Optimized Information Flow for Transformer Tracking
Abstract
One-stream Transformer trackers have shown outstanding performance in challenging benchmark datasets over the last three years, as they enable interaction between the target template and search region tokens to extract target-oriented features with mutual guidance. Previous approaches allow free bidirectional information flow between template and search tokens without investigating their influence on the tracker’s discriminative capability. In this study, we conducted a detailed study on the information flow of the tokens and based on the findings, we propose a novel Optimized Information Flow Tracking (OIFTrack) framework to enhance the discriminative capability of the tracker. The proposed OIFTrack blocks the interaction from all search tokens to target template tokens in early encoder layers, as the large number of non-target tokens in the search region diminishes the importance of target-specific features. In the deeper encoder layers of the proposed tracker, search tokens are partitioned into target search tokens and non-target search tokens, allowing bidirectional flow from target search tokens to template tokens to capture the appearance changes of the target. In addition, since the proposed tracker incorporates dynamic background cues, distractor objects are successfully avoided by capturing the surrounding information of the target. The OIFTrack demonstrated outstanding performance in challenging benchmarks, particularly excelling in the one-shot tracking benchmark GOT-10k, achieving an average overlap of 74.6%. The code, models, and results of this work are available at https://github.com/JananiKugaa/OIFTrack.
keywords:
Transformer Tracking , Visual Object Tracking , Vision Transformer , One-stream Tracking[1]organization=Department of Computational Mathematics, University of Moratuwa, country=Sri Lanka \affiliation[2]organization=Department of Interdisciplinary Studies, University of Jaffna, country=Sri Lanka \affiliation[3]organization=Department of Computer Science, University of Jaffna, country=Sri Lanka
1 Introduction
Visual Object Tracking (VOT) involves estimating the location and size of an object from the initial frame of a video sequence and persistently tracking it across successive frames. A wide range of applications relies on VOT across various domains, including video surveillance (Choubisa et al., 2023), automated driving (Bai et al., 2022), augmented reality (Baker et al., 2023), mobile robotics (Zhang et al., 2023), traffic monitoring (Yang et al., 2023b), and human-computer interaction (Cao, 2023). Although many single VOT approaches have been proposed in the last three decades, achieving tracking robustness at a human-level standard remains a significant challenge due to various complicating factors encountered in real-world scenarios, such as appearance variations, occlusions, motion blurring, background clutter, and the presence of similar object distractors.
In the last decade, deep learning-based approaches, particularly those utilizing Convolutional Neural Network (CNN) based tracking methods, have demonstrated outstanding performance. Specifically, Siamese-based CNN tracking methods (Li et al., 2019; Chen et al., 2020; Zhang et al., 2020; Danelljan et al., 2020; Voigtlaender et al., 2020; Guo et al., 2021; Mayer et al., 2021; Thanikasalam et al., 2019; Liang et al., 2023) have shown excellent performance in appearance-based single-object tracking. Siamese-based trackers employ two identical CNN branches (Krizhevsky et al., 2017) to independently extract features from a target template and a search region, then locate the target within the search region by computing the similarity between the target and search region features using a simple cross-correlation operation. Although Siamese-based trackers have successfully balanced tracking accuracy and efficiency, their performance is considerably limited due to the neglect of the global context in feature extraction by CNNs. Furthermore, the correlation operation is inadequate for capturing non-linear interactions, such as occlusion, deformation, and rotation between the target template and search region, thereby limiting the tracking performance of Siamese-based trackers. Due to the limitations of CNNs in VOT, a few recent tracking approaches (Kugarajeevan et al., 2023) have employed Transformers in single-object tracking.
Transformer (Vaswani et al., 2017), initially introduced in the field of Natural Language Processing (NLP) and became popular due to its parallelization capabilities, scalability to handle long sequences, and effectiveness in capturing contextual information through attention mechanisms. Inspired by the success of Transformers in NLP tasks, researchers have modified (Dosovitskiy et al., 2021) the architecture for vision tasks, demonstrating outstanding performance in various domains such as object detection (Liu et al., 2023), image generation (Kim et al., 2023), image classification (Zhou et al., 2023), semantic segmentation (Shi et al., 2023), and point cloud comprehension (Yu et al., 2023). Over the past three years, owing to the tremendous success of Transformers in various computer vision tasks, researchers have developed a set of Transformer-based VOT approaches (Kugarajeevan et al., 2023), demonstrating excellent performance on benchmark datasets.
Transformer-based tracking approaches (Chen et al., 2023; Wei et al., 2023; Gao et al., 2023; Xie et al., 2023; He et al., 2023; Cai et al., 2023; Song et al., 2023; Gopal & Amer, 2024; Yang et al., 2023c; Kang et al., 2023; Zhao et al., 2023a; Ye et al., 2022; Chen et al., 2022; Cui et al., 2022; Lin et al., 2022; Fu et al., 2022; Gao et al., 2022; Song et al., 2022; Yu et al., 2021; Yan et al., 2021; Chen et al., 2021) have shown better tracking accuracies than the CNN-based trackers in the last three years. In some early approaches, Transformers were utilized as a correlation module alongside the CNN backbone within a two-stream pipeline, combining both CNN and Transformer architectures (Gao et al., 2022; Song et al., 2022; Yu et al., 2021; Yan et al., 2021; Chen et al., 2021) for feature extraction and relation modeling. Since these hybrid CNN-Transformer VOT approaches still depend on a CNN for feature extraction, they are unable to capture a global feature representation of a target object. To address this limitation, some approaches (Lin et al., 2022; Fu et al., 2022) completely replace the CNN backbone with the Transformer in a two-stream pipeline, extracting features of the template and search region using two individual Transformer models. However, as these two-stream Transformer trackers fail to consider the information flow between the template and search region during feature extraction, their tracking abilities are considerably limited. To address this limitation, more recently, researchers have introduced one-stream Transformer-based approaches (Chen et al., 2023; Wei et al., 2023; Gao et al., 2023; Xie et al., 2023; He et al., 2023; Cai et al., 2023; Song et al., 2023; Kang et al., 2023; Zhao et al., 2023a; Cui et al., 2022; Ye et al., 2022; Chen et al., 2022) in VOT, combining feature extraction and relation modeling into a unified approach using a single Transformer model. A recent study (Kugarajeevan et al., 2023) showed that one-stream Transformer-based approaches outperformed CNN-based, CNN-Transformer, and two-stream Transformer-based approaches by a large margin in terms of tracking accuracies on all challenging benchmark datasets.

In the initial phase of one-stream Transformer tracking approaches, tokens are generated from the patches of the target template and search regions, and then they are concatenated. Subsequently, attention among all these concatenated tokens is computed using the self-attention mechanisms of the encoder layers of the Transformer. Computing attention between all concatenated target template and search region tokens demonstrated promising performance by facilitating information flow (Ye et al., 2022) between template and search tokens, enabling both regions to extract target-specific features and accurately locate the target. As shown in Fig. 1, previously proposed One-stream Transformer tracking approaches compute the attention between all target and search region tokens to enable the information flow and showed outstanding performances. However, no proper studies have been conducted to justify whether the attention of search region tokens on the target template tokens supports or reduces the discriminative ability of the trackers. Therefore, there is a need to investigate the attention mechanisms between different types of tokens in one-stream Transformer tracking.
Tracking a target object by only considering the initial target template is challenging, especially in long-term tracking scenarios where the target undergoes significant appearance changes. Some one-stream Transformer trackers (Cui et al., 2022; Lan et al., 2023) address this challenge by incorporating temporal cues of the target object through the use of dynamic templates in tracking. However, similar to other one-stream Transformer trackers, these trackers concatenate the target template, dynamic template, and search region tokens, and then compute the attention between all concatenated tokens without investigating the impact of attention among different groups of tokens.
In this study, we investigate the information flow among the tokens of the target template, dynamic template, and search region in the one-stream Transformer tracking paradigm by systematically analyzing the attention between different groups of tokens. Based on experimental findings, it is evident that the information flow from a subset of search region tokens, which are generated from background patches, to the initial target template and dynamic target template tokens, reduces the tracker’s discriminative capability. We have also observed that the information flow from the subset of search region tokens containing target cues to the initial and dynamic target template tokens enhances target-specific feature extraction and is also used to capture the appearance changes of the target.
In previous tracking approaches, dynamic target templates are generated by tightly cropping the high-confidence target in an intermediate frame and then using those temporal cues to enhance tracking performance. In this work, we have also investigated how to maximize the utilization of temporal cues in the one-stream Transformer tracking paradigm. Our experimental study found that, instead of tightly cropping the dynamic target, cropping it with additional dynamic background cues enriches the tracking performances by providing valuable surrounding information of the target object. We have also found that including the dynamic background cues helps to accurately locate the target in the search region and is also used to avoid distractor objects in subsequent frames.
Based on our experimental analysis, we have proposed a novel one-stream Transformer tracker and called it as the Optimized Information Flow Tracker (OIFTrack). To utilize the temporal cues in tracking, the dynamic target template and dynamic background are included in the proposed OIFTrack approach. As the initial step of the tracker, tokens are generated from the patches of the initial target template, dynamic target template with the background region, and the search region and considered as four groups: initial target template tokens, dynamic target template tokens, dynamic background tokens, and search region tokens. In the early encoder layers of the proposed tracker, the information flow from the search region tokens and dynamic background tokens to the initial target template tokens, as well as the information flow from the search region tokens to the dynamic target tokens, is blocked to prevent disturbance to the tracker-specific feature extraction. In the deeper encoder layers of the proposed tracker, search region tokens are categorized into two groups: target search tokens and non-target search regions, based on the attention scores of the search tokens with the initial and dynamic target template tokens. After the token grouping in deeper encoder layers, information flow from target search tokens to both initial and dynamic target template tokens is allowed to enrich the target-specific feature extraction and capture the target’s appearance changes for more accurate localization. The proposed OIFTrack approach blocks the information flow between tokens using a simple attention masking technique. In summary, our contributions revolve around four fundamental aspects:
-
1.
We propose an optimized information flow mechanism for the interaction among input tokens, achieved by dividing them into four groups in early layers and five groups in deeper layers, effectively blocking unnecessary information flows that disrupt the discriminative capability of the tracker.
-
2.
We have incorporated dynamic background cues into the proposed tracker to avoid distractor objects and locate the target more accurately. To our knowledge, no previous Transformer trackers have considered the importance of dynamic background cues.
-
3.
In contrast to previous approaches employing learnable or complex modules, we have utilized a simple and efficient mechanism to partition the search tokens into target and non-target categories based on their attention scores from initial target and dynamic target tokens.
-
4.
We perform extensive experiments and evaluations to demonstrate the efficacy of our tracker. Our OIFTrack framework showed outstanding performance in various tracking benchmarks, such as GOT-10k (Huang et al., 2019), LaSOT (Fan et al., 2019), TrackingNet (Muller et al., 2018), and UAV123 (Mueller et al., 2016).
2 Related Work
In this section, we review the literature on Transformer-based tracking approaches and information flow techniques related to the proposed optimized information flow mechanism.
2.1 Two-stream Transformer Trackers
Until recently, two-stream tracking pipeline-based approaches have shown state-of-the-art performances in VOT with high computational efficiency. In this pipeline of trackers, initial target template and search region features are independently extracted using a neural network model, and then the target is located in the search region by finding the similarity of target features in the search region features.
Transformers were initially introduced into the two-stream tracking pipeline as a feature fusion module (Chen et al., 2021; Gao et al., 2022; Song et al., 2022; Yan et al., 2021; Yu et al., 2021), replacing the correlation modules of CNN-based Siamese trackers. In these CNN-Transformer-based two-stream trackers, a CNN backbone is employed to extract the features of both target template and search region. The extracted CNN features are then flattened and concatenated before being fed to a Transformer to capture feature dependencies using the attention mechanism. Finally, the enhanced search region features are input to a prediction head to locate the target. While some early CNN-Transformer trackers adopted Transformer architectures, such as DETR (Carion et al., 2020) in STARK (Yan et al., 2021) tracker, from the object detection task with minor modifications, recent approaches have recognized issues specific to Transformer-based tracking and subsequently adjusted their architectures. CNN-Transformer based trackers have demonstrated superior performance compared to CNN-based trackers by employing a trainable Transformer instead of the linear cross-correlation operation.
Some of the recent two-stream Transformer trackers (Lin et al., 2022; Fu et al., 2022) replaced the CNN backbone with two individual but identical Transformers to extract the features of both the target template and search region. Since these trackers utilized the global feature representations of the Transformers in both feature extraction and future fusion they outperformed the CNN-Transformer based trackers in terms of accuracy.
Although the two-stream Transformer trackers showed better performance than the CNN-based trackers due to the learnable feature fusion modules and the global feature learning capability of the Transformers, they extracted the target template and search region features individually. Therefore, the search region features are extracted without knowledge of the target cues, and as a result, the importance of target-specific features in the search region fails to be considered. To address this limitation, recent Transformer trackers enable information flow between target template and search region tokens from the early encoder layers, and these trackers are known as one-stream Transformer trackers.
2.2 One-Stream Transformer Trackers
One-stream Transformer trackers (Chen et al., 2022; Cui et al., 2022; Ye et al., 2022; Lan et al., 2023; Xie et al., 2023; Gao et al., 2023; Wu et al., 2023; Zhao et al., 2023b; Wei et al., 2023; Chen et al., 2023) combine the feature extraction and future fusion processes and enable the bidirectional information flow between target template and search region tokens. In one-stream Transformer trackers, a set of encoder layers is utilized with the self-attention mechanism to jointly extract the features of the target and template tokens. Finally , the features of the search region tokens from the last encoder layer are fed to a prediction head to locate the target. As these trackers enhance target-specific feature extraction, they improve the discriminative capability of the tracker, resulting in outstanding performances compared to both CNN-based trackers and two-stream Transformer based trackers.
In the last two years, a considerable number of one-stream Transformer trackers have been proposed, incorporating bidirectional information flow between target template and search region tokens. OSTrack (Ye et al., 2022) is well-known as one such tracker due to its outstanding performances in benchmark datasets and highly parallelized architecture. It utilized a Masked Auto Encoder (MAE) (He et al., 2022) based pre-trained model to initialize the encoder layers of the tracker, resulting in a remarkable performance boost. In addition, a candidate elimination module is included in OSTrack to remove background tokens from search regions, thereby increasing the computational efficiency of the tracker. Due to OSTrack’s outstanding tracking performance in many benchmark datasets, several follow-up approaches (Lan et al., 2023; Xie et al., 2023; Gao et al., 2023) have been proposed within the one-stream tracking pipeline. Although OSTrack and follow-up approaches showed better performance than the two-stream Transformer trackers, they allowed bidirectional information flow between all target and search region tokens without evaluating the influence of tokens on discriminative target objects from the surroundings. As a result, their tracking performances are considerably limited. Moreover, since OSTrack and some of the follow-up approaches fail to consider temporal information, their tracking performances are considerably poor in long tracking sequences, especially when the target undergoes severe appearance changes.
A few recent approaches (Cui et al., 2022; Lan et al., 2023; Xie et al., 2023; Chen et al., 2023) have enhanced the tracking performances of one-stream Transformer trackers by incorporating the temporal cues of the target. In these trackers, dynamic target tokens are extracted from an intermediate frame with high-confidence detection and then concatenated with the initial target template and search region tokens. Some of these trackers follow special mechanisms to select the dynamic target template, such as the MixFormer (Cui et al., 2022) tracker, which used a learnable score prediction module to select reliable dynamic templates based on predicted confidence scores. Although these trackers enhance the tracking performance by incorporating dynamic tokens, they allow bidirectional information flow between all initial target, dynamic target, and search region tokens without considering their discriminative capability. In addition, most of these trackers fail to consider dynamic background cues, which would allow the tracker to incorporate surrounding information of the target for more accurate localization in the search frame.
In the proposed work, instead of allowing free bidirectional information flow between all target and search region tokens as in previous one-stream Transformer approaches, unnecessary information flow between tokens is blocked to enhance the discriminative capability of the tracker. Additionally, surrounding information of the dynamic target is included in the proposed work to accurately locate the target and avoid distractor objects in the search frame.
2.3 Information Flow Variants in One-Stream Tracking
All of the one-stream Transformer trackers freely allowed bidirectional information flow between target and search region tokens in encoder layers without any restrictions. However, recently, a few trackers have controlled the information flow between tokens for various purposes. The recently proposed SeqTrack (Chen et al., 2023) and ARTrack (Wei et al., 2023) approaches restrict the information flow between tokens in decoder layers to prevent tokens from attending to subsequent tokens. However, in the encoder layer of these trackers, attention features are extracted by freely allowing bidirectional information flow between target and search region tokens.
The GRM tracker (Gao et al., 2023) restricts the information flow between the template and search tokens by allowing only a subset of search region tokens, determined by the selection of a learnable adaptive token division module, to interact with template tokens. The GRM approach performs as a two-stream tracker in some encoder layers, as all search tokens are rejected by the division module for interaction with template tokens in those layers, and performs as a one-stream tracker in some other layers, as all search tokens are selected for interaction. While functioning as a two-stream tracker in certain encoder layers, the GRM tracker individually extracts attention features from the target and search region tokens, which may result in the failure to extract target cues from the search tokens in those layers, potentially leading to a decrease in tracking performance.
Recently proposed, the F-BDMTrack approach (Yang et al., 2023a) blocks the information flow between the foreground and background tokens of the target template using a fore-background agent learning module. Additionally, the information flow between the foreground and background tokens of the search region is also restricted using that module to enhance the discriminative capability of the tracker. After the fore-background module, a distribution-aware attention module is used to prevent the incorrect interaction between the foreground and background tokens by modeling foreground-background distribution similarities. In this tracker, ground-truth bounding boxes are used to identify the foreground and background tokens of the template, while a pseudo bounding box generation technique is employed to identify the foreground in the search region.
Although the GRM and F-BDMTrack approaches block information flow between different groups of tokens for various purposes, they employ a learnable module for token grouping from early encoder layers. Therefore, a search token may be identified as a potential target token in one layer and as a background token in another, due to variations in the knowledge level of the learnable module between early and deeper layers, that may lead to poor tracking performance. In contrast to previous approaches, the proposed OIFTrack approach is carefully designed with a simple and neat architecture. Additionally, by conducting the search token partitioning only in deeper encoder layers using the learned knowledge from the middle encoder layers and blocking the information flow accordingly, it achieves more accurate identification of target and non-target tokens from the search region in a simple and fast manner.
3 Methodology
In this section, we introduce our one-stream Transformer tracking approach, termed as OIFTrack, which relies on optimizing information flow between tokens. Initially, we delve into the specifics of the baseline tracking model, followed by an explanation of how the proposed tracker utilizes the temporal cues for enhanced tracking. Subsequently, we provide a detailed description of the proposed optimized information flow mechanism. Finally, we outline the background token elimination technique and details of the prediction head within this section.
3.1 Baseline Tracking Model
In this section, we explore the baseline tracking model used in one-stream Transformer trackers. All of the previous approaches (Ye et al., 2022; Chen et al., 2022; Cui et al., 2022) employed this baseline model to establish their tracking methodologies.
In the one-stream Transformer tracking paradigm, a tracker takes the initial target template and search region as inputs, and then produces the location of the target in the search region as the output. As the first step, template and search region images are divided into non-overlapping patches, each of size . The total number of target template patches () and search region patches () can be calculated as follows:
| (1) |
After partitioning the patches, a learnable linear projection layer is employed to generate template and search patch embeddings from their respective patches. Subsequently, the spatial information of the template and search patches is individually embedded using a learnable position embedding scheme. The outcome of the embeddings is known as tokens, and we refer to the target template and search region tokens as and , respectively. Before being fed to the encoder layers of the Transformer, these tokens are concatenated to generate a sequence of tokens [ ; ] with a total length of .
In the next phase of the one-stream Transformer tracking pipeline, attention features for the concatenated tokens are computed through a multi-head attention (MHA) block and a then fed to a feed-forward network (FFN) in each encoder layer. The self-attention of head in an encoder layer is computed as follows:
| (2) |
where, Query (), Key () and Value () are the three linear projections of the input matrix and represents the feature dimension of . The MHA block of the one-stream tracker captures a wide range of relationships and dependencies between input tokens through linear projection while concurrently processing them with multiple independent attention heads. The process of MHA can be formulated as follows:
| (3) |
where is the number of attention heads in the tracker and denotes the output projection matrix.
In the encoder layer of the baseline tracking model, the concatenated target and search region tokens () are obtained from previous layer and then considered as the input tokens. After a normalization operation, the attention features of these tokens are computed by the MAH block and then added to the input tokens. Following another normalization operation, the combined features are fed into the FFN block of the encoder layer to obtain the output tokens. In summary, the operations of the encoder layer can be expressed as:
| (4) |
where is the output tokens of the encoder layer.
From the output tokens () of the last encoder layer of the baseline tracking model, the search region tokens () are extracted and fed into a prediction head to locate the target within the search region.
Most one-stream Transformer tracking approaches (Ye et al., 2022; Chen et al., 2022; Wu et al., 2023; Zhao et al., 2023a) only utilize the baseline tracking model with free bidirectional information flow. In contrast, the proposed OIFTrack approach goes further by enhancing the tracking performance of the baseline tracker through the incorporation of temporal cues and the optimization of information flow between the tokens.
3.2 Temporal Cues Utilization
Capturing and utilizing the temporal information is important in VOT, especially in long-term tracking scenarios where the appearance of the target may undergo significant changes. While many one-stream Transformer trackers (Ye et al., 2022; Chen et al., 2022; Wu et al., 2023; Zhao et al., 2023a) have shown better performance on benchmark datasets, their effectiveness is considerably limited by their failure to incorporate temporal cues in tracking, relying solely on the initial target template to locate the target in long-term sequences. Although some recent approaches (Lan et al., 2023; Cui et al., 2022; Xie et al., 2023) have included temporal cues by incorporating dynamic templates, our focus is on further enriching the utilization of temporal cues within the one-stream Transformer tracking paradigm.
Background cues are important in VOT as they are used to capture the surrounding information of the target object. Some Transformer tracking approaches (Mayer et al., 2022; Wang et al., 2021; He et al., 2023) expand the size of the target template to match the size of the search region, even though it increases the computational complexity of the tracker, aiming to incorporate the surrounding background information of the target. However, it is observed that the surrounding information of the initial target template becomes less useful for locating the target after a set of frames, especially in long-term tracking scenarios. Moreover, these approaches extract features from both the actual target region and a large portion of background regions together in the template, resulting in the distraction of target-specific features. Therefore, in the proposed approach, we have utilized the background cues from the dynamic template since they are very close to the surrounding region of the target in the search region while keeping the initial template without any additional background patches.

In the proposed OIFTrack approach, we include the dynamic target template from an intermediate frame in which the target object was located with high confidence. In addition to the dynamic target template, as shown in Fig. 2, we extract a few additional patches from the surrounding region of the dynamic target and consider them as dynamic background patches. Since nearby similar objects are also identified as dynamic background patches, the proposed tracker is able to successfully avoid distractor objects in the search region. In addition, unlike previous approaches, the proposed tracker restricts the information flow from dynamic background patches to the initial target template patches, ensuring that the target-specific features of the initial template remain undistracted.
In the proposed tracker, similar to the initial target template and search region patches, the dynamic target template image with background is divided into non-overlapping patches, each of size . After the linear projection and positional embedding, dynamic target template tokens and dynamic background tokens are generated; we refer to them as and , respectively. Before being fed to the encoder layers of the Transformer, these tokens are concatenated with the initial target template and search region tokens to generate a sequence of input tokens [; ; ; ]. In the first frame of a tracking sequence, the dynamic target and dynamic background tokens are initialized by incorporating the target and surrounding cues in the initial frame. In every fixed frame interval, based on the highest confidence score, these tokens are updated to obtain the temporal cues.
3.3 Optimized Information Flow between Tokens

We have conducted a comprehensive analysis of the information flow between target template and search tokens, focusing on enhancing the performance of one-stream tracking further, and have discovered several informative findings. In the search region tokens, the number of non-target tokens is higher compared to those containing the target cues, as all of these trackers search for the target in a large region. In many frames, most of the non-target search tokens contain background cues, while a few others contain cues of distractor objects. We have found that the information flow from the large number of background search tokens to the fewer number of target template tokens gives more influence to the background rather than the target, thereby reducing the importance of target-specific features in the template. In addition, information flow from search tokens with distractor cues reduces the originality of target-specific cues in the template, leading to drifting problems. However, we have also found that bidirectional interaction between target template tokens and search tokens containing target cues is crucial, as it is used to enrich the target-specific feature extraction, enabling the tracker to capture the appearance changes of the target.
We have expanded the comprehensive analysis of information flow between tokens by incorporating dynamic target tokens and dynamic background tokens. Consistent with previous findings, the information flow from dynamic background tokens to the initial target template tokens reduces the importance of target-specific features, while bidirectional information flow between dynamic target template and initial template tokens strengthens target-specific feature extraction.
Based on the findings, the proposed OIFTrack approach, instead of employing the free bidirectional information flow used in previous approaches, optimizes the information flow by blocking certain unnecessary token interactions that might distract the discriminative capability of the tracker. In the early encoder layer of the OIFTrack approach, the concatenated tokens are categorized as initial target template tokens, dynamic target template tokens, dynamic background tokens, and search tokens, and then the unnecessary information flows between these categories are blocked. The search tokens are maintained as a single category in the early layers because these layers lack sufficient knowledge about target-specific cues to perform partitioning. As shown in Fig. 3, in the deeper encoder layer of the proposed work, the number of token categories is increased by partitioning the search region tokens into non-target tokens and tokens with target cues, and then unnecessary information flows between these categories are blocked. We blocked the unnecessary information flow between tokens by utilizing the attention masking technique. In this technique, some attention scores in the matrix are manually set to negative infinity to prevent the interaction between corresponding tokens. The attention score matrix () is computed as follows:
| (5) |
since the Softmax operation is used to calculate the attention features by using the score matrix, as given in Equation 2, the information flow between the selected tokens is completely ignored in the proposed tracker.
The proposed OIFTrack approach obtained the initial target ([]), dynamic target ([]), dynamic background ([]), and search region () tokens and then concatenated them as a sequence of input tokens ([; ; ; ]). In an early encoder layer , the attention features of the initial target template tokens are computed by obtaining the Query () from the initial template tokens and the Key () and Value () from both the initial target template and dynamic target template tokens, while ignoring the information flow from both the search tokens and dynamic background tokens. The attention feature extraction process of initial target template tokens in the layer can be expressed as follows:
| (6) |
In that early encoder layer, attention features of dynamic tokens is computed by obtaining the Queries ( and ) from corresponding dynamic tokens and the Keys ( and ) and Values ( and ) from initial target template, dynamic target template, and dynamic background tokens, while ignoring the information flow from the search tokens. The attention feature extraction process of dynamic template and background tokens in an early layer can be expressed as follows:
| (7) |
In that early encoder layer, attention feature extraction process of search tokens can be expressed as follows:
| (8) |
As the last step of the feature extraction in the early encoder layer, the extracted attention features are concatenated and then fed to the FFN block. This process can be expressed as:
| (9) |
where are the output tokens of the encoder layer.
In the deeper encoder layers of the proposed approach, search region tokens are partitioned into target search tokens and non-target search tokens. This partition is carried out based on the attention scores of the search region tokens in relation to the initial target template and dynamic target template tokens. As the initial step in this partitioning process, attention score weights of all search region tokens are computed as follows:
| (10) |
We have only used the center region tokens of the initial target and dynamic target in the above computation to accurately identify the target search tokens. Since the obtained weighted score matrix () represents the relevance of search region tokens to the initial target and dynamic target template tokens, we sorted the scores and selected the corresponding top-K tokens as search tokens with target cues, while the remaining were considered as non-target search tokens.
After the search token partitioning, a deeper encoder layer receives the initial target ([]), dynamic target ([]), dynamic background ([]), target search ([]), and non-target search ([]) tokens from previous layer and then concatenated them as a sequence of tokens ([; ; ; ; ]). The attention features of the initial target tokens are extracted by blocking the information flow from both the dynamic background tokens and the non-target search tokens, as described in the following equation:
| (11) |
In that deeper encoder layer, the attention features of the dynamic target tokens are computed by blocking the information flow from non-target search tokens, and this process is expressed as follows:
| (12) |
Additionally, the attention features of the dynamic background tokens are extracted by restricting the information flow from all search region tokens, as follows:
| (13) |
The attention features of the search tokens () are obtained by allowing interaction with all other tokens, and this process can be written as:
| (14) |
As the last step of the feature extraction in the deeper encoder layer, the extracted attention features are concatenated and then fed to the FFN block. This process can be expressed as:
| (15) |
Finally, from the output tokens of the last encoder layer of the proposed tracker, search region tokens are separated and then fed to a prediction head to locate the target. The overall tracking framework of the proposed OIFTrack approach is depicted in Fig. 3. It illustrates the attention feature extraction mechanism of the deeper encoder layers on the left side while demonstrating the difference in information flow between early and deeper encoder layers on the right side. Since the proposed optimized information flow mechanism enables bidirectional information flow among all tokens extracted from the initial target, dynamic target, and target search regions, the proposed tracker can effectively capture the appearance changes of the target object compared to previous approaches. Moreover, as the proposed optimized information flow mechanism blocks information flow from tokens containing non-target cues to tokens containing target cues, target-specific features are extracted more accurately, thereby enriching the discriminative capability of the tracker.
3.4 Background Token Elimination
While the proposed OIFTrack approach enhances tracking accuracy, its computational efficiency is reduced due to the increase in the total number of input tokens resulting from the incorporation of tokens from the dynamic template. To address this issue, we eliminate a set of non-target search tokens in some encoder layer of the proposed tracker.
In one-stream Transformer tracking, a large portion of input tokens comes from the search region, with many of them containing only background cues. Therefore, eliminating the background tokens from the concatenated input tokens in deeper layers is one of the strategies to reduce the number of computations. Although the background token elimination mechanism is utilized in some previous approaches (Ye et al., 2022; Lan et al., 2023), we incorporated dynamic target cues to accurately identify the search tokens containing only background cues. Similar to the search token partitioning, Equation 10 is used to identify the search region tokens that have background cues, based on their lowest attention scores relative to the initial and dynamic template tokens. Then, among the tokens with the lowest scores, number of tokens are selected based on their poor attention scores and subsequently eliminated from the input token set.
3.5 Prediction Head
The prediction head of the proposed tracker obtains the search region features from the final encoder layer and then reshapes them back into two dimensions with the size of to train the convolution-based heads. Similar to other single-stream Transformer trackers (Ye et al., 2022; Lan et al., 2023), the prediction head of the proposed OIFTrack consists of three components: a classification head, an offset head, and a size head. These heads are used to generate classification scores, correct discretization errors, and predict the width and height of the target, respectively. The target state in the search region is determined by selecting the position with the highest confidence classification score and incorporating the corresponding offset and size coordinates to calculate the size of the bounding box at that position.
The classification and regression losses of the prediction head components are used to train the proposed tracker. The overall loss function is calculated as a weighted combination of the losses of components: a focal loss (Law & Deng, 2018) for the classification head (), a generalized IoU loss () (Rezatofighi et al., 2019) for the offset head, and an loss for the size head. It can be expressed as:
| (16) |
where = 2 and = 5 are the regularization parameters in our experiments as in (Yan et al., 2021).
4 Experiments
4.1 Implementation Details
The proposed OIFTrack approach is implemented in Python using the PyTorch framework, and both training and evaluation are conducted on a Tesla P100 GPU with 16 GB of memory.
The architecture of the proposed tracker, except for the prediction head, is similar to the encoder part of ViT-B (Dosovitskiy et al., 2021). Similar to many other one-stream trackers, we utilize the pre-trained MAE (He et al., 2022) model as the backbone to initialize the Transformer architecture of the proposed approach. In our tracker, the search and target template sizes are set as pixels and pixels, respectively. Both are divided into non-overlapping patches, each with a size of pixels. Although some one-stream trackers trained their model in two variants with search region sizes of and pixels, we did not train the other variant due to limitations in our GPU memory. In an intermediate frame of the proposed tracker, the dynamic region is cropped, resized to pixels, with the central pixels assigned for the dynamic target, and the remaining surrounding pixels assigned for the dynamic background. In addition, in the proposed tracker, the token partitioning for the search tokens was conducted from the encoder layer.
The proposed OIFTrack approach was trained on the training sets of LaSOT (Fan et al., 2019), TrackingNet (Muller et al., 2018), GOT-10k (Huang et al., 2019) and COCO 2017 (Lin et al., 2014) benchmarks to evaluate the performance on the testset of LaSOT, UAV123 and TrackingNet. In addition, our approach was exclusively trained on the GOT-10k training set to evaluate its performance on the test set of that dataset, following the protocol described in (Huang et al., 2019). During training, we employ a few data augmentation techniques such as brightness jittering and horizontal flipping to enhance the generality of the tracker. The AdamW (Loshchilov & Hutter, 2019) optimizer is used to train the model. The proposed tracker is trained for 300 epochs, with 60k image pairs used in each epoch. The model was trained with a learning rate of 1e-4, and it was decreased by a factor of 10 after 240 epochs. For the GOT-10k dataset, training was conducted for 100 epochs, and the learning rate was decreased by a factor of 10 after 80 epochs.
4.2 Evaluation Protocols
Similar to other VOT approaches, we have utilized the percentage of average overlap (AO), Success Rate at a 0.5 threshold (SR0.5), and the Success Rate at a 0.75 threshold (SR0.75) to measure tracking performances on the GOT-10k dataset. For other benchmarks, we use the percentage of Area Under Curve (AUC) score, precision (P), and normalized precision (Pn) to measure performances.
4.3 Ablation Studies

| Model | Information flow | GOT-10k | ||
|---|---|---|---|---|
| AO | ||||
| Baseline | Free Bidirectional | 71.0 | 80.1 | 67.3 |
| A | to blocked | 71.4 | 80.6 | 67.8 |
4.3.1 Blocking Information flow from Search to Target Template Tokens
We have conducted detailed ablation studies to justify the design of the proposed tracker and to verify the choice of parameters. The ablation experiments were conducted by training the models on the training set of the GoT-10K dataset and then comparing their performances on its test set. Additionally, we utilized the heatmap of the classification head to demonstrate the effectiveness of the proposed tracker.
Based on our comprehensive analysis of token interactions, we found that allowing bidirectional information flow from search region tokens to target template tokens reduces the discriminative capability of the tracker. To justify these findings, we trained a model, denoted as model A in Fig. 4, by blocking the information flow from search tokens to target template tokens and compared its performance with that of the baseline model, which freely allows bidirectional information flow between all tokens.
Based on the experimental results in Table 1, since the information flow from a large number of non-target tokens in the search region reduces the importance of target-specific features, the performance of the baseline model is poorer than that of model A. In addition, the visualization of the heatmap in Fig. 4 also justifies the blocking by showing that the classification scores of the distractor object are higher in the baseline model compared to model A.
4.3.2 Importance of the Dynamic Background Cues
Differing from other approaches, we have utilized dynamic target and dynamic background cues to capture the temporal appearance changes of the target and learn the surrounding information of the target, respectively. From an adjacent high-confidence detection frame, dynamic target and background cues are extracted in the proposed tracker and used to incorporate temporal information. To justify our design concept, we trained two separate models, referred to as model B and model C, by including dynamic template cues and both dynamic target and background cues, respectively.
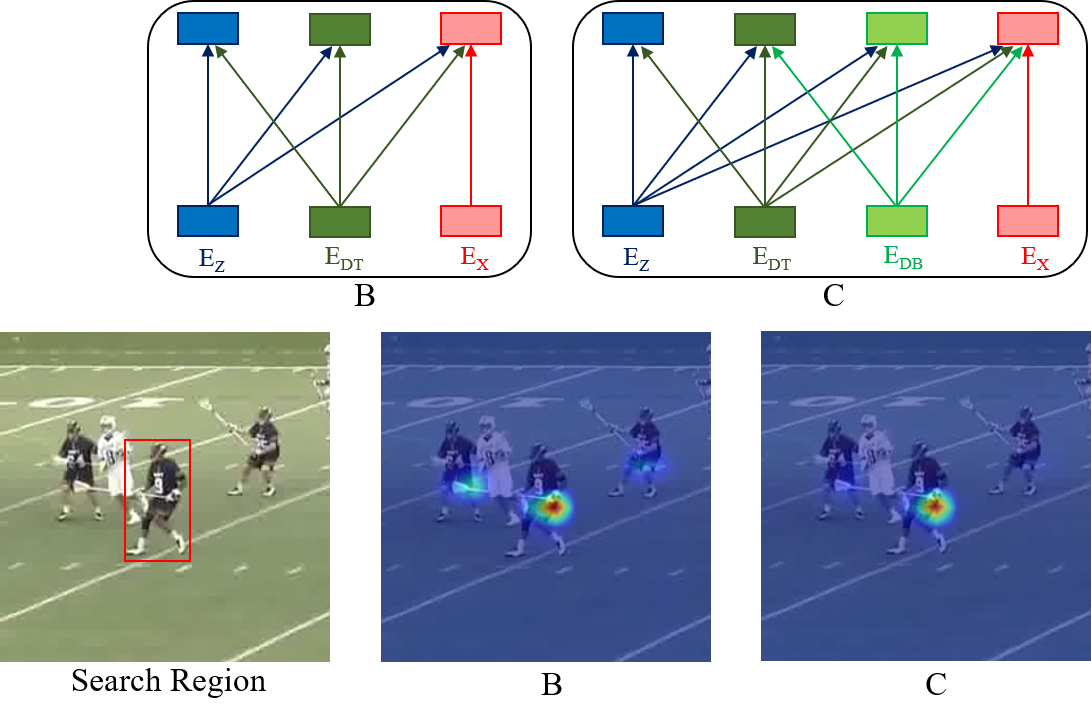
Experimental results in Table 2 clearly show that including the dynamic target cues enhances tracking performance, as evidenced by the comparison between Model A and Model B. However, the substantial increase in tracking performance from Model B to Model C clearly indicates the importance of dynamic target cues in tracking. In addition, to justify the inclusion of dynamic background cues in the proposed tracker, we have compared the heatmap of classification scores for a search region in Model B and Model C. As shown in Fig. 5, while Model B equally assigns importance to a nearby distractor object, Model C effectively ignores that distractor by capturing the surrounding information of the target from dynamic background cues.
| Model | Token Groups | Blocked | GOT-10k | |||||
|---|---|---|---|---|---|---|---|---|
| Information Flow | AO | |||||||
| A | ✓ | - | - | ✓ | to | 71.4 | 80.6 | 67.8 |
| B | ✓ | ✓ | - | ✓ | to , | 71.3 | 80.8 | 68.4 |
| to | ||||||||
| C | ✓ | ✓ | ✓ | ✓ | to , | 73.2 | 84.1 | 69.9 |
| to , | ||||||||
| to , | ||||||||
| to | ||||||||
4.3.3 Effectiveness of Search Token Partitioning in Deeper Layers
In the deeper encoder layers of the proposed tracker, search region tokens are partitioned into target search tokens and non-target search tokens. To demonstrate the effectiveness of search token partitioning in deeper layers and to justify the interaction between token groups, we trained two models, referred to as Model D and Model E. The early layers of these two models are identical to those of Model C, and their information flow in deeper layers is illustrated in Fig. 6. In both of these models, we blocked the information flow from non-target tokens to both initial target and dynamic target tokens as they reduce the importance of target-specific feature extraction.

| Model | Token Groups | Blocked | GOT-10k | |||||||
| Information Flow | AO | |||||||||
| C | ✓ | ✓ | ✓ | ✓ | - | - | to , to , | 73.2 | 84.1 | 69.9 |
| to , to | ||||||||||
| D | ✓ | ✓ | ✓ | - | ✓ | ✓ | to , to , | 74.6 | 85.6 | 71.9 |
| to , to , | ||||||||||
| to | ||||||||||
| E | ✓ | ✓ | ✓ | - | ✓ | ✓ | to , to , | 73.2 | 84.3 | 70.2 |
| to , to | ||||||||||
From the experimental results on the GOT-10k dataset, as summarized in Table 3, it is clearly observed that partitioning search region tokens in deeper layers and then allowing the interaction from target search tokens to initial and dynamic target tokens enhances the tracking performances since both Models D and E showed better performance than Model C. It is also observed that allowing the information flow from non-target search tokens to dynamic background tokens reduces tracking performance, as the background cues from the large number of non-target tokens distract the dynamic background cues. This is evident in the poorer tracking performance of Model E compared to Model D.
| Number of Tokens | GOT-10k | ||
|---|---|---|---|
| AO | |||
| 20 Tokens | 73.5 | 84.5 | 71.0 |
| 40 Tokens | 73.6 | 84.1 | 71.2 |
| 64 Tokens | 74.6 | 85.6 | 71.9 |
| 89 Tokens | 73.4 | 83.9 | 70.2 |
At the onset of deeper encoder layers, we choose K search tokens as target search tokens, determined by their attention score weights as outlined in Equation 10. We have selected 64 target search tokens () based on experimental results. The summary of experimental results used to determine K is provided in Table 4.
4.4 Experimental Results and Comparisons
| Trackers | Source | GOT-10k | TrackingNet | LaSOT | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AO | AUC | P | AUC | P | ||||||
| OIFTrack | Ours | 74.6 | 85.6 | 71.9 | 84.1 | 89.0 | 82.8 | 69.6 | 79.5 | 75.4 |
| SMAT (Gopal & Amer, 2024) | WACV’24 | 64.5 | 74.7 | 57.8 | 78.6 | 84.2 | 75.6 | 61.7 | 71.1 | 64.6 |
| GRM (Gao et al., 2023) | CVPR’23 | 73.4 | 82.9 | 70.4 | 84.0 | 88.7 | 83.3 | 69.9 | 79.3 | 75.8 |
| F-BDMTrack-256 (Yang et al., 2023a) | ICCV’23 | 72.7 | 82.0 | 69.9 | 83.7 | 88.3 | 82.6 | 69.9 | 79.4 | 75.8 |
| TATrack-B (He et al., 2023) | AAAI’23 | 73.0 | 83.3 | 68.5 | 83.5 | 88.3 | 81.8 | 69.4 | 78.2 | 74.1 |
| ROMTrack (Cai et al., 2023) | ICCV’23 | 72.9 | 82.9 | 70.2 | 83.6 | 88.4 | 82.7 | 69.3 | 78.8 | 75.6 |
| CTTrack-B (Song et al., 2023) | AAAI’23 | 71.3 | 80.7 | 70.3 | 82.5 | 87.1 | 80.3 | 67.8 | 77.8 | 74.0 |
| MATTrack (Zhao et al., 2023a) | CVPR’23 | 67.7 | 78.4 | - | 81.9 | 86.8 | - | 67.8 | 77.3 | - |
| GdaTFT (Liang et al., 2023) | AAAI’23 | 65.0 | 77.8 | 53.7 | 77.8 | 83.5 | 75.4 | 64.3 | 68.0 | 68.7 |
| BANDT (Yang et al., 2023c) | IEEE TCE’23 | 64.5 | 73.8 | 54.2 | 78.5 | 82.7 | 74.5 | 64.4 | 72.4 | 67.0 |
| HiT-Base (Kang et al., 2023) | ICCV’23 | 64.0 | 72.1 | 58.1 | 80.0 | 84.4 | 77.3 | 64.6 | 73.3 | 68.1 |
| OSTrack-256 (Ye et al., 2022) | ECCV’22 | 71.0 | 80.4 | 68.2 | 83.1 | 87.8 | 82.0 | 69.1 | 78.7 | 75.2 |
| MixFormer-22k (Cui et al., 2022) | CVPR’22 | 70.7 | 80.0 | 67.8 | 83.1 | 88.1 | 81.6 | 69.2 | 78.7 | 74.7 |
| SimTrack-B/16 (Chen et al., 2022) | ECCV’22 | 69.8 | 78.8 | 66.0 | 82.3 | 86.5 | 80.2 | 69.3 | 78.5 | 74.0 |
| AiATrack (Gao et al., 2022) | ECCV’22 | 69.6 | 80.0 | 63.2 | 82.7 | 87.8 | 80.4 | 69.0 | 79.4 | 73.8 |
| CSWinTT (Song et al., 2022) | CVPR’22 | 69.4 | 78.9 | 65.4 | 81.9 | 86.7 | 79.5 | 66.2 | 75.2 | 70.9 |
| SwinTrack-B(Lin et al., 2022) | NeurlPS’22 | 69.4 | 78.0 | 64.3 | 82.5 | 87.0 | 80.4 | 69.6 | 78.6 | 74.1 |
| SparseTT (Fu et al., 2022) | IJCAI’22 | 69.3 | 79.1 | 63.8 | 81.7 | 86.6 | 79.5 | 66.0 | 74.8 | 70.1 |
| ToMP (Mayer et al., 2022) | CVPR’22 | - | - | - | 81.5 | 86.4 | 78.9 | 68.5 | 79.2 | 73.5 |
| DTT (Yu et al., 2021) | ICCV’21 | 68.9 | 79.8 | 62.2 | 79.6 | 85.0 | 78.9 | 60.1 | - | - |
| STARK (Yan et al., 2021) | ICCV’21 | 68.8 | 78.1 | 64.1 | 82.0 | 86.9 | 79.1 | 67.1 | 77.0 | 72.2 |
| TransT (Chen et al., 2021) | CVPR’21 | 67.1 | 76.8 | 60.9 | 81.4 | 86.7 | 80.3 | 64.9 | 73.8 | 69.0 |
| TrDiMP (Wang et al., 2021) | CVPR’21 | 67.1 | 77.7 | 58.3 | 78.4 | 83.3 | 73.1 | 63.9 | 73.0 | 61.4 |
| SiamGAT (Guo et al., 2021) | CVPR’21 | 62.7 | 74.3 | 48.8 | - | - | - | 53.9 | 63.3 | 53.0 |
| SiamR-CNN (Voigtlaender et al., 2020) | CVPR’20 | 64.9 | 72.2 | 68.4 | 81.2 | 85.4 | 80.0 | 64.8 | 72.2 | 60.8 |
| PrDiMP (Danelljan et al., 2020) | CVPR’20 | 63.4 | 73.8 | 54.3 | 75.8 | 81.6 | 70.4 | 59.8 | - | - |
| Ocean (Zhang et al., 2020) | ECCV’20 | 61.1 | 72.1 | 47.3 | - | - | - | 56.0 | 65.1 | 56.6 |
| DiMP (Bhat et al., 2019) | ICCV’19 | 61.1 | 71.7 | 49.2 | 74.0 | 80.1 | 68.7 | 56.9 | - | - |
| SiamRPN++ (Li et al., 2019) | CVPR’19 | - | - | - | 73.3 | 80.0 | 69.4 | 49.6 | 56.9 | 49.1 |
The tracking performance of the proposed OIFTrack approach was evaluated on the GOT-10K (Huang et al., 2019), LaSOT (Fan et al., 2019), TrackingNet (Muller et al., 2018), and UAV123 (Mueller et al., 2016) benchmarks and the reported results of the state-of-the-art trackers are used for comparison. We have compared the performances of the proposed tracker with Transformer-based trackers: GRM (Gao et al., 2023), TATrack (He et al., 2023), ROMTrack (Cai et al., 2023), CTTrack (Song et al., 2023), MATTrack (Zhao et al., 2023a), HiT (Kang et al., 2023), OSTrack (Ye et al., 2022), MixFormer (Cui et al., 2022), SimTrack (Chen et al., 2022), SwinTrack (Lin et al., 2022), and SparseTT (Fu et al., 2022) CNN-Transformer based trackers: SMAT (Gopal & Amer, 2024), BANDT (Yang et al., 2023c), AiATrack (Gao et al., 2022), CSWinTT (Song et al., 2022), ToMP (Mayer et al., 2022), DTT (Yu et al., 2021), STARK (Yan et al., 2021), TransT (Chen et al., 2021), and TrDiMP (Wang et al., 2021), and CNN-based trackers: GdaTFT (Liang et al., 2023), SiamGAT (Guo et al., 2021), SiamR-CNN (Voigtlaender et al., 2020), PrDiMP (Danelljan et al., 2020), Ocean (Zhang et al., 2020), DiMP (Bhat et al., 2019), and SiamRPN++ (Li et al., 2019). While some trackers trained and evaluated their models on both small and large search region sizes of and respectively, we only consider the reported results of search region models to compare performances without bias. The tracking robustness comparison of the proposed tracker for the GOT-10K, LaSOT, and TrackingNet datasets is provided in Table 5.
4.4.1 GOT-10k
We evaluate our tracker using GOT-10k to assess its one-shot tracking capability, as the training object classes in GOT-10k do not overlap with the testing object classes. Also, the evaluation results of this dataset remain unbiased toward familiar objects, as tracking models exclusively train on the GOT-10k training set. We strictly adhere to GOT-10K protocols for training, and the proposed tracker’s performance is measured based on evaluation results obtained from the dataset’s official evaluation server.
Experimental results in Table 5 clearly indicate the superior performance of the proposed OIFTrack approach, as it outperforms recent one-stream Transformer trackers and other competitors by a considerable margin. Our tracker achieved a 74.6% AO score, which is a 1.2% improvement compared to the second-top performing tracker, GRM (Gao et al., 2023). Similarly, the proposed OIFTrack demonstrated a 2.3% and 1.5% improvement over the second-top performing trackers in terms of success rate at 0.5 threshold and 0.75 threshold, respectively. The outstanding performance of the proposed tracker on the GOT-10K benchmark illustrates its one-stream tracking capability by extracting more discriminative features for unseen object classes.
4.4.2 TrackingNet
The TrackingNet dataset has a massive number of tracking sequences with a large diversity of target object classes, varying resolutions, and frame rates. Based on the experimental results, our tracker demonstrated better performance than state-of-the-art trackers, achieving a top AUC score of 84.1% and a normalized precision score of 89.0%, while also achieving the second-best precision score of 82.8%. The superior performance of OIFTrack on the TrackingNet dataset demonstrates its robustness in real-world tracking capabilities.
4.4.3 LaSOT
The LaSOT benchmark dataset contains a large-scale collection of long-term tracking sequences obtained from various challenging scenarios. The average length of a test sequence is almost 2500 frames, and the dataset contains 280 sequences in the test set. Based on the experimental results Table in 5, our OIFTrack approach showed competitive performances in the LaSOT benchmark with a top normalized precision score of 79.5%, the second-highest AUC score of 69.6%, and the third-highest precision score of 75.4%. In addition to the overall performance evaluation, we have conducted attribute-wise performance measures on LaSOT, and the success plots are shown in Fig. 8. The competitive performance of the OIFTrack approach on LaSOT showed its long-term tracking capabilities in challenging scenarios.
4.4.4 UAV123
We evaluate the performance of our tracker on the UAV123 dataset to determine its effectiveness in aerial tracking. The UAV123 dataset (Mueller et al., 2016) comprises 123 video sequences captured by unmanned aerial vehicles (UAVs). Tracking targets in the UAV123 dataset presents a challenge due to the relatively small size of target objects in aerial tracking sequences, coupled with frequent changes in both the target object’s position and the camera’s orientation. As reported in Table 6, our tracker achieved competitive results, showing comparability with recent trackers like OSTrack-256 (Ye et al., 2022) and ARTrack-256 (Wei et al., 2023). Specifically, our tracker attained an AUC score of 68.6% and a Precision of 90.3%.
| Trackers | Year | UAV123 | |
|---|---|---|---|
| AUC | P | ||
| SMAT (Gopal & Amer, 2024) | 2024 | 64.3 | 83.9 |
| HiT-Base (Kang et al., 2023) | 2023 | 65.6 | - |
| ARTrack-256 (Wei et al., 2023) | 2023 | 67.7 | - |
| MATTrack (Zhao et al., 2023a) | 2023 | 68.0 | - |
| TransT (Chen et al., 2021) | 2021 | 68.1 | 87.6 |
| OSTrack-256 (Ye et al., 2022) | 2022 | 68.3 | 88.8 |
| STARK (Yan et al., 2021) | 2021 | 68.5 | 89.5 |
| CTTrack-B (Song et al., 2023) | 2023 | 68.8 | 89.5 |
| OIFTrack | 68.6 | 90.3 | |
4.5 Discussion


In this study, we propose a novel one-stream Transformer tracker that blocks unnecessary information flow between tokens, rather than relying on the free bidirectional information flow used in previous approaches. In addition, we have utilized dynamic temporal cues to capture surrounding information about the target, which is then leveraged to mitigate the influence of distractor objects in the search region. To demonstrate the effectiveness of the proposed OIFTrack approach, the heatmap of the classification scores for a search region is visualized and shown in Fig. 7. Based on the figure, it is evident that in the heatmap of the baseline tracker, the target and similar distractor objects have equal scores, as the information flow from a large number of background tokens in search region distracts the target-specific features. Although the classification scores of the distractor are reduced in the heatmap of Model A by blocking unnecessary flow from search to target, they are entirely diminished in the heatmap of Model C after capturing the surrounding information of the target from dynamic background cues. Furthermore, the classification scores of the target became stronger in Model D after allowing the interaction of target search tokens with other tokens that have target cues.
In addition to the overall performance, our tracker demonstrated better performance in many tracking scenarios compared to other Transformer-based trackers, as shown in Fig. 8 through attribute-wise comparison. Since our OIFTrack approach captures the appearance changes of the target from the interaction between the initial target, dynamic target, and target search tokens, it exhibited superior performance in rotation, scale variation, deformation, as well as full and partial occlusion scenarios compared to other one-stream Transformer trackers. Furthermore, our tracker performs well in background clutter and camera motion scenarios due to its ability to capture the surrounding information of the target.
Our OIFTrack runs at an average speed of 21 FPS on a single core of a Tesla P100 GPU and it contains 92.63 million parameters and 33.82 giga floating point operations (FLOPS). Based on computational efficiency, our tracker is slightly lower than similar approaches such as OSTrack and GRM, due to our incorporation of dynamic target and background cues into the tracking process. As another limitation, although our tracker showed better performance in long-term tracking according to the results on the LaSOT benchmark, the difference between our performance and that of competitors is marginal. Since the probability of wrong identification of the dynamic template in long-term sequences is high, that may be the reason for this performance degradation.
5 Conclusion
In this work, we present a novel one-stream Transformer tracker aimed at enhancing target-specific feature extraction and utilizing surrounding information of the target. We have analyzed the information flow between tokens and then removed the unnecessary flows using a simple attention masking mechanism. In addition, we utilized dynamic background cues to capture the surrounding information of the target, thereby reducing the impact of distractor objects. Through extensive experiments on popular benchmark datasets, the proposed OIFTrack approach demonstrated outstanding performance, especially in one-shot tracking.
CRediT authorship contribution statement
Janani Kugarajeevan: Conceptualization, Methodology, Investigation, Implementation, Validation, Writing - Original Draft, Visualization. Kokul Thanikasalam: Conceptualization, Investigation, Methodology, Supervision, Writing - Original Draft. Amirthalingam Ramanan: Conceptualization, Supervision, Writing - Review & Editing. Subha Fernando: Conceptualization, Supervision, Writing - Review & Editing
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data availability
Following publicly available benchmark datasets are used in this study.
-
1.
GOT-10k: http://got-10k.aitestunion.com
-
2.
TrackingNet: https://tracking-net.org
- 3.
- 4.
References
- Bai et al. (2022) Bai, Z., Wu, G., Qi, X., Liu, Y., Oguchi, K., & Barth, M. J. (2022). Infrastructure-based object detection and tracking for cooperative driving automation: A survey. In 2022 IEEE Intelligent Vehicles Symposium (IV) (pp. 1366–1373). doi:10.1109/IV51971.2022.9827461.
- Baker et al. (2023) Baker, L., Ventura, J., Langlotz, T., Gul, S., Mills, S., & Zollmann, S. (2023). Localization and tracking of stationary users for augmented reality. The Visual Computer, (pp. 1432–2315). doi:10.1007/s00371-023-02777-2.
- Bhat et al. (2019) Bhat, G., Danelljan, M., Gool, L. V., & Timofte, R. (2019). Learning discriminative model prediction for tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 6182–6191).
- Cai et al. (2023) Cai, Y., Liu, J., Tang, J., & Wu, G. (2023). Robust object modeling for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9589–9600).
- Cao (2023) Cao, X. (2023). Eye tracking in human-computer interaction recognition. In 2023 IEEE International Conference on Sensors, Electronics and Computer Engineering (pp. 203–207). doi:10.1109/ICSECE58870.2023.10263468.
- Carion et al. (2020) Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020). End-to-end object detection with transformers. In European Conference on Computer Vision (pp. 213–229). Springer.
- Chen et al. (2022) Chen, B., Li, P., Bai, L., Qiao, L., Shen, Q., Li, B., Gan, W., Wu, W., & Ouyang, W. (2022). Backbone is all your need: a simplified architecture for visual object tracking. In Proceedings of the European Conference on Computer Vision (pp. 375–392). Springer.
- Chen et al. (2023) Chen, X., Peng, H., Wang, D., Lu, H., & Hu, H. (2023). Seqtrack: Sequence to sequence learning for visual object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14572–14581).
- Chen et al. (2021) Chen, X., Yan, B., Zhu, J., Wang, D., Yang, X., & Lu, H. (2021). Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 8126–8135).
- Chen et al. (2020) Chen, Z., Zhong, B., Li, G., Zhang, S., & Ji, R. (2020). Siamese box adaptive network for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 6668–6677).
- Choubisa et al. (2023) Choubisa, M., Kumar, V., Kumar, M., & Khanna, D. S. (2023). Object tracking in intelligent video surveillance system based on artificial system. In 2023 International Conference on Computational Intelligence, Communication Technology and Networking (pp. 160–166). doi:10.1109/CICTN57981.2023.10140727.
- Cui et al. (2022) Cui, Y., Jiang, C., Wang, L., & Wu, G. (2022). MixFormer: End-to-end tracking with iterative mixed attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13608–13618).
- Danelljan et al. (2020) Danelljan, M., Gool, L. V., & Timofte, R. (2020). Probabilistic regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7183–7192).
- Dosovitskiy et al. (2021) Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S. et al. (2021). An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (pp. 1–21). URL: https://openreview.net/forum?id=YicbFdNTTy.
- Fan et al. (2019) Fan, H., Lin, L., Yang, F., Chu, P., Deng, G., Yu, S., Bai, H., Xu, Y., Liao, C., & Ling, H. (2019). Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5374–5383).
- Fu et al. (2022) Fu, Z., Fu, Z., Liu, Q., Cai, W., & Wang, Y. (2022). SparseTT: Visual tracking with sparse transformers. In Proceedings of the International Joint Conference on Artificial Intelligence (pp. 905–912).
- Gao et al. (2022) Gao, S., Zhou, C., Ma, C., Wang, X., & Yuan, J. (2022). AiATrack: Attention in attention for transformer visual tracking. In Proceedings of the European Conference on Computer Vision (pp. 146–164). Springer.
- Gao et al. (2023) Gao, S., Zhou, C., & Zhang, J. (2023). Generalized relation modeling for transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18686–18695).
- Gopal & Amer (2024) Gopal, G. Y., & Amer, M. A. (2024). Separable self and mixed attention transformers for efficient object tracking. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 6708–6717).
- Guo et al. (2021) Guo, D., Shao, Y., Cui, Y., Wang, Z., Zhang, L., & Shen, C. (2021). Graph attention tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9543–9552).
- He et al. (2022) He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2022). Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16000–16009).
- He et al. (2023) He, K., Zhang, C., Xie, S., Li, Z., & Wang, Z. (2023). Target-aware tracking with long-term context attention. Proceedings of the AAAI Conference on Artificial Intelligence, 37, 773–780. doi:10.1609/aaai.v37i1.25155.
- Huang et al. (2019) Huang, L., Zhao, X., & Huang, K. (2019). Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE transactions on pattern analysis and machine intelligence, 43, 1562–1577.
- Kang et al. (2023) Kang, B., Chen, X., Wang, D., Peng, H., & Lu, H. (2023). Exploring lightweight hierarchical vision transformers for efficient visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9612–9621).
- Kim et al. (2023) Kim, S., Jo, D., Lee, D., & Kim, J. (2023). Magvlt: Masked generative vision-and-language transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 23338–23348).
- Krizhevsky et al. (2017) Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). ImageNet classification with deep convolutional neural networks. Communications of the ACM, 60, 84–90.
- Kugarajeevan et al. (2023) Kugarajeevan, J., Kokul, T., Ramanan, A., & Fernando, S. (2023). Transformers in single object tracking: An experimental survey. IEEE Access, 11, 80297–80326. doi:10.1109/ACCESS.2023.3298440.
- Lan et al. (2023) Lan, J.-P., Cheng, Z.-Q., He, J.-Y., Li, C., Luo, B., Bao, X., Xiang, W., Geng, Y., & Xie, X. (2023). ProContEXT: Exploring progressive context transformer for tracking. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (pp. 1–5).
- Law & Deng (2018) Law, H., & Deng, J. (2018). Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (pp. 734–750).
- Li et al. (2019) Li, B., Wu, W., Wang, Q., Zhang, F., Xing, J., & Yan, J. (2019). SiamRPN++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4282–4291).
- Liang et al. (2023) Liang, Y., Li, Q., & Long, F. (2023). Global dilated attention and target focusing network for robust tracking. Proceedings of the AAAI Conference on Artificial Intelligence, 37, 1549–1557. doi:10.1609/aaai.v37i2.25241.
- Lin et al. (2022) Lin, L., Fan, H., Zhang, Z., Xu, Y., & Ling, H. (2022). SwinTrack: A simple and strong baseline for transformer tracking. In Proceedings of the Advances in Neural Information Processing Systems (pp. 16743–16754). Curran Associates, Inc. volume 35.
- Lin et al. (2014) Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., & Zitnick, C. L. (2014). Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision (pp. 740–755).
- Liu et al. (2023) Liu, Y., Schiele, B., Vedaldi, A., & Rupprecht, C. (2023). Continual detection transformer for incremental object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 23799–23808).
- Loshchilov & Hutter (2019) Loshchilov, I., & Hutter, F. (2019). Decoupled weight decay regularization. In International Conference on Learning Representations (pp. 1–18). URL: https://openreview.net/forum?id=Bkg6RiCqY7.
- Mayer et al. (2022) Mayer, C., Danelljan, M., Bhat, G., Paul, M., Paudel, D. P., Yu, F., & Van Gool, L. (2022). Transforming model prediction for tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 8731–8740).
- Mayer et al. (2021) Mayer, C., Danelljan, M., Paudel, D. P., & Van Gool, L. (2021). Learning target candidate association to keep track of what not to track. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 13444–13454).
- Mueller et al. (2016) Mueller, M., Smith, N., & Ghanem, B. (2016). A benchmark and simulator for uav tracking. In Computer Vision – ECCV 2016 (pp. 445–461).
- Muller et al. (2018) Muller, M., Bibi, A., Giancola, S., Alsubaihi, S., & Ghanem, B. (2018). Trackingnet: A large-scale dataset and benchmark for object tracking in the wild. In Proceedings of the European Conference on Computer Vision (pp. 300–317).
- Rezatofighi et al. (2019) Rezatofighi, H., Tsoi, N., Gwak, J., Sadeghian, A., Reid, I., & Savarese, S. (2019). Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 658–666).
- Shi et al. (2023) Shi, H., Hayat, M., & Cai, J. (2023). Transformer scale gate for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3051–3060).
- Song et al. (2023) Song, Z., Luo, R., Yu, J., Chen, Y.-P. P., & Yang, W. (2023). Compact transformer tracker with correlative masked modeling. Proceedings of the AAAI Conference on Artificial Intelligence, 37, 2321–2329. doi:10.1609/aaai.v37i2.25327.
- Song et al. (2022) Song, Z., Yu, J., Chen, Y.-P. P., & Yang, W. (2022). Transformer tracking with cyclic shifting window attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 8791–8800).
- Thanikasalam et al. (2019) Thanikasalam, K., Fookes, C., Sridharan, S., Ramanan, A., & Pinidiyaarachchi, A. (2019). Target-specific siamese attention network for real-time object tracking. IEEE Transactions on Information Forensics and Security, 15, 1276–1289.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (pp. 1–17). Curran Associates, Inc. volume 30.
- Voigtlaender et al. (2020) Voigtlaender, P., Luiten, J., Torr, P. H., & Leibe, B. (2020). Siam R-CNN visual tracking by re-detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 6578–6588).
- Wang et al. (2021) Wang, N., Zhou, W., Wang, J., & Li, H. (2021). Transformer meets tracker: Exploiting temporal context for robust visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1571–1580).
- Wei et al. (2023) Wei, X., Bai, Y., Zheng, Y., Shi, D., & Gong, Y. (2023). Autoregressive visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9697–9706).
- Wu et al. (2023) Wu, Q., Yang, T., Liu, Z., Wu, B., Shan, Y., & Chan, A. B. (2023). Dropmae: Masked autoencoders with spatial-attention dropout for tracking tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14561–14571).
- Xie et al. (2023) Xie, F., Chu, L., Li, J., Lu, Y., & Ma, C. (2023). VideoTrack: Learning to track objects via video transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 22826–22835).
- Yan et al. (2021) Yan, B., Peng, H., Fu, J., Wang, D., & Lu, H. (2021). Learning spatio-temporal transformer for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 10448–10457).
- Yang et al. (2023a) Yang, D., He, J., Ma, Y., Yu, Q., & Zhang, T. (2023a). Foreground-background distribution modeling transformer for visual object tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (pp. 10117–10127).
- Yang et al. (2023b) Yang, H. F., Cai, J., Liu, C., Ke, R., & Wang, Y. (2023b). Cooperative multi-camera vehicle tracking and traffic surveillance with edge artificial intelligence and representation learning. Transportation Research Part C: Emerging Technologies, 148, 103982. doi:https://doi.org/10.1016/j.trc.2022.103982.
- Yang et al. (2023c) Yang, K., Zhang, H., Shi, J., & Ma, J. (2023c). Bandt: A border-aware network with deformable transformers for visual tracking. IEEE Transactions on Consumer Electronics, 69, 377–390. doi:10.1109/TCE.2023.3251407.
- Ye et al. (2022) Ye, B., Chang, H., Ma, B., Shan, S., & Chen, X. (2022). Joint feature learning and relation modeling for tracking: A one-stream framework. In Proceedings of the European Conference on Computer Vision (pp. 341–357). Springer.
- Yu et al. (2021) Yu, B., Tang, M., Zheng, L., Zhu, G., Wang, J., Feng, H., Feng, X., & Lu, H. (2021). High-performance discriminative tracking with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9856–9865).
- Yu et al. (2023) Yu, H., Qin, Z., Hou, J., Saleh, M., Li, D., Busam, B., & Ilic, S. (2023). Rotation-invariant transformer for point cloud matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5384–5393).
- Zhang et al. (2023) Zhang, J., Yang, X., Wang, W., Guan, J., Ding, L., & Lee, V. C. (2023). Automated guided vehicles and autonomous mobile robots for recognition and tracking in civil engineering. Automation in Construction, 146, 104699. doi:https://doi.org/10.1016/j.autcon.2022.104699.
- Zhang et al. (2020) Zhang, Z., Peng, H., Fu, J., Li, B., & Hu, W. (2020). Ocean: Object-aware anchor-free tracking. In Proceedings of the European Conference on Computer Vision Workshops (pp. 771–787). Springer.
- Zhao et al. (2023a) Zhao, H., Wang, D., & Lu, H. (2023a). Representation learning for visual object tracking by masked appearance transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18696–18705).
- Zhao et al. (2023b) Zhao, H., Wang, D., & Lu, H. (2023b). Representation learning for visual object tracking by masked appearance transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18696–18705).
- Zhou et al. (2023) Zhou, W., Dou, P., Su, T., Hu, H., & Zheng, Z. (2023). Feature learning network with transformer for multi-label image classification. Pattern Recognition, 136, 109203.