Ordinary Differential Equation-based CNN for Channel Extrapolation over RIS-assisted Communication
Abstract
The reconfigurable intelligent surface (RIS) is considered as a promising new technology for reconfiguring wireless communication environments. To acquire the channel information accurately and efficiently, we only turn on a fraction of all the RIS elements, formulate a sub-sampled RIS channel, and design a deep learning based scheme to extrapolate the full channel information from the partial one. Specifically, inspired by the ordinary differential equation (ODE), we set up connections between different data layers in a convolutional neural network (CNN) and improve its structure. Simulation results are provided to demonstrate that our proposed ODE-based CNN structure can achieve faster convergence speed and better solution than the cascaded CNN.
Index Terms:
Convolutional neural network, RIS, channel extrapolation, ordinary differential equation, sub-sample.I Introduction
With the increasing demands for communication services, the number of connected devices continues to augment exponentially and new, blossoming service requirements pose more constraints on the network. At the same time, the increased power consumption and hardware cost remain key issues [1]. A recent technological breakthrough that holds the potential to overcome these technological bottlenecks is reconfigurable intelligent surface (RIS). It can be coated on any environmental object in a cost-effective manner, thereby facilitating the large scale deployment. Due to the physical characteristics of RIS, it can reflect incident electromagnetic waves, and adjust their amplitude and phase in a controlled manner. In other words, RIS can manipulate the communication environment in an intelligent way. Furthermore, the reflection elements of RIS usually work in a passive state, which makes RIS have low power consumption [2]. Hence, RIS is considered as a promising technology and attracts more and more attention.
Similar to the case of other communication systems [3], the acquisition of channel state information (CSI) is an important problem and has become a hot research topic in RIS-assisted communication systems. In [4], Ardah et al. designed a two-stage channel estimation framework with high resolution. In [5], the atomic norm minimization was resorted to implement the channel estimation over RIS-aided MIMO system in the millimeter wave frequency band.
All of the above works depend on the hypothetical statistical model. However, in the actual communication scenario, the radio scattering conditions change rapidly with time and are very complicated. This makes the traditional methods have some limitations [3]. With the development of the artificial intelligence, the application of deep learning (DL) in RIS-aided systems has attracted extensive attention. In [6], the authors adopted fully connected neural networks to estimate the RIS channel and detect the symbols. In [7], Elbir et al. designed a twin convolutional neural network (CNN) to estimate the direct and the cascaded channel in a RIS-aided communication system. However, due to the passive characteristics of RIS, the channels from the source to RIS and that from RIS to destination are coupled, and the size of the equivalent channel is in scale with the number of the RIS elements, which is usually large enough to accurately manipulate an incoming electromagnetic (EM) field. Thus, it would cost many pilot resource to directly achieve the equivalent channel of large size at destination. Thus, how to reduce the overhead of the channel estimation is an interesting topic over the RIS-aided network. Recently, Taha et al. used a small part of RIS elements to sub-sample the channels, and optimize the beamforming vector of RIS with the channel estimated at the selected elements [8].
In this paper, we further examine the channel compression over the physical space for RIS-aided communication. After selecting a fraction of the RIS elements, we achieve the equivalent channel formed by the source, the destination and the chosen RIS elements. Then, we extrapolate the channels to all elements from those estimated at chosen elements, where DL is adopted. Furthermore, inspired by the ordinary differential equation (ODE), we modify the structure of the cascaded CNN by adding cross-layer connections, namely introducing coefficients and linear calculations between the network layers. The proposed ODE-based CNN can obtain more accurate solutions, and its performance can be verified to be better than the cascaded CNN.
II System And Channel Model
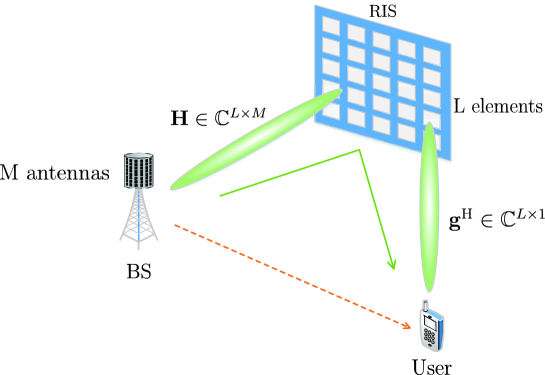
As shown in Fig. 1, let us consider an indoor scenario, where multiple-antenna base station (BS) communicates with a single-antenna user via RIS reflection. A BS is equipped with a uniform linear array (ULA) with antennas. RIS is in the form of a uniform planar array (UPA) and consists of elements, where and separately denotes the sizes along the horizontal and vertical dimensions. Moreover, the orthogonal frequency division multiplexing (OFDM) scheme is adopted and the number of subcarriers is . Since the indoor environment is easy to be blocked by objects or people, the direct channel between the BS and the user may be destroyed. Thus, we only consider the channel reflected by RIS, i.e., the cascaded channel, instead of the direct channel. Obviously, the cascaded channel consists of two parts: the link from the BS to the RIS, i.e., , and that from the RIS to the user, i.e., . The received signal at the -th subcarrier of the user can be given as
| (1) |
where is a diagonal matrix, i.e., , is the downlink transmitted signal at the -th sub-carrier, and is the addictive white Gaussian noise. Due to the lack of signal processing capability at RIS, is the same at different sub-carriers. Notice that in represents the phase shift introduced by each RIS element while controls this element’s on-off state, which will be described in the following. Moreover, the channel between BS and RIS at the -th subcarrier is given by
| (2) |
where is the complex channel gain along the -th scattering path at the carrier frequency , is the time delay, and , are the spatial steering vectors, with and as the azimuth angle and elevation angle of the receiver, respectively, and as the angle of departure (AoD). Correspondingly, can be written as
| (3) |
where the vector and the vector . is the carrier wavelength and denotes antenna spacing. Furthermore, represents the Kronecker product operator and represents the transpose. Moreover, can be given by
| (4) |
Correspondingly, the channel between the RIS and the user at the -th subcarrier is
| (5) |
where the structure of is similar to that of .
The cascaded channel matrix between BS and the user at the -th subcarrier can be defined as , where , and has a size of . Then, let us define the vector , where represents the -th column of . Within the RIS communication system, it is proved that the optimal is closely related with all the cascaded channels at subcarriers, i.e., [9]. Hence, our aim is to estimate .
III Proposed Channel Extrapolation Method
III-A Framework Design
Theoretically, we can send a pilot matrix of size to directly recover with the linear estimator, where represents the time duration of . From the Bayesian estimation theory, we can effectively recover when . However, in massive MIMO systems, both and are relatively large. Then, a significant number of pilot needs to be employed, which drastically decreases the spectrum efficiency of the transmission. To overcome this bottleneck, we can utilize a fraction of RIS elements and sub-sample . Without loss of generality, we set the number of the selected RIS elements as , which can be implemented through setting the parameters , in , . Specifically, for the chosen elements, we set their and as and 1, respectively. For others, the corresponding amplitude parameter is 0. After this operation, the size of the sub-sampled cascaded channel at the -th subcarrier is reduced to . Correspondingly, the sub-sampled cascaded channel at subcarriers can be written as . Obviously, compared with , a pilot sequence of shorter time duration would be required to estimate .
If the power of the pilot sequence is large enough, we can estimate with quite high accuracy. However, we should utilize to infer the unknown cascaded channel at the non-chosen RIS elements. Thus, in the following, we construct a DL-based framework to extrapolate from . It may be worth noting that the selection pattern for the RIS elements can impact the performance of the channel extrapolation and should be optimized. This topic is beyond the scope of this paper, though. Further, we adopt the uniform sampling scheme.
III-B ODE-based Channel Extrapolation
As mentioned above, the input of the network is , and its output is . The task of our network is to learn the mapping function from to . In other words, we want to estimate the complete channel through the sub-sample version, which is made possible by the correlation between different RIS elements.
The channel extrapolation is similar to the super-resolution in the field of image processing. For this kind of problem, CNN has great advantages and is very suitable to use the correlation between data elements for information completion. In order to get better network performance, we can increase the number of data layers or modify the network structure. However, more layers will result in higher calculational requirements. Moreover, when the number of layers reaches a certain number, the improvement become less and less. Sometimes, the excessive deepening of the network causes the gradient explosion and disappearance. Thus, optimizing the network structure is more widely used than simply deepening the neural network. Theoretically, if we add some proper connections between layers, the performance of the network may be better, like residual neural network (ResNet) [10].
Recently, ODE have been introduced to the neural network and utilized to describe the latent relation between different data layers [11]. With such powerful characterization, we could speed up the convergence and learning performance of the CNN. Moreover, with the development of mathematical science, it is possible to use the numerical solutions of differential equations to modify the network structure and obtain possible gains. Here, we incorporate two numerical approximation methods, i.e., LeapFrog and Runge-Kutta methods, into CNN. The main difference between them lies in the approximation accuracy.
: LeapFrog method is a second-order approximation scheme and can be written as
| (6) |
where denotes the derivative at and can be seen as an interval of width . Applying (6) for the CNN, we can connect the ()-th layer with the ()-th one. The corresponding relationship can be formulated as:
| (7) |
where represents the output data of the -th layer, and is an operation containing a ReLu activation function, a convolution layer and a multiplier.
Remark 1
The LeapFrog method is an improved version of the forward Euler equation, which can be written as . The forward Euler method is the simplest first-order approximation of ODE and has a similar structure with ResNet.
: The theory of the numerical ODEs suggests that a higher-order approximation results in less truncation error and higher accuracy. Hence, we turn to the Runge-Kutta methods, which are common numerical methods for ODE and can be expressed as [12]
| (8) |
and , while has the form of
| (9) |
where represents the number of stages; and , like in (8), are the related coefficients of the -th stage.
If we set , we obtain the 3-stage Runge-Kutta equation as the basic structure in our work, which can be expressed as
| (10) |
where , , can be separately written as
| (11) | ||||
| (12) | ||||
| (13) |

With (10) - (13), we can construct an improved CNN structure, referred to as RK3-Block and depicted in Fig. 2 (b). Correspondingly, the constraints among different layers in this block can be written as
| (14) | ||||
| (15) |
where the positions of , , are presented in Fig. 2 (b), and the operation contains two ReLu activation functions and two convolution layers. Similar to RK3-Block, with (7), we can obtain a modified CNN structure from the LeapFrog approximation and refer to it as LF-Block, which includes three data layers. As shown in Fig. 2 (a), we can cascade several RK3-Blocks or LF-Blocks to deepen the network for better results.
III-C Learning Scheme
The valid input of our network is the sub-sampled channel , and the label is the entire cascaded channel . In order to facilitate the training and the generation of data, we set the entries of related with the non-chosen RIS elements as 0 and obtain the resultant matrix , whose non-zero entries are same with those of . Correspondingly, we treat as the raw input of the ODE-based CNN.
Then, we reshape the raw input data and the label of the network as and , respectively. Both and are real-valued matrices with the size of . Correspondingly, the output of this network can be written as , where is the estimate of . In our proposed network, there are convolutional layers. In the -th layer, the input is processed by convolutional kernels of size . Note that and represent the height and the width of the convolutional kernels. Normally, the size of the output data in each convolutional layer depends on and , and it is usually slightly smaller than the input data.
During the learning stage, the parameter vector is optimized by minimizing the mean squared error (MSE) between the output and the target , where the vector contains all the model parameters of the -th layer, . Hence, the loss function can be written as
| (16) |
where is the norm of matrix and denotes the batch size for training. Here, the adaptive moment estimation (Adam) [13] algorithm is adopted to achieve the best , which is controlled by the learning rate .
| Layer | Output size | Activation | Kernel size | Strides |
|---|---|---|---|---|
| Conv2D | None | |||
| RK3-Block | ReLu | |||
| Conv2D | None |
| Sampling Rate | Method | |||||||
|---|---|---|---|---|---|---|---|---|
|
|
|
||||||
| 1/2 | 0.00001 / -39.59dB | 0.00002 / -35.53dB | 0.00003 / -32.37dB | |||||
| 1/4 | 0.00002 / -33.77dB | 0.00009 / -28.18dB | 0.00012 / -26.78dB | |||||
| 1/8 | 0.00086 / -18.12dB | 0.00133 / -16.25dB | 0.00151 / -15.69dB | |||||
| 1/16 | 0.0155 / -5.7dB | 0.01834 / -4.95dB | 0.01929 / -4.69dB | |||||
IV Simulation Results

In this section, we evaluate the channel extrapolation performance of ODE-based CNN through numerical simulation. We first describe the communication scenario and dataset source, and then show the parameters of the training network. Finally, we show the simulation results and explain the performance of our proposed network.
The scenario we consider is an indoor scene with user, BS and RIS. To generate this scenario, we resort to the indoor distributed massive MIMO scenario I1 of the DeepMIMO dataset, which is generated based on the Wireless InSite [14].
The ULA at BS has antennas, i.e., , while the size of the RIS’s UPA is , i.e., . The carrier frequency of channel estimation is GHz. The OFDM signal bandwidth is set as MHz, while the number of subcarriers is . The antenna spacing is , and the number of paths is . Furthermore, the activated users are located from the -st row to the -th row. Each row contains users, and the total number of users is . The users are split in two parts, i.e., the training and the test groups, according to the ratio . The sampling rate is separately set as and .
In the simulations, we adopt three network structures for comparison, i.e., the ODE-RK3 structure formed by some RK3-Blocks, the ODE-LF structure containing several LF-Blocks and the cascaded CNN network. For fairness, all CNNs have layers and the same number of parameters. The ODE-based network contains RK3-Blocks or LF-Blocks (each block consists of convolutional layers), a head convolutional layer and a tail convolutional layer. Considering ODE-RK3 structure as an example, we list the layer parameters of the CNN in TABLE I. Specially, in the hidden layers, the number of neurons is , and is adopted as the activation function, i.e., . The kernel size of the first convolutional layer is , and that of the remainder convolutional layers is set as . The learning rate is initialized as and decreases with increased iteration times. Specifically, after iterations, the learning rate reduces by for every epochs.
TABLE II shows the performance of different network structures. It can be noted that the proposed ODE CNN is always superior to the cascaded CNN network, and this gain enhances with the increase of the sampling rate . The RK3 structure with three-order performs better than the third-order LF structure. When sampling rates are and , the ODE-RK3 structure can achieve satisfactory results. Furthermore, in terms of channel extrapolation normalized MSE (NMSE), the ODE-RK3 network at performs better than the CNN network at , which means that the length of the pilot for the sub-sampled channel estimation can be reduced through introducing the ODE structure. If the compression ratio is relatively low, such as , the performance of the ODE-based CNN is not significantly better than that of the cascaded CNN due to the reduced raw input information for the channel extrapolation.

Fig. 3 depicts the curves of NMSE with respect to the number of epochs. Two structures (the ODE-RK3 and cascaded CNN structures) and two sample rates ( and ) are considered here. It can be seen that with the increase of iteration time, all the NMSE curves present a downward trend and reach the stable levels after epochs. Furthermore, for a given sampling rate, the NMSEs of the ODE-based CNN are always lower than those of the cascaded CNN. Fig. 4 depicts the training loss of different CNN structures versus epochs. It can be checked from Fig. 4 that, with fixed rate , the training loss in the ODE-RK3 network decreases faster than that in the cascaded CNN network, which means that the ODE-based network can be trained more quickly than CNN.

So far, we considered the channel extrapolation at the same frequency band. However, our proposed scheme can still be used for the case with frequency difference. In actual systems, such as the frequency division duplexing system, the uplink and downlink channels operate in different frequency bands. Fig. 5 shows the performance of the ODE-RK3 and the cascaded CNN structures under different frequency gaps. As can be seen from Fig. 5, both ODE-RK3 and CNN structures are affected by the frequency gaps. As the frequency difference increases, the NMSE of channel extrapolation slightly augments. It is worth noting that the ODE-RK3 structure always performs better than cascaded CNN, which proves the stability and effectiveness of the proposed ODE-based CNN.
V Conclusion
In this paper, we have examined a RIS-assisted MIMO communication system, and designed an ODE-based CNN to extrapolate the cascaded channel. In our scheme, only part of the full CSI is needed. Hence, some of the RIS elements could be turned off through spatial sampling, which greatly reduces the length of the pilot sequence in the channel estimation phase and improves the resource utilization. Simulation results have demonstrated that the proposed extrapolation scheme can effectively compress the large-scale RIS channel over the physical space. Moreover, the ODE-based structure can speed up the convergence and improve the performance of the cascaded CNN.
References
- [1] F. Rusek, D. Persson, B. K. Lau, E. G. Larsson, T. L. Marzetta, O. Edfors, and F. Tufvesson, “Scaling up MIMO: Opportunities and challenges with very large arrays,” IEEE Signal Process. Mag., vol. 30, no. 1, pp. 40–60, Jan. 2013.
- [2] W. Yan, X. Yuan, Z. He, and X. Kuai, “Passive beamforming and information transfer design for reconfigurable intelligent surfaces aided multiuser MIMO systems,” IEEE J. Sel. Areas Commun., pp. 1–1, 2020.
- [3] J. Ma, S. Zhang, H. Li, F. Gao, and S. Jin, “Sparse Bayesian learning for the time-varying massive MIMO channels: Acquisition and tracking,” IEEE Trans. Commun., vol. 67, no. 3, pp. 1925–1938, Mar. 2019.
- [4] K. Ardah, S. Gherekhloo, A. L. F. de Almeida, and M. Haardt, “TRICE: An efficient channel estimation framework for RIS-aided MIMO communications,” arXiv:2008.09499, 2020. [Online]. Available: https://arxiv.org/abs/2008.09499.
- [5] J. He, H. Wymeersch, and M. Juntti, “Channel estimation for RIS-aided mmWave MIMO systems via atomic norm minimization,” arXiv:2007.08158, 2020. [Online]. Available: https://arxiv.org/abs/2007.08158.
- [6] S. Khan, K. S Khan, N. Haider, and S. Y. Shin, “Deep-learning-aided detection for reconfigurable intelligent surfaces,” arXiv:1910.09136, 2020. [Online]. Available: https://arxiv.org/abs/1910.09136.
- [7] A. M. Elbir, A. Papazafeiropoulos, P. Kourtessis and S. Chatzinotas, “Deep channel learning for large intelligent surfaces aided mm-wave massive MIMO systems,” IEEE Wireless Commun. Lett., vol. 9, no. 9, pp. 1447-1451, Sept. 2020.
- [8] A. Taha, M. Alrabeiah, and A. Alkhateeb, “Enabling large intelligent surfaces with compressive sensing and deep learning,” arXiv:1904.10136v2, 2019. [Online]. Available: https://arxiv.org/abs/1904.10136v2.
- [9] S. Lin, B. Zheng, G. C. Alexandropoulos, M. Wen, M. Di Renzo, and F. Chen, “Reconfigurable intelligent surfaces with reflection pattern modulation: Beamforming design and performance analysis,” IEEE Wireless Commun. Lett., pp. 1-1, Oct. 2020.
- [10] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, pp. 770-778, Dec. 2016.
- [11] R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. Duvenaud, “Neural ordinary differential equations,” arXiv:1806.07366v5, 2019. [Online]. Available: https://arxiv.org/abs/1806.07366.
- [12] X. He, Z. Mo, P. Wang, Y. Liu, M. Yang, and J. Cheng, “ODE-inspired network design for single image super-resolution,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, pp. 1732-1741, Jun. 2019.
- [13] O. P. Kingma and J. Ba, “ADAM: A method for stochastic optimization,” arXiv:1412.6980, 2014, [Online]. Available: https://arxiv.org/abs/1412.6980
- [14] A. Alkhateeb, “DeepMIMO: A generic deep learning dataset for millimeter wave and massive MIMO applications,” in Proc. Information Theory and Applications Workshop (ITA), San Diego, CA, pp. 1-8, Feb. 2019.