One size doesn’t fit all: Predicting the Number of Examples for In-Context Learning
Abstract
In-context learning (ICL) refers to the process of adding a small number of localized examples (ones that are semantically similar to the input) from a training set of labelled data to an LLM’s prompt with an objective to effectively control the generative process seeking to improve the downstream task performance. Existing ICL approaches use an identical number of examples (a pre-configured hyper-parameter) for each data instance. Our work alleviates the limitations of this ‘one fits all’ approach by dynamically predicting the number of examples for each data instance to be used in few-shot inference with LLMs. In particular, we employ a multi-label classifier, the parameters of which are fitted using a training set, where the label for each instance in the training set indicates if using a specific value of (number of most similar examples from 0 up to a maximum value) leads to correct -shot downstream predictions. Our experiments on a number of text classification benchmarks show that AICL substantially outperforms standard ICL by up to 17%.
One size doesn’t fit all: Predicting the Number of Examples for In-Context Learning
Manish Chandra, Debasis Ganguly and Iadh Ounis University of Glasgow Glasgow, United Kingdom [email protected], [email protected], [email protected]
1 Introduction
Large Language Models (LLMs) exhibit remarkable abilities to model text semantics in an abstract and general manner without any task specific training Radford et al. (2018). In-context learning (ICL)111also interchangeably known as few-shot learning or retrieval-augmented generation (RAG) with ground-truth labels makes use of this abstract representation and knowledge representation capabilities of LLMs Brown et al. (2020); Arora et al. (2022); Weidinger et al. (2022) to address a range of different downstream tasks. For instance, such models can provide effective solutions for tasks including assessing reviews Mysore et al. (2023), answering questions Li et al. (2023a), recommending relevant documents Pradeep et al. (2023) etc., by using only a small number of (even zero) examples without any task-specific training.


More formally, ICL refers to the process of conditioning an LLM’s decoder (frozen parameters) towards generating potentially relevant outputs that could then be interpreted in the context of a specific task, e.g., words such as ‘great’ and ‘wow’ can be mapped to a positive sentiment Schick et al. (2020). The output of an LLM’s decoder is controlled by varying the input to the LLM, which is usually structured in the form of an instruction (the task description), and a small number of representative examples Ni et al. (2022). Figure 1(a) shows an example of how ICL works for the downstream task of movie review sentiment analysis. It can be seen that both demonstrations (shown in blue) and the current instance form a part of the input to an LLM. Researchers have worked towards adapting an ICL workflow in several ways, which range from using localised examples Liu et al. (2022a) instead of random ones, to diversifying these examples Levy et al. (2023), and also ideally ordering them Kumar and Talukdar (2021); Rubin et al. (2022). What prior work has not addressed so far is the effect of dynamically selecting the number of examples in an ICL workflow. Our idea takes motivation from information retrieval (IR), where different queries exhibit different levels of retrieval performance mainly due to the inherent characteristic of the information need itself Kanoulas et al. (2011), or how well-formulated the query is Datta et al. (2022). Drawing the parallel that a query in IR is analogous to a test instance in ICL and that the localised examples are potentially relevant documents Rubin et al. (2022), we hypothesise that some test instances are associated with better candidates for training examples (i.e., examples which are useful in the sense that including them as a part of the prompt leads to correct predictions), and hence including a small number of these examples should be adequate. On the other hand, the retrieval quality for some test instances used as queries do not yield good candidates, as a result of which, one needs to further look down the ranked list to collect the useful ones Bahri et al. (2020); Ganguly and Yilmaz (2023). The parallel with IR means that the notion of relevance of a document to a query needs to be replaced by the downstream usefulness of an example to a test instance.
The idea of choosing a variable number of localised examples is also somewhat similar to selecting a variable-sized neighborhood for -NN classification Zhong et al. (2017), where the key idea is that a homogeneous neighborhood is likely to require a relatively small-sized neighborhood for a correct prediction, and a heterogeneous one would likely require a larger one (see Figure 1(b)). The same idea can be applied to ICL, where a test instance that is similar to a number of training instances with conflicting labels may require a larger number of examples.
In our work, we apply a supervised learning based workflow to learn a mapping between the features of a test instance (embedding plus the label distribution of its neighborhood) and the ideal number of examples that should be used in ICL for the downstream prediction. More specifically, for each instance of the training set we vary - the number of ICL examples - within a range of to a pre-configured maximum value (say ) and store each indicator of whether a particular value of leads to a correct prediction as an -length Boolean vector (e.g., the indicator for in Figure 1(a) is negative, whereas the one for is positive). We then train a multi-label classifier on these pairs of instances and the Boolean indicators, the assumption being that similar instances with similar label distributions should also exhibit a similar distribution over the values of leading to correct -shot learning. During inference time, for each test instance, we apply the multi-label classifier to obtain a candidate list of predicted values, and we select the one for which the prediction confidence is the highest. We then use these many examples for the ICL-based downstream prediction. This means that as per the schematics of Figure 1(a), we can potentially find out a ‘green path’ leading to a correct prediction for each test instance among several other ‘red paths’ that lead to incorrect ones.
2 Related Work
Prompt tuning and searching.
LLMs, when scaled from millions to billions of parameters, have been demonstrated to be adaptable to a broad set of tasks due to instruction tuning Ouyang et al. (2022); Brown et al. (2020), in the sense that they are not only able to produce semantically correct and coherent text, but are also able to adapt themselves surprisingly well with small changes in contexts supplied as inputs, commonly called prompts Arora et al. (2022). Previous research studies the problem of constructing an appropriate prompt for LLMs from two broad perspectives: a) prompt tuning in the embedding space Li and Liang (2021); Liu et al. (2022b); Qin and Eisner (2021); Liu et al. (2023), and b) prompt searching in the text space Lu et al. (2022); Zhang et al. (2023); Diao et al. (2023); Liu et al. (2022a); Shi et al. (2023). Prompt tuning is a lightweight alternative to fine-tuning, which keeps language model parameters frozen and instead optimizes a sequence of continuous task-specific vectors. The key idea of prompt tuning is to inject task-specific embedding into hidden layers and then tune these embeddings using gradient-based optimization. However, these methods require the modification of the original inference process of the model, which is impractical for the case of black-box LLM services, such as GPT3 Brown et al. (2020). Furthermore, prompt tuning introduces additional computational and storage costs, which is typically expensive for LLMs. A more efficient way is to optimize prompting via searching appropriate demonstration samples and ordering them in the original text space.
In-context Learning (ICL).
ICL has advanced the use of LLMs for task-specific applications with minimal examples, forming a solid foundation for subsequent investigations into optimizing this learning paradigm Dong et al. (2022). In ICL, a small number of labeled examples from a training set are appended to a prompt instruction to control the text generation of LLM so that it is beneficial to a downstream task Mysore et al. (2023); Li et al. (2022); Ni et al. (2021); Pradeep et al. (2023). In addition to leveraging ICL for a purely generative task, e.g., question answering or abstractive summarisation Brown et al. (2020); Li et al. (2023a); Tang et al. (2023), a more common use is in a predictive task, such as text classification Lu et al. (2022); Milios et al. (2023); Wei et al. (2021), where each class is specified by a set of words, commonly called a verbaliser Schick and Schütze (2021). Once each class for a predictive task is well-defined, the generated text can be mapped to the most likely class by using the probabilities of the tokens generated by the decoder.
A crucial aspect of ICL is the adept selection and utilization of the demonstrations for task comprehension. Recent works have explored the dynamics of in-context examples, elucidating how ICL enhances the language model’s performance across various NLP tasks by providing a minimal set of examples at inference time Han et al. (2023). Furthermore, the effectiveness of ICL is significantly shaped by the strategies for selecting and ordering demonstrations. For instance, the work in Luo et al. (2023) expanded the applicability of retrieval-based ICL approaches by demonstrating that even simple word-overlap similarity measures such as BM25 outperform randomly selected demonstrations. Methods such as KATE Liu et al. (2022a) also showed that localised examples work better than random ones. Different from KATE that uses a fixed-size neighbourhood for each data instance, we propose to modify a standard ICL workflow by employing a variable number of examples.
3 Proposed Methodology

3.1 Standard In-Context Learning (ICL)
In-context learning (ICL), unlike supervised learning, does not involve training a set of parameters on labeled examples. Rather, the posteriors are now a function of the following: a) text of the input test instance, b) the decoder parameters of a pre-trained LLM, c) a prompt instruction, and d) optionally, a set of input examples, commonly called -shot prompting Liu et al. (2022a). Formally,
| (1) |
where, different from a supervised setup, the function does not have a parameterized representation that can be learned using a training set with gradient descent. The function itself depends on the pre-trained frozen parameters of an LLM, the current inputs for which a label is to be predicted, and a prompt comprising a set of text units denoted by . This set of Equation 1 (where each , a training set of labelled data instances) in ICL is usually comprised of localised examples, i.e., examples that are topically similar to the current instance Liu et al. (2022a); Luo et al. (2024). Particularly for our experiments, we employ SBERT Reimers and Gurevych (2019) as the neighborhood similarity computation function as per the findings of Liu et al. (2022a).
3.2 Adaptive ICL
We now describe our methodology that uses a variable number of examples by extending the standard ICL workflow of Equation 1. We call our method ‘Adaptive In-Context Learning’, or AICL for short. The idea of AICL centres around choosing the context in a data-driven manner, i.e., making a function of the data, i.e., the current instance itself. This is analogous to choosing a different value of for a -NN based non-parametric model or choosing a different rank cut-off for top-retrieved set of documents for different queries Bahri et al. (2020); Ganguly and Yilmaz (2023). The motivation is that classifying some instances would be more difficult than others, in which cases they are potentially to benefit from a larger value of (more context). On the other hand, for relatively easier data instances, using too much context may be detrimental for an effective prediction.
Formally speaking, the difference of AICL with that of ICL (Equation (1)) is that the value , indicating the size of the neighborhood, is no longer a constant. Instead, we denote it by a parameterised function such that
| (2) |
where , and is an upper bound on the number of example instances.
Figure 2 presents an overarching view of the AICL workflow. In contrast to ICL, AICL involves an additional phase of training a classifier, of Equation (2), to predict an appropriate number of examples by leveraging the training instances (the ‘classifier training’ block in Figure 2). The ‘LLM inference’ block shows the inference phase, where, given a test instance, we first predict the number of examples to be used and then follow the standard ICL procedure with those many examples fed as part of the additional context to the LLM.
Obtaining the ground-truth values of the number of ICL examples for each training set instance.
For each training set instance , we first execute -shot inference with progressively increasing values of within , where is a pre-configured threshold (specifically, in our experiments). This is depicted by the progressively increasing colored dotted regions within the ‘classifier training’ block of Figure 2. After obtaining posteriors for an instance of the training set, we construct an dimensional Boolean vector, the component of which indicates if using ICL examples lead to a correct downstream prediction for the current instance (note that since is a training set instance, the knowledge of its true label is available). Formally speaking,
| (3) |
where is an dimensional Boolean vector (note that we allow provision for the number of examples to be 0 as well, thus allowing provision for zero-shot prediction).
Training a multi-label classifier.
As a next step, we learn a parameterized map from the inputs to the dimensional indicators on the number of ICL examples, i.e.,
| (4) |
where as defined in Equation 3 and is a set of parameters learned via cross-entropy loss. Our decision to use a multi-label classification approach is motivated from a set of initial experiments, where we found that it outperformed a multi-class classifier approach (which we thus do not report in the paper). The most likely reason why a multi-label classifier works more effectively for this predictive task is that it allows provision to select the most likely candidate number of ICL examples from a number of alternatives rather than relying on a single predicted value of .
Of course, this also means that there needs to be a precise selection criteria to choose the number of examples to be used in the inference time from a list of choices, i.e., the result of the multi-label prediction where the predicted label is 1 (sigmoid posterior is higher than 0.5). We tried two different heuristics for this selection - i) choosing the smallest index from the dimensional vector with a predicted value of 1 (sigmoid > 0.5), and ii) selecting the component with the highest confidence (sigmoid posterior). Again after conducting a set of initial experiments, we found that the second heuristics almost always outperforms the first one, and hence our workflow of Figure 2 employs the max-confidence heuristic for predicting the number of ICL examples to be used during inference (see Equation 2). More formally,
| (5) |
where denotes the posteriors (sigmoid values) obtained from a multi-label classifier trained with the labels as defined in Equation 3.
Distribution of the downstream-task class labels as additional features.
The multi-label classifier means that the number of ICL examples depend only on the document content, or in other words, topically similar content potentially requires a similar number of ICL examples for accurate predictions. However, this does not take into account the class label distribution (the values) of the examples. In fact, it is reasonable to assume that an instance with a more homogeneous neighborhood (in terms of the class label distribution) likely indicates an easier instance and hence may require a smaller number of examples, whereas a more heterogeneous neighborhood may indicate a larger number of examples (e.g., see Figure 1(b)).
This hypothesis means that the use of neighborhood class distribution as additional features to encode each training data instance () is likely to lead to a better predictor , which in turn, is likely to lead to better estimations of for AICL. Specifically, to incorporate the class prior information to aid predicting the number of ICL examples, we append an dimensional vector ( is the number of class labels) to each SBERT embedded input vector . The component of this vector contains the class label of the neighbor in , i.e., . With this modification, the multi-label classifier now learns:
| (6) |
where denotes the class label distribution of nearest neighbors, and denotes the concatenation operator.
4 Evaluation
Dataset Task #Classes Document Type Avg Len (#words) SST2 Sentiment Analysis 2 Movie Reviews 19.3 TREC Question classification 6 Open Domain Questions 10.2 CoLA Grammatical Error Detection 2 News and Wikipedia 6.7 RTE Language Inference 2 Miscellaneous 52.4
4.1 Research Questions and Datasets
In Section 3, we proposed a classifier-based approach to learn the optimal number of examples. In our experiments, we compare this approach for adaptive -shot with fixed -shot on standard datasets for text classification. In particular, we investigate the following research questions.
-
•
RQ-1: Does adaptively selecting the number of examples in ICL (AICL) lead to improved downstream effectiveness?
-
•
RQ-2: Do the class labels of the neighbouring training set examples act as useful features to improve AICL performance?
-
•
RQ-3: Does AICL generalise well across different LLMs or datasets?
-
•
RQ-4: Can the multi-label classification model (Equation 6) be trained effectively on a small subsample of the training set, thus reducing the number of LLM calls during the training?
As per the setup of Ma et al. (2023); Zhang et al. (2022), we conducted our experiments on four standard text classification datasets, namely SST2, TREC Li and Roth (2002), CoLA and RTE. Except TREC, the other three datasets are part of the GLUE benchmark Wang et al. (2018) exhibiting diversity in: i) domain, e.g., from movie reviews to news, ii) number of classes, ranging from 2 to 6, iii) average length of the documents ranging from sentences (e.g., 6.7 words on an average in CoLA) to relatively large text (e.g., 52.4 words on an average in RTE). This diversity in the characteristics of the respective datasets (see Table 1) thus allows provision to assess the generalizability of our proposed approach. More details on each dataset is as follows.
-
•
SST2: The Stanford Sentiment Treebank (SST) corpus consists of sentences extracted from movie reviews. The SST2 (also called SST-binary) dataset is a subset of SST, specifically prepared for the task of binary sentiment classification by discarding neutral sentences.
-
•
TREC: The task is that of open-domain question classification of fact-based questions categorized into a total of 6 types Ma et al. (2023), constituting labeled questions in the training set and in the test set.
-
•
CoLA: The Corpus of Linguistic Acceptability (CoLA) dataset consists of sentences from linguistics publications annotated for grammatical correctness. It has a wide coverage of syntactic and semantic phenomena.
-
•
RTE: The Recognizing Textual Entailment (RTE) dataset comes from a series of annual textual entailment challenges. The authors of the GLUE benchmark Wang et al. (2018) combined the data from RTE1, RTE2, RTE3 and RTE5.
Llama-2-7b Phi-2 Llama-2-13b Method Prec Rec F1 Prec Rec F1 Prec Rec F1 SST2 0-shot 0 .7227 .6123 .5589 0 .8988 .8919 .8914 0 .7341 .6443 .5891 FICL 9 .8744 .8687 .8682 10 .9279 .9253 .9252 9 .8912 .8733 .8809 AICL(E) 8.63 .9089 .8946 .8925 6.39 .9307 .9300 .9300 5.73 .9175 .9065 .9028 AICL(E+N) 8.23 .9099 .8964 .8954 5.64 .9350 .9345 .9345 4.89 .9189 .9071 .9034 AICL* 1.27 .9765 .9753 .9753 .17 .9865 .9863 .9863 .84 .9866 .9859 .9848 TREC 0-shot 0 .1697 .1687 .0100 0 .6289 .4273 .3526 0 .3212 .3685 .3016 FICL 9 .7388 .7324 .6608 8 .6842 .6582 .6192 9 .7612 .7922 .7071 AICL(E) 9.60 .7654 .8049 .7325 4.72 .7146 .7549 .7196 5.51 .7659 .8218 .7383 AICL(E+N) 9.58 .7682 .8075 .7357 5.57 .7254 .7673 .7291 4.93 .7737 .8288 .7532 AICL* 3.35 .8496 .9334 .8616 1.27 .9337 .9294 .9313 2.25 .9513 .9367 .9413 CoLA 0-shot 0 .5585 .5323 .3699 0 .4315 .4899 .2558 0 .6474 .4321 .3455 FICL 10 .6240 .6415 .6008 9 .7071 .6306 .6433 8 .7167 .6338 .6472 AICL(E) 8.32 .6556 .6741 .6582 7.73 .7289 .6471 .6601 2.33 .7412 .6447 .6667 AICL(E+N) 7.43 .6580 .6765 .6616 7.93 .7392 .6486 .6613 1.99 .7432 .6558 .6714 AICL* 2.42 .9417 .9281 .9299 .69 .9663 .9232 .9413 .78 .9408 .9466 .9483 RTE 0-shot 0 .4913 .4992 .3985 0 .6741 .6741 .6741 0 .5345 .5444 .4403 FICL 10 .6095 .6051 .5967 1 .7347 .7239 .7240 4 .6287 .6233 .6214 AICL(E) 8.57 .6304 .6277 .6227 2.44 .7536 .7412 .7415 5.16 .7592 .6441 .6700 AICL(E+N) 8.32 .6342 .6311 .6252 1.15 .7551 .7465 .7471 3.68 .7631 .6485 .6738 AICL* .95 .9783 .9783 .9783 .81 .9296 .9214 .9234 .65 .9734 .9733 .9733
4.2 Methods Investigated
Baselines.
We compare our proposed AICL methodology with the following baselines:
-
•
0-shot: This approach tests a model’s innate capabilities, i.e., the capability to operate without any training data (information on class labels). Specifically, this requires setting in Equation 1.
-
•
FICL Liu et al. (2022a) (Fixed ICL): This refers to the standard method of applying a static (fixed) number of localized (semantically similar) examples as input. The number of examples to use in FICL is determined by optimizing by means of grid search on a validation set, which comprises of the training set (the same training set is also used in AICL).
Variants of AICL.
We employ the following variants for our proposed methodology of employing a variable number of ICL examples.
- •
-
•
AICL with Embedding + Neighborhood class labels - AICL(E+N): Similar to AICL(E) except that the input to the multi-label classifier is now the embedding of a training data instance along with the class labels of its neighbors (see Equation 6).
As part of the analysis, we also report the performance of AICL under an ideal setting, i.e., when one can choose the best prediction from among a set of predictions obtained with different values of in -shot LLM-based inference by making use of the test set labels. Despite being non-pragmatic, this method provides an upper bound on the effectiveness that could, in principle, be obtained with the AICL framework. To avoid unfair comparisons of AICL* with AICL, we gray out the AICL* results indicating that these results are only to be used as an apex-line.
Corresponding to RQ-4, since constructing the ground-truth via Equation 3 requires a total of LLM calls for each training instance, for efficiency reasons, we first train the multi-label classifier of the AICL workflow only on a subset of training data obtained by randomly sampling of data from each class. Later on, as post-hoc analysis towards answering RQ-4, we also investigate if AICL results further improve (or degrade) with larger (or smaller) subsets sampled from the training data.



4.3 Model and hyper-parameter settings
To learn the number of examples to be used during inference, the AICL workflow relies on training the predictor (multi-label classifier of Equations 4 and 6), which in turn, depends on the ground-truth labels ( of Equation 3) of the number of examples that lead to correct predictions via LLM-based few-shot inference. But this means that these ground-truth labels depend on a particular choice of the LLM that is used during the training phase to check the accuracy of the downstream task labels (see Equation 3).
To analyze the variations that may be caused due to this choice of LLMs, we conduct our experiments on three different LLMs - two each from the same family with different sizes, and one from a different family. The objective is to analyze the effects of variations in AICL’s performance corresponding to the size of a model from the same family, or variations in characteristics in models across different families. In particular, as instances of LLMs from the same family we use Meta’s Llama-2-7b and Llama-2-13b Touvron et al. (2023), whereas as another LLM from a different family, we use Microsoft’s Phi-2 Li et al. (2023b). Details on these models are as follows: Llama-2 is a collection of open-source pretrained and fine-tuned text models with a maximum context length of 4096 tokens (we use the 7B and the 13B parameter models). Phi-2 Li et al. (2023b) is a transformer with 2.7 billion parameters. It is trained on documents comprising Python code, StackOverflow, websites and natural language text generated by GPT-3.5. Phi-2 with less than 3B parameters has been shown to yield comparable performance with those achieved with much larger number of parameter, e.g., the 13B variant of Llama-2. The maximum input length of Phi-2 is 2048 tokens.
In our experiments, we set (the maximum number of ICL examples) to (see Equation 3). Furthermore, for training the multi-label classifier parameters of Equations 4 and 6, we choose a single hidden layer network with 64 neurons. These decision choices are based on initial experiments of hyper-parameter tuning conducted on the SST2 dataset with the Llama-2-7b model.
4.4 Results




Main observations.
Table 2 shows a comparison between different ICL approaches on the four datasets. The reported precision, recall and F-scores are averaged over 5 runs of the experiments. The number of examples in FICL, as shown in the corresponding column, were obtained by a grid search over from 1 to 10 on a validation set. From Table 2, it can be seen that AICL(E+N) turns out to be the best among the competing approaches - this method being statistically distinguishable than the FICL results (McNemar’s test with 95% confidence interval). The likely reason it outperforms the baselines is that AICL is able to effectively adapt the number of examples to use, thereby preventing itself from the degradation effects of non-relevant (not useful) examples. In effect, it learns a latent relationship between the topical content and the quantity of context required to guide the decoder’s output towards improving a downstream task. Our observations reveal that RQ-1 is answered in the affirmative, i.e., an adaptive selection of the number of examples in ICL does improve the downstream effectiveness.
For the AICL approaches, we report the average number of examples, as predicted by the output of the multi-label classifier (Equations 4 and 6), in the column named . In contrast to the grid-searched integer values in FICL, for AICL the number of examples () is an average over the test instances, and hence is a non-integer.
One interesting observation is that the oracle version of AICL (AICL*) performs substantially better than AICL with much smaller values of , which testifies the fact that selecting the correct value of independently for each test instance can lead to large improvements in few-shot prediction effectiveness. This also means that there is a scope to further improve the AICL workflow.
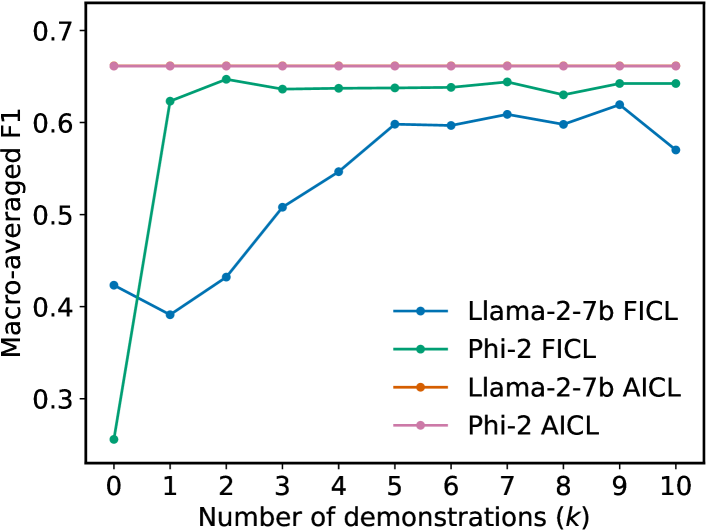
Sensitivity Analysis of FICL (Fixed- ICL).
Figure 3 shows the F1-scores of FICL on the test splits of the different datasets with a varying number of demonstrations. Firstly, it can be observed from Figure 3 that there is no consistent improvement in the performance of FICL with an increase in . Since the FICL results are sensitive to , it is difficult to choose a particular value of for a given downstream task because such a grid search is not a practical solution as the ground-truth is not supposed to be known apriori. We already showed in Table 2 that optimizing by grid search on a validation set produces worse results than AICL. Additionally, Figure 3 shows that the AICL results also outperform FICL with optimized on the test set. This indicates that AICL can, in principle, be deployed on any downstream task without requiring any hyper-parameter optimization of .
Effect of neighbourhood.
Among the two variants of AICL, it can be seen from Table 2 that the use of neighbor class labels (the ‘E+N’ variant) yields better results than the ablated (‘E’ variant), which means that RQ-2 is answered in affirmative. In relation to RQ-3, Table 2 shows that the improvements in AICL with respect to FICL is consistent across different datasets and also across different LLMs.
Multi-label classifier in AICL with reduced training data.
It is evident from Table 2 that for each dataset, the best value of in FICL differs from one LLM to another. This means to construct the correct ground-truth for training the multi-label classifier in AICL (Equation 6), LLM predictions need to be made for each instance, which means that the total number of LLM invocations is , where denotes the training set.
A solution to reduce training time is to use a small subsample of the training data to learn the parameters of Equation 6. Figure 4 shows the variations in F1 scores for different proportions of the training set used to learn . An interesting observation is that AICL is able to outperform the baseline with as small a proportion as 30% (or even less in some cases) of the training set being used to train , which means that RQ-4 is answered in the affirmative.
5 Conclusion and Future work
To improve the effectiveness of LLM-based few-shot inference, we proposed a supervised multi-label classification approach that learns how many examples to use for which data instance. The classifier itself is trained on a set of labeled examples, where the ground-truth for each training data instance constitutes the set of (number of examples) that lead to correct downstream task prediction via -shot LLM inference.
References
- Arora et al. (2022) Simran Arora, Avanika Narayan, Mayee F. Chen, Laurel Orr, Neel Guha, Kush Bhatia, Ines Chami, Frederic Sala, and Christopher Ré. 2022. Ask me anything: A simple strategy for prompting language models.
- Bahri et al. (2020) Dara Bahri, Yi Tay, Che Zheng, Donald Metzler, and Andrew Tomkins. 2020. Choppy: Cut transformer for ranked list truncation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, page 1513–1516, New York, NY, USA. Association for Computing Machinery.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Datta et al. (2022) Suchana Datta, Debasis Ganguly, Derek Greene, and Mandar Mitra. 2022. Deep-qpp: A pairwise interaction-based deep learning model for supervised query performance prediction. In WSDM ’22: The Fifteenth ACM International Conference on Web Search and Data Mining, Virtual Event / Tempe, AZ, USA, February 21 - 25, 2022, pages 201–209. ACM.
- Diao et al. (2023) Shizhe Diao, Pengcheng Wang, Yong Lin, and Tong Zhang. 2023. Active prompting with chain-of-thought for large language models.
- Dong et al. (2022) Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. 2022. A survey for in-context learning. arXiv preprint arXiv:2301.00234.
- Ganguly and Yilmaz (2023) Debasis Ganguly and Emine Yilmaz. 2023. Query-specific variable depth pooling via query performance prediction. In SIGIR, pages 2303–2307. ACM.
- Han et al. (2023) Xiaochuang Han, Daniel Simig, Todor Mihaylov, Yulia Tsvetkov, Asli Celikyilmaz, and Tianlu Wang. 2023. Understanding in-context learning via supportive pretraining data. arXiv preprint arXiv:2306.15091.
- Kanoulas et al. (2011) Evangelos Kanoulas, Ben Carterette, Paul D. Clough, and Mark Sanderson. 2011. Evaluating multi-query sessions. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’11, page 1053–1062, New York, NY, USA. Association for Computing Machinery.
- Kumar and Talukdar (2021) Sawan Kumar and Partha P. Talukdar. 2021. Reordering examples helps during priming-based few-shot learning. In ACL/IJCNLP (Findings), volume ACL/IJCNLP 2021 of Findings of ACL, pages 4507–4518. Association for Computational Linguistics.
- Levy et al. (2023) Itay Levy, Ben Bogin, and Jonathan Berant. 2023. Diverse demonstrations improve in-context compositional generalization. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1401–1422, Toronto, Canada. Association for Computational Linguistics.
- Li et al. (2022) Minghan Li, Xueguang Ma, and Jimmy Lin. 2022. An encoder attribution analysis for dense passage retriever in open-domain question answering. In Proceedings of the 2nd Workshop on Trustworthy Natural Language Processing (TrustNLP 2022), pages 1–11, Seattle, U.S.A. Association for Computational Linguistics.
- Li et al. (2023a) Tianle Li, Xueguang Ma, Alex Zhuang, Yu Gu, Yu Su, and Wenhu Chen. 2023a. Few-shot in-context learning on knowledge base question answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6966–6980, Toronto, Canada. Association for Computational Linguistics.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, Online. Association for Computational Linguistics.
- Li and Roth (2002) Xin Li and Dan Roth. 2002. Learning question classifiers. In Proceedings of the 19th International Conference on Computational Linguistics - Volume 1, COLING ’02, page 1–7, USA. Association for Computational Linguistics.
- Li et al. (2023b) Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. 2023b. Textbooks are all you need ii: phi-1.5 technical report. arXiv preprint arXiv:2309.05463.
- Liu et al. (2022a) Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. 2022a. What makes good in-context examples for GPT-3? In Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, pages 100–114, Dublin, Ireland and Online. Association for Computational Linguistics.
- Liu et al. (2022b) Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. 2022b. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 61–68, Dublin, Ireland. Association for Computational Linguistics.
- Liu et al. (2023) Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2023. Gpt understands, too. AI Open.
- Lu et al. (2022) Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086–8098, Dublin, Ireland. Association for Computational Linguistics.
- Luo et al. (2023) Man Luo, Xin Xu, Zhuyun Dai, Panupong Pasupat, Mehran Kazemi, Chitta Baral, Vaiva Imbrasaite, and Vincent Y Zhao. 2023. Dr. icl: Demonstration-retrieved in-context learning. arXiv preprint arXiv:2305.14128.
- Luo et al. (2024) Man Luo, Xin Xu, Yue Liu, Panupong Pasupat, and Mehran Kazemi. 2024. In-context learning with retrieved demonstrations for language models: A survey.
- Ma et al. (2023) Huan Ma, Changqing Zhang, Yatao Bian, Lemao Liu, Zhirui Zhang, Peilin Zhao, Shu Zhang, Huazhu Fu, Qinghua Hu, and Bingzhe Wu. 2023. Fairness-guided few-shot prompting for large language models. In Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS).
- Milios et al. (2023) Aristides Milios, Siva Reddy, and Dzmitry Bahdanau. 2023. In-context learning for text classification with many labels. In Proceedings of the 1st GenBench Workshop on (Benchmarking) Generalisation in NLP, pages 173–184, Singapore. Association for Computational Linguistics.
- Mysore et al. (2023) Sheshera Mysore, Andrew Mccallum, and Hamed Zamani. 2023. Large language model augmented narrative driven recommendations. In Association for Computing Machinery, RecSys ’23, page 777–783, New York, NY, USA.
- Ni et al. (2022) Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernandez Abrego, Ji Ma, Vincent Zhao, Yi Luan, Keith Hall, Ming-Wei Chang, and Yinfei Yang. 2022. Large dual encoders are generalizable retrievers. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9844–9855, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Ni et al. (2021) Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernández Ábrego, Ji Ma, Vincent Y. Zhao, Yi Luan, Keith B. Hall, Ming-Wei Chang, and Yinfei Yang. 2021. Large dual encoders are generalizable retrievers.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, volume 35, pages 27730–27744. Curran Associates, Inc.
- Pradeep et al. (2023) Ronak Pradeep, Kai Hui, Jai Gupta, Adam D. Lelkes, Honglei Zhuang, Jimmy Lin, Donald Metzler, and Vinh Q. Tran. 2023. How does generative retrieval scale to millions of passages?
- Qin and Eisner (2021) Guanghui Qin and Jason Eisner. 2021. Learning how to ask: Querying LMs with mixtures of soft prompts. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5203–5212, Online. Association for Computational Linguistics.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding with unsupervised learning. OpenAI.
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China. Association for Computational Linguistics.
- Rubin et al. (2022) Ohad Rubin, Jonathan Herzig, and Jonathan Berant. 2022. Learning to retrieve prompts for in-context learning. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2655–2671, Seattle, United States. Association for Computational Linguistics.
- Schick et al. (2020) Timo Schick, Helmut Schmid, and Hinrich Schütze. 2020. Automatically identifying words that can serve as labels for few-shot text classification. In Proceedings of the 28th International Conference on Computational Linguistics, pages 5569–5578, Barcelona, Spain (Online). International Committee on Computational Linguistics.
- Schick and Schütze (2021) Timo Schick and Hinrich Schütze. 2021. Exploiting cloze-questions for few-shot text classification and natural language inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 255–269, Online. Association for Computational Linguistics.
- Shi et al. (2023) Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org.
- Tang et al. (2023) Yuting Tang, Ratish Puduppully, Zhengyuan Liu, and Nancy Chen. 2023. In-context learning of large language models for controlled dialogue summarization: A holistic benchmark and empirical analysis. In Proceedings of the 4th New Frontiers in Summarization Workshop, pages 56–67, Singapore. Association for Computational Linguistics.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023. Llama 2: Open foundation and fine-tuned chat models.
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, Brussels, Belgium. Association for Computational Linguistics.
- Wei et al. (2021) Jason Wei, Chengyu Huang, Soroush Vosoughi, Yu Cheng, and Shiqi Xu. 2021. Few-shot text classification with triplet networks, data augmentation, and curriculum learning. arXiv preprint arXiv:2103.07552.
- Weidinger et al. (2022) Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, et al. 2022. Taxonomy of risks posed by language models. In 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 214–229.
- Zhang et al. (2022) Yiming Zhang, Shi Feng, and Chenhao Tan. 2022. Active example selection for in-context learning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9134–9148, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Zhang et al. (2023) Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2023. Automatic chain of thought prompting in large language models. In The Eleventh International Conference on Learning Representations (ICLR 2023).
- Zhong et al. (2017) Xiao-Feng Zhong, Shi-Ze Guo, Liang Gao, Hong Shan, and Jing-Hua Zheng. 2017. An improved k-nn classification with dynamic k. In Proceedings of the 9th International Conference on Machine Learning and Computing, ICMLC ’17, page 211–216, New York, NY, USA. Association for Computing Machinery.