2022
[2]\fnmMohammad-Reza \surFeizi-Derakhshi
1]\orgdivDepartment of Computer Engineering, \orgnameShabestar Branch, Islamic Azad University, \orgaddress\cityShabestar, \stateEast Azerbaijan, \countryIran
[2]\orgdivComputerized Intelligence Systems Laboratory, Department of Computer Engineering, \orgnameUniversity of Tabriz, \orgaddress\street29 Bahman Blvd., \cityTabriz, \stateEast Azerbaijan, \countryIran
Persian topic detection based on Human Word association and graph embedding
Abstract
This paper proposes a framework for topic detection in social media based on Human Word Association (HWA). Identifying topics within these platforms has become a significant challenge. Although substantial work has been done in English, much less has been conducted in Persian, especially for Persian microblogs. Furthermore, existing research primarily focuses on frequent patterns and semantic relationships, often neglecting the structural aspects of language. Our proposed framework utilizes HWA, a method that imitates mental capabilities for word association. This approach also calculates the Associative Gravity Force (AGF), demonstrating how words relate. Using this concept, a graph can be generated from which topics can be extracted through graph embedding and clustering. We applied this approach to a Persian language dataset collected from Telegram and conducted several experimental studies to evaluate its performance. The Experimental results indicate that our method outperforms other topic detection approaches.
keywords:
Tpoic detection, Human Word Association, social network, Graph embedding, hdbscan1 Introduction
Analyzing social media posts can help understand public events and people’s opinions, concerns, and expectations COVIDTrendingTopics . Identifying and examining social media topics aids in understanding the nature of emerging fields. This paper proposes a framework for topic detection based on Human Word Association (HWA). We used various combinations of graph embedding methods and clustering algorithms to determine the optimal approach. Initially, a stream of social media posts was captured. These posts’ word co-occurrence was then obtained as a second step for HWA detection. This calculation led to a co-occurrence graph, to which the HWA-based AGF (Associative Gravity Force) formulation was applied, resulting in an AGF graph. Topics were then extracted using clustering algorithms. Each cluster could contain different topics. To achieve this, it was necessary to convert the graph into vector space, for which graph embedding methods were employed. Given the high dimensionality of this vector space, a dimension reduction method named UMAP was incorporated into the framework. Figure 1 presents the general structure of our proposed framework. When compared to other topic modeling methods, our framework demonstrated superior performance. Here are the main contributions of this work:
-
•
Imitation of human mental ability for word association to extract topics in social networks
-
•
Use of keyword co-occurrence for topic detection in social media messages
-
•
Use of graphs to model the framework
-
•
Development of a framework to extract topics from posts in the Persian language

1.1 Human Word Association
An intuitive method for analyzing Human Word Association (HWA) is to conduct surveys. These surveys are standard in psychology and linguistics, with the most popular being the free association test (FAT) and the free association norm (FAN). In these tests, participants are asked to write the first word that comes to mind in response to a given stimulus word. Studies have shown that Human Word Association is asymmetric, meaning the association strength between two words can vary depending on their order. Nelson et al. conducted a test with 6,000 participants and found, for example, that while the tuple (good, bad) is symmetric (since about 75% of the participants answered ’good’ for the word ’bad’ and about 76% wrote ’bad’ in response to ’good’), the tuple (canary, bird) is asymmetric. Approximately 69% of people answered ’canary’ for the word ’bird’, but only 6% responded with ’bird’ when presented with ’canary’ Nelson2000 Nelson2004 Klahold2014 . Therefore, the proposed method must account for this asymmetry to simulate HWA accurately. In this paper, we employ a formulation named AGF for this purpose.
1.2 Graph Embedding
Graph embedding methods fall into three standard categories: factorization-based, random walk-based, and deep learning-based Goyal2018 . This paper utilizes random walk-based methods, specifically the Deep Walk and Node2Vec models. These methods are advantageous when the graph is sufficiently large and cannot be fully measured Goyal2018 . We evaluated the results to choose the superior approach.
-
•
Deep walk DeepWalk involves the probability of observing the last k node and the subsequent k node of a random walk (RW) centered on the i-th vertex, as illustrated in equation 1.
(1) The model generates several random walks, each of length 2k + 1, to perform optimizations over the sum of the log-likelihoods of each random walk. Edges are then reconstructed from node embedding using dot-product-based decoders Goyal2018 .
-
•
Node2Vec node2vec maintains high-order accessibility between nodes by maximizing the likelihood of subsequent nodes appearing in a random walk of fixed length. The main distinction is that Node2Vec uses a distorted random walk, balancing between breadth-first search (BFS) and depth-first search (DFS) graph searches. As a result, Node2Vec provides higher quality and more informative embeddings than Deep Walk. By striking the right balance, Node2Vec can preserve community structure and structural equivalence between nodes Goyal2018 .
1.3 Dimension Reduction
Dimensionality reduction is a powerful tool for machine learning practitioners dealing with large and high-dimensional datasets.
-
•
t-SNE tsne is one of the most widely utilized techniques for visualization. It is well-suited for visualizing high-dimensional datasets and employs graph-based algorithms for low-dimensional data representation. However, t-SNE does not scale well with rapidly increasing sample sizes, and attempts to speed it up lead to substantial memory consumption. Therefore, using t-SNE for clustering is not optimal.
-
•
UMAP mcinnes2020umap offers several advantages over t-SNE, including increased speed and better preservation of the data’s global structure. UMAP operates similarly to t-SNE by constructing a high-dimensional graph representation of the data, then optimizing a low-dimensional graph to match as closely as possible. Fig 2 provides a visualization demonstrating the application of UMAP on a 2D projection of 3D data. Understanding the theory behind UMAP makes it easier to find out the parameters of the algorithm. The two most commonly used parameters, and , effectively control the balance between local and global structures in the final projection.

1.4 Clustering for Topic Detection
Clustering is a method used to identify topic communities. This paper evaluates the effectiveness of two different approaches, K-means, and HDBSCAN.
-
•
K-means is a well-known iterative clustering algorithm based on iterative relocation. It partitions a dataset into k clusters, minimizing the mean squared distance between the instances and the cluster centers TextClustering .
-
•
HDBSCAN HDBSCAN developed by Campello et al., is a clustering algorithm where DBSCAN requires a minimum cluster size and a distance threshold epsilon as user-defined input parameters. Unlike DBSCAN, HDBSCAN implements various epsilon values, requiring only the minimum cluster size as a single input parameter. The cluster selection method returns the cluster with the highest stability over epsilon. This approach allows for the identification of variable density clusters without the need to select an appropriate distance threshold.
2 Related Works
This section examines various methods in the field of subject recognition in social networks. This operation is divided into two categories in some sources: document pivot and feature pivot Aiello2013 ; EnhancedHbGraph . While other sources divide the feature pivot category into two categories: based on the feature and the probabilistic topic model Indra2018 ; HUPM ; HUPC . The document-based approach is a subject recognition technique that uses document clustering based on similarities. This technique was developed based on First Story Recognition (FSD) research. Feature pivot approaches cluster documents based on Feature selection. Determining the threshold value and probabilistic model are two methods for document feature selection. One of the threshold value determination approaches is the TF-IDF. In contrast, one of the features based on the probabilistic subject model is the document burst. The Burst document has a higher frequency of occurrence than other documents. Most scientific achievements in the field of topic modeling are based on the Dirichlet latent allocation method (LDA) Aiello2013 ; Blei2003 . LDA is a probabilistic model built on BoW 111Bag of Word and widely used for subject modeling. Word repetition rates are extracted from documents to calculate the probability distribution of words that are likely to be found in topics.
Most topic modeling improvements are based on frequent pattern mining(FPM). This method has several applications in many fields, such as clustering and classification. Frequent pattern mining is a conventional method for detecting topics on Twitter data streams, and various frameworks are available Saeed2019 .
In SFPM , a soft frequent pattern mining(SFPM) is designed to overcome the topic detection problem. This study aims to find all word co-occurrence with a value greater than two, so the probability of each word is calculated separately. After finding top-K frequent words, a co-occurrence vector is formed to add the words that occurred together to the top-K word vectors. As an improvement to this approach, in Gaglio2015 , by adding a named entity recognition weight boost to enhance word score, a system has been designed to overcome the limitation of SFPM in dealing with dynamic and real-time scenarios. A method called HUI-Miner has been introduced in Liu2012 to identify a set of high-utility itemsets without generating a candidate. This method has been used in HUPM ; HUPC ; Gaglio2015 to find high utility itemsets in the domain of topic detection on Twitter. HUPC introduced a high utility pattern clustering method (HUPC). After determining each pattern’s utility and extracting high utility patterns, this method selects top-K very similar patterns using the modularity-based clustering method and KNN classification method. Also, HUPM uses a high utility pattern mining method (HUPM) to find a group of frequently used words, and then a data structure called TP-tree is used to extract the pattern of the main topic. Saeed et al. EnhancedHbGraph ; Saeed2019 ; Saeed2018 ; Saeed2020 introduced a dynamic heartbeat graph (DHG). This algorithm creates a subgraph for each sentence. These subgraphs are then added to the main graph and applied to the entire graph based on the degree of coherence of the words (edges between nodes) Asgari-Chenaghlu2021 . The methods that have been introduced so far are based on the frequency of patterns or the co-occurrence of words. The semantic relationship between words needs to be addressed in approaches. TopicBert uses a combination of transformers with an incremental community detection algorithm to identify topics. On the one hand, transformers provide a semantic relationship between words in different contexts. On the other hand, the graph mining technique improves the accuracy of the resulting subjects with the help of simple structural rules TopicBert . It should be noted that the topic detection problem is a natural language processing problem, so the linguistic approaches still need to be investigated. Therefore, language structural methods and text processing will improve the results. Khadivi et al. in HWA_Embedding_MRK use Human Word association (HWA) as a structural language technique to imitate the human mental ability to associate words. They also employed embedding techniques for better results. As previous researches show, It is better to illustrate social network mining using Graphs. This framework is a graph mining method that uses HWA.
3 Proposed Method
In principle, FPM methods cannot track the order of items as they are applied to transactions and itemsets. However, employing linguistic structure processing methods proves promising when dealing with social media posts, a form of natural language processing. One beneficial strategy to reinforce these methods involves understanding how humans interpret topics. A technical solution can be developed by concentrating on the human ability to identify associations between words. To comprehend association building, a concept known as HWA is utilized to extract topics that accurately represent the flow of data in social networks. The social network data stream can be considered a sequence of posts received chronologically. All recently received posts within a fixed time window (for example, 12 hours) can be represented as a batch of posts like where is, post in window . It should be noted that in this paper, a post is the text of that post after pre-processing and removing stopwords. If be a set of words in the window , it can be said that . In other words, is a set of words; each word is a member of the word set of the same window. The final purpose of this paper is to extract topics from window , which is presented as . This article proposes a method with 4 phases to carry out this process; each phase has its steps. These phases and steps are described in the following. The flowchart of this phase and their steps are also shown in figure 3.

Phase 1: data preparation
Step 1: Posts on social networks are likely to include noise, such as typos, emojis, mentions, hashtags, or URLs. This noise could result in numerous issues; hence, it is essential to pre-process these posts to reduce the noise level. A tokenizer, specifically created for parsing social network posts, has been employed for this task. This tokenizer splits tokens based on different types of separators and identifies the token type. Examples of token types include emojis, URLs, hashtags, mentions, numerals, and simple or compound words. 4 provides an example of the output of this tokenizer. Subsequently, apart from numbers and words, all tokens of the post are eliminated, including stop words. A list of tokens processed by the tokenizer will proceed to the second step to calculate the co-occurrence.

Step 2: A post, after pre-processing, is represented as . This post can also be illustrated using a graph. The co-occurrence graph of post is defined as . ̵The reason is, each vertex of the graph represents each word of the post, and the edge between two different vertices symbolizes a weight function, as shown in eq. 2. To use this graph to generate another graph, a graph for batch (described later), Each node also has two properties and . These properties are added to reduce the Computational complexity of generating that graph. As is set, property indicates the frequency of words. Also, represents the number of posts where the word occurred; for now, its initial value is 1. An example of this graph is represented in fig.5.
| (2) |
where is calculated as eq.3. If and are assumed to be two different words, and both have occurred in , then their co-occurrence is equal to 1; otherwise, it is 0;
| (3) |
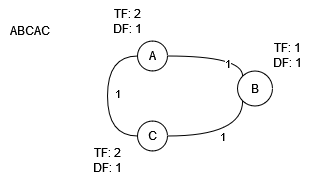
As the data stream receives and new posts arrive, the newly captured post’s graph will be generated and added to the previous graph. A more extensive graph will be achieved at the end of the batch. This graph, named Batch CooC graph (BCG), is defined as . The difference between the Batch CooC graph and Post CooC graph is that in BCG, All nodes(V) are members of , and edges, which are CooC(x,y), are calculated using eq. 4. An example of this process can be seen in Fig. 6.
| (4) |
| (5) |
| (6) |
The process of generating BCG and updating the weight of the edges and nodes properties is explained in Algorithm 1.

Phase2: HWA
As the time window is completed and the graph generation process is over, the BCG graph becomes quite large in terms of vertices and edges, leading to computational complexity. Therefore, a solution is needed to prune the graph and remove extra information. One basic solution is to use linguistic-based methods, and the method employed in this article is based on HWA.
Step 3: As each vertex of the BCG graph represents a word, word ranking becomes the first step in identifying important and frequent words, known as keywords. This framework uses a method derived from the conventional TF-IDF method. is formulated as eq. 7.
| (7) |
Words in with a high value are the most important words, referred to as Keywords. Deciding how many words to select requires a threshold, referred to as Rate in this paper. Choosing a fixed rate is incorrect, given that the number of words in each window varies. Therefore, h% of words with high will be selected as keywords. Various experiments have been performed to achieve an optimal rate. Based on the parameter tuning in Table 1, the best value is . Therefore, words not in the top 10% will be pruned from the .
Step 4: In this step, to replicate a human perception of HWA and the symmetric and asymmetric combination of word association, a concept called CIMAWA has been used, defined as eq. 8.
| (8) |
is a damping factor assumed to be 0.1 based on the experiment results. CIMAWA is used to calculate AGF in the next step.
Step 5: The Associative Gravity Force (AGF) quantifies the strength of the association of word x with word y in a text window. In other words, it calculates the gravitational pull of word concerning the word . It should be noted that according to the CIMAWA concept, will be different from . The function used in this paper to calculate the power of word association (AGF) is given in eq. 9.
| (9) |
Step 6: By calculating the Associative Gravity Force, the previous parameters should be replaced with new parameters; in other words, a new graph will be created. Although this new graph has fewer parameters, these parameters provide more information about the type of relationship between vertices (words); Because they are generated using linguistic structures. This paper proposes a new graph structure. it is defined as (, ) where are the keywords of as nodes, and is the weight of each directed edge called AGF, which can be calculated using phase 2. Unlike the CooC graph, the AGF graph is a directed graph. Fig 7 shows a sample of the AGF graph.

.
Phase 3: Graph Processing
Up until this point, posts and words have been converted into graphs. The goal is to identify their topics, and one of the best ways to interact with the social network graph is to find the community. Therefore, this graph must be processed in an understandable way to the algorithm. For this purpose, the graph embedding method has been used. The following phase will involve clustering.
Step 7: This paper suggests using Graph Embedding. Two methods, DeepWalk and Node2Vec, have been evaluated to identify a more accurate method. Different parameter values of these algorithms are tested to select the best algorithm, and the best values are set. The results of the parameter tuning, as well as the evaluation results of both algorithms in section 4.2, show that Node2Vec performs best. These vectors will be clustered in the following phase to find communities, but the graph is very dense. This may reduce the accuracy of the topic extraction. One way to increase accuracy is to reduce the dimension.
Step 8: Dimensionality reduction is a powerful tool for machine learning practitioners to visualize and understand large, high-dimensional datasets. UMAP can be used as an effective preprocessing step to boost the performance of density-based clustering. As in the graph embedding step, the UMAP parameters are fully tuned. The main parameter is , and its value is considered 2 based on the experiments. The parameter tuning results are given in section 4.2, and the evaluation results are given in section 4.4.
Phase 4: Topic Extraction
Extracting topics from a social network graph is similar to finding communities in social networks. One way to detect communities is by applying clustering to the social network graph. As previously mentioned, a social network is a high-density graph. Also, topics in social networks have a hierarchical structure. Given these considerations, different clustering methods are evaluated in this paper.
Step 9: Once the embedding of each node is prepared, they are clustered. This paper evaluated two different clustering algorithms: K-means and HDBSCAN. The primary purpose of doing this is to find topics over a period of time. To find optimum parameters for each of the clustering algorithms, several experiments have been conducted. The selected values for these parameters are presented in Table 1 and discussed in 4.2. The results of each method within the proposed framework are shown in section 4.4.
4 Experiments and Results
This section presents the experimental results obtained by the proposed framework. All implementations were done in Anaconda Python 3.8 and ran on a PC with a 3.60GHz Core i7-7700 processor with 32 GB RAM and a Linux Mint operating system. The performance of the proposed work is compared with each other and with the results of other models. All comparative models are also implemented and executed over the dataset introduced in 4.1, using evaluation metrics in section 4.3.
4.1 Dataset
To evaluate the performance of the proposed algorithm, the Sep_General_Tel01 dataset Sep-TD-Tel , provided by the Computerized Intelligence Systems Laboratory (ComInSyS)222cominsys.ir is used. This dataset has been prepared due to the limited resources in Persian and the high popularity of the Telegram social network in Iran. The Telegram network is considered a microblog. A microblog is a small content designed to engage an audience quickly. Microblogs are short blog posts (less than 300 words) that can contain images, GIFs, links, infographics, videos, and audio. Figure 8 illustrates the histogram of the character length of Telegram posts.

In this work, the official API published by Telegram is used. The implemented framework can fetch text messages and media (such as images, documents, and videos). In order to respect privacy principles, only data related to channels and public groups have been used for collection. Unlike existing datasets, which are often collected from the Twitter social network and require keywords to fetch information, the Telegram network does not need any. This dataset is also collected without using any keywords. This dataset contains more than ten thousand records of messages sent to public channels and groups in one month between 12 Dey 1395 (1 January 2017) and 12 Bahman 1395 (31 January 2017). This data includes two major topics: ”The death of Ayatollah Hashemi Rafsanjani” and ”The fire in the Plasco building”. Due to the nature of this research, only the text of the messages sent has been used. To process posts, this database is divided into sixty 12-hour windows. To evaluate and compare the results of this paper, it is necessary to compare the extracted topics with GT. For this purpose, nine windows with the most news value and the best match with the two cloud themes have been labeled out of the sixty available windows. These windows are {14, 15, 16, 17, 18, 37, 38, 39, 40}. To perform this operation, four experts were used for labeling, and the final label was the result of the opinions of these individuals. A summary of information about this database to better understand the timeline of this database is given in Figure 9.

4.2 Parameters Setup
All of the parameters used in this framework are shown in Table 1. This table represents the methods used in this paper, their parameters, their range, and the selected value for each one. Table 1 summarizes the parameters used in the framework. The framework has been executed with different values for each parameter and fixed ones for the others. Different methods have been used in this paper, and each method has different parameters. For example, and represent Keyword rating and damping factor, respectively, which are parameters used in HWA methods. Both parameters are tuned in various numbers to find a suitable value. For instance, parameter has an initial value of 5 and a termination value of 50. This parameter will increase by 5. Unlike this, some parameters have fixed values. For example, parameters like ’number of walks’, which shows the number of walks to sample for each node, and ’walk length’, which represents the length of each walk, have fixed values of 64 and 8, respectively. Besides that, some parameters have a list of values. Parameters and in the Node2Vec method are of this type. Nevertheless, these parameters in DeepWalk are fixed.
| Method | Parameters | Span | Value |
| HWA | Keyword Rate(h) | range( 5, 50, 5) | 10 |
| Damping factor( ) | range(0.1, 1.0, 0.1) | 0.1 | |
| GE(Node2Vec) | number of walks | 64 | |
| walk length | 8 | ||
| dimensionality of the feature vectors(D) | 32 | ||
| window size(W) | 10 | ||
| number of iterations(epoch) | range(10,1000,10) | 100 | |
| in-out parameter(p) | [0.25, 0.50, 1.0, 2.0, 4.0] | 0.50 | |
| return parameter(Q) | [0.25, 0.50, 1.0, 2.0, 4.0] | 1.0 | |
| GE(Deepalk) | number of walks | 64 | |
| walk length | 8 | ||
| dimensionality of the feature vectors(D) | 32 | ||
| window size(W) | 10 | ||
| number of iterations(epoch) | range(10,1000,10) | 100 | |
| in-out parameter(p) | 1 | ||
| return parameter(Q) | 1 | ||
| MAP | Number of neighbors | 2 | |
| Clustering (Kmeans) | Number of clusters | range(2,20,1) | 8 |
| Max iteration | 300 | ||
| Clustering (Hdbscan) | Min cluster size | 5 |
4.3 Evaluation Metrics
As topic detection involve identifying groups or clusters, clustering evaluation is relevant in topic detection tasks. Cluster evaluation is the process of measuring the quality and performance of a clustering output. Cluster evaluation can help to find out how well the proposed framework works. If ground truth is available, it can be used by methods that compare the clustering against the ground truth and measure. ”ground truth” is the labeling of the data, such as a human expert’s judgment or a benchmark dataset. Two measures, F-measure and FS criterion, are adopted to evaluate the clustering quality. It is desirable to maximize the F-measure and minimize the FS criterion of clusters.
4.3.1 FS criterion
Evaluating the quality of a multi-labeled clustering system is challenging. One of the challenges in evaluating multi-labeled clustering systems is that traditional measures, such as class and cluster Entropy333code can found at: https://github.com/mkhadivi/ClusterEvaluation, do not consider multi-labeling. To overcome this, we used a novel measure called the FS criterion FS . This criterion can be used to evaluate not only the performance of the whole clustering system but also the performance of each cluster or class.
In FS criterion444code can be found at: https://github.com/cominsys/FS_criterion, results should be evaluated using a metric that reflects the ”goodness” of the result. This metric is cluster FS. In addition, a metric is needed to evaluate the ”compactness” of the results, called class FS. Suppose a set of samples, a set of true classes(given by an expert) and a set of given clusters(usually determined by a system), each sample in can be assigned to some of the classes in and the same sample can be assigned to some of the clusters in . The following metrics are defined.
-
•
FS Cluster
FS Cluster measures the degree of diversity or mixed membership within individual clusters. A lower cluster criterion value suggests that the cluster has a more homogeneous distribution of class labels or attributes, indicating well-defined and coherent clusters. Conversely, a higher cluster criterion value implies a more mixed or heterogeneous distribution of class labels or attributes within the cluster, indicating less well-defined clusters. So, the lower score is the best. Score of cluster is defined as:(10) where denotes number of classes and is the Sum of the score of samples in cluster which are assigned to class . Total cluster score for all clusters is defined as:
(11) where and denote number of classes and clusters respectively.
-
•
FS Class criterion
Class criterion evaluates how well the created clusters represent data points of the same class. The optimal FS criterion value for a class is zero. If samples of the same class exist in several clusters, the class criterion score increases. Score of class is defined as:(12) where denotes number of clusters and is the Sum of the score of samples in class which are assigned to cluster . Total class score for all classes is defined as:
(13) where and denote number of classes and clusters respectively.
It is important to note that these two metrics work in the opposite direction: reducing cluster criterion increases class criterion and vice versa. Therefore, a measurement criterion based on these two criteria will be useful. For this purpose, the arithmetic weighted average can be used. The total criterion is defined based on the following:
(14) where is the corresponding cluster criterion weight, and is the standard class criterion weight. This proposed method uses an equal weight for both of them. Table 2 shows this metric’s results.
4.3.2 Topic Evaluation
To evaluate the correctness of the extracted threads, a metric is needed to compare the topics in the GT and the system. This paper uses Topic Precision and Topic Recall as performance evaluation scales. F-measure is a combination of Topic Precision and Topic Recall. All three of these criteria have been used to evaluate all windows.
-
•
Topic Precision
The number of extracted Topics that match the Topics in GT.(15) -
•
Topic Recall
The number of correctly extracted Topics from GT Topics.(16) -
•
Topic F1-Measure
Using the above concepts, F-measure is defined as follows(17)
These metrics results are presented in Table 3.
4.4 Results
For an overall analysis of the algorithm performance, the proposed framework demonstrated the best values in both FS criterion and Topic evaluation, as per Tables 2 and 3. This work combines AGF with different graph embedding and clustering techniques. These tables show that combining AGF with the Node2Vec graph embedding method and the HDbscan clustering algorithm exhibits the best performance. Figure 10 displays the progression of the top three topics in each window over the ’Hashemi death’ super topic to visualize the trends. The topics this framework identifies appear on the left of the charts and align with the right-coming topics, which constitute Ground Truth. The temporal trend of these topics and how they change over time can be observed. As the plot indicates, window 16 is the change window wherein the event’s first sub-topic, ’Heart attack’, emerged.

| Method | FS criterion | ||
|---|---|---|---|
| Cluster | Class | Total | |
| AGF + Node2Vec+ HDbscan (proposed) | 1.328505 | 0.690471 | 1.009488202 |
| AGF + deep walk + HDbscan (proposed) | 1.594577 | 0.645277 | 1.119927096 |
| AGF + Node2Vec+ kmeans (proposed) | 1.402442 | 0.750816 | 1.076629029 |
| AGF + deep walk + kmeans (proposed) | 1.470772 | 1.273735 | 1.372253661 |
| AGF(base) AGF_base | 1.530920 | 0.738440 | 1.134680404 |
| Twevent twevent | 1.721218 | 0.388564 | 1.05489122 |
| HUPM HUPM | 1.729917 | 0.362058 | 1.045987555 |
| HUPC HUPC | 1.520165 | 0.825380 | 1.172772534 |
| Method | Topic Evaluation | ||
|---|---|---|---|
| Precision | Recall | F-Measure | |
| AGF + Node2Vec+ HDbscan (proposed) | 0.825926 | 0.510293 | 0.630831 |
| AGF + deep walk + HDbscan (proposed) | 0.774018 | 0.507079 | 0.612738 |
| AGF + Node2Vec+ kmeans (proposed) | 0.825555 | 0.480134 | 0.607154 |
| AGF + deep walk + kmeans (proposed) | 0.818182 | 0.465517 | 0.593407 |
| AGF (base) AGF_base | 0.497221 | 0.819564 | 0.618938 |
| TweEvent twevent | 0.620762 | 0.482383 | 0.542894 |
| HUPM HUPM | 0.895330 | 0.299086 | 0.448387 |
| HUPC HUPC | 0.941176 | 0.172414 | 0.291439 |
5 Conclusion
This paper proposes a trending topic detection framework utilizing HWA combined with graph embedding techniques and clustering methods. This framework is applied to social media posts collected from Telegram. Initially, the co-occurrence of words in posts is extracted. Then, the calculations are performed using HWA, leading to generating the AGF graph. This graph is then input into a graph embedding algorithm. Finally, after dimension reduction, the vectors obtained are clustered together to group similar topics. This approach is applied to a Persian language dataset collected from Telegram, and several experimental studies are conducted to assess its performance. The experimental results indicate that this framework outperforms other prevalent topic detection approaches.
Declarations
Funding
No funds, grants, or other support were received.
Conflict of interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Availability of data and materials
The dataset generated during the current study, Sep_TD_Tel01, is available in the Mendeley repository, https://doi.org/10.17632/372rnwf9pc.
Authors’ contributions
Mehrdad Ranjbar-Khadivi: Conceptualization, Methodology, Investigation, Data curation, Validation, Writing - original draft. Mohammad-Reza Feizi-Derakhshi: Project administration, Formal analysis, Supervision. Shahin Akbarpour: Supervision. Babak Anari: Supervision.
Ethics approval
Not applicable.
References
- \bibcommenthead
- (1) Asgari-Chenaghlu, M., Nikzad-Khasmakhi, N., Minaee, S.: Covid-Transformer: Detecting COVID-19 Trending Topics on Twitter Using Universal Sentence Encoder. arXiv (2020). https://doi.org/10.48550/ARXIV.2009.03947
- (2) Nelson, D.L., McEvoy, C.L., Dennis, S.: What is free association and what does it measure? Memory and Cognition (2000). https://doi.org/10.3758/BF03209337
- (3) Nelson, D.L., McEvoy, C.L., Schreiber, T.A.: The University of South Florida Free Association, Rhyme, and Word Fragment Norms. https://doi.org/10.3758/BF03195588
- (4) Klahold, A., Uhr, P., Ansari, F., Fathi, M.: Using word association to detect multitopic structures in text documents. IEEE Intelligent Systems 29, 40–46 (2014). https://doi.org/10.1109/MIS.2013.120. 2
- (5) Goyal, P., Ferrara, E.: Graph embedding techniques, applications, and performance: A survey. Knowledge-Based Systems 151, 78–94 (2018). https://doi.org/10.1016/j.knosys.2018.03.022
- (6) Perozzi, B., Al-Rfou, R., Skiena, S.: Deepwalk: online learning of social representations, pp. 701–710. ACM, ??? (2014). https://doi.org/10.1145/2623330.2623732. https://dl.acm.org/doi/10.1145/2623330.2623732
- (7) Grover, A., Leskovec, J.: node2vec: Scalable feature learning for networks. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 855–864. ACM, New York, NY, USA (2016). https://doi.org/10.1145/2939672.2939754
- (8) van der Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of Machine Learning Research 9(86), 2579–2605 (2008)
- (9) McInnes, L., Healy, J., Melville, J.: UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction (2020)
- (10) Coenen, A., Pearce, A.: Understanding UMAP. https://pair-code.github.io/understanding-umap/
- (11) Seo, Y.-W., Sycara, K.: Text clustering for topic detection. Technical Report CMU-RI-TR-04-03, Carnegie Mellon University, Pittsburgh, PA (January 2004)
- (12) Campello, R.J.G.B., Moulavi, D., Sander, J.: Density-Based Clustering Based on Hierarchical Density Estimates. https://doi.org/10.1007/978-3-642-37456-2_14. http://link.springer.com/10.1007/978-3-642-37456-2_14
- (13) Aiello, L.M., Petkos, G., Martin, C., Corney, D., Papadopoulos, S., Skraba, R., Goker, A., Kompatsiaris, I., Jaimes, A.: Sensing trending topics in twitter. IEEE Transactions on Multimedia (2013). https://doi.org/10.1109/TMM.2013.2265080
- (14) Saeed, Z., Abbasi, R.A., Razzak, I., Maqbool, O., Sadaf, A., Xu, G.: Enhanced heartbeat graph for emerging event detection on twitter using time series networks. Expert Systems with Applications 136, 115–132 (2019). https://doi.org/10.1016/j.eswa.2019.06.005
- (15) Indra, Winarko, E., Pulungan, R.: Trending topics detection of indonesian tweets using bn-grams and doc-p. Journal of King Saud University - Computer and Information Sciences (2018). https://doi.org/10.1016/j.jksuci.2018.01.005
- (16) Choi, H.-J., Park, C.H.: Emerging topic detection in twitter stream based on high utility pattern mining. Expert Systems with Applications 115, 27–36 (2019). https://doi.org/10.1016/j.eswa.2018.07.051
- (17) Huang, J., Peng, M., Wang, H.: Topic detection from large scale of microblog stream with high utility pattern clustering. In: Proceedings of the 8th Workshop on Ph.D. Workshop in Information and Knowledge Management, pp. 3–10. ACM, ??? (2015). https://doi.org/10.1145/2809890.2809894. https://dl.acm.org/doi/10.1145/2809890.2809894
- (18) Blei, D., Ng, A., Jordan, M.: Latent dirichlet allocation. Journal of Machine Learning Research 3, 993–1022 (2003)
- (19) Saeed, Z., Abbasi, R.A., Razzak, M.I., Xu, G.: Event detection in twitter stream using weighted dynamic heartbeat graph approach [application notes]. IEEE Computational Intelligence Magazine 14, 29–38 (2019). https://doi.org/10.1109/MCI.2019.2919395
- (20) Petkos, G., Papadopoulos, S., Aiello, L., Skraba, R., Kompatsiaris, Y.: A soft frequent pattern mining approach for textual topic detection. In: Proceedings of the 4th International Conference on Web Intelligence, Mining and Semantics (WIMS14) - WIMS ’14, pp. 1–10. ACM Press, New York, New York, USA (2014). https://doi.org/10.1145/2611040.2611068
- (21) Gaglio, S., Lo Re, G., Morana, M.: Real-time detection of twitter social events from the user’s perspective. In: 2015 IEEE International Conference on Communications (ICC), pp. 1207–1212 (2015). https://doi.org/10.1109/ICC.2015.7248487
- (22) Liu, M., Qu, J.: Mining high utility itemsets without candidate generation. In: Proceedings of the 21st ACM International Conference on Information and Knowledge Management - CIKM ’12, p. 55. ACM Press, New York, New York, USA (2012). https://doi.org/10.1145/2396761.2396773
- (23) Saeed, Z., Abbasi, R.A., Sadaf, A., Razzak, M.I., Xu, G.: Text stream to temporal network - a dynamic heartbeat graph to detect emerging events on twitter. In: Advances in Knowledge Discovery and Data Mining, pp. 534–545. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-93037-4_42
- (24) Saeed, Z., Abbasi, R.A., Razzak, I.: Evesense: What can you sense from twitter? In: Advances in Information Retrieval, pp. 491–495. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-45442-5_64
- (25) Asgari-Chenaghlu, M., Feizi-Derakhshi, M.-R., Farzinvash, L., Balafar, M.-A., Motamed, C.: Topic Detection and Tracking Techniques on Twitter: A Systematic Review. Complexity 2021, 1–15 (2021). https://doi.org/10.1155/2021/8833084
- (26) Asgari-Chenaghlu, M., Feizi-Derakhshi, M.-R., Farzinvash, L., Balafar, M.-A., Motamed, C.: Topicbert: A cognitive approach for topic detection from multimodal post stream using bert and memory–graph. Chaos, Solitons & Fractals 151, 111274 (2021). https://doi.org/10.1016/j.chaos.2021.111274
- (27) Khadivi, M.R., Akbarpour, S., Feizi-Derakhshi, M.-R., Anari, B.: A Human Word Association based model for topic detection in social networks. arXiv (2023). https://doi.org/10.48550/ARXIV.2301.13066. https://arxiv.org/abs/2301.13066
- (28) Ranjbar-Khadivi, M., Feizi-Derakhshi, M.-R., Forouzandeh, A., Gholami, P., Feizi-Derakhshi, A.-R., Zafarani-Moattar, E.: Sep_TD_Tel01 (2022). https://doi.org/10.17632/372rnwf9pc
- (29) Feizi-Derakhshi, M.-R.: A Measure to Evaluate Multi-labeled Clustering Systems. https://github.com/cominsys/FS_criterion
- (30) Benny, A., Philip, M.: Keyword based tweet extraction and detection of related topics. Procedia Computer Science 46, 364–371 (2015). https://doi.org/10.1016/j.procs.2015.02.032. 1
- (31) Li, C., Sun, A., Datta, A.: Twevent: segment-based event detection from tweets. In: Proceedings of the 21st ACM International Conference on Information and Knowledge Management - CIKM ’12, p. 155. ACM Press, New York, New York, USA (2012). https://doi.org/10.1145/2396761.2396785