Optimal Control Operator Perspective and a Neural Adaptive Spectral Method
Abstract
Optimal control problems (OCPs) involve finding a control function for a dynamical system such that a cost functional is optimized. It is central to physical systems in both academia and industry. In this paper, we propose a novel instance-solution control operator perspective, which solves OCPs in a one-shot manner without direct dependence on the explicit expression of dynamics or iterative optimization processes. The control operator is implemented by a new neural operator architecture named Neural Adaptive Spectral Method (NASM), a generalization of classical spectral methods. We theoretically validate the perspective and architecture by presenting the approximation error bounds of NASM for the control operator. Experiments on synthetic environments and a real-world dataset verify the effectiveness and efficiency of our approach, including substantial speedup in running time, and high-quality in- and out-of-distribution generalization.
Code — https://github.com/FengMingquan-sjtu/NASM.git
1 Introduction
Although control theory has been rooted in a model-based design and solving paradigm, the demands of model reusability and the opacity of complex dynamical systems call for a rapprochement of modern control theory, machine learning, and optimization. Recent years have witnessed the emerging trends of control theories with successful applications to engineering and scientific research, such as robotics (Krimsky and Collins 2020), aerospace technology (He et al. 2019), and economics and management (Lapin, Zhang, and Lapin 2019) etc.
We consider the well-established formulation of optimal control (Kirk 2004) in finite time horizon . Denote and as two vector-valued function sets, representing state functions and control functions respectively. Functions in (resp. ) are defined over and have their outputs in (resp. ). State functions and control functions are governed by a differential equation. The optimal control problem (OCP) is targeted at finding a control function that minimizes the cost functional (Kirk 2004; Lewis, Vrabie, and Syrmos 2012):
| (1a) | |||||
| s.t. | (1b) | ||||
| (1c) | |||||
where is the dynamics of differential equations; evaluates the cost alongside the dynamics and evaluates the cost at the termination state ; and is the initial state. We restrict our discussion to differential equation-governed optimal control problems, leaving the control problems in stochastic networks (Dai and Gluzman 2022), inventory management (Abdolazimi et al. 2021), etc. out of the scope of this paper. The analytic solution of Eq. 1 is usually unavailable, especially for complex dynamical systems. Thus, there has been a wealth of research towards accurate, efficient, and scalable numerical OCP solvers (Rao 2009) and neural network-based solvers (Kiumarsi et al. 2017). However, both classic and modern OCP solvers are facing challenges, especially in the big data era, as briefly discussed below.
1) Opacity of Dynamical Systems. Existing works (Böhme and Frank 2017a; Effati and Pakdaman 2013; Jin et al. 2020) assume the dynamical systems a priori and exploit their explicit forms to ease the optimization. However, real-world dynamical systems can be unknown and hard to model. It raises serious challenges in data collection and system identification (Ghosh, Birrell, and De Angelis 2021), where special care is required for error reduction.
2) Model Reusability. Model reusability is conceptually measured by the capability of utilizing historical data when facing an unprecedented problem instance. Since solving an individual instance of Eq. 1 from scratch is expensive, a reusable model that can be well adapted to new problems is welcomed for practical usage.
3) Running Paradigm. Numerical optimal control solvers traditionally use iterative methods before picking the control solution, thus introducing a multiplicative term regarding the iteration in the running time complexity. This sheds light on the high cost of solving a single OC problem.
4) Control Solution Continuity. Control functions are defined on a continuous domain (typically time) despite being intractable for numerical solvers. Hence resorting to discretization in the input domain gives rise to the trade-off in the precision of the control solution and the computational cost, as well as the truncation errors. While the discrete solution can give point-wise queries, learning a control function for arbitrary time queries is much more valued.
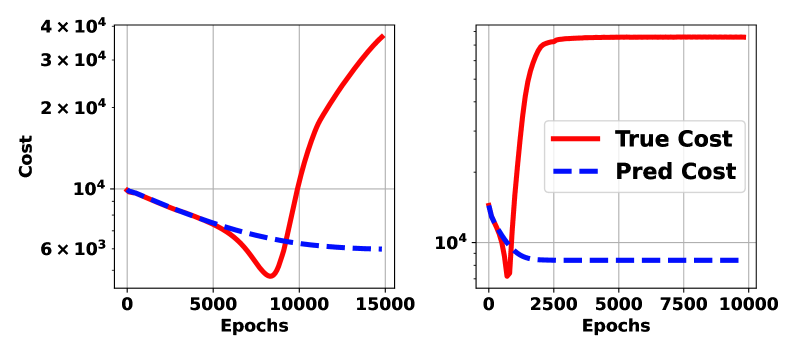
5) Running Phase. The two-phase models (Chen, Shi, and Zhang 2018; Wang, Bhouri, and Perdikaris 2021; Hwang et al. 2022) can (to some extent) overcome the above issues at the cost of introducing an auxiliary dynamics inference phase. This thread of works first approximate the state dynamics by a differentiable surrogate model and then, in its second phase, solves an optimization problem for control variables. However, the two-phase paradigm increases computational cost and manifests inconsistency between the two phases. A motivating example in Fig. 1 shows that the two-phase paradigm leads to failures. When the domain of phase-2 optimization goes outside the training distribution in phase-1, it might collapse.
Table 1 compares the methods regarding the above aspects. We propose an instance-solution operator perspective for learning to solve OCPs, thereby tackling the issues above. The highlights are:
| Methods | Phase | Continuity | Dynamics | Reusability | Paradigm |
|---|---|---|---|---|---|
| Direct (Böhme and Frank 2017a) | Single | Discrete | Required | No | Iterative |
| Two-Phase (Hwang et al. 2022) | Two | Discrete | Dispensable1 | Partial2 | Iterative |
| PDP (Jin et al. 2020) | Single | Discrete | Required | No | Iterative |
| DP (Tassa, Mansard, and Todorov 2014) | Single | Discrete | Required | No | Iterative |
| NCO (ours) | Single | Continuous | Dispensable | Yes | One-pass |
-
1
if phase-1 uses PINN loss (Wang, Bhouri, and Perdikaris 2021): required.
-
2
only phase-1 is reusable.
1) We propose the Neural Control Operator (NCO) method of optimal control, solving OCPs by learning a neural operator that directly maps problem instances to solutions. The system dynamics is implicitly learned during the training, which relies on neither any explicit form of the system nor the optimization process at test time. The operator can be reused for similar OCPs from the same distribution without retraining, unlike learning-free solvers. Furthermore, the single-phase direct mapping paradigm avoids iterative processes with substantial speedup.
2) We instantiate a novel neural operator architecture: NASM (Neural Adaptive Spectral Method) to implement the NCO and derive bounds on its approximation error.
3) Experiments on both synthetic and real systems show that NASM is versatile for various forms of OCPs. It shows over 6Kx speedup (on synthetic environments) over classical direct methods. It also generalizes well on both in- and out-of-distribution OCP instances, outperforming other neural operator architectures in most of the experiments.
Background and Related Works. Most OCPs can not be solved analytically, thus numerical methods (Körkel* et al. 2004) are developed. An OCP numerical method has three components: problem formulation, discretization scheme, and solver. The problem formulations fall into three categories: direct methods, indirect methods, and dynamic programming. Each converts OCPs into infinite-dimensional optimizations or differential equations, which are then discretized into finite-dimensional problems using schemes like finite difference, finite element, or spectral methods. These finite problems are solved by algorithms such as interior-point methods for nonlinear programming and the shooting method for boundary-value problems. These solvers rely on costly iterative algorithms and have limited ability to reuse historical data.
In addition, our work is also related to the neural operators, which are originally designed for solving parametric PDEs. Those neural operators learn a mapping from the parameters of a PDE to its solution. For example, DeepONet (DON) (Lu et al. 2021) consists of two sub-networks: a branch net for input functions (i.e. parameters of PDE) and a trunk net for the querying locations or time indices. The output is obtained by computing the inner product of the outputs of branch and trunk networks. Another type of neural operator is Fourier transform based, such as Fourier Neural Operator (FNO) (Li et al. 2020). The FNO learns parametric linear functions in the frequency domain, along with nonlinear functions in the time domain. The conversion between those two domains is realized by discrete Fourier transformation. There are many more architectures, such as Graph Element Network (GEN) (Alet et al. 2019), Spectral Neural Operator(SNO) (Fanaskov and Oseledets 2022) etc., as will be compared in our experiments.
2 Methodology
In this section, we will present the instance-solution control operator perspective for solving OCPs. The input of operator is an OCP instance , and the output is the optimal control function , i.e. . Then we propose the Neural Control Operator (NCO), a class of end-to-end OCP neural solvers that learn the underlying infinite-dimensional operator via a neural operator. A novel neural operator architecture, the Neural Adaptive Spectral Method (NASM), is implemented for NCO method.
Instance-Solution Control Operator Perspective of OCP Solvers
This section presents a high-level instance-solution control operator perspective of OCPs. In this perspective, an OCP solver is an operator that maps problem instances (defined by cost functionals, dynamics, and initial conditions) into their solutions, i.e. the optimal controls. Denote the problem instance by , with its optimal control solution . The operator is defined as , a mapping from cost functional to optimal control.
In practice, the non-linear operator can hardly have a closed-form expression. Therefore, various numerical solvers have been developed, such as direct method and indirect method, etc, as enumerated in the related works. All those numerical solvers can be regarded as approximate operators of the exact operator . To measure the quality of the approximated operator, we define the approximation error as the distance between the cost of the solution and the optimal cost. Let be the probability measure of the problem instances, assume the control dimension , and cost (subscript means the cost is dependent on ), w.l.o.g. Then the approximation error is defined as:
| (2) |
Classical numerical solvers are generally guaranteed to achieve low approximation error (with intensive computing cost). For efficiency, we propose to approximate the operator by neural networks, i.e. Neural Control Operator (NCO) method. The networks are trained by demonstration data pairs produced by some numerical solvers, without the need for explicit knowledge of dynamics. Once trained, they infer optimal control for any unseen instances with a single forward pass. As empirically shown in our experiments, the efficiency (at inference) of neural operators is consistently better than classical solvers. We will also provide an approximation error bound for our specific implementation NASM of NCO.
Before introducing the network architecture, it is necessary to clarify a common component, the Encoder, used in both classical and neural control operators. The encoder converts the infinite-dimensional input to finite-dimensional representation . Take the cost functional for example. If the cost functional is explicitly known, then the may be encoded as the symbolic expression or the parameters only. Otherwise, the cost functional can be represented by sampling on grids. After encoding, The encoded vector is fed into numerical algorithms or neural networks in succeeding modules. The encoder’s design is typically driven by the problem setting rather than the specific solver or network architecture.
Neural Adaptive Spectral Method
From the operator’s perspective, constructing an OCP solver is equivalent to an operator-learning problem. We propose to learn the operator by neural network in a data-driven manner. Now we elaborate on a novel neural operator architecture named Neural Adaptive Spectral Method (NASM), inspired by the spectral method.
The spectral method assumes that the solution is the linear combination of basis functions:
| (3) |
where the basis functions are chosen as orthogonal polynomials e.g. Fourier series (trigonometric polynomial) and Chebyshev polynomials. The coefficients are derived from instance by a numerical algorithm. The Spectral Neural Operator (SNO) (Fanaskov and Oseledets 2022) obtains the coefficients by a network.
Our NASM model is based on a similar idea but with more flexible and adaptive components than SNO. The first difference is that summation is extended to aggregation . The aggregation is defined as any mapping and can be implemented by either summation or another network. Secondly, the coefficient is obtained from Coefficient Net, which is dependent on not only instance but time index as well, inspired by time-frequency analysis (Cohen 1995). It is a generalization and refinement of (Eq. 3), for the case when the characteristics of are non-static. For example, with Fourier basis can only capture globally periodic functions, while the with the same basis can model both periodic and non-periodic functions. Lastly, the basis functions are adaptive instead of fixed. The adaptiveness is realized by parameterizing basis functions by , which is inferred from also by the neural network.
| (4) |
As a concrete example of adaptive basis functions, the adaptive Fourier series is obtained from the original basis by scaling and shifting, according to the parameter . We limit the absolute value of elements of to avoid overlapping the adaptive range of basis functions. Following this principle, one can design adaptive versions for other basis function sets.
| (5) | |||
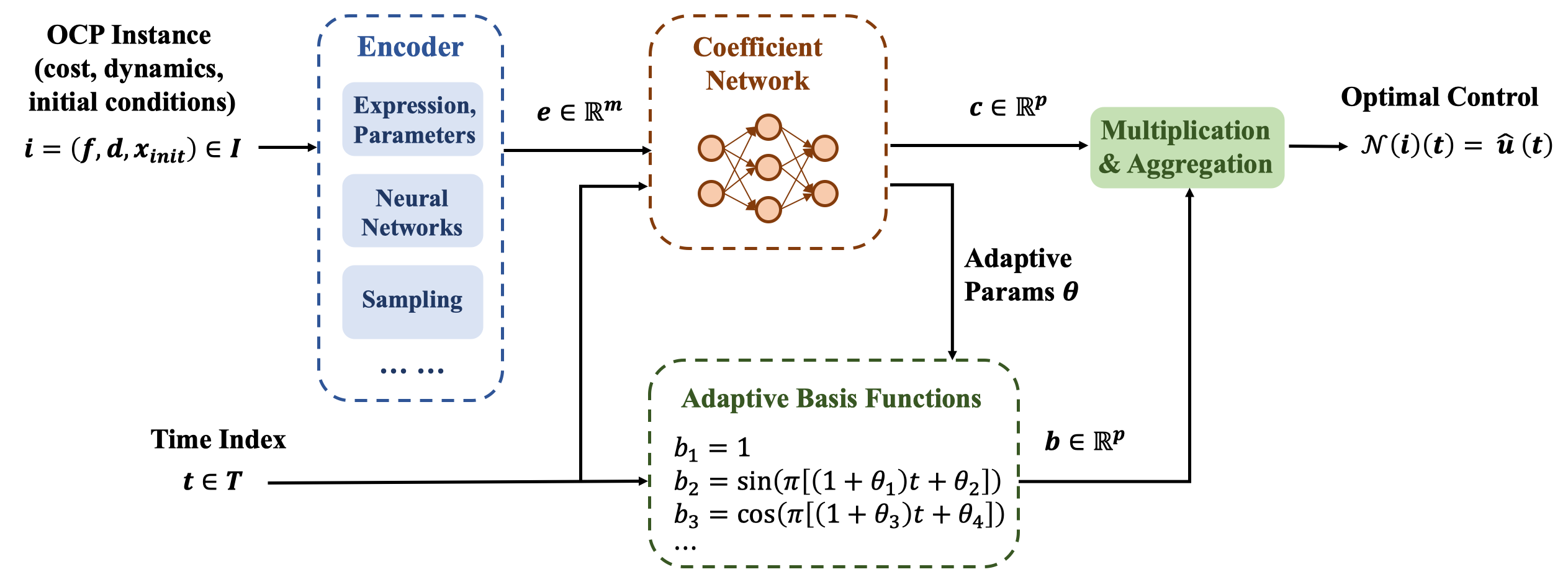
The overall architecture of NASM is given in Fig. 2. The theoretic result guarantees that there exists a network instance of NASM approximating the operator to arbitrary error tolerance. Furthermore, the size and depth of such a network are upper-bounded. The technical line of our analysis is partly inspired by (Lanthaler, Mishra, and Karniadakis 2022) providing error estimation for DeepONets.
Theorem 1 (Approximator Error, Informal).
Under some regularity assumptions, given an operator , and any error budget , there exists a NASM satisfying the budget with bounded network size and depth.
3 Experiments
We give experiments on synthetic and real-world environments to evaluate our instance-solution operator framework.
Synthetic Control Systems
Control Systems and Data Generation
We evaluate NASM on five representative optimal control systems by following the same protocol of (Jin et al. 2020), as summarized in Table 8. We postpone the rest systems to Appendix E, and only describe the details of the Quadrotor control here:
This system describes the dynamics of a helicopter with four rotors. The state consists of parts: position , velocity , and angular velocity . The control is the thrusts of the four rotating propellers of the quadrotor. is the unit quaternion (Jia 2019) representing the attitude (spacial rotation) of quadrotor w.r.t. the inertial frame. is the moment of inertia in the quadrotor’s frame, and is the torque applied to the quadrotor. We set the initial state , the initial quaternion . The matrices are coefficient matrices, see definition in Appx. E. The cost functional is defined as , with coefficients , .
In experiments presented in this section, unless otherwise specified, we temporally fix the cost functional symbolic expression, dynamics parameters, and initial condition in both training and testing. In this setting, the solution of OCP only depends on the parameter of cost, i.e. target state . The input of NCO is the cost functional only, and the information of dynamics, and initial conditions are explicitly learned. Therefore, we generate datasets (for model training/validation) and benchmarks (for model testing) by sampling target states from a pre-defined distribution. To fully evaluate the generalization ability, we define both in-distribution (ID) and out-of-distribution (OOD) (Shen et al. 2021). Specifically, we design two random variables, , and , where is a baseline goal state, and are different noise applied to ID and OOD. In Quadrotor problems for example, we set , and uniform noise , and .
The training data are sampled from ID, while validation data and benchmark sets are both sampled from ID and OOD separately. The data generation process is shown in Alg. 1 in Appendix. For a given distribution, we sample a target state and construct the corresponding cost functional and OCP instance . Then define 100 time indices uniformly spaced in time horizon , . The length of is slightly perturbed to add noise to the dataset. Then we solve the resulting OCP by the Direct Method(DM) solver and get the optimal control at those time indices. After that we sample 10 time indices , creating 10 triplets and adding them to the dataset. Repeat the process, until the size meets the requirement. The benchmark set is generated in the same way, but we store pairs ( is the optimal cost) instead of the optimal control. The dataset with all three factors (cost functional, dynamics parameters, and initial condition) changeable can be generated similarly.
Implementation and Baselines
For all systems and all neural models, the loss is the mean squared error defined below, with a dataset of samples: , the learning rate starts from 0.01, decaying every 1,000 epochs at a rate of 0.9. The batch size is , and the optimizer is Adam (Kingma and Ba 2014). The NASM uses 11 basis functions of the Fourier series. For comparison, we choose the following baselines. Other details of implementation and baselines are recorded in Appendix F.
1) Direct Method (DM): a classical direct OCP solver, with finite difference discretization and Interior Point OPTimizer (IPOPT) (Biegler and Zavala 2009) backend NLP solver.
2) Pontryagin Differentiable Programming (PDP) (Jin et al. 2020): an adjoint-based indirect method, differentiating through PMP, and optimized by gradient descent.
3) DeepONet (DON) (Lu et al. 2021): The seminal work of neural operator. The DON output is a linear combination of basis function values, and both coefficients and basis are pure neural networks.
4) Multi-layer Perceptron (MLP): A fully connected network implementation of the neural operator.
5) Fourier Neural Operator (FNO) (Li et al. 2020): A neural operator with consecutive Fourier transform layers, and fully connected layers at the beginning and the ending.
6) Graph Element Network (GEN) (Alet et al. 2019): Neural operator with graph convolution backbone.
7) Spectral Neural Operator (SNO) (Fanaskov and Oseledets 2022): linear combination of a fixed basis (Eq. 3), with neuralized coefficients. It is a degenerated version of NASM and will be compared in the ablation study part.
Results and Discussion
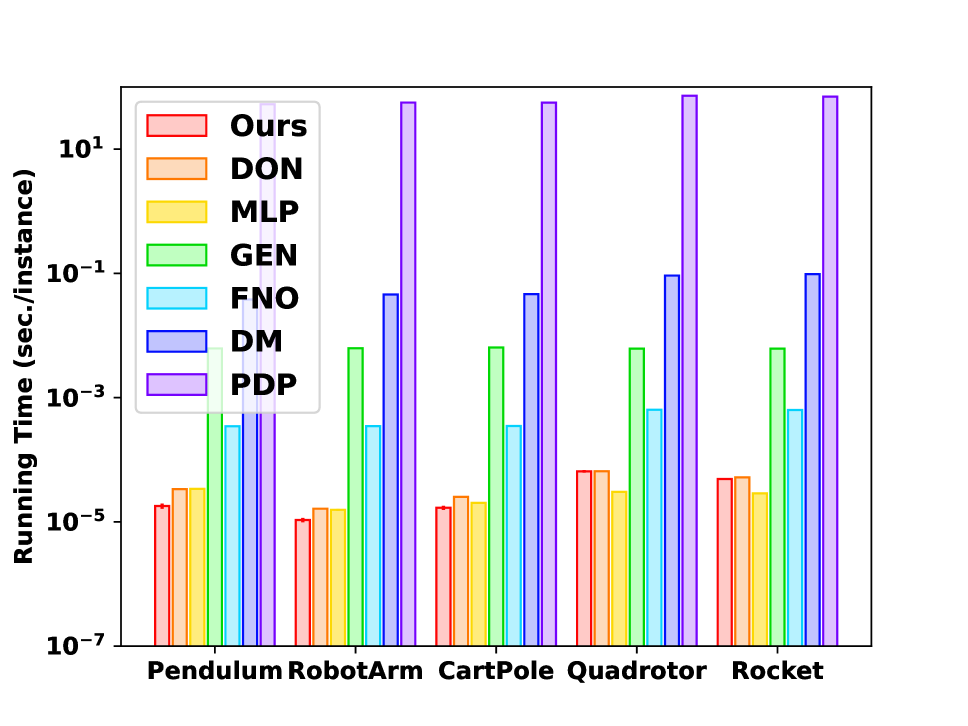
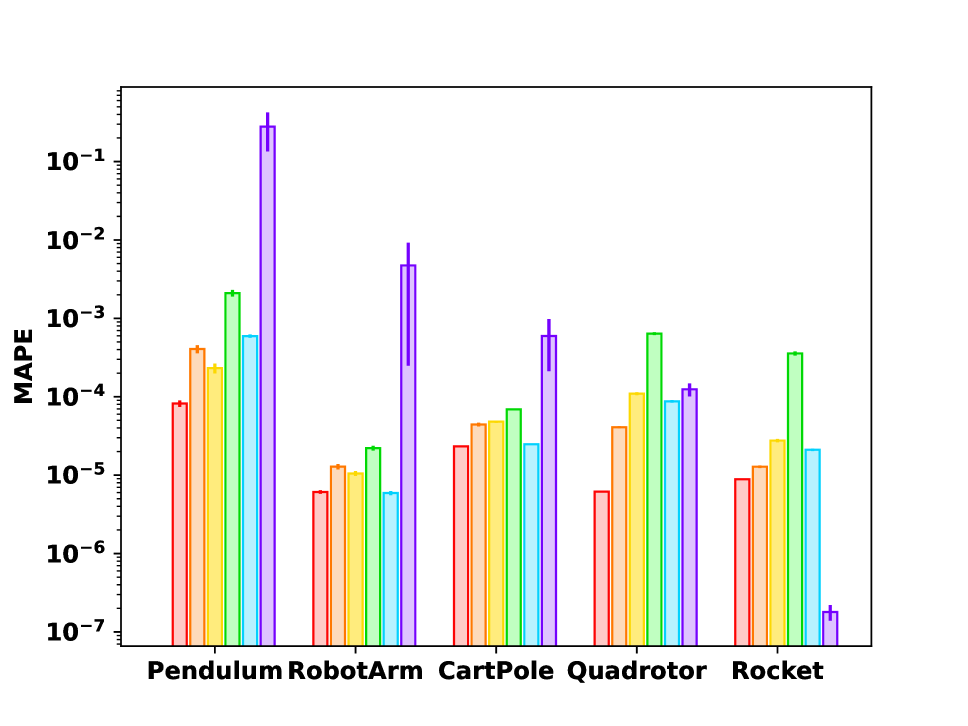
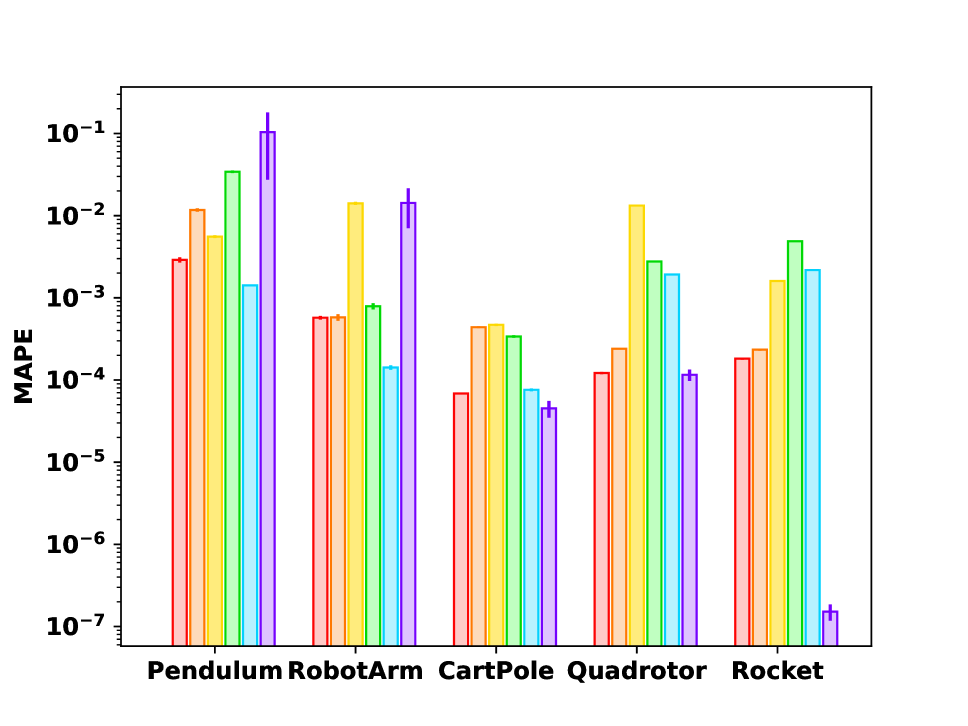
We present the numerical results on the five systems to evaluate the efficiency and accuracy of NASM and other architectures for instance-solution operator framework. The metrics of interest are 1) the running time of solving problems; 2) the quality of solution, measured by mean absolute percentage error (MAPE) between the true optimal cost and the predicted cost, which is defined as the mean of , where is the optimal cost generated by DM (regarded as ground truth), and is the cost of the solution produced by the model. The MAPE is calculated on ID/OOD benchmarks respectively, and the running time is averaged for 2,000 random problems. The results of ODE-constrained OCP are visualized in Fig. 3.
First, the comparison of the wall-clock running time is shown in Fig. 3(a) as well as in the third column of Tab. 2, which shows that the neural operator solvers are much faster than the classic solvers, although they both tested on CPU for fairness. For example, NASM achieves over 6000 times speedup against the DM solver. The acceleration can be reasoned in two aspects: 1) the neural operator solvers produce the output by a single forward propagation, while the classic methods need to iterate between forward and backward pass multiple times; 2) the neural solver calculation is highly paralleled. Among the neural operator solvers, the running time of NASM, DON, and MLP are similar. The FNO follows a similar diagram as MLP, but 10+ times slower than MLP, since it involves computationally intensive Fourier transformations. The GEN is 100+ times slower than MLP, probably because of the intrinsic complexity of graph construction and graph convolution.
| Formulation | Model | Time(sec./instance) | ID MAPE | OOD MAPE |
|---|---|---|---|---|
| Direct Method | DM | |||
| Indirect Method | PDP | |||
| Instance-Solution Control Operator | NASM | |||
| DON | ||||
| MLP | ||||
| GEN | ||||
| FNO |
The accuracy on in- and out-of-distribution benchmark sets is compared in Fig. 3(b)-3(c). Compared with other neural models, NASM achieves better or comparable accuracy in general. In addition, NASM outperforms classical PDP on more than half of the benchmarks. As a concrete example, we investigate the performance of the Quadrotor environment. From Tab. 2, one can observe that MAPE of NASM on the ID and OOD is the best among all neural models. The OOD performance is close to that of the classical method PDP, which is insensitive to distribution shift. We conjecture that both ID/OOD generalization ability of NASM results from its architecture, where coefficients and basis functions are explicitly disentangled. Such a structure may inherit the inductive bias from numerical basis expansion methods (e.g. (Kafash, Delavarkhalafi, and Karbassi 2014)), thus being more robust to distribution shifts.
For NASM in all synthetic environment experiments, we choose MLP as the backbone of Coefficient Net, Fourier adaptive basis, non-static coefficients, and summation aggregation. To justify these architecture choices, we perform an ablation study by changing or removing each of the modules, as displayed in Tab. 3. We use the abbreviation w.o. for ’without’, and w. for ’with’. The first row denotes the unchanged model, and the second and third rows are fixing basis functions, and using static (time-independent) Coefficient Net. These two modifications slightly lower the performance in both ID and OOD. The 4th row is Fourier SNO, i.e. applying the above two modifications together on NASM, which dramatically increases the error. The reason is that SNO uses a fixed Fourier basis, and thus requires the optimal control to be globally periodic for accurate interpolation, while Quadrotor control is non-periodic. If the basis of SNO changes to non-periodic, such as Chebyshev basis as in the 5th row, then the performance is covered. The result shows that the accuracy of SNO depends heavily on the choice of pre-defined basis function. In comparison, NASM is less sensitive to the choice of basis due to its adaptive nature, as the 6th row shows that changing the basis from Fourier to Chebyshev hardly changes the NASM’s performance. The 7th and 8th rows demonstrate that both replacing summation with a neural network aggregation and switching to a Convolutional network backbone do not improve the performance on Quadrotor.
| Modification | ID MAPE | OOD MAPE | |
|---|---|---|---|
| 1 | NASM | ||
| 2 | w.o. Adapt Params | ||
| 3 | w.o. Non-static Coef | ||
| 4 | SNO (Fourier) | ||
| 5 | SNO (Chebyshev) | ||
| 6 | w. Chebyshev | ||
| 7 | w. Neural Aggr | ||
| 8 | w. Conv |
Extended Experiment Result on Quadrotor
1) More Variables. In the previous experiments, only the cost function (target state) is changeable. Here, we add more variables to the network input, such that the cost function, dynamics (physical parameters e.g. wing length), and initial condition are all changeable. The in/out- distributions for dynamics and initial conditions are uniform distributions, designed similarly to that of the target state. The result is listed in Tab. 4.
| Model | Time(sec./instance) | ID MAPE | OOD MAPE |
|---|---|---|---|
| DM | |||
| PDP | |||
| NASM | |||
| DON | |||
| MLP | |||
| GEN | |||
| FNO |
2) Extreme OOD shifts and Transfer Learning. In addition to the OOD shifts in the previous experiments, we design some more extremely shifted distributions:
| Model | |||
|---|---|---|---|
| NASM | |||
| DON | |||
| MLP | |||
| GEN | |||
| FNO |
Tab. 5 shows the OOD MAPE on those distributions. From the table, one can observe that the performance of neural models decreases with more distribution shifts. When the distribution shift increases to , the results of neural models are almost unacceptable.
In practice, if large shift OOD reusability is required for some applications, we may assume a few training samples from OOD are available (i.e. few-shot). NCOs can be fine-tuned on the training samples from OOD to achieve better performance. This idea has been proposed for DeepONet transfer learning in (Goswami et al. 2022).
We follow the fine-tuning scheme proposed in (Goswami et al. 2022). We set the size of the OOD fine-tuning dataset and #epochs to be 20% of that of the ID training dataset. The learning rate is fixed at 0.001. The embedding network, basis function net, and the first two convolution blocks are all frozen during fine-tuning since we assume they keep the distribution invariant information.
| Model | |||
|---|---|---|---|
| NASM | |||
| DON | |||
| MLP | |||
| GEN | |||
| FNO |
Tab. 6 reveals that fine-tuning greatly improves neural model performance on extreme distribution shifts. Therefore, the availability of fine-tuning on extra data benefits the reusability of neural operators on OCP.
Real-world Dataset of Planar Pushing
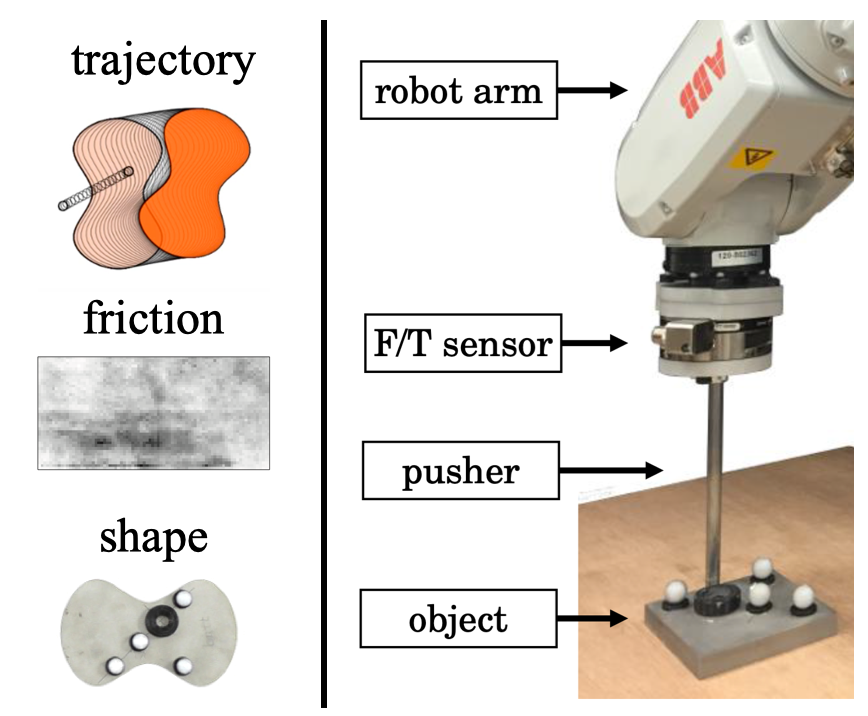
We present how to learn OC of a robot arm for pushing objects of varying shapes on various planar surfaces. We use the Pushing dataset (Yu et al. 2016), a challenging dataset consisting of noisy, real-world data produced by an ABB IRB 120 industrial robotic arm (Fig. 4, right part).
The robot arm is controlled to push objects starting from various contact positions and 9 angles (initial state), along different trajectories (target state functions), with 11 object shapes and 4 surface materials (dynamics). The control function is represented by the force exerted on to object. Left of Fig. 4 gives an overview of input variables.
We apply NASM to learn a mapping from a pushing OCP instance (represented by variables above) to the optimal control function. The input now is no longer the parameters of cost functional only, but parameters and representations of . The encoder is realized by different techniques for different inputs, such as Savitzky–Golay smoothing (Savitzky and Golay 1964) and down-sampling for target trajectories, mean and standard value extraction for friction map, and CNN for shape images.
We extract training data from ID, validation, and test data from both ID/OOD. The ID/OOD is distinguished by different initial contact positions of the arm and object. The accuracy metric MAPE is now defined as . We compare NASM performance only with neural baselines since the explicit expression of pushing OCP is unavailable, thus classical methods DM and PDP are not applicable. All neural models share the same encoder structure, while the parameters of the encoder are trained end-to-end individually for each model. The results are displayed in Tab. 7, from which one can observe that NASM outperforms all baselines in the ID MAPE and that NASM achieves the second lowest OOD MAPE, with a slight disadvantage against DON.
The design of NASM in the pushing environment is an adaptive Chebyshev basis, non-static Coefficient Net with Convolution backbone, and neuralized aggregation. The justification of the design is shown in Tab. 7. Its performance is insensitive to the choice of basis, as the second row reveals. Both the convolution backbone and the neuralized aggregation contribute to the high accuracy. A possible reason is that the control operator in the pushing dataset is highly non-smooth and noisy, thus a more complicated architecture with higher capability and flexibility is preferred.
| Model | ID MAPE | OOD MAPE |
|---|---|---|
| NASM | 0.108 ( 0.006) | 0.137 ( 0.007) |
| NASM(Fourier) | 0.113 ( 0.006) | 0.139 ( 0.009) |
| NASM(w.o. Conv) | 0.132 ( 0.008) | 0.151 ( 0.009) |
| NASM(w.o. NAggr) | 0.125 ( 0.007) | 0.172 ( 0.009) |
| DON | 0.117 ( 0.006) | 0.134 ( 0.008) |
| MLP | 0.128 ( 0.006) | 0.149 ( 0.008) |
| GEN | 0.209 ( 0.014) | 0.199 ( 0.015) |
| FNO | 0.131 ( 0.008) | 0.172 ( 0.009) |
4 Conclusion and Outlook
We have proposed an instance-solution operator perspective of OCPs, where the operator directly maps cost functionals to OC functions. We then present a neural operator NASM, with a theoretic guarantee on its approximation capability. Experiments show outstanding generalization ability and efficiency, in both ID and OOD settings. We envision the proposed model will be beneficial in solving numerous high-dimensional problems in the learning and control fields.
We currently do not specify the forms of problem instances (e.g. ODE/PDE-constrained OCP) or investigate sophisticated models for specific problems, which calls for careful designs and exploitation of the problem structures.
References
- Abdolazimi et al. (2021) Abdolazimi, O.; Shishebori, D.; Goodarzian, F.; Ghasemi, P.; and Appolloni, A. 2021. Designing a new mathematical model based on ABC analysis for inventory control problem: A real case study. RAIRO-operations research, 55(4): 2309–2335.
- Al-Tamimi, Lewis, and Abu-Khalaf (2008) Al-Tamimi, A.; Lewis, F. L.; and Abu-Khalaf, M. 2008. Discrete-time nonlinear HJB solution using approximate dynamic programming: Convergence proof. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 38(4): 943–949.
- Alet et al. (2019) Alet, F.; Jeewajee, A. K.; Villalonga, M. B.; Rodriguez, A.; Lozano-Perez, T.; and Kaelbling, L. 2019. Graph element networks: adaptive, structured computation and memory. In International Conference on Machine Learning, 212–222. PMLR.
- Anandkumar et al. (2020) Anandkumar, A.; Azizzadenesheli, K.; Bhattacharya, K.; Kovachki, N.; Li, Z.; Liu, B.; and Stuart, A. 2020. Neural operator: Graph kernel network for partial differential equations. In ICLR 2020 Workshop on Integration of Deep Neural Models and Differential Equations.
- Andersson et al. (2019) Andersson, J. A. E.; Gillis, J.; Horn, G.; Rawlings, J. B.; and Diehl, M. 2019. CasADi – A software framework for nonlinear optimization and optimal control. Mathematical Programming Computation, 11(1): 1–36.
- Bazaraa, Sherali, and Shetty (2013) Bazaraa, M. S.; Sherali, H. D.; and Shetty, C. M. 2013. Nonlinear programming: theory and algorithms. John Wiley & Sons.
- Bellman and Kalaba (1960) Bellman, R.; and Kalaba, R. 1960. Dynamic programming and adaptive processes: mathematical foundation. IRE transactions on automatic control, (1): 5–10.
- Bettiol and Bourdin (2021) Bettiol, P.; and Bourdin, L. 2021. Pontryagin maximum principle for state constrained optimal sampled-data control problems on time scales. ESAIM: Control, Optimisation and Calculus of Variations, 27: 51.
- Biegler and Zavala (2009) Biegler, L. T.; and Zavala, V. M. 2009. Large-scale nonlinear programming using IPOPT: An integrating framework for enterprise-wide dynamic optimization. Computers & Chemical Engineering, 33(3): 575–582.
- Bock and Plitt (1984) Bock, H. G.; and Plitt, K.-J. 1984. A multiple shooting algorithm for direct solution of optimal control problems. IFAC Proceedings Volumes, 17(2): 1603–1608.
- Boggs and Tolle (1995) Boggs, P. T.; and Tolle, J. W. 1995. Sequential quadratic programming. Acta numerica, 4: 1–51.
- Böhme and Frank (2017a) Böhme, T. J.; and Frank, B. 2017a. Direct Methods for Optimal Control, 233–273. Cham: Springer International Publishing. ISBN 978-3-319-51317-1.
- Böhme and Frank (2017b) Böhme, T. J.; and Frank, B. 2017b. Indirect Methods for Optimal Control, 215–231. Cham: Springer International Publishing. ISBN 978-3-319-51317-1.
- Chang, Roohi, and Gao (2019) Chang, Y.-C.; Roohi, N.; and Gao, S. 2019. Neural lyapunov control. Advances in neural information processing systems, 32.
- Chen and Chen (1995) Chen, T.; and Chen, H. 1995. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems. IEEE Transactions on Neural Networks, 6(4): 911–917.
- Chen, Shi, and Zhang (2018) Chen, Y.; Shi, Y.; and Zhang, B. 2018. Optimal control via neural networks: A convex approach. arXiv preprint arXiv:1805.11835.
- Cheng et al. (2020) Cheng, L.; Wang, Z.; Song, Y.; and Jiang, F. 2020. Real-time optimal control for irregular asteroid landings using deep neural networks. Acta Astronautica, 170: 66–79.
- Cohen (1995) Cohen, L. 1995. Time-frequency analysis, volume 778. Prentice hall New Jersey.
- Dai and Gluzman (2022) Dai, J. G.; and Gluzman, M. 2022. Queueing network controls via deep reinforcement learning. Stochastic Systems, 12(1): 30–67.
- Davis (1975) Davis, P. J. 1975. Interpolation and approximation. Courier Corporation.
- Dontchev and Zolezzi (2006) Dontchev, A. L.; and Zolezzi, T. 2006. Well-posed optimization problems. Springer.
- D’ambrosio et al. (2021) D’ambrosio, A.; Schiassi, E.; Curti, F.; and Furfaro, R. 2021. Pontryagin neural networks with functional interpolation for optimal intercept problems. Mathematics, 9(9): 996.
- Effati and Pakdaman (2013) Effati, S.; and Pakdaman, M. 2013. Optimal control problem via neural networks. Neural Computing and Applications, 23(7): 2093–2100.
- Fanaskov and Oseledets (2022) Fanaskov, V.; and Oseledets, I. 2022. Spectral Neural Operators. arXiv preprint arXiv:2205.10573.
- Gao, Kong, and Clarke (2013) Gao, S.; Kong, S.; and Clarke, E. M. 2013. dReal: An SMT solver for nonlinear theories over the reals. In Automated Deduction–CADE-24: 24th International Conference on Automated Deduction, Lake Placid, NY, USA, June 9-14, 2013. Proceedings 24, 208–214. Springer.
- Ghosh, Birrell, and De Angelis (2021) Ghosh, S.; Birrell, P.; and De Angelis, D. 2021. Variational inference for nonlinear ordinary differential equations. In International Conference on Artificial Intelligence and Statistics, 2719–2727. PMLR.
- Goswami et al. (2022) Goswami, S.; Kontolati, K.; Shields, M. D.; and Karniadakis, G. E. 2022. Deep transfer operator learning for partial differential equations under conditional shift. Nature Machine Intelligence, 1–10.
- Gühring, Kutyniok, and Petersen (2020) Gühring, I.; Kutyniok, G.; and Petersen, P. 2020. Error bounds for approximations with deep ReLU neural networks in W s, p norms. Analysis and Applications, 18(05): 803–859.
- He et al. (2019) He, X.; Li, J.; Mader, C. A.; Yildirim, A.; and Martins, J. R. 2019. Robust aerodynamic shape optimization—from a circle to an airfoil. Aerospace Science and Technology, 87: 48–61.
- Hewing et al. (2020) Hewing, L.; Wabersich, K. P.; Menner, M.; and Zeilinger, M. N. 2020. Learning-based model predictive control: Toward safe learning in control. Annual Review of Control, Robotics, and Autonomous Systems, 3: 269–296.
- Hwang et al. (2022) Hwang, R.; Lee, J. Y.; Shin, J. Y.; and Hwang, H. J. 2022. Solving pde-constrained control problems using operator learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, 4504–4512.
- Jia (2019) Jia, Y.-B. 2019. Quaternions. Com S, 477: 577.
- Jin et al. (2020) Jin, W.; Wang, Z.; Yang, Z.; and Mou, S. 2020. Pontryagin differentiable programming: An end-to-end learning and control framework. Advances in Neural Information Processing Systems, 33: 7979–7992.
- Kafash, Delavarkhalafi, and Karbassi (2014) Kafash, B.; Delavarkhalafi, A.; and Karbassi, S. 2014. A numerical approach for solving optimal control problems using the Boubaker polynomials expansion scheme. J. Interpolat. Approx. Sci. Comput, 3: 1–18.
- Khoo, Lu, and Ying (2021) Khoo, Y.; Lu, J.; and Ying, L. 2021. Solving parametric PDE problems with artificial neural networks. European Journal of Applied Mathematics, 32(3): 421–435.
- Kingma and Ba (2014) Kingma, D. P.; and Ba, J. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Kipf and Welling (2016) Kipf, T. N.; and Welling, M. 2016. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907.
- Kirk (2004) Kirk, D. E. 2004. Optimal control theory: an introduction. Courier Corporation.
- Kiumarsi et al. (2017) Kiumarsi, B.; Vamvoudakis, K. G.; Modares, H.; and Lewis, F. L. 2017. Optimal and autonomous control using reinforcement learning: A survey. IEEE transactions on neural networks and learning systems, 29(6): 2042–2062.
- Körkel* et al. (2004) Körkel*, S.; Kostina, E.; Bock, H. G.; and Schlöder, J. P. 2004. Numerical methods for optimal control problems in design of robust optimal experiments for nonlinear dynamic processes. Optimization Methods and Software, 19(3-4): 327–338.
- Krimsky and Collins (2020) Krimsky, E.; and Collins, S. H. 2020. Optimal control of an energy-recycling actuator for mobile robotics applications. In 2020 IEEE International Conference on Robotics and Automation (ICRA), 3559–3565. IEEE.
- Lanthaler, Mishra, and Karniadakis (2022) Lanthaler, S.; Mishra, S.; and Karniadakis, G. E. 2022. Error estimates for deeponets: A deep learning framework in infinite dimensions. Transactions of Mathematics and Its Applications, 6(1): tnac001.
- Lapin, Zhang, and Lapin (2019) Lapin, A.; Zhang, S.; and Lapin, S. 2019. Numerical solution of a parabolic optimal control problem arising in economics and management. Applied Mathematics and Computation, 361: 715–729.
- Lasota (1968) Lasota, A. 1968. A discrete boundary value problem. In Annales Polonici Mathematici, volume 20, 183–190. Institute of Mathematics Polish Academy of Sciences.
- Lewis, Vrabie, and Syrmos (2012) Lewis, F. L.; Vrabie, D.; and Syrmos, V. L. 2012. Optimal control. John Wiley & Sons.
- Li and Todorov (2004) Li, W.; and Todorov, E. 2004. Iterative linear quadratic regulator design for nonlinear biological movement systems. In ICINCO (1), 222–229. Citeseer.
- Li et al. (2020) Li, Z.; Kovachki, N. B.; Azizzadenesheli, K.; Bhattacharya, K.; Stuart, A.; Anandkumar, A.; et al. 2020. Fourier Neural Operator for Parametric Partial Differential Equations. In International Conference on Learning Representations.
- Lu et al. (2021) Lu, L.; Jin, P.; Pang, G.; Zhang, Z.; and Karniadakis, G. E. 2021. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3(3): 218–229.
- Mathiesen, Yang, and Hu (2022) Mathiesen, F. B.; Yang, B.; and Hu, J. 2022. Hyperverlet: A Symplectic Hypersolver for Hamiltonian Systems. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, 4575–4582.
- Mehrotra (1992) Mehrotra, S. 1992. On the implementation of a primal-dual interior point method. SIAM Journal on optimization, 2(4): 575–601.
- Nubert et al. (2020) Nubert, J.; Köhler, J.; Berenz, V.; Allgöwer, F.; and Trimpe, S. 2020. Safe and fast tracking on a robot manipulator: Robust mpc and neural network control. IEEE Robotics and Automation Letters, 5(2): 3050–3057.
- Paszke et al. (2019) Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. 2019. Pytorch: An imperative style, high-performance deep learning library. In Advances in neural information processing systems.
- Petersen and Voigtlaender (2020) Petersen, P.; and Voigtlaender, F. 2020. Equivalence of approximation by convolutional neural networks and fully-connected networks. Proceedings of the American Mathematical Society, 148(4): 1567–1581.
- Pontryagin (1987) Pontryagin, L. S. 1987. Mathematical theory of optimal processes. CRC press.
- Powell et al. (1981) Powell, M. J. D.; et al. 1981. Approximation theory and methods. Cambridge university press.
- Raissi, Perdikaris, and Karniadakis (2019) Raissi, M.; Perdikaris, P.; and Karniadakis, G. E. 2019. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics, 378: 686–707.
- Raissi, Yazdani, and Karniadakis (2020) Raissi, M.; Yazdani, A.; and Karniadakis, G. E. 2020. Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations. Science, 367(6481): 1026–1030.
- Rao (2009) Rao, A. V. 2009. A survey of numerical methods for optimal control. Advances in the Astronautical Sciences, 135(1): 497–528.
- Savitzky and Golay (1964) Savitzky, A.; and Golay, M. J. 1964. Smoothing and differentiation of data by simplified least squares procedures. Analytical chemistry, 36(8): 1627–1639.
- Shen et al. (2021) Shen, Z.; Liu, J.; He, Y.; Zhang, X.; Xu, R.; Yu, H.; and Cui, P. 2021. Towards out-of-distribution generalization: A survey. arXiv preprint arXiv:2108.13624.
- Spong, Hutchinson, and Vidyasagar (2020) Spong, M. W.; Hutchinson, S.; and Vidyasagar, M. 2020. Robot modeling and control. John Wiley & Sons.
- Tassa, Mansard, and Todorov (2014) Tassa, Y.; Mansard, N.; and Todorov, E. 2014. Control-limited differential dynamic programming. In 2014 IEEE International Conference on Robotics and Automation (ICRA), 1168–1175. IEEE.
- Tedrake (2022) Tedrake, R. 2022. Underactuated Robotics.
- Truesdell (1992) Truesdell, C. A. 1992. A First Course in Rational Continuum Mechanics V1. Academic Press.
- Wang, Bhouri, and Perdikaris (2021) Wang, S.; Bhouri, M. A.; and Perdikaris, P. 2021. Fast PDE-constrained optimization via self-supervised operator learning. arXiv preprint arXiv:2110.13297.
- Wang, Teng, and Perdikaris (2021) Wang, S.; Teng, Y.; and Perdikaris, P. 2021. Understanding and mitigating gradient flow pathologies in physics-informed neural networks. SIAM Journal on Scientific Computing, 43(5): A3055–A3081.
- Wang, Wang, and Perdikaris (2021) Wang, S.; Wang, H.; and Perdikaris, P. 2021. Learning the solution operator of parametric partial differential equations with physics-informed deeponets. Science advances, 7(40): eabi8605.
- Xie et al. (2018) Xie, S.; Hu, X.; Qi, S.; and Lang, K. 2018. An artificial neural network-enhanced energy management strategy for plug-in hybrid electric vehicles. Energy, 163: 837–848.
- Xiu and Hesthaven (2005) Xiu, D.; and Hesthaven, J. S. 2005. High-order collocation methods for differential equations with random inputs. SIAM Journal on Scientific Computing, 27(3): 1118–1139.
- Yu et al. (2018) Yu, B.; et al. 2018. The deep Ritz method: a deep learning-based numerical algorithm for solving variational problems. Communications in Mathematics and Statistics, 6(1): 1–12.
- Yu et al. (2016) Yu, K.; Bauza, M.; Fazeli, N.; and Rodriguez, A. 2016. More than a Million Ways to be Pushed. A High-Fidelity Experimental Data Set of Planar Pushing In: IEEE/RSJ IROS.
- Zhou (2020) Zhou, D.-X. 2020. Universality of deep convolutional neural networks. Applied and computational harmonic analysis, 48(2): 787–794.
- Zhou et al. (2022) Zhou, R.; Quartz, T.; De Sterck, H.; and Liu, J. 2022. Neural Lyapunov Control of Unknown Nonlinear Systems with Stability Guarantees. arXiv preprint arXiv:2206.01913.
- Zhu and Zabaras (2018) Zhu, Y.; and Zabaras, N. 2018. Bayesian deep convolutional encoder–decoder networks for surrogate modeling and uncertainty quantification. Journal of Computational Physics, 366: 415–447.
- Zhu et al. (2019) Zhu, Y.; Zabaras, N.; Koutsourelakis, P.-S.; and Perdikaris, P. 2019. Physics-constrained deep learning for high-dimensional surrogate modeling and uncertainty quantification without labeled data. Journal of Computational Physics, 394: 56–81.
Appendix A Algorithms
The data generation algorithm is listed in Alg. 1.
Input: Distribution of target state
Output: Dataset
Appendix B Related Works
OCP Solvers
Traditional numerical solvers are well developed over the decades, which are learning-free and often involve tedious optimization iterations to find an optimal solution.
Direct methods (Böhme and Frank 2017a) reformulate OCP as finite-dimensional nonlinear programming (NLP) (Bazaraa, Sherali, and Shetty 2013), and solve the problem by NLP algorithms, e.g. sequential quadratic programming (Boggs and Tolle 1995) and interior-point method (Mehrotra 1992). The reformulation essentially constructs surrogate models, where the state and control function (infinite dimension) is replaced by polynomial or piece-wise constant functions. The dynamics constraint is discretized into equality constraints. The direct methods optimize the surrogate models, thus the solution is not guaranteed to be optimal for the origin problem. Likewise, typical direct neural solvers (Chen, Shi, and Zhang 2018; Wang, Bhouri, and Perdikaris 2021; Hwang et al. 2022), termed as Two-Phase models, consist of two phases: 1) approximating the dynamics by a neural network (surrogate model); 2) solving the NLP via gradient descent, by differentiating through the network. The advantage of Two-Phase models against traditional direct methods is computational efficiency, especially in high-dimensional cases. However, the two-phase method is sensitive to distribution shift (see Fig. 1).
Indirect methods (Böhme and Frank 2017b) are based on Pontryagin’s Maximum Principle (PMP) (Pontryagin 1987). By PMP, indirect methods convert OCP (Eq. 1) into a boundary-value problem (BVP) (Lasota 1968), which is then solved by numerical methods such as shooting method (Bock and Plitt 1984), collocation method (Xiu and Hesthaven 2005), adjoint-based gradient descend (Effati and Pakdaman 2013; Jin et al. 2020). These numerical methods are sensitive to the initial guesses of the solution. Some indirect methods-based neural solvers approximate the finite-dimensional mapping from state to control (Cheng et al. 2020), or to co-state (Xie et al. 2018). The full trajectory of the control function is obtained by repeatedly applying the mapping and getting feedback from the system, and such sequential nature is the efficiency bottleneck. Another work (D’ambrosio et al. 2021) proposes to solve the BVP via a PINN, thus its trained network works only for one specific OCP instance.
Dynamic programming (DP) is an alternative, based on Bellman’s principle of optimality (Bellman and Kalaba 1960). It offers a rule to divide a high-dimensional optimization problem with a long time horizon into smaller, easier-to-solve auxiliary optimization problems. Typical methods are Hamilton-Jacobi-Bellman (HJB) equation (Al-Tamimi, Lewis, and Abu-Khalaf 2008), differential dynamical programming (DDP) (Tassa, Mansard, and Todorov 2014), which assumes quadratic dynamics and value function, and iterative linear quadratic regulator (iLQR) (Li and Todorov 2004), which assumes linear dynamics and quadratic value function. Similar to dynamic programming, model predictive control (MPC) synthesizes the approximate control function via the repeated solution of finite overlapping horizons (Hewing et al. 2020). The main drawback of DP is the curse of dimensionality on the number and complexity of the auxiliary problem. MPC alleviates this problem at the expense of optimality. Yet fast implementation of MPC is still under exploration and remains open (Nubert et al. 2020).
Differential Equation Neural solvers
A variety of networks have been developed to solve DE, including Physics-informed neural networks (PINNs) (Raissi, Perdikaris, and Karniadakis 2019), neural operators (Lu et al. 2021), hybrid models (Mathiesen, Yang, and Hu 2022), and frequency domain models (Li et al. 2020). We will briefly introduce the first two models for their close relevance to our work.
PINNs parameterize the DE solution as a neural network and learn the parameters by minimizing the residual loss and boundary condition loss (Yu et al. 2018; Raissi, Perdikaris, and Karniadakis 2019). PINNs are similar to those numerical methods e.g. the finite element method in that they replace the linear span of a finite set of local basis functions with neural networks. PINNs usually have simple architectures (e.g. MLP), although they have produced remarkable results across a wide range of areas in computational science and engineering (Raissi, Yazdani, and Karniadakis 2020; Zhu et al. 2019). However, these models are limited to learning the solution of one specific DE instance, but not the operator. In other words, if the coefficients of the DE instance slightly change, then a new neural network needs to be trained accordingly, which is time-consuming. Another major drawback of PINNs, as pointed out by (Wang, Teng, and Perdikaris 2021), is that the magnitude of two loss terms (i.e.residual loss and boundary condition loss) is inherently imbalanced, leading to heavily biased predictions even for simple linear equations.
Neural operators regards DE as an operator that maps the input to the solution. Learning operators using neural networks was introduced in the seminal work (Chen and Chen 1995). It proposes the universal approximation theorem for operator learning, i.e. a network with a single hidden layer can approximate any nonlinear continuous operator. (Lu et al. 2021) follows this theorem by designing a deep architecture named DeepONet, which consists of two networks: a branch net for input functions and a trunk net for the querying locations in the output space. The DeepONet output is obtained by computing the inner product of the outputs of branch and trunk networks. The DeepONet can be regarded as a special case of our NASM, since DeepONet is equivalent to a NASM without the convolution blocks and the projecting network. And our analysis of optimal control error bound is partly inspired by (Lanthaler, Mishra, and Karniadakis 2022), providing error estimation of DeepONet.
In addition, there exist many neural operators with other architectures. For example, another type of neural operator is to parameterize the operator as a convolutional neural network (CNN) between the finite-dimensional data meshes (Zhu and Zabaras 2018; Khoo, Lu, and Ying 2021). The major weakness of these models is that it is impossible to query solutions at off-grid points. Moreover, graph neural networks (GNNs) (Kipf and Welling 2016) are also applied in operator learning (Alet et al. 2019; Anandkumar et al. 2020). The key idea is to construct the spacial mesh as a graph, where the nodes are discretized spatial locations, and the edges link neighboring locations. Compared with CNN-based models, the graph operator model is less sensitive to resolution and is capable of inferencing at off-grid points by adding new nodes to the graph. However, its computational cost is still high, growing quadratically with the number of nodes. Another category of neural operators is Fourier transform based (Anandkumar et al. 2020; Li et al. 2020). The models learn parametric linear functions in the frequency domain, along with nonlinear functions in the time domain. The conversion between those two domains is realized by discrete Fourier transformation. The approximator architecture of NASM is inspired by the Fourier neural operators, and we replace the matrix product in the frequency domain with the convolution in the original domain.
Appendix C Approximation Error Theorems
We give the estimation for the approximation error of the proposed model. The theoretic result guarantees that there exists a neural network instance of NASM architecture approximating the operator to arbitrary error tolerance. Furthermore, the size and depth of such a network are upper-bounded. The error bound will be compared with the DON error bound derived in (Lanthaler, Mishra, and Karniadakis 2022). The technical line of our analysis is inspired by (Lanthaler, Mishra, and Karniadakis 2022) which provides error estimation for DON’s three components: encoder, approximation, and reconstructor.
Definition and Decomposition of Errors
For fair and systematic comparison, we also decompose the architecture of NASM into three components. The encoder aims to convert the infinite-dimensional input to a finite vector, as introduced in the main text. The approximator of NASM is the coefficient network that produces the (approximated) coefficients. The reconstructor is the basis functions and the aggregation, that reconstructs the optimal control via the coefficients. In this way, the approximation error of NASM can also be decomposed into three parts: 1) encoder error, 2) approximator error, and 3) reconstructor error.
For ease of analysis, the error of the encoder is temporally not considered and is assumed to be zero. The reason is that the design of the encoder is more related to the problem setting instead of the neural operator itself. In our experiment, all neural operators use the same encoder, thus the error incurred by the encoder should be almost the same. Therefore, assuming the zero encoder error is a safe simplification. In our assumption, for a given encoder , there exists an inverse mapping , such that . The non-zero encoder error is analyzed in Appx D.
For a reconstructor , its error is estimated by the mismatch between and its approximate inverse mapping, projector , weighted by push-forward measure .
| (6) | |||||
Intuitively, such reconstructor error quantifies the information loss induced by . An ideal without any information loss should be invertible, i.e. its optimal inverse is exactly , thus we have .
Given the encoder and reconstructor, and denote the encoder output is , the error induced by approximator is defined as the distance between the approximator output and the optimal coefficient vector, weighted on push-forward measure :
| (7) |
With the definitions above, we can estimate the approximation error of our NASM by the error of each of its components, as stated in the following theorem (see detailed proof in Appendix D):
Theorem 2 (Decomposition of NASM Approximation Error).
Suppose the cost functional is Lipschitz continuous, with Lipschitz constant . Define constant The approximation error (Eq. 2) of a NASM is upper-bounded by
| (8) |
Estimation of Decomposed Errors
The reconstructor error of NASM reduces to the error of interpolation by basis functions, which is thoroughly studied in approximation theory (Davis 1975; Powell et al. 1981). For the Fourier basis, we restate the existing result to establish the following theorem:
Theorem 3 (Fourier Reconstructor Error).
If defines a Lipschitz mapping ,for some , with then there exists a constant , such that for any , the Fourier basis with the summation aggregation and the associated reconstruction satisfies:
| (9) |
Furthermore, the reconstruction satisfy .
is a Sobolev space with degrees of regularity and norm. The proof (omitted here) is based on an observation that a smooth function (i.e. with large ) changes slowly with time, having small (exponentially decaying) coefficients in the high frequency.
Next, the error bound of the approximator will be presented. Notice that the approximator learns to map between two vector spaces using MLP, whose error estimation is well-studied in deep learning theory. One of the existing works (Gühring, Kutyniok, and Petersen 2020) derives the estimation based on the Sobolev regularity of the mapping. We extend their result to both MLP and Convolution (Appendix D). And the approximator error can be directly obtained from those results. We present the MLP-backbone approximator error as follows, and the Convolution-backbone error can be similarly derived.
Theorem 4 (Approximator Error (MLP backbone)).
Given operator , encoder , and reconstructor , let denote the corresponding projector. If for some , the following bound is satisfied: then there exists a constant , such that for any , there exists an approximator implemented by MLP such that:
| (10) |
Note that is defined as the number of trainable parameters of a neural network, and denotes the number of hidden layers.
In summary, we have proved that the approximation error is bounded by the sum of the reconstructor and approximator errors. Those errors can hold under arbitrary small tolerance, with bounded size and depth. The theorems hold as long as some integrative and continuous conditions are satisfied (Dontchev and Zolezzi 2006), which is trivial in many real-world continuous OCPs.
Comparasion with DeepONet Error
For fairness, we assume the DON uses the same encoder and network backbone as the NASM. Then the approximator error and the encoder error of both operators should be the same. We only need to compare the reconstructor error.
The error of DeepONet Reconstructor is analyzed in a previous work (Lanthaler, Mishra, and Karniadakis 2022), by assuming the DeepONet trunk-net learns an approximated Fourier basis. We cite the result to establish the following theorem:
Theorem 5 (DeepONet Reconstructor Error (Lanthaler, Mishra, and Karniadakis 2022)).
If defines a Lipschitz mapping ,for some , with , then there exists a constant , such that for any , there exists a trunk net (i.e. the basis function net) and the associated reconstruction satisfies:
| (11) | |||||
| (12) | |||||
| (13) |
Furthermore, the reconstruction and the optimal projection satisfy .
One can observe that the DON reconstructor error has the same form as that of NASM. However, the DON reconstructor requires a neural network (trunk-net) to implement basis functions, while NASM uses a pre-defined Fourier basis. In the degenerated form of the NASM, i.e. without adaptive parameters and neural aggregations, the NASM reconstructor has no learnable parameters. In this sense, NASM can achieve the same error bound with fewer parameters, compared with DON.
Appendix D Mathematical Preliminaries and Proofs
Preliminaries on Sobolev Space
For an open subset of and , the Sobolev space is defined by
where , and the derivatives are considered in the weak sense. is a Banach space if its norm is defined as (Sobolev norm):
In the special case is denoted by , that is, a Hilbert space for the inner product
Error estimation of MLP and CNN
The fundamental neural modules of NASM are MLP and CNN, thus the error estimation of NASM entails the error estimation of those two modules. In this section, we cite and extend their error analysis from previous work.
MLP
Firstly, the error bound of an MLP approximating a mapping in vector spaces is well-studied in the deep learning theory. One of the existing works (Gühring, Kutyniok, and Petersen 2020) derives the estimation based on the Sobolev regularity of the mapping. We cite the main result as the following lemma (notation modified for consistency):
Lemma 6 (Approximation Error of one-dimensional MLP (Gühring, Kutyniok, and Petersen 2020)).
Let , and , then there exists a constant , with the following properties: For any function with m-dimensional input and one-dimensional output in subsets of the Sobolev space :
and for any ,there exists a ReLU MLP such that:
and:
However, such error bounds of one-dimensional MLP can not be directly applied to an MLP with -dimensional output. A -dimensional MLP can not be represented by simply stacking independent one-dimensional output networks and concatenating the outputs. The key difference lies in the parameter sharing of hidden layers. To fill the gap and estimate the error of , we design a special structure of MLP without parameter sharing, as explained below.
Given independent one-dimensional output networks , denote the weight matrix of the -th layer of the as . The weight matrix of -th layer of the -dimensional MLP , denoted as , can be constructed as:
The weight of first layer is a vertical concatenation of . And the weight of any remaining layer is a block diagonal matrix, with the main-diagonal blocks being . It is easy to verify that such an approximator is computationally equivalent to the stacking of independent one-dimensional output networks .
Let , (i.e. ), and , then by Lemma 6 the approximation error is bounded by:
And the depth and size of can be calculated by comparing with any :
The above result can be summarized as another lemma:
Lemma 7 (Approximation Error of -dimensional MLP).
Let , then there exists a constant , with the following properties: For any function with -dimensional input and -dimensional output in subsets of the Hilbert space : and for any ,there exists a ReLU MLP such that:
CNN
Next, we are going to derive a similar error bound for CNNs, which has not been widely studied before. A previous work (Zhou 2020) derives the error bound for one-dimensional CNNs with a single channel, and the results do not apply in our case. Another related work (Petersen and Voigtlaender 2020) established the equivalence of approximation properties between MLPs and CNNs, as the following lemma:
Lemma 8 (Equivalence of approximation between MLPs and CNNs (Petersen and Voigtlaender 2020)).
For any input/output channel number , input size , function , and error :
(1) If there is an MLP with and satisfying , then there exists a CNN with and , and such that .
(2) If there exists a CNN with and satisfying , then there exists an MLP with and and such that .
Proof idea: The general proof idea of part (1) is to construct a lifted CNN from the MLP, such that each neuron of the MLP is replaced by a full channel of CNN, and that the lifted CNN computes an equivariant version of the MLP. And the proof of part (2) is based on the fact that convolutions are special linear maps.
The equivalence lemma (Lemma 8, Part (1)), combined with the approximation error of MLPs(Lemma 7), leads naturally to the approximation error of CNNs:
Lemma 9 (Approximation Error of CNN).
Let input/output channel number , input size , and , there exists a constant with the following properties: for any function , and error , there exists a CNN such that:
Proof of Theorem 8: Decomposition of NASM Approximation Error
Proof.
Firstly, extract the constant, and decompose the error by triangle inequality (subscript of norm omitted):
The first term is exactly the reconstructor error , by definition of push-forward:
And the second term is related to the approximator error :
∎
Extension to Non-zero Encoder Error
The approximation error estimation can be naturally extended to model non-zero encoder error, as derived in (Lanthaler, Mishra, and Karniadakis 2022). For an encoder , its error is estimated by the distance to its optimal approximate inverse mapping, decoder , weighted by measure .
| (14) | |||||
Similar to reconstructor error, this error quantifies the information loss during encoding. An ideal encoder should be invertible, i.e. the decoder , thus we have .
The estimation of depends on the specific architecture of the encoder. If the encoder can be represented by a composition of MLP and CNN, then one can derive an estimation using the lemmas in Appx. D. The error of point-wise evaluation is discussed in previous work of DeepONet (Lanthaler, Mishra, and Karniadakis 2022, Sec.3.5) and (Lu et al. 2021, Sec.3). However, the estimation of more complex encoders (e.g. the Savitzky–Golay smoothing we used in the pushing dataset) is slightly out of the scope of this paper.
When the encoder error is non-zero, the definition of the approximator error (Eq. 7) should be modified accordingly, by replacing to :
| (15) |
Appendix E Environment Settings
| System | Description | # | # |
|---|---|---|---|
| Pendulum | single pendulum | 1 | 2 |
| RobotArm | two-link robotic arm | 1 | 4 |
| CartPole | one pendulum with cart | 1 | 4 |
| Quadrotor | helicopter with 4 rotors | 4 | 9 |
| Rocket | 6-DoF rocket | 3 | 9 |
| Pushing | pushing objects on various surfaces | 1 | 3 |
Pendulum
where state , denoting the angle and angular velocity of the pendulum respectively, and control is the external torque. The initial condition , i.e. the pendulum starts from the lowest position with zero velocity. The cost functional consists of two parts: state mismatching penalty and control function regularization, and are balancing coefficients. Other constants are: , , , .
Robot Arm
The RobotArm (also named Acrobot) is a planar two-link robotic arm in the vertical plane, with an actuator at the elbow. The state is , where is the shoulder joint angle, and is the elbow (relative) joint angle, denotes their angular velocity respectively. The control is the torque at the elbow. Note that the last equation is the manipulator equation, where is the inertia matrix, captures Coriolis forces, and is the gravity vector. The details of the derivation can be found in (Spong, Hutchinson, and Vidyasagar 2020, Sec. 6.4).
The initial condition , and the target state baseline . The cost functional coefficients are . Other constants are: mass of two links , gravitational acceleration , links length , distance from joint to the center of mass , moment of inertia .
Cart-Pole
In the CartPole system, an un-actuated joint connects a pole(pendulum) to a cart that moves along a frictionless track. The pendulum is initially positioned upright on the cart, and the goal is to balance the pendulum by applying horizontal forces to the cart. The state is , where is the horizontal position of the cart, is the counter-clockwise angle of the pendulum, velocity and angular velocity of cart and pendulum respectively. We refer the reader to (Tedrake 2022, Sec. 3.2) for the derivation of the above equations.
The initial condition , and the target state baseline . The cost functional coefficients are . Other constants are: mass of cart and pole , gravitational acceleration , pole length .
Quadrotor
This system describes the dynamics of a helicopter with four rotors. The state consists of three parts: position , velocity , and angular velocity . The control is the thrusts of the four rotating propellers of the quadrotor. is the unit quaternion (Jia 2019) representing the attitude(spacial rotation) of quadrotor w.r.t. the inertial frame. is the moment of inertia in the quadrotor’s frame, and is the torque applied to the quadrotor. Our setting is similar to (Jin et al. 2020, Appx. E.1), but we exclude the quaternion from the state.
The derivation is straightforward. The first two equations are Newton’s laws of motion, and the third equation is time-derivative of quaternion (Jia 2019, Appx. B), and the last equation is Euler’s rotation equation (Truesdell 1992, Sec. I.10). The coefficient matrices and operators used in the equations are defined as follows:
We set the initial state , the initial quaternion , and the target state baseline . Cost functional coefficients , . Other constants are configured as: mass , wing length , moment of inertia , z-axis torque constant .
Rocket
The rocket system models a 6-DoF rocket in 3D space. The formulation is very close to the Quadrotor mentioned above. The state is same as that of Quadrotor, but the control is slightly different. Here denotes the total thrust in 3 dimensions. Accordingly, the torque is changed to:
We set the initial state , the initial quatenion , and the target state baseline . The cost functional coefficients , . Other constants are configured as: mass , rocket length , the moment of inertia
Pushing
In this dataset, the robot executes an open-loop straight push along a straight line of 5 cm, with different shapes of objects, materials of surface, velocity, accelerations, and contact positions and angles, see Fig. 5 for details.

The control and state trajectories are recorded at 250 Hz. The length of the recorded time horizon varies among samples, due to the difference in velocity and acceleration. We select acceleration , with initial velocity . Then define time horizon , and extract 110 time indices per instance.
The input to the encoder is 4167-dim, including a 768-dim gray-scale image of the shape, 3280-dim friction map matrix, 110-dim trajectory, and 9-dim other parameters (e.g. mass and moment of inertia). The input to the neural network (including CNN) is 801-dim, and the encoded vector is 44-dim.
Appendix F Details on Implementations
For all the systems, we have 2,000 samples in each ID/OOD validation set and 100 problems in each ID/OOD benchmark set. The size of the training set varies among systems. We set 4 convolution blocks, each with 4 kernels, and the kernel length is 16. Other detailed settings are displayed in Table 9. Note that the hyper-parameter settings may not be optimal, since they are not carefully tuned.
| System | #Params | #Train Data | #Epochs |
|---|---|---|---|
| Pendulum | 3153 | ||
| RobotArm | 1593 | ||
| CartPole | 3233 | ||
| Quadrotor | 13732 | ||
| Rocket | 10299 | ||
| Pushing | 13174 | ||
| Brachistochrone | 3153 | ||
| Zermelo | 4993 |
PDP, DM, and synthetic control systems are implemented in CasADi (Andersson et al. 2019), which are adapted from the code repository222https://github.com/wanxinjin/Pontryagin-Differentiable-Programming. For classical methods, the dynamics are discretized by Euler method. To limit the running time, we set the maximum number of iterations of PDP to 2,500.
NASM and other neural models are implemented in PyTorch (Paszke et al. 2019). The DON number of layers is tuned in the range of for each environment, to achieve the best performance. For MLP, hyper-parameters are the same or as close as that of DON. We adjust the width of the MLP layer to reach almost the same number of parameters. For FNO333https://github.com/zongyi-li/fourier˙neural˙operator, we set the number of Fourier layers to 4 as suggested in the open-source codes, and tune the network width such that the number of parameters is in the same order as that of NASM. Notice that the original FNO outputs function values at fixed time indices, which is inconsistent with our experiment setting. Thus we slightly modify it by adding time indices to its input. For GEN444https://github.com/FerranAlet/graph˙element˙networks, we set 9 graph nodes uniformly spaced in time (or space) horizon, and perform 3 graph convolution steps on them. The input function initializes the node features at time index (multiplied by weights). For any time index , the GEN output is defined as the weighted average of all node features. Both input/output weights are softmax of negative distances between and node positions.
For fairness of running time comparison, all training/testing cases are executed on an Intel i9-10920X CPU, without GPU.
Appendix G More Experiment Results on Synthetic Environment
| Model | Time(sec./instance) | ID MAPE | OOD MAPE |
|---|---|---|---|
| DM | |||
| PDP | |||
| NASM | |||
| DON | |||
| MLP | |||
| GEN | |||
| FNO |
| Model | Time(sec./instance) | ID MAPE | OOD MAPE |
|---|---|---|---|
| DM | |||
| PDP | |||
| NASM | |||
| DON | |||
| MLP | |||
| GEN | |||
| FNO |
| Model | Time(sec./instance) | ID MAPE | OOD MAPE |
|---|---|---|---|
| DM | |||
| PDP | |||
| NASM | |||
| DON | |||
| MLP | |||
| GEN | |||
| FNO |
| Model | Time(sec./instance) | ID MAPE | OOD MAPE |
|---|---|---|---|
| DM | |||
| PDP | |||
| NASM | |||
| DON | |||
| MLP | |||
| GEN | |||
| FNO |
Influence of Number of Training Samples
We test the performance of NASM and other neural operators as a function of training examples on the Quadrotor environment and display it in Table 14. As expected, the result shows that performance generally improves when the number of training samples increases. However, even when the samples are very limited (e.g. only 2000 samples), the results are still acceptable. There is a trade-off between available optimal trajectories and the generalization performance.
| Model | 2000 | 4000 | 6000 | 8000 | 10000 |
|---|---|---|---|---|---|
| NASM | |||||
| DON | |||||
| MLP | |||||
| GEN | |||||
| FNO |
Appendix H Extended Experiments on OCP with Analytical Solutions
Brachistochrone
The Brachistochrone is the curve along which a massive point without initial speed must move frictionlessly in a uniform gravitational field so that its travel time is the shortest among all curves connecting two fixed points . Formally, it can be formulated as the following OCP:
| (17a) | |||||
| s.t. | (17b) | ||||
| (17c) | |||||
And the optimal solution is defined by a parametric equation:
where the are determined by the boundary condition .
We want to examine the performance of the Instance-Solution operator using the analytical optimal solution. The x-coordinate of endpoints is fixed as , discretized uniformly into 100 intervals. Then the OCP instance is uniquely determined by , which is defined as the input of neural operators. The in-distribution(ID) is and out-of-distribution (OOD) is . The training data is still generated by the direct method(DM), not the analytical solution. The performance metric MAPE denotes the distance with the analytical solution.
The results are displayed in Table 15. The NASM backbone achieves the best ID MAPE and the second-best OOD MAPE, with the shortest running time. All neural operators have performance close to baseline solver DM, demonstrating the effectiveness of our Instance-Solution operator framework. It is interesting that the FNO backbone has a better OOD MAPE than DM, although it is trained by DM data. This result may indicate that the Instance-Solution operator can learn a more accurate solution from less accurate supervision data.
| Model | Time(sec./instance) | ID MAPE | OOD MAPE |
|---|---|---|---|
| DM | |||
| NASM | |||
| DON | |||
| MLP | |||
| GEN | |||
| FNO |
Zermelo’s Navigation Problem
Zermelo’s navigation problem searches for the optimal trajectory and the associated guidance of a boat traveling between two given points with minimal time. Suppose the speed of the boat relative to the water is a constant . And the is the heading angle of the boat’s axis relative to the horizontal axis, which is defined as the control function. Suppose are the speed of currents along directions. Then the OCP is formalized as:
| (18a) | |||||
| s.t. | (18b) | ||||
| (18c) | |||||
| (18d) | |||||
| (18e) | |||||
The analytical solution derived from PMP is an ODE, named Zermelo’s navigation formula:
| (19) |
In our experiment, we simplify as linear function , where are parameters. And we fix the initial point . Then an OCP instance is uniquely defined by a tuple , which is defined as the input of our Instance-Solution operator. For the ID and OOD, we first define a base tuple , then add with noises and for ID and OOD respectively. Again, all operators are trained with direct method(DM) solution data, and MAPE evaluates the distance toward the analytical solution.
The results are displayed in Table 16. The NASM backbone has the best performance in time, ID MAPE and OOD MAPE. Most neural operators have close ID performance to DM, supporting the feasibility of the Instance-Solution operator framework.
| Model | Time(sec./instance) | ID MAPE | OOD MAPE |
|---|---|---|---|
| DM | |||
| NASM | |||
| DON | |||
| MLP | |||
| GEN | |||
| FNO |
Appendix I Future Direction: Enforcing the Constraints
In the current setting of Instance-Solution operators, boundary conditions can not be exactly enforced, since the operators are set to be purely data-driven and physics-agnostic. Instead, the operators approximately satisfy the boundary conditions by learning from the reference solution. Such a physics-agnostic setting is designed (and reasonable) for scenarios where explicit expressions of dynamics and boundary conditions are unavailable (e.g. the Pusher experiments in Section 3.2). However, our Instance-Solution operator framework may also be applied to a physics-informed setting, by changing the network backbone to the Physics-informed neural operator (Wang, Wang, and Perdikaris 2021).
And there are more important constraints in practice, such as the input constraints (e.g. maximum thrusts of quadrotor) and state constraints (e.g. quadrotor with obstacles. In our paper, they are formulated in the form of function space. Take the state for example, we define , where is its function space, and is the full Lebesgue space. Then represents the unconstrained states, and denotes constrained states. The constrained state and control can be naturally incorporated into the PMP (Bettiol and Bourdin 2021), thus they can be modeled in our Instance-Solution framework. Again, these constraints are satisfied approximately in our model.
Inspired by the recent works that use SMT solver (Gao, Kong, and Clarke 2013) to guarantee Lyapunov stability for unknown systems (Chang, Roohi, and Gao 2019; Zhou et al. 2022), we propose a possible approach to provably satisfy the OCP constraints. Given a trained neural operator, the domain of OCP instances, and constraints, we can easily establish a first-order logic formula over real numbers, and then check the formula via the SMT solver. The solver will either prove that the neural operator satisfies all constraints for all instances within the domain or generate some counterexamples that further enhance the training dataset. If it is the latter case, the operator will be re-trained on the enhanced dataset, until the SMT solver proves that it satisfies all constraints.