PC-NeRF: Parent-Child Neural Radiance Fields under Partial Sensor Data Loss in Autonomous Driving Environments
Abstract
Reconstructing large-scale 3D scenes is essential for autonomous vehicles, especially when partial sensor data is lost. Although the recently developed neural radiance fields (NeRF) have shown compelling results in implicit representations, the large-scale 3D scene reconstruction using partially lost LiDAR point cloud data still needs to be explored. To bridge this gap, we propose a novel 3D scene reconstruction framework called parent-child neural radiance field (PC-NeRF). The framework comprises two modules, the parent NeRF and the child NeRF, to simultaneously optimize scene-level, segment-level, and point-level scene representations. Sensor data can be utilized more efficiently by leveraging the segment-level representation capabilities of child NeRFs, and an approximate volumetric representation of the scene can be quickly obtained even with limited observations. With extensive experiments, our proposed PC-NeRF is proven to achieve high-precision 3D reconstruction in large-scale scenes. Moreover, PC-NeRF can effectively tackle situations where partial sensor data is lost and has high deployment efficiency with limited training time. Our approach implementation and the pre-trained models will be available at https://github.com/biter0088/pc-nerf.
Index Terms:
Neural Radiance Fields, 3D Scene Reconstruction, Autonomous Driving.I Introduction
Reconstructing a large-scale, high-precision 3D scene is essential for autonomous vehicles to conduct environmental exploration, motion planning, and closed-loop simulation [1, 2, 3, 4, 5, 6]. The environmental information capture and sensor data utilization are vital for 3D scene reconstruction. As existing autonomous systems have difficulty accomplishing complex tasks entirely autonomously, remote operators are often required to provide some assistance [7, 8]. However, the sensor data transmitted back from the autonomous vehicles may be partially lost due to communication conditions that cannot be continuously ensured to be adequate [9]. Moreover, the sensor equipment may fail to capture adequate environmental information due to hardware malfunction and adverse weather factors [10, 11, 12, 13]. Therefore, besides environmental information capture, it is imperative to explore the sensor data utilization of the available limited sensor data for enhancing the perception capabilities of autonomous vehicles, as depicted in Fig. 1.
By utilizing conventional explicit representations such as meshes, depth maps, and voxels, it becomes possible to depict the reconstructed scene visually [15, 16, 17]. However, as the explicit representation is discrete, it cannot represent the scene at unlimited resolution [18]. Besides, the explicit features are usually sparse, which further causes a performance drop when partial sensor data is lost in real applications. Unlike explicit representations, implicit representations typically use a spatial function to describe the scene geometry continuously [19, 20] and can provide richer information about environmental features. As a trendy method of implicit representation, neural radiance fields (NeRF) [21] attract significant research interest in computer vision, robotics, and augmented reality communities [22] since they provide a continuous representation of objects and environments with high resolution. NeRF represents a scene using a fully connected deep network, which maps a single continuous 5D coordinate (spatial location and viewing direction) to the volume density and view-dependent emitted radiance at that spatial location [21].
Currently, most NeRF-related works have been carried out based on camera image data or indoor LiDAR scan data [18, 23, 24, 25, 5, 26, 27, 28, 29, 30, 20, 22, 31], with only a few works using LiDAR point cloud data in the outdoor environment [4, 32, 33, 14]. In contrast to the camera, LiDAR is comparably robust to day-and-night light changes and different weather conditions [34, 35]. Moreover, LiDAR can capture accurate distance information, which is extremely helpful for large-scale and high-accuracy outdoor mapping of the environment [36, 4]. Therefore, it is significant to explore further reconstructing the outdoor environmental representation with LiDAR-based NeRF.
The main contributions of this paper are as follows:
A large-scale and high-precision 3D scene reconstruction framework called parent-child neural radiance fields (PC-NeRF) effectively improves the reconstruction performance under partial sensor data loss in outdoor environments. We partition the entire autonomous vehicle driving environment into large blocks, denoted as parent NeRFs, and subdivide these blocks into geometric segments known as child NeRFs. This partition enables us to jointly optimize scene-level, segment-level, and point-level scene representations.
To our knowledge, our proposed PC-NeRF is the first NeRF-based large-scale 3D scene reconstruction method using sparse and partially lost LiDAR point clouds, even though NeRF is a dense volumetric representation typically constructed using large amounts of sensor data. Our proposed PC-NeRF improves the data utilization efficiency of the remaining point cloud by constructing segment-level representations.
With extensive experiments, our proposed PC-NeRF has been validated for its high deployment efficiency. Training for just one epoch in most evaluation scenarios is sufficient to achieve high-precision 3D reconstruction results, even under severe partial sensor data loss conditions.
II Related Works
With NeRF’s inherent advantages of continuous dense volumetric representation, NeRF-based techniques in novel view synthesis [32, 33, 14, 30, 28, 29], scene reconstruction [37, 5, 26, 27, 38, 30, 28, 29], and localization systems [23, 24, 25, 4, 31, 39] have rapidly developed and are highly referential and informative. NeRF’s ability to model continuous scene representations is also an essential basis for our proposed PC-NeRF, which uses LiDAR data as inputs and divides the spaces into different scales. Therefore, this section reviews the literature on LiDAR-based NeRF and space-division-based NeRF.
II-A LiDAR-Based NeRF
Motivated by NeRF’s capability to render photo-realistic novel image views, several works have explored the potential of NeRF on LiDAR point cloud data for novel view synthesis [32, 33, 14] and robot navigation [4, 31, 39].
The goal of novel view synthesis is to generate a view of a 3D scene from a viewpoint where no real sensor image has been captured, allowing the opportunity to observe real scenes from a virtual perspective. Neural Fields for LiDAR (NFL) [14] combines the rendering power of neural fields with a detailed, physically motivated model of the LiDAR sensing process, thus enabling it to accurately reproduce key sensor behaviors like beam divergence, secondary returns, and ray dropping. LiDAR-NeRF [32] converts the 3D point cloud into the range pseudo image in 2D coordinates and then optimizes three losses, including absolute geometric error, point distribution similarity, and realism of point attributes. Similar to LiDAR-NeRF, NeRF-LiDAR [33] has also employed the spherical projection strategy and consists of three key components: NeRF reconstruction of the driving scenes, realistic LiDAR point clouds generation, and point-wise semantic label generation. However, if more than one laser point is projected onto the same pseudo-pixel, only the one with the smallest distance is retained [32]. Besides, it is particularly noticeable when using small resolution range pseudo images, as spherical projections can lead to significant information loss [40].
In robotics, LiDAR-based NeRF is usually proposed for localization and mapping. IR-MCL [31] focuses on the problem of estimating the robot’s pose in an indoor environment using 2D LiDAR data. With the pre-trained network, IR-MCL can synthesize 2D LiDAR scans for an arbitrary robot pose through volume rendering. However, the error between the synthesized and real scans is relatively large. NeRF-LOAM [4] presents a novel approach for simultaneous odometry and mapping using neural implicit representation with 3D LiDAR data. NeRF-LOAM employs sparse octree-based voxels combined with neural implicit embeddings, decoded into a continuous signed distance function (SDF) by a neural implicit decoder. However, NeRF-LOAM cannot currently operate in real-time with its unoptimized Python implementation. LocNDF [39] utilizes neural distance fields (NDFs) for robot localization, demonstrating the direct learning of NDFs from range sensor observations. LocNDF has raised the challenge of addressing real-time constraints, and our work endeavors to investigate this challenge.
In contrast to projecting the LiDAR point cloud onto a range pseudo-image, our proposed PC-NeRF handles 3D LiDAR point cloud data directly. Besides learning the LiDAR beam emitting process, our proposed PC-NeRF explores the deployment performance of NeRF-based methods.
II-B Space-Division-Based NeRF
When large-scale scenes such as where the autonomous vehicles drive need to be represented with high precision, the model capacity of a single NeRF is limited in capturing local details with acceptable computational complexity [5, 26, 27]. For large-scale 3D scene reconstruction tasks, Mega-NeRF [5], Block-NeRF [26], and Switch-NeRF [27] have adopted the NeRF sub-module solution. Mega-NeRF decomposes a scene into cells with centroids and initializes a corresponding set of model weights. At query time, Mega-NeRF produces opacity and color for a given position and direction using the model weights closest to the query point. Like Mega-NeRF, Block-NeRF [26] proposes dividing large environments into individually trained Block-NeRFs, which are then rendered and combined dynamically at inference time. For rendering a target view, a subset of the Block-NeRFs are rendered and then composited based on their geographic location compared to the camera. Switch-NeRF [27] proposes a novel end-to-end large-scale NeRF with learning-based scene decomposition and designs a gating network to dispatch 3D points to different NeRF sub-networks. The gating network can be optimized with the NeRF sub-networks for different scene partitions by design with the Sparsely Gated Mixture of Experts.
Regarding space-division-based NeRF on a smaller scale, further space division is employed for faster and higher-quality rendering [28, 29, 30]. DeRF [28] proposes Voronoi Diagrams spatial decomposition and provides more efficient inference (with the same rendering quality) and higher-quality rendering (for the same inference cost) than the original NeRF [21]. KiloNeRF [29] demonstrates that real-time rendering is possible using thousands of tiny MLPs instead of one extensive multilayer perceptron network (MLP). Rather than representing the entire scene with a single, high-capacity MLP, KiloNeRF represents the scene with thousands of small MLPs. Neural Sparse Voxel Fields (NSVF) [30] define a set of voxel-bounded implicit fields organized in a sparse voxel octree to model local properties in each cell. Specifically, NSVF assigns a voxel embedding at each vertex of the voxel and obtains the representation of a query point inside the voxel by aggregating the voxel embeddings at the eight vertices of the corresponding voxel. The aggregating vertice voxel embedding is further passed through an MLP to predict the geometry and appearance of that query point.
Our work also draws on the ideas of spatial division on both large-scale and small-scale for autonomous driving scene representation. The proposed PC-NeRF divides the holistic driving spaces into multiple large blocks and further extracts the geometric segments in each block for detailed local representation.
III Parent-Child Neural Radiance Fields (PC-NeRF) Framework
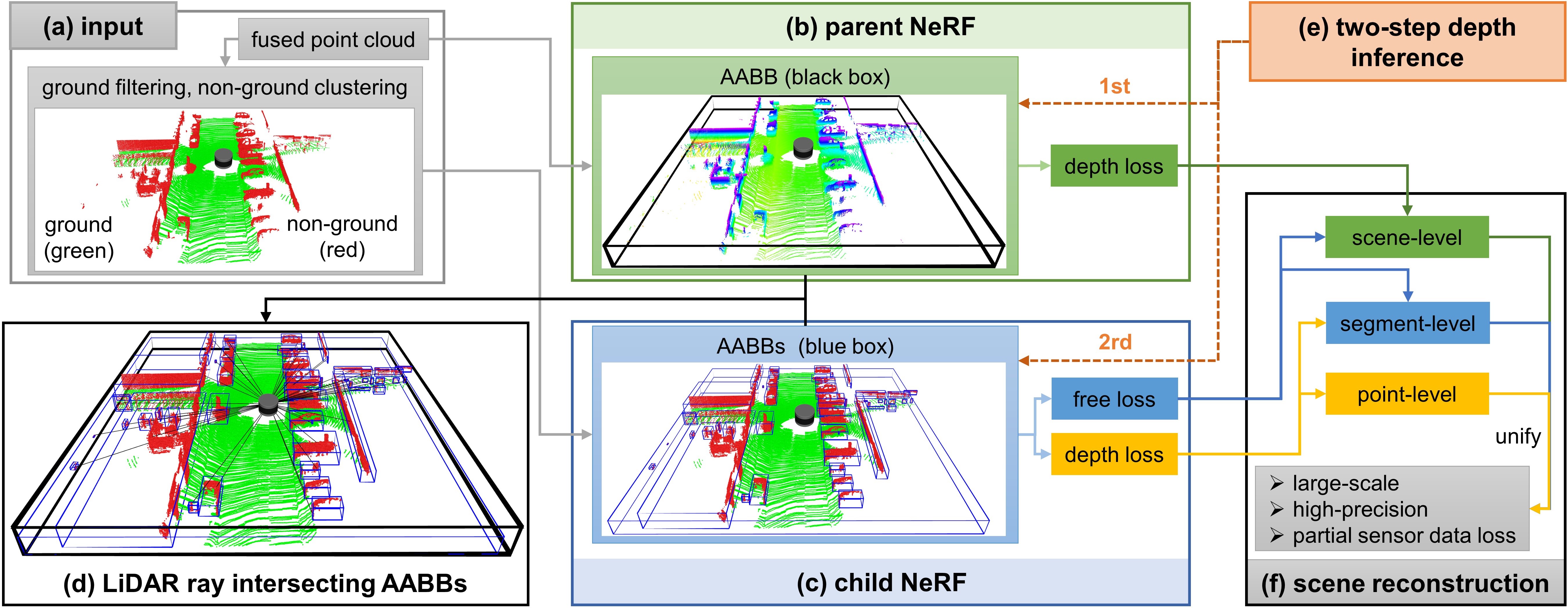
To further explore the large-scale high-precision 3D scene reconstruction based on LiDAR and NeRF and improve the reconstruction performance under partial sensor data loss, we propose a parent-child neural radiance field (PC-NeRF) framework, as shown in Fig. 2. We divide the entire autonomous vehicle driving environment into large blocks, i.e., parent NeRFs, and geometric segments within the blocks, i.e., child NeRFs, to jointly optimize scene-level, segment-level, and point-level scene representation. With LiDAR point cloud data collected by autonomous vehicles as input, we design parent NeRF depth loss, child NeRF depth loss, and child NeRF free loss to train our PC-NeRF model. Moreover, we propose a two-step depth inference method to realize segment-to-point inference.
III-A Parent NeRF
To efficiently represent the autonomous vehicle’s traversing environment, we construct multiple rectangular-shaped parent NeRFs (as Fig. 2(b) illustrates) one after the other along the vehicle’s trajectory, creating a new parent NeRF when the autonomous vehicle orientation variation exceeds a given threshold. Constructing parent NeRF requires three considerations: the effective LiDAR point cloud utilization, the driving environment representation, and the NeRF near/far bounds calculation. Since the point clouds become sparser the further away from the LiDAR origin while the NeRF model itself is a dense volumetric representation, laser points within a certain distance from the LiDAR origin rather than the holistic point clouds are chosen to train our proposed PC-NeRF model. Besides, the driving environments featured with roads, walls, and vehicles can be tightly enclosed by bounding boxes. Therefore, each parent NeRF’s space is represented as a large Axis-Aligned Bounding Box (AABB) in our work, which also makes it easier to calculate the related near and far bounds for rendering.
III-B Child NeRF
To further represent the environment at the segment and point levels and efficiently capture the approximate environmental distributions under partial sensor data loss, we divide the point clouds in a parent NeRF into multiple child NeRFs that enclose each environmental geometric segment. Since the geometric segment quantity is limited and the child NeRFs’ space can also be represented by AABBs, building child NeRFs from the raw point cloud is a fast way to generate detailed environmental representations. With less space volume, child NeRFs can represent a larger environment with the same model capacity by learning more detailed volumetric densities of segments. In addition, segment-level child NeRFs can compensate for the inadequate parts of the environmental representation caused by the sparsity of LiDAR point clouds.
The point cloud allocation for child NeRF can be divided into the following three steps, and the results are shown in Fig. 2(a) and Fig. 2(c). Step 1: Extract the ground point clouds from the fused point clouds related to road ground, roadside sidewalk, etc. The ground plane is one significant geometric segment in the driving environment and is spatially adjacent to the other individual geometric segments. Therefore, distinguishing it helps to extract other geometric segments further accurately. Step 2: Cluster the remaining non-ground point clouds into various segments using region-growing clustering. The advantages of the utilized clustering method are excellent scalability for operation on large-scale point clouds and the adaptive ability to cluster different shaped and sized objects. Step 3: Construct child NeRF AABBs. The AABBs of the segmented point clouds obtained from step 1 and step 2 can be used as child NeRFs’ spatial extent. After the division process above, the fused point clouds are distributed into a limited quantity of child NeRFs.
III-C Training PC-NeRF
In NeRF volume rendering, the depth value of a ray is synthesized from the weighted sampling depth values between the near and far bounds and by:
| (1) |
where represents a ray with camera or LiDAR origin oriented as , and the volume rendering integration weights is calculated by:
| (2) |
where is the visibility of from origin , and is the volumetric density at .
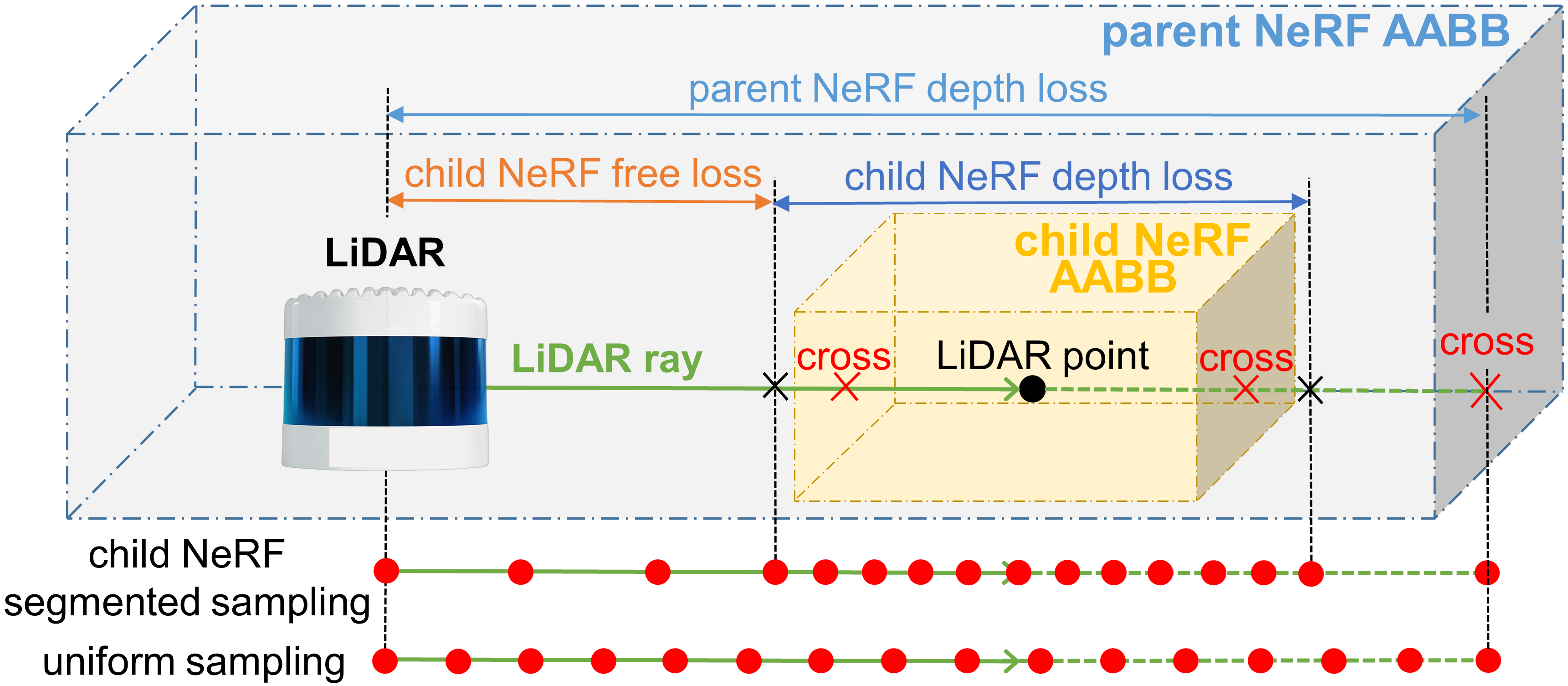
We apply LiDAR point cloud data to train our proposed PC-NeRF with model parameters . In the global coordinate system, the LiDAR origin position of the -th frame is represented as . The depth, direction, and the corresponding child NeRF order number of the -th laser point in the -th point cloud are , and respectively. Then, we can get one LiDAR ray . We further design three LiDAR losses and child NeRF segmented sampling for our proposed PC-NeRF model, illustrated in Fig. 3.
Parent NeRF depth loss: In Sec. III-A, the autonomous vehicle driving environment is represented efficiently using parent NeRF. We use the intersection of the LiDAR ray with its corresponding parent NeRF surface as the far bound . To adequately represent the volumetric distribution of the whole driving environment, we set parent NeRF depth loss as:
| (3) |
where the integration lower limit is set to 0. It is also recommended to set as or considering the space occupied by the LiDAR or the autonomous vehicle. And is an extension of SmoothL1Loss that shifts the turning point from to to improve model sensitivity.
The commonly used depth inference approach uses the synthetic depth between the scene’s near and far bounds as the inference depth [21, 31, 37, 23, 25], which is used in Eq. 3 and calculated as follows:
| (4) |
Segment-to-point hierarchical representation strategy: To find object surface points effectively and address the reduction of point cloud data, we further propose a segment-to-point hierarchical representation strategy. The depth difference between parent NeRF near and far bounds in large-scale outdoor scenes can be about ten times greater than that in indoor scenes, making it more difficult for the NeRF model to find the object surface through sampling. Given that it is much easier to find segment-level child NeRF space than to find point-level object surface points between the parent NeRF near and far bounds, we propose a segment-to-point hierarchical representation strategy, which first finds the child NeRFs that intersect the LiDAR ray and then finds object surface points inside the child NeRFs that intersect the LiDAR ray.
We use the intersections of the LiDAR ray with its corresponding child NeRF surface as the child NeRF near and far bounds . It is pretty evident that the depth difference between child NeRF near and far bounds is much smaller than that between parent NeRF near and far bounds. Considering that the object surface has a certain thickness and the object surface may appear at the child NeRF bounds, we slightly inflate the child NeRF near and far bounds as , where is a small inflation coefficient.
Child NeRF free loss: To make the process of finding the segment-level child NeRF’s corresponding space faster, we propose the child NeRF free loss in Eq. 5 as no opaque objects exist in and no objects can be observed in in a large number of cases.
| (5) |
Child NeRF depth loss: Based on child NeRF free loss, we propose child NeRF depth loss to find object surface points inside the child NeRF, which is calculated by:
| (6) |
To let the child NeRF free loss and the child NeRF depth loss have a smooth transition at the child NeRF bounds, is further modified to:
| (7) |
where is a constant designed to represent the smooth transition interval on a LiDAR ray between the child NeRF free loss and the child NeRF depth loss.
To sum up, the total training loss from one LiDAR ray contains all the losses mentioned above:
| (8) |
where , and are the parameter to jointly optimize different losses.
Child NeRF segmented sampling: To efficiently find the objects in large-scale scenes even under partial sensor data loss, we propose a child NeRF segmented sampling method for objects more likely to be found in and around the child NeRFs. Assuming that points are sampled uniformly along the LiDAR rays, the child NeRF segmented sampling is sampling points in and sampling in , as shown in Fig. 3. Therefore, child NeRF segmented sampling guarantees that at least points are sampled inside child NeRF, which means that at least sampling points are sampled near the real object.
III-D Two-step Depth Inference
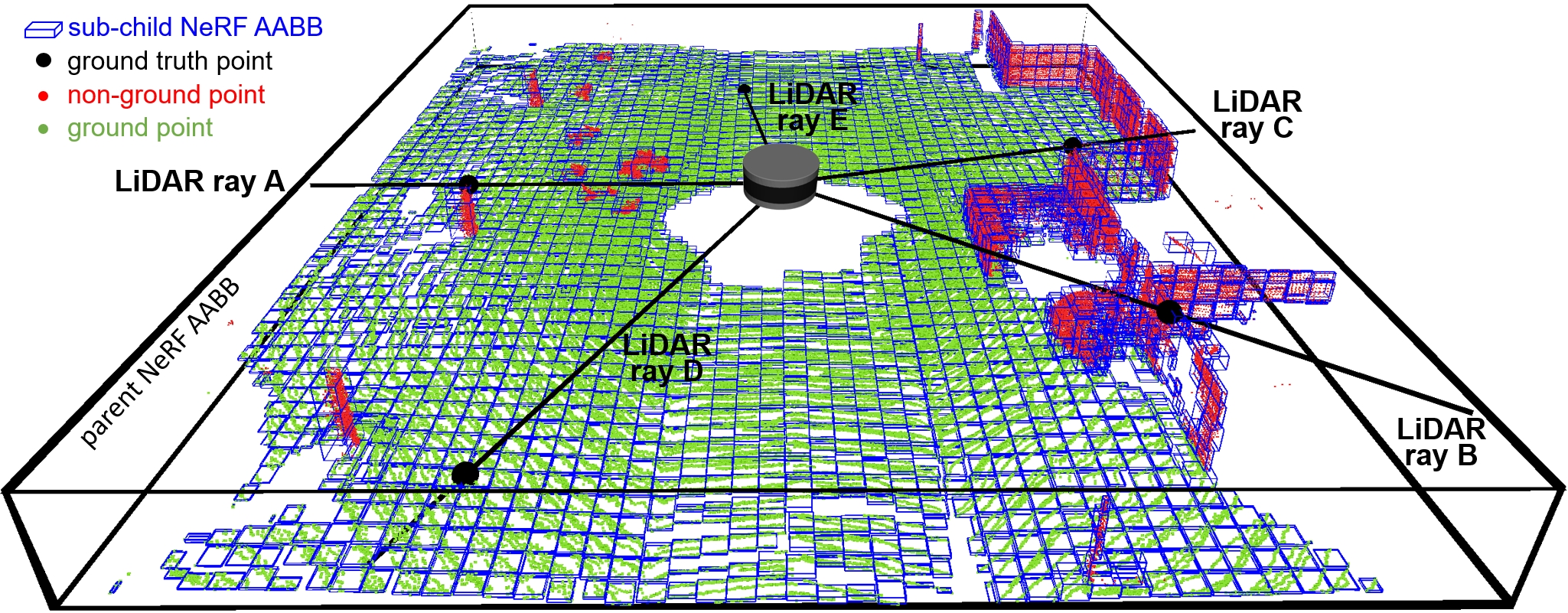
Most current depth inference methods are one-step depth inference methods, similar to Eq. 4. In contrast, we provide a two-step depth inference method to infer more accurately based on the remaining sensor data. We first search in the parent NeRF AABB to acquire the child NeRF AABBs potentially intersecting the LiDAR ray and then conduct further inference in the child NeRF AABB’s near and far bounds intersecting with the LiDAR ray, as shown in Fig. 4(a). To this end, we first select the child NeRF whose AABB outer sphere intersects the ray and then use the Axis Aligned Bounding Box intersection test proposed by Haines [41], which can readily process millions of voxels or AABBs in real time [30]. If the LiDAR ray does not intersect any child NeRF AABB, the space extent of all child NeRF AABBs for this LiDAR ray should be slightly inflated in incremental steps, and the above inference should be performed again.
To reduce the potentially severe impact of mistaking free space for object space, we keep the inferred depth values within one of the child NeRF near and far bounds, as shown in the first subfigure of Fig. 4(b). In real-world applications, the LiDAR ray usually intersects multiple child NeRF AABBs. In that case, we select the child NeRF AABB whose space area includes the weight (as Eq. 2 calculates) peak value, as the LiDAR ray cannot penetrate opaque objects when it emits, as shown in the first and third subfigure of Fig. 4(b). Furthermore, suppose the peak weight value is not in any child NeRF AABB. In that case, the child NeRF with the maximum weight integration , i.e., the most likely existence range of an object on the LiDAR ray, is selected, as shown in the second subfigure of Fig. 4(b). Moreover, the weight integration is calculated by Eq. 9. When the LiDAR ray only intersects one single child NeRF AABB, we can directly select it as the object area, as shown in the last two subfigures of Fig. 4(b). Note that the child NeRF weight integration may be minimal, in which case the LiDAR ray does not intersect any child NeRF and no depth value needs to be inferred. The inferred depth value of each LiDAR ray is calculated by Eq. 10.
| (9) |
| (10) |
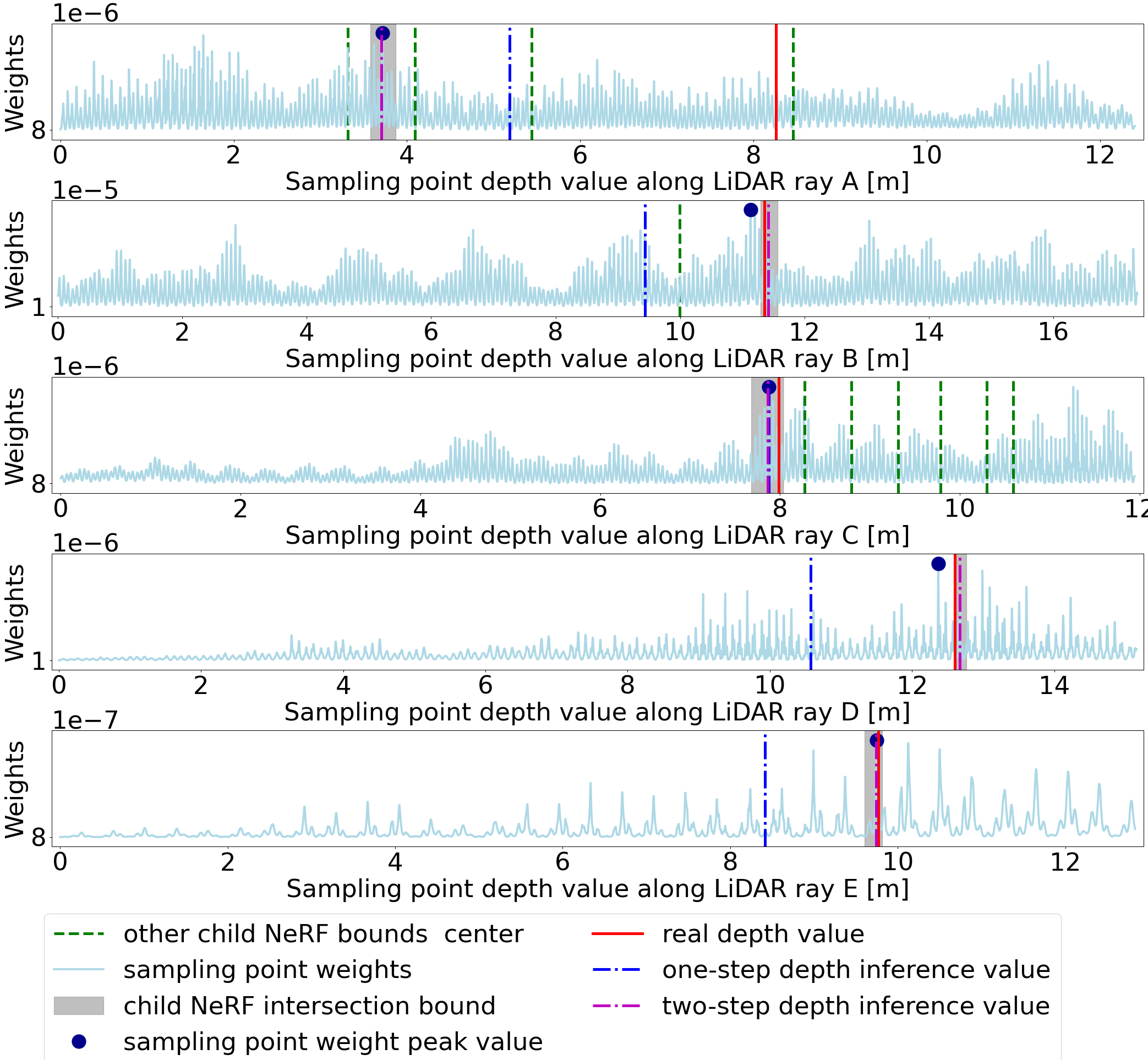
IV Experiments
IV-A Experiment Setups
Datasets: We evaluate our approach using two publicly available outdoor datasets, including the MaiCity [17] and KITTI odometry datasets [42]. The MaiCity dataset contains 64-beam noise-free synthetic LiDAR scans in virtual urban-like environments. KITTI odometry dataset also contains 64-beam LiDAR data collected by the vehicle in real-world urban environments and provides a localization benchmark. Moreover, we further use semantic labels from SemanticKITTI [43] to filter out movable objects. In Sec. IV-B and Sec. IV-D, we sample one test scan out of every five scans and use the other scans for training, the same as the dataset split in some previous works, such as NeRF-LOAM [4] and NFL [14].
Metrics: We evaluate the novel LiDAR view synthesis and the 3D Reconstruction performance of our method. For the novel LiDAR view synthesis, We compare the reconstructed depth value with the real depth of each LiDAR ray on the test set and report the mean average absolute error (Avg. Error []) and mean accuracy at two thresholds ([email protected] and Acc@1 [%]). Moreover, for 3D reconstruction, we report the chamfer distance (CD []) and F-score at two thresholds ([email protected] and F-score@1).
Baselines: A standard pipeline for generating new LiDAR views is constructing a 3D point cloud map and then using the ray-casting approach [44] to query new point clouds from the map. We implement this pipeline, which voxelizes the 3D point cloud map into a 3D voxel map to speed up the query but may slightly reduce accuracy, as a baseline method named MapRayCasting. In addition, we also extend the original NeRF model proposed by Mildenhall [21] by replacing a camera ray with a LiDAR ray as IR-MCL [31], named OriginalNeRF.
Training details: We train our proposed PC-NeRF and all the baselines on an NVIDIA GeForce RTX 3090 and use Adam [45] as the training optimizer. The initial learning rate is set to and is adjusted using Pytorch’s MultiStepLR strategy, where the adjustment milestones are and the adjustment factor is . In Sec. IV-B and Sec. IV-C, , , , , and of our proposed PC-NeRF are set to , , , , and , respectively. This group of parameters is not specifically tuned for a single scene but is valid for all experimental scenes. Except as specifically noted, our proposed PC-NeRF uses only one training epoch to achieve the demonstrated accuracy. Both our PC-NeRF and OriginalNeRF use the hierarchical volume sampling strategy along the LiDAR ray proposed in NeRF [21], where the points number and for coarse and fine sampling along the ray are 768 and 1536, respectively. However, for coarse sampling, our PC-NeRF uses the Child NeRF segmented sampling proposed in Sec. III-C, while OriginalNeRF samples uniformly along the LiDAR rays.
IV-B Evaluation for 3D Reconstruction in Different Scales
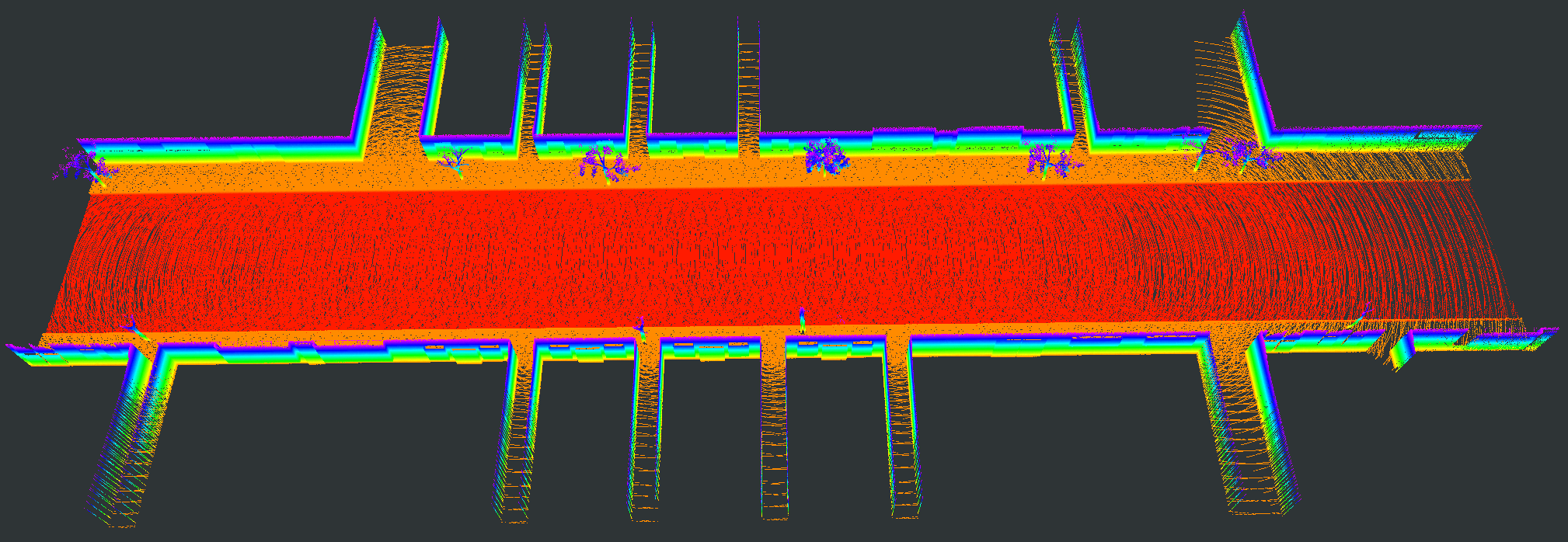
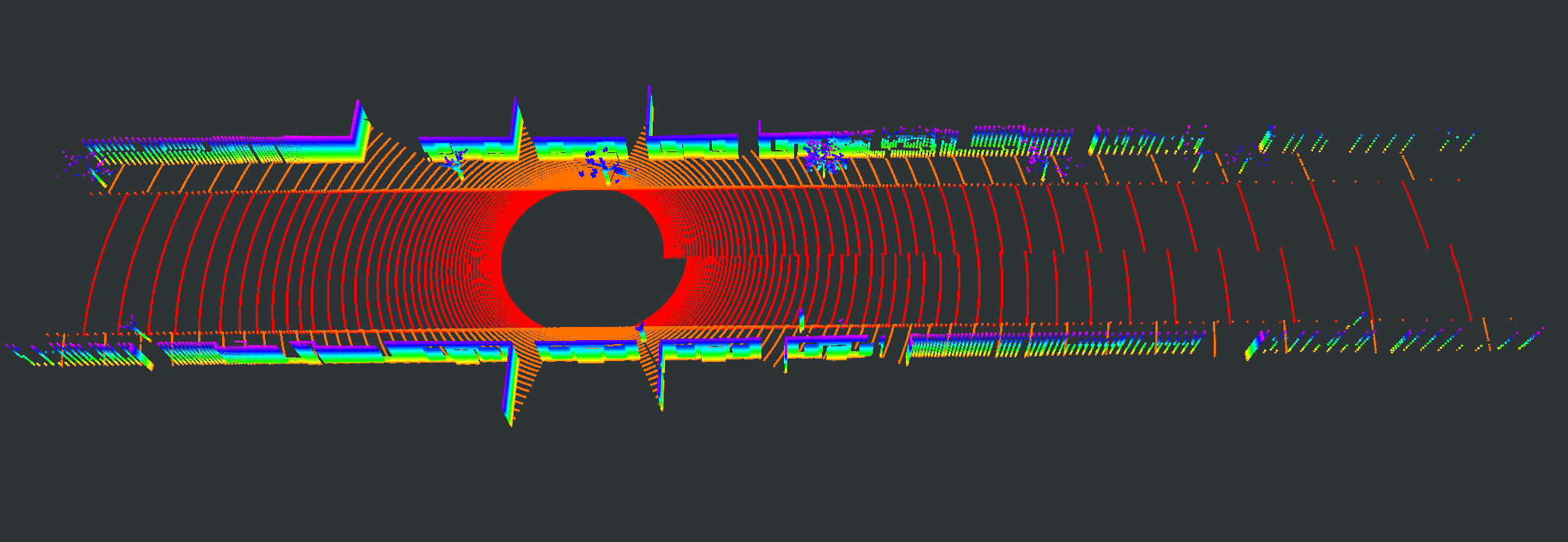
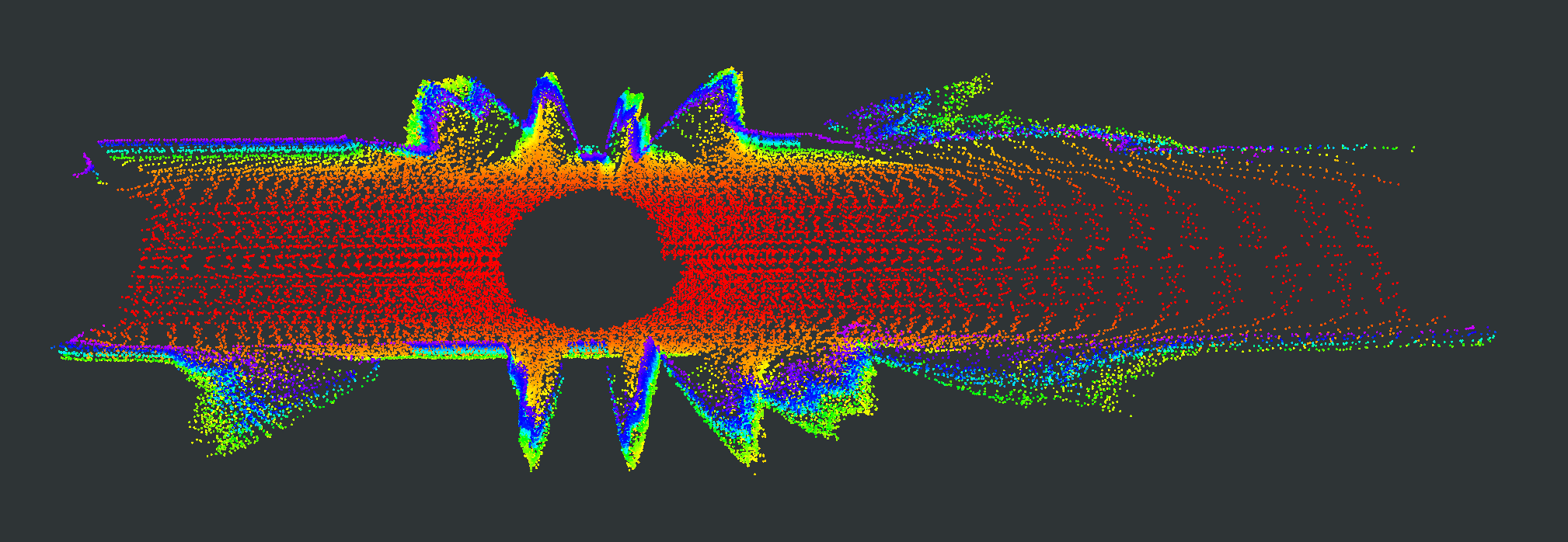
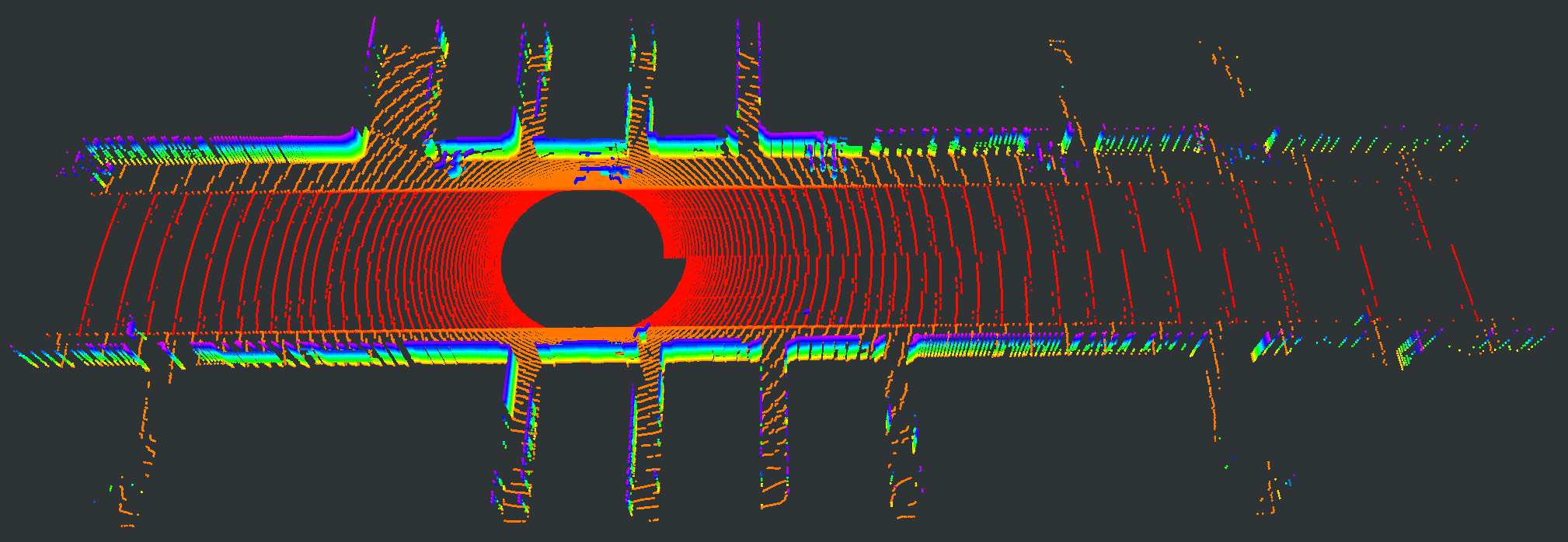
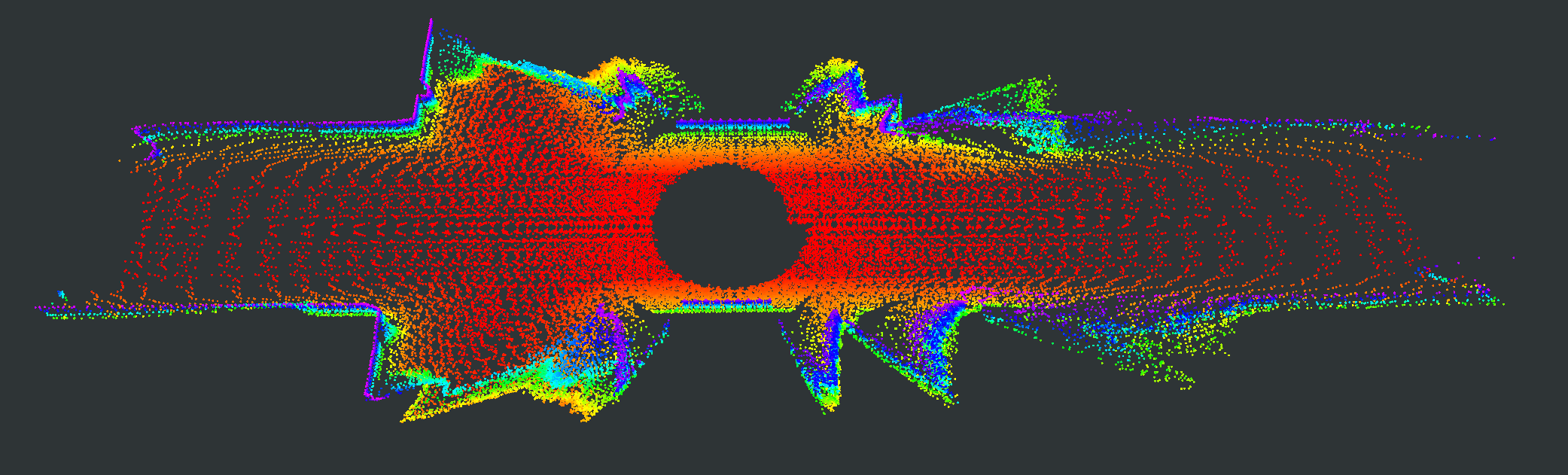
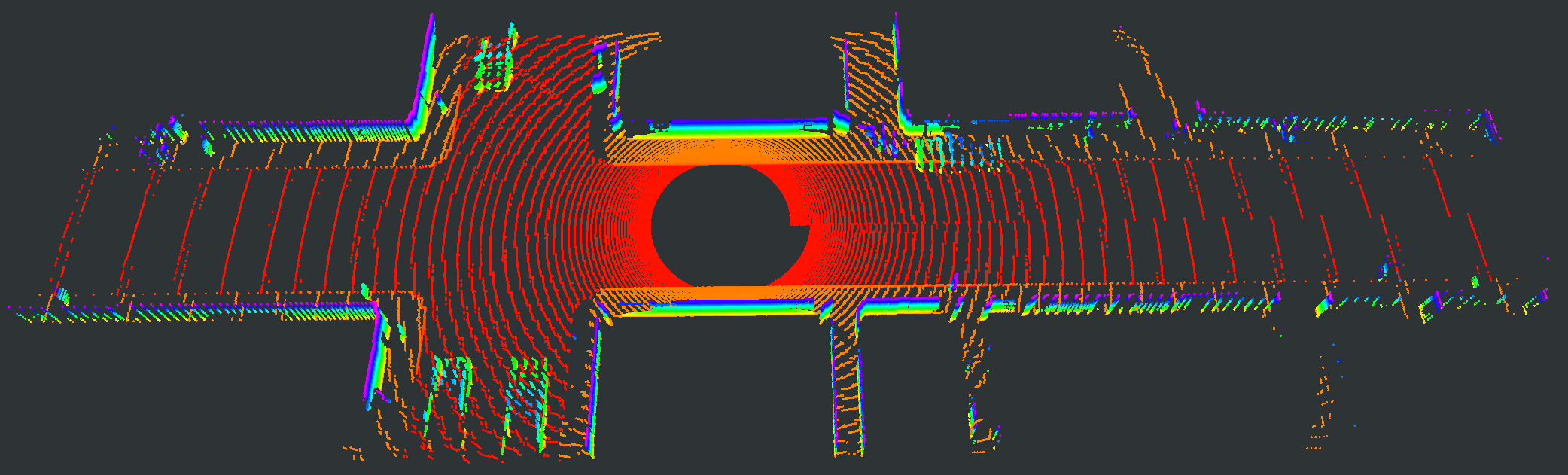
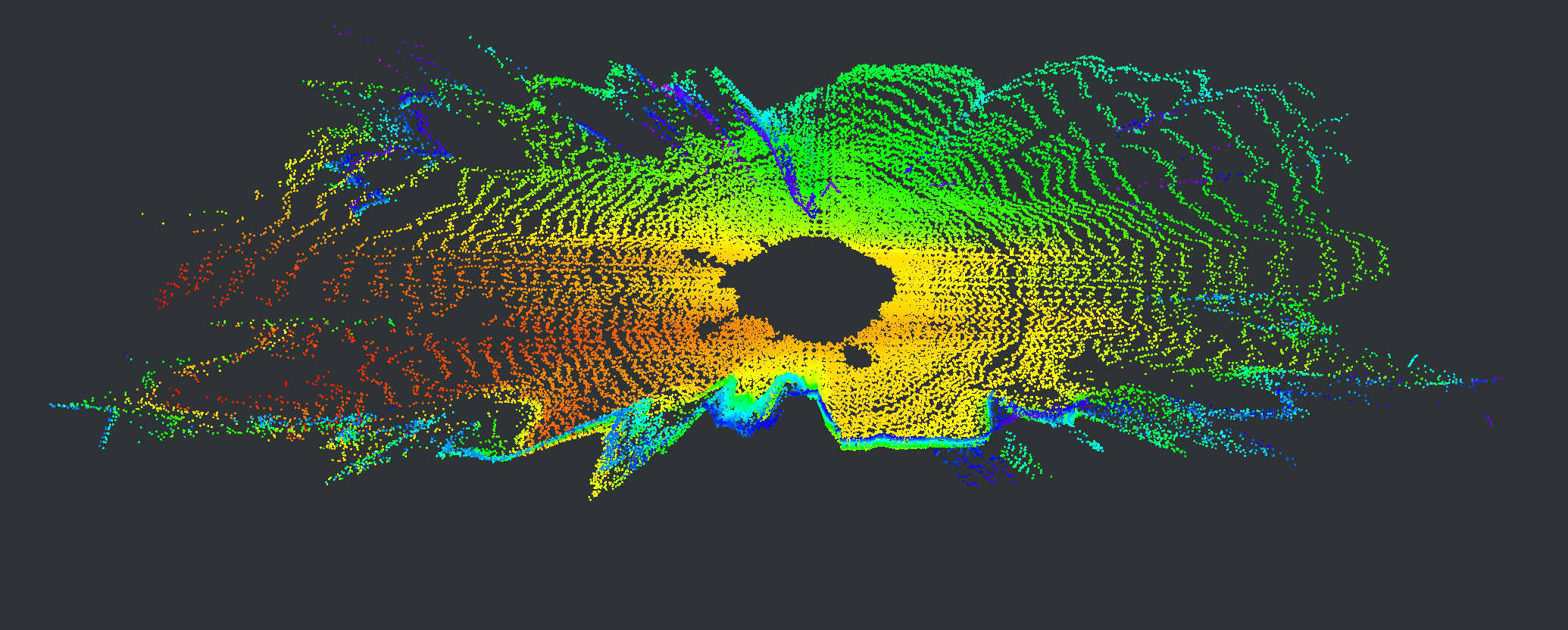
We evaluate our proposed PC-NeRF’s inference accuracy and deployment potential in different scales qualitatively and quantitatively. We conduct experiments on the MaiCity and KITTI datasets using 50 consecutive scans as a scene, corresponding to the small-scale evaluation since each NeRF model is trained and evaluated only by one scene. As shown in Fig. 5, MapRayCasting and OriginalNeRF can roughly reconstruct the environment while losing many environmental details. Especially when the input sensor data is distributed centrally over large spatial segments such as the ground, OriginalNeRF tends to be trained overfitting to the representation of larger objects and ignoring smaller objects, as shown in rows 2 and 3 of column 6 of Fig. 5. In contrast, our proposed PC-NeRF achieves better results compared to the baselines by optimizing the scene-level, segment-level, and point-level environmental representations concurrently, as shown in the last column of Fig. 5. We also report the quantitative results for small-scale scenes in Tab. I. As shown in Tab. I, our proposed PC-NeRF performs much better than MapRayCasting and OriginalNeRF and achieves a high novel LiDAR view synthesis accuracy (e.g. Avg. Error 0.50) and 3D reconstruction accuracy (e.g. CD 0.23). Moreover, our proposed two-step depth inference has much better inference accuracy than the one-step depth inference and is highly stable on our proposed PC-NeRF. Therefore, for the subsequent experiments in Sec. IV-C and Sec. IV-D, we use the one-step depth inference and the two-step depth inference for OriginalNeRF and our proposed PC-NeRF, respectively. Compared to OriginalNeRF, which uses ten epochs of training, our proposed PC-NeRF demonstrates good deployment potential because our proposed PC-NeRF yields better results using only one training and does not change any model parameters for different scenes.
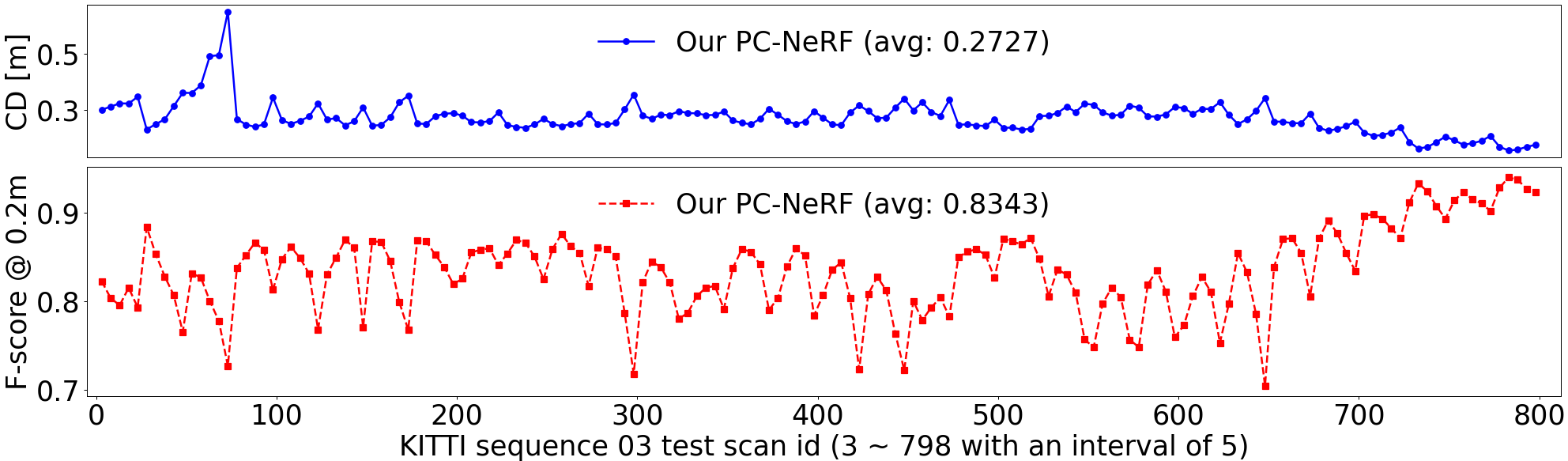
To further explore the deployment potential, we test our proposed PC-NeRF on large-scale scenes. According to Sec. III-A, we divide the KITTI 03 sequence (800 scans, ) into 32 sequential scenes and each PC-NeRF model is trained and evaluated on one scene. The spatial extent of each scene is about , overlapping with that of neighbouring scenes. In the 30th scene, our proposed PC-NeRF trains three epochs because one or two epochs of training result in the failure of two-step depth inference. Additionally, our proposed PC-NeRF trains only one epoch on all the remaining 31 scenes. As a comparison, OriginalNeRF trains three epochs on all 32 scenes. From Tab. II and Fig. 6, it can be seen that our proposed PC-NeRF is trained to achieve a high novel LiDAR view synthesis accuracy (e.g., Avg. Error 0.66) and 3D reconstruction accuracy (e.g., CD 0.28), further demonstrating its promising deployment potential in large-scale environments.
| Scene | Pointcloud Map | Scan | GT | MapRayCasting | OriginalNeRF | PC-NeRF | ||||
|---|---|---|---|---|---|---|---|---|---|---|
|
|
|||||||||
|
|
|||||||||
|
|
|||||||||
|
|









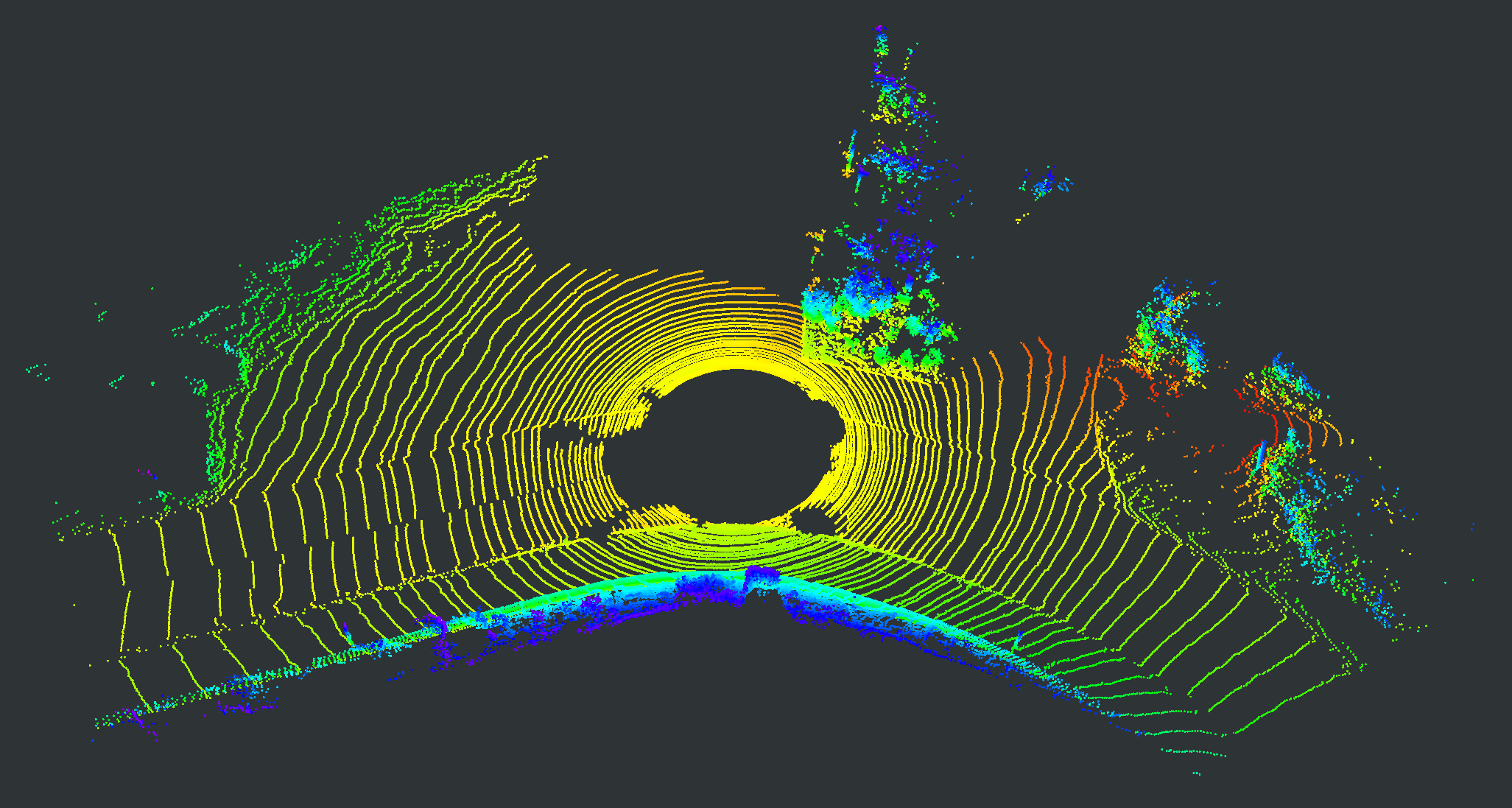
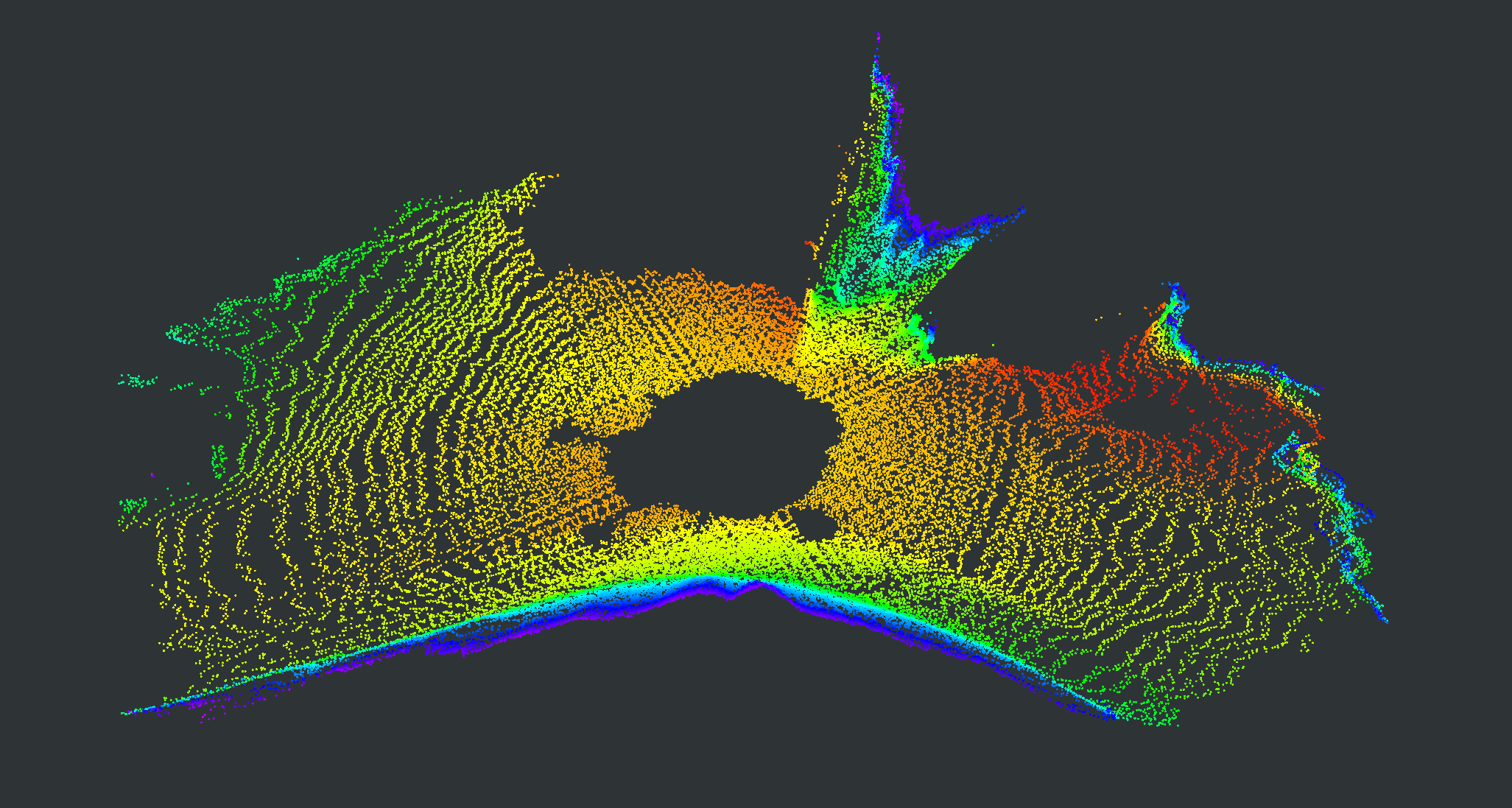
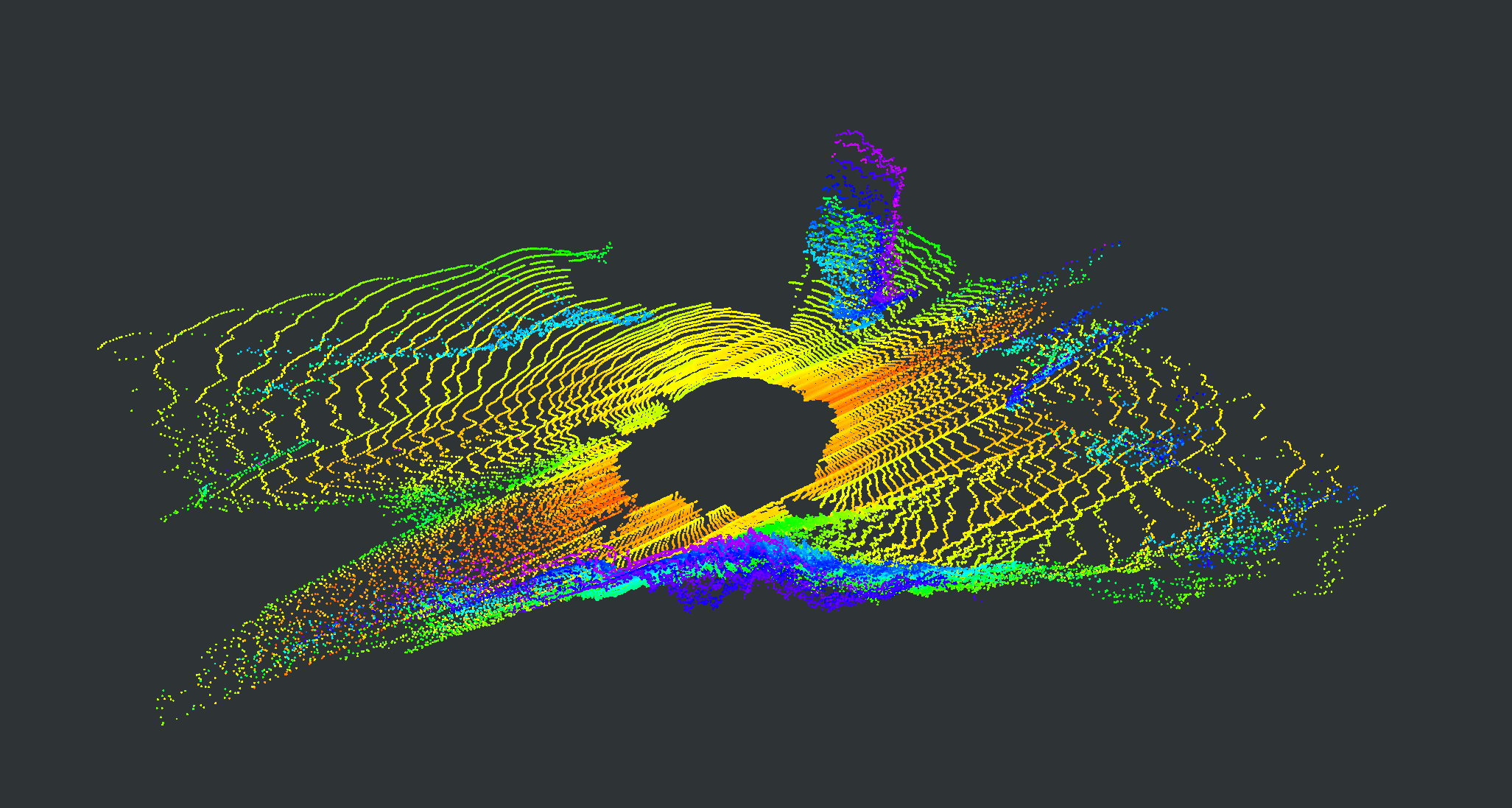
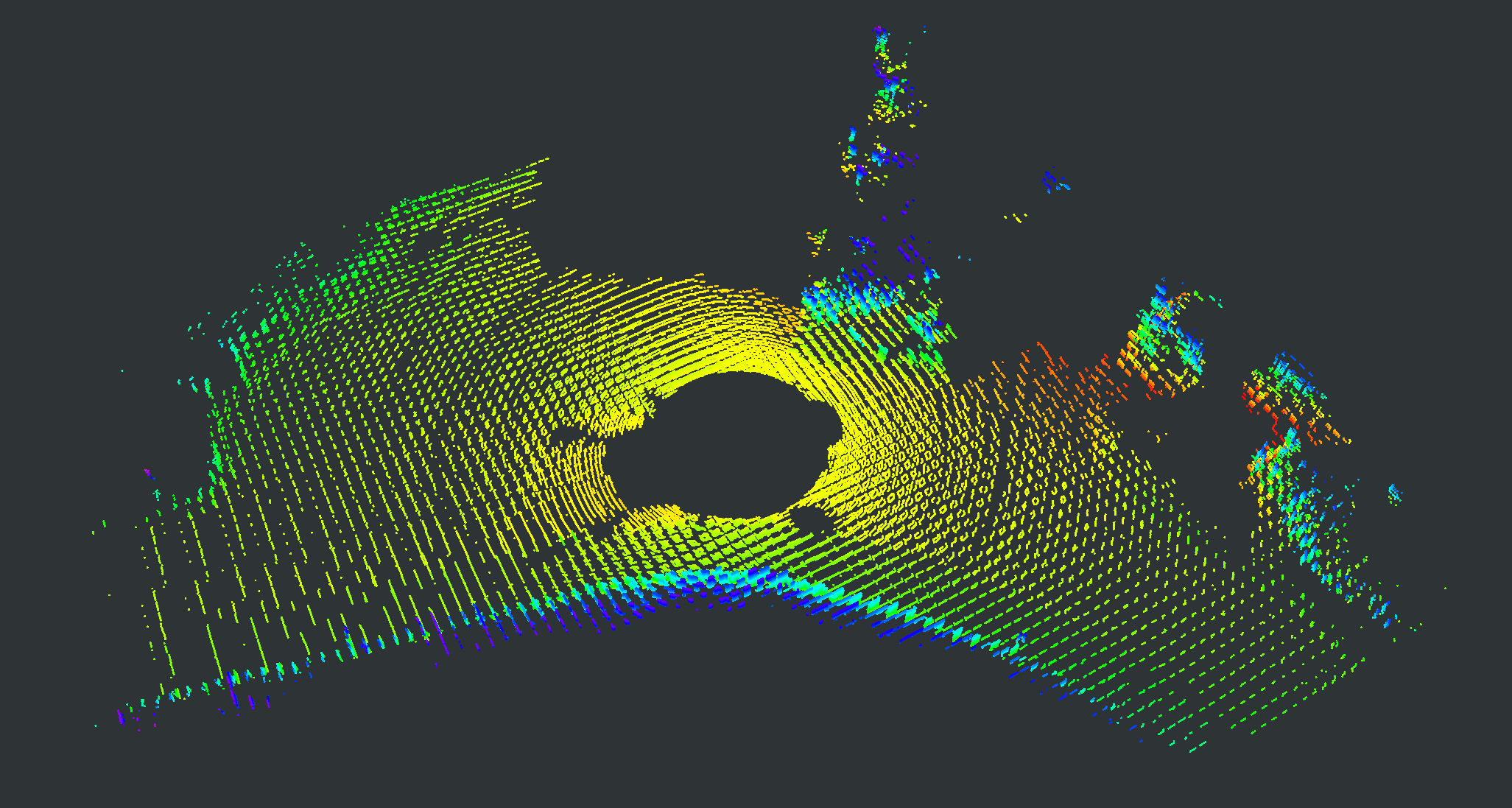
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MaiCity-sequence00-0-49 | MaiCity-sequence01-0-49 | ||||||||||||||||||||||||||||||||||||||||||
| MapRayCasting | - | - | 0.841 | 49.873 | 78.040 | 0.600 | 0.736 | 0.917 | 0.744 | 55.836 | 80.781 | 0.505 | 0.754 | 0.943 | |||||||||||||||||||||||||||||
| OriginalNeRF | one-step | 10 | 3.357 | 0.004 | 0.247 | 3.184 | NaN | 0.224 | 3.699 | 0.312 | 2.009 | 3.399 | NaN | 0.249 | |||||||||||||||||||||||||||||
| OriginalNeRF | two-step | 10 | 0.588 | 83.991 | 87.956 | 0.315 | 0.918 | 0.962 | 0.459 | 85.548 | 91.387 | 0.233 | 0.919 | 0.975 | |||||||||||||||||||||||||||||
| PC-NeRF | one-step | 1 | 1.755 | 2.575 | 23.879 | 1.279 | 0.070 | 0.868 | 2.025 | 2.189 | 16.672 | 1.455 | 0.056 | 0.808 | |||||||||||||||||||||||||||||
| PC-NeRF | two-step | 1 | 0.303 | 88.956 | 93.579 | 0.172 | 0.955 | 0.985 | 0.392 | 86.798 | 92.568 | 0.185 | 0.935 | 0.981 | |||||||||||||||||||||||||||||
| KITTI-sequence00-1151-1200 | KITTI-sequence03-751-800 | ||||||||||||||||||||||||||||||||||||||||||
| MapRayCasting | - | - | 0.871 | 44.358 | 77.823 | 0.466 | 0.740 | 0.949 | 0.472 | 46.988 | 36.969 | 0.274 | 0.836 | 0.798 | |||||||||||||||||||||||||||||
| OriginalNeRF | one-step | 10 | 5.251 | 0.261 | 1.515 | 3.289 | 0.012 | 0.321 | 1.590 | 8.887 | 53.757 | 0.850 | 0.328 | 0.924 | |||||||||||||||||||||||||||||
| OriginalNeRF | two-step | 10 | 0.515 | 64.566 | 91.948 | 0.223 | 0.888 | 0.994 | infer error | ||||||||||||||||||||||||||||||||||
| PC-NeRF | one-step | 1 | 2.331 | 5.790 | 27.583 | 1.620 | 0.178 | 0.836 | 5.116 | 0.482 | 2.483 | 4.192 | 0.022 | 0.236 | |||||||||||||||||||||||||||||
| PC-NeRF | two-step | 1 | 0.488 | 66.654 | 92.131 | 0.224 | 0.891 | 0.993 | 0.397 | 51.264 | 93.495 | 0.224 | 0.878 | 0.999 | |||||||||||||||||||||||||||||
| Method |
|
|
|
CD[] |
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
- | 0.898 | 34.812 | 0.452 | 0.729 | ||||||||
| OriginalNeRF | one-step | 2.441 | 8.290 | 1.438 | 0.271 | ||||||||
| PC-NeRF | two-step | 0.658 | 43.556 | 0.273 | 0.834 |


IV-C Evaluation for 3D Reconstruction under Sensor Data Loss
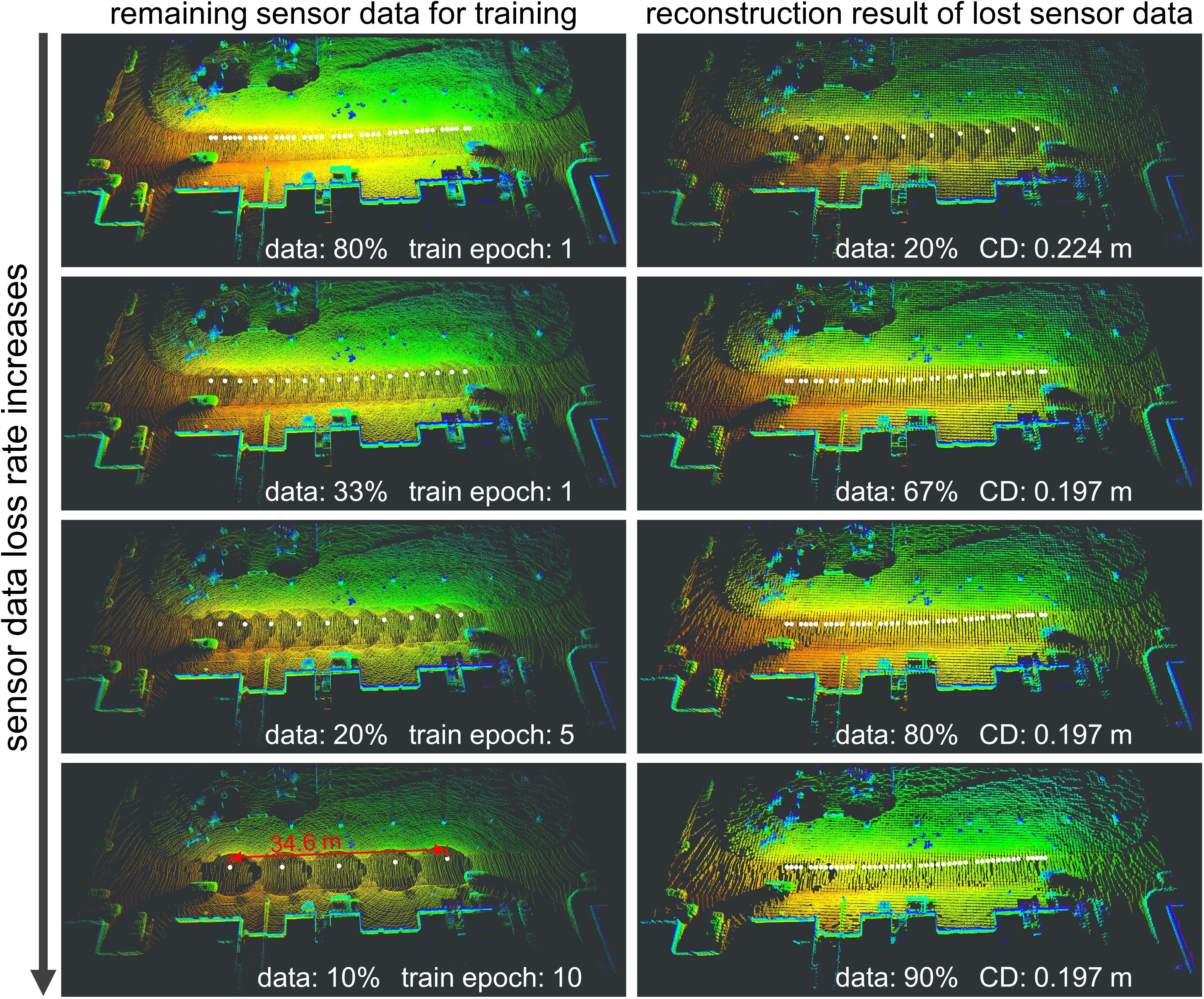
We evaluate our proposed PC-NeRF’s 3D reconstruction under sensor data loss on the MaiCity 00 and KITTI 00 sequences. In real autonomous vehicle applications, some unfavorable conditions, such as hardware failures, adverse weather factors, and unstable communication in remote control tasks, may result in different degrees of sensor data loss. To simulate this challenge, we control the sensor data loss rate by setting the proportion of training point cloud data and using all the other point cloud data as the test set.
Let us first concentrate on the number of training epochs since the fewer the number of training epochs used to meet the required 3D reconstruction accuracy, the faster our proposed PC-NeRF can be deployed. As seen in Tab. III and Fig. 1, with only one epoch training, our proposed PC-NeRF can reconstruct urban and rural road environments very well until the sensor data loss rate reaches 67. However, due to too little sensor data input for model training when increasing the sensor data loss rate from 67, our proposed PC-NeRF that continues to be trained using only one epoch fails to infer using the two-step depth inference. Therefore, we increase the number of training epochs until successful inference is achieved using the two-step depth inference. At the sensor data loss rate of 90, the lowest number of epochs required for the two-step depth inference to be effective is five for scenes from the MaiCity dataset and ten for scenes from the KITTI dataset. This difference in epoch number is because the scenes in the KITTI and MaiCity datasets are rural and urban road scenes, respectively. Urban road scenes, with more straightforward environmental geometric segments, require fewer training epochs for efficient learning.
Let us then focus on the 3D reconstruction accuracy of our proposed PC-NeRF. As Tab. III shows, using several training epochs that are no more or even much fewer than that of OriginalNeRF, our proposed PC-NeRF achieves much higher accuracy than OriginalNeRF and also higher accuracy than MapRayCasting. Surprisingly, in Tab. III, we can find that as the sensor data loss rate increases, the 3D reconstruction accuracy of our proposed PC-NeRF does not decrease but instead increases or remains relatively stable. This accuracy does not decrease because our proposed PC-NeRF can rapidly learn an approximate scene distribution at the segment level. Moreover, if the input sensor data is too much or too little during training, more training epoch is needed to fit the model. Additionally, the 3D reconstruction accuracy is higher on the MaiCity dataset than on the KITTI dataset because urban roads have fewer environmental geometric segments than rural roads, contributing more to segment-level 3D reconstruction and, in turn, to scene-level and point-level 3D reconstruction.
In summary, our proposed PC-NeRF can effectively address the challenge of sensor data loss. Even when up to 67 of the sensor data is lost, our proposed PC-NeRF can still achieve a high novel LiDAR view synthesis accuracy (e.g., Avg. Error 0.44) and 3D reconstruction accuracy (e.g., CD 0.20) using only one training epoch, presenting a good potential for deployment and reconstruction performance even under partial sensor data loss.
IV-D Ablation Study
To demonstrate the effectiveness of our method components, we conducted experiments on different components of our proposed PC-NeRF.
Effect of child NeRF free loss: In our proposed PC-NeRF, the child NeRF free loss controlled by optimizes the scene-level and segment-level environmental representation. As seen in Tab. IV, the child NeRF free loss helps improve 3D reconstruction accuracy within a specific range of variation, but too high or too low reduces the 3D reconstruction accuracy.
Effect of balancing child NeRF free loss and child NeRF depth loss: Based on child NeRF free loss, child NeRF depth loss is used to optimize the point-level and segment-level environmental representations further, making the balance between child NeRF free loss and child NeRF depth loss a critical point. As shown in Tab. V, enlarging the smooth transition interval between child NeRF free loss and child NeRF depth loss can improve the 3D reconstruction accuracy. At the same time, too large a smooth transition interval will decrease the 3D reconstruction accuracy. This accuracy decrease is because when the smooth transition interval is too large, child NeRF depth loss almost needs to supervise the sampling points on the entire ray and cannot effectively supervise the sampling points around the near and far bounds of child NeRF.
Effect of two-step depth inference: In Tab. I, it can be seen that two-step depth inference outperforms one-step depth inference in many cases, but inference errors also occur for OriginalNeRF. This inference error is because the validity of two-step depth inference is based on the model output weight distribution near the geometric segments’ distribution in the environment, as shown in Fig. 4(b). The extensive experiments in Sec. IV-B, Sec. IV-C, and Sec. IV-D demonstrate that our proposed PC-NeRF training method and two-step depth inference are highly compatible and consistently robust.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MaiCity-sequence00-0-49 (urban road) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PC-NeRF (two-step depth inference) | MapRayCasting | OriginalNeRF (one-step depth inference) | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| 20 | 4/5 | 1 | 0.303 | 93.580 | 0.172 | 0.985 | 0.841 | 78.040 | 0.600 | 0.917 | 10 | 3.357 | 0.247 | 3.184 | 0.224 | |||||||||||||||||||||||||||||||||||||||
| 25 | 3/4 | 0.287 | 93.874 | 0.166 | 0.986 | 0.825 | 78.224 | 0.597 | 0.916 | 3.440 | 0.178 | 3.289 | 0.213 | |||||||||||||||||||||||||||||||||||||||||
| 33.33 | 2/3 | 0.328 | 93.439 | 0.192 | 0.983 | 0.820 | 78.112 | 0.594 | 0.916 | 3.809 | 0.078 | 3.688 | 0.147 | |||||||||||||||||||||||||||||||||||||||||
| 50 | 1/2 | 0.245 | 94.531 | 0.143 | 0.990 | 0.801 | 78.552 | 0.581 | 0.919 | 3.512 | 0.124 | 3.372 | 0.202 | |||||||||||||||||||||||||||||||||||||||||
| 66.67 | 1/3 | 0.189 | 95.448 | 0.109 | 0.994 | 0.717 | 79.360 | 0.530 | 0.929 | 3.715 | 0.080 | 3.633 | 0.164 | |||||||||||||||||||||||||||||||||||||||||
| 80 | 1/5 | 5 | 0.177 | 95.657 | 0.106 | 0.995 | 0.473 | 86.118 | 0.367 | 0.972 | 3.356 | 0.232 | 3.174 | 0.227 | ||||||||||||||||||||||||||||||||||||||||
| 90 | 1/10 | 0.163 | 95.853 | 0.108 | 0.997 | 0.561 | 84.773 | 0.423 | 0.956 | 3.406 | 0.195 | 3.218 | 0.219 | |||||||||||||||||||||||||||||||||||||||||
| KITTI-sequence00-1151-1200 (rural road) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PC-NeRF (two-step depth inference) | MapRayCasting | OriginalNeRF (one-step depth inference) | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| 20 | 4/5 | 1 | 0.488 | 92.131 | 0.224 | 0.993 | 0.871 | 77.823 | 0.466 | 0.949 | 10 | 5.251 | 1.515 | 3.289 | 0.321 | |||||||||||||||||||||||||||||||||||||||
| 25 | 3/4 | 0.443 | 93.391 | 0.206 | 0.995 | 0.865 | 78.146 | 0.463 | 0.949 | 5.098 | 1.743 | 3.026 | 0.346 | |||||||||||||||||||||||||||||||||||||||||
| 33.33 | 2/3 | 0.447 | 93.296 | 0.206 | 0.995 | 0.858 | 78.449 | 0.459 | 0.950 | 5.361 | 1.392 | 3.166 | 0.300 | |||||||||||||||||||||||||||||||||||||||||
| 50 | 1/2 | 0.461 | 92.860 | 0.213 | 0.994 | 0.851 | 78.209 | 0.459 | 0.950 | 4.968 | 2.182 | 3.107 | 0.361 | |||||||||||||||||||||||||||||||||||||||||
| 66.67 | 1/3 | 0.439 | 93.558 | 0.197 | 0.995 | 0.855 | 78.297 | 0.459 | 0.949 | 5.561 | 1.273 | 3.687 | 0.264 | |||||||||||||||||||||||||||||||||||||||||
| 80 | 1/5 | 5 | 0.423 | 93.661 | 0.197 | 0.995 | 0.813 | 79.263 | 0.437 | 0.955 | 2.487 | 17.934 | 1.301 | 0.858 | ||||||||||||||||||||||||||||||||||||||||
| 90 | 1/10 | 10 | 0.412 | 93.665 | 0.197 | 0.995 | 0.780 | 80.210 | 0.417 | 0.960 | 5.195 | 2.058 | 3.015 | 0.335 | ||||||||||||||||||||||||||||||||||||||||
| Avg. Error[] | Acc@[%] | CD[] | F-score@ | |
| 0 | 0.5110 | 65.2321 | 0.2201 | 0.8904 |
| 1 | 0.5072 | 66.1292 | 0.2165 | 0.8939 |
| 10 | 0.4930 | 68.3496 | 0.2099 | 0.8995 |
| 100 | 0.4743 | 70.0247 | 0.2067 | 0.9000 |
| 1000 | 0.4723 | 69.5482 | 0.2092 | 0.8987 |
| 0.4646 | 69.9601 | 0.2087 | 0.8984 | |
| 0.4633 | 67.1306 | 0.2182 | 0.8936 | |
| 0.4647 | 67.1092 | 0.2185 | 0.8935 | |
| 0.4673 | 67.0546 | 0.2192 | 0.8931 | |
| 0.4663 | 67.0783 | 0.2189 | 0.8933 | |
| 0.4655 | 67.0933 | 0.2187 | 0.8934 | |
| Note: | ||||
| Avg. Error[] | Acc@[%] | CD[] | F-score@ | |
| 0.25 | 0.5113 | 66.4901 | 0.2283 | 0.8870 |
| 0.5 | 0.5113 | 66.4303 | 0.2282 | 0.8873 |
| 1 | 0.5130 | 65.9698 | 0.2286 | 0.8874 |
| 1.5 | 0.5120 | 65.8837 | 0.2290 | 0.8878 |
| 2 | 0.4884 | 66.6541 | 0.2239 | 0.8908 |
| 2.5 | 0.4446 | 68.2699 | 0.2097 | 0.8979 |
| 3 | 0.4474 | 68.6973 | 0.2073 | 0.8988 |
| 4 | 0.4492 | 69.0594 | 0.2063 | 0.8992 |
| 5 | 0.4517 | 69.3440 | 0.2063 | 0.8994 |
| 7.5 | 0.4662 | 70.5668 | 0.2068 | 0.8993 |
| 10 | 0.4683 | 70.2688 | 0.2086 | 0.8987 |
| 20 | 0.4704 | 69.7122 | 0.2081 | 0.8993 |
| Note: | ||||
V Conclusion
This paper proposes a large-scale, high-precision scene reconstruction framework called parent-child neural radiance fields (PC-NeRF), effectively improving reconstruction performance under partial sensor data loss in outdoor environments. The two modules of PC-NeRF, namely, the parent NeRF and the child NeRF, provide volumetric representations for the entire autonomous vehicle traversal environments and individual scene geometric segments. Using LiDAR rays intersecting parent NeRF and child NeRF, we design three losses, including the parent NeRF depth loss, child NeRF free loss, and child NeRF depth loss, to jointly optimize the scene-level, segment-level, and point-level scene representation. Our proposed PC-NeRF is validated with extensive experiments to achieve high-precision 3D reconstruction in large-scale scenes. Moreover, PC-NeRF has strong deployment potential, with considerable scene representation accuracy that can be achieved by training only one epoch in most test scenarios. Most importantly, PC-NeRF effectively tackles partial sensor data loss problems in real vehicle applications. Our future work will further explore the potential of PC-NeRF in object detection and localization for autonomous driving.
References
- [1] Z. Li and J. Zhu, “Point-based neural scene rendering for street views,” IEEE Transactions on Intelligent Vehicles, 2023, doi: 10.1109/TIV.2023.3304347.
- [2] X. Zhong, Y. Pan, J. Behley, and C. Stachniss, “Shine-mapping: Large-scale 3d mapping using sparse hierarchical implicit neural representations,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 8371–8377, doi: 10.1109/ICRA48891.2023.10160907.
- [3] Y. Ran, J. Zeng, S. He, J. Chen, L. Li, Y. Chen, G. Lee, and Q. Ye, “Neurar: Neural uncertainty for autonomous 3d reconstruction with implicit neural representations,” IEEE Robotics and Automation Letters, vol. 8, no. 2, pp. 1125–1132, 2023, doi: 10.1109/LRA.2023.3235686.
- [4] J. Deng, X. Chen, S. Xia, Z. Sun, G. Liu, W. Yu, and L. Pei, “Nerf-loam: Neural implicit representation for large-scale incremental lidar odometry and mapping,” arXiv preprint arXiv:2303.10709, 2023, doi: 10.48550/arXiv.2303.10709.
- [5] H. Turki, D. Ramanan, and M. Satyanarayanan, “Mega-nerf: Scalable construction of large-scale nerfs for virtual fly-throughs,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 922–12 931, doi: 10.1109/CVPR52688.2022.01258.
- [6] Y. Chang, K. Ebadi, C. E. Denniston, M. F. Ginting, A. Rosinol, A. Reinke, M. Palieri, J. Shi, A. Chatterjee, B. Morrell et al., “Lamp 2.0: A robust multi-robot slam system for operation in challenging large-scale underground environments,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 9175–9182, 2022, doi: 10.1109/LRA.2022.3191204.
- [7] H. Parr, C. Harvey, and G. Burnett, “Investigating levels of remote operation in high-level on-road autonomous vehicles using operator sequence diagrams,” 2023, doi: 10.21203/rs.3.rs-2510863/v1.
- [8] J. Zhang, J. Pu, J. Xue, M. Yang, X. Xu, X. Wang, and F.-Y. Wang, “Hivegpt: human-machine-augmented intelligent vehicles with generative pre-trained transformer,” IEEE Transactions on Intelligent Vehicles, 2023, doi: 10.1109/TIV.2023.3256982.
- [9] J. Wang, Z. Wang, B. Yu, J. Tang, S. L. Song, C. Liu, and Y. Hu, “Data fusion in infrastructure-augmented autonomous driving system: Why? where? and how?” IEEE Internet of Things Journal, 2023, doi: 10.1109/JIOT.2023.3266247.
- [10] Z. Song, Z. He, X. Li, Q. Ma, R. Ming, Z. Mao, H. Pei, L. Peng, J. Hu, D. Yao et al., “Synthetic datasets for autonomous driving: A survey,” arXiv preprint arXiv:2304.12205, 2023, doi: 10.48550/arXiv.2304.12205.
- [11] Y. Wang, L. Xu, F. Zhang, H. Dong, Y. Liu, and G. Yin, “An adaptive fault-tolerant ekf for vehicle state estimation with partial missing measurements,” IEEE/ASME Transactions on Mechatronics, vol. 26, no. 3, pp. 1318–1327, 2021, doi: 10.1109/TMECH.2021.3065210.
- [12] I. Raouf, A. Khan, S. Khalid, M. Sohail, M. M. Azad, and H. S. Kim, “Sensor-based prognostic health management of advanced driver assistance system for autonomous vehicles: A recent survey,” Mathematics, vol. 10, no. 18, p. 3233, 2022, doi: 10.3390/math10183233.
- [13] M. Waqas and P. Ioannou, “Automatic vehicle following under safety, comfort, and road geometry constraints,” IEEE Transactions on Intelligent Vehicles, vol. 8, no. 1, pp. 531–546, 2022, doi: 10.1109/TIV.2022.3177176.
- [14] S. Huang, Z. Gojcic, Z. Wang, F. Williams, Y. Kasten, S. Fidler, K. Schindler, and O. Litany, “Neural lidar fields for novel view synthesis,” arXiv preprint arXiv:2305.01643, 2023, doi: 10.48550/arXiv.2305.01643.
- [15] A. Hornung, K. M. Wurm, M. Bennewitz, C. Stachniss, and W. Burgard, “Octomap: An efficient probabilistic 3d mapping framework based on octrees,” Autonomous robots, vol. 34, pp. 189–206, 2013, doi: 10.1007/s10514-012-9321-0.
- [16] X. Hu, G. Xiong, J. Ma, G. Cui, Q. Yu, S. Li, and Z. Zhou, “A non-uniform quadtree map building method including dead-end semantics extraction,” Green Energy and Intelligent Transportation, vol. 2, no. 2, p. 100071, 2023, doi: 10.1016/j.geits.2023.100071.
- [17] I. Vizzo, X. Chen, N. Chebrolu, J. Behley, and C. Stachniss, “Poisson surface reconstruction for lidar odometry and mapping,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 5624–5630, doi: 10.1109/ICRA48506.2021.9562069.
- [18] X. Yang, G. Lin, Z. Chen, and L. Zhou, “Neural vector fields: Implicit representation by explicit learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 16 727–16 738, doi: 10.1109/CVPR52729.2023.01605.
- [19] D. Yu, M. Lau, L. Gao, and H. Fu, “Sketch beautification: Learning part beautification and structure refinement for sketches of man-made objects,” arXiv preprint arXiv:2306.05832, 2023, doi: 10.48550/arXiv.2306.05832.
- [20] P. Wang, L. Liu, Y. Liu, C. Theobalt, T. Komura, and W. Wang, “Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction,” arXiv preprint arXiv:2106.10689, 2021, doi: 10.48550/arXiv.2106.10689.
- [21] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021, doi: 10.1145/3503250.
- [22] S. Liu and J. Zhu, “Efficient map fusion for multiple implicit slam agents,” IEEE Transactions on Intelligent Vehicles, 2023, doi: 10.1109/TIV.2023.3297194.
- [23] E. Sucar, S. Liu, J. Ortiz, and A. J. Davison, “imap: Implicit mapping and positioning in real-time,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6229–6238, doi: 10.1109/ICCV48922.2021.00617.
- [24] A. Moreau, N. Piasco, D. Tsishkou, B. Stanciulescu, and A. de La Fortelle, “Lens: Localization enhanced by nerf synthesis,” in Conference on Robot Learning. PMLR, 2022, pp. 1347–1356, doi: 10.48550/arXiv.2110.06558.
- [25] Z. Zhu, S. Peng, V. Larsson, W. Xu, H. Bao, Z. Cui, M. R. Oswald, and M. Pollefeys, “Nice-slam: Neural implicit scalable encoding for slam,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 786–12 796, doi: 10.1109/CVPR52688.2022.01245.
- [26] M. Tancik, V. Casser, X. Yan, S. Pradhan, B. Mildenhall, P. P. Srinivasan, J. T. Barron, and H. Kretzschmar, “Block-nerf: Scalable large scene neural view synthesis,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8248–8258, doi: 10.1109/CVPR52688.2022.00807.
- [27] M. Zhenxing and D. Xu, “Switch-nerf: Learning scene decomposition with mixture of experts for large-scale neural radiance fields,” in The Eleventh International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=PQ2zoIZqvm
- [28] D. Rebain, W. Jiang, S. Yazdani, K. Li, K. M. Yi, and A. Tagliasacchi, “Derf: Decomposed radiance fields,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 153–14 161, doi: 10.1109/CVPR46437.2021.01393.
- [29] C. Reiser, S. Peng, Y. Liao, and A. Geiger, “Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 14 335–14 345, doi: 10.1109/ICCV48922.2021.01407.
- [30] L. Liu, J. Gu, K. Zaw Lin, T.-S. Chua, and C. Theobalt, “Neural sparse voxel fields,” Advances in Neural Information Processing Systems, vol. 33, pp. 15 651–15 663, 2020, doi: 10.5555/3495724.3497037.
- [31] H. Kuang, X. Chen, T. Guadagnino, N. Zimmerman, J. Behley, and C. Stachniss, “Ir-mcl: Implicit representation-based online global localization,” IEEE Robotics and Automation Letters, vol. 8, no. 3, pp. 1627–1634, 2023, doi: 10.1109/LRA.2023.3239318.
- [32] T. Tao, L. Gao, G. Wang, P. Chen, D. Hao, X. Liang, M. Salzmann, and K. Yu, “Lidar-nerf: Novel lidar view synthesis via neural radiance fields,” 2023, doi: 10.48550/arXiv.2304.10406.
- [33] J. Zhang, F. Zhang, S. Kuang, and L. Zhang, “Nerf-lidar: Generating realistic lidar point clouds with neural radiance fields,” arXiv preprint arXiv:2304.14811, 2023, doi: 10.48550/arXiv.2304.14811.
- [34] J. Ma, J. Zhang, J. Xu, R. Ai, W. Gu, and X. Chen, “Overlaptransformer: An efficient and yaw-angle-invariant transformer network for lidar-based place recognition,” IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 6958–6965, 2022, doi: 10.1109/LRA.2022.3178797.
- [35] K. Wang, T. Zhou, X. Li, and F. Ren, “Performance and challenges of 3d object detection methods in complex scenes for autonomous driving,” IEEE Transactions on Intelligent Vehicles, vol. 8, no. 2, pp. 1699–1716, 2022, doi: 10.1109/TIV.2022.3213796.
- [36] X. Yu, Y. Liu, S. Mao, S. Zhou, R. Xiong, Y. Liao, and Y. Wang, “Nf-atlas: Multi-volume neural feature fields for large scale lidar mapping,” arXiv preprint arXiv:2304.04624, 2023, doi: 10.48550/arXiv.2304.04624.
- [37] K. Rematas, A. Liu, P. P. Srinivasan, J. T. Barron, A. Tagliasacchi, T. Funkhouser, and V. Ferrari, “Urban radiance fields,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 932–12 942, doi: 10.1109/CVPR52688.2022.01259.
- [38] Y. Xiangli, L. Xu, X. Pan, N. Zhao, A. Rao, C. Theobalt, B. Dai, and D. Lin, “Bungeenerf: Progressive neural radiance field for extreme multi-scale scene rendering,” in European conference on computer vision. Springer, 2022, pp. 106–122, doi: 10.1007/978-3-031-19824-3_7.
- [39] L. Wiesmann, T. Guadagnino, I. Vizzo, N. Zimmerman, Y. Pan, H. Kuang, J. Behley, and C. Stachniss, “Locndf: Neural distance field mapping for robot localization,” IEEE Robotics and Automation Letters, 2023, doi: 10.1109/LRA.2023.3291274.
- [40] A. Milioto, I. Vizzo, J. Behley, and C. Stachniss, “Rangenet++: Fast and accurate lidar semantic segmentation,” in 2019 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2019, pp. 4213–4220, doi: 10.1109/IROS40897.2019.8967762.
- [41] E. Haines, “Essential ray tracing,” Glas89, pp. 33–77, 1989.
- [42] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in 2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012, pp. 3354–3361, doi: 10.1109/CVPR.2012.6248074.
- [43] J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “Semantickitti: A dataset for semantic scene understanding of lidar sequences,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9297–9307, doi: 10.1109/ICCV.2019.00939.
- [44] S. Thrun, “Probabilistic robotics,” Communications of the ACM, vol. 45, no. 3, pp. 52–57, 2002, doi: 10.1145/504729.504754.
- [45] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014, doi: 10.48550/arXiv.1412.6980.