Optimal Regulators in Geometric Robotics
Abstract
The aim of this paper is to give some existence results of optimal control of robotic systems with a Riemannian geometric view, and derive a formulation of the PMP using the intrinsic geometry of the configuration space.
Applying this result to some special cases will give the results of avoidance problems on Riemannian manifolds developed by A. Bloch et al.
We derive a formulation of the dynamic programming approach and apply it to the quadratic costs and extend the linear quadratic regulator to robotic systems on Riemannian manifolds and giving an equivalent Riccati equation. We give an optimisation aspect of the Riemannian tracking regulator of F. Bullo and R.M. Murray.
Finally, wee apply the theoretical developments to the regulation and tracking of a rigid body attitude.
Index Terms:
Optimal Control, Geometric Robotics, Dynamic Programming, PMP, Riccati Equations, LQR regulator, Tracking Regulator.I Introduction
Robotic manipulators are powerful tools to gain energy, time and money. The problem with the control of this kind of systems is the non-linearity of the dynamics. The classical approach that models the configuration space as an euclidean space and apply the Hamilton’s principle to derive the equations and give some regulation results using Lyapunov stability theorems [11] [12] [13] [14] [51].
On the other hand the work of [8] shows the efficacy of Riemannian geometry in robotics. In [18] [20] [21] [26] [27] the authors propose a Riemannian PD regulator that ensures the regulation of the configuration into a reference position with zero velocity using Lyapunov techniques [3] [10] [12] [13], but the gains can be chosen arbitrarily and are not unique. For linear systems, we solve this problem by fixing a quadratic cost and apply the LQR theory to give the unique optimal control that ensure the regulation.
The optimal control is a linear feedback of the state [31] [32] [42], and the proportional coefficient can be computed from an algebraic Riccati equation.
Computations in [33] [34] prove that we can recover the Riccati equation by applying the PMP or HJB theory for linear systems with quadratic costs. Work in [43] [44] give a geometric formulation of PMP and HJB theory for state space systems on manifold using the symplectic structure of cotangent bundle of the state space.
A. Sacoon et al showed in [39] that the form of the optimal regulator of the rigid body kinematic with and for the euclidean cost
where is the Frobenius norm,
We see that this form is not a linear feedback of configuration, this remark prevents to establish an LQR theory for robotic systems using the Euclidean formulation.
S. Berkane et al showed in [38] that the optimal control of the Riemannian cost
is
for some solution of an algebraic Riccati equation, This result encourages us to use the geometric formulation for optimal control of robotic systems.
Works in [40] of C. Liu et al consists to prove that for rigid body dynamics
The optimal control for the riemannian cost
is with are solution of algebraic Riccati equation.
The goal here is to prove that we can establish a geometric LQR theory for robotic systems, by proving that for riemannian cost, the optimal control is a riemannian PD regulator.
II Mathematical Preliminaries
Here we recall some preliminaries about geometric robotic and some functional analysis.
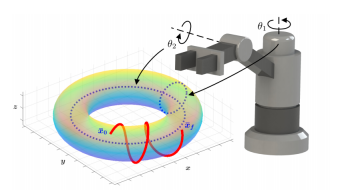
The configuration space of a robot is a dimensional manifold where is the number of rigid bodies that constitute the robot, and is the degree of freedom and is the number of holonomic constraints.
The Riemannian manifold with is the kinetic energy of the robot allow us to express trajectories of the robot subject to the potential and the control force such that by
where is the covariant derivative.
is the covariant gradient i.e the vector field that ensure and is the tangent cotangent isomorphism.
We call a state the element , that is a state is the combination of a configuration and a velocity.
The curvature tensor is defined by
with is the Levi-Civita connexion.
A locally absolutely continuous function is a function such that for , from the Lebesgue theorem [25], an absolutely continuous function is a.e differentiable and a.e, we have this result [42] [33]
Theorem II.1
Cauchy-Lipschitz in Optimal Control
for , the dynamic have a unique LAD local solution for each initial conditions on defined in an open interval.
From Mazur’s and the converse of Lebesgue dominated convergence theorems, we have the following facts, if convex and closed, is weakly closed, and if is convex and compact, is weakly compact [29].
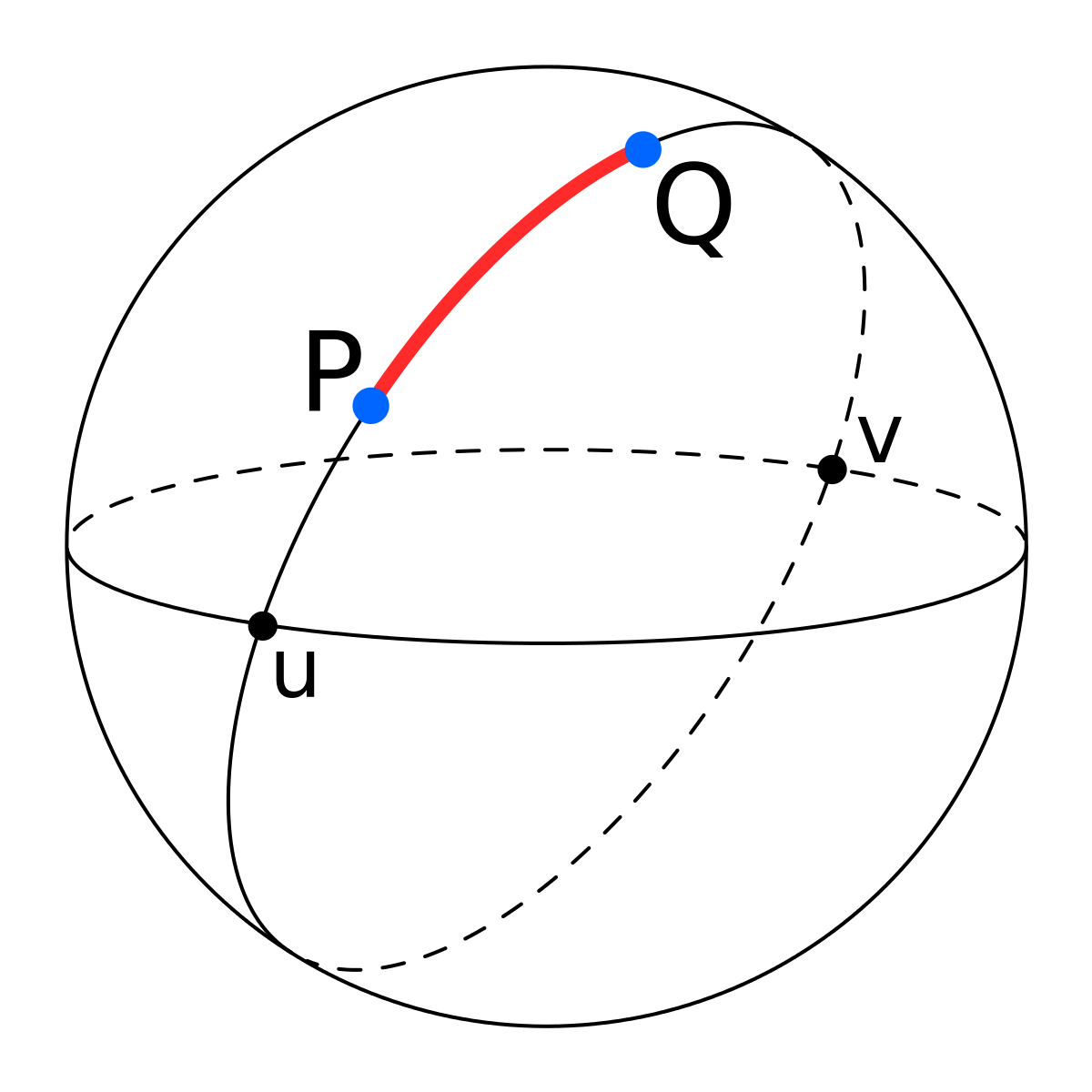
We denote by by the minimal kinetic energy that takes the robot from a configuration to another, namely .
For the function is smooth on a normal neighborhood of , and its gradient is , in fact we have .
We denote by the injectivity radius of at by the biggest number such that is a diffeomorphism.
If there is a unique minimizing geodesic that joints to .
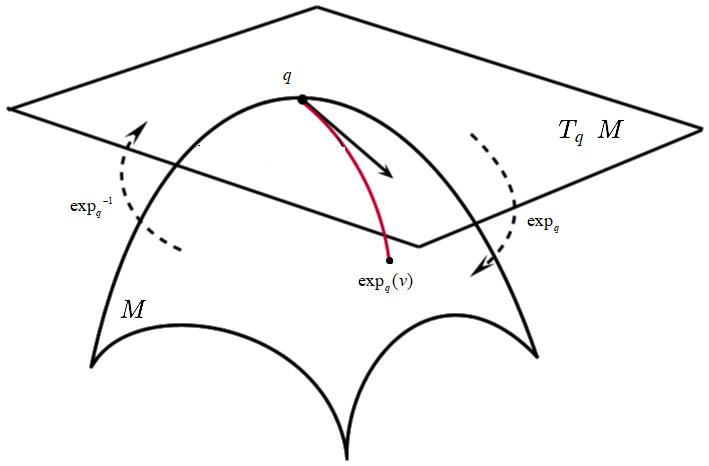
We will show that for natural cost, the optimal control is a Riemannian PD feedback, where the proportional action is exactly , the major problem of the geometric approach is fastidious computations, in practice it is very difficult to compute the exponential map neither its inverse, so we do two approximations
1)- the case where is an arbitrary manifold
.
2) the case where , we take
where is the logarithm that can be computed easily from Rodriguez formula [49] [21].
with is the projection of on the space of anti-symmetric matrices, and .
The motivation of the approximation on is that for left invariant metric, knowledge of the exponential map at gives us its values in all . On the other hand, when the metric is bi invariant, the exponential map of the metric and the Lie exponential (matrix exponential) are the same, this allows us to approximate the two logarithms.
We see that this allow us to recover the classical LQR theory, and classical results of Linear regulation, or results about regulation of rigid bodies.
It’s clear that is a Lyapunov function for the dynamic
where and satisfies .
We will prove that it’s an optimal feedback regulator for a natural cost.
III Existence Results in Optimal Control of Robotic Systems
The aim of this part is to give some existence results of optimal control laws by functional analysis tools [29], we adapt the results in [31] [33] [41] [42] to the formulation in geometric robotics.
we need the following result
Lemma III.1
Inverse of the covariante derivative Let be LAD, so there exists a unique linear operator that satisfies for all and all , and a.e in for all .
Proof :
We construct this operator locally, and we extend it by the uniqueness, we solve the equation
with initial condition , the linear Cauchy-Lipschitz theorem gives us this solution that satisfies , we see also that is a solution of this problem, so the conclusion follows.
III-A Time-optimal control result
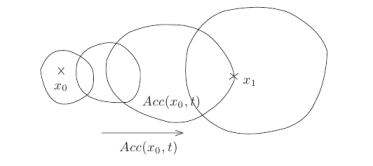
We denote by the set of controls such that the robot initialized in the trajectory is defined in , and the trajectories lies in a fixed compact .
let defined by , the accessible set is .
The fact that trajectories are lies in a fixed compact and the control lies in a convex compact implies that the accessible set is compact and depend continuously for the Hausdorff distance.
Theorem III.2
Suppose that is convex and compact, and consider the dynamic
so the accessible set is compact and depend continuously for the Hausdorff distance.
Proof :
We are interested by the dynamic
We prove the compactness of , let be a sequence of , because and that is bounded. is bounded, then, there exist such that converge weakly to .
On the other hand is bounded in , so it converges weakly for some , we know that can be compactly injected in , this proves the uniform convergence.
So we have
This conclude that is the control that gives .
Now we prove the continuous dependence
Let , . it suffices to prove that there exists such that if , so for there exists such that .
We fix , for the , we choose , we have
The fact that quantities that are in the integral are locally integrable concludes.
Remarque : The hypothesis about the trajectories that must be in a fixed compact is natural and essential in the proof.
We have this corollary
Corollary III.2.1
If for some , so there exist a time-optimal control that takes to in time , in addition .
Proof :
Let , suppose that , let (where satisfies the minimal distance, this point exists because the accessible sets are compacts). so there exists such that if for every , there exists such that . From the definition of infimum , there exists that satisfies , we take the corresponding is in closer from than , this is a contradiction.
If , so and by continuity there exists such that , this contradicts the time optimality.
III-B Cost optimal control results
Now we give existence results for optimisation of some cost, we note and is the parallel transportation along the unique minimizing geodesic (this is well defined for sufficiently close configurations), let .
Theorem III.3
Consider the dynamic and is closed and convex, so there exist an optimal control for the cost
Proof :
Let such that , so , let be a minimizing sequence i.e , this sequence is clearly bounded, so there exists a subsequence that converges to . We prove now that , we recall that is weakly closed.
Let be the trajectories with control initialized at ,
The sequence is bounded, we can extract a sequence that converges weakly to , by the Sobolev compactness theorem, this sequence converges uniformly to in , so
This confirms that because are defined in , on the other hand, we have (the norm is convex and continuous, so it is lower semi-continuous for the weak topology) and thus by uniform convergence of we have
As for the regulation problem, we can consider a tracking regulator as in this proposition
Proposition 1
Consider the dynamic and is closed and convex, so there exist an optimal control for the cost
IV Riemannian Formulation of PMP
Works in [43] [44] give a symplectic formulation of PMP for state space systems on manifolds, here we give a Riemannian formulation of PMP for robotic systems that explicitly implies the geometry of configuration space.
we start by giving an estimation of how perturbing a control changes the configuration, and it’s here where the Riemannian tensor will appears ! after that we will apply this results to the Riemannian double integrator, and recover results in [45] [46] [47] of Bloch, Silva and Colombo.
IV-A Statement of the problem
We are interesting by the following optimisation problem
with and , we take and are smooth, and we want to minimize
Our problem is to give a necessary condition for that verifies .
IV-B Simple variations of control
The tangent bundle of the configuration space (state space) is furnished with the Sasaki metric [24] [25], for is the exponential map.
let and , we denote by the optimal trajectory, and we define the following perturbation of the optimal control if and otherwise, it is clear that , and we will show that in fact, for sufficiently small.
the first step is to give the configuration by mean of the optimal configuration when the initial conditions are close.
Lemma IV.1
Perturbation analysis
let the dynamic
and , so with is the solution of the linear equation
and .
Proof :
By continuous dependence on initial conditions, we can write for some .
Applying on the family of equations that satisfies and using the fact that if we invert two covariant derivative the curvature will appears, we conclude by putting .
Now we can estimate the configuration of the robot when there is small variations of the control with the following result :
Lemma IV.2
for the dynamic
with as initial conditions.
so with in and is the solution of the linear equation
and ,
Proof :
It’s clear that when , we easily establish that .
The previous lemma concludes.
IV-C Riemannian geometric PMP
Now we can give an intrinsic formulation of PMP for robotic systems.
Theorem IV.3
Intrinsic formulation of PMP
consider the robot dynamic with , so if is optimal for the cost as defined in the statement problem, there exists that satisfies Hamilton’s ODE
and , and satisfies the minimization principle a.e
where , and is constant along these trajectories.
Proof :
We suppose in first time that , so it’s a terminal value optimisation problem, , the following step is to estimate
using previous lemma, we have , define solution of
with . so the expression is constant. It’s derivative is
Where is the operator such that
we conclude by taking the adjoint operator.
On a , the fact that is optimal, and are arbitrary, we conclude that
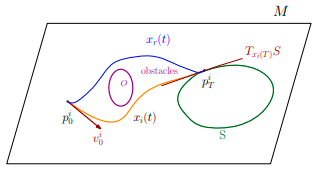
IV-D Avoidance problem in robotics
Here we apply the developed result to the particular case
we want to minimize the cost
with is the avoidance function, it looks like with is the number of obstacles, and the obstacles are , we have the following result as in [45] [46] [47].
Theorem IV.4
Avoidance problem
the optimal control of the Riemannian double integrator for the cost is the solution of the equation
with and .
Proof :
The Hamiltonian is a strict convex function on , so minimum is the unique critical point of
This gives .
On the other hand, computations gives
by the fact , we have .
This concludes.
IV-E Optimal regulation
we can give a result about regulation in finite time.
Proposition 2
Curvature and Regulation
let the dynamic and the cost
then the optimal control is solution of the Jacobi equation
with and
Proof :
Same computations as for previous theorem.
V HJB theory and applications
Here we give the formulation of HJB theory in the case of robotic systems, formulation in [43] [44] gives a symplectic one for dynamical systems on manifolds, here we give a Riemannian formulation for robotic systems.
V-A Riemannian formulation of HJB
Let and be smooth, we are interesting by solving the optimal control problem as exposed in the statement of the problem.
as in [9] [38] [37], we can prove that if the value function is smooth with and and .
We introduce the Hamiltonian
We have the following theorem.
Theorem V.1
We suppose that , and the Lagrangian is coercive in
So it satisfies the Hamilton Jacobi Bellman PDE
with terminal value
with is the gradient associated to the Sasaki metric on the tangent bundle.
Proof :
Let and , we denote the value function by
where are solutions of the robot dynamic, and .
for we take , and for we choose an optimal control, the cost of this control is
so we have
let
and this gives
By choosing an optimal control we obtain
and this is the Riemannian formulation of HJB equation.
One can also prove that under some suppositions, is the unique viscosity solution
[33] [30] of the HJB equation.
V-B Strategy of optimal control by HJB
The strategy of optimal control by HJB is the following, we compute the minimum of the Hamiltonian
and the argument is . We solve HJB equation and express the optimal control as a feedback.
We verify now that this construction gives us an optimal control
This confirms optimality.
The optimal control verify then
In particular when , the value function is non increasing along optimal trajectories.
V-C Optimal Regulation (Riemannian-LQR)
Here we look for a regulator that takes the configuration to a reference one with zero velocity, and minimize the cost for the dynamic .
we will prove that the optimal control is for some that solves an algebraic Riccati equation.
Theorem V.2
LQR-Theory
the optimal control of the Riemannian double integrator for the natural cost is a PD regulator with and is the unique positive definite matrix that satisfies the algebraic Riccati equation
when satisfies .
Proof :
We denote by the initial condition of the system, so the function
is the solution of HJB equation with
this function is convex in for all and in , she reach her minimum at , because , solving the HJB equation will conclude.
So is equivalent to
A candidate function to solve HJB is
we have so we replace
to obtain , putting this in the HJB equation gives
so Riccati equations to solve for are
To write these equations as in the classical LQR theory, we put , , , et ,
Riccati equation takes the following form
that have unique solution that is positive definite. This gives . It is clear that and so is controllable, and , so by the classical result in LQR theory, there exists unique solution positive definite for the Riccati equation, we recover the formula well known in LQR theory
On the other hand,
is a Lyapunov function of the optimal feedback.
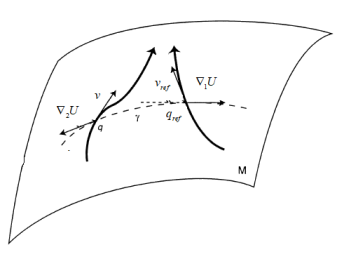
V-D Optimal Tracking
Here we give an optimisation aspect of the tracking regulator exposed in [16] [8], we will show by computations on Riemannian manifolds and using the dynamic programming approach that the optimal regulator for a natural cost is the PD+FF regulator exposed by F. Bullo and R. Murray.
Theorem V.3
Optimisation Aspect of Tracking Regulator
let be a smooth reference trajectory for the dynamic , consider the natural cost
So the optimal control is a feedback such that
with where is the solution of the Riccati equation
with the terminal condition .
Proof :
A candidate function to solve HJB is
Hamiltonian is
so , this gives
Some computations gives
the compatibility of the pair gives
now we compute , for this
en using the fact that is constant we conclude that , this gives
such that , the Hamiltonian becomes rearranging terms at HJB gives
we conclude by taking
using the fact that , the equation becomes
this can be rewritten as
or by the differential Riccati equation
The optimal feedback is then
with .
VI Applications and Simulations
VI-A Rigid body
We apply the previous theoretical developments to a rigid body with fixed point, we recall that the rigid body is a very interesting mechanical system [21] [49]. The configuration space is the Lie group .
The kinetic energy of the rigid body is left invariant, so we can compute the kinetic energy by his restriction to the tangent space of at , explicitly .
By the canonical isomorphism given by
where is the commutator of matrices.
We denote by the inverse of , in face these two isomorphisms preserves the Lie algebra structure, and then we can rewrite the dynamic equations
where .
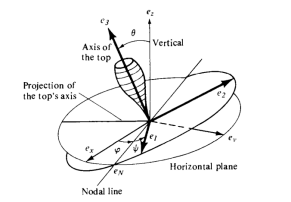
We recall that , , et ,
We simulate the theoretical developments using MATLAB, in order to solve the kinematic , we use the following Euler-Lie algorithm
VI-B Optimal regulation
We are interested by the optimal regulation of the configuration to by minimizing the cost
The optimal regulator is
for .
We take in the simulations , and . This gives .
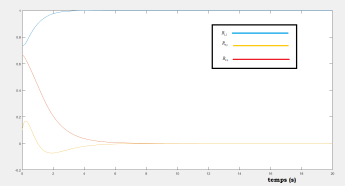
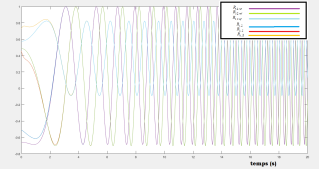
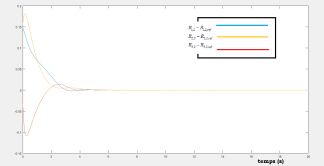
Simulations results :
Applying the previous control laws gives the following figures that shows the efficacy of the proposed optimal regulator, we see that the diagonal components converges to 1, and the other to 0, this conclude that .
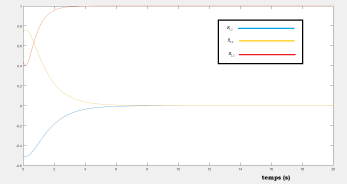
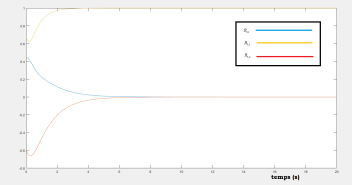
VI-C Optimal tracking
We are interested by the optimal tracking of the configuration to the smooth reference one by minimizing the cost
When the metric is bi invariant, parallel transportation along the unique minimizing geodesic for two sufficiently close configurations is exactly the right translation, so we do this approximation
and by computations in [21] [26], the optimal regulator is
and the PD action is
for , we take , .
So , we choose and is the unique trajectory such as .
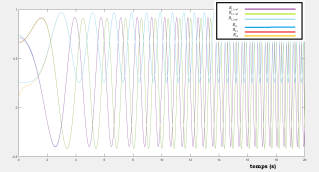
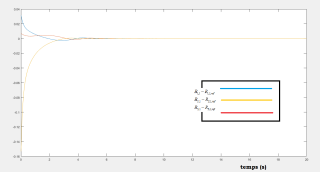
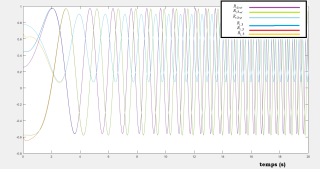
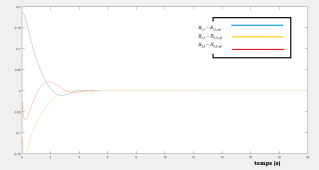
Simulations results :
The following figures shows the efficacy of the proposed regulator, we see that all the components of the attitude converge to the reference one.
VII Conclusion
Using functional analysis tools, we give some existence results about optimal control of robotic systems using an intrinsic formulation.
We give an intrinsic formulation of PMP for robotic systems that involves explicitly the Riemannian curvature tensor, we then recover results of Bloch, Silva and Colombo [45] [46] [47].
Finally the LQR extension for robotic systems with the geometric formulation is given using dynamic programming approach, and we give an optimisation aspect of the tracking regulation of F. Bullo and R. Murray in [21] [26].
References
- [1] A. Bousclet, M.C. Belhadjoudja, Techniques de Géométrie Riemannienne en Robotique, Séminaires de l’École Nationale Polytechnique, 2020.
- [2] Andrei Kolmogorov S.Fomin, Introductory Real Analysis, Dover Books on Mathematics, 1975.
- [3] Felice Ronga, Anlayse Réelle Post-Élémentaire, Verlag nicht ermittelbar, 2007.
- [4] Manfredo Do-Carmo, Differential Geometry of Curves and Surfaces, Dover Publications inc, 2017.
- [5] O’Neill Barrett, Elementary Differential Geometry, Academic Press, 2nd edition, 2006.
- [6] Frank W.Warner, Foundations of Differentiable Manifolds and Lie Groups, Springer-Verlag New York, 1983.
- [7] John.Lee, Riemannian Geometry, An Introduction to Curvature, Springer-Verlag New York, 1997.
- [8] Vladimir.I Arnold, Mathematical Methods of Classical Mechanics, Springer-Verlag, 1989.
- [9] Jean-Louis Basdevant, Variationnal Principels in Physics, Springer, 2010.
- [10] Andrea Baccioti, Lionel Rosier, Liapounov Functions and Stability in Control Theory, Springer- Verlag Berlin Heidelberg, 2005.
- [11] Suguru Arimoto, Advances in Robot Control, Springer-Verlag Berlin Heidelberg, 2006.
- [12] Hassan Khalil, Nonlinear Systems, Pearson, 2001.
- [13] Jean-Jaques Slotine, Applied Nonlinear Control, Pearson, 1990.
- [14] Suguru Arimoto, Control Theory of Multi-fingered Hands, A Modelling and Analytical-Mechanics Approach for Dexterity and Intelligence, Springer-Verlag London, 2008.
- [15] D. Wang, N.H. McClamroch, Position and Force Control for Constrained Manipulator Motion :Lyapunov’s Direct Method, IEEE Transactions on Robotics and Automation, 1993.
- [16] Richard M. Murray, Zexiang Li, S.Shankar Sastry, A Mathematical Introduction to Robotic Manipulation, CRC Press, 1 st edition, 1994.
- [17] J.M Selig, Geometrical Methods in Robotics, Springer-Verlag New York, 1996.
- [18] Suguru Arimoto, Morio Yoshida, Masahiro Sekimoto, Kenji Tahara, A Riemannian Geomtry Approach for Control of Robotic Systems under Constraints, SICE Journal of Control, Measurement, and System Integration Volume 2, 2009.
- [19] Suguru Arimoto, Masahiro Sekimoto, Sadao Kawamura and Ji-Hun Bae, Skilled Motion Plannings of Multi-Body Systems Based upon Riemannian Distance, IEEE Internation Conference on Robotics and Automation, 2008.
- [20] Suguru Arimoto, Morio Yoshida, Masahiro Sekimoto, Kenji Tahara, A Riemannian Geomtry Approach for dynamics and control of object manipulation under constraints, IEEE Internation Conference on Robotics and Automation, 2009.
- [21] Francesco Bullo, Andrew D.Lewis, Geometric Control of Mechanical Systems, Springer-Verlag New York, 2005.
- [22] Rouchon Pierre, Nasradine Aghannan, An Intrinsic Observer for a Class of Lagrangian Systems, IEEE Transaction on Automation and Control, 2003.
- [23] David A.Anisi, Riemannian Observer for Euler-Lagrange Systems, IFAC Proceedings volumes, 2007.
- [24] Shigeo Sasaki, On the Differential Geometry of Tangent Bundles of Riemannian Manifolds, Tohuko Math, 1958.
- [25] Shigeo Sasaki, On the Differential Geometry of Tangent Bundles of Riemannian Manifolds II, Tohuko Math, 1961.
- [26] Francesco Bullo, Richard M.Murray, Tracking for fully actuated mechanical systems: a geometric framework, Automatica, 1999.
- [27] Bousclet Anis, Belhadjoudja Mohamed Camil, Geometric Control of a Robot’s tool, International Journal of Engineering Systems Modelling and Simulation, Arxiv, Optimiszation and Control, 2021.
- [28] Claudio Altafini, Geometric Control Methods for Nonlinear Systems and Robotic Applications, Ph.D Thesis, Royal Institue of Technology, University of Stockholm, Sweden, 2001.
- [29] H. Brezis, Functional Analysis : Theory and Application, Dunod, 2005.
- [30] A. Bressan, Viscosity Solutions of Hamilton-Jacobi Equations and Optimal Control Problems, Technical report S.I.S.S.A, Triestee, Italy, 2003.
- [31] E. Trelat, Commande Optimale : Théorie et Application, Vuibert, 2005.
- [32] Rudolf E. Kalman, Peter L. Falb, Michael A. Arbib, Topics In Mathematical System Theory, McGraw Hill Education, 1969.
- [33] A. Bressan, Introduction to the Mathematical Theory of Control, Amer Inst of Mathematical Sciences, 2007.
- [34] L.C. Evans, A Mathematical Introduction to Optimal Control Theory, University of California, Berkley, 2010.
- [35] C.C. Remsing, Control and Integrability on , Internation Conference of Applied Mathematics and Engineering, London, 2010.
- [36] A. Sacoon, A.P. Seguiar, J.Hauser, Lie Group Projection Operator Approach : Optimal Control on , IEE Transactions on Automatic Control, 2013.
- [37] A. Bloch, J. Marsden, P. Crouch, A.K. Sanyal, Optimal Control and Geodesics on Quadratic Matrix Lie Groups, Foundations of Computational Mathematics, 2008.
- [38] S. Berkane, A. Tayebi, Some Optimisation Aspects on the Lie Group , IFAC-PapersOnLine 48-3, 2015.
- [39] A. Sacoon, J. Hauser, A.P. Aguiar, Exploration of Kinematic Optimal Controlon the Lie Group , In 8th IFAC Symposium on Nonlinear Control Systems, 2010.
- [40] C.Liu, S. Tang, J. Guo, Intrinsic Optimal Control for Mechnical Systems on Lie Groups, Advances in Mathematical Physics, 2017.
- [41] H. Fleming, W. Ri2017. shel, Deterministic and Stochastic Optimal Control, Springer-Verlag New York, 1975.
- [42] B. Lee, L. Markus, Foundations of Optimal Control Theory, John Wiley & Sonos Ltd, 1967.
- [43] V. Jurdjevic, Geometric Control Theory, Cambridge University Press, 2008.
- [44] V. Jurdjevic, Optimal Control and Geometry : Integrable Systems, Cambridge University Press, 2016.
- [45] A. Bloch, M. Camarinha, L. Colombo, Variational Point-obstacle Avoidance on Riemannian Manifolds, Mathematics of Control, Signals and Systems, 2021.
- [46] A. Bloch, M. Camarinha, L. Colombo, Dynamic interpolation for obstacle Avoidance on Riemannian manifolds, Published Online arxiv,2018.
- [47] A. Bloch, M. Camarinha, L. Colomo, R. Banavar, S. Chandrasekaran, Variational collision and obstacle avoidance of multi-agent systems on Riemannian manifolds, European Control Conference,2020.
- [48] F. Bullo, Nonlinear Control of Mechanical Systems : A Riemannian Geometry Approach, Ph.D Thesis, California Insitute of Technology, 1999.
- [49] S. Berkane, Hybrid Attitude Control and Estimation on , Ph.D Thesis, University of Wastern Ontario, December 2017.
- [50] L. Pontryagin, Mathematical Theory of Optimal Processes, CRC Press, 1987.
- [51] W. Khalil and E. Dombre, Modeling, Identification and Control of Robots, Paris : Hermès science publications, 1999.
- [52] R. Bonnali, A. Bylard, A. Cauligi, T. Lew, M. Pavone, Trajectory Optimization on Manifolds : A Theoritically-Guarenteed Embeeded Sequential Convex Programming Approach, Robotics : Science and Systems, 2019.
- [53] John Lee, Introduction to Smooth Manifolds, Springer-Verlag New York, 2012.