Parameter calibration with Consensus-based Optimization for interaction dynamics driven by neural networks
Abstract.
We calibrate parameters of neural networks that model forces in interaction dynamics with the help of the Consensus-based global optimization method (CBO). We state the general framework of interaction particle systems driven by neural networks and test the proposed method with a real dataset from the ESIMAS traffic experiment. The resulting forces are compared to well-known physical interaction forces. Moreover, we compare the performance of the proposed calibration process to the one in [4] which uses a stochastic gradient descent algorithm.
1. Introduction
Modelling interacting particle dynamics such as traffic, crowd dynamics, schools of fish and flocks of birds has attracted the attention of many research groups in the recent decades. Most models use physically-inspired interaction forces resulting from potentials to capture the observed behaviour. In fact, the gradient of the potential is used as driving force for interacting particle systems formulated with the help of ordinary differential equation (ODE). These models are able to represent the main features of the dynamics, but as for all models we cannot be sure that they deliver the whole truth. The idea in [4] was therefore to replace the physical-inspired models by neural networks, train the networks with real data and compare the resulting forces.
In the recent years it became obvious that neural networks are able to represent a lot of details from the dataset. It may be possible that there are details captured that are not even noticed by humans and therefore do not appear in physical models which are built to reproduce observations of the modeller.
In the following we recall the general dynamic of interaction particle systems driven by neural networks as proposed in [4]. Then we shortly describe the global optimization method ’Consensus-based optimization’ that we use for the real-data based calibration the network. Finally, we present the numerical results obtained by the calibration process and compare them to the ones resulting from the calibration with the stochastic gradient descent method reported in [4].
2. Interacting particle systems driven by neural networks
We consider interacting particle dynamics described by systems of ODEs of the following form
| (1) |
where represents the interaction force resulting for in its interaction with The initial condition of the particles is given by real dataset In order to compare the results to the ones in [4] we restrict the class of neural networks to feed-forward networks. However, note that the approach discussed here allows for general neural networks while the discussion in [4] considers feed-forward networks and can only be generalized to neural networks allowing for back propagation.
2.1. Feed-forward neural networks
In the following we consider feed-forward artificial neural networks of the form
Definition 1.
A feed-forward artificial neural network (NN) is characterized by
-
-
Input layer:
where is the input (feature) in (1) and is the number of neurons without the bias unit .
-
-
Hidden layers: for
-
-
Output layer:
Note that the output layer has no bias unit. The entry of the weight matrix describes the weight from neuron to the neuron . For notational convenience, we assemble all entries in a vector with
For the numerical experiment we use for and For an illustration of the NN structure we refer the interested reader to [4]. In the numerical section we consider an NN with one input and 5 units in the hidden layer.
3. Parameter Calibration
We formulate the task of the parameter calibration as an optimization problem. Let denote the vector of parameters to be calibrated. This could be the weights of the neural network and some other parameters, as for example the average length and the maximal speed of the cars which we will consider in the application. As we want the network to recover the forces hidden in the real data dynamics, we define the cost function for the parameter calibration as
| (2) |
where denotes the trajectories of the cars obtained by the traffic experiment, and are reference values for the parameters. The parameter allows to balance the two terms in the cost functional. In case no reference values of the parameters are available, we set in the numerical section.
3.1. Consensus-based optimization (CBO)
We solve the parameter calibration problem with the help of a Consensus-based optimization method [3]. In more details, we choose the variant introduced in [2] which is tailored for high-dimensional problems involving the calibration of neural networks. The CBO dynamics is itself a stochastic interacting particle system with agents given by stochastic differential equations (SDEs). The evolution of the agents is influenced by two terms. On the one hand, there is a deterministic term that aims to confine the positions of the agents at a weighted mean. On the other hand, there is a stochastic term that allows for exploration of the state space. The details are the following
| (3) |
with drift and diffusion parameters , independent -dimensional Brownian motions and initial conditions drawn uniformly from the parameter set of interest. A main role plays the weighed mean
By its construction, agents with lower cost have more weight in the mean as the ones with higher cost. The parameter allows to adjust this difference of the weights. For more information on the CBO method and its proof of convergence on the mean-field level we refer the interested reader to [5] and the references therein. As indicated by the notation above, the agents used in the CBO method are different realizations of parameter vectors that we consider for the calibration. For the numerical results NN4 we consider a neural network with weights, i.e., . Moreover, we assume the maximal speed as additional parameter. Hence, for fixed we have for the -th CBO agent
4. Numerical results and conclusion
For the calibration of the parameters we consider real data from the project ESIMAS [1]. As we want to compare the results to the well-known follow-the-leader model for traffic flow (LWR) we recall its details
| (4a) | ||||
| (4b) | ||||
Here is either or To be prepared for a reasonable comparison, we consider for the neural network dynamics
| (5a) | ||||
| (5b) | ||||
supplemented with initial data . This leads to To evaluate the models and compute the corresponding cost we solve all ODEs with an explicit Euler scheme. For details we refer to [4]. The number in the notation , and corresponds to the number of nonbias neurons in the hidden layer.
4.1. Data processing and numerical schemes
The data collection of the ESIMAS project contains vehicle data from 5 cameras that were placed in a tunnel section on the German motorway A3 nearby Frankfurt/Main [1]. The data is processed in the exact same way as in [4]. Files with the processed data can be found online111https://github.com/ctotzeck/NN-interaction.
The SDE which represents the CBO scheme is solved with the scheme proposed in [2]. In particular, we set and the maximal number of time steps to The mini-batch size of the CBO scheme is and we have CBO agents in total. In each time step we update one randomly chosen mini-batch. The initial values are chosen as follows
4.2. Resulting forces and comparison
Figure 1 (left) shows the velocities resulting from the parameter calibration process. We find that the estimates velocities for the NN approaches are higher than the velocities of the LWR based models. The difference is most significant in data set The plot on the right shows the average of the resulting forces for the different models. The forces of the NN approaches resemble linear approximations of the forces corresponding to the LWR models.
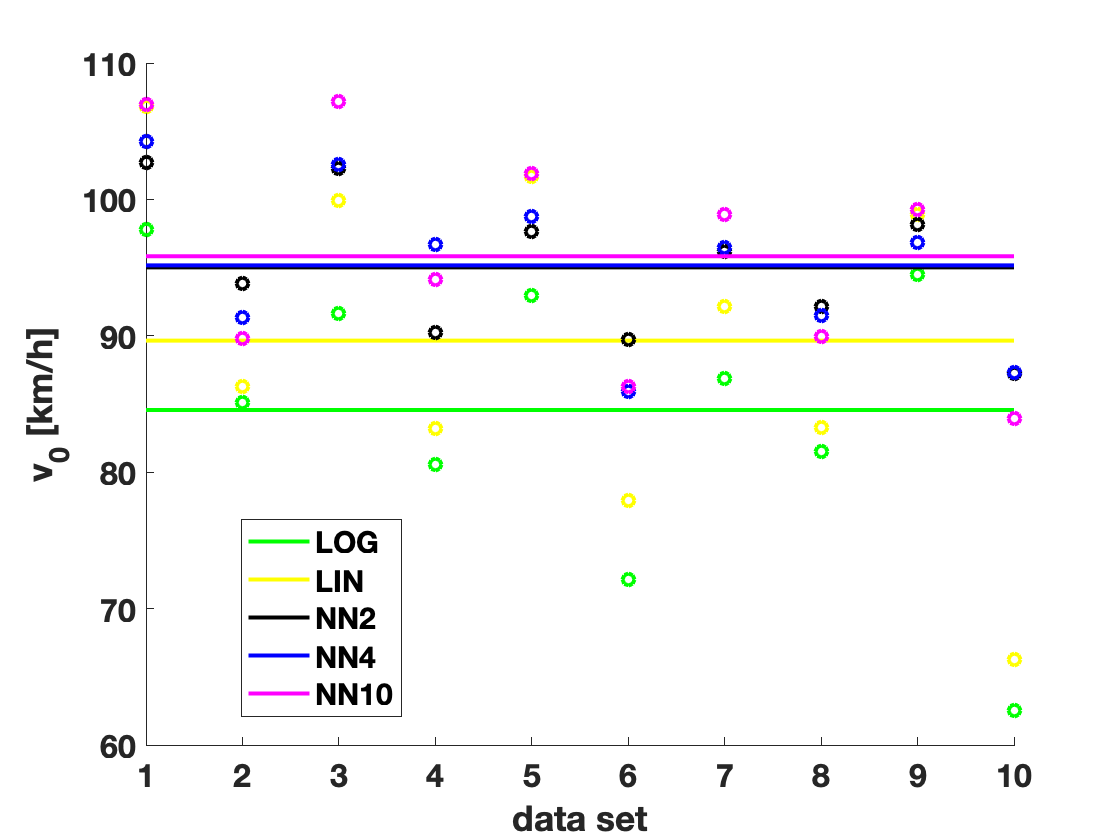
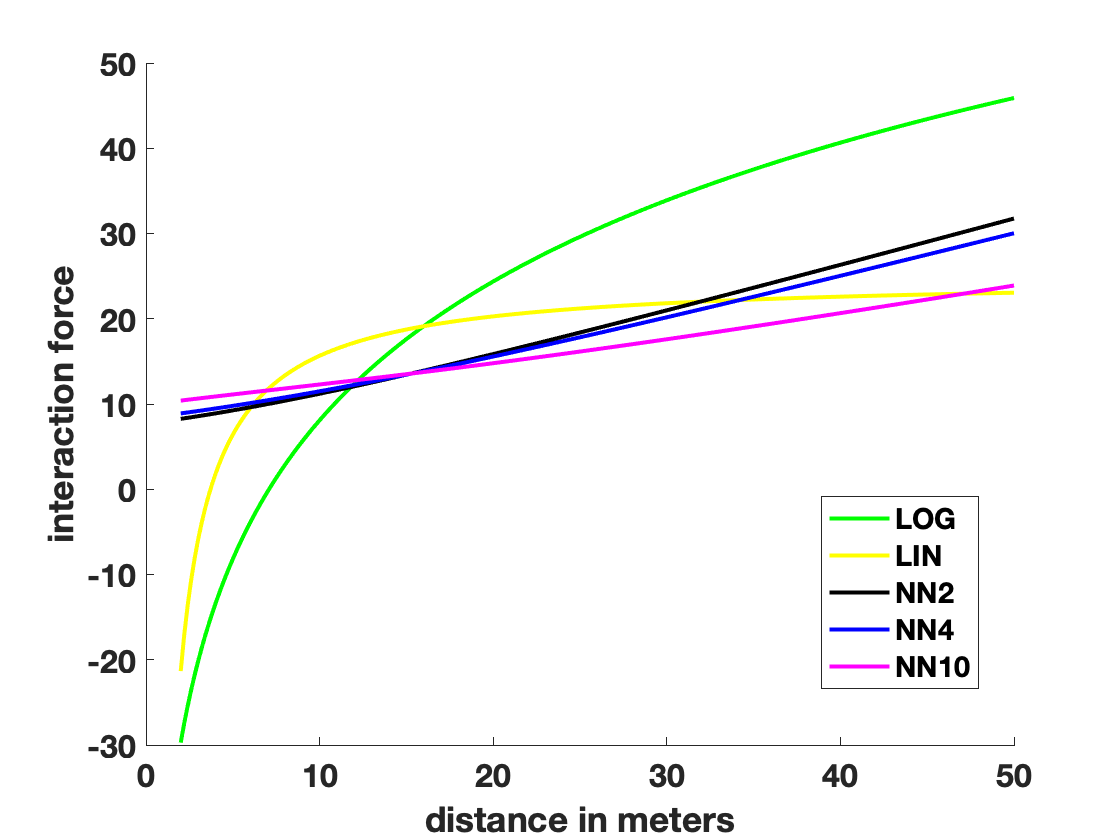
The car length appears only in the LWR models. Its optimized values for the different data sets are given in Table 1. We see that the lengths for the linear model are smaller than the ones in the logarithmic model. This is in agreement with the results obtained with stochastic gradient descent and shown in [4].
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Lin | 3.5969 | 3.76 | 4.17 | 2.19 | 3.02 | 2.81 | 5.92 | 5.86 | 2.14 | 3.65 | 3.71 |
| Log | 7.15 | 7.21 | 8.05 | 8.17 | 6.19 | 5.00 | 8.10 | 8.46 | 5.63 | 6.91 | 7.09 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| NN2 | 47.95 | 46.49 | 98.07 | 44.97 | 23.69 | 29.72 | 40.69 | 55.75 | 11.50 | 68.91 | 46.77 |
| NN4 | 47.82 | 46.09 | 97.01 | 51.84 | 23.33 | 26.71 | 41.60 | 55.29 | 11.16 | 67.60 | 46.84 |
| NN10 | 47.90 | 45.78 | 99.20 | 42.50 | 22.16 | 24.40 | 41.18 | 56.68 | 10.01 | 66.01 | 45.58 |
| Lin | 44.41 | 41.29 | 93.73 | 30.86 | 19.00 | 37.98 | 38.00 | 56.40 | 8.18 | 46.24 | 41.61 |
| Log | 53.53 | 50.31 | 109.36 | 65.24 | 26.50 | 52.93 | 38.09 | 58.22 | 14.54 | 52.75 | 52.15 |
Finally, we summarize the cost values after parameter calibration in Table 2. The least values of every column are highlighted. It is obvious that the LWR model with linear force outperforms the other models. The results of the NN approaches are better than the ones of the LWR model with logarithmic force.
4.2.1. Comparison to calibration with stochastic gradient descent
In comparison to the parameter calibration based on the stochastic gradient descent method reported in [4], we find that the CBO approach finds better parameters for both LWR models. In fact, the resulting cost values are significantly smaller after the calibration with CBO. For the NN approaches the results are in good agreement. A clear decision in favour of the LWR approach or the NN ansatz was not possible based on the results of [4]. After the training with CBO the LWR with linear force seems to outperform all other approaches. Note that we used NN with very simple structure here, it may be worth to test more sophisticated network structures in future work.
References
- [1] S. Lamberty M. Oeser E. Kallo, A. Fazekas. Microscopic traffic data obtained from videos recorded on a german motorway. Mendeley Data 10.17632/tzckcsrpn6.1, 2019.
- [2] L. Li Y. Zhu J. A. Carrillo, S. Jin. A consensus-based global optimization method for high dimensional machine learning problems. ESAIM:COCV, 27(S5), 2021.
- [3] O. Tse S. Martin R. Pinnau, C. Totzeck. A consensus-based model for global optimization and its mean-field limit. Math. Mod. Meth. Appl. Sci., 27(1):183–204, 2017.
- [4] C. Totzeck S. Göttlich. Optimal control for interaction particle systems driven by neural networks. arXiv:2104.01383, 2021.
- [5] C. Totzeck. Trends in consensus-based optimization. arXiv:2104.01383, 2021.