Optimum-statistical Collaboration Towards General and Efficient Black-box Optimization
Abstract
In this paper, we make the key delineation on the roles of resolution and statistical uncertainty in hierarchical bandits-based black-box optimization algorithms, guiding a more general analysis and a more efficient algorithm design. We introduce the optimum-statistical collaboration, an algorithm framework of managing the interaction between optimization error flux and statistical error flux evolving in the optimization process. We provide a general analysis of this framework without specifying the forms of statistical error and uncertainty quantifier. Our framework and its analysis, due to their generality, can be applied to a large family of functions and partitions that satisfy different local smoothness assumptions and have different numbers of local optimums, which is much richer than the class of functions studied in prior works. Our framework also inspires us to propose a better measure of the statistical uncertainty and consequently a variance-adaptive algorithm VHCT. In theory, we prove the algorithm enjoys rate-optimal regret bounds under different local smoothness assumptions; in experiments, we show the algorithm outperforms prior efforts in different settings.
1 Introduction
Black-box optimization has gained more and more attention nowadays because of its applications in a large number of research topics such as tuning the hyper-parameters of optimization algorithms, designing the hidden structure of a deep neural network, and resource investments (Li et al., 2018; Komljenovic et al., 2019). Yet, the task of optimizing a black-box system often has a limited budget for evaluations due to its expensiveness, especially when the objective function is nonconvex and can only be evaluated by an estimate with uncertainty (Bubeck et al., 2011b; Grill et al., 2015). Such limitation haunts practitioners’ deployment of machine learning systems and invites scientists’ investigation for the authentic roles of resolution (optimization error) and uncertainty (statistical error) in black-box optimization. Indeed, it raises a question of optimum-statistical trade-off: how can we better balance resolution and uncertainty along the search path to create efficient black-box optimization algorithms?


Among different categories of black-box optimization methods such as Bayesian algorithms (Shahriari et al., 2016; Kandasamy et al., 2018) and convex black-box algorithms (Duchi et al., 2015; Shamir, 2015), this paper focuses on the class of hierarchical bandits-based optimization algorithms introduced by (Auer et al., 2007; Bubeck et al., 2011b). These algorithms search for the optimum by traversing a hierarchical partition of the parameter space and look for the best node inside the partition. Existing results, such as Bubeck et al. (2011b); Grill et al. (2015); Shang et al. (2019); Bartlett et al. (2019); Li et al. (2022), heavily rely on some specific assumptions of the smoothness of the blackbox objective and the hierarchical partition. However, their assumptions are only satisfied by a small class of functions and partitions, which limits the scope of their analysis. To be more specific, existing studies all focus on optimizing “exponentially-local-smooth” functions (see; Eqn. (3)), which can have an exponentially increasing number of sub-optimums as the parameter space partition proceeds deeper (Grill et al., 2015; Shang et al., 2019; Bartlett et al., 2019). For instance, Grill et al. (2015) designed a difficult function (shown in Figure 1(a)) that can be optimized by many existing algorithms because it satisfies the exponential local-smooth assumption. However, functions and partitions that do not satisfy exponential local-smoothness, but with a bounded or polynomially increasing number of near-optimal regions have been overlooked in the current literature of black-box optimization. A simple example is Figure 1(b), which is not exponentially smooth but has a trivial unique optimum. Such a simple example depresses all previous analyses in existing studies due to their dependency on the exponential local-smoothness assumption. What is worse, different designs of the uncertainty quantifier can generate different algorithms and thus may require different analyses. Consequently, a more unified theoretical framework to manage the interaction process between the optimization error flux and the statistical error flux is desirable and beneficial towards general and efficient black-box optimization.
In this work, we deliver a generic perspective on the optimum-statistical collaboration inside the exploration mechanism of black-box optimization. Such a generic perspective holds regardless of the local smoothness condition of the function or the design of uncertainty quantification, generalizing its applicability to a larger class of functions (e.g., Figure 1(b)) and algorithms with different uncertainty quantification methods. Our analysis for the proposed general algorithmic framework only relies on mild assumptions. It allows us to analyze functions with different levels of smoothness and also inspired us to propose a variance-adaptive black-box algorithm VHCT.
In summary, our contributions are:
-
•
We identify two decisive components of exploration in black-box optimization: the resolution descriptor (Definition 1) and the uncertainty quantifier (Definition 2). Based on the two components, we introduce the optimum-statistical collaboration (Algorithm 1), a generic framework for collaborated optimism in hierarchical bandits-based black-box optimization.
-
•
We provide a unified analysis of the proposed framework (Theorem 3.1) that is independent of the specific forms of the resolution descriptor and the uncertainty quantifier. Due to the flexibility of the resolution descriptor, this analysis includes all black-box functions who satisfy the general local smoothness assumption (Condition (GLS)) and have a finite near-optimality dimension (Definition (1)), which are excluded from prior works.
-
•
Furthermore, the framework inspires us to propose a better uncertainty quantifier, namely the variance-adaptive quantifier (VHCT). It leads to effective exploration and advantages our bandit policy by utilizing the variance information learnt from past samplers. Theoretically, we show that the proposed framework secures different regret guarantees in the face of different smoothness assumptions, and VHCT leads to a better convergence when the reward noise is small. Our experiments validate that the proposed variance adaptive quantifier is more efficient than the existing anytime algorithms on various objectives.
Related Works. Pioneer bandit-based black-box optimization algorithms such as HOO (Bubeck et al., 2011b) and HCT (Azar et al., 2014) require complicated assumptions of both the the black-box objective and the parameter partition, including weak lipschitzness assumption. Recently, Grill et al. (2015) proposed the exponential local smoothness assumption (Eqn. (3)) to simplify the set of assumptions used in prior works and proposed POO to meta-tune the smoothness parameters. Some follow-up algorithms such as GPO (Shang et al., 2019) and StroquOOL (Bartlett et al., 2019) are also proposed. However, both GPO and StroquOOL require the budget number beforehand, and thus they are not anytime algorithms (Shang et al., 2019; Bartlett et al., 2019). Also, the analyses of these algorithms all rely on the exponential local smoothness assumption (Grill et al., 2015).
2 Preliminaries
Problem Formulation. We formulate the problem as optimizing an implicit objective function , where is the parameter space. The sampling budget (number of evaluations) is denoted by an unknown constant , which is often limited when the cost of evaluating is expensive. At each round (evaluation) , the algorithm selects a and receives an stochastic feedback , modeled by
where the noise is only assumed to be mean zero, bounded by for some constant , and independent from the historical observed algorithm performance and the path of selected ’s. Note that the distributions of are not necessarily identical. We assume that there exists at least one point such that it attains the global maximum , i.e., . The goal of a black-box optimization algorithm is to gradually find such that is close to the global maximum within the limited budget.
Regret Analysis Framework. We measure the performance of different algorithms using the cumulative regret. With respect to the optimal value , the cumulative regret is defined as
It is worth noting that an alternative measure of performance widely used in the literature (e.g., Shang et al., 2019; Bartlett et al., 2019) is the simple regret . Both simple and cumulative regrets measure the performance of the algorithm but are from different aspects. The former one focuses on the convergence of the algorithm’s final round output, and the latter cares about the overall loss during the whole algorithm training. The cumulative regret is useful in scenarios such as medical trials where ill patients are included in the each run and the cost of picking non-optimal treatments for all subjects shall be measured. This paper chooses to study the cumulative regret, while in the literature, there were discussions on the relationship between these two (Bubeck et al., 2011a).
Hierarchical partitioning. We use the hierarchical partitioning to discretize the parameter space into nodes, as introduced by Munos (2011); Bubeck et al. (2011b); Valko et al. (2013). For any non-negative integer , the set partitions the whole space . At depth , a single node covers the entire space. Every time we increase the level of depth, each node at the current depth level will be separated into two children; that is, Such a hierarchical partition naturally inspires algorithms which explore the space by traversing the partitions and selecting the nodes with higher rewards to form a tree structure, with being the root. We remark that the binary split for each node we consider in this paper is the same as in the previous works such as Bubeck et al. (2011b); Azar et al. (2014), and it would be easy to extend our results to the K-nary case (Shang et al., 2019). Similar to Grill et al. (2015), we refer to the partition where each node is split into regular, same-sized children as the standard partitioning.
Given the objective function and hierarchical partition , we introduce a generalized definition of near-optimality dimension, which is a natural extension of the notion defined by Grill et al. (2015).
Near-optimality dimension. For any positive constants and , and any function that satisfies , , we define the near-optimality dimension of with respect to the partition and function as
| (1) |
if exists, where is the number of nodes on level such that .
In other words, for each , is the number of near-optimal regions on level that are -close to the global maximum so that any algorithm should explore these regions. controls the polynomial growth of this quantity with respect to the function . It can be observed that this general definition of covers the near optimality dimension defined in Grill et al. (2015) by simply setting and the coefficient for some constants and .
The rationale of introducing the generalized notion is that, although the number of nodes in the partition grows exponentially when increases, the number of near-optimal regions of the objective function may not increase as fast, even if the near-optimal gap converges to 0 slowly. The particular choice of in Grill et al. (2015) indicates that , which may be over-pessimistic and makes it a non-ideal setting for analyzing functions that change rapidly and don’t have exponentially many near-optimal regions.
Such a generalized definition becomes extremely useful when dealing with functions that have different local smoothness properties, and therefore our framework can successfully analyze a much larger class of functions. We establish our general regret bound based on this notion of near-optimality dimension in Theorem 3.1.
It is worth mentioning that taking a slowly decreasing , although reduces the number of near-optimal regions, does not necessarily imply that the function is easier to optimize. As will be shown in Section 3 and 4, is often taken to be the local smoothness function of the objective. A slowly decreasing makes the function much more unsmooth than a function with exponential local smoothness, and hence is still hard to optimize.
Additional Notations. At round , we use to represent the maximum depth level explored in the partition by an algorithm. For each node , we use to denote the number of times it has been pulled and to denote the -th reward observed for the node, evaluated at a pre-specified within , which is the same as in Azar et al. (2014); Shang et al. (2019). Note that in the literature, it is also considered that follows some distribution supported on , e.g., Bubeck et al. (2011b).
3 Optimum-statistical Collaboration
This section defines two decisive quantities (Resolution Descriptor and Uncertainty Quantifier) that play important roles in the proposed optimum-statistical collaboration framework. We then introduce the general optimum-statistical collaboration algorithm and provide its theoretical analysis.
Definition 1.
(Resolution Descriptor ). Define to be the resolution for each level , which is a function that bounds the change of around its global optimum and measures the current optimization error, i.e., for any global optimum ,
| () |
where is the node on level in the partition that contains the global optimum .
Definition 2.
(Uncertainty Quantifier ). Let be the uncertainty estimate for the node at time , which aims to bound the statistical estimation error of , given pulled values from this node. Recall that is the number of pulls for node until time , and let be the online estimator of , we expect that ensures for some constant , where
| () |
With a slight abuse of notation, we rewrite as when no confusion is caused. When , is naturally taken to be since the node is never pulled. To ensure the above probability requirement holds, it is reasonable to make because when the number of pulls is fixed, the statistical error should not decrease.
Given the above definitions of the resolution descriptor and the uncertainty quantifier at each node, we introduce the optimum-statistical collaboration algorithm in Algorithm 1 that guides the tree-based optimum search path, under different settings of and .

The basic logic behind Algorithm 1 is that at each time , the selection policy will continuously search nodes from the root to leaves, until finding one node satisfying and then pull this node.
The end-goal of the optimum-statistical collaboration is that, after pulling enough number of times, the following relationship holds along the shortest path from the root to the deepest node that contains the global maximum (If there are multiple global maximizers, the process only needs to find one of them) :
| (2) |
with slightly abused notation of to represent the uncertainty quantifier of the -th node in the traverse path (refer to Figure 2). In other words, the two terms collaborate on the optimization process so that is controlled by for each node of the traverse path, and they both become smaller when the exploration algorithm goes deeper. Figure 2 illustrate the above dynamic process more clearly with an example tree on the standard partition. We remark that Eqn. (2) only needs to be guaranteed on the traverse path at each time instead of the whole exploration tree to avoid any waste of the budget. For the same purpose, all the proposed algorithms only require to be slightly larger than or equal to on each level.
We state the following theorem, which is a general regret upper bound with respect to any choice of and , and any design of the selection policy that follows the optimum statistical collaboration framework, with only a mild condition on the result of the policy in each round.
Theorem 3.1.
(General Regret Bound) Suppose that under a sequence of probability events , the policy ensures that at each time , the node pulled in line 9 in Algorithm 1 satisfies , where is an absolute constant. Then for any integer and any , we have the following bound on the cumulative regret with probability at least ,
where , is the near-optimality dimension w.r.t. and .
Notice that in Theorem 3.1, we do not specify the form of , , or the specific selection policy of the algorithm. Therefore, our result is general and it can be applied to any function and partition that has a well defined with resolution , and any algorithm that satisfies the algorithmic framework. The requirement is mild and natural in the sense that it indicates the selects a “good” node to pull at each time that is at least close to the optimum relatively with respect to or , with probability . Note that with a good choice of , can reduce to a subset of , hence is bounded in . The terms that involve and are random due to , but can still be explicitly bounded when the they are well designed. Specific regret bounds for different choices of and a new are provided in the next section.
4 Implementation of Optimum-statistical Collaboration
Provided the optimum-statistical collaboration framework and its analysis, we discuss the some specific forms of the resolution descriptor and the uncertainty quantifier and elaborate the roles these definitions played in the optimization process. We then introduce a novel VHCT algorithm based on one variance-adaptive choice of , which is a better quantifier of the statistical uncertainty.
4.1 The Resolution Descriptor (Definition 1)
The resolution descriptor is often measured by the global or local smoothness of the objective function (Azar et al., 2014; Grill et al., 2015). We first discuss the local smoothness assumption used by prior works and show its limitations, and then introduce a generalized local smoothness condition.
Local Smoothness. Grill et al. (2015) assumed that there exist two constants s.t.
| (3) |
The above equation states that the function is -smooth around the maximum at each level . It has been considered in many prior works such as Shang et al. (2019); Bartlett et al. (2019). The resolution descriptor is naturally taken to be .
However, such a choice of local smoothness is too restrictive as it requires that the function and the partition are both “well-behaved” so that the function value becomes exponentially closer to the optimum when as increases. A simple counter-example is the function defined on the domain with defined to be (as shown in Figure 1(b)). Under the standard binary partition, it is easily to prove that it doesn’t satisfy Eqn. (3) for any given constants . It might be possible to design a particular partition for such that Eqn. (3) holds. However, such a partition is defined in hindsight since one have no knowledge of the objective function before the optimization. Beyond the above example, it is also easy to design other non-monotone difficult-to-optimize functions that cannot be analyzed by prior works. It thus inspires us to introduce a more general -local smoothness condition for the objective to analyze functions and partitions that have different levels of local smoothness.
General Local Smoothness. Assume that there exists a function s.t.
| (GLS) |
In the same example , it can be shown that satisfies Condition (GLS) with . Therefore, it fits in our framework by setting and a valid regret bound can be obtained for given a properly chosen , since in this case (refer to details in Subsection 4.4). In general, we can simply set within the optimum-statistical collaboration framework, and Theorem 3.1 can be utilized to analyze functions and partitions that satisfy Condition (GLS) with any such as , for some or even , as long as the corresponding near-optimality dimension is finite for some . Determining the class of smoothness functions that can generate nontrivial regret bounds would be an interesting future direction. Given such a generalized definition and the general bound in Theorem 3.1, we can provide the convergence analysis for a much larger class of black-box objectives and partitions, beyond those that satisfy Eqn. (3).
4.2 The Uncertainty Quantifier (Definition 2)
Tracking Statistics. To facilitate the design of , we first define the following tracking statistics. Trivially, the mean estimate and the variance estimate of the rewards at round are computed as
The variance estimate is defined to be negative infinity when since variance is undefined in such cases. We now discuss two specific choices of .
Nonadaptive Quantifier (in HCT). Azar et al. (2014) proposed the uncertainty quantifier with the following form in their High Confidence Tree (HCT) algorithm:
where is the bound of the error noise , is an increasing function of , is the confidence level, and are two tuning constants. By Hoeffding’s inequality, the above is a high-probability upper bound for the statistical uncertainty. Note that HCT is also a special case of our OSC framework and its analysis can be done by following Theorem 3.1. In what follows, we propose an better algorithm with an improved uncertainty quantifier.
Variance Adaptive Quantifier (in VHCT). Based on our framework of the statistical collaboration, a tighter measure of the statistical uncertainty can boost the performance of the optimization algorithm, as the goal in Eqn. (2) can be reached faster. Motivated by prior works that use variance to improve the performance of multi-armed bandit algorithms Audibert et al. (2006, 2009), we propose the following variance adaptive uncertainty quantifier, and naturally the VHCT algorithm in the next subsection, which is an adaptive variant of the in HCT.
| (4) |
The notations and are the same as those in HCT. The uniqueness of the above is that it utilizes the node-specified variance estimations, instead of a conservative trivial bound . Therefore, the algorithm is able to adapt to different noises across nodes, and is achieved faster at the small-noise nodes. This unique property grants VHCT an advantage over all existing non-adaptive algorithms.
4.3 Algorithm Example - VHCT
Based on the proposed optimum-statistical collaboration framework and the novel adaptive , we propose a new algorithm VHCT as a special case of Algorithm 1 and elaborate its capability to adapt to different noises. Algorithm 2 provides the short version of the pseudo-code and the complete algorithm is provided in Appendix B.
The proposed VHCT, similar to HCT, also maintains an upper-bound for each node to decide collaborative optimism. In particular, for any node , the upper-bound is computed directly from the average observed reward for pulling as
with defined as in Eqn. (4) and tuned by the input. Note that for unvisited nodes. To better utilize the tree structure in the algorithm, we also define the tighter upper bounds . Since the maximum upper bound of one node cannot be greater than the maximum of its children, is defined to be
The quantities and serve a similar role of the upper confidence bound in UCB bandit algorithm (Bubeck et al., 2011b), and the selection policy of VHCT is simply selecting the node with the highest in the given set , which is shown in Algorithm 2. We prove that selection policy guarantees that with high probability in Appendix B, as we required in Theorem 3.1.
Follow the notation of Azar et al. (2014), we define a threshold value for each node to represent the minimal number of times it has been pulled, such that the algorithm can explore its children nodes, i.e.,
Only when , we expand the search into ’s children. This notation helps to compare the exploration power of VHCT with HCT. Note that when the variances of the nodes are small, of VHCT would be inversely proportional to and thus smaller than that of HCT. As a consequence, the thresholds is smaller in VHCT than in HCT, and thus VHCT explores more efficiently in low noise regimes.
4.4 Regret Bound Examples
We now provide upper bounds on the expected cumulative regret of VHCT, which serve as instances of our general Theorem 3.1 when and are specified. Note that some technical adaptions are made to obtain a bound for the regret. The regret bounds depend on the upper bound of variance in history across all the nodes that have been pulled, meaning for a constant . Since the noise is bounded, such a notation is always well defined and bounded above. The represents our knowledge of the noise variance after searching and exploring the objective function, which can be more accurate than the trivial choice , e.g., when the true noise is actually bounded by for some unknown constant . We focus on two choices of the local smoothness function in Condition (GLS) and their corresponding near-optimal dimensions, i.e., that matches previous analyses such as Grill et al. (2015); Shang et al. (2019), and , which is the local smoothness of the counter example in Figure 1(b). For other choices of , we believe similar regret upper bounds may be derived using Theorem 3.1.
Theorem 4.1.
Theorem 4.2.
The proof of these theorems are provided in Appendix C and Appendix D respectively. We first remark that the above regret bounds are actually loose because we do not a delicate individual control over the variances in different nodes. Instead, a much conservative analysis is conducted.
In the literature, Grill et al. (2015); Shang et al. (2019) have proved that the cumulative regret bounds of HOO, HCT are both when the objective function satisfies Condition (GLS) with , while our regret bound in Theorem 4.1 is of order . Although the two rates are the same with respect to the increasing of , our result explicitly connects the variance and the regret, implying a positive relationship between these two. Therefore, we expect the variance adaptive algorithm VHCT to converge faster than the non-adaptive algorithms such as HOO and HCT, when there is only low or moderate noise. The theoretical results of prior works rely on the smoothness assumption , thus are not able to deliver a regret analysis for functions and partitions with other (e.g. in Theorem 4.2). Providing analysis for prior algorithms on functions and partitions with different smoothness assumptions is another interesting future direction to explore. However, we conjecture that VHCT should still outperform the non-adaptive algorithms in these cases since its is a tighter measure of the statistical uncertainty. This theoretical observation is also validated in our experiments.
We emphasize that the near-optimality dimensions are defined with respect to different local smoothness functions in Theorem 4.1 and Theorem 4.2. Specifically, when the objective is -smooth, Theorem 4.1 holds even if the number of near-optimal regions increase exponentially when the partition proceeds deeper, i.e., when . When the function is only -smooth, Theorem 4.2 holds only when the number of near-optimal regions grows polynomially, i.e., when .
5 Experiments
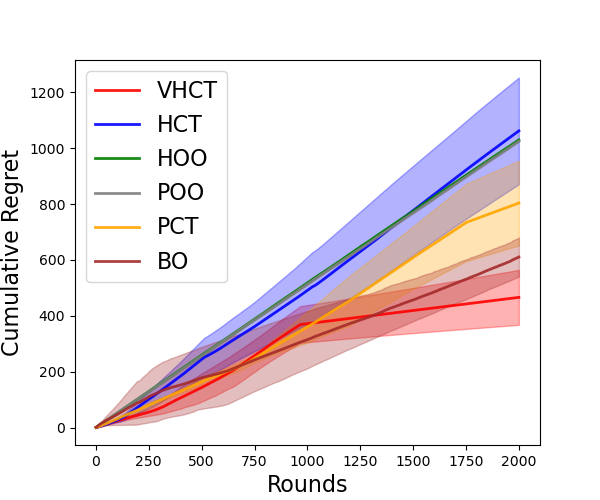
In this section, we empirically compare the proposed VHCT algorithm with the existing anytime blackbox optimization algorithms, including T-HOO (the truncated version of HOO), HCT, POO, and PCT (POO + HCT, (Shang et al., 2019)), and Bayesian Optimization algorithm BO (Frazier, 2018) to validate that the proposed variance-adaptive uncertainty quantifier can make the convergence of VHCT faster than non-adaptive algorithms. We run every algorithm for 20 independent trials in each experiment and plot the average cumulative regret with 1-standard deviation error bounds. The experimental details and additional numerical results on other objectives are provided in Appendix E.



We use a noisy Garland function as the synthetic objective, which is a typical blackbox objective used by many works such as Shang et al. (2019) and has multiple local minimums and thus very hard to optimize. For the real-life experiments, we use hyperparameter tuning of machine learning algorithms as the blackbox objectives. We tune the RBF kernel and the L2 regularization parameters when training Support Vector Machine (SVM) on the Landmine dataset (Liu et al., 2007), and the batch size, the learning rate, and the weight decay when training neural networks on the MNIST dataset (Deng, 2012). As shown in Figure 3, the new choice of SE makes VHCT the fastest algorithm among the existing ones. All the experimental results validate our theoretical claims in Section 4.
6 Conclusions
The proposed optimum-statistical collaboration framework reveals and utilizes the fundamental interplay of resolution and uncertainty to design more general and efficient black-box optimization algorithms. Our analysis shows that different regret guarantees can be obtained for functions and partitions with different local smoothness assumptions, and algorithms that have different uncertainty quantifiers. Based on the framework, we show that functions that satisfy the general local smoothness property can be optimized and analyzed, which is a much larger class of functions compared with prior works. Also, we propose a new algorithm VHCT that can adapt to different noises and analyze its performance under different assumptions of the smoothness of the function.
There are still some limitations of our work. For example, VHCT still needs the prior knowledge of the smoothness function to achieve its best performance. Also, the analyses in Theorem 4.1 and 4.2 are smoothness-specific. Therefore, our framework also introduces many interesting future working directions, for example, (1) whether a unified regret upper bound for different -local smooth functions could be derived for one particular algorithm; (2) whether the regret bound obtained in Theorem 4.2 is minimax-optimal for those ; (3) whether there exists an algorithm that is truly smoothness-agnostic, i.e., it does not need the smoothness property of the objective function.
References
- Audibert et al. (2006) Jean-Yves Audibert, Remi Munos, and Csaba Szepesvári. Use of variance estimation in the multi-armed bandit problem. 01 2006.
- Audibert et al. (2009) Jean-Yves Audibert, Rémi Munos, and Csaba Szepesvári. Exploration-exploitation tradeoff using variance estimates in multi-armed bandits. Theoretical Computer Science, 410(19):1876–1902, 2009.
- Auer et al. (2007) Peter Auer, Ronald Ortner, and Csaba Szepesvári. Improved rates for the stochastic continuum-armed bandit problem. In Nader H. Bshouty and Claudio Gentile, editors, Conference on Learning Theory, pages 454–468, 2007.
- Azar et al. (2014) Mohammad Gheshlaghi Azar, Alessandro Lazaric, and Emma Brunskill. Online stochastic optimization under correlated bandit feedback. In International Conference on Machine Learning, pages 1557–1565. PMLR, 2014.
- Bartlett et al. (2019) Peter L. Bartlett, Victor Gabillon, and Michal Valko. A simple parameter-free and adaptive approach to optimization under a minimal local smoothness assumption. In 30th International Conference on Algorithmic Learning Theory, 2019.
- Bubeck et al. (2011a) Sébastien Bubeck, Rémi Munos, and Gilles Stoltz. Pure exploration in finitely-armed and continuous-armed bandits. Theoretical Computer Science, 412(19):1832–1852, 2011a.
- Bubeck et al. (2011b) Sébastien Bubeck, Rémi Munos, Gilles Stoltz, and Csaba Szepesvári. X-armed bandits. Journal of Machine Learning Research, 12(46):1655–1695, 2011b.
- Dai et al. (2020) Zhongxiang Dai, Bryan Kian Hsiang Low, and Patrick Jaillet. Federated bayesian optimization via thompson sampling. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 9687–9699. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper/2020/file/6dfe08eda761bd321f8a9b239f6f4ec3-Paper.pdf.
- Deng (2012) Li Deng. The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6):141–142, 2012.
- Duchi et al. (2015) John C. Duchi, Michael I. Jordan, Martin J. Wainwright, and Andre Wibisono. Optimal rates for zero-order convex optimization: The power of two function evaluations. IEEE Transactions on Information Theory, 61(5):2788–2806, 2015. doi: 10.1109/TIT.2015.2409256.
- Frazier (2018) Peter I. Frazier. A tutorial on bayesian optimization, 2018. URL https://arxiv.org/abs/1807.02811.
- Golovin et al. (2017) Daniel Golovin, Benjamin Solnik, Subhodeep Moitra, Greg Kochanski, John Karro, and D Sculley. Google vizier: A service for black-box optimization. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1487–1495, 2017.
- Grill et al. (2015) Jean-Bastien Grill, Michal Valko, Remi Munos, and Remi Munos. Black-box optimization of noisy functions with unknown smoothness. In Advances in Neural Information Processing Systems. Curran Associates, Inc., 2015.
- Kandasamy et al. (2018) Kirthevasan Kandasamy, Akshay Krishnamurthy, Jeff Schneider, and Barnabas Poczos. Parallelised bayesian optimisation via thompson sampling. In Amos Storkey and Fernando Perez-Cruz, editors, Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 of Proceedings of Machine Learning Research, pages 133–142. PMLR, 09–11 Apr 2018.
- Kawaguchi et al. (2016) Kenji Kawaguchi, Yu Maruyama, and Xiaoyu Zheng. Global continuous optimization with error bound and fast convergence. Journal of Artificial Intelligence Research, 56:153–195, 2016.
- Komljenovic et al. (2019) Dragan Komljenovic, Darragi Messaoudi, Alain Cote, Mohamed Gaha, Luc Vouligny, Stephane Alarie, and Olivier Blancke. Asset management in electrical utilities in the context of business and operational complexity. In World Congress on Resilience, Reliability and Asset Management, 07 2019.
- Li et al. (2018) Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hyperband: A novel bandit-based approach to hyperparameter optimization. Journal of Machine Learning Research, 18(185):1–52, 2018.
- Li et al. (2022) Wenjie Li, Qifan Song, Jean Honorio, and Guang Lin. Federated x-armed bandit, 2022. URL https://arxiv.org/abs/2205.15268.
- Li et al. (2023) Wenjie Li, Haoze Li, Jean Honorio, and Qifan Song. Pyxab – a python library for -armed bandit and online blackbox optimization algorithms, 2023. URL https://arxiv.org/abs/2303.04030.
- Liu et al. (2007) Qiuhua Liu, Xuejun Liao, and Lawrence Carin. Semi-supervised multitask learning. In J. Platt, D. Koller, Y. Singer, and S. Roweis, editors, Advances in Neural Information Processing Systems, volume 20. Curran Associates, Inc., 2007. URL https://proceedings.neurips.cc/paper/2007/file/a34bacf839b923770b2c360eefa26748-Paper.pdf.
- Maillard (2019) Odalric-Ambrym Maillard. Mathematics of statistical sequential decision making. PhD thesis, Université de Lille, Sciences et Technologies, 2019.
- Maurer and Pontil (2009) Andreas Maurer and Massimiliano Pontil. Empirical bernstein bounds and sample variance penalization. arXiv preprint arXiv:0907.3740, 2009.
- Munos (2011) Rémi Munos. Optimistic optimization of a deterministic function without the knowledge of its smoothness. In J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc., 2011.
- Shahriari et al. (2016) Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P. Adams, and Nando de Freitas. Taking the human out of the loop: A review of bayesian optimization. Proceedings of the IEEE, 104(1):148–175, 2016.
- Shamir (2015) Ohad Shamir. An optimal algorithm for bandit and zero-order convex optimization with two-point feedback. Journal of Machine Learning Research, 18, 07 2015.
- Shang et al. (2019) Xuedong Shang, Emilie Kaufmann, and Michal Valko. General parallel optimization a without metric. In Algorithmic Learning Theory, pages 762–788, 2019.
- Valko et al. (2013) Michal Valko, Alexandra Carpentier, and Rémi Munos. Stochastic simultaneous optimistic optimization. In Proceedings of the 30th International Conference on Machine Learning, volume 28 of Proceedings of Machine Learning Research, pages 19–27. PMLR, 17–19 Jun 2013.
- Wang et al. (2020) Chi-Hua Wang, Zhanyu Wang, Will Wei Sun, and Guang Cheng. Online regularization for high-dimensional dynamic pricing algorithms. arXiv preprint arXiv:2007.02470, 2020.
- Wang et al. (2022) ChiHua Wang, Wenjie Li, Guang Cheng, and Guang Lin. Federated online sparse decision making. ArXiv, abs/2202.13448, 2022.
Appendix A Proof of the General Regret Bound in Theorem 3.1
Proof. We decompose the cumulative regret into two terms that depend on the high probability events . Denote the simple regret at each iteration to be , then we can perform the following regret decomposition
where we have denoted the first summation term in the second equality to be and the second summation term to be . The last inequality is because we have that both and are bounded by [0, 1], and thus . Now note that the instantaneous regret can be written as
where we have denoted and . It means that the regret under the events can be decomposed into two terms and .
Note that by the definition of the sequence , it is a bounded martingale difference sequence since and , where is defined to be the filtration generated up to time . Therefore by Azuma’s inequality on this sequence, we get
with probability . A even better bound can be obtained using the fact that if . However, is not a dominating term and using only improves it in terms of the multiplicative constant. Now the only term left is and we bound it as follows.
where is a constant between and to be tuned later. The second inequality is because when we select , we have by the Optimum-statistical Collaboration Framework. Also, under the event , we have . The first term can be bounded as
where and is the near-optimality dimension with respect to . The third inequality is because we only expand a node into two children, so (Note that we do not have any requirements on the number of children of each node, so the binary tree argument here can be easily replaced by a -nary tree with ). Also since we only select a node when its parent is already selected enough number of times such that at a particular time , we have satisfies . By the definition of in the near-optimality dimension, we have
and thus the final upper bound for . Therefore for any , with probability at least , the cumulative regret is upper bounded by
Appendix B Notations and Useful Lemmas
B.1 Preliminary Notations
The notations here follow those in Shang et al. [2019] and Azar et al. [2014] except for those related to the node variance. These notations are needed for the proof of the main theorem.
-
•
At each time , denote the node selected by the algorithm where is the level and is the index.
-
•
denotes the optimal-path selected at each iteration
-
•
denotes the maximum depth of the tree at time .
-
•
with ,
-
•
For any and , denotes the set of all nodes at level at time .
-
•
For any and , denotes the subset of that contains only the internal nodes (no leaves).
-
•
is the set of time steps when is selected.
-
•
is the set of time steps when the children of are selected.
-
•
is the last time is selected.
-
•
is the last time when the children of is selected.
-
•
is the time when is expanded.
-
•
is the estimate of the variance of the node at time .
-
•
denotes all the nodes in the exploration tree at time
-
•
is the upper bound on the node variance in the tree.
Note that if the variance of a node is zero, we can always pull one more round to make it non-zero. Therefore, here we simply assume that the variance is larger than a fixed small constant for the clarity of proof, which will not affect our conclusions.
B.2 Useful Lemmas for the Proof of Theorem 4.1 and Theorem 4.2
Lemma B.1.
We introduce the following event
where is the arm corresponding to node If
then for any fixed t, the event holds with probability at least .
Proof. Again, denotes all the nodes in the tree. The probability of can be bounded as
where the second inequality is by taking in Lemma B.6, we have
Now note that the number of nodes in the tree is always (loosely) bounded by since we need at least one pull to expand a node, we know that
Lemma B.2.
Given the parameters and as in Lemma B.1, the regret when the events fail to hold is bounded as
with probability at least
Proof. We first split the time horizon in two phases: the first phase until and the rest. Thus the regret bound becomes
The first term can be easily bounded by . Now we bound the second term by showing that the complement of the high-probability event hardly ever happens after . By Lemma B.1
Therefore we arrive to the conclusion in the lemma.
Lemma B.3.
At time under the event , for the selected node and its parent , we have the following set of inequalities for any choice of the local smoothness function in Algorithm 3
Proof. Recall that is the optimal path traversed. Let and be the node which immediately follows in (i.e., . By the definition of values, we have the following inequality
where the last equality is from the fact that the algorithm selects the child with the larger value. By iterating along the inequality until the selected node and its parent we obtain
Thus for any node we have that Furthermore, since the root node is a an optimal node in the path . Therefore, there exists at least one node which includes the maximizer and has the the depth . Thus
Note that by the definition of , under event
| (5) | ||||
where the first inequality holds by the definition of and the second one holds by . Similarly the parent node satisfies the above inequality
By Lemma B.4, we know . If is a leaf, then by our definition . Otherwise, there exists a leaf containing the maximum point which has as its ancestor. Therefore we know that , so is always an upper bound for . Now we know that
Recall that the algorithm selects a node only when and thus the statistical uncertainty is large, i.e., , and the choice of , we get
where we used the fact for any . For the parent , since and thus , we know that
The above inequality implies that the selected node must have a optimal parent under .
Lemma B.4.
( Upper Bounds ) Under event , we have that for any optimal node and any choice of the smoothness function in Algorithm 3, is an upper bound on
Proof. The proof here is similar to that of Lemma 5 in Shang et al. [2019]. Since we have
where the last inequality is by the event ,
Lemma B.5.
(Details for Solving ) For any choice of , the solution to the equation for the proposed VHCT algorithm in Section 4 is
| (6) |
Proof. First, we define the following variables for ease of notatioins
Therefore the original equation can be written as,
Note that the above is a quadratic equation of , therefore we arrive at the solution
B.3 Supporting Lemmas
Lemma B.6.
Let be i.i.d. random variables taking their values in , where . Let be the mean and variance of . For any and with probability at least , we have
Proof. This lemma follows the results in Lemma B.7. Note that , we can define then and they are variables. Therefore for any and , with probability at least , we have
Since the variance of is the same as the variance of . Therefore we have
Lemma B.7.
(Bernstein Inequality, Theorem 1 in Audibert et al. [2009]) Let be i.i.d. random variables taking their values in Let be their common expected value. Consider the empirical and variance defined respectively
Then, for any and with probability at least
Furthermore, introducing
where denotes the minimum of and we have for any and with probability at least
holds simultaneously for .
Appendix C Proof of Theorem 4.1
C.1 The choice of .
When , we have the following choice of by Lemma B.5.
| (7) | ||||
Since variance is non-negative, we have . When the variance term is small, the other two terms are small. We also have the following upper bound for .
where we define the constant .
C.2 Main proof
This part of the proof follows Theorem 3.1. Let be an integer that satisfies to be decided later.
By Lemma B.3, we have and thus the following inequality
Now we bound the two terms and of separately.
where in the second inequality we used the upper bound of in Section B. The last inequality is by the formula for the sum of a geometric sequence and the following result.
Next we bound the second term in the summation. By the Cauchy-Schwarz Inequality,
Recall that our algorithm only selects a node when for its parent, i.e. when the number of pulls is larger than the threshold and the algorithm finds the node by passing its parent. Therefore we have
So we have the following set of inequalities.
Note that in the second equality, we have used the definition of , . Moreover, the third equality relies on the following fact
The next equality is just by change of variables . In the last inequality, we used the fact that for any , covers all the internal nodes at level , so the set of the children of covers . In other words, we have proved that
Therefore we have
If we let the dominating terms in (a) and (b) be equal, then
Substitute the above choice of into the original inequality, then the dominating terms in (a) and (b) reduce to because , where is a constant that does not depend on the variance. The non-dominating terms are all , we get
| (8) |
where is another constant. Finally, combining all the results in Theorem 3.1, Lemma B.2, Eqn. (8), we can obtain the upper bound
The expectation in the theorem can be shown by directly taking as in Theorem 3.1.
Appendix D Proof of Theorem 4.2
D.1 Choice of the Threshold
By Lemma B.5, we get that when , we can solve for as follows.
where we again define a new constant .
D.2 Main Proof
The failing confidence interval part can be easily done as in Section C since is also a high-probability event at each time . We start from the bound on . By Theorem 3.1 and similar to what we have done in Theorem 4.1, we decompose over different depths. Let be an integer to be decided later, then we have
Now we bound the two terms and of separately. By Lemma B.3, we have .
Next we bound the second term in the summation. By the Cauchy-Schwarz Inequality,
Recall that our algorithm only selects a node when for its parent, i.e. when the number of pulls is larger than the threshold and the algorithm finds the node by passing its parent. Therefore we have
So we have the following set of inequalities.
Note that in the second equality, we have used the definition of . Moreover, the third equality relies on the following fact
The next equality is just by change of variables . In the last inequality, we used the fact that for any , covers all the internal nodes at level , so the set of the children of covers . In other words, we have proved that
Therefore we have the following inequality
If we let the dominating terms in (a) and (b) be equal, then
Substitute the above choice of into the original inequality, then the dominating terms in (a) and (b) reduce to because , where is a constant that does not depend on the variance. The non-dominating terms are all , we get
| (9) |
where is another constant. Finally, combining all the results in Theorem 3.1, Lemma B.2, Eqn. (9), we can obtain the upper bound
The expectation in the theorem can be shown by directly taking as in Theorem 3.1.
Appendix E Experiment Details
In this appendix, we provide more experiment details and additional experiments as a supplement to Section 5. For the implementation of all the algorithms, we utilize the publicly available code of POO and HOO at the link https://rdrr.io/cran/OOR/man/POO.html and the PyXAB library [Li et al., 2023]. For all the experiments in Section 5 and Appendix E.2, we have used a low-noise setting where to verify the advantage of VHCT.
E.1 Experimental Settings
Remarks on Bayesian Optimization Algorithm. For the implementation of the Bayesian Optimization algorithm BO, we have used the publicly available code at https://github.com/SheffieldML/GPyOpt, which is also recommended by Frazier [2018]. For the acquisition function and the prior of BO, we have used the default choices in the aforementioned package. We emphasize that BO is much more computationally expensive compared with the other algorithms due to the high computational complexity of Gaussian Process. The other algorithms in this paper (HOO, HCT, VHCT, etc.) take at most minutes to reach the endpoint of every experiment, where as BO typically needs a few days to finish. Moreover, the performance (cumulative regret) of BO is not comparable with our algorithm.
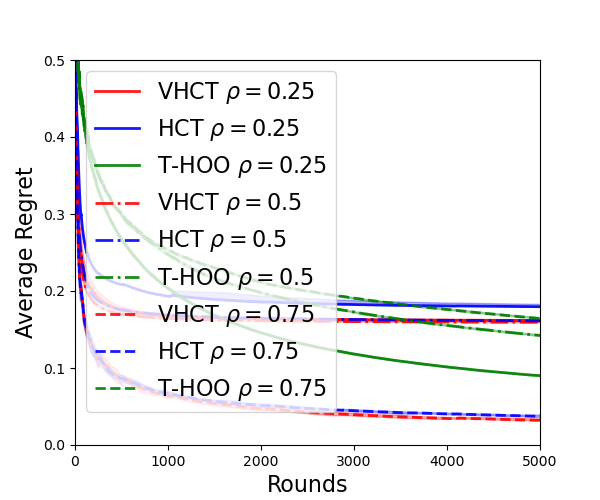
Synthetic Experiments. In Figure 4, we provide the performances of the different algorithms (VHCT, HCT, T-HOO) that need the smoothness parameters under different parameter settings . Here, we choose to plot an equivalent notion, the average regret instead of the cumulative regret because some curves have very large cumulative regrets, so it would be hard to compare them with the other curves. In general, or are good choices for VHCT and HCT, and is a good choice for T-HOO. Therefore, we use these parameter settings in the real-life experiments and the additional experiments in the next subsection. For POO and PCT, we follow Grill et al. [2015] and use . The unknown bound is set to be for all the algorithms used in the experiments.


Landmine Dataset. The landmine dataset contains 29 landmine fields, with each field consisting of different number of positions. Each position has some features extracted from radar images, and machine learning models (like SVM) are used to learn the features and detect whether a certain position has landmine or not. The dataset is available at http://www.ee.duke.edu/~lcarin/LandmineData.zip. We have followed the open-source implementation at https://github.com/daizhongxiang/Federated_Bayesian_Optimization to process the data and train the SVM model. We tune two hyper-parameters when training SVM, the RBF kernel parameter from [0.01, 10], and the regularization from [1e-4, 10]. The model is trained on the training set with the selected hyper-parameter and then evaluated on the testing set. The testing AUC-ROC score is the blackbox objective to be optimized.
MNIST Dataset and Neural Network. The MNIST dataset can be downloaded from http://yann.lecun.com/exdb/mnist/ and is one of the most famous image classification datasets. We have used stochastic gradient descent (SGD) to train a two-layer feed-forward neural network on the training images, and the objective is the validation accuracy on the testing images. We have used ReLU activation and the hidden layer has 64 units. We tune three different hyper-parameters of SGD to find the best hyper-parameter, specifically, the mini batch-size from [1, 100], the learning rate from [1e-6, 1], and the weight decay from [1e-6, 5e-1].
E.2 Additional Experiments
In this subsection, we provide additional experiments on some other nonconvex optimization evaluation benchmarks. They are used in many optimization researches to evaluate the performance of different optimization algorithms, including the convergence rate, the precision and the robustness such as Azar et al. [2014], Shang et al. [2019], Bartlett et al. [2019]. Detailed discussions of these functions can be found at https://en.wikipedia.org/wiki/Test_functions_for_optimization Although some of these function values (e.g., the Himmelblau function) are not bounded in on the domain we select, the convergence rate of different algorithms will not change as long as the function is uniformly bounded over its domain. To commit a fair comparison (i.e., sharing similar signal/noise ratio), we have re-scaled all the objectives listed below to be bounded by .
We list the functions used and their mathematical expressions as follows.
- •
- •
- •
- •





As can be observed in all the figures, VHCT is one of the fastest algorithms, which validates our claims in the theoretical analysis. We remark that Himmelblau is very smooth after the normalization by its maximum absolute value on (890) and thus a relatively easier task compared with functions such as Rastrigin. DoubleSine contain many local optimums that are very close to the global optimum. Therefore, the regret differences between VHCT and HCT are expected to be small in these two cases.
E.3 Performance of VHCT in the High-noise Setting
Apart from the low-noise setting, we have also examined the performance of in the high-noise setting. In the following experiments, we have set the noise to be . Note that the function values are in , therefore such a noise is very high. As discussed in Section 4.4, it should be expected that the performance of is similar to or only marginally better than in this case. As shown in Figure 7, the performance of and are similar, which matches our expectation.



