Optimal Kernel for Kernel-Based Modal Statistical Methods
Abstract
Kernel-based modal statistical methods include mode estimation, regression, and clustering. Estimation accuracy of these methods depends on the kernel used as well as the bandwidth. We study effect of the selection of the kernel function to the estimation accuracy of these methods. In particular, we theoretically show a (multivariate) optimal kernel that minimizes its analytically-obtained asymptotic error criterion when using an optimal bandwidth, among a certain kernel class defined via the number of its sign changes.
Keywords: Optimal kernel, kernel mode estimation, modal linear regression, mode clustering
1 Introduction
The mode for a continuous random variable is a location statistic where a probability density function (PDF) takes a local maximum value. It provides a good and easy-to-interpret summary of probabilistic events: one can expect many sample points in the vicinity of a mode. Besides, the mode has several desirable properties for data analysis. One of them is that it is robust against outliers and skew or heavy-tailed distributions as a statistic that expresses the centrality of data following a unimodal distribution. The mean is not robust at all, which often causes troubles in real applications. Another desirable property of the mode is that it can be naturally defined even in multivariate settings or non-Euclidean spaces. For example, the median and quantiles are intrinsically difficult to define in these cases due to the lack of an appropriate ordering structure. Also, the mode works well for multimodal distributions without loss of interpretability.
These attractive properties of the mode are utilized not only in location estimation but also in other data analysis techniques such as regression and clustering. Among various modal statistical methods, kernel-based methods have been widely used, presumably because they retain the inherent goodness of the mode and are easy to use in that they can be implemented with simple estimation algorithms, such as mean-shift algorithm (Comaniciu and Meer, 2002; Yamasaki and Tanaka, 2020) for kernel mode estimation (Parzen, 1962; Eddy, 1980; Romano, 1988) and for mode clustering (Casa et al., 2020), and iteratively reweighted least squares algorithm (Yamasaki and Tanaka, 2019) for modal linear regression (Yao and Li, 2014; Kemp et al., 2020). Also, their good estimation accuracy is an important advantage: for example, kernel mode estimation generally has the best estimation accuracy in mode estimation in the sense that it attains the minimax-optimal rate regarding the used sample size (Hasminskii, 1979; Donoho et al., 1991).
Estimation accuracy of such kernel-based methods depends on the kernel function used as well as the bandwidth. Nevertheless, the selection of a kernel has not been well studied, and some questions remain unanswered. For instance, for univariate kernel mode estimation, Granovsky and Müller (1991) have derived the optimal kernel, which minimizes the asymptotic mean squared error (AMSE) of a kernel mode estimate using an optimal bandwidth among a certain kernel class defined via the number of sign changes. Whether their argument can be extended to multivariate cases, however, has not been clarified yet. We are also interested in optimal kernels for other kernel-based modal statistical methods, such as modal linear regression and mode clustering, for which the problem of kernel selection has not been elucidated enough, as far as we are aware. The objective of this paper is to study the problem of kernel selection for various kernel-based modal statistical methods in the multivariate setting.
In the main part of this paper (Sections 2–4), with the aim of simplifying the presentation, we focus on kernel mode estimation (Parzen, 1962; Eddy, 1980; Romano, 1988) as a representative kernel-based modal statistical method. In Section 2, we address multivariate extension of the study on the optimal kernel by Granovsky and Müller (1991). For multivariate cases, we need some additional assumptions on the structure of the kernels to allow systematic discussion on the optimal kernel, so we mainly consider two commonly-used kernel classes, radial-basis kernels (RKs) and product kernels (PKs). In Section 2.1, we show basic asymptotic behaviors of the mode estimator, such as asymptotic normality of the mode estimator that can apply to general kernels including RKs and PKs, which is a modification of the existing statement in (Mokkadem and Pelletier, 2003). The characterization of the asymptotic behaviors leads to the AMSE of the mode estimator and the optimal bandwidth, providing the basis for our subsequent discussion on the optimal kernel. We then construct theories for the optimal RK in Section 2.2, and study PKs in Section 2.3. As one of the consequences, the optimal RK is found to improve the AMSE by more than 10 % compared with the commonly used Gaussian kernel, and the improvement is greater in higher dimensions. In view of the slow nonparametric convergence rate of mode estimation, this improvement would significantly contribute to higher sample efficiency. Moreover, on the basis of the consideration in Sections 2.2 and 2.3, in Section 2.4 we compare these two kernel classes in terms of the AMSE, and show that, among non-negative kernels, the optimal RK is better than any PK regardless of the underlying PDF. Section 3 gives some additional discussion. In Section 4 we show results of simulation experiments to examine to what extent the theories on the kernel selection (the results in Section 2) based on the asymptotics reflect the real performance in a finite sample size situation, which supports the usefulness of our discussion.
We show that our discussion can be further adapted to other kernel-based modal statistical methods, such another mode estimation method (Abraham et al., 2004), modal linear regression (Yao and Li, 2014; Kemp et al., 2020), and mode clustering (Comaniciu and Meer, 2002; Casa et al., 2020). For these methods, we can obtain results similar to, but not completely the same as, those for the kernel mode estimation. Section 5 gives method-specific results on kernel selection.
The remaining part of this paper consists of a concluding section and appendix sections: Section 6 summarizes our results and presents possible directions for future work. Appendices give proofs of the theories on the optimal RK and of the theorems for the asymptotic behaviors of the kernel mode estimator and modal linear regression, which are presented newly in this paper.
2 Optimal Kernel for Kernel Mode Estimation
2.1 Basic Asymptotic Behaviors
In general, for a continuous random variable, its mode refers either to a point where its PDF takes a local maximum value, or to a set of such local maximizers. If we followed such definitions of the mode, the design of an estimator corresponding to each mode and theoretical statements regarding such an estimator will become complicated in a multimodal case. So as to evade such a technical complication, we assume, unless stated otherwise, that the PDF has a unique global maximizer (see (A.3) in Appendix A). Let be a -variate continuous random variable, and assume that it has a PDF . Then, we define the mode of as
| (1) |
Suppose that an independent and identically distributed (i.i.d.) sample is drawn from . The kernel mode estimator (KME) is a plugin estimator
| (2) |
where the kernel density estimator (KDE)
| (3) |
is used as a surrogate for the PDF in (1), where is a kernel function defined on , and where is a parameter regarding the scale of the kernel and is called a bandwidth. Here, we assume that the KDE also has a unique global maximizer.
Evaluating the KME amounts to solving the optimization problem (2) where the objective function is in general non-convex, so how one solves it is itself a very important problem. In this paper, however, as we are mainly interested in elucidating properties of the KME, we assume that the KME is evaluated by a certain means, so that how to solve it is beyond the scope of this paper.
In what follows, for a set , we let denote the set of all nonnegative elements in . Thus, , and represents the set of nonnegative real numbers. For later use, we introduce the multi-index notation: For , let . It then follows that and are equivalent, where is the -dimensional zero vector. For a multi-index and a vector , let . The factorial of a multi-index is defined as . Let , where .
For a kernel function on and a multi-index , we let
| (4) |
be the (multivariate) moment of indexed by . Throughout this paper, we assume using a -th order kernel of an even integer . Here, we say that defined on is -th order if it satisfies the following moment condition: For ,
| (5) |
Also, note that the condition (5) for implies normalization of the kernel.
Here we consider the standard situation where the Hessian matrix of the PDF at the mode is non-singular, where . Existing works (Yamato, 1971; Rüschendorf, 1977; Mokkadem and Pelletier, 2003) have revealed basic statistical properties of the KME such as consistency and asymptotic distribution. In the following, we provide a theorem modified from that of, especially, (Mokkadem and Pelletier, 2003): it shows the asymptotic bias (AB), variance-covariance matrix (AVC), and AMSE of , along with asymptotic normality, for a more general kernel class than those covered by existing proofs. This modification is essential for our purpose, since it covers the RKs that will be discussed in the next section, whereas the existing proofs do not.
Theorem 1.
Assume Assumption A.1 in Appendix A with an even integer . Then, the KME asymptotically follows a normal distribution with the following AB and AVC:
| (6) |
where , where with
| (7) |
and where is the matrix defined as with
| (8) |
Moreover, the AMSE is given by
| (9) |
where is the Euclidean norm in and where denotes the trace of a square matrix .
A plausible approach to selecting the bandwidth and kernel is by making the AMSE (9) as small as possible. Noting to hold under our assumptions (see (A.4) and (A.6)), the stationary condition of the AMSE with respect to leads to the optimal bandwidth,
| (10) |
which strictly minimizes the AMSE.111 The optimal bandwidth (10) depends on the inaccessible PDF and its mode , via , , and , and thus it cannot be used in practice as it is. However, it is possible to use a plugin estimator of the bandwidth which replaces these inaccessible quantities with their consistent estimates, and the discussion on the optimal kernel below holds also for the estimated optimal bandwidth. Moreover, substituting the optimal bandwidth into the AMSE, the bandwidth-optimized AMSE becomes
| (11) |
The bandwidth-optimized AMSE (11) depends on the kernel function used in the KDE through and , so that one may consider further optimizing the bandwidth-optimized AMSE with respect to the kernel function. However, it also depends on the sample-generating PDF via , and moreover, the dependence on the kernel and that on the PDF are mixed in a complex way in the AMSE expression (11), so it seems quite difficult to study kernel optimization in the multivariate setting without additional assumptions. Furthermore, a resulting optimal kernel should depend on the PDF. A multivariate kernel without any structural assumptions is also difficult to implement in practice. We would thus introduce some structural assumptions on kernel functions, and consider optimization of the bandwidth-optimized AMSE under such assumptions. Under appropriate structural assumptions on kernel functions the optimal kernel function turns out not to depend on the PDF , as will be shown in the following sections.
2.2 Optimal Kernel in Radial-Basis Kernels
In multivariate kernel-based methods, RKs have been most commonly used. We first consider the kernel optimization among the class of RKs. We say that a kernel is an RK if there is a function on such that is represented as .
For an RK , by means of the cartesian-to-polar coordinate transformation, the functional is rewritten in terms of as
| (12) |
with , where , and where is a kernel-independent factor given by
| (13) | ||||
Note that , and so does , vanishes once any index in the multi-index is odd, which includes the case where is odd, and that is equal to . One then has , where
| (14) |
where so that denotes the Laplacian operator.
Also, the functional for an RK reduces to
| (15) |
with and . This implies that , that is, is proportional to the identity matrix .
Therefore, the bandwidth-optimized AMSE (11) becomes
| (16) | ||||
in which the kernel-dependent factor is alone.222Although implicit in the notations here, and are functionals of . We will use the notation etc. when we want to make the dependence on explicit, but also use such abbreviations otherwise.
As one can see, the bandwidth-optimized AMSE (16) for an RK is decomposed into a product of the kernel-dependent factor, which we call the AMSE criterion, and the remaining PDF-dependent part. This fact implies that an RK minimizing the AMSE criterion also minimizes the AMSE, that is it is optimal, among the class of RKs for every PDF satisfying the requirements of Theorem 1.
For an RK , as stated above, vanishes for with odd , so that one needs to consider the even moment condition alone, which can be translated into the moment condition for as follows:
| (17) |
where is the index set defined as
| (18) |
Thus, if one focuses on the functional form of the AMSE criterion, one might consider the following variational problem (we name it ‘type-1’ because it depends on the first derivative of via ).
However, this problem has no solution, as shown in the next proposition.
Proposition 1.
Problem 1 has no solution.
Proof.
One has by definition. It should never be equal to zero under the moment condition (17). Indeed, if one had , either or should be equal to zero, whereas should be nonzero due to the moment condition (17). cannot be equal to zero either, since otherwise should be equal to zero identically, implying that is a constant, contradicting the condition .
We next show that the infimum of is zero. Take and satisfying (17) with and (for example, and defined later). Consider the linear combination of and with . One then has , so that satisfies (17) unless , in which case one has so that the order of is strictly higher than . On the other hand, substituting into the inequality , multiplying both sides with , and taking the integral over , one has
| (19) |
for any . One therefore has as , proving that the infimum of is equal to zero. ∎
This proposition states that the approach to kernel selection via simply minimizing the AMSE criterion among the entire class of -th order RKs is not a theoretically viable option. One may be able to discourage this approach from a practical standpoint as well. As shown above, one can make the AMSE criterion arbitrarily close to zero by considering a sequence of kernels for which approaches zero. For such a sequence of kernels, however, the optimal bandwidth diverges toward infinity. It then causes the effect of the next leading order term of the AB, which is , to be non-negligible in the MSE when the sample size is finite, thereby invalidating the use of the AMSE criterion to estimate the MSE in a finite sample situation.
The above discussion suggests that, in order to avoid diverging behaviors of the optimal bandwidth and to obtain results meaningful in a finite sample situation, one should consider optimization of the AMSE criterion within a certain kernel class which at least excludes those kernels with vanishing leading-order moments. Since such an approach can give a kernel with the smallest AMSE criterion at least among the considered class, it would be superior to other kernel design methods that are not based on any discussion of the goodness of resulting higher-order kernels in kernel classes of the same order, such as jackknife (Schucany and Sommers, 1977; Wand and Schucany, 1990), as well as those that optimize alternative criteria other than the AMSE criterion, such as the minimum-variance kernels (Eddy, 1980; Müller, 1984). The existing researches (Gasser and Müller, 1979; Gasser et al., 1985; Granovsky and Müller, 1989, 1991) can be interpreted as following this approach, and they have focused on the relationship between the order of the kernel and the number of sign changes. More concretely, on the basis of the observation that any -th order univariate kernel should change its sign at least times on , they considered kernel optimization among the class of -th order kernels with exactly sign changes (which we call the minimum-sign-change condition). They have also shown that the minimum-sign-change condition excludes kernels with small leading-order moments, which cause the difficulties discussed above in the minimization of the AMSE criterion. In addition, and importantly, they succeeded in obtaining a closed-form solution of the resulting kernel optimization problem under the minimum-sign-change condition.
In this paper, we also take the same approach as the one by (Gasser and Müller, 1979; Gasser et al., 1985; Granovsky and Müller, 1989, 1991): under the moment condition (17), one can show that changes its sign at least times on ; see Lemma B.2. Then, we consider the following modified problem to which the minimum-sign-change condition (P2-3) is added.
Here, the conditions (P2-2)–(P2-5) are technically required in the proof. The conditions (P2-2) and (P2-4) for making the problem well-defined and the condition (P2-5) which is close to would be almost non-restrictive. The minimum-sign-change condition (P2-3) for implies that the kernel is non-negative, under the normalization condition in (P2-1). Thus, the minimum-sign-change condition (P2-3) for higher orders can be regarded as a sort of extension of the non-negativity condition.
In the same way as that by (Gasser and Müller, 1979; Gasser et al., 1985), we can show when that this problem is solvable and the solution is provided as follows.
Theorem 2.
For every and , a solution of Problem 2333 Note that a solution of Problem 2 has freedom on its scale, i.e., for any , is also a solution of Problem 2. is
| (20) |
where the coefficients with are given by
| (21) |
The kernel is also represented as
| (22) | ||||
where is the gamma function and where is the Jacobi polynomial (Szegö, 1939) defined by
| (23) |
Alternatively, we can consider the following problem with another minimum-sign-change condition (P3-3) that is defined for the first derivative of a kernel.
The minimum-sign-change condition (P3-3) for implies that the kernel is non-negative and non-increasing, under the normalization condition in (P3-5) and the end-point condition (P3-5). Therefore, the minimum-sign-change condition for the first derivative (P3-3) can be seen as a more restrictive version of the minimum-sign-change condition for the kernel itself (P2-3). Additionally note that the change of (P2-5) to (P3-5) stems from the difference in proof techniques used for Theorems 2 and 3.
We can show that this problem has the same solution even for general even orders , on the basis of the proof techniques in (Granovsky and Müller, 1989, 1991).
This type-1 optimal kernel is a truncation of a polynomial function with terms of degrees and has a compact support (see Figure 1). It should be emphasized that the optimal kernel is a truncated kernel even though we have not assumed truncation a priori, and that the truncation of the optimal kernel is a consequence of the minimum-sign-change condition and the optimality with respect to the AMSE criterion. In particular, the 2nd order optimal kernel (where ), often called a Biweight kernel, is optimal among non-negative RKs (from Theorem 2). The kernel can be represented by the product of the -variate Biweight RK and a polynomial function as
| (24) |
Berlinet (1993) pointed out that in a variety of kernel-based estimation problems the optimal kernels of different orders often form a hierarchy, in the sense that an optimal kernel can be represented as a product of a polynomial and the corresponding lowest-order kernel called the basic kernel: See also Section 3.11 of (Berlinet and Thomas-Agnan, 2004). According to their terminology, for example, the statement of Theorem 2 or 3 can be concisely summarized as follows: Among the class of RKs, the Biweight hierarchy minimizes the AMSE of the kernel mode estimator for any under the minimum-sign-change condition for the kernel or its first derivative.
However, it also should be noted that the kernel optimization problem was formulated without considering several regularity conditions other than the moment condition that ensure the asymptotic normality and are for deriving the AMSE. The kernel is not twice differentiable at the edge of its support. In this respect, does not satisfy all the sufficient conditions in Theorem 1 for deriving the AMSE (see (A.7) and (A.14) in Assumption A.1 in Appendix). On the other hand, one can still add a small enough perturbation to to make it twice differentiable at the edge of its support as well, while keeping other conditions to hold, as well as having the change of the value of the AMSE criterion arbitrarily small. Namely, Problem 2 or 3 and its solutions still tell us the lower bound of achievable AMSE under the minimum-sign-change condition, as well as the shape of kernels which will achieve AMSE close to the bound (it also implies that the problem of minimizing the AMSE under all the conditions for Theorem 1 has no solution). From these considerations, we expect that, despite the lack of theoretical guarantee for the asymptotic normality of KME, this trouble is not so destructive and will provide a practically good performance among the minimum-sign-change kernels; See also simulation experiments in Section 4.
2.3 Optimal Kernel in Product Kernels
In this section we consider optimization of the bandwidth-optimized AMSE with respect to the kernel among the class of PKs, where a kernel is a PK if there exists a function on such that for all . To simplify the discussion, we assume in this paper that as a kernel on is symmetric and -th order, making the resulting PK to be -th order as well. We furthermore assume that satisfies the minimum-sign-change condition (P2-3) or (P3-3).
Under these assumptions, simple calculations lead to
| (25) | ||||
| (26) |
Therefore, the bandwidth-optimized AMSE (11) becomes
| (27) | ||||
where is given by
| (28) |
Equation (27) shows that the bandwidth-optimized AMSE for the PK is also decomposed into a product of the kernel-dependent factor and the PDF-dependent factor. One can therefore take the kernel-dependent factor as the AMSE criterion for the PK.
We have not succeeded in deriving the optimal minimizing this criterion. In the following, we consider instead a lower bound of the AMSE criterion, which will be compared with the optimal value of the criterion for the RK in the next section. The bound we discuss is derived as follows:
| (29) | ||||
where the last inequality holds strictly if since the solutions of the two minimization problems involved will become different. The first minimization problem is a univariate case of Theorem 2 or Theorem 3 (or (Granovsky and Müller, 1991, Corollary 1)): the Biweight hierarchy provides the optimal among the -th order kernels satisfying the minimum-sign-change condition (P3-3). The second minimization problem, which is an instance of the type-0 problems, has been solved by Granovsky and Müller (1989): for even , the kernel
| (30) |
minimizes among -th order kernels that change their sign times on . The type-0 optimal kernel is a truncation of a polynomial function with terms of degrees , and forms the Epanechnikov hierarchy, with the Epanechnikov kernel as the basic kernel. We have therefore obtained a lower bound
| (31) |
of the AMSE criterion for the PK model.
2.4 Comparison between Radial-Basis Kernels and Product Kernels
We have so far studied the RKs and the PKs separately. One may then ask which of these classes of kernels will perform better. In this section we discuss this question.
Our approach to answering this question is basically grounded on a comparison between the AMSE of the optimal RK and that of the optimal PK. There are, however, difficulties in this approach: One is that the optimal PK, as well as its AMSE, is not known, which prevents us from comparing the RKs and the PKs directly in terms of the AMSE. Another is that the PDF-dependent factor of the AMSE takes different forms between the RKs and the PKs. Most evidently, in (14) and (28), the quantities which contribute to the AB of for the RKs and the PKs, respectively, cross derivatives of the PDF are present in the former whereas they are absent in the latter. Such differences in the PDF-dependent factors hinder direct comparison between the RKs and the PKs in terms of the AMSE in the general setting, in a PDF-independent manner.
The only exception is the case , where the PDF-dependent factor takes the same form for the RKs and the PKs, and consequently one can compare the AMSEs for RKs and PKs, regardless of the PDF. In the case of , simple calculations show and . Therefore, the ratio of the lower bound of the AMSE for PK that derives from (31) to the AMSE for the optimal RK becomes
| (32) |
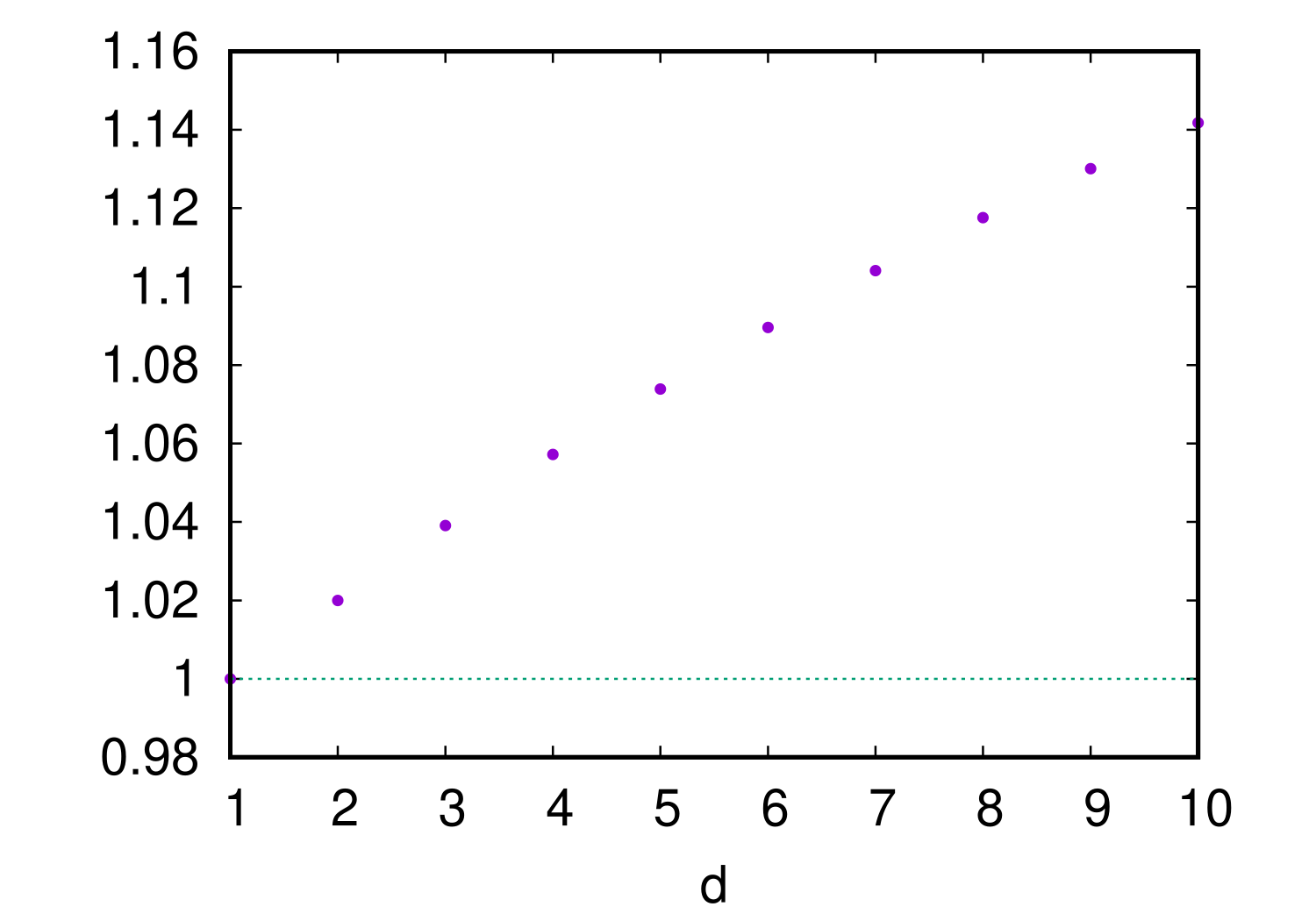
Figure 2 shows how the ratio depends on the dimension . One observes that it increases monotonically with . Since the ratio is larger than 1 for (note that there is no distinction between the RKs and the PKs when ), one can conclude that the optimal second-order non-negative RK achieves the AMSE that is smaller than those with any second-order non-negative PK.
It should be emphasized that the above superiority result of the optimal RK over the PKs is limited to the second-order () case. As mentioned above, for one cannot compare the RKs and the PKs in terms of the AMSE in a PDF-independent manner. Consequently, depending on the PDF, there might be some PKs with better AMSE values than the optimal RK for , some examples of which will be shown in the simulation experiments in Section 4.
2.5 Optimal Kernel in Elliptic Kernels
Kernel methods in the multivariate setting may use a kernel function together with a linear transformation, in order to calibrate the difference in scales and shearing across the coordinates. In this section we assume for simplicity that an RK is to be combined with a linear transformation. For a matrix representing an area-preserving linear transformation in (hence ) and an RK (the base kernel), the transformed kernel is often called an elliptic kernel. In this section, we discuss the optimal base kernel and optimal transformation for kernel mode estimation based on an elliptic kernel.
Using the elliptic kernel is equivalent to using the kernel with the transformed sample drawn from , which is defined by , for estimation of the mode of . Multiplying the resulting mode estimate by from left yields the KME with of , an estimate of the mode . This view, together with the calculations
| (33) |
where , reveals that the AB and AVC of the KME using reduce to
| (34) | ||||
| (35) |
and that their kernel-dependent factors remain and of . Therefore, as long as (or equivalently ) is fixed such that the AB of the KME is non-zero, an argument similar to the ones in Section 2 leads to the optimal bandwidth and the same AMSE criterion with respect to . Thus, the kernel is optimal as a base kernel even under such a transformation .
One may furthermore consider optimizing (equivalently ) via
| (36) |
which comes from the linear-transformation-dependent factor of the bandwidth-optimized AMSE. We have so far not succeeded in obtaining a closed-form solution of the optimization problem (36), although a numerical optimization might be possible with plug-in estimates of and .
It would be worth mentioning that in some cases one can make the AB equal to zero by a certain choice of , whereas in some other cases one cannot make the AB equal to zero by any choice of . Furthermore, whether one can make the AB equal to zero via the choice of depends on the (-st order term of the Taylor expansion of around the mode , and the dependence seems to be quite complicated. Consequently, optimization of the linear transformation in terms of the AMSE is difficult to tackle in a manner similar to that adopted in the previous sections, because the assumption that the AB does not vanish does not necessarily hold. Although we have not succeeded in providing a complete specification as to when one can make the AB equal to zero via the choice of , we describe in the following some cases where the AB can be made equal to zero by a certain choice of and some other cases where the AB cannot be equal to zero by any choice of .
The following two propositions provide cases where the AB can be made zero by an appropriate choice of .
Proposition 2.
Assume . Assume the -st order term of the Taylor expansion of around the mode be of the form
| (37) |
with linearly independent. Then there is a choice of with which the AB (34) is made equal to zero.
We show that there exists a positive definite which satisfies
| (38) |
The left-hand side is calculated as
| (39) |
where the summation on the right-hand side is to be taken with respect to all the permutations of . Due to the assumption of the linear independence of , there exists the duals of satisfying . Take as a basis of the orthogonal complement of . Then forms a basis of . Let
| (40) |
with the zero matrix , where the notation means that is positive definite. One then has for . It implies that all the coefficients of on the right-hand side of (39) vanish, proving (38) to hold with the above .
Proposition 3.
Assume . Assume the -st order term of the Taylor expansion of around the mode be of the form
| (41) |
where spans a -dimensional subspace of . Assume further that holds with coefficients satisfying . Then there is a choice of with which the AB (34) is made equal to zero.
One can find a subset of of size , which consists of linearly independent vectors. Without loss of generality we assume that are linearly independent. Choosing
| (42) |
with , the duals of in the subspace spanned by , and with , a basis of the orthogonal complement of , one has
| (46) |
One can thus show that the following holds:
| (47) |
The following propositions provide cases where the AB cannot be equal to zero by any choice of .
Proposition 4.
Assume . Assume the -st order term of the Taylor expansion of around the mode be of the form
| (48) |
where , are positive definite. Then the AB (34) cannot be equal to zero by any choice of .
In the case of one can prove the following proposition.
Proposition 5.
If, around its mode , admits the expression
| (49) |
where is nonzero, and where
| (50) |
is a positive definite quadratic form, then there is no which makes the AB to vanish.
We show that in this case no choice of which is positive definite will make the quantity vanishing. Indeed, one can write
| (51) |
One observes that has positive eigenvalues only, since and are both positive definite. We thus have , which in turn implies that the matrix is invertible. Hence the quantity in (51) is nonvanishing with an arbitrary choice of .
Proposition 4 can be proven similarly. The term in this case is represented as , where the matrix is a sum of terms of the form with coefficients which are products of , and is hence positive definite. The term is therefore nonzero irrespective of the choice of .
We close this section by showing a complete specification as to when the AB can be made equal to zero via the choice of in the most basic case .
Proposition 6.
Assume . The third-order term of the Taylor expansion of around the mode is either:
-
•
0 identically, in which case the AB is equal to zero with an arbitrary ,
-
•
of the form with , any two of which are linearly independent, in which case there is a choice of with which the AB is equal to zero,
-
•
other than any of the above, in which case the AB cannot be made equal to zero by any choice of .
A proof is given in Appendix D.
3 Additional Discussion
3.1 Degree of Goodness of Optimal Kernel and Heuristic Findings
| Kernel | ||||
|---|---|---|---|---|
| 2 | Biweight | 0.1083 [1.0000] | ||
| Triweight | 0.1095 [1.0105] | |||
| Tricube | 0.1121 [1.0345] | |||
| Cosine | 0.1135 [1.0475] | |||
| Epanechnikov | 0.1 | 0.75 | 0.1179 [1.0883] | |
| Triangle | 1 | 0.1188 [1.0971] | ||
| Gaussian | 0.5 | 0.1213 [1.1198] | ||
| Logistic | 0.1476 [1.3629] | |||
| Sech | 0.5 | 0.1727 [1.5949] | ||
| Laplace | 1 | 0.125 | 0.3048 [2.8133] | |
| 4 | 0.3729 [1.0000] | |||
| 0.4005 [1.0737] | ||||
| -1.5 | 0.4451 [1.1935] | |||
| -21.6 | 1.6314 [4.3743] | |||
| 6 | 1.0149 [1.0000] | |||
| 1.0760 [1.0600] | ||||
| 7.5 | 1.2639 [1.2453] | |||
| 5.7451 [5.6609] |
We are interested in not only specifying the optimal kernel, but also in how the kernel selection will affect the AMSE. To quantify the degree of suboptimality of kernels, we define, for a -variate -th order kernel , the AMSE ratio as the ratio of the bandwidth-optimized AMSE (11) for to that for the optimal RK . The AMSE ratio depends only on if the bandwidth-optimized AMSEs for and share the same PDF-dependent factor, which is the case for RKs (including univariate ones) and PKs with (see Section 2.4). Table 1 shows the comparison of the AMSE criteria and the AMSE ratios in the univariate case. An empirical observation is that truncated kernels, such as a Triweight and an Epanechnikov in addition to the optimal Biweight kernel, are better than non-truncated kernels including a Sech, a Laplace, and . This tendency still holds even for multivariate RKs and PKs. Figure 3 shows the AMSE ratios for several multivariate RKs.
| \begin{overpic}[height=142.26378pt,bb=0 0 360 252]{./amseratios1.png}\put(18.0,60.0){\small(a)}\end{overpic} | \begin{overpic}[height=142.26378pt,bb=0 0 360 252]{./amseratios2.png}\put(18.0,60.0){\small(b)}\end{overpic} |
For example, the AMSE ratio for the most frequently used Gaussian kernel , approximately equals to 1.1198, 1.1547, 1.1864, 1.2151, 1.2413, 1.2652, 1.2870, 1.3071, 1.3256, 1.3428 for , and monotonically approaches as goes to infinity.
3.2 Other Criteria
We here mention that the optimality of the kernel is not limited to the scenario in which the AMSE is used as the criterion. In this section, the univariate case is assumed for simplicity, but its multivariate extension is straightforward.
Grund and Hall (1995) have studied the asymptotic error (AE) for and the optimal bandwidth minimizing it. Although they have clarified only the -dependence of the optimal bandwidth, we can go one step further beyond their discussion and clarify the kernel-dependence: the optimal bandwidth is represented as , where it is difficult to derive a closed-form expression for , but it is a PDF-dependent and kernel-independent coefficient. If this optimal bandwidth is used, then the AE reduces to
| (52) |
where denotes the random variable following the standard normal distribution, and where the expectation is taken with respect to . Since the kernel-dependent factor of the AE is , which is the same as that for the AMSE, the kernel also minimizes the AE among minimum-sign-change kernels, even when .
Also, from (Mokkadem and Pelletier, 2003), it can be found that the KME satisfies the law of the iterated logarithm. In the scaling , it holds that
| (53) |
in other words, becomes relatively compact, and its limit set, in which the rescaled AB is included almost surely, is given by
| (54) |
Then, the combination of the bandwidth (10) minimizing the AMSE and the kernel uniformly minimizes the size of the limit set of , which is proportional to .
3.3 Singular Hessian
Although it has been so far assumed that the Hessian matrix is non-singular at the mode (see (A.4) in Assumption A.1), this section provides a consideration on the optimal kernel when the Hessian matrix is singular. Since the multivariate singular case is so intricate that even its convergence rate remains an open problem, we suppose and hence at the mode .
Vieu (1996); Mokkadem and Pelletier (2003) have studied the singular case, where the PDF satisfies , and for instead of . The non-singular case studied in Section 2 corresponds to . Note that the integer should be an odd number for to take a maximum at .
A weak convergence of the KME holds even in the singular case, in a somewhat different manner, where the requirements on the moments of the kernel are weakened to
| (55) |
In other words, the conditions , , required in the moment condition (5) in the non-singular case, are no longer needed in the singular case. Together with several additional conditions (see (Mokkadem and Pelletier, 2003) for the details), asymptotically follows a normal distribution with
| (56) |
where , . Moreover, the bias-variance decomposition leads straightforwardly to the asymptotic error (AE), instead of the AMSE, of the KME :
| (57) |
which has the same functional form regarding the bandwidth and kernel-dependent terms , as those of the AMSE (9) for the univariate non-singular case. The optimal bandwidth minimizing the AE can be calculated in the same way as that for the conventional one (10). Also, the AE criterion reduces to .
| Kernel | |||||
|---|---|---|---|---|---|
| Biweight | 0.1369 [1.0000] | 0.1729 [1.0098] | |||
| Triweight | 0.1426 [1.0418] | 0.1851 [1.0815] | |||
| Tricube | 0.1381 [1.0089] | ||||
| Cosine | 0.1404 [1.0257] | 0.1728 [1.0095] | |||
| Epanechnikov | 0.75 | 0.1455 [1.0631] | 0.1781 [1.0405] | ||
| Triangle | 1 | 0.1564 [1.1427] | 0.1999 [1.1674] | ||
| Gaussian | 1.5 | 7.5 | 0.1813 [1.3246] | 0.2683 [1.5675] | |
| Logistic | 0.2797 [2.0435] | 0.5223 [3.0507] | |||
| Sech | 2.5 | 30.5 | 0.3757 [2.7443] | 0.7714 [4.4614] | |
| Laplace | 12 | 360 | 0.125 | 0.8548 [6.2441] | 1.9955 [11.6563] |
| 0.3729 [2.7244] | 0.7033 [4.1083] | ||||
| 0 | – | 1.0145 [5.9282] |
The essential difference of the discussion on the optimal kernel under the singular case from that under the non-singular case arises from the difference between the required moment conditions (55) and (5): As mentioned above, a kernel function is not required to satisfy the -th moment condition for in the singular case. For example, when and , any symmetric 2nd order kernel does not satisfy (5), but does satisfy the singular version (55) of the moment conditions. The kernel , of course, minimizes the AE criterion among the conventional -th order kernels satisfying the minimum-sign-change condition, regardless of . However, there is a possibility to improve the AE criterion by using a lower order kernel satisfying (55).
We investigated two simple cases by calculating the AE criterion for several kernels, and report the results in Table 2, where the AE criterion is given by and for and , respectively. In the case , where any symmetric 2nd order kernel, as well as any 4th order kernel, fulfills the conditions (55), one can observe that a Biweight kernel is better than . In the case , where at least three types of kernels, symmetric 2nd and 4th order kernels and 6th order kernels, satisfy the conditions (55), Table 2 shows that a Tricube kernel gives the minimal value of the AE criterion among the kernels we investigated. Thus, we have confirmed that the kernel which is optimal under the non-singular case may not be optimal under the singular case, where a lower order kernel may improve the asymptotic estimation accuracy. Although we have not succeeded in deriving an optimal kernel in the singular case, an empirical finding that truncated kernels perform well would be useful.
4 Simulation Experiment
The analysis in the previous sections on the optimal kernel is based on the asymptotic normality and the evaluation of the AMSE, derived from the asymptotic expansion of the KME. While the leading-order term of the bandwidth-optimized AMSE (11) is , the next-leading-order term is if one uses symmetric kernels such as RKs and PKs. Although the bandwidth-optimized AMSE ignores all but the leading-order term, those ignored terms may affect behaviors of the KME and thus its MSE when the sample size is finite. In this section, via simulation studies, we examine how well the kernel selection based on the AMSE criterion reflects the real performance of the KME and verify practical goodness of the optimal RK in a finite sample situation.
We tried the three cases regarding the dimension, , and used synthetic i.i.d. sample sets of size , 102400, drawn from the distribution , where denotes the normal distribution with mean and variance-covariance matrix , and where is the all-1 -vector and is the identity matrix. The modes of the sample-generating distribution are located at for , respectively. Because a symmetric distribution such as the normal distribution does not satisfy assumption (A.6), skewed distributions were used in the experiments. As 2nd order kernels, we examined the optimal Biweight , Epanechnikov , Gaussian , and Laplace kernels, as well as PKs of , , and if . For the higher orders and , in addition to the optimal kernels , three RKs , , and designed via jackknife (Schucany and Sommers, 1977; Wand and Schucany, 1990), an alternative method for designing a higher-order kernel, on the basis of , , and (see Section C), and four PKs with , , , and were also examined. Note that the RKs , , and and PKs of , and are not twice differentiable at some points and thus do not exactly satisfy all the conditions of Theorem 1 on the asymptotic behaviors of the KME. For each kernel, we used the optimal bandwidth (10) calculated from the sample-generating PDF and its mode444It should be noted that this procedure makes access to the sample-generating PDF, which is unavailable in practice. See Footnote 1. The purpose of our simulation experiments here is not to evaluate performance in practical settings but rather to see how the MSE of the KME with the bandwidth optimized with respect to the AMSE behaves in the finite- situation, so that we used the bandwidth values exactly optimized with respect to the AMSE.. In these settings, the smallest AMSE among those of the kernels examined is given by the RK for or and PK with for and . On the basis of 1000 trials, we calculated the MSE and its standard deviation (SD), and the results are reported in Table 3, along with the MSE ratio, defined as the ratio of the MSE of each kernel to that for the kernel with the same and when . Table 3 also shows the results of the Welch test with -value cutoff 0.05, with the null hypothesis that the MSE of interest be equal to the best MSE for the same .
| Kernel | AMSE ratio | MSE ratio | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | [1.0000] | [1.0000] | |||||||
| [1.0883] | [1.0805] | |||||||||
| [1.1198] | [1.1307] | |||||||||
| [2.8133] | [2.5243] | |||||||||
| 4 | [1.0000] | [1.0000] | ||||||||
| [1.0737] | [1.0334] | |||||||||
| [1.1935] | [1.2712] | |||||||||
| [4.3743] | [4.5026] | |||||||||
| 6 | [1.0000] | [1.0000] | ||||||||
| [1.0602] | [0.9882] | |||||||||
| [1.2453] | [1.3804] | |||||||||
| [5.6609] | [6.6836] | |||||||||
| 2 | 2 | RK | [1.0000] | [1.0000] | ||||||
| RK | [1.0887] | [1.0930] | ||||||||
| RK | [1.1547] | [1.1557] | ||||||||
| RK | [2.4495] | [2.4801] | ||||||||
| PK of | [1.0231] | [1.0265] | ||||||||
| PK of | [1.0984] | [1.0945] | ||||||||
| PK of | [2.8944] | [2.7722] | ||||||||
| 4 | RK | [1.0000] | [1.0000] | |||||||
| RK | [1.0817] | [1.0218] | ||||||||
| RK | [1.2552] | [1.2955] | ||||||||
| RK | [3.9734] | [4.3494] | ||||||||
| PK of | [0.9948] | [1.0191] | ||||||||
| PK of | [1.0579] | [1.0409] | ||||||||
| PK of | [1.2215] | [1.2666] | ||||||||
| PK of | [4.9457] | [5.0237] | ||||||||
| 6 | RK | [1.0000] | [1.0000] | |||||||
| RK | [1.0700] | [0.9913] | ||||||||
| RK | [1.3282] | [1.4056] | ||||||||
| RK | [5.4536] | [6.3369] | ||||||||
| PK of | [1.0419] | [1.0463] | ||||||||
| PK of | [1.0966] | [1.0226] | ||||||||
| PK of | [1.3577] | [1.4379] | ||||||||
| PK of | [7.3943] | [7.7113] | ||||||||
| 3 | 2 | RK | [1.0000] | [1.0000] | ||||||
| RK | [1.0864] | [1.0879] | ||||||||
| RK | [1.1864] | [1.2013] | ||||||||
| RK | [2.3660] | [2.6195] | ||||||||
| PK of | [1.0448] | [1.0531] | ||||||||
| PK of | [1.1098] | [1.1095] | ||||||||
| PK of | [2.9686] | [2.9563] | ||||||||
| 4 | RK | [1.0000] | [1.0000] | |||||||
| RK | [1.0861] | [0.9960] | ||||||||
| RK | [1.3143] | [1.4119] | ||||||||
| RK | [3.9987] | [4.7381] | ||||||||
| PK of | [0.9765] | [0.9896] | ||||||||
| PK of | [1.0301] | [0.9774] | ||||||||
| PK of | [1.2284] | [1.3195] | ||||||||
| PK of | [5.4110] | [5.4249] | ||||||||
| 6 | RK | [1.0000] | [1.0000] | |||||||
| RK | [1.0769] | [0.9527] | ||||||||
| RK | [1.4103] | [1.6260] | ||||||||
| RK | [5.7653] | [7.2246] | ||||||||
| PK of | [1.0606] | [1.0471] | ||||||||
| PK of | [1.1092] | [1.0206] | ||||||||
| PK of | [1.4384] | [1.6303] | ||||||||
| PK of | [9.1885] | [8.8902] |
For , the MSE ratios were approximately close to the AMSE ratios, which suggests that the AMSE criterion serves as a good indicator of real performance. Also, the optimal Biweight kernel achieved the best estimation result for every and as expected from the asymptotic theories. Although differences between MSEs for the Biweight kernel and those for other truncated kernels (RK and PKs of and ) were not significant especially for smaller , differences between them and those for non-truncated kernels (RKs and and PK of ) were statistically significant with -value 0.05 for most combinations of and .
For the higher orders , truncated kernels performed well, whereas non-truncated ones gave significantly larger MSEs. This tendency is the same as in the case . However, the experimental results for the higher-order kernels exhibited deviations from the asymptotic theories: except for the case of , even with the largest sample size investigated, the smallest MSE values were achieved by kernels other than that with the minimum AMSE ( for when , and PK of for and RK for when ). Such deviations would be ascribed to the fact that asymptotics ignores residual terms of the AMSE as described at the beginning of this section. The ratio between the leading-order and next-leading-order terms of the AMSE for the considered RKs and PKs is , which gets larger as and/or increase. Therefore, for the residual terms to be negligible, one needs more sample points for larger and/or . In the cases of , even might not have been large enough to accurately reflect the small difference less that about 10 % in the AMSE into the difference of MSE, for the PDFs used. However, considering that those kernels which performed inferior to the best-performing ones still performed close to the theoretical optimum with a difference less than 10 % in the AMSE criterion and that their experimental difference was not significant, it can be found that even though the AMSE criterion may not be a quantitative performance index for higher-order kernels, it is still suggestive for real performance.
5 Optimal Kernel for Other Methods
5.1 In-Sample Mode Estimation
A mode estimator considered in (Abraham et al., 2004), which we call the in-sample mode estimator (ISME), is defined as the location of a sample point where a value of the KDE (3) becomes maximum among those at sample points:
| (58) |
The ISME can be evaluated efficiently with the quick-shift (QS) algorithm (Vedaldi and Soatto, 2008). Although the QS algorithm has an extra tuning parameter in addition to and , which may affect the quality of the estimator, it has an advantage that it converges in a finite number of iterations irrespective of the kernel used as far as the sample size is finite, making it computationally efficient.
Abraham et al. (2004) have proved in their Corollary 1.1 that, in the large-sample asymptotics, the ISME converges in distribution to an asymptotic distribution of the KME if the bandwidth satisfies as . A simple calculation shows that, if we use the optimal bandwidth in (10), the requirement for the bandwidth is fulfilled for satisfying , that is, for any when ; when ; and when . Accordingly, at least for these cases, the ISME has the same AMSE and the same AMSE criterion as the KME, so that the results on the optimal kernel still hold for the ISME as well: especially, minimizes the AMSE criterion of the ISME among the minimum-sign-change RKs, for the above-mentioned combinations of and .
5.2 Modal Linear Regression
Modal linear regression (MLR) (Yao and Li, 2014) aims to obtain a conditional mode predictor as a linear model. In addition to intrinsic good properties rooted in a conditional mode, the MLR has an advantage that resulting parameter and regression line are consistent even for a heteroscedastic or asymmetric conditional PDF, compared with robust M-type estimators which are not consistent in these cases (Baldauf and Santos Silva, 2012).
Let be a pair of random variables in following a certain joint distribution. MLR assumes that the conditional distribution of conditioned on is such that the conditional PDF satisfies for any , where is an underlying MLR parameter. For given i.i.d. samples of , the MLR adopts, as the estimator of the parameter , the global maximizer of the kernel-based objective function with argument ,
| (59) |
with the kernel defined on and the bandwidth .
In (Kemp et al., 2020, Theorem 3), the asymptotic normality of the MLR has been proved. They have considered the case where a 2nd order kernel is used and the AVC is relatively dominant compared with the AB by assuming . We provide an extension of their theorem which allows the use of a higher-order kernel and provides an explicit expression of the AB. Note that the vectorization operator is defined as the -vector for an matrix , and that we adopt the definition that the operator applied to a function with a matrix argument is the nabla operator with respect to the vectorization of the argument. The same definition applies to the Hessian operator as well.
Theorem 4.
Assume Assumption E.1 for an even integer . Then, the vectorization of the MLR parameter estimator asymptotically follows a normal distribution with the following AB and AVC:
| (60) |
where the abbreviations , , and are defined by
| (61) | ||||
In the above, is defined as
| (62) |
and is the matrix defined via (8). Moreover, the AMSE is obtained as
| (63) |
By following the same line as the argument in Section 2, for instance, one can optimize the bandwidth in terms of the AMSE, and furthermore show that the AMSE criterion becomes if an RK is used, which implies that the kernel is optimal. These results are generalization of (Yamasaki and Tanaka, 2019) for and .
5.3 Mode Clustering
In mode clustering, a cluster is defined via the gradient flow of the PDF regarded as a scalar field. A limiting point of the gradient flow defines a center of the cluster corresponding to its domain of attraction. For the mean-shift-based mode clustering (Comaniciu and Meer, 2002; Yamasaki and Tanaka, 2020), the KDE is often plugged into . Although clustering error for mode clustering using the KDE is difficult to evaluate in general dimensions, Casa et al. (2020) have analyzed clustering error rate in the univariate case in detail.
Here we review their discussion in a fairly simplified setting: we consider the univariate case and assume that the PDF and KDE are bimodal, as depicted in Figure 4. In this setting, the true clusters and estimated clusters are
| (64) | ||||
with the local minimizers and of the PDF and KDE, respectively, and the clustering error rate (CER) becomes
| (65) |
In Figure 4, the red area represents the CER. The green area is , and the blue area is approximated as , which is negligible in the asymptotic situation. Therefore, the relationship ‘green area¡red area (CER) green blue areas’ implies that the CER asymptotically equals to the green area, : the asymptotic mean CER (AMCER) reduces to
| (66) |
On the basis of the fact that the form of the asymptotic distribution of the local minimizer is the same as that of the mode, the AMCER behaves like the AE for the mode, discussed in Section 3.2.
Casa et al. (2020) have shown -dependence of the optimal bandwidth minimizing the AMCER. We further show the kernel dependence of the optimal bandwidth and the optimal kernel: Since the AMCER behaves like the AE for the mode, the optimal bandwidth minimizing the AMCER becomes , , and the resulting kernel optimization problem becomes equivalent to the type-1 kernel optimization problem for the KME with the AE criterion as the objective function. Thus, the kernel minimizes the AMCER for the optimal bandwidth among the -th order minimum-sign-change kernels.
6 Conclusion
In this paper, we have studied the kernel selection, particularly optimal kernel, for the kernel mode estimation, by extending the existing approach for the univariate setting by (Gasser and Müller, 1979; Gasser et al., 1985; Granovsky and Müller, 1989, 1991). This approach is based on asymptotics, and it seeks a kernel function that minimizes the main term of the AMSE for the optimal bandwidth among kernels (or their derivatives) that change their sign the minimum number of times required by their order. Theorems 2 and 3 are the main novel theoretical contribution, which shows that the Biweight hierarchy provides the optimal RK for every dimension and even order and , respectively. We have also studied the PK model, and compared it with the RK model. As a result, we have found that the 2nd order optimal RK is superior in terms of the AMSE to the PK model using any non-negative kernel. Simulation studies confirmed the superiority of the optimal Biweight kernel among the non-negative kernels, as well as truncated kernels including the optimal kernel , which gave better accuracy even in higher orders .
The theories on the optimal kernel are also effective for other kernel-based modal statistical methods. In Section 5, we show the optimal kernel for in-sample mode estimation, modal linear regression, and univariate mode clustering. Although elucidation of the optimal kernel for other methods that might be relevant such as principal curve estimation or density ridge estimation (Ozertem and Erdogmus, 2011; Sando and Hino, 2020) and multivariate mode clustering, in which it is difficult to represent asymptotic errors explicitly, is an open problem, studying them analytically or experimentally will also be interesting.
A Proof of Asymptotic Behaviors of Kernel Mode Estimation
Regularity conditions for Theorem 1, i.e., sufficient conditions for deriving the expressions (6), (9) of the AB, AVC, and AMSE along with the asymptotic normality of the KME, are listed below. They consist of the conditions on the sample (A.1), mode and PDF (A.2)–(A.6), kernel (A.6)–(A.14), and bandwidth (A.15) and (A.16).
Assumption A.1 (Regularity conditions for Theorem 1).
For finite and even ,
-
(A.1)
is a sample of i.i.d. observations from .
-
(A.2)
is times differentiable in (i.e., and , are continuous at ).
-
(A.3)
has a unique and isolated maximizer at (i.e., for all , due to (A.2), and for a neighborhood of ).
-
(A.4)
, satisfies , and is non-singular.
-
(A.5)
for all s.t. , and is bounded for all s.t. .
-
(A.6)
, and satisfy .
-
(A.7)
is bounded and twice differentiable in and satisfies the covering number condition, , and .
-
(A.8)
.
-
(A.9)
for all s.t. .
-
(A.10)
for all s.t. , and for some s.t. .
-
(A.11)
for all s.t. .
-
(A.12)
is bounded and satisfies , , and for some , for all .
-
(A.13)
has a finite determinant.
-
(A.14)
, satisfies the covering number condition.
-
(A.15)
(i.e., ).
-
(A.16)
.
Definition A.1 ((Pollard, 1984, Definition 23) and (Mokkadem and Pelletier, 2003, Section 2)).
-
•
Let be a probability measure on and be a class of functions in . For each , define the covering number as the smallest value of for which there exist functions such that for each . We set if no such exists.
-
•
Let be a function defined on . Let be the class of functions consisting of arbitrarily translated and scaled versions of . We say that satisfies the covering number condition if is bounded and integrable on , and if there exist and such that for any probability measure on and any .
For example, the RK and the PK fulfill the covering number condition in (A.7) if has bounded variations in both cases.
We give a proof of the asymptotic normality of the KME , which is a modification of the proof of (Mokkadem and Pelletier, 2003, Theorem 2.2), below.
Proof of Theorem 1.
Pollard (1984) gives the following lemma on uniform consistency (see his Theorem 37 in p. 34):
Lemma A.1.
Let be a function on satisfying the covering number condition, and be a sequence of positive numbers satisfying . If there exists such that , then
| (A.17) |
where is the expectation value with respect to the distribution of the random vector , and where is a sample of i.i.d. observations of .
Also, one has the following lemma (see (Bochner, 2005, Theorem 1.1.1)):
Lemma A.2.
Let be a function on satisfying , , and , be a function on satisfying , and be a sequence of positive numbers satisfying . Then one has that, for any of continuity of ,
| (A.18) |
Applying Lemma A.1 with and , under (A.1), the covering number condition of (A.7), (A.15), and (A.16), ensures that
| (A.19) |
Also, Lemma A.2 with and under the fact , the continuity of (A.2), (A.7), (A.8), and (A.15) implies that
| (A.20) |
According to these results, one has a.s., which implies the consistency of to from contradiction to the -definition of limit: for any , there exists a such that if .
Because maximizes (i.e., ) and and hence are twice differentiable (A.7), Taylor’s approximation of at around shows
| (A.21) |
that is, if is invertible, where satisfies . We thus study the asymptotic behaviors of and below.
Applying Lemma A.1 with , and under (A.1), the covering number condition of (A.14), (A.15), and (A.16), and the consistency of to shows that converges to . Moreover, integration-by-parts and Lemma A.2 with and , under the continuity of (A.2), (A.4), (A.7), (A.8), and (A.15), leads that, for every satisfying ,
| (A.22) | ||||
that is, . Combining these results, one can find that is consistent to the matrix .
We next show that asymptotically follows the normal distribution with the mean and the variance-covariance matrix , on the basis of Lyapounov’s central limit theorem. The critical difference from the existing proof by (Mokkadem and Pelletier, 2003) is on the assumptions (A.6) and (A.10), which affects on the calculation of the mean of . On the basis of the multivariate Taylor expansion of around under the setting that is even,
| (A.23) |
where lies in -neighborhood of and depends on , one has that
| (A.24) | ||||
Because (A.3), integrations of -th summands vanish due to finiteness of , (A.5) and (A.9), and integration of the -nd residual term is asymptotically ignorable due to boundedness of , (A.5), (A.11), and (A.15), one can approximate the asymptotic mean of as
| (A.25) |
under the assumptions (A.6) and (A.10). Moreover, by using Lemma A.2 with and under the continuity of (A.2), (A.12), and (A.15), one can calculate the variance-covariance matrix of with the definition (A.13):
| (A.26) | ||||
Finally, by applying Slutsky’s theorem to these pieces, the proof on asymptotic normality of is finished. ∎
The condition (A.6) is added to those in (Mokkadem and Pelletier, 2003), to ensure that the main term of AB does not vanish. Also, the condition (A.10) is a modification of condition (A5) iii) in (Mokkadem and Pelletier, 2003), the latter of which does not apply to RKs unlike their description. However, it should be noted that the kernel does not satisfy the twice differentiability among the sufficient conditions on the kernel. Eddy (1980) has studied behaviors of the KME within -neighborhood of the mode and tried the proof without assuming that the kernel is twice differentiable (such that the kernel fulfills their requirements), but their proof is not rigorous in that it does not consider the possibility that the KME exists outside of that neighborhood. We have considered several methods, including the proof in (Eddy, 1980), and then concluded that twice differentiability of appears to be necessary for deriving the AMSE.
B Theories on Optimal Kernel
B.1 Relationships between the Moment Condition and the Number of Sign Changes
In this section we describe relationships between the moment condition and the number of sign changes of a kernel. We first introduce several notations. To represent a kernel class defined from the moment condition, we introduce, for integers , , and satisfying ,
| (B.1) |
where denotes the Pochhammer symbol. Also, we represent a class of functions on with the prescribed number of sign changes as
| (B.2) |
Here, the number of the sign changes is defined as follows:
Definition B.1.
A function defined on a finite or infinite interval is said to change its sign times on , if there are subintervals , , where , such that:
-
(i)
(or ) for all , and there exists such that (or ), for each .
-
(ii)
If , for all , , .
Note that a function could have an interval over which it equals to zero and that a point where its sign changes does not have to be uniquely determined. Additionally, we introduce the following term:
Definition B.2.
Functions and defined on a finite or infinite interval are said to share the same sign-change pattern if the same set of subintervals in Definition B.1 applies to both and .
In the following, we provide a lemma (Lemma B.2) about the minimum number of sign changes of a -th order RK. It is a multivariate extension of (Gasser et al., 1985, Lemma 2) stating that a univariate -th order kernel changes its sign at least times on , and becomes a basis for the condition (P2-3) in Problem 2 and condition (P3-3) in Problem 3. The following Lemma B.1 is for Lemmas B.2 and B.12.
Lemma B.1.
Let be measurable subsets of with , where is the Lebesgue measure on , and assume that they are ordered in the sense that for any and any with the inequality holds almost surely. Let be a measurable function which does not change its sign inside each , . Assume further that holds. Then the following matrix is non-singular:
| (B.7) |
Proof.
Assume to the contrary that is singular. Then there exists a non-zero vector which satisfies . Rewriting it component-wise, one has
| (B.8) |
where we let
| (B.9) |
Take an interval with and . Then is integrable, does not change its sign on , and . From (B.8) and the mean value theorem, there exists satisfying . Since is an even function of , one has . The zeros are all distinct. Thus is factorized as
| (B.10) |
where is a polynomial not identically equal to 0. The degree of the right-hand side is therefore at least , whereas from (B.9) the degree of is at most , leading to contradiction. ∎
Lemma B.2.
For and even , if a function defined on is such that or , then changes its sign at least times on .
Proof.
Assume that changes its sign times on , and decompose into subintervals according to the way in Definition B.1: the sign of changes alternately in these subintervals.
Proof for . Lemma B.1 shows that the matrix
| (B.11) |
is non-singular. Assume as opposed to the statement of this lemma. Then, from the moment conditions , one would have
| (B.12) |
This contradicts the non-singularity of . Thus, holds, i.e., changes its sign at least times on .
Proof for . For the matrix
| (B.13) |
one can take a similar proof as the case for . ∎
Also, in the case of , we can know the order in which the kernel changes its sign:
Lemma B.3.
Let and or , and assume that a function is defined on and such that . Then, for and for , where the subintervals of are defined according to Definition B.1. Moreover, .
Proof.
Proof for . A 2nd order kernel satisfying the normalization condition and the minimum-sign-change condition is non-negative, and the statements for any and are trivial.
Proof for . The sign change of minimum-sign-change 4-th order kernel occurs at a single point, which is denoted as . If one assumes that for , then one has the following contradiction: On the basis of the mean value theorem of integration,
| (B.14) | ||||
where . Thus, for and for . Also, one has
| (B.15) | ||||
where . Therefore, is confirmed. ∎
B.2 Proof of Theorem 2
First we show that the kernel satisfies all the conditions of Problem 2.
Proof.
The fact that satisfies (P2-3), that is, it changes its sign times on , is a direct consequence of the well-known property of the Jacobi polynomials, that with has simple zeros in the interval , together with the rightmost expression in (22) of . Differentiability of on and boundedness and continuity in the sense of ‘a.e.’ of (condition (P2-2)), finiteness of (condition (P2-4)), and the behavior as (condition (P2-5)) follow straightforwardly from the fact that, from the rightmost expression in (22), is a polynomial restricted to the finite interval with a double zero at .
We thus show in the following that holds, that is, satisfies the moment condition (P2-1). Let
| (B.16) | ||||
where
| (B.17) | ||||
Using the identity (Prudnikov et al., 1986, Section 2.22.2, Item 11)
| (B.18) |
where
| (B.19) |
is the binomial coefficient extended to real-valued arguments, and where denotes the Beta function, one has
| (B.20) |
The values of for are therefore
| (B.24) |
These in turn imply that the moments of are given by
| (B.28) |
showing that holds. (The fact that for can alternatively be understood on the basis of the expression (B.17) and the orthogonality relation (B.70) of the Jacobi polynomials.) ∎
Then, we introduce two polynomials related to the kernel , before the succeeding proof:
| (B.29) |
is an original polynomial of before truncated. Also, the function is defined such that the first derivative of becomes , and is a polynomial function with terms of -nd degree.
In the following, we give Lemma B.6 on the properties of functions and .
Lemma B.5.
Suppose that has coefficients , . Then, , ; , ; and , are strictly monotonically increasing (resp. decreasing) for , when (resp. ).
Proof.
Lemma B.6.
Proof.
The symmetric polynomial function has zeros inside and double zeros at , Thus, its coefficients become and .
Using the relationship of the Jacobi polynomial
| (B.31) |
which appears in (Askey, 1975, p.7), one has
| (B.32) |
Then, on the basis of the factorized expression of ,
| (B.33) |
one has (resp. ) when (resp. ).
Finally, we provide a proof of Theorem 2 below:
Proof of Theorem 2.
Suppose that satisfies the conditions (P2-1)–(P2-5) and has the same -th moment as that of . For this setting, because satisfies (P2-1)–(P2-5) (shown in Lemma B.4), the disturbance needs to satisfy the moment conditions
| (B.35) |
From the radial symmetry, odd-order moment conditions are automatically fulfilled. Additionally, it should be noted that does not need to have a compact support, which makes the kernel’s optimality not limited to just the class of truncation kernels. In contrast, the following proof requires the condition (P2-5) (i.e., ).
The following calculations are performed to derive the inequality (B.38). On the basis of the integral by part, , , combination of the moment conditions (B.35) and the fact that the polynomial defined in (B.29) has -th degree terms, one has
| (B.36) | ||||
Secondly, integral by part, together with and , shows
| (B.37) | ||||
Collecting these pieces, one can obtain the following inequality:
| (B.38) | ||||
where the equality holds just when , which holds only if due to the moment condition .
Thus, since the kernels and have the same value of -th moment, in order to prove the optimality of with respect to the AMSE criterion, it is sufficient to prove
| (B.39) |
for , instead of showing . We prove the inequality (B.39) for order , below.
Proof for . First, we provide the proof for . Lemma B.6 shows for . Also, since is non-negative due to the minimum-sign-change condition and for , the disturbance , has to be non-negative. Thus, (B.39) holds.
Proof for . We next show the theorem for . The only sign change of minimum-sign-change 4-th order kernel goes from positive to negative at some point from Lemma B.3.
Next we consider the other case with , where the followings are satisfied:
| (B.40) | ||||
| (B.41) |
From the equation
| (B.42) |
one has
| (B.43) |
which leads us to obtain
| (B.44) |
On the basis of the mean value theorem of integration, one gets
| (B.45) | ||||
for , where we use and that is monotonically decreasing for , which result from Lemma B.6. This inequality implies the completion of the proof. ∎
B.3 Proof of Theorem 3
B.3.1 Reformulation of Problem 3
In this section, we provide a proof of Theorem 3 that is a multivariate RK extension of the existing results by (Granovsky and Müller, 1991). We here reformulate Problem 3 to Problem B.2, to which we can almost directly apply the proof in the existing works.
Problem 3 includes both the function and derivative in its formulation, which makes the problem difficult to handle. Under the condition (P3-5) (i.e., as ), integration-by-parts yields the equation,
| (B.46) | ||||
This equation allows us to rewrite the objective function (P3) as a functional of only, and shows the following lemma that allows us to represent the moment condition (P3-1) in terms of .
Lemma B.7.
For and even , assume that holds as and that is continuous a.e. Then the following two conditions are equivalent:
-
(i)
and is differentiable.
-
(ii)
.
Thus, the following problem is equivalent to Problem 3 in the sense that a solution of one of the problems is a solution of the other.
Problem B.1.
The kernel optimization problem B.1 still has scale indeterminacy of a solution, as described also in Footnote 3. Indeed, one has the following lemma.
Lemma B.8.
Let and For a function and , we define a scale-transformed function . Then, one has
| (B.47) |
B.3.2 Auxiliary Lemmas
Here we introduce notations and lemmas that will be used for proofs in the next sections. Let be a positive integer. For functions defined on , define
| (B.49) |
Let be the space of square-integrable functions on with weight . This is a Hilbert space equipped with the inner product . Note however that, for any nonnegative integer , one has , as the integral of over with weight diverges.
With a measurable subset of , define
| (B.50) |
and let be the space of square-integrable functions on with weight . Let be a compact measurable subset of , and let . One has that and are both subspaces of , and that the map from to is an isomorphism (Conway, 2007, page 25). We therefore identify and via this isomorphism.
Let be a finite subset of , and let
| (B.51) |
For fixed and , is a subspace of with dimension equal to .
Lemma B.9.
Assume that a function satisfies for any with and for all . Then .
Proof.
In view of the above direct-sum decomposition of , the subspace is regarded as the restriction of
| (B.52) |
to . The orthogonal complement of in is given, via Lemma B.10 below, by
| (B.53) | ||||
From the assumption of this lemma, the function belongs to the orthogonal complement of . On the other hand, is a closed subspace in thanks to (Rudin, 1991, Theorem 1.42), since is finite-dimensional. One can therefore conclude that holds, implying , and the statement of the lemma follows. ∎
Lemma B.10.
Let be a Hilbert space, and let be subsets of satisfying . Then holds.
Proof.
Since , one has and hence . One similarly has , and thus . On the other hand, take and . Noting that is represented as with and , one has
| (B.54) |
where the final equality is due to and , implying that holds. This proves . ∎
It should be noted that the above lemma holds regardless of the dimensionality or the closedness of .
B.3.3 Prove that the optimal solution is a polynomial kernel
The following lemma is an RK extension of (Granovsky and Müller, 1989, Theorem), and it states the functional form that an optimal solution of Problem B.2 should take.
Lemma B.11.
Proof of Lemma B.11.
Step 1
Define , and let be a sequence of functions satisfying with positive numbers satisfying as . The function set is weakly compact as a bounded set in the Hilbert space equipped with the scalar product . It is thus found that there exists a subsequence of weakly converging to a function . Note that this convergence particularly shows , and one has
| (B.55) |
which implies .
In the rest of Step 1, we show that satisfies (P5-1), (P5-3), and (P5-6): implies that
| (B.56) |
where , are -dependent constants. Introducing and a -independent constant , from the condition (P5-5) for (that is, ), one has
| (B.57) | ||||
Because converges to and , one has
| (B.58) |
From these results, one has
| (B.59) |
which implies that satisfies (P5-1) and (P5-6) for . Moreover, since it also holds that (P5-3), otherwise and have a interval (say ) where their signs do not coincide (so with ), which contradicts that converges to .
Step 2
On the basis of the fact that proved in Step 1, we here show a functional form of . We introduce the function class
| (B.60) |
Then, one has that for with a sufficiently small absolute value and any bounded non-identically-zero function satisfying , where denotes the support of and . For the optimality of , for all is necessary, because ,
| (B.61) |
and is not identically zero since is away from 0 due to the proof by contradiction with the condition (P5-3) for and Lemma B.2. This implies that should lie in the orthogonal complement of , that is, , which is proved by applying Lemma B.9. The result implies that takes a form of , where is a polynomial with terms of degree in . Also, the boundedness of , in addition to the functional form of derived above, concludes that the support of is bounded.
Step 3
Hereafter we show that an optimal solution has no discontinuity and that, for a polynomial satisfying , takes a form
| (B.62) |
Then, we prove the following lemma.
Lemma B.12.
Let be a subset of with , where denotes the Lebesgue measure on . Let be a function defined in (B.62) and be the support of . Assume that takes the same sign over , and that and share the same sign-change pattern. Then either or is zero.
Proof of Lemma B.12.
Assume to the contrary that both and are strictly positive. Since , one can take an ordered partition of with for all , with which, for and with one has almost surely. We let and with
| (B.63) | |||
| (B.64) |
One has due to the assumption . Furthermore, let and define
| (B.65) |
Note that is equivalent to on when .
We now want to set so that and the function share the same moments of orders in . It will be achieved if satisfies , since the -st moments of and are and , respectively. Applying Lemma B.1 with shows that is invertible, so that the assertion makes the moments of and to coincide.
With the above , let , where is the sign of on . One has by construction, which implies . On the other hand, one has
| (B.66) |
Since vanishes outside , we have
| (B.67) |
For a sufficiently small , the function has the same sign as on , and it is equal to outside . Therefore, and share the same sign-change pattern, and one consequently has . The above inequality implies that for a sufficiently small one has , leading to contradiction. ∎
We consider, as in Definition B.1, subintervals partitioning according to the sign of . Since is a polynomial of degree with odd-degree terms only, the number of the above subintervals is at most . Lemma B.12 states that, for each of the subintervals, the support of either contains its interior as a whole or not, and cannot contain only some fraction of it in terms of the Lebesgue measure. Since and is bounded, the only possibility is therefore that the closure of equals to , where is the largest zero of , that is, .
B.3.4 Prove that the optimal polynomial kernel is uniquely determined
The following lemma is an RK extension of (Granovsky and Müller, 1989, Lemma 2), and shows that a polynomial function suggested by the above lemma is uniquely determined.
Lemma B.13.
For and even , there exists a unique constant and a unique polynomial with terms of degree in , such that satisfies
| (B.68) |
Also, the resulting polynomial is such that .
Here, suppose that is given such that gets to 1 for the sake of simplicity of description, since in and in (P5-6) have a one-to-one correspondence and it is possible, as can be seen from Lemma B.8 on the scale transformation. Then, we will show that satisfying the conditions (instead of ) is uniquely determined.
Proof of Lemma B.13.
For odd , we introduce one of the normalized Jacobi polynomials on :
| (B.69) |
where is a normalization constant, and define . It is straightforward to show that satisfies the orthogonality relation
| (B.70) | ||||
where the last equality follows from the orthogonality relation of the Jacobi polynomials:
| (B.71) |
Since the Jacobi polynomial is a polynomial of degree , is a polynomial with terms of degree in , so that one can write
| (B.72) |
where . Furthermore, since any polynomial of degree is represented as a linear combination of , any polynomial with terms of degree in for odd is represented as a linear combination of . This in particular means that, for odd , with is represented as a linear combination of , so that the orthogonality (B.70) implies that satisfies the moment conditions , .
Any polynomial with terms of degree in can be represented as a linear combination of , . So, the polynomial in the statement of the theorem can be written as
| (B.73) |
The coefficient is evaluated, via the moment conditions of , as
| (B.74) | ||||
where . Therefore, has a unique representation,
| (B.75) |
where is variable and other components are fixed. Considering additionally determines uniquely.
Proof.
C Supplemental Information on Appeared Kernels
Here, we provide supplemental information on the kernels used in our simulation experiments in Section 4. More specifically, we give the expressions of , , and for those kernels.
Proposition C.1.
For the kernel , the functionals , , and become
| (C.1) | ||||
The following is on the information about the kernels , , and , which are designed as higher-order extensions of Epanechnikov, Gaussian, Laplace kernels according to the jackknife (Schucany and Sommers, 1977; Wand and Schucany, 1990). These kernels respectively belong to Epanechnikov, Gaussian, and Laplace hierarchies, and take the forms of product between polynomials and Epanechnikov, Gaussian, and Laplace kernels.
Proposition C.2.
The kernel is a -variate, -th order kernel, where
| (C.2) | ||||
and the functionals , , and of become
| (C.3) | ||||
Proposition C.3.
The kernel is a -variate, -th order kernel, where
| (C.4) |
where is the Laguerre polynomial (Szegö, 1939). Also, the functionals , , and of become
| (C.5) | ||||
Proposition C.4.
The kernel is a -variate, -th order kernel, where
| (C.6) |
and where , , are determined as
| (C.7) |
Also, the functionals , , and of become
| (C.8) | ||||
D Proof of Proposition 6
This appendix provides a proof of Proposition 6. In the case , the third-order term of the Taylor expansion of around its mode is represented as a real binary cubic form, i.e., a homogeneous degree-3 polynomial of : , where are proportional to appropriate third-order partial derivatives of at . Properties of such a real binary cubic form that are invariant under reversible linear transforms of is characterized by the algebraic curve defined as the set of satisfying . Putting aside the trivial case , classification of the algebraic curve can be done on the basis of classification of the set of solutions of the cubic equation of a real-valued variable : it has either:
-
•
a single real solution, which is triply degenerate,
-
•
two real distinct solutions, one of which is doubly degenerate,
-
•
three real distinct solutions, or
-
•
a real and two complex solutions.
Accordingly, the third-order term of the Taylor expansion of at the mode is either:
-
(D.1)
0 identically,
-
(D.2)
of the form ,
-
(D.3)
of the form with linearly independent,
-
(D.4)
of the form with , any two of which are linearly independent, or
-
(D.5)
of the form , where with positive definite.
In the case (D.1), the AB is trivially 0 for any choice of . The cases (D.4) and (D.5) have already been covered in Propositions 3 and 4, respectively. What remains is to consider the cases (D.2) and (D.3), which are dealt with in the following lemmas, completing the proof of Proposition 6.
Lemma D.1.
with is non-zero irrespective of the choice of the positive definite .
Proof.
One has
| (D.6) |
and the coefficient of in the above expression is non-zero because of the positive-definiteness of . ∎
Lemma D.2.
with linearly independent is non-zero irrespective of the choice of the positive definite .
Proof.
One has
| (D.7) |
and the coefficient of in the above expression is non-zero because of the positive-definiteness of . ∎
The general treatment should require a higher-order analog of Sylvester’s law of inertia for quadratic forms, that is, classification of homogeneous degree- polynomials of variables under the equivalence relation where two polynomials are equivalent if and only if one of them can be transformed into the other via applying an invertible linear transform on to its variables. This problem seems to be less explored compared with that on , and is already complicated even when : see e.g. Banchi (2015). We therefore do not attempt to extend Proposition 6 to more general cases in this paper, and defer the problem to a future investigation.
E Proof of Asymptotic Behaviors of the Modal Linear Regression
Theorem 4 on asymptotic behaviors of the MLR parameter estimator can be proved in the manner almost same as that of Theorem 1, under the following regularity conditions:
Assumption E.1 (Regularity conditions for Theorem 4).
For finite and even ,
-
(E.1)
is a sample of i.i.d. observations from .
-
(E.2)
for some .
-
(E.3)
The parameter space is compact subset of , and has a nonempty interior ; .
-
(E.4)
for any fixed such that (no multicollinearity).
-
(E.5)
is times differentiable in for all .
-
(E.6)
has a unique and isolated maximizer at for all (i.e., for all , , and for a neighborhood of , for all ).
-
(E.7)
, satisfies for all , and in (61) is non-singular.
-
(E.8)
for all and s.t. , and is bounded in for all and s.t. .
-
(E.9)
, , and is such that in (61) is non-zero.
-
(E.10)
is bounded and twice differentiable in and satisfies the covering number condition, , and .
-
(E.11)
.
-
(E.12)
for all s.t. .
-
(E.13)
for all s.t. , and for some s.t. .
-
(E.14)
for all s.t. .
-
(E.15)
is bounded and satisfies , , and for some , for all .
-
(E.16)
has a finite determinant .
-
(E.17)
, satisfies the covering number condition.
-
(E.18)
.
-
(E.19)
.
Acknowledgements
This work was supported by Grant-in-Aid for JSPS Fellows, Number 20J23367.
References
- Abraham et al. (2004) C. Abraham, G. Biau, and B. Cadre. On the asymptotic properties of a simple estimate of the mode. ESAIM: Probability and Statistics, 8:1–11, 2004.
- Askey (1975) R. Askey. Orthogonal Polynomials and Special Functions, volume 21. SIAM, 1975.
- Baldauf and Santos Silva (2012) M. Baldauf and J. M. C. Santos Silva. On the use of robust regression in econometrics. Economics Letters, 114(1):124–127, 2012.
- Banchi (2015) M. Banchi. Rank and border rank of real ternary cubics. Bollettino dell’Unione Matematica Italiana, 8(1):64–80, 2015.
- Berlinet (1993) A. Berlinet. Hierarchies of higher order kernels. Probability Theory and Related Fields, 94(4):489–504, 1993.
- Berlinet and Thomas-Agnan (2004) A. Berlinet and C. Thomas-Agnan. Reproducing Kernel Hilbert Spaces in Probability and Statistics. Kluwer Academic Publishers, 2004.
- Bochner (2005) S. Bochner. Harmonic Analysis and the Theory of Probability. Courier Corporation, 2005.
- Casa et al. (2020) A. Casa, J. E. Chacón, and G. Menardi. Modal clustering asymptotics with applications to bandwidth selection. Electronic Journal of Statistics, 14(1):835–856, 2020.
- Comaniciu and Meer (2002) D. Comaniciu and P. Meer. Mean shift: A robust approach toward feature space analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(5):603–619, 2002.
- Conway (2007) J. B. Conway. A Course in Functional Analysis. Sprinnger, second edition, 2007.
- Donoho et al. (1991) D. L. Donoho, R. C. Liu, et al. Geometrizing rates of convergence, III. The Annals of Statistics, 19(2):668–701, 1991.
- Eddy (1980) W. F. Eddy. Optimum kernel estimators of the mode. The Annals of Statistics, 8(4):870–882, 1980.
- Gasser and Müller (1979) T. Gasser and H.-G. Müller. Kernel estimation of regression functions. In T. Gasser and M. Rosenblatt, editors, Smoothing Techniques for Curve Estimation, pages 23–68. Springer, 1979.
- Gasser et al. (1985) T. Gasser, H.-G. Müller, and V. Mammitzsch. Kernels for nonparametric curve estimation. Journal of the Royal Statistical Society. Series B (Methodological), 47:238–252, 1985.
- Granovsky and Müller (1989) B. L. Granovsky and H.-G. Müller. On the optimality of a class of polynomial kernel functions. Statistics & Risk Modeling, 7(4):301–312, 1989.
- Granovsky and Müller (1991) B. L. Granovsky and H.-G. Müller. Optimizing kernel methods: a unifying variational principle. International Statistical Review/Revue Internationale de Statistique, 59(3):373–388, 1991.
- Grund and Hall (1995) B. Grund and P. Hall. On the minimisation of error in mode estimation. The Annals of Statistics, 23(6):2264–2284, 1995.
- Hasminskii (1979) R. Hasminskii. Lower bound for the risks of nonparametric estimates of the mode. Contributions to Statistics, pages 91–97, 1979.
- Kemp et al. (2020) G. C. R. Kemp, P. M. D. C. Parente, and J. M. C. Santos Silva. Dynamic vector mode regression. Journal of Business & Economic Statistics, 38(3):647–661, 2020.
- Mokkadem and Pelletier (2003) A. Mokkadem and M. Pelletier. The law of the iterated logarithm for the multivariate kernel mode estimator. ESAIM: Probability and Statistics, 7:1–21, 2003.
- Müller (1984) H.-G. Müller. Smooth optimum kernel estimators of densities, regression curves and modes. The Annals of Statistics, 12(2):766–774, 1984.
- Ozertem and Erdogmus (2011) U. Ozertem and D. Erdogmus. Locally defined principal curves and surfaces. Journal of Machine Learning Research, 12:1249–1286, 2011.
- Parzen (1962) E. Parzen. On estimation of a probability density function and mode. The Annals of Mathematical Statistics, 33(3):1065–1076, 1962.
- Pollard (1984) D. Pollard. Convergence of Stochastic Processes. Springer Science & Business Media, 1984.
- Prudnikov et al. (1986) A. P. Prudnikov, Y. A. Brychkov, and O. I. Marichev. Integrals and Series, Volume 2: Special Functions. Gordon and Brewach Science Publishers, 1986.
- Romano (1988) J. P. Romano. On weak convergence and optimality of kernel density estimates of the mode. The Annals of Statistics, 16(2):629–647, 1988.
- Rudin (1991) W. Rudin. Functional Analysis. McGraw-Hill, second edition, 1991.
- Rüschendorf (1977) L. Rüschendorf. Consistency of estimators for multivariate density functions and for the mode. Sankhyā: The Indian Journal of Statistics, Series A, 39(3):243–250, 1977.
- Sando and Hino (2020) K. Sando and H. Hino. Modal principal component analysis. Neural Computation, 32(10):1901–1935, 2020.
- Schucany and Sommers (1977) W. Schucany and J. P. Sommers. Improvement of kernel type density estimators. Journal of the American Statistical Association, 72(358):420–423, 1977.
- Szegö (1939) G. Szegö. Orthogonal Polynomials, volume 23. American Mathematical Society, 1939.
- Vedaldi and Soatto (2008) A. Vedaldi and S. Soatto. Quick shift and kernel methods for mode seeking. In European Conference on Computer Vision, pages 705–718, 2008.
- Vieu (1996) P. Vieu. A note on density mode estimation. Statistics & Probability Letters, 26(4):297–307, 1996.
- Wand and Schucany (1990) M. P. Wand and W. R. Schucany. Gaussian-based kernels. Canadian Journal of Statistics, 18(3):197–204, 1990.
- Yamasaki and Tanaka (2019) R. Yamasaki and T. Tanaka. Kernel selection for modal linear regression: Optimal kernel and irls algorithm. In 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), pages 595–601, Dec 2019.
- Yamasaki and Tanaka (2020) R. Yamasaki and T. Tanaka. Properties of mean shift. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(9):2273–2286, 2020.
- Yamato (1971) H. Yamato. Sequential estimation of a continuous probability density function and mode. Bulletin of Mathematical Statistics, 14(3):1–12, 1971.
- Yao and Li (2014) W. Yao and L. Li. A new regression model: modal linear regression. Scandinavian Journal of Statistics, 41(3):656–671, 2014.