Persistent spectral based machine learning (PerSpect ML) for drug design
Abstract
In this paper, we propose persistent spectral based machine learning (PerSpect ML) models for drug design. Persistent spectral models, including persistent spectral graph, persistent spectral simplicial complex and persistent spectral hypergraph, are proposed based on spectral graph theory, spectral simplicial complex theory and spectral hypergraph theory, respectively. Different from all previous spectral models, a filtration process, as proposed in persistent homology, is introduced to generate multiscale spectral models. More specifically, from the filtration process, a series of nested topological representations, i,e., graphs, simplicial complexes, and hypergraphs, can be systematically generated and their spectral information can be obtained. Persistent spectral variables are defined as the function of spectral variables over the filtration value. Mathematically, persistent multiplicity (of zero eigenvalues) is exactly the persistent Betti number (or Betti curve). We consider 11 persistent spectral variables and use them as the feature for machine learning models in protein-ligand binding affinity prediction. We systematically test our models on three most commonly-used databases, including PDBbind-2007, PDBbind-2013 and PDBbind-2016. Our results, for all these databases, are better than all existing models, as far as we know. This demonstrates the great power of our PerSpect ML in molecular data analysis and drug design.
Key words: Differential geometry, principal curvatures, electron density field, critical point, isosurface, eigenvalue
1 Introduction
Data-driven learning models are among the most important and rapidly evolving areas in chemoinformatics and bioinformatics [24, 37]. Greatly benefit from the accumulation of experimental data, machine learning and deep learning models have contributed significantly to various aspects of virtual screening in drug design. In particular, machine-learning-based scoring functions have dramatically increased the accuracy of binding affinity prediction and delivered better results than traditional physics-based, knowledge-based and empirical-based models [21]. Featurization or feature engineering is key to the performance of machine learning and deep learning models in biomolecular systems. To characterize the structural, physical, chemical, and biological properties, more than 5000 molecular descriptors and chemical descriptors are proposed [37, 24]. These descriptors cover information from molecular formula, fragments, motifs, topological features, geometric features, conformation properties, hydrophobicity, electronic properties, steric properties, etc. They are widely-used in quantitative structure-activity relationship (QSAR) and quantitative structure-property relationship (QSPR) models. More importantly, these descriptors can be combined to form a fixed-length vector, known as molecular fingerprint. These equal-sized molecular fingerprints are representations of molecules and can be used as input features for machine learning models. Various softwares, such as RDkit [20], Open babel [35], ChemoPy [10], etc, are built for the automatical generation of these molecular descriptors.
Recently, advanced mathematics models, including algebraic topology, differential geometry and algebraic graph theory, are proposed for the representation and featurization of biomolecular systems and can significantly enhance the performance of learning models in drug design [49, 48, 29, 5]. Different from other molecular descriptors, three unique kinds of invariants, i.e., topological invariant (Betti numbers), geometric invariant (curvatures) and algebraic graph invariant (eigenvalues), are considered. The combination of these invariants with learning models has achieved great successes in various aspects of drug design, including protein-ligand binding affinity prediction [8, 7, 34, 9, 33], protein stability change upon mutation prediction [6, 5], toxicity prediction [51], solvation free energy prediction [46, 45], partition coefficient and aqueous solubility [52], binding pocket detection [54], and drug discovery [17]. More interestingly, these advanced-mathematics-based machine learning models have constantly achieved some of the best results in D3R Grand challenge [31, 32, 30].
Motivated by the great success of these advance mathematics models in drug design, we propose persistent spectral (PerSpect) theory and persistent spectral based machine learning (PerSpect ML). Our persistent spectral theory cover three basic models, including PerSpect graph [47], PerSpect simplicial complex and PerSpect hypergraph. Mathematically, graph, simplicial complex and hypergraph and three topological models for structure characterization. Based on them, spectral graph theory [11, 39], spectral simplicial complex [13, 27, 18, 2] and spectral hypergraph [16, 42, 12, 25, 3] are proposed. In spectral graph models, Laplacian matrixes are proposed as the algebraic description of graphs. The eigen spectral information of the Laplacian matrix, including Fiedler value, Cheeger constant, vertex and edge expansion, graph heat kernel and flow, etc, can then be used in characterization of graph properties [11, 39]. In spectral simplicial complex, combinatorial Laplacians or Hodge Laplacians can be defined from boundary matrixes, which characterize the topological connection between low-dimensional simplexes and high-dimensional simplexes. Essentially, graph Laplacian describes the relation between 1-simplexes (edges) and 0-simplexes (vertices), while combinatorial Laplacians are the generalization of the relation to higher-dimensional simplexes, such as, 2-simplexes (triangles), 3-simplexes (tetrahedrons), etc. In spectral hypergraph, boundary matrix or incident matrix can be defined between hyperedges and vertices. Hypergraph Laplacian matrix can then be constructed from the incident matrix. Hypergraph Laplacians can also be defined as combinatorial Laplacians of the Clique complex, which is induced from the hypergraph.
Different from all previous spectral models, persistent spectral theory describe structures from not one but multiple different scales. This multiscale representation is achieved through a filtration process, which is the key component of persistent homology [14, 56]. During the filtration process, a nested sequence of topological structures, which can be graphs, simplicial complexes, or hypergraphs, can be systematically generated. Their spectral properties, which are changed with filtration values, are defined as PerSpect variables. These PerSpect variables characterize not only the global topological information, but also the geometric information that directly related to topological variations, in a way similar as persistent homology. Therefore, PerSpect variables can be used in both qualitative description and quantitative characterization. In particular, persistent multiplicity (of zero eigenvalues) is exactly persistent Betti number. This means that PerSpect theory incorporates persistent homology information. Moreover, PerSpect variables can be discretized into feature vectors for various learning models, such as support vector machine, random forest, gradient boost tree, neural network, convolution neural network, etc. The unique multiscale properties of these features, which balance structure complexity and data simplification, enables a better structure representation and can boost the performance of learning models.
In this paper, we consider PerSpect simplicial complex based ML model for protein-ligand binding affinity prediction in drug design. We train our model on three widely-used protein-ligand databases [23], including PDBbind-2007, PDBbind-2013 and PDBbind-2016. Similar to existing models, Pearson correlation coefficient (PCC) and root-mean square error (RMSE) are used as measurements for the performance of the model. We systematically compare our prediction results with all the state-of-art results in protein-ligand binding affinity prediction, as far as we known. It has been found that our PerSpect ML model has delivered the best results in terms of both PCC and RMSE in all the three test cases [22, 21, 15, 50, 19, 40, 41, 55, 1, 15, 4].
2 Theory and methods
2.1 Topological representations
 |
Graph
Graph or network models have been applied to various material, chemical and biological systems. In these models, atoms and bonds are usually simplified as vertices and edges. Mathematically, a graph representation can be denoted as , where are vertex set with the total number. Here denotes the edge set.
Simplical complex
A simplicial complex is the generalization of a graph into its higher-dimensional counterpart. The simplicial complex is composed of simplexes. Each simplex is a finite set of vertices, and can be viewed geometrically as, a point (0-simplex), an edge (1-simplex), a triangle (2-simplex), a tetrahedron (3-simplex), and their k-dimensional counterpart (k-simplex). More specifically, a -simplex is the convex hull formed by affinely independent points as follows,
The -th dimensional face of () is the convex hull formed by vertices from the set of points . The simplexes are the basic components for a simplicial complex.
A simplicial complex is a finite set of simplexes that satisfy two conditions. Firstly, any face of a simplex from is also in . Secondly, the intersection of any two simplexes in is either empty or a shared face. A -th chain group is an Abelian group generated by oriented -simplexes , which are simplexes together with an orientation, i.e., ordering of their vertex set. The boundary operator () for an oriented -simplex can be denoted as,
Here is a oriented -simplex, which is generated by the original set of vertices except . The boundary operator maps a simplex to its faces and it guarantees that .
To facilitate a better description, we use notation to indicate that is a face of , and notation if they have the same orientation, i.e., oriented similarly. For two oriented -simplexes, and , of a simplicial complex , they are upper adjacent, denoted as , if they are faces of a common -simplex; they are lower adjacent, denoted as , if they share a common -simplex as they face. Moreover, if the orientations (or signs) of their common lower simplex are the same, it is called similar common lower simplex ( and ); if their orientations are differently, it is called dissimilar common lower simplex ( and ). The (upper) degree of a -simplex , denoted as , is the number of -simplexes, of which is a face.
Hypergraph
A hypergraph is a generalization of graph in which an edge is made of a set of vertices. Mathematically, a hypergraph consists of a set of vertices (denoted as ), and a set of hyperedges (denoted as ). Each hyperedge contains an arbitrarily number of vertices, and can be regarded as a subset of . A hyperedge is said to be incident with a vertex , when the vertice is in the hyperedge, i.e., . Note that a hypergraph can also be viewed as a generalization of simplicial complex.
An illustration of graph, simplicial complex and hypergraph can be found in Figure 1. These topological representations are made from the same set of vertices, but they characterize different topological connections.
2.2 Spectral theories
A systematic characterization, identification, comparison, and analysis of structure data, from material, chemical and biological systems, are usually complicated due to their high dimensionality and complexity. Spectral graph theory is proposed to reduce the data dimensionality and complexity by studying the spectral information of connectivity matrixes, constructed from the structure data. These connectivity matrixes include incidence matrix, adjacency matrix, (normalized) Laplacian matrix, Hessian matrix, etc. Spectral information includes eigenvalues, eigenvectors, eigenfunctions, and other related properties, such as, Cheeger constant, edge expansion, vertex expansion, graph flow, graph random walk, heat kernel of graph, etc. Mathematically, spectral graph theory can be generalized into spectral simplicial complex and spectral hypergraph.
Spectral graph
In spectral graph theory, a graph is represented by its adjacency matrix and Laplacian matrix [11, 39, 26, 44]. The adjacency matrix describes the connectivity information and can be expressed as,
The degree of a vertex is the total number of edges that are connected to vertex , i.e., . The vertex diagonal matrix can be defined as,
Laplacian matrix, also known as admittance matrix and Kirchhoff matrix, is defined as . More specifically, it can be expressed as,
| (1) |
The Laplacian matrix has many important properties. It is always positive-semidefinite, thus all its eigenvalues are non-negative. In particular, the number (multiplicity) of zero eigenvalues equals to an topological invariant, known as , which counts the number of connected components in the graph. The second smallest eigenvalue, i.e., the first non-zero eigenvalue, is called Fiedler value or algebraic connectivity, which describes the general connectivity of the graph. The corresponding eigenvector can be used to subdivide the graph into two well-connected subgraphs. All eigenvalues and eigenvectors form an eigen spectrum and spectral graph theory studies the properties of the graph eigen spectrum.
There are two types of normalized Laplacian matrixes, including the symmetric normalized Laplacian matrix, which is defined as , and random walk normalized Laplacian, which is defined as .
Spectral simplicial complex
The spectral simplicial complex theory studies the spectral properties of combinatorial Laplacian (or Hodge Laplacian) matrixes, that are constructed based on a simplicial complex [13, 27, 18, 2, 28, 36, 38, 43].
For an oriented simplicial complex, its -th boundary (or incidence) matrix can be defined as follows,
| (5) |
These boundary matrixes satisfy the condition that . The -th combinatorial Laplacian matrix can be expressed as follows,
Note that -th combinatorial Laplacian is,
Further, if the highest order of the simplicial complex is , then the -th combinatorial Laplacian matrix is .
The above combinatorial Laplacian matrixes can be explicitly described in terms of the simplex relations. More specifically, , i.e., when , can be expressed as,
| (9) |
It can be seen that this expression is exactly the graph Laplacian as in Eq. (1). Further, when , can be expressed as [27],
| (14) |
The eigenvalues of combinatorial Laplacian matrixes are independent of the choice of the orientation [18]. Further, the multiplicity of zero eigenvalues, i.e., the total number of zero eigenvalues, of equals to the -th Betti number . Geometrically, is the number of connected components, is the number of circles or loops, and is the number of voids or cavities.
We can define the -th combinatorial down Laplacian matrix as and combinatorial up Laplacian matrix as . These matrixes have very interesting spectral properties [2]. Firstly, eigenvectors associated nonzero eigenvalues of are orthogonal to eigenvectors from nonzero eigenvalues of ; Secondly, nonzero eigenvalues of of are either the eigenvalues of or those of ; Thirdly, eigenvectors associated with nonzero eigenvalues of are either eigenvectors of or those of .
Spectral hypergraph
Laplacian matrixes can also be defined on hypergraph [16, 42, 12, 25, 3]. One way to do that is to employ a clique expansion, in which a graph is construct from a hypergraph by replacing each hyperedge with an edge for each pair of vertices in this hyperedge. A graph Laplacian matrix can then be defined on this hypergraph-induced graph. Note that the clique expansion also generate a clique complex, and combinatorial Laplacian matrixes can also be constructed based on it.
The other way is to directly use the incidence matrix. In a hypergraph, an incidence matrix can be defined as follows,
| (17) |
The vertex diagonal matrix is,
The hypergraph adjacent matrix is then defined as . And the unnormalized hypergraph Laplacian matrix is defined as,
Similar to the graph models, the symmetric normalized hypergraph Laplacian is defined as with the identity matrix. The random walk hypergraph Laplacian is defined as .
2.3 Persistent spectral theory
 |
Filtration
A filtration process naturally generates a mutliscale representation [14]. Filtration parameter, denoted as and key to the filtration process, is usually chosen as sphere radius (or diameter) for point cloud data, edge weight for graphs, and isovalue (or level set value) for density data. A systematical increase (or decrease) of the value for the filtration parameter will induce a sequence of hierarchical topological representations, which can be not only simplicial complexes, but also graphs and hypergraphs. For instance, a filtration operation on a distance matrix, i.e., a matrix with distances between any two vertices as its entries, can be defined by using a cutoff value as the filtration parameter. More specifically, if the distance between two vertices is smaller than the cutoff value, an edge is formed between them. In this way, a systematical increase (or decrease) of the cutoff value will deliver a series of nested graphs, with the graph produced at a lower cutoff value as a part (or a subset) of the graph produced at a larger cutoff value. Similarly, nested simplicial complexes can be constructed by using various definitions of complexes, such as Vietoris-Rips complex, ech complex, Alpha complex, cubical complex, Morse complex, etc. Nested hypergraphs can also be generated by using a suitable definition of hyperedge.
Persistent spectral theory
The essential idea of our PerSpect theory is to provide a new mathematical representation that characterize the intrinsic topological and geometric information of the data. Different from all previous spectral models, our PerSpect theory considers not the eigen spectrum information of the graph, simplicial complex or hypergraph, constructed from a data at a particular scale, instead they focus on the variation of the eigen spectrum of these topological representations during a filtration process. Stated differently, our PerSpect theory studies the change of eigen spectrum in an “evolution” process, during which the structure of graph, simplicial complex or hypergraph “evolves” from a set of isolated vertices to a fully-connected topology, according to their inner structure connectivity and a predefined filtration parameter.
Mathematically, a filtration operation will deliver a nested sequence of graphs as follows,
Here -th graph is generated at a certain filtration value . Computationally, we can equally divide the filtration region (of the filtration parameter) into intervals and consider topological representations at each interval. A series of Laplacian matrixes can be generated from these graphs. Further, a nested sequence of simplicial complexes can also be generated from a filtration process,
Similarly, the -th simplicial complex is generated at filtration value . Combinatorial Laplacian matrix series can be constructed from these simplicial complexes. Note that the size of these Laplacian matrixes may be different. Moreover, with a suitable filtration process, a nested sequence of hypergraph can be generated as follows,
Hypergraph Laplacian matrix series can be constructed accordingly.
PerSpect theory studies the variation of the spectral information from the series of Laplacian matrixes. PerSpect variables and functions can be defined on the series of eigen spectrums. These PerSpect variables can incorporate both geometric and topological information in them. For instance, the multiplicity (or number) of zero eigenvalues equals to Betti number , thus persistent multiplicity, which is defined as the multiplicity of zero eigenvalues over a filtration process, is exactly the Persistent Betti number or Betti curve. Further, we can consider the basic statistic properties, such as mean, standard deviation, maximum and minimum, of all non-zero eigenvalues, and define four other PerSpect variables, i.e., persistent mean, persistent standard deviation, persistent maximum and persistent minimum. Other spectral information, including algebraic connectivity, modularity, Cheeger constant, vertex/edge expansion, and other flow, random walk, and heat kernel related properties, can also be generalized into their corresponding PerSpect variables or functions.
 |
As an illustration, we consider a PerSpect simplicial complex model of fullerene C60. We choose cutoff distance as filtration parameter and use Vietoris-Rips complex to construct simplicial complex. Figure 2 demonstrates the generated sequence of nested simplicial complexes and their corresponding combinatorial Laplacian matrixes. Notation means the -th dimension, and only Laplacian matrixes at to are illustrated. It can be seen that, during the filtration process, complexes have been systematically generated and the simplicial complex evolve from a set with isolated vertices to a fully-connected complete topology. The corresponding Laplacian matrixes characterize this evolution process very well. For , at the very start of the filtration, there are only 60 vertices (0-simplex), thus a 60*60 all-zero Laplacian matrix is generated. As the increase of filtration value, the size of matrix remains unchanged, while more and more -1 value appears at its off-diagonal part. When the filtration value is large enough, a complete graph is obtained, and a full matrix, i.e., all diagonal entries are 60 and off-diagonal entries are -1, is generated according to Eq.(9). For , at early stage of filtration, there exists no edges (1-simplexes) thus no Laplacian matrices. With edges emerging as the filtration value increases, matrixes are generated. Different from the case, the size of matrix increases systematically with the number of edges. Off-diagonal entries have both value 1 and -1 due to the orientation of the edge. When the filtration value is large enough, all edges will be either upper adjacent or not lower adjacent, thus matrix becomes a diagonal matrix with all its diagonal entry value as 60, according to Eq.(14). For , no Laplacian matrixes exist at the beginning stage of filtration, as no 2-simplexes are generated. The size of matrixes also increases with the filtration and eventually evolve into a diagonal matrix with its diagonal entries all as 60 according to Eq.(14). Mathematically, higher dimensional Laplacian matrixes can also be systematically generated.
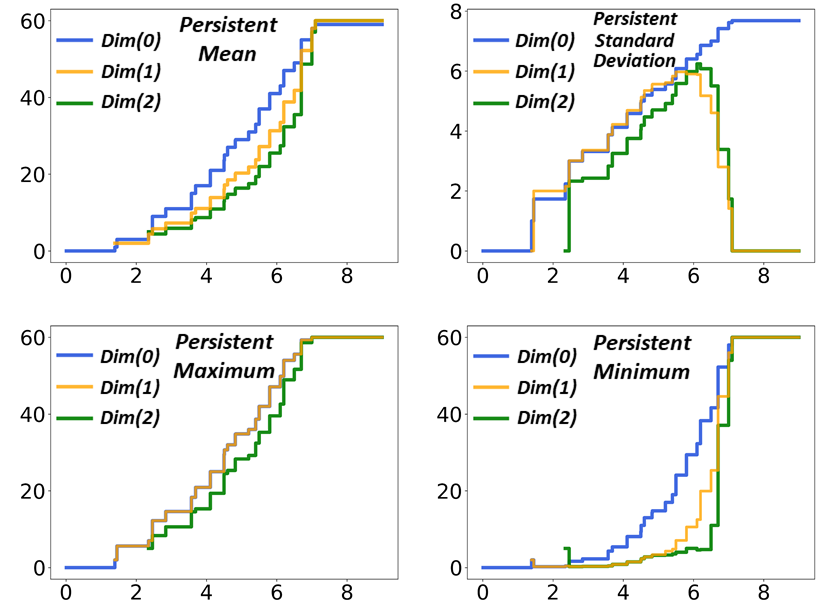 |
Further, we can study PerSpect variables for fullerene C60. Figure 3 shows the comparison between persistent barcode and persistent multiplicity. It can be seen that the persistent multiplicity is equivalent to the persistent Betti function [53], defined as the summation of persistent barcodes. In this way, the persistent homology information is naturally embedded into persistent multiplicity. Figure 4 shows the persistent mean, persistent standard deviation, persistent maximum and persistent minimum for C60. It can be seen that these PerSpect variables change with the filtration value. Each variation of PerSpect variables indicates a certain change of the simplicial complex. At filtration size 7.10 Å, a complete simplicial complex is achieved, i.e., any vertices will form a -simplex. The corresponding has eigenvalues 0 (with multiplicity 1) and 60 (with multiplicity 59). The size for the corresponding is 1770*1770, and its eigenvalues are all 60 (with multiplicity 1770). The size for complete corresponding is 34220*34220, and its eigenvalues are also 60 (with multiplicity 34220).
 |
2.4 PerSpect ML and its application in drug design
PerSpect based machine learning models
Essentially, our PerSpect theory provides a mathematical representation of data, thus can work as a featurization for machine learning models. More specifically, PerSpect variables and functions can be discretized into feature vectors for different learning models. Other than the multiplicity of zero eigenvalues and non-zero eigenvalue statistic properties as mentioned above, spectral indexes from molecular descriptors can also be considered [37]. For a Laplacian matrix with eigenvalues , commonly-used spectral indexes include, sum of eigenvalues (Laplacian graph energy), sum of absolute deviation of eigenvalues (generalized average graph energy with the average eigenvalue), spectral moments ( with the order of moment), quasi-Wiener index ( with and the number of all nonzero eigenvalues), spanning tree number (), etc. Different from previous spectral index based molecular descriptors, which are extracted from a specific graph structure, a series of spectral index, i.e., an index vector, are considered from graphs, simplicial complexes, or hypergraphs obtained from the filtration process. Another potential featurization representation is to construct two dimensional (2D) images from these PerSpect variables [5]. The image representation will be more suitable for deep learning models.
PerSpect models for drug design
Mathematical representations, that characterize biomolecular structural, physical, chemical and biological properties, are key to the success of machine learning models for drug design. For PerSpect ML based drug design, we consider element-specific (ES) biomolecular topological modeling [5]. Instead of using biomolecular topologies from either all-atom models or coarse-grained models (such as Cα), we decompose a biomolecule into different point sets, each with only one type of atoms, and construct topological representations for each set. For instance, a protein structure can be decomposed into 5 different points sets, that contain hydrogen(H), carbon(C), nitrogen(N), oxygen(O), and sulfur(S), separatively. Ligands are usually composed of totally 10 types of points sets, with the other 5 types of atoms including phosphorus(P), fluoride(F), chloride(Cl), bromide(Br) and iodine(I), respectively. Our PerSpect models can be employed on each set or each pair of atom sets. In this way, a detailed topological characterization of the biomolecular structure is obtained.
Further, for protein-ligand binding affinity prediction, we consider the interactive distance matrix (IDM) defined as follows [5],
| (19) |
Here and are coordinates for the - and -th atoms, and is their Euclidean distance. Two sets and are atom coordinate sets for protein and ligand respectively. Only connections (or interactions) between protein atoms and ligand atoms are considered. Connections between atoms within either protein or ligand are ignored by setting their distance as , i.e., an infinity large value. Element-specific interactive distance matrixes (ES-IDM) are considered for protein-ligand binding affinity prediction. That is to say there are totally 4*9=36 types of matrixes between 4 types of atoms from protein, including C, N, O, and S, and 9 types of atoms from ligand, including C, N, O, S, P, F, Cl, Br and I.
To characterize electrostatic properties, the interactive electrostatic matrix (IEM) is defined as follows [5],
| (21) |
Here and are partial charges for the -th and -th atoms, parameter is constant value. In our calculation is set to be 100. In this matrixes, electrostatic interactions between atoms within either protein or ligand are dismissed by setting their value as . Only interactions between protein and ligand are considered. For element-specific interactive electrostatic matrix (ES-IEM), there are totally 5*10=40 types, between 5 types of atoms from protein, including H, C, N, O, and S, and 10 types of atoms from ligand, including H, C, N, O, S, P, F, Cl, Br and I.
3 Results and discussions
In this section, we consider PerSpect simplicial complex based machine learning model for the protein-ligand binding affinity prediction, one of the most important task in drug design.
3.1 Data preparation
We choose three most commonly-used protein-ligand databases [23] for their binding affinity prediction, namely PDBbind-2007, PDBbind-2013 and PDBbind-2016. The data are downloaded from PDBbind (www.pdbbind.org.cn). For each database, the core set is regarded as the test set, all entries in refined set except the ones in the core set form the training set. The detailed data information can be found in Table 1.
| Version | Refined set | Training set | Core set (test set) |
|---|---|---|---|
| v2007 | 1300 | 1105 | 195 |
| v2013 | 1959 | 2764 | 195 |
| v2016 | 4057 | 3772 | 285 |

3.2 Parameter setting
In our ES-IDM based PerSpect simplicial complex models, the distance value is considered as the filtration parameter. The filtration value goes from 0.00 to 25.00 Å. For discretization, Laplacian matrixes are generated with a step of 0.10 Å. That is to say, a totally 250 Laplacian matrixes are generated from each filtration process. Further, in ES-IEM based PerSpect models, the interaction strength is used as the filtration parameter and its value goes 0.00 to 1.00. The Laplacian matrix is generated with a step of 0.01, meaning totally 100 Laplacian matrixes for each filtration process. Further, we consider 11 PerSpect features, including persistent multiplicity for both and , persistent mean, persistent standard deviation, persistent maximum, persistent minimum, persistent Laplacian graph energy, persistent generalized mean graph energy, persistent spectral moment (second order), persistent quasi-Wiener index and persistent spanning tree number. Note that other the persistent multiplicity, all other PerSpect variables are calculated only for Laplacians. To sum up, in our ES-IDMs, there are 36 types of atom combinations as stated above, and the total number of features are 36[types]*250[persistence]*11[eigen feature]. Similarly, there are 50 types of ES-IEMs, and the number of features are 50[types]*100[persistence]*11[eigen feature].
Since we have a large feature vector, decision-tree based models are considered to avoid overfitting. In particular, gradient boost tree (GBT) model have delivered better results in protein-ligand binding affinity prediction. The parameters of GBT are listed in the Table 2. Note that 10 independent regressions are conducted and the medians of 10 PCCs and RMSEs are computed as the performance measurement of our PerSpect ML model.
| No. of estimators | Max depth | Minimum sample split | Learning rate |
|---|---|---|---|
| 40000 | 6 | 2 | 0.001 |
| Loss function | Max features | Subsample size | Repetition |
| least square | square root | 0.7 | 10 times |
| ES-IDM | ES-IEM | ES-IDM+ES-IEM | |
|---|---|---|---|
| PDBbind-2007 | 0.829(1.868) | 0.816(1.941) | 0.836(1.847) |
| PDBbind-2013 | 0.781(2.005) | 0.786(1.979) | 0.793(1.956) |
| PDBbind-2016 | 0.830(1.764) | 0.832(1.757) | 0.840(1.724) |
3.3 Basic results
 |
We consider three GBT models with features from ES-IDM model, ES-IEM model, and combined ES-IDM and ES-IEM mode, respectively. The three models are tested on three databases and an average PCC around 0.800 is obtained. Our PerSpect based GBT results are listed in Table 3. We compare the predicted binding affinity values with the experimental ones, and illustrate the results for the three datasets in Fig. 5.
Further, to have a better understanding of the performance of our models, we have systematically compare our predictions with the state-of-the-art results in literatures [22, 21, 15, 50, 19, 40, 41, 55, 1, 15, 4], as far as we known. The results are illustrated in Figs. 6, 7, and 8. It can be seen that our PerSpect models have achieved the highest PCCs for all three datasets. Further, our RMSE results are also the lowest among all the existing models. This demonstrates the great power of PerSpect theory in biomolecular representation.

4 Conclusion
In this paper, we propose persistent spectral models based machine learning (PerSpect ML) for drug design. Three PerSpect models, including persistent spectral graph, persistent spectral simplicial complex and persistent spectral hypergraph, are proposed. A series of persistent spectral variables, including persistent mulitiplicity, persistent mean, persistent maximum, etc, are considered for biomolecular structure characterization and used as features for machine learning models. We systematically test our models on three commonly-used protein-ligand binding databases. Our PerSpect models can achieve the best results for all three datasets.
Funding
This work was supported in part by Nanyang Technological University Startup Grant M4081842.110, Singapore Ministry of Education Academic Research fund Tier 1 RG31/18 and Tier 2 MOE2018-T2-1-033.
References
- [1] K. Afifi and A. F. Al-Sadek. Improving classical scoring functions using random forest: The non-additivity of free energy terms’ contributions in binding. Chemical biology & drug design, 92(2):1429–1434, 2018.
- [2] S. Barbarossa and S. Sardellitti. Topological signal processing over simplicial complexes. arXiv preprint arXiv:1907.11577, 2019.
- [3] Sergio Barbarossa and Mikhail Tsitsvero. An introduction to hypergraph signal processing. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6425–6429. IEEE, 2016.
- [4] F. Boyles, C. Deane, and G. Morris. Learning from the ligand: using ligand-based features to improve binding affinity prediction. 2019.
- [5] Z. X. Cang, L. Mu, and G. W. Wei. Representability of algebraic topology for biomolecules in machine learning based scoring and virtual screening. PLoS computational biology, 14(1):e1005929, 2018.
- [6] Z. X. Cang and G. W. Wei. Analysis and prediction of protein folding energy changes upon mutation by element specific persistent homology. Bioinformatics, 33(22):3549–3557, 2017.
- [7] Z. X. Cang and G. W. Wei. Integration of element specific persistent homology and machine learning for protein-ligand binding affinity prediction. International journal for numerical methods in biomedical engineering, p. 10.1002/cnm.2914, 2017.
- [8] Z. X. Cang and G. W. Wei. TopologyNet: Topology based deep convolutional and multi-task neural networks for biomolecular property predictions. PLOS Computational Biology, 13(7):e1005690, 2017.
- [9] Z. X. Cang and G. W. Wei. Integration of element specific persistent homology and machine learning for protein-ligand binding affinity prediction. International journal for numerical methods in biomedical engineering, 34(2):e2914, 2018.
- [10] D. S. Cao, Q. S. Xu, Q. N. Hu, and Y. Z. Liang. ChemoPy: freely available python package for computational biology and chemoinformatics. Bioinformatics, 29(8):1092–1094, 2013.
- [11] F. Chung. Spectral graph theory. American Mathematical Society, 1997.
- [12] Joshua Cooper and Aaron Dutle. Spectra of uniform hypergraphs. Linear Algebra and its applications, 436(9):3268–3292, 2012.
- [13] B. Eckmann. Harmonische funktionen und randwertaufgaben in einem komplex. Commentarii Mathematici Helvetici, 17(1):240–255, 1944.
- [14] H. Edelsbrunner, D. Letscher, and A. Zomorodian. Topological persistence and simplification. Discrete Comput. Geom., 28:511–533, 2002.
- [15] E. N. Feinberg, D. Sur, Z. Q. Wu, B. E. Husic, H. H. Mai, Y. Li, S. S. Sun, J. Y. Yang, B. Ramsundar, and V. S. Pande. Potentialnet for molecular property prediction. ACS central science, 4(11):1520–1530, 2018.
- [16] K. Q. Feng and W. C. W. Li. Spectra of hypergraphs and applications. Journal of number theory, 60(1):1–22, 1996.
- [17] C. Grow, K. F. Gao, D. D. Nguyen, and G. W. Wei. Generative network complex (GNC) for drug discovery. arXiv preprint arXiv:1910.14650, 2019.
- [18] D. Horak and J. Jost. Spectra of combinatorial Laplace operators on simplicial complexes. Advances in Mathematics, 244:303–336, 2013.
- [19] J. Jiménez, M. Skalic, G. Martinez-Rosell, and G. De Fabritiis. KDEEP: Protein–ligand absolute binding affinity prediction via 3D-convolutional neural networks. Journal of chemical information and modeling, 58(2):287–296, 2018.
- [20] G. Landrum. RDKit: Open-source cheminformatics. 2006.
- [21] H. J. Li, K. S. Leung, M. H. Wong, and P. J. Ballester. Improving AutoDock Vina using random forest: the growing accuracy of binding affinity prediction by the effective exploitation of larger data sets. Molecular informatics, 34(2-3):115–126, 2015.
- [22] J. Liu and R. X. Wang. Classification of current scoring functions. Journal of chemical information and modeling, 55(3):475–482, 2015.
- [23] Z. H. Liu, Li Y., Han L., Liu J., Zhao Z. X., Nie W., Liu Y. C., and Wang R. X. PDB-wide collection of binding data: current status of the PDBbind database. Bioinformatics, 31(3):405–412, 2015.
- [24] Y. C. Lo, S. E. Rensi, W. Torng, and R. B. Altman. Machine learning in chemoinformatics and drug discovery. Drug discovery today, 23(8):1538–1546, 2018.
- [25] Linyuan Lu and Xing Peng. High-ordered random walks and generalized laplacians on hypergraphs. In International Workshop on Algorithms and Models for the Web-Graph, pp. 14–25. Springer, 2011.
- [26] B. Mohar, Y. Alavi, G. Chartrand, and O. R. Oellermann. The laplacian spectrum of graphs. Graph theory, combinatorics, and applications, 2(871-898):12, 1991.
- [27] A. Muhammad and M. Egerstedt. Control using higher order laplacians in network topologies. In Proc. of 17th International Symposium on Mathematical Theory of Networks and Systems, pp. 1024–1038. Citeseer, 2006.
- [28] S. Mukherjee and J. Steenbergen. Random walks on simplicial complexes and harmonics. Random structures & algorithms, 49(2):379–405, 2016.
- [29] D. D. Nguyen, Z. X. Cang, and G. W. Wei. A review of mathematical representations of biomolecular data. Physical Chemistry Chemical Physics, 2020.
- [30] D. D. Nguyen, Z. X. Cang, K. D. Wu, M. L. Wang, Y. Cao, and G. W. Wei. Mathematical deep learning for pose and binding affinity prediction and ranking in D3R Grand Challenges. Journal of computer-aided molecular design, 33(1):71–82, 2019.
- [31] D. D. Nguyen, Z. X. Cang, K. D. Wu, M. L. Wang, Y. Cao, and G. Wei. Wei. Mathematical deep learning for pose and binding affinity prediction and ranking in D3R Grand Challenges. Journal of computer-aided molecular design, 33(1):71–82, 2019.
- [32] D. D. Nguyen, K. F. Gao, M. L. Wang, and G. W. Wei. MathDL: Mathematical deep learning for D3R Grand Challenge 4. Journal of computer-aided molecular design, pp. 1–17, 2019.
- [33] D. D. Nguyen and G. W. Wei. AGL-Score: Algebraic graph learning score for protein-ligand binding scoring, ranking, docking, and screening. Journal of chemical information and modeling, 59(7):3291–3304, 2019.
- [34] D. D. Nguyen, T. Xiao, M. L. Wang, and G. W. Wei. Rigidity strengthening: A mechanism for protein–ligand binding. Journal of chemical information and modeling, 57(7):1715–1721, 2017.
- [35] N. M. O’Boyle, M. Banck, C. A. James, C. Morley, T. Vandermeersch, and G. R. Hutchison. Open Babel: An open chemical toolbox. Journal of cheminformatics, 3(1):33, 2011.
- [36] O. Parzanchevski and R. Rosenthal. Simplicial complexes: spectrum, homology and random walks. Random Structures & Algorithms, 50(2):225–261, 2017.
- [37] T. Puzyn, J. Leszczynski, and M. T. Cronin. Recent advances in QSAR studies: methods and applications, volume 8. Springer Science & Business Media, 2010.
- [38] S. Shukla and D. Yogeshwaran. Spectral gap bounds for the simplicial Laplacian and an application to random complexes. Journal of Combinatorial Theory, Series A, 169:105134, 2020.
- [39] D. A. Spielman. Spectral graph theory and its applications. In 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07), pp. 29–38. IEEE, 2007.
- [40] M. M. Stepniewska-Dziubinska, P. Zielenkiewicz, and P. Siedlecki. Development and evaluation of a deep learning model for protein–ligand binding affinity prediction. Bioinformatics, 34(21):3666–3674, 2018.
- [41] M. Y. Su, Q. F. Yang, Y. Du, G. Q. Feng, Z. H. Liu, Y Li, and R. X. Wang. Comparative assessment of scoring functions: The CASF-2016 update. Journal of chemical information and modeling, 59(2):895–913, 2018.
- [42] Liang Sun, Shuiwang Ji, and Jieping Ye. Hypergraph spectral learning for multi-label classification. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 668–676, 2008.
- [43] J. J. Torres and G. Bianconi. Simplicial complexes: higher-order spectral dimension and dynamics. arXiv preprint arXiv:2001.05934, 2020.
- [44] U. Von Luxburg. A tutorial on spectral clustering. Statistics and computing, 17(4):395–416, 2007.
- [45] B. Wang, C. Z. Wang, K. D. Wu, and G. W. Wei. Breaking the polar-nonpolar division in solvation free energy prediction. Journal of computational chemistry, 39(4):217–233, 2018.
- [46] B. Wang, Z. X. Zhao, and G. W. Wei. Automatic parametrization of non-polar implicit solvent models for the blind prediction of solvation free energies. The Journal of chemical physics, 145(12):124110, 2016.
- [47] R. Wang, D. D. Nguyen, and G. W. Wei. Persistent spectral graph. arXiv preprint arXiv:1912.04135, 2019.
- [48] G. W. Wei. Mathematics at the eve of a historic transition in biology. Computational and Mathematical Biophysics, 5(1), 2017.
- [49] G. W. Wei. Persistent homology analysis of biomolecular data. Journal of Computational Physics, 305:276–299, 2017.
- [50] M. Wójcikowski, M. Kukiełka, M. M. Stepniewska-Dziubinska, and P. Siedlecki. Development of a protein–ligand extended connectivity (PLEC) fingerprint and its application for binding affinity predictions. Bioinformatics, 35(8):1334–1341, 2019.
- [51] K. D. Wu and G. W. Wei. Quantitative toxicity prediction using topology based multi-task deep neural networks. Journal of chemical information and modeling, p. 10.1021/acs.jcim.7b00558, 2018.
- [52] K. D. Wu, Z. X. Zhao, R. X. Wang, and G. W. Wei. TopP–S: Persistent homology-based multi-task deep neural networks for simultaneous predictions of partition coefficient and aqueous solubility. Journal of computational chemistry, 39(20):1444–1454, 2018.
- [53] K. L. Xia, X. Feng, Y. Y. Tong, and G. W. Wei. Persistent homology for the quantitative prediction of fullerene stability. Journal of Computational Chemsitry, 36:408–422, 2015.
- [54] R. D. Zhao, Z. X. Cang, Y. Y. Tong, and G. W. Wei. Protein pocket detection via convex hull surface evolution and associated Reeb graph. Bioinformatics, 34(17):i830–i837, 2018.
- [55] L. Z. Zheng, J. R. Fan, and Y. G. Mu. OnionNet: a multiple-layer intermolecular-contact-based convolutional neural network for protein–ligand binding affinity prediction. ACS omega, 4(14):15956–15965, 2019.
- [56] A. Zomorodian and G. Carlsson. Computing persistent homology. Discrete Comput. Geom., 33:249–274, 2005.