Outcome-guided Sparse K-means for Disease Subtype Discovery via Integrating Phenotypic Data with High-dimensional Transcriptomic Data
Abstract
The discovery of disease subtypes is an essential step for developing precision medicine, and disease subtyping via omics data has become a popular approach. While promising, subtypes obtained from existing approaches are not necessarily associated with clinical outcomes. With the rich clinical data along with the omics data in modern epidemiology cohorts, it is urgent to develop an outcome-guided clustering algorithm to fully integrate the phenotypic data with the high-dimensional omics data. Hence, we extended a sparse K-means method to an outcome-guided sparse K-means (GuidedSparseKmeans) method. An unified objective function was proposed, which was comprised of (i) weighted K-means to perform sample clusterings; (ii) lasso regularizations to perform gene selection from the high-dimensional omics data; (iii) incorporation of a phenotypic variable from the clinical dataset to facilitate biologically meaningful clustering results. By iteratively optimizing the objective function, we will simultaneously obtain a phenotype-related sample clustering results and gene selection results. We demonstrated the superior performance of the GuidedSparseKmeans by comparing with existing clustering methods in simulations and applications of high-dimensional transcriptomic data of breast cancer and Alzheimer’s disease. Our algorithm has been implemented into an R package, which is publicly available on GitHub (https://github.com/LingsongMeng/GuidedSparseKmeans).
Keywords: Outcome-guided clustering; sparse K-means; Disease subtype; Phenotypic data; Transcriptomic data
Zhiguang Huo, Department of Biostatistics, University of Florida, 2004 Mowry Road, Gainesville, FL 32611-7450, USA
E-mail: [email protected]
1 Introduction
Historically, many complex diseases were thought of as a single disease, but modern omics studies have revealed that a single disease can be heterogeneous and contain several disease subtypes. Identification of these disease subtypes is an essential step toward precision medicine, since different subtypes usually show distinct clinical responses to different treatments (Abramson et al., 2015). Disease subtyping via omics data has been prevalent in the literature, and representative diseases include lymphoma (Rosenwald et al., 2002), glioblastoma (Parsons et al., 2008; Verhaak et al., 2010), breast cancer (Lehmann et al., 2011; Parker et al., 2009), colorectal cancer (Sadanandam et al., 2013), ovarian cancer (Tothill et al., 2008), Parkinson’s disease (Williams-Gray and Barker, 2017) and Alzheimer’s disease (Bredesen, 2015). Using breast cancer as an example, the landmark paper by Perou et al. (2000) was among the first to identify five clinically meaningful subtypes (i.e., Luminal A, Luminal B, Her2-enriched, Basal-like and Normal-like) via transcriptomic profiles, and these subtypes had shown distinct disease mechanisms, treatment responses and survival outcomes (Van’t Veer et al., 2002). These molecular subtypes were further followed up by many clinical trial studies for the development of precision medicine (Von Minckwitz et al., 2012; Prat et al., 2015).
In the literature, many existing clustering algorithms have been successfully applied for disease subtyping, including hierarchical clustering (Eisen et al., 1998), K-means (Dudoit and Fridlyand, 2002), mixture model-based approaches, (Xie et al., 2008; McLachlan et al., 2002) and Bayesian non-parametric approaches (Qin, 2006). Due to the high dimensional nature of the transcriptomic data (i.e., large number of genes and relatively small number of samples), it is generally assumed that only a small subset of intrinsic genes was relevant to disease subtypes (Parker et al., 2009). To capture these intrinsic genes and eliminate noise genes, sparse clustering methods were proposed, including sparse K-means or hierarchical clustering (Witten and Tibshirani, 2010) methods, and penalized mixture models (Pan and Shen, 2007; Wang and Zhu, 2008). In addition, due to the accumulation of multi-omics dataset (e.g., RNA-Seq, DNA methylation, copy number variation) in public data repositories, other methods (Shen et al., 2009; Wang et al., 2014; Huo et al., 2017; Cunningham et al., 2020) sought to identify disease subtypes via integrating multi-omics data.
While promising, it has been pointed out that the same omics data may be comprised of multi-facet clusters (Gaynor and Bair, 2017; Nowak and Tibshirani, 2008). In other words, different configurations of sample clusters defined by separated sets of genes may co-exist. For example, the desired subtype-related configuration could be driven by disease-related genes, while other configurations of clusters could be driven by sex-related genes, or other genes of unknown confounders. Without specifying disease-related genes, a sparse clustering algorithm tends to identify the configuration with the most distinguishable subtype patterns and separable genes, which optimizes the objective function of the algorithm. However, it is very likely that the resulting subtypes are not related to the disease, and the selected genes are not relevant to the desired biological process. Nowadays, biomedical studies usually collected comprehensive clinical information, which were quite relevant to the disease of interest and could potentially provide guidance for disease subtyping. Using breast cancer as an example, estrogen receptors (ER), progesterone receptors (PR), and human epidermal growth factor receptor 2 (HER2) are hallmarks of breast cancer, which could provide mechanistic insight about the disease pathology. Incorporating such clinical information will greatly facilitate the identification of disease related subtypes and intrinsic genes, and enhance the interpretability of disease subtyping results. Therefore, it is urgent to develop a clustering algorithm to fully integrate phenotypic data with high-dimensional omics data. Hence, our goal in this paper is to develop a clinical-outcome-guided clustering algorithm. Throughout this paper, we use clinical outcome variable and phenotypic data interchangeably, to indicate the potential outcome guidance for the clustering algorithm.
Many statistical challenges exist to achieve this goal. (i) Only a subset of intrinsic genes is biological relevant to the disease, how to select genes that can best separate disease subtype clusters out of tens of thousands genes from the high dimensional data? (ii) The clinical outcome variables can be of any data type, including continuous, binary, ordinal, count, survival data, etc. How to incorporate various types of clinical outcome variables, as a guidance in determining disease subtype clusters? (iii) Since both the phenotypic data and the intrinsic omics data are utilized, how to balance the contribution of them in determining the subtype clusters? (iv) How to benchmark whether the resulting subtype clusters are relevant to guidance of the clinical outcome variable? There have been some efforts in the literature to address parts of these issues. Bair and Tibshirani (2004) proposed a two-step clustering method, in which they pre-selected a list of genes based on the association strength (e.g., Cox score) with the survival outcome, and then used the selected genes to perform regular K-means. However, these pre-selected genes were purely driven by clinical outcomes, and thus might not guarantee to be good separators of the subtype clusters. Therefore, there is still lack of a unified outcome-guided clustering algorithm that can simultaneously solve all these challenges.
In this paper, we extended from the sparse K-means algorithm by Witten and Tibshirani (2010), and proposed an outcome-guided clustering (GuidedSparseKmeans) framework by incorporating clinical outcome variable, which will simultaneously solve all these challenges in a unified formulation. We demonstrated the superior performance of our method in both simulations and gene expression applications of both breast cancer and Alzheimer’s disease.
2 Motivating example
To demonstrate the motivation of the outcome-guided clustering (GuidedSparseKmeans) method, we used the METABRIC (Curtis et al., 2012) breast cancer gene expression data as an example, which contained 12,180 genes and 1,870 samples after preprocessing. Detailed descriptions of the METABRIC data and the preprocessing procedure are available in Section 4.2. We used the overall survival information as the clinical guidance for the GuidedSparseKmeans (namely, Survival-GuidedSparseKmeans), and compared with the non-outcome-guided method (the sparse K-means) and the two-step method (pre-select genes via Cox score, and then perform regular K-means). We used Silhouette score (Rousseeuw, 1987) to benchmark the distinction of subtype patterns of each method, for which a larger value represented both better separation between clusters and better cohesion within respective clusters. We further evaluated the association between the resulting subtypes and the overall survival to examine the biological interpretation of the subtypes derived from each method.
Figure 1a shows the heatmap of the subtype clustering results from the non-outcome-guided method (the sparse K-means). 408 genes (on rows) were selected and the 1,870 samples were partitioned into 5 clusters (on columns). Since the sparse K-means algorithm purely sought for a good clustering performance, it achieved the most homogeneous heatmap patterns within each subtype cluster (mean Silhouette score = 0.099). However, the resulting Kaplan-Meier survival curves (Figure 1b) of the five disease subtypes were not well-separated (), which implied that the subtype clustering results purely driven by the transcriptomic profile may not necessarily be clinically meaningful.
Figure 1c shows the heatmap of the subtype clustering results from the Survival-GuidedSparseKmeans. 384 genes (on rows) were selected and the 1,870 samples were partitioned into 5 clusters (on columns). The heatmap patterns within each subtype cluster were still visually homogeneous (mean Silhouette score = 0.073). However, the GuidedSparseKmeans achieved distinct survival separation of the 5 subtype clusters (, Figure 1d), which was statistically significant and clinically meaningful. This is expected because the GuidedSparseKmeans integrated transcriptomic data with phenotypic data, seeking for good performance in both clustering result and clinical relevancy.
Figure 1e shows the heatmap of the subtype clustering results from the two-step clustering method. 400 genes (on rows) were selected and the 1,870 samples were partitioned into 5 clusters (on columns). Although the two-step method achieved more distinct survival separation of the 5 subtype clusters (, Figure 1f), we observed the large inter-individual variability within each subtype cluster (mean Silhouette score = 0.058), which may further hamper the accurate diagnosis of the future patients.
Collectively, the sparse K-means algorithm assured homogeneous subtype clustering patterns, but the resulting subtypes might not be clinically meaningful. The two-step method encouraged the subtypes to be clinically relevant, but might result in high inter-individual variabilities within each subtype cluster. And our proposed GuidedSparseKmeans simultaneously sought for homogeneous subtype clustering patterns and relevant clinical interpretations, which will be more applicable in biomedical applications.






3 Method
3.1 K-means and sparse K-means
3.1.1 K-means algorithm
Consider the gene expression value of gene and subject . Throughout this manuscript, we used the gene expression data as the example to illustrate our method, which is easy to be generalized to other types of omics data (e.g., DNA methylation, copy number variation, etc), or even non-omics data. The K-means method (MacQueen et al., 1967) aims to partition subjects into clusters such that the within-cluster sum of squares (WCSS) is minimized:
| (1) |
where is a collection of indices of the subjects in cluster with ; is the number of subjects in cluster ; and denotes the dissimilarity of gene between subject and subject .
3.1.2 Sparse K-means algorithm
Since transcriptomic data are usually high-dimensional, with large number of genes and relatively small number of samples (), it is generally assumed that only a small subset of intrinsic genes will contribute to the clustering result (Parker et al., 2009). To achieve gene selections in the high-dimensional setting, Witten and Tibshirani (2010) developed a sparse K-means method with lasso regularization on gene-specific weights. Lasso regularization is a technique to perform feature selection developed in regression setting (Tibshirani, 1996), which has been used in clustering setting as well (Witten and Tibshirani, 2010). Since directly adding lasso regularization to Equation 1 would lead to trivial solution (i.e., all weights are 0), they instead proposed to maximize the weighted (between cluster sum of square). This was because minimizing the of a gene was equivalent to maximizing the of the gene, as and (total sum of square) is a constant for any gene. Thus the objective function of the sparse K-means algorithm is the following (Equation 2),
| (2) |
subject to .
In Equation 2, denotes the weight for gene with ; the norm penalty will facilitate gene selection (i.e., only a small subset of genes have non-zero weights); is a tuning parameter to control the number of nonzero weights (larger will result in more selected genes); and the norm penalty will encourage selecting more than one genes because otherwise, only one gene with the largest will be selected.
3.2 GuidedSparseKmeans
In order to incorporate the contribution from a clinical outcome variable, we proposed to use a gene specific award term . represents the association strength between gene and a clinical outcome variable, which will help guide gene selections. For example, , where is the expression levels of gene , and is the vector of clinical outcome. The objective function of the GuidedSparseKmeans is as follows:
| (3) |
subject to ,
where is the tuning parameter controlling the balance between the clustering separation ability of gene (i.e., ) and the guidance of the clinical outcome variable .
is normalized against such that the range of is , which is comparable to the range of .
Thus, by maximizing Equation 3,
we will select genes with both strong clustering separation ability and strong association with the clinical outcome variable.
In order to accommodate various types of clinical outcome variables, we proposed to calculate based on a univariate regression model , where a clinical outcome variable is the dependent variable and the expression of gene is the independent variable. To be specific, the guiding term is defined as the pseudo R-squared proposed by Cox and Snell (1989) for :
where is the number of subjects; is the likelihood of null model (i.e., intercept only model); and is the likelihood of the model . Since the univariate regression model can be linear models, generalized linear models, Cox models, or other regression models, the proposed can accommodate a wide variety of clinical outcome variables (e.g., continuous, binary, ordinal, count, survival data, etc). We acknowledge that could be also defined using the pseudo R-squared proposed by McFadden et al. (1977), Tjur (2009), Nagelkerke et al. (1991), Efron (1978) or McKelvey and Zavoina (1975), or simply the absolute value of the Pearson correlation coefficient between and y.
To quantify whether the subtype clustering results are relevant to the clinical outcome variable, we further proposed a relevancy score by calculating the Pearson correlation of and ,
| (4) |
where and . Since represents the non-zero weights of the selected genes that are associated with the clustering result, and is associated with the clinical outcome variable, the relevancy score indirectly quantifies the association between the subtype clustering results and the guidance of the clinical outcome variable.
Remark 1
In Equation 3, controls the balance between the separation ability of gene (i.e., ) and the guidance of the clinical outcome variable . When , Equation 3 reduces to Equation 2. Therefore, the sparse -means algorithm is a special case of the GuidedSparseKmeans when . When , the gene-specific weights are purely driven by the clinical outcome variable (i.e., only genes with large will be selected). Equation 3 reduces to the two-step clustering algorithm, and the clustering results are determined by the weighted K-means algorithm based on these pre-selected genes. Therefore, the two-step algorithm is also essentially a special case of the GuidedSparseKmeans when . And in Section 3.4 we proposed to use sensitivity analysis to find the optimal to balance these two terms.
3.3 Optimization
Given the selected values of , , and , the optimization procedure is carried out as the following:
-
1.
Denote , where is an indicator function and is the largest element in vector . We chose throughout this manuscript. In the later breast cancer application example, we performed sensitivity analysis to demonstrate that the difference choice of did not have a large impact on the clustering results. Initialize as .
-
2.
Holding fixed, update by weighted K-means:
20 random initial centers were considered in the starting of the weighted K-means, and the cluster result with the maximized objective function (among these 20 trials) was adopted as the output for the weighted K-means.
-
3.
Holding fixed, update as the following:
where is the soft-thresholding operator defined as ; ; is chosen such that , otherwise, if .
-
4.
Iterate Step 2-3 until the stopping rule is satisfied, where t is the number of iterations.
In Step 2, the optimization of clusters is essentially applying a weighted K-means algorithm on the original gene expression data, since the weights will change the relative scale of the data, and the and are not functions of . In Step 3, fixing the clusters , the optimization of weights is a convex problem, and a closed form solution of can be derived by Karush-Kuhn-Tucker (KKT) conditions (Boyd and Vandenberghe, 2004; Witten and Tibshirani, 2010).
3.4 Selection of tuning parameter
The GuidedSparseKmeans objective function (Equation 3) has three tuning parameters: is the number of clusters; controls the number of selected genes; and controls the balance between the clustering separation ability and the guidance from the clinical outcome. Below are our guidelines on how to select these tuning parameters.
3.4.1 Selection of
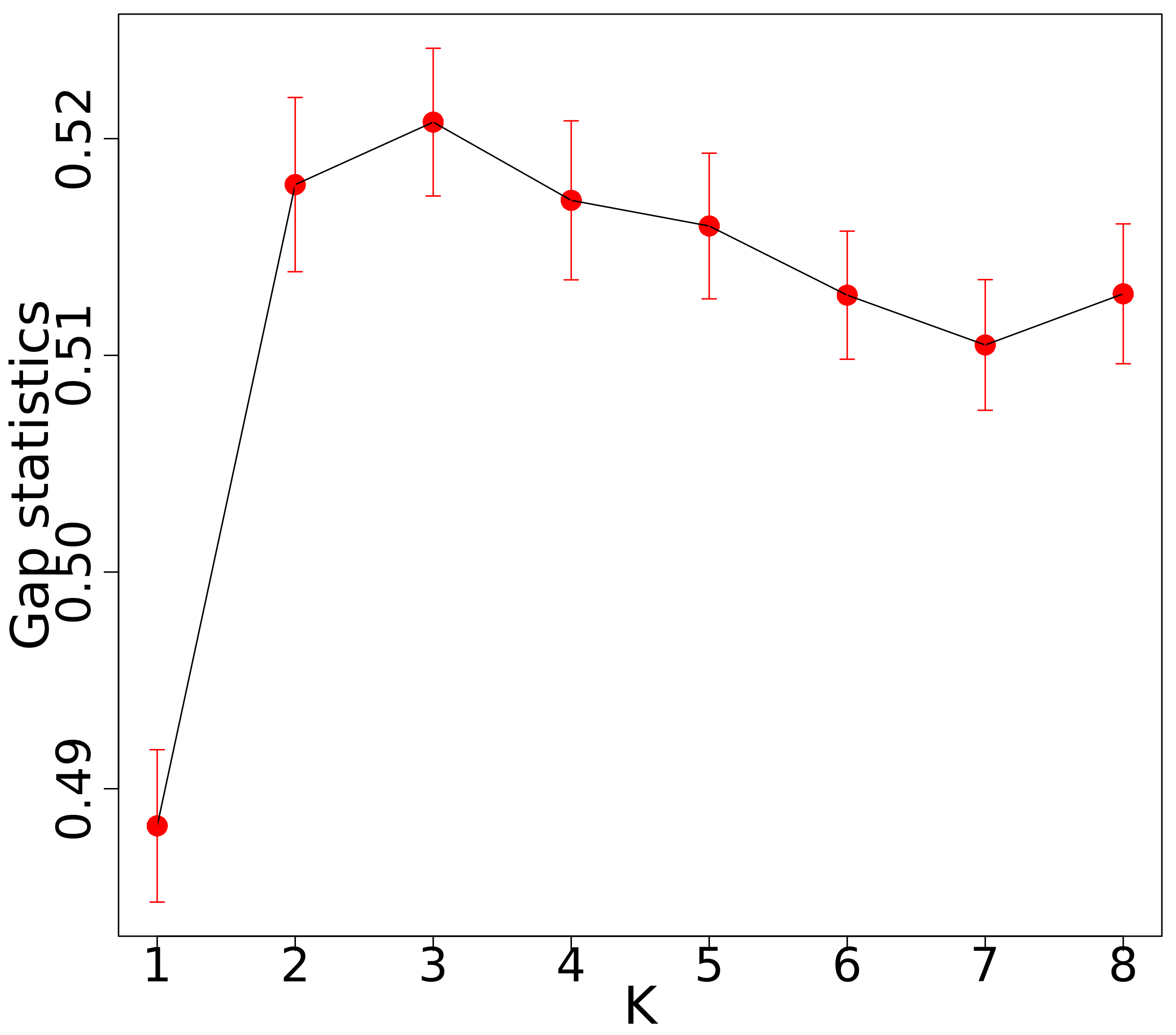
How to select number of clusters has been widely discussed in the literature (Milligan and Cooper, 1985; Kaufman and Rousseeuw, 2009; Sugar and James, 2003; Tibshirani and Walther, 2005; Tibshirani et al., 2001). Here, we suggested to be estimated using the gap statistics (Tibshirani et al., 2001) or prediction strength (Tibshirani and Walther, 2005). Alternatively, can be set as a specific number in concordance with the prior knowledge of the disease. In our simulation, we selected top genes (e.g., ) with the largest ’s, and used gap statistics to select based on the pre-selected genes. The gap statistics is the difference between observed WCSS and the background expectation of WCSS calculated from random permutation of the original data. The rationale behind this is that the underlying true number of clusters K should occur when this difference (observed WCSS – background expected) is maximized (Tibshirani et al., 2001).
3.4.2 Selection of
The tuning parameter controls the balance between the separation ability of gene (i.e., ) and the guidance of the clinical outcome variable . We recommend to use sensitivity analysis to select . When , the selected genes as well as the clustering results are purely driven by the guidance of the clinical outcome variable . As gradually decreases, we expect stable results of gene selection and clustering results, until a certain transition point. After the transition point, we expect the separation ability becomes dominant, and both gene selection and clustering results may change. Therefore, our rationale is to identify the transition point , which is the smallest such that the clustering results and the gene selection results are stable with respect to any . Below is the detailed algorithm:
-
1.
Let , for . Obtain the clustering result and gene weight for each by applying the GuidedSparseKmeans, where is pre-estimated, and is pre-set so that genes can be selected by the GuidedSparseKmeans ( is the proportion of the total number of genes in the expression dataset and is recommended to set between 3% and 6%). We set throughout this paper. Since both and are fixed, we use to denote , and to denote . For , we further calculate the adjusted Rand index (Hubert and Arabie, 1985) (ARI) between and as . Similarly, we calculate the Jaccard index (Jaccard, 1901) between and as , where is an indicator function. ARI measures the agreement of two clustering results, and the Jaccard index measures the agreement of two gene sets (see Section 4 for details).
-
2.
For , calculate ; as the standard deviation of ’s for ; ; and as the standard deviation of ’s for .
-
3.
We calculate as the largest such that , where we set the fudge parameter to avoid the zero variation. Similarly, we calculate as the largest such that . and mimic the transition points for the clustering result and gene selection result, respectively.
-
4.
We select as
-
5.
If (or ) is very stable for all , it is possible that (or ) will not be obtained. Under this scenario, is not sensitive to clustering (or gene selection result). Since , we will set (or ) to let its alternative component (or ) to decide the proper .
Based on the above algorithm, the clustering results and gene selection results will not be sensitive to if .
3.4.3 Selection of
After and are selected, we extend the gap statistics procedure in the sparse K-means algorithm (Witten and Tibshirani, 2010) to estimate , which controls the number of selected genes:
-
1.
Pre-specify a set of candidate tuning parameter .
-
2.
Create permuted datasets by randomly permuting subjects for each gene feature of the observed data .
-
3.
Compute the gap statistics for each candidate tuning parameter as the following:
where is the log weighted value on the observed data with and being the optimum solution. Similarly, is the log weighted value on the permutated data and their corresponding optimum solutions.
-
4.
Choose such that the is maximized.



4 Result
We evaluated the performance of the GuidedSparseKmeans on simulation datasets and two gene expression profiles of breast cancer and Alzheimer’s disease, and compared with the non-outcome-guided method (the sparse K-means) and the two-step clustering method (regular K-means with pre-selected genes via Cox score). We used the adjusted Rand index (Hubert and Arabie, 1985) (ARI) to benchmark the clustering performance, which evaluates the similarity between a clustering result and the underlying truth (ranges from 0 [random agreement] to 1 [perfect agreement]). We used the Jaccard index (Jaccard, 1901) to benchmark the similarity of the selected genes to the underlying intrinsic genes, which is defined as the ratio of the number of genes from both gene sets to the number of genes from either one of the gene sets (ranges from 0 [no intersection between the two gene sets] to 1 [identical gene sets]).
4.1 Simulation
4.1.1 Simulation setting
To evaluate the performance of the GuidedSparseKmeans and to compare with the non-outcome-guided method (the sparse K-means), we simulated a study with subtypes. To best preserve the nature of genomic data, we simulated intrinsic genes (i.e., genes defining subtype clusters), confounding impacted genes (i.e., genes defining other configurations of clusters), and noise genes with correlated gene structures (Song and Tseng, 2014; Huo et al., 2016). In addition, we generated a continuous outcome variable as the clinical guidance. Below is the detailed data generative process.
-
1.
Intrinsic genes.
-
1.
Simulate subjects for subtype and the number of subjects in the study is . For each simulated data, the expected number of subjects is 300.
-
2.
Simulate gene modules (). Denote as the number of features in module (). In each module, sample the number of genes by . Therefore, there will be an average of 400 intrinsic genes.
-
3.
Denote as the baseline gene expression of subtype of the study and . Denote as the template gene expression of subtype and module . We calculate the template gene expression by , where is the fold change for each module and . is set to be 1.
-
4.
Add biological variation to the template gene expression and generate for each module , subject of subtype . is set to be 3 unless otherwise specified.
-
5.
Simulate the covariance matrix for genes in subtype and module . First sample , where , denotes the inverse Wishart distribution, is the identity matrix and is the matrix with all elements equal to 1. The is calculated by standardizing such that all the diagonal elements are equal to 1.
-
6.
Simulate gene expression values for subject in subtype and module as , where , and .
-
1.
-
2.
Phenotypic variables.
-
1.
Simulate clinical outcomes as for subject and in subtype , where and . The clinical outcome variation is set to be 8 such that the magnitude of of the intrinsic genes in this simulation is similar to the breast cancer example (Section 4.2).
-
1.
-
3.
Confounding impacted genes.
-
1.
Simulate confounding variables. Confounding variables can be demographic factors such as race, gender, or other unknown confounding variables. These variables will define other configurations of sample clustering patterns, and thus complicate disease subtype discovery. For each confounding variable , we simulate modules. For each module , sample number of genes . Therefore, there will be an average of 1,600 confounding impacted genes.
-
2.
For each confounding variable in the study, the samples are randomly divided into subclasses, which represents the configuration of clusters for confounding variables.
-
3.
Denote as the template gene expression in subclass and module . We calculate the template gene expression by , where is the fold change for each module and , is the same as the one in a3.
-
4.
Add biological variation to the template gene expression and generate . Similar to Step a5 and a6, we simulate gene correlation structure within modules of confounder impacted genes.
-
1.
-
4.
Noise genes.
-
1.
Simulate 8,000 noninformative noise genes denoted by . We generate template gene expression . Then, we add noise to the template gene expression and generate .
-
1.
For each simulated data, the expected number of genes is 10,000, including 400 intrinsic genes, 1,600 confounding impact genes, and 8,000 noise genes.
4.1.2 Simulation results
In this section, we first showed the tuning parameter estimation results of the GuidedSparseKmeans using one simulation dataset. As shown in Figure 2a, the gap statistics introduced in Section 3.4.1 successfully identified as the optimal number of clusters, which had the largest gap statistics. The guidance term was calculated as the from univariate linear regressions. We applied the sensitivity analysis algorithm introduced in Section 3.4.2 to select for the simulated dataset. Figure 2c shows the value of for each and Figure 2d shows the value of for each . Then, and were obtained. Therefore, we set in this specific simulation via sensitivity analysis. We applied the gap statistics algorithm introduced in Section 3.4.3 to select for the simulated dataset. Figure 2b shows the gap statistics for each candidate (). The tuning parameter was chosen to be 13.5 and the number of selected genes was 370, which was close to the underlying truth (389 intrinsic genes).
Then, we compared the performance of the GuidedSparseKmeans and the non-outcome-guided algorithm (the sparse K-means). The number of clusters was estimated via the gap statistics in Section 3.4.1. The tuning parameter for the GuidedSparseKmeans for each single simulation was selected based on sensitivity analysis (See Section 3.4.2 for details). For a fair comparison, we selected the tuning parameter such that the numbers of genes selected using the GuidedSparseKmeans and the sparse K-means were close to the number of intrinsic genes in each simulation (i.e., 400).
Table 1 shows the comparison results of two methods with the biological variation . The GuidedSparseKmeans (mean ARI = 0.730) outperformed the sparse K-means (mean ARI = 0.178) in terms of clustering accuracy. In addition, in terms of gene selection, the GuidedSparseKmeans (mean Jaccard index = 0.728) outperformed the sparse K-means (mean Jaccard index = 0.179). To ensure the performance difference between the two methods was due to methodology itself instead of the specific tuning parameter selection, we also tried other number of selected genes (800 and 1,200) for all methods. As shown in Table S1, the GuidedSparseKmeans still outperformed its competing method. Further, we compared the gene selection performance in terms of the area under the curve (AUC) of a ROC curve, which aggregated the performance of all candidate tuning parameter ’s. And not surprisingly, the GuidedSparseKmeans (mean AUC = 0.881) achieved better performance than the sparse K-means (mean AUC = 0.590). Further, under the settings with varying biological variation ( to 5 with interval 0.25), Figure 3a and Figure 3b show that the GuidedSparseKmeans still outperformed the sparse K-means algorithm in terms of both clustering and gene selection accuracy, though the performance of both methods decreased as the biological variation increased.
Additionally, we also compared the GuidedSparseKmeans with the sparse K-means under the settings with (i) varying clinical outcome variation, (ii) different number of true intrinsic genes, (iii) different number of confounding impacted genes, and (iv) different choice of number of clusters . (i) By increasing the clinical outcome variation ( and ), we mimicked the decrease association of the disease subtypes and the clinical variable. Table S2 shows that the performance of the GuidedSparseKmeans got worse when the clinical outcome variation increased. This is not surprising because our algorithm relied on the clinical outcome variable to enhance feature selection. And the performance of the GuidedSparseKmeans still outperformed the performance of the sparse K-means. (ii) By increasing number of true intrinsic genes (400, 800, and 1,200 genes), we mimicked larger signals in intrinsic genes. As shown in Table S3, the performance of both the GuidedSparseKmeans and the sparse K-means improved with increasing number of intrinsic genes. And comparing these two methods, the GuidedSparseKmeans still outperformed the sparse K-means. (iii) By increasing number of confounding impacted genes (1,200, 1,600, and 2,000 genes), we mimicked more complicated confounding effect, and thus we expected it to be more difficult to identify the underlying disease subtypes. As expected, the performance of both the GuidedSparseKmeans and the sparse K-means deteriorated with increasing number of confounding impacted genes (Table S4). And comparing these two methods, the GuidedSparseKmeans still outperformed the sparse K-means. (iv) In simulation, the underlying number of clusters is 3. To examine the impact of misspecification of , we varied the number of clusters . The result is shown in Table S5. yielded the best performance in terms of clustering result and gene selection. When or , the performance gradually decreased. Thus, the misspecification of had great effects in the simulation since the 3 clusters in the simulations were clearly separated.
We further used cross-validation to examine the generalizability and replicability of the GuidedSparseKmeans in simulation. We first simulated one dataset based on the basic simulation setting in Section 4.1.1. Then we randomly divided the dataset into a training dataset (50% of the total samples) and a testing dataset (50% of the total samples). After applying the GuidedSparseKmeans on the training data to obtain selected genes, we used weighted K-means to get clustering results with the selected genes. This procedure was repeated 50 times. Table S6 shows the cross-validation evaluation results. The cross-validation ARI (0.712) was close to the mean ARI (0.730) in Table 1, which demonstrated that the generalizability and replicability of the GuidedSparseKmeans.
Clustering results Gene selection results ARI Jaccard index AUC GuidedSparseKmeans 0.730 (0.017) 0.728 (0.016) 0.881 (0.008) sparse K-means 0.178 (0.018) 0.179 (0.018) 0.590 (0.010)


4.2 METABRIC breast cancer example
In this section, we evaluated the performance of the GuidedSparseKmeans in the METABRIC breast cancer gene expression dataset (Curtis et al., 2012), which included samples from tumor banks in the UK and Canada. The METABRIC cohort contained gene expression profile of 24,368 genes and 1,981 subjects, as well as various types of clinical outcome variables including the Nottingham prognostic index (NPI, continuous variable); Estrogen receptor status (ER, binary variable); HER2 receptor status (HER2, ordinal variable); and overall survival. We used each of these 4 phenotypic variables as the clinical guidance for the GuidedSparseKmeans, respectively. All datasets are publicly available at https://www.cbioportal.org. We matched the gene expression data to the clinical data by removing missing samples. After filtering out 50% low expression genes based on the average expression level of each gene, we scaled the data such that each gene has mean expression value 0 and standard deviation 1. After these preprocessing procedures, we ended up with 12,180 gene features and 1,870 subjects.
For each of these outcome variables, we calculated as the or pseudo- from the univariate regression between gene and an outcome variable, where we used the linear model for continuous outcomes; generalized linear models for binary and ordinal outcomes; and the Cox regression model for survival outcomes. We set the tuning parameter based on the gap statistics analysis, which is consistent with acknowledgement that there are 5 types of breast cancer by the PAM50 definition (Parker et al., 2009). The tuning parameter of GuidedSparseKmeans was selected automatically (See methods in Section 3.4.2). We selected the tuning parameter such that the number of selected genes was closest to 400. To benchmark the performance of the GuidedSparseKmeans, we further compared with the non-outcome-guided clustering algorithm (the sparse K-means) and the two-step clustering method, with number of selected genes around 400 (See Table 2). Fixing similar number of selected genes for different methods will minimize the influence resulted from unequal number of selected genes. and emphasize the comparisons of methodologies themselves.
4.2.1 Evaluating the clustering performance
Since we did not have the underlying true clustering result, we used the survival difference between subtypes to examine whether the resulting subtypes were clinically meaningful. As shown in Figure 1, Figure 4, and Table 2, the Kaplan-Meier survival curves of the five disease subtypes obtained from each GuidedSparseKmeans method or the two-step method were well separated with significant p-values, but not for the non-outcome-guided method (the sparse K-means). This is not unexpected because except for the sparse K-means method, all the other methods have guidance from clinical outcomes. Remarkable, even though the NPI-GuidedSparseKmeans, the ER-GuidedSparseKmeans, and the HER2-GuidedSparseKmeans did not utilize any survival information, they still achieved good survival separation. Probable reason could be that these clinical outcome variables were all related to the disease, and thus could impact the overall survival.
We further compared the clustering results obtained from each method with the PAM50 subtypes, which were considered as the gold standard for breast cancer subtypes. Table 2 shows that the ARI values from four types of GuidedSparseKmeans (0.237 0.292) were greater than the ARI values from the sparse K-means (0.017) or the two-step method (0.177), indicating that the subtype results from the GuidedSparseKmeans were closer to the gold standard than those from the sparse K-means or the two-step method. These results are expected because the GuidedSparseKmeans could utilize the clinical outcome variables to obtain biologically interpretable clustering results.
For the heatmap patterns, in general the sparse K-means achieved the most homogenous clustering results (mean Silhouette = 0.099), followed by the GuidedSparseKmeans (mean Silhouette = 0.065 0.108), and the two-step method achieved the most heterogenous clustering results (mean Silhouette = 0.058). Notably, the HER2-GuidedSparseKmeans achieved even better mean Sillhouette score than the spares K-means (mean Silhouette = 0.108).
To examine whether the subtype clusters from the GuidedSparseKmeans were relevant to the guidance of the clinical outcome variables, we calculated the relevancy score by Equation 4. Not surprisingly, the ER-GuidedSparseKmeans achieved the highest relevancy score (0.764), followed by NPI-GuidedSparseKmeans (0.690), Survival-GuidedSparseKmeans (0.559), and HER2-GuidedSparseKmeans (0.305) indicating the clustering results from the GuidedSparseKmeans with each of four clinical outcomes reasonably reflected the information of their clinical outcomes.
To ensure the performance difference between the two methods was due to methodology itself instead of the specific tuning parameter selection, we also tried other targeted number of selected genes (800, 1,200 and 1,600) for all methods. As shown in Table S7 the GuidedSparseKmeans still outperformed its competing methods.
Collectively, as discussed in the motivating example, the sparse K-means algorithm only sought for homogeneous subtype clustering patterns, regardless of whether the resulting subtypes were clinically meaningful. The two-step method only sought for subtypes that were clinically meaningful, which could result in high inter-individual variabilities within each subtype cluster. And the GuidedSparseKmeans sought for both homogeneous subtype clustering patterns and relevant clinical interpretations.






Method Guidance Genes Relevancy ARI Silhouette p-value Time NPI(continuous) 399 0.690 0.237 0.065 31 secs Guided ER(binary) 411 0.764 0.292 0.093 3.3 mins SparseKmeans HER2(ordinal) 394 0.305 0.292 0.108 19.2 mins Survival 384 0.559 0.244 0.073 2.9 mins sparse K-means 408 0.017 0.099 0.072 9.8 mins two-step method Survival 400 0.177 0.058 2.5 mins
4.2.2 Evaluating the gene selection performance
To evaluate whether the selected genes were biologically meaningful, we performed pathway enrichment analysis via the BioCarta pathway database using the Fisher’s exact test. Figure 5 shows the jitter plot of p-values for all pathways obtained from each method. Using as significance cutoff, the points above the black horizon line are the significantly enriched pathways without correcting for multiple comparisons. We observed that the genes selected from the GuidedSparseKmeans (number of significant pathways = 7 10) and the two-step method (number of significant pathways = 9) had better biological interpretation than the sparse K-means method (number of significant pathways = 4). Also, the top p-values from the GuidedSparseKmeans were lower than those from the two-step method. Notably, the genes selected by the ER-GuidedSparseKmeans and the HER2-GuidedSparseKmeans were enriched in HER2 pathway, with and , respectively. This is in line with previous research that ER signaling pathway and HER2 signaling pathway are closely related to breast cancer (Giuliano et al., 2013). In addition, the genes selected by the GuidedSparseKmeans with each of four clinical outcomes were enriched in ATRBRCA pathway, which has been found closely related to breast cancer susceptibility (Paul and Paul, 2014). However, these hallmark pathways of breast cancer were not picked up by the sparse K-means algorithm or the two-step method, and only the GuidedSparseKmeans selected the most biologically interpretable genes.

4.2.3 Evaluating the computing time
The computing time for the GuidedSparseKmeans in this real application was 31 seconds for continuous outcome guidance, 2.9 minutes for survival outcome guidance, 3.3 minutes for binary outcome guidance, and 19.2 minutes for ordinal outcome guidance. Since our high-dimensional expression data contains 12,180 genes and 1,870 samples, such computing time is reasonable and applicable in large transcriptomic applications.
In general, the computing time of our method was faster than the sparse K-means method (9.8 minutes), except for the ordinal outcome guidance. This was because we used to guide the initialization of the weights instead of equal weight initialization in the sparse K-means, which saved lots of time in the first step weighted K-means iteration. The ordinal-outcome-GuidedSparseKmeans was slow, because of the slow fitting of ordinal logistic regression models. Our methods were generally slower than the two-step method, except for the continuous outcome guidance. This was because the two-step method only needed to update the clustering assignment once, while ours needed to iteratively update the clustering assignment and gene weight. The continuous-outcome-GuidedSparseKmeans was super-fast (31 seconds), because the of univariate linear models can be efficiently calculated as the square of the Pearson correlation between a gene and the outcome variable.
4.2.4 Model sensitivity and generalizability
In the optimization procedure (Section 3.3), we chose as the initial number of selected genes. To examine the impact this initial number on the clustering results, we performed sensitivity analysis by varying . As shown in Table S8, the varying choice of did not seem to have large impact the clustering results and the feature selection result.
To examine the impact of choices of number of clusters, we varied the number of clusters . The result is shown in Table S9. The performance of different ’s were similar, and there was not a that could simultaneously achieve the best relevancy score, ARI with PAM 50, Silhouette score, and survival p-value. The choices of had greater effects on the simulation than the real data application since the clusters in the simulations were clearly separated, while in the real data and the difference between clusters ere gradual instead of steep.
Further, we used cross-validation to evaluate the generalizability and the replicability of the results from the GuidedSparseKmeans. To be specific, we randomly split the data (n = 1,870) into a training dataset (n = 935) and testing dataset (n = 935). We applied the GuidedSparseKmeans algorithm on the training dataset and obtain the selected genes. Then we used the selected genes to predict the clustering result in the testing dataset. This procedure was repeated 50 times, and the mean ARI (compared to PAM) or median survival p-values were reported. As shown in Table S10, the cross-validation clustering accuracy (compared to PAM) for the NPI-GuidedSparseKmeans, the ER-GuidedSparseKmeans, the HER2-GuidedSparseKmeans, and the Survival-GuidedSparseKmeans were 0.265, 0.296, 0.296, and 0.212, respectively, which were close to the mean ARI 0.237, 0.292, 0.292, and 0.244 in Table 2. The survival p-values from the cross-validation were still very significant, though they were a little bit larger than the whole dataset, which was because we only used half the sample size. These results reveal that the result from the GuidedSparseKmeans are generalizable and replicable.
4.3 Alzheimer disease example
In this section, we applied the sparse K-means and the GuidedSparseKmeans to an RNA-seq dataset of Alzheimer disease (AD). AD is a devastating neurodegenerative disorder affecting elder adults, with neurofibrillary tangles and neuritic plaques as disease hallmarks. The dataset we used included 30,727 transcripts from post mortem fusiform gyrus tissues of 217 AD subjects, which is available at https://www.ncbi.nlm.nih.gov under GEO ID GSE125583 (Srinivasan et al., 2020). After normalizing the gene expression data, filtering out 50% low expression genes based on the average expression level of each gene, and scaling each gene to mean 0 and standardization 1, we ended up with 15,363 gene features. We utilized the Braak stage as the clinical outcome variable, which is a semiquantitative measure of severity of neurofibrillary tangles (Braak and Braak, 1991). Since the Braak system has 6 stages (1 6), we treated it as a continuous variable, and calculated as the from the univariate linear regression between gene and the Braak stage. We set the tuning parameter to be consistent with the number of Braak stages. The tuning parameter of GuidedSparseKmeans was selected automatically using the method in Section 3.4.2. The tuning parameter was selected such that the number of selected genes was 396, which was closest to 400. The computing time for this example was only 7 seconds. Also, the sparse K-means was applied to obtain about 400 genes and the computing time was 22 seconds.
The resulting heatmap of the selected genes from the sparse K-means and the GuidedSparseKmeans in Figure 6 showed a gradient effect from left (green color, lower level of expression) to right (red color, higher level of expression). We labeled the clusters using the integers 1 to 6 which corresponds to the gene expression level from low to high. To evaluate whether the resulting AD subtypes were biologically meaningful, we calculated the Pearson correlation between the subtype labels and the Braak stages. The correlation coefficients were 0.056 and 0.282 for the sparse K-means and the GuidedSparseKmeans respectively, indicating that the AD subtypes obtained by the GuidedSparseKmeans were more related to neurofibrillary tangles (a key hallmark of AD) than those obtained by the sparse K-means. These results are expected since the GuidedSparseKmeans could take advantage of the clinical responses.
To examine whether clusters from the GuidedSparseKmeans were relevant to the guidance of the clinical outcome variable Braak staging, we calculated the relevancy score by Equation 4. The relevancy score was high (Rel = 0.309), which is not unexpected because the GuidedSparseKmeans reflected the information of the clinical outcome. To further examine whether the genes selected from the GuidedSparseKmeans were biologically meaningful, we performed pathway enrichment analysis via the BioCarta pathway database using the Fisher’s exact test. Notably, the genes selected by the Braak-GuidedSparseKmeans were enriched in GPCR signaling pathway () and NOS1 signaling pathway (), both of which were involved in the neuropathological processes of AD (Zhao et al., 2016; Reif et al., 2011). However, these hallmark pathways were not picked up by the sparse K-means method. Therefore, compared with the sparse K-means, the GuidedSparseKmeans successfully identified AD subtypes and the intrinsic genes that were both closely related to AD.


5 Discussion
Since our method can only accommodate one clinical outcome variable, one issue is how to properly select the clinical guidance given multiple available clinical outcomes. We suggest to select the outcome variable of the most biological interest as clinical guidance, based on domain knowledges. Taking the Alzheimer’s disease as an example, the variable Braak stage was chosen due to its important role of measuring the severity of neurofibrillary tangles in AD. If no domain knowledge can be used or one prefers a data driven approach, we suggest to try several outcome variables as guidance, and decide the best outcome guidance based on the biological interpretability of the clustering results (i.e., survival difference, pathway analysis). For example, in the breast cancer application, we would recommend the clustering result obtained by the HER2-GuidedSparseKmeans since it led to both the most significant survival difference and meaningful pathway analysis result. To further address this issue, we will develop a multivariate outcome-guided sparse K-means in the future, which will incorporate multiple outcomes variables as the clinical guidance.
Properly specifying the disease-related clinical outcomes is essential for the disease subtyping. If the guidance term (clinical outcome) has no association with the underlying disease subtype, the result from the GuidedSparseKmeans may further deviate from the true subtypes. However, we still think our algorithm has its unique merit because many hallmark clinical variables have been established for many diseases (e.g., ER for breast cancer, braak stage for Alzheimer’s disease). With the advancement of biomedical research, more disease-related clinical outcomes will be discovered, and our algorithm will become more applicable.
In this manuscript, we estimated the tuning parameters of the GuidedSparseKmeans , , and by gap statistics, sensitivity analysis, and extended gap statistics, respectively. Other approaches that can simultaneously estimate tuning parameters were recently proposed (Li et al., 2019). One future direction is to develop methods to jointly estimate these tuning parameters. We also considered the effects of the number of selected genes and mis-specification of the number of clusters on clustering and gene selection performance of the GuidedSparseKmeans. The GuidedSparseKmeans still outperformed the sparse K-means regardless of the number of selected genes in simulations and breast cancer application, respectively. In simulation, the mis-specification of had large impacts on the clustering performance of the GuidedSparseKmeans, while in the breast cancer application, the performance of the GuidedSparseKmeans was slightly affected by different . This is reasonable since the simulation datasets have clear and direct clusters but in the real data and the difference between clusters are gradual instead of steep.
In summary, we proposed an outcome-guided sparse K-means algorithm, which is capable of identifying subtype clusters via integrating clinical data with high-dimensional omics data. Our innovative methodology simultaneously solves many statistical challenges, including gene selections from high-dimensional omics data; incorporations of various types of clinical outcome variable (e.g., continuous, binary, ordinal, count or survival data) as guidance; automatic selections of tuning parameters to balance the contribution between the intrinsic genes and the clinical outcome variable; and evaluations of the relevancy of the resulting subtype clusters and the outcome variable. The superior performance of our method was demonstrated in simulations, cancer application (breast cancer gene expression data), and complicated neurodegenerative disease (Alzheimer’s disease). The computing time for the GuidedSparseKmeans was fast, especially for the continuous outcome guidance, with 31 seconds for the breast cancer application with 12,180 genes and 1,870 samples, and 7 seconds for the Alzheimer’s disease application with 15,363 genes and 217 samples. Our method has been implemented in R package “GuidedSparseKmeans”, which is available at GitHub (https://github.com/LingsongMeng/GuidedSparseKmeans). With the accumulation of rich clinical data and omics data in public data repositories, we expect our innovative and fast method can be very applicable in identifying disease phenotype related subtypes.
6 Acknowledgement
L.M., D.A., and Z.H. are partially supported by NIH 2R01AI067846, G.T. is partially supported by NIH R01CA190766, R01MH111601, and R21LM012752.
7 Data Availability Statement
The METABRIC breast cancer gene expression dataset and the Alzheimer disease RNA-seq dataset that support the findings of this study are openly available at https://www.cbioportal.org, and https://www.ncbi.nlm.nih.gov under GEO ID GSE125583, respectively.
References
- Abramson et al. (2015) Abramson, V. G., Lehmann, B. D., Ballinger, T. J. and Pietenpol, J. A. (2015) Subtyping of triple-negative breast cancer: Implications for therapy. Cancer, 121, 8–16.
- Bair and Tibshirani (2004) Bair, E. and Tibshirani, R. (2004) Semi-supervised methods to predict patient survival from gene expression data. PLoS biology, 2, e108.
- Boyd and Vandenberghe (2004) Boyd, S. and Vandenberghe, L. (2004) Convex optimization. Cambridge university press.
- Braak and Braak (1991) Braak, H. and Braak, E. (1991) Neuropathological stageing of alzheimer-related changes. Acta neuropathologica, 82, 239–259.
- Bredesen (2015) Bredesen, D. E. (2015) Metabolic profiling distinguishes three subtypes of alzheimer’s disease. Aging, 7, 595–600.
- Cox and Snell (1989) Cox, D. and Snell, E. (1989) Analysis of Binary Data, vol. 32. CRC Press.
- Cunningham et al. (2020) Cunningham, N., Griffin, J. E. and Wild, D. L. (2020) Particlemdi: particle monte carlo methods for the cluster analysis of multiple datasets with applications to cancer subtype identification. Advances in Data Analysis and Classification, 14, 463–484.
- Curtis et al. (2012) Curtis, C., Shah, S. P., Chin, S.-F., Turashvili, G., Rueda, O. M., Dunning, M. J., Speed, D., Lynch, A. G., Samarajiwa, S., Yuan, Y. et al. (2012) The genomic and transcriptomic architecture of 2,000 breast tumours reveals novel subgroups. Nature, 486, 346.
- Dudoit and Fridlyand (2002) Dudoit, S. and Fridlyand, J. (2002) A prediction-based resampling method for estimating the number of clusters in a dataset. Genome Biology, 3, 1–21.
- Efron (1978) Efron, B. (1978) Regression and anova with zero-one data: Measures of residual variation. Journal of the American Statistical Association, 73, 113–121.
- Eisen et al. (1998) Eisen, M. B., Spellman, P. T., Brown, P. O. and Botstein, D. (1998) Cluster analysis and display of genome-wide expression patterns. Proceedings of the National Academy of Sciences, 95, 14863–14868.
- Gaynor and Bair (2017) Gaynor, S. and Bair, E. (2017) Identification of relevant subtypes via preweighted sparse clustering. Computational statistics & data analysis, 116, 139–154.
- Giuliano et al. (2013) Giuliano, M., Trivedi, M. V. and Schiff, R. (2013) Bidirectional crosstalk between the estrogen receptor and human epidermal growth factor receptor 2 signaling pathways in breast cancer: molecular basis and clinical implications. Breast Care, 8, 256–262.
- Hubert and Arabie (1985) Hubert, L. and Arabie, P. (1985) Comparing partitions. Journal of classification, 2, 193–218.
- Huo et al. (2016) Huo, Z., Ding, Y., Liu, S., Oesterreich, S. and Tseng, G. (2016) Meta-analytic framework for sparse k-means to identify disease subtypes in multiple transcriptomic studies. Journal of the American Statistical Association, 111, 27–42.
- Huo et al. (2017) Huo, Z., Tseng, G. et al. (2017) Integrative sparse -means with overlapping group lasso in genomic applications for disease subtype discovery. The Annals of Applied Statistics, 11, 1011–1039.
- Jaccard (1901) Jaccard, P. (1901) Étude comparative de la distribution florale dans une portion des alpes et des jura. Bull Soc Vaudoise Sci Nat, 37, 547–579.
- Kaufman and Rousseeuw (2009) Kaufman, L. and Rousseeuw, P. J. (2009) Finding groups in data: an introduction to cluster analysis, vol. 344. Wiley. com.
- Lehmann et al. (2011) Lehmann, B. D., Bauer, J. A., Chen, X., Sanders, M. E., Chakravarthy, A. B., Shyr, Y. and Pietenpol, J. A. (2011) Identification of human triple-negative breast cancer subtypes and preclinical models for selection of targeted therapies. The Journal of clinical investigation, 121, 2750.
- Li et al. (2019) Li, Y., Zeng, X., Lin, C.-W. and Tseng, G. (2019) Simultaneous estimation of number of clusters and feature sparsity in clustering high-dimensional data. arXiv preprint arXiv:1909.01930.
- MacQueen et al. (1967) MacQueen, J. et al. (1967) Some methods for classification and analysis of multivariate observations. In Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, vol. 1, 281–297. Oakland, CA, USA.
- McFadden et al. (1977) McFadden, D. et al. (1977) Quantitative methods for analyzing travel behavior of individuals: some recent developments. Institute of Transportation Studies, University of California Berkeley.
- McKelvey and Zavoina (1975) McKelvey, R. D. and Zavoina, W. (1975) A statistical model for the analysis of ordinal level dependent variables. Journal of mathematical sociology, 4, 103–120.
- McLachlan et al. (2002) McLachlan, G. J., Bean, R. and Peel, D. (2002) A mixture model-based approach to the clustering of microarray expression data. Bioinformatics, 18, 413–422.
- Milligan and Cooper (1985) Milligan, G. W. and Cooper, M. C. (1985) An examination of procedures for determining the number of clusters in a data set. Psychometrika, 50, 159–179.
- Nagelkerke et al. (1991) Nagelkerke, N. J. et al. (1991) A note on a general definition of the coefficient of determination. Biometrika, 78, 691–692.
- Nowak and Tibshirani (2008) Nowak, G. and Tibshirani, R. (2008) Complementary hierarchical clustering. Biostatistics, 9, 467–483.
- Pan and Shen (2007) Pan, W. and Shen, X. (2007) Penalized model-based clustering with application to variable selection. Journal of Machine Learning Research, 8, 1145–1164.
- Parker et al. (2009) Parker, J. S., Mullins, M., Cheang, M. C., Leung, S., Voduc, D., Vickery, T., Davies, S., Fauron, C., He, X., Hu, Z. et al. (2009) Supervised risk predictor of breast cancer based on intrinsic subtypes. Journal of clinical oncology, 27, 1160–1167.
- Parsons et al. (2008) Parsons, D. W., Jones, S., Zhang, X., Lin, J. C.-H., Leary, R. J., Angenendt, P., Mankoo, P., Carter, H., Siu, I.-M., Gallia, G. L. et al. (2008) An integrated genomic analysis of human glioblastoma multiforme. Science, 321, 1807–1812.
- Paul and Paul (2014) Paul, A. and Paul, S. (2014) The breast cancer susceptibility genes (brca) in breast and ovarian cancers. Frontiers in bioscience (Landmark edition), 19, 605.
- Perou et al. (2000) Perou, C. M., Sørlie, T., Eisen, M. B., van de Rijn, M., Jeffrey, S. S., Rees, C. A., Pollack, J. R., Ross, D. T., Johnsen, H., Akslen, L. A. et al. (2000) Molecular portraits of human breast tumours. Nature, 406, 747–752.
- Prat et al. (2015) Prat, A., Pineda, E., Adamo, B., Galván, P., Fernández, A., Gaba, L., Díez, M., Viladot, M., Arance, A. and Muñoz, M. (2015) Clinical implications of the intrinsic molecular subtypes of breast cancer. The Breast, 24, S26–S35.
- Qin (2006) Qin, Z. S. (2006) Clustering microarray gene expression data using weighted chinese restaurant process. Bioinformatics, 22, 1988–1997.
- Reif et al. (2011) Reif, A., Grünblatt, E., Herterich, S., Wichart, I., Rainer, M. K., Jungwirth, S., Danielczyk, W., Deckert, J., Tragl, K.-H., Riederer, P. et al. (2011) Association of a functional nos1 promoter repeat with alzheimer’s disease in the vita cohort. Journal of Alzheimer’s Disease, 23, 327–333.
- Rosenwald et al. (2002) Rosenwald, A., Wright, G., Chan, W. C., Connors, J. M., Campo, E., Fisher, R. I., Gascoyne, R. D., Muller-Hermelink, H. K., Smeland, E. B., Giltnane, J. M. et al. (2002) The use of molecular profiling to predict survival after chemotherapy for diffuse large-b-cell lymphoma. New England Journal of Medicine, 346, 1937–1947.
- Rousseeuw (1987) Rousseeuw, P. J. (1987) Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of computational and applied mathematics, 20, 53–65.
- Sadanandam et al. (2013) Sadanandam, A., Lyssiotis, C. A., Homicsko, K., Collisson, E. A., Gibb, W. J., Wullschleger, S., Ostos, L. C. G., Lannon, W. A., Grotzinger, C., Del Rio, M. et al. (2013) A colorectal cancer classification system that associates cellular phenotype and responses to therapy. Nature medicine, 19, 619–625.
- Shen et al. (2009) Shen, R., Olshen, A. B. and Ladanyi, M. (2009) Integrative clustering of multiple genomic data types using a joint latent variable model with application to breast and lung cancer subtype analysis. Bioinformatics, 25, 2906–2912.
- Song and Tseng (2014) Song, C. and Tseng, G. C. (2014) Hypothesis setting and order statistic for robust genomic meta-analysis. The annals of applied statistics, 8, 777.
- Srinivasan et al. (2020) Srinivasan, K., Friedman, B. A., Etxeberria, A., Huntley, M. A., van Der Brug, M. P., Foreman, O., Paw, J. S., Modrusan, Z., Beach, T. G., Serrano, G. E. et al. (2020) Alzheimer’s patient microglia exhibit enhanced aging and unique transcriptional activation. Cell reports, 31, 107843.
- Sugar and James (2003) Sugar, C. A. and James, G. M. (2003) Finding the number of clusters in a dataset. Journal of the American Statistical Association, 98.
- Tibshirani (1996) Tibshirani, R. (1996) Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B (Methodological), 267–288.
- Tibshirani and Walther (2005) Tibshirani, R. and Walther, G. (2005) Cluster validation by prediction strength. Journal of Computational and Graphical Statistics, 14, 511–528.
- Tibshirani et al. (2001) Tibshirani, R., Walther, G. and Hastie, T. (2001) Estimating the number of clusters in a data set via the gap statistic. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 63, 411–423.
- Tjur (2009) Tjur, T. (2009) Coefficients of determination in logistic regression models—a new proposal: The coefficient of discrimination. The American Statistician, 63, 366–372.
- Tothill et al. (2008) Tothill, R. W., Tinker, A. V., George, J., Brown, R., Fox, S. B., Lade, S., Johnson, D. S., Trivett, M. K., Etemadmoghadam, D., Locandro, B. et al. (2008) Novel molecular subtypes of serous and endometrioid ovarian cancer linked to clinical outcome. Clinical Cancer Research, 14, 5198–5208.
- Van’t Veer et al. (2002) Van’t Veer, L. J., Dai, H., Van De Vijver, M. J., He, Y. D., Hart, A. A., Mao, M., Peterse, H. L., Van Der Kooy, K., Marton, M. J., Witteveen, A. T. et al. (2002) Gene expression profiling predicts clinical outcome of breast cancer. nature, 415, 530–536.
- Verhaak et al. (2010) Verhaak, R. G., Hoadley, K. A., Purdom, E., Wang, V., Qi, Y., Wilkerson, M. D., Miller, C. R., Ding, L., Golub, T., Mesirov, J. P. et al. (2010) Integrated genomic analysis identifies clinically relevant subtypes of glioblastoma characterized by abnormalities in PDGFRA, IDH1, EGFR, and NF1. Cancer cell, 17, 98–110.
- Von Minckwitz et al. (2012) Von Minckwitz, G., Untch, M., Blohmer, J.-U., Costa, S. D., Eidtmann, H., Fasching, P. A., Gerber, B., Eiermann, W., Hilfrich, J., Huober, J. et al. (2012) Definition and impact of pathologic complete response on prognosis after neoadjuvant chemotherapy in various intrinsic breast cancer subtypes. J Clin Oncol, 30, 1796–1804.
- Wang et al. (2014) Wang, B., Mezlini, A. M., Demir, F., Fiume, M., Tu, Z., Brudno, M., Haibe-Kains, B. and Goldenberg, A. (2014) Similarity network fusion for aggregating data types on a genomic scale. Nature methods, 11, 333.
- Wang and Zhu (2008) Wang, S. and Zhu, J. (2008) Variable selection for model-based high-dimensional clustering and its application to microarray data. Biometrics, 64, 440–448.
- Williams-Gray and Barker (2017) Williams-Gray, C. H. and Barker, R. A. (2017) parkinson disease: Defining pd subtypes - a step toward personalized management? Nature Reviews Neurology, 13.
- Witten and Tibshirani (2010) Witten, D. M. and Tibshirani, R. (2010) A framework for feature selection in clustering. Journal of the American Statistical Association, 105, 713–726.
- Xie et al. (2008) Xie, B., Pan, W., Shen, X. et al. (2008) Penalized model-based clustering with cluster-specific diagonal covariance matrices and grouped variables. Electronic Journal of Statistics, 2, 168–212.
- Zhao et al. (2016) Zhao, J., Deng, Y., Jiang, Z. and Qing, H. (2016) G protein-coupled receptors (gpcrs) in alzheimer’s disease: a focus on bace1 related gpcrs. Frontiers in aging neuroscience, 8, 58.