Person Re-identification based on Robust Features in
Open-world11footnotemark: 1
Abstract
Deep learning technology promotes the rapid development of person re-identifica-tion (re-ID). However, some challenges are still existing in the open-world. First, the existing re-ID research usually assumes only one factor variable (view, clothing, pedestrian pose, pedestrian occlusion, image resolution, RGB/IR modality) changing, ignoring the complexity of multi-factor variables in the open-world. Second, the existing re-ID methods are over depend on clothing color and other apparent features of pedestrian, which are easily disguised or changed. In addition, the lack of benchmark datasets containing multi-factor variables is also hindering the practically application of re-ID in the open-world. In this paper, we propose a low-cost and high-efficiency method to solve shortcomings of the existing re-ID research, such as unreliable feature selection, low efficiency of feature extraction, single research variable, etc. Our approach based on pose estimation model improved by group convolution to obtain the continuous key points of pedestrian, and utilize dynamic time warping () to measure the similarity of features between different pedestrians. At the same time, to verify the effectiveness of our method, we provide a miniature dataset which is closer to the real world and includes pedestrian changing clothes and cross-modality factor variables fusion. Extensive experiments are conducted and the results show that our method achieves Rank-1: 60.9%, Rank-5: 78.1%, and mAP: 49.2% on this dataset, which exceeds most existing state-of-art re-ID models.
keywords:
person re-identification, open-world, , pose estimation, feature extraction1 Introduction
Person re-identification (re-ID) is an important branch of computer vision, which achieves the cross-camera tracking of the target person with a breakthrough of time and space limitation of single camera, with broad prospects in the field of public security, Intelligent security, etc. Great progress has been made in research in re-ID due to the development of deep learning techniques, presenting results that can perform relatively high recognition accuracy in public dataset[1]. However, most of those are results of re-ID in close-world based on the hypothesis of only one factor variable (view, clothing, pedestrian pose, pedestrian occlusion, image resolution, RGB/IR modality) changed. Plenty of difficulties and challenges occur in the transition of re-ID research from closed-world to open-world owing to the complexity of multi-factor variables in open-world[2]. Specifically, related difficulties and challenges[3, 4, 5] include: i) lacking of the re-ID benchmark datasets which containing multi-factor variables has led to existing re-ID research centering on only a few factor variables; ii) Existing re-ID research rely on unreliable pedestrian apparent features that be easily disguised or changed; iii) Existing re-ID models are inefficient in extracting pedestrian features from images and are easily effected by images factors (resolution ratio, color, light, angle, etc.).
Due to the lack of benchmark datasets of re-ID in open-world, re-ID research based on deep learning can only focus on a few factor variables and cannot cope with the situation of multi-factor changes in open-world. The existing re-ID benchmark datasets belong to closed-world, most of which only contain single-factor variable. For instance, the common benchmark datasets such as ReID – Market1501[6], CUHK03[7], DukeMTMC – ReID[8] only contain the view factor. It is considered effective to create open-world re-ID dataset with multi-factor variables to improve the usability of re-ID deep learning model in open-world. However, the collection of dataset is difficult since it not only consumes considerable manpower and resources, but also involve sensitive privacy issues, which makes it hard to build a dataset in most of the countries that pay high attention to citizen privacy security. Therefore, we use other methods to search for general pedestrian robust features instead of training re-ID deep learning model. Then, we transform those general pedestrian robust features into reliable pedestrian identity information that we can rely on to re-identify this specific pedestrian.
Basically, a person’s identity should be decided by his biological features (lineament, height, etc.), but not his unreliable apparent features (clothes, shoes, haircuts, etc.)[9]. However, the pedestrian identification based on existing re-ID models highly relies on such unreliable apparent information which can easily be artificially changed or disguised on purpose, leading to a low usability of re-ID research in open-world. It is always a difficult task to extract biological features of pedestrian, since there is a high relativity between the quality of those extracted features and the factors of an image including resolution ratio, light, angle, color, not to mention the artificial disguise of features. Thus what matters more is how to search for an effective method to extract some stable biological features from images. What we considered is a pedestrian’s gait as biological features that is almost fixed in an uninterrupted period of time[10]. At the meantime, since the pose estimation model[11, 12] is robust to image resolution, color, view and other open-world variables, we extract pedestrian skeleton key points as general robust feature information based on pose estimation. Moreover, the continuous frame images can transform the general robust feature information of pedestrians into reliable identity information which has advantages of long distance and longtime effectiveness[10].
Our method is presented under the circumstances of multi-factor variables in open-world. We use the pose estimation model to extract the continuous feature information of pedestrian skeleton key points based on video continuous frames instead of using unreliable apparent feature information of pedestrian during cross-camera tracking, those continuous feature information of pedestrian skeleton key points is specific identity information of pedestrian. Then according to the similarities of matching each pedestrian’s identity information to re-identify the specific pedestrian. Compared with existing re-ID models, there are three main advantages of our method. Firstly, the continuous feature information of pedestrian skeleton key points extracted by pose estimation model is robust and not easy to be disguised or changed. Secondly, our method is more efficient in extracting pedestrian features owing to the insensitivity of the pose estimation model to image resolution, color, view and other factors. Lastly, we consider the distance between feature vectors as optimization problem, and slove it based on dynamic programming, which makes our results more accurate. These above make our method improve the usability of re-ID in open-world in the absence of relevant datasets.
Our study is based on assumptions where we analyze and sum up existing re-ID research, then propose a method combining deep learning with traditional algorithms to solve the problem of low availability of re-ID in open-world. We proved the effectiveness of our methodology based on experiment under the condition of pedestrian changing clothes and cross-modality, then compared it with existing state-of-art re-ID research. At the same time, our approach overcomes the challenge of lacking relevant dataset. The contribution of this paper can be summarized as follows:
-
1.
We reveal the poor usability of the existing re-ID research in open-world, and the fact that existing re-ID research are derailed from the real world. Moreover, we further demonstrate the disadvantages of the existing re-ID on the basis of previous research.
-
2.
Combined with previous research, we optimized algorithm by using global constrains, lower-bounded function, early stop and other optimization strategies. We also analyzed the computational complexity of various optimization combinations, which can provide reference for related research. Moreover we improved the pose estimation model HigherHRNet by replacing a part of residual blocks with ResNeXt blocks, reducing the space complexity of the algorithm.
-
3.
We presented a micro dual-factor re-ID dataset based on video frame sequence including pedestrian changing clothes and cross-modality. The total parameters of this modified network decreased by 15%. The number of FLOPs of forward reasoning decreased by 5%. The network performance was improved by 0.5%, with average accuracy(AP) reaching 67.9% and 66.9% on COCO2017 verification dataset and test dataset respectively.
2 Related Work
Some existing re-ID models have been used in open-world, however, the performance of these models needs to be further improved in open-world. According to the types of features that extracted by the model, these models are divided into two categories, based on the apparent features and the biological features of pedestrians.
Research Based on Apparent Features. The DG-Net[1] model contains a generation module, which encodes each pedestrian into appearance code and structure code, and then exchanges appearance code and structure code between different pedestrians, so that the model can learn different attributes of the same pedestrian features to improve the performance of the model. Although the DG-Net model learned different attributes(appearance and structure features) of the same pedestrian during training, it still cannot cope with the multi-factor variables change in open-world. There are two main reasons: i) The attribute features, such as facial features, learned by the model are unstable and easily disguised. ii) The model has low efficiency in extracting pedestrian attribute feature information from the image and cannot counter the interference of factors such as image resolution. Similarly, the ReIDCaps[13] model has the same disadvantage. Baseline of AGW[14] can better adapt to single-/cross-modality, but it does not involve the impact of other factors on the performance of the model, and only uses the image information of a single frame.
Research Based on Biological Features. [9] propose an idea using radio signals to collect pedestrian feature information as a basis for re-ID. Although this collected information belongs to biological features of pedestrian, it is also unstable and easily disguised artificially, such as carrying interference sources. In addition, special equipment is required to transmit or receive radio signals, which makes it unrealistic to equip on a large scale. Research based on depth maps[15, 16, 17, 18, 19] can capture reliable identity information of pedestrians, alone with a certain anti-interference ability against external factors, in theory, which can promote the implementation of re-ID in open-world. However, special equipment is required for capturing images with depth information, making it unsuitable for large-scale deployment. Some recent research have taken a new perspective to extract pedestrian contour features as a basis for re-identification[3, 4]. However, regret to say that these research cannot promote the application of re-ID in open-world, for two reasons: i) Pedestrian contour features are easily changed with changes in clothing, making it lack of a long-term effects. ii) Even without the influence of external factors, it can still be difficult to accurately extract the contours of pedestrians especially in some complex occasions such as covering, clothing or pedestrians traveling at night.
Similarities and differences with gait recognition research. Gait recognition[10, 20, 21], a relatively new research field, has some similarities and differences compared with our research. Different from the existing gait recognition research, our method benefits from the pose estimation model, which can obtain more stable and reliable feature information of pedestrian skeleton key points from images, without the usage of segmentation or spatial subtraction to obtain the pedestrian’s unstable body contour features. and our method has more relaxed constraints without following assumptions: i) The silhouette of the pedestrian should be segmented from the background. ii) Pedestrians’ body contours will not change after cloth-changing. iii) Pedestrian pixels should not be too few in the image. On the other hand, what our research is similar to the existing gait recognition research is that both research are based on continuous frames of video with the usage of the related information between each frames.
3 Problem Description
Most of the existing re-ID research are under the condition of close-world, assuming that only one factor variable (view, clothing, pedestrian pose, pedestrian occlusion, image resolution, RGB/IR modality) changing, which is far from reality. Research in open-world faces greater difficulties and challenges due to the complexity of the scene. From the perspective of probability theory, we can simply describe the difference between re-ID in close-world and open-world. Define the set of open-world factor variables as , , Event represents being affected by the factor in during pedestrian retrieval, and event represents successfully retrieve a pedestrian across the camera. Then, re-ID in close-world can be expressed as a conditional probability , while it can be expressed as in open-world .
We have revealed in the previous part that the existing re-ID model is extremely dependent on apparent information of pedestrian such as color of cloth when judging the identity of pedestrians under the situation that this information is extremely unreliable under the background of multi-factor changes in open-world[3, 4, 5]. In order to further illustrate the dependence of the re-ID model in close-world on the color of pedestrian clothing, we take the state-of-art model DG-Net, which has learned multiple feature (appearance and structure) information, as an example. We remove the final classification layer of DG-Net, output the 1024-dimensional feature vectors before and after the change of the same pedestrian on the testset PRCC in [3], then calculate the cosine similarity of these feature vectors. Result is shown in Fig. 3.1. Generally, the cosine similarity of the feature vectors is low with the highest value less than 0.4. In the 1024-dimensional space, there is a relatively large directional deviation between the eigenvectors while showing a reverse trend. Though the DG-Net model learns the attribute information of pedestrians during training, it still relies heavily on apparent information of pedestrian such as the colors of clothing.

Here comes the question: how to weaken the dependence of the re-ID model on the apparent information of pedestrians when judging the identity of pedestrians? An effective method is to train a deep learning model based on the re-ID dataset of multi-factor in open-world to make this model robust to multi-factor variables, but it is unrealistic. Therefore, instead of directly solving this problem, we use the idea of limitation to further abstract this problem. Thus, this issue can be transformed into searching a way that the re-ID model judge the identity of the pedestrians without relying on their apparent information.
4 Methodology
Specifically, in our method, continuous frame images are used as the input of pose estimation model, while the time series features of the pedestrian skeleton key points are obtained and used as the basis of re-identification. It’s a common case that the lengths of two time series features are unequal, since the length depends on the number of video frames. Therefore, we consider this distance measurement of time series features as an optimization problem. Based on the idea of dynamic programming, we use dynamic time warping () to solve the distance between time series features, then select the features closest to the model feature as query results, so as to complete the matching of pedestrians with the same identity.
Good models (or methods) should occupy as little computing resource or storage space as possible. It is inevitable that there will be computational redundancy since our method includes both traditional algorithms and deep learning techniques. According to the characteristics of our method, we divide it into two stages: stage.1 based on deep learning and stage.2 based on traditional algorithm and use corresponding optimization strategies for these two stages to reduce the computational complexity of the algorithm. Since the detection accuracy of skeleton key points will affect the subsequent feature matching, and considering that there are few pixels of the person in the surveillance video, the HigherHRNet[11] network with ultra-high detection accuracy and high-resolution feature maps is considered to be an appropriate pose estimation model. However, the HigherHRNet network has a large number of parameters, with more than 300 convolutional layers, and numerous stacked residual blocks. [22] shows that the ResNeXt block is better than the residual block, and the group convolution has a smaller number of parameters. Thus we replace some of the residual blocks in the network with the ResNeXt block using group convolution, and the improved network is denoted as HigherHRNetX. Stage.2 regarding the distance solution between time series features as an optimization problem will undoubtedly increase the computational complexity of the algorithm. In view of the characteristics of , we use optimization strategies such as global constraints, lower-bounded functions, and early stop to reduce the complexity, and quantitatively analyze the effects of each strategy.
Denote HigherHRNetXt as a function , the output as a time series sequence . The obtained continuous frames information of pedestrian to be required at place is defined as , ; the information of suspected pedestrian at place is defined as , . Obtain the time series features of skeletons key points of and , as , . Thus, the distance between and can be written as the following function: . The lengths of time series features and are , respectively. Consider the solution of the distance between and as an optimization problem, which is the following constrained minimization problem :
| (4.1) |
Eq.(4.1) can be solved based on the [23] algorithm to obtain the best warping path of and . Denote the minimum matching distance as . The shorter the distance , the higher the similarity between and , and the greater the probability value ; conversely, the lower the similarity, the smaller the probability value .
4.1 Assumptions
Our research focus on the image field, that is, only extracting information from the image. Obviously, more image information brings more benefit to our research. At the same time, the open-world contains many factor variables. Each additional factor variable in the research process of re-ID will make the research more difficult. At present, no specific way to deal with all the open-world factor variables has been found in our research. So we need to establish the following assumptions:
Assumption 1. The feature information obtained by the re-ID model is only obtained from the image, and does not contain auxiliary information such as text.
Assumption 2. Suppose the pedestrian to be retrieved is , and the query image about is a continuous frame, that is, . is the frame of , is the initial query information of , and is the video frame rate.
Assumption 3. Denote pedestrian clothing as factor , image cross-modality as factor , {. We accomplish our research on and .
Assumption 1 makes the problem in Part.3 equivalent to how to make the re-ID model use the pedestrian biological feature information in the image to identify pedestrians. At the same time, on the basis of Assumption 1, 2 and 3, our research problem is determined as ’under the influence of pedestrian changing clothes, cross-modality, based on continuous frames of video, how the re-ID study extract the biological features of pedestrians in the image and complete the recognition of specific pedestrians,’ that is .
4.2 HigherHRNetXt Network

ResNeXt block. As an improvement to the network residual block convolution structure, ResNeXt uses a group convolution method to make the convolutional network improve the performance and reduce the total number of network parameters without increasing the depth and width, but only changing the base. , is the base, which represents the number of identical branches in a module; is the branch of the same topology. Fig. 4.1 illustrates the architecture comparison between residual block and ResNeXt block.
HigherHRNetXt Structure. Replace part of the residual blocks in HigherHRNet with ResNeXt blocks, the network structure is shown in Fig. 4.2.

4.3 Dynamic Time Warping ()
algorithm, first proposed by Japanese scholar Itakura, uses the idea of dynamic programming to solve the minimum distance between two time series and with equal or unequal length, and has high accuracy in measuring the similarity of time series. algorithm is widely applied and there are many related research. In order to improve the computational efficiency of while reducing computational cost, we set some constraints on . We will introduce these constraints and analyze the computational complexity of each optimization strategy.
4.3.1 constraint conditions

Global Constraints. Constraining the search space of can reduce the number of elements to be calculated, and reduce the time complexity of the algorithm. Therefore, we set a boundary line in the search space, that is, the Sakoe-Chiba[24] constraint. The location of the search boundary is determined by the width of the warping window. ,, is the length of the sequence. If the set of euclidean distances of each element in time series and is a matrix , the constraint can be visualized by projecting into Cartesian coordinate, as shown in Fig. 4.3. The constrained reduces the time complexity of the algorithm due to the reduction of its search space, at the same time avoids excessive curvature of the warping path. The warping window of is as follows:
| (4.2) |
Lower Bounding Constraints. When sequence with a total number of matches the template sequence , it is necessary to filter out sequences that are not similar to in sequence . We use LB KIM[25] lower bound function and denote the start element, end element, maximum element, and minimum element of the sequence as , and the elements at the corresponding position of the template sequence are denoted as . The lower bound distance function can be obtained, which is defined as follows:
| (4.3) |
According to the lower bound theorem[25], . Assuming that there is a similarity threshold , if , then . Thus, we only need to calculate the value of the lower bound function between sequences, and compare it with to filter out some dissimilar sequences to greatly reducing the computational complexity of the algorithm.
Early Abandon[26]. The lower bound function can only roughly filter out dissimilar sequences, but the remaining sequences may not have high similarity to the template sequence. Our goal is to find sequences with high similarity to , so we need to stop the sequence matching between dissimilar sequences as soon as possible. Denote the threshold of the cumulative distance of matching between sequences as . In the path search process, if the cumulative distance between the two sequences , then matching is terminated.
4.3.2 Analysis of computational complexity
Assume. the template sequence with length ; sequence set , in which the length of sequence is . Then computational complexity of can be expressed as , and the computational cost can be approximately expressed as .
We analyze the influence of the optimization conditions in Part.4.3.1 on the calculation cost of the original one by one. Denote , , as the calculation cost of global constraint, lower bound function, and early stop impact on the original . Then the following formula holds:
| (4.4) |
| (4.5) |
| (4.6) |
| (4.7) |
in Eq.(4.5) is the element that does not belong to the warping window ; in Eq.(4.6) is the sequence filtered by lower bound function , and ; in Eq.(4.7), . Obviously, , and are all smaller than . These optimization conditions are independent of each other, it is easy to get the following conclusion that when these optimization conditions are combined, the calculation cost of will be less than the cost of caused by any single optimization condition. We can further infer that the cost of our method is:
| (4.8) |
Obviously, it’s clear that the cost of our method satisfies:
| (4.9) |
| (4.10) |
5 Results and Analysis
Our experiment is divided into two parts, corresponding to the two stages of our method. Specifically, Part.5.1 is the performance experiment of the improved estimation model HigherHRNetXt; Part.5.2 is the performance experiment of the entire Pose- in the context of two-factor variables. Part.5.3 is the analysis of the influence of the main hyperparameters during the Pose- experiment on the results of 5.2 experiment.
5.1 HigherHRNetXt
Dataset. The COCO dataset contains more than 200,000 images and 250,000 pedestrians marked with 17 key points. HigherHRNetXt is trained on the COCO train2017 dataset and evaluated on the COCO val2017 and test-dev2017 dataset. The training set contains 57,000 images. The validation set and testset contain 5,000 and 20,000 images respectively.
Training. We use Adam optimization algorithm to learn network weights. The hardware facilities are 4 sets of 2080Ti, each with 8-batch size. The basic learning rate is 0.001. Data augmentation includes: random rotation, random translation. Image size scaling to 512512, training 300 epochs. The deep learning framework is Pytorch1.5 and using ImageNet pre-training weights to initialize the network.
| Method | Datasets | Backbone | #Params | GFLOPs | AP |
| HigherHRNet | val2017 | HRNet-W32 | 28.6M | 47.9 | 67.1 |
| HigherHRNetXt(ours) | val2017 | HRNetXt-W32 | 24.3M | 45.5 | 67.9 |
| HigherHRNet | test-dev2017 | - | - | - | 66.4 |
| HigherHRNetXt(ours) | test-dev2017 | - | - | - | 66.9 |
Test. The test image size is scaled to 512512 without additional data augmentation and the test scale is single. Hardware: 2080Ti. Software: Pytorch 1.5. After adding the ResNeXt module, HigherHRNet has reduced the number of parameters by 15%, FLOPS decreased by 5%, and performance has been improved. The average accuracy (AP) on the COCO val2017 and COCO test2017 datasets reached 67.9% and 66.9% with improvement of 0.8% and 0.5%, respectively. The results are shown in Table 5.1. Compared with the existing bottom-up state-of-art open source pose estimation models, the results are shown in Table 5.2.
| Method | Backbone | InputSize | #Params | GFLOPs | AP |
| OpenPose | - | - | - | - | 61.8 |
| Hourglass | Hourglass | 512 | 277.8M | 206.9 | 56.6 |
| PersonLab | ResNet-152 | 1401 | 68.7M | 405.5 | 66.5 |
| PifPaf | - | - | - | - | 66.7 |
| Bottom-up HRNet | HRNet-W32 | 512 | 28.5M | 38.9 | 64.1 |
| HigherHRNet | HRNet-w32 | 512 | 28.6M | 47.9 | 66.4 |
| HigherHRNetXt(ours) | HRNetXt-w32 | 512 | 24.3M | 45.5 | 66.9 |
5.2 Pose-
Dataset. At present, there is no open-world re-ID dataset containing multiple factors. To test the effectiveness of our method, we provide a micro re-ID testset including pedestrian changing and cross-modality two-factor variables, which contains 41 pedestrians, and each pedestrian changes two sets of clothes with different colors (each pedestrian with 40 consecutive frame images). At the same time, the AlignGan[27] model is used to convert RGB images to infrared radiation (IR) images. A sample of the dataset is shown in Fig. 5.1.

Evaluation Standard. The evaluation of the re-ID model is based on Cumulative Matching Characteristics(CMC) and mean Average Precision(mAP).
Test. The key points of pedestrian skeleton do not include facial key points. The input images are normalized. Hyperparameter settings: , , . Hardware facilities: 4 sets of 2080Ti. Deep learning framework: Pytorch 1.5. Our method is evaluated on the micro testset together with the existing open source video-based state-of-art re-ID models. The results are shown in Table 5.3. In the context of two-factor variables of pedestrian clothing and cross-modality, our method achieves Rank-1: 60.9% and mAP: 49.2% on the testset, which both surpass other state-of-art re-ID models.
| Methods | Source | Rank-1 | Rank-5 | mAP |
| ETAP-Net[28] | CVPR2018 | 36.6 | 68.2 | 38.4 |
| TriNet[29] | arXiv2017 | 34.1 | 61.0 | 34.4 |
| RRU+STIM[30] | AAAI2019 | 41.5 | 63.4 | 33.2 |
| STE-NVAN[31] | BMVC2019 | 46.3 | 75.5 | 42.3 |
| Part-Aligned[32] | ECCV2018 | 48.8 | 73.2 | 42.6 |
| RevisitTempPool[33] | BMVC2019 | 43.9 | 70.7 | 40.1 |
| Pose-(ours) | 60.9 | 78.1 | 49.2 |
5.3 Hyperparameter analysis
The main hyperparameters in our method are concentrated in Stage.2, including the cumulative distance threshold , the warping window width , and the lower bound threshold . Their values will affect the matching accuracy of the time series features of and . If the value of these hyperparameters is too small, a lot of information will be lost; if the value is too large, the calculation complexity of the algorithm cannot be reduced. Therefore, we conducted some experiments independently to determine the values of these hyperparameters. The experimental results are shown in Fig. 5.2. The initial value of is 10, the end value is 40, and the step length is 10; the initial value of is 3, the end value is 8, and the step length is 1; the initial value of is 0.2, the end value is 0.8, and the step length is 0.2.

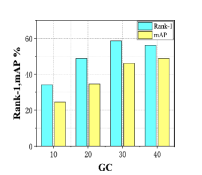

It can be seen from Fig. 5.2 that the suitable value of is 30; the suitable value set of is {6,7,8}; the suitable value set of is {0.6,0.8}. Theoretically the larger the value of these hyperparameters, the higher the complexity of the algorithm. Therefore, when the experimental results of Rank-1 and mAP are similar, the smaller values should be selected as much as possible. Moreover, the hyperparameters , , and are mutually independent, so their respective optimal values are the optimal values of the combination. For this testset, , , and are determined to be 7, 30, and 0.6 respectively.
However, we randomly combined the values of these hyperparameters in the experiment with 6 groups: , , , , , and . Results are shown in Fig. 5.3. The experimental results shows that hyperparameters combination are better than . We theoretically analyze that , , and are independent of each other, but there is a slight deviation between the experimental results and the theoretical results. We believe that it is caused by the testset being too small.

6 Conclusions
This paper analyzes the reasons for the poor availability of existing re-ID research in open-world, then analyzes and refines the existing re-ID research problems under the research assumptions. Farther more, we propose a method of combining deep learning and traditional algorithms methods to solve this problem, and the optimization strategies are adopted to optimize the algorithm. Compared with the existing re-ID research, our method proposed in this paper has three advantages. Moreover, it overcomes the problem of lack of open-world re-ID dataset and improves the usability of re-ID in open-world. To the best of our knowledge, we are the first to conduct experiments on re-ID under the double-factor background of pedestrian clothing and cross-modality.
Our method is mainly oriented, hoping to further stimulate more research on re-ID in open-world. There are still shortcomings of our model. For example, Pose- almost completely discards the color features information of pedestrians, which causes a waste of feature information, especially when the information obtained is limited. So, we guess that combining our method with the existing re-ID model will have better performance. However, limited by our small test dataset, it seems to be difficult for a further experiment, which is our next work.
Acknowledgments
This research is supported by the Zhejiang Provincial Public Welfware Technological Project of China under Grant No.LGF20F020007 and the National Natural Science Foundation of China under Grant No.11801511.
References
- [1] Z. Zheng, X. Yang, Z. Yu, L. Zheng, Y. Yang, J. Kautz, Joint discriminative and generative learning for person re-identification, in: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2138–2147.
- [2] Y. J. Li, L. Zhuo, J. Zhang, J. F. Li, H. Zhang, A survey of person re-identification, Zidonghua Xuebao/Acta Automatica Sinica 44 (9) (2018) 1554–1568.
- [3] Q. Yang, A. Wu, W. S. Zheng, Person re-identification by contour sketch under moderate clothing change, IEEE Transactions on Pattern Analysis and Machine Intelligence, (2020) 1–1.
- [4] Y.-J. Li, Z. Luo, X. Weng, K. M. Kitani, Learning shape representations for clothing variations in person re-identification (2020). arXiv:2003.07340.
- [5] F. Wan, Y. Wu, X. Qian, Y. Chen, Y. Fu, When person re-identification meets changing clothes, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2020, pp. 830–831.
- [6] L. Zheng, L. Shen, L. Tian, S. Wang, Q. Tian, Scalable person re-identification: A benchmark, in: 2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1116–1124.
- [7] W. Li, R. Zhao, T. Xiao, X. G. Wang, Deepreid: Deep filter pairing neural network for person re-identification, in: Computer Vision & Pattern Recognition, 2014, pp. 152–159.
- [8] Z. Zheng, L. Zheng, Y. Yang, Unlabeled samples generated by gan improve the person re-identification baseline in vitro, in: 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 3774–3782.
- [9] L. Fan, T. Li, R. Fang, R. Hristov, Y. Yuan, D. Katabi, Learning longterm representations for person re-identification using radio signals, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 10699–10709.
- [10] C. P. Lee, A. W. C. Tan, K. M. Lim, Review on vision-based gait recognition: Representations, classification schemes and datasets, American Journal of Applied ences 14 (2) (2017) 252–266.
- [11] B. Cheng, B. Xiao, J. Wang, H. Shi, L. Zhang, Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 5386–5395.
- [12] K. Sun, B. Xiao, D. Liu, J. Wang, Deep high-resolution representation learning for human pose estimation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5693–5703.
- [13] Y. Huang, J. Xu, Q. Wu, Y. Zhong, P. Zhang, Z. Zhang, Beyond scalar neuron: Adopting vector-neuron capsules for long-term person re-identification, IEEE Transactions on Circuits and Systems for Video Technology 30 (10) (2020) 3459–3471.
- [14] M. Ye, J. Shen, G. Lin, T. Xiang, L. Shao, S. C. H. Hoi, Deep learning for person re-identification: A survey and outlook (2020). arXiv:2001.04193.
- [15] M. Munaro, A. Fossati, A. Basso, E. Menegatti, L. V. Gool, One-Shot Person Re-Identification with a Consumer Depth Camera, Springer London, 2013.
- [16] J. Lorenzo-Navarro, M. Castrillón-Santana, D. Hernández-Sosa, An study on re-identification in rgb-d imagery, in: International Workshop on Ambient Assisted Living, 2012, pp. 200–207.
- [17] A. Haque, A. Alahi, L. Fei-Fei, Recurrent attention models for depth-based person identification, in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 1229–1238.
- [18] A. Wu, W. Zheng, J. Lai, Robust depth-based person re-identification, IEEE Transactions on Image Processing 26 (6) (2017) 2588–2603.
- [19] N. Karianakis, Z. Liu, Y. Chen, S. Soatto, Reinforced temporal attention and split-rate transfer for depth-based person re-identification (2018). arXiv:1705.09882.
- [20] Z. Zhang, M. Hu, Y. Wang, A survey of advances in biometric gait recognition, in: Chinese Conference on Biometric Recognition, 2011, pp. 150–158.
- [21] I. Rida, N. Almaadeed, S. Almaadeed, Robust gait recognition: a comprehensive survey, IET Biometrics 8 (1) (2019) 14–28.
- [22] S. Xie, R. Girshick, P. Dollar, Z. Tu, K. He, Aggregated residual transformations for deep neural networks, in: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE Computer Society, Los Alamitos, CA, USA, 2017, pp. 5987–5995.
- [23] A. P. Shanker, A. N. Rajagopalan, Off-line signature verification using dtw, Pattern Recognition Letters 28 (12) (2007) 1407–1414.
- [24] T. Górecki, M. Łuczak, The influence of the sakoe–chiba band size on time series classification, Journal of Intelligent and Fuzzy Systems (2019) 1–13.
- [25] Sang-Wook Kim, Sanghyun Park, W. W. Chu, An index-based approach for similarity search supporting time warping in large sequence databases, in: Proceedings 17th International Conference on Data Engineering, 2001, pp. 607–614.
- [26] M. S. Kim, S. W. Kim, M. Shin, Optimization of subsequence matching under time warping in time-series databases, in: Acm Symposium on Applied Computing, 2005, pp. 581–586.
- [27] X. Mao, Q. Li, H. Xie, Aligngan: Learning to align cross-domain images with conditional generative adversarial networks (2017). arXiv:1707.01400.
- [28] Y. Wu, Y. Lin, X. Dong, Y. Yan, Y. Yang, Exploit the unknown gradually: One-shot video-based person re-identification by stepwise learning, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 5177–5186.
- [29] A. Hermans, L. Beyer, B. Leibe, In defense of the triplet loss for person re-identification (2017). arXiv:1703.07737.
- [30] Y. Liu, Z. Yuan, W. Zhou, H. Li, Spatial and temporal mutual promotion for video-based person re-identification, Proceedings of the AAAI Conference on Artificial Intelligence 33 (2019) 8786–8793.
- [31] C.-T. Liu, C.-W. Wu, Y.-C. F. Wang, S.-Y. Chien, Spatially and temporally efficient non-local attention network for video-based person re-identification (2019). arXiv:1908.01683.
- [32] Y. Suh, J. Wang, S. Tang, T. Mei, K. M. Lee, Part-aligned bilinear representations for person re-identification, in: Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 402–419.
- [33] J. Gao, R. Nevatia, Revisiting temporal modeling for video-based person reid (2018). arXiv:1805.02104.