PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text
Abstract
Scene text detection and recognition have been well explored in the past few years. Despite the progress, efficient and accurate end-to-end spotting of arbitrarily-shaped text remains challenging. In this work, we propose an end-to-end text spotting framework, termed PAN++, which can efficiently detect and recognize text of arbitrary shapes in natural scenes. PAN++ is based on the kernel representation that reformulates a text line as a text kernel (central region) surrounded by peripheral pixels. By systematically comparing with existing scene text representations, we show that our kernel representation can not only describe arbitrarily-shaped text but also well distinguish adjacent text. Moreover, as a pixel-based representation, the kernel representation can be predicted by a single fully convolutional network, which is very friendly to real-time applications. Taking the advantages of the kernel representation, we design a series of components as follows: 1) a computationally efficient feature enhancement network composed of stacked Feature Pyramid Enhancement Modules (FPEMs); 2) a lightweight detection head cooperating with Pixel Aggregation (PA); and 3) an efficient attention-based recognition head with Masked RoI. Benefiting from the kernel representation and the tailored components, our method achieves high inference speed while maintaining competitive accuracy. Extensive experiments show the superiority of our method. For example, the proposed PAN++ achieves an end-to-end text spotting F-measure of 64.9 at 29.2 FPS on the Total-Text dataset, which significantly outperforms the previous best method. Code will be available at: git.io/PAN.
Index Terms:
End-to-End Text Spotting, Text Detection, Kernel Representation, Segmentation.1 Introduction
READING text in natural scenes is a fundamental task in numerous computer vision applications, such as text retrieval, office automation, and visual question answering. In virtue of the powerful representation of deep neural networks [1, 2], scene text detection and recognition has witnessed great progress in the past a few years [3, 4, 5, 6, 7, 8]. Nonetheless, three main limitations still exist in these methods and hamper their deployment to real-world applications.

| Representation | Curved Text | Adjacent Text | One-Stage |
|---|---|---|---|
| Quadrilateral Rep. | ✓ | ✓ | |
| Pixel-Wise Rep. | ✓ | ✓ | |
| BBox-Pixel Rep. | ✓ | ✓ | |
| Kernel Rep. (ours) | ✓ | ✓ | ✓ |
First, many works tackle text detection and recognition as separate tasks by focusing on either text detection or text recognition alone. For most existing text detectors [12, 3, 4], a convolutional neural network is first used to generate feature maps of an input image, and then rectangular or polygonal bounding boxes of scene texts are generated using a decoder. On the other side, text recognition methods [5, 6, 13] often conduct a sequential prediction network on top of image patches of text lines. To date, few methods explore the complementarity between these two tasks. As a result, computation overhead is introduced when assembling these standalone methods into a single scene text reading system.
Second, most end-to-end text spotters [14, 7, 15] are typically designed to read horizontal or oriented text lines. These methods assume that the layout of scene texts is straight, and both their detection and recognition components are developed upon this assumption. However, besides straight text lines, text lines with irregular character arrangements are very common in natural scenes, for example, texts in signboards and posters on streets. The methods dedicated to straight text lines would fail to correctly detect and recognize text lines of curved shapes as shown in Fig. 1(a).
Last, the efficiency of existing end-to-end text spotters [14, 7, 15, 8, 16] remains insufficient for real-world applications. Although a few recent methods [8, 16] have improved the accuracy of end-to-end arbitrarily-shaped text spotting, they suffer from low inference speed due to their heavy models or complicated pipelines. Thus, how to design an efficient and accurate end-to-end spotter for arbitrarily-shaped texts remains largely unsolved.
To address the above issues, built upon our preliminary results published in [4, 17], here we employ the kernel representation to describe a text line by a text kernel (central region) surrounded by peripheral pixels. This is inspired by systematically studying (dis)advantages of the existing scene text representations listed in Fig. 1. The quadrilateral representation [3, 9, 7] is the most commonly used one. As shown in Fig. 1(a), it is specifically designed for straight text lines and fails to provide a tight boundary for a curved text line. In contrast, the pixel-wise representation proposed in [10] is flexible enough to locate curved text lines. Note that with this representation, adjacent text lines can be conglutinated as shown in Fig. 1(b). Although the bounding-box-pixel (bbox-pixel) representation (see Fig. 1(c)) proposed in Mask R-CNN [18] can solve the problems mentioned above, it still follows “detect-then-segment” paradigm [18], which is often time-consuming. In contrast, as shown in Fig. 1(d), our kernel representation can effectively distinguish curved text lines lying closely, which is not inferior to the bbox-pixel representation. Besides, it can be predicted through a single convolutional network, which is conceptually simple and suitable for real-time applications.
By leveraging the advantages of the kernel representation, we further present an end-to-end arbitrarily-shaped text spotter, namely, PAN++111PAN++ is an extended version of the text detector Pixel Aggregation Network (PAN) proposed in our conference paper [17]., which can achieve a good balance between accuracy and inference speed. PAN++ follows the pipeline shown in Fig. 3(h), which contains two main steps: 1) detecting text lines via a segmentation network; and 2) recognizing text content via an attention-based decoder.
To achieve high efficiency, we reduce the time cost of each step by the following four designs: 1) First, a lightweight backbone network (e.g., ResNet18 [19]) is employed for the segmentation network. However, features extracted by a lightweight backbone typically have small receptive fields and weak representation capabilities. 2) To remedy this defect, we propose a low-computation feature enhancement network, which is composed of stacked Feature Pyramid Enhancement Modules (FPEMs). Considering that FPEM is a U-shaped module built by separable convolutions (see Fig. 5), it can enhance multi-scales features with the minimal computation overhead. Moreover, FPEM is stackable, which allows us to compensate for the depth of the network by stacking FPEMs to the lightweight backbone. 3) To detect text lines, we design a simple detection head along with Pixel Aggregation (PA). The detection head predicts text regions, text kernels, and instance vectors, and PA assembles predictions of the network into complete text lines. 4) Finally, to recognize text content, we present a feature extractor termed Masked RoI and a lightweight recognition head that contains only two LSTM [20] layers and two multi-head attention layers [21]. Benefiting from the above designs, PAN++ achieves a high inference speed while keeping competitive accuracy.
Compared with our conference versions PSENet [4] and PAN [17], the major extension of PAN++ lies in the text recognition module and the end-to-end text spotting framework. In conference versions, we proposed the kernel representation and applied it to text detection. Different from the predecessors, we extend the text detector to an end-to-end text spotter that can fast detect and recognize arbitrarily-shaped text lines. To this end, we reconstruct the overall architecture of PAN++, and carefully integrate a tailored feature extractor (i.e., Masked RoI) and a lightweight text recognition head in the architecture.
Besides, we also improve the text detection module when inheriting it from the conference version [17]. 1) We systematically compare our kernel representation with other existing text representations. 2) We simplify the FPEM by combining the original FPEM proposed in [17] and FFM [17] into a single module, which is more effective. 3) We make PA be aware of background elements by adding a background item to the discrimination loss.

Combining these improvements, we upgrade the original text detector into an efficient end-to-end arbitrarily-shaped text spotter (i.e., PAN++). To show the effectiveness of our method, we conduct extensive experiments on four challenging benchmark datasets, namely, Total-Text [23], CTW1500 [24], ICDAR 2015 [25], MSRA-TD500 [26], and RCTW-17 [61]. Note that, Total-Text and CTW1500 are datasets created for curved text detection. As shown in Fig. 2, on the Total-Text dataset, the end-to-end text spotting F-measure of “PAN++ 736” reaches 68.6%, which is 4.4 points higher than ABCNet [24], while its inference speed is faster. Moreover, “PAN++ 512” reaches 29.2 FPS, which is 11 FPS faster than the best counterparts. At the same time, it still achieves a competitive end-to-end text spotting F-measure (64.9%), which is higher than most existing methods. Finally, PAN++ also shows promising detection and recognition performance on other benchmarks, including multi-oriented and long text datasets.

In summary, our main contributions are four-fold.
-
•
We provide the definition of the kernel representation, and systematically compare it with other widely-used text representations, showing that our kernel representation is conceptually simple and flexible, and friendly to real-time applications.
-
•
Based on the kernel representation, we propose a new framework for end-to-end arbitrarily-shaped text spotting, termed PAN++, which achieves an excellent balance between accuracy and inference speed.
-
•
We design and improve a series of efficient components tailored to our framework, including a feature enhancement network consisting of stacked Feature Pyramid Enhancement Modules (FPEMs), a detection head with Pixel Aggregation (PA), a feature extractor (Masked RoI), and an lightweight attention-based recognition head.
-
•
The proposed PAN++ achieves the state-of-the-art performance on curved text benchmarks, simultaneously keeping a fast inference speed. It is notable that PAN++ (S: 512) yields an end-to-end F-measure of 64.9% at 29.2 FPS on the Total-Text dataset, which is 11 FPS faster than the previous best method with competitive accuracy.
2 Related Work
We briefly review some work most relevant to ours.
2.1 End-to-End Text Spotting
End-to-end text spotters aim to detect and recognize text lines simultaneously in a unified network. In the past years, the emergence of deep learning has greatly improved the performance of text spotting. As shown in Fig. 3, we summarize representative text spotters relevant to ours in the deep learning era. These methods can be roughly divided into two categories: 1) regular text spotter, and 2) arbitrarily-shaped text spotter.
2.1.1 Regular Text Spotter
Inspired by Faster R-CNN [27], Li et al. [14] proposed the first framework for horizontal text spotting, which contains a text proposal network for text detection and a CTC-based method for text recognition, as shown in Fig. 3(a). Meanwhile, Busta et al. [28] designed a similar framework to the work in [14]. But its detection head works better for both horizontal and multi-oriented text instances. NguyenVan et al. [29] developed an end-to-end text reading framework by incorporating a pooling-based scene text proposal technique, where false alarms elimination and words recognition are performed simultaneously. Subsequently, Liu et al. [7] proposed a multi-oriented text spotter shown in Fig. 3 (b), termed FOTS, which is equipped with a new RoI extractor (i.e., RoIRotate) to extract the features of quadrilateral text instances. A similar framework is also developed by He et al. [15], whose recognition head is implemented by an attention-based sequence-to-sequence decoder. Although these methods have achieved good performance across straight text benchmarks (e.g., IC15 [25] and MSRA-TD500 [26]), they fail to detect and recognize text lines of curved shapes (see Fig. 1(a)).
2.1.2 Arbitrarily-Shaped Text Spotter
As illustrated in Fig. 3(c), Liao et al. [8] proposed Mask TextSpotter (MTS) by adding character-level supervision to Mask R-CNN [18] to detect and recognize text lines and characters simultaneously. This is probably the first arbitrarily-shaped text spotter. Note that character-level annotations are not always available. The improved version [30] of Mask TextSpotter removed the dependence of character-level annotations. CharNet in [31] is the first one-stage arbitrarily-shaped text spotter as shown in Fig. 3(d). Similar to Mask TextSpotter, it requires character-level annotations for training. Feng et al. [32] proposed TextDragon as shown in Fig. 3(e), which contains a novel RoI extractor (i.e., RoISlide) to represent a text line by features of multiple text segments. Qin et al. [16] designed an arbitrarily-shaped text spotter as shown in Fig. 3(f), where an attention-based text recognition head was added on Mask R-CNN to simultaneously detect and recognize irregular text lines. Recently, Liu et al. [22] formulated irregular text instances with parameterized Bezier curves, and proposed a regression-based arbitrarily-shaped text spotter ABCNet (see Fig. 3(g)). Note that pixel-based (mask) representation used in the previous methods [4, 8, 16] may be more flexible and reliable than the Bezier curve representation due to the fact that the latter one can only represent a series of curves under specific constraints.
2.1.3 Real-time Arbitrarily-Shaped Text Spotter
In [7], Liu et al. proposed a fast text spotter FOTS to detect and recognize multi-oriented texts. However, FOTS cannot process curved text lines. Most methods [8, 30, 31, 32, 16] mentioned in Sec. 2.1.2 have achieved high accuracies on arbitrarily-shaped text spotting, but the inference speed is rarely addressed in those methods.
This inspires us to design an improved pixel-based representation and develop an effective end-to-end text spotting framework based on it in this work.

2.2 Scene Text Detection
Scene text detection is a critical part of text spotting systems. Recently, methods based on deep learning have become the mainstream of text detection. Tian et al. [12] and Liao et al. [33] successfully adapted object detection frameworks for text detection, and achieved good performance on horizontal text datasets. Then researchers took orientations of text instances into consideration and developed different methods [3, 34, 9] to detect multi-oriented text instances. Most of these methods make text detection by regressing quadrilateral bounding boxes, failing to detect curved text lines. To detect curved text lines, some early works [35, 34] followed a bottom-up framework to first detect characters or text fragments and then link them. Recently, some researchers designed segmentation-based methods [36, 4, 17] or combined the advantages of segmentation and box/point regression [37, 11, 38], achieving excellent performances on curved text detection benchmarks. These methods were designed to solve text detection alone and typically text recognition is achieved using a separate model.
2.3 Scene Text Recognition
Scene text recognition is the last step in text spotting systems, which aims to decode sequence of characters from the visual input. Existing text recognizers can be roughly split into three categories, namely, 1) character-based text recognizers, 2) CTC [39]-based text recognizers, and 3) attention-based text recognizers. Character-based text recognizers [40, 41] mostly first detect individual characters and then group them into words. CTC-based methods [42, 43, 5, 44] often stack RNN on top of CNN to capture long-range sequence features. These methods are trained with CTC loss [39], and their the final prediction are produced by removing duplicated outputs in the testing phase. In attention-based methods [45, 46, 6, 13], RNN or Transformer [21] is used to predict a character at each step based on the features from attention mechanisms and previous steps. The process will stop when it predicts the end-of-sequence (EOS) or reaches the maximum number of steps. To recognition irregular text lines, Shi et al. [6] and Zhan et al. [47] used a spatial rectification network to rectify irregularly-shaped text lines into straight ones before recognition. Besides that, some recent works [45, 13] applied the attention mechanism on two-dimensional feature maps to recognize texts with irregular shapes.
3 Proposed Method
3.1 Kernel Representation
As presented in Fig. 1 (d), the kernel representation formulates a text line as a text kernel surrounded by peripheral pixels. In other words, for each given text line, we first locate it through the text kernel (the central region of the text line). Then, we recover the complete shape of the text line by involving text pixels around the text kernel.
In general, there are four advantages of our kernel representation. 1) As a pixel-based representation, it is flexible enough to represent text lines of arbitrary shapes; 2) Because there are large geometrical margins among text kernels, the kernel representation can accurately distinguish adjacent text instances, solving the conglutination problem caused by adjacent text lines shown in Fig. 1 (b); 3) The kernel representation is totally pixel-based, meaning that it can be easily predicted by a single fully convolutional network, which is friendly to real-time applications. 4) The label of the kernel representation can be simply generated without additional annotations, as shown in Fig. 10.
3.2 Overall Architecture
Based on the kernel representation, we develop an efficient text spotting framework termed PAN++, whose architecture is illustrated in Fig. 4. For high efficiency, the backbone network (CNN) should be lightweight, such as ResNet18. However, the features produced by the lightweight backbone network often have small receptive fields and weak representation capabilities. To handle this problem, we propose a feature enhancement network that can refine the features efficiently. It consists of several stacked Feature Pyramid Enhancement Modules (FPEMs). As shown in Fig. 5, FPEM is stackable and computationally efficient, which can be attached behind the backbone network and makes features deeper and more expressive than before. For text detection, we propose a simple detection head with Pixel Aggregation (PA), which predicts: 1) text regions to describe the complete shapes of text lines, 2) text kernels to distinguish different text lines, and 3) instance vectors to recover complete text lines from text kernels, and then these predictions are combined into the text line by PA. For text recognition, Masked RoI is employed to extracted feature patches of text lines, and an attention-based recognition head is proposed to recognize text content.
In the inference phase, we firstly feed an input image of a size of to a lightweight backbone network (e.g., ResNet18 [19]). Four feature maps (see Fig. 4 (b)) are generated by conv2, conv3, conv4, and conv5 stages of the backbone network, whose resolutions are 1/4, 1/8, 1/16 and 1/32 compared with the input image, respectively. Then, we reduce the channel number of each feature map to 128 via 11 convolutions, and obtain a thin feature pyramid (see Fig. 4 (c)). The feature pyramid is enhanced by stacked FPEMs. After obtaining enhanced feature pyramid (see Fig. 4 (d)), we upsample and concatenate the feature maps of feature pyramid into the final feature map for follow-up text detection and recognition. The final feature map is termed (see Fig. 4 (e)), whose size is . Next, based on the feature map , the detection head predicts text regions, text kernels, and instance vectors, and then Pixel Aggregation (PA) assembles them into complete text lines (see Fig. 4 (i)). During text recognition, we first reduce the channel number of feature map to 128 by a 33 convolution and apply Masked RoI to extract the feature patches according to the predicted text lines. Finally, using the extracted feature patches as input, the recognition head recognizes the text content in each patch, as shown in Fig. 4 (j).
During training, we use loss functions , , , and to optimize the predicted text regions, text kernels and instance vectors, respectively. At the same time, the loss function is applied to optimize the prediction of the recognition head. To maintain the consistency of recognition features, we use ground-truth bounding boxes to extract feature patches in the training phase.
3.3 Feature Pyramid Enhancement Module

The Feature Pyramid Enhancement Module (FPEM) is the basic unit of the feature enhancement network, which is U-shaped as presented in Fig. 5. FPEM consists of two phases, including up-scale enhancement and down-scale enhancement phases. The up-scale enhancement is applied to the input feature pyramid, which enhances the input feature maps with strides of 32, 16, 8, and 4 pixels iteratively. In the down-scale enhancement phase, the input is the feature pyramid generated by up-scale enhancement, and the enhancement is conducted from 4-stride to 32-stride iteratively. Finally, the output feature pyramid is the element-wise addition result of the input feature pyramid and the feature pyramid produced by the down-scale enhancement.
As shown in the dashed boxes in Fig. 5, we employ the separable convolution [48] (a 33 depthwise convolution followed by a 11 projection) instead of the regular convolution to implement the join part of FPEM. Therefore, FPEM is capable of enlarging the receptive field (thanks to 33 depthwise convolutions) and deepening the network (thanks to 11 projections) with a small computation overhead.
Similar to FPN [51], FPEM can enhance multi-scale feature maps by fusing the low-level and high-level information. Beyond that, there are two other advantages of FPEM. 1) FPEM is a stackable module. With the increment of stack number , the feature maps will be more adequately integrated, and their receptive fields will become larger. 2) FPEM is computationally efficient. Benefiting from separable convolutions, FPEM only involve marginal computational overhead. As reported in Table VIII, the model equipped with FPEMs runs 8.7 FPS faster than the model with FPN on the IC15 dataset, while keeping a higher end-to-end text spotting F-measure.
3.4 Text Detection
3.4.1 Detection Head

The detection head of PAN++ consists of only two convolutions, as shown in Fig. 6. The outputs of the detection head are text regions, text kernels, and instance vectors. 1) Text regions keep the complete shape of text lines, but closely lying text lines are often overlapping (see Fig. 4 (f)). 2) In contrast, text kernels can easily distinguish adjacent text instances, but they lose the complete shape of text lines (see Fig. 4 (g)). 3) The instance vector is a high-dimensional representation that contains instance information of each pixel. In other words, pixels belonging to the same text line tend to have similar instance vectors (see Fig. 4 (h)). Therefore, instance vectors can direct the pixels in text regions towards the corresponding text kernel, which successfully combines the advantages of text regions and text kernels.
The three outputs complement each other and make it possible to describe text lines of arbitrary shapes.
3.4.2 Pixel Aggregation

Pixel aggregation (PA) is applied to optimize instance vectors and assemble the outputs of the detection head. We borrow the idea of clustering to design PA. As shown in Fig. 7, if we treat different text lines as different clusters, their text kernels are cluster centers, and the pixels inside text regions are the samples the samples to be clustered.
Naturally, to cluster pixels to the corresponding text kernels (see the green arrows in Fig. 7), the distance between the pixel and the text kernel inside the same text lines should be minimized. In the training phase, we use an aggregation loss formulated as Equ. 1 to implement this rule.
| (1) |
| (2) |
Generally, the aggregation loss is employed to pull the text pixel to the target text kernel. The symbols in Eqns. (1) and (2) are defined as follows:
-
•
: the number of text lines.
-
•
: the text region of the th text line.
-
•
: the text kernel of the text line .
-
•
: the distance between the text pixel and the text kernel .
-
•
: the ReLU function, ensuring the output is non-negative.
-
•
: the instance vector of the pixel .
-
•
: the instance vector of the text kernel , which can be calculated by: .
-
•
: a constant, which is set to 0.5 experimentally.
Besides that, the cluster centers need to keep discrimination correspondingly. As a result, the instance vector of the text kernel should keep a certain distance from other text kernels and the background, as shown in the red arrows in Fig. 7. This rule can be summarized as a discrimination loss as follows:
| (3) |
| (4) |
| (5) |
The goal of the discrimination loss is to push the text kernels and the background away from each other. The following is the definition of the symbols in Eqns. (3), (4), and (5).
-
•
: the background.
-
•
: the distance between the text kernel and the background.
-
•
: the distance between the text kernel and the text kernel .
-
•
: a constant, which is set to 3 in all experiments.
In the testing phase, we utilize the predicted instance vector to guide the pixels in text regions to the corresponding text kernel. As shown in Fig. 8, the post-processing has three steps as follows: 1) finding the connected components in the segmentation result of text kernels, and each connected component is regarded as a text kernel; 2) for each text kernel , involving its neighbor pixel (4-way) in text regions when the Euclidean distance of their instance vectors is less than ; 3) repeating the second step until there is no available neighbor pixel in text regions.

3.5 Text Recognition
3.5.1 Masked RoI
Masked RoI is an RoI extractor used to extract the fixed-size feature patches for arbitrarily-shaped text lines. It contains four steps: 1) calculating the minimal upright bounding rectangle containing the target text line; 2) extracting the feature patch within the upright bounding rectangle. 3) filtering noise features by multiplying the feature patch by a binary mask, where the weight outside the target text line is 0. 4) resizing the feature patch to a fixed size. These steps can be summarized as Eqn. (6).
| (6) |
where is the binary mask of the th text line. refers to the upright bounding rectangle of a binary mask. is the operation of cropping the feature patch inside an upright RoI region from the feature map . means element-wise multiplication. represents the operation of resizing the feature map’s size to via bilinear interpolation. In all experiments, and are set to 8 and 32 pixels, respectively.
The proposed Masked RoI has two benefits: 1) The binary mask of the target text line can eliminate the noise features caused by the background or other text lines, so as to accurately extract the features of arbitrarily-shaped text lines. 2) Masked RoI skips the spatial rectification step (e.g., STN in ASTER [6]), reducing the time cost of feature extraction.
Although our Masked RoI is somewhat analogous to RoI Masking proposed in [16], there is a major distinction between them. In RoI Masking [16], the mask used to filter noise features is an instance-wise attention map, whose weight is soft (i.e., a floating number). This approach is not suitable for our PAN++, which cannot predict instance-wise soft masks of text lines. Differently, our Masked RoI removes noise by the binary mask, which can be easily generated by PA. Moreover, the noise weight in the binary mask is 0. Therefore, the proposed Masked RoI can remove noise more thoroughly than RoI Masking.
3.5.2 Recognition Head
Our recognition head is a seq2seq model equipped with multi-head attention [21]. As shown in Fig. 9, it is composed of a starter and a decoder.
The starter is proposed to find the start of the string (SOS), which is not necessarily the left-most region of an arbitrarily-shaped text line. The starter only contains a linear transformation (embedding layer) and a multi-head attention layer . As described in Eqn. (7), the embedding layer transfer the SOS symbol (one-hot) to a 128-dim vector, and then this vector is fed to the multi-head attention layer along with the flatten feature patch , producing SOS’s feature vector , which is also the input of the decoder at the initial time step.
| (7) |
The decoder is made up of only two LSTM layers and one multi-head attention layer . At time step 0 (initial time step), the decoder takes SOS’s feature vector and zero LSTM initial states as input. At time step 1, we input the hidden state of time step 0 into LSTM along with the SOS symbol, and predict the output symbol of time step 1. After that, the output symbol of the previous step is fed into LSTM until predicting the end of the string (EOS) token. We formulate this process as follows:
| (8) |
| (9) |
| (10) |
Here, 0 represents zero states. All input symbols (including SOS and EOS) are represented by one-hot vectors, followed by an embedding layer . is the output symbol of the time step . During training, the input symbols of the decoder are characters in the ground-truth sequence.
Our recognition head is lightweight while maintaining good accuracy. Our recognition head has no encoder, and its decoder only contains two LSTM layers and an attention layer. Moreover, our attention layer is based on multi-head attention, which can effectively fuse temporal (LSTM) features and visual (CNN) features. Besides that, the computational cost of multi-head attention is lower than the common attention module used in [13].

3.6 Label Generation
As presented in Fig. 4 (f)(g), our method predicts the masks of text regions and text kernels. Therefore, the corresponding mask label is required for training.
For text regions, their mask labels can be directly generated by filling ground-truth bounding boxes, where the text pixel is 1 and the non-text pixel is 0. Here, we denote the mask label of the text region as .
For text kernels, we generate their mask labels by shrinking the original bounding boxes by a certain margin and filling them. As shown in Fig. 10, the polygon with a blue border denotes the original bounding box of a text line. To generate the label of the text kernel, we firstly utilize the Vatti clipping algorithm [52] to shrink the original bounding box by pixels and get shrunk bounding box (see Fig. 10 (a)). After that, the shrunk bounding box is transferred into a binary mask, which is the label of the text kernel. For convenience, we denote the mask labels of text kernels as .
During the label generation of text kernels, if we consider a shrinking rate , the shrinking margin between the original bounding box and the shrunk bounding box can be calculated as:
| (11) |
Here, is the function of computing the area of a polygon. is the function of computing the perimeter of a polygon. In the training phase, we can control the scale of target text kernels by adjusting the shrinking rate .

3.7 Loss Function
Our loss function can be formulated as Eqn. (12).
| (12) |
where and are the loss functions for text detection and recognition, respectively.
Specifically, the loss function of text detection can be written as:
| (13) |
where is the loss for text region segmentation. is the loss for text kernel segmentation. and are used to balance the importance of , , and . We set to 0.5 and 0.25 in all experiments.
Considering the extreme imbalance of text and non-text pixels, we follow [4, 17] and adopt dice loss [53] to optimize the segmentation result of text regions and of text kernels . Therefore, and are formulated as:
| (14) |
| (15) |
Here, and refer to the value of the th pixel in the segmentation result and the ground truth of the text regions, respectively. Similarly, and means the th pixel value in the prediction and the ground truth of text kernels, respectively. We also adopt Online Hard Example Mining (OHEM) [54] to ignore simple non-text pixels when calculating . Note that, we only take text pixels into consideration when calculating , and .
The loss function of text recognition is:
| (16) |
where is the ground-truth transcription (text content) containing EOS symbol. denotes the number of characters in the transcription. is the th character in the transcription.
4 Experiment
To validate the effectiveness of the proposed PAN++, we evaluate it on two challenging tasks: 1) text detection and 2) end-to-end text spotting.
| Method | Scale | Backbone | External Dataset | Total-Text | CTW1500 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F-measure | FPS | Precision | Recall | F-measure | FPS | ||||
| CTPN [12] | S: 600 | VGG16 | - | - | - | - | 60.4† | 53.8† | 56.9† | 7.1† | |
| SegLink [34] | 7681280 | VGG16 | 30.3∗ | 23.8∗ | 26.7∗ | - | 42.3† | 40.0† | 40.8† | 10.7† | |
| EAST [3] | 7201280 | VGG16 | 50.0∗ | 36.2∗ | 42.0∗ | - | 78.7† | 49.1† | 60.4† | 21.2† | |
| DeconvNet [23] | 224224 | VGG16 | 33.0 | 40.0 | 36.0 | - | - | - | - | - | |
| CTD+TLOC [24] | S: 600 | ResNet50 | - | - | - | - | 77.4 | 69.8 | 73.4 | 13.3 | |
| PAN++ (ours) | S: 320 | ResNet18 | 82.6 | 72.9 | 77.4 | 84.9 | 82.9 | 76.3 | 79.5 | 84.2 | |
| S: 512 | ResNet18 | 87.1 | 79.0 | 82.8 | 53.1 | 85.2 | 80.3 | 82.7 | 52.7 | ||
| S: 640 | ResNet18 | 89.2 | 80.3 | 84.5 | 38.3 | 85.2 | 81.1 | 83.1 | 36.0 | ||
| TextSnake [37] | 512512 | VGG16 | SynthText | 82.7 | 74.5 | 78.4 | 12.4 | 67.9 | 85.3 | 75.6 | - |
| TextField [55] | 768768 | VGG16 | SynthText | 81.2 | 79.9 | 80.6 | - | 83.0 | 79.8 | 81.4 | - |
| CRAFT [56] | L: 1280 | VGG16 | SynthText | 87.6 | 79.9 | 83.6 | 4.8 | 86.0 | 81.1 | 83.5 | 7.6 |
| LOMO [57] | S: 512 | ResNet50 | SynthText | 88.6 | 75.7 | 81.6 | 4.4 | 89.2 | 69.6 | 78.4 | - |
| SPCNet [11] | S: 800 | ResNet50 | IC17-MLT | 83.0 | 82.8 | 82.9 | 4.6 | - | - | - | - |
| PAN++ (ours) | S: 320 | ResNet18 | SynthText | 85.6 | 75.1 | 80.0 | 84.9 | 84.5 | 76.5 | 80.3 | 84.2 |
| S: 512 | ResNet18 | SynthText | 88.4 | 80.5 | 84.2 | 53.1 | 86.9 | 80.4 | 83.5 | 52.7 | |
| S: 640 | ResNet18 | SynthText | 89.9 | 81.0 | 85.3 | 38.3 | 87.1 | 81.1 | 84.0 | 36.0 | |
4.1 Datasets
4.1.1 Curved Text Datasets
Total-Text [23] is a dataset for arbitrarily-shaped text detection and spotting, containing horizontal, multi-oriented, and curved text lines. This dataset consists of 1,255 training images and 300 testing images, all of which are annotated with polygons and transcriptions at the word level.
CTW1500 [24] is a widely used dataset for arbitrarily-shaped text detection. It has 1,000 training images and 500 testing images. Different from the Total-Text dataset, the images in this dataset are labeled at the text line level. The text lines in the CTW1500 dataset are long and annotated by 14-points polygons.
4.1.2 Straight Text Datasets
ICDAR 2015 (IC15) [25] is a commonly used dataset for end-to-end text detection and recognition. It contains a total of 1,500 images, 1,000 of which are used for training and the remaining are for testing. In this dataset, text lines are annotated by quadrangles and transcriptions at the word level.
MSRA-TD500 [58] includes 300 training images and 200 test images with text line level annotations. It contains multi-lingual, multi-oriented, and long text lines, and all of them are labeled at the text line level. Because its training set is small, we follow the previous works [3, 59, 37] to include the 400 images of HUST-TR400 [60] as training data.
RCTW-17 [61] is a competition on reading Chinese Text in images. It provide a large-scale dataset that consists of 12,000 images, where 8,346 for training and the rest for testing. Every image in this dataset is annotated with text line quadrilaterals and text transcripts.
4.1.3 Datasets for Pre-training or Jointly Training
SynthText [62] is a large-scale synthetically generated dataset containing 800K synthetic images. There are a large number of multi-oriented text lines, which are annotated at word-level and character-level rotated bounding boxes, as well as corresponding transcriptions. Following [34, 59, 37], this dataset is used for pre-training or jointly training models of PAN++.
COCO-Text [63] contains 63,686 images and three versions of the annotations (V1.1, V1.4, and V2.0). In V2.0, there are 239,506 annotated text lines, which are labeled with word-level polygons and transcriptions. This dataset is usually used for pre-training or jointly training in previous text spotters [16, 22].
ICDAR 2017 MLT (IC17-MLT) [64] is a multi-language scene text dataset. It consists of 7,200 training images, 1,800 validation images, and 9,000 test images. The dataset is composed of natural scene images with nine languages, and these images are labeled with word-level quadrangles and transcriptions. Following [16, 22], we use the English samples in the training set to pre-train or jointly train our text spotting models.
4.2 Experiments on Curved Text Datasets
4.2.1 Experiment Settings
To test the performance of PAN++ on arbitrarily-shaped text, we conduct experiments on Total-Text and CTW1500 and compare it with previous start-of-the-art methods. In these experiments, we use the ResNet [2] pre-trained on ImageNet [65] as the backbone network of our method. In addition, we set the dimension of the instance vector to 4, the negative-positive ratio of OHEM to 3, the shrinking rate of the text kernel to 0.7, and the distance threshold of PA to 3.
Following the common practices [3, 4, 8, 22], we ignore the blurred text regions labeled as “DO NOT CARE” during training, and apply random scale, random horizontal flip, random rotation, and random crop on training images. All models are optimized by using ADAM [66] optimizer with a batch size of 16 on 4 GPUs. The initial learning rate is set to . Similar to [67], we use the “poly” learning rate strategy in which the initial rate is multiplied by , and the is set to 0.9 in all experiments. In the testing phase, we resize the input image to different scales and report the performance on text detection and end-to-end text spotting tasks. All results are tested with a batch size of 1 on a V100 GPU and a 2.20GHz CPU in a single thread unless otherwise stated.
In the text detection task, to make fair comparisons, we train PAN++ (without the recognition head) with two widely used strategies as follows: 1) following [68, 3, 17] to train models without external text datasets; 2) following [34, 17, 4] to fine-tune models pre-trained on external text dataset (e.g., SynthText and IC17-MLT). In the first strategy, we train our method for 36K iterations. In the second one, we first pre-train models on the external text dataset for 50K iterations and then fine-tune the pre-trained models for 36K iterations.
In the text spotting task, the training strategies used in previous works [7, 22, 8, 16] can also be divided into two categories: 1) fine-tuning models pre-trained on external text datasets, and 2) jointly training models on multiple text datasets. For fair comparisons, we train our end-to-end text spotting models using the two strategies respectively. Specifically, when using the fine-tuning strategy, we first pre-train models on the training images in the SynthText, COCO-Text, and IC17-MLT datasets for 150K iterations, and then we fine-tune the pre-trained models on Total-Text or CTW1500 for 7K iterations. For the jointly training strategy, we train our models for 150K iterations on the joint dataset that includes all training samples in SynthText, COCO-Text, IC17-MLT, Total-Text and IC15.
4.2.2 Curved Text Detection Results
As shown in Table I, without pre-training on external text datasets, PAN++ with the shorter side being 320 pixels yields an F-measure of 79.5% on CTW1500, surpassing most of the counterparts, including some methods (e.g., TextSnake [37]) pre-trained on SynthText (79.5% vs. 78.4%). Moreover, our inference speed is 8 times faster than TextSnake and 4 times faster than EAST [3] (the fastest method before). It notable that when fine-tuning the model pre-trained on SynthText, PAN++ (S: 640) achieves the best F-measure of 84.0%, outperforming all counterparts while still keeping the fastest inference speed (36 FPS).
Similar results are also on the Total-Text dataset. When the shorter side is 320 pixels, the inference speed of our method reaches 84.9 FPS, which is at least 6 times faster than previous methods, while the F-measure is still very competitive (80.0%). The best F-measure of our method is 85.3%, surpassing current state-of-the-art methods over 1.7 points. Meanwhile, its speed is close to 40 FPS, which is still 3 times faster than the second-fastest TextSnake [37].
These results prove the superiority of the proposed PAN++ (detection only) in arbitrarily-shaped text detection, in terms of accuracy and speed. We present some qualitative curved text detection results in Fig. 11 (a)(b), which demonstrates that the detection components of PAN++ can elegantly locate text lines with complex shapes.
4.2.3 Curved Text Spotting Results
| Method | Scale | Backbone | Training Strategy | External Dataset | Total-Text | ||
| None | Full | FPS | |||||
| TextNet [69] | L: 920 | ResNet50 | Finetune | SynthText | 54.0 | - | 2.7 |
| CharNet [31] | L: 2280 | ResNet50 | Finetune | SynthText, IC15, IC17-MLT | 66.2 | - | 1.2 |
| TextDragon [32] | - | VGG16 | Finetune | SynthText, IC15 | 48.8 | 74.8 | - |
| ABCNet [22] | S: 800 | ResNet50 | Finetune | SynthText, COCO-Text, IC19-MLT | 64.2 | 75.7 | 17.9 |
| PAN++ (ours) | S: 512 | ResNet18 | Finetune | SynthText, COCO-Text, IC17-MLT | 63.5 | 74.0 | 29.2 |
| S: 640 | ResNet18 | Finetune | SynthText, COCO-Text, IC17-MLT | 66.4 | 77.3 | 24.1 | |
| S: 736 | ResNet18 | Finetune | SynthText, COCO-Text, IC17-MLT | 67.1 | 77.4 | 21.1 | |
| TextBoxes [33] | MS | ResNet50 | Jointly Train | SynthText, IC13, IC15 | 36.3 | 48.9 | 1.4 |
| Mask TextSpotter [8] | S: 1000 | ResNet50 | Jointly Train | SynthText, IC13, IC15 | 52.9 | 71.8 | 4.8 |
| Mask TextSpotter v2 [30] | S: 1000 | ResNet50 | Jointly Train | SynthText, IC13, IC15, SCUT | 65.3 | 77.4 | - |
| Qin et al. [16] | S: 900 | ResNet50 | Jointly Train | SynthText, IC15, COCO-Text, IC17-MLT, Private Data | 67.8 | - | 4.8 |
| PAN++ (ours) | S: 512 | ResNet18 | Jointly Train | SynthText, IC15, COCO-Text, IC17-MLT | 64.9 | 75.7 | 29.2 |
| S: 640 | ResNet18 | Jointly Train | SynthText, IC15, COCO-Text, IC17-MLT | 66.7 | 77.5 | 24.1 | |
| S: 736 | ResNet18 | Jointly Train | SynthText, IC15, COCO-Text, IC17-MLT | 68.6 | 78.6 | 21.1 | |
End-to-end text spotting results on the Total-Text dataset are reported in Table II. Compared with the previous fastest ABCNet [22], our method with shorter side being 640 pixels runs 1.3 times faster, while our end-to-end text spotting F-measure is 2.2 points higher (66.4% vs. 64.2%). When adopting a larger input scale or jointly training strategy, the performance of our method can be further improved. With low-resolution input (the shorter side being 512 pixels), the inference speed of our method reaches 29.2, at least 11 FPS faster than previous methods. At the same time, its end-to-end text spotting F-measure is 64.9%, which is higher than most counterparts. It is notable that PAN++ achieves the best end-to-end text spotting F-measure of 68.6%, which is much better than the second-best method (Qin et al. [16]) and our speed is 4 times faster (21.1 FPS vs. 4.8 FPS).
These results indicate that the proposed method achieves state-of-the-art performance in the text spotting task, significantly outperforming existing methods, especially in the inference speed. Some qualitative results of end-to-end curved text spotting in shown in Fig. 12 (a).
4.3 Experiments on Straight Text Datasets
4.3.1 Experiment Settings
| Method | Scale | Backbone | External Dataset | IC15 | MSRA-TD500 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F-measure | FPS | Precision | Recall | F-measure | FPS | ||||
| CTPN [12] | S: 600 | VGG16 | 74.2 | 51.6 | 60.9 | 7.1 | - | - | - | - | |
| RRPN [68] | : 1000 | VGG16 | 82.0 | 73.0 | 77.0 | - | 82.0 | 68.0 | 74.0 | - | |
| EAST [3] | 7201280 | VGG16 | 83.6 | 73.5 | 78.2 | 13.2 | 87.3 | 67.4 | 76.1 | - | |
| PixelLink [36] | 7681280 | VGG16 | 82.9 | 81.7 | 82.3 | 7.3 | 81.1 | 73.0 | 76.8 | 3.0 | |
| DeepReg [70] | MS | VGG16 | 82.0 | 80.0 | 81.0 | - | 77.0 | 70.0 | 74.0 | 1.1 | |
| PAN++ (ours) | S: 736 | ResNet18 | 85.5 | 77.2 | 81.2 | 28.2 | 81.6 | 80.3 | 80.9 | 32.5 | |
| S: 896 | ResNet18 | 86.7 | 78.4 | 82.3 | 19.2 | 82.4 | 82.1 | 82.2 | 22.6 | ||
| SegLink [34] | 7681280 | VGG16 | SynthText | 73.1 | 76.8 | 75.0 | - | 86.0 | 70.0 | 77.0 | 8.9 |
| SSTD [71] | 704704 | VGG16 | Private Data | 80.2 | 73.9 | 76.9 | 7.7 | - | - | - | - |
| RRD [72] | 10241024 | VGG16 | SynthText | 85.6 | 79.0 | 82.2 | 6.5 | 87.0 | 73.0 | 79.0 | 10 |
| MCN [73] | 512512 | VGG16 | SynthText | 72.0 | 80.0 | 76.0 | - | 88.0 | 79.0 | 83.0 | - |
| TextSnake [37] | 7681280 | VGG16 | SynthText | 84.9 | 80.4 | 82.6 | 1.1 | 83.2 | 73.9 | 78.3 | 1.1 |
| LOMO [57] | L: 1536 | ResNet50 | SynthText | 91.3 | 83.5 | 87.2 | - | - | - | - | - |
| SPCNet [11] | S: 800 | ResNet50 | IC17-MLT | 88.7 | 85.8 | 87.2 | 4.6 | - | - | - | |
| PAN++ (ours) | S: 736 | ResNet18 | SynthText | 85.9 | 80.4 | 83.1 | 28.2 | 85.3 | 84.0 | 84.7 | 32.5 |
| S: 896 | ResNet18 | SynthText | 88.7 | 80.7 | 84.5 | 19.2 | 89.6 | 86.3 | 87.9 | 22.6 | |
| S: 896 | ResNet50 | IC17-MLT | 91.4 | 83.9 | 87.5 | 12.6 | 91.4 | 85.6 | 88.4 | 14.3 | |
We also evaluate the performance of PAN++ on straight text datasets, including IC15 and MSRA-TD500. IC15 is a representative benchmark for the text detection task and the text spotting task, and MSRA-TD500 is a dataset annotated at the text line level and often used to benchmark long text detection. During training, the shrinking rate on IC15 and MSRA-TD500 are set to 0.5 and 0.7, respectively. Other model settings, data augmentations, and training settings are the same as those in Sec. 4.2.1. In the testing phase, we rescale the shorter side of the input image to 736 or 896 pixels for fair comparisons with previous methods.
4.3.2 Straight Text Detection Results
Straight text detection results are presented in Table III. On the IC15 dataset, PAN++ (the shorter side being 736 pixels) yields an F-measure of 81.2% at 28.2 FPS without pre-training on external text dataset. Compared with the previous fastest method EAST [3], our method surpasses EAST by 3.0 points in F-measure, while our method runs 2 times faster. Fine-tuning on the SynthText dataset can further increase the F-measure of our method to 83.1%, which is 0.5 points higher than TextSnake [37], but our method can run 25 times faster. Because IC15 contains many small texts, previous methods [11, 72, 57] usually employ high-resolution input and a heavy backbone to ensure detection accuracy. With these setting, the best F-measure of our method reaches 87.5%, which is higher than all counterparts. Even in this case, our inference speed is still the fastest (12.6 FPS).
On the MSRA-TD500 dataset, our method yields F-measures of 80.9% and 84.7% when using the external text dataset or not. Compared with previous state-of-the-art methods, our method enjoys higher accuracy and faster inference speed. Notably, the best F-measure of our method is 88.4%, which is at least 5.4 points higher than previous methods. This result indicates that our method is also robust for long straight text detection.
In conclusion, the proposed PAN++ (detection only) can also accurately detect straight text lines. Some qualitative results of straight text detection are shown in Fig. 11 (c)(d).

4.3.3 Straight Text Spotting Results
| Method | Scale | Backbone | Training Strategy | External Dataset | IC15 | ||||
| S | W | G | N | FPS | |||||
| Stradvision [25] | - | - | - | - | 43.7 | - | - | - | - |
| MCLAB [34, 5] | - | - | - | 67.9 | - | - | - | - | |
| He et al. [15] | - | PVA | Finetune | SynthText | 82 | 77 | 63 | - | - |
| FOTS [7] | L: 2240 | ResNet50 | Finetune | IC17-MLT | 81.1 | 75.9 | 60.8 | - | 7.5 |
| CharNet [31] | L: 2280 | ResNet50 | Finetune | SynthText, IC17-MLT, Total-Text | 82.4 | 78.9 | 67.6 | 62.7 | 1.2 |
| TextNet [69] | MS | ResNet50 | Finetune | SynthText | 78.7 | 74.9 | 60.5 | - | |
| TextDragon [32] | - | VGG16 | Finetune | SynthText, Total-Text | 82.5 | 78.3 | 65.2 | - | - |
| PAN++ (ours) | S: 736 | ResNet18 | Finetune | SynthText, COCO-Text, IC17-MLT | 79.4 | 74.9 | 65.6 | 64.7 | 24.5 |
| S: 896 | ResNet18 | Finetune | SynthText, COCO-Text, IC17-MLT | 80.6 | 76.0 | 66.4 | 65.7 | 18.6 | |
| S: 896 | ResNet50 | Finetune | SynthText, COCO-Text, IC17-MLT | 82.5 | 77.4 | 68.7 | 67.6 | 13.8 | |
| Deep TextSpotter [28] | 608608 | Darknet19 | Jointly Train | SynthText, IC13 | 54.0 | 51.0 | 47.0 | - | 9.0 |
| Mask TextSpotter [8] | S: 1000 | ResNet50 | Jointly Train | SynthText, IC13, Total-Text | 77.3 | 69.9 | 60.3 | - | 4.8 |
| Mask TextSpotter v2 [30] | S: 720 | ResNet50 | Jointly Train | SynthText, IC13, Total-Text, SCUT | 74.2 | 69.2 | 63.5 | - | 3.8 |
| Qin et al. [16] | S: 900 | ResNet50 | Jointly Train | SynthText, COCO-Text, IC17-MLT, Total-Text, Private Data | 83.4 | 79.9 | 68.0 | - | 4.8 |
| PAN++ (ours) | S: 736 | ResNet18 | Jointly Train | SynthText, COCO-Text, IC17-MLT, Total-Text | 80.5 | 75.8 | 66.2 | 65.6 | 24.5 |
| S: 896 | ResNet18 | Jointly Train | SynthText, COCO-Text, IC17-MLT, Total-Text | 81.3 | 76.4 | 67.4 | 66.6 | 18.6 | |
| S: 896 | ResNet50 | Jointly Train | SynthText, COCO-Text, IC17-MLT, Total-Text | 82.7 | 78.2 | 69.2 | 68.0 | 13.8 | |
Table IV summarizes end-to-end text spotting results on the IC15 dataset. Note that, the F-measure with a generic lexicon (denoted as “G”) is the most important metric in the IC15 dataset. When the shorter side is 736 pixels, the speed of our method reaches 24.5 FPS, which is 3 to 7 times faster than previous methods. Meanwhile, it still has a competitive “G” F-measure of 66.2, surpassing most counterparts including Mask TextSpotter V2 [30] (66.2% vs. 63.5%). With ResNet50 as the backbone, our method achieves the best “G” F-measure of 69.2%, which is 1.2 points higher than the previous best text spotter (Qin et al. [16]). At the same time, our inference speed is still the fastest (13.8 FPS).
These results show that in addition to curved text, our PAN++ can also achieve an excellent balance between accuracy and speed when detecting and recognizing straight text. We present some qualitative straight text spotting results in Fig. 12 (b).

4.4 Experiments on Chinese Text Dataset
4.4.1 Experiment Setting
We choose the RCTW-17 [61] dataset to test the effectiveness of our method in detecting and recognizing Chinese text, which is a commonly used language that is completely different from English. Due to the number of character categories is large (up to 3,000), the detection and recognition of Chinese text is challenging. RCTW-17 has the same detection metric as English text datasets (e.g., IC15 [25]), but it uses the average edit distance (AED) [61] as the recognition metric. For a fair comparison, we randomly selected 1,000 images from the RCTW-17 training set as the validation set, and trained all models for 300 epochs in the remaining training set without using external text datasets. Other model settings, data augmentations, and training settings are the same as those in Sec. 4.2.1. In the testing phase, we rescale the shorter side of the input image to 736 pixels.
| Method | Scale | Backbone | RCTW-17 | ||
|---|---|---|---|---|---|
| F | AED | FPS | |||
| SegLink [34] + CRNN [5] | 7681280 | VGG16 | 53.9 | 25.1 | 5.9 |
| PAN++ (ours) | S: 736 | ResNet18 | 65.1 | 23.4 | 18.5 |
| S: 896 | ResNet50 | 68.0 | 22.2 | 10.7 | |
4.4.2 Chinese Text Results
The text detection and recognition performance on the RCTW-17 dataset are reported in Table V. With ResNet18 [19] as the backbone, our PAN++ obtains 65.1 text detection F-measure and 23.4 AED, which is 11.2 points (65.1% vs. 53.9%) and 1.7 points (23.4% vs. 25.1%) better than those of the baseline (SegLink [34] + CRNN [5]). At the same time, our method runs 3 times faster than the baseline (18.5 FPS vs. 5.9 FPS). When using a heavier backbone (i.e., ResNet50 [19]) and a larger input scale, the text detection F-measure and AED of our method further improve to 68.0% and 22.2%, 14.1 points (68.0% vs. 53.9%) and 2.9 points (22.2% vs. 25.1%) better than the baseline, while keeping a faster inference speed (10.7 FPS vs. 5.9 FPS). Some qualitative Chinese text detection and recognition results are presented in Fig. 12 (c). These results prove that our PAN++ can also works well in Chinese text detection and recognition.
4.5 Comparison with Conference Versions
The key points of PAN++ and its conference versions are summarized as follows:
-
•
PSENet [4] (Text Detector): Kernel Representation, PSE;
-
•
PAN [17] (Text Detector): FPEM, PA;
-
•
PAN++ (E2E Text Spotter): Masked RoI, Recognition Head, FPEM (improved), PA (improved);
As an extension of conference versions, PAN++ evolves from the original text detector to an end-to-end (E2E) arbitrarily-shaped text spotter. To this end, we rebuild the overall architecture of PAN++ and carefully integrate a feature extractor (i.e., Masked RoI) and a lightweight recognition head in it.
Besides that, when inheriting the kernel representation, FPEM, and PA from the conference versions, we make some improvements as follows: 1) We systematically compare our kernel representation with other mainstream representations, and prove that our representation is friendly to real-time applications. 2) We simplify the FPEM by combining the old FPEM [17] and FFM [17] into a single module, which is more effective. 3) We improve PA and make it aware of background elements by adding a background item to the discrimination loss.
| Method | Total-Text (S: 640) | IC15 (S: 736) | ||
|---|---|---|---|---|
| F | FPS | F | FPS | |
| PSENet-1s [4] | 78.1 | 4.5 | 76.9 | 3.8 |
| PAN [17] | 83.5 | 39.6 | 80.3 | 26.1 |
| PAN + PA (impr) | 84.0 | 38.2 | 80.7 | 28.0 |
| PAN++ (detection only): PAN + PA (impr) + FPEM (impr) | 84.5 | 38.3 | 81.2 | 28.2 |
With the above-mentioned improvements, PAN++ can simultaneously detect and recognize arbitrarily-shaped text, which is impossible with models in conference versions. Moreover, PAN++ also achieve better text detection performance than its predecessors. As reported in Table 4.5, under the same or better inference speed, the F-measure of PAN++ is 84.5% on the Total-Text dataset, which is 1.0 points better than PAN [17], and 6.4 points better than PSENet [4]. Similar results are also on the IC15 dataset. These results prove that the improvements we made in this work are effective and important for a fast end-to-end text spotter.
4.6 Ablation Study
4.6.1 Experiment Settings
To analyze PAN++ in depth, we conduct ablation studies on both curved and straight text datasets (e.g., Total-Text and IC15). In these experiments, we use ResNet18 as the default backbone network. During training, we train text detection models without external text datasets and use the fine-tuning strategy to train text spotting models. The shrinking rate on Total-Text and IC15 is set to 0.7 and 0.5, respectively. In the testing phase, the shorter sides of the images in Total-Texts and IC15 are fixed at 640 and 736 pixels, respectively. No lexicon is used to refine the recognition results. Other model settings, data augmentations, and training/testing settings follow the settings in Sec. 4.2.1.
4.6.2 Can text kernels be used as detection results?
As mentioned in Sec.3.1, the text kernel is the central region of a text line, which is used to locate and separate adjacent text lines during the segmentation process. It cannot cover the complete shape of a text line and cannot be directly used as the detection result. As shown in Fig. 14, the text detection F-measure of the model that only uses text kernel is much lower than the models with the default setting. In addition, we use a text recognizer CRNN [5] to recognize the text in the text kernel, and we find that CRNN fails to recognize it as shown in Fig. 13.
These results demostrate that the text kernel cannot be used alone as the detection result, and it needs to be combined with other parts (i.e., text regions and instance vectors) of the kernel representation.

4.6.3 Influence of the Shrinking Rate
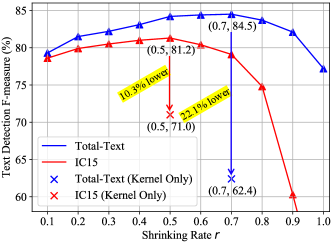
To study the impact of the shrinking rate on the text detection performance, we compare the text detection F-measure of models with different shrinking rates. Specifically, we vary the shrinking rate from 0.1 to 1 and evaluate PAN++ (detection only) on Total-Text and IC15 datasets. As shown in Fig. 14, the F-measures on both datasets drop when the shrinking rate is too large or too small. When is too large (i.e., ), text kernels may fail to separate the text lines lying close to each other. When is too small (i.e., ), a whole text line may be incorrectly divided into several connected components in the testing phase. Experimentally, the shrinking rate is set to 0.5 on IC15, and 0.7 on other datasets by default.
Note that, when the shrinking rate is equal to 1, the text kernel is the same as the text region, and the detection module will degenerate to a binary segmentation network without PA In this case, the text detection F-measure drops sharply on Total-Text and IC15, because the model loses the capability to distinguish adjacent text lines as shown in Fig. 1 (b).
4.6.4 Influence of the Stack Number of FPEMs
We study the effect of the stack number of FPEMs on text spotting performance, by varying the stack number from to . Note that, when the stack number is equal to 0, there is no FPEM and the final feature map is generated by upsampling and concatenating the feature pyramid (see Fig. 4 (c)). From Table VII, we find that the text spotting F-measures on both datasets keep rising with the growth of and begins to level off when the stack number is greater than 2. The stack number is a trade-off between accuracy and speed. Although FPEM has a low computational cost, the model will slow down when the stack number is large. Specifically, an additional FPEM takes up to 2ms per image. To keep a good balance between performance and speed, is set to 2 by default.
| Param. (M) | Total-Text | IC15 | |||
|---|---|---|---|---|---|
| F | Time (ms) | F | Time (ms) | ||
| 0 | 13.1 | 64.5 | 0.6 | 63.7 | 0.7 |
| 1 | 13.2 | 66.0 | 2.2 | 64.2 | 2.8 |
| 2 | 13.3 | 66.4 | 3.8 | 64.7 | 4.4 |
| 3 | 13.4 | 66.5 | 5.1 | 64.8 | 6.6 |
| 4 | 13.5 | 66.6 | 6.5 | 64.9 | 8.7 |
4.6.5 Effectiveness of FPEM
To verify the effectiveness of FPEM, we first compare the performance of models with and without this module. As reported in Table VII, the model with 2-stacked FPEMs () obtains the F-measure of 66.4% on the Total-Text dataset, which is 1.9 points higher that of the model without FPEM ().
Second, we compare our feature enhancement network (2-stacked FPEMs) with other widely used methods, including FPN [51], PAFPN [74], and NAS-FPN [75]. For fair comparisons, we directly replace the feature enhancement network with other methods and evaluate them under the same experiment setting mentioned in Sec. 4.6.1. In Table VIII, we find that our method achieves comparable or even better text spotting performance than counterparts, while our time cost and parameter number are much lower. Concretely, our 2-stacked FPEMs yields the end-to-end text spotting F-measure of 66.4% on Total-Text, which is better than FPN [51] (65.9%) and close to NAS-FPN [75] (66.9%). However, the time cost of our method is only 1/3 of FPN and 1/10 of NAS-FPN (3.8 ms vs. 12.1 ms and 41.2 ms), and our parameters is 1/2 of FPN and 1/4 of NAS-FPN (13.3 M vs. 20.3 M and 46.9 M).
In conclusion, the proposed FPEM can obtain a good balance between accuracy and inference speed/parameter number, benefiting from the separable convolution and stackable design. It is a good choice to enhance the feature from a lightweight backbone, at least for text detection and end-to-end text spotting tasks.
| Method | Param. (M) | Total-Text | IC15 | ||
|---|---|---|---|---|---|
| F | Time (ms) | F | Time (ms) | ||
| 2-Stacked FPEMs (ours) | 13.3 | 66.4 | 3.8 | 64.7 | 4.4 |
| FPN [51] | 20.3 | 65.9 | 12.1 | 64.5 | 15.6 |
| PAFPN [74] | 23.8 | 66.2 | 13.4 | 64.7 | 17.7 |
| NAS-FPN [75] | 46.9 | 66.9 | 41.2 | 65.1 | 54.3 |
4.6.6 Effectiveness of PA

We study the effectiveness of PA by removing it from the pipeline. In detail, we set in Eqn. (13) to 0 during training and merge all neighbor text pixels in step 2 of post-processing. Comparing the model with PA (see Table IX #1), the F-measure of the model without PA (see Table IX #2) drops over 1.0 points, which indicates the effectiveness of PA.
In Fig. 15, we also present some text kernel results predicted by models with and without PA. We find that the model with PA tends to predict higher-quality text kernels, which can effectively reduce the incorrect cases including 1) dividing a text line into several parts and 2) connecting two adjacent text lines
From these results, we claim that PA has two benefits: 1) As an auxiliary loss (see Eqns. (1) and (3)), it can improve the segmentation result of the model and make it more compact and accurate; 2) As a post-processing step (see Fig. 8), it can deal with the conflict pixel problem by aggregating conflict pixels to the correct text kernel.
| # | Backbone | w/ PA | Total-Text | IC15 | ||
|---|---|---|---|---|---|---|
| F-measure | FPS | F-measure | FPS | |||
| 1 | ResNet18 | ✓ | 66.4 | 24.1 | 64.7 | 24.5 |
| 2 | ResNet18 | 64.9 | 24.9 | 62.9 | 25.0 | |
| 3 | ResNet50 | ✓ | 67.2 | 20.2 | 65.0 | 18.1 |
| 4 | VGG16 | ✓ | 67.8 | 9.2 | 66.2 | 8.7 |
4.6.7 Effectiveness of Masked RoI
As shown in Table XI #1 and #2, we show the effectiveness of Masked RoI. Higher text spotting F-measure is achieved in the presence of Masked RoI. The model with the proposed Masked RoI outperforms the one with the naive RoI extractor (removing the masking operation in Masked RoI) by at least 1.1%. The underlying reason is that without Masked RoI, the model may fail to recognize text lines in a noisy background.
4.6.8 Effectiveness of Recognition Head
To test the effectiveness of our recognition head, we compare it with some state-of-the-art methods, including SAR [13] and Transformer [21]. For fair comparisons, we replace our recognition head with other methods and evaluate them under the same experiment setting mentioned in Sec. 4.6.1. As shown in Table XI, our recognition head outperform SAR [13] in terms of accuracy and inference speed. Especially in terms of speed, the time cost of our method is only 1/2 of SAR’s (2.3ms vs 5.0ms), which is important when encountering the image with dense text. Compared with Transformer [21], our method yields a comparable F-measure (66.4% vs. 67.0%) at a speed of 2.3ms per text line, which is 10 times faster.
These results demonstrate that our recognition head keeps a good balance between accuracy and inference speed. It may benefit from the designs as follows: 1) Unlike SAR and Transformer, our method has no encoder, skipping the time cost of the encoder; 2) We adopt the multi-head attention layer, whose computational cost is lower than that of SAR; 3) Our decoder only contains two LSTM layers and one attention layer.
4.6.9 Influence of the Backbone Network
To analyze the capability of the proposed PAN++, we replace the lightweight backbone to heavier backbone (i.e., ResNet50 and VGG16). As shown in Table IX #1, #3, and #4, heavier backbones can bring over 1 points improvement on both Total-Text and IC15 datasets. However, the reduction of FPS brought by the heavy backbone is also apparent.
| Framework | Total-Text | ||
|---|---|---|---|
| F-measure (Det) | F-measure (E2E) | FPS | |
| End-to-End (ours) | 86.0 | 66.4 | 24.1 |
| Separate | 84.9 | 63.4 | 16.0 |
4.6.10 End-to-End Framework vs. Separate Framework
To prove the superiority of the end-to-end text spotting framework, we compare the performance of the end-to-end text spotting model with a separate model comprised of a independent detector and recognizer. For fair comparisons, we separate the end-to-end PAN++ into a text detector and a text recognizer, and each of them has its own feature encoding network (i.e., ResNet18 + 2-stacked FPEMs).
As reported in Table X, under the same experiment settings, the end-to-end model achieve 86.0% text detection (Det) F-measure and 66.4% end-to-end (E2E) text spotting F-measure, which are 1.1 and 3.0 points better than the separate model. Meanwhile, the inference speed of the end-to-end model has obvious advantages over the separate model.
These results indicate that the end-to-end text spotting framework is much better than the separate framework in terms of accuracy and inference speed. The potential reasons are as follows: 1) In the end-to-end framework, the detection module and the recognition module are jointly trained, so the backbone features can be optimized by the detection loss and the recognition loss simultaneously. As a result, the feature representation capacity in the end-to-end framework is stronger than the separate framework, which effectively reduces false-positive results. 2) Due to the shared backbone, The end-to-end framework skips the time cost of image feature encoding in text recognition, so its speed is much faster than that of the separate framework.
| # | Rec. Head | w/ Masked RoI | Total-Text | IC15 | ||
|---|---|---|---|---|---|---|
| F | Time (ms) | F | Time (ms) | |||
| 1 | Ours | ✓ | 66.4 | 2.3 | 64.7 | 2.6 |
| 2 | Ours | 65.1 | 2.3 | 63.6 | 2.6 | |
| 3 | SAR [13] | ✓ | 66.1 | 5.0 | 64.2 | 5.2 |
| 4 | Transformer [21] | ✓ | 67.0 | 19.5 | 65.2 | 20.1 |

4.7 Network Output Visualization
Some intermediate results of the model are shown in Fig. 16, which includes the results of text regions, text kernels, instance vectors, and attention masks. We find that the text regions (see Fig. 16 (b)) keep the complete shapes of text lines, and text kernels (see Fig. 16 (c)) can distinguish different text lines clearly. In Fig. 16 (d), we reduce the dimension of the instance vector to 3 through PCA and project it to the RGB field. We find that pixels and text kernels belonging to a text line tend to have similar colors.
Fig. 16 (e) shows the attention mask generated by the recognition head’s starter, which accurately locates the start of the string. Fig. 16 (f) are attention masks of the recognition head’s decoder at each step, which provides a great tool to analyze the performance of the recognition head. We find that the attention masks of the decoder can focus on the correct position even when recognizing the irregular text line.
4.8 Robustness Analysis
To further demonstrate the robustness of the proposed PAN++, we evaluate the model without recognition head trained on one dataset and test on other datasets. Because this experiment aims to test the generalization of our method, we do not use external datasets during training, and we also remove the recognition head that needs to be trained on the large-scale dataset. In the testing phase, we set the shorter sides of test images in Total-Text, CTW1500, IC15, and MSRA-TD500 datasets to 640, 640, 736, and 736, respectively.
Based on the annotation level, we divide the datasets into two groups, which are word level and text line level datasets. SynthText, ICDAR 2015, and Total-Text are annotated at the word level, and CTW1500 and MSRA-TD500 are annotated at the text line level.
The cross-dataset results of PAN++ are shown in Table 4.8. Notably, the model trained on SynthText (a synthetic dataset) has fairish performances on IC15 and Total-Text, which indicates that even without any manually annotated data, our method can satisfy the scene text detection with low precision requirements. The model trained on manually annotated dataset has over 62 text detection F-measure in the cross-dataset evaluation, which is competitive. Furthermore, in the cross-dataset evaluation at the text line level, the F-measure of all models exceeds 78, even though these models are trained on curved/straight text datasets and tested on another dataset. These results demonstrate that the detection part of PAN++ can be well generalized to unseen datasets.
| Annotation | Train SetTest Set | Precision | Recall | F-measure |
|---|---|---|---|---|
| Word Level | SynthTextIC15 | 68.2 | 44.6 | 53.9 |
| SynthTextTotal-Text | 71.5 | 40.2 | 51.5 | |
| IC15Total-Text | 71.1 | 56.4 | 62.9 | |
| Total-TextIC15 | 78.7 | 68.6 | 73.3 | |
| Text Line Level | CTW1500MSRA-TD500 | 80.3 | 79.0 | 79.7 |
| MSRA-TD500CTW1500 | 84.1 | 73.0 | 78.2 |
4.9 Speed Analysis
Table XIII present the time cost of all components of PAN++. We find that the time cost of text recognition accounts for half of the total time cost. Therefore, an obvious way to increase speed in practical applications is to run the recognition component in parallel through a basic producer-consumer model, which can reduce the time cost to the original 1/2. We conduct the speed analysis on Total-Text. We evaluate all testing images and calculate the average speed. These results are tested with 1 batch size on one V100 GPU and one 2.20GHz CPU in a single thread.
| Method | Time consumption (ms) | FPS | |||
|---|---|---|---|---|---|
| Backbone | FPEMs | Detection (w/ PA) | Recognition | ||
| PAN++ 512 | 5.2 | 3.0 | 1.4 + PA: 3.5 | 21.2 | 29.2 |
| PAN++ 640 | 7.1 | 3.8 | 2.1 + PA: 5.8 | 22.7 | 24.1 |
| PAN++ 736 | 9.0 | 4.4 | 2.8 + PA: 7.6 | 23.6 | 21.1 |
4.10 Failure Cases and Discussion

As demonstrated in previous experiments, the proposed PAN++ works well in most cases of arbitrarily-shaped text detection and recognition. It still fails for some difficult images, such as detecting large character spacing (see Fig. 17 (a)) or text-like areas (see Fig. 17 (b)) and recognizing texts in fancy font styles (see Fig. 17 (c). Large character spacing is a problem widely existing in other state-of-the-art methods, which needs linguistic features to solve it. For text-like areas and text in fancy font styles, the main reason for them is the lack of training samples, and we believe that these problems will alleviate when we have sufficient training samples of them.
5 Conclusion
In this work, we have considerably extended the kernel representation for text spotting, which first appeared in our conference versions. We have also thoroughly discussed its feasibility in real-time arbitrarily-shaped text recognition. In particular, To further strengthen this representation, here we have developed an efficient framework for end-to-end arbitrarily-shaped text spotting, where we have managed to speed up all parts in the text spotting procedure by carefully designing a series of lightweight modules, including 1) a feature enhancement network with stacked FPEMs, 2) a detection head with PA, and 3) a recognition head with Masked RoI.
We have verified the performance of PAN++ on both text detection and end-to-end text spotting tasks. The experiment results demonstrate that our method offers advantages in both accuracy and inference speed compared with a few previous state-of-the-art methods. We hope that our PAN++ can serve as a cornerstone for real-world text understanding applications.
Acknowledgments
This work was supported by the Natural Science Foundation of China under Grant 61672273 and Grant 61832008, the Science Foundation for Distinguished Young Scholars of Jiangsu under Grant BK20160021. This work was in part supported by Alibaba Group through Alibaba Innovative Research (AIR) Program.
References
- [1] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [2] K. He, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,” in Proc. Eur. Conf. Comp. Vis., 2016.
- [3] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He, and J. Liang, “EAST: an efficient and accurate scene text detector,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017.
- [4] W. Wang, E. Xie, X. Li, W. Hou, T. Lu, G. Yu, and S. Shao, “Shape robust text detection with progressive scale expansion network,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019.
- [5] B. Shi, X. Bai, and C. Yao, “An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 11, pp. 2298–2304, 2016.
- [6] B. Shi, M. Yang, X. Wang, P. Lyu, C. Yao, and X. Bai, “Aster: An attentional scene text recognizer with flexible rectification,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 9, pp. 2035–2048, 2018.
- [7] X. Liu, D. Liang, S. Yan, D. Chen, Y. Qiao, and J. Yan, “FOTS: Fast oriented text spotting with a unified network,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2018.
- [8] P. Lyu, M. Liao, C. Yao, W. Wu, and X. Bai, “Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes,” in Proc. Eur. Conf. Comp. Vis., 2018.
- [9] M. Liao, B. Shi, and X. Bai, “Textboxes++: A single-shot oriented scene text detector,” IEEE Trans. Image Process., vol. 27, no. 8, pp. 3676–3690, 2018.
- [10] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2015.
- [11] E. Xie, Y. Zang, S. Shao, G. Yu, C. Yao, and G. Li, “Scene text detection with supervised pyramid context network,” in Proc. AAAI Conf. Artificial Intell., 2019.
- [12] Z. Tian, W. Huang, T. He, P. He, and Y. Qiao, “Detecting text in natural image with connectionist text proposal network,” in Proc. Eur. Conf. Comp. Vis., 2016.
- [13] H. Li, P. Wang, C. Shen, and G. Zhang, “Show, attend and read: A simple and strong baseline for irregular text recognition,” in Proc. AAAI Conf. Artificial Intell., 2019.
- [14] H. Li, P. Wang, and C. Shen, “Towards end-to-end text spotting with convolutional recurrent neural networks,” in Proc. IEEE Int. Conf. Comp. Vis., 2017.
- [15] T. He, Z. Tian, W. Huang, C. Shen, Y. Qiao, and C. Sun, “An end-to-end textspotter with explicit alignment and attention,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2018.
- [16] S. Qin, A. Bissacco, M. Raptis, Y. Fujii, and Y. Xiao, “Towards unconstrained end-to-end text spotting,” in Proc. IEEE Int. Conf. Comp. Vis., 2019.
- [17] W. Wang, E. Xie, X. Song, Y. Zang, W. Wang, T. Lu, G. Yu, and C. Shen, “Efficient and accurate arbitrary-shaped text detection with pixel aggregation network,” in Proc. IEEE Int. Conf. Comp. Vis., 2019.
- [18] K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask R-CNN,” in Proc. IEEE Int. Conf. Comp. Vis., 2017.
- [19] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016.
- [20] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [21] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. Advances in Neural Inf. Process. Syst., 2017.
- [22] Y. Liu, H. Chen, C. Shen, T. He, L. Jin, and L. Wang, “Abcnet: Real-time scene text spotting with adaptive bezier-curve network,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2020.
- [23] C. K. Ch’ng and C. S. Chan, “Total-text: A comprehensive dataset for scene text detection and recognition,” in Proc. Int. Conf. Document Analysis Recogn., 2017.
- [24] L. Yuliang, J. Lianwen, Z. Shuaitao, and Z. Sheng, “Detecting curve text in the wild: New dataset and new solution,” arXiv preprint arXiv:1712.02170, 2017.
- [25] D. Karatzas, L. Gomez-Bigorda, A. Nicolaou, S. Ghosh, A. Bagdanov, M. Iwamura, J. Matas, L. Neumann, V. R. Chandrasekhar, S. Lu, et al., “Icdar 2015 competition on robust reading,” in Proc. Int. Conf. Document Analysis Recogn., 2015.
- [26] C. Yao, X. Bai, W. Liu, Y. Ma, and Z. Tu, “Detecting texts of arbitrary orientations in natural images,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2012.
- [27] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Proc. Advances in Neural Inf. Process. Syst., 2015.
- [28] M. Busta, L. Neumann, and J. Matas, “Deep textspotter: An end-to-end trainable scene text localization and recognition framework,” in Proc. IEEE Int. Conf. Comp. Vis., 2017.
- [29] D. NguyenVan, S. Lu, S. Tian, N. Ouarti, and M. Mokhtari, “A pooling based scene text proposal technique for scene text reading in the wild,” Pattern Recogn., vol. 87, pp. 118–129, 2019.
- [30] M. Liao, P. Lyu, M. He, C. Yao, W. Wu, and X. Bai, “Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes,” IEEE Trans. Pattern Anal. Mach. Intell., 2019.
- [31] L. Xing, Z. Tian, W. Huang, and M. R. Scott, “Convolutional character networks,” in Proc. IEEE Int. Conf. Comp. Vis., 2019.
- [32] W. Feng, W. He, F. Yin, X.-Y. Zhang, and C.-L. Liu, “Textdragon: An end-to-end framework for arbitrary shaped text spotting,” in Proc. IEEE Int. Conf. Comp. Vis., 2019.
- [33] M. Liao, B. Shi, X. Bai, X. Wang, and W. Liu, “Textboxes: A fast text detector with a single deep neural network,” in Proc. AAAI Conf. Artificial Intell., 2017.
- [34] B. Shi, X. Bai, and S. Belongie, “Detecting oriented text in natural images by linking segments,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017.
- [35] S. Tian, Y. Pan, C. Huang, S. Lu, K. Yu, and C. Lim Tan, “Text flow: A unified text detection system in natural scene images,” in Proc. IEEE Int. Conf. Comp. Vis., 2015.
- [36] D. Deng, H. Liu, X. Li, and D. Cai, “PixelLink: Detecting scene text via instance segmentation,” in Proc. AAAI Conf. Artificial Intell., 2018.
- [37] S. Long, J. Ruan, W. Zhang, X. He, W. Wu, and C. Yao, “TextSnake: A flexible representation for detecting text of arbitrary shapes,” Proc. Eur. Conf. Comp. Vis., 2018.
- [38] C. Xue, S. Lu, and W. Zhang, “MSR: Multi-scale shape regression for scene text detection,” in Proc. Int. Joint Conf. Artificial Intell., 2019.
- [39] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in Proc. Int. Conf. Mach. Learn., 2006.
- [40] A. Bissacco, M. Cummins, Y. Netzer, and H. Neven, “Photoocr: Reading text in uncontrolled conditions,” in Proc. IEEE Int. Conf. Comp. Vis., 2013.
- [41] M. Jaderberg, A. Vedaldi, and A. Zisserman, “Deep features for text spotting,” in Proc. Eur. Conf. Comp. Vis., 2014.
- [42] B. Su and S. Lu, “Accurate scene text recognition based on recurrent neural network,” in Proc. Asian Conf. Comp. Vis., 2014.
- [43] B. Su and S. Lu, “Accurate recognition of words in scenes without character segmentation using recurrent neural network,” Pattern Recogn., vol. 63, pp. 397–405, 2017.
- [44] P. He, W. Huang, Y. Qiao, C. C. Loy, and X. Tang, “Reading scene text in deep convolutional sequences,” in Proc. AAAI Conf. Artificial Intell., 2016.
- [45] X. Yang, D. He, Z. Zhou, D. Kifer, and C. L. Giles, “Learning to read irregular text with attention mechanisms.,” in Proc. Int. Joint Conf. Artificial Intell., 2017.
- [46] Z. Cheng, Y. Xu, F. Bai, Y. Niu, S. Pu, and S. Zhou, “Aon: Towards arbitrarily-oriented text recognition,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2018.
- [47] F. Zhan and S. Lu, “ESIR: End-to-end scene text recognition via iterative image rectification,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019.
- [48] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
- [49] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- [50] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” arXiv preprint arXiv:1502.03167, 2015.
- [51] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017.
- [52] B. R. Vatti, “A generic solution to polygon clipping,” Communications of the ACM, vol. 35, no. 7, pp. 56–63, 1992.
- [53] F. Milletari, N. Navab, and S.-A. Ahmadi, “V-net: Fully convolutional neural networks for volumetric medical image segmentation,” in Int. Conf. 3D Vision, 2016.
- [54] A. Shrivastava, A. Gupta, and R. Girshick, “Training region-based object detectors with online hard example mining,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016.
- [55] Y. Xu, Y. Wang, W. Zhou, Y. Wang, Z. Yang, and X. Bai, “Textfield: Learning a deep direction field for irregular scene text detection,” IEEE Trans. Image Process., vol. 28, no. 11, pp. 5566–5579, 2019.
- [56] Y. Baek, B. Lee, D. Han, S. Yun, and H. Lee, “Character region awareness for text detection,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019.
- [57] C. Zhang, B. Liang, Z. Huang, M. En, J. Han, E. Ding, and X. Ding, “Look more than once: An accurate detector for text of arbitrary shapes,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019.
- [58] C. Yao, X. Bai, W. Liu, Y. Ma, and Z. Tu, “Detecting texts of arbitrary orientations in natural images,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2012.
- [59] P. Lyu, C. Yao, W. Wu, S. Yan, and X. Bai, “Multi-oriented scene text detection via corner localization and region segmentation,” arXiv preprint arXiv:1802.08948, 2018.
- [60] C. Yao, X. Bai, and W. Liu, “A unified framework for multioriented text detection and recognition,” IEEE Trans. Image Process., vol. 23, no. 11, pp. 4737–4749, 2014.
- [61] B. Shi, C. Yao, M. Liao, M. Yang, P. Xu, L. Cui, S. Belongie, S. Lu, and X. Bai, “ICDAR2017 competition on reading Chinese text in the wild (rctw-17),” in Proc. Int. Conf. Document Analysis Recogn., 2017.
- [62] A. Gupta, A. Vedaldi, and A. Zisserman, “Synthetic data for text localisation in natural images,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016.
- [63] A. Veit, T. Matera, L. Neumann, J. Matas, and S. Belongie, “Coco-text: Dataset and benchmark for text detection and recognition in natural images,” arXiv preprint arXiv:1601.07140, 2016.
- [64] N. Nayef, F. Yin, I. Bizid, H. Choi, Y. Feng, D. Karatzas, Z. Luo, U. Pal, C. Rigaud, J. Chazalon, et al., “ICDAR2017 robust reading challenge on multi-lingual scene text detection and script identification-rrc-mlt,” in Proc. Int. Conf. Document Analysis Recogn., 2017.
- [65] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2009.
- [66] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [67] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017.
- [68] J. Ma, W. Shao, H. Ye, L. Wang, H. Wang, Y. Zheng, and X. Xue, “Arbitrary-oriented scene text detection via rotation proposals,” IEEE Trans. Multimedia, vol. 20, no. 11, pp. 3111–3122, 2018.
- [69] Y. Sun, C. Zhang, Z. Huang, J. Liu, J. Han, and E. Ding, “Textnet: Irregular text reading from images with an end-to-end trainable network,” in Proc. Asian Conf. Comp. Vis., 2018.
- [70] W. He, X.-Y. Zhang, F. Yin, and C.-L. Liu, “Deep direct regression for multi-oriented scene text detection,” in Proc. IEEE Int. Conf. Comp. Vis., 2017.
- [71] P. He, W. Huang, T. He, Q. Zhu, Y. Qiao, and X. Li, “Single shot text detector with regional attention,” in Proc. IEEE Int. Conf. Comp. Vis., 2017.
- [72] M. Liao, Z. Zhu, B. Shi, G.-s. Xia, and X. Bai, “Rotation-sensitive regression for oriented scene text detection,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2018.
- [73] Z. Liu, G. Lin, S. Yang, J. Feng, W. Lin, and W. L. Goh, “Learning markov clustering networks for scene text detection,” Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2018.
- [74] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, “Path aggregation network for instance segmentation,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2018.
- [75] G. Ghiasi, T.-Y. Lin, and Q. V. Le, “NAS-FPN: Learning scalable feature pyramid architecture for object detection,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019.