Out-of-Dynamics Imitation Learning from Multimodal Demonstrations
Abstract
Existing imitation learning works mainly assume that the demonstrator who collects demonstrations shares the same dynamics as the imitator. However, the assumption limits the usage of imitation learning, especially when collecting demonstrations for the imitator is difficult. In this paper, we study out-of-dynamics imitation learning (OOD-IL), which relaxes the assumption to that the demonstrator and the imitator have the same state spaces but could have different action spaces and dynamics. OOD-IL enables imitation learning to utilize demonstrations from a wide range of demonstrators but introduces a new challenge: some demonstrations cannot be achieved by the imitator due to the different dynamics. Prior works try to filter out such demonstrations by feasibility measurements, but ignore the fact that the demonstrations exhibit a multimodal distribution since the different demonstrators may take different policies in different dynamics, which hinders learning an accurate measurement. We develop a better transferability measurement to tackle this newly-emerged challenge. We first design a novel sequence-based contrastive clustering algorithm to cluster demonstrations from the same mode to avoid the mutual interference of demonstrations from different modes and then learn the transferability of each demonstration with an adversarial-learning based algorithm in each cluster. Experiment results on several MuJoCo environments, a driving environment and a simulated robot environment show that the proposed transferability measurement more accurately finds and down-weights non-transferable demonstrations and outperforms prior works on the final imitation learning performance. We show the videos of our experiment results on our website.
Keywords: Imitation Learning, Out-of-Dynamics Imitation Learning
1 Introduction
Imitation learning is a widely-used policy learning paradigm to solve robotics and control tasks, which learns the policy from demonstrations [1, 2]. Standard imitation learning assumes that the demonstrator who collects the demonstrations shares the same dynamics with the imitator, which means that their state spaces, action spaces and the transition models are all the same [3, 4, 5]. However, such strict assumption limits the practical usage of imitation learning, especially when it is difficult to collect demonstrations in the imitator’s environment.
In this paper, we relax the assumption to that the demonstrator and the imitator share the same state space but the dynamics could be different, i.e., their action spaces and the transition models could be different. We name the new imitation learning setting as out-of-dynamics imitation learning (OOD-IL). The new assumption poses fewer requirements on the demonstrator and enables imitation learning to utilize a broader range of demonstrations. For example, in autonomous driving, to learn the policy of an autonomous vehicle in a new city, we may use the database of driving behavior of human vehicles containing useful information instead of manually collecting demonstrations on the autonomous vehicle. But such a database cannot be used by standard imitation learning since the vehicles have different dynamics and the city environments can be different. Furthermore, in real applications, it is often difficult and expensive to obtain enough data from a single source, thus it is beneficial to utilize data from a mixture of massive data sources for better real-world performance.


As shown in Figure 1(a), OOD-IL introduces a challenge that the mixture of demonstrations collected in different dynamics may not be achievable by the imitator, and thus are non-transferable. The state-of-the-art work constructs feasibility measurement to down-weight the non-transferable demonstrations by learning a unimodal policy from a feasibility-MDP (f-MDP) [6]. However, as shown in Figure 1(b), we notice that the prior work overlooks an important fact: the demonstrations collected from different demonstrators exhibit a multimodal distribution since different demonstrators may take different policies. The multimodal demonstrations make it difficult to learn a unimodal policy from the f-MDP as well as learn an accurate feasibility measurement. Furthermore, f-MDP suffers from slow and inaccurate optimization difficulties due to a step-by-step optimization procedure.
In this paper, we address OOD-IL with the above challenges by developing a better transferability measurement to determine how transferable each demonstration is for the imitator. To fully remove the interference from multimodal distribution, we design a sequence-based contrastive clustering algorithm to simultaneously learn a hidden space and cluster the trajectories in the hidden space, which ensures each cluster introduces a unimodal trajectory distribution. Then we learn the transferability for each cluster respectively by generative adversarial imitation learning (GAIL) [5], a much easier-to-optimize objective than f-MDP. The discriminator in GAIL distinguishes transitions from the demonstrators’ distribution to the imitators’ distribution, which serves as the transferability measurement to indicate the likelihood for a demonstration trajectory to be reproduced by the imitator. Experiment results on several MuJoCo environments, a driving environment, and a simulated Franka Panda Arm environment show that by reweighting demonstrations with the proposed transferability measurement, the final imitation learning policy outperforms all baselines and achieves the state-of-the-art performance.
2 Related Works
Standard Imitation Learning. Imitation learning learns a policy to imitate the behavior in demonstrations. Existing algorithms can be roughly categorized into three types: Behavior Cloning (BC), Inverse Reinforcement Learning (IRL), and Generative Adversarial Imitation Learning (GAIL). BC utilizes supervised learning to directly learn the policy from state-action pairs [7]. Following works propose dataset aggregation [3] or policy aggregation [8, 9] to address the compounding errors problem in BC. Torabi et al. [10] try to learn from state sequences by first recovering the actions through an inverse dynamics model and then conducting behavior cloning. IRL first recovers the reward function from demonstrations and then learns the policy using the learned reward [11, 12, 4, 13]. GAIL-based works match the occupancy measure between the learned policy and the demonstrations through adversarial learning to seek the optimal policy [5, 14]. Also, GAIL is demonstrated to successfully imitate state sequences [15, 16, 17]. However, all the methods assume that the demonstrator and the imitator share the same dynamics, which violates the assumption of OOD-IL.
Out-of-dynamics Imitation Learning. To address the OOD-IL problem, there are works learning a correspondence model [18] between the demonstrator and the imitator [19, 20, 21, 22, 23]. However, these methods assume that strict correspondence, i.e. a one-to-one mapping between the state spaces and action spaces, exists between the demonstrator and the imitator. This assumption can be violated in real-world applications, e.g., a 7-DoF robot arm and a 3-DoF robot arm have no such correspondence since some behavior of the 7-DoF robot cannot be realized by the 3-DoF robot. Recent works relax the assumption to that the demonstrator and the imitator only share the state space [24, 25]. One line of work aims to maximally follow the demonstrations [24, 26, 27, 28], but following the non-transferable demonstrations is impossible.
Cao et al. [25] develop a feasibility measurement to down-weight non-transferable demonstrations by learning an inverse dynamics model, but the learned inverse dynamics may not generalize to all the demonstrations. To address this difficulty, the state-of-the-art work improves the feasibility by learning the optimal policy in f-MDP [6]. However, f-MDP suffers from two limitations. Firstly, f-MDP enforces one unimodal policy to maximally imitate the demonstrations but the demonstrations with a multimodal distribution are hard to be modeled by such a policy. Secondly, at each time step, only when the policy is optimized in all prior time steps can it be optimized to maximize the reward at the current time step. Such inappropriate design makes it difficult and inefficient to learn the optimal policy of f-MDP. We instead use the discriminator in GAIL to learn the transferability measurement.
Contrastive Clustering. Unsupervised deep clustering methods with the aid of contrastive representation learning have been proposed for computer vision [29, 30, 31] and natural language processing [32]. To decompose the intrinsic multimodal distribution of demonstrations, we also adopt the intuition of jointly learning representations and clustering in an end-to-end manner. While prior works either focus on visual representations in the form of a single fixed-length vector [30, 31] or rely on data augmentations with a heavy computational burden [32], our Sequence-based Contrastive Clustering is unique in handling trajectory data with various sequential lengths, by utilizing simple and efficient down-sampling to construct positive pairs of contrastive learning.
3 Out-of-dynamics Imitation Learning
In OOD-IL, we aim to learn a policy for the agent of interest (the imitator) from demonstrations collected from multiple demonstrators with different dynamics from the imitator. Formally, we model both the demonstrators and the imitator as a standard Markov decision process (MDP) . Here is the state space, is the action space, is the transition probability and is the reward function, which is solely defined on states and shared between the demonstrators and the imitator. Such design aims to satisfy the basic requirement of imitation learning that the demonstrators and the imitator should finish the same task [24, 25]. is the shared discount factor. The action spaces and the transition probability of different demonstrators and the imitator are different. In particular, we use to indicate the MDP of the imitator. A policy for the imitator defines a probability distribution over the action space in a given state. The policy is evaluated by the expected return, which is defined by , where indicates the time step.
We formalize the policy learning as an imitation learning problem where the reward function is unknown. We aim to learn the policy from a set of demonstrations collected by different demonstrators where each trajectory is a sequence of states . Here we use state trajectories since different action spaces make it impossible to imitate actions. Since we put no assumption on the dynamics of the demonstrators, there is no guarantee that an optimal policy could be learned, e.g., in the extreme case, all the demonstrations could be non-transferable and a random policy will be learned. Our goal is to learn a policy with as high return as possible.
Since the dynamics of the demonstrators and the imitator are different, the transitions in the demonstrations may not be realizable by the imitator, i.e., no action in the imitator’s action space could make . Such demonstrations provide no useful information for the imitator and are non-transferable. However, given such a set of demonstrations from a mixture of demonstrators, it is non-trivial to directly test whether a trajectory is achievable by reproducing the trajectory in the target environment since there is no action in demonstrations. Furthermore, different demonstrators may take different policies due to different dynamics and may take different actions even at the same state111This work mainly focuses on the case where the dynamics are nearly-deterministic like robotic applications so unimodal policies can rarely realize multimodal demonstrations.. This multimodal distribution of the demonstrations makes prior works on transferability measurement ineffective. In this paper, we aim to remove the interference from the multimodal distribution of the demonstrations and learn transferability to mitigate the negative impact of non-transferable demonstrations.
3.1 Sequence-based Contrastive Clustering
Since directly imitating from a mixture of demonstrations will make a unimodal policy suffer, we need to fully capture and decompose the intrinsic multimodal distribution of data collected from different demonstrators. Thus, we cluster demonstrations before learning their transferability to make sure they belong to a unimodal distribution. Motivated by contrastive learning [33], we learn a sequence feature extractor and a distance metric in the sequence feature space by contrastive learning over carefully-designed positive and negative pairs. We construct positive pairs by randomly subsampling fixed-length sub-trajectories from the same demonstration and treat sub-trajectories of different demonstrations as negative pairs. Such a design satisfies our requirement since the positive pairs are from the same trajectory, and thus are from the same mode. At each batch, we first sample trajectories from and for each trajectory , we take two sub-trajectories and . We then derive the contrastive learning loss for this batch of sub-trajectories as follows:
| (1) |
where is the feature extractor modeled as a recurrent neural network and indicates the cosine distance. The loss maximizes the cosine similarity of features between positive pairs.
We embed contrastive learning into clustering to simultaneously ensure that the positive pairs are close and the clustering structure is learned. We first initialize a matrix of size , where is the dimension of the output of and each column of represents the center of cluster , with clusters in total. For each input sub-trajectory , we assign a one-hot cluster label as follows:
| (2) |
where we assign the cluster label with the nearest cluster center to a sub-trajectory. Then we introduce the clustering objective with the contrastive learning loss embedded into it:
| (3) |
Every time we update the feature extractor , we reassign the cluster label of each sub-trajectory by Eqn. (2) and update the cluster center by the following process:
| (4) |
where is an indicator taking only when the condition is satisfied and otherwise, and automatically controls the learning rate. We simultaneously optimize the contrastive learning objective and the clustering objective to encourage them to benefit from each other, where the cluster structure is learned to keep trajectories from the same mode to be in the same cluster. Our contrastive clustering algorithm derives clusters of trajectories , where contains trajectories with cluster label . We show the algorithm procedure in Appendix.

3.2 Adversarial Transferability Measurement
Given that the sequence-based contrastive clustering algorithm removes the mutual interference of demonstrations from different modes, we then learn the transferability within each cluster. We design a new transferability measurement by an adversarial-learning algorithm based on generative adversarial imitation learning (GAIL) [5]. Our key insight is that the GAIL discriminator output indicates the likelihood for a state transition to either come from the demonstration distribution or the policy distribution. We train a GAIL policy and a GAIL discriminator for each cluster of trajectories. The loss is defined as follows:
| (5) |
Here indicates the current policy in training and indicates the discriminator. We use label for the state transitions in the demonstrations and for the state transitions collected from the policy.
After convergence, the discriminator for each mode outputs a value in reflecting how likely an input transition is drawn from the state transition distribution derived by the imitator’s policy. Thus for a state transition in the demonstrations, if it has a discriminator output close to , it is more possible to be drawn from the imitator’s policy and achievable by the imitator. Thus, we quantify the transferability for a state transition as follows:
| (6) |
Note that the discriminator is strengthened by the adversarial training paradigm and thus has a strong ability to discriminate whether a transition is from the demonstrations or the imitator’s policy. The optimization of the discriminator is demonstrated to be efficient and effective [5], which requires no time-consuming step-by-step optimization in f-MDP [6].
Transferablity-sampling Imitation Learning. We finally embed the transferability quantified by Eqn. (6) into imitation learning. We normalize the transferability of all the state transitions into a sampling distribution, where state transitions with larger transferability will be sampled more often:
| (7) |
Using the fixed sampling distribution , we can embed our transferability into any imitation-learning-from-observations algorithm [10, 5, 14]. We use GAIL [5] here to train the final policy:
| (8) |
4 Experiments
We experiment with three MuJoCo environments, a simulated Driving environment, and a simulated Franka Panda Arm environment. We compare our approach with a standard imitation learning algorithm: GAIL [5], imitation learning with a measure of feasibility: ID [25] and f-MDP [6]. The original ID learns the inverse dynamics model from random trajectories far from demonstrations and thus makes the learned inverse dynamics not work well on demonstrations. We create an advanced ID baseline by learning a GAIL policy to generate trajectories as the data for inverse dynamic learning. Such trajectories are closer to demonstrations and make the inverse dynamics work better on demonstrations. We call the original ID as ID-Random and the advanced ID as ID-GAIL.
We further conduct analyses including an ablation study to verify the efficacy of each component and include a visualization of the learned transferability, the results for different compositions of demonstrations, and the performance gain when we are given a larger budget to collect demonstrations in the Appendix. Code is available at https://github.com/EvieQ01/OODIL.
4.1 MuJoCo

Environments. We illustrate the environments in Figure 3. The HalfCheetah is an agent with two legs and a body. We create different dynamics by discounting the force of the front leg and the back leg with two factors and respectively. We create a mixture of demonstrators by setting as (i) , (ii) , (iii) , (iv) . The imitator has the original force: as . The Hopper is an agent with one leg consisting of joints. We create different dynamics by varying the gravitational constant. We create a mixture of demonstrators by setting the gravitational constant as (i) , (ii) , (iii) , (iv) . For the imitator, we use a gravitational constant of . The Walker2d is an agent with two legs where each leg consists of joints. We create different dynamics by using different frictions for the feet, i.e., the link that touches the ground. We create a mixture of demonstrators by setting the friction as (i) , (ii) , (iii) , (iv) . For the imitator, we use a friction of . For all three MuJoCo environments, we follow prior works [6, 25] to collect fewer demonstrations from more transferable environments. We collect demonstrations respectively for four dynamics in HalfCheetah, for Hopper and for Walker2d with interaction steps per demonstration. We train expert agents with Trust Region Policy Optimization (TRPO) [34] to generate demonstrations.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/89d7c622-959b-42e0-8cf0-6fa09a1c2ccd/x5.png)
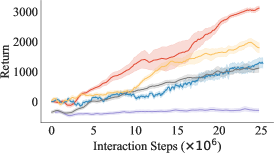

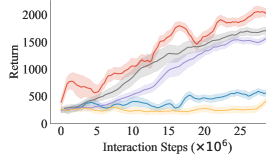
Results. We show the expected return w.r.t. the number of interaction steps for the three environments in Figure 4. In all three environments, we observe that the proposed method achieves the highest return. The baselines even show lower performance than naive GAIL under such multimodal distribution of source demonstrations because f-MDP learns a unimodal policy from the multimodal trajectory distribution, which cannot realize the demonstration trajectories, while ID fails to learn an accurate inverse dynamics model from random trajectories. The results demonstrate the importance of clustering trajectories of the same mode. By learning the transferability in each cluster, we can accurately filter out non-transferable demonstrations and learn from transferable demonstrations.
4.2 Driving
Environment. In the driving environment, we can easily decide and interpret whether the target car can reproduce the route in the demonstrations. As shown in Figure 5(a), we create a task where a car drives starting from anywhere at the bottom side and ends at the top side. Two obstacles are set with the center at width and width respectively. We create different dynamics by setting obstacles with different widths and setting different speeds for the car, which simulates a realistic scenario where different car models are driving at different places. The reward function is defined as for each interaction step, for reaching the goal, and for hitting the obstacle. In this environment, the different lengths and paths of the demonstration trajectories introduce a clear multimodal distribution, which can demonstrate the importance of clustering trajectories into an accurate mode. We create three demonstrators by setting the obstacles width as , and and setting the speed as , and respectively. For the target environment, we set the obstacle width as and the speed as . We collect , , and interaction steps of demonstrations from each source dynamics, by handmade rules.


Results. As is shown in Figure 5(b), we observe that the proposed method outperforms all other baselines. Though ID performs well at the first few interaction steps but the performance drops much then, which can be explained by that the feasibility learned by ID could find good demonstrations in the first few batches of data but makes errors then. That means ID can only learn partially correct feasibility. Instead, our method learns accurate transferability to filter out non-transferable demonstrations and converges stably to a high return. f-MDP, as the state-of-the-art method for filtering non-transferable demonstrations, could not work well on this multimodal distribution of demonstrations, further indicating the importance of clustering trajectories into the correct mode.
4.3 Simulated Franka Panda
Environment. The environment simulates the Franka Panda Robot Arm222https://www.franka.de/ with degrees of freedom (DoF), which is implemented in the PyBullet [35]. We create a task of pushing a box from one side of the desk to the other. With the box set at a base position and the robot arm set at a random position with Gaussian distribution, we set the target at the right of the desk. We create different dynamics by disabling different joints of the Robot arm. As shown in Figure 6(a), we create three demonstrators by disabling the No. , , and joint respectively while disabling the No. and joints for the target imitator. The environment aims to address a real problem to leverage historical data on any robot to learn a policy for a new robot. Similar to the MuJoCo environment, we import more demonstrations from the more dissimilar demonstrator, where the number of interaction steps is , , and for the environment disabling No. , , and respectively. The reward function is defined as the current distance to the starting point, and an extra for the box reaching the other side of the table and for the box dropping to the ground or the robot going past the box to the other side of the desk. We make demonstrations by handmade rules.


Results. The expected return w.r.t. the number of interaction steps is shown in Figure 6(b). Our proposed method outperforms all the baselines by a large margin. Directly applying GAIL introduces a low performance, which indicates that the demonstrations from other robots cannot be directly utilized to learn a new robot. The experiments show that the proposed method can serve as a data cleaning step to clean the dataset from other robots for a real-robot transfer learning problem.
4.4 Analysis

Ablation Study. To verify that both our contrastive clustering algorithm and the adversarial-learning based algorithm contribute to the final performance, we compare the performance of our method with its variants by removing the clustering step and learning the transferability directly from the whole set of demonstrations (Ours w/o Cluster), and removing both clustering and the transferability (Ours w/o Cluster, Tran), which directly imitates the whole set of demonstrations. We conduct these experiments in the Driving environment.
The results are shown in Figure 7. We observe that Ours outperforms Ours w/o Cluster, which demonstrates that clustering trajectories within the same mode is important and our contrastive clustering algorithm achieves this goal. Ours w/o Cluster outperforms Ours w/o Cluster, Tran, which demonstrates that transferability is important to filter out non-transferable demonstrations and learn from more transferable ones.
5 Conclusion
We propose a new approach to address out-of-dynamics imitation learning (OOD-IL). Noticing that the demonstrations exhibit a multimodal distribution, we propose a sequence-based contrastive clustering algorithm to make trajectories from the same mode fall into the same cluster. We then propose an adversarial-learning based algorithm to learn the transferability of each cluster with the discriminator output. Experimental results on three MuJoCo environments, a driving environment, and a simulated robot environment show that the proposed method can learn a transferability measure to accurately filter out non-transferable demonstrations and learn from more transferable ones.
Limitations and future work. While our work has substantially advanced OOD-IL, we believe that this problem merits further study. One primary limitation of our current method is that our method may not afford the computational cost of transferability learning when the number of clusters increases to hundreds or thousands. Pre-training or meta-training [36] before transferability learning may help boost learning efficiency, which is left for future work. A limitation of deploying our method into a real system is that it may not respect safety constraints due to exploration during both transferability learning and imitation learning. Although this challenge is common for real systems, out-of-dynamics learning may exacerbate it and safe policy learning techniques can be adopted. Another promising future direction is to exploit a wider variety of demonstrations, thus enabling large-scale imitation learning. Although our work relaxes the stringent assumption of identical dynamics, it is also limited since we assumed that collected demonstrations are optimal in the target environment, while it might not hold true in varying dynamics. In the future, we plan to address this combined challenge of multimodal OOD-IL and learning from sub-optimal demonstrations [37].
Acknowledgments
We would like to acknowledge the support of our wonderful coworkers: Yang Shu, Baixu Chen, Haixu Wu, and Yipeng Huang, whose generous help is an integral part of this work. This work was supported by the National Key Research and Development Plan (2020AAA0109201), National Natural Science Foundation of China (62022050 and 62021002), Beijing Nova Program (Z201100006820041), and BNRist Innovation Fund (BNR2021RC01002).
References
- Zhang et al. [2018] T. Zhang, Z. McCarthy, O. Jow, D. Lee, X. Chen, K. Goldberg, and P. Abbeel. Deep imitation learning for complex manipulation tasks from virtual reality teleoperation. In ICRA, 2018.
- Codevilla et al. [2018] F. Codevilla, M. Müller, A. López, V. Koltun, and A. Dosovitskiy. End-to-end driving via conditional imitation learning. In ICRA, 2018.
- Ross et al. [2011] S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In AISTATS, 2011.
- Ziebart et al. [2008] B. D. Ziebart, A. L. Maas, J. A. Bagnell, and A. K. Dey. Maximum entropy inverse reinforcement learning. In AAAI, 2008.
- Ho and Ermon [2016] J. Ho and S. Ermon. Generative adversarial imitation learning. In NeurIPS, 2016.
- Cao et al. [2021] Z. Cao, Y. Hao, M. Li, and D. Sadigh. Learning feasibility to imitate demonstrators with different dynamics. In CoRL, 2021.
- Bain and Sammut [1995] M. Bain and C. Sammut. A framework for behavioural cloning. In Machine Intelligence 15, 1995.
- Daumé et al. [2009] H. Daumé, J. Langford, and D. Marcu. Search-based structured prediction. Machine learning, 2009.
- Ross and Bagnell [2010] S. Ross and D. Bagnell. Efficient reductions for imitation learning. In AISTATS, 2010.
- Torabi et al. [2018] F. Torabi, G. Warnell, and P. Stone. Behavioral cloning from observation. In IJCAI, 2018.
- Abbeel and Ng [2004] P. Abbeel and A. Y. Ng. Apprenticeship learning via inverse reinforcement learning. In ICML, 2004.
- Ng et al. [2000] A. Y. Ng, S. J. Russell, et al. Algorithms for inverse reinforcement learning. In ICML, 2000.
- Finn et al. [2016] C. Finn, S. Levine, and P. Abbeel. Guided cost learning: Deep inverse optimal control via policy optimization. In ICML, 2016.
- Fu et al. [2018] J. Fu, K. Luo, and S. Levine. Learning robust rewards with adverserial inverse reinforcement learning. In ICLR, 2018.
- Schroecker and Isbell [2017] Y. Schroecker and C. L. Isbell. State aware imitation learning. In NeurIPS, 2017.
- Torabi et al. [2019] F. Torabi, G. Warnell, and P. Stone. Generative adversarial imitation from observation. In ICML Workshop on Imitation, Intent, and Interaction (I3), 2019.
- Sun et al. [2019] W. Sun, A. Vemula, B. Boots, and D. Bagnell. Provably efficient imitation learning from observation alone. In ICML, 2019.
- Nehaniv et al. [2002] C. L. Nehaniv, K. Dautenhahn, et al. The correspondence problem. Imitation in animals and artifacts, 41, 2002.
- Englert et al. [2013] P. Englert, A. Paraschos, J. Peters, and M. P. Deisenroth. Addressing the correspondence problem by model-based imitation learning. In ICRA Workshop on Autonomous Learning, 2013.
- Calinon et al. [2007] S. Calinon, F. Guenter, and A. Billard. On learning, representing, and generalizing a task in a humanoid robot. IEEE Transactions on Systems, Man, and Cybernetics, 2007.
- Eppner et al. [2009] C. Eppner, J. Sturm, M. Bennewitz, C. Stachniss, and W. Burgard. Imitation learning with generalized task descriptions. In ICRA, 2009.
- Zhang et al. [2021] Q. Zhang, T. Xiao, A. A. Efros, L. Pinto, and X. Wang. Learning cross-domain correspondence for control with dynamics cycle-consistency. In ICLR, 2021.
- Wang et al. [2022] Z. Wang, Z. Cao, Y. Hao, and D. Sadigh. Weakly supervised correspondence learning. arXiv preprint arXiv:2203.00904, 2022.
- Liu et al. [2019] F. Liu, Z. Ling, T. Mu, and H. Su. State alignment-based imitation learning. In ICLR, 2019.
- Cao and Sadigh [2021] Z. Cao and D. Sadigh. Learning from imperfect demonstrations from agents with varying dynamics. IEEE Robotics and Automation Letters (RA-L), 2021.
- Sharma et al. [2018] P. Sharma, L. Mohan, L. Pinto, and A. Gupta. Multiple interactions made easy (mime): Large scale demonstrations data for imitation. In CoRL, 2018.
- Gangwani and Peng [2020] T. Gangwani and J. Peng. State-only imitation with transition dynamics mismatch. In ICLR, 2020.
- Radosavovic et al. [2020] I. Radosavovic, X. Wang, L. Pinto, and J. Malik. State-only imitation learning for dexterous manipulation. arXiv preprint arXiv:2004.04650, 2020.
- Caron et al. [2018] M. Caron, P. Bojanowski, A. Joulin, and M. Douze. Deep clustering for unsupervised learning of visual features. In ECCV, 2018.
- Zhong et al. [2020] H. Zhong, C. Chen, Z. Jin, and X.-S. Hua. Deep robust clustering by contrastive learning. arXiv preprint arXiv:2008.03030, 2020.
- Li et al. [2021] Y. Li, P. Hu, Z. Liu, D. Peng, J. T. Zhou, and X. Peng. Contrastive clustering. In AAAI, 2021.
- Zhang et al. [2021] D. Zhang, F. Nan, X. Wei, S. Li, H. Zhu, K. McKeown, R. Nallapati, A. Arnold, and B. Xiang. Supporting clustering with contrastive learning. In NAACL, 2021.
- Chen et al. [2020] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. In ICML, 2020.
- Schulman et al. [2015] J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz. Trust region policy optimization. In ICML, 2015.
- Coumans and Bai [2016] E. Coumans and Y. Bai. Pybullet, a python module for physics simulation for games, robotics and machine learning. 2016.
- Finn et al. [2017] C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In ICML, 2017.
- Wu et al. [2019] Y.-H. Wu, N. Charoenphakdee, H. Bao, V. Tangkaratt, and M. Sugiyama. Imitation learning from imperfect demonstration. In ICML, 2019.
Appendix A Contrastive Clustering Algorithm
With the objectives introduced in the main text, we show our full contrastive clustering algorithm in Algorithm 1.
Appendix B Details for Contrastive Clustering
We further discuss the considerations of the design of contrastive clustering algorithm. Firstly, for varied-length sequences, it is difficult to design a proper distance metric to ensure that trajectories from the same mode are close, because common distance metrics such as per-step L2 or cosine distance on states cannot be used. Thus, contrastive learning is a good choice for learning the distance metric in a latent space for clustering. Secondly, separating contrastive learning and clustering into two stages may not find the optimal hidden space for clustering, while co-optimizing them can make them benefit from each other.
Implementation Details. For the implementation of the contrastive learning algorithm, in the subsampling step, we fix the length of the sub-trajectories, which is no longer than steps since RNN usually suffers from catastrophic forgetting with long sequences. For the MuJoCo environment, the sub-trajectory length is fixed at . For the Driving environment, the sub-trajectory length is fixed at . For the Simulated Robot environment, the sub-trajectory length is fixed at . For training, we randomly sample the sub-trajectories with a fixed stride and make sure each sub-trajectory has the same length. After convergence, we use the representation of a sub-trajectory for clustering. We set the batch size of contrastive clustering as . We first pre-train the feature extractor only with the contrastive learning loss for iterations before initializing and then train with the whole loss for iterations. For the number of clusters , we set it as , , and at initialization for MuJoCo, Driving, and Robot Arm respectively. For the feature extractor, we use a one-layer LSTM model to extract representation for trajectories and set the dimension for the hidden state as . The hyper-parameter is fixed to for all three environments. Learning rate is fixed to with Adam optimizer.
Appendix C Additional Experimental Results
C.1 Parameter Sensitivity


There are two key hyperparameters: cluster number and the trade-off weight between and in our method. We investigate the sensitivity of the performance of our method to the hyperparameters. We show the expected return after convergence under different hyperparameters in Figure 8. The solid lines with shades show the mean and standard deviation of the expected return of our method and the dashed lines on top show the oracle optimal performance that the policy may achieve by only selecting and learning from the optimal demonstrations.
Results. We observe that when is small, the converged model suffers from high variance and lower mean return, as a small number of clusters are not sufficient to capture all single modalities. Meanwhile, our method with larger achieves consistent performance, because more clusters guarantee a clear separation between different modalities. Once the cluster number is enough to capture all the modalities, more clusters do not improve the performance. Nevertheless, we note that larger brings extra computational cost since every cluster requires training a GAIL model, so we set to , , and respectively for environments in consideration of the trade-off between efficiency and effectiveness. For the sensitivity of , we find that our framework works well under the value of ranging from to , and leads to a severe drop in performance, mainly because too much emphasis on will cause all samples to collapse into one or two clusters and the contrastive clustering algorithm becomes unable to separate different modalities.
Discussion on the choice of . While in real scenarios when is unknown to us, we can estimate it empirically by dimension reduction and then visualizing trajectories. If one wants to get an optimal K, a grid search around this approximation may be needed, but often an approximation is good enough. Note that the number of modes has no direct relationship with the number of source domains, especially in a real-world scenario: data can be collected every day, and each day can be seen as a source, but they may all fall into a certain number of modes, i.e., the number of modes will not increase unlimitedly. After contrastive clustering, transferability learning on each cluster can be done in parallel, which can save time. Only a subset of demonstrations can also be easier to fit, compared to fitting the whole dataset, which also boosts learning efficiency.
C.2 Visualization of Transferability
We visualize the transferability computed by the proposed method as well as all our baselines on the Driving environment. As is shown in Figure 9, the deeper the color, the higher transferability of the trajectory. We can observe that our method can mostly filter out non-transferable demonstrations (red arrow) for the target environment while assigning high transferability for transferable ones (green arrow).

C.3 Effect of the Ratio of Transferable and Non-transferable Demonstrations
To investigate the influence of the composition of the demonstrations on the final imitation performance, we conduct experiments on three MuJoCo environments with different ratios of the demonstrations from the four source demonstrators. For Hopper, we set the gravitational constant as (i) , (ii) , (iii) , (iv) . We fix the number of trajectories for (i) and (ii), i.e. relatively transferable demonstrations, and change the number of trajectories for (iii) and (iv). For Walker2d, we set friction to (i) , (ii) , (iii) , (iv) . For HalfCheetah, the compositions of demonstrations are set the same as in original paper, which is (i) (, ), (ii) (, 1), (iii) (, ), (iv) (, ) with setting (, ) as the discount factor of the force of the front leg and the back leg. The ratio configurations and the results are shown in Table 1, Table 2, Table 3 respectively for three environments.
We observe that in the Hopper environment, with the increase of non-transferable trajectories, the performance of naive GAIL deteriorates and other baselines also drop dramatically due to the multimodal distribution effect, while our method shows stable performance with a high return against the changes in the composition of the source demonstrations. Moreover, comparing with the converged result of our method under different ratios, we observe that increasing non-transferable trajectories does not influence the final return of our method much, which indicates that our transferability measurement stably and accurately filters out non-transferable trajectories. Even for the easiest setting: with an equal number of transferable and non-transferable demonstrations, our method still outperforms GAIL. The results show that non-transferable demonstrations consistently influence imitation learning performance and measurement to filter out non-transferable demonstrations is important. Experiments on the other environments show similar results, demonstrating the robustness of our method under various scenarios.
| Composition | Naive GAIL | fMDP | ID w/o GAIL | ID w/ GAIL | Ours |
|---|---|---|---|---|---|
| 2926468 | 2947412 | 1547362 | 2287315 | 3259198 | |
| 2845360 | 2662699 | 1335787 | 2022253 | 3261206 | |
| 2761358 | 2361537 | 1176154 | 1042730 | 3104340 | |
| 2137685 | 2791468 | 836218 | 1314412 | 3049331 | |
| 1083244 | 1040760 | 908191 | 71482 | 3113413 | |
| 739184 | 1276458 | 764260 | 671126 | 2890556 |
| Composition | Naive GAIL | fMDP | ID w/o GAIL | ID w/ GAIL | Ours |
|---|---|---|---|---|---|
| 318290 | 283190 | 1688218 | 1703175 | 2077216 | |
| 28872 | 24937 | 34592 | 32839 | 173173 | |
| 32765 | 21348 | 31129 | 34930 | 1664166 | |
| 28774 | 339131 | 34573 | 32064 | 162987 |
| Composition | Naive GAIL | fMDP | ID w/o GAIL | ID w/ GAIL | Ours |
|---|---|---|---|---|---|
| 2389897 | 404246 | 2031312 | 221086 | 3008117 | |
| 288284 | 247308 | 2126110 | 206786 | 2997209 | |
| 2201502 | 1613409 | -327119 | 1273546 | 3246134 | |
| 2367897 | 389232 | 1808146 | 1315414 | 298171 |
C.4 Additional Experiments on Simulated Robot
We also conduct additional experiments on simulated Franka Panda Arm to better verify our proposed method. We create three demonstrators by disabling the No. joints, the No. joint, and using fully-able joints respectively while disabling the No. joints for the target imitator. We import demonstrations with the number of interaction steps , , and for each source environment respectively. The reward function and the task are set as the same as that of the original task in the main paper. The result is shown in Fig. 10. Another setting is created similarly by disabling the No. joints, the No. , and the No. joint respectively while disabling the No. joints for the target imitator, with the result presented in Fig. 10.


C.5 Generalization to More Demonstrations
In real-world applications, there are situations where demonstrations in the original database are insufficient and new demonstrations are continuously collected from different sources to augment the database. We further demonstrate that the proposed method can use augmented demonstrations more effectively. We conduct experiments in the MuJoCo Walker2d experiment. We firstly collect , , and demonstrations from environment (i) , (ii) , (iii) , (iv) respectively. The demonstrations are not enough to learn an optimal policy, but our method can still learn a transferability model and f-MDP and ID can learn a feasibility model. Then we add , , and demonstrations from environment (v) , (vi) , and (vii) respectively. Then we require all the methods not to re-train the transferability or the feasibility model but directly predict the transferability or feasibility for new demonstrations. The experiments aim to test the generalization ability of the model to filter out non-transferable demonstrations.
As shown in Fig. 11(a), when we only have insufficient demonstrations, we observe that the proposed method still achieves the highest point compared with other baselines, which demonstrates that we are able to use the demonstrations more efficiently even when they are insufficient.
Moreover, in Fig. 11(b), we are given new demonstrations. To use them selectively, we first use our contrastive-clustering LSTM model to assign a cluster label to each demonstration according to Eqn. (2). We then generate the transferability for the new demonstrations with the GAIL model in that cluster according to Eqn. (6). Note that we do not re-train the clustering model here with the new demonstrations but directly apply the clustering model and the GAIL model for transferability to cluster new demonstrations. For a fair comparison, we finetune the policy starting from the same checkpoint achieved by our method. The proposed method achieves the highest performance, which means that the proposed method possesses the capability of generalizing to unseen demonstrations. This generalization to new demonstrations can be extremely meaningful, which serves as a practical method to satisfy our intention of continually collecting more useful information from multiple sources. We do not require any extra computation other than a one-time inference, which is efficient to use.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/89d7c622-959b-42e0-8cf0-6fa09a1c2ccd/x19.png)


C.6 Comparison with a K-means Variant

To demonstrate the significance of our Sequence-based Contrastive Clustering algorithm, we conducted the following experiments on the Driving environment by K-Means clustering with the number of clusters = (as the same in our method).
Specifically, we down-sampled each trajectory with a fixed stride to uniformly generate a fixed-length subsample, and applied the K-means algorithm directly to these sub-trajectories and therefore assign each trajectory to a cluster. Then, on each of these clusters, we learn the transferability respectively. The result of using transferability generated by K-Means clustering for the final imitation learning is presented in Fig. 12.
We observed that the lacking of a contrastive learning step may cause difficulty in obtaining a high-quality unimodal clustering, which is essential for learning an accurate transferability measurement, and further cause a final performance drop. One way our contrastive clustering method is superior to K-means is that performing K-means on uniformly random-sampled sub-trajectories may introduce high variance into the clustering results, while our method, which makes different subsamples of the same trajectory as positive pairs and minimize their distance in the hidden representation space, can mitigate such instability. Also, the extracted representations are used for clustering, so it is beneficial if they are learned with the clustering step in a coherent manner.