Optimal consumption under a drawdown constraint over a finite horizon
Abstract
This paper studies a finite horizon utility maximization problem on excessive consumption under a drawdown constraint. Our control problem is an extension of the one considered in Angoshtari et al. (2019) to the model with a finite horizon and an extension of the one considered in Jeon and Oh (2022) to the model with zero interest rate. Contrary to Angoshtari et al. (2019), we encounter a parabolic nonlinear HJB variational inequality with a gradient constraint, in which some time-dependent free boundaries complicate the analysis significantly. Meanwhile, our methodology is built on technical PDE arguments, which differs from the martingale approach in Jeon and Oh (2022). Using the dual transform and considering the auxiliary variational inequality with gradient and function constraints, we establish the existence and uniqueness of the classical solution to the HJB variational inequality after the dimension reduction, and the associated free boundaries can be characterized in analytical form. Consequently, the piecewise optimal feedback controls and the time-dependent thresholds for the ratio of wealth and historical consumption peak can be obtained.
Keyword: Optimal consumption, drawdown constraint, parabolic variational inequality, gradient constraint, free boundary.
1 Introduction
Optimal portfolio and consumption via utility maximization has always been one of the core research topics in quantitative finance. Starting from the seminal works Merton (1969) and Merton (1971), a large amount of studies can be found in the literature by considering various incomplete market models, trading constraints, risk factors, etc. One notable research direction is to refine the measurement of consumption performance by encoding the impact of past consumption behavior. The so-called addictive habit formation preference recommends that the utility shall be generated by the difference between the current consumption rate and the historical weighted average of the past consumption. In addition, the infinite marginal utility mandates the addictive habit formation constraint that the consumption level needs to stay above the habit formation level, representing that the agent’s standard of living can never be compromised. Along this direction, fruitful results can be found in various market models, see among Constantinides (1990), Detemple and Zapatero (1992), Schroder and Skiadas (2002), Munk (2008), Englezos and Karatzas (2009), Yu (2015), Yu (2017), Yang and Yu (2022), Angoshtari et al. (2022), Bo et al. (2022), Angoshtari et al. (2023) and references therein.
Another rapidly growing research stream is to investigate the impact of the past consumption maximum instead of the historical average. The pioneering work Dybvig (1995) examines an extension of Merton’s problem under a ratcheting constraint on consumption rate such that the consumption control needs to be non-decreasing. Arun (2012) later generalizes the model in Dybvig (1995) by considering a drawdown constraint such that the consumption rate can not fall below a proportion of the past consumption maximum. Angoshtari et al. (2019) revisit the problem by considering a drawdown constraint on the excessive dividend rate up to the bankruptcy time, which can be regarded as an extension of the problem in Arun (2012) to the model with zero interest rate. Jeon and Park (2021) further extend the work in Arun (2012) by considering general utility functions using the martingale duality approach where the dual optimal stopping problem is examined therein. Tanana (2021) employs the general duality approach and establishes the existence of optimal consumption under a drawdown constraint in incomplete semimartingale market models. Jeon and Oh (2022) recently generalizes the approach in Jeon and Park (2021) to the model with a finite horizon and addresses the existence of a solution to the dual optimal stopping problem.
On the other hand, inspired by the time non-separable preference rooted in the habit formation preference, some recent studies also incorporate the past consumption maximum into the utility function as an endogenous reference level. Guasoni et al. (2020) first adopt the Cobb-Douglas utility that is defined on the ratio between the consumption rate and the past consumption maximum and obtain the feedback controls in analytical form. Deng et al. (2022) choose the same form of the linear habit formation preference and investigate an optimal consumption problem when the difference between the consumption rate and the past spending peak generates the utility. Later, the preference in Deng et al. (2022) is generalized to an S-shaped utility in Li et al. (2021) to account for the agent’s loss aversion over the relative consumption. Liang et al. (2022) extends the work in Deng et al. (2022) by considering the change of risk aversion parameter concerning the reference level where an additional drawdown constraint is also required. Li et al. (2022) incorporates the dynamic life insurance control and expected bequest with an additional drawdown constraint on the consumption control.
As an important add-on to the existing literature, the present paper revisits the optimal excessive consumption problem under drawdown constraint as in Angoshtari et al. (2019), however, with a finite investment horizon. We summarize the main contributions of the present paper as two-fold:
-
(i)
From the modelling perspective, it is well documented that heterogenous agents may have diverse choices of investment horizons in practice. In fact, as the agent’s time horizon changes, the risk tolerance should be adjusted accordingly. Typically, agents seek more stable assets for short-term horizon and would call for a more aggressive strategy for the longer-term investment. Our model and research outcomes to incorporate a terminal horizon provide the flexibility to meet versatile needs in applications with different choices of investment horizons.
Similar to Angoshtari et al. (2019), we adopt the classical power utility with the relative risk aversion coefficient . On one hand, many empirical studies suggest that the risk aversion of the agent should be relatively constant over wealth levels, which is an important merit of the power utility function. On the other hand, the power utility function enjoys the homogeneity, which enables us to reduce the dimension of the HJB equation by changing variables (see (2.6)). As a result, it is sufficient for us to focus on one state variable in studying the HJB equation and its dual PDE, which significantly simplifies the technical proofs to establish the regularity of the solution and the analytcial characterization of the time-dependent free boundary curves.
-
(ii)
From the methodology perspective, we encounter the associated parabolic HJB variational inequality with gradient constraint. It is well known that the global regularity of the parabolic problem requires a more delicate analysis of the time-dependent free boundaries and the smooth fit conditions. Some previous arguments in Angoshtari et al. (2019) crucially rely on the constant free boundary points as well as some explicit expressions of the value function, which are evidently not applicable in our framework due to time dependence. The present paper contributes to some new and rigorous proofs to establish the existence and the uniqueness of the classical solution to the associated HJB variational inequality (2.30) (see Theorem 4.1). Moreover, to verify that the dual transform is well defined, we can show that the solution is indeed increasing and concave in (see Lemma 2.3).
We stress that, in many existing studies using the dual transform, see Chen et al. (2012), Chen and Yi (2012), Dai and Yi (2009), Guan et al. (2019) among others, the dual domain is often the entire , which facilitates some classical PDE arguments. In our framework, due to the drawdown constraint (see (2.1) and (2.2) for the description of the constraint), there exists a threshold for the ratio of the wealth level and the past consumption peak such that the minimum consumption plan needs to maintain at a subsistence level (see (2.23)) whenever the ratio falls below that threshold. As a result, the left boundary is mapped to an unknown finite boundary , . Employing the boundary condition at in (2.41), we extend the variational inequality with a gradient constraint to an auxiliary variation inequality (3.1) with both function and gradient constraints in the unbounded domain . We can then apply several further transformations (see Propositions 3.8, 3.10 and 3.11) and modify some technical arguments in Chen et al. (2019) and Chen and Yi (2012) to establish the existence and uniqueness of the solution in regularity to the primal parabolic HJB variational inequality (see Theorem 4.1). More importantly, we provide some tailor-made and technical arguments to characterize the associated time-dependent free boundaries in analytical form such that the smooth fit conditions hold (see Theorem 4.2).
With the help of our new PDE results, we can derive the optimal consumption and portfolio in piecewise feedback form and identify all analytical time-dependent thresholds for the ratio between the wealth level and the past consumption maximum, dividing the domain into three regions for different consumption behaviors (see Theorem 2.1). In addition, the analytical threshold functions allow us to theoretically verify their quantitative dependence on the constraint parameter .
The rest of the paper is organized as follows. In Section 2, we introduce the market model and the utility maximization problem under a consumption drawdown constraint. By dimension reduction using the homogeneity of power utility, we formulate the associated HJB variational inequality and its dual problem. In Section 3, we first analyze the dual linear parabolic variational inequality by considering some auxiliary problems with gradient and function constraints. By showing the existence and uniqueness of the solution to the auxiliary problems and characterizing their free boundaries, we obtain the unique classical solution to the dual HJB variational inequality. In Section 4, using the results from the dual problem, we establish the unique classical solution to the primal HJB variational inequality and verify the optimal feedback controls and all associated time-dependent thresholds in analytical form. In Section 5, we conclude our theoretical contributions and discuss some future research directions.
2 Market Model and Problem Formulation
2.1 Model setup
Let be a standard filtered probability space, where satisfies the usual conditions. We consider a financial market consisting of one riskless asset and one risky asset, and the terminal time horizon is denoted by . The riskless asset price satisfies where represents the constant interest rate. The risky asset price follows the dynamics
where is an -adapted Brownian motion and the drift and volatility are given constants. It is assumed that the excessive return , i.e., the risky asset’s return is higher than the interest rate.
Let represent the dynamic amount that the investor allocates in the risky asset and denote the dynamic consumption rate by the investor. In this paper, we consider a drawdown constraint on the excess consumption rate in the sense that cannot go below a fraction of its past maximum that
| (2.1) |
Here, the non-decreasing reference process is defined as the historical excessive spending maximum
| (2.2) |
and is the initial reference level.
In our setting, stands for the subsistence consumption level that may refer to some mandated daily expenses in practice. On top of that, the drawdown constraint (2.1) is imposed to reflect some practical situations that some decision makers may psychologically feel painful when there is a decline in the consumption plan comparing with the past spending peak. In particular, some large expenditures not only spur some long term continuing spending such as maintenance and repair, but also lift up the investor’s standard of living that affects the future consumption decisions. Moreover, by interpreting the consumption control as dividend payment, Angoshtari et al. (2019) also discussed another motivation of the drawdown constraint that some shareholders feel disappointment when there is a decline in dividend policies.
The self-financing wealth process is then governed by the SDE that
which can be equivalently written by
| (2.3) |
with the initial wealth .
Let denote the set of admissible controls if is -progressively measurable, is -predictable, the integrability condition holds and the drawdown constraint is satisfied a.s. for all .
The goal of the agent is to maximize the expected utility of the excessive consumption rate up to time under the drawdown constraint, where is the bankruptcy time defined by .
To embed the control problem into a Markovian framework and facilitate the dynamic programming arguments, we choose the consumption running maximum process in (2.2) as the second state process. The value function of the stochastic control problem over a finite time horizon is given by
| (2.4) |
where the constant denotes the subjective time preference parameter, and stands for the agent’s relative risk aversion coefficient.
We first note that the problem (2.4) is an extension of the control problem considered in Angoshtari et al. (2019) to the model with a finite horizon. Some new mathematical challenges arise as we encounter a parabolic variational inequality with time-dependent free boundaries. One main contribution of the present paper is that all time-dependent free boundaries stemming from the control constraint can be characterized in analytical form (see (4.13), (4.14) and (4.15) in Thereom 4.2), allowing us to identify time-dependent thresholds for the ratio between the wealth level and the past consumption running maximum to choose among different optimal feedback consumption strategies, see (2.23) in Theorem 2.1.
On the other hand, if we interpret in problem (2.4) as a control of consumption rate and regard in (2.3) as the resulting wealth process under the control pair , then the control problem (2.4) is actually equivalent to a finite horizon optimal consumption problem under a drawdown constraint in the financial market with zero interest rate (as in the SDE (2.3) of under the control ). The finite horizon optimal consumption problem under a drawdown constraint has been studied by Jeon and Oh (2022), however, under the crucial assumptions that the interest rate and the initial wealth is sufficiently large that (see Assumption 3.1 in Jeon and Oh (2022)). Based on the martingale and duality approach, the original control problem in Jeon and Oh (2022) is transformed into an infinite series of optimal stopping problems, which requires the optimal wealth process to be strictly positive that and hence has to be mandated as an upper bound on .
In contrast, we have interest rate in the equivalent optimal consumption problem, and no constraint on or is imposed because we allow the wealth process to hit zero on or before the terminal horizon and will terminate the investment and consumption control once the bankruptcy occurs. Therefore, the main results and the approach in Jeon and Oh (2022) can not cover our problem (2.4) with and . Instead, we rely on the technical analysis of the HJB variational inequality. Note that the interest rate does not appear in SDE (2.3) and the objective function in (2.4), our main results, especially all associated wealth thresholds, do not depend on . Some major challenges are characterizing the free boundaries caused by the control constraint and the global regularity of the solution to the HJB variational inequality.
2.2 The control problem and main result
By heuristic dynamic programming arguments and the martingale optimality condition, we note that the term holds whenever the monotone process is strictly increasing, and the associated HJB variational inequality can be written as
| (2.5) |
where
It is straightforward to see that the value function in (2.4) is homogeneous of degree with respect to and such that . As a result, we can consider the change of variable
| (2.6) |
and reduce the dimension that
| (2.7) |
It then follows that
| (2.12) |
Moreover, let us consider the auxiliary controls and . The HJB equation (2.5) can be rewritten as
| (2.17) |
where .
We first present the main result of the paper, and its proof is deferred to Section 4.
Theorem 2.1 (Verification Theorem).
There exists a unique classical solution to problem (2.17), and is the unique classical solution to problem (2.5). Moreover, we have that
| (2.18) |
The optimal feedback controls of the problem (2.4) are given by
| (2.19) | |||
| (2.23) | |||
| (2.24) | |||
| (2.25) |
where and are free boundaries to problem (2.30), which are characterized analytically in Theorem 4.2.
Remark 2.2.
In what follows, we first elaborate the intuition behind the existence of the free boundary such that for in Theorem 2.1.
In Section 4 of Jeon and Oh (2022), it is shown by duality and martingale approach that there exists an optimal adjustment boundary such that: (i) if , the optimal consumption satisfies ; (ii) if , the resulting running maximum process is increasing and if , the optimal consumption can be chosen in the form of such that the resulting immediately jumps from to a new global maximum level . As a result, the free boundary can be used to split the whole domain of into two regions connected in variable and the controlled two dimensional process only diffuses within the region for any . The only possibility for to occur is at the initial time , at which instant the process jumps immediately to .
Motivated by the result in Jeon and Oh (2022), we conjecture and will verify later in our model that there also exists such a time-dependent free boundary , which is the critical threshold of the wealth-to-consumption-peak ratio under the optimal control such that if , the resulting immediately jumps from to a new global maximum level . If , the agent chooses the excessive consumption rate staying in .
Given this conjectured free boundary , the domain can be split into two regions and , which are connected in the time variable . We will first study the existence of a classical solution to the HJB variational inequality with the time-dependent free boundary and characterize in the analytical form in Theorem 4.2. Building upon the classical solution to the HJB variational inequality, we then derive the piecewise feedback functions for the optimal control. Finally, the verification theorem on the optimal control guarantees the validity of our conjecture and the existence of such a free boundary for the optimal control . We note that a similar hypothesis on the existence of a constant free boundary (independent of ) is also made and verified in Angoshtari et al. (2019) for the infinite horizon stochastic control problem using the verification theorem on the optimal control.
Based on the variational inequality (2.5) and the main results in Verification Theorem 2.1, we plot the numerical illustrations of the value function, the optimal feedback functions of portfolio and consumption in terms of the wealth variable while fixing and in Figure 1 as below:





As shown in Figure 1, the value function is strictly increasing and concave in the wealth variable . More importantly, both optimal feedback functions of portfolio and consumption rate are increasing in . However, comparing with the Merton’s solution, the optimal portfolio is no longer a constant proportion strategy of the wealth level, in fact, it is even not simply concave or convex in the wealth variable depending on the ratio of the wealth and the past consumption peak. The right-bottom panel also illustrates the piecewise consumption behavior in Theorem 2.1: when , the optimal consumption ; when , the optimal consumption is the first order condition ; and when , the optimal consumption is equal to the historical consumption peak.
2.3 The dual variational inequality
We plan to employ the dual transform to linearize the HJB variational inequality (2.17) and study the existence of its classical solution. To this end, we first show below that the dual transform is well defined.
Lemma 2.3.
The solution of the problem (2.17) satisfies
| (2.26) | |||
| (2.27) |
Proof.
From the transformation (2.7) between and , let us first show the concavity of . Suppose that there exists a point such that , then
which is a contradiction to (2.17), hence in .
Next, if there exists a point such that and , then
which also leads to a contradiction. Therefore, if there exists a point such that , we must have , thus (2.17) becomes
| (2.28) |
which yields that . Moreover, by the definition (2.4) of and the transformation (2.7) between and , we know in , thus attains the minimum at the point . It then follows that , and
We next show the strict monotonicity of . By the definition (2.4) of and the transformation (2.7), we know that in . Combining with the inequality in (2.17), we have
Moreover, by the concavity of , we know is strictly decreasing in . Hence, if there exists a point such that , it holds that
which yields a contradiction. Therefore, we have that (2.27) holds. ∎
As is increasing and concave in , we can choose the candidate optimal feedback control by the first order condition that
Considering the constraint , we can choose the candidate optimal feedback control
| (2.29) |
Then (2.17) becomes
| (2.30) |
For the conjectured free boundary in Remark 2.2 under the optimal control , using the relationship between and , can also be divided into two regions, namely the continuation region and the jump region denoted by and (see the illustration in Fig. 1) that
| (2.31) | |||
| (2.32) |
Later, we will rigorously characterize and two regions and in analytical form in Theorem 4.2.
To tackle the nonlinear parabolic variational inequality (2.30), we employ the convex dual transform that
As , is concave in . It implies that the critical value satisfies
| (2.33) |
By , there exists , the inverse of in such that
| (2.34) |
Then
| (2.35) |
which leads to
| (2.36) | |||
| (2.37) |
Hence, strictly decreases in , strictly decreases and is convex in . Moreover, it follows from (2.35) that we have
| (2.38) |
In addition, define , which implies that
| (2.39) |
Combining (2.35) with the boundary condition (2.39), we obtain
Therefore, we have
Let be the critical value satisfying , it holds that
| (2.40) |
The linear dual variational inequality of (2.30) can be written as
| (2.41) |
where
which is continuously differentiable in . Moreover, we define .
3 The Solution to the Dual Variational Inequality (2.41)
3.1 Auxiliary dual variational inequality
Taking advantage of the boundary condition of on , we can expand the solution to the problem (2.41) from to the enlarged domain . Let us consider that satisfies the auxiliary variational inequality on that
| (3.1) |
It follows that
For the variational inequality above, we consider the following regimes and associated free boundaries:
We plot in Figure 2 the numerical illustration of the above free boundaries as below:
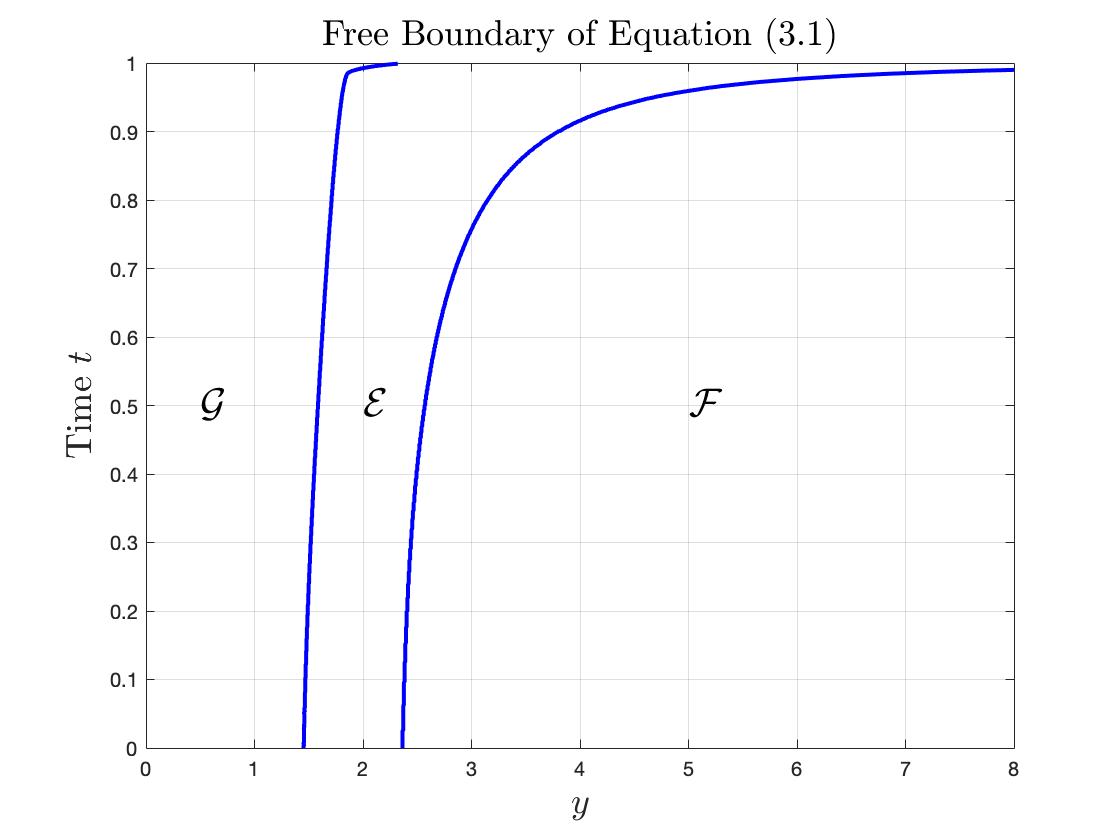
To simplify some analysis, let us further set , and . It follows that satisfies
| (3.2) |
where and
The transformed regimes and the associated free boundaries of the variational inequality (3.2) are plotted in Figure 3 as below.

Considering
| (3.4) |
we can work with another auxiliary dual variational inequality of that
| (3.7) |
where
In what follows, we will first study the existence and uniqueness of the solution to the auxiliary problem (3.7) and investigate its associated free boundary curve. Then, based on the transform (3.4), we can examine the auxiliary variational inequalities (3.2) and (3.1). Finally, we can conclude the existence and uniqueness of the solution to the dual variational inequality (2.41).
3.2 Characterization of the free boundary in (3.7)
Let us first analyze the auxiliary variational inequality (3.7), which is a parabolic variational inequality with both gradient constraint and function constraint. We can obtain the existence and uniqueness of the solution in to problem (3.7) in the next result, where the Sobolev space is defined by
In order to obtain the existence and properties of the solution to problem (3.7), we first consider the following problem, for any , satisfies
| (3.11) |
where .
Lemma 3.1.
Proof.
We can solve the problem (3.11) using the standard penalty approximation method. Consider satisfies
| (3.18) |
where is the penalty function satisfying
Using the standard fixed point theorem, we are able to show that there exists a solution to the penalty problem (3.18). Letting , we obtain a solution to problem (3.11).
The estimate (3.12) follows from the facts and the boundary condition . Moreover, based on the boundary condition , we have the uniqueness of the solution to problem (3.11) and then the comparison principle for problem (3.11) holds true.
Now we will show (3.13). For any , set , then satisfies
| (3.23) |
Using the comparison principle between (3.11) and (3.23), we have that
which leads to the desired result (3.13).
For each , define
We next show that is finite for . Suppose that there exists a such that . Together with (3.13), it holds that
which implies
| (3.27) |
where .
Note that
it follows that there exists a constant such that
Let . We next show that is a super-solution to (3.27) on .
When is small enough, we can deduce
Together with , we know that satisfies
The comparison principle implies that
Moreover, we have
which leads to
which is a contradiction. As a result, is finite for each , and it implies that (3.14) holds. ∎
Proposition 3.2.
Proof.
Denote , then is the solution of problem (3.7). It is easy to see that (3.29) and (3.30) can be derived from (3.12) and (3.13).
We next show (3.31). Suppose , then
By the comparison principle, we have
It hence holds that
which implies that is decreasing in . This, together with (3.14), implies (3.31).
We are ready to show the uniqueness of the solution to problem (3.7) by contradiction. Suppose are two solutions to the problem (3.7). Denote , and let . It then holds that
Denote and . Suppose , by condition (3.31), it is easy to show that there exists a point , which implies , and we have
By condition (3.29) and the maximum principle, we know
which contradicts the definition of and hence .
We then conclude that
This, together with the condition (3.31), implies that
which is a contradiction to the definition of . The proof is then complete. ∎
As a direct result of the uniqueness of solution to problem (3.7), the comparison principle for problem (3.7) holds.
Recall the transformation in (3.4), we have the following regions (see the numerical illustrations in Figure 3) that
Note that satisfies and . For each , let us define
| (3.34) |
Proposition 3.3.
The curve defined in (3.34) satisfies for and
| (3.35) |
Moreover, strictly decreases in . In particular,
| (3.36) |
Proof.
The result (3.35) follows from definitions of and . By the variational inequality (3.7), we have
which leads to . Hence, by the definition of , we know .
Next, we show that is finite for . Suppose that there exists a such that . It then holds that
which implies that satisfies
| (3.37) |
Note that
There exists a constant such that
Let . We next show that is a super-solution to (3.37) on . In view that
Together with , we know that satisfies
The comparison principle implies that
Moreover, it is easy to see that
which implies that
leading to a contradiction.
Finally, we show the strict monotonicity of . For any , suppose , i.e. According to , we have , . By the definition (3.34) of , we obtain
Hence, we obtain the monotonicity of . Suppose that is not strictly monotone and there exists , such that
Denote . Then we have
where is small enough. It then follows that
Together with the fact that , Hopf’s principle implies that
leading to a contradiction.
Moreover, it follows from the monotonicity of and that the result (3.36) holds. ∎
Let us next focus on the domain . In view of the definition of , is a unique solution to problem (3.7). On the domain , satisfies
| (3.41) |
where . In order to analyze the free boundary arising from gradient constraint, we follow the similar idea in Chen and Yi (2012) and consider the parabolic obstacle problem
| (3.42) |
where
| (3.43) |
3.3 Characterization of the free boundary in problem (3.42)
Following the standard penalty approximation method as to show the existence of solution to the problem (3.7), it is easy to conclude the next result, and its proof is hence omitted.
Lemma 3.4.
There exists a unique to problem (3.42) for any .
To study some properties of the free boundary in (3.42), let us first define
Proposition 3.5.
There exists a function such that
| (3.44) |
and is decreasing in such that
| (3.45) | |||
| (3.46) |
Particularly, is strictly decreasing on and is continuous.
Proof.
The conjectured free boundary in Remark 2.2 and all the transformations in Section 2 imply that is connected in direction. Note that , let us define
By the definitions of and , we get the desired result (3.44).
We next show the monotonicity of . By the variational inequality (3.42), we have
which implies . That is, for , . It follows that
For any such that , we define an auxiliary function
We show that is the solution to problem (3.42) in the domain . By the definition of , we have that , , and
Moreover, if , then . Hence, we have
Thus, is a -solution to problem (3.42) in the domain . The uniqueness of the solution to (3.42) yields that
By the definition of , we obtain , and is decreasing in .
Next, we show (3.45). Suppose that there exists such that , by the monotonicity of , we have
The strong maximum principle implies that
It contradicts with Hence, (3.45) holds true.
In view of the definition of and the fact , we have
| (3.50) | |||
| (3.51) |
Suppose that there exists such that , then we have
Thanks to (3.51), we claim the strict monotonicity of in . Indeed, suppose that exists such that
Then we have
Applying the equation at , we have
which contradicts with (3.51). The claim therefore holds.
Following the proof of the strictly monotonicity of in Theorem 3.5, we can conclude the continuity of . ∎
As strictly decreases and is continuous in on , there exists an inverse function of denoted by , . Let us define
| (3.54) |
Lemma 3.6.
We have that
| (3.55) |
where is continuous and strictly decreases in with
| (3.56) |
Proof.
Note that strictly decreases in , we know decreases in . Because the strict monotonicity of is equivalent to the continuity of and the continuity of is equivalent to the strict monotonicity of , we conclude that and strictly decreases in .
We next establish the dependence of on the parameter in the following result.
Lemma 3.7.
The free boundary of problem (3.42) is decreasing in .
Proof.
By the definition of , we have
Let us choose . It holds that
For , denote as the solution to the following problem
| (3.57) |
The comparison principle implies that , for . In particular, we have that
where is the free boundary of problem (3.57), . According to (3.55), we have that , i.e., decreases in . ∎
3.4 The solution to problem (3.2)
In this subsection, we first use the solution to problem (3.42) to construct the solution to problem (3.41), and then obtain the solution to problem (3.7). Using the transform (3.4) between and , we can further obtain the solution to problem (3.2). Following the same proof of Theorem 4.6 in Chen and Yi (2012), we can get the next result.
Proposition 3.8.
Let be the solution to problem (3.42) and let us define
| (3.58) |
Then is the unique solution to problem (3.41) satisfying
| (3.59) | |||
| (3.60) |
Moreover, if we define
| (3.61) |
then is the solution to problem (3.7). In addition, let be given in (3.54) and let be given in (3.34), and are free boundaries of problem (3.7) such that
| (3.62) | |||
| (3.63) | |||
| (3.64) |
We also have the next result
Lemma 3.9.
The solution to problem (3.7) satisfies
| (3.65) | |||
| (3.66) |
In view of and the definition of , is continuous across the free boundary . By the strong maximum principle, it is easy to show inequalities (3.65)-(3.66) in Lemma 3.9 using standard arguments, and its proof is omitted.
Based on the relationship (3.4), it is straightforward to see that is a -solution to problem (3.2). Hence, we have the following theorem.
Proposition 3.10.
Proof.
It follows from transform (3.4) that is the unique solution to (3.2). The regularity of can be deduced from the regularity of . The uniqueness of solution to problem (3.7) leads to the uniqueness of solution to the problem (3.2). Using the transform (3.4), we can deduce (3.67)-(3.69) from (3.62)-(3.64), and (3.70)-(3.71) from (3.65)-(3.66). ∎
3.5 The solution to the dual variational inequality (2.41)
Using the transform , where is the solution to problem (3.2), we first show that is the solution to problem (3.1).
Proposition 3.11.
4 Proof of Main Results
4.1 The solution to the HJB variational inequality (2.30)
Theorem 4.1.
Proof.
Using the fact that and (3.76), we can deduce the existence of a continuous inverse function of that It follows from (3.75) and the boundary condition on that we have . Set
Then is continuous. Moreover, we have
Hence, is a solution to problem (2.30) using the dual transform (2.33)-(2.40) and the fact that is the unique solution of (2.41). As , we have (4.1). In addition, (3.76) implies the desired result (4.2).
We then show the estimate (4.3). By its definition, we know and
Next we will show the right hand side of (4.3). In view of (3.30) and the fact
then
Hence
together with the terminal condition , we obtain
In what follows, we show the uniqueness of the solution to problem (2.30) by the contradiction argument. Suppose are two distinct solutions to problem (2.30) satisfying (4.4) that , where
It follows from the definition of that
Denote and . We have that
then it holds that
| (4.5) |
We next show the right hand side of (4.1) is non-negative. Denote
It holds in that
Hence, we obtain . In view that
and the facts that and
we deduce that is increasing in . It then follows that , and the right hand side of (4.1) is nonnegative. Therefore, satisfies the following linear equation
where the coefficients in the operator are all determined. To apply the maximum principle, we need the boundary conditions on the parabolic boundary . By the definition of , we have
Figure 4
Define . Denote , where and , as illustrated in the above figure. We claim that . If it is not true, then we consider . So we have
It follows that
By the condition (4.4), we have . Together with , we obtain , and hence
By the maximum principle, we know
which leads to a contradiction with the definition of . Hence, , and .
In view that
we have , for , which contradicts the definition of . The uniqueness of the solution to problem (2.30) then follows. ∎
4.2 Proof of Theorem 2.1
First, the next result gives the analytical characterization of free boundaries and in Theorem 2.1.
Theorem 4.2.
Let be the solution to problem (3.42), and be defined in (3.54). There exist three free boundaries and to problem (2.30) such that
| (4.10) | |||
| (4.11) | |||
| (4.12) |
Moreover, for , we have the analytical form in terms of that
| (4.13) | |||
| (4.14) | |||
| (4.15) |
Here, are continuous in . In particular, our conjectured free boundary in Remark 2.2 is now characterized analytically by (4.13).
In addition, the candidate optimal feedback control given in (2.29) satisfies that
| (4.19) |
Proof.
First, by (2.35)-(2.36), we have
According to (3.76), is strictly decreasing in , it follows that
The above results, together with (3.73)-(3.74), imply the existence of a free boundary such that (4.11)-(4.12) hold true.
Using the transform , and , we have that
where the last equality is due to the expression of in (3.58) and the fact that .
Next, we show (4.19). In the domain , we have
where is given by (2.29). Then, let us consider two free boundaries and in problem (2.30) satisfying that
| (4.22) |
By the strict concavity (4.2) of , we get the desired result (4.10). Moreover, the strict concavity of , together with definition (2.29) of , implies the expression (4.19).
Next, we continue to show (4.14) and (4.15). In view of (2.34) and (2.36), for any fixed , the first equation of (4.22) implies that satisfies
Similarly, it follows from the second equation of (4.22) that satisfies
The continuity of can be deduced from the expressions in (4.13)-(4.15), the continuity of and with respect to .
∎
Proof.
As , we deduce that
Hence, increases in . ∎
Building upon that is strictly concave and strictly increases in in Theorem 4.1, we can see that problem (2.30) is equivalent to problem (2.17). Let , we can then show that is the solution to problem (2.5).
Proof of Theorem 2.1.
By Theorem 4.1 and Theorem 4.2, it is straightforward to check that is the unique solution in to problem (2.5) and also (2.18) holds. In view of (4.11)-(4.12), if , then
for ; if , then
To prove the optimality of feedback control (2.19) and (2.23), it suffices to show that the following two conditions hold for all and :
-
(i)
The following SDE admits a unique strong solution that
(4.23) Furthermore, the feedback controls are admissible.
-
(ii)
It holds that
For simplicity, we write as in the following.
We first prove that condition (i) holds. By the form of , and Remark 2.2, we know that the consumption running maximum process satisfies for all with given by (4.23). Hence, if the processes and satisfying (4.23) exist, then it is easy to check that are admissible. To show that has a unique strong solution, by Theorem 7 in section 3 of Chapter 5 of Protter (2005), one needs to show that the functionals
and
defined for and for continuous functions , are functional Lipschitz in the sense of Protter (2005). Note that one can apply the similar arguments as used in Appendix A of Angoshtari et al. (2019) to prove the Lipschitz property of the feedback functions and . Therefore, for any and continuous functions and , we have
Hence, is functional Lipschitz. Similarly, is also functional Lipschitz.
To prove condition (ii), let us introduce a sequence of stopping times as
with as . By an application of Itô’s formula to on , we have
where stands for the continuous part of . Taking expectations on both sides, we obtain
| (4.24) |
By plugging back the feedback controls in (2.19) and (2.23) and the fact that is the solution to problem (2.5), for , we have
| (4.25) |
and hence
| (4.26) |
For and satisfying , by the continuity of , and as well as the fact that , we have (4.2) and (4.26) hold. Furthermore, for and satisfying , by employing the feedback controls, it occur only at the initial time and immediately jumps from to a new global maximum level , which together with the fact that yields (4.2) and (4.26). Then, it follows from (4.2) that
Letting in above equation and using Monotone Convergence Theorem, we obtain
| (4.27) |
Additionally, note that the value function of the utility maximization problem on terminal wealth under a drawdown constraint with power utility function is less than the value function of Merton investment problem with power utility function ( in our context) that
where is the set of admissible strategies for Merton problem. Similar to Lemma A.3 of Angoshtari et al. (2019), there exists a constant such that for all , independent of and . Therefore, it holds that
Using the standard transversality condition in the Merton problem, the fact , the terminal condition , the boundary condition , and the Dominated Convergence Theorem, we have that
| (4.28) | |||||
Combining (4.27) and (4.28), we deduce that the first equality in condition (ii) holds.
Finally, in view that the feedback controls are admissible, we readily obtain
For the inverse inequality, repeating the arguments in the proof of (4.2) with any admissible strategies and corresponding state process , we have
Because is the unique classical solution to problem (2.5), the second term and the third term on the right side of the above equation are non-negative, we obtain that
Letting and applying the similar arguments in the proof of condition (i), we conclude that the reverse inequality holds, which completes the proof. ∎
5 Conclusions
We revisit the optimal consumption problem under drawdown constraint formulated in Angoshtari et al. (2019) by featuring the finite investment horizon. For this stochastic control problem under control-type constraint, we contribute to the theoretical study on the existence and uniqueness of the classical solution to the parabolic HJB variational inequality. In particular, the consumption drawdown constraint induces some time-dependent free boundaries that deserve careful investigations. Using the dual transform and considering the auxiliary variational inequality with both function and gradient constraints, we develop some technical arguments to obtain the regularity of the unique solution as well as some analytical characterization of the associated time-dependent free boundaries such that the smooth fit conditions hold. As a result, we are able to derive and verify the optimal portfolio and consumption strategies in the piecewise feedback form.
For future research extensions, it will be interesting to study other finite-time horizon optimal consumption problems when the utility function depends on the endogenous reference with respect to the past consumption maximum such as the formulation in Deng et al. (2022) and Li et al. (2021). Some new techniques are needed due to more wealth regimes and free boundary curves. It is also an appealing problem to study the finite-time horizon optimal consumption problems under habit formation constraint as investigated in Angoshtari et al. (2022) and Angoshtari et al. (2023), where the dual transform can no longer linearize the variational inequality. New technical tools are needed to cope with the nonlinear dual parabolic variational inequality.
Acknowledgements: The authors sincerely thank anonymous referees for their valuable comments and suggestions that improved the paper significantly. X. Chen is supported by NNSF of China no.12271188. X. Li is supported by Hong Kong RGC grants under no. 15216720 and 15221621. F. Yi is supported by NNSF of China no.12271188 and 12171169. X. Yu is supported by the Hong Kong RGC General Research Fund (GRF) under grant no. 15306523 and the Hong Kong Polytechnic University research grant under no. P0039251.
References
- Angoshtari et al. (2019) B. Angoshtari, E. Bayraktar, and V. R. Young. Optimal dividend distribution under drawdown and ratcheting constraints on dividend rates. SIAM Journal on Financial Mathematics, 10: 547-577, 2019.
- Angoshtari et al. (2022) B. Angoshtari, E. Bayraktar, and V. R. Young. Optimal investment and consumption under a habit-formation constraint. SIAM Journal on Financial Mathematics. 13: 321-352, 2022.
- Angoshtari et al. (2023) B. Angoshtari, E. Bayraktar, and V. R. Young. Optimal consumption under a habit-formation constraint: the deterministic case. SIAM Journal on Financial Mathematics, 14:557-597, 2023.
- Arun (2012) T. Arun. The merton problem with a drawdown constraint on consumption. Preprint, available at arXiv:1210.5205, 2012.
- Bo et al. (2022) L. Bo, S. Wang, and X. Yu. A mean field game approach to equilibrium consumption under external habit formation. Stochastic Processes and their Applications, 178, 104461, 2024.
- Chen et al. (2012) X. Chen, Y. Chen, and F. Yi. Parabolic variational inequality with parameter and gradient constraints. Journal of Mathematical Analysis and Applications, 385: 928-946, 2012.
- Chen et al. (2019) X. Chen, X. Li, and F. Yi. Optimal stopping investment with non-smooth utility over an infinite time horizon. Journal of Industrial and Management Optimization, 15: 81-96, 2019.
- Chen and Yi (2012) X. Chen, and F. Yi. A problem of singular stochastic control with optimal stopping in finite horizon. SIAM Journal on Control and Optimization, 50: 2151-2172, 2012.
- Constantinides (1990) G. M. Constantinides. Habit formation: A resolution of the equity premium puzzle. Journal of Political Economy. 98(3): 519-543, 1990.
- Dai and Yi (2009) M. Dai, and F. Yi. Finite horizon optimal investment with transaction costs: A parabolic double obstacle problem. Journal of Differential Equations, 246: 1445-1469, 2009.
- Deng et al. (2022) S. Deng, X. Li, H. Pham, and X. Yu. Optimal consumption with reference to past spending maximum. Finance and Stochastics, 26: 217-266, 2022.
- Detemple and Zapatero (1992) J. Detemple, and F. Zapatero. Optimal consumption-portfolio policies with habit formation. Mathematical Finance, 2: 251-274, 1992.
- Dybvig (1995) P. H. Dybvig. Dusenberry’s racheting of consumption: optimal dynamic consumption and investment given intolerance for any decline in standard of living. Review of Economic Studies, 62: 287-313, 1995.
- Englezos and Karatzas (2009) N. Englezos, and I. Karatzas. Utility maximization with habit formation: dynamic programming and stochastic PDEs. SIAM Journal on Control and Optimization, 48: 481-520, 2009.
- Guasoni et al. (2020) P. Guasoni, G. Huberman, and D. Ren. Shortfall aversion. Mathematical Finance, 30(3): 869-920, 2020.
- Guan et al. (2019) C. Guan, F. Yi, and X. Chen. A fully nonlinear free boundary problem arising from optimal dividend and risk control model. Mathematical Control and Related Fields, 9: 425-452, 2019.
- Jeon et al. (2024) J. Jeon, T. Kim and Z. Yang. The finite-horizon retirement problem with borrowing constraint: A zero-sum stopper vs. singular-controller game. Preprint, available at SSRN: http://dx.doi.org/10.2139/ssrn.4364441.
- Jeon and Oh (2022) J. Jeon, and J. Oh. Finite horizon portfolio selection problem with a drawdown constraint on consumption. Journal of Mathematical Analysis and Applications, 506(1): 125542, 2022.
- Jeon and Park (2021) J. Jeon, and K. Park. Portfolio selection with drawdown constraint on consumption: a generalization model. Mathematical Methods of Operations Research, 93(2): 243–289, 2021.
- Li et al. (2021) X. Li, X. Yu, and Q. Zhang. Optimal consumption with loss aversion and reference to past spending maximum. SIAM Journal on Financial Mathematics, 15(1): 121-160, 2024.
- Li et al. (2022) X. Li, X. Yu, and Q. Zhang. Optimal consumption and life insurance under shortfall aversion and a drawdown constraint. Insurance: Mathematics and Economics, 108:25-45.
- Liang et al. (2022) Z. Liang, X. Luo, and F. Yuan. Consumption-investment decisions with endogenous reference point and drawdown constraint. Mathematics and Financial Economics, 17:285-334, 2023.
- Merton (1969) R. C. Merton. Lifetime portfolio selection under uncertainty: The continuous-time case. Review of Economics and Statistics, 51: 247-257, 1969.
- Merton (1971) R. C. Merton. Optimal consumption and portfolio rules in a continuous-time model. Journal of Economic Theory, 3: 373–413, 1971.
- Munk (2008) C. Munk. Portfolio and consumption choice with stochastic investment opportunities and habit formation in preferences. Journal of Economic Dynamics and Control, 32: 3560-3589, 2008.
- Protter (2005) P. E. Protter, Stochastic Integration and Differential Equations, Stoch. Model. Appl. Probab. 21, 2nd ed., Springer-Verlag, Berlin, 2005.
- Schroder and Skiadas (2002) M. Schroder, and C. Skiadas. An isomorphism between asset pricing models with and without linear habit formation. The Review of Financial Studies. 15(4): 1189-1221, 2002.
- Tanana (2021) A. Tanana. Utility maximization with ratchet and drawdown constraints on consumption in incomplete semimartingale markets. The Annals of Applied Probability, 33(5): 4127-4162, 2023.
- Yang and Yu (2022) Y. Yang, and X. Yu. Optimal entry and consumption under habit formation. Advances in Applied Probability, 54(2): 433-459, 2022.
- Yu (2015) X. Yu. Utility maximization with addictive consumption habit formation in incomplete semimartingale markets. The Annals of Applied Probability, 25(3): 1383-1419, 2015.
- Yu (2017) X. Yu. Optimal consumption under habit formation in markets with transaction costs and random endowments. The Annals of Applied Probability, 27(2): 960-1002, 2017.
- (32)