On the High Symmetry of Neural Network Functions
Research and Development
TOELT LLC
Switzerland
[email protected]
Department of Computer Science
Lucerne University of Applied Sciences and Arts
Switzerland
Abstract
Training neural networks means solving a high-dimensional optimization problem. Normally the goal is to minimize a loss function that depends on what is called the network function, or in other words the function that gives the network output given a certain input. This function depends on a large number of parameters, also known as weights, that depends on the network architecture. In general the goal of this optimization problem is to find the global minimum of the network function. In this paper it is discussed how due to how neural networks are designed, the neural network function present a very large symmetry in the parameter space. This work shows how the neural network function has a number of equivalent minima, in other words minima that give the same value for the loss function and the same exact output, that grows factorially with the number of neurons in each layer for feed forward neural network or with the number of filters in a convolutional neural networks. When the number of neurons and layers is large, the number of equivalent minima grows extremely fast. This will have of course consequences for the study of how neural networks converges to minima during training. This results is known, but in this paper for the first time a proper mathematical discussion is presented and an estimate of the number of equivalent minima is derived.
Keywords Machine Learning, Neural Networks, Symmetry
1 Introduction
Note that this short paper is not meant to review existing results or to analyze deeply the consequences of the high symmetry of neural networks. The only goal is to formalise and calculate the number of equivalent points in parameter space for a feed forward neural network. I hope this can be helpful to someone. The resul highlighted in this short paper (notably without references so far), is known and therefore it is no new contribution. But to the best of my knowledge no one has ever analyzed the problem formally and shown from where this high symmetry is coming from in a short and concise form. I hope the mathematics shown here can be helpful in this regard. I claim not to be the first to have noticed this of course, but I think this paper shows for the first time from where the symmetry comes from.
I plan to add references and search for similar contribution soon and update this short paper accordingly.
The contribution of this short paper is the Symmetry Theorem for Feed Forward Neural Networks, or in other words that for a FFNN with layers the network function has a very high symmetry in -space. With we have indicated a vector of all the network parameters (or weights), and with x a generic (possibly multi-dimensional) input observation. More precisely there are ( being the number of neurons in layer ) sets of parameters that gives the exact same value of the network function for the same input x. As a direct consequence, the loss function can not have just one absolute minimum, but always ones, all with the same value of . The paper is organised as follows. In Section 2 the formalism and notation are discussed. In Section 3 the conclusions and important further research developments are discussed.
2 Formalism
In this section the case for feed forward neural networks (FFNN) is discussed and the definition of equivalent minima and their exact number depending on the network architecture is respectively given and calculated.
Let us consider a simple FFNN. An example with just two hidden layers is depicted in Figure 1. The symbol indicates the weight between neuron in layer and neuron in layer , where by convention layer 0 is the input layer.

Normally each neuron will also have a bias as input but for simplicity we will neglect them, since the final general results is not influenced by this simplification. We will indicate the output of a generic neuron in layer with
| (1) |
where is the activation function in layer . For simplicity we will assume that all layers, except the output one, will have the same activation function . is the number of neurons in layer , indicates, as already mentioned, the weight between neuron in layer and neuron in layer . By convention layer 0 will be the input layer, and therefore , the component (or feature) of a generic input observation. In matrix form the output of layer can be written as
| (2) |
or by using the matrix symbols and
| (3) |
Now let us consider the example in Figure 1, and suppose to switch neuron 1 and 2 in layer 1. Suppose to do that by also switching the respective connections, or in other words by switching also the respective weights. To clarify this concept, after switching neurons 1 and 2 in leayer 1, one would end up with the network depicted in Figure 2 where the irrelevant parts have been colored in light gray to only highlight the changes that the switch have generated.
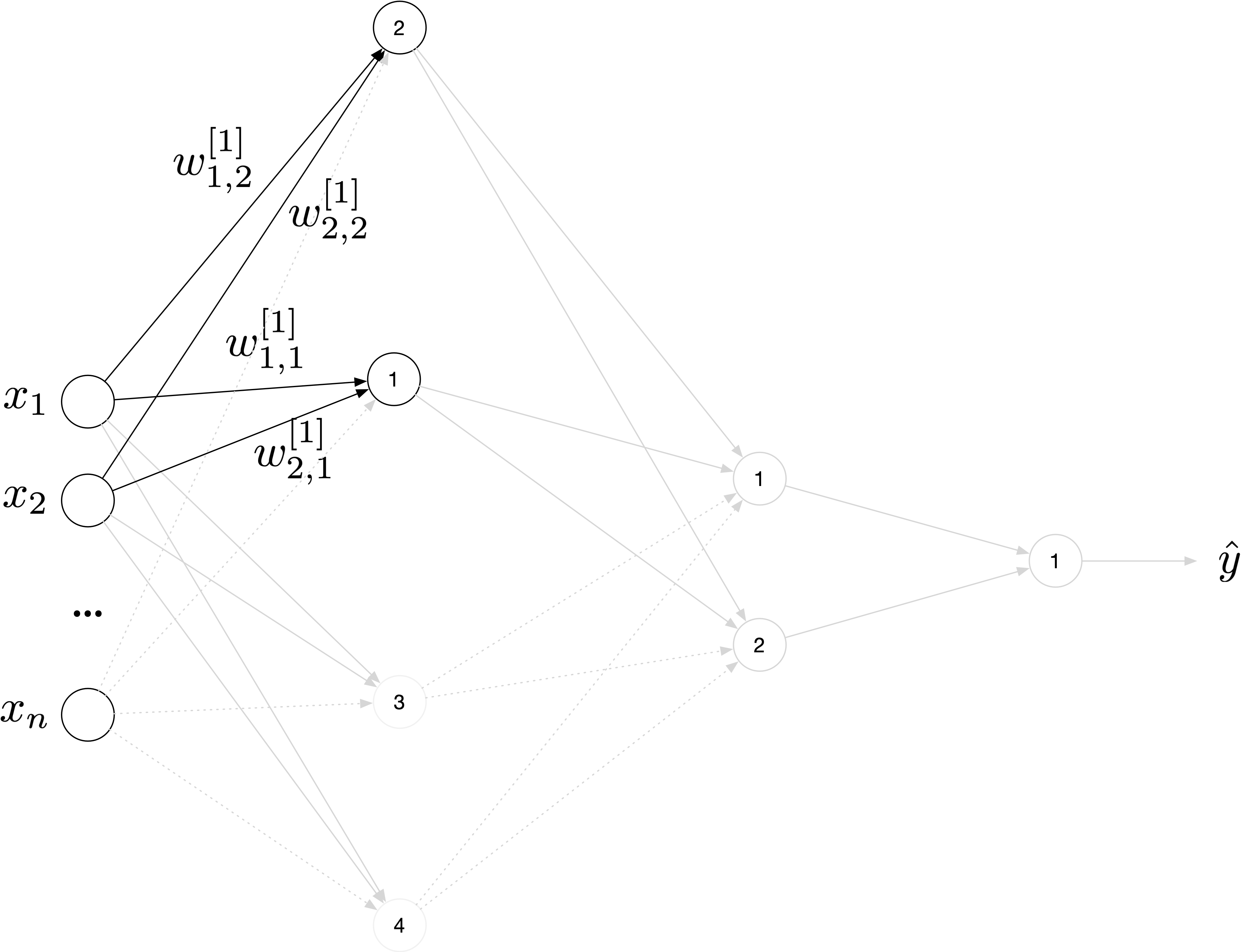
The neuron switch, performed as described, will have the result of effectively switching the first and second entry in the output vector . Note that this can be equivalently achieved by switching rows 1 and 2 in . To summarize, switching two generic neurons and in layer as described, is equivalent to switching rows and in the weight matrix . Switching two neurons is equivalent to a reordering of the neurons in layer , and there are possible ways of ordering the neurons in layer . Now is important to note that by switching two neurons as described will give naturally a different output of the network function. But we can easily correct this by simply switching columns and in . To see why this is the case let us consider switching neuron and in layer as described. This will result in an output vector given by
| (4) |
where rows and has been swapped. Now let us consider what happens to the output of layer . If is not changed the output vector will be of course different than the one before the swap of the neurons. But by swapping the columns and in and indicating the new weight matrix with , the output vector will remain unchanged. In fact
| (5) |
That means that by simultaneosuly swapping two rows and in , and indicating the new weight matrix with , and the two columns and in the output of the network will not change. We have effectively found two set of weights
and
that will give the exact same value for the loss function and for all the predictions. As discussed there are possible ways of organising the neurons in layer that will give a set of weights with the property of keeping the neural network output and loss function unchanged. One can say that the neural network is invariant to neuron swaps as described in the text. This property is general for all layers (excluded the input and the output) . So in total one can create possible set of weights that will give the exact same predictions and loss function value. In a small network with three hidden layers, each with 128 neurons the number of equivalent set of weights is that is approximately . This is very large number indicating that in the parameter space the loss function will have this number of equivalent minima. Where again with equivalent minima we intend location in parameter space that will give the same value of the loss function and the exact same predictions.
Let us formally define a generalized neuron switch.
Definition 2.1.
A generalized - neuron switch is a transformation of the set of weights that is described by
| (6) |
where the notation indicates the switch of rows and and the switch of columns and . This matrix transformation is equivalent to switch neurons and in layer as described in the text.
One can say that and are invariant under a generalized - neuron switch. There are a total of generalized - neuron switches possible in a FFNN with layers (including the output layer). Let us also define the concept of equivalent set of parameters for a given FFNN.
Definition 2.2.
Two set of parameters ) and ) are said to be equivalent for a given FFNN when and for any input .
So the conclusion of this paper can be stated in the following theorem.
Theorem 2.1 (Symmetry Theorem for Feed Forward Neural Networks).
Given a FFNN with layers, each having neurons, there exist equivalent sets of weights.
The proof has been given in the previous discussion.
2.1 Convolutional Neural Neural Networks
The same approach can be used for convolutional neural networks (CNNs). In fact the order of the filters in each convolution is not relevant and therefore also in CNNs we have a high symmetry. this time the relevant parameters are not the number of neurons in each layer, but the number of filters in each convolutional layer. Details for CNNs will be developed by the author in a subsequent publication.
3 Conclusions
For any point in parameter space there are always additional points in parameter space that give the same loss function value and the same network output as . This highlight the very high symmetry of the network function in parameter space as the number grows as with the number of neurons in a given layer and the total number of layers. That also means that if the network function cannot have one single minima, but if there is one then there will be that will be equivalent according to Defintion 2.2.