Comparing these editing methods, we also observed a notable drop in efficacy and generalization after hundreds of edits with ROME and MEMIT, whereas these values decreased significantly after only 30 edits with MEND. This indicates that in sequential editing scenarios, the MEND method struggled to successfully integrate new knowledge into LLMs after several edits.
Unrelated facts were perturbed as the number of edits increased. The locality metric served as an indicator of perturbation for unrelated facts. It became evident that for each editing method, the locality decreased significantly. Additionally, an observation emerged: when the locality of the edited model was low, the performance of downstream tasks was also low. This observation underscores that perturbations of irrelevant knowledge compromise the general abilities of the edited model.
PRUNE can effectively maintain the editing performance. This is shown by the solid lines of Figure 4 and could be analyzed from two aspects. On the one hand, when the number of edits was small, the editing performance of each editing method coupled with PRUNE was about the same as the unrestrained method. On the other hand, it significantly mitigated the forgetting of editing facts and the perturbation of irrelevant facts when the number of edits was large during the sequential editing. Specifically, when the number of edits reached 150, the editing performance of MEMIT was very low. But when coupled with PRUNE, its performance remained relatively stable.
5.6 Editing Facts Forgetting Analysis

In section 3, the analysis was conducted to elucidate the reasons behind the degradation in general abilities with an increasing number of edits. Subsequent experiments quantitatively demonstrated the effectiveness of the proposed PRUNE. Here, we delve into qualitative analysis to explain why editing facts are forgotten and how PRUNE can mitigate this forgetting.
Initially, a set of editing facts was collected, where . ROME was employed for analysis, and the original matrix was defined as . During sequential editing, ROME computed key-value pairs of the last subject token to generate for each edit to incorporate new facts, satisfying the equation: . However, when evaluating editing performance, the edited model obtained from the last edit was utilized, thus computing values555Since ROME only modifies one matrix, the remains the same across these edited models.: . After adopting PRUNE to ROME, this equation became . We hypothesized that if was similar to , the editing fact could be maintained.
Denote , , and . Specifically, these corresponding values of the first 100 edits were used, as they are more prone to be forgotten than the last 100. Principal Component Analysis (PCA) [18] was employed to visualize these values. The first two principal components of each value were calculated and illustrated, as they can represent most of its features [66]. As shown in Figure 5, on the one hand, the discrepancy between the principal components of and was markedly large. This indicates that after 200 edits to the model, the values corresponding to the first 100 facts stored in the edited matrix are severely corrupted, leading to significant forgetfulness. On the other hand, after adopting PRUNE, the discrepancy between the principal components of and was small. This demonstrates that PRUNE effectively maintains the values and mitigates the forgetting of editing facts.
6 Conclusion
In this paper, a theoretical analysis is firstly conducted to elucidate that the bottleneck of the general abilities during sequential editing lies in the escalating value of the condition number. Subsequently, a plug-and-play framework called PRUNE is proposed to apply restraints to preserve general abilities and maintain new editing knowledge simultaneously. Comprehensive experiments on various editing methods and LLMs demonstrate the effectiveness of this method. We aspire that our analysis and method will catalyze future research on continual model editing.
Limitations & Future Work
The limitations of our work are discussed as follows. Firstly, while this paper focuses on editing a single fact at a time in sequential model editing, some studies have explored updating hundreds or thousands of facts simultaneously in batch editing. Therefore, investigating batch-sequential editing could enhance the scalability of model editing and remains further research. Secondly, for the experimental settings, it is necessary to explore the performance of larger-size models and more editing methods on more downstream tasks. Thirdly, the current focus of editing knowledge primarily revolves around factual knowledge. However, it is also important to investigate whether editing other types of knowledge will affect general abilities and whether PRUNE is effective in this situation. Additionally, the proposed PRUNE is only applied once after the completion of the last edit. But it could also be utilized multiple times during the sequential editing process, and we intuitively believe that this approach would be more conducive to preserving the general abilities of the model. These aspects are yet to be fully understood and warrant a more comprehensive study.
References
- Albano et al. [1988] Alfonso M Albano, J Muench, C Schwartz, AI Mees, and PE Rapp. Singular-value decomposition and the grassberger-procaccia algorithm. Physical review A, 38(6):3017, 1988.
- Bird et al. [2020] Sarah Bird, Miro Dudík, Richard Edgar, Brandon Horn, Roman Lutz, Vanessa Milan, Mehrnoosh Sameki, Hanna Wallach, and Kathleen Walker. Fairlearn: A toolkit for assessing and improving fairness in ai. Microsoft, Tech. Rep. MSR-TR-2020-32, 2020.
- Cao et al. [2021] Nicola De Cao, Wilker Aziz, and Ivan Titov. Editing factual knowledge in language models. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pages 6491–6506. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021.emnlp-main.522. URL https://doi.org/10.18653/v1/2021.emnlp-main.522.
- Chen et al. [2017] Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. Reading wikipedia to answer open-domain questions. In Regina Barzilay and Min-Yen Kan, editors, Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Papers, pages 1870–1879. Association for Computational Linguistics, 2017. doi: 10.18653/V1/P17-1171. URL https://doi.org/10.18653/v1/P17-1171.
- Chen et al. [2023] Shuo Chen, Jindong Gu, Zhen Han, Yunpu Ma, Philip H. S. Torr, and Volker Tresp. Benchmarking robustness of adaptation methods on pre-trained vision-language models. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/a2a544e43acb8b954dc5846ff0d77ad5-Abstract-Datasets_and_Benchmarks.html.
- Chen et al. [2024] Zhuotong Chen, Zihu Wang, Yifan Yang, Qianxiao Li, and Zheng Zhang. PID control-based self-healing to improve the robustness of large language models. CoRR, abs/2404.00828, 2024. doi: 10.48550/ARXIV.2404.00828. URL https://doi.org/10.48550/arXiv.2404.00828.
- Cheng et al. [2023] Wenhua Cheng, Weiwei Zhang, Haihao Shen, Yiyang Cai, Xin He, and Kaokao Lv. Optimize weight rounding via signed gradient descent for the quantization of llms. CoRR, abs/2309.05516, 2023. doi: 10.48550/ARXIV.2309.05516. URL https://doi.org/10.48550/arXiv.2309.05516.
- Cobbe et al. [2021] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021. URL https://arxiv.org/abs/2110.14168.
- Cohen et al. [2023] Roi Cohen, Eden Biran, Ori Yoran, Amir Globerson, and Mor Geva. Evaluating the ripple effects of knowledge editing in language models. CoRR, abs/2307.12976, 2023. doi: 10.48550/ARXIV.2307.12976. URL https://doi.org/10.48550/arXiv.2307.12976.
- Da et al. [2021] Jeff Da, Ronan Le Bras, Ximing Lu, Yejin Choi, and Antoine Bosselut. Analyzing commonsense emergence in few-shot knowledge models. In Danqi Chen, Jonathan Berant, Andrew McCallum, and Sameer Singh, editors, 3rd Conference on Automated Knowledge Base Construction, AKBC 2021, Virtual, October 4-8, 2021, 2021. doi: 10.24432/C5NK5J. URL https://doi.org/10.24432/C5NK5J.
- Dagan et al. [2005] Ido Dagan, Oren Glickman, and Bernardo Magnini. The PASCAL recognising textual entailment challenge. In Joaquin Quiñonero Candela, Ido Dagan, Bernardo Magnini, and Florence d’Alché-Buc, editors, Machine Learning Challenges, Evaluating Predictive Uncertainty, Visual Object Classification and Recognizing Textual Entailment, First PASCAL Machine Learning Challenges Workshop, MLCW 2005, Southampton, UK, April 11-13, 2005, Revised Selected Papers, volume 3944 of Lecture Notes in Computer Science, pages 177–190. Springer, 2005. doi: 10.1007/11736790\_9. URL https://doi.org/10.1007/11736790_9.
- Dai et al. [2022] Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 8493–8502. Association for Computational Linguistics, 2022. doi: 10.18653/v1/2022.acl-long.581. URL https://doi.org/10.18653/v1/2022.acl-long.581.
- Dedieu [1997] Jean-Pierre Dedieu. Condition operators, condition numbers, and condition number theorem for the generalized eigenvalue problem. Linear algebra and its applications, 263:1–24, 1997.
- Dettmers et al. [2023] Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh. Spqr: A sparse-quantized representation for near-lossless LLM weight compression. CoRR, abs/2306.03078, 2023. doi: 10.48550/ARXIV.2306.03078. URL https://doi.org/10.48550/arXiv.2306.03078.
- Gandikota et al. [2023] Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Erasing concepts from diffusion models. CoRR, abs/2303.07345, 2023. doi: 10.48550/ARXIV.2303.07345. URL https://doi.org/10.48550/arXiv.2303.07345.
- Geva et al. [2021] Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pages 5484–5495. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021.emnlp-main.446. URL https://doi.org/10.18653/v1/2021.emnlp-main.446.
- Geva et al. [2022] Mor Geva, Avi Caciularu, Kevin Ro Wang, and Yoav Goldberg. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 30–45. Association for Computational Linguistics, 2022. doi: 10.18653/v1/2022.emnlp-main.3. URL https://doi.org/10.18653/v1/2022.emnlp-main.3.
- Gewers et al. [2022] Felipe L. Gewers, Gustavo R. Ferreira, Henrique Ferraz de Arruda, Filipi Nascimento Silva, Cesar H. Comin, Diego R. Amancio, and Luciano da Fontoura Costa. Principal component analysis: A natural approach to data exploration. ACM Comput. Surv., 54(4):70:1–70:34, 2022. doi: 10.1145/3447755. URL https://doi.org/10.1145/3447755.
- Gliwa et al. [2019] Bogdan Gliwa, Iwona Mochol, Maciej Biesek, and Aleksander Wawer. SAMSum corpus: A human-annotated dialogue dataset for abstractive summarization. In Lu Wang, Jackie Chi Kit Cheung, Giuseppe Carenini, and Fei Liu, editors, Proceedings of the 2nd Workshop on New Frontiers in Summarization, pages 70–79, Hong Kong, China, November 2019. Association for Computational Linguistics. doi: 10.18653/v1/D19-5409. URL https://aclanthology.org/D19-5409.
- Gong et al. [2024] Zhuocheng Gong, Jiahao Liu, Jingang Wang, Xunliang Cai, Dongyan Zhao, and Rui Yan. What makes quantization for large language model hard? an empirical study from the lens of perturbation. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors, Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada, pages 18082–18089. AAAI Press, 2024. doi: 10.1609/AAAI.V38I16.29765. URL https://doi.org/10.1609/aaai.v38i16.29765.
- Gu et al. [2024] Jia-Chen Gu, Hao-Xiang Xu, Jun-Yu Ma, Pan Lu, Zhen-Hua Ling, Kai-Wei Chang, and Nanyun Peng. Model editing can hurt general abilities of large language models. CoRR, abs/2401.04700, 2024. doi: 10.48550/ARXIV.2401.04700. URL https://doi.org/10.48550/arXiv.2401.04700.
- Gupta et al. [2024] Akshat Gupta, Anurag Rao, and Gopala Anumanchipalli. Model editing at scale leads to gradual and catastrophic forgetting. CoRR, abs/2401.07453, 2024. doi: 10.48550/ARXIV.2401.07453. URL https://doi.org/10.48550/arXiv.2401.07453.
- Gupta et al. [2023] Anshita Gupta, Debanjan Mondal, Akshay Krishna Sheshadri, Wenlong Zhao, Xiang Lorraine Li, Sarah Wiegreffe, and Niket Tandon. Editing commonsense knowledge in GPT. CoRR, abs/2305.14956, 2023. doi: 10.48550/ARXIV.2305.14956. URL https://doi.org/10.48550/arXiv.2305.14956.
- Harder et al. [2020] Frederik Harder, Matthias Bauer, and Mijung Park. Interpretable and differentially private predictions. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020, pages 4083–4090. AAAI Press, 2020. doi: 10.1609/AAAI.V34I04.5827. URL https://doi.org/10.1609/aaai.v34i04.5827.
- Hartvigsen et al. [2023] Tom Hartvigsen, Swami Sankaranarayanan, Hamid Palangi, Yoon Kim, and Marzyeh Ghassemi. Aging with GRACE: lifelong model editing with discrete key-value adaptors. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/95b6e2ff961580e03c0a662a63a71812-Abstract-Conference.html.
- Hase et al. [2023] Peter Hase, Mohit Bansal, Been Kim, and Asma Ghandeharioun. Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language models. CoRR, abs/2301.04213, 2023. doi: 10.48550/ARXIV.2301.04213. URL https://doi.org/10.48550/arXiv.2301.04213.
- Hu et al. [2024] Chenhui Hu, Pengfei Cao, Yubo Chen, Kang Liu, and Jun Zhao. Wilke: Wise-layer knowledge editor for lifelong knowledge editing. CoRR, abs/2402.10987, 2024. doi: 10.48550/ARXIV.2402.10987. URL https://doi.org/10.48550/arXiv.2402.10987.
- Huang et al. [2023] Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. CoRR, abs/2311.05232, 2023. doi: 10.48550/ARXIV.2311.05232. URL https://doi.org/10.48550/arXiv.2311.05232.
- Ji et al. [2023] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Comput. Surv., 55(12):248:1–248:38, 2023. doi: 10.1145/3571730. URL https://doi.org/10.1145/3571730.
- Jiang et al. [2024] Shuoran Jiang, Qingcai Chen, Youcheng Pan, Yang Xiang, Yukang Lin, Xiangping Wu, Chuanyi Liu, and Xiaobao Song. Zo-adamu optimizer: Adapting perturbation by the momentum and uncertainty in zeroth-order optimization. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors, Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada, pages 18363–18371. AAAI Press, 2024. doi: 10.1609/AAAI.V38I16.29796. URL https://doi.org/10.1609/aaai.v38i16.29796.
- Kwiatkowski et al. [2019] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: a benchmark for question answering research. Trans. Assoc. Comput. Linguistics, 7:452–466, 2019. doi: 10.1162/TACL\_A\_00276. URL https://doi.org/10.1162/tacl_a_00276.
- Lee et al. [2019] Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. Latent retrieval for weakly supervised open domain question answering. In Anna Korhonen, David R. Traum, and Lluís Màrquez, editors, Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 6086–6096. Association for Computational Linguistics, 2019. doi: 10.18653/V1/P19-1612. URL https://doi.org/10.18653/v1/p19-1612.
- Levy et al. [2017] Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. Zero-shot relation extraction via reading comprehension. In Roger Levy and Lucia Specia, editors, Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), Vancouver, Canada, August 3-4, 2017, pages 333–342. Association for Computational Linguistics, 2017. doi: 10.18653/v1/K17-1034. URL https://doi.org/10.18653/v1/K17-1034.
- Li et al. [2020] Hui-Jia Li, Lin Wang, Yan Zhang, and Matjaž Perc. Optimization of identifiability for efficient community detection. New Journal of Physics, 22(6):063035, 2020.
- Li et al. [2023] Zhoubo Li, Ningyu Zhang, Yunzhi Yao, Mengru Wang, Xi Chen, and Huajun Chen. Unveiling the pitfalls of knowledge editing for large language models. CoRR, abs/2310.02129, 2023. doi: 10.48550/ARXIV.2310.02129. URL https://doi.org/10.48550/arXiv.2310.02129.
- Lin [2004] Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL https://aclanthology.org/W04-1013.
- Lin et al. [2024] Zihao Lin, Mohammad Beigi, Hongxuan Li, Yufan Zhou, Yuxiang Zhang, Qifan Wang, Wenpeng Yin, and Lifu Huang. Navigating the dual facets: A comprehensive evaluation of sequential memory editing in large language models. CoRR, abs/2402.11122, 2024. doi: 10.48550/ARXIV.2402.11122. URL https://doi.org/10.48550/arXiv.2402.11122.
- Luo and Tseng [1994] Zhi-Quan Luo and Paul Tseng. Perturbation analysis of a condition number for linear systems. SIAM Journal on Matrix Analysis and Applications, 15(2):636–660, 1994.
- Ma et al. [2023] Jun-Yu Ma, Jia-Chen Gu, Zhen-Hua Ling, Quan Liu, and Cong Liu. Untying the reversal curse via bidirectional language model editing. CoRR, abs/2310.10322, 2023. doi: 10.48550/ARXIV.2310.10322. URL https://doi.org/10.48550/arXiv.2310.10322.
- Ma et al. [2024] Jun-Yu Ma, Jia-Chen Gu, Ningyu Zhang, and Zhen-Hua Ling. Neighboring perturbations of knowledge editing on large language models. CoRR, abs/2401.17623, 2024. doi: 10.48550/ARXIV.2401.17623. URL https://doi.org/10.48550/arXiv.2401.17623.
- Meng et al. [2022] Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. In NeurIPS, 2022. URL https://arxiv.org/abs/2202.05262.
- Meng et al. [2023] Kevin Meng, Arnab Sen Sharma, Alex J. Andonian, Yonatan Belinkov, and David Bau. Mass-editing memory in a transformer. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=MkbcAHIYgyS.
- Mitchell et al. [2022a] Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D. Manning. Fast model editing at scale. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022a. URL https://openreview.net/forum?id=0DcZxeWfOPt.
- Mitchell et al. [2022b] Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D. Manning, and Chelsea Finn. Memory-based model editing at scale. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato, editors, International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pages 15817–15831. PMLR, 2022b. URL https://proceedings.mlr.press/v162/mitchell22a.html.
- Pearl [2001] Judea Pearl. Direct and indirect effects. In Jack S. Breese and Daphne Koller, editors, UAI ’01: Proceedings of the 17th Conference in Uncertainty in Artificial Intelligence, University of Washington, Seattle, Washington, USA, August 2-5, 2001, pages 411–420. Morgan Kaufmann, 2001. URL https://dslpitt.org/uai/displayArticleDetails.jsp?mmnu=1&smnu=2&article_id=126&proceeding_id=17.
- Peng et al. [2023] Baolin Peng, Michel Galley, Pengcheng He, Hao Cheng, Yujia Xie, Yu Hu, Qiuyuan Huang, Lars Liden, Zhou Yu, Weizhu Chen, and Jianfeng Gao. Check your facts and try again: Improving large language models with external knowledge and automated feedback. CoRR, abs/2302.12813, 2023. doi: 10.48550/arXiv.2302.12813. URL https://doi.org/10.48550/arXiv.2302.12813.
- Qin et al. [2022] Bin Qin, Fu-Lai Chung, and Shitong Wang. KAT: A knowledge adversarial training method for zero-order takagi-sugeno-kang fuzzy classifiers. IEEE Trans. Cybern., 52(7):6857–6871, 2022. doi: 10.1109/TCYB.2020.3034792. URL https://doi.org/10.1109/TCYB.2020.3034792.
- Radford et al. [2019] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Singh et al. [2024] Chandan Singh, Jeevana Priya Inala, Michel Galley, Rich Caruana, and Jianfeng Gao. Rethinking interpretability in the era of large language models. CoRR, abs/2402.01761, 2024. doi: 10.48550/ARXIV.2402.01761. URL https://doi.org/10.48550/arXiv.2402.01761.
- Smith [1967] Russell A Smith. The condition numbers of the matrix eigenvalue problem. Numerische Mathematik, 10:232–240, 1967.
- Stewart and Sun [1990] Gilbert W Stewart and Ji-guang Sun. Matrix perturbation theory. (No Title), 1990.
- Sun [2000] Ji-guang Sun. Condition number and backward error for the generalized singular value decomposition. SIAM Journal on Matrix Analysis and Applications, 22(2):323–341, 2000.
- Touvron et al. [2023] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, et al. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288, 2023. doi: 10.48550/arXiv.2307.09288. URL https://doi.org/10.48550/arXiv.2307.09288.
- Vaccaro [1994] Richard J Vaccaro. A second-order perturbation expansion for the svd. SIAM Journal on Matrix Analysis and Applications, 15(2):661–671, 1994.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, editors, Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 5998–6008, 2017. URL https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html.
- Vig et al. [2020] Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart M. Shieber. Investigating gender bias in language models using causal mediation analysis. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020.
- Wall et al. [2003] Michael E Wall, Andreas Rechtsteiner, and Luis M Rocha. Singular value decomposition and principal component analysis. In A practical approach to microarray data analysis, pages 91–109. Springer, 2003.
- Wang et al. [2023] Peng Wang, Ningyu Zhang, Xin Xie, Yunzhi Yao, Bozhong Tian, Mengru Wang, Zekun Xi, Siyuan Cheng, Kangwei Liu, Guozhou Zheng, and Huajun Chen. Easyedit: An easy-to-use knowledge editing framework for large language models. CoRR, abs/2308.07269, 2023. doi: 10.48550/arXiv.2308.07269. URL https://doi.org/10.48550/arXiv.2308.07269.
- Wang et al. [2024] Xiaohan Wang, Shengyu Mao, Ningyu Zhang, Shumin Deng, Yunzhi Yao, Yue Shen, Lei Liang, Jinjie Gu, and Huajun Chen. Editing conceptual knowledge for large language models. CoRR, abs/2403.06259, 2024. doi: 10.48550/ARXIV.2403.06259. URL https://doi.org/10.48550/arXiv.2403.06259.
- Wedin [1972] Per-Åke Wedin. Perturbation bounds in connection with singular value decomposition. BIT Numerical Mathematics, 12:99–111, 1972.
- Wu et al. [2023] Suhang Wu, Minlong Peng, Yue Chen, Jinsong Su, and Mingming Sun. Eva-kellm: A new benchmark for evaluating knowledge editing of llms. CoRR, abs/2308.09954, 2023. doi: 10.48550/ARXIV.2308.09954. URL https://doi.org/10.48550/arXiv.2308.09954.
- Yao et al. [2023] Yunzhi Yao, Peng Wang, Bozhong Tian, Siyuan Cheng, Zhoubo Li, Shumin Deng, Huajun Chen, and Ningyu Zhang. Editing large language models: Problems, methods, and opportunities. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 10222–10240. Association for Computational Linguistics, 2023. URL https://aclanthology.org/2023.emnlp-main.632.
- Yu et al. [2024] Lang Yu, Qin Chen, Jie Zhou, and Liang He. MELO: enhancing model editing with neuron-indexed dynamic lora. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors, Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada, pages 19449–19457. AAAI Press, 2024. doi: 10.1609/AAAI.V38I17.29916. URL https://doi.org/10.1609/aaai.v38i17.29916.
- Zhang et al. [2024] Ningyu Zhang, Yunzhi Yao, Bozhong Tian, Peng Wang, Shumin Deng, Mengru Wang, Zekun Xi, Shengyu Mao, Jintian Zhang, Yuansheng Ni, Siyuan Cheng, Ziwen Xu, Xin Xu, Jia-Chen Gu, Yong Jiang, Pengjun Xie, Fei Huang, Lei Liang, Zhiqiang Zhang, Xiaowei Zhu, Jun Zhou, and Huajun Chen. A comprehensive study of knowledge editing for large language models. CoRR, abs/2401.01286, 2024. doi: 10.48550/ARXIV.2401.01286. URL https://doi.org/10.48550/arXiv.2401.01286.
- Zhang et al. [2023] Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, Longyue Wang, Anh Tuan Luu, Wei Bi, Freda Shi, and Shuming Shi. Siren’s song in the AI ocean: A survey on hallucination in large language models. CoRR, abs/2309.01219, 2023. doi: 10.48550/arXiv.2309.01219. URL https://doi.org/10.48550/arXiv.2309.01219.
- [66] Chujie Zheng, Fan Yin, Hao Zhou, Fandong Meng, Jie Zhou, Kai-Wei Chang, Minlie Huang, and Nanyun Peng. On prompt-driven safeguarding for large language models. In ICLR 2024 Workshop on Secure and Trustworthy Large Language Models.
- Zhong et al. [2023] Zexuan Zhong, Zhengxuan Wu, Christopher D. Manning, Christopher Potts, and Danqi Chen. Mquake: Assessing knowledge editing in language models via multi-hop questions. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 15686–15702. Association for Computational Linguistics, 2023. URL https://aclanthology.org/2023.emnlp-main.971.
Appendix A Theoretical Analysis Based on Perturbation Theory
Here, we provide a detailed analysis and proof of Section 3.2. We begin by introducing some definitions and then present several preliminary lemmas and theorems. These lemmas and theorems are finally used to prove Theorem 3, which is most relevant to our problem discussed in Section 3.2.
A.1 Definition
We discuss the problem , where is a perturbation of given by . We assume remains unchanged and represents the corresponding change, satisfying . Here , .
It is noteworthy that in the following derivation, denotes the conjugate transpose of , represents the generalized inverse of , and represents 2-norm [51].
To simplify the problem, we apply a rotation. Specifically, let be a unitary matrix with , and let be a unitary matrix with , where refers to the rank. Then
| (7) |
where is square and nonsingular. If we set
| (8) |
then
| (9) |
We will call these transformed, partitioned matrices the reduced form of the problem. Many statements about the original problem have revealing analogues in the reduced form.
In this form, is replaced by and is replaced by . If and are partitioned in the forms
| (10) |
where , then
| (11) |
and
| (12) |
Moreover, the norm of the residual vector
| (13) |
is given by
| (14) |
Here, we define the symbol :
| (15) |
and for any () the symbol , for the spectral norm:
| (16) |
A.2 Preliminary Lemmas & Theorems
After introducing some definitions, we give some preliminary lemmas and theorems, which are used to prove Theorem 3.
Lemma 1 Let
be the condition number of . If is nonsingular, then
| (17) |
If in addition
then is perforce nonsingular and
| (18) |
Moreover
| (19) |
Lemma 2 In the reduced form the matrices and are acute if and only if is nonsingular and
| (20) |
In this case, if we set
then
and
| (21) |
Lemma 3 The matrix
satisfies
| (22) |
and
| (23) |
Theorem 1 Let be an acute perturbation of , and let
| (24) |
Then
| (25) |
Proof.
Let
| (26) |
| (27) |
, hence
| (28) |
From Lemma 1 we have the following bound:
| (29) |
By Lemma 3
| (30) |
| (31) |
| (32) |
and likewise
| (33) |
∎
Theorem 2 In Theorem 1, let
| (34) |
and suppose that
| (35) |
so that
| (36) |
Then
| (37) |
and
| (38) |
A.3 Core Theorem
Finally, we give the core theorem used in main paper. Some symbols and definitions have been claimed in Appendix A.1 and A.2.
Theorem 3 Let and , where , and is an acute perturbation of . Then
| (41) |
Proof.
By Lemma 2, write
| (42) |
Then
| (43) |
and
| (44) |
Now
| (45) |
∎
Readers can refer to this work [51] for more details of perturbation analysis.
Returning to our problem, consider , where . Let , where is the corresponding perturbation matrix. Assuming remains constant, there exists such that satisfies . And we have and . Applying Theorem 3, we obtain
| (48) |
where , , , and are directly related, and each term on the right-hand side involves . This means that the relative perturbation of the vector is constrained by . According to Theorem 2, , where is the condition number of . This indicates that is a robust indicator of the impact of on the vector .
Appendix B Experimental Setup
B.1 Baseline Editing Methods
Three popular model editing methods were selected as baselines including:
-
MEND [43]666https://github.com/eric-mitchell/mend: it learned a hypernetwork to produce weight updates by decomposing the fine-tuning gradients into rank-1 form.
-
ROME [41]777https://github.com/kmeng01/rome: it first localized the factual knowledge at a specific layer in the transformer MLP modules, and then updated the knowledge by directly writing new key-value pairs in the MLP module.
-
MEMIT [42]888https://github.com/kmeng01/memit: it extended ROME to edit a large set of facts and updated a set of MLP layers to update knowledge.
The ability of these methods was assessed based on EasyEdit999https://github.com/zjunlp/EasyEdit [58], an easy-to-use knowledge editing framework which integrates the released codes and hyperparameters from previous methods.
B.2 Editing Datasets and Evaluation Metrics
Table 2 shows the examples of two datasets.
| Datasets | Editing prompt |
|---|---|
| CounterFact | In America, the official language is |
| ZsRE | Which was the record label for New Faces, New Sounds? |
Besides, following previous works [41, 43, 42], the editing performance metrics for the CounterFact dataset and ZsRE dataset are efficacy, generalization and locality, but there are some computational differences. In the main paper, the metrics of editing performance are calculated for the CounterFact dataset. For the ZsRE dataset, here are the details:
Efficacy validates whether the edited models could recall the editing fact under editing prompt . The assessment is based on Efficacy Score (ES) representing as: .
Generalization verifies whether the edited models could recall the editing fact under the paraphrase prompts via Generalization Score (GS): .
Locality verifies whether the output of the edited models for inputs out of editing scope remains unchanged under the locality prompts via Locality Score (LS): , where was the original answer of .
B.3 Hyperparameters of PRUNE
When conducting experiments, for different editing methods, LLMs and editing datasets, the hyperparameter in function of PRUNE is different. Table 3 shows the details of this hyperparameter. is the base of the natural logarithm.
| Datasets | Models | ROME | MEMIT | MEND |
|---|---|---|---|---|
| CounterFact | GPT-2 XL | 1.2 | 1.2 | 1.2 |
| LLaMA-2 | 1.2 | 1.2 | ||
| LLaMA-3 | 1.5 | - | ||
| ZsRE | LLaMA-2 | 1.2 |
B.4 Task Prompts
The prompts for each downstream task were illustrated in Table 4.
| Reasoning: |
| Q: {QUESTION} A: Let’s think step by step. {HINT} Therefore, the answer (arabic numerals) is: |
| NLI: |
| {SENTENCE1} entails the {SENTENCE2}. True or False? answer: |
| Open-domain QA: |
| Refer to the passage below and answer the following question. Passage: {DOCUMENT} Question: {QUESTION} |
| Summarization: |
| {DIALOGUE} TL;DR: |
B.5 Experiments Compute Resources
We used NVIDIA A800 80GB GPU for experiments. For LLaMA-2 (7B) and LLaMA-3 (8B), it occupies about 40+GB memory and costs about 3 hours for each editing method to run 200 edits and then to test downstream tasks . For GPT-2 XL (1.5B), it needs 10+GB and costs about 1.5 hours for each editing method to run 200 edits and then to test downstream tasks.
Appendix C Experimental Results
C.1 Results of General Abilities
Figure 6 and 7 show the downstream task performance of edited models with GPT-2 XL and LLaMA-3 (8B) on CounterFact dataset. Figure 8 shows the downstream task performance of edited models with LLaMA-2 (7B) on ZsRE dataset. Due to limitations of computing resources, experiments were conducted using only LLaMA-2 (7B) on the ZsRE dataset. We will supplement experiments with other LLMs in the future.

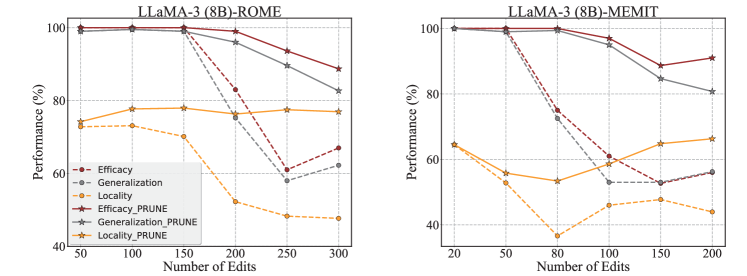

C.2 Results of Editing Performance
Figure 9 and 10 shows the editing performance of edited models with GPT-2 XL and LLaMA-3 (8B) on CounterFact dataset. Figure 11 shows the editing performance of edited models with LLaMA-2 (7B) on ZsRE dataset.



C.3 Results of another function for PRUNE
In the main paper, function is used in in PRUNE to restrain . Here we use the function, which could be represented as: . Here was a hyperparameter and was set as 2 in this section. Figure 12 and 13 respectively show some downstream task performance and editing performance with function on CounterFact dataset.
Compared with Figure 6 and 9, we observed that although the function in PRUNE played a role in preserving general abilities and maintaining editing performance, its effectiveness was noticeably inferior to that of the function when the number of edits was large.


C.4 Condition number with PRUNE
Figure 14 shows after coupling with PRUNE, the condition number of MEMIT is significantly restrained.

Appendix D Broader Impacts
This work offers significant advancements in the field of model editing for LLMs. By addressing the challenge of preserving general abilities while performing sequential edits, PRUNE facilitates continual learning and adaptability in LLMs. This can lead to several positive impacts, such as:
Enhanced Adaptability. It enables LLMs to update their knowledge base quickly and accurately without extensive retraining. This adaptability is crucial in dynamic environments where up-to-date information is vital, such as real-time translation services, personalized learning systems, and interactive virtual assistants.
Resource Efficiency. By mitigating the need for full retraining, PRUNE significantly reduces computational resources and energy consumption. This aligns with sustainable AI and makes it more feasible to deploy LLMs in resource-constrained settings.
Improved Performance in Specialized Tasks. PRUNE’s ability to perform targeted edits without compromising overall model performance can enhance LLMs’ effectiveness in specialized domains, such as medical diagnostics, legal analysis, and technical support, where precise and updated knowledge is essential.
While this work offers many benefits, there are potential negative societal impacts that must be considered:
Misuse for Malicious Purposes. The capability to edit LLMs efficiently could be exploited to inject harmful or biased information into models, thereby spreading disinformation or propaganda. This risk is particularly concerning in applications involving social media and news dissemination where LLMs might generate or amplify misleading content.
Fairness. Unintended biases could be introduced during the editing process, potentially exacerbating existing biases in LLMs. This could lead to unfair treatment or misrepresentation of specific groups, especially if the editing is not conducted with proper oversight and consideration of ethical implications.
Privacy Concerns. The ability to update models quickly might also pose privacy risks, as models could be edited to include sensitive or personal information. Ensuring that editing processes do not compromise individual privacy is critical, particularly in applications involving personal data.
To mitigate these potential negative impacts, several strategies could be implemented:
Gated Release and Monitoring. Limiting access to the framework through gated releases and monitoring its usage can help prevent misuse.
Bias and Fairness Audits. Conducting regular audits to assess and address biases in the model editing process can help ensure that edits do not unfairly impact any specific group. Developing guidelines for ethical editing practices is also essential.
Privacy Protection Measures. Establishing clear protocols for handling sensitive data during the editing process can help protect privacy. Anonymization and encryption techniques should be employed to safeguard personal information.
By considering both the positive and negative impacts and implementing appropriate mitigation strategies, this work can contribute to the responsible and ethical advancement of model editing technologies.