Perceptual Quality Assessment for Digital Human Heads
Abstract
Digital humans are attracting more and more research interest during the last decade, the generation, representation, rendering, and animation of which have been put into large amounts of effort. However, the quality assessment of digital humans has fallen behind. Therefore, to tackle the challenge of digital human quality assessment issues, we propose the first large-scale quality assessment database for three-dimensional (3D) scanned digital human heads (DHHs). The constructed database consists of 55 reference DHHs and 1,540 distorted DHHs along with the subjective perceptual ratings. Then, a simple yet effective full-reference (FR) projection-based method is proposed to evaluate the visual quality of DHHs. The pretrained Swin Transformer tiny is employed for hierarchical feature extraction and the multi-head attention module is utilized for feature fusion. The experimental results reveal that the proposed method exhibits state-of-the-art performance among the mainstream FR metrics. The database is released at https://github.com/zzc-1998/DHHQA.
Index Terms— Digital human head, quality assessment database, full-reference, projection-based
1 Introduction
Digital humans are digital simulations and models of human beings on computers, which have been widely employed in applications such as games, automobiles, metaverse, etc. Current research scopes are mainly focused on the generation, representation, rendering, and animation of digital humans [1]. However, with the rapid development of VR/AR technologies, more and more viewers have a higher demand on visual quality of digital humans, which makes it necessary to carry out quality assessment studies on digital humans. Unfortunately, the collection of digital human models is very expensive and time-consuming, which requires the assistance of professional three-dimensional (3D) scanning devices and human subjects. Moreover, large-scale quality assessment subjective experiments on the visual quality of digital humans are not available currently. Therefore, we conduct both subjective and objective quality assessment studies for digital human heads in this paper and we hope this study can promote the development of digital human quality assessment (DHQA).
In this paper, we first propose a large-scale quality assessment database for digital human heads (DHHs). A total of 255 human subjects are invited to participate in the DHH scanning experiment. We carefully select 55 high-quality generated DHH models as the reference stimuli (the DHH models are in the format of textured meshes), which cover both male and female, young and old subjects. Then we manually degrade the reference DHHs with 7 types of distortions including surface simplification, position compression, UV compression, texture sub-sampling, texture compression, color noise, and geometry noise, and obtain 1,540 distorted DHHs in total. A well-controlled subjective experiment is conducted to collect mean opinion scores (MOS) for distorted DHHs. Consequently, we obtain the largest subject-rate quality assessment database for digital human heads (DHHQA). We validate several mainstream quality assessment metrics for the benchmark. Further, we specifically design a deep neural network (DNN) based full-reference (FR) quality assessment method to boost the performance on DHH quality evaluation. The experimental results show that the proposed method has a better correlation with the subjective ratings.
| Database | Source | Subject-rated Models | Content | Description |
|---|---|---|---|---|
| SJTU-PCQA [2] | 10 | 420 | Colored Point Cloud | Humans, Statues |
| WPC [3] | 20 | 740 | Colored Point Cloud | Fruit, Vegetables, Tools |
| LSPCQA [4] | 104 | 1,240 | Colored Point Cloud | Animals, Humans, Vehicles, Daily objects |
| CMDM [5] | 5 | 80 | Colored Mesh | Humans, Animals, Statues |
| TMQA [6] | 55 | 3,000 | Textured Mesh | Statues, Animals, Daily objects |
| DHHQA(Ours) | 55 | 1,540 | Textured Mesh | Scanned Real Human Heads |
2 Related Works
2.1 Digital Human
Sensing, Modeling, and driving digital humans have been popular research topics in computer vision and computer graphics. Namely, 3D human pose and shape estimation [7, 8] are of great significance for the representation of digital human models. Digital human animation generation [9, 10] aims to drive digital human motion activities with text or audio. However, little attention is paid to the visual quality assessment of digital humans.
2.2 3D Quality Assessment
Currently, 3D quality assessment (3D-QA) mainly focuses on point cloud quality assessment (PCQA) and mesh quality assessment (MQA). To cope with the challenge of visual quality assessment of 3D models, substantial efforts have been made to carry out 3D quality assessment databases [2, 3, 4, 5, 6] and the detailed comparison with the proposed database is listed in Table 1, from which we can find that the proposed DHHQA database is the first large-scale database specially designed for DHHs.
The objective quality assessment methods for 3D-QA can be generally categorized into two types: model-based methods [3, 4, 5, 11, 12] and projection-based methods [2, 6, 13, 14, 15]. Model-based methods extract features directly from 3D models while projection-based methods infer the visual quality of 3D models from the rendered projections. Although the model-based methods are invariant to viewpoints, it is difficult to efficiently extract quality-aware features from 3D models since high-quality 3D models usually contain large numbers of dense points/vertices. While the projection-based methods can make use of the mature image/video quality assessment (IQA/VQA) models, therefore gaining better performance.

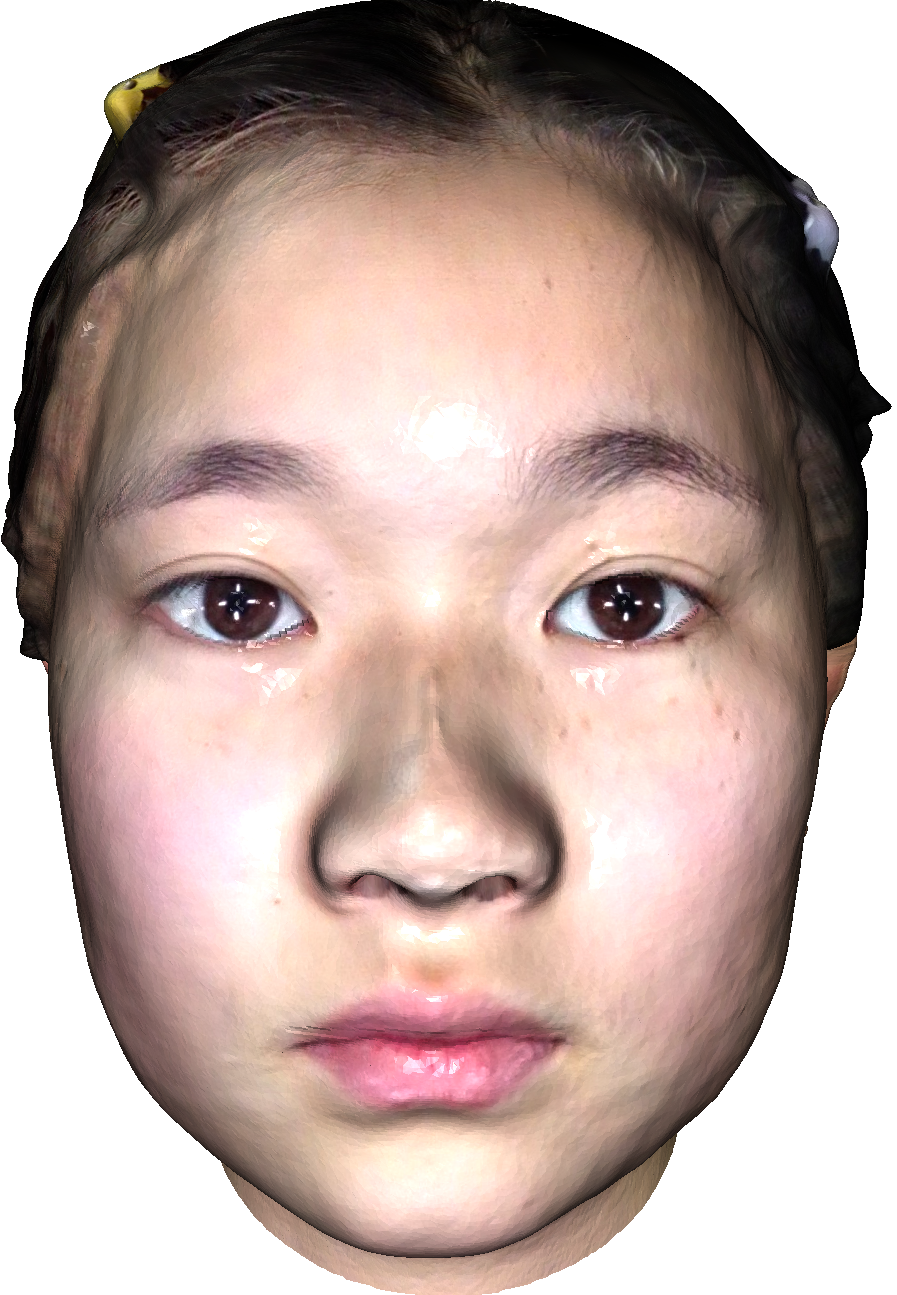


3 Database Construction
3.1 DHH Collection & Distortion Generation
To gather the source models of DHHs, we invite 255 human subjects (aged from 12 to 60) to participate in the scanning experiment with the Bellus3D ††https://www.bellus3d.com app. Finally, a total of 55 DHHs are manually chosen as the source DHH models. Samples of the selected DHHs are exhibited in Fig. 1. Then 7 types of common distortions are applied to degrade the reference DHH models: (a) Surface simplification (SS): The algorithm proposed in [16] is employed to simplify the DHH models and the simplification rate is set as {0.4, 0.2, 0.1, 0.05}; (b) Position Compression (PC): The Draco ††https://github.com/google/draco library is applied to quantize the position attributes of the DHH models with compression parameter qp set as {6, 7, 8, 9}; (c) UV Map Compression (UMC): The Draco library is applied to quantize the texture coordinate attributes with the compression parameter qt set as {7,8,9,10}; (d) Texture Down-sampling (TD): The reference texture maps (40964096) are down-sampled with resolutions of {20482048, 10241024, 512512, 256256}; (e) Texture Compression (TC): The JPEG compression is used to compress the texture maps with quality levels set as {3, 10, 15, 20}; (f) Geometry Noise (GN): Gaussian noise is introduced to the vertices of the DHH models with set as {0.05, 0.1, 0.15, 0.2}; (g) Color Noise (CN): Gaussian noise is added to the texture maps with set as {20, 40, 60, 80}. To sum up, 1,540 = 5574 distorted DHH models are generated and the degradation levels are manually defined to cover the most quality range.








3.2 Subjective Quality Assessment Experiment
Following the recommendation of ITU-R BT.500-13 [17], we conduct the subjective quality assessment experiment in a well-controlled laboratory environment. All the DHH models are rendered into projections from the front and left side viewpoint and the reference as well as distorted projections are at the same time for evaluation. The projections are shown in random order with an interface designed by Python Tkinter on an iMac monitor which supports the resolution up to 4096 2304, the screenshot of which is illustrated in Fig. 3. 22 males and 18 females are invited to participate in the subjective experiment. The whole experiment is divided into 11 sessions. Each session contains 140 distorted DHH models and is attended by at least 20 participants. In all, more than 30,800 = 1,54020 subjective ratings are collected.
After the subjective experiment, we calculate the z-scores from the raw ratings as follows:
| (1) |
where , , and is the number of images judged by subject . The ratings from unreliable subjects according to ITU-R BT.500-13 [17]. The corresponding z-scores are linearly rescaled to and the mean opinion scores (MOSs) are computed by averaging the rescaled z-scores. The MOS distribution is exhibited in Fig. 4, from which we can see that the quality ratings cover most of the quality range.


4 Objective Quality Assessment
To provide useful guidelines for quality-oriented digital human systems, we propose a simple yet effective full-reference (FR) projection-based method to predict the visual quality of DHH models. The framework of the proposed method is illustrated in Fig. 5, which includes the feature extraction, the feature fusion module, and the feature regression module. Only the front projections are used for feature extraction.
4.1 Feature Extraction
Following the common process of mapping the reference and distorted projections into quality embeddings with DNNs, the pretrained Swin Transformer tiny (ST-t) [18] is employed as the feature extraction backbone since it takes up less training and inference resources. Considering the visual information is perceived hierarchically from simple low-level features (e.g., noise and texture) to complex high-level features (e.g., semantic information), we employ the hierarchical structure for feature extraction:
| (2) | ||||
where represents the features from the -th stage, stands for the average pooling operation, denotes the pooled results from the -th stage, and indicates the concatenation operation. Given the input reference and distorted front projections and , the quality-aware features can be obtained as:

| (3) |
where is the hierarchical ST-t encoder, and represent the quality-aware embeddings for the input reference and distorted front projections.
4.2 Feature Fusion
To actively relate the quality-aware information between the reference and distorted embeddings, we utilize the multi-head attention operation for feature fusion:
| (4) | ||||
where indicates the multi-head attention operation where is used to guide the attention learning of , is the fused quality-aware embedding, and is the final quality embedding.
4.3 Feature Regression
With the final quality embedding , two-stage fully-connected (FC) layers are employed for feature regression:
| (5) |
where represents the predicted quality scores and stands for the fully-connected layers. Moreover, the L1 loss is utilized as the loss function:
| (6) |
where is the size of the mini-batch, and are quality labels and predicted quality scores respectively.
5 Experiment
5.1 Implementation Details & Competitors
The ST-t backbone is fixed with weights pretrained on the ImageNet [19] and only the feature fusion and regression modules are trained. The Adam optimizer [20] is used with the initial learning rate set as 1e-4 and the number of training epochs is set as 50. The batch size is set as 32. The 10801920 front projections are resized into the resolution of 256456 and patches with the resolution of 224224 as the input. We conduct the 5-fold cross validation on the DHHQA database and the average results of the 5 folds are recorded as the final performance. It’s worth mentioning that there is no content overlap between the training and testing sets. Several mainstream FR-IQA methods are validated for comparison as well, which include PSNR, SSIM [21], MS-SSIM [22], GMSD [23], LPIPS [24], and PieAPP [25]. These methods are validated using the same front projections on the same testing sets as the proposed method and the average results are recorded as the final performance. We also include the performance of some classic FR point cloud quality assessment (PCQA) methods such as p2point[26], p2plane[27] and PSNR-yuv[28] through converting the DHHs from textured meshes to point clouds. Additionally, all the quality scores predicted by the IQA methods are processed with five-parameter logistic regression to deal with the scale difference.
5.2 Performance Discussion
The performance results are shown in Table 2, from which we can several inspections: (a) The proposed method achieves the higher performance among all the competitors and is about 0.03 ahead of the second place competitor LPIPS (0.9286 vs. 0.8935) in terms of SRCC, which shows the effectiveness of the proposed method for predicting the visual quality of DHH models; (b) Comparing the performance of MS-SSIM and SSIM, we can conclude that the multi-scale features can greatly help boost the performance since the MS-SSIM surpasses SSIM by almost 0.12 in terms of SRCC, which also reflects the rationality of the proposed hierarchical ST-t structure; (c) The learning-based methods (LPIPS, PieAPP, and proposed method) are all superior to the handcrafted-based methods. It can be explained that the handcrafted-based IQA methods are developed mainly for natural scene images (NSIs). However, the prior knowledge for perceptual quality differs from NSIs to DHH projections since the projections are artificially rendered with computers rather than captured with cameras. By actively learning the prior knowledge from the DHH projections, the learning-based methods can yield better performance consequently.
| Model | SRCC | PLCC | KRCC | RMSE |
|---|---|---|---|---|
| MSE-p2point | 0.2891 | 0.2916 | 0.2359 | 21.0813 |
| MSE-p2plane | 0.2698 | 0.2961 | 0.2250 | 21.0502 |
| PSNR-yuv | 0.1761 | 0.2272 | 0.1369 | 21.4299 |
| PSNR | 0.8347 | 0.8371 | 0.6405 | 11.5822 |
| SSIM | 0.7355 | 0.7253 | 0.5388 | 14.5221 |
| MS-SSIM | 0.8557 | 0.8396 | 0.6653 | 11.4953 |
| GMSD | 0.8411 | 0.8350 | 0.6534 | 11.6441 |
| LPIPS | 0.8935 | 0.8881 | 0.7085 | 9.7194 |
| PieAPP | 0.8769 | 0.8723 | 0.6857 | 10.3552 |
| Proposed | 0.9286 | 0.9320 | 0.7585 | 7.2910 |
6 Conclusion
In this paper, we propose a large-scale digital human head quality assessment database to deal with the issues of digital human quality assessment. 55 reference DHHs are selected and each reference DHH is degraded with 7 types of distortions under 4 levels, which generates a total of 1,540 distorted DHH models. Then a subjective quality assessment experiment is carried out to obtain the MOSs of the distorted DHH models. Afterward, a simple yet effective FR projection-based method is proposed by employing the pretrained Swin Transformer tiny as the backbone. The hierarchical quality-aware features are extracted from the reference and distorted DHHs’ front projections and fused with the multi-head attention module. The experimental results show that the proposed method outperforms the mainstream FR-IQA methods, which demonstrates its effectiveness for predicting the visual quality levels of DHHs.
References
- [1] Wenmin Zhu, Xiumin Fan, and Yanxin Zhang, “Applications and research trends of digital human models in the manufacturing industry,” Elsevier VRIH, vol. 1, no. 6, pp. 558–579, 2019.
- [2] Qi Yang, Hao Chen, Zhan Ma, Yiling Xu, Rongjun Tang, and Jun Sun, “Predicting the perceptual quality of point cloud: A 3d-to-2d projection-based exploration,” IEEE TMM, pp. 1–1, 2020.
- [3] Qi Liu, Honglei Su, Zhengfang Duanmu, Wentao Liu, and Zhou Wang, “Perceptual quality assessment of colored 3d point clouds,” IEEE TVCG, 2022.
- [4] Yipeng Liu, Qi Yang, Yiling Xu, and Le Yang, “Point cloud quality assessment: Dataset construction and learning-based no-reference metric,” ACM TOMM, 2022.
- [5] Y. Nehmé, F. Dupont, J. P. Farrugia, P. Le Callet, and G. Lavoué, “Visual quality of 3d meshes with diffuse colors in virtual reality: Subjective and objective evaluation,” IEEE TVCG, vol. 27, no. 3, pp. 2202–2219, 2021.
- [6] Yana Nehmé, Florent Dupont, Jean-Philippe Farrugia, Patrick Le Callet, and Guillaume Lavoué, “Textured mesh quality assessment: Large-scale dataset and deep learning-based quality metric,” arXiv preprint arXiv:2202.02397, 2022.
- [7] Julieta Martinez and et al., “A simple yet effective baseline for 3d human pose estimation,” in IEEE ICCV, 2017, pp. 2640–2649.
- [8] Dario Pavllo and et al., “3d human pose estimation in video with temporal convolutions and semi-supervised training,” in IEEE/CVF CVPR, 2019, pp. 7753–7762.
- [9] Jun Liu and et al., “Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding,” IEEE TPAMI, vol. 42, no. 10, pp. 2684–2701, 2019.
- [10] Amir Shahroudy, Jun Liu, Tian-Tsong Ng, and Gang Wang, “Ntu rgb+ d: A large scale dataset for 3d human activity analysis,” in IEEE/CVF CVPR, 2016, pp. 1010–1019.
- [11] Zicheng Zhang, Wei Sun, Xiongkuo Min, Tao Wang, Wei Lu, Wenhan Zhu, and Guangtao Zhai, “A no-reference visual quality metric for 3d color meshes,” in ICMEW. IEEE, 2021, pp. 1–6.
- [12] Zicheng Zhang, Wei Sun, Xiongkuo Min, Tao Wang, Wei Lu, and Guangtao Zhai, “No-reference quality assessment for 3d colored point cloud and mesh models,” IEEE TCSVT, 2022.
- [13] Yu Fan and et al., “A no-reference quality assessment metric for point cloud based on captured video sequences,” in IEEE MMSP. IEEE, 2022, pp. 1–5.
- [14] Zicheng Zhang, Wei Sun, Yucheng Zhu, Xiongkuo Min, Wei Wu, Chen Ying, and Guangtao Zhai, “Treating point cloud as moving camera videos: A no-reference quality assessment metric,” arXiv preprint arXiv:2208.14085, 2022.
- [15] Zicheng Zhang, Wei Sun, Xiongkuo Min, Quan Zhou, Jun He, Qiyuan Wang, and Guangtao Zhai, “Mm-pcqa: Multi-modal learning for no-reference point cloud quality assessment,” arXiv preprint arXiv:2209.00244, 2022.
- [16] Michael Garland and Paul S Heckbert, “Simplifying surfaces with color and texture using quadric error metrics,” in IEEE Proceedings Visualization, 1998, pp. 263–269.
- [17] RECOMMENDATION ITU-R BT, “Methodology for the subjective assessment of the quality of television pictures,” International Telecommunication Union, 2002.
- [18] Ze Liu and et al., “Swin transformer: Hierarchical vision transformer using shifted windows,” in IEEE/CVF CVPR, 2021, pp. 10012–10022.
- [19] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in IEEE/CVF CVPR, 2009, pp. 248–255.
- [20] Diederik P Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” in ICLR, 2015.
- [21] Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE TIP, vol. 13, no. 4, pp. 600–612, 2004.
- [22] Z. Wang, E.P. Simoncelli, and A.C. Bovik, “Multiscale structural similarity for image quality assessment,” in IEEE ACSSC, 2003, vol. 2, pp. 1398–1402 Vol.2.
- [23] Wufeng Xue, Lei Zhang, Xuanqin Mou, and Alan C. Bovik, “Gradient magnitude similarity deviation: A highly efficient perceptual image quality index,” IEEE TIP, vol. 23, no. 2, pp. 684–695, 2014.
- [24] Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in IEEE/CVF CVPR, 2018, pp. 586–595.
- [25] Ekta Prashnani, Hong Cai, Yasamin Mostofi, and Pradeep Sen, “Pieapp: Perceptual image-error assessment through pairwise preference,” in IEEE/CVF CVPR, 2018, pp. 1808–1817.
- [26] Paolo Cignoni, Claudio Rocchini, and Roberto Scopigno, “Metro: measuring error on simplified surfaces,” in Computer graphics forum. Wiley Online Library, 1998, vol. 17, pp. 167–174.
- [27] Dong Tian, Hideaki Ochimizu, Chen Feng, Robert Cohen, and Anthony Vetro, “Geometric distortion metrics for point cloud compression,” in 2017 IEEE ICIP. IEEE, 2017, pp. 3460–3464.
- [28] Eric M Torlig and et al., “A novel methodology for quality assessment of voxelized point clouds,” in Appl. digit. image process. XLI. SPIE, 2018, vol. 10752, pp. 174–190.