Parallelizing Explicit and Implicit Extrapolation Methods for Ordinary Differential Equations
Abstract
Numerically solving ordinary differential equations (ODEs) is a naturally serial process and as a result the vast majority of ODE solver software are serial. In this manuscript we developed a set of parallelized ODE solvers using extrapolation methods which exploit “parallelism within the method” so that arbitrary user ODEs can be parallelized. We describe the specific choices made in the implementation of the explicit and implicit extrapolation methods which allow for generating low overhead static schedules to then exploit with optimized multi-threaded implementations. We demonstrate that while the multi-threading gives a noticeable acceleration on both explicit and implicit problems, the explicit parallel extrapolation methods gave no significant improvement over state-of-the-art even with a multi-threading advantage against current optimized high order Runge-Kutta tableaus. However, we demonstrate that the implicit parallel extrapolation methods are able to achieve state-of-the-art performance (2x-4x) on standard multicore x86 CPUs for systems of stiff ODEs solved at low tolerance, a typical setup for a vast majority of users of high level language equation solver suites. The resulting method is distributed as the first widely available open source software for within-method parallel acceleration targeting typical modest compute architectures.
I Introduction
The numerical approximation of ordinary differential equations (ODEs) is a naturally serial time stepping process, meaning that methods for parallelizing the solution of such ODEs requires either tricks or alternative solvers in order to exploit parallelism. The most common domain, and one of the most common applications in scientific computing, is the parallel solution of large-scale systems of ODEs (systems of millions or more equations) which arise from the semi-discretization of partial differential equations. For such cases, the size of the system allows for parallel efficiency to be achieved by parallelizing some of the most expensive computations, such as implicit parallelism of BLAS [1]/LAPACK [2], sparse linear solvers, or preconditioner computations, on compute clusters and with heterogeneous GPU+CPU compute. Commonly used open source softwares such as Sundials [3] and DifferentialEquations.jl [4] help users automate the parallelism in such cases. However, for this manuscript we look in the opposite direction at parallelism for small systems of ODEs ().
Parallel computing on small systems of equations comes with a separate set of challenges, namely that computations can easily become dominated by overhead. For this reason, most software for accelerating the parallel solution of ODEs focus on the parallelization of generating ensembles of solutions, i.e. generating the solution to a small system of ODEs over a set of parameters or initial conditions. Examples of this include the ensembles interface in DifferentialEquations.jl [4]. However, in many cases the ensemble form may not be easy to exploit. One key example is in parameter estimation or model calibration routines which are typically done with some gradient-based optimization technique and requires one realization of the model at a given parameter before advancing. Given questions on the Julia [5] Discourse demonstrate that the vast majority of users both typically solve ODE systems and have multi-core compute available (e.g. Core i5/i7 chips with 2-16 processors), investigated whether the most standard ODE solve cases could benefit from some form of parallelism.
Prior research has developed a large amount of theory around potential solvers for such problems which fall into the categories of parallel-in-time (PIT) methods and within-step parallelism methods [6]. Parallel-in-time methods address the issue by effectively stepping the ODE at multiple time points simultaneously, similar to the ensemble approach, and impose a nonlinear system constraint to relax the initial conditions of the future points to arrive at a sufficiently smooth solution. An open source software for PIT methods, XBraid, does exist but focuses on large compute hardware [7]. Documents from the XBraid tutorials [8] estimate current PIT methods outperform classical solvers at cores111Private correspondences and tests with DifferentialEquations.jl also confirm a similar cutoff point with PIT methods, making them impractical for standard compute hardware. Thus while PIT methods are a promising direction for accelerating ODE solving for the exascale computers targeted by the XBraid project [7], these methods do not suffice for the core nature of standard consumer computing devices.
However, promising prior results exist within the within-step parallelism research. Nowak 1998 parallelized the implicit extrapolation methods and showed that the parallelization did improve performance [9], though its tests did not compare against multithreaded (sparse) factorizations like is seen in modern suites such as UMFPACK [10] in SuiteSparse [11], no comparison was made against optimized solver softwares such as CVODE [3] or LSODA [12], and no open source implementation exists for this method. Additionally, Ketcheson (2014) [13] demonstrated that within-step parallel extrapolation methods for non-stiff ODEs can outperform dop853, an efficient high-order Runge-Kutta method [14] . Two notable issues with this study are that (a) no optimized open source software exists for this method for further investigation, (b) the study did not investigate whether such techniques could be useful for stiff ODEs, which tend to be the most common type of ODEs for many applications from biology and chemistry to engineering models. These results highlight that it may be possible to achieve state-of-the-art (SOA) performance by exploiting parallelism, though no software is readily available.
In this manuscript we build off of the prior work in within-method parallel extrapolation to build an open source software in Julia [5] targeting ODE systems on standard compute architectures. We demonstrate that this new solver is the most efficient solver for this class of equations when high accuracy is necessary, and demonstrate this with benchmarks that include many methods from DifferentialEquations.jl [4], SUNDIALS [3] (CVODE), LSODA [12], and more. To the best of our knowledge, this is the first demonstration that a within-step parallel solver can be the most efficient method for this typical ODE and hardware combination.
II Extrapolation Methods
Our exposition of extrapolation methods largely follows that of Hairer I [14] and II [15], and [16]. Take the ODE:
| (1) |
with some known initial condition over a time span . The extrapolation methods are variable-order and variable-step methods which generate higher precision approximations of ODE solutions computed at different time step-sizes. For the current order of the algorithm, we generate at the current time-step for each order from 1 to . For the approximation at , the algorithm chooses a subdividing sequence which discretizes into further fixed smaller steps between . Choosing a sequence of the form:
| (2) |
Generates internal step-sizes by . The subdividing sequences vary with order, having smaller time-steps in higher orders for finer resolution. The algorithm chosen for this is suitably an efficient implicit/explicit method between is of order.
The tabulation of calculations generate starting-stage of extrapolation computation, denoted by:
| (3) | ||||
Extrapolation methods use the interpolating polynomial
| (4) |
such that to obtain a higher order approximation by extrapolating the step size to . Concretely, we define . In order to find , we can solve the linear system of variables and equations formed by equations (3) and (4). This conveniently generates an array of approximations with different orders which allows simple estimates of local error and order variability techniques:
Aitken-Neville’s algorithm uses Lagrange polynomial interpolation formulae [17, 18] to make: (4):
| (5) |
Finally, the order is .
As shown in (2), the subdividing sequence should be positive and strictly increasing. Common choices are:
The ”Harmonic” sequence generates the most efficient load balancing and utilization of multi-threading in parallel computing which is discussed more in Section III.
II-A Explicit Methods
II-A1 Extrapolation Midpoint Deuflhard and HairerWanner
Both the algorithms use explicit midpoint method for internal step-size computations. The representation used here is in the two-step form, which makes the algorithm symmetric and has even powers in asymptotic expansion [22]
| (6) | ||||
The difference between them arises from the step-sizing controllers. The ExtrapolationMidpointDeufhard is based on the Deuflhard’s DIFEX1 [19] adaptivity behaviour and ExtrapolationMidpointHairerWanner is based on Hairer’s ODEX [14] adaptivity behaviour.
The extrapolation is performed using barycentric formula which based on the lagrange barycentric interpolation [23]. The interpolation polynomial is given by:
| (7) | ||||
Extrapolating the limit , we get:
| (8) | ||||
Where are the extrapolation weights, are the extrapolation coefficients and denotes the subdividing sequence.
The choice for baryentric formula instead of Aitken-Neville is mainly due to reduced computation cost of ODE solution at each time-step [16]. The extrapolation weights and coefficients can be easily computed and stored as tableau’s. The yields the computation cost to be for the precomputation where is the maximal order than can be achieved by the method.The extrapolation method of order generates a method of error in order of [14], [16].
It can be analysed that computational cost of with Aitken-Neville for is (), where is the extrapolation order and d is the dimension of the [16]. The computation cost of (8) is simply (a linear combination all across d dimensions) [16].
Numerical Stability and Analysis: In comparison The numerical performance follows similar behaviour as that of Aitken-Neville in the subdividing sequences of Romberg and Bulrisch, where the absolute error decreases as extrapolation order increases [24]. However, in the harmonic sequence, the numerical stability in both cases of extrapolation remains up-to as much as up-to 15 order and then it diverges [16].
II-B Implicit Methods
We will consider implicit methods as basis for internal step-size calculation using subdividing sequences in extrapolation methods. They are widely used for solving stiff ODEs (maybe write more why implicit methods are suited for it).
II-B1 Implicit Euler Extrapolation
The ImplicitEulerExtrapolation uses the Linearly-Implicit Euler Method for internal step-sizing. Mathematically:
| (9) | ||||
where and is the identity and jacobian matrix respectively. Clearly, the method is non-symmetrical and consequently would have non-even powers of global error expansion. The methods are stable with [15]. The extrapolation scheme used is Aitken-Neville (5).
II-B2 Implicit Euler Barycentric Extrapolation
We experimented with barycentric formulas [23] to replace extrapolation algorithm in ImplicitEulerExtrapolaton. Since there are no even powers in global error expansion, the barycentric formula [23] needs to changed as follows:
| (10) | ||||
Extrapolating the limit , we get:
| (11) | ||||
Consequently, the extrapolation method of order generates a method of error in order of .
II-B3 Implicit Hairer Wanner Extrapolation
For implicit extrapolation, symmetric methods would be beneficial to provide higher order approximations. The naive suitable candidate is the trapezoidal rule, but the resulting method is not stiffly stable and hence undesirable for solving stiff ODEs [25], [14].
G. Bader and P. Deuflhard [26], [19] developed the linearly-implicit midpoint rule with Gragg’s smoothing [27], [28] as extension of popular Gragg-Bulirsch-Stoer (GBS) [21] method. The algorithm is given by:
| (12) | ||||
Followed by Gragg’s Smoothing [27], [28]:
| (13) | ||||
The Gragg’s smoothing [27], [28] implementation in OrdinaryDiffEq.jl 222https://github.com/SciML/OrdinaryDiffEq.jl/pull/1212 improved the stability of algorithm resulting in lower evaluations, time steps and linear solves. Consequently, it increased the accuracy and speed of the solvers.
The extrapolation scheme used is similar to extrapolation midpoint methods, namely the barycentric formula [23] (8). One of the trade-offs for the increased stability from Gragg’s smoothing [27], [28] is the reduced order of error for the extrapolation method. As stated earlier, the barycentic formula provides and error of order which gets reduced to in the case of Implicit Hairer Wanner Extrapolation [14], [26]. The algorithm requires to use even subdividing sequence and hence we are using multiples of 4 of the common sequences in the implementation. Furthermore, the convergence tests for these methods333https://github.com/SciML/OrdinaryDiffEq.jl/blob/master/test/algconvergence/ode_extrapolation_tests.jl are written in the test suite of OrdinaryDiffEq.jl.
II-C Adaptive time-stepping and order of algorithms
The methods follow a comprehensive step-sizing and order selection strategy. The adaptive time-stepping is mostly followed on the lines of Hairer’s ODEX [14] adaptivity behaviour. The error at order is expressed as:
| (14) | ||||
and the scaled error is represented as:
| (15) | ||||
Finally, the is calculated using the standard-controller:
| (16) | ||||
Where is the safety factor, is the minimum scaling and is the maximum scaling. For the optimal order selection, the computation relies on the ”work calculation” which is stage-number per step-size , .
The stage-number includes the no. of RHS function evaluations, jacobian matrix evaluation, and forward and backward substitutions. These are pre-computed according the subdividing sequence and stored as a cache. More details about these calculations can be found here.444https://github.com/utkarsh530/DiffEqBenchmarks/blob/master/Extrapolation_Methods/Extrapolation_Methods.pdf These work calculations form the basis of order-selection. The order-selection is restricted between the window and appropriate conditions are passed to convergence monitor. Briefly describing, it checks the convergence in the window and subsequently accepts the order which has the most significant work reduction during increasing/decreasing the order and . Detailed description can be found at order and step-size control in [14].
III Parallelization of the Algorithm
III-A Choosing Subdividing Sequences for Static Load Balancing
The exploit of parallelism arises from the computation of . evaluations of are done to find the solution . These evaluations are independent and are thus parallelizable. However, because of the small systems being investigated, dynamic load balancing overheads are much too high to be relied upon and thus we tailored the parallelism implementation to make use of a static load balancing scheme as follows. Each requires calls to the function , and if the method is implicit then there is an additional back substitutions and one LU factorization. While for sufficiently large systems the LU-factorization is the dominant cost due to its growth for an ODE system, in the ODE regime with our BLAS [1]/LAPACK [2] implementations555RecursiveFactorization.jl notably outperforms OpenBLAS in this regime. we find that this cost is close enough to the cost of a back substitution that we can roughly assume requires “work units” in both the implicit and explicit cases method cases.
If we consider the multiples of harmonic subdividing sequence is 2, 4, 6, 8, 10, 12, … then the computation of needs work. Because is a numerical approximation of order we can simply give each a processor if processors are available. The tasks would not finish simultaneously due to different amount of work. With Multiple Instruction and Multiple Data Stream (MIMD) processors, multiple computations can be loaded to one processor to calculate say and on a single processor, resulting in function evaluations . Consequently, each processor would contain and computations and we require processors. This is an effective load-balancing and all processes would finish simultaneously due to an approximately constant amount of work per chunk.
Julia provides compose-able task-based parallelism. To take advantage of the regularity of our work and this optimized static schedule, we avoid some of the overheads associated with this model such as task-creation and scheduling by using Polyester.jl’s [29] @batch macro, which allows us to run our computation on long-lived tasks that can remain active with a spin-lock between workloads, thereby avoiding the need for rescheduling. We note that this load-balancing is not as simple in sequences of Romberg and Bulirsch, and thus in those cases we multi-thread computations over constant processors only. For this reason, the homonic subdividing sequence is preferred for performance in our implementation.
III-B Parallelization of the LU Factorization
One of the most important ways multi-threading is commonly used within implicit solvers is within the LU factorization. The LU factorization is multi-threaded due to expensive complexity. For Jacobian matrices smaller than , commonly used BLAS/LAPACK implementations such as OpenBLAS, MKL, and RecursiveFactorization.jl are unable to achieve good parallel performance. However, the implicit extrapolation methods require solving linear systems with respect to for each sub-time step . Thus for the within-method parallel implicit extrapolation implementation we manually disabled the internal LU factorization multi-threading and parallelized the LU factorization step by multi-threading the computation of this ensemble of LU factorizations. If the chosen order is sufficiently then a large number of would be chosen and thus parallel efficiency would be achieved even for small matrices. In the results this will be seen as the lower tolerance solutions naturally require higher order methods, and this is the regime where the implicit extrapolation methods demonstrably become SOA.
IV Benchmark Results
The benchmarks we use work-precision diagrams to allow simultaneous comparisons between speed and accuracy. Accuracy is computed against reference solutions at tolerance. All benchmarks were computed on a AMD EPYC 7513 32-Core processor ran at 8 threads666While more threads were available, we did not find more threads to be beneficial to accelerating these computations..
IV-A Establishing Implementation Efficiency
To establish these methods as efficient versions of extrapolation methods, we benchmarked these new implementations against standard optimized extrapolation implementations. The most widely used optimized implementations of extrapolation methods come from Hairer’s FORTRAN suite [30], with ODEX [14] as a GBS [21] extrapolation method and SEULEX as a linear implicit Euler method. Figure 1 illustrates that our implementation outperforms the ODEX [14] FORTRAN method by 6x on the 100 Independent Linear ODEs problem. And similar to what was shown in Ketcheson 2014 [13], we see that the parallelized extrapolation methods were able to outperform the dop853 high order Runge-Kutta method implementation of Hairer by around 4x (they saw closer to 2x). However, when we compare the explicit extrapolation methods against newer optimized Runge-Kutta methods like Verner’s efficient 9th order method [31], we only matched the SOA777In the shown Figure 1, the methods are approximately 1.5x faster, though on this random linear ODE benchmark, different random conditions lead to different performance results, averaging around 0.8x-2x, making the speedup generally insignificant, which we suspect is due to the explicit methods being able to exploit less parallelism than the implicit variants. Thus for the rest of the benchmarks we focused on the implicit extrapolation methods. In Figure 2 we benchmarked the implicit extrapolation methods against the Hairer SEULEX [30] implementation on the ROBER [32] problem and demonstrated an average of 4x acceleration over the Hairer implementations, establishing the efficiency of this implementation of the algorithm.

IV-B State-Of-The-Art Performance for Small Stiff ODE Systems
To evaluate performance of extrapolation methods, we benchmarked the parallel implicit extrapolation implementations on the following set of standard test problems [15]:
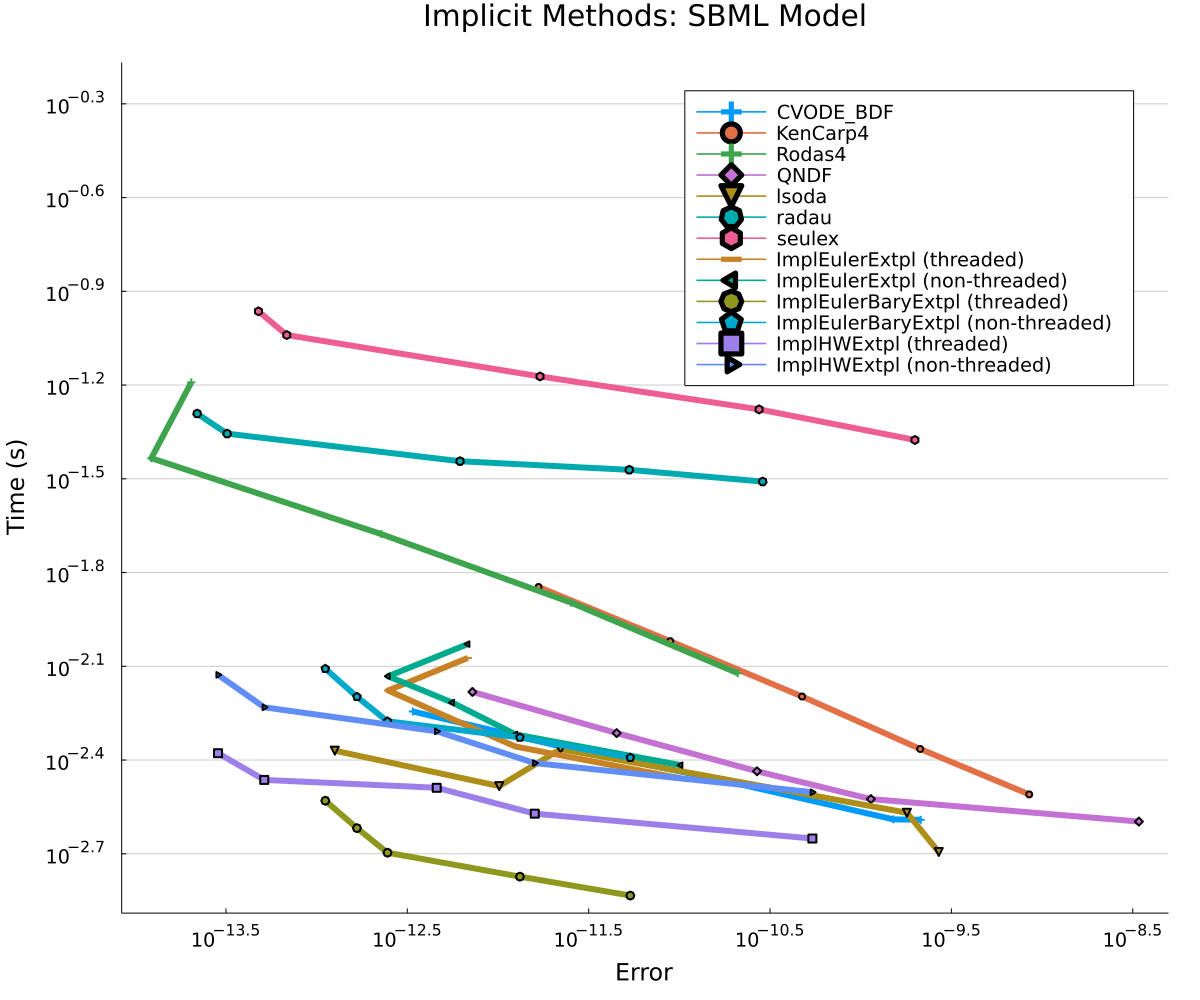
Figures 2-6 show the Work-Precision Diagrams with each of the respective problems with low tolerances. Implicit Euler Extrapolation outperforms other solvers with lower times at equivalent errors. However, very small systems (3-7 ODEs) show a disadvantage when threading is enabled, indicating that overhead is not overcome at this size, but the non-threaded version still achieves SOA by about 2x over the next best methods (Rodas4 and radau) and matching lsoda on HIRES. By 20 ODEs, the multi-threaded form becomes more efficient and is the SOA algorithm by roughly 2.5x. But by the 109 ODEs of the QSP model, the multi-threaded form is noticeably more efficient than the non-multithreaded and the extrapolation methods outperformed lsoda BDF and CVODE’s BDF method by about 2x. Together these results show the implicit extrapolation methods as SOA for small ODE systems, with a lower bound on when multi-threading is beneficial.




V Discussion
If one follows the tutorial coding examples for the most common differential equation solver suites in high-level languages (R’s deSolve [38], Python’s SciPy [39] , Julia’s DifferentialEquations.jl [4], MATLAB’s ODE Suite [40]), the vast majority of users in common case of ODEs will receive no parallel acceleration even though parallel hardware is readily available888Unless the function is sufficiently expensive, like when it is a neural network evaluation. In this manuscript we have demonstrated how the theory of within-method parallel extrapolation methods can be used to build a method which achieves SOA for the high accuracy approximation regime on this typical ODE case. We distribute this method as open source software: existing users of DifferentialEquations.jl [4] can make use of this technique with no changes to their code beyond the characters for the algorithm choice. As such, this is the first demonstration the authors know of for automated acceleration of ODE solves on typical small-scale ODEs using parallel acceleration.999The codes can be found at:
https://github.com/utkarsh530/ParallelExBenchmarks.jl
Lastly, the extrapolation methods were chosen as the foundation because their arbitrary order allows the methods to easily adapt the number of parallel compute chunks to different core counts. This implementation and manuscript statically batched the compute in a way that is independent of the specific core count, leading to generality in the resulting method. However, the downside of this approach is that extrapolation methods are generally inefficient in comparison to other methods such as Rosenbrock [41] or SDIRK [42] methods. In none of the numerous stiff ODE benchmarks by Harier II [15] or the SciML suite101010https://github.com/SciML/SciMLBenchmarks.jl do the implicit extrapolation methods achieve SOA performance. Thus while the parallelization done here was able to achieve SOA, even better results could likely be obtained by developing parallel Rosenbrock [41] or SDIRK [42] methods (using theory described in [6]) and implementing them using our parallelization techniques. This would have the trade-off of being tied to a specific core count, but could achieve better performance through tableau optimization.
Acknowledgments
This material is based upon work supported by the National Science Foundation under grant no. OAC-1835443, SII-2029670, ECCS-2029670, OAC-2103804, and PHY-2021825. We also gratefully acknowledge the U.S. Agency for International Development through Penn State for grant no. S002283-USAID. The information, data, or work presented herein was funded in part by the Advanced Research Projects Agency-Energy (ARPA-E), U.S. Department of Energy, under Award Number DE-AR0001211 and DE-AR0001222. We also gratefully acknowledge the U.S. Agency for International Development through Penn State for grant no. S002283-USAID. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government or any agency thereof. This material was supported by The Research Council of Norway and Equinor ASA through Research Council project ”308817 - Digital wells for optimal production and drainage”. Research was sponsored by the United States Air Force Research Laboratory and the United States Air Force Artificial Intelligence Accelerator and was accomplished under Cooperative Agreement Number FA8750-19-2-1000. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the United States Air Force or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.
References
- [1] J. J. Dongarra, J. Du Croz, S. Hammarling, and I. S. Duff, “A set of level 3 basic linear algebra subprograms,” ACM Transactions on Mathematical Software (TOMS), vol. 16, no. 1, pp. 1–17, 1990.
- [2] E. Anderson, Z. Bai, C. Bischof, L. S. Blackford, J. Demmel, J. Dongarra, J. Du Croz, A. Greenbaum, S. Hammarling, A. McKenney et al., LAPACK users’ guide. SIAM, 1999.
- [3] A. C. Hindmarsh, P. N. Brown, K. E. Grant, S. L. Lee, R. Serban, D. E. Shumaker, and C. S. Woodward, “SUNDIALS,” ACM Transactions on Mathematical Software, vol. 31, no. 3, pp. 363–396, sep 2005. [Online]. Available: https://doi.org/10.1145%2F1089014.1089020
- [4] C. Rackauckas and Q. Nie, “Differentialequations.jl–a performant and feature-rich ecosystem for solving differential equations in julia,” Journal of Open Research Software, vol. 5, no. 1, 2017.
- [5] J. Bezanson, A. Edelman, S. Karpinski, and V. B. Shah, “Julia: A fresh approach to numerical computing,” SIAM review, vol. 59, no. 1, pp. 65–98, 2017.
- [6] K. Burrage, Parallel and sequential methods for ordinary differential equations. Clarendon Press, 1995.
- [7] “XBraid: Parallel multigrid in time,” http://llnl.gov/casc/xbraid.
- [8] J. Schroder and R. Falgout, “Xbraid tutorial,” in 18th Copper Mountain Conference on Multigrid Methods. Colorado, 2017.
- [9] U. Nowak, R. Ehrig, and L. Oeverdieck, “Parallel extrapolation methods and their application in chemical engineering,” in International Conference on High-Performance Computing and Networking. Springer, 1998, pp. 419–428.
- [10] T. A. Davis, “Algorithm 832: Umfpack v4. 3—an unsymmetric-pattern multifrontal method,” ACM Transactions on Mathematical Software (TOMS), vol. 30, no. 2, pp. 196–199, 2004.
- [11] T. Davis, W. Hager, and I. Duff, “Suitesparse,” URL: faculty. cse. tamu. edu/davis/suitesparse. html, 2014.
- [12] L. Petzold, “Automatic selection of methods for solving stiff and nonstiff systems of ordinary differential equations,” SIAM journal on scientific and statistical computing, vol. 4, no. 1, pp. 136–148, 1983.
- [13] D. Ketcheson and U. bin Waheed, “A comparison of high-order explicit runge–kutta, extrapolation, and deferred correction methods in serial and parallel,” Communications in Applied Mathematics and Computational Science, vol. 9, no. 2, pp. 175–200, 2014.
- [14] E. Hairer, S. P. Norsett, and G. Wanner, “Solving ordinary differential equations i: Nonsti problems, volume second revised edition,” 1993.
- [15] Hairer and Peters, Solving Ordinary Differential Equations II. Springer Berlin Heidelberg, 1991.
- [16] K. Althaus, “Theory and implementation of the adaptive explicit midpoint rule including order and stepsize control,” 2018. [Online]. Available: https://github.com/AlthausKonstantin/Extrapolation/blob/master/Bachelor%20Theseis.pdf
- [17] A. Aitken, “On interpolation by iteration of proportional parts, without the use of differences,” Proceedings of the Edinburgh Mathematical Society, vol. 3, no. 1, pp. 56–76, 1932.
- [18] E. H. Neville, Iterative interpolation. St. Joseph’s IS Press, 1934.
- [19] P. Deuflhard, “Order and stepsize control in extrapolation methods,” Numerische Mathematik, vol. 41, no. 3, pp. 399–422, 1983.
- [20] W. Romberg, “Vereinfachte numerische integration,” Norske Vid. Selsk. Forh., vol. 28, pp. 30–36, 1955.
- [21] R. Bulirsch and J. Stoer, “Numerical treatment of ordinary differential equations by extrapolation methods,” Numerische Mathematik, vol. 8, no. 1, pp. 1–13, 1966.
- [22] H. J. Stetter, “Symmetric two-step algorithms for ordinary differential equations,” Computing, vol. 5, no. 3, pp. 267–280, 1970.
- [23] J.-P. Berrut and L. N. Trefethen, “Barycentric lagrange interpolation,” SIAM review, vol. 46, no. 3, pp. 501–517, 2004.
- [24] M. Webb, L. N. Trefethen, and P. Gonnet, “Stability of barycentric interpolation formulas for extrapolation,” SIAM Journal on Scientific Computing, vol. 34, no. 6, pp. A3009–A3015, 2012.
- [25] G. G. Dahlquist, “A special stability problem for linear multistep methods,” BIT Numerical Mathematics, vol. 3, no. 1, pp. 27–43, 1963.
- [26] G. Bader and P. Deuflhard, “A semi-implicit mid-point rule for stiff systems of ordinary differential equations,” Numerische Mathematik, vol. 41, no. 3, pp. 373–398, 1983.
- [27] W. B. Gragg, “Repeated extrapolation to the limit in the numerical solution of ordinary differential equations.” CALIFORNIA UNIV LOS ANGELES, Tech. Rep., 1964.
- [28] B. Lindberg, “On smoothing and extrapolation for the trapezoidal rule,” BIT, vol. 11, no. 1, pp. 29–52, mar 1971. [Online]. Available: https://doi.org/10.1007%2Fbf01935326
- [29] C. Elrod, “Polyester.jl,” https://github.com/JuliaSIMD/Polyester.jl, 2021.
- [30] E. Hairer, “Fortran and matlab codes,” 2004.
- [31] J. H. Verner, “Numerically optimal runge–kutta pairs with interpolants,” Numerical Algorithms, vol. 53, no. 2, pp. 383–396, 2010.
- [32] H. Robertson, “Numerical integration of systems of stiff ordinary differential equations with special structure,” IMA Journal of Applied Mathematics, vol. 18, no. 2, pp. 249–263, 1976.
- [33] A. M. Zhabotinsky, “Belousov-zhabotinsky reaction,” Scholarpedia, vol. 2, no. 9, p. 1435, 2007.
- [34] R. J. Field and R. M. Noyes, “Oscillations in chemical systems. iv. limit cycle behavior in a model of a real chemical reaction,” The Journal of Chemical Physics, vol. 60, no. 5, pp. 1877–1884, 1974.
- [35] E. Schäfer, “A new approach to explain the “high irradiance responses” of photomorphogenesis on the basis of phytochrome,” Journal of Mathematical Biology, vol. 2, no. 1, pp. 41–56, 1975.
- [36] J. G. Verwer, “Gauss–seidel iteration for stiff odes from chemical kinetics,” SIAM Journal on Scientific Computing, vol. 15, no. 5, pp. 1243–1250, 1994.
- [37] G. Bidkhori, A. Moeini, and A. Masoudi-Nejad, “Modeling of tumor progression in nsclc and intrinsic resistance to tki in loss of pten expression,” PloS one, vol. 7, no. 10, p. e48004, 2012.
- [38] K. Soetaert, T. Petzoldt, and R. W. Setzer, “Solving differential equations in r: package desolve,” Journal of statistical software, vol. 33, pp. 1–25, 2010.
- [39] P. Virtanen, R. Gommers, T. E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright et al., “Scipy 1.0: fundamental algorithms for scientific computing in python,” Nature methods, vol. 17, no. 3, pp. 261–272, 2020.
- [40] L. F. Shampine and M. W. Reichelt, “The matlab ode suite,” SIAM journal on scientific computing, vol. 18, no. 1, pp. 1–22, 1997.
- [41] H. Rosenbrock, “Some general implicit processes for the numerical solution of differential equations,” The Computer Journal, vol. 5, no. 4, pp. 329–330, 1963.
- [42] R. Alexander, “Diagonally implicit runge–kutta methods for stiff ode’s,” SIAM Journal on Numerical Analysis, vol. 14, no. 6, pp. 1006–1021, 1977.
- [43] C. Li, M. Donizelli, N. Rodriguez, H. Dharuri, L. Endler, V. Chelliah, L. Li, E. He, A. Henry, M. I. Stefan et al., “Biomodels database: An enhanced, curated and annotated resource for published quantitative kinetic models,” BMC systems biology, vol. 4, no. 1, pp. 1–14, 2010.
- [44] M. Hucka, A. Finney, H. M. Sauro, H. Bolouri, J. C. Doyle, H. Kitano, A. P. Arkin, B. J. Bornstein, D. Bray, A. Cornish-Bowden et al., “The systems biology markup language (sbml): a medium for representation and exchange of biochemical network models,” Bioinformatics, vol. 19, no. 4, pp. 524–531, 2003.
- [45] Y. Ma, S. Gowda, R. Anantharaman, C. Laughman, V. Shah, and C. Rackauckas, “Modelingtoolkit: A composable graph transformation system for equation-based modeling,” 2021.
VI Appendix
VI-A Models
The first test problem is the ROBER Problem:
| (17) | ||||
The initial conditions are and . The time span for integration is .[32], [15] The second test problem is OREGO:
| (18) | |||
| (19) | |||
| (20) |
The initial conditions are and . The time span for integration is . The third test problem is HIRES:
| (21) | ||||
| (22) | ||||
| (23) | ||||
| (24) | ||||
| (25) | ||||
| (26) | ||||
| (27) | ||||
| (28) | ||||
| (29) |
The initial conditions are:
| (30) |
The time span for integration is . The fourth test problem is POLLU:
| (31) | ||||
| (32) | ||||
| (33) | ||||
| (34) | ||||
| (35) | ||||
| (36) | ||||
| (37) | ||||
| (38) | ||||
| (39) | ||||
| (40) | ||||
| (41) | ||||
| (42) | ||||
| (43) | ||||
| (44) | ||||
| (45) | ||||
| (46) | ||||
| (47) | ||||
| (48) | ||||
| (49) | ||||
| (50) | ||||
| (51) | ||||
| (52) | ||||
| (53) | ||||
| (54) | ||||
| (55) |
The time span for integration is .
VI-B Benchmarks
VI-B1 100 Linear ODEs
The test tolerances for the solvers in the benchmark Fig. 1 are relative tolerances in the range of and corresponding absolute tolerances are .
| Extrapolation Method/Order | minimum | initial | maximum |
|---|---|---|---|
| Midpoint Deuflhard | 5 | 10 | 11 |
| Midpoint Hairer Wanner | 5 | 10 | 11 |
VI-B2 Rober
The test tolerances for the solvers in the benchmark Fig. 2 are relative tolerances in the range of and corresponding absolute tolerances are . The integrator used for reference tolerance at is CVODE_BDF [3]. The parameters for the solvers are tuned to these settings:
| Extrapolation Method/Order | minimum | initial | maximum |
|---|---|---|---|
| Implicit Euler | 3 | 5 | 12 |
| Implicit Euler Barycentric | 4 | 5 | 12 |
| Implicit Hairer Wanner | 2 | 5 | 10 |
VI-B3 Orego
The test tolerances for the solvers in the benchmark Fig. 3 are relative tolerances in the range of and corresponding absolute tolerances are . The integrator used for reference tolerance at is Rodas5 [15]. The parameters for the solvers are tuned to these settings:
| Extrapolation Method/Order | minimum | initial | maximum |
|---|---|---|---|
| Implicit Euler | 3 | 4 | 12 |
| Implicit Euler Barycentric | 3 | 4 | 12 |
| Implicit Hairer Wanner | 2 | 5 | 10 |
VI-B4 Hires
The test tolerances for the solvers in the benchmark Fig. 4 are relative tolerances in the range of and corresponding absolute tolerances are . The integrator used for reference tolerance at is Rodas5 [15]. The parameters for the solvers are tuned to these settings:
| Extrapolation Method/Order | minimum | initial | maximum |
|---|---|---|---|
| Implicit Euler | 4 | 7 | 12 |
| Implicit Euler Barycentric | 4 | 7 | 12 |
| Implicit Hairer Wanner | 3 | 6 | 10 |
VI-B5 POLLUTION
The test tolerances for the solvers in the benchmark Fig. 5 are relative tolerances in the range of and corresponding absolute tolerances are . The integrator used for reference tolerance at is CVODE_BDF [3]. The parameters for the solvers are tuned to these settings:
| Extrapolation Method/Order | minimum | initial | maximum |
|---|---|---|---|
| Implicit Euler | 5 | 6 | 12 |
| Implicit Euler Barycentric | 5 | 6 | 12 |
| Implicit Hairer Wanner | 3 | 6 | 10 |
VI-B6 QSP Model
The test tolerances for the solvers in the benchmark Fig. 6 are relative tolerances in the range of and corresponding absolute tolerances are . The integrator used for reference tolerance at is CVODE_BDF [3]. The parameters for the solvers are tuned to these settings:
| Extrapolation Method/Order | minimum | initial | maximum |
|---|---|---|---|
| Implicit Euler | 8 | 9 | 12 |
| Implicit Euler Barycentric | 7 | 8 | 12 |
| Implicit Hairer Wanner | 2 | 5 | 10 |