[1]\fnmYanxi \surHou
1]\orgdivSchool of Data Science, \orgnameFudan University, \orgaddress\streetYangpu District, \cityShanghai, \countryChina
Online Prediction of Extreme Conditional Quantiles via B-Spline Interpolation
Abstract
Extreme quantiles are critical for understanding the behavior of data in the tail region of a distribution. It is challenging to estimate extreme quantiles, particularly when dealing with limited data in the tail. In such cases, extreme value theory offers a solution by approximating the tail distribution using the Generalized Pareto Distribution (GPD). This allows for the extrapolation beyond the range of observed data, making it a valuable tool for various applications. However, when it comes to conditional cases, where estimation relies on covariates, existing methods may require computationally expensive GPD fitting for different observations. This computational burden becomes even more problematic as the volume of observations increases, sometimes approaching infinity. To address this issue, we propose an interpolation-based algorithm named EMI. EMI facilitates the online prediction of extreme conditional quantiles with finite offline observations. Combining quantile regression and GPD-based extrapolation, EMI formulates as a bilevel programming problem, efficiently solvable using classic optimization methods. Once estimates for offline observations are obtained, EMI employs B-spline interpolation for covariate-dependent variables, enabling estimation for online observations with finite GPD fitting. Simulations and real data analysis demonstrate the effectiveness of EMI across various scenarios.
keywords:
Extreme conditional quantile, generalized Pareto distribution, quantile regression, B-splines.1 Introduction
In fields of statistical analysis such as risk management, finance, and environmental analysis, quantiles play a fundamental role in understanding data distributions and their various characteristics (Allen et al, 2012). Quantiles act as dividing points, segmenting the range of a probability distribution into continuous intervals with equal probabilities. Among the commonly used quantiles, the extreme quantile assumes a critical role, especially when rare events carry significant implications. This particular quantile sheds light on the tail behavior of a distribution and finds wide applications in decision-making, policy formulation, and strategic planning (Resnick, 2008). Estimating the extreme quantile of a distribution, given a dataset comprising identically distributed observations, naturally involves using the sample quantile as a non-parametric estimation. This non-parametric approach performs admirably when the extreme quantile remains moderately high, i.e., as and . In such cases, a sufficient number of observations lie above the quantile level . However, when the observation size is not large enough and the observations above the more extreme quantile become scarce as , the non-parametric estimators are no longer inefficient and may cause serious underestimation (He et al, 2022). This presents a concern for accurately assessing risk, making informed financial decisions, and devising effective environmental strategies.
An alternative way to estimate extreme quantiles involves extrapolation beyond the range of observed data. Extreme Value Theory (EVT) offers a systematic framework for precisely this purpose, allowing us to analyze the tail of a distribution and model the excess distribution above a prefixed threshold. The core principle of EVT is embodied in the famous Fisher-Tippett-Gnedenko theorem (Balkema and De Haan, 1974), which states that under certain conditions, the limiting distribution of extreme values can fall into the Generalized Pareto Distribution (GPD). The excess distribution, denoted as , is defined as follows:
where is the right endpoint of the distribution function , and serves as a large threshold. According to the Fisher-Tippett-Gnedenko theorem, as approaches the right endpoint, i.e., , the excess distribution converges to the GPD as:
where is the cumulative distribution function of the GPD. Here, and are called the shape and scale parameters, respectively. Various methods, such as the Pickands estimator (Pickands III, 1975,) probability-weighted moments method (Hosking et al, 1985), and maximum likelihood method (Smith, 1987), are available for estimating these parameters.
In light of the limiting distribution of extreme values, extensive research efforts have been dedicated to the estimation of extreme quantiles through extrapolation techniques. Among these methods, the Block Maxima Method (BMM) stands out as a widely used approach (Naveau et al, 2009). BMM involves partitioning the dataset into non-overlapping blocks and selecting the maximum observation within each block. The distribution of these block maxima is then fitted to the GPD to estimate extreme quantiles. A more general and flexible variant of BMM, known as the Peak Over Threshold (POT) method, has gained more attention (Ferreira and De Haan, 2015). Unlike BMM, which only considers the maximum observation in each block, POT broadens its scope to encompass several large values. To facilitate this, POT employs a threshold that isolates the exceedances, ensuring that they fall within the tail of the distribution. Subsequently, POT models these exceedances using the GPD, allowing for the estimation of extreme quantiles with increased flexibility and accuracy.
While the BMM and POT have proven effective in estimating extreme quantiles, they exhibit a limitation. In essence, they do not account for dependencies between variables. Consequently, these methods may not be suitable for scenarios where extreme events are influenced by complex interplays of covariates. To address this limitation, conditional quantile regression emerges as a powerful extension of classical regression, offering a comprehensive approach to modeling the conditional quantiles of covariates (Koenker and Hallock, 2001). Consider a two-variable case where the distribution of a response variable depends on a set of covariates . Here, denotes the feature dimension. In this context, the conditional quantile is defined as , where is the generalized inverse of the conditional distribution function of . When the extreme quantile is moderately high, can be efficiently estimated via simple models like linear conditional quantile regression. However, when dealing with scenarios where the quantile satisfies
these estimation methods may introduce substantial biases.
In such cases, the combination of EVT and conditional quantile regression becomes essential. One common approach relies on the fact that, under mild conditions,
where is a real parameter, is the inverse function of and is a suitable positive function. Please see (Li and Wang, 2019), (Wang and Li, 2013), (Wang et al, 2012), (Xu et al, 2022) for more details. In this paper, we focus on an alternative way that employs the GPD to approximate the tail distribution. The resulting methods for extreme conditional quantile regression typically involve two key components: i) first estimating the intermediate conditional quantile at an intermediate level through classic conditional quantile regression, and ii) then modeling the exceeding data above the threshold using the GPD. Notable examples of such methods can be found in the work of Hou et al (2022).
While existing extreme conditional quantile regression methods have achieved significant success, they exhibit certain limitations. These limitations become apparent when the response variable is influenced by covariates , as the conditional quantile becomes dependent on . In other words, the threshold varies with different observations , resulting in different sets of exceeding data used to fit the GPD. Consequently, both the scale and shape parameters of the GPD also become dependent on . To estimate these covariate-dependent parameters, one must conduct conditional quantile regression and extreme distribution fitting once for each observation. This is computationally complex since most existing methods are time-consuming in the above two steps (Velthoen et al, 2019). More critically, practical scenarios often involve online streaming data, where the observations continually emerge over time. In such cases, the dataset’s size can become substantial or even infinite (Granello and Wheaton, 2004). Under this circumstance, applying existing methods becomes impractical, as performing GPD fitting for each observation becomes computationally burdensome and unacceptable.
To solve this issue, in this paper, we propose an offline algorithm denoted as EMI (stands for Extrapolation via Mathematical programs with equilibrium constraints and B-spline Interpolation). Given finite offline historical observations, our algorithm contains two main stages. First, EMI employs linear conditional quantile regression to estimate an intermediate quantile, , which serves as the threshold. The exceedances beyond this threshold are modeled using a GPD with scale and shape parameters that depend on the covariates. Notably, EMI innovatively formulates these regression and fitting tasks as a bilevel programming problem, where the lower- and upper-level functions represent the check function and maximum likelihood function, respectively. For each offline observation, we obtain the corresponding estimated parameters by solving the bilevel programming with classic optimization methods, such as interior point algorithms and active set algorithms. Second, EMI employs B-spline interpolation for the scale and shape parameters. The interpolation is conducted on each feature dimension of the covariates. For online observations with features falling outside the range of offline data, EMI leverages the nearest available data points for estimation. This innovative approach eliminates the need for infinite repeated GPD fitting when encountering new online data. Numerical simulations and real-world analysis further illustrate the effectiveness of EMI in extreme conditional quantile estimation.
2 Methodology
2.1 Conditional Quantile Estimation via GPD Approximation
Conditional quantile estimation is a statistical technique that focuses on modeling and analyzing conditional quantiles of a response variable concerning one or more predictor variables. The techniques involved in conditional quantile estimation include quantile regression and various non-parametric approaches. The motivation behind conditional quantile estimation is typically different from that of traditional mean-based modeling. While traditional regression techniques, like linear regression, focus on estimating the conditional mean of the response variable, conditional quantile methods seek to estimate quantiles, which offer a more comprehensive view of the conditional distribution. This approach is particularly useful when dealing with non-normally distributed data, outliers, or when the interest is in understanding the variability at different points in the distribution.
We consider here the setting where the response depends on covariates . Denote the conditional distribution of the variable as and marginal distribution of as . Suppose observations , where is generated from given . The conditional quantile of given at the quantile level is defined as , where is the generalized inverse of the conditional distribution function of . The conditional quantile can be calculated as the solution to the following optimization problem
| (2.1) |
where is the so-called check function (Koenker and Bassett Jr, 1978). Quantile regression is one of the most widely used techniques for conditional quantile estimation. It extends traditional regression by estimating the conditional quantiles directly. We follow the standard parametric assumption that the true conditional quantile has a linear form as
| (2.2) |
where is a parameter vector associated with the level and denotes the true parameter. With observations , the parameter can be estimated by solving an optimization problem corresponding to the empirical counterpart of (2.1):
| (2.3) |
The conditional quantile estimation of given is thus calculated as
| (2.4) |
The empirical linear estimation of the conditional quantile works effectively when the quantile level is moderately high. However, as the quantile level approaches and , the expected number of observations exceeding becomes insufficient. In such cases, empirical linear estimation of the conditional quantile is no longer feasible, necessitating extrapolation beyond observed data. Extrapolation is the process of estimating or predicting values beyond the range of the available data. It is a common practice in various fields, including finance, environmental science, insurance, and reliability analysis, where the primary interest lies in understanding and managing extreme events, such as financial market crashes, natural disasters, rare disease occurrences, or equipment failures. To address this need for extrapolation, we turn to the GPD, which offers an excellent approximation of the tail distribution of the conditional distribution of given . More specifically, given a large threshold , , and , the exceedance given satisfies
| (2.5) |
where and we require for . Here is the extreme value index, and is a scale related to the quantile level of the threshold . When , there is a finite right endpoint in the support of the distribution of , that is, for all . When , the exceedance given has an exponential distribution with mean . When , the exceedance given has a heavy tail with up to -th finite moments. Note that for any higher threshold , the exceedance given again follows the generalized Pareto distribution with the same shape parameter but a different scale parameter.
Once the threshold is set, the next step involves estimating the parameters of the GPD. In the absence of covariates, a standard way of estimating the GPD parameters is the maximum likelihood method, which provides asymptotically normal estimators in the unconditional case with (Drees et al, 2004). To estimate the covariate-dependent variables and , we also use the maximum likelihood method. Specifically, given observations and the threshold , we define the exceedances of the observations above the threshold as
| (2.6) |
where . In other words, whenever the value is below the threshold. Denoe the log-likelihood function as
| (2.7) |
and the loss function is calculated only on positive as
Then, to estimate and , we can apply the censored maximum likelihood method via solving the following optimization problem
| (2.8) |
Inverting the distribution function in (2.5), we have an approximation of the quantile for probability level by taking and . As a result, we have that
| (2.9) |
where for simplicity, we define
| (2.10) |
We denote the solution of the problem (2.8) as and . Therefore, using plug-in estimators, the prediction of the extreme conditional quantile is
| (2.11) |
It is important to note that the estimations in (2.3) and (2.8) are usually implemented individually, such as the stages two and three of the algorithm in [12]. However, the combination of (2.3) and (2.8) is essentially a bilevel programming problem when the threshold in (2.8) equals the conditional quantile determined by (2.2) and (2.3). In the following, we apply algorithms of bilevel programming to obtain the joint estimation in (2.3) and (2.8).
2.2 Stage 1: Offline Quantile Estimation via Bilevel Programming
In this section, we formulate the extreme quantile estimation via GPD approximation as a bilevel programming problem. Bilevel programming, a class of optimization problems characterized by their hierarchical structure, has found wide-ranging applications across diverse domains including economics, engineering, transportation, and environmental management (Sinha et al, 2017). These problems feature a unique interplay between two optimization tasks: an upper-level decision-maker seeks to optimize a given objective while factoring in the response of a lower-level decision-maker, who, in turn, optimizes their objective in response to the upper-level decisions. To illustrate this concept in our context, we combine (2.3) and (2.8) and obtain
| (2.12) |
where and the prefixed level is given. The conditional quantile regression and the maximum likelihood function are denoted as the lower- and upper-level functions of (2.12), respectively.
The hierarchical structure of bilevel programming introduces unique challenges that pose difficulties for existing solution methods. For instance, penalty function methods address bilevel optimization by solving a sequence of unconstrained optimization problems. These unconstrained problems are derived by introducing a penalty term that quantifies the extent of constraint violation. The penalty term typically relies on a parameter, taking a zero value for feasible solutions and a positive value (indicating minimization) for infeasible ones. However, many penalty function methods require the upper-level function to be convex, which conflicts with the non-convex nature of the log-likelihood function (2.7). This discrepancy arises from the fact that the Hessian matrix is not semi-positive definite. Consequently, various penalty methods, such as those proposed by Aiyoshi and Shimizu (1981) and Lv et al (2007), tend to be ineffective in addressing the problem. Additionally, nested evolutionary algorithms have gained popularity for dealing with bilevel problems (Sinha et al, 2014). These algorithms involve solving a lower-level optimization problem for each upper-level member, which are typically employed in two main ways. The first approach combines an evolutionary algorithm at the upper level with classical algorithms at the lower level (Mathieu et al, 1994). In contrast, the second approach leverages evolutionary algorithms at both the upper and lower levels (Angelo et al, 2013). While these nested strategies can be effective, they face a significant computational burden, rendering them impractical for large-scale bilevel problems.
To handle problem (2.12) effectively, we first reformulate the lower-level function as
The above problem can be transformed into a linear program as
| (2.13) | ||||
where are Lagrange multiplicators. With (2.13), the bilevel programming (2.12) can be rewritten as
| (2.14) |
where we let and . Then, we replace the constraints in problem (2.14) with its Karush-Kuhn-Tucker (KKT) conditions. These conditions manifest as Lagrangian and complementarity constraints, simplifying the bilevel optimization problem into a single-level constrained optimization problem. Define the augmented Lagrangian (AL) function as
where are the Lagrange multiplicators. The derivatives of with respect to the parameters are given as follows:
| (2.15) |
Therefore, the problem (2.14) is reformulated as
| (2.16) |
where denotes the variable set for a prefixed and level . Problem (2.16) is a special case of mathematical programs with equilibrium constraints (MPEC), in which the constraints include the complementarity conditions
MPEC plays an important role in various fields, such as the Stackelberg game in economic sciences, and problem (2.16) could be efficiently solved via interior point algorithm or active set algorithm. For more details on these algorithms, we refer readers to the work of [16]. In the following, we leave out the solutions of the Lagrange multiplicators. and denote the solutions of problem (2.16) as for simplicity.
2.3 Stage 2: Online Prediction via B-Spline Interpolation
Note that the solution to (2.16) is derived given a specific covariate . This leads to estimations and that are inherently covariate-dependent. To illustrate this, recall that and are utilized in modeling the exceedances over a threshold. We estimate this threshold through (2.4), based on a prefixed . Consequently, the estimated threshold becomes intricately linked to the covariates, . This, in turn, results in varying exceedances for different values of , ultimately leading to distinct GPD models and covariate-dependent estimations, namely and .
In practice, we often encounter situations where we need to deal with an infinite number of future observations, in addition to the finite historical observations at hand. A typical example is the realm of online streaming data, continually generated from various sources (Gaber et al, 2005). Online streaming data finds applications across diverse industries, including finance, transportation, and e-commerce. Notably, streaming data volumes can be vast, occasionally approaching infinity. When it comes to the task of conditional quantile estimation with these infinite observations from online streaming data, applying (2.16) entails solving the problem an infinite number of times. This introduces a significant computational complexity that poses a substantial challenge.
To alleviate the computational burden associated with solving (2.16) for possible infinite observations, we employ B-spline interpolation. To clarify, let us denote the finite offline observations as for and the future online observations as for where we allow to tend to infinite. It is important to note that we assume the covariates for the two observation sets are distinct. B-spline interpolation empowers us to solve (2.16) only times, obtaining estimations for any number of data points, even as approaches infinity. In more specific terms, assume that we have obtained for , for given offline observations by solving (2.16). Notably, the estimations and are solely linked to the choice of , which is assumed to be the same for both offline and online observations in our paper. As a result, for , the estimations of and remain consistent with those for . Therefore, we only need to apply B-spline interpolation to estimate the extreme value index and the scale for .
B-splines, which stand for “Basis splines”, hold a pivotal role in the realm of numerical analysis and computer-aided design. They provide a powerful method for representing and approximating complex curves and surfaces, as well as for solving various mathematical and engineering problems. B-splines are piecewise polynomials, and the positions where the pieces meet are known as knots, which are defined as a non-decreasing sequence of real numbers
where is the knot number. Provided that , we can define the B-splines of degree over the knots using a recursive formulation. Specifically, the -th B-spline can be calculated by
where are real numbers taken from the knot sequence . When , is identically zero. The foundation of B-splines begins with the initial B-spline of order zero, represented as:
In simpler terms, a B-spline operates over knots, strictly adhering to their non-decreasing order. B-splines contribute meaningfully only within the range defined by the first and last knots, remaining zero elsewhere. It is worth noting that while two B-splines can share some of their knots, two B-splines defined over exactly the same set of knots are identical. In essence, a B-spline is uniquely characterized by its knot sequence.
B-splines provide a powerful method for approximating complex functions. In scenarios where the covariants are multi-dimensional, we estimate the covariate-dependent variables and the scale as
Here, represent the sets of knots, with each set containing knots. It is assumed that falls within the range defined by the boundary knots and . The choice of , representing the maximum degree of approximation, is crucial. While higher degrees tend to yield more accurate estimates, they also come with increased computational complexity. Here, we opt for , a well-known choice commonly referred to as cubic spline interpolation. To determine the coefficients , for , we introduce the B-spline matrix as
We further define the feature vector as follows
where and represents the -th entry of observation . For pairs , we we can determine the coefficients by solving the following matrix equation
| (2.17) |
with the boundary knots satisfy
for . The solution to this equation is denoted as . Then for new observation , we can estimate the corresponding extreme value index by
when . For cases where falls beyond the range of boundary knots and , the estimation of the extreme value index can be expressed as follows
where is determined by minimizing the absolute difference as
In summary, we estimate as
| (2.18) |
Similarly, the scale parameter can be estimated using B-spline interpolation as:
| (2.19) |
In this expression, the coefficients for are determined by solving the matrix equation given by:
| (2.20) |
and satisfying
In this way, the estimation of extreme conditional quantile for observation is calculated as
| (2.21) |
We summarize our method in Algorithm 1.
It is important to emphasize that B-spline interpolation, while highly effective for approximating scale and shape parameters, does introduce a degree of bias into the estimation process. This trade-off is essential as it significantly reduces computational time, making it a valuable tool for online observations. For this specific context, there is no need to engage in solving the censored maximum likelihood problem required for GPD distribution fitting when dealing with online data. Instead, we capitalize on historical offline data to perform the approximation using B-spline interpolation. It is noteworthy that the solutions derived from equations like (2.17) and (2.20) exclusively rely on the historical dataset. Consequently, we can obtain these solutions well in advance of the arrival of new online data. This proactive approach implies that once the online data is observed, we can directly substitute the results into (2.21) to efficiently obtain the parameter estimations, thus drastically reducing the computational burden associated with online data processing.
3 Experiments















3.1 Setup
In this section, we conduct some simulations to investigate the performance of our proposed EMI. We generate offline data and online data in the same way. Specifically, we generate the covariates independently from the standard uniform distribution. The response is generated by
where we consider two models of the univariate variable :
-
•
Model 1: is the absolute value of a random variable drawn from the t-distribution with the zero location and degree satisfying
-
•
Model 2: is the absolute value of a random variable drawn from the GPD with the location equal to , the scale parameter equal to , and the shape parameter satisfying
Note that both models are heavy-tailed, where the degrees of t-distribution and the shape parameters of GPD all depend on the covariates. We set and . Without loss of generality, we set and . We aim to estimate the conditional quantile function corresponding to extreme probability levels and . The intermediate quantile level is set to .
To assess the performance, we conduct replications and calculate the average relative prediction square error (ARSE) on the online data . For the -th replication, the ARSE is defined as
Here is the estimator calculated according to Eq. (2.21) and is the true conditional quantile. For comparison, we apply the traditional method (denoted as Linear) which solves the following problem
| (3.1) |
with . Linear estimates the conditional quantile as the linear function of :
where and denote the solutions to (3.1).


3.2 Estimation Results
The comparison of our proposed EMI to the Linear approach is presented in Fig. 1 and Fig. 2. For each chosen extreme quantile , we generated data with various combinations of online data size and feature dimension . We observe that when the quantile level is close to , the ARSE of both methods grows. This behavior is expected since, in such cases, observations above the quantile become scarce. However, our EMI clearly outperforms the Linear approach with a significantly lower ARSE. This superior performance can be attributed to two key factors. Firstly, EMI leverages the GPD to approximate the tail distribution of the data, enabling extrapolation beyond the observation range. Secondly, when sufficient offline historical data is available, B-spline interpolation can effectively capture the relationship between and covariate-dependent parameters, resulting in better interpolation outcomes.
To further analyze the impact of the offline data size on estimation results, we conduct experiments with different offline data sizes ranging from to , as shown in Fig. 3(a). The results reveal that, as the offline data size increases, the ARSE of our EMI gradually decreases while exhibiting reduced variance. This trend is due to the fact that larger data size can improve the performance of B-spline interpolation, particularly in cases where falls beyond the observation range. Additionally, we examine the influence of different thresholds on the estimation. Fig. 3(b) shows that across various threshold choices, our EMI consistently exhibits superior estimation results compared to the Linear approach.








3.3 Bias Analysis
We then study the bias introduced by the B-spline interpolation. For comparison, given each online observation , we do not apply B-spline interpolation but fit the tail distribution into a GPD and estimate the shape and scale parameters, respectively. To be specific, we directly solve the following bilevel programming
| (3.2) |
Denote the solutions to problem (3.2) as . Then the conditional quantile is estimated as
| (3.3) |
We denote the above method as EMI w/o. Interp., denoting EMI without B-spline interpolation. We conducte performance tests under various extreme quantile levels , and the results are summarized in Fig.4, Fig.5, and Fig. 6. Notably, we observe that EMI performs slightly less effectively when employing B-spline interpolation, which coincides with our expectations. However, it is important to emphasize that B-spline interpolation allows us to bypass the complex computations involved in fitting the GPD, which leads to more practical applications.

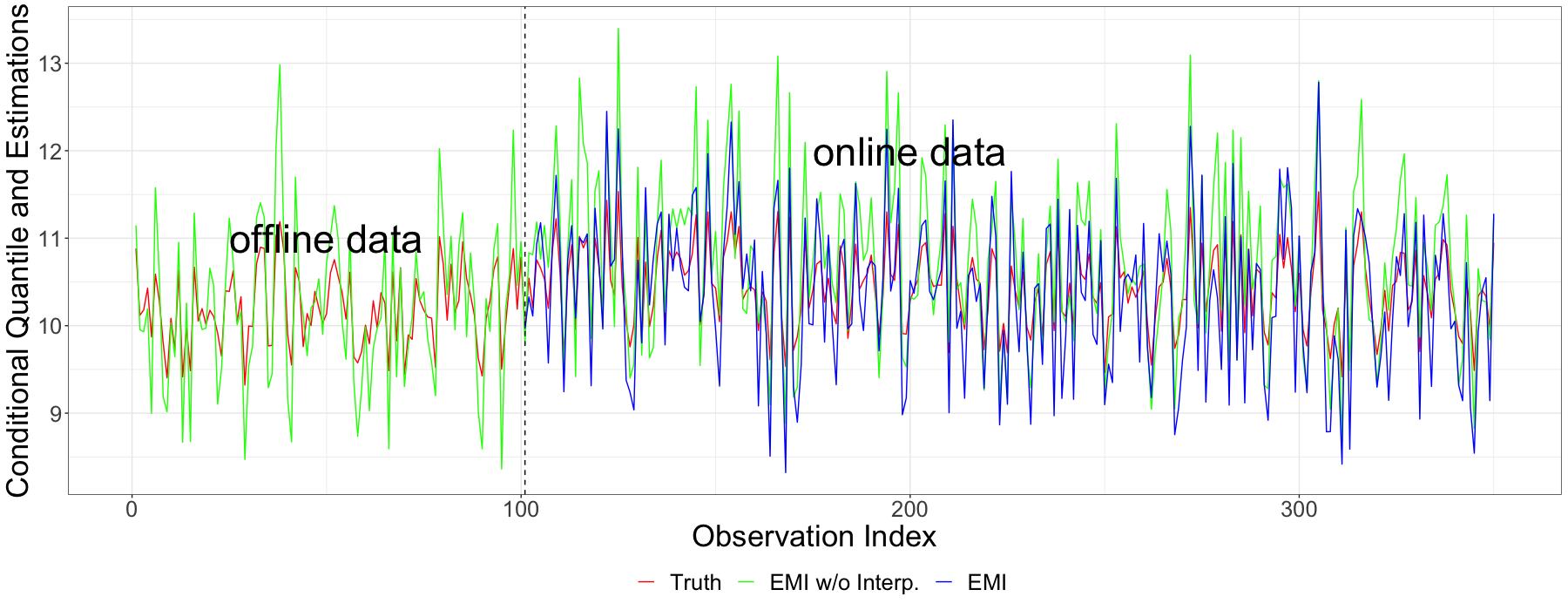




3.4 Results of Online Data
In our final scenario, we consider a more realistic situation where online data is observed incrementally, one data point at a time. At each time step , we observe a new pair . The current observation set at time , denoted as , are the union of the new observation and the observation set from the previous time step . This is represented as:
for . The initial observation set at time consists of only offline data as and . For comparison, the Linear method solves the following linear quantile regression problem at each time step :
On the other hand, the EMI w/o. Interp. method applies extrapolation based on the GPD and solves the following optimization problem at each time step :
| (3.4) |
Here, is a set of transformed observations defined as for each , and and are solutions of (3.4). We put the results in Fig 7, Fig 8 and Fig 9. Comparing the EMI method with the Linear method, we observe that the performance of EMI is consistently better. Additionally, when compared to EMI w/o. Interp., the performance of EMI is slightly worse, which is consistent with previous experimental results. In Fig 10 and Fig 11, we present visualizations of extreme conditional quantile estimates for online data streams. To keep the presentation concise, we select only a portion of the data. These figures demonstrate EMI’s effectiveness in capturing changes in conditional quantiles.
4 Application
| Name | Mean | Standard deviation | Skewness | Min. | Max. | |
|---|---|---|---|---|---|---|
| Market return | 0.16 | 2.23 | -0.29 | -15.35 | 12.00 | |
| Three-month yield change | -0.22 | 24.43 | -0.57 | -182.00 | 192.00 | |
| Equity volatility | 0.83 | 0.43 | 3.06 | 0.28 | 4.70 | |
| Credit spread change | -0.02 | 8.86 | 0.74 | -48.00 | 60.00 | |
| Term spread change | 0.15 | 20.66 | 0.09 | -168.00 | 146.00 | |
| TED spread | 121.52 | 94.42 | 1.74 | 6.34 | 591.00 | |
| Real estate excess return | -0.08 | 2.38 | 0.04 | -14.49 | 16.58 |
| Company | Start time | End time | |
|---|---|---|---|
| S&P | S&P 500 | January 1st, 1971 | December 28th, 2002 |
| AAPL | Apple Inc. | January 1st, 1981 | December 28th, 2002 |
| BA | The Boeing Company | January 1st, 1971 | December 28th, 2002 |
| JPM | JPMorgan Chase & Co. | January 1st, 1981 | December 28th, 2002 |
In this section, we apply our algorithm EMI to estimate the extreme conditional quantile of a real dataset, consisting of the daily stock price of the S&P 500 and three companies (see Table 2). The weekly return is derived from daily index observations. The covariates employed in our analysis include ret (weekly return), marketret (weekly market return), yield3m (three-month yield change), mktsd (equity volatility), credit (credit spread change), term (term spread change), ted (short-term TED spread), and housing (real estate excess return), as documented in ( Adrian and Brunnermeier, 2016). More specificity, the variables are defined as:
-
•
: The weekly loss, namely the weekly return;
-
•
: The weekly market return of S&P 500;
-
•
: The change in the three-month yield from the Federal Reserve Board’s release. We use the change in the three-month treasury bill rate because we find that the change, not the level, is most significant in explaining the tails of financial sector market-valued asset returns;
-
•
: Equity volatility, which is computed as the -day rolling standard deviation of the daily CRSP equity market return;
-
•
: The change in the credit spread between Moody’s Baarated bonds and the ten-year Treasury rate from the Federal Reserve Board’s release;
-
•
: The change in the slope of the yield curve, measured by the spread between the composite long-term bond yield and the three-month bill rate obtained from the Federal Reserve Board’s release;
-
•
: A short-term TED spread, which is defined as the difference between the three-month LIBOR rate and the three-month secondary market treasury bill rate. This spread measures short-term funding liquidity risk. We use the three-month LIBOR rate that is available from the British Bankers’ Association, and obtain the three-month Treasury rate from the Federal Reserve Bank of New York;
-
•
: The weekly real estate sector returns over the market financial sector return (from the real estate companies with SIC code -).





We present a summary of the variables in Table 1. At time , we assume that the response is related to covariates at time . As a result, the quantile of response depends on the covariate in a linear form:
In our data analysis, our primary focus is on estimating the extreme conditional quantile at the level for S&P 500 and for three companies using EMI. Initially, we conduct a brief visual assessment to ascertain the suitability of the heavy-tail assumption for our data. As depicted in Fig. 12, the returns exhibit heavy tails on both ends. However, our emphasis lies in scrutinizing significant losses, directing our analysis towards the upper tail losses of the weekly returns, specifically, the extremely large losses. For S&P 500 and each company, we follow the setting in Section 3.4 to estimate the extreme conditional quantile of future weekly returns employing historical data. To be specific, let and , where represents the total time span and denotes the -th weekly data. At each time point , the observation set is defined as:
In essence, we leverage the data from the past ten years to estimate the extreme conditional quantile of the subsequent four weekly returns.



We summarize our results in Fig. 13 (S&P), Fig. 14 (AAPL), Fig. 15 (BA) and Fig. 16 (JPM). 2008). We observe that the index of S&P 500 exhibits the lowest conditional quantiles, indicating that it has the most robust capability to resist risk. Among the three companies studied, the conditional quantile of losses of AAPL is much larger compared to BA and JPM. It probably reflects the fact that technical companies may suffer more risk during the crisis period. In conclusion, our empirical analysis demonstrates that the proposed method for extreme conditional quantile serves as a good risk measure, particularly when considering loss values in tail regions.
5 Conclusion
In this paper, we introduce an algorithm called EMI designed for estimating extreme conditional quantiles. Operating with finite offline observations, our approach approximates the exceedance above a predetermined threshold using the GPD. We formulate the extrapolation process by rewriting it as bilevel programming, making it amenable to efficient solutions through conventional optimization techniques. To enhance flexibility and computational efficiency, we incorporate B-spline interpolation for covariate-dependent parameters. This interpolation capability empowers EMI to estimate conditional quantiles for potentially infinite online data, avoiding the computational complexity associated with GPD fitting. Empirical experiments convincingly demonstrate that our proposed EMI consistently outperforms the linear conditional regression model.
6 Acknowledgment
Yanxi Hou’s work was supported by the MOE Laboratory for National Development and Intelligent Governance, Fudan University, the National Natural Science Foundation of China Grant 72171055, and the Natural Science Foundation of Shanghai Grant 20ZR1403900.
References
- \bibcommenthead
- Adrian and Brunnermeier [2016] Adrian T, Brunnermeier MK (2016) Covar. American Economic Review 106(7):1705–1741
- Aiyoshi and Shimizu [1981] Aiyoshi E, Shimizu K (1981) Hierarchical decentralized systems and its new solution by a barrier method. IEEE Transactions on Systems, Man and Cybernetics 11(6):444–449
- Allen et al [2012] Allen L, Bali TG, Tang Y (2012) Does systemic risk in the financial sector predict future economic downturns? The Review of Financial Studies 25(10):3000–3036
- Angelo et al [2013] Angelo JS, Krempser E, Barbosa HJ (2013) Differential evolution for bilevel programming. In: 2013 IEEE Congress on Evolutionary Computation, pp 470–477
- Balkema and De Haan [1974] Balkema AA, De Haan L (1974) Residual life time at great age. The Annals of Probability 2(5):792–804
- Drees et al [2004] Drees H, Ferreira A, De Haan L (2004) On maximum likelihood estimation of the extreme value index. Annals of Applied Probability 14(3):1179–1201
- Ferreira and De Haan [2015] Ferreira A, De Haan L (2015) On the block maxima method in extreme value theory: PWM estimators. The Annals of Statistics 3(1):276–298
- Gaber et al [2005] Gaber MM, Zaslavsky A, Krishnaswamy S (2005) Mining data streams: A review. ACM Sigmod Record 34(2):18–26
- Granello and Wheaton [2004] Granello DH, Wheaton JE (2004) Online data collection: Strategies for research. Journal of Counseling & Development 82(4):387–393
- He et al [2022] He Y, Peng L, Zhang D, et al (2022) Risk analysis via generalized pareto distributions. Journal of Business & Economic Statistics 40(2):852–867
- Hosking et al [1985] Hosking JRM, Wallis JR, Wood EF (1985) Estimation of the generalized extreme-value distribution by the method of probability-weighted moments. Technometrics 27(3):251–261
- Hou et al [2022] Hou Y, Kang SK, Lo CC, et al (2022) Three-step risk inference in insurance ratemaking. Insurance: Mathematics and Economics 105:1–13
- Koenker and Bassett Jr [1978] Koenker R, Bassett Jr G (1978) Regression quantiles. Econometrica 46(1):33–50
- Koenker and Hallock [2001] Koenker R, Hallock KF (2001) Quantile regression. Journal of Economic Perspectives 15(4):143–156
- Li and Wang [2019] Li D, Wang HJ (2019) Extreme quantile estimation for autoregressive models. Journal of Business & Economic Statistics 37(4):661–670
- Luo et al [1996] Luo ZQ, Pang JS, Ralph D (1996) Mathematical Programs with Equilibrium Constraints. Cambridge University Press, Cambridge, England
- Lv et al [2007] Lv Y, Hu T, Wang G, et al (2007) A penalty function method based on Kuhn–Tucker condition for solving linear bilevel programming. Applied Mathematics and Computation 188(1):808–813
- Mathieu et al [1994] Mathieu R, Pittard L, Anandalingam G (1994) Genetic algorithm based approach to bi-level linear programming. Operations Research 28(1):1–21
- Naveau et al [2009] Naveau P, Guillou A, Cooley D, et al (2009) Modelling pairwise dependence of maxima in space. Biometrika 96(1):1–17
- Pickands III [1975] Pickands III J (1975) Statistical inference using extreme order statistics. The Annals of Statistics 3(1):119–131
- Resnick [2008] Resnick SI (2008) Extreme Values, Regular Variation, and Point Processes. Springer Science & Business Media, Berlin, Germany
- Sinha et al [2014] Sinha A, Malo P, Frantsev A, et al (2014) Finding optimal strategies in a multi-period multi-leader–follower Stackelberg game using an evolutionary algorithm. Computers & Operations Research 41:374–385
- Sinha et al [2017] Sinha A, Malo P, Deb K (2017) A review on bilevel optimization: From classical to evolutionary approaches and applications. IEEE Transactions on Evolutionary Computation 22(2):276–295
- Smith [1987] Smith RL (1987) Estimating tails of probability distributions. The Annals of Statistics 15(3):1174–1207
- Velthoen et al [2019] Velthoen J, Cai JJ, Jongbloed G, et al (2019) Improving precipitation forecasts using extreme quantile regression. Extremes 22:599–622
- Wang and Li [2013] Wang HJ, Li D (2013) Estimation of extreme conditional quantiles through power transformation. Journal of the American Statistical Association 108(503):1062–1074
- Wang et al [2012] Wang HJ, Li D, He X (2012) Estimation of high conditional quantiles for heavy-tailed distributions. Journal of the American Statistical Association 107(500):1453–1464
- Xu et al [2022] Xu W, Hou Y, Li D (2022) Prediction of extremal expectile based on regression models with heteroscedastic extremes. Journal of Business & Economic Statistics 40(2):522–536