On the Scheduling Policy for Multi-process WNCS under Edge Computing ††thanks: Y. Qiu, S. Wu and Y. Wang are with the Harbin Institute of Technology, Shenzhen, Guangdong, 518055, China. E-mail: [email protected], [email protected], [email protected]
Abstract
This paper considers a multi-process and multi-controller wireless networked control system (WNCS). There are independent linear time-invariant processes in the system plant which represent different kinds of physical processes. By considering the edge computing, the controllers are played by edge server and cloud server. Each process is measured by a sensor, and the status updates is sent to controller to generate the control command. The link delay of cloud server is longer than that of edge server. The processing time of status update depends on the characteristic of servers and processes. By taking into account such conditions, we mainly investigate how to choose the destination of status updates to minimize the system’s average Mean Square Error (MSE), edge server or cloud server? To address this issue, we formulate an infinite horizon average cost Markov Decision Process (MDP) problem and obtain the optimal scheduling policy. The monotonicity of the value function in MDP is characterized and then used to show the threshold structure properties of the optimal scheduling policy. To overcome the curse of dimensionality, we propose a low-complexity suboptimal policy by using additive separable structure of value function. Furthermore, the processing preemption mechanism is considered to handle the status updates more flexible, and the consistency property is proved. On this basis, a numerical example is provided. The simulation results illustrate that the controller selection is related to the timeliness of process and show the performance of the suboptimal policy. We also find that the optimal policy will become a static policy in which the destination of status update is fixed when the wireless channel is error free.
Index Terms:
WNCS, multi-process system, Edge computing, age of information, preemption, scheldulingI Introduction
In a wireless networked control system (WNCS), to ensure the accuracy of control and the stability of design, it is necessary to describe the timeliness and error of the system quantitatively. There are two commonly used parameters: Age of information (AoI) and Mean Square Error (MSE). The concept of AoI was proposed in [1], which can accurately quantify the timeliness of status information. Typically, the AoI is defined as the time elapsed since the most recently received status update was generated at the sensor. Unlike AoI, MSE is mainly used to measure the system’s error, which can describe the change rates of different sources. It is widely used, especially in the control system, such as the multi-sensor control system in [2].
Based on AoI and MSE, the research under the background of WNCS has yielded many beneficial results. Some literature study the scheduling polices to optimize the system AoI or MSE. For example, the work in [3] studies wireless networks with multiple users under the problem of AoI minimization and develops a low-complexity transmission scheduling algorithm. The authors in [4] extend the multiple users system to incorporate stochastic packet arrivals and optimal packet management and proposes an index-prioritized random access policy by minimizing the AoI. The works in [1] and [5] obtained the optimal actions in current state by designing the indicator based on latency and reliability, respectively. The authors in [5] and [6] study different lengths of source status and give the optimal policies in many cases by minimizing the system AoI. Based on [6], the work in [7] investigates the preemption mechanism in channel and prove the structural properties of the optimal policy. The non-uniform status model was further extended in [8], which is no longer limited to a single source and considers the situation of multiple processes with different status updates. The work in [9] introduces an optimal policy considering the change rate of different sources by minimizing the system MSE.
In WNCS, smaller delay means more accurate control, but the existing scheduling policies can not reduce the inherent delay in uplink and downlink. Therefore, edge computing was proposed to decrease prolonged delays in some time-critical tasks. In some WNCS, a small set of special servers was deployed near the sensors. These special servers are called edge servers, which nearby sensors can reach via wireless connections. In [10] and [11], edge computing is added to the sensor network. The authors in [10] introduce that the sensors can only full-offload the task, i.e., each status update can only be processed by one server, which can not be divided into multiple parts and handed over to multiple servers. The work in [12] introduces a neural network for training the system model and considers the processing time on server. The work in [13] uses the existing cloud processing center to build an edge computing model, and the results show that the computing capacity is different between edge server and cloud server. The authors in [11] propose a universal model which uses delay and computational capacity to distinguish different servers. The full task offloading without task migration in sensor network is also considered in [11].
Most existing works, e.g., [2]-[11], assume that the system has only one controller, and it takes the same time for different status updates to generate the control command. However, for the WNCS system containing edge computing, there are often multiple controllers in the system, and the controllers are mainly divided into edge servers and cloud servers. In addition, the time of generating control commands is also different. The edge servers are less potent in both resources and computational ability than remote cloud servers. It take longer time to process state information and generate control commands than cloud servers [12]. Moreover, to timely respond to time-critical tasks and improve system performance, the preemption mechanism commonly exists on the server, and tasks with higher priority can preempt the ongoing task. Therefore, some questions naturally arise: How to select the status update destination, remote cloud server or edge server, to optimize the system performance? Due to the randomness in the actual process, the server-side cannot perform the best action in every time slot; how to allocate the priority between different status updates to get the preemption policy that minimizes the MSE of the system? These questions motivate the study in this paper.
In this paper, the scheduling problem in WNCS with independent processes is studied, and we are interested in minimizing the average MSE. By referring to the model in [8] and [11], we adopt edge computing in the system model and consider that the state updates need to be processed in multiple time slots to generate control commands. Moreover, to handle the status updates more flexibly, we add the preemption mechanism on the basis of [8]. The main contributions of this paper are summarized as follows:
-
•
This paper considers a multi-process WNCS and applies the edge computing. The different processes stands for different physical processes, which status updates need different processing time on the same server. Meanwhile, we use link delay and computing power to describe edge server and cloud server. By introducing the AoI and remaining processing time of each process, the problem of how to scheduling status updates can be described as an infinite horizon average cost Markov Decision Process (MDP). Thus the scheduling policy of minimizing the MSE of the system is obtained.
-
•
A suboptimal policy is proposed to reduce the computational complexity. Along the proof of exists studies, we have the additive separable structure of value function. The original MDP problem can be divided into multiple small tasks. The simulation result shows that the performance of proposed suboptimal policy is near to optimal policy.
-
•
The processing preemption mechanism is considered in this paper. In order to handle the status updates more flexibly, we allow the task with higher priority to preempt the processing task on server. The preemption optimal policy is obtained by solving the formulated MDP problem. Then the consistency property of the preemption optimal policy is proved.
The rest of this paper is organized as follows. In Section II, we introduce the system model, formulate the problem and prove some structure properties. Section III presents a low-complexity suboptimal policy. Section IV further extends to the preemption mechanism on controller and characterizes the consistency property of its optimal policy. Simulation result and analysis are provided in Section V. Finally, conclusions are drawn in Section VI.
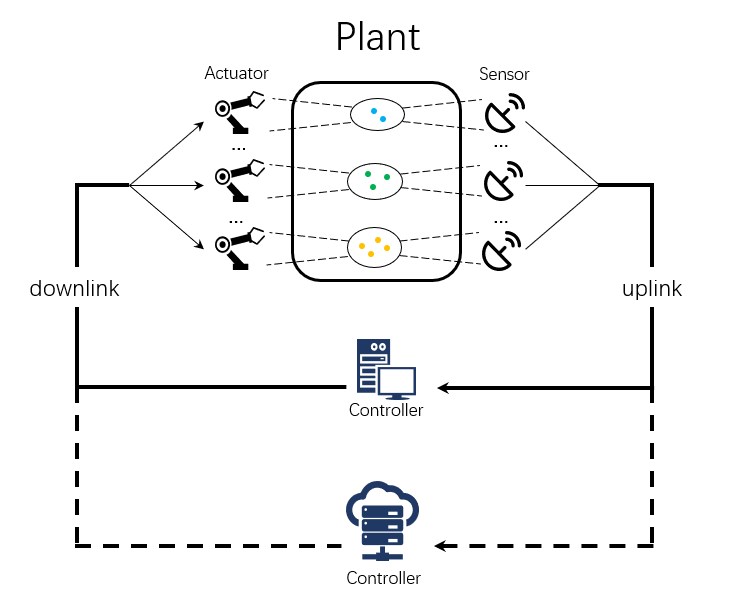
II System Model And Problem Formulation
II-A System Model
We consider a multi-process WNCS. As shown in Fig.1, there are processes and sensors in the system, and each sensor samples its corresponding process[14]-[15]. For the uplink and downlink wireless channel, we adopt the orthogonal channel which can transmit multiple status updates at the same time. The controller in the system consists of an edge server and a cloud server. Same as the assumption in [11] and [16], compared with the remote server, the edge server has a smaller uplink and downlink delay but longer task processing time. In Fig.1, different color of dots in the circle represents different physical processes and the number of dots represents the dimension of process, e.g., the processing time required for generating control command from video signals is not the same as that from audio signals.
A time-slotted system is considered, where time is divided into slots with equal duration. And we model each process as a discrete linear time-invariant system [17]:
| (1) |
where and represent the process index and time slot, respectively. is the state of the -th process in -th time slot and is the executed control command. represents the normally distributed noise with the distribution of the -th process and we assume that is a positive semi-definite. and represent the state transition matrix and command control coefficient of process , respectively. In this article, we consider the case that all processes remain unchanged within a single time slot. The goal of the system is to keep the state of each process close to .
In wireless channel, the transmission success probability for a status updates is set as . As described in [14] [18][19], it is assumed that there is a perfect feedback channel between each sensor and the destination, so that each sensor will immediately inform whether the transmission is successful and determine the destination of the next time slot.
To generate effective control commands, the controller must maintain an accurate estimate of plant state. When the controller receives the status information from sensor successfully, it can use the timestamp to estimate the plant state. Define as the AoI of the status information generated by process . The estimation of , denoted by , can be expressed as:
| (2) |
We denote and as the uplink and downlink delay, respectively. Assuming that the controller knows the delay of control command transmitted to the actuator. The goal of the system is to keep the state of each process close to . When the state information has been processed completely, the control command on actuator and the control command on controller have the following relationship:
| (3) |
where is the command generation coefficient.
Let denote the long-term average MSE of the system, which is given by
| (4) |
where represents the MSE of each process, which can be calculated by combining (1)-(3), given as:
| (5) |
This equation constructs the mapping between AoI and MSE and can simplify the calculation.
For the processing time, different tasks on the same server is not equal, and the same task on different server is also different. For each physical process , we denote the state information length , which is equal to the number of elements in . The number of bits per element in the state matrix and the number of CPU cycles needed to process one bit are denoted by and , respectively. The number of time slots required for process one status update is then given by [20]
| (6) |
where (in Hz) is the CPU frequency of the processor and (in seconds) is the time duration in each slot.
We assume that the edge computing system is stable such that the link delay is time invariable and a server can execute at most one task at a time. Because the remote cloud servers can be modeled as edge servers but with long link delay and more powerful processing capability, we do not explicitly differentiate between the edge servers and the remote cloud servers[11].
In order to describe the control performance of the system more accurately, we make a common assumption in the following:
Assumption:The transition matrix of each process satisfies that ()>1. It means that without control, the system will be unstable, which is why the control system exists. This assumption makes the control necessary.
Here (.) stands for Spectral radius.
II-B Problem Formulation
For edge servers, the uplink and downlink delays are and , respectively. Moreover, the processing time on edge server of state is defined as . For a cloud server (or called the remote server), the uplink and downlink delays are defined as and , respectively. And the processing time on remote server of state is defined as .
In order to facilitate the subsequent representation, we make some assumptions which are similar to the existing works in [11] [21]-[22]. For the edge server, the uplink and downlink delay are set to be time slot, i.e., , and the processing time is set to be twice the dimension of . For the cloud server, we set the uplink and downlink delay to time slots, i.e., , and the processing time is numerically the same as the dimension of . e.g., for a task with a dimension of 1, if dispatched to the edge server, the uplink and downlink delays are both 1, and the processing time is ; if dispatched to the cloud server, the uplink and downlink delays are both 2 and the processing time is 1. This can be extended to a general case and will be introduced in the following. But note that, the uploading and downloading of a task do not consume any computing resource of the servers, so a server can process a task while transmitting other tasks at the same time.
Our goal is to jointly control every process to minimize the system MSE under non-uniform status update and edge computing system. This problem can be modeled as a MDP problem, and the system space can be expressed as where is the collection of all feasible states. Each parameter is described as follows:
In order to record the AoI information of all processes, we set . For different process , we define as the AoI at the beginning of slot . We set be the upper limits of the AoI for process . For tractability [23], we assume that is finite, but can be arbitrarily large.
Let be the state space for the remote server, stands for the index of process which is transmitting in the uplink, stands for the index of process which is being computed on the remote server, stands for the index of process which control command is transmitting from controller. records the number of slot that are left to be computed.
Let be the state space for the edge server, stands for the index of process which is being computed on the edge server, records the number of slot that are left to be computing.
The status information in transmission is like a queue and arrives at the server in the order of FCFS [16]. Therefore, to expand to the general case, just add index element for representing the process according to different uplink and downlink delays.
The action space is defined as , where represent the index of process where status update is transmitted to the remote server and edge server, respectively.
For each variable, we can write the update rules as follows:
When both the uplink and downlink transmission are successful:
| (7) |
| (8) |
| (9) |
In other conditions, (7) will change to when the uplink transmission failed. When the downlink transmission failed, just replace the and to in (8) and (9), respectively.
The one-stage cost only depends on the current state and is defined as
| (10) |
The set of scheduling decisions for all possible states is called a scheduling policy , where is the collection of all feasible scheduling policies. As a result, under a feasible stationary policy , the average MSE of the system starting from a given initial state is given by:
| (11) |
We are seeking for the policy which can minimize average MSE of the system in the following:
| (12) |
According to [23, Propositions 5.2.1], the optimal policy can be obtained by solving the following Bellman equation.
Lemma 1: There exists a unique scalar and a value function satisfying:
| (13) |
where is the optimal value to (12) for all initial state and the optimal policy which can achieve the optimal value satisfies:
| (14) |
It can be observed that the argument of the value function in (13) is only the state . If it is extended to the general situation and the action is also regarded as the argument of the function, the state-action cost function is obtained as follows:
| (15) |
It is evident from Lemma 1 and (14) that the optimal policy relies upon the value function . In order to obtain , we have to solve the Bellman equation in (13). But disappointingly, there is no closed-form solution in (13). The numerical solution can only be obtained by iterative methods such as value iteration or policy iteration. Furthermore, the design of the numerical solution corresponding to the optimal policy cannot provide more suggestions and will consume a lot of computing resources, especially in the high dimension problem.
Therefore, if the structural properties of the optimal policy can be obtained, it can be used to reduce the computational complexity of the policy and verify the final numerical result.
By the dynamics in (7)-(9) and using the relative value iteration algorithm, we can show the following properties of the value function :
Theorem 1: For any state , , satisfy that , , , and , we have .
Proof: The proof can be found in the online version.
Theorem 2: For the state which satisfies and have the following type policy:
If , then . Where and is the same with except , . is any positive integer number.
Proof: The proof can be found in the online version.
From Theorem 1 and Theorem 2, we present the threshold type policy of the MDP. The structural result will simplify off-line computation and facilitate the online application of scheduling policy. Note that we mainly focus on the case in which the remote server and edge server are idle, i.e., and . Because the result in other conditions agrees with intuition in other conditions, e.g., when the status information of process is transmitting to the remote server, or the remote server is computing the status information of process , the edge server will serve other processes except process . Also, this result can be extended to the single server model.
III Low-Complexity Suboptimal policy
In the MDP mentioned above, the computational complexity will become very high when too many elements are in the state space, which is called the curse of dimensionality. So we proposed a suboptimal policy, which sacrifices a small amount of performance in exchange for a significant reduction in computational complexity.
Let and be the system average MSE and the value function under an unchained base policy . From the proof of [8], there exists satisfying the following Bellman equation.
| (16) |
where is the next state from state under the given action . Obviously, the state cost is independent of the action and (16) can be further written as
| (17) | ||||
For each process , we define as the state space and is the set of all feasible states. The action space is the same as SectionII. The transmit probability can also be derived from the previous description, which is omitted here. After the definition, we show that has the following additive separable structure.
Lemma 2: Given any unchain policy, the value function in (16) can be express as , where for each , have the following property:
| (18) | ||||
where and are the average MSE and value function of each process under policy , respectively.
Proof: Along the line of proof of [[24], Lemma3], we have the additive separable structure of the value function under a unchain base policy and by making use of the relationship between the joint distribution and marginal distribution. So, we have the equation holds. Then, by substituting into (16), it can be easily checked that the equality in (18) holds.
Now, we approximate the value function in Bellman equation with , and is given in (18). Then, according to (17) we develop a deterministic scheduling suboptimal policy in the following:
| (19) |
The proposed deterministic policy in (19) likes the one iteration step in the standard policy iteration algorithm. It divides the original MDP into multiple small tasks. Though the number of problem states has not decreased, the dimensionality of each small task has been reduced.
In [23, proposition 5.4.2] and [25, Theorem 8.6.6], the convergence of the sub-optimal algorithm is proved. In addition, in [24, Theorem 1] and [8, Lemma 3], similar sub-optimal strategies are also adopted, which also proves that the proposed suboptimal algorithm is superior to other random algorithms.
When there are multiple processes in the plant, this suboptimal algorithm will significantly reduce the complexity of the calculation, making it possible to deal with multi-process problems. In general, in order to obtain the deterministic suboptimal policy, it is necessary to calculate the value function of each process , the computational complexity of the proposed sub-optimal algorithm is: . In contrast, the computational complexity required to obtain the optimal policy by calculating is , where and represent the number of feasible states in the set and , respectively.
IV Scheduling Under Preemption Mechanism
Due to the noisy channel, status information cannot transmit successfully in every slot. The controller may be idle if only one status is allowed to send the state to controller at a slot. Moreover, the worse the channel, the longer the controller will be idle.
The orthogonal channel we adopted allows that multiple sensors can transmit status updates at the same time slot [26], some "standby status information" can be transmitted with the "optimal status information" in the same time slot. When the “optimal status information” transmit failed, the server can process the “standby status information” instead. Work with the preemption mechanism, it can significantly reduce the idle time of the server without reducing the system performance.
In order to facilitate the description of the calculating process on the controller, we call the status update as information task. Preemption means when a higher priority task arrives at the controller, the controller will terminate the currently processing task and execute the newly arrived task. The preempted but not completed task will continue to be executed after the current task is completed when no other preemption occurs later. As shown in Fig.2, task 1 arrives at the server first. When task 1 is being processed, task 2 with higher priority arrives. The server immediately stops executing task 1 and instead performs task 2. When task 3 with a lower priority arrives, the server does not respond. After task 2 is completed, the server continues to execute task 1 that has not been completed before. The preemption mechanism makes that the server can switch to another task and resume the current task later. Therefore, the server can handle tasks more flexibly, and the average MSE of the system will also be reduced.
The goal is the same as Section II, to minimize the system MSE. To investigate the scheduling policy on each controller, we assume the system has sensors, and both sensors can transmit their status updates to server in a time slot using the orthogonal channel. Furthermore, this problem can be extended to general situation. In addition, the task processing time and uplink and downlink delay of the server are the same as the remote server in the system model.
The state space is defined as which consists all possible states.
which records the AoI of each process. For different process , we defined as the AoI at the beginning of slot . We set be the upper limits of the AoI for process .
, these parameters characterize the processing task. represents the index of the process in which status is computing on controller and represents no task is processing. records the number of slots that are left to computing. When the task is preempted, the number of time slots in the controller will increase, and records the increasing time slot length of processing tasks.
, these parameters characterize the preempted task. represents the index of the preempted task and represents no task is processing. records the number of slots that are left to computing. records the increasing time slot length of preempted tasks.
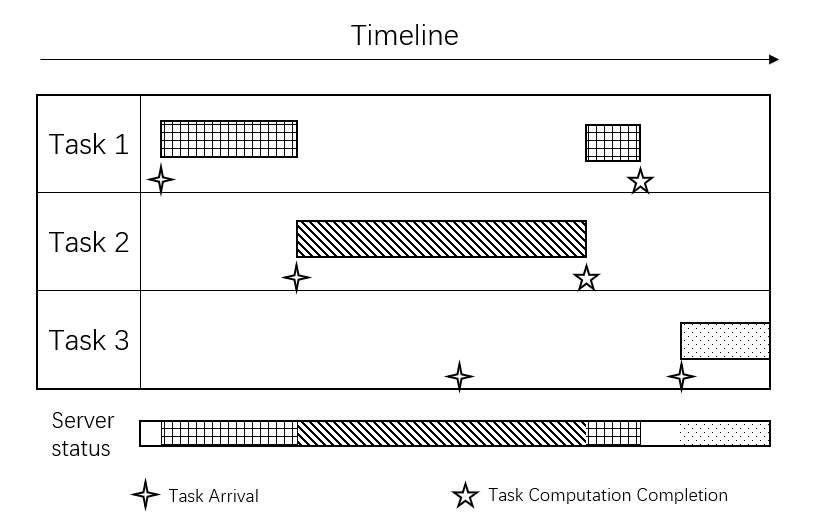
and characterize the task which has been processed completed. is the index of the process in which the control command is being transmitted to actuator, and represents no task is being transmitted. Moreover, records the increasing time slot length of the process in which the control command is being transmitted.
The action is in the action space , where means do not preempt and means the status of process preempt the processing task. Note that, the current task will be canceled when and the processing task is from process .Because the current task is obsolete and will not reduced the MSE after completion under this situation.
At the -th time slot, we assume the system state is where , and . The state transition formula is given below, and the transition will be written in the order of the success and failure of the downlink channel transmission.
When the downlink transmission is successful, we have:
| (20) |
| (21) |
| (22) |
| (23) |
When the downlink transmission is failed, the only difference with the success situation is in (20). The rest part , , and are the same as (21) (22) (23). Therefore, it will not be described again. Furthermore, the dynamics of the system AoI in (20) is changed to:
| (24) |
The characteristics of state cost are the same as those in Section II. The one-stage cost only depends on the current state and is defined as:
| (25) |
For the preemption model, it has consistency properties. Theorem 3 Consistency. If , then where denotes and is the index of status which is calculating on the server.
Proof: See in Appendix C
In other words, Theorem 3 shows that the process status will not be preempted until it is processed completely when the server takes the optimal action successfully.
V SIMULATION RESULT AND ANALYSIS
In this section, we give some parameter settings in simulation and present the numerical result. Besides, the structure of the optimal policies in Section III and IV can verify the numerical result. In addition, we consider a greedy baseline policy for comparison, in which the top two processes with the highest MSE can transmit their status to the controller and the highest one has the priority to choose the controller first.
V-A Setting of system parameters
In the simulation, we consider four processes and their dimensions decrease in turn:
where , is the state transmition matrix in (1). As for the noise in (1), like most previous studies, is set to an identity matrix where .
The controller parameter settings in the simulation are shown in Table 1. Where the function can obtain the dimension of independent variable, e.g., .
| o 0.4X[2,c]|X[3,c]|X[2,c]|X[3,c] Parameter | Value | Parameter | Value |
|---|---|---|---|
| 1 | 0 | ||
| 1 | 0 | ||
| size() |
V-B Scheduling simulation result
In order to more vividly show the difference in processing tasks between the edge server and the remote server. We first simulate the case where there are only two processes in the system plant.
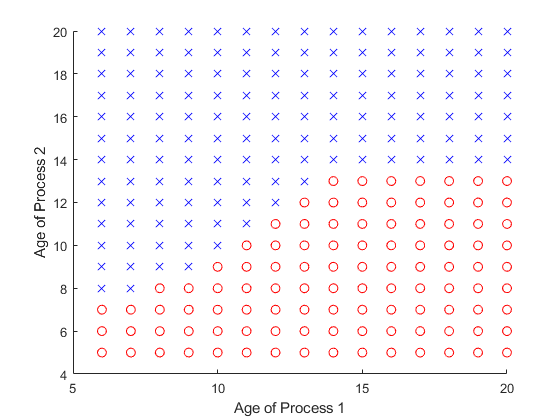
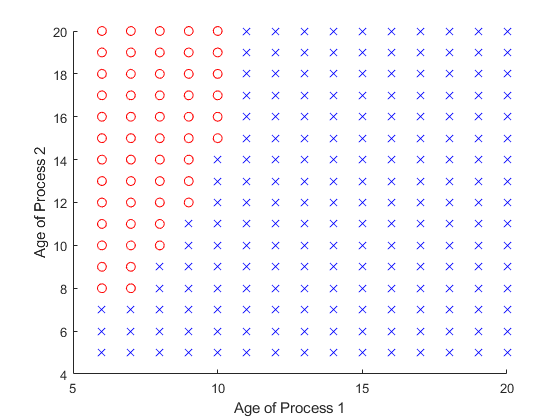
In Fig.3 and Fig.4, the transmission success probability are all set to . Fig.3 is the optimal scheduling policy when only process 1 and process 4 in system. It is obvious that all the actions are , which means the status information from process 1 always send to remote controller and the status information from process 4 always send to edge server. Fig.4 is the optimal scheduling policy when only process 1 and process 2 in system. Different from Fig.3, there are different actions in different states, and appears in the upper left corner of Fig.4.
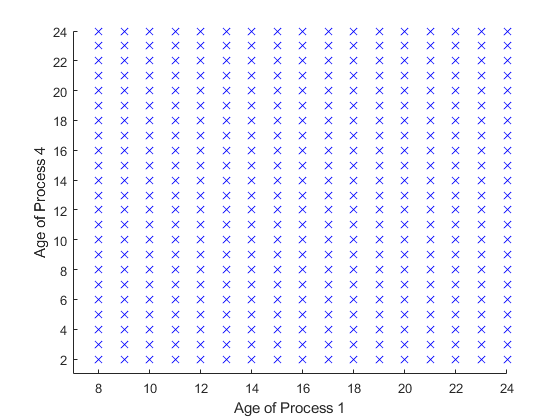
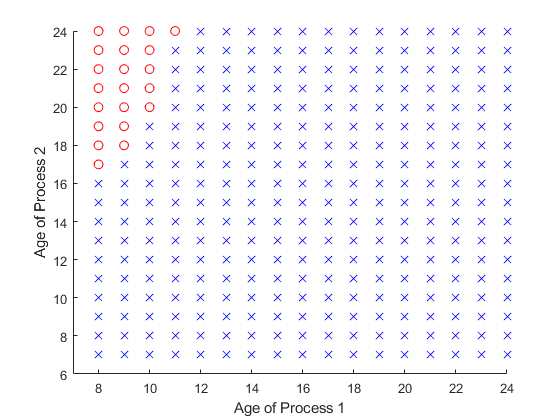
It can be found that there are some subtle differences between the two cases, and the first case is more intuitive, that is, each process corresponds to a controller, e.t., the destination of status updates are deterministic. Nevertheless, in the second case, the optimal policy does not entirely form as two closed loops. It seems a bit counter-intuitive. But under this parameter setting, we can find that, for process 1, if the status is sent to the remote controller, the entire control process needs time slots from sampling to completing. Besides, if the status is sent to edge server, the control loop needs time slots. For process 2 the control loop needs and , respectively. Obviously, it is the best choice for both process1 and process2 to send the status information to the remote server. Also, the controller can calculate status information when another status is transmitting, i.e., in the control loop can calculate another status. Therefore, when the MSE of process1 is much smaller than the MSE of process2, process 2 will choose a better action for itself, and process 1 can only choose a non-optimal action. However, there is no such trade-off in case 1, where the processing time of status differs significantly. Process1 and process4 are choosing their own optimal conditions, respectively.
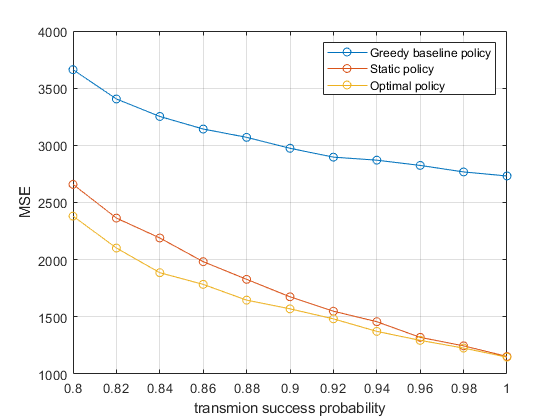
To verify the performance of various policies, we considered the greedy baseline policy and static policy in addition to the optimal policy. The static policy means that each process will only transmit the status information to the corresponding controller and will not transmit it to other controllers.
Since the optimal policy in case 1 is entirely equal to the static policy, performance simulation is only performed for case 2. We have done Monte Carlo simulations of 40,000 time slots with different values of . The result is shown in Fig.5.
Compared with the greedy baseline policy, the performance of optimal policy is greatly improved. While for the static policy, it is vastly improved only when the transmission success probability is low. This is because the optimal policy in Fig.4, only the upper left corner is different from the static policy, and the lower the transmission success probability, the easier it is to reach these different states. When the transmission success probability is 1, these states will not be reached at all.
For the case where the number of processes in the system is more than that of the controller, we consider the case where process1, process2, and process3 are in the system. When the states of both controllers have been determined, the optimal policy is a three-dimensional diagram. In order to see the optimal policy more intuitively, we intercepted a plane in the three-dimensional coordinate system like Fig.6, which satisfies .
The results are shown in Fig.7. There are four regions in the graph. It is a threshold policy, which is similar to the optimal policy in a two-dimensional case. When the action is given, the set of actions in the optimal policy is a simply connected region.
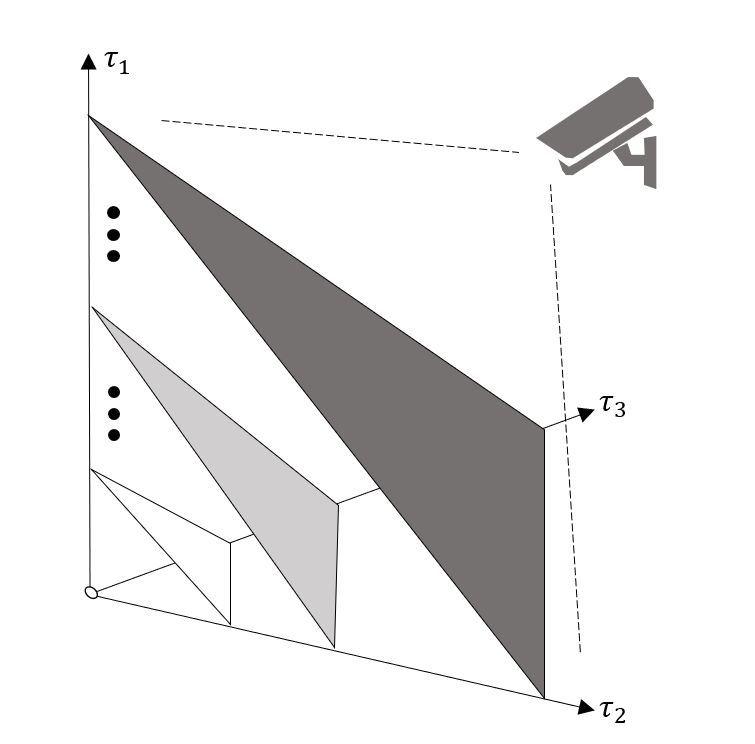
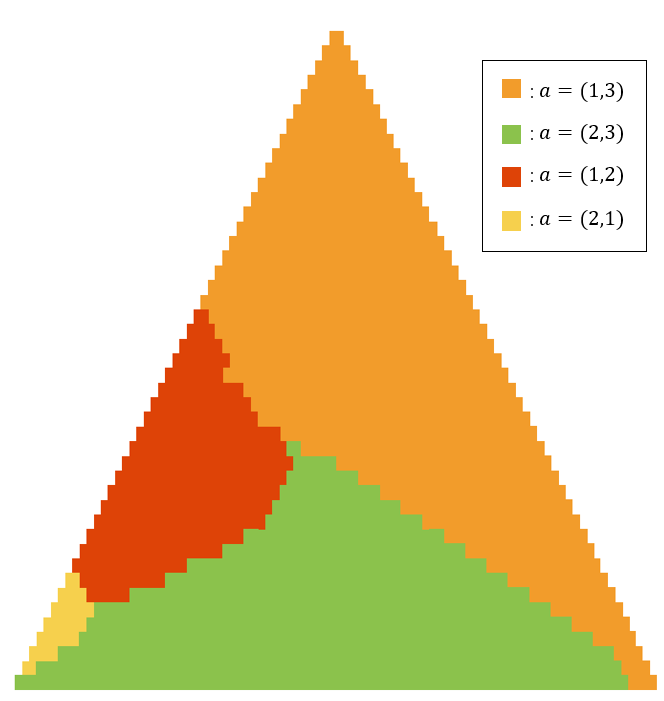
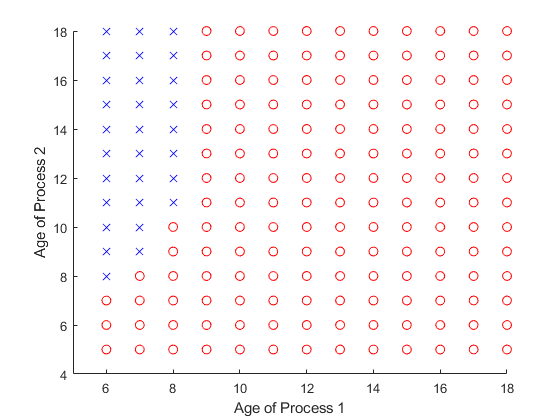
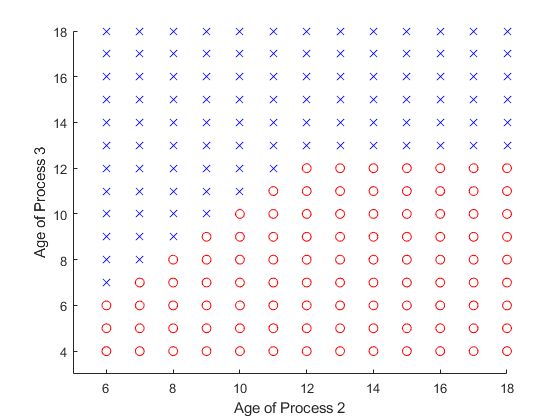
Fig.8 represents the optimal policy on remote server when the edge server is occupied by the status from process 3, e.g. and . Fig.9 represents the optimal policy on edge server when the remote server is occupied by the status from process 1, e.g. and .
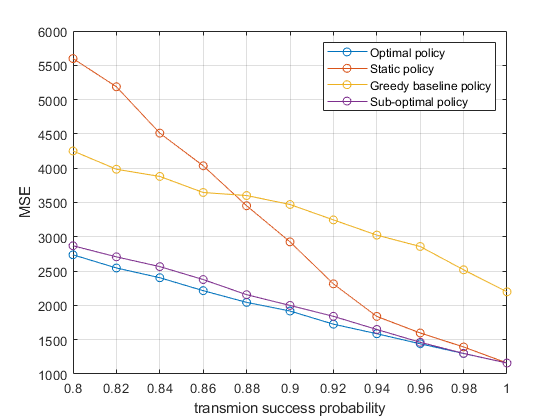
In Fig.10, the optimal policy we obtained is compared with sub-optimal, greedy, and static policies. It can be observed that compared with the greedy baseline policy, the proposed optimal policy still has a significant improvement. When the transmission success probability is closer to 1, the performance of optimal policy, sub-optimal policy, and static policy tend to be the same. It is also observed that the performance of sub-optimal policy is close to optimal policy.
V-C Application of preemption mechanism
Fig.11 and Fig.12 are the optimal preemption policy when the remote server processes the tasks of process 1 and process 2, respectively. It is a threshold policy, which is the same as the theory in Section IV. Furthermore, according to the nature of the Theorem 3, when preemption action is executed, the currently running task will not be preempted.
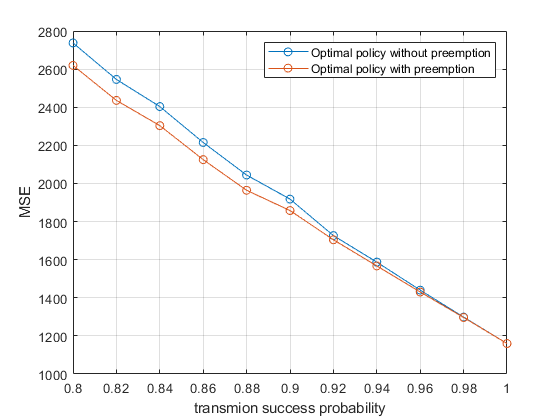
We compared the performance with the preemption mechanism and the performance without the preemption mechanism. After adding the preemption policy into the optimal policy in Fig.10, Fig.13 is obtained. It can be found that the higher transmission success probability, the more minor performance improvement, and the overall performance improvement is not significant. Although there are many actions to perform preemption in Fig.11 and Fig.12, preemption is based on the execution of non-optimal actions. Therefore, for WNCS with a periodic status update, although the preemption mechanism will not reduce system performance, it will not significantly improve the system performance.
In the simulation, we can find that compared with the static policy, the performance of our proposed polices is much improved when the transmission success probability is low. Meanwhile, the performance of the optimal policy is the same as that of the static policy when the wireless channel is perfect, i.e., the transmission success probability is set to . This is because the optimal policy is the same as static policy when the wireless channel is perfect, and the AoI of all processes will change periodically.
VI Conclusion
In this paper, we study the scenario of multi-process and edge computing in WNCS intending to minimize the system MSE. We have formulated this problem as an MDP problem and proposed a low complexity suboptimal policy based on random policy. For the obtained optimal policy, by characterizing the monotonicity property of the value function, we prove the structural characteristics of the optimal policy. For the imperfect channel, we also discuss the preemption mechanism on the server and prove that the preemption action is the current optimal action and will not be preempted before the task is completed, which we call consistency properties.
For the preemption mechanism on the server, the performance improvement is not apparent. Because it will not perform non-optimal actions when the channel is reliable. We will further study the event-triggered WNCS system. Because the state generation is random, it is expected that the preemption mechanism will more significantly improve system performance.
Appendix A Proof of Theorem 1
We prove Lemma 2 using the relative value iteration algorithm(RVIA) [23, Chapter 5.3] and mathematical induction. In order to make the description clearly, we briefly present the RVIA at the beginning. For each system state , we denote the value function at iteration by , where . Define the state-action cost function at iteration as:
| (26) |
Note that is related to the right-hand side of the Bellman equation in (13). For each , RVIA can be used to find according to:
| (27) |
where is some fixed state. According to [23, Proposition 5.3.2], the generated sequence converges to under any initialization of , i.e.,
| (28) |
where satisfies the Bellman equation in (13). Let be the scheduling action attains to the minimum of the first term in (27) at the -th iteration for all , i.e.
| (29) |
Define , where denotes the scheduling action of the process under state . We refer to as the optimal policy at iteration .
By the introduction of above, we will prove Lemma 2 through the RVIA using mathematical induction. Consider two system states and . According to (28), it is sufficient to prove Lemma 2 by show that for any and such that , and .
| (30) |
holds for all
First we initialize for all . We initialize and can easily find (30) holds for . Assume (30) holds for some . We will prove that (30) holds for . By (27), we have
| (31) | ||||
where is due to the optimal of for at iteration . By (26) and (27), we have
| (32) | ||||
Then we compare with for all possible . For each process , we need to consider all cases under the feasible actions. According to (7)-(9), we can check that , and hold for all corresponding actions. Thus, by the induction hypothesis, we have which implies that , i.e., (30) holds for . Therefore, by induction, we know that (30) holds for any . By taking limits on both sides of (30) and by (28). Now, we complete the proof.
Appendix B Proof of Theorem 2
From [9] and [27] we define the discounted cost under a deterministic and stationary policy and an initial state by
| (33) |
Note that (33) is different from (15), the independent variable is policy instead of action. Define and , where is some fixed state. Because there exists an optimal policy to the average cost counterpart of the cost function (33), the limit of as goes to exits and is the relative value function in (13), i.e.,
| (34) |
From the mapping in (34), we can analyze the properties of by examining by value iteration. We further define the dynamic programming operator for a given measurable function : as
| (35) |
is a contraction mapping and follows from Hernndez-Lerma [24]. By Banach fixed-point theorem,
| (36) |
If the dynamic operator preserves such properties, (36) can guarantees that certain properties holds for . e.g. we can obtain the structure of by verifying that the dynamic operator (34) preserves the same structure[14].
For the clarity of later proof, we set the number of processes in the plant to 3 and express the state space as . In addition, the value of is only related to , so we set in the following proof.
Take action as the optimal action of state , and compare it with action here. The other non-optimal actions can also be compared with the same steps. This Theorem is equivalent to the following:
(1) If , then .
(2) If , then .
where , , , and , is any positive integer.
Then we prove (1) the structure properties by showing that has the same structure, and (2) can be proved in the same way.
In the case that and .
If , from Theorem 2, we obtain
Then we assume , the same with (37) we have
| (39) | ||||
beacuse which implies that
| (40) |
Meanwhile, from Lemma 2 there exist
| (41) |
| (42) |
According to the existing conditions (38)
| (43) |
which causes
| (44) |
When (44) violate the monotonicity and consistency of the value function and hence the assumption is incorrect. Therefore, when . Same as the proof in Lemma2, it can be obtained by mathematical induction that this formula holds for any positive integer . The proof is done and other cases can be proved in the same steps.
Appendix C Proof of theorem 3
Consider the case that and . Other cases can be easily extended. In order to simplify the expression, we omit the completely equal parameters in the proof. The state can be expressed as , where and represent the remaining computing time of the two processes in plant, respectively. Without loss of generality, assume that , i.e.the server will compute the status from sensor 1 at -th time slots, and will continue calculate the status information of the last time slot at th time slot.
By the assumption, we have
| (45) | ||||
| (46) | ||||
(45) indicates the action is better than , and (46) indicates the action is better than . Meanwhile, the inequality (45) and (46) also can be further simplified to:
| (47) |
| (48) |
If , then the Left side of inequality (45) can be expressed as
| (49) |
Because , so we have:
| (50) |
One the other hands, due to the monotonicity, we have
| (51) |
Combine (50) and (51), it is obviously that
| (52) |
We can found that (52) is contradict to (47). Therefore, different from proving that action is optimal, the contradiction just prove is better than . It is also necessary to prove that action is better than the rest. The proof is exactly the same as (45)-(52), and is omitted here.
References
- [1] C.-H. Tsai and C.-C. Wang, “Unifying aoi minimization and remote estimation—optimal sensor/controller coordination with random two-way delay,” in IEEE INFOCOM 2020-IEEE Conference on Computer Communications, pp. 466–475, IEEE, 2020.
- [2] X. Zang, W. Liu, Y. Li, and B. Vucetic, “Over-the-air computation systems: Optimal design with sum-power constraint,” IEEE Wireless Communications Letters, vol. 9, no. 9, pp. 1524–1528, 2020.
- [3] Y.-P. Hsu, “Age of information: Whittle index for scheduling stochastic arrivals,” in 2018 IEEE International Symposium on Information Theory (ISIT), pp. 2634–2638, IEEE, 2018.
- [4] Z. Jiang, B. Krishnamachari, S. Zhou, and Z. Niu, “Can decentralized status update achieve universally near-optimal age-of-information in wireless multiaccess channels?,” in 2018 30th International Teletraffic Congress (ITC 30), vol. 1, pp. 144–152, IEEE, 2018.
- [5] K. Huang, W. Liu, M. Shirvanimoghaddam, Y. Li, and B. Vucetic, “Real-time remote estimation with hybrid arq in wireless networked control,” IEEE Transactions on Wireless Communications, vol. 19, no. 5, pp. 3490–3504, 2020.
- [6] S. Wu, X. Ren, S. Dey, and L. Shi, “Optimal scheduling of multiple sensors with packet length constraint,” IFAC-PapersOnLine, vol. 50, no. 1, pp. 14430–14435, 2017.
- [7] B. Wang, S. Feng, and J. Yang, “When to preempt? age of information minimization under link capacity constraint,” Journal of Communications and Networks, vol. 21, no. 3, pp. 220–232, 2019.
- [8] B. Zhou and W. Saad, “Minimum age of information in the internet of things with non-uniform status packet sizes,” IEEE Transactions on Wireless Communications, vol. 19, no. 3, pp. 1933–1947, 2019.
- [9] S. Wu, X. Ren, S. Dey, and L. Shi, “Optimal scheduling of multiple sensors with packet length constraint,” IFAC-PapersOnLine, vol. 50, no. 1, pp. 14430–14435, 2017.
- [10] B. Wang, C. Wang, W. Huang, Y. Song, and X. Qin, “A survey and taxonomy on task offloading for edge-cloud computing,” IEEE Access, vol. 8, pp. 186080–186101, 2020.
- [11] Z. Han, H. Tan, X.-Y. Li, S. H.-C. Jiang, Y. Li, and F. C. Lau, “Ondisc: Online latency-sensitive job dispatching and scheduling in heterogeneous edge-clouds,” IEEE/ACM Transactions on Networking, vol. 27, no. 6, pp. 2472–2485, 2019.
- [12] H. Shiri, J. Park, and M. Bennis, “Massive autonomous UAV path planning: A neural network based mean-field game theoretic approach,” in 2019 IEEE Global Communications Conference (GLOBECOM), pp. 1–6, IEEE, 2019.
- [13] P. Skarin, W. Tärneberg, K.-E. Årzen, and M. Kihl, “Towards mission-critical control at the edge and over 5g,” in 2018 IEEE international conference on edge computing (EDGE), pp. 50–57, IEEE, 2018.
- [14] S. Feng and J. Yang, “Minimizing age of information for an energy harvesting source with updating failures,” in 2018 IEEE International Symposium on Information Theory (ISIT), pp. 2431–2435, IEEE, 2018.
- [15] M. A. Abd-Elmagid and H. S. Dhillon, “Average peak age-of-information minimization in UAV-assisted IoT networks,” IEEE Transactions on Vehicular Technology, vol. 68, no. 2, pp. 2003–2008, 2018.
- [16] M. Jia, J. Cao, and W. Liang, “Optimal cloudlet placement and user to cloudlet allocation in wireless metropolitan area networks,” IEEE Transactions on Cloud Computing, vol. 5, no. 4, pp. 725–737, 2015.
- [17] K. Huang, W. Liu, Y. Li, B. Vucetic, and A. Savkin, “Optimal downlink–uplink scheduling of wireless networked control for industrial iot,” IEEE Internet of Things Journal, vol. 7, no. 3, pp. 1756–1772, 2019.
- [18] E. T. Ceran, D. Gündüz, and A. György, “A reinforcement learning approach to age of information in multi-user networks,” in 2018 IEEE 29th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), pp. 1967–1971, IEEE, 2018.
- [19] K. Chen and L. Huang, “Age-of-information in the presence of error,” in 2016 IEEE International Symposium on Information Theory (ISIT), pp. 2579–2583, IEEE, 2016.
- [20] X. Wang, M. Fang, C. Xu, H. H. Yang, X. Sun, X. Chen, and T. Q. Quek, “When to preprocess? keeping information fresh for computing enable internet of things,” arXiv preprint arXiv:2108.01919, 2021.
- [21] W. Liu, G. Nair, Y. Li, D. Nesic, B. Vucetic, and H. V. Poor, “On the latency, rate, and reliability tradeoff in wireless networked control systems for iiot,” IEEE Internet of Things Journal, vol. 8, no. 2, pp. 723–733, 2020.
- [22] M. Gorlatova, H. Inaltekin, and M. Chiang, “Characterizing task completion latencies in fog computing,” arXiv preprint arXiv:1811.02638, 2018.
- [23] D. P. Bertsekas, “Dynamic programming and optimal control 3rd edition, volume ii,” Belmont, MA: Athena Scientific, 2011.
- [24] Y. Cui, V. K. Lau, and Y. Wu, “Delay-aware bs discontinuous transmission control and user scheduling for energy harvesting downlink coordinated mimo systems,” IEEE Transactions on Signal Processing, vol. 60, no. 7, pp. 3786–3795, 2012.
- [25] M. L. Puterman, Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, 2014.
- [26] K. M. Hosny and M. M. Darwish, “New set of multi-channel orthogonal moments for color image representation and recognition,” Pattern Recognition, vol. 88, pp. 153–173, 2019.
- [27] X. Ren, J. Wu, S. Dey, and L. Shi, “Attack allocation on remote state estimation in multi-systems: Structural results and asymptotic solution,” Automatica, vol. 87, pp. 184–194, 2018.