Optimal Scene Graph Planning with Large Language Model Guidance
Abstract
Recent advances in metric, semantic, and topological mapping have equipped autonomous robots with semantic concept grounding capabilities to interpret natural language tasks. This work aims to leverage these new capabilities with an efficient task planning algorithm for hierarchical metric-semantic models. We consider a scene graph representation of the environment and utilize a large language model (LLM) to convert a natural language task into a linear temporal logic (LTL) automaton. Our main contribution is to enable optimal hierarchical LTL planning with LLM guidance over scene graphs. To achieve efficiency, we construct a hierarchical planning domain that captures the attributes and connectivity of the scene graph and the task automaton, and provide semantic guidance via an LLM heuristic function. To guarantee optimality, we design an LTL heuristic function that is provably consistent and supplements the potentially inadmissible LLM guidance in multi-heuristic planning. We demonstrate efficient planning of complex natural language tasks in scene graphs of virtualized real environments.
I INTRODUCTION
Advances in robot perception and computer vision have enabled metric-semantic mapping [1, 2, 3, 4, 5, 6, 7, 8, 9], offering rich information in support of robot autonomy. Beyond single-level maps, hierarchical models encode topological relations among local maps and semantic elements [10, 11]. A scene graph [11] is a prominent example that models buildings, floors, rooms, objects, and occupancy in a unified hierarchical representation. Scene graph construction can be done from streaming sensor data [12, 5, 13]. The metric, semantic, and topological elements of such models offer the building blocks for robots to execute semantic tasks [14]. The objective of this work is to approach this challenge by generalizing goal-directed motion planning in flat geometric maps to natural language task planning in scene graphs.
Connecting the concepts in a natural language task to the real-world objects they refer to is a challenging problem, known as symbol grounding [15]. Large language models (LLMs), such as GPT-3 [16], BERT [17], and LLaMA [18], offer a possible resolution with their ability to relate entities in an environment model to concepts in natural language. Chen et al. [19, 20] use LLMs for scene graph labeling, showing their capability of high-level understanding of indoor scenes. Shah et al. [21] use GPT-3 to parse text instructions to landmarks and the contrastive language image pre-training (CLIP) model [22] to infer a joint landmark-image distribution for visual navigation. Seminal papers [23, 24] in the early 2000s established formal logics and automata as powerful representations of robot tasks. In work closely related to ours, Chen et al. [25] show that natural language tasks in 2D maps encoded as sets of landmarks can be converted to signal temporal logic (STL) [26] via LLM re-prompting and automatic syntax correction, enabling the use of existing temporal logic planners [27, 28, 29, 30, 31]. Beyond temporal logics, other expressive robot task representations include the planning domain definition language [32], Petri nets [33, 34], and process algebra [35]. However, few of the existing works have considered task specification in hierarchical models. We use an LLM to translate a natural language task defined by the attributes of a scene graph to a linear temporal logic (LTL) formula. We describe the scene graph to the LLM via an attribute hierarchy and perform co-safe syntax checking to ensure generation of correct and finite-path verifiable LTL. Further, we develop an approach to obtain task execution guidance from the LLM, which is used to accelerate the downstream task planning algorithm.
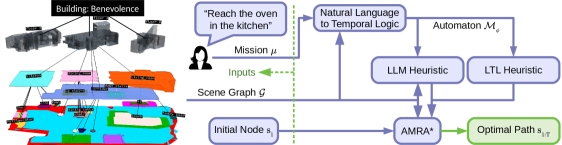
Given a symbolically grounded task representation, the next challenge is to plan its execution in a hierarchical model efficiently. A key component for achieving efficiency in traditional goal-oriented planning in single-level environments is the use of guidance from a heuristic function. Heuristics play a critical role in accelerating both search-based [38, 39] and sampling-based [40, 41] planners. More complex tasks than goal reaching involve sequencing, branching, and recurrence, making heuristic guidance even more important for efficiency. Our work is inspired by Fu et al. [29] who develop an admissible heuristic for LTL planning in probabilistic landmark maps. We extend the approach by (a) generalizing to hierarchical scene graphs via multi-resolution planning, (b) designing a consistent LTL heuristic allowing acceleration over admissible-only heuristic planning, and (c) introducing an LLM heuristic allowing acceleration from LLM semantic guidance while retaining optimality guarantees via multi-heuristic planning. Our approach is enabled by the anytime multi-resolution multi-heuristic A* (AMRA*) [37], which combines the advantages of multi-resolution A* [42] and multi-heuristic A* [39]. Our key contribution is to define the nodes, edges, and costs of a hierarchical planning domain from a scene graph and to introduce guidance from a consistent LTL heuristic and a semantically informed LLM heuristic.
Related works consider object search and semantic goal navigation in unknown environments, represented as semantic occupancy maps [43], topological maps [44], or scene graphs [45, 46]. Shah et al. [43] develop an exploration approach that uses an LLM to score subgoal candidates and provide an exploration heuristic. Kostavelis et al. [44] perform place recognition using spatial and temporal proximity to obtain a topological map and encode the connectivity of its attributes in a navigation graph to enable Dijkstra planning to semantically specified goals. Amiri et al. [45] employ a scene graph generation network to construct a scene graph from images and a partially observable Markov decision process to obtain an object-search policy. Ravichandran et al. [46] embed partial scene graph observations in feature space using a graph neural network (GNN) and train value and policy GNNs via proximal policy optimization. In contrast with these works, we consider significantly more general missions but perform planning in a known scene graph.
In summary, this paper makes the following contributions.
-
•
We use an LLM to translate natural language to LTL tasks over the attributes of a scene graph.
-
•
We construct a hierarchical planning domain capturing the structure of the scene graph and LTL task.
-
•
We design new LTL and LLM heuristic functions for planning, and prove that the LTL heuristic is consistent.
-
•
We employ hierarchical multi-heuristic planning to guarantee efficiency (due to LLM semantic guidance) and optimality (due to LTL consistent guidance), despite potential inadmissibility of the LLM heuristic.
II PROBLEM STATEMENT
Consider an agent planning a navigation mission specified in terms of semantic concepts, such as objects and regions, in a known environment. We assume that the environment is represented as a scene graph [11].
Definition 1.
A scene graph is a graph with node set , edge set , and attribute sets for . Each attribute is associated with a subset of the nodes .
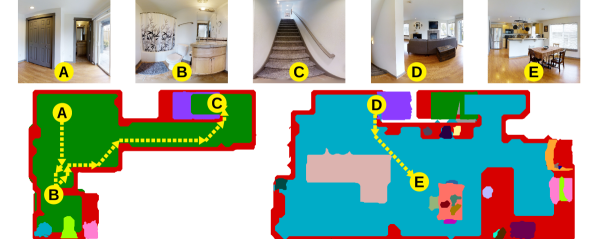
A scene graph provides a hierarchical semantic description of an environment, such as a building, in terms of floors, rooms, objects, and occupancy (see Fig. 1). For example, the graph nodes may represent free space, while the objects may be encoded as an attribute set such that an object is associated with a free region around it. Similarly, rooms may be represented as a set such that a room is associated with a free-space region .
Given the initial agent location , and a cost function , our objective is to plan a sequence of scene graph nodes (path) that achieves a mission with minimal cost. We assume is provided in natural language using terms from the attribute sets of the scene graph. An example scene graph mission is provided in Fig. 1.
To interpret a natural language mission, we define atomic propositions whose combinations can capture the mission requirements. An atomic proposition associated with attribute of the scene graph evaluates true at node if belongs to the nodes that satisfy attribute . We denote this by . The set of all atomic propositions at is denoted by:
| (1) |
Intuitively, being means that the agent is at node that satisfies attribute , e.g., reaching an object in or being in a room in . Avoiding an object or leaving a room can be specified via the negation of such propositions. To determine which atomic propositions are satisfied at a particular node, we define a labeling function.
Definition 2.
Consider a scene graph with atomic propositions . A labeling function maps a node to a set of atomic propositions that evaluate at .
The labels along a path are obtained as and are called a word. A word contains information about the objects, rooms, and floors that an agent visits along its path in a scene graph. We can decide whether the agent path satisfies a mission by interpreting its word. We denote a word that satisfies a mission by , and define the precise semantics of this notation in Sec. III. With this, we are ready to state the problem of natural language mission planning in scene graphs.
Problem.
Given a scene graph , natural language mission over the attributes of , cost function , and initial node , plan a path that satisfies with minimal cost:
| (2) | ||||
| s.t. | ||||
III NATURAL LANGUAGE TO TEMPORAL LOGIC
We use an LLM to translate natural language missions to logic formulas over the scene graph propositions . The key challenge is to describe the structure of a scene graph to an LLM and ask it to translate a mission to a logic formula . We focus on linear temporal logic (LTL) [47] with syntax in Table. I due to its popularity and sufficient expressiveness to capture temporal ordering of propositions.
We require a syntactically co-safe formula [48] to allow checking its satisfaction over finite agent paths. A co-safe LTL formula can be satisfied by a word that consists of a finite prefix followed by a (potentially infinite) continuation that does not affect the formula’s truth value. LTL formulas that contain only and temporal operators when written in negated normal form ( appears only in front of atomic propositions) are syntactically co-safe [48].
To use an LLM for scene understanding, it is necessary to design a prompt that describes the scene graph succinctly. Otherwise, the input might exceed the model token limit or confuse the model about the relationship between the sentences. For this aim, we simplify the scene graph into an attribute hierarchy that compactly represents scene entities in a YAML format. In our setup, the top level of contains floors . The rooms on floor are defined as , and nested as children of floor . Additionally, each room stores connections to other rooms on the same floor. Similarly, the objects in room , , are stored as children of room . Each entity in is tagged with a unique ID to differentiate rooms and objects with the same name. See Fig. 2a for an example attribute hierarchy. In our examples, we define attributes for floors, rooms, and objects and the attribute hierarchy contains levels but this can be extended to more generalized attribute sets (e.g., level for object affordances). The attribute hierarchy removes the dense node and edge descriptions in which are redundant for mission translation, leading to a significant reduction in prompt size.
Given the natural language mission and the attribute hierarchy , the first call to the LLM is only responsible to extract unique IDs from the context of , outputting . This step facilitates LTL translations by separating high-level scene understanding from accurate LTL generation. Specifically, this step links contextually rich specifications, which can be potentially difficult to be parsed, to unequivocal mission descriptions that are void of confusion for the LLM when it comes to LTL translation (Fig. 2b). The list of entities involved in the mission are extracted from using regular expression, and stored as . This allows to inform the LLM about the essential parts of the mission , without providing . The savings in prompt size are used to augment the prompt with natural language to LTL translation examples expressed in pre-fix notation. For instance, is expressed as in pre-fix format. This circumvents the issue of balancing parenthesis over formula . Ultimately, the LTL translation prompt includes , , and the translation examples (Fig. 2c).
| Syntax (Semantics) | |||||
|---|---|---|---|---|---|
| (Atomic Proposition) | (Or) | (Until) | |||
| (Negation) | (Imply) | (Eventually) | |||
| (And) | (Next) | (Always) | |||
The translated LTL formula is verified for syntactic correctness and co-safety using an LTL syntax checker. Further calls of the LLM are made to correct if it does not pass the checks, up to a maximum number of allowed verification steps, after which human feedback is used to rephrase the natural language specification (Fig. 2d). Once the mission is successfully translated into a co-safe LTL formula , we can evaluate whether an agent path and its corresponding word satisfy by constructing an automaton representation of (Fig. 2e).
Definition 3.
A deterministic automaton over atomic propositions is a tuple , where is a set of states, is the power set of called alphabet, is a transition function that specifies the next state from state under label , is a set of final states, and is an initial state.
A co-safe LTL formula can be translated into a deterministic automaton using model checking tools such as PRISM [49, 50] or Spot [51]. The automaton checks whether a word satisfies . A word is accepted by , i.e., , if and only if the state obtained after transitions for is contained in the final states . Hence, a path satisfies a co-safe LTL formula if and only if its word contains a prefix that is accepted by .
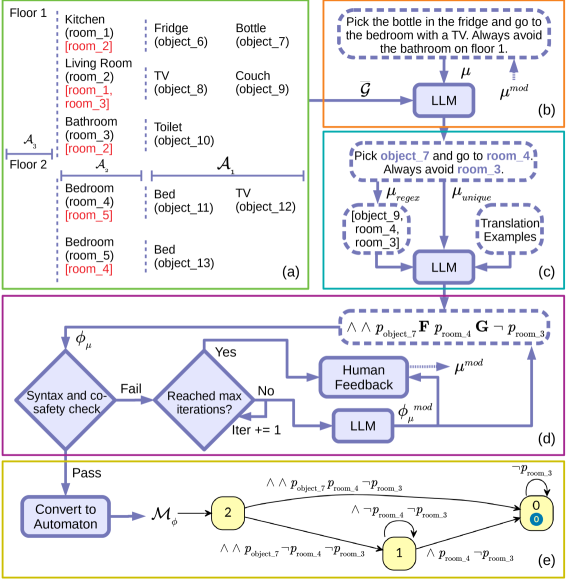
IV OPTIMAL SCENE GRAPH PLANNING
We use the structure of the scene graph with guidance from the automaton and the LLM’s mission semantics understanding to achieve efficient and optimal planning.
IV-A AMRA* Planning
We perform mission planning using AMRA* [37]. The key challenge is to define a hierarchical planning domain and heuristic functions that describe the scene graph and mission. AMRA* requires several node sets and action sets for different planning resolution levels, . Each level has an associated cost function . The algorithm defines an anchor level , as , , and requires an initial state and a goal region . AMRA* allows multiple heuristics for each level but requires the anchor-level heuristics to be consistent to guarantee optimality. A heuristic is consistent with respect to cost if . We construct the levels , initial state , and goal region required for running AMRA* from the scene graph and the automaton in Sec. IV-B. We define two heuristics, , which is used in the anchor level and other levels, and for other levels, in Sec. IV-C and Sec. IV-D, respectively, and prove that is consistent.
IV-B Hierarchical Planning Domain Description
Given scene graph with initial node and automaton , we construct a hierarchical planning domain with levels corresponding to each scene graph attribute . Given an attribute set , we define , where is the node set associated with attribute . Then, the node set corresponding to level of the planning domain is defined as . We define the actions as transitions from to in with associated cost . A transition from and exists if the following conditions are satisfied:
-
1.
the transition is from of attribute to the boundary of attribute such that , for with and ,
-
2.
the automaton transitions are respected: , where is the label at ,
-
3.
the transition is along the shortest path, , where is the shortest feasible path between two scene graph nodes.
The transition cost is defined as .
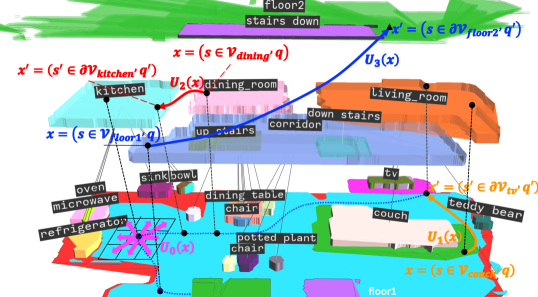
Since , we can define the AMRA* anchor level as with actions derived from the scene graph edges , automaton transitions, and . The initial state and goal region are defined as and .
The hierarchical planning domain is illustrated in Fig. 3. Four levels, occupancy (), objects (), rooms () and floors (), are used in our experiments. For example, in the object level, the agent can take an action to move directly from the couch to the TV with transition cost computed as the shortest path in the occupancy level.
IV-C LTL Heuristic
To ensure optimal AMRA* planning, a consistent heuristic is required at the anchor level. Inspired by the admissible but inconsistent heuristic in [29], we design a consistent LTL heuristic function that approximates the scene graph distance to using information from the automaton and the scene graph attributes. We require that the scene graph cost satisfies the triangle inequality, i.e., for any . Then, we define the cost between two labels as
| (3) |
which is a lower bound on the transition cost from to in the metric space of cost function . Next, we define a lower bound on the transition cost from automaton state with label to an accepting state as:
| (4) |
The function can be pre-computed via Dijkstra’s algorithm on the automaton . We also define a next labeling function that tracks the least-cost label sequence returned by Dijkstra’s algorithm with , , .
Proposition 1.
The heuristic function defined below is consistent:
| (5) | ||||
Proof.
Consider a state with label . For any that is reachable from in one step, we have two cases to handle. When :
When , with , we have:
IV-D LLM Heuristic
In this section, we seek to assist AMRA* by developing an LLM heuristic that captures the hierarchical semantic information of the scene graph. The LLM heuristic uses all attributes at a node , the current automaton state , and the attribute hierarchy , and returns an attribute-based guide that helps the AMRA∗ to search in the right direction for an optimal path. We design the prompt to ask for LLM attribute-based guidance with components as follows:
-
•
environment description from its attribute hierarchy ,
-
•
list of motions , where , , describes movements on from attribute to that the LLM model uses to generate its guides,
-
•
an example of the mission and how to response,
-
•
description of the mission , current attributes, remaining task given the automaton state , and request for guidance on how to finish the task.
The LLM model returns a sequence of function calls , , , in XML format, easing response parsing [52]. Each function call returns a user-defined cost, e.g., Euclidean distance between attributes: , where are the center of and , respectively. The total cost of the LLM functions is used as an LLM heuristic . Due to the LLM query delay and its limited query rates, the sequence of function calls suggested by the LLM model is obtained offline stored and used to calculate the heuristic online in AMRA* based on the user-defined cost.

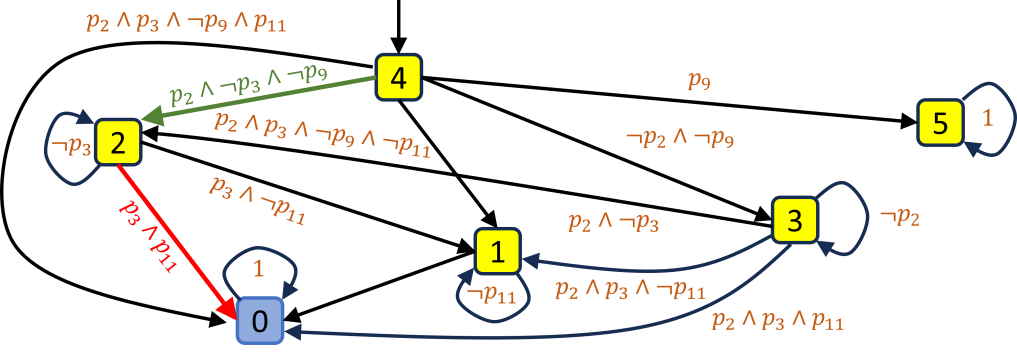
Fig. 4 illustrates a sample prompt and response. The prompt first describes how the attributes are connected based on the attribute hierarchy . Each attribute is mentioned with a unique ID to avoid confusing the LLM, as shown in the first paragraph of the prompt in Fig. 4. The second part of the prompt provides a list of possible functions used to guide the agent, such as to move from room to room , or to reach an object in room . The third component provides an example of a mission and how the LLM should response. The last component describes the current attributes and the remaining mission, generated based on the current automaton state , and requests LLM to generate a high-level plan using the provided functions.
The automaton state represents how far we have achieved the mission. Thus, to describe the remaining mission, we run Dijkstra’s algorithm on the automaton to find the shortest path from to an accepting state in . We obtain a set of atomic prepositions evaluated true along the path, and concatenate their descriptions to describe the remaining mission in the prompt. For example, the desired mission is to “go to the bedroom 2, then visit the kitchen 3, reach the oven 11, while always avoid the TV 9". Let the atomic prepositions be defined as , , , and , where the indices correspond to the ID of the room or object.
The task can be described using an LTL as follows: whose automaton graph generated from Spot [51] is shown in Fig. 5 with the initial state and the final states . The agent is currently in room 1 and have been already visited room 2, i.e. on . The shortest path from to the accepting state is marked by red arrows in Fig. 5. Along this path, and turn , causing the remaining mission to be to“visit the kitchen 3 and reach the oven 11" (Fig. 4). The atomic preposition leads to a sink state if it evaluates , and never appears in the next mission, leading to an optimistic LLM heuristic.
| Allensville | \pbox6cmClean all vases in the dining room. Eventually water the potted plants in the bathrooms one after another. |
|---|---|
| Benevolence | \pbox6cmVisit the bathroom on floor 0 and avoid the sink, then go to the dining room and sit on a chair. Always avoid the living room and the staircase next to it. |
| Collierville | \pbox6cmClean all the corridors, except the one on floor 0. |
| 1st iter. time (sec.) | 1st iter. | opt. time (sec.) | |
|---|---|---|---|
| ALL | 0.0007 | 1.3763 | 8.9062 |
| OCC | 0.0244 | 1.0827 | 8.3144 |
| OBJ | 3.7460 | 1.0387 | 24.936 |
| ROOM | 3.6878 | 1.0306 | 13.1352 |
| FLR | 3.8106 | 1.0369 | 13.3287 |
| NO-LLM | 3.3260 | 1.0318 | 24.2516 |
| A* | 1.1202 | 1.0997 | 11.7594 |
| Allensville(1-floor) | Benevolence(3-floor) | Collierville(3-floor) | |
|---|---|---|---|
| ALL | 0.24/1.69/3.50 | 0.32/1.24/11.82 | 0.009/1.26/5.48 |
| NO-LLM | 0.36/1.34/6.33 | 2.82/1.18/21.57 | 1.16/1.38/8.13 |
| A* | 0.15/1.08/3.23 | 1.33/1.16/14.22 | 1.19/1.06/7.04 |
V EVALUATION
To evaluate our method, we use Allensville (1-floor), Benevolence (3-floor) and Collierville (3-floor) from the 3D Scene Graph dataset [11]. For each scene, we designed 5 missions (some are shown in Table II). For each mission, we used 5 initial positions across different floors and rooms.
We use GPT-4 [53] to translate missions to LTL formulas, and Spot [51] for LTL formulas to automata as described in Sec. III. Following Sec. IV-D, we use GPT-4 [53] to generate the LLM heuristic function . Given a scene graph , the mission described by the automaton , the LTL heuristic , and the LLM heuristic , we construct the hierarchical planning domain and run AMRA*.
Fig. 6 shows a path in Benevolence for the mission in Table II. Starting from the empty room on floor 0, the agent goes to the bathroom entrance without approaching the sink, and then proceeds upstairs to floor 1, finally reaching a chair in the dining room without entering the living room.
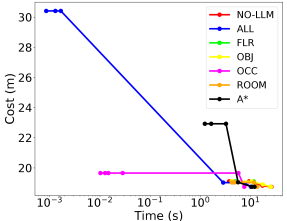
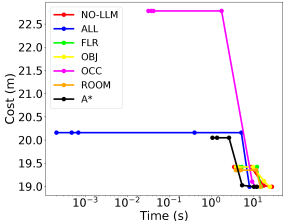
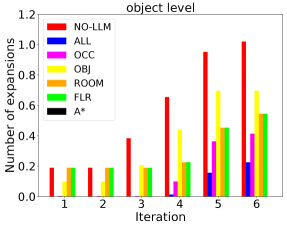
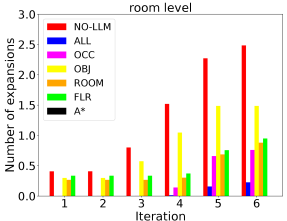
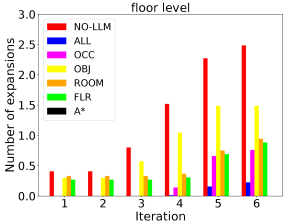
Since planning domains with different hierarchy levels and different heuristics per level can be constructed, we compare different setups to investigate the benefit of using our LLM heuristic. With all hierarchy levels having an LTL heuristic, we design 7 setups: occupancy level only without LLM heuristic (A*), all levels available but without LLM heuristics (NO-LLM), all levels with LLM heuristics (ALL), and one of the levels with LLM heuristic (OCC, OBJ, ROOM, FLR). Fig. 8 shows that the ALL setup manages to return a feasible path much faster than others thanks to the LLM guidance across all hierarchical levels, while it also approaches the optimal solution within similar time spans.
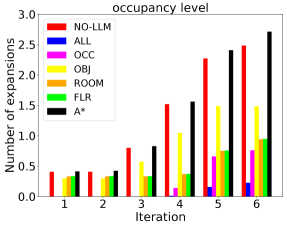
As an anytime algorithm, AMRA* starts searching with large weight on the heuristics, then reuses the results with smaller heuristic weights. As the planning iterations increase, the path gets improved. When the heuristic weight decays to 1, we obtain an optimal path. To further investigate the benefits of using LLM heuristics, we compare the number of node expansions per planning iteration. As shown in Fig. 8, applying our LLM heuristic to any hierarchy level reduces the node expansions significantly, which indicates that our LLM heuristic produces insightful guidance to accelerate AMRA*. An exciting observation is that the more hierarchy levels we use our LLM heuristic in, the more efficient the algorithm is. This encourages future research to exploit scene semantic information further to accelerate planning.
AMRA* allows a robot to start executing the first feasible path, while the path optimization proceeds in the background. Tables IV and IV shows the time required to compute the first path, the path cost relative to the optimal path, and the time required to find an optimal path. The ALL configuration outperforms other setups in speed of finding the first path and the optimal path when the scene gets more complicated.
VI CONCLUSION
We demonstrated that an LLM can provide symbolic grounding, LTL translation, and semantic guidance from natural language missions in scene graphs. This information allowed us to construct a hierarchical planning domain and achieve efficient planning with LLM heuristic guidance. We managed to ensure optimality via multi-heuristic planning, including a consistent LTL heuristic. Our experiments show that the LLM guidance is useful at all levels of the hierarchy for accelerating feasible path generation.
References
- [1] J. McCormac, A. Handa, A. Davison, and S. Leutenegger, “Semanticfusion: Dense 3d semantic mapping with convolutional neural networks,” in IEEE International Conference on Robotics and Automation (ICRA), 2017, pp. 4628–4635.
- [2] S. Bowman, N. Atanasov, K. Daniilidis, and G. Pappas, “Probabilistic Data Association for Semantic SLAM,” in IEEE International Conference on Robotics and Automation (ICRA), 2017.
- [3] J. Dong, X. Fei, and S. Soatto, “Visual-inertial-semantic scene representation for 3d object detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 3567–3577.
- [4] M. Shan, Q. Feng, and N. Atanasov, “OrcVIO: Object residual constrained Visual-Inertial Odometry,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020.
- [5] A. Rosinol, A. Violette, M. Abate, N. Hughes, Y. Chang, J. Shi, A. Gupta, and L. Carlone, “Kimera: From SLAM to spatial perception with 3D dynamic scene graphs,” The International Journal of Robotics Research (IJRR), vol. 40, no. 12-14, pp. 1510–1546, 2021.
- [6] E. Zobeidi, A. Koppel, and N. Atanasov, “Dense Incremental Metric-Semantic Mapping for Multi-Agent Systems via Sparse Gaussian Process Regression,” IEEE Transactions on Robotics (T-RO), vol. 38, no. 5, pp. 3133–3153, 2022.
- [7] A. Asgharivaskasi and N. Atanasov, “Semantic OcTree Mapping and Shannon Mutual Information Computation for Robot Exploration,” IEEE Transactions on Robotics (T-RO), vol. 39, no. 3, pp. 1910–1928, 2023.
- [8] J. Wilson, Y. Fu, A. Zhang, J. Song, A. Capodieci, P. Jayakumar, K. Barton, and M. Ghaffari, “Convolutional Bayesian Kernel Inference for 3D Semantic Mapping,” in IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 8364–8370.
- [9] S. Zhi, M. Bloesch, S. Leutenegger, and A. J. Davison, “SceneCode: Monocular Dense Semantic Reconstruction Using Learned Encoded Scene Representations,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [10] C. Estrada, J. Neira, and J. Tardos, “Hierarchical SLAM: real-time accurate mapping of large environments,” IEEE Transactions on Robotics, vol. 21, no. 4, pp. 588–596, 2005.
- [11] I. Armeni, Z.-Y. He, J. Gwak, A. R. Zamir, M. Fischer, J. Malik, and S. Savarese, “3D Scene Graph: A Structure for Unified Semantics, 3D Space, and Camera,” in IEEE International Conference on Computer Vision (ICCV), 2019, pp. 5664–5673.
- [12] A. Rosinol, A. Gupta, M. Abate, J. Shi, and L. Carlone, “3D Dynamic Scene Graphs: Actionable Spatial Perception with Places, Objects, and Humans,” in Robotics: Science and Systems (RSS), 2020.
- [13] N. Hughes, Y. Chang, and L. Carlone, “Hydra: A real-time spatial perception system for 3D scene graph construction and optimization,” in Robotics: Science and Systems (RSS), 2022.
- [14] J. Crespo, J. C. Castillo, O. M. Mozos, and R. Barber, “Semantic information for robot navigation: A survey,” Applied Sciences, vol. 10, no. 2, 2020.
- [15] S. Tellex, T. Kollar, S. Dickerson, M. R. Walter, A. G. Banerjee, S. Teller, and N. Roy, “Approaching the symbol grounding problem with probabilistic graphical models,” AI Magazine, vol. 32, no. 4, pp. 64–76, 2011.
- [16] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” Advances in neural information processing systems (NeurIPS), vol. 33, pp. 1877–1901, 2020.
- [17] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint:1810.04805, 2018.
- [18] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and Efficient Foundation Language Models,” arXiv preprint:2302.13971, 2023.
- [19] W. Chen, S. Hu, R. Talak, and L. Carlone, “Extracting zero-shot common sense from large language models for robot 3D scene understanding,” arXiv preprint:2206.04585, 2022.
- [20] ——, “Leveraging large language models for robot 3D scene understanding,” arXiv preprint arXiv:2209.05629, 2022.
- [21] D. Shah, B. Osiński, B. Ichter, and S. Levine, “LM-Nav: Robotic navigation with large pre-trained models of language, vision, and action,” in Conference on Robot Learning (CoRL), 2022, pp. 492–504.
- [22] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” in International Conference on Machine Learning (ICML), 2021, pp. 8748–8763.
- [23] C. Belta, A. Bicchi, M. Egerstedt, E. Frazzoli, E. Klavins, and G. J. Pappas, “Symbolic planning and control of robot motion [grand challenges of robotics],” IEEE Robotics and Automation Magazine, vol. 14, no. 1, pp. 61–70, 2007.
- [24] H. Kress-Gazit, G. E. Fainekos, and G. J. Pappas, “Temporal-Logic-Based Reactive Mission and Motion Planning,” IEEE Transactions on Robotics, vol. 25, no. 6, pp. 1370–1381, 2009.
- [25] Y. Chen, J. Arkin, Y. Zhang, N. Roy, and C. Fan, “AutoTAMP: Autoregressive task and motion planning with LLMs as translators and checkers,” arXiv preprint:2306.06531, 2023.
- [26] O. Maler and D. Nickovic, “Monitoring temporal properties of continuous signals,” in Formal Techniques, Modelling and Analysis of Timed and Fault-Tolerant Systems, 2004, pp. 152–166.
- [27] T. Wongpiromsarn, U. Topcu, N. Ozay, H. Xu, and R. M. Murray, “TuLiP: a software toolbox for receding horizon temporal logic planning,” in International Conference on Hybrid Systems: Computation and Control (HSCC), 2011, pp. 313–314.
- [28] C. I. Vasile and C. Belta, “Sampling-based temporal logic path planning,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2013, pp. 4817–4822.
- [29] J. Fu, N. Atanasov, U. Topcu, and G. J. Pappas, “Optimal temporal logic planning in probabilistic semantic maps,” in IEEE International Conference on Robotics and Automation (ICRA), 2016, pp. 3690–3697.
- [30] P. Purohit and I. Saha, “DT*: Temporal logic path planning in a dynamic environment,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 3627–3634.
- [31] Y. Kantaros and M. M. Zavlanos, “STyLuS*: A temporal logic optimal control synthesis algorithm for large-scale multi-robot systems,” The International Journal of Robotics Research (IJRR), vol. 39, no. 7, pp. 812–836, 2020.
- [32] M. Fox and D. Long, “PDDL2. 1: An extension to PDDL for expressing temporal planning domains,” Journal of artificial intelligence research, vol. 20, pp. 61–124, 2003.
- [33] J. Kim, A. Desrochers, and A. Sanderson, “Task planning and project management using petri nets,” in IEEE International Symposium on Assembly and Task Planning, 1995, pp. 265–271.
- [34] P. Lv, G. Luo, Z. Ma, S. Li, and X. Yin, “Optimal multi-robot path planning for cyclic tasks using petri nets,” Control Engineering Practice, vol. 138, p. 105600, 2023.
- [35] S. Karaman, S. Rasmussen, D. Kingston, and E. Frazzoli, “Specification and planning of uav missions: a process algebra approach,” in American Control Conference (ACC), 2009, pp. 1442–1447.
- [36] F. Xia, A. R. Zamir, Z.-Y. He, A. Sax, J. Malik, and S. Savarese, “Gibson Env: Real-World Perception for Embodied Agents,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [37] D. M. Saxena, T. Kusnur, and M. Likhachev, “AMRA*: Anytime multi-resolution multi-heuristic A*,” in IEEE International Conference on Robotics and Automation (ICRA), 2022, pp. 3371–3377.
- [38] P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,” IEEE Transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968.
- [39] S. Aine, S. Swaminathan, V. Narayanan, V. Hwang, and M. Likhachev, “Multi-heuristic A*,” The International Journal of Robotics Research (IJRR), vol. 35, no. 1-3, pp. 224–243, 2016.
- [40] J. D. Gammell, S. S. Srinivasa, and T. D. Barfoot, “Informed RRT*: Optimal sampling-based path planning focused via direct sampling of an admissible ellipsoidal heuristic,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2014, pp. 2997–3004.
- [41] J. D. Gammell, T. D. Barfoot, and S. S. Srinivasa, “Batch Informed Trees (BIT*): Informed asymptotically optimal anytime search,” The International Journal of Robotics Research (IJRR), vol. 39, no. 5, pp. 543–567, 2020.
- [42] W. Du, F. Islam, and M. Likhachev, “Multi-resolution A*,” in International Symposium on Combinatorial Search, vol. 11, no. 1, 2020, pp. 29–37.
- [43] D. Shah, M. Equi, B. Osiński, F. Xia, B. Ichter, and S. Levine, “Navigation with large language models: Semantic guesswork as a heuristic for planning,” in Conference on Robot Learning (CoRL), 2023.
- [44] I. Kostavelis, K. Charalampous, A. Gasteratos, and J. K. Tsotsos, “Robot navigation via spatial and temporal coherent semantic maps,” Engineering Applications of Artificial Intelligence, vol. 48, pp. 173–187, 2016.
- [45] S. Amiri, K. Chandan, and S. Zhang, “Reasoning with scene graphs for robot planning under partial observability,” IEEE Robotics and Automation Letters (RAL), vol. 7, no. 2, pp. 5560–5567, 2022.
- [46] Z. Ravichandran, L. Peng, N. Hughes, J. D. Griffith, and L. Carlone, “Hierarchical representations and explicit memory: Learning effective navigation policies on 3d scene graphs using graph neural networks,” in IEEE International Conference on Robotics and Automation (ICRA), 2022, pp. 9272–9279.
- [47] A. Pnueli, “The temporal semantics of concurrent programs,” Theoretical computer science, vol. 13, no. 1, pp. 45–60, 1981.
- [48] O. Kupferman and M. Y. Vardi, “Model checking of safety properties,” Formal methods in system design, vol. 19, pp. 291–314, 2001.
- [49] M. Kwiatkowska, G. Norman, and D. Parker, “Prism: Probabilistic symbolic model checker,” in Computer Performance Evaluation: Modelling Techniques and Tools, 2002.
- [50] J. Klein, C. Baier, P. Chrszon, M. Daum, C. Dubslaff, S. Klüppelholz, S. Märcker, and D. Müller, “Advances in probabilistic model checking with PRISM: variable reordering, quantiles and weak deterministic büchi automata,” International Journal on Software Tools for Technology Transfer, vol. 20, no. 2, pp. 179–194, 2018.
- [51] A. Duret-Lutz, E. Renault, M. Colange, F. Renkin, A. G. Aisse, P. Schlehuber-Caissier, T. Medioni, A. Martin, J. Dubois, C. Gillard, and H. Lauko, “From Spot 2.0 to Spot 2.10: What’s new?” in International Conference on Computer Aided Verification (CAV), 2022, pp. 174–187.
- [52] S. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor, “ChatGPT for robotics: Design principles and model abilities,” Microsoft, Tech. Rep. MSR-TR-2023-8, February 2023. [Online]. Available: https://www.microsoft.com/en-us/research/publication/chatgpt-for-robotics-design-principles-and-model-abilities/
- [53] OpenAI, “GPT-4 Technical Report,” in arXiv: 2303.08774, 2023.