One-shot Active Learning Based on Lewis Weight Sampling for Multiple Deep Models
Abstract
Active learning (AL) for multiple target models aims to reduce labeled data querying while effectively training multiple models concurrently. Existing AL algorithms often rely on iterative model training, which can be computationally expensive, particularly for deep models. In this paper, we propose a one-shot AL method to address this challenge, which performs all label queries without repeated model training.
Specifically, we extract different representations of the same dataset using distinct network backbones, and actively learn the linear prediction layer on each representation via an -regression formulation. The regression problems are solved approximately by sampling and reweighting the unlabeled instances based on their maximum Lewis weights across the representations. An upper bound on the number of samples needed is provided with a rigorous analysis for .
Experimental results on 11 benchmarks show that our one-shot approach achieves competitive performances with the state-of-the-art AL methods for multiple target models.
1 Introduction
The rapid advancements in deep learning have led to a substantial increase in demand for extensive labeled data points to effectively train high-performance models. However, data labeling remains costly due to its reliance on human labor. To address this challenge, active learning (AL) [37, 35] has emerged as an effective strategy to mitigate annotation costs. This approach estimates the potential utility of different unlabeled instances in improving the performance of a target model and selectively queries the labels of the most beneficial instances from the oracle (i.e., an expert who can provide the ground-truth label). A typical practice of AL conducts label querying and model updating iteratively to exploit the insights from model decisions, i.e., selecting one or a small batch of instances based on the model predictions and updating the target model in each iteration until the labeling budget is exhausted [11, 20]. This paradigm has been widely applied in real-world scenarios [19, 39].
Recently, there has been a significant surge in the demand for the deployment of machine learning systems on diverse resource-constrained devices [13, 18, 30]. For example, speech recognition and face recognition systems usually need to support various types of machines with varying computing and memory resources. As a result, the task of training multiple models with varying complexities using the same labeled dataset has arisen [3], leading to a new setting of AL where multiple target models are to be learned simultaneously [42].
Tang and Huang [42] provide both theoretical and empirical evidence showcasing the potential of AL in alleviating the substantial data labeling burden associated with training multiple target models. They propose an iterative AL algorithm DIAM and validate its effectiveness for multiple deep models. However, the use of iterative AL methods results in a significant increase in model training cost. This is due to the requirement of training multiple deep models at each query iteration. A potential solution is increasing the querying batch size of conventional batch-mode AL methods. Nevertheless, this may lead to redundant querying [48]. A more cost-effective strategy could be one-shot or single-shot querying, which selects the required number of unlabeled instances and makes all label queries within one iteration devoid of retraining the models.
Most existing one-shot AL methods query a representative set of instances using the distance between feature vectors [48, 44, 21, 40]. However, this approach faces challenges when handling multiple deep models, as the same instance can exhibit different feature representations in different models. This phenomenon arises due to the intrinsic representation learning of deep models, where data representations are implicitly optimized during the training process and varied network architectures yield distinct embeddings. These embeddings may contain abundant information to facilitate data selection. However, such information has not been well exploited by existing one-shot AL methods. Therefore, they may not yield optimal performance in the setting of multiple models.
In this paper, we propose a one-shot AL method for multiple deep models, accompanied by rigorous theoretical analysis. Our method is based on the fact that a deep model can be viewed as a linear prediction layer (i.e., multiple neuron models) and a nonlinear feature extractor (i.e., the network backbone). Therefore, training multiple deep models can be described as learning linear prediction layers from the outputs of distinct network backbones. In this way, active learning from diverse data representations can be formulated as optimizing a shared sampling matrix to minimize the error of each linear predictor. To facilitate computation and analysis, we consider the learning of the prediction layer as an regression problem with . In particular, our empirical studies place particular emphasis on the case of , i.e. squared loss, which is one of the most commonly used loss functions in deep learning. Specifically, suppose that there are models and () is the feature matrix obtained by feeding the dataset into the -th network backbone. Let be an -Lipschitz function with . Typical choices of are activation functions such as ReLU, Sigmoid, and so on. We abuse the notation and apply to a vector coordinatewise, i.e. . Suppose that are label vectors and the task is to minimize the loss over for all models simultaneously. Since the construction of is independent of , we henceforth assume that , with a single label vector . Therefore, we seek a shared reweighted sampling matrix such that we can, from the labels of the sampled instances , approximately solve the regression problem for all models simultaneously.
The simplest case is when there is a single model, i.e., . In this case, Gajjar et al. [15] are the first to study the problem of actively learning a single neuron model. They cast the problem as a least-squares regression problem (i.e. ) and find an such that
where is the minimizer, is an absolute constant and is an accuracy parameter. Recall that is the Lipschitz constant of . Gajjar et al. [15] also show that the additive term is necessary. For and general , we seek approximate solutions with the following error guarantee of a similar form on each individual model:
| (1) |
where is the minimizer for model and is a constant depending only on . Gajjar et al.[15] construct to be a leverage score sampling matrix and solve with . At the core of their argument lies the classical fact that such an gives an subspace embedding for , i.e., for all simultaneously. In fact, it is not necessary to sample the rows of according to the exact leverage scores ; any sampling probability proportional to for -th row will suffice, with the number of samples being proportional to . This very fact motivates us to tackle the task of data selection from diverse representations by sampling the rows according to the maximum of leverage scores across ’s, i.e., letting . Solving for each model by with will then achieve (1) for . This indicates that the queried instances are effective in learning each of the linear predictors, which fits our problem well. A potential caveat is that the number of samples needed will be proportional to , which could be as large as . However, empirical studies show that this is not the case for real-world datasets (see Section 3.2) and our approach will thus be efficient.
For general , instead of leverage scores, it is natural to consider Lewis weights, which can be seen as generalizations of leverage scores for general (see Section 3.1 for the definition). It is known that an Lewis weight sampling matrix give an subspace embedding, i.e., for all simultaneously [10]. The approach mentioned above extends to general naturally, attaining (1) for general , by sampling according to the maximum Lewis weights and solving an -regression problem for with an -version of .
Theoretical Results.
For , Gajjar et al. devised an algorithm using queries [17], with an analysis specific to . We generalize the approach to the Lewis weight sampling for and extend it to , giving the following theorem.
Theorem 1.1 (Informal version of Corollary 3.7).
Let denote the Lewis weights of and . Suppose that . There exists a randomized algorithm which samples
unlabeled instances and outputs solutions such that (1) holds for and all with probability at least 0.9.
Note that for a single matrix , the sum and so Theorem 1.1 implies a sample complexity of , recovering the result in [17] for (222An updated version of [17] improves the query complexity to [16], while the analysis remains specific to . We would like to note that the technique of -dependence improvement can similarly be employed here, yielding queries for general . We leave the details of the proof to future work.).
Empirical Findings.
Extensive experiments are conducted on 11 classification and regression benchmarks with 50 distinct deep models. In Section 3.2, we empirically observe that the sum of the maximum leverage scores grows very slowly as the number of models increases. This result reveals the strong correlation among the leverage scores of different deep representations, providing a direction for interpreting deep representation learning [23, 33]. In Section 4, we validate the effectiveness of our method with fine-tuning and vanilla learning scenarios of deep models for both the -regression loss and cross-entropy loss. The results show that our method outperforms other one-shot baselines. Even when comparing with the state-of-the-art iterative AL methods for multiple models, our approach achieves competitive performance.
2 Related Work
Active learning has been extensively studied in the past decades [37, 35]. With a limited query budget, many methods try to query the labels of the most useful instances for a target model by designing effective selection criteria, which commonly depend on two notions, informativeness and representativeness. Informativeness-based criteria prefer instances where the target model has a highly uncertain prediction [28, 47, 22], while representativeness-based criteria prefer instances which can help reduce the distribution gap between the queried instances and the entire dataset [12, 4, 36]. While most existing methods focus on improving the performance of a specific target model, Tang and Huang [42] extend the setting of AL to multiple target models. In this scenario, the active learner seeks to enhance the performance of every target model simultaneously by selective querying. Their work demonstrates that the query complexity of AL for multiple models can be upper bounded by that of an appropriately designed single model. Based on this insight, they propose an iterative algorithm called DIAM, which queries the labels of the instances located in the joint disagreement regions among multiple models. Although the method is effective, a significant concern is the substantial cost incurred by training multiple deep models at each iteration.
To reduce the computational cost of repetitive model training, one-shot AL algorithms have been proposed to query all useful instances in a single batch, thereby avoiding the need for model updates. Yang and Loog [48] employ existing AL methods with pseudo-labeling to obtain a candidate set of diverse instances and select queries based on the feature distance between unlabeled instances and candidate instances. Viering et al. [44] select representative data points by the kernelized discrepancy methods, e.g., Maximum Mean Discrepancy (MMD) [1], and give error bounds under different assumptions on data distribution. Jin et al. [21] propose a one-shot AL method for deep image segmentation. Their approach uses self-supervised learning to obtain more informative representations and selects diverse instances based on clustering results and feature distances. In addition, Coreset [36] and Transductive Experimental Design [49] are implicit one-shot AL methods. However, all the aforementioned one-shot AL methods cannot handle the distinct representations of multiple deep models.
Although most existing AL methods rely on heuristics lacking theoretical analysis, AL with Lewis weight sampling has been well studied for active -regression problems , where the matrix is fully accessible while the label vector needs to be queried [7, 6, 34, 5, 31]. Provable guarantees are obtained for -approximate solutions, i.e., , where is the output of the algorithm and the true minimizer. For , Parulekar et al. [34] show that samples suffice. For , Chen and Price [7] solve the problem optimally with queries. For , Chen and Derezinski [6] propose the first algorithm to solve the problem with sublinear query complexity, i.e., . For , Musco et al. [31] show that queries suffice. Recently, Gajjar et al. [15] extend such sampling method to the single neuron model for , which inspires our work. They establish a multiplicative constant-factor error bound of the form (1) using samples. This has been further improved to in [17].
3 Our Approach
3.1 Preliminaries
Notation.
Suppose that the dataset has instances and each has a ground-truth label . The given data consist of a small labeled set , used for model initialization, and a large unlabeled set , used for active querying. Here, and it is assumed that . A neural network can be viewed as the composition of a network backbone and a linear prediction layer composed by an activation function . The prediction of the network is given by , where is the feature matrix obtained by feeding the dataset into the network backbone. Denote by the corresponding label vector that needs to be queried. In our theoretical analysis, we assume that , has full column rank, the network backbone is fixed during the learning of and is -Lipschitz continuous with .
For , the norm of a vector is defined to be , where is the -th coordinate of .
For a matrix , the operator norm of is defined as . For integer , we use to denote the set . We write if and if there exists a constant depending only on such that . We also write if and .
Lewis Weights Sampling.
We shall define the Lewis weights and state a classical result that Lewis weight sampling gives subspace embeddings, which is the starting point of our algorithm.
Definition 3.1 ( Lewis Weights).
Let . Suppose that and its -th row is . The Lewis weights of are such that , where is a diagonal matrix with diagonal elements .
We remark that Lewis weights satisfy that and . When , Lewis weights are exactly the leverage scores. Next, we define subspace embedding and sampling matrix. Then, we state the result that Lewis weight sampling gives subspace embeddings.
Definition 3.2 ( Subspace Embedding).
Let and be the distortion parameter. A matrix is said to be an -subspace-embedding matrix for if it holds simultaneously for all vectors that .
Definition 3.3 (Sampling Matrix).
Let . Suppose that such that and are the standard basis vectors of . A matrix is called a reweighted sampling matrix if the rows of are i.i.d. copies of random vector , where with probability , . The number of rows in is called the sample size.
Lemma 3.4 (Constant-factor Subspace Embedding, [10, Theorem 7.1]).
Given . Suppose that for all , where
is a sampling parameter. Let . If is a reweighted sampling matrix with sampling probability for all , then is an -subspace-embedding matrix for with probability at least .
We note that our main theorem only requires constant-factor subspace embedding property of the sampling matrix and, therefore, we can ignore the dependence on in the bounds for subspace embeddings. The case of is proved by Cohen and Peng [10] and the case of is originally due to Bourgain et al. [2].
The following are stability results of Lewis weights, due to [10].
Lemma 3.5 (Lemmata 5.3 and 5.4 of [10]).
Suppose and are the Lewis weights of . Let be weights such that
Then it holds for all that
where when or when .
3.2 An Empirical Observation
To address the challenges of distinct representations from multiple deep models, one solution is to sample the unlabeled instances by their maximum Lewis weight (i.e. ) among different representations. Recall that the sample size is proportional to , this strategy will not save the number of queries if this sum is times larger than that of a single regression problem. Therefore, we would like first to examine the sum of maximum Lewis weights across representations as it will determine the potential query savings. In the following empirical studies, we mainly consider the case of (i.e., squared loss), where the Lewis weight becomes exactly the leverage score.
| Dataset | #Training | #Testing | #Label | Task |
| MNIST [25] | 60,000 | 10,000 | 10 | Classification |
| Fashion-MNIST [46] | 60,000 | 10,000 | 10 | Classification |
| Kuzushiji-MNIST [8] | 60,000 | 10,000 | 10 | Classification |
| SVHN [32] | 73,257 | 26,032 | 10 | Classification |
| EMNIST-digits [9] | 240,000 | 40,000 | 10 | Classification |
| EMNIST-letters [9] | 88,800 | 14,800 | 26 | Classification |
| CIFAR-10 [24] | 50,000 | 10,000 | 10 | Classification |
| CIFAR-100 [24] | 50,000 | 10,000 | 100 | Classification |
| Biwi [14] | 10,317 | 5,361 | 2 | Regression |
| FLD [41] | 13,466 | 249 | 10 | Regression |
| CelebA [29] | 162,770 | 19,962 | 10 | Regression |









| Dataset | mean accuracy | std. deviation | maximum | minimum |
|---|---|---|---|---|
| MNIST | 94.79 | 4.39 | 97.61 | 72.99 |
| F.MNIST | 81.76 | 3.03 | 85.09 | 67.32 |
| K.MNIST | 74.79 | 7.94 | 85.61 | 51.31 |
| CIFAR-10 | 48.54 | 3.36 | 53.01 | 36.92 |
| CIFAR-100 | 11.34 | 2.14 | 16.85 | 7.63 |
| SVHN | 45.53 | 7.62 | 60.98 | 31.88 |
| EMNIST-l. | 70.04 | 14.21 | 83.23 | 25.84 |
| EMNIST-d. | 95.12 | 3.64 | 97.76 | 76.13 |
Empirical Settings.
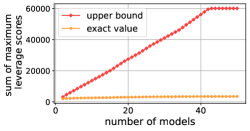
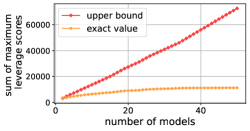
We conduct experiments on 11 datasets, the details are summarized in Table 1. For each dataset, we randomly sample 3000 instances to train the models with 20 epochs, then extract features for the whole dataset and calculate their leverage scores. We use the squared loss in model training and keep all other settings the same as the OFA project. We employ 50 distinct network architectures as the target models. These architectures are published by a recent NAS method OFA [3] for accommodating diverse resource-constraint devices, ranging from NVIDIA Tesla V100 GPU to mobile devices. To demonstrate the distinctness of these models, we report the initial performances of the models on the classification datasets in Table 2. It can be observed that the model performances are significantly diverse. It aligns well with our problem setting. Figure 1 shows the theoretical upper bound and the exact values of the sum of the maximum leverage score of each instance across different representations.
Results.
We first plot the upper bound of the sum of the maximum leverage scores across multiple representations as the number of models increases. For matrices of rows, it clearly holds that . This upper bound is plotted in red color, which grows almost linearly until it reaches the number of instances .
We examine the exact values of the sum of maximum leverage scores across multiple representations. All figures show that the exact sum grows very slowly as the number of models increases. This suggests highly consistent discrimination power of most instances across different representations, as the leverage score when is exactly the leverage score, which measures how hard an instance can be linearly represented by others. Therefore, a small number of discriminating examples suffices to effectively train multiple models. leverage scores also provide a possible direction to interpret the behavior of deep representation learning, as prior works have not discovered any simple form of correlation among the diverse representations obtained by different model architectures [23, 33].
3.3 The Algorithm
Based on our empirical observations, we propose to sample and reweight unlabeled instances based on their maximum Lewis weights across multiple representations. Specifically, given the feature matrices of the labeled and unlabeled instances (denoted by and , respectively), our algorithm begins with calculating the Lewis weights of the unlabeled instances based on each of their feature representations. Next, a normalized maximum Lewis weight among multiple representations for each unlabeled instance is obtained:
In the querying phase, we conduct i.i.d. sampling with replacement on the unlabeled set using a probability distribution . The sampling process is repeated until distinct unlabeled instances are sampled. Let denote the set of indices of unlabeled instances that are selected for label query. We reweight each of the instance with index by . Finally, both the initially labeled instances with weight and the reweighted queried instances will be used to update each of the target model. Note that, although may contain repeated entries, each instance will be queried only once and reoccurrences will not incur additional query cost. We present our algorithm in Algorithm 1.
3.4 Theoretical Guarantees
Our main result is as follows, which can be seen as the guarantee for a single model.
Theorem 3.6.
Let , be an -Lipschitz function with , be the data matrix and be the target vector. Consider a reweighted sampling matrix with row sampling probability , where are some quantities and .
Suppose that satisfy that , where
| (2) |
Then, if is a reweighted sampling matrix as described above and , where , it holds with probability at least 0.9 that
where and is a constant depending only on .
The proof of Theorem 3.6 is deferred to the next section (Section 3.5). Our analysis also suggests that an -subspace-embedding can be obtained using samples, removing the factor in [45], which may be of independent interest. See Appendix A for discussions. Below we show the guarantee for multiple models, which follows easily as a corollary of Theorem 3.6.
Corollary 3.7.
Let be data matrices and . Let be an -Lipschitz function with and be the target vector. There exists an algorithm that makes
| (3) |
queries and outputs solutions such that (1) holds for all with probability at least 0.9.
Proof.
Let , then for any fixed , it holds that . Also, . The sampling probability , which is exactly our sampling scheme in Algorithm 1. Take
then satisfies the condition (2) in Theorem 3.6, whence the conclusion follows. ∎
Remark.
The proof of Corollary 3.7 implies the same guarantee for Algorithm 1 if is set to be the quantity for in (3). Indeed, the proof of Corollary 3.7 shows that the guarantee holds as soon as the variable in Algorithm 1 reaches the desired amount in (3), which allows double counting of identical sampled rows; setting to be the same value will only result in a larger number of samples and the guarantee will persist.
3.5 Proof of Theorem 3.6
We first need a simple inequality.
Fact 3.8.
Suppose that and . It holds that
Let . Theorem 3.6 is proved by the following chain of inequalities.
where inequalities (A) and (C) use Fact 3.8, inequality (D) uses [15, Claim 1]. Inequality (E) follows from that
where inequality (EA) holds because is a subspace embedding matrix for , inequality (EB) is from the constraint of our approximate solution in Line 19, inequality (EC) holds with probability at least by Markov’s inequality and inequality (ED) follows from Fact 3.8.
We shall prove inequality (B) in the following lemma. We note that the following lemma is proved in [15, Lemmata 2 and 3], but their sampling complexity is with an additional factor compared with ours. We improve their result by using the reduction technique and removing the -net argument.
Lemma 3.9.
Suppose that and such that for all and . Let and be a reweighted sampling matrix of with row sampling probabilities , where . If
then with probability at least and fixed constant , it holds for all pairs of vectors with and that
Proof.
Let and . Denote to be the set . We shall try to upper bound
for .
Since taking the -th moment of the maximum is a convex function and , the symmetrization trick yields that
where ’s are Rademacher variables. It follows from Lemma 3.4 that is a -subspace embedding matrix of with probability at least . Furthermore, by Lemma 3.11, with probability at least , the Lewis weights of are upper bounded by . Let denote the event on that the above two conditions hold. Then Pr. We assume the following proof is conditioned on .
Next, we prove the conditional expectation over and when conditioned on satisfies that
| (4) |
Once (4) is established, it would follow Markov’s inequality that
and then a union bound that
which would complete the proof after rescaling to .
Now we focus on the proof of (4), which mostly follows the same approach of Theorem 15.13 in [26]. Let
Then and . We also denote
so (4) can be rewritten as
We shall split the sum in into two parts: large Lewis weights and small Lewis weights. Specifically, we define to be the reweighted Lewis weight of and .
First consider those coordinates not in (small Lewis weights).
where the last inequality follows from the fact (see [26, Lemma 15.17]) that
| (5) |
and (by the definition of ) that .
Next we consider the coordinates in (large Lewis weights). We have
where the second line follows from the fact that reweighted Lewis weights of are upper bounded by . By the triangle inequality, we have
where
To bound , we introduce the associated distance so that it is enough to bound it by the estimated entropy of . We define the distance to be
| (6) |
and the norm
| (7) |
By the tail bound of Dudley’s integral (see e.g. [43, Theorem 8.1.6]), it holds that
According to Lemma 3.10, it holds that
For , the entropy estimate in [26, Proposition 15.18] gives that
For , it follows from the entropy estimate in [26, Proposition 15.19] and a similar argument to that for that
By the property of subgaussian variables (see e.g. [5, Proposition 4.12]), we have
Hence, given , as long as , it follows that
Therefore, taking expectation over while conditioned on , we have that . Rescaling completes the proof of (4), as desired. ∎
Lemma 3.10.
Proof.
For , we have
where the inequality (A) follows from the fact that , (B) follows from triangle inequality and , (C) follows from (5) and (E) is obtained by .
For , we have
where we use Hölder’s inequality with and in the third line.
Lemma 3.11.
Let . Suppose that and such that for all . Let and be a reweighted sampling matrix of with row sampling probabilities , where . If , then the Lewis weights of are upper bounded by with probability at least .
Proof.
Let be the -th row of . Without loss of generality, suppose . Hence, the Lewis weights of are . We claim that
holds with probability at least . Let and then we have . First, we have and . Besides, we have that
By matrix Chernoff bound, it follows that
Setting guarantees the failure probability to be at most , proving the claim. Therefore, we have that
holds with probability at least . Hence, it follows that
Applying [5, Lemma A.2] and setting gives that . ∎
Lemma 3.12.
Let . Suppose that and for all and . Let , where are independent Rademacher variables. Then the following tail bound holds:
Proof.
The tail bound is proven by Dudley’s integral tail bound
where is the -covering number of and diam is the diameter of the space . In our setting, is the subspace . From [26, Equation (15.17) and (15.18)], the diameter is bounded by . By Dudley’s integral, we have . The upper bound of the integral was proven in [26, Theorem 15.13], assuming that . The same proof can go through when the upper bound of , with [26, Eq. (15.17)] replaced with
where
In the proof of [26], is our , and the factor is replaced with due to the change of Lewis weights’ upper bound from to .
The main difficulty is to upper bound , which is again done by using Dudley’s integral. The argument to upper bound the integral in [26, Theorem 15.13] still goes through when the upper bound of Lewis weights is changed, yielding that . Combining the diameter of and the inequality for gives us the result. ∎
4 Experiment
In this section, we conduct experiments to validate the effectiveness of our method333All experiments are conducted on a machine with four GeForce RTX 3090 graphic cards and an Intel Xeon Gold 5317 CPU. The source code is included in the supplementary material for experiment reproducibility.. Due to the space limitation, some empirical settings and experimental results are presented in the appendix.
Empirical Settings.
We incorporate two learning scenarios in our experiments, i.e., fine-tuning and vanilla deep learning. The first one is a common learning scenario for big models. It first pre-trains the model on preliminary tasks. Then, the weights of the network backbone are fixed, and only the prediction heads are fine-tuned on downstream tasks. This setting aligns well with our problem formulation. The second scenario is the default learning scheme, i.e., updating all the parameters of the network with the training dataset.
We employ 50 distinct network architectures as the target models. These architectures are published by a recent NAS method OFA [3] for accommodating diverse resource-constraint devices, ranging from NVIDIA Tesla V100 GPU to mobile devices. It aligns well with our problem setting. We conduct experiments on 11 datasets, including 8 classification benchmarks: MNIST [25], Fashion-MNIST [46], Kuzushiji-MNIST [8], SVHN [32], EMNIST-letters and EMNIST-digits [9], CIFAR-10 and CIFAR-100 [24]; and 3 regression benchmarks: Biwi [14], FLD [41] and CelebA [29]. The specifications of the datasets and model configurations are deferred to the Appendix C.1. The active learning settings are outlined as follows.
-
•
For the scenario of vanilla deep learning, we conduct performance comparisons on the classification benchmarks. Specifically, 3000 instances are sampled uniformly from the training set to initialize the models. The other compared methods will then select 3000 unlabeled instances from the remaining data points for querying at each iteration, while our method conducts one-shot querying with budgets of 9000 and 15000 instances. The cross-entropy loss is employed in model training. In this scenario, the one-shot methods also query 3000 instances per batch for better comparison. However, these methods select batches independently.
-
•
For the fine-tuning scenario, we use the regression datasets. Initially, 500 instances are sampled uniformly from the training set to fine-tune each network. Then, we fix the backbone parameters and actively query the labels among the remaining instances. Afterwards, 50 linear prediction layers with mean squared error (MSE) loss and ReLU activation function are trained on the updated labeled dataset, utilizing the features extracted by different network backbones. In this scenario, all the compared methods have the same query budgets of 3000 and 6000 instances.








| MNIST | F.MNIST | K.MNIST | SVHN | CIF.10 | CIF.100 | EMN.l. | EMN.d. | |
| 46.643 | 47.597 | 46.765 | 52.228 | 45.493 | 53.532 | 73.522 | 120.840 | |
| 23.937 | 24.419 | 24.502 | 26.011 | 25.541 | 30.498 | 36.280 | 40.231 | |
| 24.060 | 24.293 | 24.455 | 25.792 | 25.173 | 28.655 | 34.291 | 42.719 | |
| Our | 5.299 | 5.366 | 5.354 | 5.605 | 5.350 | 5.57 | 9.717 | 12.711 |
| Coreset | 5.200 | 5.201 | 5.285 | 5.466 | 5.450 | 5.745 | 8.984 | 11.043 |
| Random | 4.317 | 4.333 | 4.402 | 4.583 | 4.567 | 4.712 | 7.317 | 8.027 |
We compare our algorithm with the following methods in the vanilla deep learning scenario.
-
•
(iterative) [42]: The state-of-the-art iterative AL method for multiple target models, which prefers the instances in the joint disagreement regions of multiple models.
- •
-
•
(iterative) [38]: This strategy selects the instances that the target models have the most inconsistent predictions. The inconsistency is evaluated by KL divergence.
- •
-
•
(one-shot) : This strategy selects instances uniformly from the unlabeled pool.
In the fine-tuning scenario, fewer existing methods are available. Specifically, we compare our algorithm with , and methods. Although is usually implemented in an iterative fashion, we employ a large query batch size for it to unify the query settings. Our method selects and reweights the unlabeled instances based on the leverage scores (i.e., ) in both scenarios. Note that, in the fine-tuning scenario, our implementations remove the constraint in Line 18 in Algorithm 1 for better examination of the practicability. In the vanilla deep learning scenario, we use the default training scheme of deep models to replace Line 18 in Algorithm 1. The mean accuracy and the mean MSE are used to evaluate the performances of multiple target models for classification and regression tasks, respectively.






Experiment Results.
We report the performance comparison results in Figure 2 and Figure 3. In the scenario of vanilla deep learning, we can observe that our one-shot method achieves comparable performances with the other iterative AL methods in most cases. This phenomenon indicates that our method can significantly reduce the costs of training multiple deep model while preserving its proficiency in the ability of query saving. is the worst one. We find that it causes a severe class imbalance according to the results in Table 5 in the appendix. This may explain its inferior performances. is usually worse than . Note that, the problem settings of [36] and our work are different. there are 50 distinct target networks to be learned in our experiment. The implementation in [42] solves the coreset problem based on the features extracted by the supernet. A drawback of this approach is that the selected instances may not be useful for other models, because the data representations are different. We believe this is the reason that why is less effective than Random in our setting. method achieves comparable performances with . The reason may also be evidenced by the results in Table 5 in the appendix that their class imbalance ratios are highly consistent, implies that the mean entropy scores tend to have an extremely small standard deviation. The performances of are less stable. It is effective in the datasets associated with MNIST, but fails on the others. This deficiency has not been observed in our method.
In the scenario of fine-tuning, Figure 3 shows that our approach outperforms than the other baselines with different querying budgets in terms of achieving better mean MSE. These results indicate that our method is effective and robust to different query budgets, it can effectively identify the desired number of useful unlabeled instances under diverse representations to learn linear prediction layers.
We further examine the running time of different AL methods. The results are reported in Table 3. For the one-shot methods Coreset and Random, we report their running time of one-shot querying 15000 instances. It can be observed that the cost of repeated model training is prohibitive in AL for multiple deep models, demonstrating the advantages of one-shot querying. Among the active selection methods, is the slowest approach because it selects instances based on the predictions of the unlabeled dataset in the latter half of training epochs of each target model. Generating the predictions from multiple models could be expensive, particularly with a large unlabeled pool. and exhibit similar time costs. Both of them need to feed the unlabeled instances into 50 models to obtain their predictions.
In the fine-tuning scenario, all the compared methods conduct one-shot querying and linear prediction layers are trained with the same computational costs. As a result, the running time of the compared methods is comparable. The results are deferred to Table 6 in the appendix.
5 Conclusion
In this paper, we propose a one-shot AL algorithm for multiple deep models. The task is formulated as seeking a shared reweighted sampling matrix to approximately solve multiple -regression problems for neuron models on distinct deep representations. Our approach is to sample and reweight the unlabeled instances based on their maximum Lewis weights across different representations. We establish an upper bound on the number of samples needed by our algorithm to achieve constant-factor approximations for multiple models and general . Our techniques on the one hand substantially improve the upper bound on the number of samples of [15] in the case of single model and , on the other hand remove the factor in [45] for Lewis weight sampling to obtain -subspace-embedding. Extensive experiments are conducted on 11 benchmarks and 50 deep models. We observe that the sum of the maximum Lewis weights with grows very slowly as the number of target models increases, providing a direction for interpreting deep representation learning. The performance comparisons show that our algorithm achieves competitive performances with the state-of-the-art AL methods for multiple deep models.
Acknowledgments
S.-J. Huang is supported in part by the National Science and Technology Major Project (2020AAA0107000), the Natural Science Foundation of Jiangsu Province of China (BK20222012, BK20211517), and NSFC (62222605). Y. Li is supported in part by the Singapore Ministry of Education (AcRF) Tier 2 grant MOE-T2EP20122-0001 and Tier 1 grant RG75/21. Y.-P. Tang was supported in part by the China Scholarship Council during his visit to Nanyang Technological University, where most of this work was done. The authors would like to thank Aarshvi Gajjar, Chinmay Hedge, Christopher Musco and Xingyu Xu for pointing out an error in an earlier proof of Theorem 3.6.
References
- [1] Karsten M. Borgwardt, Arthur Gretton, Malte J. Rasch, Hans-Peter Kriegel, Bernhard Schölkopf, and Alexander J. Smola. Integrating structured biological data by kernel maximum mean discrepancy. In Proceedings of the 14th Annual International Conference on Intelligent Systems for Molecular Biology, pages 49–57, 2006.
- [2] J. Bourgain, J. Lindenstrauss, and V. Milman. Approximation of zonoids by zonotopes. Acta Mathematica, 162:73 – 141, 1989.
- [3] Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. Once-for-all: Train one network and specialize it for efficient deployment. In Proceedings of the 7th International Conference on Learning Representations, 2019.
- [4] Rita Chattopadhyay, Zheng Wang, Wei Fan, Ian Davidson, Sethuraman Panchanathan, and Jieping Ye. Batch mode active sampling based on marginal probability distribution matching. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 741–749, 2012.
- [5] Cheng Chen, Yi Li, and Yiming Sun. Online active regression. In Proceedings of the 39th International Conference on Machine Learning, pages 3320–3335. PMLR, 2022.
- [6] Xue Chen and Michal Derezinski. Query complexity of least absolute deviation regression via robust uniform convergence. In Proceedings of the 34th Annual Conference on Learning Theory, pages 1144–1179. PMLR, 2021.
- [7] Xue Chen and Eric Price. Active regression via linear-sample sparsification. In Proceedings of the 32nd Annual Conference on Learning Theory, pages 663–695. PMLR, 2019.
- [8] Tarin Clanuwat, Mikel Bober-Irizar, Asanobu Kitamoto, Alex Lamb, Kazuaki Yamamoto, and David Ha. Deep learning for classical japanese literature. arXiv cs.CV/1812.01718, 2018.
- [9] Gregory Cohen, Saeed Afshar, Jonathan Tapson, and André van Schaik. EMNIST: an extension of MNIST to handwritten letters. arXiv cs.CV//1702.05373, 2017.
- [10] Michael B Cohen and Richard Peng. row sampling by Lewis weights. In Proceedings of the 47th Annual ACM Symposium on Theory of Computing, pages 183–192, 2015.
- [11] David Cohn, Les Atlas, and Richard Ladner. Improving generalization with active learning. Machine Learning, 15(2):201–221, 1994.
- [12] Sanjoy Dasgupta and Daniel Hsu. Hierarchical sampling for active learning. In Proceedings of the 25th International conference on Machine learning, pages 208–215, 2008.
- [13] Lei Deng, Guoqi Li, Song Han, Luping Shi, and Yuan Xie. Model compression and hardware acceleration for neural networks: A comprehensive survey. Proceedings of the IEEE, 108(4):485–532, 2020.
- [14] Gabriele Fanelli, Matthias Dantone, Juergen Gall, Andrea Fossati, and Luc Van Gool. Random forests for real time 3d face analysis. International journal of computer vision, 101:437–458, 2013.
- [15] Aarshvi Gajjar, Christopher Musco, and Chinmay Hegde. Active learning for single neuron models with lipschitz non-linearities. In Procedings of the 26th International Conference on Artificial Intelligence and Statistics, pages 4101–4113. PMLR, 2023.
- [16] Aarshvi Gajjar, Wai Ming Tai, Xingyu Xu, Chinmay Hegde, Christopher Musco, and Yi Li. Agnostic active learning of single index models with linear sample complexity. In Proceedings of COLT, page to appear, 2024.
- [17] Aarshvi Gajjar, Xingyu Xu, Chinmay Hegde, and Christopher Musco. Improved bounds for agnostic active learning of single index models. In RealML Workshop NeurIPS, 2023.
- [18] Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey. International Journal of Computer Vision, 129:1789–1819, 2021.
- [19] Steven C. H. Hoi, Rong Jin, Jianke Zhu, and Michael R. Lyu. Semi-supervised SVM batch mode active learning for image retrieval. In Proceedings of the 21st IEEE Conference on Computer Vision and Pattern Recognition, 2008.
- [20] Sheng-Jun Huang, Rong Jin, and Zhi-Hua Zhou. Active learning by querying informative and representative examples. IEEE Transactions on pattern analysis and machine intelligence, 36(10):1936–1949, 2014.
- [21] Qiuye Jin, Mingzhi Yuan, Qin Qiao, and Zhijian Song. One-shot active learning for image segmentation via contrastive learning and diversity-based sampling. Knowledge-Based Systems, 241:108278, 2022.
- [22] Andreas Kirsch, Joost van Amersfoort, and Yarin Gal. Batchbald: Efficient and diverse batch acquisition for deep bayesian active learning. In Proceedings of the 33rd Conference on Neural Information Processing Systems, pages 7026–7037, 2019.
- [23] Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. In Proceedings of the 36th International conference on machine learning, pages 3519–3529. PMLR, 2019.
- [24] Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009.
- [25] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- [26] Michel Ledoux and Michel Talagrand. Probability in Banach Spaces: isoperimetry and processes, volume 23. Springer Science & Business Media, 1991.
- [27] David D Lew is and Jason Catlett. Heterogeneous uncertainty sampling for supervised learning. In Machine Learning: Proceedings of the 11th International Conference, pages 148–156. Elsevier, 1994.
- [28] David D. Lewis and William A. Gale. A sequential algorithm for training text classifiers. In W. Bruce Croft and C. J. van Rijsbergen, editors, Proceedings of the 17th Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval, pages 3–12. ACM/Springer, 1994.
- [29] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In 2015 IEEE International Conference on Computer Vision, 2015.
- [30] Gaurav Menghani. Efficient deep learning: A survey on making deep learning models smaller, faster, and better. ACM Computing Surveys, 55(12):1–37, 2023.
- [31] Cameron Musco, Christopher Musco, David P Woodruff, and Taisuke Yasuda. Active linear regression for norms and beyond. In Proceedings of the 63rd IEEE Annual Symposium on Foundations of Computer Science, pages 744–753. IEEE, 2022.
- [32] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. In NIPS 2011 Workshop on Deep Learning and Unsupervised Feature Learning, 2011.
- [33] Thao Nguyen, Maithra Raghu, and Simon Kornblith. Do wide and deep networks learn the same things? uncovering how neural network representations vary with width and depth. In Proceedings of the 8th International Conference on Learning Representations, 2020.
- [34] Aditya Parulekar, Advait Parulekar, and Eric Price. L1 regression with lewis weights subsampling. Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques, 2021.
- [35] Pengzhen Ren, Yun Xiao, Xiaojun Chang, Po-Yao Huang, Zhihui Li, Brij B Gupta, Xiaojiang Chen, and Xin Wang. A survey of deep active learning. ACM computing surveys, 54(9):1–40, 2021.
- [36] Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. In Proceedings of the 6th International Conference on Learning Representations, 2018.
- [37] Burr Settles. Active learning literature survey. Technical report, University of Wisconsin-Madison, 2009.
- [38] H Sebastian Seung, Manfred Opper, and Haim Sompolinsky. Query by committee. In Proceedings of the 5th annual workshop on Computational learning theory, pages 287–294, 1992.
- [39] Haochen Shi and Hui Zhou. Deep active sampling with self-supervised learning. Frontiers of Computer Science, 17(4):174323, 2023.
- [40] Neta Shoham and Haim Avron. Experimental design for overparameterized learning with application to single shot deep active learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [41] Yi Sun, Xiaogang Wang, and Xiaoou Tang. Deep convolutional network cascade for facial point detection. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition, pages 3476–3483, 2013.
- [42] Ying-Peng Tang and Sheng-Jun Huang. Active learning for multiple target models. In Proceedings of the 36th Conference on Neural Information Processing Systems, 2022.
- [43] Roman Vershynin. High-Dimensional Probability: An Introduction with Applications in Data Science, volume 47. Cambridge University Press, 2018.
- [44] Tom J Viering, Jesse H Krijthe, and Marco Loog. Nuclear discrepancy for single-shot batch active learning. Machine Learning, 108(8-9):1561–1599, 2019.
- [45] David P Woodruff and Taisuke Yasuda. Online lewis weight sampling. In Proceedings of the 2023 Annual ACM-SIAM Symposium on Discrete Algorithms, pages 4622–4666. SIAM, 2023.
- [46] Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv cs.LG/1708.07747, 2017.
- [47] Yifan Yan and Sheng-Jun Huang. Cost-effective active learning for hierarchical multi-label classification. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, pages 2962–2968, 2018.
- [48] Yazhou Yang and Marco Loog. Single shot active learning using pseudo annotators. Pattern Recognition, 89:22–31, 2019.
- [49] Kai Yu, Jinbo Bi, and Volker Tresp. Active learning via transductive experimental design. In Proceedings of the 23rd International conference on Machine learning, pages 1081–1088, 2006.
Appendix A Subspace Embedding
We note that there are mainly two kinds of Lewis weight sampling. The first kind is to retain or discard each row independently. Specifically, the -th row of is retained with probability and discarded with probability . The resulting sampled matrix has a random number of rows. The second kind has a fixed, prescribed number of sampled rows. Each sample is i.i.d. chosen to be the -th row of with probability , where are weights satisfying that . We use sampling of the second kind (recall Definition 3.3) in our algorithm. However, our main result (Theorem 3.6) still works for the first kind of sampling matrices, see Appendix B for details.
In this section, we give the sample complexity for subspace embedding with distortion for , using both kinds of sampling schemes.
For , Woodruff and Yasuda [45] consider the first kind of sampling and give a sample complexity of for -subspace embeddings. This is the first result for that has an dependence, as the only prior result was with an dependence [2]. Still, based on the result of [2], we can improve the analysis of [45] and remove the undesired factor in their sample complexity. We have the following theorem.
Theorem A.1.
Let , and . Let where is Lewis weight of for and be the oversampling parameter. Let be the reweighted sampling matrix in which the -th row
With probability at least , has nonzero rows and .
We only sketch the changes in the proof of [45]. First, in the sampling we do not use -one-sided Lewis weights but the exact Lewis weights of . True Lewis weights do not affect the symmetrization trick. After the symmetrization step, we remove the part of flattening matrix in their proof. Instead, we claim: (1) By [2, Theorem 7.3], is a -subspace embedding matrix of . (2) By [5, Lemma A.1] and Lemma 3.5, Lewis weights of are uniformly upper bounded by . Conditioned on (1) and (2), it suffices to prove
This -th moment upper bound can be derived in the same fashion as the end of the proof of Lemma 3.9. Then applying the Markov inequality gives us with probability at least .
The next theorem gives the sample complexity for subspace embedding for in which samplings are i.i.d. and the probability of every row being sampled is .
Theorem A.2.
Let , and . Suppose that the Lewis weights of are . Let and be a reweighted sampling matrix whose -th row with probability . Set , then with probability at least , we have .
We only highlight the necessary changes in the proof of Theorem A.2.
Appendix B Result for the Other Sampling Method
In this section, we prove that our main result Theorem 3.6 still holds if the reweighted sampling matrix is defined to be of the first kind:
where and . Accordingly, Lines 6–11 of Algorithm 1 are changed to the following lines.
Appendix C Detailed Experimental Settings and Additional Results
C.1 Detailed Settings
All experiments are run on two GPU servers, each equipped with four GeForce RTX 3090 graphic cards, an Intel Xeon Gold 5317 CPU and 128 GB Memory. The details of the datasets are presented in Table 1. The configurations of 50 deep models are specified in Table 4. Note that the network dentition and pre-trained weights of each configuration can be downloaded from the GitHub page of the OFA project [3].
| flops@[email protected]_finetune@75 | flops@[email protected]_finetune@75 |
| flops@[email protected]_finetune@75 | LG-G8_lat@[email protected]_finetune@25 |
| LG-G8_lat@[email protected]_finetune@25 | LG-G8_lat@[email protected]_finetune@25 |
| LG-G8_lat@[email protected]_finetune@25 | s7edge_lat@[email protected]_finetune@25 |
| s7edge_lat@[email protected]_finetune@25 | s7edge_lat@[email protected]_finetune@25 |
| s7edge_lat@[email protected]_finetune@25 | note8_lat@[email protected]_finetune@25 |
| note8_lat@[email protected]_finetune@25 | note8_lat@[email protected]_finetune@25 |
| note8_lat@[email protected]_finetune@25 | note10_lat@[email protected]_finetune@75 |
| note10_lat@[email protected]_finetune@75 | note10_lat@[email protected]_finetune@75 |
| note10_lat@[email protected]_finetune@75 | note10_lat@[email protected]_finetune@25 |
| note10_lat@[email protected]_finetune@25 | note10_lat@[email protected]_finetune@25 |
| note10_lat@[email protected]_finetune@25 | pixel1_lat@[email protected]_finetune@75 |
| pixel1_lat@[email protected]_finetune@75 | pixel1_lat@[email protected]_finetune@75 |
| pixel1_lat@[email protected]_finetune@75 | pixel1_lat@[email protected]_finetune@25 |
| pixel1_lat@[email protected]_finetune@25 | pixel1_lat@[email protected]_finetune@25 |
| pixel2_lat@[email protected]_finetune@25 | pixel2_lat@[email protected]_finetune@25 |
| pixel2_lat@[email protected]_finetune@25 | pixel2_lat@[email protected]_finetune@25 |
| 1080ti_gpu64@[email protected]_finetune@25 | 1080ti_gpu64@[email protected]_finetune@25 |
| 1080ti_gpu64@[email protected]_finetune@25 | 1080ti_gpu64@[email protected]_finetune@25 |
| v100_gpu64@[email protected]_finetune@25 | v100_gpu64@[email protected]_finetune@25 |
| v100_gpu64@[email protected]_finetune@25 | v100_gpu64@[email protected]_finetune@25 |
| tx2_gpu16@[email protected]_finetune@25 | tx2_gpu16@[email protected]_finetune@25 |
| tx2_gpu16@[email protected]_finetune@25 | tx2_gpu16@[email protected]_finetune@25 |
| cpu_lat@[email protected]_finetune@25 | cpu_lat@[email protected]_finetune@25 |
| cpu_lat@[email protected]_finetune@25 | cpu_lat@[email protected]_finetune@25 |
We follow the training settings of [42] in our experiment of the vanilla deep learning scenario. Specifically, at each query iteration, each target model will be initialized with the pre-trained weights on ImageNet and trained for 20 epochs on the labeled dataset with batch size 32. SGD optimizer is employed with learning rate , momentum coefficient and weight decay factor . A dropout rate of is used in the training process.
In our experiments of the fine-tuning scenario, we train a linear prediction layer with ReLU activation function using mean squared loss. The training specifications are introduced as follows. The SGD optimizer is employed with a learning rate of and a weight decay coefficient of . The layer is trained for 30 epochs with training batch size . We set the random seed to 0 for reproducibility. Please refer to the submitted source code to reproduce our results.
The implementations of each compared method are introduced as follows. We use the code in [42] to implement DIAM, Coreset and Entropy methods. Specifically, DIAM first obtains the predictions of the unlabeled instances using the models in the latter half of training epochs of each target network. Then, it selects the batch of instances that multiple models have inconsistent predictions. Coreset selects data points based on the representation of the pre-trained super-net in OFA. Entropy calculates the entropy scores of unlabeled instances based on the predictions of each target model. Subsequently, it selects the instances with the highest mean entropy scores across multiple model predictions.










C.2 Additional results
C.2.1 Study on Mean Percentage of Covered Instances
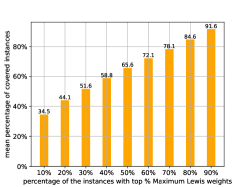
We further examine how many instances with high leverage scores under the representation of a single model can be covered by the maximum leverage score sampling. The statistics are calculated as follows: We first get the intersection between the sets of instances that have the top highest leverage score under the representation of model (denoted by ) and top highest Maximum leverage score (denoted by ). Then, we divide the cardinality of this subset by the number of unlabeled instances. Finally, we calculate this value for each and compute the average to obtain the mean percentage of covered instances, i.e.,
We report the mean percentage of covered instances of 50 deep models in Figure 4. It can be observed that is about on most datasets (except for Biwi), that is, covers on average about of the instances with high leverage scores of each representation for most datasets. For all datasets, as increases, increases rapidly. These phenomena suggest that sampling a modest number of instances by maximum leverage scores can effectively train multiple deep models, as there are a significant fraction of instances with high leverage scores shared across different models.
C.2.2 Study on the Class Imbalance Ratio
Another metric of interest for AL classification algorithms is the class imbalance ratio, which is defined as , where is the indicator function. Some active query strategies may cause severe class imbalance, rendering them hardly generalizable to other target models and learning tasks. This issue becomes more significant for multiple target models. In this experiment, we examine the class imbalance ratios of different AL methods in the classification tasks. Specifically, we compare the ratios after the third AL iteration, where a total of 12000 labeled instances are present, including the initially labeled set. The results are reported in Table 5.
We can observe that our proposed method consistently produces a balanced labeled dataset. Its class imbalanced ratio is very close to that of the sampling. On the other hand, suffers from the class imbalance, suggesting that the training instances with different classes exhibit diverse intra-class distances under deep representation. This implies that the instances sampled by may have a large distribution gap with the dataset. obtains a similar class imbalance ratio to that of , which might appear counter-intuitive, given that prefers the instances near the decision boundary and such instances are typically less likely to be class-balanced. A possible reason is that the mean entropy scores of the unlabeled instances may have a small standard deviation, potentially diminishing the advantages of using for identifying the most informative instances, in the setting of multiple target models.
| MNIST | F.MNIST | K.MNIST | SVHN | CIF.10 | CIF.100 | EMN.l. | EMN.d. | |
| DIAM | 2.007 | 3.250 | 1.472 | 2.121 | 1.525 | 4.390 | 2.216 | 2.811 |
| QBC | 1.867 | 6.721 | 1.987 | 4.474 | 5.212 | 13.607 | 9.178 | 10.664 |
| Coreset | 3.561 | 3.708 | 2.116 | 2.330 | 1.871 | 6.000 | 5.375 | 4.491 |
| Random | 1.262 | 1.091 | 1.067 | 3.008 | 1.062 | 1.511 | 1.092 | 1.222 |
| Entropy | 1.331 | 1.077 | 1.091 | 3.052 | 1.087 | 1.439 | 1.088 | 1.166 |
| Our | 1.217 | 1.081 | 1.050 | 2.993 | 1.098 | 1.440 | 1.109 | 1.209 |
| Methods | Biwi | FLD | CelebA |
|---|---|---|---|
| Random | 1.217 | 1.383 | 1.202 |
| Coreset | 1.483 | 1.883 | 3.667 |
| Our | 1.551 | 1.850 | 5.817 |
| QBC | 1.632 | 1.800 | 4.110 |