[1]\fnmZachary \surFrangella \equalcontThese authors contributed equally to this work.
These authors contributed equally to this work.
1]\orgdivManagement Science and Engineering, \orgnameStanford University, \orgaddress\street475 Via Ortega, \cityStanford, \postcode94305, \stateCA
2]\orgdivSystems Engineering, \orgnameCornell University, \orgaddress\street136 Hoy Rd, \cityIthaca, \postcode14850, \stateNY
3]\orgdivElectrical Engineering and Computer Science, \orgnameMassachusetts Institute of Technology, \orgaddress\street50 Vassar St, Cambridge, \cityCambridge, \postcode02139, \stateMA
4]\orgdivOperations Research and Financial Engineering, \orgnamePrinceton University, \orgaddress\street98 Charlton St, \cityPrinceton, \postcode08540, \stateNJ
On the (linear) convergence of Generalized Newton Inexact ADMM
Abstract
This paper presents GeNI-ADMM, a framework for large-scale composite convex optimization that facilitates theoretical analysis of both existing and new approximate ADMM schemes. GeNI-ADMM encompasses any ADMM algorithm that solves a first- or second-order approximation to the ADMM subproblem inexactly. GeNI-ADMM exhibits the usual -convergence rate under standard hypotheses and converges linearly under additional hypotheses such as strong convexity. Further, the GeNI-ADMM framework provides explicit convergence rates for ADMM variants accelerated with randomized linear algebra, such as NysADMM and sketch-and-solve ADMM, resolving an important open question on the convergence of these methods. This analysis quantifies the benefit of improved approximations and can inspire the design of new ADMM variants with faster convergence.
keywords:
ADMM, Inexactness, Linearization, Randomized Numerical Linear Algebra1 Introduction
The Alternating Direction Method of Multipliers (ADMM) is one of the most popular methods for solving composite optimization problems, as it provides a general template for a wide swath of problems and converges to an acceptable solution within a moderate number of iterations [1]. Indeed, [1] implicitly promulgates the vision that ADMM provides a unified solver for various convex machine learning problems. Unfortunately, for the large-scale problem instances routinely encountered in the era of Big Data, ADMM scales poorly and cannot provide a unified machine learning solver for problems of all scales. The scaling issue arises as ADMM requires solving two subproblems at each iteration, whose cost can increase superlinearly with the problem size. As a concrete example, in the case of -logistic regression with an data matrix, ADMM requires solving an -regularized logistic regression problem at each iteration [1]. With a fast-gradient method, the total complexity of solving the subproblem is [2], where is the condition number of the problem. When and are in the tens of thousands or larger—a moderate problem size by contemporary machine learning standards—and is large, such a high per-iteration cost becomes unacceptable. Worse, ill-conditioning is ubiquitous in machine learning problems; often , in which case the cost of the subproblem solve becomes superlinear in the problem size.
Randomized numerical linear algebra (RandNLA) offers promising tools to scale ADMM to larger problem sizes. Recently [3] proposed the algorithm NysADMM, which uses a randomized fast linear system solver to scale ADMM up to problems with tens of thousands of samples and hundreds of thousands of features. The results in [3] show that ADMM combined with the RandNLA primitive runs 3 to 15 times faster than state-of-the-art solvers on machine learning problems from LASSO to SVM to logistic regression. Unfortunately, the convergence of randomized or approximate ADMM solvers like NysADMM is not well understood. NysADMM approximates the -subproblem using a linearization based on a second-order Taylor expansion, which transforms the -subproblem into a Newton-step, i.e., a linear system solve. It then solves this system approximately (and quickly) using a randomized linear system solver. The convergence of this scheme, which combines linearization and inexactness, is not covered by prior theory for approximate ADMM; prior theory covers either linearization [4] or inexact solves [5] but not both.
In this work, we bridge the gap between theory and practice to explain the excellent performance of a large class of approximate linearized ADMM schemes, including NysADMM [3] and many methods not previously proposed. We introduce a framework called Generalized Newton Inexact ADMM, which we refer to as GeNI-ADMM (pronounced genie-ADMM). GeNI-ADMM includes NysADMM and many other approximate ADMM schemes as special cases. The name is inspired by viewing the linearized -subproblem in GeNI-ADMM as a generalized Newton-step. GeNI-ADMM allows for inexactness in both the -subproblem and the -subproblem. We show GeNI-ADMM exhibits the usual -convergence rate under standard assumptions, with linear convergence under additional assumptions. Our analysis also clarifies the value of using curvature in the generalized Newton step: approximate ADMM schemes that take advantage of curvature converge faster than those that do not at a rate that depends on the conditioning of the subproblems. As the GeNI-ADMM framework covers any approximate ADMM scheme that replaces the -subproblem by a linear system solve, our convergence theory covers any ADMM scheme that uses fast linear system solvers. Given the recent flurry of activity on fast linear system solvers within the (randomized) numerical linear algebra community [6, 7, 8], our results will help realize these benefits for optimization problems as well. To demonstrate the power of the GeNI-ADMM framework, we establish convergence of NysADMM and another RandNLA-inspired scheme, sketch-and-solve ADMM, whose convergence was left as an open problem in [9].
1.1 Contributions
Our contributions may be summarized concisely as follows:
-
1.
We provide a general ADMM framework GeNI-ADMM, that encompasses prior approximate ADMM schemes as well as new ones. It can take advantage of second-order information and allows for inexact subproblem solves.
-
2.
We show that GeNI-ADMM converges ergodically with the usual ergodic rate, despite all the approximations it makes. Further, it converges at a linear rate under strong convexity.
- 3.
1.2 Roadmap
In Section 2, we formally state the optimization problem that we focus on in this paper and briefly introduce ADMM. In Section 3 we introduce the Generalized Newton Inexact ADMM framework and review ADMM and its variants. Section 4 gives various technical backgrounds and assumptions needed for our analysis. Section 5 establishes that GeNI-ADMM converges at an -rate in the convex setting. Section 6 then shows that, when the objective is strongly convex, GeNI-ADMM converges linearly. In Section 7, we apply our theory to establish convergence rates for two methods that naturally fit into our framework, and we illustrate these results numerically in Section 8.
1.3 Notation and preliminaries
We call a matrix psd if it is positive semidefinite. We denote the convex cone of real symmetric psd matrices by . We denote the Loewner ordering on by , that is if and only if is psd. Given a matrix , we denote its spectral norm by . If is a smooth function we denote its smoothness constant by . We say a positive sequence is summable if .
2 Problem statement and ADMM
Let be finite-dimensional inner-product spaces with inner-product and norm . We wish to solve the convex constrained optimization problem
| (1) |
with variables and , where and are closed convex sets, is a smooth convex function, is a convex proper lower-semicontinuous (lsc) function, and and are bounded linear operators.
Remark 1.
Often, the constraint is presented as for some non-zero vector however, by increasing the dimension of by and replacing by , we can make . Thus, our setting of is without loss of generality.
We can write problem (1) as the saddle point problem
| (2) |
where is a closed convex set. The saddle-point formulation will play an important role in our analysis. Perform the change of variables and define the Lagrangian
Then (2) may be written concisely as
| (3) |
The ADMM algorithm (Algorithm 1) is a popular method for solving (1). Our presentation uses the scaled form of ADMM [1, 10], which uses the change of variables , this simplifies the algorithms and analysis, so we maintain this convention throughout the paper.
3 Generalized Newton Inexact ADMM
As shown in Algorithm 1, at each iteration of ADMM, two subproblems are solved sequentially to update variables and . ADMM is often the method of choice when the -subproblem has a closed-form solution. For example, if , the -subproblem is soft thresholding, and if is the indicator function of a convex set , the -subproblem is projection onto [11, §6]. However, it may be expensive to compute even with a closed-form solution. For example, when and is the psd cone, the -subproblem requires an eigendecomposition to compute the projection, which is prohibitively expensive for large problems [12].
Let us consider the -subproblem
| (4) |
In contrast to the -subproblem, there is usually no closed-form solution for the -subproblem. Instead, an iterative scheme is often used to solve it inaccurately, especially for large-scale applications. This solve can be very expensive when the problem is large. To reduce computational effort, many authors have suggested replacing this problem with a simplified subproblem that is easier to solve. We highlight several strategies to do so below.
Augmented Lagrangian linearization.
One strategy is to linearize the augmented Lagrangian term in the ADMM subproblem and replace it by the quadratic penalty for some (carefully chosen) positive definite matrix . More formally, the strategy adds a quadratic term to form a new subproblem
which is substantially easier to solve for an appropriate choice of . One canonical choice is , where is a constant. For this choice, the quadratic terms involving cancel, and we may omit constants with respect to , resulting in the subproblem
Here, an isotropic quadratic penalty replaces the augmented Lagrangian term in (4). This strategy allows the subproblem solve to be replaced by a proximal operator with a (possibly) closed-form solution. This strategy has been variously called preconditioned ADMM, proximal ADMM, and (confusingly) linearized ADMM [13, 14, 4].
Function approximation.
The second strategy to simplify the -subproblem, is to approximate the function by a first- or second-order approximation [4, 10, 3], forming the new subproblem
| (5) |
where is the Hessian of at . The resulting subproblem is quadratic and may be solved by solving a linear system or (for ) performing a linear update, as detailed below in Section 3.1.1.
Inexact subproblem solve.
The third strategy is to solve the ADMM subproblems inexactly to achieve some target accuracy, either in absolute error or relative error. An absolute-error criterion chooses the subproblem error a priori [5], while a relative error criterion requires the subproblem error to decrease as the algorithm nears convergence, for example, by setting the error target at each iteration proportional to [15].
Approximations used by GeNI-ADMM.
The GeNI-ADMM framework allows for any combination of the three strategies: augmented Lagrangian linearization, function approximation, and inexact subproblem solve. Consider the generalized second-order approximation to
| (6) |
where and is a sequence of psd matrices that approximate the Hessian of . GeNI-ADMM uses this approximation in the -subproblem, resulting in the new subproblem
| (7) | ||||
We refer to (7) as a generalized Newton step. The intuition for the name is made plain when , in which case the update becomes
| (8) |
Equation (8) shows that the -subproblem reduces to a linear system solve, just like the Newton update. We can also interpret GeNI-ADMM as a linearized proximal augmented Lagrangian (P-ALM) method [16, 17]. From this point of view, GeNI-ADMM replaces in the P-ALM step by its linearization and adds a specialized penalty defined by the -norm.
GeNI-ADMM also replaces the -subproblem of ADMM with the following problem
| (9) |
Incorporating the quadratic term allows us to linearize the augmented Lagrangian term, which is useful when is very complicated.
However, even with the allowed approximations, it is unreasonable to assume that (7), (9) are solved exactly at each iteration. Indeed, the hallmark of the NysADMM scheme from [3] is that it solves (7) inexactly (but efficiently) using a randomized linear system solver. Thus, the GeNI-ADMM framework allows for inexactness in the and -subproblems, as seen in Algorithm 2.
Algorithm 2 differs from ADMM (Algorithm 1) in that a) the and -subproblems are now given by (7) and (9) and b) both subproblems may be solved inexactly. Given the inexactness and the use of the generalized Newton step in place of the original -subproblem, we refer to Algorithm 2 as Generalized Newton Inexact ADMM (GeNI-ADMM). The inexactness schedule is controlled by the forcing sequences that specify how accurately the and -subproblems are solved at each iteration. These subproblems have different structures that require different notions of accuracy. To distinguish between them, we make the following definition.
Definition 1 (-minimizer and -minimum).
Let be strongly-convex and let .
-
•
(-minimizer) Given , we say is an -minimizer of and write
In words, is nearly equal to the argmin of in set .
-
•
(-minimum) Given , we say gives an -minimum of and write
In words, produces nearly the same objective value as the argmin of in set .
Thus, from Definition 1 and Algorithm 2, we see for each iteration that is an -minimizer of the -subproblem, while gives an -minimum of the -subproblem.
3.1 Related work
The literature on the convergence of ADMM and its variants is vast, so we focus on prior work most relevant to our setting. Section 3.1 lists some of the prior work that developed and analyzed the approximation strategies described in Section 3. GeNI-ADMM differs from all prior work in Section 3.1 by allowing (almost) all these approximations and more. It also provides explicit rates of convergence to support choices between algorithms. Moreover, many of these algorithms can be recovered from GeNI-ADMM.
| Reference | Convergence | ||||
| rate | Problem | ||||
| class | Augmented Lagrangian Linearization | Function | |||
| approximation | Subproblem | ||||
| inexactness | |||||
| Eckstein and Bertsekas [5] | ✗ | Convex | ✗ | ✗ | |
| absolute error | |||||
| He and Yuan [14] | Ergodic | Convex | ✗ | ✗ | |
| Monteiro and Svaiter [18] | Ergodic | Convex | ✗ | ✗ | ✗ |
| Ouyang et al. [19] | Stochastic | ||||
| convex | ✗ | ||||
| stochastic first-order | ✗ | ||||
| Ouyang et al. [4] | Ergodic | Convex | |||
| first-order | ✗ | ||||
| Deng and Yin [13] | Linear | Strongly convex | ✗ | ✗ | |
| Eckstein and Yao [15] | ✗ | Convex | ✗ | ✗ | |
| relative error | |||||
| Hager and Zhang [20] | Ergodic | ||||
| Convex, | |||||
| Strongly convex | ✗ | ||||
| relative error | |||||
| Yuan et al. [21] | Locally | ||||
| linear | Convex | ✗ | ✗ | ||
| Ryu and Yin [10] | ✗ | Convex | |||
| partial first-order | ✗ | ||||
| This work | Ergodic | ||||
| Linear | Convex, | ||||
| Strongly convex | |||||
| partial generalized second-order | |||||
| absolute error |
3.1.1 Algorithms recovered from GeNI-ADMM
Various ADMM schemes in the literature can be recovered by appropriately selecting the parameters in Algorithm 2. Let us consider a few special cases to highlight important prior work on approximate ADMM, and provide concrete intuition for the general framework provided by Algorithm 2.
NysADMM
The NysADMM scheme [3] assumes the problem is unconstrained . We maintain this assumption for simplicity of exposition, although it is unnecessary. GeNI-ADMM specializes to NysADMM taking , and , where denotes the Hessian of at the th iteration. Unlike the original NysADMM scheme of [3], we include the regularization term , where . This inclusion is required for theoretical analysis but seems unnecessary in practice (see Section 7.1 for a detailed discussion). Substituting this information into (8) leads to the following update for the -subproblem.
| (10) |
Sketch-and-solve ADMM
If , , and is chosen to be a matrix such that is easy to factor, we call the resulting scheme sketch-and-solve ADMM. The name sketch-and-solve ADMM is motivated by the fact that such a can often be obtained via sketching techniques. However, the method works for any , not only ones constructed by sketching methods. The update is given by
We provide the full details of sketch-and-solve ADMM in Section 7.2. To our knowledge, sketch-and-solve ADMM has not been previously proposed or analyzed.
Proximal/Generalized ADMM
Set , and fix and , where and are symmetric positive definite matrices. Then GeNI-ADMM simplifies to
which is the Proximal/Generalized ADMM of Deng and Yin [13].
Linearized ADMM
Primal Dual Hybrid Gradient
Gradient descent ADMM
Consider two linearization schemes from Ouyang et al. [4]. The first scheme we call gradient descent ADMM (GD-ADMM) is useful when it is cheap to solve a least-squares problem with . GD-ADMM is obtained from GeNI-ADMM by setting , and for all . The update (8) for GD-ADMM simplifies to
| (11) |
The second scheme, linearized-gradient descent ADMM (LGD-ADMM), is useful when is not simple, so that the update (11) is no longer cheap. To make the -subproblem update cheaper, it linearizes the augmented Lagrangian term by setting for all in addition to linearizing . In this case, (8) yields the update
| (12) |
Observe in the unconstrained case, when , the updates (11) and (12) are equivalent and generate the same iterate sequences when initialized at the same point [23]. Indeed, they are both generated by performing a gradient step on the augmented Lagrangian (7), for suitable choices of the parameters. Notably, this terminology differs from [4], who refer to (11) as “linearized ADMM” (L-ADMM) and (12) as “linearized preconditioned ADMM” (LP-ADMM). We choose our terminology to emphasize that GD-ADMM accesses via its gradient, as in the literature the term “linearized ADMM” is usually reserved for methods that access through its prox operator [14, 11, 13].
In the remainder of this paper, we will prove convergence of Algorithm 2 under appropriate hypotheses on the sequences and .
4 Technical preliminaries and assumptions
We introduce some important concepts that will be central to our analysis. The first is -relative smoothness, which is crucial to establish that GeNI-ADMM benefits from curvature information provided by the Hessian.
Definition 2 (-relative smoothness).
We say is -relatively smooth with respect to the bounded function if there exists such that for all
| (13) |
That is, the function is smooth with respect to the -norm. Definition 2 generalizes relative smoothness, introduced in [24] to analyze Newton’s method. The definition in [24] takes to be the Hessian of , . When belongs to the popular family of generalized linear models, then (13) holds with a value of that is independent of the conditioning of the problem [24]. For instance, if is quadratic and , then (13) holds with equality for . Conversely, if we take , which corresponds to GD-ADMM, then , the smoothness constant of . Our theory uses the fact that is much smaller than the smoothness constant for methods that take advantage of curvature, and relies on to characterize the faster convergence speed of these methods.
Definition 3 (-subgradient).
Let be a convex function and . We say that is an -subgradient for at if, for every , we have
We denote the set of -subgradients for at by .
Clearly, any subgradient is an -subgradient, so Definition 3 provides a natural weakening of a subgradient. The -subgradient is critical for analyzing -subproblem inexactness, and our usage in this context is inspired by the convergence analysis of inexact proximal gradient methods [27]. We shall need the following proposition whose proof may be found in [25, Proposition 4.3.1].
Proposition 1.
Let , , and be convex functions. Then for any , the following holds:
-
1.
if and only if , that is gives an -minimum of .
-
2.
With Proposition 1 recorded, we prove the following lemma in Section A.2 of the appendix, which will play a critical role in establishing the convergence of GeNI-ADMM.
Lemma 1.
Let give an -minimum of the -subproblem. Then there exists an with such that
4.1 Assumptions
In this section, we present the main assumptions required by our analysis.
Assumption 1 (Existence of saddle point).
Assumption 2 (Regularity of and ).
The function is twice-continuously differentiable and is -relatively smooth with respect to . The function is finite-valued, convex, and lower semi-continuous.
Assumption 2 is also standard. It ensures that it makes sense to talk about the Hessian of and that is relatively smooth. Note assuming is without loss of generality, for we can always redefine , and will be -relatively smooth with respect to .
Assumption 3 (Forcing sequence summability and approximate subproblem oracles).
Let and be given forcing sequences, we assume they satisfy
Further we define the constants , . Observe and are finite owing to the summability hypotheses. Moreover, we assume Algorithm 2 is equipped with oracles for solving the and -subproblems, which at each iteration produce approximate solutions , satisfying:
The conditions on the and subproblem oracles are consistent with those of [5], which requires the sum of the errors in the subproblems to be summable. The approximate solution criteria of Assumption 3 are also easily met in practical applications, as the subproblems are either simple enough to solve exactly, or can be efficiently solved approximately via iterative algorithms. For instance, with LGD-ADMM the -subproblem is simple to solve enough exactly, while for NysADMM the -subproblem is efficiently solved via conjugate gradient with a randomized preconditioner.
Assumption 4 (Regularity of and ).
We assume there exists constants and , such that
| (14) |
Moreover, we also assume that The sequences satisfy
| (15) | ||||
where is a non-negative summable sequence, that is, .
The first half of Assumption 4 is standard, and essentially requires that and define norms. For most common choices of and these assumptions are satisfied, they are also readily enforced by adding on a small multiple of the identity. The addition of a small regularization term is common practice in popular ADMM solvers, such as OSQP [28], as it avoids issues with degeneracy and increases numerical stability.
The second part of the assumption requires that ( and () eventually not differ much on the distance of () to (). Assumptions of this form are common in analyses of optimization algorithms that use variable metrics. For instance, He et al. [29] which develops an alternating directions method for monotone variational inequalities, assumes their equivalents of the sequences and satisfy
| (16) |
More recently, Rockafellar [30] analyzed the proximal point method with variable metrics, under the assumption the variable metrics satisfy (16). Thus, Assumption 4 is consistent with the literature and is, in fact, weaker than prior work, as (16) implies (15). Assumption 4 may always be enforced by changing the ’s and ’s only finitely many times.
We also define the following constants which shall be useful in our analysis,
Note Assumption 4 implies . Moreover, for any it holds that
5 Sublinear convergence of GeNI-ADMM
This section establishes our main theorem, Theorem 1, which shows that Algorithm 2 enjoys the same -convergence rate as standard ADMM.
Theorem 1 (Ergodic convergence).
Define constants , , . Let denote the optimum of (1). For each , denote , and , where and are the iterates produced by Algorithm 2 with forcing sequences and with and . Instate Assumptions 1-4. Then, the suboptimality gap satisfies
Furthermore, the feasibility gap satisfies
Consequently, after iterations,
Theorem 1 shows that, with a constant value of and appropriate forcing sequences, the suboptimality gap and the feasibility residuals both go to zero at a rate of . Hence, the overall convergence rate of ADMM is preserved despite all the approximations involved in GeNI-ADMM. However, some schemes yield better constants than others.
To see this difference, consider the case when is a convex quadratic function and . Let be the Hessian of . Consider (a) NysADMM (10) and (b) GD-ADMM (11). Further, suppose that NysADMM and GD-ADMM are initialized at . The rates of convergence guaranteed by Theorem 1 for Algorithm 2 for both methods are outlined in Table 2.
| Method | NysADMM | GD-ADMM |
| Feasibility gap | ||
| Suboptimality gap |
In the first case, the relative smoothness constant satisfies , while in the second, , which is the largest eigenvalue of . Comparing the rates in Table 2, we see NysADMM improves over GD-ADMM whenever
Hence NysADMM improves significantly over GD-ADMM when exhibits a decaying spectrum, provided is not concentrated on the top eigenvector of . We formalize the latter property in the following definition.
Definition 4 (-incoherence).
Let be the largest eigenpair of . We say is -incoherent if there exists such that:
| (17) |
Definition 4 is a weak form of the incoherence condition from compressed sensing and matrix completion, which plays a key role in signal and low-rank matrix recovery [31, 32]. In words, is -incoherent if its energy is not solely concentrated on the top eigenvector of and can be expected to hold generically. The parameter controls the allowable concentration. When , is orthogonal to , so its energy is distributed amongst the other eigenvectors. Conversely, the closer is to , the more is allowed to concentrate on .
Using -incoherence, we can say more about how NysADMM improves on GD-ADMM.
Proposition 2.
Suppose is -incoherent and where . Then, the following bound holds
Hence if , where , then
The proof of Proposition 2 is given in Section A.2. Proposition 2 shows when is -incoherent and has a decaying spectrum, NysADMM yields a significant improvement over GD-ADMM. As a concrete example, consider when , then Proposition 2 implies the ergodic convergence of NysADMM is twice as fast as GD-ADMM. We observe this performance improvement in practice; see Section 8 for corroborating numerical evidence. Just as Newton’s method improves on gradient descent for ill-conditioned problems, NysADMM is less sensitive to ill-conditioning than GD-ADMM.
We now move to proving Theorem 1.
5.1 Our approach
To prove Theorem 1, we take the approach in Ouyang et al. [4], and analyze GeNI-ADMM by viewing Eq. 1 through its formulation as saddle point problem Eq. 2. Let , , and , where . Define the gap function
| (18) |
The gap function naturally arises from the saddle-point formulation Eq. 2. By construction, it is concave in its first argument and convex in the second, and satisfies the important inequality
which follows by definition of being a saddle-point. Hence the gap function may be viewed as measuring the distance to the saddle .
Further, given a closed set and we define
| (19) | ||||
The following lemma of Ouyang et al. [4] relates the gap function to the suboptimality and feasibility gaps. As the proof is elementary, we provide it in Section A.2 for completeness.
Lemma 2.
For any , suppose and , where . Then
| (20) |
In other words, is an approximate solution of (1) with suboptimality gap and feasibility gap . Further, if , for any such that and , we have .
5.2 Controlling the gap function
Lemma 2 shows the key to establishing convergence of GeNI-ADMM is to achieve appropriate control over the gap function. To accomplish this, we use the optimality conditions of the and subproblems. However, as the subproblems are only solved approximately, the inexact solutions satisfy perturbed optimality conditions. To be able to reason about the optimality conditions under inexact solutions, the iterates must remain bounded. Indeed, if the iterates are unbounded, they can fail to satisfy the subproblem optimality conditions arbitrarily badly. Fortunately, the following proposition shows the iterates remain bounded.
Proposition 3 (GeNI-ADMM iterates remain bound).
Let , and be given. Instate Assumptions 1-4. Run Algorithm 2, then the output sequences are bounded. That is, there exists , such that
The proof of Proposition 3 is provided in Section A.2.
As the iterates remain bounded, we can show that the optimality conditions are approximately satisfied at each iteration. The precise form of these perturbed optimality conditions is given in Lemmas 3 and 4. Detailed proofs establishing these lemmas are given in Section A.2.
Lemma 3 (Inexact -optimality condition).
Lemma 4 (Inexact -optimality condition).
Instate Assumptions 1-4. Suppose is an -minimum of the -subproblem under Definition 1. Then for some absolute constant we have
| (22) |
When the approximate optimality conditions of Lemmas 3 and 4 collapse to the exact optimality conditions. We also note while Lemma 3 (Lemma 4) necessarily holds when ( is an -approximate minimizer (-minimum), the converse does not hold. With Lemmas 3 and 4 in hand, we can establish control of the gap function for one iteration.
Lemma 5.
Instate Assumptions 1-4.. Let denote the iterates generated by Algorithm 2 at iteration . Set , then the gap function satisfies
Proof.
From the definition of ,
Our goal is to upper bound . We start by bounding as follows:
where uses convexity of and -relative smoothness of , and uses convexity of . Inserting the upper bound on into the expression for , we find
| (23) | ||||
Now, using the inexact optimality condition for the -subproblem (Lemma 3), the above display becomes
| (24) | |||
| (25) |
Similarly, applying the inexact optimality for the -subproblem (Lemma 4), we further obtain
| (26) | ||||
We now simplify (5.2) by combining terms. Some basic manipulations show the terms on line 2 of (5.2) may be rewritten as
We can combine the preceding display with the second term of line 1 in (5.2) to reach
where Inserting the preceding simplification into (5.2), we reach
| (27) | ||||
Now, we bound the first two leading terms in line 1 of (27) by invoking the identity to obtain
Similarly, to bound the third and fourth terms in (27), we again invoke which yields
Putting everything together, we conclude
as desired. ∎
5.3 Proof of Theorem 1
Proof.
From Lemma 5, we have for each that
Now, summing up the preceding display from to and using , we obtain
We now turn to bounding . Using the definition of , we find
Now using our hypotheses on the sequence in (15), we obtain
Inserting the previous bound into , we reach
Next, we bound .
Last, is a telescoping sum, hence
Using our bounds on through , we find
Now, as , the convexity of in its second argument yields
| (28) | ||||
Define . Since , by (28) we reach
Let . Then we can bound as
By (28), given the fact , we also have
where the equality follows from the definition of . Hence for any
and therefore
We finish the proof by invoking Lemma 2.
6 Linear convergence of GeNI-ADMM
In this section, we seek to establish linear convergence results for Algorithm 2. In general, the linear convergence of ADMM relies on strong convexity of the objective function [1, 33, 11]. Consistently, the linear convergence of GeNI-ADMM also requires strong convexity. Many applications of GeNI-ADMM fit into this setting, such as elastic net [34]. However, linear convergence is not restricted to strongly convex problems. It has been shown that local linear convergence of ADMM can be guaranteed even without strong convexity [21]. Experiments in Section 8 show the same phenomenon for GeNI-ADMM: it converges linearly after a couple of iterations when the iterates reach some manifold containing the solution. The linear convergence theory of GeNI-ADMM provides a way to understand this phenomenon. We first list the additional assumptions required for linear convergence:
Assumption 5 (Optimization is over the whole space).
The sets and in (1) satisfy
Assumption 5 states that the optimization problem in (1) is over the entire spaces and , not closed subsets. This assumption is met in many practical optimization problems of interest, where . Moreover, it is consistent with prior analyses such as Deng and Yin [13], who specialize their analysis to the setting of the last sentence.
Assumption 6 (Regularity of ).
The function is finite valued, strongly convex with parameter , and smooth with parameter .
Assumption 6 imposes standard regularity conditions on , in addition to the conditions of Assumption 2.
Assumption 7 (Non-degeneracy of constraint operators).
The linear operators and are invertible.
Assumption 7 is consistent with prior analyses of ADMM-type schemes under strong convexity, such as Deng and Yin [13], who make this assumption in their analysis of Generalized ADMM. Moreover, the assumption holds in many important application problems, especially those that arise from machine learning where, typically, and .
Assumption 8 (Geometric decay of the forcing sequences).
There exists a constant such that the forcing sequences , satisfy
| (29) |
Moreover, we assume Algorithm 2 is equipped with oracles for solving the and -subproblems, which at each iteration produce approximate solutions , satisfying:
Assumption 8 replaces Assumption 3 and requires the inexactness sequences to decay geometrically. Compared with the sublinear convergence result, linear convergence requires more accurate solutions to the subproblems. Again, since the -subproblem inexactness is weaker than the -subproblem inexactness, should have a faster decay rate than the decay rate () of .
The requirement that the forcing sequences decay geometrically is somewhat burdensome, as it leads to the subproblems needing to be solved to higher accuracy sooner than if the forcing sequences were only summable. Fortunately, this condition seems to be an artifact of the analysis; our numerical experiments with strongly convex (Section 8.2) only use summable forcing sequences but show linear convergence of GeNI-ADMM.
6.1 Our approach
Inspired by Deng and Yin [13], we take a Lyapunov function approach to proving linear convergence. Let , and . We define the Lyapunov function:
where
Our main result in this section is the following theorem, which shows the Lyapunov function converges linearly to .
Theorem 2.
The proof of Theorem 2 is deferred to Section 6.3. As for all , Theorem 2 implies the iterates converge linearly to optimum . Thus, despite inexactly solving approximations of the original ADMM subproblems, GeNI-ADMM still enjoys linear convergence when the objective is strongly convex. An unattractive aspect of Theorem 2 is the requirement that satisfy . Although this condition can be enforced by adding a damping term to , this is undesirable as a large regularization term can lead GeNI-ADMM to converge slower. We have found that this condition is unnecessary—our numerical experiments do not enforce this condition, yet GeNI-ADMM achieves linear convergence. We believe this condition to be an artifact of the analysis, which stems from lower bounding the term in Lemma 7.
6.2 Sufficient descent
From Theorem 2, to establish linear convergence of GeNI-ADMM, it suffices to show decreases geometrically. We take two steps to achieve this. First, we show that decreases for every iteration (Lemma 7). Second, we show that decreases geometrically by a factor of with respect to and some small error terms that stem from inexactness (Lemma 8).
As in the convex case, the optimality conditions of the subproblems play a vital role in the analysis. Since the subproblems are only solved approximately, we must again consider the inexactness of the solutions in these two steps. For the first step, we use strong convexity of and convexity of with appropriate perturbations to account for the inexactness. We call these conditions perturbed convexity conditions, as outlined in Lemma 6.
Lemma 6 (Perturbed convexity).
Instate the assumptions of Theorem 2. Let and be the inexact solutions of and -subproblems under Definition 1. Recall is a saddle point of (1). Then for some constant , the following inequalities are satisfied:
-
1.
(Semi-inexact -strong convexity)
(31) -
2.
(Semi-inexact -convexity)
(32)
A detailed proof of Lemma 6 is presented in Section A.3. In Lemma 6, we call (31) and (32) semi-inexact (strong) convexity because () is part of the exact saddle point but () is an inexact subproblem solution. With Lemma 6, we establish a descent-type inequality, which takes into inexactness.
Lemma 7 (Inexact sufficient descent).
Define , then the following descent condition holds.
| (33) | ||||
Proof.
Adding the inequalities (31) and (32) together, and using the relation , we reach
Recalling the definitions of , , and , and using the identity , we arrive at
Now, for the term , Cauchy-Schwarz implies
Hence we obtain
as desired. ∎
Given the inexact sufficient descent condition (33), the next step in proving linear convergence is to show (33) leads to a contraction relation between and .
Lemma 8 (Inexact Contraction Lemma).
Under the assumptions of Theorem 2, there exists constants , and such that
| (34) |
The proof of Lemma 8, and an explicit expression for , appears in Section A.3. As in Theorem 2, the constant gives the rate of linear convergence and depends on the conditioning of and the constraint matrices and . The better the conditioning, the faster the convergence, with the opposite holding true as the conditioning worsens. With Lemma 8 in hand, we now prove Theorem 2.
6.3 Proof of Theorem 2
Proof.
By induction on (34), we have
where the second inequality uses Assumption 8 to reach , and the third inequality uses to bound the sum by the sum of the geometric series. Hence, we have shown the first claim. The second claim follows immediately from the first via a routine calculation.
7 Applications
This section applies our theory to establish convergence rates for NysADMM and sketch-and-solve ADMM.
7.1 Convergence of NysADMM
We begin with the NysADMM scheme from [3]. Recall NysADMM is obtained from Algorithm 2 by setting , using the exact Hessian , and setting . Instantiating these selections into Algorithm 2, we obtain NysADMM, presented as Algorithm 3. Compared to the original NysADMM, Algorithm 3 adds a regularization term to the Hessian. In theory, when is only convex, this regularization term is required to ensure the condition of Assumption 2, as the Hessian along the optimization path may fail to be uniformly bounded below. The addition of the term removes this issue. However, the need for this term seems to be an artifact of the proof, as Zhao et al. [3] runs Algorithm 3 on non-strongly convex objectives with , and convergence is still obtained. Similarly, we set in all our experiments, and convergence consistent with our theory is obtained. Hence, in practice, we recommend setting , or some small value, say , so that convergence isn’t slowed by unneeded regularization.
The -subproblem for NysADMM is a linear system. NysADMM solves this system using the Nyström PCG method from [7]. The general convergence of NysADMM was left open in [3], which established convergence only for quadratic . Moreover, the result in [3] does not provide an explicit convergence rate. We shall now rectify this state of affairs using Theorem 1. We obtain the following convergence guarantee by substituting the parameters defining NysADMM (with the added term) into Theorem 1.
Corollary 1 (Convergence of NysADMM).
Instate the assumptions of Theorem 1. Let . Set , , , and in Algorithm 2. Then
and
Here and are the same as in Theorem 1.
NysADMM converges at the same -rate as standard ADMM, despite all the approximations it makes. Thus, NysADMM offers the same level of performance as ADMM, but is much faster due to its use of inexactness. This result is empirically verified in Section 8, where NysADMM converges almost identically to ADMM. Corollary 1 supports the empirical choice of a constant step-size , which was shown to have excellent performance uniformly across tasks in [3]: the theorem sets and for quadratic functions, and satisfies for loss functions such as the logistic loss. We recommend setting as the default value for GeNI-ADMM. Given NysADMM’s superb empirical performance in [3] and the firm theoretical grounding given by Corollary 1, we conclude that NysADMM provides a reliable framework for solving large-scale machine learning problems.
7.2 Convergence of sketch-and-solve ADMM
Sketch-and-solve ADMM is obtained from GeNI-ADMM by setting to be an approximate Hessian computed by a sketching procedure. The two most popular sketch-and-solve methods are the Newton sketch [35, 36, 37] and Nyström sketch-and-solve [38, 39, 7]. Both methods use an approximate Hessian that is cheap to compute and yields a linear system that is fast to solve. ADMM together with sketching techniques, provides a compelling means to handle massive problem instances. The recent survey [9] suggests using sketching to solve a quadratic ADMM subproblem for efficiently solving large-scale inverse problems. However, it was previously unknown whether the resulting method would converge. Here, we formally describe the sketch-and-solve ADMM method and prove convergence.
Sketch-and-solve ADMM is obtained from Algorithm 2 by setting
| (35) |
where is an approximation to the Hessian at the th iteration, and is a constant chosen to ensure convergence. The term ensures that the approximate linearization satisfies the -relative smoothness condition when is chosen appropriately, as in the following lemma:
Lemma 9.
Suppose is -relatively smooth with respect to its Hessian . Construct as in (35) and select such that for every . Then
Proof.
By relative smoothness we have,
Now,
The desired claim now immediately follows.
Lemma 9 shows we can ensure relative smoothness by selecting appropriately. Assuming relative smoothness, we may invoke Theorem 1 to guarantee that sketch-and-solve ADMM converges. Unlike with NysADMM, we find it is necessary to select carefully (such as in Lemma 9) to ensure the relative smoothness condition holds, otherwise sketch-and-solve ADMM will diverge, see Section 8.3 for numerical demonstration. This condition is somewhat different from those in prior sketching schemes in optimization, such as the Newton Sketch [35, 36], where convergence is guaranteed as long as the Hessian approximation is invertible.
Corollary 2.
Suppose is -relatively smooth with respect to its Hessian and instate the assumptions of Theorem 1. In Algorithm 2, Set with , , and . Then
and
Here variables and , diameters , , and , and constants , , , , , , and are all defined as in Theorem 1.
Remark 2.
It is not hard to see Corollary 2 also holds for any if the satisfy
for some , and . Many sketching methods can ensure this relative error condition with high probability [40] by choosing the sketch size proportional to the effective dimension of [7, 36].
Corollary 2 shows sketch-and-solve ADMM obtains an -convergence rate. The main difference between NysADMM and sketch-and-solve is the additional error term due to the use of the approximate Hessian, which results in a slightly slower convergence rate. In this sense, sketch-and-solve ADMM can be regarded as a compromise between NysADMM () and gradient descent ADMM () — with the convergence rate improving as the accuracy of the Hessian approximation increases.
8 Numerical experiments
In this section, we numerically illustrate the convergence results developed in Section 5 and Section 6 for several methods highlighted in Section 3.1.1 that fit into the GeNI-ADMM framework: sketch-and-solve ADMM (Algorithm 4), NysADMM (Algorithm 3), and “gradient descent” ADMM (GD-ADMM) (11). As a baseline, we also compare to exact ADMM (Algorithm 1) to see how various approximations or inexactness impact the convergence rate. We conduct three sets of experiments that verify different aspects of the theory:
-
•
Section 8.1 verifies that NysADMM, GD-ADMM and sketch-and-solve ADMM converge sublinearly for convex problems. Moreover, we observe a fast transition to linear convergence, after which all methods but GD-ADMM converge quickly to high accuracy.
-
•
Section 8.2 verifies that NysADMM, GD-ADMM, and sketch-and-solve ADMM converge linearly for strongly convex problems.
-
•
Section 8.3 verifies that, without the correction term, sketch-and-solve ADMM diverges, showing the necessity of the correction term in Section 7.2.
We consider three common problems in machine learning and statistics in our experiments: lasso [41], elastic net regression [42], and -logistic regression[43]. All experiments use the realsim dataset from LIBSVM [44], accessed through OpenML [45], which has samples and features. Our experiments use a subsample of realsim, consisting of random samples, which ensures the objective is not strongly convex for lasso and -logistic regression.
All methods solve the -subproblem exactly, and every method, except NysADMM, solves their -subproblem exactly. NysADMM solves the linear system in Algorithm 3 inexactly using Nyström PCG. At each iteration, the following absolute tolerance on the PCG residual is used for determining the termination of Nyström PCG:
where and are the ADMM primal and dual residuals at the previous iteration. We multiply a summable sequence by the geometric mean of the primal and dual residuals at the previous iteration. The geometric mean of the primal and dual residuals is a commonly used tolerance for PCG in practical ADMM implementations such as OSQP [46]—despite this sequence not being apriori summable.
For NysADMM, a sketch size of is used to construct the Nyström preconditioner, and for sketch-and-solve ADMM, we use a sketch size to form the Hessian approximation. For sketch-and-solve ADMM, the parameter in (35) is chosen by estimating the error of the Nyström sketch using power iteration.
We use a bound on the duality gap as the stopping criterion for each algorithm. The details of how the bound on the duality gap bound is computed are presented in Appendix B. All our experiments use a tolerance of . An algorithm is terminated when the bound on the duality falls below or has completed 500 iterations.
All experiments are performed in the Julia programming language [47] on a MacBook Pro with a M1 Max processor and 64GB of RAM. To compute the “true” optimal values, we use the commercial solver Mosek [48] (with tolerances set low for high accuracy and presolve turned off to preserve the problem scaling) and the modeling language JuMP [49, 50].
8.1 GeNI-ADMM converges sublinearly and locally linearly on convex problems
To illustrate the global sublinear convergence of GeNI-ADMM methods on convex objectives, we look at the performance of ADMM, NysADMM, GD-ADMM, and sketch-and-solve ADMM on solving a lasso and -logistic regression problem with the realsim dataset. Note, as the number of samples is smaller than the number of features, the corresponding optimization problems are convex but not strongly convex.
Lasso regression


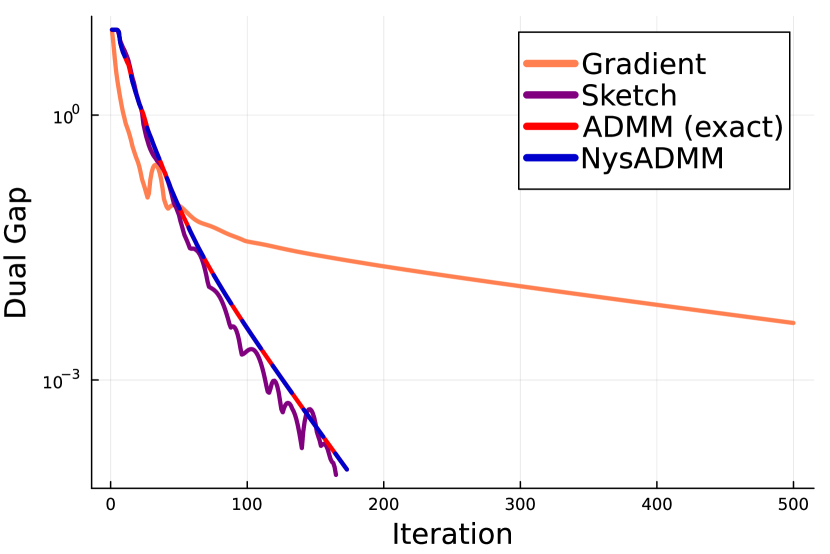

The lasso regression problem is to minimize the error of a linear model with an penalty on the weights:
| minimize |
This can be easily transformed into the form (1) by taking , , , , and . We set , where is the value above which the all zeros vector is optimal111This can be seen from the optimality conditions, which we state in Appendix B of the appendix.. We stop the algorithm when the gap is less than , or after iterations.
The results of lasso regression are illustrated in Figure 1. Figure 1 shows all methods initially converge at sublinear rate, but quickly transition to a linear rate of convergence after reaching some manifold containing the solution. ADMM, NysADMM, and sketch-and-solve ADMM (which use curvature information) all converge converge much faster then GD-ADMM, confirming the predictions of Section 5 that methods which use curvature information will converge faster than methods that do not. Moreover, the difference in convergence between NysADMM and ADMM is negligible, despite the former having a much cheaper iteration complexity due to the use of inexact linear system solves.
Logistic Regression




For the logistic regression problem, with data , where . We define
where we define . The loss is the negative of the log likelihood, . Thus, the optimization problem is
| minimize |
We set , where is the value above which the all zeros vector is optimal. For NysADMM, the preconditioner is re-constructed after every 20 iterations. For sketch-and-solve ADMM, we re-construct the approximate Hessian at every iteration. Since the -subproblem is not a quadratic program, we use the L-BFGS [51] implementation from the Optim.jl package [52] to solve the -subproblem.
Figure 2 presents the results for logistic regression. The results are consistent with the lasso experiment—all methods initially converge sublinearly before quickly transitioning to linear convergence, and methods using better curvature information, converge faster. In particular, although sketch-and-solve-ADMM converges slightly faster than GD-ADMM, its convergence is much slower than NysADMM, which more accurately captures the curvature due to using the exact Hessian. The convergence of NysADMM and ADMM is essentially identical, despite the former having a much cheaper iteration cost due to approximating the -subproblem and using inexact linear system solves.
8.2 GeNI-ADMM converges linearly on strongly convex problems


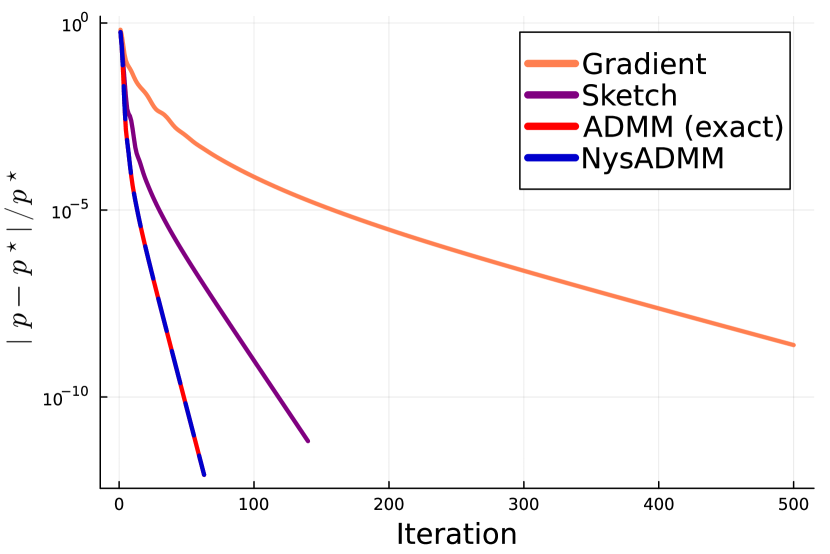
To verify the linear convergence of GeNI-ADMM methods in the presence of strong convexity, we experiment with the elastic net problem:
| minimize |
We set , and use the same problem data and value of as the lasso experiment. The results of the elastic-net experiment are presented in Figure 3. Comparing Figures 1 and 3, we clearly observe the linear convergence guaranteed by the theory in Section 6. Although in Figure 1, ADMM and NysADMM quickly exhibit linear convergence, Figure 3 clearly shows strong convexity leads to an improvement in the number of iterations required to converge. Moreover, we see methods that make better use of curvature information converge faster than methods that do not, consistent with the results of the lasso and logistic regression experiments.


8.3 Sketch-and-solve ADMM fails to converge without the correction term
To demonstrate the necessity of the correction term in Section 7.2, we run sketch-and-solve ADMM on lasso and -logistic regression without the correction term. Figure 4 presents the results of these simulations. Without the correction term in (35), sketch-and-solve ADMM quickly diverges on the lasso problem. For the logistic regression problem, it oscillates and fails to converge. These results highlight the importance of selecting this term appropriately as discussed in Section 7.2.
9 Conclusion and future work
In this paper, we have developed a novel framework, GeNI-ADMM, that facilitates efficient theoretical analysis of approximate ADMM schemes and inspires the design of new, practical approximate ADMM methods. GeNI-ADMM generalizes prior approximate ADMM schemes as special cases by allowing various approximations to the and -subproblems, which can then be solved inexactly. We have established the usual ergodic -convergence rate for GeNI-ADMM under standard hypotheses, and linear convergence under strong convexity. We have shown how to derive explicit rates of convergence for ADMM variants that exploit randomized numerical linear algebra using the GeNI-ADMM framework, We have provided convergence results for NysADMM and sketch-and-solve ADMM as special cases, resolving whether these schemes are globally convergent. Numerical experiments on real-world data generally show an initial sublinear phase followed by linear convergence, validating the theory we developed.
There are several interesting directions for future work. Our analysis shows that in approximate ADMM schemes, a better approximation usually leads to faster convergence. However, a better approximation usually makes more complex and the resulting subproblem harder to solve. A comprehensive study of the trade-off between theoretical convergence speed and subproblem complexity depending on the choice of will be an important future research direction. Our numerical experiments show that GeNI-ADMM can achieve linear convergence locally in the neighborhood of the optimal solution, even for problems that are not strongly convex. Existing studies have proved that exact ADMM exhibits local linear convergence without strong convexity [21]. It would be interesting to establish local linear convergence for GeNI-ADMM schemes without strong convexity, a phenomenon observed in all our experiments (Section 8). Extending GeNI-ADMM to the multiblock setting is another exciting avenue for future work. Such an extension will likely be nuanced, as standard multi-block ADMM can diverge on convex objectives [53]. Our theoretical analysis shows that curvature information provides an advantage in approximate ADMM schemes. This observation can help the design of efficient ADMM-type methods for a broader range of applications, including stochastic and nonconvex optimization.
Appendix A Proofs not appearing in the main paper
A.1 Proofs for Section 4
We begin with the following lemma, which plays a key role in the proof of Lemma 1. For a proof, see Example 1.2.2. in Chapter XI of [26].
Lemma 10 (-subdifferential of a quadratic function).
Let , where is a symmetric positive definite linear operator. Then
Proof of Lemma 1
Proof.
Observe the function defining the -subproblem may be decomposed as with
Now, by hypothesis gives an -minimum of . Hence by Proposition 1,
Thus, we have where and . Applying Lemma 10, with and , we reach
The desired claim now immediately follows from using .
A.2 Proofs for Section 5
Proof of Proposition 2
Proof.
Using the eigendecomposition, we may decompose as
So
Recalling that with , we may put everything together to conclude
proving the first claim. The second claim follows immediately from the first.
Proof of Lemma 2
Proof.
By definition of
| (36) |
Now, suppose , and . Then, combining these hypotheses with (36) and using that is the optimum, we reach
Observe if then , contradicting the preceding inequality. Thus , which yields the second statement, and completes the proof.
Proof of Proposition 3
Lemma 11 (Exact Gap function 1-step bound ).
Let denote the iterates generated by Algorithm 2 at iteration , when we solve the subproblems exactly. Then, the following inequality holds
Proof.
The argument is identical to the proof of Lemma 5. Indeed, the only difference is , as the subproblems are solved exactly. So the same line of argumentation may be applied, except the exact subroblem optimality conditions are used.
We now prove Proposition 3.
Proof.
First, observe that item 2. is an immediate consequence of item 1, so it suffices to show item 1. To this end, plugging in , using , and rearranging, we reach
Defining the norm , the preceding inequality may be rewritten as
Now, our inexactness hypothesis (Assumption 3) along with -strong convexity of the -subproblem (which follows by Assumption 2) implies
Using and , we find
Hence we have,
Defining the summable sequence , the preceding display may be written as
Now, Assumption 4 implies that . Combining this inequality with induction on , we find
Hence,
It follows immediately that:
and so the sequence is bounded, which in turn implies and are bounded.
Proof of Lemma 3
Proof.
Throughout the proof, we shall denote by , the function defining the -subproblem at iteration . The exact solution of the -subproblem shall be denoted by . To begin, observe that:
Now,
Here uses , and that is the exact solution of the -subproblem, while uses that is an minimizer of the -subproblem and that has a Lipschitz gradient. Now, as the iterates all belong to a compact set, it follows that . So,
This establishes the first inequality, and the second inequality follows from the first by plugging into the expression for .
Proof of Lemma 4
Proof.
Proof. By hypothesis, is an -approximate minimizer of the -subproblem, so Lemma 1 shows there exists a vector with , such that
Rearranging, using Cauchy-Schwarz, along with the boundedness of the iterates, the preceding display becomes
where the last display uses , and absorbs constant terms to get the constant .
A.3 Proofs for Section 6
Proof of Lemma 6
Proof.
-
1.
We begin by observing that strong convexity of implies
Decomposing as , the preceding display may be rewritten as
Now, the exact solution of the -subproblem at iteration satisfies . Moreover, is an minimizer of the -subproblem, and is Lipschitz continuous. Combining these three properties, it follows there exists a vector satisfying:
Consequently, we have
Utilizing the preceding relation, along with the fact that the iterates are bounded, we reach
-
2.
As , and , we have
So, adding together the two inequalities and rearranging, we reach
Now using boundedness of the iterates and , Cauchy-Schwarz yields
Proof of Lemma 8
We wish to show for some , that the following inequality holds
To establish this result, it suffices to show the inequality
We accomplish this by upper bounding each term that appears in , by terms that appear in the left-hand side of the preceding equality. To that end, we have the following result.
Lemma 12 (Coupling Lemma).
Under the assumptions of Theorem 2, the following statements hold:
-
1.
Let , . Then for some constant , we have
-
2.
There exists constants , , such that
-
3.
For all , we have
Proof of Lemma 12
Proof.
-
1.
Observe by -smoothness of , that
Here the last inequality uses with , the identity (valid for all )
So, rearranging and using , we reach
Now, using and , we reach
-
2.
This inequality is a straightforward consequence of the relation
Indeed, using the identity , we reach
Consequently
which is precisely the desired claim.
-
3.
Young’s inequality implies for all , that
The desired claim now follows from -smoothness of .
Appendix B Dual gap bounds for ADMM
In this section, we derive bounds for the duality gap for the machine learning examples we consider in Section 8. The derivation is largely inspired by [54, 55]. We consider problems of the form
| minimize | (37) |
where is some loss function, which we assume to be convex and differentiable. (The latter is not necessary but is convenient for our purposes.)
Dual problem.
We introduce new variable and reformulate the primal problem (37) as
| minimize | (38) | |||||
| subject to |
The Lagrangian is then
Taking minimization over and , we get the dual function
Thus, the dual problem is
| maximize | (39) | |||||
| subject to |
Importantly, for any dual feasible point , we have that
where and are optimal solutions to (37) and (39) respectively. It immediately follows that
| (40) |
We will call this the relative dual gap.
Dual feasible points.
The optimality conditions of (38) are (after eliminating )
| (41) |
Inspired by the second condition, we construct a dual feasible point by taking and then projecting onto the norm ball constraint. Specifically, we take
When , we can verify that is dual feasible:
Assuming not all , then this dual variable is optimal when constructed with . This fact can be easily seen by using the optimality conditions of (37), that is contained in the subdifferential, i.e.,
By rearranging, we have the conditions
Thus, when constructed with , is contained within the norm ball and therefore optimal by (41). Note that these optimality conditions also tell us that is a solution to (37) if and only if , where the function is applied elementwise.
This construction and the bound (40) suggest a natural stopping criterion. For any primal feasible point, we construct a dual feasible point . Using the dual feasible point, we evaluate the duality gap. We then terminate the solver if the relative gap is less than some tolerance as
If this condition is met, we are guaranteed that the true relative error is also less than from (40).
References
- \bibcommenthead
- Boyd et al. [2011] Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning 3, 1–122 (2011)
- Bubeck [2015] Bubeck, S.: Convex optimization: Algorithms and complexity. Foundations and Trends® in Machine Learning 8(3-4), 231–357 (2015)
- Zhao et al. [2022] Zhao, S., Frangella, Z., Udell, M.: NysADMM: faster composite convex optimization via low-rank approximation. In: International Conference on Machine Learning, vol. 162, pp. 26824–26840 (2022). PMLR
- Ouyang et al. [2015] Ouyang, Y., Chen, Y., Lan, G., Pasiliao, E.: An accelerated linearized alternating direction method of multipliers. SIAM Journal on Imaging Sciences 8(1), 644–681 (2015)
- Eckstein and Bertsekas [1992] Eckstein, J., Bertsekas, D.P.: On the Douglas—Rachford splitting method and the proximal point algorithm for maximal monotone operators. Mathematical Programming 55(1), 293–318 (1992)
- Lacotte and Pilanci [2020] Lacotte, J., Pilanci, M.: Effective dimension adaptive sketching methods for faster regularized least-squares optimization. In: Advances in Neural Information Processing Systems (2020)
- Frangella et al. [2021] Frangella, Z., Tropp, J.A., Udell, M.: Randomized Nyström preconditioning. arXiv preprint arXiv:2110.02820 (2021)
- Meier and Nakatsukasa [2022] Meier, M., Nakatsukasa, Y.: Randomized algorithms for Tikhonov regularization in linear least squares. arXiv preprint arXiv:2203.07329 (2022)
- Buluc et al. [2021] Buluc, A., Kolda, T.G., Wild, S.M., Anitescu, M., Degennaro, A., Jakeman, J.D., Kamath, C., Kannan, R.-R., Lopes, M.E., Martinsson, P.-G., et al.: Randomized algorithms for scientific computing (RASC). Technical report, Oak Ridge National Lab.(ORNL), Oak Ridge, TN (United States) (2021)
- Ryu and Yin [2022] Ryu, E.K., Yin, W.: Large-scale Convex Optimization: Algorithms & Analyses Via Monotone Operators, (2022). Cambridge University Press
- Parikh and Boyd [2014] Parikh, N., Boyd, S.: Proximal algorithms. Foundations and Trends® in Optimization 1(3), 127–239 (2014)
- Rontsis et al. [2022] Rontsis, N., Goulart, P., Nakatsukasa, Y.: Efficient semidefinite programming with approximate admm. Journal of Optimization Theory and Applications 192(1), 292–320 (2022)
- Deng and Yin [2016] Deng, W., Yin, W.: On the global and linear convergence of the generalized alternating direction method of multipliers. Journal of Scientific Computing 66(3), 889–916 (2016)
- He and Yuan [2012] He, B., Yuan, X.: On the o(1/n) convergence rate of the Douglas–Rachford alternating direction method. SIAM Journal on Numerical Analysis 50(2), 700–709 (2012)
- Eckstein and Yao [2018] Eckstein, J., Yao, W.: Relative-error approximate versions of douglas–rachford splitting and special cases of the admm. Mathematical Programming 170(2), 417–444 (2018)
- Hermans et al. [2019] Hermans, B., Themelis, A., Patrinos, P.: QPALM: a Newton-type proximal augmented Lagrangian method for quadratic programs. In: 2019 IEEE 58th Conference on Decision and Control (CDC), pp. 4325–4330 (2019). IEEE
- Hermans et al. [2022] Hermans, B., Themelis, A., Patrinos, P.: QPALM: a proximal augmented Lagrangian method for nonconvex quadratic programs. Mathematical Programming Computation, 1–45 (2022)
- Monteiro and Svaiter [2013] Monteiro, R.D., Svaiter, B.F.: Iteration-complexity of block-decomposition algorithms and the alternating direction method of multipliers. SIAM Journal on Optimization 23(1), 475–507 (2013)
- Ouyang et al. [2013] Ouyang, H., He, N., Tran, L., Gray, A.: Stochastic alternating direction method of multipliers. In: International Conference on Machine Learning, pp. 80–88 (2013). PMLR
- Hager and Zhang [2020] Hager, W.W., Zhang, H.: Convergence rates for an inexact admm applied to separable convex optimization. Computational Optimization and Applications 77(3), 729–754 (2020)
- Yuan et al. [2020] Yuan, X., Zeng, S., Zhang, J.: Discerning the linear convergence of ADMM for structured convex optimization through the lens of variational analysis. J. Mach. Learn. Res. 21, 83–1 (2020)
- Chambolle and Pock [2011] Chambolle, A., Pock, T.: A first-order primal-dual algorithm for convex problems with applications to imaging. Journal of Mathematical Imaging and Vision 40, 120–145 (2011)
- Zhao et al. [2021] Zhao, S., Lessard, L., Udell, M.: An automatic system to detect equivalence between iterative algorithms. arXiv preprint arXiv:2105.04684 (2021)
- Gower et al. [2019] Gower, R.M., Kovalev, D., Lieder, F., Richtárik, P.: RSN: randomized subspace Newton. In: Advances in Neural Information Processing Systems (2019)
- Bertsekas et al. [2003] Bertsekas, D., Nedic, A., Ozdaglar, A.: Convex Analysis and Optimization vol. 1, (2003). Athena Scientific
- Hiriart-Urruty and Lemaréchal [1993] Hiriart-Urruty, J.-B., Lemaréchal, C.: Convex Analysis and Minimization Algorithms II vol. 305, (1993). Springer
- Schmidt et al. [2011] Schmidt, M., Roux, N., Bach, F.: Convergence rates of inexact proximal-gradient methods for convex optimization. Advances in Neural Information Processing Systems 24 (2011)
- Stellato et al. [2020] Stellato, B., Banjac, G., Goulart, P., Bemporad, A., Boyd, S.: OSQP: an operator splitting solver for quadratic programs. Mathematical Programming Computation 12(4), 637–672 (2020)
- He et al. [2002] He, B., Liao, L.-Z., Han, D., Yang, H.: A new inexact alternating directions method for monotone variational inequalities. Mathematical Programming 92, 103–118 (2002)
- Rockafellar [2023] Rockafellar, R.T.: Generic linear convergence through metric subregularity in a variable-metric extension of the proximal point algorithm. Computational Optimization and Applications, 1–20 (2023)
- Candes and Romberg [2007] Candes, E., Romberg, J.: Sparsity and incoherence in compressive sampling. Inverse problems 23(3), 969 (2007)
- Candes and Recht [2012] Candes, E., Recht, B.: Exact matrix completion via convex optimization. Communications of the ACM 55(6), 111–119 (2012)
- Nishihara et al. [2015] Nishihara, R., Lessard, L., Recht, B., Packard, A., Jordan, M.: A general analysis of the convergence of ADMM. In: International Conference on Machine Learning, pp. 343–352 (2015). PMLR
- Friedman et al. [2010] Friedman, J., Hastie, T., Tibshirani, R.: Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software 33(1), 1 (2010)
- Pilanci and Wainwright [2017] Pilanci, M., Wainwright, M.J.: Newton sketch: A near linear-time optimization algorithm with linear-quadratic convergence. SIAM Journal on Optimization 27(1), 205–245 (2017)
- Lacotte et al. [2021] Lacotte, J., Wang, Y., Pilanci, M.: Adaptive Newton sketch: Linear-time optimization with quadratic convergence and effective Hessian dimensionality. In: International Conference on Machine Learning, pp. 5926–5936 (2021). PMLR
- Derezinski et al. [2021] Derezinski, M., Lacotte, J., Pilanci, M., Mahoney, M.W.: Newton-less: Sparsification without trade-offs for the sketched newton update. Advances in Neural Information Processing Systems 34, 2835–2847 (2021)
- Bach [2013] Bach, F.: Sharp analysis of low-rank kernel matrix approximations. In: Conference on Learning Theory (2013)
- Alaoui and Mahoney [2015] Alaoui, A., Mahoney, M.W.: Fast randomized kernel ridge regression with statistical guarantees. In: Advances in Neural Information Processing Systems (2015)
- Karimireddy et al. [2018] Karimireddy, S.P., Stich, S.U., Jaggi, M.: Global linear convergence of Newton’s method without strong-convexity or Lipschitz gradients. arXiv (2018). https://arxiv.org/abs/1806.00413
- Tibshirani [1996] Tibshirani, R.: Regression selection and shrinkage via the lasso. Journal of the Royal Statistical Society Series B 58(1), 267–288 (1996)
- Zou and Hastie [2005] Zou, H., Hastie, T.: Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society Series B: Statistical Methodology 67(2), 301–320 (2005)
- Hastie et al. [2015] Hastie, T., Tibshirani, R., Wainwright, M.: Statistical Learning with Sparsity: the Lasso and Generalizations, (2015). CRC press
- Chang and Lin [2011] Chang, C.-C., Lin, C.-J.: LIBSVM: a library for support vector machines. ACM Transactions on Intelligent Systems and Technology (TIST) 2(3), 1–27 (2011)
- Vanschoren et al. [2013] Vanschoren, J., Rijn, J.N., Bischl, B., Torgo, L.: Openml: networked science in machine learning. SIGKDD Explorations 15(2), 49–60 (2013)
- Schubiger et al. [2020] Schubiger, M., Banjac, G., Lygeros, J.: Gpu acceleration of admm for large-scale quadratic programming. Journal of Parallel and Distributed Computing 144, 55–67 (2020)
- Bezanson et al. [2017] Bezanson, J., Edelman, A., Karpinski, S., Shah, V.B.: Julia: A fresh approach to numerical computing. SIAM Review 59(1), 65–98 (2017)
- ApS [2022] ApS, M.: The MOSEK Optimization Toolbox for MATLAB Manual. Version 10.0. (2022). http://docs.mosek.com/9.0/toolbox/index.html
- Dunning et al. [2017] Dunning, I., Huchette, J., Lubin, M.: Jump: A modeling language for mathematical optimization. SIAM Review 59(2), 295–320 (2017) https://doi.org/10.1137/15M1020575
- Legat et al. [2021] Legat, B., Dowson, O., Dias Garcia, J., Lubin, M.: MathOptInterface: a data structure for mathematical optimization problems. INFORMS Journal on Computing 34(2), 672–689 (2021) https://doi.org/10.1287/ijoc.2021.1067
- Liu and Nocedal [1989] Liu, D.C., Nocedal, J.: On the limited memory bfgs method for large scale optimization. Mathematical Programming 45(1), 503–528 (1989)
- Mogensen and Riseth [2018] Mogensen, P.K., Riseth, A.N.: Optim: A mathematical optimization package for Julia. Journal of Open Source Software 3(24), 615 (2018) https://doi.org/10.21105/joss.00615
- Chen et al. [2016] Chen, C., He, B., Ye, Y., Yuan, X.: The direct extension of admm for multi-block convex minimization problems is not necessarily convergent. Mathematical Programming 155(1-2), 57–79 (2016)
- Kim et al. [2007] Kim, S.-J., Koh, K., Lustig, M., Boyd, S., Gorinevsky, D.: An interior-point method for large-scale -regularized least squares. IEEE journal of selected topics in signal processing 1(4), 606–617 (2007)
- Koh et al. [2007] Koh, K., Kim, S.-J., Boyd, S.: An interior-point method for large-scale l1-regularized logistic regression. Journal of Machine Learning Research 8(Jul), 1519–1555 (2007)