On the Feasible Region of Efficient Algorithms for Attributed Graph Alignment
Abstract
Graph alignment aims at finding the vertex correspondence between two correlated graphs, a task that frequently occurs in graph mining applications such as social network analysis. Attributed graph alignment is a variant of graph alignment, in which publicly available side information or attributes are exploited to assist graph alignment. Existing studies on attributed graph alignment focus on either theoretical performance without computational constraints or empirical performance of efficient algorithms. This motivates us to investigate efficient algorithms with theoretical performance guarantee. In this paper, we propose two polynomial-time algorithms that exactly recover the vertex correspondence with high probability. The feasible region of the proposed algorithms is near optimal compared to the information-theoretic limits. When specialized to the seeded graph alignment problem under the seeded Erdős–Rényi graph pair model, the proposed algorithms extends the best known feasible region for exact alignment by polynomial-time algorithms.
I Introduction
The graph alignment problem, also referred to as the graph matching or noisy graph isomorphism problem, is the problem of finding the correspondence between the vertices of two correlated graphs. This problem has been given increasing attention for its applications in social network de-anonymization. For instance, datasets of social networks are typically anonymized for privacy protection. However, an attacker may be able to de-anonymize the dataset by aligning its user-user connection graph with that of publicly available data. Attributed graph alignment is a variant of graph alignment in which side information, referred to as attributes of vertices, is also publicly available in addition to the user-user connection information. This variant is motivated by the fact that there might exist publicly available attribute information in social networks. For example, the anonymized network Netflix has users’ movie-watching history and ratings publicly available. Moreover, the examination of the proposed model provides both achievability and converse results for various well-known variations of the Erdős–Rényi graph alignment problems. These variations include the traditional graph alignment problem without attributes, the seeded graph alignment problem, and the bipartite alignment problem. Consequently, the study of attributed graph alignment introduces a novel perspective for investigating these problems within an integrated framework.
In this paper, we focus on the attributed graph alignment problem under the attributed Erdős–Rényi pair model , first proposed in [1]. In this model, a base graph is generated on the vertex set where the vertices from the set represent users and the rest of the vertices represent attributes. Between each pair of users, an edge is generated independently and identically with probability to represent their connection. For each user-attribute pair, an edge is generated independently and identically with probability to represent their association. Note that there are no edges between attributes. The graph is then independently subsampled to two graphs and , where each user-user edge is subsampled with probability and each user-attribute edge is subsampled with probability . To model the anonymization procedure, a random permutation chosen uniformly at random is applied to the users in to generate an anonymized version . Our goal in this model is to achieve exact alignment, i.e., to exactly recover the permutation using and .
For the attributed graph alignment problem, and the graph alignment problem in general, two often asked questions are the following. First, for what region of graph statistics is exact alignment feasible with unlimited computational power? This region is usually referred to as the information-theoretically feasible region or the information-theoretic limits. Second, for what region of graph statistics is exact alignment feasible with polynomial-time algorithms? This region is usually referred to as the feasible region of polynomial-time algorithms. Characterizing these two feasible regions and their relationship is of utmost importance to developing a fundamental understanding of the graph alignment problem.
There has been extensive studies on these two questions under the Erdős–Rényi pair model without attributes. A line of research focuses on the information-theoretic limits of exact alignment [2, 3, 4, 5]. Roughly speaking, it is shown that exact alignment is information-theoretically feasible when the intersection graph is dense enough. A sharp threshold of exact alignment has been established, while there still exists some gap between the converse and the achievability results. Another line of research focuses on polynomial-time algorithms for exact alignment [6, 7, 8, 9, 10]. Compared to the information-theoretic limits, the existing polynomial-time algorithms further require higher edge correlation between the pair of graphs to achieve exact alignment. The question of whether there exists polynomial-time algorithms that achieve the known information-theoretic limits is still left open.
For the attributed graph alignment problem, the information-theoretic limit has been studied in [1], where the feasible region (achievability results) and infeasible region (converse results) are characterized with a gap in between in some regimes. However, the feasible region of polynomial-time algorithms for attributed graph alignment has not been studied before, and it is the focus of this paper. In this work, we propose two polynomial-time algorithms for attributed graph alignment and characterize their feasible regions. The two algorithms are designed for two different regimes of parameters based on the richness of attribute information: the algorithm AttrRich is designed for the regime where , referred to as the attribute-information rich regime; and the algorithm AttrSparse is designed for the regime where , referred to as the attribute-information sparse regime. In both algorithms, we first explore the user-attribute connections to align a set of anchor users, and then utilize the user-user connections to the anchors to align the rest of users. Due to the regime difference, AttrRich is able to generate a much larger set of anchors in the first step than AttrSparse. Therefore, AttrRich and AttrSparse make use of the anchors differently in the second step: AttrRich explores one-hop user-user connections to align the rest of users, while AttrSparse explores one-hop or multiple-hop user-user connections to align the rest of users depending on the sparsity of user-user connections. This idea of matching vertices based on common neighbor witnesses has been explored to construct efficient graph alignment algorithms under the context of seeded graph alignment [11, 12, 13, 14]. In this work, we employ this idea in a two-step procedure under the setting of attributed graphs, and analyze its performance through a careful treatment of the dependency between the two steps.
Our characterizations of the feasible regions of AttrRich and AttrSparse are illustrated in Figure 1 as areas and , respectively. The information-theoretically feasible and infeasible regions given in [1] are also illustrated in the figure for comparison. We can see that there is a gap between the feasible region achieved by AttrRich and AttrSparse and the known information-theoretically feasible region. It is left open whether this gap is a fundamental limit of polynomial-time algorithms 111We comment that in the line of work [15, 16, 17], the authors have explored efficient algorithms for a closely-related problem known as attributed network alignment. In this problem, attributes are attached to both vertices and edges, in contrast to the exclusive association with vertices in attributed graph alignment. The focus in this line of work is the empirical performance rather than the theoretical feasible region.
In addition, we specialize the feasible region of the proposed algorithms to the context of the seeded Erdős–Rényi graph alignment problem, and demonstrate that the specialized feasible region includes certain range of parameters that is not known to be achievable in the literature.
Our results reveal that attributes possibly facilitate graph alignment in a much more significant way when computational efficiency is a priority. We demonstrate this possible impact of attributes under the sparse regime in Figure 2. In Figure 2(a), we let so there is no information from the attributes, which is equivalent to the graph alignment problem without attributes; in Figure 2(b), we let . We keep , and assume the value of can be an arbitrarily large constant but not tending to infinity in both settings for ease of comparison. Comparing these two figures, we can see that when increases from to , the information-theoretic limits in terms of user-user parameters ( and ) improve a bit as expected. However, a more fundamental improvement is in the feasible region achievable by polynomial-time algorithms. In Figure 2(a), the green region above is achievable by a polynomial-time algorithm proposed in [10], where is known as the Otter’s constant. The red region below is not known to be achievable by any polynomial-time algorithms. Moreover, in [18], this red region is conjectured to be infeasible by any polynomial-time algorithm.222We note that the conjecture presented in [18] pertains to the sparse regime where . In contrast, for the dense regime, it is conjectured in [19] that no polynomial-time algorithm can achieve exact alignment if . In comparison, in Figure 2(b), the green region above the information theoretic limit, which is presented as the dotted curve, is achievable by our proposed polynomial-time algorithm AttrRich (assuming and ). Therefore, if is indeed the right threshold between achievable and impossible under polynomial-time algorithms for graph alignment without attributes in the sparse regime, a small amount of attribute information lowers this threshold to an arbitrarily small constant.
II Model
In this section, we describe a random process that generates a pair of correlated graphs, which we refer to as the attributed Erdős–Rényi pair model . Under this model, we define the exact alignment problem.
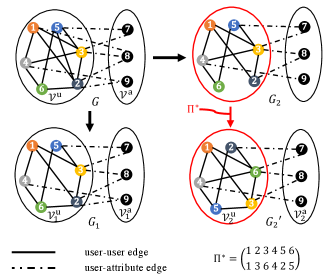
Base graph generation. We first generate a base graph , whose vertex set consists of two disjoint sets, the user vertex set and the attribute vertex set . There are two types of edges in the base graph , the user-user edges (edges connecting a pair of users) and the user-attribute edges (edges connecting a user vertex and an attribute vertex). The user-user edges are generated independently and identically with probability , and the user-attribute edges are generated independently and identically with probability . Throughout this paper, we assume that and . We write if vertices and are connected in graph .
Edge subsampling. From the base graph , we obtain two correlated graphs and by subsampling the edges in independently. More specifically, we get and by independently including each user-user edge in with probability and independently including each user-attribute edge with probability . Throughout this paper, we assume that and .
Anonymization. From the generated as above, we get an anonymized graph by applying an unknown permutation on the user vertices of , where is drawn uniformly at random from the set of all possible permutations on . We use to denote the user vertex set of and use to denote the user vertex set of . Finally, we remark that this subsampling process is a special case of an earlier described attributed Erdős–Rényi pair model in [1].
Exact alignment. Given an observable pair , our goal is to recover the unknown permutation , which allows us to recover the original labels of user vertices in the anonymized graph . We say exact alignment is achieved with high probability (w.h.p.) if . It is worth mentioning that due to the symmetry among user vertices. Thus, we later assume without loss of generality that the underlying true permutation is the identity permutation.
Related random graph models. A closely related graph generation model is the correlated stochastic block model [20, 21, 22]. In this model, the base graph is instead generated from the stochastic block model, where vertices are grouped into latent blocks, and edges are formed between blocks with specific probabilities, capturing the underlying community structure in the network. The base graph is then subsampled into the two generated graphs and . In the proposed attributed Erdős–Rényi graph pair models, users and attributes can be viewed as two communities in the correlated stochastic block model. However, a key distinction lies in the fact that the attributed Erdős–Rényi graph pair model specifies the correspondence between attributes in the two graphs, whereas the correlated stochastic block model does not disclose such information.
Another well-studied graph alignment model with side information is the seeded Erdős–Rényi graph pair model [11, 12, 13, 14], where we have access to part of the true correspondence between user vertices. To make a comparison between the seeded Erdős–Rényi graph pair model and the proposed model, here we describe the seeded Erdős–Rényi pair model in detail. We first sample a base graph from the Erdős–Rényi graph on vertices with edge probability . Then two correlated copies and are obtained by independently subsampling the edges in the base graph where each edge is preserved with probability . The anonymized graph is obtained by applying an unknown permutation on , where is drawn uniformly at random. Let and denote the vertex sets of and respectively. Then, a subset of size is chosen uniformly at random and we define the vertex pairs as the seed set. The graph pair together with the seed set are given and the goal of the exact alignment is to recover the underlying permutation for the remaining vertices w.h.p.
Comparing the seeded Erdős–Rényi pair model and the attributed Erdős–Rényi pair model, we can see that the seed set and the attribute set both provide side information to assist the alignment of the remaining vertices. Nevertheless, there are two main differences between the two models. First, in the attributed Erdős–Rényi pair model, we allow different edge probabilities and subsampling probabilities for user-user edges and user-attribute edges, whereas in the seeded Erdős–Rényi pair model, the edge probability is identical for all edges and so is the subsampling probability. Second, while there are edges between seeds in seeded Erdős–Rényi pair model, there are no attribute-attribute edges in the attributed Erdős–Rényi pair model. However, it can be shown that the existence of edges between seeds has no influence on the information-theoretic limits for exact alignment in the seeded Erdős–Rényi pair model (see Lemma 1 in [23]). This further suggests that regarding the task of exact alignment, the information-theoretic limits on attributed graph alignment recover the information-theoretic limits on seeded Erdős–Rényi graph alignment if we specialize and in the attributed Erdős–Rényi pair model .
Other notation. Our algorithms rely on exploring the neighborhood similarity of user vertices in and . Here we introduce our notation of local neighborhoods. We define as the set of attribute neighbors of a user vertex in and as the set of attribute neighbors of a user vertex in . For two user vertices and in the same graph, let be the length of the shortest path connecting and via user-user edges. For a user vertex , we define the set of -hop user neighbors of vertex as for any positive integer . By convention, when , we simply write . The quantities and are defined similarly for user vertices in .
Reminder of the Landau notation.
| Notation | Definition |
|---|---|
| and |
III Main results
In this section, we propose two polynomial-time algorithms for the attributed graph alignment problem. Their feasible regions are characterized in the following two theorems.
Theorem 1.
Theorem 2.
III-A Algorithm AttrRich
In this subsection, we propose the first algorithm that leads to the achievable region in Theorem 1. This algorithm is designed for the attribute-information rich regime, hence named AttrRich.
-
•
Input: The graph pair and thresholds and .
-
•
Step 1: Align through attribute neighbors. In this step, we only consider the edge connections between users and attributes, and use these information to find the matching for a set of vertices which will be later referred to as anchors. For each pair of users and , compute the number of common attribute neighbors
(6) If , add into . We refer to vertex pairs in the set as anchor. If there exists conflicting pairs in , i.e., two distinct pairs and with or , set and declare failure. Otherwise, set for all pairs .
-
•
Step 2: Align through user neighbors. In the previous step, we have aligned the anchors using the edges between users and attributes. In this step, we will align the non-anchor vertices by their edge connections to the anchors. Let
denote the set of all unmatched vertices in and let
denote the set of all unmatched vertices in . For each unmatched pair and , consider the user neighbors of and the user neighbors of that are matched as pairs in , and compute the number of such matched pairs for
(7) For each , if for a unique , set . Otherwise, declare failure. If is not a bijection from to , declare failure.
-
•
Output: The estimated permutation .
In this algorithm, there are two threshold parameters and . In the following analysis, we choose
| (8) |
where with constant , and
| (9) |
where with constant .
Remark 1 (Complexity of Algorithm AttrRich).
In Algorithm AttrRich, the time complexity for computing for all pairs is since there are pairs and for each pair, there are attributes to consider. Similarly, the time complexity for computing for all pairs is at most . Therefore, if , the time complexity of Algorithm AttrRich is and if , the time complexity of Algorithm AttrRich is .
III-B Algorithm AttrSparse
In this subsection, we propose the second algorithm that leads to the achievable region in Theorem 2. This algorithm is designed for the attribute-information sparse regime, hence named AttrSparse. In Step 2 of this algorithm, we consider two different cases. In the case when the user-user connection is dense, we perform a similar process as in Step 2 of Algorithm AttrRich. In the case when the user-user connections is sparse, we call a seeded alignment algorithm proposed in [13], which is restated in Subsection III-C.
-
•
Input: The graph pair , three thresholds , and , an integer , and the model parameters and .
-
•
Step 1: Align through attribute neighbors. Similar to Step 1 of Algorithm AttrRich, for each pair of users and , we compute the quantity
(10) Unlike Step 1 of Algorithm AttrRich, we create an anchor set using a different threshold . If , add into . We refer to vertex pairs in the set as anchors. If there exists conflicting pairs in , i.e., two distinct pairs and with or , set and declare failure.
-
•
Step 2: Align through user-user edges.
-
–
If , we perform the similar process as in Step 2 of Algorithm AttrRich to align the non-anchor vertices. Define
and
For each unmatched pair and , compute as defined in (7). For each , if for a unique , set . Otherwise, declare failure. If is not a bijection from to , declare failure.
-
–
If , run Algorithm III-C with the induced subgraphs on user vertices and , the seed set , and parameters and .
-
–
-
•
Output: The estimated permutation .
In this algorithm, there are four parameters , , and that we can choose. In the following analysis, we choose to be the same value as in (9),
| (11) |
(cf. the same as in Theorem 2),
| (12) |
and
| (13) |
Remark 2 (Complexity of Algorithm AttrSparse).
In Algorithm AttrSparse, the time complexity for computing for all pairs is since there are pairs and for each pair, there are attributes to consider. The time complexity of computing for all pairs is and that of Algorithm III-C is as given in [13], which can be improved with better data structures. Therefore, if , the complexity of Algorithm AttrSparse is ; Otherwise its complexity is .
III-C Seeded alignment in the sparse regime [13, Algorithm 3]
Except for the two graphs and , this algorithm takes a seed set as input. The seed set consists of vertex pairs such that . The algorithm utilizes this seed set to align the rest of vertices.
-
•
Input: The graph pair , the seed set , a threshold , and an integer .
-
•
Align high-degree vertices. Let
and
For each pair of unseeded vertices and , and for each pair of their neighbors and , compute
where denotes the set of user vertices such that in the induced subgraph with the set of vertices removed. Let
If , add into set . Add all the vertex pairs from to . If there exists conflicting pairs in , i.e., two distinct pairs and with or , set and declare failure.
-
•
Align low-degree vertices. Let
and
For all pairs of unmatched vertices and , if is adjacent to a user vertex in and is adjacent to a user vertex in such that , then set .
-
•
Finalize and output: For each vertex pair , set . If is a bijection from to , output , otherwise declare failure.
IV Discussion
In this section, we compare the feasible region in Theorems 1 and 2 to existing works. In Section IV-A, we compare the feasible region with the information-theoretic limits in [1]. It is shown that there still exists a gap between the feasible region of the proposed algorithms and the information-theoretic limit. In Section IV-B, we specialize the feasible region of the proposed algorithm to the context of seeded graph alignment problem, and compare the specialized feasible region to the information-theoretic limits as well as the best-known feasible regions by polynomial-time algorithms for exact alignment in literature given in [13] and [14]. It is shown that while having a gap to the information-theoretic limit, the proposed Algorithms AttrRich and AttrSparse achieves exact recovery in certain range of parameters that is unknown to be feasible by any existing efficient algorithms. In Section IV-C, we consider the bipartite alignment problem which is another special case. We show that the proposed Algorithm AttrRich provides an alternative polynomial-time algorithm to the theoretically optimal Hungarian Algorithm [24], with a slightly lower complexity.
IV-A Comparison to the information theoretic limits
The information-theoretic limits of attributed graph alignment were established in [1]. The version for the subsampling model is stated as follows.
Theorem 3 (Theorem 1 in [1]).
Consider the attributed graph pair with , , , and .
Achievability:
In the regime where , if
then exact alignment is achievable w.h.p.
In the regime where , if
where
then exact alignment is achievable w.h.p.
Converse: If
then no algorithm achieves exact alignment w.h.p.
IV-B Specialization to the seeded Erdős–Rényi graph alignment
In this subsection, we specialize the feasible region of proposed algorithm to the seeded Erdős–Rényi graph alignment problem, and compare the feasible region with that of the existing algorithms. Consider an attributed Erdős–Rényi graph pair with and . Then these attributes can be viewed as seeds and can be viewed as a graph pair generated from a seeded Erdős–Rényi pair model , and the edges between the these vertices are all removed.333The information theoretic limit of exact alignment in the seeded graph alignment problem remains the same after removing the edges between attributes (see Lemma 1 in [23]). For simplicity, we write
later on. In our comparisons, we always assume that , and .
We first specialize the feasible regions of Algorithm AttrRich in Theorem 1 and Algorithm AttrSparse in Theorem 2 to the seeded graph alignment problem.
Corollary 1 (Feasible region of Algorithm AttrRich).
Consider the seeded graph pair with , and . Assume that
| (14) |
and that there exists some constant such that
| (15) |
Then there exists a polynomial time algorithm, namely, Algorithm AttrRich with parameters
that achieves exact alignment w.h.p. Here, with constant and with constant .
Corollary 2 (Feasible region of Algorithm AttrSparse).
Consider the seeded graph pair with , and . Assume that
| (16) |
| (17) |
and that there exists some constant such that
| (18) |
Then there exists a polynomial time algorithm, namely, Algorithm AttrSparse with parameters
and
that achieves exact alignment w.h.p.
Remark 3.
Now we compare the proposed algorithms to the best known polynomial-time algorithms in the literature [13] and [14]. The comparison of their feasible regions is summarized in the following theorem, the proof of which is postponed to Section VIII-B.
Theorem 4 (Comparison of polynomial-time algorithms).
Consider the seeded Erdős–Rényi pair model with , and . Assume that parameters , and satisfy any of the following four sets of conditions:
or
or
or
for some positive constant . Then the proposed algorithms achieve exact alignment w.h.p., while none the of existing algorithms in [13, 14] is known to achieve exact alignment w.h.p. On the other hand, when
the feasible region of the proposed algorithms is a strict subset of that in [13].
Remark 4.
The polynomial-time algorithms for graph alignment under the unseeded Erdős–Rényi graph pair model proposed in [9] and [10] trivially imply polynomial-time algorithm for seeded graph alignment. However, the feasible regions of algorithms in [9] and [10] both require additional conditions on the subsampling probability . Therefore, we do not include them to the comparison in this section.
Remark 5.
As shown in Corollaries 1 and 2, the two proposed algorithms achieve exact alignment in two mutually exclusive regimes. Theorem 4 summarizes the comparison between the union of the feasible regions of the two proposed algorithms and the union of the feasible regions in [13] and [14]. Regions , , and in Theorem 4 correspond to the top left blue area in Fig. 4. Region in Theorem 4 corresponds to the bottom right blue area in Fig. 4.
As stated in Theorem 4, Corollaries 1 and 2 introduce some new feasible region in the regime (the top-left blue corner in Fig. 4). To understand the improvement over the feasible region in [13], recall that the proposed algorithms in this work align vertices two steps: initially aligning a group of anchor vertices by exploring the seeds within their one-hop neighborhood, and subsequently aligning the remaining unmatched vertices with the assistance of the anchors in their respective one-hop neighborhood. In contrast, the algorithm proposed in [13] for this scenario aligns all vertices by exploring the one-hop seed neighbors of the non-seed vertices, which closely resembles the first step of the proposed algorithms. This is why the proposed algorithms expand the feasible region introduced in [13]. To grasp the improvements made over the feasible region in [14], note that the algorithm introduced in [14] performs a similar two-step process as the algorithms in this work. The primary distinction lies in the second step of matching. In [14], the matched vertices from the first step, along with the seeds, act as anchors in the second step. In contrast, our proposed algorithms utilize only the matched vertices from the first step as anchors. We comment that the improvement of the proposed algorithms over the algorithm in [14] mainly comes from the tightness of analysis.
For completeness of the comparison, we restate the feasible regions of algorithms in [13, 14] as follows.
Theorem 5 (Theorem 4 in [13]).
Consider the seeded Erdős–Rényi pair model . Suppose can be written as for some constants and such that
Assume that
| (19) |
Then there exists a polynomial-time algorithm, namely, Algorithm 2 in [13], that achieves exact alignment w.h.p. Moreover, the algorithm runs in time.
Theorem 6 (Theorem 3 in [13]).
Consider the seeded Erdős–Rényi pair model with for a fixed constant , and . Assume that
| (20) |
and
| (21) |
Then Algorithm III-C with the parameters
achieves exact alignment w.h.p. Moreover, the algorithm runs in time.
Theorem 7 (Theorem 2 in [14]).
Consider the seeded Erdős–Rényi pair model with and . Assume that
| (22) |
and
| (23) |
where denotes the mutual information between a pair of correlated edges in and . Then there exists a polynomial-time algorithm, namely, the TMS algorithm in [14], that achieves exact alignment w.h.p.
IV-C Specialization to the bipartite alignment
Consider an attributed Erdős–Rényi graph pair with or . Then and reduce to two bipartite graphs with edges connected only between users and attributes. In this special case, conditions (1) and (2) reduce to a single condition: If there exists some positive constant such that
| (24) |
then Algorithm AttrRich achieves exact alignment w.h.p. In contrast, Corollary 1 in [1] implies that the maximum likelihood estimator exactly recovers w.h.p if
| (25) |
Moreover, the maximum likelihood estimator can be computed in polynomial time by first computing the similarity score for each pair of vertices as and then solving the balanced assignment problem using the famous Hungarian Algorithm first proposed in [24]. From conditions (24) and (25), we can see that the feasible region of Algorithm AttrRich is completely covered by the feasible region of the Hungarian Algorithm. By the above argument, the maximum likelihood estimator requires time complexity to compute the similarity score for all pairs of vertices and the Hungarian Algorithm can be implemented with time complexity [25]. Therefore, if , the time complexity of the maximum likelihood estimator is and if , the time complexity of the maximum likelihood estimator is . In comparison, the time complexity of Algorithm AttrRich in this special case is always .
V Proof of Theorem 1
Recall that our algorithm consists of the following two steps: Step 1 (Align through attribute neighbors) produces a set that we refer to as the set of anchor pairs based on the defined in (6); Step 2 (Align through user neighbors) aligns the remaining vertices based on the defined in (7). Moreover, recall that we assume without generality that the true underlying permutation is the identity permutation. Our proof of Theorem 1 analyzes the following corresponding error events.
-
•
Step 1 Error Event. Define
The event guarantees that the anchor set found in the first step only contains correctly matched pairs.
-
•
Step 2 Error Events. Define
and
In the special case that , i.e., all the vertices are matched in Step 1, we set events and to be empty by convention and thus . In the case that , event corresponds to the event that all non-anchor vertices are correctly matched through their user neighbors.
We first show that implies that Algorithm AttrRich does not declare failure and it outputs . Under event , it follows that there exists no conflicting pairs in , so Algorithm AttrRich does not declare failure at Step 1 and for each vertex , we have . Furthermore, implies that . Now we consider two different cases to complete the proof.
-
•
: In this case, all the vertices are correctly aligned through attribute neighbors. Therefore, Algorithm AttrRich terminates at Step 1 and outputs .
-
•
: In this case, not all the vertices are aligned through attribute neighbors. Then event guarantees that for each , we have
and
Thus, the algorithm does not declare failure at Step 2 and we have for each , . Finally, it follows that is a bijection and .
Next, to prove Theorem 1, it suffices to show that . However, both events and are based on two random sets and . If we apply the union bound to upper bound the probability of and without any restriction on the size of and , the bound will be very loose. Our key idea of the proof is to analyze the error events of Step 2 by conditioning on a carefully chosen event. Specifically, let the set of vertex pairs correctly matched through attribute neighbors be denoted as
Note that since only counts the correctly matched pairs. Then we consider the following auxiliary event:
where (cf. the constant in Theorem 1). To prove that , it then suffices to prove that . Notice that event guarantees that the anchor set found in the first step only contains correctly matched pairs. It follows that event implies . Therefore, event restricts the size of the set , so we can apply a much tighter union bound to upper bound the probability of and if we condition on the event .
We now analyze . Note that
| (26) |
where (26) follows by the union bound. With Lemmas 1–4 below, it is easy to see that .
Lemma 1.
Consider with and . Assume that
Then
Lemma 2.
Consider with and . Assume that
Then
Lemma 3.
Consider with and . Assume there exists some constant such that
| (27) | ||||
| (28) |
Then .
Lemma 4.
Consider with and . Assume there exists some constant such that
| (29) | ||||
| (30) |
Then .
VI Proof of Theorem 2
Recall that Algorithm AttrSparse consists of the following two steps: In Step 1 (Align through attribute neighbors), the algorithm produces a set , which we refer to as the set of anchor pairs based on defined in (6); In Step 2 (Align through user neighbors), the algorithm performs two different processes depending on the sparsity of the user-user connections. In case when the user-user connection is sparse , the algorithm treats the anchors found in Step 1 as seeds and runs Algorithm III-C. In case the user-user connection is dense , the algorithm explores the anchor vertices in the one-hop neighborhood of each non-anchor user vertex to align them. To prove Theorem 2, we first consider two error events associated with Step 1, and then we separately consider the two different cases for Step 2.
Define
Event guarantees the anchors found in Step 1 only contain correctly matched pairs. Let
and define
Event guarantees the size of anchor set is large. Given , we first show that algorithm AttrSparse outputs the correct permutation w.h.p., i.e, . We consider two different cases for .
-
•
. Recall that in this regime of , Algorithm III-C is applied in Step 2. Notice that the choice of set only depends on the user-attribute edges, so it is independent of all user-user edges. Therefore, by symmetry, when we run Algorithm III-C, we can view the seed set as a set chosen uniformly at random over all subsets with size and thus Theorem 6 can directly be applied. So it suffices to show that the conditions in Theorem 6 are satisfied under event . Event implies that and event implies that . Moreover, because we assume that , we have by Theorem 6 with .
-
•
. Recall that in this regime of , we perform a similar process as Step 2 of Algorithm AttrRich. We align the non-anchor vertices by exploring the anchors in their one-hop neighborhood. Similarly to the analysis for Theorem 1, we define two error events associated with this steps. Define
and
From the proof of Theorem 1, we know that . Therefore, we have
The statement follows from the Lemma below.
Lemma 5.
Consider with and . Suppose that . Then we have
Lemma 6.
Consider with and . Suppose that . Then we have
Finally, we have
Lemma 7.
Consider with and . Assume that there exists some constant such that
| (31) |
Then .
Lemma 8.
Consider with and . Assume that
Then .
VII Proof of Lemmas
In this section, we prove the lemmas stated in the proofs of Theorems 1 and 2. To this end, we first state two technical lemmas that bound the binomial tail probability.
Lemma 9 (Theorem 1 in [26]).
Let . Then we have:
-
•
for ;
-
•
for ,
where denotes the the Kullback–Leibler divergence between and .
Lemma 10 (Lemma 4.7.2 in [27]).
Let . Then we have
for any .
The following lemma gives an approximation for the Kullback–Leibler divergence term in Lemmas 9 and 10.
Lemma 11.
(Approximation of KL-divergence) Assume that , , and . Then we have
| (32) | ||||
| (33) |
VII-A Proof of Lemma 1
Recall that we defined error event Here we prove under the assumption that . To bound the probability of , we first consider distribution of random variable . For two different vertices and such that , it follows from the definition of the model that . Moreover, notice that
because and . Now, we can upper bound the probability of error event as
| (34) | ||||
| (35) | ||||
| (36) | ||||
| (37) |
where (34) follows from the union bound, (35) follows from Lemma 9, (36) follows from Lemma 11 and (37) follows since constant .
VII-B Proof of Lemma 2
Recall that we defined auxiliary event , where . Here we prove under the assumption that . To show this, we first consider the distribution of random variable and upper bound the probability of event . For each vertex , it follows from the definition of the model that . Notice that
because and . We can upper bound the probability of the tail event using Lemma 9:
| (38) |
where (38) follows from Lemma 11. For simplicity, we denote by from this point. By (38) and the assumption that , we have .
Furthermore, notice that for each different , the random variable are independent and identically distributed. Therefore, the number of vertices with is distributed according to the Binomial distribution
By the upper bound (38), for any positive number , we have
| (39) |
Recall that , where is a positive constant. We have
| (40) | ||||
| (41) |
where (40) follows from (38), and (41) follows since . Finally, we can upper bound the probability of event as
| (42) | |||
| (43) | |||
| (44) | |||
| (45) | |||
| (46) |
where (42) follows from (39), (43) follows from Lemma 9, (44) follow from the Taylor expansion of the function and the fact that and , (45) follows since and finally, (46) follows from the fact that .
VII-C Proof of Lemma 3
Here we prove that the conditions (27) and (28) imply . Recall that we defined events
To analyze the conditional event , first notice that implies that only identical pairs are in the anchor set, i.e., . Thus, we obtain a simplified expression of the conditional event as
The condition on the auxiliary event further implies that the number of identical pairs that are not discovered in the anchor set is at most , i.e., . Here, recall that . We note that implies that the unmatched users set , which is taken care of by a separate analysis in the proof of Theorem 1. For the remaining analysis in this Lemma, we only consider the case where , and consequently we have .
Applying the union bound on the conditional error event, we have
| (47) | ||||
| (48) | ||||
| (49) |
In (47), we have as the upper limit in the summation because of conditioning on . Equation (48) follows from the union bound.
Next, we upper bound . Recall
counts the number of aligned anchor neighbors of a user vertex. To see the conditional distribution of , notice that conditioned on events and , the whole anchor set only contains identical pairs and is of size . Thus, we get the following simpler expression
Here this random variable is the summation of independent and identically distributed Bernoulli random variables. Each Bernoulli random variable takes value 1 when a pair of anchor vertices connect to vertex 1 in both and , and this happens with probability . We therefore have . To upper bound the probability in (49), we use the Chernoff bound from Lemma 9 and get
| (50) |
Plugging (50) into the previous (49), we finally have
| (51) | ||||
| (52) | ||||
| (53) | ||||
| (54) | ||||
Here (51) follows from the KL-divergence approximation (32) in Lemma 11. We get (52) by plugging in and applying assumption (28) . Equation (53) follows because . Equation (54) follows from the condition (27), which requires that for a constant .
VII-D Proof of Lemma 4
Here we prove that conditions (29) and (30) imply . The conditioned events here are exactly the same as those of Lemma 3, and we use a similar proof strategy. Recall that we defined the event
To analyze the conditional event , we reuse the same observation from the proof of Lemma 3, that only identical pairs are in the anchor set. Thus, we are able to simplify the expression as
where the number of unaligned identical pairs . Here, we also have , because implies that the unmatched users set , which is taken care of by a separate analysis in the proof of Theorem 1.
Applying the union bound on the conditional error event, we get
| (55) | ||||
| (56) |
Here we further upper bound in (56). Recall that
represents the number of aligned anchor neighbors of user vertex in and user vertex in , Notice that conditioned on events and , the anchor set only contains identical pairs and is of size . Thus, we get the following simpler expression
Here the random variable is the summation of independent and identically distributed Bernoulli random variables. Each Bernoulli random variable takes value 1 when a pair of anchor vertices in connect to vertex 1 in and vertex 2 in and this happens with probability . Therefore, we have . We then apply Chernoff bound in Lemma 9 and get
| (57) |
Plugging (57) into (56) , we have
| (58) | ||||
| (59) | ||||
| (60) | ||||
| (61) | ||||
| (62) |
Here (58) follows from the KL-divergence approximation formula (33) in Lemma 11. We get (59) by plugging in and applying assumption (30) . Equation (60) follows from the fact that , and condition that . Equation (61) follows from the condition (29).
VII-E Proof of Lemma 5
Recall that we defined events
Here we prove that under the assumption that . By the analogous argument as for equations (49) and (50) respectively, we have that
| (63) |
and
| (64) |
Finally, plugging equation (64) into equation (63) gives
| (65) | |||
| (66) |
where (65) follows from the KL-divergence approximation (32) in Lemma 11 and (66) follows because .
VII-F Proof of Lemma 6
Recall that we defined event
Here we prove that under the assumption that . By the analogous argument as for equations (56) and (57), we have that
| (67) |
and
| (68) |
Plugging equation (68) into equation (67) gives
| (69) | |||
| (70) |
where (69) follows from the KL-divergence approximation formula (33) in Lemma 11 and (70) follows because and .
VII-G Proof of Lemma 7
Recall that we defined error event . Here we prove under the assumption that . To bound the probability of , we first consider the distribution of random variable . For two different vertices and such that , it follows from the definition of the model that . Moreover, notice that
since . Therefore, we can upper bound the probability of error event as
| (71) | |||
| (72) | |||
| (73) | |||
where (71) follows by the union bound, (72) follows from Lemma 9, and (73) follows since in (5) we assume that and .
VII-H Proof of Lemma 8
Recall that we defined error event , where . Here we prove under the assumption that . To show this, we first consider the distribution of random variable and lower bound the probability of event . For each vertex , it follows from the definition of the model that . Notice that
We can lower bound the probability of the tail event using Lemma 10 as
| (74) | |||
| (75) |
where (74) follows since and that . Furthermore, notice that for each different , the random variable are independent and identically distributed. Therefore, the number of vertices with is distributed according to the Binomial distribution
By the lower bound (75), for any positive number , we have
| (76) |
Finally we can upper bound the probability of event as
| (77) | |||
| (78) | |||
VII-I Proof of Lemma 11
(1) Proof for equation (32): From the definition of the KL-divergence between and , we have
| (79) |
Here equation (VII-I) follows from the Taylor series for the logarithm for . Within the terms from (VII-I), we have that and , we thus get and . We therefore have
| (80) |
Here, the last equality (80) follows because .
VIII Detailed discussion in seeded alignment
In this section, we provide further details on the discussion in the seeded graph alignment problem in Section IV-B. We prove Remark 3 and Theorem 4 by comparing the feasible regions in Corollaries 1 and 2 to the information theoretic feasible region and the best known feasible region by efficient algorithms in literature.
VIII-A Comparison to the information-theoretic limits
Let us first compare the feasible region of Algorithms AttrRich and AttrSparse to the information theoretic limit of seeded alignment. The next corollary follows readily from Theorem 3.
Corollary 3 (Information-theoretic limits on seeded graph alignment).
Consider the seeded Erdős–Rényi pair model , with , , and .
Achievability:
In the regime where , if
| (84) |
then exact alignment is achievable w.h.p.
In the regime where , if
| (85) |
where
then exact alignment is achievable w.h.p.
Converse: If
then no algorithm achieves exact alignment w.h.p.
To compare the feasible region of Corollary 3 to the feasible regions of Corollaries 1 and 2, we consider two different regimes for .
-
1.
. In this regime, the feasible region in Corollary 3 is given by condition (84): . In Corollary 1, condition (15) requires that . Since we assume that , we can see that condition (15) implies condition (84). Therefore, the feasible region in Corollary 1 is a subset of the feasible region in Corollary 3.
-
2.
. In this regime, the feasible region in Corollary 3 is given by condition (85): . Since and , it follows that . Moreover, since and , we have . Therefore, condition (85) is satisfied and thus Corollary 3 applies in this regime while Corollaries 1 and 2 requires further conditions to apply. Therefore, the feasible regions in Corollaries 1 and 2 are both subsets of the feasible region in Corollary 3.
VIII-B Comparison to existing efficient algorithms
In this subsection, we prove Theorem 4 by thoroughly comparing the feasible region of the proposed algorithms in Corollaries 1 and 2 to that of the existing algorithms in Theorems 5, 6 and 7. We discuss three regimes for .
Case 1: . Recall that . Therefore, we have in this regime. For the discussion in this regime, we first show that both Corollaries 1 and 2 apply in this regime. We then show that the feasible region in Corollaries 1 and 2 extends the feasible region for exact alignment in Theorems 5, 6 and 7.
To see Corollary 1 applies in this regime, note that when , condition (14) implies condition (15) . Therefore, the feasible region in Corollary 1 simplifies to condition (14), which is non-empty when , and are large enough. To see Corollary 2 applies in this regime, we notice that conditions (16) and (17) together imply that which is exactly the case in this regime.
Now we move on to compare the feasible region in Corollaries 1 and 2 to that in Theorems 5, 6 and 7. We consider three different regimes for .
Case 1.1: . For this regime of , both Theorems 5 and 6 apply. We will show that the feasible regions in Corollaries 1 and 2 are covered by the feasible region in Theorem 6 to illustrate that the proposed algorithms do not introduce any new feasible region in this regime. In this and all later cases, we always set when we apply Theorem 6.
We first argue that the feasible region in Corollary 1 is a subset of that in Theorem 6. This is because condition (14) implies condition (21) under the assumption that and , and condition (15) implies condition (20) under the assumption that .
Now we move on to show that the feasible region in Corollary 2 is also a subset of that in Theorem 6. This is because conditions (17) and (18) together imply condition (21) under the assumption that and , and condition (17) implies condition (20) under the assumption that .
Case 1.2: . In this case, both Theorems 5 and 6 apply. We will show that the feasible regions in Corollaries 1 and 2 are covered by the feasible region in Theorem 5 to illustrate that the proposed algorithms do not introduce any new feasible region in this regime.
Firstly, we argue that the feasible region in Corollary 1 is a subset of that in Theorem 5. Note that because , we can write for some and such that and Because , we have . Then the statement follows because condition (14) implies condition (19) under the assumption that .
Now we move on to show that the feasible region in Corollary 2 is also covered by the feasible region in Theorem 5. This is because again we have and it follows that conditions (17) and (18) together imply condition (19) under that assumption that .
Case 1.3: . In this regime, Theorem 6 does not apply since . We compare the feasible regions in Corollaries 1 and 2 to those in Theorems 5 and 7 to show that the proposed algorithms strictly improve the best known feasible region in this regime.
To compare with the existing results, we first consider the feasible region achieved by the proposed algorithms. Because we are in the dense regime , conditions (15) and (17) are satisfied. Then conditions for Corollaries 1 and 2 reduce to constraints on . The constraint in Corollary 1 is given by (14) , and the constraint in Corollary 2 is given by (16) and (18), which can be written as . Taking the union of the two constraints on , the feasible region of the proposed algorithm simplifies to
| (86) |
Now, we move on to consider the feasible region in Theorem 5. Because , if we write for some and , we must have . Therefore, we have in this regime and the feasible region in Theorem 5 reduces to
| (87) |
From the above argument, we see that if condition (86) is satisfied while condition (87) and at least one of conditions (22) and (23) in Theorem 7 are not, then the proposed algorithms achieve exact w.h.p. while none of the existing works [13] and [14] do. In the following, we further consider three sub-cases for to discuss which one of conditions (22), (23) and (87) is the bottleneck condition in the existing works [13] and [14] and to see the range of that is feasible by the proposed algorithms while not by [13] and [14].
-
•
Suppose . In this sub-case, condition (23) implies condition (22) and condition (87) implies condition (23). Then the bottleneck condition is condition (23). Therefore, if condition (86) is satisfied and , the proposed algorithms achieve exact alignment w.h.p while the algorithms in [13] and [14] do not. Such exists because and thus .
-
•
Suppose and . In this sub-case, condition (22) implies condition (23) and condition (87) implies condition (22). Then the bottleneck condition is condition (22). Therefore, if condition (86) is satisfied and , the proposed algorithms achieve exact alignment w.h.p while the algorithms in [13] and [14] do not. Such exists because under the assumption that .
-
•
Suppose . In this sub-case, condition (22) implies condition (23) and condition (22) implies condition (87) . Then the bottleneck condition is condition (87). Therefore, if condition (86) is satisfied and , the proposed algorithms achieve exact alignment w.h.p while the algorithms in [13] and [14] do not. Such exists because .
To summarize, in the regime of , the proposed Algorithms AttrRich and AttrSparse together strictly improve the best known feasible region for exact alignment when . In the other two regimes for , the feasible region of the proposed algorithms is a strict subset of that in [13].
Case 2: and for some positive constant that satisfies and (cf. the constant in Corollary 1). In this regime, we have . For the discussion in this regime, we first show that Corollary 1 applies in this regime while Corollary 2 does not. We then show that the feasible region in Corollary 1 is a subset of the feasible regions in Theorems 5 and 6 from existing work [13].
Since we have , it follows that implies , i.e., condition (15) implies (14). Therefore, the feasible region in Corollary 1 simplifies to condition (15) which holds true when and are large enough. As we argued in Case 1, Corollary 2 requires , so Corollary 2 does not apply in this regime.
Now we move on to compare the feasible region in Corollary 1 to that in Theorems 5 and 6. We further consider two different regimes for .
Case 2.1: . We can see that Theorem 6 applies in this regime since . Condition (21) is satisfied without any further assumptions since . Moreover, condition (15) implies condition (20) under the assumption that and thus the feasible region in Corollary 1 is a subset of the feasible region in Theorem 6.
Case 2.2: . Since and we assume that , we can write , where , , and . Therefore, Theorem 5 applies in this regime. Furthermore, condition (19) in Theorem 5 is satisfied since . We can see that all the conditions in Theorem 5 are satisfied in this regime without any further assumptions.
For Corollary 1, we have , i.e., condition (15) is satisfied. We can see that all conditions in Corollary 1 are also satisfied in this regime without any further assumptions.
To summarize, in the regime and , the feasible region of the proposed algorithms is a subset of the feasible region given by existing work [13].
Case 3: . In this regime, we have . For the same reason as in Case 2, Corollary 1 applies while Corollary 2 does not. We will show that the feasible region in Corollary 1 extends the best known region for exact alignment in Theorems 5, 6 and 7. We discuss two regimes for . Case 3.1: . We first point out that Theorem 7 does not apply in this regime. This is because and , so condition (22) cannot be satisfied. Therefore, we focus on showing that the feasible region in Corollary 1 strictly improves in the feasible regions in Theorem 6. This is because is equivalent as , and it follows that condition (20) implies condition (15) . So in the case when and the proposed Algorithm AttrRich achieves exact alignment w.h.p., while the algorithms in [13] does not.
Case 3.2: . This case is included in the feasible region of both Corollary 1 and Theorem 5 for the same reason as in Case 2. Theorem 7 further requires conditions (22) and (23) to apply in this regime.
To summarize, in the regime , the proposed Algorithm AttrRich strictly improves the best known feasible region for exact alignment in the case when . In the case when , the feasible region by the proposed algorithms is a subset of that in existing literature [13].
From the above discussion, when specialized to the seeded Erdős–Rényi graph pair model, the feasible region in Corollaries 1 and 2 strictly improves the best known feasible region in [13] and [14], as shown in the blue area in Fig. 4. We note, however, that there is also some region that is feasible by existing results but not feasible by the proposed algorithms in this paper, as shown in the red area in Fig. 4.
Acknowledgment
This work was supported in part by the NSERC Discovery Grant No. RGPIN-2019-05448, the NSERC Collaborative Research and Development Grant CRDPJ 54367619, and the NSF grant CNS-2007733.
References
- Zhang et al. [2021] N. Zhang, W. Wang, and L. Wang, “Attributed graph alignment,” in Proc. IEEE Internat. Symp. Inf. Theory, 2021, pp. 1829–1834.
- Pedarsani and Grossglauser [2011] P. Pedarsani and M. Grossglauser, “On the privacy of anonymized networks,” in Proc. Ann. ACM SIGKDD Conf. Knowledge Discovery and Data Mining (KDD), 2011, pp. 1235–1243.
- Cullina and Kiyavash [2016] D. Cullina and N. Kiyavash, “Improved achievability and converse bounds for Erdős-Rényi graph matching,” ACM SIGMETRICS Perform. Evaluation Rev., vol. 44, no. 1, p. 63–72, June 2016.
- Cullina and Kiyavash [2017] D. Cullina and N. Kiyavash, “Exact alignment recovery for correlated Erdős-Rényi graphs,” 2017. [Online]. Available: https://arxiv.org/abs/1711.06783
- Wu et al. [2022] Y. Wu, J. Xu, and S. H. Yu, “Settling the sharp reconstruction thresholds of random graph matching,” IEEE Transactions on Information Theory, vol. 68, no. 8, pp. 5391–5417, 2022.
- Dai et al. [2019] O. Dai, D. Cullina, N. Kiyavash, and M. Grossglauser, “Analysis of a canonical labeling algorithm for the alignment of correlated erdős-rényi graphs,” ACM SIGMETRICS Perform. Evaluation Rev., vol. 47, pp. 96–97, 12 2019.
- Ding et al. [2021] J. Ding, Z. Ma, Y. Wu, and J. Xu, “Efficient random graph matching via degree profiles,” Probability Theory and Related Fields, vol. 179, pp. 29–115, 2021.
- Fan et al. [2020] Z. Fan, C. Mao, Y. Wu, and J. Xu, “Spectral graph matching and regularized quadratic relaxations: Algorithm and theory,” in Proceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, H. D. III and A. Singh, Eds., vol. 119. PMLR, 13–18 July 2020, pp. 2985–2995.
- Mao et al. [2023a] C. Mao, M. Rudelson, and K. Tikhomirov, “Exact matching of random graphs with constant correlation,” Probability Theory and Related Fields, vol. 186, no. 1-2, pp. 327–389, 2023.
- Mao et al. [2023b] C. Mao, Y. Wu, J. Xu, and S. H. Yu, “Random graph matching at otter’s threshold via counting chandeliers,” in Proceedings of the 55th Annual ACM Symposium on Theory of Computing, 2023, pp. 1345–1356.
- Korula and Lattanzi [2014] N. Korula and S. Lattanzi, “An efficient reconciliation algorithm for social networks,” Proc. VLDB Endow., vol. 7, no. 5, p. 377–388, jan 2014.
- Yartseva and Grossglauser [2013] L. Yartseva and M. Grossglauser, “On the performance of percolation graph matching,” in Proceedings of the First ACM Conference on Online Social Networks, ser. COSN ’13. New York, NY, USA: Association for Computing Machinery, 2013, p. 119–130. [Online]. Available: https://doi.org/10.1145/2512938.2512952
- Mossel and Xu [2020] E. Mossel and J. Xu, “Seeded graph matching via large neighborhood statistics,” Random Structures & Algorithms, vol. 57, no. 3, pp. 570–611, 2020.
- Shirani et al. [2017] F. Shirani, S. Garg, and E. Erkip, “Seeded graph matching: Efficient algorithms and theoretical guarantees,” in Proc. Asilomar Conf. Signals, Systems, and Computers, 2017, pp. 253–257.
- Zhang and Tong [2016] S. Zhang and H. Tong, “Final: Fast attributed network alignment,” in Proc. Ann. ACM SIGKDD Conf. Knowledge Discovery and Data Mining (KDD), ser. KDD ’16. New York, NY, USA: Association for Computing Machinery, 2016, p. 1345–1354.
- Zhang and Tong [2019] ——, “Attributed network alignment: Problem definitions and fast solutions,” Proc. IEEE Trans. Knowl. Data Eng., vol. 31, no. 9, pp. 1680–1692, 2019.
- Zhou et al. [2021] Q. Zhou, L. Li, X. Wu, N. Cao, L. Ying, and H. Tong, Attent: Active Attributed Network Alignment. New York, NY, USA: Association for Computing Machinery, 2021, p. 3896–3906.
- Yu [2023] S. H. Yu, “Matching in networks: Fundamental limits and efficient algorithms,” Ph.D. dissertation, Duke University, 2023.
- Mao et al. [2022] C. Mao, Y. Wu, J. Xu, and S. H. Yu, “Testing network correlation efficiently via counting trees,” arXiv preprint arXiv:2110.11816, 2022.
- Onaran et al. [2016] E. Onaran, S. Garg, and E. Erkip, “Optimal de-anonymization in random graphs with community structure,” in 2016 50th Asilomar Conference on Signals, Systems and Computers, 2016, pp. 709–713.
- Cullina et al. [2016] D. Cullina, K. Singhal, N. Kiyavash, and P. Mittal, “On the simultaneous preservation of privacy and community structure in anonymized networks,” arXiv preprint arXiv:1603.08028, 2016.
- Lyzinski et al. [2015] V. Lyzinski, D. E. Fishkind, M. Fiori, J. T. Vogelstein, C. E. Priebe, and G. Sapiro, “Graph matching: Relax at your own risk,” IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 1, pp. 60–73, 2015.
- Zhang et al. [2023] N. Zhang, Z. Wang, W. Wang, and L. Wang, “Attributed graph alignment,” 2023. [Online]. Available: https://arxiv.org/abs/2102.00665
- Kuhn and Yaw [1955] H. W. Kuhn and B. Yaw, “The Hungarian method for the assignment problem,” Naval Res. Logist. Quart, pp. 83–97, 1955.
- Munkres [1957] J. Munkres, “Algorithms for the assignment and transportation problems,” Journal of the Society for Industrial and Applied Mathematics, vol. 5, no. 1, pp. 32–38, 1957. [Online]. Available: http://www.jstor.org/stable/2098689
- Hoeffding [1963] W. Hoeffding, “Probability inequalities for sums of bounded random variables,” Journal of the American Statistical Association, vol. 58, no. 301, pp. 13–30, 1963.
- Ash [1990] R. Ash, Information Theory, ser. Dover books on advanced mathematics. Dover Publications, 1990.