OphCLIP: Hierarchical Retrieval-Augmented Learning for Ophthalmic Surgical Video-Language Pretraining
Abstract
Surgical practice involves complex visual interpretation, procedural skills, and advanced medical knowledge, making surgical vision-language pretraining (VLP) particularly challenging due to this complexity and the limited availability of annotated data. To address the gap, we propose OphCLIP, a hierarchical retrieval-augmented vision-language pretraining framework specifically designed for ophthalmic surgical workflow understanding. OphCLIP leverages the OphVL dataset we constructed, a large-scale and comprehensive collection of over 375K hierarchically structured video-text pairs with tens of thousands of different combinations of attributes (surgeries, phases/operations/actions, instruments, medications, as well as more advanced aspects like the causes of eye diseases, surgical objectives, and postoperative recovery recommendations, etc). These hierarchical video-text correspondences enable OphCLIP to learn both fine-grained and long-term visual representations by aligning short video clips with detailed narrative descriptions and full videos with structured titles, capturing intricate surgical details and high-level procedural insights, respectively. Our OphCLIP also designs a retrieval-augmented pretraining framework to leverage the underexplored large-scale silent surgical procedure videos, automatically retrieving semantically relevant content to enhance the representation learning of narrative videos. Evaluation across 11 datasets for phase recognition and multi-instrument identification shows OphCLIP’s robust generalization and superior performance.
1 Introduction


The advancement of surgical AI offers opportunities to enhance surgeons’ capabilities and revolutionize surgical workflows [47, 66, 56]. A key objective is to develop a generalist multi-modal system that can comprehend diverse surgical scenes and communicate with medical professionals using natural language [57], enhancing preoperative planning, intraoperative assistance, and postoperative management. While surgical data science has made progress in uni-modal tasks like surgical phase recognition [34, 58, 67, 18], instrument segmentation [81, 62, 6, 29, 45, 46], and lesion detection [63, 3, 64, 24, 40], the exploration of multi-modal representation learning remains limited.
In general computer vision, models like CLIP [50] have shown success in understanding visual concepts through natural language supervision [32, 36], enabling a shift from task-specific to generalist models [42, 82, 83] with less downstream task-specific fine-tuning [80, 68]. However, surgical multi-modal representation learning poses unique challenges, including specialized medical terminology, and limited data availability, making large-scale datasets difficult to achieve. These challenges, along with the need for expert annotations and the complexity of surgical video data, which often span several hours and involve domain-specific activities within a confined field of view, highlight the gap between general computer vision datasets [38, 50, 2] and surgical datasets [18, 74, 17], as shown in Fig. 1, demanding an innovative solution for surgical multi-modal representation learning.
In this work, we develop OphVL, the first large-scale VLP dataset for ophthalmic surgery understanding, featuring 375K carefully processed video-text pairs from 7.5K hours of narrative open-source surgical videos. These videos cover a diverse set of attributes, including surgeries, phases, instruments, medications, and advanced aspects like eye disease causes, surgical objectives, and postoperative recovery recommendations. Unlike previous datasets with noisy and weakly aligned video-text pairs [37], OphVL applies extensive data processing and large language models (LLMs) to align the video-text pairs and enrich the textual information. Specifically, we define a set of essential concepts (surgery type, operation type, instrument, medication, anatomy, and surgical objectives) and use LLMs to refine narrative texts to focus on these concepts, enriching the textual information at observational and reasoning levels. We then segment video clips and pair them with narrations, while linking full videos to title summaries to create hierarchical video-text pairs at both clip and video levels. Most previous datasets focus only on narrative videos [37, 2] and overlook the potential of large-scale silent surgical videos. Therefore, our OphVL also includes 30K silent videos as an additional knowledge base for the following pretraining.
We introduce OphCLIP, a hierarchical retrieval-augmented VLP framework for ophthalmic video-language pretraining, designed to leverage hierarchical video-text pairs from the OphVL dataset. This approach is inspired by how surgeons often break down the understanding of long surgical videos into shorter activity segments, using this granular knowledge to inform their grasp of silent procedural videos. Surgeons often begin by studying narrated surgical videos to learn specific techniques, building foundational knowledge through the sequence of narrations and the title summaries. When transitioning to silent videos with similar content, they leverage these learned representations to effectively transfer the knowledge.
Similarly, OphCLIP learns short- and long-term visual representations by pairing short video clips with detailed narrative texts for fine-grained features and longer video segments with high-level title summaries for broader context. This approach captures procedural flow and high-level decision-making by integrating both fine- and coarse-grained information. We also introduce retrieval-based augmentation during the pretraining, by constructing a dynamic knowledge base from large-scale silent surgical videos, storing visual and textual embeddings. By retrieving semantically similar silent videos, we add them as auxiliary supervisory signals, facilitating knowledge transfer across narrative and silent procedure videos. OphCLIP integrates these signals into its pretraining framework, learning robust, transferable representations for diverse ophthalmic procedures and achieving state-of-the-art zero-shot performance, as shown in Fig. 1. Our contributions are as follows:
-
OphVL Dataset: We constructed OphVL, the first large-scale and most comprehensive VLP dataset for ophthalmic surgical understanding to date, comprising 375K clip-text pairs with a total duration of 7.5K hours, which is 15 larger than the current largest surgical VLP dataset. OphVL includes tens of thousands of different combinations of attributes, such as surgeries, phases/actions, instruments, medications, as well as more advanced aspects like the causes of eye diseases, surgical objectives, and postoperative recovery recommendations.
-
OphCLIP: We present OphCLIP, a hierarchical ophthalmic surgical VLP framework that aligns short video clips with narrative texts and full videos with high-level summaries, enhancing both fine-grained and long-term visual representation learning. By incorporating silent videos using retrieval-based supervision, OphCLIP enriches its video understanding and learns robust representations for diverse surgical procedures.
-
Comprehensive Zero-shot Evaluation: We conduct extensive evaluations and ablation studies of OphCLIP across 11 datasets (sub-datasets) in two tasks: phase and multi-instrument recognition, demonstrating strong generalizationability across tasks of varying granularities.
2 Related Work
| Datasets | Modality | Source | Pairs Generation | Text | Videos | Images | Pairs/QA/Clips | Avg. Clip Length |
|---|---|---|---|---|---|---|---|---|
| HowTo100M [37] | Natural | Self-built | Automatic | Caption | 1.2M | - | 136M | 4s |
| ANet-Captions [26] | Natural | Public | Manual | Caption | 20K | - | 100K | - |
| Endo-FM [71] | Endoscope | Public&Private | - | - | - | 500M | 33K | 5s |
| SurgVLP [74] | Endoscope | Self-built | Automatic | Caption | 1,326 | - | 25K | 6s |
| GenSurg+ [17] | Endoscope | Public | Automatic | Caption | 1.8K | - | 17K | 45s |
| Surg-QA [30] | Endoscope | Public&Self-built | Automatic | QA | 2,151 | - | 102K | 20s |
| GP-VLS [56] | Endoscope | Public | Automatic | QA | - | - | 120K | - |
| OphNet2024 [18] | Ophthalmic Scope | Self-built | Manual | FSL | 1,969 | - | 17,508/14,674 | 18s/22s |
| OphVL (Ours) | Ophthalmic Scope | Self-built | Semi-automatic | Caption | 44,290 | 960M | 375K | 72s |
Surgical Vision-Language Pretraining. Recent research on deep learning for surgical applications has primarily focused on uni-modal tasks. However, it has largely overlooked advancements in next-generation vision-language models (VLMs) [61, 70, 76] and GPT frameworks [69, 79, 43, 49], which enables broader computer vision applications. Many studies have demonstrated the efficacy of utilizing natural language supervision from aligned text to acquire robust visual representations [2, 77]. These methods typically leverage contrastive learning [44] to associate videos (or images) with their corresponding narrations (or captions). However, they face sample efficiency challenges with surgical VLP datasets due to noisy transcriptions, limited variability in phase-level descriptions, and strong temporal dependencies in surgical procedures. Recent work has improved data efficiency and zero-shot performance in CLIP-like models through techniques such as text augmentation via EDA [33], masked token modeling [65], captioning loss [73], and knowledge-based, hierarchical-aware augmentations [75, 78]. However, the limited scale of surgical video-language pretraining datasets and unique challenges of surgical videos, such as extended durations, narrow fields of view, and procedural variability, continue to restrict the development and evaluation of surgical VLMs.
Video Data for Self-Supervision. Recent studies increasingly leverage video data for enhancing self-supervised learning in VLMs [55, 27, 28]. Large datasets from millions of publicly available YouTube videos support training across diverse scenarios, and localized narratives provide dense, frame-level annotations that benefit both single-image and temporal tasks. In medical applications, similar efforts have been directed toward constructing large-scale multimodal datasets, utilizing sources like hospital-based radiological reports [25, 9] and publicly accessible platforms such as YouTube and Twitter [21, 22, 74, 39, 7] for vision-language pretraining. Although video data introduces noise from varying quality and unfiltered content, advancements in automatic speech recognition (ASR) mitigate this issue by enabling large-scale extraction of cleaner text data directly from audio tracks, improving dataset relevance and model reliability [22]. Large language models (LLMs) further aid annotation by offering context-aware insights, reducing manual labeling needs, and enhancing coherence.
Retrieval-augmented Models. In the NLP field, retrieval-augmented language models leverage external knowledge to boost performance across tasks [5, 52]. Similarly, recent advancements in the vision-language domain retrieve semantically related samples to enhance tasks, such as image recognition [35, 23], captioning [31, 53, 54, 72], and knowledge-based visual question answering [60]. While vision-language pretraining [19] has adopted retrieval-augmentation, with the CLIP model for cross-modal retrieval, it mainly targets images and is suboptimal for surgical video data, particularly in linking narrative and silent procedural videos. In contrast, our OphCLIP builds a dynamically updated knowledge base with video titles as queries for efficient cross-video retrieval and pretraining.
3 Data Engine

We develop OphVL, a dataset of large-scale ophthalmic surgery video-text pairs for VLP. OphVL curation pipeline comprises the following steps: (1) collecting real-world ophthalmic surgery channel and video data, (2) filtering ophthalmic surgery videos based on a specific “narrative style”, (3) extracting and denoising video segments and narration texts from videos using various models, tools, and algorithms, (4) rewriting narration texts via LLMs to focus on essential surgery-specific concepts, and finally, (5) extracting frames from video clips to construct video-text pairs.
3.1 Collecting Clip and Text Pairs from YouTube
Collecting Representative Channels and Videos. In collaboration with three practicing ophthalmologists, we compile a comprehensive list of over 3K terms relevant to ophthalmic surgery, derived from extensive literature review. These terms encompass but are not limited to, surgical names, procedural steps, instrument usage, medications, and postoperative complications. Using these keywords, we manually search YouTube to identify ophthalmic surgery channels. Based on our experience, channel-based searches yield a more concentrated and higher-quality collection of ophthalmic surgical videos than individual keyword searches. Ultimately, we identify the YouTube channel IDs for 410 ophthalmic surgery videos and download them in bulk. During the download process, we prioritize the highest-resolution versions, filtering out videos shorter than 30 seconds or with resolution below 224p, resulting in a collection of approximately 100K videos.
Filtering for Narrative-Style Surgical Videos. In this step, we assess each video from each channel to determine (1) whether it depicts real ophthalmic surgeries or contains usable surgery segments, and (2) whether it qualifies as a narrated video with rich explanatory voiceover. For (1), we identify relevant videos by extracting keyframes, which are automatically generated using PySceneDetect to mark the start or end of scenes with significant visual changes. We then train and apply a ResNet50 image classifier to determine if the keyframes are microscope images of ophthalmic surgeries. Videos with over 80% of keyframes classified as ophthalmic microscope images are labeled as valid videos. For (2), we use it to detect the proportion of human voice in the video, setting a threshold of 0.2. Videos below this threshold are flagged as silent or lacking sufficient explanatory narration. For these videos, we collect their titles and clip metadata to construct a knowledge base, which we use to enhance representation learning.
3.2 Text Extraction using ASR and Text Denoising
To tackle the challenges of ASR with medical terminology in YouTube captions, we employed the large-scale open-source Whisper Large-V3 model [51] for speech-to-text conversion by directly transcribing entire speech segments. We then developed a transcription denoising and quality control pipeline consisting of: (i) applying the Rake keyword extraction algorithm to identify key phrases (up to four words) and refining them by removing stopwords [52]; (ii) using SurgicBERTa [4], a language model pre-trained on surgical texts, to validate and correct each refined entry for alignment with known surgical terminology and context; (iii) conditioning a large language model with example prompts to correct spelling errors within sentence context; and (iv) prompting the language model to provide structured summaries of the captions, focusing on key components such as surgery type, phase/action, instrument, medication, anatomical target, and procedure goal.
3.3 Aligning Clip/Image and Text Pair
Due to frequent sentence segmentation discontinuity in Whisper transcriptions—where coherent sentences are often split across multiple timestamps, we develop a heuristic algorithm that merges timestamps based on punctuation and linking words, ensuring semantic continuity and improving GPT-4o summaries. For clip extraction, we align segments with subtitle timestamps. For silent videos, the classifier (Sec. 3.1) samples frames at 1 FPS to extract surgical clips. Titles and metadata are collected to build a knowledge base, enhancing representation learning. Finally, for all clip-text pairs, frames are extracted at 0.5 FPS for pre-training.
3.4 OphVL Statistics
As shown in Tab. 1, the final OphVL dataset comprises 375,198 clip-text pairs extracted from 13,654 narrated videos and 30,636 silent videos (totaling 9363 hours). On average, the clips have a duration of 72 seconds and a resolution of 1500912, with over 65% of the videos having a resolution equal to or greater than 1280720. According to our rough estimation, our textual concepts include tens of thousands of different combinations of attributes, such as surgeries, surgical phases/operations/actions, surgical instruments, medications, as well as more advanced aspects like the causes of eye diseases, surgical objectives, and postoperative recovery recommendations. Please refer to the supplementary for more dataset statistical details.
4 OphCLIP
We introduce OphCLIP, the hierarchical retrieval-augmented video-language pretraining framework, including hierarchical video-text correspondences (Sec. 4.1), our contrastive learning approach for fine- and coarse-grained representations (Sec. 4.2), and our strategy for leveraging silent videos as a knowledge base to enhance representation learning (Sec. 4.3).
4.1 Hierarchically Video-text Correspondences
We leverage our curated OphVL dataset to train OphCLIP. The OphVL dataset, illustrated in Fig. 3, is a partially hierarchically annotated video collection, denoted as . Here, contains narrative videos () paired with clip-level narrations () that describe surgical observations and reasoning, as well as high-level video summaries (). In contrast, comprises silent videos () paired only with video-level summaries (). Each video, whether narrative or silent, is segmented into clips, represented as , with each clip providing a visual counterpart to the narration in narrative videos. For instance, a clip’s narration describes “The anterior chamber is under-filled…” while the high-level title summarizes the procedure as “Application of B-HEX in a small-pupil Phaco surgery…”. This hierarchical text structure allows the model to capture both fine-grained surgical details at the clip level and overall procedural goals at the video level, enabling robust vision-language representations across diverse granularity levels.
4.2 Hierarchical Vision-language Pretraining
OphCLIP has two pretraining stages: clip- and video-level pretraining to learn fine, short-term, and coarse, long-term representations, respectively. OphCLIP adopts CLIP-like architecture [50], using visual and textual encoders, and , to generate embeddings for frames and texts. A single set of visual and textual encoders is used across both pretraining stages. For clip-level pretraining, each video clip is paired with its narration to learn short-term representations, denoted as and . At video level, the entire video (including both narrative and silent types) is paired with a summary text to form long-term features, represented by and . This high-level summary captures the overall semantic context, supporting deeper long-term reasoning within visual representations.
Clip-level Pretraining. For OphCLIP’s clip-level pretraining, we use an InfoNCE loss [44] to align short-term video clips with their corresponding narration texts . This objective maximizes similarity between visual features and textual features , as shown below in Eq. 1:
| (1) |
where is the batch size. Positive pairs consist of temporally aligned video-text pairs, while other pairs in the batch serve as negatives, enabling OphCLIP to learn from short-term video-text correspondences.
To further refine visual features, we incorporate SimSiam self-supervision [8]. By applying random augmentations to create two views of each video clip, we maximize similarity within positive pairs, formalized as :
|
|
(2) |
The combined clip-level objective, , strengthens fine-grained visual-textual alignment.
Video-level Pretraining. At the video level, we aim to capture long-term procedural context by aligning each narrative video’s high-level title summary with a sequence of video segments . This process uses the following loss:
| (3) |
This objective aligns the entire video representation with its summary while treating summaries from other videos as negatives. To efficiently obtain long-term visual representations for whole procedure videos, we aggregate short-term video clip features using average pooling. This approach ensures computational efficiency and preserves frame-wise visual features, represented as .
4.3 Silent Videos as Knowledge Pool
In addition to learning representations from the narrative videos, our OphCLIP explores silent surgical videos to form a contextual knowledge base that facilitates knowledge transfer and enriches multi-modal representations, as shown in Fig. 3. Using the title of a narrative video as a query, the retriever matches it to relevant silent videos stored in the memory bank, enhancing OphCLIP’s long-term visual representations by integrating additional procedural context from these silent videos.
Query Encoding. To retrieve relevant information from silent videos, we first encode the titles of narrative videos as query embeddings. Specifically, we use the PubMedBERT [16] as the query encoder to transform the title text into a high-dimensional embedding:
| (4) |
This query embedding , based on the video’s title, captures its semantic essence and is used to find related content in a silent video pool. Encoding the title text into embeddings allows efficient retrieval within the text modality, avoiding inaccuracies from CLIP’s limited visual understanding of ophthalmic videos.
Memory Bank. The memory bank module stores multi-modal representations of silent videos. Each silent video is encoded by the visual encoder , and its corresponding title text is encoded by the text encoder and above-mentioned query encoder . We use title embeddings as keys in the memory bank, with values comprising visual and textual embeddings of ophthalmic videos and corresponding texts:
|
|
(5) |
where represents the number of silent videos in the OphVLP dataset. In our memory bank, both visual and textual representations are stored and updated dynamically to improve hierarchical vision-language pretraining.
| Task | Dataset | CLIP [50] | SLIP [41] | LaCLIP [10] | CLIP [50] | CLIP [50] | OphCLIP |
|---|---|---|---|---|---|---|---|
| VTIB16 | VITB16 | VITB16 | RN50 | RN50 | RN50 | ||
| CLIP400M | YFCC100M | LAION-400M | CLIP400M | OphVL | OphVL | ||
| Phase | Cat-21 [48] | 11.5 / 2.6 | 7.7 / 2.4 | 9.6 / 3.6 | 13.3 / 2.7 | 28.8 / 17.6 | 41.4 / 28.8 |
| Cataract-1K [14] | 5.4 / 1.6 | 5.7 / 2.8 | 10 / 1.7 | 6.9 / 2.0 | 20.8 / 15.9 | 62.8 / 48.5 | |
| Cataract-101 [59] | 9.9 / 4.1 | 7.3 / 2.6 | 9.8 / 2.4 | 10.0 / 3.3 | 36.2 / 25.5 | 39.3 / 33.7 | |
| CatRelDet [12] | 9.5 / 7.0 | 10.2 / 6.4 | 11.8 / 4.4 | 15.3 / 11.9 | 26.7 / 23.7 | 32.6 / 34.2 | |
| LensID [13] | 10.6 / 6.5 | 10.6 / 6.3 | 25.8 / 17.8 | 22.9 / 16.3 | 45.5 / 32.1 | 59.3 / 41.0 | |
| Instrument | Cataract-1K [14] | 100.0 / 13.9 | 100.0 / 13.9 | 100.0 / 13.9 | 100.0 / 13.9 | 80.8 / 15.3 | 45.1 / 21.2 |
| CatInstSeg [11] | 100.0 / 20.2 | 100.0 / 20.2 | 100.0 / 20.2 | 100.0 / 20.2 | 87.3 / 20.3 | 51.1 / 28.3 |
| Method | OphNet-O | OphNet-P [18] | CaDIS-F | CaDIS-C [15] |
| Acc / F1 | Acc / F1 | FPR / mAP | FPRs / mAP | |
| CLIP [50] | 0.7 / 0.4 | 3.2 / 0.7 | 13.0 / 8.9 | 28.1 / 22.5 |
| LaCLIP [10] | 1.0 / 0.3 | 3.2 / 0.7 | 13.0 / 8.9 | 30.1 / 22.6 |
| CLIP* [50] | 2.5 / 0.8 | 5.0 / 1.6 | 13.1 / 9.3 | 28.5 / 22.6 |
| OphCLIP | 7.1 / 2.3 | 18.2 / 4.8 | 14.7 / 10.6 | 28.7 / 23.5 |
Retriever. As shown in Fig. 3, our retriever component leverages the query embedding to perform a maximum inner product search (MIPS) on the memory keys, identifying the top- silent videos most relevant to the queried narrative video. Specifically, we compute similarity with for each key embedding in memory, selecting the top- indices that yield the highest similarity scores:
| (6) |
Then, the retrieved video-level multi-modal representations from most relevant silent videos are considered as positive samples to the queried narrative video. We conduct the contrastive learning as Eq. 7 shows:
|
|
(7) |
Thus, the final video-level pretraining loss is:
| (8) |
We leverage the retrieved similar entities to introduce diverse supervisory signals from additional video-text pairs, facilitating knowledge transfer across narrative and silent procedure videos. Our method captures richer contextual information by pairing each video-level feature of the narrative videos with their title text embedding and the retrieved multi-modal embeddings. This approach not only enhances model robustness but also enables efficient retrieval within million-scale datasets. We employ an alternating training strategy, optimizing for a few batches followed by optimizing for a few batches, and repeating this cycle. This strategy optimizes the visual and textual for both short-term and long-term features and also avoids the catastrophic forgetting issue [1, 75]. Please refer to the supplementary for more implementation details.
5 Experiments
| Method | Data (%) | Cat-21 [48] | Cataract-1K [14] |
|---|---|---|---|
| Acc / F1 | F1 / mAP | ||
| CLIP [50] | 100 | 48.2 / 32.6 | 0.0 / 14.1 |
| CLIP* [50] | 100 | 59.4 / 40.5 | 2.0 / 14.2 |
| OphCLIP [41] | 100 | 72.1 / 57.9 | 11.6 / 18.8 |
| CLIP [50] | 10 | 40.1 / 17.3 | 0.0 / 15.5 |
| CLIP* [50] | 10 | 47.6 / 26.6 | 1.0 / 15.8 |
| OphCLIP [41] | 10 | 59.5 / 41.6 | 15.6 / 22.2 |
5.1 Datasets
To evaluate our approach, we conduct experiments on two downstream tasks, i.e., phase recognition and multi-instrument recognition, using 12 datasets (or sub-datasets). (1) Phase Recognition: Five datasets are used for this task: Cat-21 [48] (11 classes), Cataract-1K [14] (12 classes), Cataract-101 [59] (10 classes), CatRelDet [12] (5 classes), OphNet (96 phases, 232 operations) [18], and LensID [13] (3 classes). The implantation and rest phase recognition task represents a specialized configuration of phase recognition, wherein video frames are labeled with only three-phase categories: pre-implantation, implantation, and post-implantation of the lens. OphNet additionally provides both phase and operation labels, offering finer granularity for classification. (2) Multi-instrument Recognition: We select four datasets for multi-instrument recognition: Cataract-1K [14] (9 classes), CatInstSeg [11] (11 classes), and CaDIS [15] (12 classes, 35 classes). CaDIS also provides labels at different levels of granularity.
5.2 Zero-shot Recognition
In this section, we demonstrate the zero-shot transfer performance of our pretrained OphCLIP model across various downstream tasks. Following CLIP [50], we keep the pretrained visual and text encoders fixed and format class labels as sentence prompts for classification.
Phase Recognition. As shown in Tab. 2, methods pretrained on OphVL dataset, including CLIP, consistently outperform baselines like vanilla CLIP [50] and SLIP [41] across all surgical phase recognition datasets. This demonstrates the impact of our ophthalmic-specific pretraining dataset. Fig. 4 also highlights OphCLIP’s capability to understand ophthalmic-specific concepts across both visual and linguistic modalities. The model not only recognizes relevant anatomical and procedural elements in ophthalmic images but also aligns these elements with corresponding medical terminology and context in textual descriptions. This cross-modal understanding enables OphCLIP to focus on regions within the visual data that contribute most significantly to the semantics, demonstrating that the model effectively prioritizes clinically relevant areas.

| Model | OphVL | KB | Prompt | Cat-21 [48] | Cataract-1K [14] |
|---|---|---|---|---|---|
| CLIP [50] | Caption | 13.3 / 2.7 | 6.1 / 2.3 | ||
| CLIP [50] | Caption | 28.8 / 17.6 | 20.8 / 15.9 | ||
| OphCLIP | Caption | 34.9 / 22.9 | 60.5 / 44.7 | ||
| OphCLIP | Mix | 41.3 / 27.7 | 55.9 / 43.0 | ||
| OphCLIP | Caption | 39.9 / 28.2 | 61.3 / 47.2 | ||
| OphCLIP | Mix | 41.4 / 28.8 | 62.8 / 48.5 |
Multi-instrument Recognition. To perform surgical instrument recognition with pretrained vision-language models, each instrument class is converted into a text prompt. For each input image, we compute cosine similarities between image features and these prompts, generating a similarity score per class. Since instrument recognition is a multi-label task, sigmoid activation is applied to these scores, allowing the model to output independent probabilities for each instrument. As shown in Tab. 2, baseline models like CLIP and SLIP [41] show high False Positive Rates (FPR) in instrument recognition, with 100% FPRs on Cataract-1K [14] and CatInstSeg [11], indicating substantial false detections. In contrast, OphCLIP significantly reduces false positives, as shown in Fig. 4. This demonstrates the effectiveness of OphCLIP’s ophthalmic-specific pretraining, enhancing its ability to detect surgical instruments accurately and reduce errors.
Fine-grained vs. Coarse-grained. Tab. 3 shows that OphCLIP outperforms other models in both phase recognition across different granularities. For OphNet-O (fine-grained) and OphNet-P (coarse-grained), OphCLIP achieves 18.2% / 4.8% and 7.1% / 2.3% (Acc / F1), significantly surpassing CLIP and LaCLIP [10]. In instrument recognition, OphCLIP achieves an FPR of 14.7% / mAP of 10.6% on CaDIS-F and an FPR of 28.7% / mAP of 23.5% on CaDIS-C, indicating lower false positives and higher precision. These results confirm OphCLIP’s robust performance and adaptability in tasks of different granularities.
5.3 Few/Full-shot Linear Probing
As shown in Tab. 4, we evaluate pretrained method’s visual encoder on Cat-21 and Cataract-1K using linear probing with both 10% and 100% of the data. Our OphCLIP demonstrates substantial performance gains over both CLIP variants, particularly with 100% of the data. These results show that OphCLIP’s visual encoder provides strong, transferable representations for diverse surgical tasks, serving as an effective generalist backbone.
5.4 Ablation Studies
We conduct an ablation study on surgical phase downstream datasets to examine the effect of OphCLIP’s components (Tab. 5). Models pretrained with OphVL consistently outperform those without it, showing notable accuracy gains across all tasks. Adding a knowledge base (KB) with more silent videos further boosts performance, evidenced by higher F1 scores on Cataract-1K. Prompt choice also plays a key role in zero-shot phase recognition. The “Mix” prompt, which includes keywords like “instrument,” “medication,” and “goal”, outperforms the “Caption” prompt. This is due to the specialized OphVL corpus focusing on instruments, medications, and procedural goals, enabling better concept capture and improved predictions.
6 Limitation
Despite our efforts with OphVL and OphCLIP to enhance perception in ophthalmic surgeries, biases from open-source videos persist, including regional practice variations and inconsistent terminology. Secondly, though OphVL covers a wide range of surgeries, research mainly focuses on cataract procedures due to their prevalence and accessibility, making our validation dataset primarily cataract-based. This limits our ability to validate the model across other surgeries like glaucoma and corneal procedures. While OphCLIP outperforms baseline models in phase recognition and multi-instrument classification, the limited variety restricts evaluation on more complex tasks like anomaly detection and other advanced challenges.
7 Conclusion
In this work, we introduce OphCLIP, a specialized vision-language pretraining framework designed for ophthalmic surgery. By constructing the comprehensive OphVL dataset, which includes over 375K clip-text pairs and tens of thousands of ophthalmic surgery-related concepts (surgeries, procedures, instruments, medications, surgical goals, etc.), we enable robust hierarchical learning of both fine-grained and long-term visual representations. Our approach leverages both narrative and silent videos through innovative retrieval-based supervision, resulting in enhanced understanding and generalization across surgical phases and multi-instrument identification tasks. This research sets a new benchmark for ophthalmic surgical workflow understanding and opens avenues for more specialized and context-aware AI applications in ophthalmic surgery.
Supplementary Material
8 OphVL Dataset
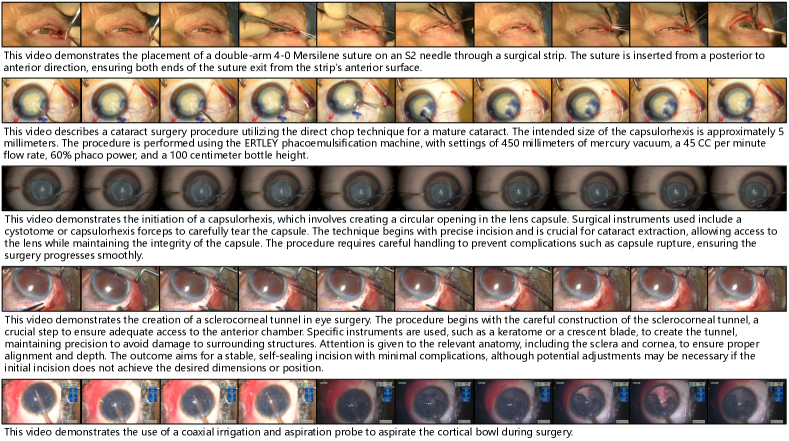
Fig. 6 illustrates the clip-text pair samples we constructed. Through our data processing pipeline, OphVL achieves high-quality modality alignment between ophthalmic surgery videos and descriptive texts.
9 Experiments
9.1 Implementation Details.
| Hyper-parameter | Value | |
| Epochs | 60 | |
| Clip-level Pretraining | Batch Size | 120 |
| Image Size | 224 | |
| # of Frames | 8 | |
| Text Length | 77 | |
| Clip-level Pretraining | Batch Size | 140 |
| Image Size | 224 | |
| # of Frames | 8 | |
| # of Retrieved Videos | 1 | |
| Text Length | 77 | |
| Optimization | Learning Rate | 8e-5 |
| Scheduler | Cosine | |
| Optimizer | Adam | |
| Momentum | 0.9 | |
| Loss Function | Temperature | 0.1 |
| Weight of | 0.5 | |
| Weight of | 0.5 | |
Architecture. We use the CLIP-like architecture [50] with two branches, i.e., visual and textual encoders. We use the ResNet-50 as the visual encoder from the ImageNet initialization. We apply BioClinicalBert [20] as the textual encoder, which is pretrained on the clinical notes. Then we apply the average pooling at the visual features to generate the visual embeddings. We apply a linear projection layer at the end of Bert model’s token to generate textual embeddings. We use as the dimensionality of the embedding space.
Pretraining Setups. In total, we use RTX- with GB and train for days. We first perform clip-level pretraining for epochs and then apply the hierarchical pretraining strategy, which alternatively trains with epochs of clip-level video-text pairs, followed by epochs of video-level video-text pairs. We use a batch of for the clip- and video-level pretraining, respectively. More hyper-parameter details can be found in Tab. 6.
9.2 Evaluation Setup.
We evaluate the representation ability of our OphCLIP using two types of downstream tasks: surgical phase recognition and surgical tool recognition. Additionally, we conduct zero-shot evaluation and linear probing to assess the model’s multi-modal alignment and visual representation capabilities. Tables 11-19 list the specific label names we used for the downstream validation datasets. The labels for the OphNet [18] dataset can be found in the online table: https://docs.google.com/spreadsheets/d/1p5lURkth587-lxYwd6eOSmSxPpvIqvyuOKW-4B49PT0/edit?gid=0#gid=0
Surgical Phase Recognition. This task evaluates the model’s understanding of surgical scenes by classifying video frames into predefined surgical phases. It requires the model to identify instruments, anatomical structures, and their interactions by extracting meaningful visual patterns. To focus on multi-modal representation learning, we exclude temporal modeling and analyze frame-level understanding instead.
Surgical Tool Recognition. This task tests the model’s ability to detect and classify surgical instruments within video frames. By analyzing visual features like shape, texture, and contextual cues, the model demonstrates object-level understanding without reliance on broader workflow context. We assess its robustness in identifying tools despite variations in orientation, scale, or occlusion, emphasizing the quality of learned visual representations.
| Instrument Label | Textual Prompt |
|---|---|
| Capsulorhexis Forceps | This video shows capsulorhexis forceps. |
| Capsulorhexis Cystotome | This video shows capsulorhexis cystotome. |
| Katena Forceps | This video shows katena forceps. |
| Irrigation-Aspiration | This video shows irrigation aspiration. |
| Slit Knife | This video shows slit knife. |
| Phacoemulsification Tip | This video shows phacoemulsification tip. |
| Spatula | This video shows spatula. |
| Gauge | This video shows gauge. |
| Lens Injector | This video shows lens injector. |
| Incision Knife | This video shows incision knife. |
Zero-shot Evaluation. To perform frame-wise classification tasks for surgical phase and tool recognition, we construct textual prompts tailored to the class labels. For phase recognition, we address their high-level definitions by breaking them down into essential components such as phase, instrument, medication, and goal. These are referred to as keyword-only prompts as shown in Tab. 10. Additionally, we leverage Large Language Models (LLMs) to generate caption-only prompts, which are detailed descriptive sentences that incorporate relevant surgical instruments, anatomical structures, and events for each phase. These prompts help align the textual domain of pretraining with the downstream task corpus. For tool recognition, we create human-like descriptive sentences to minimize the textual domain gap, ensuring better alignment between pretraining and downstream corpus, as shown in Tab. 7. This approach facilitates robust zero-shot performance by bridging differences in textual contexts.
Linear-Probing Evaluation. For linear-probing, we freeze the visual encoder and train a linear classifier on the extracted features. No image augmentations are applied during training. The linear classifier is implemented as a linear Support Vector Machine (SVM) with a “linear” kernel. We fit the model on the training and validation sets, then evaluate its performance on a separate test set. For few-shot linear-probing, we use a -percentage shot approach, tailored for surgical video data. Specifically, we sample 10% of the videos from the training set, ensuring no data leakage while maintaining a balanced number of samples across classes. This setup allows for a fair evaluation of the model’s generalization with limited supervision.
More Ablation Experiments Tab. 9 presents additional results of ablation experiments on the Cataract-101 [59] and CatRelDet [12] datasets.
| Instrument Label | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| Capsulorhexis Forceps | 6.1 | 100.0 | 11.5 | 100 |
| Capsulorhexis Cystotome | 4.8 | 100.0 | 9.1 | 85 |
| Katena Forceps | 1.6 | 100.0 | 3.1 | 28 |
| Irrigation-Aspiration | 25.4 | 100.0 | 40.5 | 451 |
| Slit Knife | 1.6 | 100.0 | 3.1 | 28 |
| Phacoemulsification Tip | 30.7 | 100.0 | 46.9 | 545 |
| Spatula | 40.3 | 100.0 | 57.4 | 716 |
| Gauge | 24.0 | 100.0 | 38.7 | 426 |
| Lens Injector | 3.7 | 100.0 | 7.2 | 66 |
| Incision Knife | 1.2 | 100.0 | 2.4 | 22 |
| Macro Avg. | 13.9 | 100.0 | 22.0 | 2475 |
10 Limitation
Data Bias. The OphVL dataset is sourced from YouTube, showcasing diverse styles, resolutions, and screen elements. This diversity enhances the evaluation of a model’s generalization ability but may also impact its effectiveness and performance. Some videos in the dataset contain subtitles, watermarks, or additional video windows. Furthermore, regional variability introduces discrepancies in surgical descriptions, such as differences in surgical standards, nomenclature, and definitions influenced by cultural or demographic factors. These characteristics in OphVL reflect the complexity of real-world surgical environments, where ophthalmic microscopes may inherently display various windows or parameters during recording. While these factors pose challenges, they also present opportunities to develop models that are better equipped to handle such diversity.
Downstream Task Limitation. The zero-shot downstream evaluation datasets for OphCLIP are sourced from publicly available datasets, leveraging their high-quality characteristics and ensuring fair comparisons. However, due to the limited diversity of these datasets—most of which primarily focus on phase recognition and instrument classification in ophthalmology—it is challenging to validate the model on a broader range of vision-language understanding tasks, such as lesion identification or anomaly detection. While the Cataract-1K dataset includes annotations for two types of anomalies, lens rotation and pupil reaction, it does not provide frame-level annotations for these cases.
| Model | OphVL | KB | Prompt | Cataract-101 [59] | CatRelDet [12] |
|---|---|---|---|---|---|
| CLIP [50] | Caption | 10.0 / 3.3 | 15.3 / 11.9 | ||
| CLIP [50] | Caption | 36.2 / 25.5 | 26.7 / 23.7 | ||
| OphCLIP | Caption | 37.1 / 31.9 | 33.6 / 35.4 | ||
| OphCLIP | Mix | 31.9 / 28.4 | 34.5 / 36.1 | ||
| OphCLIP | Caption | 41.1 / 34.7 | 33.6 / 35.3 | ||
| OphCLIP | Mix | 39.3 / 33.7 | 32.6 / 34.2 |
| Phase Label | Caption Only Prompt | Keyword Only Prompt | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Incision |
|
|
||||||||
| Viscoelastic |
|
|
||||||||
| Capsulorhexis |
|
|
||||||||
| Hydrodissection |
|
|
||||||||
| Phacoemulsification |
|
|
||||||||
| Irrigation/Aspiration |
|
|
||||||||
| Capsule Pulishing |
|
|
||||||||
| Lens Implantation |
|
|
||||||||
| Lens positioning |
|
|
||||||||
| Viscoelastic_Suction |
|
|
||||||||
| Anterior_Chamber Flushing |
|
|
||||||||
| Tonifying/Antibiotics |
|
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d1d57983-9101-40e9-8422-e6753cbd52f0/x5.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d1d57983-9101-40e9-8422-e6753cbd52f0/x6.png)

| ID | Phase |
|---|---|
| 0 | Antibiotikum |
| 1 | Hydrodissektion |
| 2 | Incision |
| 3 | Irrigation-Aspiration |
| 4 | Kapselpolishing |
| 5 | Linsenimplantation |
| 6 | Phako |
| 7 | Rhexis |
| 8 | Tonisieren |
| 9 | Visco-Absaugung |
| 10 | Viscoelasticum |
| 11 | not_initialized |
| ID | Phase |
|---|---|
| 0 | Incision |
| 1 | Viscoelastic |
| 2 | Capsulorhexis |
| 3 | Hydrodissection |
| 4 | Phacoemulsification |
| 5 | Irrigation/Aspiration |
| 6 | Capsule Pulishing |
| 7 | Lens Implantation |
| 8 | Lens positioning |
| 9 | Viscoelastic_Suction |
| 10 | Anterior_Chamber Flushing |
| 11 | Tonifying/Antibiotics |
| ID | Phase |
|---|---|
| 0 | Incision |
| 1 | Viscous agent injection |
| 2 | Rhexis |
| 3 | Hydrodissection |
| 4 | Phacoemulsificiation |
| 5 | Irrigation and aspiration |
| 6 | Capsule polishing |
| 7 | Lens implant setting-up |
| 8 | Viscous agent removal |
| 9 | Tonifying and antibiotics |
| ID | Phase |
|---|---|
| 0 | Implantation |
| 1 | Irrigation_Aspiration and Visc_Suction |
| 2 | Phacoemulsification |
| 3 | Rhexis |
| 4 | Rest |
| ID | Phase |
|---|---|
| 0 | Linsenimplantation |
| 1 | Linsenimplantation_before |
| 2 | Linsenimplantation_after |
| ID | Instrument |
|---|---|
| 0 | spatula |
| 1 | 27 gauge cannula |
| 2 | slit knife |
| 3 | phaco tip |
| 4 | capsulorhexis forceps |
| 5 | cartridge |
| 6 | I/A handpiece |
| 7 | cannula |
| 8 | katena forceps |
| 9 | eye retractors |
| 10 | angled incision knife |
| ID | Instrument |
|---|---|
| 0 | Capsulorhexis Forceps |
| 1 | Capsulorhexis Cystotome |
| 2 | Katena Forceps |
| 3 | Irrigation-Aspiration |
| 4 | Slit Knife |
| 5 | Phacoemulsification Tip |
| 6 | Spatula |
| 7 | Gauge |
| 8 | Lens Injector |
| 9 | Incision Knife |
| ID | Instrument |
|---|---|
| 0 | I/A Handpiece |
| 1 | Marker |
| 2 | Rycroft Cannula Handle |
| 3 | Eye Retractors |
| 4 | Cotton |
| 5 | Secondary Knife Handle |
| 6 | Surgical Tape |
| 7 | Troutman Forceps |
| 8 | Hydrodissection Cannula Handle |
| 9 | Vitrectomy Handpiece |
| 10 | Iris Hooks |
| 11 | Rycroft Cannula |
| 12 | Lens Injector |
| 13 | Secondary Knife |
| 14 | Mendez Ring |
| 15 | Primary Knife |
| 16 | Capsulorhexis Cystotome |
| 17 | I/A Handpiece Handle |
| 18 | Micromanipulator |
| 19 | Charleux Cannula |
| 20 | Phacoemulsifier Handpiece |
| 21 | Viscoelastic Cannula |
| 22 | Capsulorhexis Forceps |
| 23 | Phacoemulsifier Handpiece Handle |
| 24 | Lens Injector Handle |
| 25 | background |
| 26 | Hydrodissection Cannula |
| 27 | Capsulorhexis Cystotome Handle |
| 28 | Needle Holder |
| 29 | Suture Needle |
| 30 | Bonn Forceps |
| 31 | Primary Knife Handle |
| ID | Instrument |
|---|---|
| 0 | I/A Handpiece |
| 1 | Cap. Forceps |
| 2 | Eye Retractors |
| 3 | Lens Injector |
| 4 | Tissue Forceps |
| 5 | Surgical Tape |
| 6 | Ph. Handpiece |
| 7 | Cannula |
| 8 | Secondary Knife |
| 9 | Cap. Cystotome |
| 10 | Primary Knife |
| 11 | Micromanipulator |
References
- Ashutosh et al. [2023] Kumar Ashutosh, Rohit Girdhar, Lorenzo Torresani, and Kristen Grauman. Hiervl: Learning hierarchical video-language embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23066–23078, 2023.
- Bain et al. [2021] Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. In Proceedings of the IEEE/CVF international conference on computer vision, pages 1728–1738, 2021.
- Bernal et al. [2015] Jorge Bernal, F Javier Sánchez, Gloria Fernández-Esparrach, Debora Gil, Cristina Rodríguez, and Fernando Vilariño. Wm-dova maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians. Computerized medical imaging and graphics, 43:99–111, 2015.
- Bombieri et al. [2023] Marco Bombieri, Marco Rospocher, Simone Paolo Ponzetto, and Paolo Fiorini. Surgicberta: a pre-trained language model for procedural surgical language. International Journal of Data Science and Analytics, 2023.
- Borgeaud et al. [2022] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pages 2206–2240. PMLR, 2022.
- Cerón et al. [2022] Juan Carlos Ángeles Cerón, Gilberto Ochoa Ruiz, Leonardo Chang, and Sharib Ali. Real-time instance segmentation of surgical instruments using attention and multi-scale feature fusion. Medical Image Analysis, 81:102569, 2022.
- Chen et al. [2023] Jun Chen, Ming Hu, Darren J. Coker, Michael L. Berumen, Blair Costelloe, Sara Beery, Anna Rohrbach, and Mohamed Elhoseiny. Mammalnet: A large-scale video benchmark for mammal recognition and behavior understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13052–13061, 2023.
- Chen and He [2021] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15750–15758, 2021.
- Chen et al. [2024] Zhihong Chen, Maya Varma, Jean-Benoit Delbrouck, Magdalini Paschali, Louis Blankemeier, Dave Van Veen, Jeya Maria Jose Valanarasu, Alaa Youssef, Joseph Paul Cohen, Eduardo Pontes Reis, et al. Chexagent: Towards a foundation model for chest x-ray interpretation. arXiv preprint arXiv:2401.12208, 2024.
- Fan et al. [2024] Lijie Fan, Dilip Krishnan, Phillip Isola, Dina Katabi, and Yonglong Tian. Improving clip training with language rewrites. Advances in Neural Information Processing Systems, 36, 2024.
- Fox et al. [2020] Markus Fox, Mario Taschwer, and Klaus Schoeffmann. Pixel-based tool segmentation in cataract surgery videos with mask R-CNN. In 33rd IEEE International Symposium on Computer-Based Medical Systems, CBMS 2020, Rochester, MN, USA, July 28-30, 2020, pages 565–568. IEEE, 2020.
- Ghamsarian et al. [2020] Negin Ghamsarian, Mario Taschwer, Doris Putzgruber-Adamitsch, Stephanie Sarny, and Klaus Schoeffmann. Relevance detection in cataract surgery videos by spatio- temporal action localization. In 25th International Conference on Pattern Recognition, ICPR 2020, Virtual Event / Milan, Italy, January 10-15, 2021, pages 10720–10727. IEEE, 2020.
- Ghamsarian et al. [2021] Negin Ghamsarian, Mario Taschwer, Doris Putzgruber-Adamitsch, Stephanie Sarny, Yosuf El-Shabrawi, and Klaus Schoeffmann. Lensid: A cnn-rnn-based framework towards lens irregularity detection in cataract surgery videos. In Medical Image Computing and Computer Assisted Intervention - MICCAI 2021 - 24th International Conference, Strasbourg, France, September 27 - October 1, 2021, Proceedings, Part VIII, pages 76–86. Springer, 2021.
- Ghamsarian et al. [2024] Negin Ghamsarian, Yosuf El-Shabrawi, Sahar Nasirihaghighi, Doris Putzgruber-Adamitsch, Martin Zinkernagel, Sebastian Wolf, Klaus Schoeffmann, and Raphael Sznitman. Cataract-1k dataset for deep-learning-assisted analysis of cataract surgery videos. Scientific data, 11(1):373, 2024.
- Grammatikopoulou et al. [2021] Maria Grammatikopoulou, Evangello Flouty, Abdolrahim Kadkhodamohammadi, Gwenolé Quellec, Andre Chow, Jean Nehme, Imanol Luengo, and Danail Stoyanov. Cadis: Cataract dataset for surgical rgb-image segmentation. Medical Image Analysis, 71:102053, 2021.
- Gu et al. [2020] Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pretraining for biomedical natural language processing, 2020.
- Honarmand et al. [2024] Mohammadmahdi Honarmand, Muhammad Abdullah Jamal, and Omid Mohareri. Vidlpro: A video-language pre-training framework for robotic and laparoscopic surgery. arXiv preprint arXiv:2409.04732, 2024.
- Hu et al. [2024] Ming Hu, Peng Xia, Lin Wang, Siyuan Yan, Feilong Tang, Zhongxing Xu, Yimin Luo, Kaimin Song, Jurgen Leitner, Xuelian Cheng, et al. Ophnet: A large-scale video benchmark for ophthalmic surgical workflow understanding. arXiv preprint arXiv:2406.07471, 2024.
- Hu et al. [2023] Ziniu Hu, Ahmet Iscen, Chen Sun, Zirui Wang, Kai-Wei Chang, Yizhou Sun, Cordelia Schmid, David A Ross, and Alireza Fathi. Reveal: Retrieval-augmented visual-language pre-training with multi-source multimodal knowledge memory. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 23369–23379, 2023.
- Huang et al. [2019] Kexin Huang, Jaan Altosaar, and Rajesh Ranganath. Clinicalbert: Modeling clinical notes and predicting hospital readmission. arXiv preprint arXiv:1904.05342, 2019.
- Huang et al. [2023] Zhi Huang, Federico Bianchi, Mert Yuksekgonul, Thomas J Montine, and James Zou. A visual–language foundation model for pathology image analysis using medical twitter. Nature medicine, 29(9):2307–2316, 2023.
- Ikezogwo et al. [2024] Wisdom Ikezogwo, Saygin Seyfioglu, Fatemeh Ghezloo, Dylan Geva, Fatwir Sheikh Mohammed, Pavan Kumar Anand, Ranjay Krishna, and Linda Shapiro. Quilt-1m: One million image-text pairs for histopathology. Advances in neural information processing systems, 36, 2024.
- Iscen et al. [2023] Ahmet Iscen, Mathilde Caron, Alireza Fathi, and Cordelia Schmid. Retrieval-enhanced contrastive vision-text models. arXiv preprint arXiv:2306.07196, 2023.
- Jha et al. [2021] Debesh Jha, Pia H Smedsrud, Dag Johansen, Thomas De Lange, Håvard D Johansen, Pål Halvorsen, and Michael A Riegler. A comprehensive study on colorectal polyp segmentation with resunet++, conditional random field and test-time augmentation. IEEE journal of biomedical and health informatics, 25(6):2029–2040, 2021.
- Johnson et al. [2019] Alistair EW Johnson, Tom J Pollard, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Yifan Peng, Zhiyong Lu, Roger G Mark, Seth J Berkowitz, and Steven Horng. Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs. arXiv preprint arXiv:1901.07042, 2019.
- Krishna et al. [2017] Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In International Conference on Computer Vision (ICCV), 2017.
- Kumar et al. [2023] Akash Kumar, Ashlesha Kumar, Vibhav Vineet, and Yogesh Singh Rawat. A large-scale analysis on self-supervised video representation learning. arXiv e-prints, pages arXiv–2306, 2023.
- Kwon et al. [2024] Donghyeon Kwon, Minsu Cho, and Suha Kwak. Self-supervised learning of semantic correspondence using web videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2142–2152, 2024.
- Laina et al. [2017] Iro Laina, Nicola Rieke, Christian Rupprecht, Josué Page Vizcaíno, Abouzar Eslami, Federico Tombari, and Nassir Navab. Concurrent segmentation and localization for tracking of surgical instruments. In Medical Image Computing and Computer-Assisted Intervention- MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, September 11-13, 2017, Proceedings, Part II 20, pages 664–672. Springer, 2017.
- Li et al. [2024a] Jiajie Li, Garrett Skinner, Gene Yang, Brian R Quaranto, Steven D Schwaitzberg, Peter CW Kim, and Jinjun Xiong. Llava-surg: Towards multimodal surgical assistant via structured surgical video learning. arXiv preprint arXiv:2408.07981, 2024a.
- Li et al. [2024b] Jiaxuan Li, Duc Minh Vo, Akihiro Sugimoto, and Hideki Nakayama. Evcap: Retrieval-augmented image captioning with external visual-name memory for open-world comprehension. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13733–13742, 2024b.
- Li et al. [2023] Kunchang Li, Yali Wang, Yizhuo Li, Yi Wang, Yinan He, Limin Wang, and Yu Qiao. Unmasked teacher: Towards training-efficient video foundation models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19948–19960, 2023.
- Li et al. [2021] Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, and Junjie Yan. Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm. arXiv preprint arXiv:2110.05208, 2021.
- Liu et al. [2023] Yang Liu, Jiayu Huo, Jingjing Peng, Rachel Sparks, Prokar Dasgupta, Alejandro Granados, and Sebastien Ourselin. Skit: a fast key information video transformer for online surgical phase recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 21074–21084, 2023.
- Long et al. [2022] Alexander Long, Wei Yin, Thalaiyasingam Ajanthan, Vu Nguyen, Pulak Purkait, Ravi Garg, Alan Blair, Chunhua Shen, and Anton van den Hengel. Retrieval augmented classification for long-tail visual recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6959–6969, 2022.
- Lüddecke and Ecker [2022] Timo Lüddecke and Alexander Ecker. Image segmentation using text and image prompts. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7086–7096, 2022.
- Miech et al. [2019a] Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. In ICCV, 2019a.
- Miech et al. [2019b] Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2630–2640, 2019b.
- Ming et al. [2023] Hu Ming, Wang Lin, Yan Siyuan, Ma Don, Ren Qingli, Xia Peng, Feng Wei, Duan Peibo, Ju Lie, and Ge Zongyuan. Nurvid: A large expert-level video database for nursing procedure activity understanding. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023.
- Mohapatra et al. [2022] Subhashree Mohapatra, Girish Kumar Pati, Manohar Mishra, and Tripti Swarnkar. Upolyseg: A u-net-based polyp segmentation network using colonoscopy images. Gastroenterology Insights, 13(3):264–274, 2022.
- Mu et al. [2022] Norman Mu, Alexander Kirillov, David Wagner, and Saining Xie. Slip: Self-supervision meets language-image pre-training. In European conference on computer vision, pages 529–544. Springer, 2022.
- Ni et al. [2022] Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, and Haibin Ling. Expanding language-image pretrained models for general video recognition. In European Conference on Computer Vision, pages 1–18. Springer, 2022.
- Nori et al. [2023] Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. Capabilities of gpt-4 on medical challenge problems. arXiv preprint arXiv:2303.13375, 2023.
- Oord et al. [2018] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Pakhomov et al. [2019] Daniil Pakhomov, Vittal Premachandran, Max Allan, Mahdi Azizian, and Nassir Navab. Deep residual learning for instrument segmentation in robotic surgery. In Machine Learning in Medical Imaging: 10th International Workshop, MLMI 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, October 13, 2019, Proceedings 10, pages 566–573. Springer, 2019.
- Pakhomov et al. [2020] Daniil Pakhomov, Wei Shen, and Nassir Navab. Towards unsupervised learning for instrument segmentation in robotic surgery with cycle-consistent adversarial networks. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8499–8504. IEEE, 2020.
- Pakkasjärvi et al. [2023] Niklas Pakkasjärvi, Tanvi Luthra, and Sachit Anand. Artificial intelligence in surgical learning. Surgeries, 4(1):86–97, 2023.
- Primus et al. [2018] Manfred Jürgen Primus, Doris Putzgruber-Adamitsch, Mario Taschwer, Bernd Münzer, Yosuf El-Shabrawi, László Böszörményi, and Klaus Schoeffmann. Frame-based classification of operation phases in cataract surgery videos. In MultiMedia Modeling - 24th International Conference, MMM 2018, Bangkok, Thailand, February 5-7, 2018, Proceedings, Part I, pages 241–253. Springer, 2018.
- Qin et al. [2022] Ziyuan Qin, Huahui Yi, Qicheng Lao, and Kang Li. Medical image understanding with pretrained vision language models: A comprehensive study. arXiv preprint arXiv:2209.15517, 2022.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Radford et al. [2023] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492–28518. PMLR, 2023.
- Ram et al. [2023] Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. In-context retrieval-augmented language models. Transactions of the Association for Computational Linguistics, 11:1316–1331, 2023.
- Ramos et al. [2023] Rita Ramos, Bruno Martins, Desmond Elliott, and Yova Kementchedjhieva. Smallcap: lightweight image captioning prompted with retrieval augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2840–2849, 2023.
- Sarto et al. [2022] Sara Sarto, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Retrieval-augmented transformer for image captioning. In Proceedings of the 19th international conference on content-based multimedia indexing, pages 1–7, 2022.
- Schiappa et al. [2023] Madeline C Schiappa, Yogesh S Rawat, and Mubarak Shah. Self-supervised learning for videos: A survey. ACM Computing Surveys, 55(13s):1–37, 2023.
- Schmidgall et al. [2024a] Samuel Schmidgall, Joseph Cho, Cyril Zakka, and William Hiesinger. Gp-vls: A general-purpose vision language model for surgery. arXiv preprint arXiv:2407.19305, 2024a.
- Schmidgall et al. [2024b] Samuel Schmidgall, Ji Woong Kim, Jeffrey Jopling, and Axel Krieger. General surgery vision transformer: A video pre-trained foundation model for general surgery. arXiv preprint arXiv:2403.05949, 2024b.
- Schoeffmann et al. [2018a] Klaus Schoeffmann, Heinrich Husslein, Sabrina Kletz, Stefan Petscharnig, Bernd Münzer, and Christian Beecks. Video retrieval in laparoscopic video recordings with dynamic content descriptors. Multim. Tools Appl., 77(13):16813–16832, 2018a.
- Schoeffmann et al. [2018b] Klaus Schoeffmann, Mario Taschwer, Stephanie Sarny, Bernd Münzer, Manfred Jürgen Primus, and Doris Putzgruber. Cataract-101: video dataset of 101 cataract surgeries. In Proceedings of the 9th ACM multimedia systems conference, pages 421–425, 2018b.
- Schwenk et al. [2022] Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A-okvqa: A benchmark for visual question answering using world knowledge. In European conference on computer vision, pages 146–162. Springer, 2022.
- Seenivasan et al. [2023] Lalithkumar Seenivasan, Mobarakol Islam, Gokul Kannan, and Hongliang Ren. Surgicalgpt: end-to-end language-vision gpt for visual question answering in surgery. In International conference on medical image computing and computer-assisted intervention, pages 281–290. Springer, 2023.
- Shvets et al. [2018] Alexey A Shvets, Alexander Rakhlin, Alexandr A Kalinin, and Vladimir I Iglovikov. Automatic instrument segmentation in robot-assisted surgery using deep learning. In 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), pages 624–628, 2018.
- Silva et al. [2014] Juan Silva, Aymeric Histace, Olivier Romain, Xavier Dray, and Bertrand Granado. Toward embedded detection of polyps in wce images for early diagnosis of colorectal cancer. International journal of computer assisted radiology and surgery, 9:283–293, 2014.
- Smedsrud et al. [2021] Pia H Smedsrud, Vajira Thambawita, Steven A Hicks, Henrik Gjestang, Oda Olsen Nedrejord, Espen Næss, Hanna Borgli, Debesh Jha, Tor Jan Derek Berstad, Sigrun L Eskeland, Mathias Lux, Håvard Espeland, Andreas Petlund, Duc Tien Dang Nguyen, Enrique Garcia-Ceja, Dag Johansen, Peter T Schmidt, Ervin Toth, Hugo L Hammer, Thomas de Lange, Michael A Riegler, and Pål Halvorsen. Kvasir-Capsule, a video capsule endoscopy dataset. Scientific Data, 8(1):142, 2021.
- Sun et al. [2019] Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. Videobert: A joint model for video and language representation learning. In Proceedings of the IEEE/CVF international conference on computer vision, pages 7464–7473, 2019.
- Varghese et al. [2024] Chris Varghese, Ewen M Harrison, Greg O’Grady, and Eric J Topol. Artificial intelligence in surgery. Nature Medicine, pages 1–12, 2024.
- Wagner et al. [2023] Martin Wagner, Beat-Peter Müller-Stich, Anna Kisilenko, Duc Tran, Patrick Heger, Lars Mündermann, David M Lubotsky, Benjamin Müller, Tornike Davitashvili, Manuela Capek, et al. Comparative validation of machine learning algorithms for surgical workflow and skill analysis with the heichole benchmark. Medical Image Analysis, 86:102770, 2023.
- Wang et al. [2018] Bairui Wang, Lin Ma, Wei Zhang, and Wei Liu. Reconstruction network for video captioning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7622–7631, 2018.
- Wang et al. [2023a] Guangyu Wang, Guoxing Yang, Zongxin Du, Longjun Fan, and Xiaohu Li. Clinicalgpt: large language models finetuned with diverse medical data and comprehensive evaluation. arXiv preprint arXiv:2306.09968, 2023a.
- Wang et al. [2024] Guankun Wang, Long Bai, Wan Jun Nah, Jie Wang, Zhaoxi Zhang, Zhen Chen, Jinlin Wu, Mobarakol Islam, Hongbin Liu, and Hongliang Ren. Surgical-lvlm: Learning to adapt large vision-language model for grounded visual question answering in robotic surgery. arXiv preprint arXiv:2405.10948, 2024.
- Wang et al. [2023b] Zhao Wang, Chang Liu, Shaoting Zhang, and Qi Dou. Foundation model for endoscopy video analysis via large-scale self-supervised pre-train. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 101–111. Springer, 2023b.
- Xu et al. [2024] Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, and Weidi Xie. Retrieval-augmented egocentric video captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13525–13536, 2024.
- Yu et al. [2022] J Yu, Z Wang, V Vasudevan, L Yeung, M Seyedhosseini, and Y Wu. Contrastive captioners are image-text foundation models. a rXiv preprint, 2022.
- Yuan et al. [2023] Kun Yuan, Vinkle Srivastav, Tong Yu, Joel L Lavanchy, Pietro Mascagni, Nassir Navab, and Nicolas Padoy. Learning multi-modal representations by watching hundreds of surgical video lectures. arXiv preprint arXiv:2307.15220, 2023.
- Yuan et al. [2024a] Kun Yuan, Vinkle Srivastav, Nassir Navab, and Nicolas Padoy. Hecvl: Hierarchical video-language pretraining for zero-shot surgical phase recognition. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 306–316. Springer, 2024a.
- Yuan et al. [2024b] Kun Yuan, Vinkle Srivastav, Nassir Navab, and Nicolas Padoy. Procedure-aware surgical video-language pretraining with hierarchical knowledge augmentation. arXiv preprint arXiv:2410.00263, 2024b.
- Yuan et al. [2021] Xin Yuan, Zhe Lin, Jason Kuen, Jianming Zhang, Yilin Wang, Michael Maire, Ajinkya Kale, and Baldo Faieta. Multimodal contrastive training for visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6995–7004, 2021.
- Zhang et al. [2018] Bowen Zhang, Hexiang Hu, and Fei Sha. Cross-modal and hierarchical modeling of video and text. In Proceedings of the european conference on computer vision (ECCV), pages 374–390, 2018.
- Zhang et al. [2023] Hongbo Zhang, Junying Chen, Feng Jiang, Fei Yu, Zhihong Chen, Jianquan Li, Guiming Chen, Xiangbo Wu, Zhiyi Zhang, Qingying Xiao, et al. Huatuogpt, towards taming language model to be a doctor. arXiv preprint arXiv:2305.15075, 2023.
- Zhou et al. [2018] Luowei Zhou, Yingbo Zhou, Jason J Corso, Richard Socher, and Caiming Xiong. End-to-end dense video captioning with masked transformer. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8739–8748, 2018.
- Zhou et al. [2023] Zijian Zhou, Oluwatosin Alabi, Meng Wei, Tom Vercauteren, and Miaojing Shi. Text promptable surgical instrument segmentation with vision-language models. Advances in Neural Information Processing Systems, 2023.
- Zou et al. [2023] Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, et al. Generalized decoding for pixel, image, and language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15116–15127, 2023.
- Zou et al. [2024] Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once. Advances in Neural Information Processing Systems, 36, 2024.