PatchComplete: Learning Multi-Resolution Patch Priors for 3D Shape Completion on Unseen Categories
Abstract
While 3D shape representations enable powerful reasoning in many visual and perception applications, learning 3D shape priors tends to be constrained to the specific categories trained on, leading to an inefficient learning process, particularly for general applications with unseen categories. Thus, we propose PatchComplete, which learns effective shape priors based on multi-resolution local patches, which are often more general than full shapes (e.g., chairs and tables often both share legs) and thus enable geometric reasoning about unseen class categories. To learn these shared substructures, we learn multi-resolution patch priors across all train categories, which are then associated to input partial shape observations by attention across the patch priors, and finally decoded into a complete shape reconstruction. Such patch-based priors avoid overfitting to specific train categories and enable reconstruction on entirely unseen categories at test time. We demonstrate the effectiveness of our approach on synthetic ShapeNet data as well as challenging real-scanned objects from ScanNet, which include noise and clutter, improving over state of the art in novel-category shape completion by 19.3% in chamfer distance on ShapeNet, and 9.0% for ScanNet. 111Source code available here.
1 Introduction

The prevalence of commodity RGB-D sensors (e.g., Intel RealSense, Microsoft Kinect, iPhone, etc.) has enabled significant progress in 3D reconstruction, achieving impressive tracking quality [26, 18, 29, 8, 44, 13] and even large-scale reconstructed datasets [11, 4]. Unfortunately, 3D scanned reconstructions remain limited in geometric quality due to clutter, noise, and incompleteness (e.g., as seen in the objects in Figure 1). Understanding complete object structures is fundamental towards constructing effective 3D representations, that can then be used to fuel many applications in robotic perception, mixed reality, content creation, and more.
Recently, significant progress has been made in shape reconstruction, across a variety of 3D representations, including voxels [9, 14, 38], points [16, 47], meshes [43, 12, 34], and implicit field representations [30, 22, 15, 19, 33, 3, 17, 36]. However, these methods tend to rely heavily on strong synthetic supervision, producing impressive reconstructions on similar train class categories but struggling to generalize to unseen categories. This leads to an expensive compute and data requirement in adapting to new objects in different scenarios, whose class categories may not necessarily have been seen during training and so must be re-trained or fine-tuned for.
In order to encourage more generalizable 3D feature learning to represent shape characteristics, we observe that while different class categories may have very different global structures, local geometric structures are often shared (e.g., a long, thin structure could represent a chair leg, a table leg, a lamp rod, etc.). We thus propose to learn a set of multi-resolution patch-based priors that captures such shared local substructures across the training set of shapes, which can be applied to shapes outside of the train set of categories. Our local patch-based priors can thus capture shared local structures, across different resolutions, that enable effective shape completion on novel class categories of not only synthetic data but also challenging real-world observations with noise and clutter.
We propose PatchComplete, which first learns patch priors for shape completion by correlating regions of observed partial inputs to the learned patch priors through an attention-based association, and decoding to reconstruct a complete shape. These patch priors are learned at different resolutions to encompass potentially different sizes of local substructures; we then learn to fuse the multi-resolution priors together to reconstruct the output complete shape. This enables learning generalizable local 3D priors that facilitate effective shape completion even for unseen categories, outperforming state of the art in synthetic and real-world observations by 19.3% and 9.0% on Chamfer Distance.
In summary, our contributions are:
-
•
We propose generalizable 3D shape priors by learning patch-based priors that characterize shared local substructures that can be associated with input observations by cross-attention. This intermediate representation preserves structure explicitly, and can be effectively leveraged to compose complete shapes for entirely unseen categories.
-
•
We design a multi-resolution fusion of different patch priors at various resolutions in order to effectively reconstruct a complete shape, enabling multi-resolution reasoning about the most informative learned patch priors to recover both global and local shape structures.
2 Related Work
2.1 3D Shape Reconstruction and Completion
Understanding how to reconstruct 3D shapes is an essential task for 3D machine perception. In particular, the task of shape completion to predict a complete shape from partial input observations has been studied by various works toward understanding 3D shape structures. Recently, many works have leveraged deep learning techniques to learn strong data-driven priors for shape completion, focusing on various different representations, e.g. volumetric grids [45, 14], continuous implicit functions [31, 22, 30, 7, 40, 36, 37], point clouds [32], and meshes [12, 20, 34, 35]. These works tend to focus on strong synthetic supervision on a small set of train categories, achieving impressive performance on unseen shapes from train categories, but often struggling to generalize to unseen classes. We focus on learning more generalizable, local shape priors in order to effectively reconstruct complete shapes on unseen class categories.
2.2 Few-Shot and Zero-Shot 3D Shape Reconstruction
Several works have been developed to tackle the challenging task of few-shot or zero-shot shape reconstruction, as observations in-the-wild often contain a wide diversity of objects. In the few-shot scenario where several examples of novel categories are available, Wallace and Hariharan [42] learn to refine a given category prior. Michalkiewicz et al. [23] further propose to learn compositional shape priors for single-view reconstruction.
In the zero-shot scenario without any examples seen for novel categories, Naeem et al. [25] learn priors from seen categories to generate segmentation masks for unseen categories. Zhang et al. [48] additionally proposed to use spherical map representations to learn priors for the reconstruction of novel categories. Thai et al. [39] recently developed an approach to transfer knowledge from an RGB image for shape reconstruction. We also tackle a zero-shot shape reconstruction task, by learning a multi-resolution set of strong local shape priors to compose a reconstructed shape.
Several recent works have explored learning shape priors by leveraging a VQ-VAE backbone with autoregressive prediction to perform shape reconstruction [24, 46]. In contrast, we propose to learn multi-resolution shape priors without requiring any sequence interpretation, which enables direct applicability to real-world scan data that often contains noise and clutter. Additionally, hierarchical reconstruction has shown promising results for shape reconstruction [2, 6]. Our approach also takes a multi-resolution perspective, but learns explicit shape and local patch priors and their correlation to input partial observations for robust shape completion.
3 Method
3.1 Overview

Our method aims to learn effective 3D shape priors that enable general shape completion from partial input scan data, on novel class categories not seen during training. Key to our approach is the observation that 3D shapes often share repeated local patterns – for instance, chairs, tables, and nightstands all share a support surface, and chair or table legs can share a similar structure with lamp rods. Inspired by this, we regard a complete object as a set of substructures, where each substructure represents a local geometric region. We thus propose PatchComplete to learn such local priors and assemble them into a complete shape from a partial scan. An overview of our approach is shown in Figure 2.
3.2 Learning Local Patch-Based Shape Priors

We first learn local shape priors from ground-truth train objects. We represent both the input partial scan and the ground-truth shape as 3D truncated signed distance field grids of size . Figure 3 illustrates the process of learning local shape priors. We learn to build mappings from local regions in incomplete input observations to local priors based on complete shapes, in order to robustly reconstruct the complete shape output.
We first aim to learn patch-based priors, which we extract from learnable global shape priors . We denote as the set of ground-truth train objects in the -th category. These priors are initialized per train category based on mean-shift clustering within shapes in . Thus is a set of representative samples in each category, which are encoded parallel to the input scan .
Both encoders are analogously structured as 3D convolutional encoders which spatially downsample by a factor of , resulting in a 3D encoding of size ; . The input encoding (from ) are uniformly chunked into patches , =1,…,; similarly, the encoded priors (from ) are chunked into patches .
We then use each local part to query for the most informative encodings of complete local regions , building this mapping based on cross-attention [41]. Then for each input patch, we calculate its similarity with all local patches in representative shapes on training categories:
| (1) |
where is the dimension of the encoded vectors of ; is the category number. We then reconstruct complete shape patches by:
| (2) |
where is the set of chunks (of resolution ) from shapes in all categories , where each is paired with . We can then recompose to the predicted full shape .
Loss.
We use an reconstruction loss to train the learned local patch priors. Note that are learned along with the network weights, enabling learning the most effective global shape priors for the shape completion task.
3.3 Multi-Resolution Patch Learning

In Section 3, we learn to complete shapes in a single patch resolution . Since local substructures may exist at various scales, we learn patch priors under varying resolutions, which we then use to decode a complete shape. We use three patch resolutions (=4, 8, 32), for which we learn patch priors. This results in three pairs of trained {input encoder, prior encoder} (see Figure 3). Given a partial input scan , each pair outputs a set of 1) input patch features , and 2) prior patch features , under the resolution of =4, 8, 32. In this section, we decode a complete shape from these multi-resolution patch priors.
Since stores the patch priors, we use it as the (key, value) term into an attention module, where each input patch feature is used to query for the most informative prior features in under different resolutions, from which we complete partial patches in feature spaces with a multi-scale fashion. We formulate this process by
| (3) |
where we concatenate input patch feature with the attention result to compensate information loss on observable regions. This outputs as the intermediate feature of the -th patch; . denotes the number of patches under the resolution ; . We recompose all generated patch features into a volume . Note that the dimension of each grid feature in and equals to (see Eq. 1). Then is with the dimension of .
We then sequentially use 3D convolution decoders to upsample and concatenate from low to high resolution to fuse all the shape features as in
| (4) |
In Eq. 4, has a lower resolution than . We then use deconvolution layers to upsample to match the resolution of , and then concatenate them together. We recursively fuse into , which produces as the final fusion result with the resolution of . An extra upsampling followed by a convolution layer is adopted to upsample into our shape prediction with the dimension of .
In training the feature fusion, we fix all parameters from the {input encoder, prior encoder} under the three resolutions, since they are pre-trained on Section 3 and provide better-learned priors and attention maps under these strong constraints. The whole pipeline for this section can be found in Figure 4.
We use an loss to supervise the TSDF value regression. We weight the loss to penalize false predictions based on the predicted signs as Eq. 5 shows, which represents whether this voxel grid is occupied or not. It is also used in the loss function in Section 3.
| (5) |
In Eq. 5, represents the false positive TSDF values, where the ground truth has negative signs and the prediction has positive signs, which in general indicates the missing predictions. represents false negative TSDF values, where the ground truth has positive signs and the prediction has negative signs, which indicates extra predictions. means those predicted TSDF values with the same signs as the ground-truth. During training, we choose the weight for false positive () as 5, and the weight for false negative () as 3.
3.4 Implementation Details
We train our approach on a single NVIDIA A6000 GPU, using an Adam optimizer with batch size 32 for a synthetic dataset and batch size 16 for a real-world dataset, and an initial learning rate of 0.001. We train for 80 epochs until convergence, and then decrease the learning rate by half after epoch 50. We use the same settings for learning priors and the multi-resolution decoding, which train for 4 and 15.5 hours respectively. For additional network architecture details, we refer to the supplemental material.
Note that for training for real scan data, we first pre-train on synthetic data and then fine-tune only the input encoder. We use 112 shape priors in our method, which are clustered from 3202 train shapes, and represented as TSDFs with truncation of 2.5 voxels.
4 Experiments and Analysis
4.1 Experimental Setup
Datasets.
We train and evaluate our approach on synthetic shape data from ShapeNet [5] as well as on challenging real-world scan data from ScanNet [11]. For ShapeNet data, we virtually scan the objects to create partial input scans, following [27, 14]. We use 18 categories during training, and test on 8 novel categories, resulting in 3,202/1,325 train/test models with 4 partial scans for each model.
For real data, we use real-scanned objects from ScanNet extracted by their bounding boxes, with corresponding complete target data given by Scan2CAD [1]. We use 8 categories for training, comprising 7,537 train samples, and test on 6 novel categories of 1,191 test samples.
For all experiments, objects are represented as signed distance grids with truncation of 2.5 voxel units for ShapeNet and 3 voxel units for ScanNet. The objects in ShapeNet are normalized into the unit cube, while we keep the scaling for ScanNet objects, and save their voxel sizes separately to keep the real size information. Additionally, to train and evaluate on real data, all methods are first pre-trained on ShapeNet and then fine-tuned on ScanNet.
Baselines.
We evaluate our approach against various state-of-the-art shape completion methods. We compare with state-of-the-art shape completion methods 3D-EPN [14] and IF-Nets [7], which learn effective shape completion on dense voxel grids and with implicit neural field representations, respectively, without any focus on unseen class categories. We further compare to the state-of-the-art few-shot shape reconstruction approach of Wallace and Hariharan [42] (referred to as Few-Shot) leveraging global shape priors, which we apply in our zero-shot unseen category scenario. Finally, AutoSDF [24] uses a VQ-VAE module with a transformer-based autoregressive model over latent patch priors to produce TSDF shape reconstruction.
Evaluation Metrics.
To evaluate the quality of reconstructed shape geometry, we use Chamfer Distance (CD) and Intersection over Union (IoU) between predicted and ground truth shapes. To evaluate methods that output occupancy grids, we use occupancy thresholds used by the respective methods to obtain voxel predictions, i.e. 0.4 for [42] and 0.5 for [7]. To evaluate methods that output signed distance fields, we extract the iso-surface at level zero with marching cubes [21]. 10K points are sampled on surfaces for CD calculation. Both Chamfer distance and IoU are evaluated on objects in the canonical system, and we report Chamfer Distance scaled by .
| Chamfer Distance () | IoU | |||||||||
| 3D-EPN [14] | Few-Shot [42] | IF-Nets [7] | Auto-SDF [24] | Ours | 3D-EPN [14] | Few-Shot [42] | IF-Nets [7] | Auto-SDF [24] | Ours | |
| Bag | 5.01 | 8.00 | 4.77 | 5.81 | 3.94 | 0.738 | 0.561 | 0.698 | 0.563 | 0.776 |
| Lamp | 8.07 | 15.10 | 5.70 | 6.57 | 4.68 | 0.472 | 0.254 | 0.508 | 0.391 | 0.564 |
| Bathtub | 4.21 | 7.05 | 4.72 | 5.17 | 3.78 | 0.579 | 0.457 | 0.550 | 0.410 | 0.663 |
| Bed | 5.84 | 10.03 | 5.34 | 6.01 | 4.49 | 0.584 | 0.396 | 0.607 | 0.446 | 0.668 |
| Basket | 7.90 | 8.72 | 4.44 | 6.70 | 5.15 | 0.540 | 0.406 | 0.502 | 0.398 | 0.610 |
| Printer | 5.15 | 9.26 | 5.83 | 7.52 | 4.63 | 0.736 | 0.567 | 0.705 | 0.499 | 0.776 |
| Laptop | 3.90 | 10.35 | 6.47 | 4.81 | 3.77 | 0.620 | 0.313 | 0.583 | 0.511 | 0.638 |
| Bench | 4.54 | 8.11 | 5.03 | 4.31 | 3.70 | 0.483 | 0.272 | 0.497 | 0.395 | 0.539 |
| Inst- Avg | 5.48 | 9.75 | 5.37 | 5.76 | 4.23 | 0.582 | 0.386 | 0.574 | 0.446 | 0.644 |
| Cat- Avg | 5.58 | 9.58 | 5.29 | 5.86 | 4.27 | 0.594 | 0.403 | 0.581 | 0.452 | 0.654 |
4.2 Evaluation on Synthetic Data
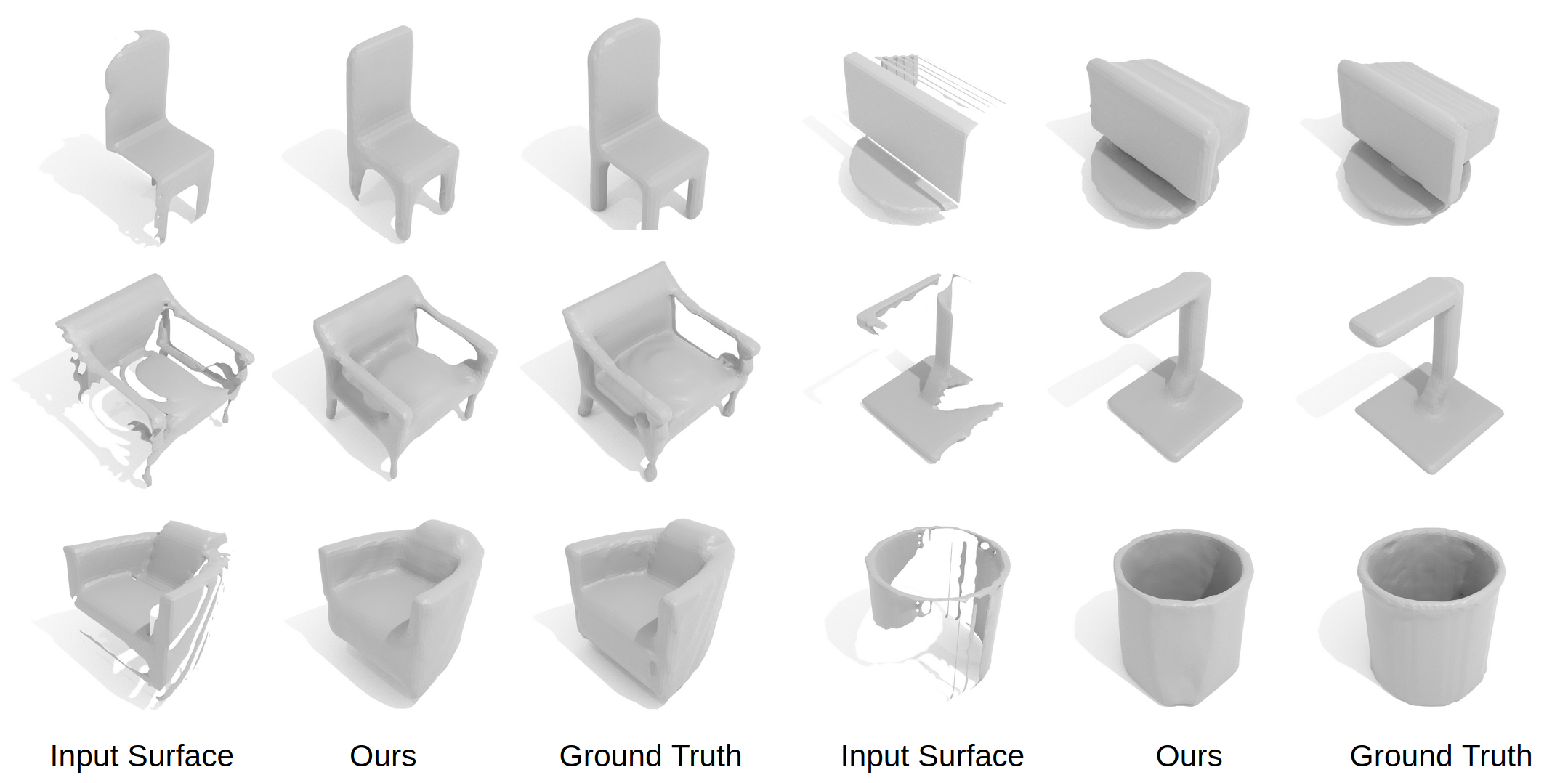
In Table 1, we evaluate our approach in comparison with prior arts on unseen class categories of synthetic ShapeNet [5] data. Our approach on learning attention-based correlation to learned local shape priors results in notably improved reconstruction performance, with coherent global and local structures, as shown in Figure 5. In Table 1, our work outperforms other baselines both instance-wise and category-wise. One of the key factors is that our method learns multi-scale patch information from seen categories to complete unseen categories with enough flexibility, while most of the other baselines are designed for 3D shape completion on known categories, which hardly leverage shape priors across categories.

4.3 Evaluation on Real Scan Data
Table 2 evaluates our approach in comparison with prior arts on real scanned objects from unseen categories in ScanNet [11]. Here, input scans are not only partial but often contain noise and clutter; our multi-resolution learned priors enable more robust shape completion in this challenging scenario. Results in Figure 6 further demonstrate that our approach presents more coherent shape completion than prior methods by using cross-attention with learnable priors, which better preserves the global structures in coarse and cluttered environments.
| Chamfer Distance () | IoU | |||||||||
| 3D-EPN [14] | Few-Shot [42] | IF-Nets [7] | Auto-SDF [24] | Ours | 3D-EPN [14] | Few-Shot [42] | IF-Nets [7] | Auto-SDF [24] | Ours | |
| Bag | 8.83 | 9.10 | 8.96 | 9.30 | 8.23 | 0.537 | 0.449 | 0.442 | 0.487 | 0.583 |
| Lamp | 14.27 | 11.88 | 10.16 | 11.17 | 9.42 | 0.207 | 0.196 | 0.249 | 0.244 | 0.284 |
| Bathtub | 7.56 | 7.77 | 7.19 | 7.84 | 6.77 | 0.410 | 0.382 | 0.395 | 0.366 | 0.480 |
| Bed | 7.76 | 9.07 | 8.24 | 7.91 | 7.24 | 0.478 | 0.349 | 0.449 | 0.380 | 0.484 |
| Basket | 7.74 | 8.02 | 6.74 | 7.54 | 6.60 | 0.365 | 0.343 | 0.427 | 0.361 | 0.455 |
| Printer | 8.36 | 8.30 | 8.28 | 9.66 | 6.84 | 0.630 | 0.622 | 0.607 | 0.499 | 0.705 |
| Inst- Avg | 8.60 | 8.83 | 8.12 | 8.56 | 7.38 | 0.441 | 0.387 | 0.426 | 0.386 | 0.498 |
| Cat- Avg | 9.09 | 9.02 | 8.26 | 8.90 | 7.52 | 0.440 | 0.386 | 0.426 | 0.389 | 0.495 |

| ShapeNet [5] | ScanNet [11] | |||||||
|---|---|---|---|---|---|---|---|---|
| Inst-CD | Cat-CD | Inst-IoU | Cat-IoU | Inst-CD | Cat-CD | Inst-IoU | Cat-IoU | |
| Ours ( priors only) | 11.97 | 11.62 | 0.35 | 0.37 | 10.40 | 11.33 | 0.41 | 0.39 |
| Ours ( priors only) | 4.89 | 4.92 | 0.61 | 0.62 | 7.67 | 7.84 | 0.49 | 0.49 |
| Ours ( priors only) | 4.45 | 4.50 | 0.64 | 0.64 | 7.37 | 7.63 | 0.48 | 0.48 |
| Ours | 4.23 | 4.27 | 0.64 | 0.65 | 7.38 | 7.52 | 0.50 | 0.50 |
4.4 Ablation Analysis
Does multi-resolution patch learning help shape completion for novel categories?
In Table 3, we evaluate shape completion with each resolution in comparison with our multi-resolution approach. Learning only global shape priors (i.e., ) tends to overfit to seen train categories, while the local patch resolutions can provide more generalizable priors. Combining all results in complementary feature learning for the most effective shape completion results.
Does cross-attention to learn local priors help?
We evaluate our approach to learn both local priors and their correlation to input observations with cross-attention in Table 4, which shows that this enables more effective shape completion on unseen categories. Here, the no attention experiment replaces the attention score calculation in Eq. 1 by using MLPs (on concatenated input/prior features) to predict weights for each input-prior pair.
| ShapeNet [5] | ScanNet [11] | |||||||
|---|---|---|---|---|---|---|---|---|
| Inst-CD | Cat-CD | Inst-IoU | Cat-IoU | Inst-CD | Cat-CD | Inst-IoU | Cat-IoU | |
| Ours (no attention) | 4.90 | 4.98 | 0.61 | 0.62 | 7.80 | 8.09 | 0.49 | 0.48 |
| Ours | 4.69 | 4.74 | 0.61 | 0.63 | 7.58 | 7.84 | 0.48 | 0.49 |
| Inst-CD | Cat-CD | Inst-IoU | Cat-IoU | |
|---|---|---|---|---|
| Scratch | 7.61 | 7.73 | 0.50 | 0.50 |
| Ours | 7.38 | 7.52 | 0.50 | 0.50 |
What is the effect of synthetic pre-training for real scan completion?
Table 5 shows the effect of synthetic pre-training for shape completion on real scanned objects. This encourages learning more robust priors to output cleaner local structures as given in the synthetic data, resulting in improved performance on real scanned objects.
| Inst-CD | Cat-CD | Inst-IoU | Cat-IoU | |
|---|---|---|---|---|
| Ours (fixed priors) | 4.31 | 4.34 | 0.64 | 0.65 |
| Ours | 4.23 | 4.27 | 0.64 | 0.65 |
Does learning the priors help completion?
In Table 6, we evaluate our learnable priors in comparison with using fixed priors (by mean-shift clustering of train objects) for shape completion on ShapeNet [5]. Learned priors receive gradient information to adapt to best reconstruct the shapes, enabling improved performance over a fixed set of priors.
What is the effect of the train category split?
Our novel category split was designed based on the number of objects in each category, to mimic real-world scenarios where object categories with larger numbers of observations are used for training.
| Inst-CD | Cat-CD | Inst-IoU | Cat-IoU | |
|---|---|---|---|---|
| Category Split 1 | 4.30 | 4.29 | 0.65 | 0.66 |
| Category Split 2 | 4.19 | 4.25 | 0.68 | 0.67 |
| Ours | 4.23 | 4.27 | 0.64 | 0.65 |
To show that our approach is independent of the category splitting strategy, we add two new settings for evaluation on ShapeNet [5]. We use the same overall categories (26) as originally, then randomly shuffle them for train/novel categories. Table 7 shows that all the splits achieve similar results, which indicates that our approach is robust across different splits. It is because the learned patch priors share universal partial information among categories, which reduces the dependency on train categories for shape completion tasks. Figure 7 shows qualitative results for novel category samples in the alternative splits.
4.5 Limitations
While PatchComplete has presented a promising step towards learning more generalizable shape priors, various limitations remain. For instance, output shape completion is limited by the dense voxel grid resolution in representing fine-scale geometric details. Additionally, detected object bounding boxes are required for real scan data as input to independent shape completion predictions, while formulation considering other objects in the scene or an end-to-end framework could learn more effectively from global scene contextual information.
5 Conclusion
We have proposed PatchComplete to learn effective local shape priors for shape completion that enables robust reconstruction for novel class categories at test time. This enables learning shared local substructures across a variety of shapes that can be mapped to local incomplete observations by cross attention, with multi-resolution fusion producing coherent geometry at global and local scales. This enables robust shape completion even for unseen categories with different global structures, across synthetic as well as challenging real-world scanned objects with noise and clutter. We believe that such robust reconstruction of real scanned objects takes an important step towards understanding 3D shapes, and hope this inspires future work in understanding real-world shapes and scene structures.
Acknowledgements
This project is funded by the Bavarian State Ministry of Science and the Arts and coordinated by the Bavarian Research Institute for Digital Transformation (bidt).
References
- [1] Avetisyan, A., Dahnert, M., Dai, A., Savva, M., Chang, A.X., Nießner, M.: Scan2cad: Learning cad model alignment in rgb-d scans (2018)
- [2] Bechtold, J., Tatarchenko, M., Fischer, V., Brox, T.: Fostering generalization in single-view 3d reconstruction by learning a hierarchy of local and global shape priors (2021)
- [3] Chabra, R., Lenssen, J.E., Ilg, E., Schmidt, T., Straub, J., Lovegrove, S., Newcombe, R.: Deep local shapes: Learning local sdf priors for detailed 3d reconstruction. In: European Conference on Computer Vision. pp. 608–625. Springer (2020)
- [4] Chang, A.X., Dai, A., Funkhouser, T., Halber, M., Niessner, M., Savva, M., Song, S., Zeng, A., Zhang, Y.: Matterport3D: Learning from RGB-D data in indoor environments. International Conference on 3D Vision (3DV) (2017)
- [5] Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., Xiao, J., Yi, L., Yu, F.: Shapenet: An information-rich 3d model repository (2015)
- [6] Chen, Z., Zhang, Y., Genova, K., Fanello, S., Bouaziz, S., Haene, C., Du, R., Keskin, C., Funkhouser, T., Tang, D.: Multiresolution deep implicit functions for 3d shape representation (2021)
- [7] Chibane, J., Alldieck, T., Pons-Moll, G.: Implicit functions in feature space for 3d shape reconstruction and completion (2020)
- [8] Choi, S., Zhou, Q.Y., Koltun, V.: Robust reconstruction of indoor scenes. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5556–5565. IEEE (2015)
- [9] Choy, C.B., Xu, D., Gwak, J., Chen, K., Savarese, S.: 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In: European conference on computer vision. pp. 628–644. Springer (2016)
- [10] Curless, B., Levoy, M.: A volumetric method for building complex models from range images. In: Proceedings of the 23rd annual conference on Computer graphics and interactive techniques. pp. 303–312 (1996)
- [11] Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scannet: Richly-annotated 3d reconstructions of indoor scenes (2017)
- [12] Dai, A., Nießner, M.: Scan2mesh: From unstructured range scans to 3d meshes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5574–5583 (2019)
- [13] Dai, A., Nießner, M., Zollhöfer, M., Izadi, S., Theobalt, C.: Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface reintegration. ACM Transactions on Graphics (TOG) 36(3), 24 (2017)
- [14] Dai, A., Qi, C.R., Nießner, M.: Shape completion using 3d-encoder-predictor cnns and shape synthesis (2017)
- [15] Deng, B., Lewis, J.P., Jeruzalski, T., Pons-Moll, G., Hinton, G., Norouzi, M., Tagliasacchi, A.: Nasa neural articulated shape approximation. In: European Conference on Computer Vision. pp. 612–628. Springer (2020)
- [16] Fan, H., Su, H., Guibas, L.J.: A point set generation network for 3d object reconstruction from a single image. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 605–613 (2017)
- [17] Genova, K., Cole, F., Sud, A., Sarna, A., Funkhouser, T.: Local deep implicit functions for 3d shape. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4857–4866 (2020)
- [18] Izadi, S., Kim, D., Hilliges, O., Molyneaux, D., Newcombe, R., Kohli, P., Shotton, J., Hodges, S., Freeman, D., Davison, A., et al.: Kinectfusion: real-time 3d reconstruction and interaction using a moving depth camera. In: Proceedings of the 24th annual ACM symposium on User interface software and technology. pp. 559–568. ACM (2011)
- [19] Jiang, C., Sud, A., Makadia, A., Huang, J., Nießner, M., Funkhouser, T., et al.: Local implicit grid representations for 3d scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6001–6010 (2020)
- [20] Li, X., Liu, S., Kim, K., Mello, S.D., Jampani, V., Yang, M.H., Kautz, J.: Self-supervised single-view 3d reconstruction via semantic consistency. In: European Conference on Computer Vision. pp. 677–693. Springer (2020)
- [21] Lorensen, W.E., Cline, H.E.: Marching cubes: A high resolution 3d surface construction algorithm. ACM siggraph computer graphics 21(4), 163–169 (1987)
- [22] Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., Geiger, A.: Occupancy networks: Learning 3d reconstruction in function space (2019)
- [23] Michalkiewicz, M., Tsogkas, S., Parisot, S., Baktashmotlagh, M., Eriksson, A., Belilovsky, E.: Learning compositional shape priors for few-shot 3d reconstruction (2021)
- [24] Mittal, P., Cheng, Y.C., Singh, M., Tulsiani, S.: AutoSDF: Shape priors for 3d completion, reconstruction and generation. In: CVPR (2022)
- [25] Naeem, M.F., Örnek, E.P., Xian, Y., Gool, L.V., Tombari, F.: 3d compositional zero-shot learning with decompositional consensus (2021)
- [26] Newcombe, R.A., Izadi, S., Hilliges, O., Molyneaux, D., Kim, D., Davison, A.J., Kohi, P., Shotton, J., Hodges, S., Fitzgibbon, A.: Kinectfusion: Real-time dense surface mapping and tracking. In: Mixed and augmented reality (ISMAR), 2011 10th IEEE international symposium on. pp. 127–136. IEEE (2011)
- [27] Nie, Y., Lin, Y., Han, X., Guo, S., Chang, J., Cui, S., Zhang, J., et al.: Skeleton-bridged point completion: From global inference to local adjustment. Advances in Neural Information Processing Systems 33, 16119–16130 (2020)
- [28] Nie, Y., Lin, Y., Han, X., Guo, S., Chang, J., Cui, S., Zhang, J.: Skeleton-bridged point completion: From global inference to local adjustment. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H. (eds.) Advances in Neural Information Processing Systems. vol. 33, pp. 16119–16130. Curran Associates, Inc. (2020)
- [29] Nießner, M., Zollhöfer, M., Izadi, S., Stamminger, M.: Real-time 3d reconstruction at scale using voxel hashing. ACM Transactions on Graphics (TOG) (2013)
- [30] Park, J.J., Florence, P., Straub, J., Newcombe, R., Lovegrove, S.: Deepsdf: Learning continuous signed distance functions for shape representation (2019)
- [31] Peng, S., Niemeyer, M., Mescheder, L., Pollefeys, M., Geiger, A.: Convolutional occupancy networks (2020)
- [32] Stutz, D., Geiger, A.: Learning 3d shape completion under weak supervision. International Journal of Computer Vision 128(5), 1162–1181 (2020)
- [33] Takikawa, T., Litalien, J., Yin, K., Kreis, K., Loop, C., Nowrouzezahrai, D., Jacobson, A., McGuire, M., Fidler, S.: Neural geometric level of detail: Real-time rendering with implicit 3d shapes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11358–11367 (2021)
- [34] Tang, J., Han, X., Pan, J., Jia, K., Tong, X.: A skeleton-bridged deep learning approach for generating meshes of complex topologies from single rgb images. In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition. pp. 4541–4550 (2019)
- [35] Tang, J., Han, X., Tan, M., Tong, X., Jia, K.: Skeletonnet: A topology-preserving solution for learning mesh reconstruction of object surfaces from rgb images. IEEE transactions on pattern analysis and machine intelligence (2021)
- [36] Tang, J., Lei, J., Xu, D., Ma, F., Jia, K., Zhang, L.: Sa-convonet: Sign-agnostic optimization of convolutional occupancy networks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6504–6513 (2021)
- [37] Tang, J., Xu, D., Jia, K., Zhang, L.: Learning parallel dense correspondence from spatio-temporal descriptors for efficient and robust 4d reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6022–6031 (2021)
- [38] Tatarchenko, M., Dosovitskiy, A., Brox, T.: Octree generating networks: Efficient convolutional architectures for high-resolution 3d outputs. In: Proceedings of the IEEE international conference on computer vision. pp. 2088–2096 (2017)
- [39] Thai, A., Stojanov, S., Upadhya, V., Rehg, J.M.: 3d reconstruction of novel object shapes from single images (2021)
- [40] Tretschk, E., Tewari, A., Golyanik, V., Zollhöfer, M., Stoll, C., Theobalt, C.: Patchnets: Patch-based generalizable deep implicit 3d shape representations (2021)
- [41] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017)
- [42] Wallace, B., Hariharan, B.: Few-shot generalization for single-image 3d reconstruction via priors (2019)
- [43] Wang, N., Zhang, Y., Li, Z., Fu, Y., Liu, W., Jiang, Y.G.: Pixel2mesh: Generating 3d mesh models from single rgb images. In: Proceedings of the European conference on computer vision (ECCV). pp. 52–67 (2018)
- [44] Whelan, T., Leutenegger, S., Salas-Moreno, R.F., Glocker, B., Davison, A.J.: Elasticfusion: Dense slam without a pose graph. Proc. Robotics: Science and Systems, Rome, Italy (2015)
- [45] Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., Xiao, J.: 3d shapenets: A deep representation for volumetric shapes (2015)
- [46] Yan, X., Lin, L., Mitra, N.J., Lischinski, D., Cohen-Or, D., Huang, H.: Shapeformer: Transformer-based shape completion via sparse representation. arXiv preprint arXiv:2201.10326 (2022)
- [47] Yang, G., Huang, X., Hao, Z., Liu, M.Y., Belongie, S., Hariharan, B.: Pointflow: 3d point cloud generation with continuous normalizing flows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4541–4550 (2019)
- [48] Zhang, X., Zhang, Z., Zhang, C., Tenenbaum, J.B., Freeman, W.T., Wu, J.: Learning to reconstruct shapes from unseen classes (2018)
Appendix
In this supplementary material, we describe the data generation (Sec. A), settings for baseline methods (Sec. B), evaluation of category-wise error bars on ShapeNet and ScanNet (Sec. C), evaluation on seen categories for all the methods on ScanNet (Sec. D), additional ablation studies (Sec. E), network parameters and specifications (Sec. F), and additional qualitative results (Sec. G).
Appendix A Data Generation
ShapeNet [5]
We use ShapeNet222The license can be found here: https://shapenet.org/, received permission after registration without personally identifiable information or offensive content to test our performance on synthetic data. In order to generate watertight meshes as ground truth, we first normalize ShapeNet CAD models, and render depth maps under 20 different viewpoints for each model. We then use volumetric fusion [10] to generate truncated signed distance fields (TSDFs) with truncation value as 2.5 voxel units. Finally, we choose 4 views of TSDF as the input, which mimic the partial scan in real data (e.g., ScanNet). The main idea can be referred to [28]333https://github.com/yinyunie/depth_renderer.
We split the training and testing object categories on ShapeNet as follows. The 18 training categories are table, chair, sofa, cabinet, clock, bookshelf, piano, microwave, stove, file cabinet, trash bin, bowl, display, keyboard, dishwasher, washing machine, pots, faucet, and guitar; and the 8 novel testing categories are bathtub, lamp, bed, bag, printer, laptop, bench, and basket.
ScanNet [11]
We use ScanNet444The license can be found here: https://github.com/ScanNet/ScanNet, filled out an agreement without personally identifiable information or offensive content to test our method on real-world data. The inputs are directly extracted from ScanNet scenes based on the bounding box annotations from Scan2CAD [1]555The license can be found here::https://github.com/skanti/Scan2CAD, filled out an agreement without personally identifiable information or offensive content. We keep their real scale and convert them to voxel grids with truncation value at 3 voxel units, and save their voxel size separately. These inputs could contain walls, floors, or other cluttered backgrounds, which are transformed to canonical space to be aligned with the ShapeNet model coordinate system. The ground-truths are the corresponding complete and watertight ShapeNet meshes based on Scan2CAD annotations, which are generated with the similar method as above.
We split the training and testing object categories on ScanNet as follows. The 8 training categories are chair, table, sofa, trash bin, cabinet, bookshelf, file cabinet, and monitor; and the 6 novel testing categories are bathtub, lamp, bed, bag, basket, and printer, and each category has more than 50 samples for testing.
Alternative Train Category Splits
Here are two new category splits for the last ablation study. For Category Split 1, the 8 novel testing categories are trash bin, bed, piano bench, chair, monitor, lamp, laptop, washing machine. For Category Split 2, the 8 novel testing categories are basket, bookshelf, bowl, cabinet, laptop, pot, sofa, stove.
Appendix B Baseline Comparisons
We use the authors’ original implementations and hyperparameters in all the baselines for fair comparisons.
3D-EPN [14]
3D-EPN is a two-stage network, which completes partial 3D scans first and then reconstructs the completed shapes to a higher resolution by retrieving priors from a category-wise shape pool. In our case, priors for novel categories are not accessible, thus, we only compare its 3D Encoder-Predictor Network (the 3D completion model) on our dataset.
Wallace and Hariharan [42] (Few-Shot)
This method uses a few-shot learning strategy for single view completion with averaged shape prior for each category. For a fair comparison with other works, we adapt it to a zero-shot learning mechanism here. We pre-compute the averaged shape priors for each training category; during training, we use two voxel encoder modules in parallel for the occupied voxel grids inputs and the averaged shape priors based on the input category; in the testing step, since we cannot provide shape priors for novel categories, we average shape prior from all the training categories, and use this averaged shape prior as input to the prior encoder module, along with the testing samples for shape completion.
IF-Net [7]
IF-Net can predict implicit shape representations conditioned on different input modalities. (e.g., voxels, point clouds). We use occupied surface voxel grids as inputs, and use point clouds sampled from watertight ShapeNet meshes as the ground-truths for training and testing. We also normalize the ground-truth meshes from the ScanNet dataset to sample points.
AutoSDF [24]
AutoSDF learns latent patch priors using VQ-VAE along with a transformer-based autoregressive model for 3D shape completion, and manually picks the unknown patches during testing. Following their settings, we apply their method by using ground-truth SDFs as the training data; during testing on the ShapeNet data, we choose the patches that have more than 400 voxel grids (each patch has voxel grids) with negative signs as the unknown patches (unseen parts) that need to be generated.
Note that since AutoSDF work focuses on multi-model shape completion and produces multiple output possibilities, we report the performance of only the best prediction among the nine given an oracle to indicate the best (highest IoU value with respect to ground truth).
Furthermore, as there are no absolutely unknown patches for ScanNet scans because of the cluttered environments, we use the pipeline of their single view reconstruction task. We first replace their ResNet in resnet2vq_model with three 3D encoders (the same as 3D-EPN encoders) to extract the encoding features of desired dimensions; then we train this modified model along with the pre-trained pvq_vae_model with partial ScanNet inputs; finally we test our partial ScanNet inputs along with all the pre-trained models: resnet2vq_model, pvq_vae_model, and rand_tf_model.
Appendix C Category-wise Evaluations with Error Bars
Table 8 and Table 9 show the category-wise error bars on ShapeNet and ScanNet respectively; each method is run times to obtain the error bars.
| Chamfer Distance () | IoU | |||||||||
| 3D-EPN [14] | Few-Shot [42] | IF-Nets [7] | Auto-SDF [24] | Ours | 3D-EPN [14] | Few-Shot [42] | IF-Nets [7] | Auto-SDF [24] | Ours | |
| Bag | 5.01 | 8.00 | 4.77 | 5.81 | 3.94 | 0.738 | 0.561 | 0.698 | 0.563 | 0.776 |
| Lamp | 8.07 | 15.10 | 5.70 | 6.57 | 4.68 | 0.472 | 0.254 | 0.508 | 0.391 | 0.564 |
| Bathtub | 4.21 | 7.05 | 4.72 | 5.17 | 3.78 | 0.579 | 0.457 | 0.550 | 0.410 | 0.663 |
| Bed | 5.84 | 10.03 | 5.34 | 6.01 | 4.49 | 0.584 | 0.396 | 0.607 | 0.446 | 0.668 |
| Basket | 7.90 | 8.72 | 4.44 | 6.70 | 5.15 | 0.540 | 0.406 | 0.502 | 0.398 | 0.610 |
| Printer | 5.15 | 9.26 | 5.83 | 7.52 | 4.63 | 0.736 | 0.567 | 0.705 | 0.499 | 0.776 |
| Laptop | 3.90 | 10.35 | 6.47 | 4.81 | 3.77 | 0.620 | 0.313 | 0.583 | 0.511 | 0.638 |
| Bench | 4.54 | 8.11 | 5.03 | 4.31 | 3.70 | 0.483 | 0.272 | 0.497 | 0.395 | 0.539 |
| Inst- Avg | 5.48 | 9.75 | 5.37 | 5.76 | 4.23 | 0.582 | 0.386 | 0.574 | 0.446 | 0.644 |
| Cat- Avg | 5.58 | 9.58 | 5.29 | 5.86 | 4.27 | 0.594 | 0.403 | 0.581 | 0.452 | 0.654 |
| Chamfer Distance () | IoU | |||||||||
| 3D-EPN [14] | Few-Shot [42] | IF-Nets [7] | Auto-SDF [24] | Ours | 3D-EPN [14] | Few-Shot [42] | IF-Nets [7] | Auto-SDF [24] | Ours | |
| Bag | 8.83 | 9.10 | 8.96 | 9.30 | 8.23 | 0.537 | 0.449 | 0.442 | 0.487 | 0.583 |
| Lamp | 14.27 | 11.88 | 10.16 | 11.17 | 9.42 | 0.207 | 0.196 | 0.249 | 0.244 | 0.284 |
| Bathtub | 7.56 | 7.77 | 7.19 | 7.84 | 6.77 | 0.410 | 0.382 | 0.395 | 0.366 | 0.480 |
| Bed | 7.76 | 9.07 | 8.24 | 7.91 | 7.24 | 0.478 | 0.349 | 0.449 | 0.380 | 0.484 |
| Basket | 7.74 | 8.02 | 6.74 | 7.54 | 6.60 | 0.365 | 0.343 | 0.427 | 0.361 | 0.455 |
| Printer | 8.36 | 8.30 | 8.28 | 9.66 | 6.84 | 0.630 | 0.622 | 0.607 | 0.499 | 0.705 |
| Inst- Avg | 8.60 | 8.83 | 8.12 | 8.56 | 7.38 | 0.441 | 0.387 | 0.426 | 0.386 | 0.498 |
| Cat- Avg | 9.09 | 9.02 | 8.26 | 8.90 | 7.52 | 0.440 | 0.386 | 0.426 | 0.389 | 0.495 |
Appendix D Evaluation on Seen Categories
Table 10 shows the comparisons on seen train categories with state of the art on real-world data from ScanNet [11]. We evaluate 1060 samples for 7 seen categories including: chair, table, sofa, trash bin, cabinet, bookshelf, and monitor; categories are selected as those which have more than 50 test samples.
Table 10 shows that our performance on seen categories is on par with state of the art, particularly when evaluating category averages, as our learned multiresolution priors maintain robustness across categories. Note that similar to the previous evaluation, AutoSDF results are reported as the best among their nine predictions with the highest IoU value given an oracle to indicate the best choice. Our method thus achieves performance on par with state of the art on seen categories, and notably improves shape completion for unseen categories.
| Chamfer Distance () | IoU | |||||||||
| 3D-EPN [14] | Few-Shot [42] | IF-Nets [7] | Auto-SDF [24] | Ours | 3D-EPN [14] | Few-Shot [42] | IF-Nets [7] | Auto-SDF [24] | Ours | |
| Trash Bin | 5.03 | 5.65 | 5.23 | 4.48 | 4.44 | 0.61 | 0.70 | 0.62 | 0.66 | 0.68 |
| Chair | 9.99 | 6.88 | 7.93 | 6.00 | 7.14 | 0.40 | 0.46 | 0.43 | 0.49 | 0.45 |
| Bookshelf | 4.87 | 4.33 | 5.17 | 4.12 | 3.80 | 0.53 | 0.65 | 0.58 | 0.61 | 0.61 |
| Table | 8.74 | 7.13 | 10.15 | 6.72 | 6.60 | 0.47 | 0.50 | 0.46 | 0.49 | 0.54 |
| Cabinet | 4.60 | 4.36 | 5.64 | 4.53 | 4.17 | 0.76 | 0.80 | 0.74 | 0.78 | 0.79 |
| Sofa | 4.94 | 4.28 | 7.87 | 4.58 | 4.53 | 0.69 | 0.75 | 0.67 | 0.72 | 0.73 |
| Monitor | 5.75 | 4.98 | 6.39 | 5.92 | 4.74 | 0.52 | 0.59 | 0.53 | 0.49 | 0.56 |
| Inst Avg | 7.94 | 6.18 | 7.65 | 5.68 | 6.02 | 0.50 | 0.56 | 0.51 | 0.55 | 0.55 |
| Cat Avg | 6.27 | 5.37 | 6.91 | 5.20 | 5.06 | 0.57 | 0.63 | 0.58 | 0.61 | 0.62 |
Appendix E Additional Ablation Studies
Runtime efficiency.
We evaluate runtime efficiency in Table 11. Times are measured for each method for a single shape prediction (running with batch size of 1), averaged over 20 samples. Here, Ours ( only) denotes our approach with only single-resolution priors.
| 3D-EPN | Few-Shot | IF-Nets | AutoSDF | Ours ( only) | Ours ( only) | Ours ( only) | Ours |
| 0.015 | 0.004 | 0.421 | 0.958 | 0.025 | 0.017 | 0.016 | 0.063 |
What is the impact of the number of priors?
We evaluate the effect of different numbers of priors on ShapeNet data in Table 12 (with 50% priors and 150% priors). We see that performance degrades with 50% priors, while further increasing the prior number reaches a performance plateau (and requiring additional storage). In our approach, our prior storage takes 14.68 MB in memory.
| Inst-CD | Cat-CD | Inst-IoU | Cat-IoU | |
|---|---|---|---|---|
| Ours (50% priors) | 4.41 | 4.45 | 0.632 | 0.640 |
| Ours | 4.23 | 4.27 | 0.644 | 0.654 |
| Ours (150% priors) | 4.22 | 4.30 | 0.638 | 0.647 |
What is the effect of different multi-resolution combinations?
We considered patch resolutions of , , , and . We found and to perform very similarly (variance of IoU and CD), and used to potentially resolve more detailed patches.
We evaluate alternative multi-resolution combinations in Table 13, which shows that all resolutions benefit the more detailed chamfer evaluation (whereas IoU only penalizes non-intersections, rather than how far the predictions are from the GT object).
| Inst-CD | Cat-CD | Inst-IoU | Cat-IoU | |
|---|---|---|---|---|
| Ours ( with ) | 4.30 | 4.35 | 0.642 | 0.651 |
| Ours ( with ) | 4.35 | 4.42 | 0.644 | 0.654 |
| Ours (all resolutions) | 4.23 | 4.27 | 0.644 | 0.654 |
What is the impact of the concatenation in Eq. 3.
We evaluate the effectiveness of concatenation in Eq. 3 in the main paper in Table 14, considering the attention-based term only (the core of our approach). We note that when excluding the attention-based term, this does not consider local patches anymore and becomes similar to the encoder-decoder training of 3D-EPN. As the attention-based learning of correspondence to local priors is the core of our approach, this produces the most relative benefit, with a slight improvement when combining the terms together.
Ablation for fixed priors, no pre-training, and no attention on priors only.
We evaluate this scenario as the lower bound for our task in Table 15, which produces significantly worse results due to the lack of learnable priors in combination with attention.
| Inst-CD | Cat-CD | Inst-IoU | Cat-IoU | |
|---|---|---|---|---|
| Ours (fixed priors, no pre-training, and no-attention on priors only) | 9.53 | 9.73 | 0.35 | 0.37 |
| Ours | 7.38 | 7.52 | 0.50 | 0.50 |
Appendix F Model Architecture Details
Figure 8 details our model architecture. Figure 8 (a), (b) and (c) respectively present the submodule for learning patch priors at resolutions , , and . The network in Figure 8 (d) shows our multi-resolution patching learning stage. Inputs are partial scans and the learnable shape priors, and the outputs are completed shapes. The specifications of encoder and decoder blocks in these models are shown in Figure 9.



Appendix G Additional Qualitative Results
Figure 10 shows more examples for qualitative results on ShapeNet, and Figure 11 shows more examples for qualitative results on ScanNet scans.







