PC2WF: 3D Wireframe Reconstruction from Raw Point Clouds
Abstract
We introduce PC2WF, the first end-to-end trainable deep network architecture to convert a 3D point cloud into a wireframe model. The network takes as input an unordered set of 3D points sampled from the surface of some object, and outputs a wireframe of that object, i.e., a sparse set of corner points linked by line segments. Recovering the wireframe is a challenging task, where the numbers of both vertices and edges are different for every instance, and a-priori unknown. Our architecture gradually builds up the model: It starts by encoding the points into feature vectors. Based on those features, it identifies a pool of candidate vertices, then prunes those candidates to a final set of corner vertices and refines their locations. Next, the corners are linked with an exhaustive set of candidate edges, which is again pruned to obtain the final wireframe. All steps are trainable, and errors can be backpropagated through the entire sequence. We validate the proposed model on a publicly available synthetic dataset, for which the ground truth wireframes are accessible, as well as on a new real-world dataset. Our model produces wireframe abstractions of good quality and outperforms several baselines.
1 Introduction
Many practical 3D sensing systems, like stereo cameras or laser scanners, produce unstructured 3D point clouds. That choice of output format is really just a "smallest common denominator", the least committal representation that can be reliably generated with low-level signal processing. Most users would prefer a more efficient and more intuitive representation that describes the scanned object’s geometry as a compact collection of geometric primitives, together with their topological relations. Specifically, many man-made objects are (approximately) polyhedral and can be described by corners, straight edges and/or planar surfaces. Roughly speaking there are two ways to abstract a point cloud into a polyhedral model: either find the planar surfaces and intersect them to find the edges and corners, e.g., Schnabel et al. (2007); Fang et al. (2018); Coudron et al. (2018); or directly find the salient corner and/or edges, e.g., Jung et al. (2016); Hackel et al. (2016).
A wireframe is a graph representation of an object’s shape, where vertices correspond to corner points (with high Gaussian curvature) that are linked by edges (with high principal curvature). Wireframes are a good match for polyhedral structures like mechanical parts, furniture or building interiors. In particular, since wireframes focus on the edge structure, they are best suited for piece-wise smooth objects with few pronounced crease edges (whereas they are less suitable for smooth objects without defined edges or for very rough ones with edges everywhere). We emphasise that wireframes are not only a "compression technique" to save storage. Their biggest advantage in many applications is that they are easy to manipulate and edit, automatically or interactively in CAD software, because they make the salient contours and their connectivity explicit. Reconstructed wireframes can drive and help to create 3D CAD models for manufacturing parts, metrology, quality inspection, as well as visualisation, animation, and rendering.
Inferring the wireframe from a noisy point cloud is a challenging task. We can think of the process as a sequence of steps: find the corners, localise them accurately (as they are not contained in the point cloud), and link them with the appropriate edges. However, these steps are intricately correlated. For example, corner detection should "know" about the subsequent edge detection: curvature is affected by noise (as any user of an interest point detector can testify), so to qualify as a corner a 3D location should also be the plausible meeting point of multiple, non-collinear edges. Here we introduce PC2WF, an end-to-end trainable architecture for point cloud to wireframe conversion. PC2WF is composed of a sequence of feed-forward blocks, see Fig. 1 for the individual steps of the pipeline. First a "backbone" block extracts a latent feature encoding for each point. The next block identifies local neighbourhoods ("patches") that contain corners and regresses their 3D locations. The final block links the corners with an overcomplete set of plausible candidate edges, collects edge features by pooling point features along each edge, and uses those to prune the candidate set to a final set of wireframe edges. All stages of the architecture that have trainable parameters support back-propagation, such that the model can be learned end-to-end. We validate PC2WF with models from the publicly available ABC dataset of CAD models, and with a new furniture dataset collected from the web. The experiments highlight the benefit of explicit, integrated wireframe prediction: on the one hand, the detected corners are more complete and more accurate than with a generic corner detector; on the other hand, the reconstructed edges are more complete and more accurate than those found with existing (point-wise) edge detection methods.
2 Related Work
Relatively little work exists on the direct reconstruction of 3D wireframes. We review related work for the subtasks of corner and edge detection, as well as works that reconstruct wireframes in 2D or polyhedral surface models and geometric primitives in 3D.
Corner Detection. Corner points play a fundamental role in both 2D and 3D computer vision. A 3D corner is the intersection point of 3 (locally) non-collinear surfaces. Corners have a well-defined location and a local neighbourhood with non-trivial shape (e.g., for matching). Collectively the set of corners often is sufficient to tightly constrain the scale and shape of an object. Typical local methods for corner detection are based on the 2-moment matrix of the points (resp. normals) in a local neighbourhood (Głomb, 2009; Sipiran & Bustos, 2010; 2011), a straight-forward generalisation of the 2D Harris operator first proposed for 2D images (Harris et al., 1988). Also other 2D corner detectors like Susan (Smith & Brady, 1997) have been generalised to 3D (Walter et al., 2009).
Point-level Edge Point Detection. A large body of work is dedicated to the detection of 3D points that lie on or near edges. The main edge feature is high local curvature (Yang & Zang, 2014). Related features, such as symmetry (Ahmed et al., 2018), change of normals (Demarsin et al., 2007), and eigenvalues (Bazazian et al., 2015; Xia & Wang, 2017) can also be used for edge detection. Hackel et al. (2016; 2017) use a combination of several features as input for a binary edge-point classifier. After linking the points into an adjacency graph, graph filtering can be used to preserve only edge points (Chen et al., 2017). EC-Net (Yu et al., 2018) is the first method we know of that detects edge points in 3D point clouds with deep learning.
Learning Structured Models. Many methods have been proposed to abstract point clouds into more structured 3D models, e.g., triangle meshes (Lin et al., 2004; Remondino, 2003; Lin et al., 2004), polygonal surfaces (Fang et al., 2018; Coudron et al., 2018), simple parametric surfaces (Schnabel et al., 2007; 2008; Li et al., 2019). From the user perspective, the ultimate goal would be to reverse-engineer a CAD model (Gonzalez-Aguilera et al., 2012; Li et al., 2017b; Durupt et al., 2008). Several works have investigated wireframe parsing in 2D images (Huang et al., 2018; Huang & Gao, 2019). LCNN (Zhou et al., 2019a) is an end-to-end trainable system that directly outputs a vectorised wireframe. The current state-of-the-art appears to be the improved LCNN of Xue et al. (2020), which uses a holistic "attraction field map" to characterise line segments. Zou et al. (2018) estimate the 3D layout of an indoor scene from a single perspective or panoramic image with an encoder-decoder architecture, while Zhou et al. (2019b) obtain a compact 3D wireframe representation from a single image by exploiting global structural regularities. Jung et al. (2016) reconstruct 3D wireframes of building interiors under a Manhattan-world assumption. Edges are detected heuristically by projecting the points onto 2D occupancy grids, then refined via least-squares fitting under parallelism/orthogonality constraints. Wireframe extraction in 2D images is simplified by the regular pixel grid. For irregular 3D points the task is more challenging and there has been less work.
Another related direction of research is 3D shape decomposition into sets of simple, parameterised primitives (Tulsiani et al., 2017; Li et al., 2017a; Zou et al., 2017; Sharma et al., 2018; Du et al., 2018). Most approaches use a coarse volumetric occupancy grid as input for the 3D data, which works well for shape primitive fitting but only allows for rather inaccurate localisation of edges and vertices. Li et al. (2019) propose a method for fitting 3D primitives directly to raw point clouds. A limiting factor of their approach is that only a fixed maximum number of primitive instances can be detected. This upper bound is hard-coded in the architecture and prevents the network from fitting more complex structures. Nan & Wonka (2017) propose Polyfit to extract polygonal surfaces from a point cloud. Polyfit first selects an exhaustive set of candidate surfaces from the raw point cloud using RANSAC, and then refines the surfaces. Similarly to our PC2WF, Polyfit works best with objects made of straight edges and planar surfaces. The concurrent work Wang et al. (2020) proposed a deep neural network that is trained to identify a collection of parametric edges.
In summary, most 3D methods are either hand-crafted for restricted, schematic settings, or only learn to label individual "edge points". Here we aim for an end-to-end learnable model that directly maps a 3D point cloud to a vectorised wireframe.
3 Method
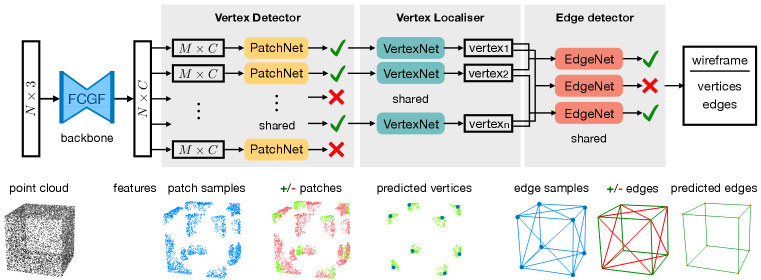
Our full architecture is depicted in Fig. 1. In the following we describe each block and, where necessary, discuss training and inference procedures. We denote a point cloud of 3D points with where represents the 3D coordinates of point . The 3D wireframe model of the point cloud is denoted by and it is defined, analogously to an undirected graph, by a set of vertices which are connected by a set of edges . As the vertices represent points in the 3D space we can think of them as being described by 3D coordinates .
Overall Pipeline. Our feed-forward pipeline consists of four blocks: (1) a convolutional backbone that extracts per-point features; (2) a vertex detector that examines patches of the point cloud and decides which ones contain vertices; (3) a vertex localiser that outputs the location of the vertex within a patch; (4) an edge detector that instantiates candidate edges and prunes them to a wireframe.
Backbone. PC2WF first extracts a feature vector per 3D point that encodes its geometric context. Our pipeline is compatible with any (hand-coded or learned) function that outputs a fixed-size descriptor vector per point. We use Fully Convolutional Geometric Features (FCGF, Choy et al., 2019b), which are compact and capture broad spatial context. The backbone operates on sparse tensors (Choy et al., 2019a) and efficiently computes 32-dimensional features in a single, 3D fully-convolutional pass.
Vertex Detector. This block performs binary classification of local patches (neighbourhoods in the point cloud) into those (few) that contain a corner and those that do not. Only patches detected to contain a corner are passed on to the subsequent block. While one could argue that detecting the presence of a vertex and inferring its 3D coordinates are two facets of the same problem, we found it advantageous to separate them. Detecting first whether a patch is likely to contain a corner, then constructing its 3D coordinates reduces the computational cost, as we discard patches without corners early. Empirically it also reduces false positives and increases localisation accuracy.
Our patch generation is similar to EC-Net (Yu et al., 2018). A patch contains a fixed number of points, chosen by picking a patch centroid and finding the closest points in terms of geodesic distance on the underlying surface. The geodesic distance avoids "shortcuts" in regions with thin structures or high curvature. To approximate the geodesic distance, the entire point cloud is linked into a -nearest neighbour graph, with edge weights proportional to Euclidean distance. Point-to-point distances are then found as shortest paths on that graph. During training we randomly draw positive samples that contain a corner and negative ones that do not. To increase the diversity of positive samples, the same corner can be included in multiple patches with different centroids. For the negative samples, we ensure to draw not only patches on flat surfaces, but also several patches near edges, by doing this negative samples with strong curvature are well represented. For inference, patch seeds are drawn using farthest point sampling. The vertex detector takes as input the (indexed) features of the points in the patch, max-pooled per dimension to achieve permutation invariance, and outputs a scalar vertex/no_vertex probability. Its loss function is binary cross-entropy.
Vertex Localiser.
The vertex detector passes on a set of patches predicted to contain a corner. The points of such a patch form the input for the localisation block. The backbone features and the 3D coordinates of all points are concatenated and fed into a multi-layer perceptron with fully connected layers, ReLU activations and batch normalisation. The MLP outputs a vector of scalar weights , where , such that the predicted vertex location is the weighted mean of the input points, . The prediction is supervised by a regression loss , summed over all corner patches. Predicting weights rather than directly the coordinates safeguards against extrapolation errors on unusual patches. We note that the localiser not only improves the corner point accuracy but also improves efficiency, by making it possible to use farthest point sampling rather than testing every input point.
Edge Detector.
The edge detection block serves to determine which pairs of (predicted) vertices are connected by an edge. Candidate edges are found by linking two vertices and , see below. To obtain a descriptor for an edge, we sample the equally spaced query locations along the line segment between the two vertices, including the endpoints: . For each we find the nearest 3D input point (by Euclidean distance) and retrieve its backbone encoding . This yields an ( edge descriptor, which is max-pooled along its first dimension, inspired by the ROI pooling in Faster-RCNN (Ren et al., 2015) and LOI pooling in LCNN (Zhou et al., 2019a). The resulting descriptor is flattened and fed through an MLP with two fully connected layers, which returns a scalar edge/no_edge score.
During training we select a number of vertex pairs from both the ground truth vertex list and the predicted vertex list , and draw positive and negative sets of edge samples, . We empirically found that evaluating all vertex pairs contained in during training leads to a large imbalance between positive and negative samples. Similar to Zhou et al. (2019a), we thus draw input edges for the edge detector from the following sets:
(a) Positive edges between ground truth vertices: This set comprises all true edges in the ground truth wireframe
(b) Negative edges between ground truth vertices: Two situations are relevant: "spurious edges", i.e., connections between two ground truth vertices that do not share an edge (but lie on the same surface, such that there are nearby points to collect features). And "inaccurate edges" where one of the endpoints is not a ground truth vertex, but not far from one (to cover difficult cases not far from a correct edge). Formally:
(c) Positive edges between predicted vertices: Connections between two "correct" predicted vertices that have both been verified to coincide with a ground truth wireframe vertex up to a small threshold . Formally:
(d) Negative edges between predicted vertices: These are (i) "wrong links" as in , between "correctly" predicted vertices; and (ii) "hard negatives" where exactly one of the two vertices is close to a ground truth wireframe vertex, to cover "near misses".
Fig. 2 visually depicts the different edge sets. To train the edge detector we randomly sample positive examples from and negative examples from . As loss function we use the balanced binary cross entropy. During inference, we go through the fully connected graph of edge candidates connecting any two (predicted) vertices. Candidates with a too high average distance to the input points (i.e., not lying on any object surface) are discarded. All others are fed into the edge detector for verification.

End-to-end training. When training the complete network, we minimise the joint loss function with balancing weights and : .
Non-Maximum Suppression (NMS) is a standard post-processing step for detection tasks, to suppress redundant, overlapping predictions. We use it (i) to prevent duplicate predictions of vertices that are very close to each other, and (ii) to prune redundant edges.
4 Experiments
We could not find any publicly available dataset of point clouds with polyhedral wireframe annotations. Thus, we collect our own synthetic datasets: a subset from ABC (Koch et al., 2019) and a Furniture dataset. ABC is a collection of one million high-quality CAD models of mechanical parts with explicitly parameterised curves, surfaces and various geometric features, from which ground truth wireframes can be generated. We select a subset of models with straight edges. It consists of 3,000 samples, which we randomly split into 2,000 for training, 500 for validation, and 500 for testing. For the furniture dataset we have collected 250 models from Google 3DWarehouse for the categories bed, table, chair/sofa, stairs, monitor and render ground truth wireframes. Examples are shown in the supplementary material. To generate point clouds, we use the virtual scanner of Wang et al. (2017). We place 14 virtual cameras on the face centres of the truncated bounding cubes of each object, uniformly shoot 16,000 parallel rays towards the object from each direction, and compute their intersections with the surfaces. Finally, we jitter all points by adding Gaussian noise , truncated to . The number of points varies between for different virtually scanned point clouds. For details, see the supplementary material.
4.1 Evaluation Measures
We first separately evaluate the vertex detection and edge detection performance of our architecture, then assess the reconstructed wireframes in terms of structural average precision and of a newly designed wireframe edit distance.
Mean Average precision mAP for vertices. To generate high quality wireframes, the predicted vertex positions must be accurate. This metric evaluates the geometric quality of vertices, regardless of edge links. A predicted vertex is considered a true positive if the distance to the nearest ground truth vertex is below a threshold . For a given we generate precision-recall curves by varying the detection threshold. Average precision (AP) is defined as the area under this curve, mAP is averaged over different thresholds .
Point-wise precision and recall for edges. We do not have a baseline that directly extracts 3D wireframe edges. Rather, existing methods label individual input points as "lying on an edge", and produce corresponding precision-recall curves (Hackel et al., 2016; Yu et al., 2018). To use this metric, we label a 3D point as "edge point" if its distance to the nearest wireframe edge is below the average point-to-point distance. As for AP, we can now check whether a predicted "edge point" is correct up to , and compute AP and mean average precision (mAP) over different .
Structural average precision for wireframes. The above two evaluation metrics looks at vertices and edges separately, in terms of geometry. In order to comprehensively evaluate the generated wireframe, we also need to take into account the connectivity. The structural average precision (sAP, Zhou et al., 2019a) metric, inspired by mean average precision, can be used to assess the overall prediction. This metric checks if the two end points of a detected edge both match the end points of a ground truth edge up to a threshold , i.e., . We report sAP for different and mean sAP (msAP).
Wireframe edit distance (WED). In order to topologically compare wireframes, we have designed a quality measure based on edit distance. We consider wireframes as geometric graphs drawn in 3D space. Distance measures commonly used in computational geometry and graph theory, such as Hausdorff distance and Frechet distance, resistance distance, or geodesic distance, do not seem to apply to our situation. Inspired by Cheong et al. (2009), we propose a wireframe edit distance (WED). It is a variant of the graph edit distance (GED), which measures how many elementary graph edit operators (vertex insertion/deletion, edge insertion/deletion, etc.) are needed to transform one graph to another. Instead of allowing arbitrary sequences of operations, which makes computing the GED NP-hard, we fix their order, see Fig. 3: (1) vertex matching; (2) vertex translation; (3) vertex insertion; (4) edge deletion; (5) edge insertion. Let the ground truth wireframe and the predicted wireframe . First, we match each vertex in to the nearest ground truth vertex in , then translate them at a cost of . New vertices are inserted where a ground truth vertex has no match (at no cost, as cost will accrue during edge insertion). After all vertex operations, we perform edge deletion and insertion based on ground truth edges at a cost of , where is the length of deleted/inserted edges. The final WED is the sum of all cost terms.

4.2 Results and Comparisons
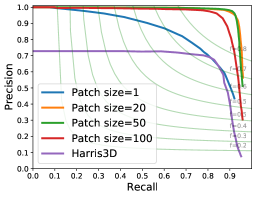
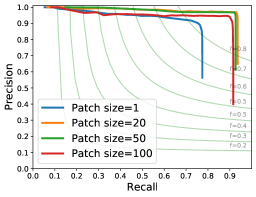
Vertex detection. We validate the PC2WF vertex detection module and compare to a Harris3D baseline (with subsequent NMS to guarantee a fair comparison) on the ABC dataset, Tab. 1. Exemplary visual results and precision-recall curves are shown in Fig. 4 and Fig.7. Harris3D often fails to accurately localise a corner point, and on certain thin structures it returns many false positives. The patch size used in our vertex detector has an impact on performance. Patch sizes between and achieve the best performance, where the precision stays at a high level over a large recall range. Patch size leads to low precision (although still better than Harris3D), confirming that per-point features, even when computed from a larger receptive field, are affected by noise and insufficient to find corners with acceptable false positive ratio. We refer the interested reader to the supplementary material for a more exhaustive ablation study.
| Dataset | ABC | furniture | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | AP | AP | AP | mAP | AP | AP | AP | mAP |
| Harris3D + NMS | 0.262 | 0.469 | 0.733 | 0.488 | 0.268 | 0.460 | 0.712 | 0.480 |
| our method | 0.856 | 0.901 | 0.925 | 0.894 | 0.847 | 0.911 | 0.924 | 0.894 |

 \setcaptionwidth
\setcaptionwidth
4.0cm
 \setcaptionwidth
\setcaptionwidth
4.0cm
 \setcaptionwidth
\setcaptionwidth
4.0cm
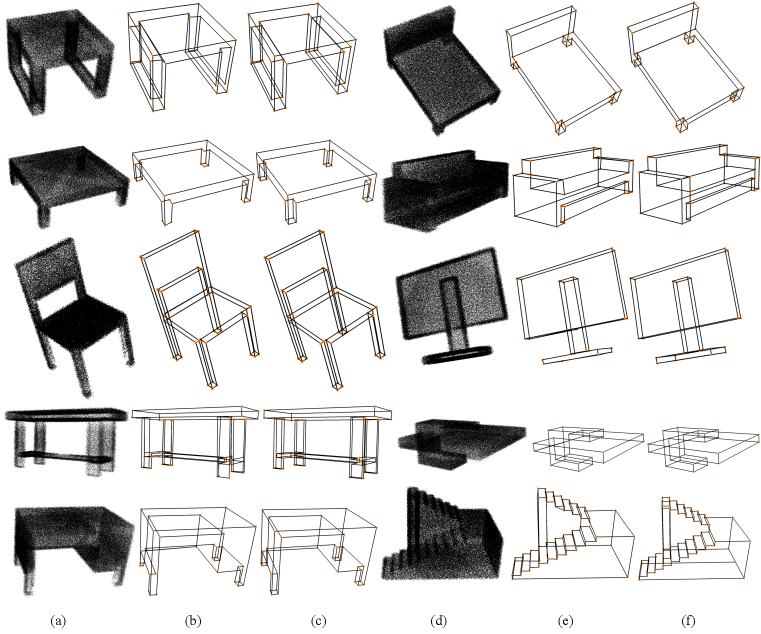
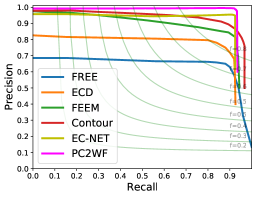
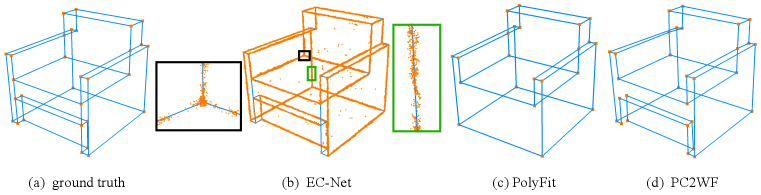
Edge prediction. Due to the limited number of methods able to extract wireframes from 3D point clouds, we compare PC2WF to recent algorithms that detect edge points, such as FREE (Bazazian et al., 2015), ECD (Ahmed et al., 2018), FEEM (Xia & Wang, 2017), Contour Detector (Hackel et al., 2016) and EC-Net (Yu et al., 2018). We also compare with Polyfit (Nan & Wonka, 2017), which is the only method able to reconstruct a vectorial representation similar to ours from a point cloud. Since Polyfit extracts planar surfaces of the object, we must convert that representation into a wireframe, which amounts to identifying the plane intersections. Precision-recall curves for all methods are shown in Fig. 7. Visual results are shown in Fig. 8. PC2WF outperforms all baselines based on hand-crafted features like FREE, ECD, FEEM and Contour Detector, as well as the deep learning method EC-Net, across all quality measures (Tab. 2). A visual comparison between the ground truth, PC2WF, EC-Net Yu et al. (2018), and Polyfit is shown in Fig. 9. One can clearly see the advantage of predicting vector edges rather than "edge points", as they lead to a much sharper result. The inevitable blur of edge points across the actual contour line, and their irregular density, make vectorisation a non-trivial problem. Polyfit and PC2WF show comparable performance for this specific point cloud. PC2WF failed to localise some corners and missed some small edges, whereas Polyfit failed to reconstruct the lower part of the armchair.

| Dataset | ABC | furniture | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | AP | AP | AP | mAPe | AP | AP | AP | mAPe |
| FREE | 0.089 | 0.365 | 0.622 | 0.359 | 0.076 | 0.355 | 0.610 | 0.347 |
| ECD | 0.401 | 0.703 | 0.834 | 0.646 | 0.405 | 0.699 | 0.840 | 0.648 |
| FEEM | 0.412 | 0.754 | 0.870 | 0.679 | 0.419 | 0.760 | 0.865 | 0.681 |
| Contour | 0.422 | 0.812 | 0.913 | 0.715 | 0.420 | 0.809 | 0.900 | 0.710 |
| PolyFit | 0.771 | 0.798 | 0.882 | 0.817 | 0.584 | 0.667 | 0.728 | 0.660 |
| EC-Net | 0.503 | 0.839 | 0.912 | 0.751 | 0.499 | 0.838 | 0.924 | 0.750 |
| our method | 0.826 | 0.907 | 0.931 | 0.888 | 0.851 | 0.951 | 0.974 | 0.925 |
Wireframe Reconstruction. We visualise PC2WF’s output wireframes in Fig. 10. Structural precision-recall curves with various patch sizes are shown in Fig. 7. For additional examples of output predictions, including cases with curved edges, please refer to the supplementary material. The results are aligned with the ones of the vertex module. Moderate patch sizes between and achieve the best performance. Tab. 3 shows the structural average precision with patch size , which exceeds the one of Polyfit. The results in terms of the wireframe edit distance are shown in Tab. 4 for PC2WF and Polyfit. The average number of predicted vertices (21.7) and ground truth vertices (20.1) per object are close, such that only few vertex insertions are needed in most cases. Although all predicted vertices need some editing, the WEDv caused by those edits is small (0.2427), meaning that the predictions are accurate. On the contrary, the 2.6 edges that need to be edited on average increase WEDe a lot more (1.4142) and dominate the WED, i.e., the inserted/deleted edges have significant length.

| Dataset | ABC | furniture | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | sAP0.03 | sAP0.05 | sAP0.07 | msAP | sAP0.03 | sAP0.05 | sAP0.07 | msAP |
| Polyfit | 0.753 | 0.772 | 0.781 | 0.769 | 0.552 | 0.590 | 0.612 | 0.585 |
| ours | 0.868 | 0.898 | 0.907 | 0.891 | 0.865 | 0.901 | 0.925 | 0.897 |
| pred #v | gt #v | edited #v | WEDv | pred #e | gt #e | edited #e | WEDe | WED | |
|---|---|---|---|---|---|---|---|---|---|
| Polyfit | 14.6 | 20.1 | 14.6 | 0.1251 | 21.9 | 30.2 | 10.2 | 4.7202 | 4.8453 |
| ours | 21.7 | 20.1 | 21.7 | 0.2427 | 32.8 | 30.2 | 2.6 | 1.4142 | 1.6569 |
5 Conclusion
We have proposed PC2WF, an end-to-end trainable deep architecture to extract a vectorised wireframe from a raw 3D point cloud. The method achieves very promising results for man-made, polyhedral objects, going one step further than low-level corner or edge detectors, while at the same time outperforming them on the isolated vertex and edge detection tasks. We see our method as one further step from robust, but redundant low-level vision to compact, editable 3D geometry. As future work we aim to address the biggest limitation of our current method which is the inability to handle wireframes with strongly curved edges.
References
- Ahmed et al. (2018) Syeda Mariam Ahmed, Yan Zhi Tan, Chee Meng Chew, Abdullah Al Mamun, and Fook Seng Wong. Edge and corner detection for unorganized 3d point clouds with application to robotic welding. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018.
- Bazazian et al. (2015) Dena Bazazian, Josep R Casas, and Javier Ruiz-Hidalgo. Fast and robust edge extraction in unorganized point clouds. In Digital Image Computing: Techniques and Applications (DICTA), 2015.
- Chen et al. (2017) Siheng Chen, Dong Tian, Chen Feng, Anthony Vetro, and Jelena Kovačević. Fast resampling of three-dimensional point clouds via graphs. IEEE Transactions on Signal Processing, 66(3):666–681, 2017.
- Cheong et al. (2009) Otfried Cheong, Joachim Gudmundsson, Hyo-Sil Kim, Daria Schymura, and Fabian Stehn. Measuring the similarity of geometric graphs. In International Symposium on Experimental Algorithms, 2009.
- Choy et al. (2019a) Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019a.
- Choy et al. (2019b) Christopher Choy, Jaesik Park, and Vladlen Koltun. Fully convolutional geometric features. In IEEE International Conference on Computer Vision (ICCV), 2019b.
- Coudron et al. (2018) Inge Coudron, Steven Puttemans, and Toon Goedemé. Polygonal reconstruction of building interiors from cluttered pointclouds. In European Conference on Computer Vision (ECCV), 2018.
- Demarsin et al. (2007) Kris Demarsin, Denis Vanderstraeten, Tim Volodine, and Dirk Roose. Detection of closed sharp edges in point clouds using normal estimation and graph theory. Computer-Aided Design, 39(4):276–283, 2007.
- Du et al. (2018) Tao Du, Jeevana Priya Inala, Yewen Pu, Andrew Spielberg, Adriana Schulz, Daniela Rus, Armando Solar-Lezama, and Wojciech Matusik. InverseCSG: Automatic conversion of 3d models to CSG trees. ACM Transactions on Graphics (TOG), 37(6):1–16, 2018.
- Durupt et al. (2008) Alexandre Durupt, Sebastien Remy, Guillaume Ducellier, and Benoît Eynard. From a 3d point cloud to an engineering CAD model: a knowledge-product-based approach for reverse engineering. Virtual and Physical Prototyping, 3(2):51–59, 2008.
- Fang et al. (2018) Hao Fang, Florent Lafarge, and Mathieu Desbrun. Planar shape detection at structural scales. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- Głomb (2009) Przemysław Głomb. Detection of interest points on 3d data: Extending the Harris operator. In Computer Recognition Systems 3, pp. 103–111. Springer, 2009.
- Gonzalez-Aguilera et al. (2012) Diego Gonzalez-Aguilera, Susana Del Pozo, Gemma Lopez, and Pablo Rodriguez-Gonzalvez. From point cloud to CAD models: Laser and optics geotechnology for the design of electrical substations. Optics & Laser Technology, 44(5):1384–1392, 2012.
- Hackel et al. (2016) Timo Hackel, Jan Dirk Wegner, and Konrad Schindler. Contour detection in unstructured 3d point clouds. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Hackel et al. (2017) Timo Hackel, Jan Dirk Wegner, and Konrad Schindler. Joint classification and contour extraction of large 3d point clouds. ISPRS Journal of Photogrammetry and Remote Sensing, 130:231–245, 2017.
- Harris et al. (1988) Christopher G Harris, Mike Stephens, et al. A combined corner and edge detector. In Alvey Vision Conference, volume 15(50), 1988.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Huang & Gao (2019) Kun Huang and Shenghua Gao. Wireframe parsing with guidance of distance map. IEEE Access, 7:141036–141044, 2019.
- Huang et al. (2018) Kun Huang, Yifan Wang, Zihan Zhou, Tianjiao Ding, Shenghua Gao, and Yi Ma. Learning to parse wireframes in images of man-made environments. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- Jung et al. (2016) Jaehoon Jung, Sungchul Hong, Sanghyun Yoon, Jeonghyun Kim, and Joon Heo. Automated 3d wireframe modeling of indoor structures from point clouds using constrained least-squares adjustment for as-built BIM. Journal of Computing in Civil Engineering, 30(4):04015074, 2016.
- Kingma & Ba (2014) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Koch et al. (2019) Sebastian Koch, Albert Matveev, Zhongshi Jiang, Francis Williams, Alexey Artemov, Evgeny Burnaev, Marc Alexa, Denis Zorin, and Daniele Panozzo. ABC: A big CAD model dataset for geometric deep learning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- Li et al. (2017a) Jun Li, Kai Xu, Siddhartha Chaudhuri, Ersin Yumer, Hao Zhang, and Leonidas Guibas. GRASS: Generative recursive autoencoders for shape structures. ACM Transactions on Graphics (TOG), 36(4):1–14, 2017a.
- Li et al. (2019) Lingxiao Li, Minhyuk Sung, Anastasia Dubrovina, Li Yi, and Leonidas J Guibas. Supervised fitting of geometric primitives to 3d point clouds. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- Li et al. (2017b) Yan-qin Li, Gui-zhong Xie, Fan-nian Meng, and De-hai Zhang. Using the point cloud data to reconstructing CAD model by 3d geometric modeling method in reverse engineering. In International Conference on Manufacturing Engineering and Intelligent Materials (ICMEIM), 2017b.
- Lin et al. (2004) Hong-Wei Lin, Chiew-Lan Tai, and Guo-Jin Wang. A mesh reconstruction algorithm driven by an intrinsic property of a point cloud. Computer-Aided Design, 36(1):1–9, 2004.
- Nan & Wonka (2017) Liangliang Nan and Peter Wonka. Polyfit: Polygonal surface reconstruction from point clouds. In IEEE International Conference on Computer Vision (ICCV), 2017.
- Remondino (2003) Fabio Remondino. From point cloud to surface: the modeling and visualization problem. International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 34, 2003.
- Ren et al. (2015) Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems (NeurIPS), 2015.
- Ronneberger et al. (2015) Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2015.
- Schnabel et al. (2007) Ruwen Schnabel, Roland Wahl, and Reinhard Klein. Efficient RANSAC for point-cloud shape detection. Computer Graphics Forum, 26(2):214–226, 2007.
- Schnabel et al. (2008) Ruwen Schnabel, Raoul Wessel, Roland Wahl, and Reinhard Klein. Shape recognition in 3d point-clouds. In International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision (WSCG), 2008.
- Sharma et al. (2018) Gopal Sharma, Rishabh Goyal, Difan Liu, Evangelos Kalogerakis, and Subhransu Maji. CSGNet: Neural shape parser for constructive solid geometry. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- Sipiran & Bustos (2010) Ivan Sipiran and Benjamin Bustos. A robust 3d interest points detector based on harris operator. In Eurographics Conference on 3D Object Retrieval (3DOR), 2010.
- Sipiran & Bustos (2011) Ivan Sipiran and Benjamin Bustos. Harris 3d: a robust extension of the Harris operator for interest point detection on 3d meshes. The Visual Computer, 27(11):963, 2011.
- Smith & Brady (1997) Stephen M Smith and J Michael Brady. SUSAN -— a new approach to low level image processing. International Journal of Computer Vision, 23(1):45–78, 1997.
- Tulsiani et al. (2017) Shubham Tulsiani, Hao Su, Leonidas J Guibas, Alexei A Efros, and Jitendra Malik. Learning shape abstractions by assembling volumetric primitives. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- Walter et al. (2009) Nicolas Walter, Olivier Aubreton, Yohan D Fougerolle, and Olivier Laligant. Susan 3d operator, principal saliency degrees and directions extraction and a brief study on the robustness to noise. In IEEE International Conference on Image Processing (ICIP), 2009.
- Wang et al. (2017) Peng-Shuai Wang, Yang Liu, Yu-Xiao Guo, Chun-Yu Sun, and Xin Tong. O-CNN: Octree-based convolutional neural networks for 3d shape analysis. ACM Transactions on Graphics (TOG), 36(4):1–11, 2017.
- Wang et al. (2020) Xiaogang Wang, Yuelang Xu, Kai Xu, Andrea Tagliasacchi, Bin Zhou, Ali Mahdavi-Amiri, and Hao Zhang. Pie-net: Parametric inference of point cloud edges. Conference on Neural Information Processing Systems (NeurIPS), 2020.
- Xia & Wang (2017) Shaobo Xia and Ruisheng Wang. A fast edge extraction method for mobile LiDAR point clouds. IEEE Geoscience and Remote Sensing Letters, 14(8):1288–1292, 2017.
- Xue et al. (2020) Nan Xue, Tianfu Wu, Song Bai, Fu-Dong Wang, Gui-Song Xia, Liangpei Zhang, and Philip H. S. Torr. Holistically-attracted wireframe parsing. arXiv preprint arXiv:2003.01663, 2020.
- Yang & Zang (2014) Bisheng Yang and Yufu Zang. Automated registration of dense terrestrial laser-scanning point clouds using curves. ISPRS Journal of Photogrammetry and Remote Sensing, 95:109–121, 2014.
- Yu et al. (2018) Lequan Yu, Xianzhi Li, Chi-Wing Fu, Daniel Cohen-Or, and Pheng-Ann Heng. EC-Net: an edge-aware point set consolidation network. In European Conference on Computer Vision (ECCV), 2018.
- Zhou et al. (2019a) Yichao Zhou, Haozhi Qi, and Yi Ma. End-to-end wireframe parsing. In IEEE International Conference on Computer Vision (ICCV), 2019a.
- Zhou et al. (2019b) Yichao Zhou, Haozhi Qi, Yuexiang Zhai, Qi Sun, Zhili Chen, Li-Yi Wei, and Yi Ma. Learning to reconstruct 3d Manhattan wireframes from a single image. In IEEE International Conference on Computer Vision (ICCV), 2019b.
- Zou et al. (2017) Chuhang Zou, Ersin Yumer, Jimei Yang, Duygu Ceylan, and Derek Hoiem. 3D-PRNN: Generating shape primitives with recurrent neural networks. In IEEE International Conference on Computer Vision (ICCV), 2017.
- Zou et al. (2018) Chuhang Zou, Alex Colburn, Qi Shan, and Derek Hoiem. LayoutNet: Reconstructing the 3d room layout from a single RGB image. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
Supplementary Material
In this supplementary document we provide further details regarding the network architecture, post-processing operations, training configurations, dataset details, as well as further experimental results.
Appendix A Implementation Details
A.1 Network Architecture
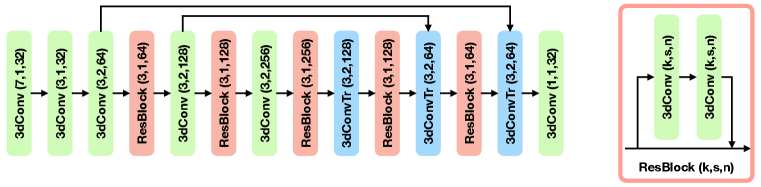
We use the FCGF feature extractor (Choy et al., 2019b) as our backbone, which has a U-Net architecture (Ronneberger et al., 2015), skip connections and ResNet blocks (He et al., 2016). It is implemented with an auto-differentiation library, the Minkowski Engine (Choy et al., 2019a), that provides sparse versions of convolutions and other deep learning layers.
A.2 Post-processing
Since the patches generated during inference may overlap, there may be redundant vertex predictions, which would cause redundant edges. To avoid this problem, we use non-maximum suppression (NMS) and remove redundant edges: for each predicted edge , we find all the edges satisfying the following conditions: , where and are the set of predicted vertices and detected edges, respectively. Among the edges that fulfil the above conditions, we retain the one with the maximum probability and remove all others. See Fig. 12(a) and (b) for a visual example.
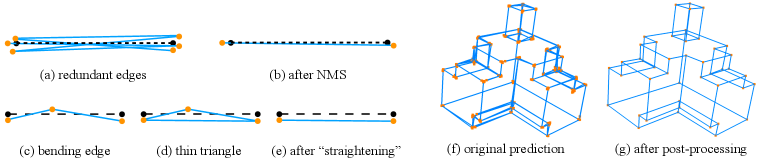
Sometimes almost collinear vertices may be present in the prediction result, which results in "bending" edges or "thin triangles" shown in Fig. 12(c) and (d). We "straighten" the edges by removing vertices lying on/near detected edges and directly connecting the other two end points (Fig. 12(e)). Fig. 12(f) and (g) shows the results before and after our post processing steps. We include an ablation study regarding the different post-processing techniques (NMS and straightening) in Table. 5. As we penalise double-predicted lines when calculating sAP, the results without NMS are much worse. Both methods contribute to improving the performance.
| sAP0.03 | sAP0.05 | sAP0.07 | msAP | |
|---|---|---|---|---|
| no NMS | ||||
| no straighten | ||||
| NMS+straighten |
A.3 Training Details
We fine-tune our PC2WF network starting from a pre-trained FCGF and optimise the parameters using ADAM Kingma & Ba (2014) with initial learning rate 0.001. The network is trained for 10 epochs and the learning rate is then decreased by a factor of two 2. We normalise each input point cloud to and set the weights in the loss function to and .
Appendix B Datasets
As mentioned in the main manuscript, we collect our own furniture dataset from the web. For the vertex and edge annotations, we use the Google SketchUp software and change the face style to wireframe mode to get an object’s edges and their intersections. The detailed statistics of the dataset are presented in Tab. 6, some examples of original 3D objects are shown in Fig. 13.
| bed | chair/sofa | table | monitor | stairs | average | |
|---|---|---|---|---|---|---|
| #models | 57 | 59 | 58 | 38 | 38 | 250 in total |
| #points | 190035.5 | 185966.3 | 150666.1 | 178835.7 | 152399.1 | 172509.2 |
| #vertices | 32.9 | 38.8 | 34.3 | 29.3 | 62.7 | 38.6 |
| #edges | 50.0 | 59.5 | 52.9 | 45.8 | 96.5 | 59.3 |

Appendix C Choice of Positive and Negative Edge Samples
In order to better understand and motivate the choice for the positive and negative examples sets used to train of the edge detector, we conduct additional experiments with different combinations, see Tab. 7. In each ablation experiment, we removed some subsets from the full set combination, and trained the whole network.
We observe that msAP drops to if only the ground truth samples are used ( and ). This means that the removal of training samples obtained from predicted vertices lowers the performance of the network (msAP for the full sets combination is ). This is due to the fact that, by using only ground truth vertices, we create a shift in the distribution of input vertices between the training and the inference phase. The model trained only on ground truth vertices apparently does not generalise well enough, and fails during inference. In the next experiment we remove the vertices based on ground truth and use only the sets created from the predicted vertices ( and ). The results show that in this case the performance drop is even larger, msAP decreases to . We speculate that, during the initial training stage, the vertex detector/localiser finds very few vertices (positive samples), making a training of the edge detection module very difficult. The samples based on ground truth ensure there are enough valid vertex examples and mitigate this problem, thus improving the learning of the network parameters.
We also observe that training the network only on the positive set ( and ) results in even worse performance (msAP: 0.586), which indicates that including well-selected negative edge samples is helpful for the training.
| sAP0.03 | sAP0.05 | sAP0.07 | msAP | |
|---|---|---|---|---|
| , | 0.715 | 0.777 | 0.788 | 0.760 |
| , | 0.651 | 0.773 | 0.795 | 0.740 |
| , | 0.525 | 0.611 | 0.622 | 0.586 |
| , , , | 0.868 | 0.898 | 0.907 | 0.891 |
Appendix D Additional Results
D.1 Quantitative results on furniture dataset
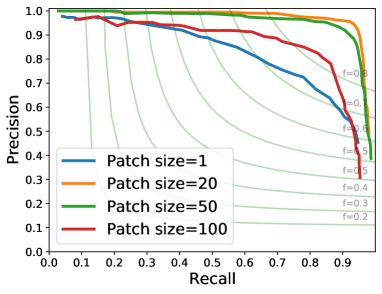
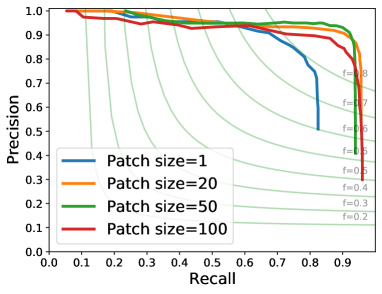
We provide additional results for vertex (Fig. 15) and edge (Fig. 15) detection on the furniture dataset for different patch sizes. Our method performs similarly well on the furniture dataset and on the ABC dataset. Moderate patch sizes, 20 ~50, achieve the best performance on both datasets.
 \setcaptionwidth
\setcaptionwidth
6cm
 \setcaptionwidth
\setcaptionwidth
6cm
D.2 Point Cloud Noise Levels
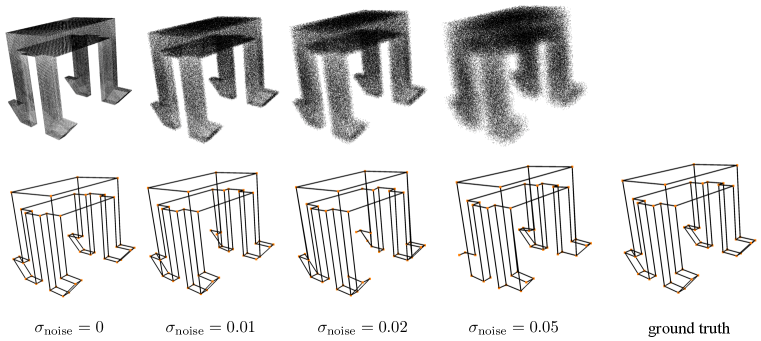
In order to investigate how the noise level affects the algorithm performance we train and test our method on point clouds with different amounts of noise. To do this we perturb the synthetic point cloud with zero mean Gaussian noise with different values of standard deviation (). Table. 8 summarises the results of the experiment for different noise levels, as we can observe the noise level does not seem to affect the performance substantially. The model trained with a higher noise level is more sensitive to the threshold for the sAP (defined in Section 4.1). In the case of , a relatively small value (0.03) leads to a less accurate result. Visual results are shown in Fig. 16. As expected the quality of the wireframe prediction tends to decrease as the noise level increases. This effect, however, strongly depends on the size of the object details: the upper part of the object, which has no small structural details, is reconstructed correctly for all the noise levels, whereas the smaller details on the lower part are not predicted as accurately when the noise gets larger.
| sAP0.03 | sAP0.05 | sAP0.07 | msAP | |
|---|---|---|---|---|
D.3 Visualisation
We show additional qualitative results, for both the ABC dataset (Fig. 17, 18, 19) and the furniture dataset (Fig. 20), with vertices in orange. Our method can successfully reconstruct wireframes from noisy point clouds. There are of course slight deviations between the predicted vertex positions and the ground truth, but they are imperceptibly small.