figurec
On Unbalanced Optimal Transport: Gradient Methods, Sparsity and Approximation Error
Abstract
We study the Unbalanced Optimal Transport (UOT) between two measures of possibly different masses with at most components, where the marginal constraints of standard Optimal Transport (OT) are relaxed via Kullback-Leibler divergence with regularization factor . Although only Sinkhorn-based UOT solvers have been analyzed in the literature with the iteration complexity of and per-iteration cost of for achieving the desired error , their positively dense output transportation plans strongly hinder the practicality. On the other hand, while being vastly used as heuristics for computing UOT in modern deep learning applications and having shown success in sparse OT problem, gradient methods applied to UOT have not been formally studied. In this paper, we propose a novel algorithm based on Gradient Extrapolation Method (GEM-UOT) to find an -approximate solution to the UOT problem in iterations with per-iteration cost, where is the condition number depending on only the two input measures. Our proof technique is based on a novel dual formulation of the squared -norm UOT objective, which fills the lack of sparse UOT literature and also leads to a new characterization of approximation error between UOT and OT. To this end, we further present a novel approach of OT retrieval from UOT, which is based on GEM-UOT with fine tuned and a post-process projection step. Extensive experiments on synthetic and real datasets validate our theories and demonstrate the favorable performance of our methods in practice. We showcase GEM-UOT on the task of color transfer in terms of both the quality of the transfer image and the sparsity of the transportation plan.
Keywords: Unbalanced Optimal Transport; Gradient Methods; Convex Optimization
1 Introduction
The optimal transport (OT) problem originated from the need to find the optimal cost to transport masses from one distribution to another distribution (Villani, 2008). While initially developed by theorists, OT has found widespread applications in statistics and machine learning (ML) (see e.g. (Ho et al., 2017; Arjovsky et al., 2017; Rabin and Papadakis, 2015)). However, standard OT requires the restricted assumption that the input measures are normalized to unit mass, which facilitates the development of the Unbalanced Optimal Transport (UOT) problem between two measures of possibly different masses (Chizat et al., 2018). The class of UOT problem relaxes OT’s marginal constraints. Specifically, it is a regularized version of Kantorovich formulation placing penalty functions on the marginal distributions based on some given divergences (Liero et al., 2017). While there have been several divergences considered by the literature, such as squared norm (Blondel et al., 2018), norm (Caffarelli and McCann, 2010), or general norm (Lee et al., 2019), UOT with Kullback-Leiber (KL) divergence (Chizat et al., 2018) is the most prominent and has been used in statistics and machine learning (Frogner et al., 2015), deep learning (Yang and Uhler, 2019), domain adaptation (Balaji et al., 2020; Fatras et al., 2021), bioinformatics (Schiebinger et al., 2019), and OT robustness (Balaji et al., 2020; Le et al., 2021). Throughout this paper, we refer to UOT penalized by KL divergence as simply UOT, unless otherwise specified. We hereby define some notations and formally present our problem of interest.
Notations: We let stand for the set while stands for the set of all vectors in with nonnegative entries. For a vector and , we denote as its -norm and as the diagonal matrix with . Let A and B be two matrices of size , we denote their Frobenius inner product as: . stands for a vector of length with all of its components equal to . The KL divergence between two vectors is defined as . The entropy of a matrix is given by .
Unbalanced Optimal Transport: For a couple of finite measures with possibly different total mass and , we denote and as the total masses, and and as the minimum masses. The UOT problem can be written as:
| (1) |
where is a given cost matrix, is a transportation plan, is a given regularization parameter. When and , (1) reduces to a standard OT problem. Let be optimal transportation plan of the UOT problem (1).
Definition 1
For , is an -approximate transportation plan of if:
| (2) |
1.1 Open Problems and Motivation
We hereby discuss the open problems within the UOT problem to better facilitate the motivation underpinning our work.
Nascent literature of gradient methods for UOT: While the existing work has well studied the class of OT problems using gradient methods or variations of the Sinkhorn algorithm (Guminov et al., 2021; Altschuler et al., 2017), the complexity theory and algorithms for UOT remain nascent despite its recent emergence. Pham et al. (2020) shows that Sinkhorn algorithm can solve the UOT problem in up to the desired error . Chapel et al. (2021) proposes Majorization-Minimization (MM) algorithm, which is Sinkhorn-based, as a numerical solver with empirical complexity. Thanks to their compatibility, gradient methods have been vastly used as heuristics for computing UOT in deep learning applications (Balaji et al., 2020; Yang and Uhler, 2019) and multi-label learning (Frogner et al., 2015). Nevertheless, no work has formally studied gradient methods applied to UOT problems. Principled study of this topic could lead to preliminary theoretical justification and guide the more refined design of gradient methods for UOT.
Lack of sparse UOT literature: There is currently no study of sparse UOT in the literature, which nullifies its usage in many applications (Pitié et al., 2007; Courty et al., 2017; Muzellec et al., 2016) in which only sparse transportation plan is of interest. On a side note, entropic regularization imposed by the Sinkhorn algorithm keeps the transportation plan dense and strictly positive (Essid and Solomon, 2018; Blondel et al., 2018).
Approximation of OT: The approximability of standard OT via UOT has remained an open problem. Recently, (Chapel et al., 2021) discusses the possibility to approximate OT transportation plan using that of UOT and empirically verifies it. Despite the well known fact that OT is recovered from UOT when and the masses are balanced, no work has analyzed the rate under which UOT converges to OT111For squared norm penalized UOT variant, (Blondel et al., 2018) showed that error in terms of transport distance is .. Characterization of approximation error between UOT and OT could give rise to the new perspective of OT retrieval from UOT, and facilitate further study of the UOT geometry and statistical bounds from the lens of OT (Bernton et al., 2022) in the regime of large .
Bottleneck of robust OT computation via UOT: The UOT formulation with small has been vastly used as a robust variant of OT222While Fatras et al. (2021) uses exactly UOT as robust OT, Le et al. (2021) considers UOT with an additional normalization constraint, i.e. , which can be solved with usual UOT algorithm with an extra normalization step. (Fatras et al., 2021; Balaji et al., 2020; Le et al., 2021). In this paper, we further highlight a major bottleneck of this approach having been neglected by the literature: though relaxing OT as UOT admits robustness to outliers, the computed UOT distance far deviates from the original OT distance. Under the naive choice of (Fatras et al., 2021; Balaji et al., 2020; Le et al., 2021), we observe that on CIFAR-10 as an example real dataset the UOT distance differs from OT by order of dozens (see Figure 14). Such large deviation from the original metric can be detrimental to target applications where the distance itself is of interest (Genevay et al., 2018). Another inherent limitation is that the solution returned by UOT is only a “relaxed” transportation plan that does not respect the marginal constraints of standard OT. This naturally raises the question whether despite the relaxation of OT as UOT, there is a way to retrieve the original OT distance and transportation plan.
1.2 Contributions
In this paper, we provide a comprehensive study of UOT that addresses all the aforementioned open problems and challenges of UOT literature. We consider the setting where KL divergences are used to penalize the marginal constraints. Our contributions can be summarized as follows:
-
•
We provide a novel dual formulation of the squared -norm regularized UOT objective, which is the basis of our algorithms. This could facilitate further algorithmic development for solving sparse or standard UOT, since the current literature is limited to the dual formulation of entropic-regularized UOT problem (Chizat et al., 2018).
-
•
Based on the Gradient Extrapolation Method (GEM), we propose GEM-UOT algorithm for finding an -approximate solution to the UOT problem in iterations with per-iteration cost, where is the condition number that depends on only the two input measures. Through GEM-UOT, we present the first i) principled study of gradient methods for UOT, ii) sparse UOT solver, and iii) algorithm that lifts the linear dependence on of Sinkhorn (Pham et al., 2020), a bottleneck in the regime of large (Sejourne et al., 2022).
-
•
To the best of our knowledge, we establish the first characterization of the approximation error between UOT and OT (in the context of KL-penalized UOT). In particular, we show that both of UOT’s transportation plan and transport distance converge to OT’s marginal constraints and transport distance with the rate . This result opens up directions that use UOT to approximate standard OT and accentuate the importance of our proposed GEM-UOT, which is the first to achieve logarithmic dependence on in the literature.
-
•
Inspired by our results on approximation error, we bring up a new perspective of OT retrieval from UOT with fine-tuned . In particular, we present GEM-OT, which obtains an -approximate solution to the standard OT problem by performing a post-process projection of UOT solution. GEM-OT is of order . While lots of work have naively relaxed OT into UOT to enjoy its unconstrained optimization structure and robustness to outliers, our results on make a further significant step by equipping such relaxation with provable guarantees.
Paper Organization: The rest of the paper is organized as follows. We introduce the background of regularized UOT problems and present our novel dual formulation in Section 2. In Section 3, we analyze the complexities our proposed algorithms GEM-UOT. The results on approximability of OT via UOT are established in Section 4. In Section 5, we experiment on both synthetic and real datasets to compare our algorithm with the state-of-the-art Sinkhorn algorithm in terms of both the performance and the induced sparsity, empirically verify our theories on approximation error, and showcase our framework on the task of color transfer. We conclude the paper in Section 6.
2 Background
In this Section, we first present the entropic regularized UOT problem, used by Sinkhorn algorithm. Then we consider the squared -norm regularized UOT and derive a new dual formulation, which is the basis for our algorithmic design.
2.1 Entropic Regularized UOT
Inspired by the literature of the entropic regularized OT problem, the entropic version of the UOT problem has been considered. The problem is formulated as:
| (3) |
where is a given regularization parameter. By (Chizat et al., 2018), optimizing the Fenchel-Legendre dual of the above entropic regularized UOT is equivalent to:
| (4) |
Remark 2
We note that existing algorithm (Pham et al., 2020) must set small to drive the regularizing term small , while the smoothness condition number of the above dual objective is large at least at the exponential order of . On the other hand, the original UOT objective is non-smooth due to KL divergences. Therefore, direct application of gradient methods to solve either the primal or the dual of entropic regularized UOT would not result in competitive convergence rate, which perhaps is the reason for the limited literature of gradient methods in the context of UOT. Recently, (Essid and Solomon, 2018; Blondel et al., 2018) also observe that entropic regularization imposed by the Sinkhorn algorithm keeps the transportation plan dense and strictly positive.
2.2 Squared -norm Regularized UOT and Sparsity
Remark 2 motivates our choice of squared -norm regularization, which would later result in better condition number in the dual formulation with only linear dependence on . Of practical interest, it also leads to sparse transportation plan empirically as later demonstrated in our experimental Section 5.3.
Remark 3
While squared -norm was well-studied as a sparsity-induced regularization in standard OT (Blondel et al., 2018; Peyré and Cuturi, 2019), for which dedicated solvers have been developed (Lorenz et al., 2019; Essid and Solomon, 2018), to the best of our knowledge, no work has considered squared -norm regularization in the context of UOT. This paper is the first to propose the squared -norm UOT problem, consequently derive feasible algorithms, and empirically investigate the sparsity of the output couplings.
The squared -norm UOT problem is formulated as:
| (5) |
where is a given regularization parameter. Let , which is unique by the strong convexity of . We proceed to establish the duality of the squared -norm UOT problem, which is based on the Fenchel-Rockafellar Theorem and would be the basis for our algorithmic development.
Lemma 4
Proof Given a convex set , we consider the convex indicator function:
and write the primal objective (5) as:
| (10) |
with . Next, we consider the functions:
whose convex conjugates are as follows:
Consider the linear operator that maps with , then is continuous and its adjoint is . Now note that the problem (6) can be rewritten as:
By the Fenchel-Rockafellar Theorem (restated as Theorem 29 in Appendix B), we obtain its dual problem as:
which is the optimization problem (10) and obtain that:
which conclude the proof of the Lemma.
An equivalent dual form of (5) can be deducted from the above Lemma (4) and presented in the next Corollary.
Corollary 5
Proof
From the dual objective (6) in Lemma 4, we replace with the dummy variable constrained by and . We have just rewritten our problem (5) as the optimization problem (11) over the convex set . We thus have (15) at the optimal solution, while (12), (13) and (14) directly follow from (7), (8) and (9).
3 Complexity Analysis of Approximating UOT
In this Section, we provide the algorithmic development based on Gradient Extrapolation Method (GEM) for approximating UOT. We first define the quantities within interest and present the regularity conditions in Section 3.1. Next, we prove several helpful properties of squared -norm UOT in Section 3.2. We then characterize the problem as composite optimization in Section 3.3, on which GEM-UOT is derived. The complexity analysis for GEM-UOT follows in Section 3.4. In Section 3.5, we consider a relaxed UOT problem that is relevant to certain practical applications, and present a easy-to-implement and practical algorithm, termed GEM-RUOT, for such setting.
3.1 List of Quantities and Assumptions
Given the two masses , we define the following notations and quantities:
We hereby present the assumptions (A1-A3) required by our algorithm. For interpretation, we also restate the regularity conditions of Sinkhorn (Pham et al., 2020) for solving UOT, where detailed discussion on how their assumptions in the original paper are equivalent to (S1-S4) is deferred to Appendix A.1.
Regularity Conditions of this Paper
(A1) , .
(A2)
.
(A3) .
Regularity Conditions of Sinkhorn
(S1) , .
(S2)
.
(S3)
.
(S4) are positive constants.
Remark 7
Compared to the regularity conditions of Sinkhorn, ours lift the strict assumptions (S3) and (S4) that put an upper bound on and the input masses. Thus our complexity analysis supports much more flexibility for the input masses and is still suitable to applications requiring large to enforce the marginal constraints. On the other hand, our method requires very mild condition (A3) on . For example, (A3) is naturally satisfied by (S4) combined with the boundedness of the grounded cost matrix which is widely assumed by the literature (Altschuler et al., 2017; Dvurechensky et al., 2018). We strongly note that our method works for any as long as , a parameter under our control, satisfies (A3).
3.2 Properties of Squared -norm UOT
We next present several useful properties and related bounds for the squared -norm UOT problem.
Lemma 8
The following identities hold:
| (16) | |||
| (17) |
Proof The identity (17) follows from (Pham et al., 2020, Lemma 4). To prove (16), we consider the function , where , we have
Simple algebraic manipulation gives:
We thus obtain that:
Differentiating with respect to :
From the above analysis, we can see that is well-defined for all and attains its minimum at . Setting , we obtain the identity (16).
The next Lemma provides bounds for both the primal and dual solutions to the squared -norm UOT problem.
Lemma 9
We have the following bounds for the optimal solution of (11):
| (18) | ||||
| (19) | ||||
| (20) | ||||
| (21) | ||||
| (22) | ||||
| (23) |
Proof Noting that and are non-negative for , we directly obtain (18) and (19) from Lemma 8. By , , and (18), we have:
| (24) |
We obtain in view of Lemma 4 that:
| (25) | |||
| (26) |
which are equivalent to:
| (27) | |||
| (28) |
By (12), we have , . Hence,
| (29) | |||
| (30) |
Note that . We have
To prove (23), we note that by Lemma 4, . Similarly, we have and thus obtain that:
which concludes the proof of this Lemma.
The local Lipschitzness of the squared -norm UOT objective is established in the following Lemma.
Lemma 10
3.3 Characterization of the Dual Objective
GEM-UOT is designed by solving the dual (11) from Corollary 5, which is equivalent to:
| (33) |
For , we consider the functions:
| (34) | ||||
| (35) |
Then the problem (33) can be rewritten as:
| (36) |
which can be characterized as the composite optimization over the sum of the locally convex smooth and the locally strongly convex by the following Lemma 11, whose proof is deferred to Appendix C.3.
Lemma 11
Let . Then is convex and -smooth in the domain , and is -strongly convex with:
The choice of in the above characterization is motivated by the next Corollary 12, which ensures that the optimal solution lies within the locality .
Corollary 12
If is an optimal solution to (36), then .
Proof
The result follows directly from Lemma 9.
3.4 Gradient Extrapolation Method for UOT (GEM-UOT)
Algorithm Description: We develop our algorithm based on Gradient Extrapolation Method (GEM), called GEM-UOT, to solve the UOT problem. GEM was proposed by (Lan and Zhou, 2018) to address problem in the form of (36) and viewed as the dual of the Nesterov’s accelerated gradient method. We hereby denote the prox-function associated with by:
and the proximal mapping associated with the closed convex set and is defined as:
| (37) |
One challenge for optimizing (36) is the fact that the component function is smooth and convex only on the locality as in Lemma 11. By Corollary 12, we can further write (36) as:
| (38) |
While minimizing the UOT dual objective, GEM-UOT hence projects its iterates onto the closed convex set through the proximal mapping to enforce the smoothness and convexity of on the convex hull of all the iterates, while ensuring they are in the feasible domain. Finally, GEM-UOT outputs the approximate solution, computed from the iterates, to the original UOT problem. The steps are summarized in Algorithm 1.
Complexity Analysis: We proceed to establish the complexity for approximating UOT. The following quantities are used in our analysis:
In the next Theorem, we further quantify the number of iterations
that is required for GEM-UOT to output the -approximate solution to .
Theorem 13
For and , the output of Algorithm 1 is the -approximate solution to the UOT problem, i.e.
| (39) |
Proof Recalling that , we get:
| (40) |
From Lemma 9, we have . Since , we further obtain that:
| (41) |
Plugging (41) into (40), we have:
| (42) |
Thus, it is left to bound . Next, we proceed establish the bound on in the following Lemma 14.
Lemma 14
If , the output of Algorithm 1 satisfies:
| (43) |
The proof of Lemma 14 can be found in Appendix C.1 where we first bound the quantity in terms of the distance between the dual iterate and dual solution, which provably vanishes to the desired error for large enough thanks to the guarantee from GEM being applied to the dual objective (37). Lemma 14 also helps in deriving the next Lemma 15, whose proof is in Appendix C.2.
Lemma 15
For , we have .
Lemma 15 is necessary to invoke Lemma 10 on the Lipschitzness of within the convex domain . In particular, we obtain from Lemma 10 with that:
| (44) |
Finally, the complexity of GEM-UOT is given by the following Corollary 16.
Corollary 16
Under the Assumptions (A1-A3), Algorithm 1 has the iteration complexity of and cost per iteration333 excludes the logarithmic terms in the complexity..
Proof Note that Algorithm 1 sets . Under the Assumptions (A1-A3), we have:
By Lemma 11 and under the Assumptions (A1-A2), we obtain that:
For convenience, we recall that . From the initialization , and Lemma 9, we have:
We thus obtain the asymptotic complexity under (A1-A3) for the following term inside :
Combining with the bounds of and above, we obtain that the iteration complexity is under the assumptions (A1-A3).
Lines 7 and 9 are point-wise update steps of vectors with entries, thereby incurring complexity.
The proximal mapping on line 8 is equivalent to solving a sparse separable quadratic program of size with sparse linear constraints and can be solved efficiently in time and with space (see Appendix C.4 for details).
The computation of the gradient on line 10 takes since the partial derivative with respect to any of its variables takes operations. Thus, the cost per iteration is in total.
The complexities of GEM-UOT and other algorithms in the literature are summarized in Table 1. GEM-UOT is asymptotically better than Sinkhorn in and , and, as mentioned before, has the edge on practicality over Sinkhorn.
| Algorithms | Assumptions | Cost per iteration | Iteration complexity |
|---|---|---|---|
| MM (Chapel et al., 2021) | Unspecified iteration complexity | - Empirical Complexity | |
| Sinkhorn (Pham et al., 2020) | (S1), (S2), (S3), (S4) | ||
| GEM-UOT (this paper) | (A1)(S1), (A2)(S2), (A3) |
Novelty and Practicality: GEM-UOT is predicated on the novel dual formulation of the squared -norm regularized UOT and the intricate design of smooth locality (Lemma 11). We note that naive application of GEM would not lead to competitive complexity. Beside function decomposition, we design the smooth locality to enforce tight bound for the condition number . The techniques can benefit follow-up work tackling squared -norm UOT. Next, we highlight the favorable features of GEM-UOT that Sinkhorn is short of:
-
•
Compatibility with modern applications: Gradient methods are specifically congruent with and thus deployed as heuristics without theoretical guarantee in many emerging UOT applications (Balaji et al., 2020; Yang and Uhler, 2019; Frogner et al., 2015). Applications (Pitié et al., 2007; Courty et al., 2017; Muzellec et al., 2016) in which only sparse transportation plan is of interest also nullify the usage of Sinkhorn, since entropic regularization imposed by it keeps the transportation plan dense and strictly positive (Essid and Solomon, 2018; Blondel et al., 2018). GEM-UOT addresses both of these problems by being the first gradient-based sparse UOT solver in the literature.
-
•
Logarithmic dependence on : In the regime of large , Sinkhorn’s linear dependence on much hinders its practicality, motivating (Sejourne et al., 2022) to alleviate this issue in the specific case of 1-D UOT. However, no algorithm for general UOT problem that could achieve logarithmic dependence on had existed before GEM-UOT. From the practical perspective, can be large in certain applications (Schiebinger et al., 2019) and, for a specific case of UOT penalized by squared norm444We recall that our paper considers UOT penalized by KL divergence, which is the most prevalent UOT variant (see more details in Section 1)., be of the order of thousands (Blondel et al., 2018).
-
•
Logarithmic dependence on : GEM-UOT is the first algorithm in the literature that achieves logarithmic dependence on . As the class of scaling algorithms, especially subsuming Sinkhorn, is known to suffer from numerical instability (De Plaen et al., 2023), GEM-UOT thus emerges as a practical solver for the high-accuracy regime.
3.5 Relaxed UOT Problem and Practical Perspectives
In this Section, we discuss the relaxed UOT problem where only the UOT distance is within interest, and propose a practical algorithm, termed GEM-RUOT, for this setting.
Motivation of Relaxed UOT Problem: Certain generative model applications (Nguyen et al., 2021) recently have adopted either OT or UOT as loss metrics for training, in which only the computation of the distance is required, while the transportation plan itself is not within interest. To this end, we consider the relaxed UOT (RUOT) problem, where the goal is to approximate the UOT distance oblivious of the transportation plan.
Practicality: Gradient methods have been shown to achieve competitive complexity in the OT literature (Guminov et al., 2021; Dvurechensky et al., 2018). The heuristic proposed by (Yang and Uhler, 2019) and based on gradient descent achieved favorable performance for solving the UOT problem. Through our complexity analysis of GEM-UOT, we want to establish the preliminary understanding of the class of gradient-based optimization when applied to UOT problem. Nevertheless, the convoluted function decomposition (36) of GEM-UOT may make it hard to implement in practice. The strong convexity constant (Lemma 11) can be small on certain real datasets, thereby hindering the empirical performance. We thus develop an easy-to-implement algorithm, called GEM-RUOT, for practical purposes that avoids the dependency on in complexity and is specialized for the RUOT problem. One interesting direction is to incorporate Adaptive Gradient Descent (Malitsky and Mishchenko, 2020) that automatically adapts to local geometry and is left for future work.
Alternative Dual Formulation: GEM-RUOT does not require intricate function decomposition and optimizes directly over the following dual formulation (6) in Lemma 4. Optimizing (6) is equivalent to:
| (46) |
which is locally smooth by the following Lemma 17, whose proof is given in Appendix C.5.
Lemma 17
Let . Then is -smooth and convex in with:
GEM-RUOT adopts the distance for its prox-function , and consequently uses the standard projection operator for the proximal mapping associated with the closed convex set as Using the convex version of GEM, GEM-RUOT optimizes directly over (46) and projects its iterates onto the closed convex set through the proximal mapping to enforce the smoothness on the convex hull of all the iterates. Finally, it returns as an -approximation of the distance and a heuristic transportation plan . The steps are summarized in Algorithm 2 and GEM-RUOT’s complexity is given in Theorem 18.
Theorem 18
If , then . Under the assumptions (A1-A3), the complexity of Algorithm 2 is .
Proof Let be an optimal solution to (46) and thus (6). Since by Lemma 9 and Remark 6, we have . From corollary 3.6 in (Lan and Zhou, 2018), we obtain:
| (47) |
Using (Lemma 9) and set by the Algorithm 2, we have:
| (48) |
Combining (47), (48), we obtain:
| (49) |
The RHS of (49) is less than if . Under the assumptions (A1-A3) and and , we have:
Since it costs per iteration to compute the gradient , the total complexity of Algorithm 2 is
.
4 Approximability of Standard OT
For balanced masses and , UOT problem reduces to standard OT. In this Section, we establish the very first characterization of the vanishing approximation error between UOT and OT in terms of . To facilitate our discussion, we formally define the standard OT problem in Section 4.1. We prove several some approximability properties of UOT in Section 4.2, which are helpful for later deriving the main results. Then in Section 4.3, we show that UOT’s transportation plan converges to the marginal constraints of standard OT in the sense with the rate . Beside transportation plan, we upperbound the difference in transport plan between OT and UOT distances by in Section 4.4.
4.1 Standard OT
When the masses lie in the probability simplex, i.e. , the standard OT problem (Kantorovich, 1942) can be formulated as:
| (50) |
where .
Definition 19
For , is an -approximation transportation plan of if:
| (51) |
where is the optimal transportation plan of the OT problem.
4.2 Approximability Properties of UOT
For any , consider the optimal solution to (6). Note that since , we have . By Lemma 9, we obtain:
| (52) |
The following Lemmas are useful for the proofs of the main Theorem 23 and 24 later.
Lemma 20
The followings hold :
| (53) | ||||
| (54) |
Proof Firstly, we show that there must exist some such that . Assume for the sake of contradiction that . Then from (14), we obtain :
where the last line contradicts (52). From (52), (12) and taking any , we have :
Similarly, we can prove that : .
Lemma 21
Define . Then the followings hold :
| (55) | ||||
| (56) |
Lemma 22
Define . Then the followings hold:
| (58) | ||||
| (59) |
4.3 Approximation of OT Transportation Plan
We prove in the next Theorem the rate at which UOT’s transportation plan converges to the marginal constraints of standard OT.
Theorem 23
For , the problem admits some optimal transportation plan such that:
| (60) |
Proof From Lemma 9, we know that is bounded by . By the Bolzano–Weierstrass Theorem, there exists a convergent subsequence where . Define the limit of this subsequence as . We first prove that is a transportation plan of the problem by showing that is a minimizer of . By the boundedness of (Lemma 9), we have and obtain:
| (61) |
where the last equality is by the continuity of . Now take any . we have:
| (62) |
Combining (61) and (62), we have , thereby proving the minimality of . Thus, is a transportation plan of the problem. Now by Lemma 22, we have:
Taking and noting that , we obtain the desired inequality (60).
The quantity measures the closeness of to in distance and is also used as the stopping criteria in algorithms solving standard OT (Altschuler et al., 2018; Dvurechensky et al., 2018). Therefore, Theorem 23 characterizes the rate by which the transportation plan of converges to the marginal constraints of . Utilizing this observation, we present the algorithm GEM-OT (Algorithm 3), which solves the problem via GEM-UOT with fine tuned and finally projects the UOT solution onto (via Algorithm 4), to find an -approximate solution to the standard OT problem . The following Theorem characterizes the complexity of GEM-OT.
Theorem 24
Proof We obtain via simple algebra and Holder inequality that:
| (63) |
We proceed to upper-bound each of the three terms in the RHS of (63). We note that is the output of GEM-UOT fed with input error , and GEM-UOT (in the context of Algorithm 3) thus sets . The first term can be bounded by Lemma 14 as:
| (64) |
where holds directly from the definition of . For the second term, we obtain from Lemma 30 that:
| (65) | ||||
| (66) |
where (65) follows Lemma 22 with and triangular inequality, and (66) is by the definition of and (64). Since , we have: and . We thus obtain that:
| (67) |
Since the divergence and -norm are non-negative, we have:
| (68) |
We recall that , which implies:
| (69) |
Combining (67), (68) and (69), we upper-bound the third term in the RHS of (63):
| (70) |
Plugging (64), (66) and (70) into (63), we have:
The complexity of GEM-OT is the total of for the PROJ() algorithm and the complexity of GEM-UOT for the specified in the algorithm. By Corollary 16, which establishes the complexity of GEM-UOT under the assumptions (A1-A3), we conclude that the complexity of GEM-OT under (A1-A2) (where (A3) is naturally satisfied by our choice of ) is
.
Remark 25
The best-known complexities in the literature of OT are respectively (Lee and Sidford, 2014) for finding exact solution, and (Luo et al., 2023; Xie et al., 2023) for finding the -approximate solution. We highlight that the complexity in Theorem 24 is the first to achieve logarithmic dependence on to obtain the -approximate solution, while still enjoying better dependence on than the exact solver (Lee and Sidford, 2014). As the prevalent entropy-regularized methods to approximate OT (Luo et al., 2023; Altschuler et al., 2017; Dvurechensky et al., 2018) have been known to suffer from numerical instability and blurring issues (Zhou and Parno, 2023), GEM-OT can emerge as a practical solver for OT specialized in the high-accuracy regime (Dong et al., 2020).
Theorem 23 would elucidate the tuning of , which has been a heuristic process in all prior work, such that the transportation plan of well respects the original structure of that of . Furthermore, we provide a novel recipe for OT retrieval from UOT, which combines Theorem 23 with a low-cost post-process projection step and can be integrated with any UOT solver beside GEM-UOT as considered in this paper.
4.4 Approximation Error between UOT and OT Distances
As discussed in Section 1.1, while a lot of work have used UOT with small as a relaxed variant of OT (Fatras et al., 2021; Balaji et al., 2020; Le et al., 2021), we could empirically illustrate noticeably large approximation error between the UOT and OT distances on real dataset. Such deviation can be detrimental to target applications including generative modelling (Fatras et al., 2021) which recently has adopted UOT in place of OT as a loss metrics for training. This further necessitates the understanding of approximation error between UOT and OT in the sense of purely transport distance. We next establish an upper bound on the approximation error between UOT and OT distances in Theorem 26.
Theorem 26
For , we define and have the following bound:
| (71) |
Proof The lower bound is straightforward. Since (the transportation plan of ) is a feasible solution to the optimization problem and (as ), we obtain that:
We proceed to prove the upper bound of the error approximation. We first define a variant of problem where the divergence is replaced by squared norm:
| (72) |
By (Blondel et al., 2018, Theorem 2), for , we have:
| (73) |
Remark 27
We highlight that deriving the approximation error for is harder than . First, KL divergence is non-smooth, which is stated in (Blondel et al., 2018) as the main reason for their choice of squared norm instead of KL to relax the marginal constraints. Second, the proof in (Blondel et al., 2018) is based on interpreting the dual of as the sum of the dual of and the a squared -norm regularization on the dual variables, so the approximation error is derived by simply bounding the dual variables.
Recall that:
and is the solution to . We further define the problem as follows:
which optimizes over the same objective cost as yet with the additional constraint that lies in the probability simplex, i.e. . We let the solution to be . Since , we have . Then Pinsker inequality gives:
Consequently, we obtain that:
| (74) |
For any , we consider as the projection of onto via Algorithm 4. Then . By Lemma 30 and 22, we have:
| (75) |
Since is a feasible solution to the optimization problem , we obtain that:
| (76) |
Note that as . We thus can write and obtain via Holder inequality that:
where for the last inequality we note that . The above is equivalent to:
| (77) |
Now combining (74), (76) and (77), we have :
Taking the limit on both sides and noting that , we obtain:
Combining with (73), we get the desired bound
where .
5 Experiments
In this Section, we empirically verify GEM-UOT’s performance and sparsity, and our theories on approximation error. To compute the ground truth value, we use the convex programming package cvxpy to find the exact UOT plan (Agrawal et al., 2018). Unless specified otherwise, we always set (according to Theorem 13).
5.1 Synthetic Data
We set . Then ’s are drawn from uniform distribution and rescaled to ensure , while ’s are drawn from normal distribution with . Entries of are drawn uniformly from . For both GEM-UOT and Sinkhorn, we vary to evaluate their time complexities in Figure
1
and test the dependency in Figure 2. Both experiments verify GEM-UOT’s better theoretical dependence on and .
 Figure 1: Comparison in number of iterations (left) and per-iteration cost (right) between GEM-UOT and Sinkhorn on synthetic data for .
Figure 1: Comparison in number of iterations (left) and per-iteration cost (right) between GEM-UOT and Sinkhorn on synthetic data for .
 Figure 2: Scalability of (for ) on synthetic data and CIFAR-10. Sinkhorn scales linearly while GEM-UOT scales logarithmically in .
Figure 2: Scalability of (for ) on synthetic data and CIFAR-10. Sinkhorn scales linearly while GEM-UOT scales logarithmically in .
Next, to empirically evaluate the efficiency of GEM-OT for approximating standard OT problem, we consider the setting of balanced masses and large with and . We compare GEM-OT with Sinkhorn (Cuturi, 2013) in wall-clock time for varying in Figure 3.

5.2 Real Datasets: CIFAR-10 and Fashion-MNIST
To practically validate our algorithms, we compare the GEM-UOT with Sinkhorn on CIFAR-10 dataset (Krizhevsky and Hinton, 2009). A pair of flattened images corresponds to the marginals , whereby the cost matrix is the matrix of distances between pixel locations. This is also the setting considered in (Pham et al., 2020; Dvurechensky et al., 2018).
We plot the results in Figure 4, which demonstrates GEM-UOT’ superior performance. Additional experiments on Fashion-MNIST dataset that further cover GEM-RUOT are presented in Appendix D.
We highlight that GEM-UOT only has logarithmic dependence on , improving over Sinkhorn’s linear dependence on which had been its major bottleneck in the regime of large (Sejourne et al., 2022).
Experiment on the scalability of in Figure 2, which is averaged over 10 randomly
chosen image pairs, empirically reasserts our favorable dependence on on the CIFAR-10 dataset.
In addition, we evaluate the behaviour of GEM-UOT for different levels of and thus in Figure 5.
 Figure 4: Primal gap of GEM-UOT and Sinkhorn on CIFAR-10.
Figure 4: Primal gap of GEM-UOT and Sinkhorn on CIFAR-10.
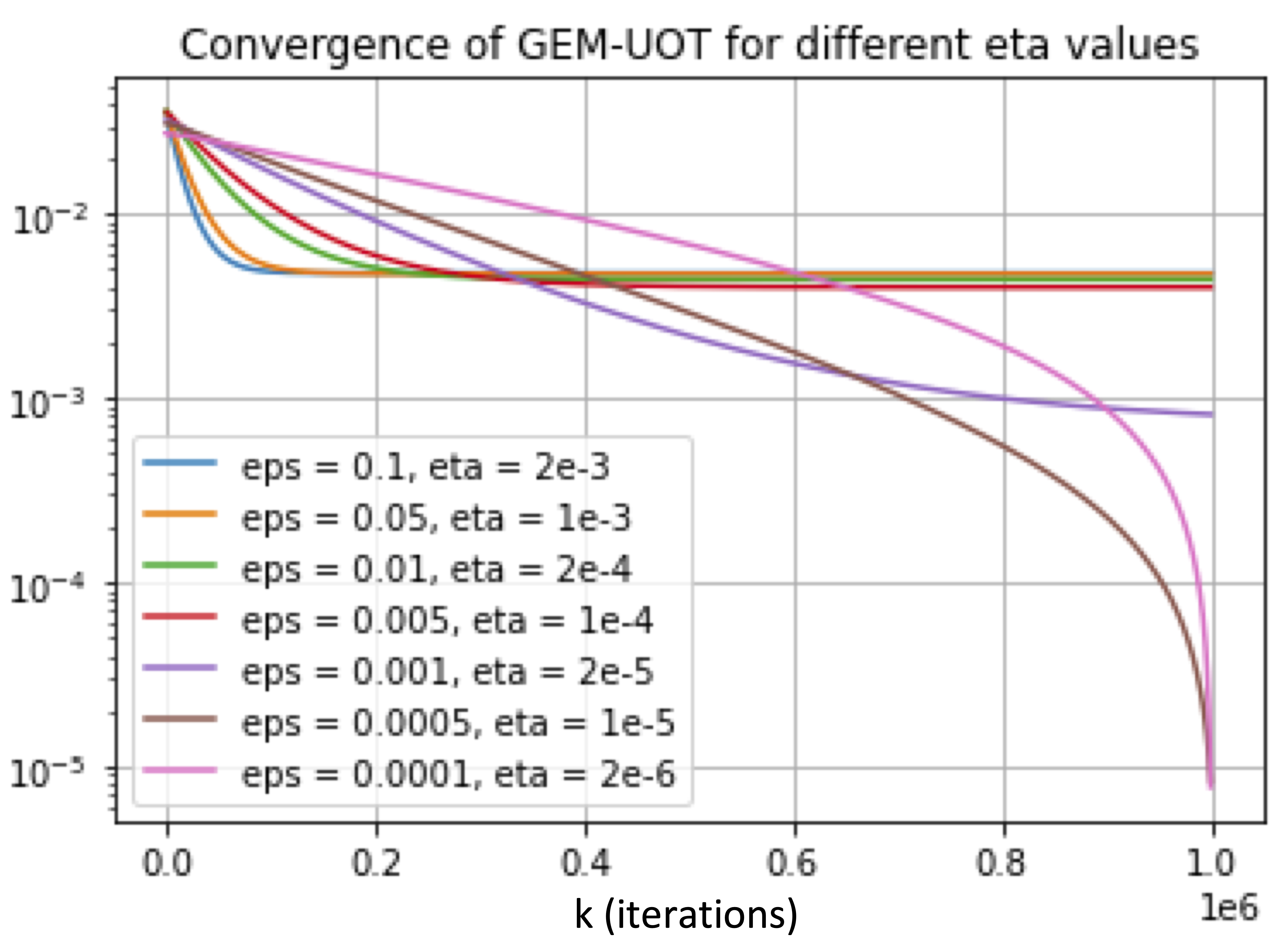 Figure 5: Algorithmic dependence on and the corresponding accuracy achieved by the algorithm on CIFAR-10 for iterations.
Figure 5: Algorithmic dependence on and the corresponding accuracy achieved by the algorithm on CIFAR-10 for iterations.
.
5.3 Sparsity of GEM-UOT
On two real datasets Fashion-MNIST and CIFAR 10, we empirically illustrate the sparseness of the transportation plans produced by GEM-UOT in Figure 6 and Figure 7, while Sinkhorn produces transportation plan with sparsity in those experiments. This result is consistent with (Blondel et al., 2018), where entropic regularization enforces strictly positive and dense transportation plan and squared- induces sparse transportation plan. To illustrate the effectiveness of as the sparse regularization, in Figure 8 we compare the heat maps of the optimal transportation plans of squared- UOT and original UOT on CIFAR 10. We set the sparsity threshold of and report the sparsity results in the following figures.
 Figure 6: sparsity on Fashion-MNIST.
Figure 6: sparsity on Fashion-MNIST.
 Figure 7: sparsity on CIFAR-10.
Figure 7: sparsity on CIFAR-10.
 Figure 8: Sparsity of squared- UOT plan (left) versus original UOT plan (right) on CIFAR 10.
Figure 8: Sparsity of squared- UOT plan (left) versus original UOT plan (right) on CIFAR 10.
5.4 Color Transfer
Color transfer is a prominent application where sparse transportation plan is of special interest (Blondel et al., 2018). This experiment shows that squared- UOT (i.e. sparse UOT) solved by GEM-UOT results in a sparse transportation plan and is thus congruent with this application, while entropic UOT solved by Sinkhorn results in strictly positive and dense transportation plan, hindering its adoption.
In particular, we conduct the UOT between the histograms of two images. Given the source image and target image both of size , we present their pixels in RGB space. Quantizing the images down to colors, we obtain the color centroids for the source and target images respectively as and , where . Then the source image’s color histogram is computed as the empirical distribution of pixels over the centroids, i.e. . The target image’s color histogram is computed similarly.
We compute the transportation plan between the two images via sparse UOT solved by GEM-UOT and entropic UOT solved by Sinkhorn, and report their qualities of color transfer in Figure 9, and the sparsity in Figure 10 and Figure 11. To demonstrate how entropic regularized UOT tend to generate dense mappings, we set the sparsity threshold of for Figure 11 while the sparsity threshold for Figure 10 is . (Note that due to the entropic regularization, Sinkhorn has sparsity under such threshold.)
 Figure 9: Quality of color transfer by GEM-UOT (solving squared- UOT) and Sinkhorn (solving entropic UOT).
Figure 9: Quality of color transfer by GEM-UOT (solving squared- UOT) and Sinkhorn (solving entropic UOT).
 Figure 10: GEM-UOT gets sparsity.
Figure 10: GEM-UOT gets sparsity.
 Figure 11: Sinkhorn gets sparsity.
Figure 11: Sinkhorn gets sparsity.
5.5 Approximation Error between UOT and OT
5.5.1 Approximation of OT Transportation Plan and OT Retrieval Gap



We investigate the approximability of OT via UOT in terms of transportation plan (Theorem 23) on synthetic data where and entries of are drawn uniformly from . The result is depicted in Figure 12.
Next, we verify the error incurred by GEM-OT (Algorithm 3) for retrieving OT solution from UOT. The choice of in GEM-OT equivalently means that the retrieval gap established in Theorem 24 can be upperbounded by where . To assert such vanishing effect of the error as grows large, we test on CIFAR-10 dataset and report the OT retrieval gap in Figure 13. We note that the OT retrieval gap also upperbounds the approximation error in transportation plan, so Figure 13 also serves as empirical verification of Theorem 23 on CIFAR-10 data.
5.5.2 Approximation Error between UOT and OT Distances
6 Conclusion
We have developed a new algorithm for solving the discrete UOT problem using gradient-based methods. Our method achieves the complexity of , where is the condition number depending on only the two input measures. This is significantly better than the only known complexity of Sinkhorn algorithm (Pham et al., 2020) to the UOT problem in terms of and dependency. In addition, we are the first to theoretically analyze the approximability of the UOT problem to find an OT solution. Our numerical results show the efficiency of the new method and the tightness of our theoretical bounds. We believe that our analysis framework can be extended to study the convergence results of stochastic methods, widely used in ML applications for handling large-scale datasets (Nguyen et al., 2018) or under nonlinear stochastic control settings (Nguyen and Maguluri, 2023). Our results on approximation error can open up directions that utilize UOT to approximate standard OT and even partial OT (Nguyen et al., 2024) using first-order methods.
APPENDIX
Appendix A Sinkhorn Algorithm
A.1 Regularity Conditions
In this Section, we will show that the assumptions used by the Sinkhorn (Pham et al., 2020) algorithm are equivalent to our stated regularity conditions (S1)-(S4). (S4) is clearly stated in their list of regularity conditions. To claim their complexity, in (Pham et al., 2020, Corollary1), they further require the condition ’’. Following their discussion in (Pham et al., 2020, Section 3.1), a necessary condition for it to hold is (and resp. ). To see that (and resp. ) is equivalent to (S1)-(S3), we note that if then (contradiction!), and .
A.2 The dependency of Sinkhorn complexity on
We note that in its pure form, Sinkhorn’s complexity has , which is excluded in (Pham et al., 2020) under their regularity condition (S4) that are constants. To see this, note that in the proof of (Pham et al., 2020, Corollary1), their quantity has the complexity and appears in Sinkhorn’s final complexity as .
Appendix B Supplementary Lemmas and Theorems
Lemma 28
For , we have:
Proof We have:
By symmetry, . Thus, .
Theorem 29 (Rockafellar (1967))
Let and be two couples of topologically paired spaces. Let be a continuous linear operator and its adjoint. Let f and g be lower semicontinuous and proper convex functions defined on E and F respectively. If there exists such that g is continuous at , then
Moreover, if there exists a maximizer then there exists satisfying and .
Appendix C Missing Proofs
C.1 Proof of Lemma 14
Let be an optimal solution to (11). Because of the projection step on line 8 of Algorithm 1, we have for . By Lemma 11, is -smooth and is -strongly convex on The GEM-UOT is based on the GEM being applied to solve the dual objective (38), which, from (Lan and Zhou, 2018, Theorem 2.1) and the proof therein, thus guarantees that the dual iterate converges to the dual solution of (38) by:
| (79) |
Furthermore, we have:
| (80) |
Now, plugging (80) into (79) gives:
| (81) |
Line 16 of Algorithm 1 further converts the dual iterate into the primal iterate as the final output. Next, we show that the convergence of the dual iterate in the sense of (81) leads to the convergence of the primal iterate to the primal solution of the primal objective (5). From the definition of in Algorithm 1 and in view of Corollary 5, we have:
The condition that is equivalent to:
Therefore,
| (82) |
C.2 Proof of Lemma 15
C.3 Proof of Lemma 11
The gradient of can be computed as:
The Hessian of can be computed as:
If , then for all which implies for all and thereby on . We can then conclude that is convex on .
Now let us consider any . By Mean Value Theorem, , such that and , such that . We then obtain:
| (since , . Similarly, ) | |||
which implies that is -smooth with .
Now let us consider . The gradient can be computed as:
For any , we have:
Therefore, is -strongly convex on with .
C.4 Projection Step of GEM-UOT
We describe the following projection step (i.e. line 8 in Algorithm 1) in more details:
| (83) |
where we further expand the objective as:
| (84) |
For abbreviation, we let where and respectively are coefficients of the variables in the linear term of (84). We also define the constants and . The objective can be written as the sum of quadratic functions as follows:
| (85) |
And the projection step is thus equivalent to solving:
| (86) | ||||
Next, we aim to derive a simplified equivalence form of (86) that is obtained by expressing the optimal with respect to fixed , and consequently optimizing over . In particular, we consider the mapping defined by:
| (87) |
the restricted domain as follows:
| (88) |
and the objective:
| (89) |
The next Lemma establishes the equivalence form for the projection problem (86).
Lemma 31
The following holds:
| (90) |
Proof For any , we have that is defined as in (87) satisfies:
Thus, we have , which implies:
| (91) |
Now, take any . We fix and , and optimize over all such that , i.e. those with and . Then, we have:
| (92) |
Note that the optimization problem over in the RHS of (92) has separable quadratic objective and separable linear constraints. Thus, simple algebra gives being defined in (87) as the optimal solution to such problem, i.e.
| (93) |
| (94) |
where the second inequality is because any implies by definition. Finally, combining (91) and (94) gives the desired statement.
Since the equivalence form of the projection step is strongly convex smooth optimization over box constraints, we can adopt projected quasi-Newton method with superlinear convergence rate (Schmidt et al., 2011, Theorem 11.2), thereby resulting in iteration complexity. Furthermore, the per iteration cost is dominated by the gradient and Hessian computation of , which can be achieved efficiently in as follows. In particular, we have for :
Thus, we conclude that the projection step can be solved in time.
C.5 Proof of Lemma 17
The gradient of can be computed as:
Let us consider any . By Mean Value Theorem, , such that and , such that . We then obtain:
| (By Lemma 28 and simple algebra ) | |||
| (since , . Similarly, ) | |||
This implies that is -smooth with .
Appendix D Experimental Result for GEM-RUOT on Fashion-MNIST dataset
We test GEM-UOT (Algorithm 1), GEM-RUOT (Algorithm 2) and Sinkhorn on the Fashion-MNIST dataset using the same setting as the experiment on CIFAR dataset in Section 5.2 and report the result in Figure 15.

References
- Agrawal et al. (2018) Akshay Agrawal, Robin Verschueren, Steven Diamond, and Stephen Boyd. A rewriting system for convex optimization problems. Journal of Control and Decision, 5(1):42–60, 2018.
- Altschuler et al. (2018) J. Altschuler, F. Bach, A. Rudi, and J. Weed. Approximating the quadratic transportation metric in near-linear time. ArXiv Preprint: 1810.10046, 2018.
- Altschuler et al. (2017) Jason Altschuler, Jonathan Weed, and Philippe Rigollet. Near-linear time approximation algorithms for optimal transport via sinkhorn iteration. In Advances in Neural Information Processing Systems, pages 1964–1974, 2017.
- Arjovsky et al. (2017) Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In International Conference on Machine Learning, pages 214–223, 2017.
- Balaji et al. (2020) Yogesh Balaji, Rama Chellappa, and Soheil Feizi. Robust optimal transport with applications in generative modeling and domain adaptation. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 12934–12944. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/9719a00ed0c5709d80dfef33795dcef3-Paper.pdf.
- Bernton et al. (2022) Espen Bernton, Promit Ghosal, and Marcel Nutz. Entropic optimal transport: Geometry and large deviations. Duke Mathematical Journal, 171(16):3363 – 3400, 2022. doi: 10.1215/00127094-2022-0035. URL https://doi.org/10.1215/00127094-2022-0035.
- Blondel et al. (2018) M. Blondel, V. Seguy, and A. Rolet. Smooth and sparse optimal transport. In AISTATS, pages 880–889, 2018.
- Caffarelli and McCann (2010) Luis A. Caffarelli and Robert J. McCann. Free boundaries in optimal transport and monge-ampère obstacle problems. Annals of Mathematics, 171(2):673–730, 2010. ISSN 0003486X. URL http://www.jstor.org/stable/20752228.
- Chapel et al. (2021) Laetitia Chapel, Rémi Flamary, Haoran Wu, Cédric Févotte, and Gilles Gasso. Unbalanced optimal transport through non-negative penalized linear regression. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 23270–23282. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/paper/2021/file/c3c617a9b80b3ae1ebd868b0017cc349-Paper.pdf.
- Chizat et al. (2018) Lenaic Chizat, Gabriel Peyré, Bernhard Schmitzer, and François-Xavier Vialard. Scaling algorithms for unbalanced optimal transport problems. Mathematics of Computation, 87(314):2563–2609, 2018.
- Courty et al. (2017) N. Courty, R. Flamary, D. Tuia, and A. Rakotomamonjy. Optimal transport for domain adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(9):1853–1865, 2017.
- Cuturi (2013) Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. In C.J. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K.Q. Weinberger, editors, Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc., 2013. URL https://proceedings.neurips.cc/paper_files/paper/2013/file/af21d0c97db2e27e13572cbf59eb343d-Paper.pdf.
- De Plaen et al. (2023) Henri De Plaen, Pierre-François De Plaen, Johan A. K. Suykens, Marc Proesmans, Tinne Tuytelaars, and Luc Van Gool. Unbalanced optimal transport: A unified framework for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3198–3207, June 2023.
- Dong et al. (2020) Yihe Dong, Yu Gao, Richard Peng, Ilya Razenshteyn, and Saurabh Sawlani. A study of performance of optimal transport. ArXiv Preprint: 2005.01182, 2020.
- Dvurechensky et al. (2018) P. Dvurechensky, A. Gasnikov, and A. Kroshnin. Computational optimal transport: Complexity by accelerated gradient descent is better than by Sinkhorn’s algorithm. In International conference on machine learning, pages 1367–1376, 2018.
- Essid and Solomon (2018) Montacer Essid and Justin Solomon. Quadratically regularized optimal transport on graphs. SIAM Journal on Scientific Computing, 40(4):A1961–A1986, 2018. doi: 10.1137/17M1132665. URL https://doi.org/10.1137/17M1132665.
- Fatras et al. (2021) Kilian Fatras, Thibault Sejourne, Rémi Flamary, and Nicolas Courty. Unbalanced minibatch optimal transport; applications to domain adaptation. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 3186–3197. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/fatras21a.html.
- Frogner et al. (2015) Charlie Frogner, Chiyuan Zhang, Hossein Mobahi, Mauricio Araya-Polo, and Tomaso Poggio. Learning with a wasserstein loss. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2, NIPS’15, page 2053–2061, Cambridge, MA, USA, 2015. MIT Press.
- Genevay et al. (2018) Aude Genevay, Gabriel Peyre, and Marco Cuturi. Learning generative models with sinkhorn divergences. In International Conference on Artificial Intelligence and Statistics, pages 1608–1617, 2018.
- Guminov et al. (2021) Sergey Guminov, Pavel E. Dvurechensky, Nazarii Tupitsa, and Alexander V. Gasnikov. On a combination of alternating minimization and nesterov’s momentum. In International Conference on Machine Learning, 2021.
- Ho et al. (2017) Nhat Ho, XuanLong Nguyen, Mikhail Yurochkin, Hung Hai Bui, Viet Huynh, and Dinh Phung. Multilevel clustering via Wasserstein means. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1501–1509. PMLR, 06–11 Aug 2017. URL https://proceedings.mlr.press/v70/ho17a.html.
- Kantorovich (1942) L. V. Kantorovich. On the translocation of masses. In Dokl. Akad. Nauk. USSR (NS), volume 37, pages 199–201, 1942.
- Krizhevsky and Hinton (2009) A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images. Master’s thesis, Department of Computer Science, University of Toronto, 2009.
- Lan and Zhou (2018) Guanghui Lan and Yi Zhou. Random gradient extrapolation for distributed and stochastic optimization. SIAM Journal on Optimization, 28(4):2753–2782, 2018.
- Le et al. (2021) Khang Le, Huy Nguyen, Quang Minh Nguyen, Tung Pham, Hung Bui, and Nhat Ho. On robust optimal transport: Computational complexity and barycenter computation. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=xRLT28nnlFV.
- Lee et al. (2019) John Lee, Nicholas P Bertrand, and Christopher J Rozell. Parallel unbalanced optimal transport regularization for large scale imaging problems. ArXiv Preprint: 1909.00149, 2019.
- Lee and Sidford (2014) Yin Tat Lee and Aaron Sidford. Path finding methods for linear programming: Solving linear programs in Õ(vrank) iterations and faster algorithms for maximum flow. In 2014 IEEE 55th Annual Symposium on Foundations of Computer Science, pages 424–433, 2014. doi: 10.1109/FOCS.2014.52.
- Liero et al. (2017) Matthias Liero, Alexander Mielke, and Giuseppe Savaré. Optimal entropy-transport problems and a new hellinger–kantorovich distance between positive measures. Inventiones mathematicae, 211(3):969–1117, Dec 2017. ISSN 1432-1297. doi: 10.1007/s00222-017-0759-8. URL http://dx.doi.org/10.1007/s00222-017-0759-8.
- Lorenz et al. (2019) Dirk A. Lorenz, Paul Manns, and Christian Meyer. Quadratically regularized optimal transport. Applied Mathematics & Optimization, 83:1919 – 1949, 2019. URL https://api.semanticscholar.org/CorpusID:85517311.
- Luo et al. (2023) Yiling Luo, Yiling Xie, and Xiaoming Huo. Improved rate of first order algorithms for entropic optimal transport. In Francisco Ruiz, Jennifer Dy, and Jan-Willem van de Meent, editors, Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, volume 206 of Proceedings of Machine Learning Research, pages 2723–2750. PMLR, 25–27 Apr 2023. URL https://proceedings.mlr.press/v206/luo23a.html.
- Malitsky and Mishchenko (2020) Yura Malitsky and Konstantin Mishchenko. Adaptive gradient descent without descent. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119, pages 6702–6712, 2020.
- Muzellec et al. (2016) Boris Muzellec, Richard Nock, Giorgio Patrini, and Frank Nielsen. Tsallis regularized optimal transport and ecological inference. In AAAI Conference on Artificial Intelligence, 2016.
- Nguyen et al. (2024) Anh Duc Nguyen, Tuan Dung Nguyen, Quang Minh Nguyen, Hoang H. Nguyen, and Kim-Chuan Toh. On partial optimal transport: Revising the infeasibility of sinkhorn and efficient gradient methods. In AAAI Conference on Artificial Intelligence, 2024. URL https://arxiv.org/pdf/2312.13970.pdf.
- Nguyen and Maguluri (2023) Hoang Huy Nguyen and Siva Theja Maguluri. Stochastic approximation for nonlinear discrete stochastic control: Finite-sample bounds. ArXiv Preprint: 2304.11854, 2023.
- Nguyen et al. (2021) Khai Nguyen, Nhat Ho, Tung Pham, and Hung Bui. Distributional sliced-wasserstein and applications to generative modeling. In International Conference on Learning Representations, 2021.
- Nguyen et al. (2018) Lam Nguyen, Phuong Ha Nguyen, Marten van Dijk, Peter Richtarik, Katya Scheinberg, and Martin Takac. SGD and hogwild! Convergence without the bounded gradients assumption. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 3750–3758. PMLR, 10–15 Jul 2018. URL https://proceedings.mlr.press/v80/nguyen18c.html.
- Peyré and Cuturi (2019) Gabriel Peyré and Marco Cuturi. Computational optimal transport. Foundations and Trends® in Machine Learning, 11(5-6):355–607, 2019.
- Pham et al. (2020) Khiem Pham, Khang Le, Nhat Ho, Tung Pham, and Hung Bui. On unbalanced optimal transport: An analysis of Sinkhorn algorithm. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 7673–7682. PMLR, 13–18 Jul 2020. URL https://proceedings.mlr.press/v119/pham20a.html.
- Pitié et al. (2007) François Pitié, Anil C. Kokaram, and Rozenn Dahyot. Automated colour grading using colour distribution transfer. Computer Vision and Image Understanding, 107(1):123–137, 2007. ISSN 1077-3142. doi: https://doi.org/10.1016/j.cviu.2006.11.011. URL https://www.sciencedirect.com/science/article/pii/S1077314206002189. Special issue on color image processing.
- Rabin and Papadakis (2015) Julien Rabin and Nicolas Papadakis. Convex color image segmentation with optimal transport distances. In SSVM, 2015.
- Rockafellar (1967) R. Tyrrell Rockafellar. Duality and stability in extremum problems involving convex functions. Pacific Journal of Mathematics, 21(1):167 – 187, 1967. doi: pjm/1102992608. URL https://doi.org/.
- Schiebinger et al. (2019) G. Schiebinger et al. Optimal-transport analysis of single-cell gene expression identifies developmental trajectories in reprogramming. Cell, 176:928–943, 2019.
- Schmidt et al. (2011) Mark Schmidt, Dongmin Kim, and Suvrit Sra. Projected Newton-type Methods in Machine Learning. In Optimization for Machine Learning. The MIT Press, 09 2011. ISBN 9780262298773. doi: 10.7551/mitpress/8996.003.0013.
- Sejourne et al. (2022) Thibault Sejourne, Francois-Xavier Vialard, and Gabriel Peyré. Faster unbalanced optimal transport: Translation invariant sinkhorn and 1-d frank-wolfe. In Gustau Camps-Valls, Francisco J. R. Ruiz, and Isabel Valera, editors, Proceedings of The 25th International Conference on Artificial Intelligence and Statistics, volume 151 of Proceedings of Machine Learning Research, pages 4995–5021. PMLR, 28–30 Mar 2022. URL https://proceedings.mlr.press/v151/sejourne22a.html.
- Villani (2008) Cédric Villani. Optimal transport: Old and New. Springer, 2008.
- Xie et al. (2023) Yiling Xie, Yiling Luo, and Xiaoming Huo. An accelerated stochastic algorithm for solving the optimal transport problem. ArXiv Preprint: 2203.00813, 2023.
- Yang and Uhler (2019) K. D. Yang and C. Uhler. Scalable unbalanced optimal transport using generative adversarial networks. In ICLR, 2019.
- Zhou and Parno (2023) Bohan Zhou and Matthew Parno. Efficient and exact multimarginal optimal transport with pairwise costs. ArXiv Preprint: 2208.03025, 2023.