Online Pseudo-Label Unified Object Detection for Multiple Datasets Training
Abstract
The Unified Object Detection (UOD) task aims to achieve object detection of all merged categories through training on multiple datasets, and is of great significance in comprehensive object detection scenarios. In this paper, we conduct a thorough analysis of the cross datasets missing annotations issue, and propose an Online Pseudo-Label Unified Object Detection scheme. Our method uses a periodically updated teacher model to generate pseudo-labels for the unlabelled objects in each sub-dataset. This periodical update strategy could better ensure that the accuracy of the teacher model reaches the local maxima and maximized the quality of pseudo-labels. In addition, we survey the influence of overlapped region proposals on the accuracy of box regression. We propose a category specific box regression and a pseudo-label RPN head to improve the recall rate of the Region Proposal Network (PRN). Our experimental results on common used benchmarks (e.g. COCO, Object365 and OpenImages) indicates that our online pseudo-label UOD method achieves higher accuracy than existing SOTA methods.
Keywords:
Unified Object Detection Semi-supervised learning Pseudo Label1 Introduction


Object detection task aims to detect various categories of objects in the wild. The training process requires corresponding scenarios images annotated with bounding boxes. Existing public datasets typically only annotate limited categories of objects (e.g. COCO [12], WIDER FACE [31], SCUT [17], Object365 [20], OpenImages [8]). However, when need to build a single large-scale (i.e. unified) dataset by fusing these public datasets, it requires vast extra annotation work. For example, if dataset consists of category , and dataset contains category , when we fuse and to a unified dataset for training, ideally all objects in of category should be fully labeled, but this process demand huge human labor costs. Therefore, various advanced methods [34, 23, 26, 35, 16, 21, 33, 28, 4] have been proposed to achieve an effective training on all categories through a strategic combination of multiple datasets, and avoid the annotating burden, also known as unified object detection (UOD) [5, 10, 32, 2, 27].
The two major challenges in the UOD task are: taxonomy difference [35, 16] and background ambiguity [34, 23, 16]. The taxonomy difference issue means the name of certain categories among different dataset are various, e.g. the ‘person’ category in a dataset might be named as ‘pedestrian’ in another one; the ‘football’ category in a dataset means American football, but means soccer in another one. The general resolutions include: manually merging the categories of multiple datasets to form a unified label space [34, 23], or train the model to learn a unified label space [35], or adaptly encoding the category names with word embedding [16]. As for the background ambiguity issue, given a unified label space, each dataset only has a subset of the overall categories fully annotated, and the remaining categories are omitted, for example, in Fig. 1(a), some categories in one dataset are not annotated in other datasets. When using general object detection methods to implement naive multiple dataset combination training in this case, the unlabelled categories are tended to be mistakenly identified as background during training, which significantly reduced the accuracy of the model. To alleviate this problem, current UOD methods apply multiple binary sigmoid operations instead of a softmax function to predict the class scores, so that the loss of each class prediction could be calculated separately on different datasets[35]. In addition, semi-supervised methods are getting popular[34, 23]. They use a pre-trained teacher models to generate offline pseudo-labels, and consequently require a two-step training scheme. In this paper, we concentrate on the background ambiguity issue and propose an online pseudo-label UOD scheme with periodically updated teacher models, which only required single-step training. As seen in Fig. 1(b), during the training process, the proposed periodical teacher update strategy ensured that the accuracy of the teacher model reached local maxima, and both the teacher model and the student model could mutually promote each other.

In addition, we notice that as the number of the annotation categories increases, the overlapped boxes problem becomes non-negligible, which significantly degrade the accuracy of the box regression. We use the classic two-stage object detector to visualize the outputs of the Region Proposal Network (RPN), as the bottom row of Fig. 2 demonstrated, there are a large number of region proposals associated with different categories overlap with each other, such as heads and faces, motorcycles and people, plates and pizza etc. Considering that the UODs use multiple sigmoid binary class predictors, a single region proposal may produce multiple predictions of different categories. Therefore, it is necessary to design a category specific box regressor in the RCN of UOD. The category specific box regression could be implemented easily in early detectors, such as Faster RCNN [19] and SSD [13], however, it conflicts with the more accurate CascadeRCNN detector [3], which has a multi-stage RCN architecture, which means the latter RCN stage needs to use the class unspecific box regression of the previous RCN stage for feature resampling. Based on this, we design a CascadeRCNN compatible category specific box regression structure to improve the box regression accuracy.
Given the situation that the RPN of the classic UOD network only conduct foreground-background classification, the unlabeled foreground objects would be treated as background in a dataset. However, other datasets may have these categories well-annotated; this phenomenon is also called cross-datasets missing annotations problem. To alleviate this problem, we designed the pseudo-label RPN training scheme, details will be discussed in the following sections.
Our main contributions includes:
-
•
To generate more accurate pseudo-labels, we propose a novel online pseudo-label UOD training scheme with periodically updated teacher models.
-
•
To alleviate the overlapped boxes problem, we propose the category specific box regression, which obviously improved the box regression accuracy of UOD.
-
•
For the background ambiguity issue, we propose the pseudo-label RPN training, which significantly improve the recall rate of the RPN head.
-
•
To the best of our knowledge, this is the first online pseudo-label UOD method, and can outperform the offline pseudo-label UOD.
- •
2 Related Work
Multiple Datasets Detection. Multiple datasets training is an effective method to improve model robustness. It has been applied in semantic segmentation [15, 9], depth estimation [18], and stereo matching [30] et al. As far as multiple datasets object detection is considered, both different semantic concepts of categories and definitions of objects and background among different datasets need to be unified. Wang et al. [26] design a partitioned detector with multiple RCN heads. Each head is actually trained on the corresponding dataset specifically. During model evaluation, the model needs to know which dataset the test image came from, thus made the detector unable to be used in actual application scenarios. Zhao et al. [34] generate offline pseudo-labels to alleviate the cross dataset missing annotations problem and improved the mAP score significantly. Xu et al. [29] propose a transferable graph R-CNN to model the class relations and improved the accuracy of the partitioned detector. But this partitioned detector again would produce duplicated outputs for the same object appearing in different datasets. Zhou et al. [35] propose a simple and effective UOD architecture, and designed an automatic method to unify label spaces of multiple datasets. Their UOD architecture achieves SOTA mAP scores on large datasets. However, the training process neglect the utilization of pseudo-labels. Meng et al. [16] propose the Detection Hub, which semantically aligned the categories across datasets by replacing one-hot category representations with word embedding, and achieved SOTA performance on wide variety of datasets. Similarly, the Detection Hub does not use pseudo labeling techniques. This paper propose a novel UOD scheme with the online pseudo-label, the category specific box regression for CascadeRCNN and the pseudo-label RPN training, which improve the UOD accuracy effectively.
Semi-Supervised Learning. The existing pseudo-label methods of the UOD training are all offline. While online pseudo-label methods have been widely used in the semi-supervised learning (SSL). In SSL, models are trained from a small amount of labeled data and a large amount of unlabeled data. As one of the most successful SSL algorithms, the online pseudo-label method uses teacher models to automatically annotate unlabeled data for training student models, and gained higher accuracy. The pseudo-labeling has been applied in image classification tasks. [1, 22] generate annotations on weakly augmented data and then apply strong augmentation on the training data with pseudo-labels. They aim to regularize model to be robust to small perturbation on model inputs or hidden states. To improve the quality of pseudo-labels, Tarvainen et al. [24] proposed that the teacher model should be updated by an EMA (Exponential Moving Average) [6] method instead of barely replicating the student model. According to these works, Liu et al. [14] adopt SSL for the object detection. They subtly use focal loss to address the issue of unbalanced pseudo-labels. Since semi-supervised object detection requires to filter false-positive predicted bounding boxes using confidence scores, they use an empirical value as threshold. However, while their teacher model is gradually promoted, this threshold might become inappropriate during training. Furthermore, common datasets use in UODs typically presented a long tail distribution, it is reasonable to set specific thresholds for classes with different amount of training data. Tanaka et al. [23] propose to determine the threshold for each class by maximizing score of both ground truth and pseudo-labels with a fixed teacher model. Wang et al. [25] propose a GMM method to determine the threshold for each class during training and obtained higher accuracy than using fixed thresholds. Different from the above SSL methods, our proposed online pseudo-label UOD periodically updated the teacher model to ensure its accuracy reach local maxima, so that higher-quality pseudo-labels could be obtained during UOD training.
3 The Proposed Approach
3.1 Preliminary of the Baseline UOD
Given separate datasets , , … , with corresponding label spaces , , , following [35], we merge them into a unified label space . Each label space is a subset of the unified label space , and different label spaces are allowed to have common categories . The goal is to train an UOD model on with label space .

Fig. 3 illustrates the structure of the UOD baseline [35], which uses a two-stage object detector with a shared backbone, a RPN head and a unified RCN head. The last Fully Connected (FC) layer of the RCN head calculates all class predictions among the unified label space . During training, the input images are sampled from the unified datasets, while each batch can only have images sampled from a specific dataset . The category predictions of are mapped to the label space of the corresponding dataset , so that the UOD model could be trained on different datasets separately. The classification loss of the baseline UOD is shown in Eq. 1, where is an image sampled from the dataset , and denotes the box annotations of . The region proposals are generated by the RPN head and are represented by . For each region proposal , the RCN head predicts all category scores of the unified label space , from which the class scores of the sub-space are selected. We use to represent the UOD model parameters. Therefore, the Binary Cross Entropy (BCE) loss could be calculated with and the ground truth class label . Since classification scores outside of are not used in the loss calculation; the cross dataset missing annotation problem do not affect the classification loss. In this way, the background ambiguity is effectively avoided in the RCN head training.
| (1) |
| (2) |
| (3) |
3.2 Online Pseudo-Label Scheme
Although existing offline pseudo-label training methods are effective in improving the accuracy of the UOD task [34, 23], it requires pre-training a teacher model for pseudo-label generation. This two-step training operation consumes more training time. In addition, during offline pseudo-label training, the teacher model is fixed and thus could not be updated with the student model, which hinders the improvement of the pseudo-labels. In this section, we are committed to research online pseudo-label methods for the UOD training, which only requires one stage of training.
Pseudo-label classification loss. Following [34, 23], we also use a high threshold and a low threshold to select pseudo-labels generated by the teacher model. The pseudo-labels with detection scores higher than are treated as positive objects. On the contrary, the pseudo-labels with detection scores lower than are treated as negative background. Otherwise, the proposals are ignored. A positive pseudo-label classification loss could be calculated following Eq. 2, in which is the pseudo-label generated by , and the region proposals are represented by , represents the class scores outside of , is the pseudo-label class label. select the positive region proposals for loss calculation. Similarly, a negative pseudo-label classification loss could be calculated through Eq. 3, in which is the pseudo-label generated by , and selected the negative region proposals for loss calculation. The overall classification loss is calculated as + + .
Analysis of classic EMA teacher updating. For online pseudo-label UOD model training, the teacher model would be first initialized with weights of the student model after a certain period of training, and needs to be continuously updated once better student model is available.
To update the teacher model, we first try to adopt the standard EMA [6] teacher model updating of SSL methods. The EMA updating is illustrated as Eq. 4, in which is the decay parameter. Experimental results indicate that the mAP score of the online pseudo-label UOD with the EMA update is much lower than that of the offline pseudo-label training. An important reason is that the offline pseudo-label training have a fixed pre-trained teacher model, and pseudo labels are obtained throughout the entire student model training process. While the online pseudo-label training only obtain the teacher model in the later stage of training.
| (4) |

Besides, we found another two problems of EMA updating, which are able to be improved. (i) The EMA offline pseudo-label training has the learning rate dilemma. On the one hand, a large learning rate is needed: considering that the EMA operation achieves the effect of improving model accuracy by averaging different input models, a low learning rate would reduce the difference between models with adjacent training time, thereby reducing the effectiveness of the EMA in improving the model accuracy, it also promotes the convergence of model. On the other hand, a small learning rate is needed for the accuracy of the student model to reach local maxima, which helps obtain a better teacher model. As shown by the yellow curve in top of Fig. 4, both the offline pseudo-label training and the EMA online pseudo-label UOD uses the step learning rate schedule. And the bottom of Fig. 4 demonstrates the mAP scores on the COCO-Split 5 datasets (we will introduce this datasets in Section 4). For the offline pseudo-label training, the pre-trained teacher model is fixed and has a constant mAP score. Before the 180K iteration, due to the high learning rate, the mAP scores of the EMA student model is low. The mAP score of the EMA teacher model is lower than the offline teacher model obviously, which lead to worse pseudo-labels. At the 180K iteration, as the learning rate decayed, the mAP scores of the EMA student model gain remarkable improvement. This is because reducing the learning rate could make the model accuracy reach a local maximum, which is common in the step learning rate schedule training. After 180K iterations, the mAP score of the EMA teacher exceeds the offline teacher model. During this period, because of the small learning rate, the model training optimization slow down. Besides, the effectiveness of EMA is weakened as the gap of mAP between the EMA teacher model and EMA student model has been narrowed. The final mAP score of the EMA student model is lower than that of the offline student model. (ii) The teacher model for EMA online pseudo-label UOD is unstable. Fig. 5 compares the pseudo-labels annotated by different EMA teacher models on the COCO, Object365 and OpenImages datasets. In this figure, the first column shows the GT annotations, and the following columns shows the pseudo-labels annotated by teacher models of the 100K, 110K and 120K iteration. The green boxes represent ground truth boxes, red boxes represent pseudo-labels with scores higher than the high threshold and yellow boxes represent those with scores higher than the low threshold . The EMA updating improves the mAP score of the teacher model continuously, but for individual images, the accuracy of pseudo-labels fluctuated. The pseudo-labels that could be detected by the 100K teacher model might be missed by the latter 110K teacher model.

Proposed periodical teacher updating. To alleviate the above two problems, we propose the periodical teacher model updating for the online pseudo-label UOD. As the top part of Fig. 4 illustrates, we apply the cosine learning rate schedule (green curve) for the online pseudo-label UOD. For each training cycle, we start with a large learning rate to accelerate the convergence of the student model, then gradually decay the learning rate to the lowest point to improve the accuracy of the student model quickly, and the teacher model is updated at the end of each cycle. The benefits are: (i) the teacher model is updated at minimum points of the learning rate, which enables its accuracy reach the local maxima, so as to improve the quality of pseudo-labels; (ii) due to the fact that the model is updated at only a few time points, it is convenient to use the computationally intensive score method [23] to calculate the optimal threshold for different categories specifically.
3.3 Category specific Box Regression for CascadeRCNN

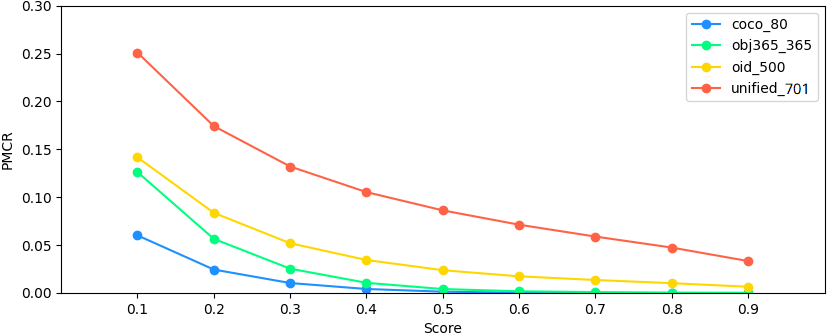
Analysis of overlapped boxes problem. As stated in 1, box predictor for different categories shares one box regression in the existing UOD models, which results in locating errors. As illustrated in Fig. 6, for quantitative analysis, we use the baseline UOD [35] on the COCO, Object365 and OpenImages datasets, and test on the validation datasets. For each test image , the RPN head extracted 1,000 proposals and sent them to the RCN head to calculate the class scores of different categories. For a given score threshold , the number of proposals with at least one class score greater than is denoted as , and the number of proposals with two or more class scores greater than is denoted as . Thus the Proposal Multiple Class Ratio could be calculated following Eq. 5 , which has a value range of . Fig. 7 illustrates that the value of PMCR would increase as the number of categories raised.
| (5) |
Category specific box regression for CascadeRCNN. The category number of the unified label space is usually very large in UOD tasks, and the overlapped boxes problem became non-negligible. Therefore, we propose the category specific box regression based on CascadeRCNN in this section. It allows the model to output category specific box regressions for difference categories. The standard RCN head uses the category unspecific box regression of previous stages to resample the features of the region proposals in the next stage. In Fig. 8, the proposed category specific box regression RCN head outputs category specific boxes. We select the box with the highest class prediction score in both the training and inference process.

3.4 Pseudo-label RPN training
The RPN head is responsible for generating candidate region proposals, indicating whether the corresponding anchor box has an object or background. As different datasets have different background definitions [34], the RPN training also suffer from the ambiguous background problem. Therefore, we also generate the pseudo-labels for this stage.
4 Experiments
Datasets. We evaluate the performance of our proposed OPL-UOD on COCO split 5 datasets. We randomly divide COCO into sub-datasets. At first, we split 80 categories into disjoint sub-category spaces with the category numbers of 14, 14, 13, 13, 13 and 13. The last sub-category space is merged in the other 5 sub-category spaces, and forms 5 sub-category spaces with the category numbers of 27, 27, 26, 26 and 26. The training images are also randomly split into 5 disjoint sub-training datasets. Each sub-training dataset and sub-validation dataset only retain the labels corresponding to the sub-category space.
For comparison with SOTA, we evaluate the OPL-UOD on three large datasets: COCO [12], Objects365 [20] and OpenImages [8]. Following the baseline UOD [35], we use the unified label space (701 categories) of multiple datasets generated by the automatic learning method.
In addition, we also test the category specific box regression on the WIDERFACE [31] face detection dataset, and the SCUT [17] head detection dataset. For all datasets except OpenImages, we use mAP at IOU thresholds 0.5 to 0.95 as evaluation metric. Following [35], for OpenImages, the official modified [email protected] is used.
Training details. Based on the baseline UOD [35] , we implement our models use the Cascade RCNN detector with ResNet50 backbone and FPN neck. In addition, we follow [14] to replace the cross entropy loss with the Focal loss [11] to alleviate the class imbalance. For weakly data augmentation, we simply use random flip and scaling of the short edge in range [640, 800]. For strongly data augmentation, color jittering, grayscale, Gaussian blur and cutout patches are randomly added. we use the SGD optimizer and set the base learning rate as 0.01. For the COCO, Object365 and OpenImages unified detection experiments, the models are trained with batch size 16 on 8 V100 GPUs. For other experiments, the models are trained with batch size 8 on 4 A10 GPUs. For the EMA updating, the decay parameter is set as 0.9996. In order to reproduce the model training results, we use a fixed random seed in all model training.
4.1 Category specific box regression

| Method | COCO | SCUT | WIDERFACE | mean |
| Category unspecific | 41.8 | 47.5 | 32.8 | 40.7 |
| Category specific |
We train the UOD models on COCO, SCUT [17] and WIDER FACE [31] datasets for 180K iterations to explore the effectiveness of the category specific box regression. Since faces and heads have a large number of overlapped boxes, the category unspecific box regression UOD inevitably would have a large positioning error. In Fig. 9, the left image shows detection boxes generated by the standard CascadeRCNN. The head box of the woman is incorrectly positioned on her face, and an additional head box is incorrectly positioned on the face of the man. The right image shows detection boxes generated by our category specific box regression CascadeRCNN, all head boxes and face boxes are accurately detected. Tab. 1 illustrates that the mean mAP score of the category specific box regression is 0.5 higher than that of the standard category unspecific box regression.
Category specific box regression is also effective in single dataset training. We train models on COCO, Objects365, and OpenImages respectively. Each dataset had a different number of classes. In addition we also trained a model on the unified dataset of the three datasets. All these models are trained for 180K iterations. Tab. 2 illustrated that the mAP scores of the category specific box regression on COCO, Objects365, OpenImages and the Unified dataset increased by 0.1, 0.3, 0.3 and 0.5 respectively. With increased number of classes, the boxes overlap more severely, and our method will achieve a greater improvement.
| Method | COCO 80 Classes | Object365 365 Classes | OpenImages 500 Classes | Unified 701 Classes |
| category unspecific | 42.0 | 22.7 | 63.0 | 39.6 |
| Category specific |
4.2 Pseudo-label RPN training
We train the pseudo-label RPN models on the COCO split 5 datasets for 270K iterations. Tab. 3 indicates that RPN recall rates of the pseudo-label RPN training are obviously higher than the standard RPN training, which verified that the pseudo-label RPN training is able to improve the recall rate of the RPN head. However, in Tab. 4, the pseudo-label RPN training had almost no improvement in mAP scores. This is because mAP scores of two-stage object detectors are mainly determined by the RCN head, and the influence of RPN head is moderate.
| Method | Split1 | Split2 | Split3 | Split4 | Split5 | Mean |
| Standard RPN | 50.3 | 46.9 | 48.8 | 50.8 | 52.5 | 49.9 |
| Pseudo-label RPN |
| Method | Split1 | Split2 | Split3 | Split4 | Split5 | Mean |
| Standard RPN | 40.4 | 36.8 | 40.8 | 42.2 | 42.8 | 40.6 |
| Pseudo-label RPN |
4.3 Online Pseudo-Labeling UOD (OPL-UOD)
In this section, we evaluate the proposed online pseudo-label UOD scheme and compared it with other UOD methods. Tab. 5 illustrated the mAP scores of different UOD models trained on the COCO split 5 datasets for 270K iterations. The top 3 rows did not use pseudo labels. The baseline UOD [35] had the mean mAP score of 39.9. The mean mAP score of the model using Focal loss is 0.5 higher. The mean mAP score of the model using cosine LR is slightly higher (+0.1) than that of the standard step LR. The middle 4th row is the offline pseudo-label training model, which use the score [23] to calculate the optimal threshold of the pre-trained teacher model. Its mAP score is 1.8 higher than the previous no pseudo-label models. However, the offline pseudo-label training required two step model training, and spent the longest model training time. The bottom 4 rows are online pseudo-label UOD models. The mAP score of the standard online EMA UOD is 1.3 higher than that of no pseudo-lable models, but is obviously lower (-0.5) than the offline pseudo-label training model. Our proposed OPL-UOD (90K iterations each cycle) achieved similar mAP scores as the offline pseudo-label training model. The mean mAP score of the OPL-UOD with pseudo-label RPN is 0.1 higher than that of the OPL-UOD. The mean mAP score of the OPL-UOD with pseudo-label RPN and category specific box regression is similar to the OPL-UOD with pseudo-label RPN. This is because the COCO has relatively less categories and the effectiveness of the category specific box regression is minor.
| Method | Split1 | Split2 | Split3 | Split4 | Split5 | Mean | Time |
| Baseline UOD | 39.5 | 36.2 | 40.3 | 41.6 | 41.7 | 39.9 | 1.0 |
| Baseline+Focal | 40.1 | 36.8 | 40.9 | 42.1 | 42.3 | 40.4 | 1.0 |
| Baseline+Focal+CosineLR | 40.2 | 36.8 | 40.8 | 42.2 | 42.8 | 40.5 | 1.0 |
| Offline UOD | 41.7 | 38.7 | 42.3 | 44.1 | 44.8 | 42.3 | 3.3 |
| Online EMA UOD | 41.1 | 38.4 | 41.6 | 43.6 | 44.3 | 41.8 | 1.9 |
| OPL-UOD | 41.5 | 38.6 | 42.3 | 44.1 | 44.9 | 42.3 | 1.9 |
| OPL-UOD+PRPN | 41.7 | 38.8 | 42.4 | 44.2 | 44.7 | 42.4 | 2.2 |
| OPL-UOD+PRPN+MBox | 41.7 | 38.8 | 42.3 | 44.2 | 44.9 | 42.4 | 2.2 |
4.4 Comparison with SOTA
Tab. 6 illustrates the mAP scores of different models on COCO, Objects365 and OpenImages datasets. For fair comparison, all models use the ResNet50 backbone. The original UOD [35] is trained for 720k iterations and has the mean mAP score of 45.3. We train the UOD for 2160k iterations and the mean mAP score increased to 46.3. The following Offline UOD and OPL-UOD models are also trained for the same 2,160k iterations. The Detection Hub [16] is trained on the COCO, Object365 and VG [7] at 1x schedule. Its mAP score on OpenImages is not available. The mAP scores on COCO and Objects365 are slightly lower than UOD [35], but they might improve with more training iterations. The mean mAP score of the offline pseudo-label training model is 1.6 higher than the UOD [35]. The proposed OPL-UOD achieved similar mAP scores as the offline pseudo-label training model. The OPL-UOD with category specific box regression achieves the highest mean mAP score on the three large datasets. The pseudo-label RPN does not improve mAP scores on these datasets.
4.5 Comparison of training time
The last column of Tab. 5 illustrates the relative training time of different training schemes. It takes 26 hours to train the baseline UOD on 4 A10 GPUs, which is used as the unit benchmark time for calculating the relative training time of other models. The Focal Loss and CosineLR don’t affect the training time of the baseline UOD. While the training time of the offline pseudo-label training scheme is 3.3 times that of the baseline UOD. The online EMA and OPL-UOD have the same training time. The pseudo-label RPN has added a small amount of training time, while the category specific box regression has little impact on training time.
5 Conclusion
We propose an online pseudo-label unified object detector, which use a periodically updated teacher model to generate pseudo-labels for the unlabelled objects to alleviate the background ambiguity problem, and use a category specific box regressor to alleviate the overlapped boxes problem. Experimental results verify that our proposed periodical updating strategy is superior to the traditional EMA updating strategy, and achieve higher mAP scores than the offline pseudo-label training. We hope our periodically updated teacher model method could also be applied to future semi-supervised learning works. Furthermore, we also propose the category specific box regression for CascadeRCNN and the pseudo-label RPN training, which could improve the model performance.
References
- [1] Berthelot, D., Carlini, N., Cubuk, E.D., Kurakin, A., Sohn, K., Zhang, H., Raffel, C.: Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring. arXiv preprint arXiv:1911.09785 (2019)
- [2] Cai, L., Zhang, Z.L., Zhu, Y., Zhang, L., Li, M., Xue, X.: Bigdetection: A large-scale benchmark for improved object detector pre-training. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) pp. 4776–4786 (2022), https://api.semanticscholar.org/CorpusID:247627817
- [3] Cai, Z., Vasconcelos, N.: Cascade r-cnn: Delving into high quality object detection. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6154–6162 (2018). https://doi.org/10.1109/CVPR.2018.00644
- [4] Chen, Y., Wang, M., Mittal, A., Xu, Z., Favaro, P., Tighe, J., Modolo, D.: Scaledet: A scalable multi-dataset object detector. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7288–7297 (2023). https://doi.org/10.1109/CVPR52729.2023.00704
- [5] Chen, Y., Wang, M., Mittal, A., Xu, Z., Favaro, P., Tighe, J., Modolo, D.: Scaledet: A scalable multi-dataset object detector. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 7288–7297 (2023), https://api.semanticscholar.org/CorpusID:259108435
- [6] Haynes, D., Corns, S., Venayagamoorthy, G.K.: An exponential moving average algorithm. In: 2012 IEEE Congress on Evolutionary Computation. pp. 1–8 (2012). https://doi.org/10.1109/CEC.2012.6252962
- [7] Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L.J., Shamma, D.A., Bernstein, M.S., Fei-Fei, L.: Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision 123, 32 – 73 (2016), https://api.semanticscholar.org/CorpusID:4492210
- [8] Kuznetsova, A., Rom, H., Alldrin, N., Uijlings, J., Krasin, I., Pont-Tuset, J., Kamali, S., Popov, S., Malloci, M., Kolesnikov, A., Duerig, T., Ferrari, V.: The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International Journal of Computer Vision 128 (03 2020). https://doi.org/10.1007/s11263-020-01316-z
- [9] Lambert, J., Liu, Z., Sener, O., Hays, J., Koltun, V.: Mseg: A composite dataset for multi-domain semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence 45(1), 796–810 (2023). https://doi.org/10.1109/TPAMI.2022.3151200
- [10] Lin, F.H., Hu, W., Wang, Y., Tian, Y., Lu, G., Chen, F., Xu, Y., Wang, X.: Universal object detection with large vision model. International Journal of Computer Vision (2022), https://api.semanticscholar.org/CorpusID:254854644
- [11] Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: 2017 IEEE International Conference on Computer Vision (ICCV). pp. 2999–3007 (2017). https://doi.org/10.1109/ICCV.2017.324
- [12] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) Computer Vision – ECCV 2014. pp. 740–755. Springer International Publishing, Cham (2014)
- [13] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C.: Ssd: Single shot multibox detector. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision – ECCV 2016. pp. 21–37. Springer International Publishing, Cham (2016)
- [14] Liu, Y.C., Ma, C.Y., He, Z., Kuo, C.W., Chen, K., Zhang, P., Wu, B., Kira, Z., Vajda, P.: Unbiased teacher for semi-supervised object detection. In: Proceedings of the International Conference on Learning Representations (ICLR) (2021)
- [15] Meletis, P., Dubbelman, G.: Training of convolutional networks on multiple heterogeneous datasets for street scene semantic segmentation. In: 2018 IEEE Intelligent Vehicles Symposium (IV). pp. 1045–1050 (2018). https://doi.org/10.1109/IVS.2018.8500398
- [16] Meng, L., Dai, X., Chen, Y., Zhang, P., Chen, D., Liu, M., Wang, J., Wu, Z., Yuan, L., Jiang, Y.G.: Detection hub: Unifying object detection datasets via query adaptation on language embedding. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11402–11411 (2023). https://doi.org/10.1109/CVPR52729.2023.01097
- [17] Peng, D., Sun, Z., Chen, Z., Cai, Z., Xie, L., Jin, L.: Detecting heads using feature refine net and cascaded multi-scale architecture. In: 2018 24th International Conference on Pattern Recognition (ICPR). pp. 2528–2533 (2018). https://doi.org/10.1109/ICPR.2018.8545068
- [18] Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., Koltun, V.: Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence 44, 1623–1637 (2019), https://api.semanticscholar.org/CorpusID:195776274
- [19] Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 39(6), 1137–1149 (2017). https://doi.org/10.1109/TPAMI.2016.2577031
- [20] Shao, S., Li, Z., Zhang, T., Peng, C., Yu, G., Zhang, X., Li, J., Sun, J.: Objects365: A large-scale, high-quality dataset for object detection. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 8429–8438 (2019). https://doi.org/10.1109/ICCV.2019.00852
- [21] Shinya, Y.: Usb: Universal-scale object detection benchmark. In: British Machine Vision Conference (2021), https://api.semanticscholar.org/CorpusID:232352700
- [22] Sohn, K., Berthelot, D., Carlini, N., Zhang, Z., Zhang, H., Raffel, C.A., Cubuk, E.D., Kurakin, A., Li, C.L.: Fixmatch: Simplifying semi-supervised learning with consistency and confidence. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neural Information Processing Systems. vol. 33, pp. 596–608. Curran Associates, Inc. (2020), https://proceedings.neurips.cc/paper_files/paper/2020/file/06964dce9addb1c5cb5d6e3d9838f733-Paper.pdf
- [23] Tanaka, Y., Yoshida, S.M., Terao, M.: Non-iterative optimization of pseudo-labeling thresholds for training object detection models from multiple datasets. In: 2022 IEEE International Conference on Image Processing (ICIP). pp. 1676–1680 (2022). https://doi.org/10.1109/ICIP46576.2022.9898014
- [24] Tarvainen, A., Valpola, H.: Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In: Neural Information Processing Systems (2017), https://api.semanticscholar.org/CorpusID:263861232
- [25] Wang, X., Yang, X., Zhang, S., Li, Y., Feng, L., Fang, S., Lyu, C., Chen, K., Zhang, W.: Consistent-teacher: Towards reducing inconsistent pseudo-targets in semi-supervised object detection. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3240–3249 (2023). https://doi.org/10.1109/CVPR52729.2023.00316
- [26] Wang, X., Cai, Z., Gao, D., Vasconcelos, N.: Towards universal object detection by domain attention. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7281–7290 (2019). https://doi.org/10.1109/CVPR.2019.00746
- [27] Wang, Z., Li, Y., Chen, X., Lim, S.N., Torralba, A., Zhao, H., Wang, S.: Detecting everything in the open world: Towards universal object detection. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 11433–11443 (2023), https://api.semanticscholar.org/CorpusID:257636989
- [28] Wu, X., Tian, Z., Wen, X., Peng, B., Liu, X., Yu, K., Zhao, H.: Towards large-scale 3d representation learning with multi-dataset point prompt training. ArXiv abs/2308.09718 (2023), https://api.semanticscholar.org/CorpusID:261030582
- [29] Xu, H., Fang, L., Liang, X., Kang, W., Li, Z.: Universal-rcnn: Universal object detector via transferable graph r-cnn. In: AAAI Conference on Artificial Intelligence (2020), https://api.semanticscholar.org/CorpusID:211146696
- [30] Yang, G., Manela, J., Happold, M., Ramanan, D.: Hierarchical deep stereo matching on high-resolution images. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5510–5519 (2019). https://doi.org/10.1109/CVPR.2019.00566
- [31] Yang, S., Luo, P., Loy, C.C., Tang, X.: Wider face: A face detection benchmark. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5525–5533 (2016). https://doi.org/10.1109/CVPR.2016.596
- [32] Ye, M., Ke, L., Li, S., Tai, Y.W., Tang, C.K., Danelljan, M., Yu, F.: Cascade-detr: Delving into high-quality universal object detection. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 6681–6691 (2023), https://api.semanticscholar.org/CorpusID:259991812
- [33] Zhang, B., Yuan, J., Shi, B., Chen, T., Li, Y., Qiao, Y.: Uni3d: A unified baseline for multi-dataset 3d object detection. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 9253–9262 (2023), https://api.semanticscholar.org/CorpusID:257496595
- [34] Zhao, X., Schulter, S., Sharma, G., Tsai, Y.H., Chandraker, M., Wu, Y.: Object detection with a unified label space from multiple datasets. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M. (eds.) Computer Vision – ECCV 2020. pp. 178–193. Springer International Publishing, Cham (2020)
- [35] Zhou, X., Koltun, V., Krähenbühl, P.: Simple multi-dataset detection. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7561–7570 (2022). https://doi.org/10.1109/CVPR52688.2022.00742