Optimizing Factual Accuracy in Text Generation through Dynamic Knowledge Selection
Abstract
Language models (LMs) have revolutionized the way we interact with information, but they often generate nonfactual text, raising concerns about their reliability. Previous methods use external knowledge as references for text generation to enhance factuality but often struggle with the knowledge mix-up (e.g., entity mismatch) of irrelevant references. Besides, as the length of the output text grows, the randomness of sampling can escalate, detrimentally impacting the factual accuracy of the generated text. In this paper, we present DKGen, which divides the text generation process into an iterative process. In each iteration, DKGen takes the input query, the previously generated text and a subset of the reference passages as input to generate short text. During the process, the subset is dynamically selected from the full passage set based on their relevance to the previously generated text and the query, largely eliminating the irrelevant references from input. To further enhance DKGen’s ability to correctly use these external knowledge, DKGen distills the relevance order of reference passages to the cross-attention distribution of decoder. We train and evaluate DKGen on a large-scale benchmark dataset. Experiment results show that DKGen outperforms all baseline models.
1 Introduction
Large language models (LLMs), such as ChatGPT, have shown remarkable capabilities in natural language generation tasks [1, 2, 3, 4, 5]. Despite this, these generative LMs primarily model the statistical relationships between subword tokens [6] and exhibit limited ability in generating factually correct text. Consequently, there is a growing concern regarding the production of nonfactual content (also called hallucination) by these LLMs [7, 8, 9, 10]. Addressing this issue is crucial for the safe use of such models into real-world applications.
Many prior studies have aimed to improve the factuality of text generation [11], and a promising approach among these involves incorporating external knowledge into the text generation process [12, 13, 14, 15, 16, 17]. These techniques generally employ either prepared external knowledge or retrieve knowledge via an information retrieval (IR) system. And the LMs are trained to select and incorporate relevant knowledge from these sources to generate text [18, 19, 15, 20, 21]. In industrial settings, the integration of external knowledge to enhance the factual accuracy of text generation has become a popular strategy, as seen in products such as New Bing111https://news.microsoft.com/the-new-Bing/ and ChatGPT plugins222https://openai.com/blog/chatgpt-plugins.
Taking New Bing as an example, it represents a new paradigm in search engines. Here, New Bing takes a user query, extracts reference passages from the top search results, and generates a text as the search answer. To explicitly display the source of the generated answer text, New Bing appends reference marks at the end of the text. These reference marks not only enhance the credibility of the generated answer text but also allow the user to trace back to the source webpage.
While the specific implementation details of New Bing remain undisclosed, such a paradigm is undeniably worth exploring in the research area. However, previous approaches present three primary concerns that may adversely affect the factual accuracy and quality of this New Bing paradigm: First, most of these models simultaneously attend to all reference passages during the generation of each token [22, 23, 24]. This design can make the generation model vulnerable to irrelevant or noisy reference passages, which might cause it to blend knowledge from these inappropriate sources [13], such as the concept mismatch illustrated in the right side of Figure 1. Secondly, these methods are inclined to decode the entire output text in a single pass. As the length of this output text extends, the randomness of the sampling may increase, negatively affecting the factual accuracy of the generated text [10]. Lastly, most of these methods lack the capacity to generate reference marks as shown in New Bing [25]. This deficiency makes it difficult for the end user to accurately locate the source reference passage, thereby undermining reliability.
In this paper, we present a model, DKGen, that breaks down the conventional single-pass knowledge-enhanced text generation process into an iterative one. In each iteration, we dynamically select a subset of knowledge that most accurately supports the generation of the current sentence, given the previously generated sentences. After completing all iterations, we concatenate the sentences generated in each iteration to form the final output text. Importantly, our method enables us to accurately append reference marks at the end of each sentence, enhancing the transparency and reliability of the generated text. Figure 1’s right side shows DKGen’s iterative generation process.

Specifically, DKGen initiates the text generation process by retrieving a large set of reference passages (e.g., top-100) via an Information Retrieval (IR) system using the input query. In each iterative step of generation, DKGen re-ranks these reference passages based on their relevance to both the previously generated text and the input query (detailed in Section 3.5). Next, DKGen uses the previously generated text, the selected relevant passages, and the query as inputs to generate a new sentence (discussed in Section 3.4). In each iteration, DKGen only generates a short text (e.g., a sentence) using carefully selected reference passages. This approach significantly mitigates issues such as knowledge mix-up from irrelevant reference passages and growing sampling randomness, thereby enhancing the factuality of the generated text. Moreover, DKGen incorporates the relevance scores as an order of importance to further augment its capacity to correctly utilize knowledge from the reference passages. This is achieved by distilling the relevance scores into the cross-attention distribution of DKGen’s decoder (elaborated in Section 3.6). Importantly, DKGen’s iterative generation does not reduce decoding efficiency, as its decoder only needs to attend to a limited number of reference passages and decode a short text in each iteration. Furthermore, we encode the reference passages only once to avoid redundant computations (analyzed in Section 3.7).
In this paper, we train and evaluate DKGen on a public benchmark dataset known as WebBrain [25], which was constructed by crawling the English Wikipedia and the corresponding reference articles. To facilitate DKGen’s iterative sentence generation training, we partition the WebBrain training dataset into sentence-level granularity (details provided in Section 4.1). In our experiments, we compare DKGen against competitive models, including ChatGPT, and find that DKGen outperforms all baseline models. The contributions of this study are threefold: (1) We introduce an iterative text generation method, which allows more flexibility of incorporating external knowledge during the generation process. This method can be applied to a wide range of existing text generation models. (2) We adapt a dataset from a public benchmark dataset to facilitate the training of iterative text generation. (3) We introduce DKGen, a model implementing the iterative text generation method. By dynamically selecting knowledge for each sentence generation, DKGen enhances the factuality of text generation, facilitating the precise assignment of reference marks to individual sentences.
2 Related Work
Factuality in Text Generation
Pre-trained language models often generate hallucinations, or factually incorrect statements [26, 27, 28, 29]. Various methods have been proposed to improve the factuality of text generation: (1) studies such as [10, 27, 28, 29] suggest that larger language models are better equipped to recall knowledge from an extensive training corpus, improving their factual accuracy. (2) some researchers seek to rectify factual errors in the post-processing stage [30, 31, 32]. (3) many downstream tasks utilize task-specific language models that have been fine-tuned for a range of text generation tasks, such as summarization, machine translation, and dialogue systems [33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 17, 47, 48, 49]; (4) a subset of studies focus on addressing factual errors in the parametric knowledge of language models, which is derived from the training corpus [50, 51, 52].(5) human feedback or demonstrations have been found to be invaluable in improving the factual accuracy of language models. For instance, InstructGPT was fine-tuned using collected human feedback to enhance truthful generation [5]. WebGPT was trained to cite its sources when generating output, enabling humans to verify factual accuracy by checking whether a claim is backed by a reliable source [8]. Many of these methods utilize external knowledge to enhance the factuality of text generation, which is considered as a promising and effective way to reduce hallucinations.
Knowledge-Augmented Text Generation
Retrieval-augmented text generation is being viewed as a promising solution to counteract hallucinations [53, 12, 25, 22]. This technique has been widely implemented in various NLP tasks such as machine translation [54], open-domain question answering [12, 21], dialogue generation [55, 56] and open-ended text generation [10, 25]. Most of these approaches produce answers by retrieving passages as reference from either a retriever or search engine, citing the reference passages to support text generation. For instance, Menick et al. [57] employ reinforcement learning via human preferences to train LLMs that can generate answers and cite relevant evidence to support their claims. In contrast, WebGPT [8] finetunes GPT-3 [3] to search and browse the internet for pertinent information. LaMDA [18] enhances factual grounding and safety by utilizing annotated data for training and empowering the model to consult external knowledge sources. Glaese et al. [56] employ various sources of evidence and guidelines to create dialogue systems. However, most of these methods remain susceptible to irrelevant knowledge from reference passages, which may cause them to blend information from different sources. In this paper, we tackle this issue by carefully selecting reference passages while generating each sentence, thereby increasing the credibility of the knowledge source.
3 Methodology
3.1 Preliminary
The problem of generating text using external knowledge can be defined as finding the text that maximizes the conditional probability given an input query and a knowledge prior . Formally, we can express this as:
| (1) |
where represents the probability of generating text given the input query and the knowledge prior . The knowledge prior is a combination of parametric knowledge stored inside the language model and external knowledge obtained from other sources such as search engines or knowledge corpora. Here, we use a reference passage set as the external knowledge, which comprises of a set of passages that can be used to support text generation.
There are two types of method for incorporating into the text generation process: (1) for decoder-only models, the reference passages can be considered an essential component of the input sequence, along with the input query (e.g., the prompt) [3]; (2) for encoder-decoder models, the reference passages can be processed either jointly or separately within the encoder, allowing the decoder to utilize the reference passages by attending to the encoder’s hidden states [22, 58]. Both types of models generate the output text by accounting for the conditional probability , where represents a token.
Many of these methods present two primary concerns that may adversely impact factuality of the generated text: (1) the decoder jointly attends to all reference passages while generating each token . This renders the decoder susceptible to irrelevant or noisy reference passages, leading it to potentially blend knowledge from such irrelevant sources, such as entities [13]; (2) these method tend to decode the full output text in a single pass. As the length of the output text increases, the randomness of sampling can escalate, detrimentally impacting the factual accuracy of the generated text [10].
3.2 Problem Formalization
In this paper, we propose dividing the process of generating the entire text in one pass into an iterative process to solve the above mentioned concerns. We initialize the process by retrieving a set of reference passage using the input query . In each generation iteration, we dynamically select a subset of reference passage to support partial text generation (e.g., a sentence ). Formally, we define the iterative text generation process as:
| (2) |
where the generated text consists of sentences . The term indicates that the sentence is supported by a subset of reference passage which is dynamically selected when generating different sentences by considering the previously generated text and the given query . Formally, we have:
| (3) |
where refers to the most proper reference passage set that can support generating the sentence .
By the definitions provided in Eq. (2) and Eq. (3), the factual accuracy of the generated text can be improved by: (1) shortening the target text during generation (e.g., sentence-level) to increase the determinacy of the sampling process; (2) supplying more precise reference passages for each sentence generation to alleviate the knowledge mix-up issue; and (3) explicitly knowing the cited reference passages for each generated sentence.
3.3 The proposed model: DKGen
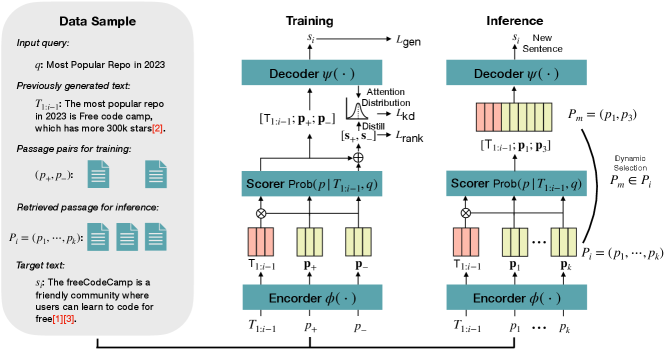
To iteratively generate the text sentence by sentence, intuitively, we can halt the decoding process upon generating a complete sentence (e.g., ). Subsequently, the previously generated text , the newly selected reference passages , and the input query can be incorporated to produce a new sentence . This paper presents the DKGen model, which adheres to this intuition while enhancing factual accuracy and text fluency through specialized model designs. Figure 2 provides an overview of DKGen.
The training procedure of DKGen (illustrated on the left side of Figure 2) optimizes it by minimizing the discrepancy between a hypothesis sentence and a ground-truth sentence , where denotes a decoder. In the process, three training losses are optimized: (1) the text generation loss , wherein the ground-truth sentence serves as the target text label (in section 3.4); (2) a ranking loss that assists the model in identifying appropriate reference passages to better support text generation (in section 3.5); and (3) a knowledge distillation loss , which employs ranking scores as soft labels to supervise the decoder’s attention distributions across different input passages (in section 3.6).
During the inference process (depicted on the right side of Figure 2), DKGen generates a new sentence by first employing a scoring model, optimized by , to evaluate all reference passages and retain a subset as the supporting passage for the current generation iteration. Then, DKGen incorporates the previously generated text , the selected reference passage , and the input query to generate the new sentence . After generating all sentences , we can get the final output text by combine the sentences, and attach the cited reference marks at the end of each sentence (in section 3.7). The following sections will discuss the details of DKGen.
3.4 Iterative Sentence Generation
DKGen employs an encoder-decoder model (e.g., BART or T5) [58, 2] as the underlying language model to perform text generation. By the Eq. (2), we take the query , the previously generated text , and the selected reference passage set (we will discuss how to select in section 3.5) as input to generate . Supposing has reference passages, we separately process and the reference passages into text sequences. Taking the -th reference passage as an example:
| (4) |
where [query], [ref], [context] and [EOS] are special tokens, which are used to help the model to distinguish different parts of the input text sequences.
Afterwards, we encode the sequences and the sequence separately to obtain their corresponding hidden states and using an encoder :
| (5) |
And then, the decoder attends over the concatenation of the hidden states of all the sequences, and outputs a text sequence with auto-regressive mechanism:
| (6) |
After obtaining sentence , we append into to get . Incorporating with query and a new reference passage set , we can generate the next sentence with the same process above. We optimize the sentence generation by minimizing the negative log-likelihood function of the ground-truth text:
| (7) |
3.5 Dynamic Knowledge Selection for Sentence Generation
In the process of iterative sentence generation, it is crucial to select the proper reference passage subset to support generating sentence . Following the Eq. (3), DKGen selects the subset from the full set by considering the the relevance of each passage . To do this, we need to compute the relevance for each passage . To be concrete, DKGen separately measures the matching degree of and . For each we have:
| (8) |
First, we compute for each reference passage . Recall that in Eq. (4) and Eq. (5), we concatenate the query with a reference passage into a text sequence , which is then fed into the encoder to obtain its hidden states. This process mirrors the ranking task using a cross-encoder (note that the encoder of BART or T5 is bi-directional) [59], which also aims to compute the relevance of a query-passage pair . Therefore, DKGen directly uses the hidden states output by Eq. (5) to compute .
Specifically, taking the -th reference passage as an example, we pool its sequence hidden states by extracting the hiden states of the [EOS] token 333Using [EOS] to represent the sequence follows the original BART paper [58]. of the sequence by: . For all reference passage, we have . We then utilize a multi-layer perceptron (MLP) to map into matching scores, and compute the using a Softmax function:
| (9) |
Second, we compute . Given and the previously generated text , we have their pooled sequence representation and . Then, we compute by:
| (10) |
where is the dimension size. Eq. (10) presents a simple yet effective measurement for the -aware reference ranking. Using it we can filter the references that are not topically consistent with the previously generated text , and therefore guarantee the topical coherence of sentences in the output text. Afterwards, we can get the reference passage subset by selecting the reference passages that have the biggest relevance score .
During the training phase, we optimize the using a Pairwise Ranking Loss , in which we use the supporting reference passage as positive passage and sample a negative passage from the corpora (see Section 4.1).
3.6 Attend to the Useful Reference through Relevance Distillation
In Section 3.5, we discuss how to select a proper reference subset to support generating a sentence . The selection process mainly consider the relevance , with which we can get by selecting reference passages with high relevance scores. This indicates that reference passages in have an importance order. Reference passage with a high score is more likely to provide useful knowledge for text generation, which implies that when decoding the output text, the decoder should pay more attention to the reference passages with higher scores. Inspired by this intuition, we design a relevance distillation mechanism to supervise the decoder’s attention distributions with the relevance scores of input passages.
Taking the -th reference passage as an example, we can extract ’s cross-attention matrix from the decoder , where and refer to the number of transformer layers and the number of attention heads stacked in the decoder. and are the token length of reference passage and the output text, respectively. The details for computing can refer to Vaswani et al. [60]. We then average over all dimensions and use a Softmax function to get the attention score distribution of all of the reference passages :
| (11) |
And we use the conditional probability computed in Section 3.5 as the reference scores, which we denote as , to supervise the attention score distribution. We use a KL divergence loss to optimize the relevance distillation:
| (12) |
Traing Loss: During the training phase, we optimize the three loss function together by:
| (13) |
where is the overall loss function and is a scalar.
3.7 Inference: Sentence Decoding with Dynamic Reference Selection
DKGen initializes inference by retrieving reference passages, denoted as , from a large passage corpora based on the input query . In this study, we employ stand-alone retrievers for this purpose, and the influence of different retrievers is discussed in Section 4.3. Subsequently, DKGen calculates the query-aware relevance, represented as , for each passage using the formulation presented in Eq. (9). In our experiments, instead of actively retrieving reference passages at each iteration, we remain the reference passage set fixed throughout the generation process, mainly considering inference efficiency. As the reference passage set is fixed, there is no need to compute repeatedly in subsequent generation iterations. At each iteration, DKGen additionally computes as per Eq. (10). The reference passages in are then sorted based on the score , and the top- passages are selected to form a subset . This subset is utilized to facilitate the generation of the sentence , as described in Section 3.4.
Decoding Efficiency Analysis One potential question regarding DKGen pertains to the efficiency of iteration generation comparing to decoding all text in a single pass. In practice, the iteration generation would not be slower. The reasons are: Firstly, the time complexity of the transformers decoder is approximately , where represents the length of the input. Instead of inputting all retrieved passages into the decoder, DKGen selectively chooses passages as input (e.g., with and ). This significantly reduces the computational burden associated with the decoder’s cross-attention. Secondly, typical text decoding strategies, such as Beam Search, exhibit a time complexity of approximately , where denotes the beam width and represents the length of the decoded text. DKGen, on the other hand, decodes only a short text at each iteration, resulting in significantly faster processing compared to decoding longer texts. In Table LABEL:tab:overall, we evaluating the per query latency of all models, verifying that DKGen is relatively more efficient than baselines.
4 Experiments
| Model | BLEU-1 | BLEU-4 | ROUGE-L | BARTScore | FactScore | TripleScore | Latency |
|---|---|---|---|---|---|---|---|
| BART | 14.52 | 2.33 | 13.57 | -4.855 | 7.01 | 13.02 | 1125 |
| BART-L | 18.61 | 5.02 | 17.45 | -4.731 | 7.49 | 13.82 | 1788 |
| FiD | 23.95 | 5.86 | 18.61 | -4.502 | 9.87 | 18.39 | 879 |
| FiD-L | 25.91 | 6.01 | 20.64 | -4.414 | 10.56 | 19.56 | 1453 |
| ReGen | 24.70 | 7.48 | 21.06 | -4.475 | 12.08 | 20.43 | 1096 |
| ReGen-L | 27.81 | 7.92 | 22.00 | -4.303 | 12.25 | 20.33 | 1565 |
| ChatGPT | 24.22 | 5.44 | 19.56 | -4.280 | 10.64 | 19.21 | - |
| ChatGPT-R | 25.19 | 5.79 | 19.35 | -4.320 | 11.98 | 22.87 | - |
| DKGen | 30.77 | 8.95 | 23.29 | -4.473 | 12.84 | 24.76 | 531 |
| DKGen-L | 31.48 | 9.26 | 23.57 | -4.452 | 13.01 | 26.43 | 1310 |
4.1 Dataset and Evaluation Metrics
We conduct experiments on the WebBrain dataset [25], a benchmark dataset specifically designed for generating factually correct text based on large web corpora. We use WebBrain-G to train all baselines, and WebBrain-R to train the retriever model employed in this paper. Each data sample in WebBrain-G consists of a query , a reference passage set , and the target text . To train DKGen, we split the target text into sentences and construct training data samples as , where the positive passage refers to the reference passage supporting the target sentence , and the negative passage is randomly sampled from . The training objective shifts from generating the target text to a sentence . For more details of WebBrain, please refer to Qian et al. [25].
BLEU [61], and ROUGE [62] are metrics employed to measure the -gram overlap between the generated text and the ground-truth text. Higher values of these metrics denote a greater similarity between the generated and ground-truth text. We utilized the nlg-eval package [63] to compute these metrics. Given the recent advancements in model-based metrics capable of assessing semantic-level text similarity, we also utilize BARTScore [64] as part of our evaluation methodology.444We use the checkpoint provided in the Github repository https://github.com/neulab/BARTScore.
To evaluate the factuality, we use TripleScore [65] and FactScore [66]. The Triple Score is computed by first extracting lexical components from the source text and the generated text to form semantic triplets using OpenIE [67]. The score is then calculated based on the precision of the semantic triplets in the generated text, with higher scores indicating more accurately generated semantic relations. The FactScore is computed by first extracting the entity-level relation of each sentence, and then it is calculated based on the precision of the entity-level relation in the generated text. Higher FactScore indicates better entity-relation factuality. Both FactScore and Triple Score were computed using the FactSumm package [68]. Note that we combine the target text and reference passages as the source text, which implies that, being supported by either the target text or the reference passages, the generated text would be considered as factually correct.
4.2 Experimental Settings
DKGen employs BART as its foundational language model. For comparison, we also report the performance of the vanilla BART [58], FiD [22], and ReGen [25]. Each of these models is initialized using off-the-shelf checkpoints provided by HuggingFace [69]. Both base and large models are trained for all baselines, with the large models denoted by the suffix "-L" (e.g., DKGen-L) for clarity. We also evaluate the performance of ChatGPT using OpenAI’s APIs. After comparing the response quality, we find the prompt “introduce [X] in Wikipedia-style” yields the most satisfactory results. Furthermore, we experiment with providing the retrieved reference passages to ChatGPT, using the prompt “introduce [X] in Wikipedia-style with the references:[references]”. We denote this variant as ChatGPT-R. We use the SPLADE [70] model as the retriever, which is trained by WebBrain-R. We will compare the impact of different retriever model in section 4.3.
Training of all baseline models was conducted using 8 Tesla V100 32G GPUs. The batch size per GPU was configured to the maximum number that wouldn’t exceed the available GPU memory. For instance, the per GPU batch sizes for DKGen and DKGen-L were set to 56 and 16 respectively. We train all models for 5 epochs. The AdamW optimizer [71] was used for optimization, with a learning rate of 5e-5. During the inference stage, 20 reference passages were retrieved from the full passage corpus of WebBrain (204M passages) as the external knowledge. For baseline models that incorporate all reference passages as input, we supplied them with the top-5 reference passages and set the maximum generation length to 256. For DKGen, we selected either 1 or 2 reference passages in each iteration, limiting the maximum sentence generation length to 64 (if the relevance score of the 2nd passage exceeded a threshold , we retained both reference passages). The iterative process would stop once 5 reference passages had been utilized.
Main Results
The overall results of the experiment are presented in Table LABEL:tab:overall, from which several key findings can be derived: (1) Regarding the -gram overlapping metrics BLEU and ROUGE, DKGen surpasses all baseline models, suggesting that it can generate text with better lexical quality; (2) Regarding the model-based metric BARTScore, DKGen falls short compared to ChatGPT and ReGen-L, indicating that there is still room for improvement in the semantic quality of DKGen (e.g., fluency and coherence); (3) Regarding factuality metrics, DKGen outperforms all baselines, which confirms the effectiveness of DKGen’s model design in enhancing the factuality of the generated text.
4.3 Discussions
Ablation Study

To evaluate the effectiveness of DKGen’s model components, we perform the following ablation studies: (1) w/o DS: integrating all reference passages into DKGen without utilizing Dynamic Selection; (2) w/o DI: eliminating the knowledge DIstillation loss, , from the training process; (3) w/o PG: excluding the Previously Generated text, , from the model input during inference; (4) w/o RP: discarding the Relevance between the Previously generated text and the reference passages, , during inference. Figure 3 presents the results of these ablation studies, from which we can draw the following conclusions: (1) the removal of any DKGen component results lead to a decline in performance, thereby validating the effectiveness of the DKGen’s model designs; (2) the largest performance drop is observed when the previously generated text is omitted, emphasizing its significance in generating subsequent sentences; (3) excluding dynamic knowledge selection also leads to a substantial decrement in performance, indicating that knowledge selection is essential for knowledge-enhanced text generation.
Impact of Retriever
In this paper, our primary focus is not on developing improved retrievers for knowledge-enhanced text generation. However, the performance of retrievers has a direct impact on the final generation outcome. Thus, we investigate the influence of various retrievers, with the results displayed in Table 2. These findings suggest that the SPLADE retriever is more effective in bolstering the generator’s overall performance. Consequently, we conduct our experiments using the retrieval results from SPLADE. Furthermore, we believe that the development of a retriever that takes into account both the query and the previously generated text could enhance DKGen’s generation performance. This remains an area for future exploration.
Case Study
| Query: Durg district |
| Ground-truth target: Durg district is a district situated in Chhattisgarh, India. The district headquarters is Durg. The district covers an area of 2,238 km². As of 2011 it is the second most populous district of Chhattisgarh (out of 18), after Raipur.[1] The district is home to two important religious sites. The principal Hindu temple, attract pilgrims from all over India. It is also the town of Bhilai Steel Plant. |
| ChatGPT: Durg district is a district in the Indian state of Chhattisgarh. The district headquarters is located in the city of Durg, which is also the largest city in the district. The district has a total area of 2,676 square kilometers and a population of approximately 3 million people. The economy of Durg district is primarily based on agriculture and industries. The district is known for its paddy cultivation. |
| DKGen: Durg district is a district in the state of Chhattisgarh in India, situated on the east bank of the river Shivnath. [2] It is the second most populous district of Chhattisgarh after its capital city, Raipur.[1] [3] The region is home to some of the biggest and prominent steel plants in the countr.[4] |
We carry out a case study to compare the text generated by DKGen and ChatGPT, presented in Table 3. Our observations from these cases reveal that: (1) DKGen produces a greater number of sentences supported by the reference or the target text compared to ChatGPT, while a large portion of the text generated by ChatGPT lacks such support (Green text vs. Other); (2) ChatGPT tends to generate more generic text than DKGen, which complicates the assessment of its factual accuracy; (3) DKGen is capable of generating reference marks at the end of each sentence, facilitating the traceability of the source text and thereby enhancing the credibility of the generated content.
5 Conclusion and Limitation
In this paper, we introduce DKGen, a model specifically designed to enhance the factual accuracy of text generation by employing dynamic knowledge selection. Instead of incorporating all available reference passages into a single-pass generator, DKGen adopts an iterative process that selects reference passages to support the generation of individual sentences. Upon completion of the iterative process, the generated sentences are combined to produce the final output. To further augment the output’s reliability, reference marks can be appended to the end of each sentence. Our experiments on a public benchmark demonstrate that DKGen outperforms all baseline models.
Knowledge-enhanced generation holds big potential applications for both academia and industry. Selecting appropriate knowledge and ascertaining the optimal moment to apply it during text generation remain challenges in need of effective solutions. In this paper, our proposed DKGen model provides a potential solution to address these concerns. However, DKGen has limitations: Firstly, it relies on heuristic strategies to select the number of reference passages, which may result in insufficient knowledge synthesis from diverse sources. Secondly, human evaluation indicates that the iterative sentence generation approach adopted by DKGen may lead to lower semantic coherence compared to producing the entire output in a single pass. We will address these limitations in the future work.
References
- Radford et al. [2019] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 2019.
- Raffel et al. [2019] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR, 2019.
- Brown et al. [2020] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- Smith et al. [2022] Shaden Smith, Mostofa Patwary, Brandon Norick, Patrick LeGresley, Samyam Rajbhandari, Jared Casper, Zhun Liu, Shrimai Prabhumoye, George Zerveas, Vijay Korthikanti, et al. Using DeepSpeed and Megatron to train Megatron-Turing NLG 530B, a large-scale generative language model. arXiv preprint arXiv:2201.11990, 2022.
- Ouyang et al. [2022] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022.
- Sennrich et al. [2016] Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. In ACL, 2016.
- Rae et al. [2021] Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446, 2021.
- Nakano et al. [2021] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. WebGPT: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.
- Zhang et al. [2022] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Lee et al. [2022] Nayeon Lee, Wei Ping, Peng Xu, Mostofa Patwary, Pascale Fung, Mohammad Shoeybi, and Bryan Catanzaro. Factuality enhanced language models for open-ended text generation. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=LvyJX20Rll.
- Ji et al. [2022] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. arXiv preprint arXiv:2202.03629, 2022.
- Lewis et al. [2020] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Red Hook, NY, USA, 2020. Curran Associates Inc. ISBN 9781713829546.
- Yu et al. [2022] Donghan Yu, Chenguang Zhu, Yuwei Fang, Wenhao Yu, Shuohang Wang, Yichong Xu, Xiang Ren, Yiming Yang, and Michael Zeng. KG-FiD: Infusing knowledge graph in fusion-in-decoder for open-domain question answering. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4961–4974, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.340. URL https://aclanthology.org/2022.acl-long.340.
- Yu et al. [2020] Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng Ji, and Meng Jiang. A survey of knowledge-enhanced text generation. arXiv preprint arXiv:2010.04389, 2020.
- Piktus et al. [2021] Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Dmytro Okhonko, Samuel Broscheit, Gautier Izacard, Patrick Lewis, Barlas Oğuz, Edouard Grave, Wen-tau Yih, et al. The web is your oyster–knowledge-intensive nlp against a very large web corpus. arXiv preprint arXiv:2112.09924, 2021.
- West et al. [2022] Peter West, Chris Quirk, Michel Galley, and Yejin Choi. Probing factually grounded content transfer with factual ablation. arXiv preprint arXiv:2203.10133, 2022.
- Shuster et al. [2021] Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. Retrieval augmentation reduces hallucination in conversation. In Findings of the Association for Computational Linguistics: EMNLP 2021. ACL, 2021.
- Thoppilan et al. [2022] Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. LaMDA: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.
- Borgeaud et al. [2021] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. arXiv preprint arXiv:2112.04426, 2021.
- Petroni et al. [2020] Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, et al. Kilt: a benchmark for knowledge intensive language tasks. arXiv preprint arXiv:2009.02252, 2020.
- Guu et al. [2020] Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. Realm: Retrieval-augmented language model pre-training. arXiv preprint arXiv:2002.08909, 2020.
- Izacard and Grave [2021] Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874–880, Online, April 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.eacl-main.74. URL https://aclanthology.org/2021.eacl-main.74.
- Lakhotia et al. [2021] Kushal Lakhotia, Bhargavi Paranjape, Asish Ghoshal, Scott Yih, Yashar Mehdad, and Srini Iyer. FiD-ex: Improving sequence-to-sequence models for extractive rationale generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3712–3727, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.301. URL https://aclanthology.org/2021.emnlp-main.301.
- Hofstätter et al. [2022] Sebastian Hofstätter, Jiecao Chen, Karthik Raman, and Hamed Zamani. Fid-light: Efficient and effective retrieval-augmented text generation. arXiv preprint arXiv:2209.14290, 2022.
- Qian et al. [2023] Hongjing Qian, Yutao Zhu, Zhicheng Dou, Haoqi Gu, Xinyu Zhang, Zheng Liu, Ruofei Lai, Zhao Cao, Jian-Yun Nie, and Ji-Rong Wen. Webbrain: Learning to generate factually correct articles for queries by grounding on large web corpus. arXiv preprint arXiv:2304.04358, 2023.
- Krathwohl [2002] David R Krathwohl. A revision of bloom’s taxonomy: An overview. Theory into practice, 41(4):212–218, 2002.
- Petroni et al. [2019] Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H Miller, and Sebastian Riedel. Language models as knowledge bases? In EMNLP, 2019.
- Aspillaga et al. [2021] Carlos Aspillaga, Marcelo Mendoza, and Alvaro Soto. Inspecting the concept knowledge graph encoded by modern language models. In Findings of ACL, 2021.
- Zhou et al. [2020] Xuhui Zhou, Yue Zhang, Leyang Cui, and Dandan Huang. Evaluating commonsense in pre-trained language models. In AAAI, 2020.
- De Cao et al. [2021] Nicola De Cao, Wilker Aziz, and Ivan Titov. Editing factual knowledge in language models. In EMNLP, 2021.
- Jang et al. [2021] Joel Jang, Seonghyeon Ye, Sohee Yang, Joongbo Shin, Janghoon Han, Gyeonghun Kim, Stanley Jungkyu Choi, and Minjoon Seo. Towards continual knowledge learning of language models. arXiv preprint arXiv:2110.03215, 2021.
- Meng et al. [2022] Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual knowledge in GPT. arXiv preprint arXiv:2202.05262, 2022.
- Cao et al. [2018] Ziqiang Cao, Furu Wei, Wenjie Li, and Sujian Li. Faithful to the original: Fact aware neural abstractive summarization. In Proceedings of the AAAI Conference on Artificial Intelligence, 2018.
- Dong et al. [2020] Yue Dong, Shuohang Wang, Zhe Gan, Yu Cheng, Jackie Chi Kit Cheung, and Jingjing Liu. Multi-fact correction in abstractive text summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 9320–9331, 2020.
- Huang et al. [2020] Luyang Huang, Lingfei Wu, and Lu Wang. Knowledge graph-augmented abstractive summarization with semantic-driven cloze reward. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020.
- Huang et al. [2021] Yichong Huang, Xiachong Feng, Xiaocheng Feng, and Bing Qin. The factual inconsistency problem in abstractive text summarization: A survey. arXiv preprint arXiv:2104.14839, 2021.
- Cao and Wang [2021] Shuyang Cao and Lu Wang. Cliff: Contrastive learning for improving faithfulness and factuality in abstractive summarization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6633–6649, 2021.
- Zhu et al. [2021] Chenguang Zhu, William Hinthorn, Ruochen Xu, Qingkai Zeng, Michael Zeng, Xuedong Huang, and Meng Jiang. Enhancing factual consistency of abstractive summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 718–733, 2021.
- Chen et al. [2021] Sihao Chen, Fan Zhang, Kazoo Sone, and Dan Roth. Improving faithfulness in abstractive summarization with contrast candidate generation and selection. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5935–5941, 2021.
- Wiseman et al. [2017] Sam Wiseman, Stuart Shieber, and Alexander Rush. Challenges in data-to-document generation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2253–2263. ACL, 2017.
- Nie et al. [2019] Feng Nie, Jin-Ge Yao, Jinpeng Wang, Rong Pan, and Chin-Yew Lin. A simple recipe towards reducing hallucination in neural surface realisation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2673–2679. ACL, 2019.
- Liu et al. [2021] Tianyu Liu, Xin Zheng, Baobao Chang, and Zhifang Sui. Towards faithfulness in open domain table-to-text generation from an entity-centric view. In AAAI, 2021.
- Su et al. [2021] Yixuan Su, David Vandyke, Sihui Wang, Yimai Fang, and Nigel Collier. Plan-then-generate: Controlled data-to-text generation via planning. Findings of EMNLP, 2021.
- Wang et al. [2021] Peng Wang, Junyang Lin, An Yang, Chang Zhou, Yichang Zhang, Jingren Zhou, and Hongxia Yang. Sketch and refine: Towards faithful and informative table-to-text generation. ACL, 2021.
- Rebuffel et al. [2022] Clément Rebuffel, Marco Roberti, Laure Soulier, Geoffrey Scoutheeten, Rossella Cancelliere, and Patrick Gallinari. Controlling hallucinations at word level in data-to-text generation. Data Mining and Knowledge Discovery, pages 318–354, 2022.
- Shen et al. [2021] Lei Shen, Haolan Zhan, Xin Shen, Hongshen Chen, Xiaofang Zhao, and Xiaodan Zhu. Identifying untrustworthy samples: Data filtering for open-domain dialogues with bayesian optimization. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, pages 1598–1608, 2021.
- Rashkin et al. [2021] Hannah Rashkin, David Reitter, Gaurav Singh Tomar, and Dipanjan Das. Increasing faithfulness in knowledge-grounded dialogue with controllable features. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, pages 704–718. ACL, 2021.
- Wu et al. [2021] Zeqiu Wu, Michel Galley, Chris Brockett, Yizhe Zhang, Xiang Gao, Chris Quirk, Rik Koncel-Kedziorski, Jianfeng Gao, Hannaneh Hajishirzi, Mari Ostendorf, et al. A controllable model of grounded response generation. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 14085–14093, 2021.
- Dziri et al. [2021] Nouha Dziri, Andrea Madotto, Osmar Zaiane, and Avishek Joey Bose. Neural path hunter: Reducing hallucination in dialogue systems via path grounding. EMNLP, 2021.
- Jiang et al. [2020] Zhengbao Jiang, Frank F Xu, Jun Araki, and Graham Neubig. How can we know what language models know? Transactions of the Association for Computational Linguistics, 2020.
- Zhong et al. [2021] Zexuan Zhong, Dan Friedman, and Danqi Chen. Factual probing is [mask]: Learning vs. learning to recall. arXiv preprint arXiv:2104.05240, 2021.
- Elazar et al. [2021] Yanai Elazar, Nora Kassner, Shauli Ravfogel, Abhilasha Ravichander, Eduard Hovy, Hinrich Schütze, and Yoav Goldberg. Measuring and improving consistency in pretrained language models. Transactions of the Association for Computational Linguistics, 9:1012–1031, 2021.
- Li et al. [2023] Minghao Li, Feifan Song, Bowen Yu, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. Api-bank: A benchmark for tool-augmented llms. arXiv preprint arXiv:2304.08244, 2023.
- Cai et al. [2021] Deng Cai, Yan Wang, Huayang Li, Wai Lam, and Lemao Liu. Neural machine translation with monolingual translation memory. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pages 7307–7318. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021.acl-long.567. URL https://doi.org/10.18653/v1/2021.acl-long.567.
- Zhu et al. [2020] Yutao Zhu, Zhicheng Dou, Jian-Yun Nie, and Ji-Rong Wen. Reboost: a retrieval-boosted sequence-to-sequence model for neural response generation. Inf. Retr. J., 23(1):27–48, 2020. doi: 10.1007/s10791-019-09364-x. URL https://doi.org/10.1007/s10791-019-09364-x.
- Glaese et al. [2022] Amelia Glaese, Nat McAleese, Maja Trębacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, Lucy Campbell-Gillingham, Jonathan Uesato, Po-Sen Huang, Ramona Comanescu, Fan Yang, Abigail See, Sumanth Dathathri, Rory Greig, Charlie Chen, Doug Fritz, Jaume Sanchez Elias, Richard Green, Soňa Mokrá, Nicholas Fernando, Boxi Wu, Rachel Foley, Susannah Young, Iason Gabriel, William Isaac, John Mellor, Demis Hassabis, Koray Kavukcuoglu, Lisa Anne Hendricks, and Geoffrey Irving. Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv:2209.14375, 2022.
- Menick et al. [2022] Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, and Nat McAleese. Teaching language models to support answers with verified quotes. arXiv preprint arXiv:2203.11147, 2022.
- Lewis et al. [2019] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019.
- Humeau et al. [2020] Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, and Jason Weston. Poly-encoders: Transformer architectures and pre-training strategies for fast and accurate multi-sentence scoring. arXiv preprint arXiv:1905.01969, 2020.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
- Papineni et al. [2002] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, July 6-12, 2002, Philadelphia, PA, USA, pages 311–318. ACL, 2002. doi: 10.3115/1073083.1073135. URL https://aclanthology.org/P02-1040/.
- Lin [2004] Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL https://aclanthology.org/W04-1013.
- Sharma et al. [2017] Shikhar Sharma, Layla El Asri, Hannes Schulz, and Jeremie Zumer. Relevance of unsupervised metrics in task-oriented dialogue for evaluating natural language generation. CoRR, abs/1706.09799, 2017. URL http://arxiv.org/abs/1706.09799.
- Yuan et al. [2021] Weizhe Yuan, Graham Neubig, and Pengfei Liu. Bartscore: Evaluating generated text as text generation. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors, Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 27263–27277, 2021. URL https://proceedings.neurips.cc/paper/2021/hash/e4d2b6e6fdeca3e60e0f1a62fee3d9dd-Abstract.html.
- Goodrich et al. [2019a] Ben Goodrich, Vinay Rao, Peter J. Liu, and Mohammad Saleh. Assessing the factual accuracy of generated text. In Ankur Teredesai, Vipin Kumar, Ying Li, Rómer Rosales, Evimaria Terzi, and George Karypis, editors, Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, August 4-8, 2019, pages 166–175. ACM, 2019a. doi: 10.1145/3292500.3330955. URL https://doi.org/10.1145/3292500.3330955.
- Goodrich et al. [2019b] Ben Goodrich, Mohammad Ahmad Saleh, Peter Liu, and Vinay Rao. Assessing the factual accuracy of text generation. In The 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD’19), 2019b.
- Angeli et al. [2015] Gabor Angeli, Melvin Jose Johnson Premkumar, and Christopher D. Manning. Leveraging linguistic structure for open domain information extraction. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, ACL 2015, July 26-31, 2015, Beijing, China, Volume 1: Long Papers, pages 344–354. The Association for Computer Linguistics, 2015. doi: 10.3115/v1/p15-1034. URL https://doi.org/10.3115/v1/p15-1034.
- Heo [2021] Hoon Heo. Factsumm: Factual consistency scorer for abstractive summarization. https://github.com/Huffon/factsumm, 2021.
- Wolf et al. [2019] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, and Jamie Brew. Huggingface’s transformers: State-of-the-art natural language processing. CoRR, abs/1910.03771, 2019. URL http://arxiv.org/abs/1910.03771.
- Formal et al. [2021] Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. SPLADE: sparse lexical and expansion model for first stage ranking. In Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Castells, Rosie Jones, and Tetsuya Sakai, editors, SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, pages 2288–2292. ACM, 2021. doi: 10.1145/3404835.3463098. URL https://doi.org/10.1145/3404835.3463098.
- Loshchilov and Hutter [2019] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7.
- Xiao et al. [2022] Shitao Xiao, Zheng Liu, Yingxia Shao, and Zhao Cao. Retromae: Pre-training retrieval-oriented language models via masked auto-encoder. In EMNLP, 2022.