#P-completeness of counting update digraphs,
cacti, and a series-parallel decomposition method
Abstract
Automata networks are a very general model of interacting entities, with applications to biological phenomena such as gene regulation. In many contexts, the order in which entities update their state is unknown, and the dynamics may be very sensitive to changes in this schedule of updates. Since the works of Aracena et. al, it is known that update digraphs are pertinent objects to study non-equivalent block-sequential update schedules. We prove that counting the number of equivalence classes, that is a tight upper bound on the synchronism sensitivity of a given network, is -complete. The problem is nevertheless computable in quasi-quadratic time for oriented cacti, and for oriented series-parallel graphs thanks to a decomposition method.
1 Introduction
Since their introduction by McCulloch and Pitts in the 1940s through the well known formal neural networks [28], automata networks (ANs) are a general model of interacting entities in finite state spaces. The field has important contributions to computer science, with Kleene’s finite state automata [25], linear shift registers [22] and linear networks [16]. At the end of the 1960s, Kauffman and Thomas (independently) developed the use of ANs for the modeling of biological phenomena such as gene regulation [24, 38], providing a fruitful theoretical framework [34].
ANs can be considered as a collection of local functions (one per component), and influences among components may be represented as a so called interaction digraph. In many applications the order of components update is a priori unknown, and different schedules may greatly impact the dynamical properties of the system. It is known since the works of Aracena et al. in [5] that update digraphs (consisting of labeling the arcs of the interaction digraphs with and ) capture the correct notion to consider a biologically meaningful family of update schedules called block-sequential in the literature. Since another work of Aracena et al. [4] a precise characterization of the valid labelings is known, but their combinatorics remained puzzling. After formal definitions and known results in Sections 2 and 3, we propose in Section 4 an explanation for this difficulty, through the lens of computational complexity theory: we prove that counting the number of update digraphs (valid -labelings) is -complete. In Section 5 we consider the problem restricted to the family of oriented cactus graphs and give a time algorithm, and finally in Section 6 we present a decomposition method leading to a algorithm for oriented series-parallel graphs.
2 Definitions
Given a finite alphabet , an automata network (AN) of size is a function . We denote the component of some configuration . ANs are more conveniently seen as local functions describing the update of each component, i.e. with . The interaction digraph captures the effective dependencies among components, and is defined as the digraph with
It is well known that the schedule of components update may have a great impact on the dynamics [6, 10, 17, 19, 29, 31]. A block-sequential update schedule is an ordered partition of , defining the following dynamics
i.e., parts are updated sequentially one after the other, and components within a part are updated in parallel. For the parallel update schedule , we have . Block-sequential update schedules are a classical family of update schedules considered in the literature, because they are perfectly fair: every local function is applied exactly once during each step. Equipped with an update schedule, is a discrete dynamical system on . In the following we will shortly say update schedule to mean block-sequential update schedule.

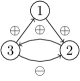
It turns out quite intuitively that some update schedules will lead to the same dynamics, when the ordered partitions are very close and the difference relies on components far apart in the interaction digraph (see an example on Figure 1). Aracena et al. introduced in [5] the notion of update digraph to capture this fact. To an update schedule one can associate its update digraph, which is a -labeling of the arcs of the interaction digraph of the AN, such that is negative () when is updated strictly before , and positive () otherwise. Formally, given an update schedule ,
Remark 1.
Loops are always labeled , hence we consider all interaction digraphs loopless.
The following result has been established: given two update schedules, if the relative order of updates among all adjacent components are identical, then the dynamics are identical.
Theorem 2 ([5]).
Given an AN and two update schedules , if then .
This leads naturally to an equivalence relation on update schedules, at the heart of the present work.
Definition 3.
if and only if .
It is very important to note that, though every update schedule corresponds to a -labeling of , the reciprocal of this fact is not true. For example, a cycle with all arcs labeled would lead to a contradiction where components are updated strictly before themselves. Aracena et al. gave a precise characterization of valid update digraphs (i.e. the ones corresponding to at least one update schedule).
Theorem 4 ([4]).
A labeling function is valid if and only if there is no cycle , with , of length such that both:
-
•
,
-
•
.
In words, the multidigraph where the labeling is unchanged but the orientation of negative arcs is reversed, does not contain a cycle with at least one negative arc (forbidden cycle).
As a corollary, one can decide in polynomial time whether a labeling is
valid.
Valid Update Digraph Problem (Valid-UD Problem)
Input: a labeling of a digraph .
Question: is valid?
Corollary 5 ([4]).
Valid-UD Problem is in .
We are interested in the following counting problem.
Update Digraphs Counting (#UD)
Input: a digraph .
Output: .
The following definition is motivated by Theorem 4.
Definition 6.
Given a directed graph , let denote the undirected multigraph underlying , i.e. with an edge for each .
Remark 7.
We can restrict our study to connected digraphs (that is, such that is connected), because according to Theorem 4 the only invalid labelings contain (forbidden) cycles. Given some with its connected components, and the subdigraph induced by , we straightforwardly have
and this decomposition can be computed in linear time from folklore algorithms.
Theorem 8.
#UD is in .
3 Further known results
The consideration of update digraphs has been initiated by Aracena et al. in 2009 [5], with their characterization (Theorem 4) in [4]. In Section 4 we will present a problem closely related to #UD that has been proven to be -complete in [4], UD Problem, and bounds that we can deduce on #UD (Corollary 10, from [3]). In [2] the authors present an algorithm to enumerate update digraphs, and prove its correctness. They also consider a surprisingly complex question: given an AN , knowing whether there exist two block-sequential update schedules such that , is -complete. The value of is known to be for bidirected cycles on vertices [31], and to equal if and only if the digraph is a tournament on vertices [3].
4 Counting update digraphs is -complete
The authors of [4] have exhibited an insightful relation
between valid labelings and feedback arc sets of a digraph. We recall that a
feedback arc set (FAS) of is a subset of arcs such that the digraph is acyclic, and its
size is . This relation is developed inside the proof of -completeness
of the following decision problem. We reproduce it as a Lemma, with its
argumentation for the sake of comprehension.
Update Digraph Problem (UD Problem)
Input: a digraph and an integer .
Question: does there exist a valid labeling of size at most ?
The size of a labeling is its number of labels. It is clear
that minimizing the number of labels (or equivalently maximizing the
number of labels) is the difficult direction, the contrary being easy
because for all is always valid (and corresponds
to the parallel update schedule ).
Lemma 9 (appears in [4, Theorem 16]).
There exists a bijection between minimal valid labelings and minimal feedback arc sets of a digraph .
Proof.
To get the bijection, we simply identify a labeling with its set of arcs labeled , denoted .
Given any valid labeling , is a FAS, otherwise there is a cycle with all its arcs label , which is forbidden.
Given a minimal FAS , let us now argue that such that is a valid labeling. First observe that for every there is a cycle in containing and no other arc of , otherwise would not be minimal (removing an arc not fulfilling this observation would give a smaller FAS). By contradiction, if creates a forbidden cycle , then to every arc labeled in we can associate, from the previous observation, a cycle containing no other arc labeled and distinct from . It follows that replacing all such arcs in with gives a cycle which now contains only arcs labeled , i.e. a cycle (recall that the orientation of arcs is reversed in forbidden cycles) with no arc in , a contradiction. ∎
Any valid labeling corresponds to a FAS, and every minimal FAS corresponds to a valid labeling, hence the following bounds hold. The strict inequality for the lower bound comes from the fact that labeling all arcs does not give a minimal FAS, as noted in [3] where the authors also consider the relation between update digraphs (valid labelings) and feedback arc sets, but from another perspective.
Corollary 10 ([4]).
For any digraph , let and be respectively the number of FAS and minimal FAS of , then .
From Lemma 9 and results on the complexity of FAS counting problems presented in [30] (one of them coming from [37]), we have the following corollary (minimum FAS are minimal, hence the identity is a parsimonious reduction from the same problems on FAS).
Corollary 11.
Counting the number of valid labelings of minimal size is -complete, and counting the number of valid labelings of minimum size is -complete.
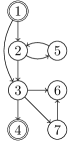
However the correspondence given in Lemma 9 does not hold in general: there may exist some FAS such that with is not a valid labeling (see Figure 2 for an example). As a consequence we do not directly get a counting reduction to #UD. It nevertheless holds that #UD is -hard, with the following reduction.
Theorem 12.
#UD is -hard.
Proof.
We present a (polynomial time) parsimonious reduction from the problem of counting the number of acyclic orientations of an undirected graph, proven to be -hard in [26].
Given an undirected graph , let denote an arbitrary total order on . Construct the digraph with the orientation of according to ,
An example is given on Figure 3. A key property is that is acyclic, because is constructed from an order on (a cycle would have at least one arc with ).

We claim that there is a bijection between the valid labelings of and the acyclic orientations of : to a valid labeling of we associate the orientation

First remark that is indeed an orientation of : each edge of is transformed into an arc of , and each arc of is transformed into an arc of . An example is given on Figure 4. Now observe that is exactly obtained from by reversing the orientation of arcs labeled by . Furthermore, a cycle in must contain at least one arc labeled by , because is acyclic and labels copy the orientation of . The claim therefore follows directly from the characterization of Theorem 4. ∎
5 Quasi-quadratic time algorithm for oriented cacti
The difficulty of counting the number of update digraphs comes from the interplay between various possible cycles, as is assessed by the parsimonious reduction from acyclic orientations counting problem to . Answering the problem for an oriented tree with arcs is for example very simple: all of the labelings are valid. Cactus undirected graphs are defined in terms of very restricted entanglement of cycles, which we can exploit to compute the number of update digraphs for any orientation of its edges.
Definition 13.
A cactus is a connected undirected graph such that any vertex (or equivalently any edge) belongs to at most one simple cycle (cycle without vertex repetition). An oriented cactus is a digraph such that is a cactus.
Cacti may intuitively be thought as trees with cycles. This is indeed the idea behind the skeleton of a cactus introduced in [12], via the following notions:
-
•
a c-vertex is a vertex of degree two included in exactly one cycle,
-
•
a g-vertex is a vertex not included in any cycle,
-
•
remaining vertices are h-vertices,
and a graft is a maximal subtree of g- and h-vertices with no two h-vertices belonging to the same cycle. Then a cactus can be decomposed as grafts and cycles (two classes called blocks), connected at h-vertices according to a tree skeleton. These notions directly apply to oriented cacti (see an example on Figure 5).

Theorem 14.
#UD is computable in time for oriented cacti.
Proof.
The result is obtained from the skeleton of an oriented cactus , since potential forbidden cycles are limited to within blocks of the skeleton. From this independence, any union of valid labelings on blocks is valid, and we have the product
where is the set of grafts of , is the set of cycles forming directed cycles, is the set of cycles not forming directed cycles, and is the number of arcs in block . Indeed, grafts cannot create forbidden cycles hence any -labeling will be valid, cycles forming a directed cycle can create exactly one forbidden cycle (with labels on all arcs), and cycles not forming a directed cycle can create exactly two forbidden cycles (one for each possible direction of the cycle). In a first step the skeleton of a cactus can be computed in linear time [12]. Then, since the size of the input is equal (up to a constant) to the number of arcs, the size of the output contains bits (upper bounded by the number of -labelings), thus naively we have terms, each of bits, and the Schönhage–Strassen integer multiplication algorithm [36] gives the result. ∎
Remark 15.
Assuming multiplications to be done in constant time in the above result would be misleading, because we are multiplying integers having a number of digits in the magnitude of the input size. Also, the result may be slightly strengthened by considering the algorithm by Fürer in 2007 [18], and maybe more efficient integer multiplication algorithms in the future, such as the algorithm recently claimed [20].
6 Series-parallel decomposition method
In this section we present a divide and conquer method in order to solve #UD, i.e. in order to count the number of valid labelings (update digraphs) of a given digraph. What will be essential in this decomposition method is not the orientation of arcs, but rather the topology of the underlying undirected (multi)graph . The (de)composition is based on defining two endpoints on our digraphs, and composing them at their endpoints. It turns out to be closely related to series-parallel graphs first formalized to model electric networks in 1892 [27]. In Subsection 6.1 we present the operations of composition, and in Subsection 6.2 we show how it applies to the family of oriented series-parallel graphs.
6.1 Sequential, parallel, and free compositions
Let us first introduce some notations and terminology on the characterization of valid labelings provided by Theorem 4. Given , we denote the multidigraph obtained by reversing the orientation of negative arcs:
For simplicity we abuse the notation and still denote the labeling of the arcs of (arcs keep their label from to ). From Theorem 4, is a valid labeling if and only if does not contain any cycle with at least one arc labeled , called forbidden cycle (it may contain cycles with all arcs labeled ). A path from to in is called negative if it contains at least one arc labeled , and positive otherwise.
Definition 16.
A source-sink labeled graph (ss-graph) is a multigraph with two distinguished vertices . A triple with a digraph such that is a ss-graph, is called an oriented ss-graph (oss-graph).
We can decompose the set of update digraphs (denoted ) into an oss-graph , based on the follow sets.
We define analogously , , , and partition as:
-
1.
-
2.
-
3.
-
4.
-
5.
-
6.
Notice that the three missing combinations, , and , would always be empty because such labelings contain a forbidden cycle. For convenience let us denote . Given any oss-graph we have
| (1) |
where . Oss-graphs may be thought as black boxes, we will compose them using the values of , regardless of their inner topologies.
Definition 17.
We define three types of compositions (see Figure 6).
-
•
The series composition of two oss-graphs and with , is the oss-graph with the one-point join of and identifying components as one single component.
-
•
The parallel composition of two oss-graphs and with , is the oss-graph with the two-points join of and identifying components and as two single components.
-
•
The free composition at of an oss-graph and a digraph with , , , is the oss-graph with the one-point join of and identifying as one single component.
Remark that the three types of compositions from Definition 17 also apply to (undirected) ss-graph . Series and free compositions differ on the endpoints of the obtained oss-graph, which has important consequences on counting the number of update digraphs, as stated in the following results. We will see in Theorem 23 from Subsection 6.2 that both series and free compositions are needed in order to decompose the family of (general) oriented series-parallel graphs (to be defined).





Lemma 18.
For , the values of for all can be computed in time (with the binary length of the values) from the values of and for all .
Proof.
The result is obtained by considering the couples of some with and some with . For example, when we take the union of any labeling in (in there is at least one path from to , all paths from to positive, and no path from to ) and any labeling in (in there is a negative path from to , and no path from to ), we obtain a valid labeling of with at least one negative path from to , and no path from to , hence an element of . We can deduce that contains these labelings. The results of this simple reasoning in all cases is presented on Table 1.
This allows to compute each value as the finite sum, for each line and column where appears, of the term . As an example we have . Summations on bits are performed in linear time with schoolbook algorithm, and multiplications on bits are performed in time from Schönhage–Strassen algorithm [36]. ∎
Lemma 19.
For , the values of for all can be computed in time (with the binary length of the values) from the values of and for all .
Proof.
The proof is analogous to Lemma 18, with Table 2. Remark that in this case, it is possible to create invalid labelings for (containing some forbidden cycle) from the union of two valid labelings for and . For example, when we take the union of any labeling in (in there is at least one path from to , all paths from to positive, and the same from to ) and any labeling in (in there is a negative path from to , and no path from to ), we obtain an invalid labeling of because the concatenation of a positive path from to with a negative path from to gives a forbidden cycle in (recall that and are identified).
∎
Lemma 20.
For , we have for all .
Proof.
The endpoints of the oss-graph are the endpoints of the oss-graph , and it is not possible to create a forbidden cycle in the union of a valid labeling on and a valid labeling of , therefore the union is always a valid labeling of , each one belonging to the part of corresponding to the part of . ∎
6.2 Application to oriented series-parallel graphs
The series and parallel compositions of Definition 17 correspond exactly to the class of two-terminal series-parallel graphs from [1, 33, 39].
Definition 21.
A ss-graph is two-terminal series-parallel (a ttsp-graph) if and only if one the following holds.
-
•
is a base ss-graph with two vertices and one edge .
-
•
is obtained by a series or parallel composition111With Definition 17 applied to (undirected) ss-graphs. of two ttsp-graphs.
In this case alone is called a blind ttsp-graph.
Adding the free composition allows to go from two-terminal series-parallel graphs to (general) series-parallel graphs [15, 39]. More precisely, it allows exactly to add tree structures to ttsp-graphs, as we argue now (ttsp-graphs do not contain arbitrary trees, its only acyclic graphs being simple paths; e.g. one cannot build a claw from Definition 21).
Definition 22.
A multigraph is series-parallel (sp-graph) if and only if all its 2-connected components are blind ttsp-graphs. A digraph such that is an sp-graph, is called an oriented sp-graph (osp-graph).
The family of sp-graphs corresponds to the multigraphs obtained by series, parallel and free compositions from base ss-graphs. See Figure 7 for an example of osp-graph illustrating Theorem 23, and the decomposition method to compute (Theorem 24).

Theorem 23.
is an sp-graph if and only if is obtained by series, parallel and free compositions from base ss-graphs, for some .
Proof sketch (see Appendix A).
Free compositions allow to build all sp-graphs, because it offers the possibility to create the missing tree structures of ttsp-graphs: arbitrary 1-connected components linking 2-connected ttsp-graphs. Moreover free compositions do not go beyond sp-graphs, since the obtained multigraphs still have treewidth 2. ∎
Theorem 24.
#UD is solvable in time on osp-graphs (without promise).
Proof sketch (see Appendix A).
This is a direct consequence of Lemmas 18, 19 and 20, because all values are in (the number of -labelings) hence on bits, the values of are trivial for oriented base ss-graphs, and we perform compositions (to reach Formula 1). The absence of promise comes from a linear time recognition algorithm in [39] for ttsp-graphs, which also provides the decomposition structure. ∎
7 Conclusion
Our main result is the -completeness of #UD, i.e. of counting the number of non-equivalent block-sequential update schedules of a given AN . We proved that this count can nevertheless be done in time for oriented cacti, and in time for oriented series-parallel graphs. This last result has been obtained via a decomposition method providing a divide-and-conquer algorithm.
Remark that cliques or tournaments are intuitively difficult instances of #UD, because of the intertwined structure of potential forbidden cycles. It turns out that is the smallest clique that cannot be build with series, parallel and free decompositions, and that series-parallel graphs (Definition 22) correspond exactly to the family of -minor-free graphs [15] (it is indeed closed by minor [35]). In further works we would like to extend this caracterization and the decomposition method to (di)graphs with multiple endpoints.
The complexity analysis of the algorithms presented in Theorems 14 and 24 may be improved, and adapted to the parallel setting using the algorithms presented in [9, 23]. One may also ask for which other classes of digraphs is computable efficiently (in polynomial time)? Since we found such an algorithm for graphs of treewidth 2, could it be that the problem is fixed parameter tractable on bounded treewidth digraphs? Rephrased more directly, could a general tree decomposition (which, according to the proof of Theorem 23, is closely related to the series-parallel decomposition for treewidth 2) be exploited to compute the solution to #UD? Alternatively, what other types of decompositions one can consider in order to ease the computation of ?
Finally, from the multiplication obtained for one-point join of two graphs (Lemma 20 on free composition), we may ask whether is an evaluation of the Tutte polynomial? From its universality [11], it remains to know whether there is a deletion-contradiction reduction. However defining a Tutte polynomial for directed graphs is still an active area of research [7, 13, 32, 42].
Acknowledgments
This work was mainly funded by our salaries as French agents (affiliated to Laboratoire Cogitamus (CN), Aix-Marseille Univ, Univ. de Toulon, CNRS, LIS, UMR 7020, Marseille, France (KP, SS and LV), Univ. Côte d’Azur, CNRS, I3S, UMR 7271, Sophia Antipolis, France (KP), and École normale supérieure de Lyon, Computer Science department, Lyon, France (LV)), and secondarily by the projects ANR-18-CE40-0002 FANs, ECOS-CONICYT C16E01, STIC AmSud 19-STIC-03 (Campus France 43478PD).
References
- [1] A. Ádám. On graphs in which two vertices are distinguished. Acta Mathematica Academiae Scientiarum Hungaricae, 12:377–397, 1964.
- [2] J. Aracena, J. Demongeot, É. Fanchon, and M. Montalva. On the number of different dynamics in Boolean networks with deterministic update schedules. Mathematical Biosciences, 242:188–194, 2013.
- [3] J. Aracena, J. Demongeot, É. Fanchon, and M. Montalva. On the number of update digraphs and its relation with the feedback arc sets and tournaments. Discrete Applied Mathematics, 161:1345–1355, 2013.
- [4] J. Aracena, É. Fanchon, M. Montalva, and M. Noual. Combinatorics on update digraphs in Boolean networks. Discrete Applied Mathematics, 159:401–409, 2011.
- [5] J. Aracena, E. Goles, A. Moreira, and L. Salinas. On the robustness of update schedules in Boolean networks. Biosystems, 97:1–8, 2009.
- [6] J. Aracena, L. Gómez, and L. Salinas. Limit cycles and update digraphs in Boolean networks. Discrete Applied Mathematics, 161:1–12, 2013.
- [7] J. Awan and O. Bernardi. Tutte polynomials for directed graphs. Journal of Combinatorial Theory, Series B, 140:192–247, 2020.
- [8] H. L. Bodlaender. A partial k-arboretum of graphs with bounded treewidth. Theoretical Computer Science, 209(1):1–45, 1998.
- [9] H. L. Bodlaender and B. de Fluiter. Parallel algorithms for series parallel graphs. In Proceedings of ESA’96, volume 1136 of LNCS, pages 277–289, 1996.
- [10] F. Bridoux, C. Gaze-Maillot, K. Perrot, and S. Sené. Complexity of limit-cycle problems in Boolean networks. arXiv:2001.07391, 2020.
- [11] T. H. Brylawski. A decomposition for combinatorial geometries. Transactions of the American Mathematical Society, 171:235–282, 1972.
- [12] R. E. Burkard and J. Krarup. A linear algorithm for the pos/neg-weighted 1-median problem on a cactus. Computing, 60:193–215, 1998.
- [13] S. H. Chan. Abelian sandpile model and Biggs-Merino polynomial for directed graphs. Journal of Combinatorial Theory, Series A, 154:145–171, 2018.
- [14] B. de Fluiter. Algorithms for graphs of small treewidth. PhD thesis, University of Utrecht, 1997.
- [15] R. J. Duffin. Topology of series-parallel networks. Journal of Mathematical Analysis and Applications, 10:303–318, 1965.
- [16] B. Elspas. The theory of autonomous linear sequential networks. IRE Trans. Circuit Theory, 6:45–60, 1959.
- [17] N. Fatès. A guided tour of asynchronous cellular automata. Journal of Cellular Automata, 9:387–416, 2014.
- [18] M. Fürer. Faster Integer Multiplication. In Proceedings of STOC’07, pages 57–66, 2007.
- [19] E. Goles, D. Maldonado, P. Montealegre, and M. Ríos-Wilson. On the complexity of asynchronous freezing cellular automata. arXiv:1910.10882, 2019.
- [20] D. Harvey and J. Van Der Hoeven. Integer multiplication in time O(n log n). HAL:hal-02070778, 2019.
- [21] J. Hopcroft and R. Tarjan. Algorithm 447: efficient algorithms for graph manipulation. Communications of the ACM, 16:372–378, 1973.
- [22] D. A. Huffman. Canonical forms for information-lossless finite-state logical machines. IRE Trans. Inform. Theory, 5:41–59, 1959.
- [23] J. Jájá. An introduction to parallel algorithms. Addison-Wesley, 1992.
- [24] S. A. Kauffman. Homeostasis and differentiation in random genetic control networks. Nature, 224:177–178, 1969.
- [25] S. C. Kleene. Representation of events in nerve nets and finite automata. Project RAND RM–704, US Air Force, 1951.
- [26] N. Linial. Hard enumeration problems in geometry and combinatorics. SIAM Journal on Algebraic Discrete Methods, 7:331–335, 1986.
- [27] P. A. MacMahon. The combinations of resistances. The Electrician, 28:601–602, 1892.
- [28] W. S. McCulloch and W. Pitts. A logical calculus of the ideas immanent in nervous activity. Journal of Mathematical Biophysics, 5:115–133, 1943.
- [29] M. Noual and S. Sené. Synchronism versus asynchronism in monotonic Boolean automata networks. Natural Computing, 17:393–402, 2018.
- [30] K. Perrot. On the complexity of counting feedback arc sets. arXiv:1909.03339, 2019.
- [31] K. Perrot, M. Montalva-Medel, P. P. B. de Oliveira, and E. L. P. Ruivo. Maximum sensitivity to update schedule of elementary cellular automata over periodic configurations. Natural Computing, 19:51–90, 2020.
- [32] K. Perrot and V. T. Pham. Chip-firing game and partial Tutte polynomial for Eulerian digraphs. Electronic Journal of Combinatorics, 23(1), 2016.
- [33] J. Riordan and C. E. Shannon. The number of two-terminal series-parallel networks. Journal of Mathematics and Physics, 21:83–93, 1942.
- [34] F. Robert. Blocs-H-matrices et convergence des méthodes itératives classiques par blocs. Linear Algebra and its Applications, 2:223–265, 1969.
- [35] N. Robertson and P. D. Seymour. Graph Minors. XX. Wagner’s conjecture. Journal of Combinatorial Theory, Series B, 92:325–357, 2004.
- [36] A. Schönhage and V. Strassen. Schnelle Multiplikation großer Zahlen. Computing, 7:281–292, 1971.
- [37] B. Schwikowski and E. Speckenmeyer. On enumerating all minimal solutions of feedback problems. Discrete Applied Mathematics, 117:253–265, 2002.
- [38] R. Thomas. Boolean formalization of genetic control circuits. Journal of Theoretical Biology, 42:563–585, 1973.
- [39] J. Valdes, R. E. Tarjan, and E. L. Lawler. The recognition of series parallel digraphs. In Proceedings of STOC’79, pages 1–12, 1979.
- [40] J. Valdes Ayesta. Parsing Flowcharts and Series-Parallel Graphs. PhD thesis, Stanford University, 1978.
- [41] J. A. Wald and C. J. Colbourn. Steiner trees, partial 2-trees, and minimum IFI networks. Networks, 13:159–167, 1983.
- [42] K. S. Yow. Tutte-Whitney polynomials for directed graphs and maps. PhD thesis, Monash University, 2019.
Appendix A Full proofs for the application of the decomposition method to oriented series-parallel graphs
The concept of decomposition tree associated to ttsp-graphs, and generalized to sp-graphs, will be useful to formalize the reasonings leading to Theorems 23 and 24.
The structure of a ttsp-graph obtained from base ss-graphs by series and parallel compositions is expressed in a ttsp-tree . It is a rooted binary tree, in which each node has one of the types s-node, p-node, leaf-node, and a label consisting in a pair of vertices from . Every node corresponds to a unique ttsp-graph which is a subgraph of , with . The leaves of the tree are of type leaf-node and correspond to base ss-graphs, they are in one-to-one correspondence with the edges of . The ss-graph associated to an s-node is the series composition of its (ordered) children, and the ss-graph associated to a p-node is the parallel composition of its (unordered) children. It is worth noticing that each ttsp-graph corresponds to at least one ttsp-tree (and possibly to many ttsp-trees, even non isomorphic ones [39, Section 2.2]), and that each ttsp-tree corresponds to a unique ttsp-graph.
To this classical definition (presented for example in [39, 14]), we add f-nodes corresponding to free compositions, leading to sp-trees, as follows. The subtlety is that the two distinguished vertices of one children of a free composition are discarded. Let and be the (ordered) children of an f-node of label with and , the ss-graph associated to this f-node is the free composition (its label does not correspond to the distinguished vertices of the ss-graph). Every node still corresponds to a unique ttsp-graph which is a subgraph of , with for all but f-nodes; and for f-nodes the distinguished vertices are that of its first (left on our figures) child. We have the same correspondence between sp-graphs and sp-trees. An example is given on Figure 8.


Now remark that all free compositions may be performed at the end of the composition process, i.e. on top of the sp-tree. Indeed, free compositions can be inductively pushed towards the root of an sp-tree using the operations presented on Figure 9, which leave the sp-graph unchanged. When all free compositions are on top of an sp-tree, we say that it is in free-on-top normal form. Thus to any sp-graph corresponds at least one sp-tree in free-on-top normal form.


Proof of Theorem 23.
For the “only if” part, let be an sp-graph, with its 2-connected components, its remaining connected components (which are therefore trees), and the set of vertices belonging to two 2-connected components among . By definition are blind ttsp-graphs, to which we can respectively associate some ttsp-trees , which are particular cases of sp-trees. Now, take an edge of sharing:
-
•
only one vertex with some , and consider the free composition of with the base ss-graph corresponding to edge (joining them at that vertex), we get an sp-tree replacing ,
-
•
its two vertices with respectively some and , and consider first the free composition of with the base ss-graph corresponding to edge (joining them at ), this gives , and second the free composition of with (joining them at ), we get an sp-tree replacing both and ,
or take a vertex and:
-
•
consider the free composition of the two sp-trees to which belongs (joining them at ), we get a new sp-tree replacing them.
Repeating this process for all edges of and all vertices , we inductively build an sp-tree corresponding to , for some . Indeed, since is connected and are only 1-connected components, all edges of will inductively be added to the sp-trees, and from the maximality of 2-connected components the free compositions given by always joins two sp-trees that are distinct. Consequently this process will eventually merge all ttsp-trees into a unique sp-tree corresponding to the whole ss-graph (at this point could be the distinguished vertices of any ttsp-tree among , and the resulting sp-tree is in free-on-top normal form).
For the “if” part, let be obtained by series, parallel and free compositions from base ss-graphs, with a corresponding sp-tree in free-on-top normal form. Thanks to the free-on-top normal form, we can adapt the tree decomposition presented in [14, Lemma 2.3.5] in order to prove that has treewidth at most 2. Let denote the forest of ttsp-trees excluding free compositions (but including all base ss-graphs). We construct the tree decompositions for the ttsp-graphs respectively corresponding to , as follows: and
-
•
for each p-node of label , set ,
-
•
for each s-node of label and labels of its two children and , set .
The tree structure of each tree decomposition is directly given by the ttsp-tree. It remains to assemble these tree decompositions according to the free compositions, in order to obtain a tree decomposition of . For each f-node of label , i.e. identifying vertices of its children, one can simply add an edge merging two tree decompositions into a single tree decomposition, between any bag containing and any bag containing (and rename as ). The result of this process is indeed a tree decomposition of :
-
•
the obtained graph is a tree, as at each step two distinct trees are merged,
-
•
all base ss-graphs (which are leaf-nodes of ) belong to ttsp-graphs, hence all edges of are covered in some bag of the tree decompositions ,
-
•
the subtree associated to each vertex is connected, because it was connected in tree decompositions , and the merge of two tree decompositions connects identified vertices.
Since has bags of size at most 3, it follows that the treewidth of is at most 2. From [8, 15, 41], the family of graphs of treewidth at most 2 equals the family of sp-graphs (via the equality with -minor-free and partial 2-trees), thus is an sp-graph. ∎
Proof of Theorem 24.
Given a directed graph , one can identify in linear time the 2-connected components of (from [21]), and check in linear time that each of them is a blind ttsp-graph (from [39, Section 2.3 and Section 3.3 for implementation details] which is based on the characterization as series-parallel reducible multigraphs from [15] and its Church-Rosser property, with the blind undirected graph oriented as in [40, Chapter 3.5]). This last algorithm also builds a ttsp-tree for each 2-connected component. In order to get an sp-tree for the whole graph, it remains to include the free compositions as in the “if” part of the proof of Theorem 23, which is also done in linear time. We are now equipped with an sp-tree (in free-on-top normal form, which is not a necessary feature) corresponding to (in the case is an osp-graph, otherwise we reject the instance).
The second (and main) part of the algorithm is a direct application of Lemmas 18, 19 and 20. For a base ss-graph with an edge oriented as we have
then by induction on the structure of the sp-tree of (which provides two distinguished vertices for the osp-graph corresponding to each node of the sp-tree) we apply Lemma 18 for s-nodes, Lemma 19 for p-nodes, and Lemma 20 for f-nodes. There are steps with the size of the input graph, because the sp-tree has one leaf-node for each arc of and is a binary tree. Finally, all values counting some number of labelings are in (the number of -labelings of the whole input digraph ), hence on bits, and the result follows. ∎