On the Convergence to a Global Solution of Shuffling-Type Gradient Algorithms
Abstract
Stochastic gradient descent (SGD) algorithm is the method of choice in many machine learning tasks thanks to its scalability and efficiency in dealing with large-scale problems. In this paper, we focus on the shuffling version of SGD which matches the mainstream practical heuristics. We show the convergence to a global solution of shuffling SGD for a class of non-convex functions under over-parameterized settings. Our analysis employs more relaxed non-convex assumptions than previous literature. Nevertheless, we maintain the desired computational complexity as shuffling SGD has achieved in the general convex setting.
1 Introduction
In the last decade, neural network-based models have shown great success in many machine learning applications such as natural language processing (Collobert and Weston, 2008; Goldberg et al., 2018), computer vision and pattern recognition (Goodfellow et al., 2014; He and Sun, 2015). The training task of many learning models boils down to the following finite-sum minimization problem:
| (1) |
where is smooth and possibly non-convex for . Solving the empirical risk minimization (1) had been a difficult task for a long time due to the non-convexity and the complicated learning models. Later progress with stochastic gradient descent (SGD) and its variants (Robbins and Monro, 1951; Duchi et al., 2011; Kingma and Ba, 2014) have shown great performance in training deep neural networks. These stochastic first-order methods are favorable thanks to its scalability and efficiency in dealing with large-scale problems. At each iteration SGD samples an index uniformly from the set , and uses the individual gradient to update the weight.
While there has been much attention on the theoretical aspect of the traditional i.i.d. (independently identically distributed) version of SGD (Nemirovski et al., 2009; Ghadimi and Lan, 2013; Bottou et al., 2018), practical heuristics often use without-replacement data sampling schemes. Also known as shuffling sampling schemes, these methods generate some random or deterministic permutations of the index set and apply gradient updates using these permutation orders. Intuitively, a collection of such individual updates is a pass over all the data, or an epoch. One may choose to create a new random permutation at the beginning of each epoch (in Random Reshuffling scheme) or use a random permutation for every epoch (in Single Shuffling scheme). Alternatively, one may use a Incremental Gradient scheme with a fixed deterministic order of indices. In this paper, we use the term unified shuffling SGD for SGD method using any data permutations, which includes the three special schemes described above.
Although shuffling sampling schemes usually show a better empirical performance than SGD (Bottou, 2009), the theoretical guarantees for these schemes are often more limited than vanilla SGD version, due to the lack of statistical independence. Recent works have shown improvement in computational complexity for shuffling schemes over SGD in various settings (Gürbüzbalaban et al., 2019; Haochen and Sra, 2019; Safran and Shamir, 2020; Nagaraj et al., 2019; Nguyen et al., 2021; Mishchenko et al., 2020; Ahn et al., 2020). In particular, in a general non-convex setting, shuffling sampling schemes improve the computational complexity in terms of for SGD from to , where is the bounded variance constant (Ghadimi and Lan, 2013; Nguyen et al., 2021; Mishchenko et al., 2020)111The computational complexity is the number of (individual) gradient computations needed to reach an -accurate stationary point (i.e. a point that satisfies .) . We summarize the detailed literature for multiple settings later in Table 1.
While global convergence is a desirable property for neural network training, the non-convexity landscape of complex learning models leads to difficulties in finding the global minimizer. In addition, there is little to no work studying the convergence to a global solution of shuffling-type SGD algorithms for a general non-convex setting. The closest line of research investigates the Polyak-Lojasiewicz (PL) condition (a generalization of strong-convexity), which demonstrates similar convergence rates as the strongly convex rates for shuffling SGD methods (Haochen and Sra, 2019; Ahn et al., 2020; Nguyen et al., 2021). In another direction, Gower et al. (2021) and Khaled and Richtárik (2020) investigates the global convergence for some class of non-convex functions, however for vanilla SGD method. Beznosikov and Takáč (2021) investigate a random shuffle version of variance reduction methods (e.g. SARAH algorithm Nguyen et al. (2017)), but this approach only can show convergence to stationary points. With a target on shuffling SGD methods and specific learning architectures, we come up with the central question of this paper:
How can we establish the convergence to global solution for a class of non-convex functions using shuffling-type SGD algorithms? Can we exploit the structure of neural networks to achieve this goal?
We answer this question affirmatively, and our contributions are summarized below.
Contributions.
-
•
We investigate a new framework for the convergence of a shuffling-type gradient algorithm to a global solution. We consider a relaxed set of assumptions and discuss their relations with previous settings. We show that our average-PL inequality (Assumption 3) holds for a wide range of neural networks equipped with squared loss function.
-
•
Our analysis generalizes the class function called star--smooth-convex. This class contains non-convex functions and is more general than the class of star-convex smooth functions with respect to the minimizer (in the over-parameterized settings). In addition, our analysis does not use any bounded gradient or bounded weight assumptions.
-
•
We show the total complexity of for a class of non-convex functions to reach an -accurate global solution. This result matches the same gradient complexity to a stationary point for unified shuffling methods in non-convex settings, however, we are able to show the convergence to a global minimizer.
1.1 Related Work
In recent years, there have been different approaches to investigate the global convergence for machine learning optimization. This includes a popular line of research that studies some specific neural networks and utilizes their architectures. The most early works show the global convergence of Gradient Descent (GD) for simple linear networks and two-layer networks (Brutzkus et al., 2018; Soudry et al., 2018; Arora et al., 2019; Du et al., 2019b). These results are further extended to deep learning architectures (Allen-Zhu et al., 2019; Du et al., 2019a; Zou and Gu, 2019). This line of research continues with Stochastic Gradient Descent (SGD) algorithm, which proves the global convergence of SGD for deep neural networks for some probability depending on the initialization process and the number of input data (Brutzkus et al., 2018; Allen-Zhu et al., 2019; Zou et al., 2018; Zou and Gu, 2019). The common theme that appeared in most of these references is the over-parameterized setting, which means that the number of parameters in the network are excessively large (Brutzkus et al., 2018; Soudry et al., 2018; Allen-Zhu et al., 2019; Du et al., 2019a; Zou and Gu, 2019). This fact is closely related to our setting, and we will discuss it throughout our paper.
Polyak-Lojasiewicz (PL) condition and related assumptions. An alternative approach is to investigate some conditions on the optimization problem that may guarantee global convergence. A popular assumption is the Polyak-Lojasiewicz (PL) inequality, a generalization of strong-convexity (Polyak, 1964; Karimi et al., 2016; Nesterov and Polyak, 2006). Using this PL assumption, it can be shown that (stochastic) gradient descent achieves the same theoretical rate as in the strongly convex setting (i.e linear convergence for GD and sublinear convergence for SGD) (Karimi et al., 2016; De et al., 2017; Gower et al., 2021). Recent works demonstrate similar results for shuffling type SGD (Haochen and Sra, 2019; Ahn et al., 2020; Nguyen et al., 2021), both for unified and randomized shuffling schemes. On the other hand, (Schmidt and Roux, 2013; Vaswani et al., 2019) propose to use a new assumption called the Strong Growth Condition (SGC) that controls the rates at which the stochastic gradients decay comparing to the full gradient. This condition implies that the stochastic gradients and their variances converge to zero at the optimum solution (Schmidt and Roux, 2013; Vaswani et al., 2019). While the PL condition for implies that every stationary point of is also a global solution, the SGC implies that such a point is also a stationary point of every individual function. However, complicated models as deep feed-forward neural networks generally have non-optimal stationary points (Karimi et al., 2016). Thus, these assumptions are somewhat strong for non-convex settings.
Although there are plenty of works investigating the PL condition for the objective function (De et al., 2017; Vaswani et al., 2019; Gower et al., 2021), not many materials devoted to study the PL inequality for the individual functions . A recent work (Sankararaman et al., 2020) analyzes SGD with the specific notion of gradient confusion for over-parameterized settings where the individual functions satisfy PL condition. They show that the neighborhood where SGD converges linearly depends on the level of gradient confusion (i.e. how much the individual gradients are negatively correlated). Taking a different approach, we investigate the PL property for individual functions and further show that our condition holds for a general class of neural networks with quadratic loss.
Over-paramaterized settings for neural networks. Most of the modern learning architectures contain deep and large networks, where the number of parameters are often far more than the number of input data. This leads to the fact that the objective loss function is trained closer and closer to zero. Understandably, in such settings all the individual functions are minimized simultaneously at 0 and they share a common minimizer. This condition is called the interpolation property (see e.g. (Schmidt and Roux, 2013; Ma et al., 2018; Meng et al., 2020; Loizou et al., 2021)) and is studied well in the literature (see e.g. (Zhou et al., 2019; Gower et al., 2021)). For a comparison, functions satisfying the strong growth condition necessarily satisfy the interpolation property. This property implies zero variance of individual gradients at the global minimizer, which allows good behavior for SGD near the solution. In this work, we slightly change this assumption which requires a small variance up to some level of the threshold . Note that when letting , our assumption exactly recovers the interpolation property.
Star-convexity and related conditions. There have been many attentions to a class of structured non-convex functions called star-convex (Nesterov and Polyak, 2006; Lee and Valiant, 2016; Bjorck et al., 2021). Star-convexity can be understood as convexity between an arbitrary point and the global minimizer . The name star-convex comes from the fact that each sublevel set is star-shaped (Nesterov and Polyak, 2006; Lee and Valiant, 2016). Zhou et al. (2019) shows that if SGD follows a star-convex path and there exists a common global minimizer for all component functions, then SGD converges to a global minimum.
In recent progress, Hinder et al. (2020) considers the class of quasar-convex functions, which further generalizes star-convexity. This property was introduced originally in (Hardt et al., 2018) under the name ‘weakly quasi-convex’, and investigated recently in literature (Hinder et al., 2020; Jin, 2020; Gower et al., 2021). This class uses a parameter to control the non-convexity of the function, where yeilds the star-convexity and approaches indicates more non-convexity (Hinder et al., 2020). Intuitively, quasar-convex functions are unimodal on all lines that pass through a global minimizer. Gower et al. (2021) investigates the performance of SGD for smooth and quasar-convex functions using an expected residual assumption (which is comparable to the interpolation property). They show a convergence rate of for i.i.d. sampling SGD with the number of total iterations , which translates to the computational complexity of . To the best of our knowledge, this paper is the first work studying the relaxation of star-convexity and global convergence for SGD with shuffling sample schemes, not for the i.i.d. version.
2 Theoretical Setting
We first present the shuffling-type gradient algorithm below. Our convergence results hold for any permutation of the training data , including deterministic and random ones. Thus, our theoretical framework is general and applicable for any shuffling strategy, including Incremental Gradient, Single Shuffling, and Random Reshuffling.
We further specify the choice of learning rate in the detailed analysis. Now we proceed to describe the set of assumptions used in our paper.
Assumption 1.
Suppose that , .
Assumption 2.
Suppose that is -smooth for all , i.e. there exists a constant such that:
| (2) |
Assumption 1 is required in any algorithm to guarantee the well-definedness of (1). In most applications, the component losses are bounded from below. By Assumption 2, the objective function is also -smooth. This Lipschitz smoothness Assumption is widely used for gradient-type methods. In addition, we denote the minimum value of the objective function . It is worthy to note the following relationship between and the component minimum values:
| (3) |
We are interested in the case where the set of minimizers of is not empty. The equality attains if and only if a minimizer of is also the common minimizer for all component functions. This condition implies that the variance of individual functions is 0 at the common minimizer.
2.1 PL Condition for Component Functions
Now we are ready to discuss the Polyak-Lojasiewicz condition as follows.
Definition 1 (Polyak-Lojasiewicz condition).
We say that satisfies Polyak-Lojasiewicz (PL) inequality for some constant if
| (4) |
where .
The PL condition for the objective function is sufficient to show a global convergence for (stochastic) gradient descent (Karimi et al., 2016; Nesterov and Polyak, 2006; Polyak, 1964). It is well known that a function satisfying the PL condition is not necessarily convex (Karimi et al., 2016). However, this assumption on is somewhat strong because it implies that every stationary point of is also a global minimizer. Our goal is to consider a class of non-convex function which is more relaxed than the PL condition on , while still having the good global convergence properties. In this paper, we formulated an assumption called “average PL inequality”, specifically for the finite sum setting:
Assumption 3.
Suppose that satisfies average PL inequality for some constant such that
| (5) |
where .
Comparisons. Assumption 3 is weaker than assuming the PL inequality for every component function . In general setting, Assumption 3 is not comparable to assuming the PL inequality for . Formally, if satisfies PL the condition for some parameter , then we have:
| (6) |
However, by equation (3) we have that . Therefore, the PL inequality for each function , cannot directly imply the PL condition on and vice versa.
In the interpolated setting where there is a common minimizer for all component function , it can be shown that the PL condition on is stronger than our average PL assumption:
On the other hand, our assumption cannot imply the PL inequality on unless we impose a strong relationship that upper bound the sum of individual squared gradients in terms of the full squared gradient , for every . For these reasons, the average PL Assumption 3 is arguably more reasonable than assuming the PL inequality for the objective function . Moreover, we show that Assumption 3 holds for a general class of neural networks with a final bias layer and squared loss function. We have the following theorem.
Theorem 1.
Let is a training data set where is the input data and is the output data for . We consider an architecture with be the vectorized weight and consists of a final bias layer :
where and are some inner architectures, which can be chosen arbitrarily. Next, we consider the squared loss . Then
| (7) |
where .
Therefore, for this application, Assumption 3 holds with .
2.2 Small Variance at Global Solutions
In this section, we change the interpolation property in previous literature (Ma et al., 2018; Meng et al., 2020; Loizou et al., 2021) by a small threshold. For any global solution of , let us define
| (8) |
We can show that when there is a common minimizer for all component functions (i.e. when the equality holds), the best variance is 0. It is sufficient for our Theorem to impose a -level upper bound on the variance :
Assumption 4.
Suppose that the best variance at is small, that is, for
| (9) |
for some .
It is important to note that in current non-convex literature, Assumption 4 alone (or, assuming alone) is not sufficient enough to guarantee a global convergence property for SGD. Typically, some other conditions on the good landscape of the loss function are needed to complement the over-parameterized setting. Thus, we have motivation to introduce our next assumption.
2.3 Generalized Star-Smooth-Convex Condition for Shuffling Type Algorithm
We introduce the definition of star-smooth-convex function as follows.
Definition 2.
The function is star--smooth-convex with respect to a reference point if
| (10) |
It is well known that when is -smooth and convex (Nesterov, 2004), we have the following general inequality for every :
| (11) |
Our class of star-smooth-convex function requires a similar inequality to hold only for the special point . Interestingly, this is related to a class of star-convex functions, which satisfies the convex inequality for the minimizer :
| (12) |
This class of functions contains non-convex objective losses and is well studied in the literature (see e.g. (Zhou et al., 2019)). Our Lemma 1 shows that the class of star-smooth-convex function is broader than the class of -smooth and star-convex functions. Therefore, our problem of interest is non-convex in general.
Lemma 1.
The function is star--smooth-convex with respect to for some constant if one of the two following conditions holds:
-
1.
is -smooth and convex.
-
2.
is -smooth and is star-convex with respect to .
Proof.
The first statement of Lemma 1 follows directly from equation (11). We have that is star--smooth-convex with respect to any reference point and .
Now we proceed to the second statement. From the star-convex property of with respect to , we have
and since is the global minimizer of . On the other hand, is -smooth and we have
which is equivalent to , . Since , , we have for
This is a star--smooth-convex function as in Definition 2 with . ∎
For the analysis of shuffling type algorithm in this paper, we consider the general assumption called the generalized star-smooth-convex condition for shuffling algorithms:
Assumption 5.
Using Algorithm 1, let us assume that there exist some constants and such that at each epoch , we have for :
| (13) |
where is a global solution of .
We note that it is sufficient for our analysis to assume the case , i.e. the individual function is star--smooth-convex with respect to for every as in Definition 2. In that case, the assumption does not depend on the algorithm progress.
Assumption 5 is more flexible than the star--smooth-convex one in (10) because an additional term for some constant allows for extra flexibility in our setting, where the right-hand side term could be negative for some .
Note that we do not impose any assumptions on bounded weights or bounded gradients. Therefore, the term cannot be uniformly bounded by any universal constant.
3 New Framework for Convergence to a Global Solution
In this section, we present our theoretical results. Our Lemma 2 first provides a recursion to bound the squared distance term :
Lemma 2.
Rearranging the results of Lemma 2, we have
| (16) |
Therefore, with an appropriate choice of learning rate that guarantee , we can unroll the recursion from Lemma 2. Thus we have our main result in the next Theorem.
Theorem 2.
Our analysis holds for arbitrarily constant values of the parameters and . In addition, we show our current analysis for every shuffling scheme. An interesting research question arises: whether the convergence results can be improved if one chooses to analyze a randomized shuffling scheme in this framework. However, we leave that question to future works.
Corollary 1.
Suppose that the conditions in Theorem 2 and Assumption 4 hold. Choose and such that with the constants
Then, the we need epochs to guarantee
| Settings | References | Complexity | Shuffling Schemes | Global Solution |
|---|---|---|---|---|
| Convex | Nemirovski et al. (2009); Shamir and Zhang (2013) (1) | ✗ | ✓ | |
| Mishchenko et al. (2020); Nguyen et al. (2021) (2) | ✓ | ✓ | ||
| PL condition | Nguyen et al. (2021) | ✓ | ✓ | |
| Star-convex related | Gower et al. (2021) (3) | ✗ | ✓ | |
| Non-convex | Ghadimi and Lan (2013) (5) | ✗ | ✗ | |
| Nguyen et al. (2021); Mishchenko et al. (2020) (5) | ✓ | ✗ | ||
| Our setting (non-convex) | This paper, Corollary 1(4) | ✓ | ✓ |
(0) We note that the assumptions in this table are not comparable and we only show the roughly complexity in terms of . In addition, to make fair comparisons, we only report the complexity of unified shuffling schemes.
(1) Standard results for SGD in convex literature often use a different set of assumptions from the one in this paper (e.g. bounded domain that for each iterate and/or bounded gradient that ). We report the corresponding complexity for a rough comparison.
(2) (Mishchenko et al., 2020) shows a bound for Incremental Gradient while (Nguyen et al., 2021) has a unified setting. We translate these results for unified shuffling schemes from these references to the convex setting.
(3) Since we cannot find a reference containing the convergence rate for vanilla SGD and star-convex functions, we adapt the reference Gower et al. (2021) here. This paper shows a result for -smooth and quasar convex function with an additional Expected Residual (ER) assumption, which is weaker than assuming smoothness for and interpolation property. The star-convex results hold when the quasar-convex parameter is 1.
(4) Since we use a different set of assumptions than the other references, we only report the rough comparison in and , where is the constant from Assumption 5 and . Note that in the framework of star-smooth-convex function. In addition, we need so that the complexity holds with arbitrary .
We explain the detailed complexity below and in the Appendix.
(5) Standard literature for SGD in non-convex setting assumes a bounded variance that , we report the rough comparison.
Computational complexity. Our global convergence result in this Corollary holds for a fixed value of in Assumption 4. Thus, when , this assumption is equivalent to assuming . The total complexity of Corollary 1 is . This rate matches the best known rate for unified sampling schemes for SGD in convex setting (Mishchenko et al., 2020; Nguyen et al., 2021). However, our result holds for a broader class of functions that are possibly non-convex. Comparing to the non-convex setting, current literature (Mishchenko et al., 2020; Nguyen et al., 2021) also matches our rate to the order of , however, we can only prove that SGD converges to a stationary point with a weaker criteria for general non-convex funtions. Table 1 shows these comparisons in various settings. Note that when using a randomized shuffling scheme, SGD often performs a better rate in terms of the data in various settings with and without (strongly) convexity. For example, in strongly convex and/or PL setting, the convergence rate of RR is , which is better than unified schemes with (Ahn et al., 2020). However, for a fair comparison, we do not report these results in Table 1 as our theoretical analysis is derived for unified shuffling scheme.
If we further assume that , the detailed complexity with respect to these constants is
We present all the detailed proofs in the Appendix. Our theoretical framework is new and adapted to the finite-sum minimization problem. Moreover, it utilizes the choice of shuffling sample schemes to show a better complexity in terms of than the complexity of vanilla i.i.d. sampling scheme.
4 Numerical Experiments
In this section, we show some experiments for shuffling-type SGD algorithms to demonstrate our theoretical results of convergence to a global solution. Following the setting of Theorem 1, we consider the non-convex regression problem with squared loss function. We choose fully connected neural networks in our implementation. We experiment with different regression datasets: the Diabetes dataset from sklearn library (Efron et al., 2004; Pedregosa et al., 2011) with 442 samples in dimension 10; the Life expectancy dataset from WHO (Repository, 2016) with 1649 trainable data points and 19 features. In addition, we test with the California Housing data from StatLib repository (Repository, 1997; Pedregosa et al., 2011) with a training set of 16514 samples and 8 features.
For the small Diabetes dataset, we use the classic LeNet-300-100 model (LeCun et al., 1998). For other larger datasets, we use similar fully connected neural networks with an additional starting layer of 900 neurons. We apply the randomized reshuffling scheme using PyTorch framework (Paszke et al., 2019). This shuffling scheme is the common heuristic in training neural networks and is implemented in many deep learning platforms (e.g. TensorFlow, PyTorch, and Keras (Abadi et al., 2015; Paszke et al., 2019; Chollet et al., 2015)).
For each dataset , we preprocess and modify the initial data lightly to guarantee the over-parameterized setting in our experiment i.e. in order to make sure that there exists a solution that interpolates the data. We do this by using a pre-training stage: firstly we use GD/SGD algorithm to find a weight that yields a sufficiently small value for the loss function (for Diabetes dataset we train to and for other datasets we train to ). Letting the input data be fixed, we change the label data to such that the weight yields a small loss function for the optimization associated with data , and the distance between and is small. Then the modified data is ready for the next stage. We summarize the data (after modification) in our experiments in Table 2.
| Data name | # Samples | # Features | Networks layers | Sources |
|---|---|---|---|---|
| Diabetes | 442 | 10 | 300-100 | Efron et al. (2004) |
| Life Expectancy | 1649 | 19 | 900-300-100 | Repository (2016) |
| California Housing | 16514 | 8 | 900-300-100 | Repository (1997) |
For each dataset, we first tune the step size using a coarse grid search for 100 epochs. Then, for example, if 0.01 performs the best, we test the second grid search for 5000 epochs. Finally, we progress to the training stage with epochs and repeat that experiment for 5 random seeds. We report the average results with confidence intervals in Figure 1.
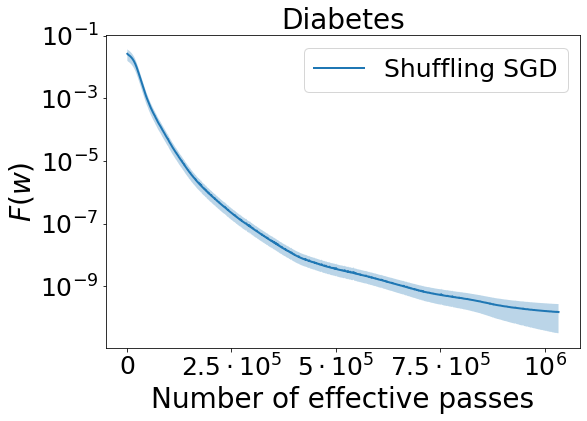
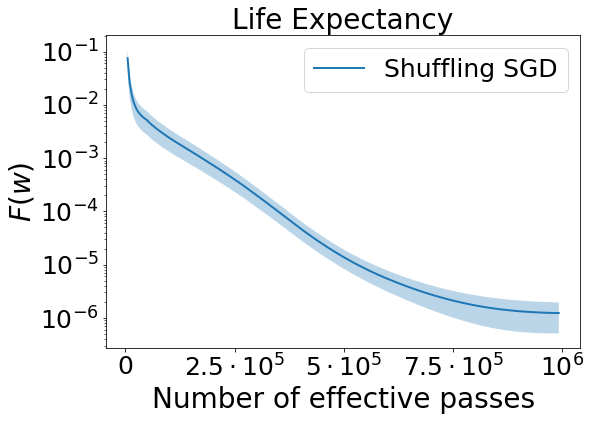
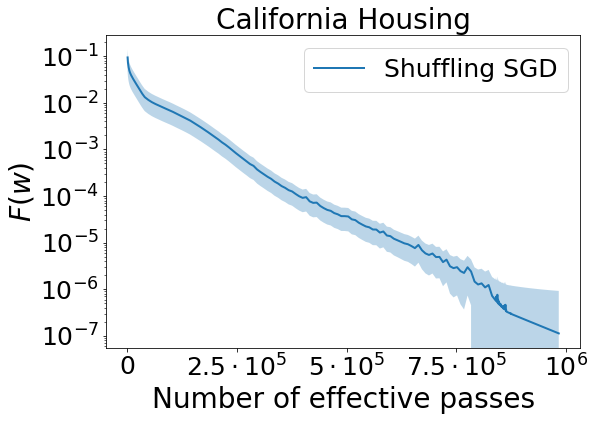
For California Housing data, Shuffling SGD fluctuates toward the end of the training process. Nevertheless, for all three datasets it converges steadily to a small value of loss function. In summary, this experiment confirms our theoretical guarantee that demonstrates a convergence to global solution for shuffling-type SGD algorithm in neural network settings.
5 Conclusion and Future Research
In this paper, our focus is on investigating the global convergence properties of shuffling-type SGD methods. We consider a more relaxed set of assumptions in the framework of star-smooth-convex functions. We demonstrate that our approach achieves a total complexity of to attain an -accurate global solution. Notably, this result aligns with the previous computational complexity of unified shuffling methods in non-convex settings, while ensuring that the algorithm converges to a global solution. Our theoretical framework revolves around the shuffling sample schemes for finite-sum minimization problems in machine learning.
We also provide insights into the relationships between our framework and well-established over-parameterized settings, as well as the existing literature on the star-convexity class of functions. Furthermore, we establish connections with neural network architectures and explore how these learning models align with our theoretical optimization frameworks.
This paper prompts several intriguing research questions, including practical network designs and more relaxed theoretical settings that can support the global convergence of shuffling SGD methods. Additionally, extending the global convergence framework to other stochastic gradient methods (Duchi et al., 2011; Kingma and Ba, 2014) and variance reduction methods (Le Roux et al., 2012; Defazio et al., 2014; Johnson and Zhang, 2013; Nguyen et al., 2017), all with shuffling sampling schemes, as well as the exploration of momentum shuffling methods (Tran et al., 2021, 2022), represents a promising direction.
An interesting research question that arises is whether the convergence results can be further enhanced by exploring the potential of a randomized shuffling scheme within this framework (Mishchenko et al., 2020). However, we leave this question for future research endeavors.
References
- Abadi et al. (2015) Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dandelion Mané, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. URL https://www.tensorflow.org/. Software available from tensorflow.org.
- Ahn et al. (2020) Kwangjun Ahn, Chulhee Yun, and Suvrit Sra. Sgd with shuffling: optimal rates without component convexity and large epoch requirements. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 17526–17535. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper/2020/file/cb8acb1dc9821bf74e6ca9068032d623-Paper.pdf.
- Allen-Zhu et al. (2019) Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via over-parameterization. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 242–252. PMLR, 09–15 Jun 2019. URL http://proceedings.mlr.press/v97/allen-zhu19a.html.
- Arora et al. (2019) Sanjeev Arora, Simon Du, Wei Hu, Zhiyuan Li, and Ruosong Wang. Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 322–332. PMLR, 09–15 Jun 2019. URL http://proceedings.mlr.press/v97/arora19a.html.
- Beznosikov and Takáč (2021) Aleksandr Beznosikov and Martin Takáč. Random-reshuffled sarah does not need a full gradient computations. arXiv preprint arXiv:2111.13322, 2021.
- Bjorck et al. (2021) Johan Bjorck, Anmol Kabra, Kilian Q. Weinberger, and Carla Gomes. Characterizing the loss landscape in non-negative matrix factorization. Proceedings of the AAAI Conference on Artificial Intelligence, 35(8):6768–6776, May 2021. URL https://ojs.aaai.org/index.php/AAAI/article/view/16836.
- Bottou et al. (2018) L. Bottou, F. E. Curtis, and J. Nocedal. Optimization Methods for Large-Scale Machine Learning. SIAM Rev., 60(2):223–311, 2018.
- Bottou (2009) Léon Bottou. Curiously fast convergence of some stochastic gradient descent algorithms, 2009.
- Brutzkus et al. (2018) Alon Brutzkus, Amir Globerson, Eran Malach, and Shai Shalev-Shwartz. SGD learns over-parameterized networks that provably generalize on linearly separable data. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=rJ33wwxRb.
- Chollet et al. (2015) Francois Chollet et al. Keras. GitHub, 2015. URL https://github.com/fchollet/keras.
- Collobert and Weston (2008) Ronan Collobert and Jason Weston. A unified architecture for natural language processing: deep neural networks with multitask learning. In William W. Cohen, Andrew McCallum, and Sam T. Roweis, editors, Machine Learning, Proceedings of the Twenty-Fifth International Conference (ICML 2008), Helsinki, Finland, June 5-9, 2008, volume 307 of ACM International Conference Proceeding Series, pages 160–167. ACM, 2008. doi: 10.1145/1390156.1390177. URL https://doi.org/10.1145/1390156.1390177.
- De et al. (2017) Soham De, Abhay Yadav, David Jacobs, and Tom Goldstein. Automated Inference with Adaptive Batches. In Aarti Singh and Jerry Zhu, editors, Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, volume 54 of Proceedings of Machine Learning Research, pages 1504–1513. PMLR, 20–22 Apr 2017. URL https://proceedings.mlr.press/v54/de17a.html.
- Defazio et al. (2014) Aaron Defazio, Francis Bach, and Simon Lacoste-Julien. Saga: A fast incremental gradient method with support for non-strongly convex composite objectives. In Advances in Neural Information Processing Systems, pages 1646–1654, 2014.
- Du et al. (2019a) Simon Du, Jason Lee, Haochuan Li, Liwei Wang, and Xiyu Zhai. Gradient descent finds global minima of deep neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 1675–1685. PMLR, 09–15 Jun 2019a. URL http://proceedings.mlr.press/v97/du19c.html.
- Du et al. (2019b) Simon S. Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh. Gradient descent provably optimizes over-parameterized neural networks. In International Conference on Learning Representations, 2019b. URL https://openreview.net/forum?id=S1eK3i09YQ.
- Duchi et al. (2011) John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12:2121–2159, 2011.
- Efron et al. (2004) Bradley Efron, Trevor Hastie, Iain Johnstone, and Robert Tibshirani. Diabetes dataset, 2004. URL https://www4.stat.ncsu.edu/~boos/var.select/diabetes.html.
- Ghadimi and Lan (2013) S. Ghadimi and G. Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM J. Optim., 23(4):2341–2368, 2013.
- Goldberg et al. (2018) Yoav Goldberg, Graeme Hirst, Yang Liu, and Meng Zhang. Neural network methods for natural language processing. Comput. Linguistics, 44(1), 2018. doi: 10.1162/COLI\_r\_00312. URL https://doi.org/10.1162/COLI_r_00312.
- Goodfellow et al. (2014) Ian J. Goodfellow, Yaroslav Bulatov, Julian Ibarz, Sacha Arnoud, and Vinay D. Shet. Multi-digit number recognition from street view imagery using deep convolutional neural networks. In Yoshua Bengio and Yann LeCun, editors, 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014. URL http://arxiv.org/abs/1312.6082.
- Gower et al. (2021) Robert Gower, Othmane Sebbouh, and Nicolas Loizou. Sgd for structured nonconvex functions: Learning rates, minibatching and interpolation. In International Conference on Artificial Intelligence and Statistics, pages 1315–1323. PMLR, 2021.
- Gürbüzbalaban et al. (2019) M. Gürbüzbalaban, A. Ozdaglar, and P. A. Parrilo. Why random reshuffling beats stochastic gradient descent. Mathematical Programming, Oct 2019. ISSN 1436-4646. doi: 10.1007/s10107-019-01440-w. URL http://dx.doi.org/10.1007/s10107-019-01440-w.
- Haochen and Sra (2019) Jeff Haochen and Suvrit Sra. Random shuffling beats sgd after finite epochs. In International Conference on Machine Learning, pages 2624–2633. PMLR, 2019.
- Hardt et al. (2018) Moritz Hardt, Tengyu Ma, and Benjamin Recht. Gradient descent learns linear dynamical systems. Journal of Machine Learning Research, 19(29):1–44, 2018. URL http://jmlr.org/papers/v19/16-465.html.
- He and Sun (2015) Kaiming He and Jian Sun. Convolutional neural networks at constrained time cost. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7-12, 2015, pages 5353–5360. IEEE Computer Society, 2015. doi: 10.1109/CVPR.2015.7299173. URL https://doi.org/10.1109/CVPR.2015.7299173.
- Hinder et al. (2020) Oliver Hinder, Aaron Sidford, and Nimit Sohoni. Near-optimal methods for minimizing star-convex functions and beyond. In Conference on Learning Theory, pages 1894–1938. PMLR, 2020.
- Jin (2020) Jikai Jin. On the convergence of first order methods for quasar-convex optimization. arXiv preprint arXiv:2010.04937, 2020.
- Johnson and Zhang (2013) Rie Johnson and Tong Zhang. Accelerating stochastic gradient descent using predictive variance reduction. In Advances in Neural Information Processing Systems, pages 315–323, 2013.
- Karimi et al. (2016) Hamed Karimi, Julie Nutini, and Mark Schmidt. Linear convergence of gradient and proximal-gradient methods under the Polyak-Łojasiewicz condition. In Paolo Frasconi, Niels Landwehr, Giuseppe Manco, and Jilles Vreeken, editors, Machine Learning and Knowledge Discovery in Databases, pages 795–811, Cham, 2016. Springer International Publishing.
- Khaled and Richtárik (2020) Ahmed Khaled and Peter Richtárik. Better theory for sgd in the nonconvex world. arXiv preprint arXiv:2002.03329, 2020.
- Kingma and Ba (2014) Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2014.
- Le Roux et al. (2012) Nicolas Le Roux, Mark Schmidt, and Francis Bach. A stochastic gradient method with an exponential convergence rate for finite training sets. In NIPS, pages 2663–2671, 2012.
- LeCun et al. (1998) Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Lee and Valiant (2016) Jasper C.H. Lee and Paul Valiant. Optimizing star-convex functions. In 2016 IEEE 57th Annual Symposium on Foundations of Computer Science (FOCS), pages 603–614, 2016. doi: 10.1109/FOCS.2016.71.
- Loizou et al. (2021) Nicolas Loizou, Sharan Vaswani, Issam Hadj Laradji, and Simon Lacoste-Julien. Stochastic polyak step-size for sgd: An adaptive learning rate for fast convergence. In Arindam Banerjee and Kenji Fukumizu, editors, Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, volume 130 of Proceedings of Machine Learning Research, pages 1306–1314. PMLR, 13–15 Apr 2021. URL http://proceedings.mlr.press/v130/loizou21a.html.
- Ma et al. (2018) Siyuan Ma, Raef Bassily, and Mikhail Belkin. The power of interpolation: Understanding the effectiveness of SGD in modern over-parametrized learning. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 3325–3334. PMLR, 10–15 Jul 2018. URL http://proceedings.mlr.press/v80/ma18a.html.
- Meng et al. (2020) Si Yi Meng, Sharan Vaswani, Issam Hadj Laradji, Mark Schmidt, and Simon Lacoste-Julien. Fast and furious convergence: Stochastic second order methods under interpolation. In Silvia Chiappa and Roberto Calandra, editors, Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 of Proceedings of Machine Learning Research, pages 1375–1386. PMLR, 26–28 Aug 2020. URL http://proceedings.mlr.press/v108/meng20a.html.
- Mishchenko et al. (2020) Konstantin Mishchenko, Ahmed Khaled Ragab Bayoumi, and Peter Richtárik. Random reshuffling: Simple analysis with vast improvements. Advances in Neural Information Processing Systems, 33, 2020.
- Nagaraj et al. (2019) Dheeraj Nagaraj, Prateek Jain, and Praneeth Netrapalli. Sgd without replacement: Sharper rates for general smooth convex functions. In International Conference on Machine Learning, pages 4703–4711, 2019.
- Nemirovski et al. (2009) A. Nemirovski, A. Juditsky, G. Lan, and A. Shapiro. Robust stochastic approximation approach to stochastic programming. SIAM J. on Optimization, 19(4):1574–1609, 2009.
- Nesterov (2004) Yurii Nesterov. Introductory lectures on convex optimization : a basic course. Applied optimization. Kluwer Academic Publ., Boston, Dordrecht, London, 2004. ISBN 1-4020-7553-7.
- Nesterov and Polyak (2006) Yurii Nesterov and Boris T Polyak. Cubic regularization of Newton method and its global performance. Mathematical Programming, 108(1):177–205, 2006.
- Nguyen et al. (2017) Lam M Nguyen, Jie Liu, Katya Scheinberg, and Martin Takáč. Sarah: A novel method for machine learning problems using stochastic recursive gradient. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 2613–2621. JMLR. org, 2017.
- Nguyen et al. (2021) Lam M. Nguyen, Quoc Tran-Dinh, Dzung T. Phan, Phuong Ha Nguyen, and Marten van Dijk. A unified convergence analysis for shuffling-type gradient methods. Journal of Machine Learning Research, 22(207):1–44, 2021. URL http://jmlr.org/papers/v22/20-1238.html.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc., 2019.
- Pedregosa et al. (2011) F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
- Polyak (1964) Boris T. Polyak. Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics, 4(5):1–17, 1964.
- Repository (2016) Global Health Observatory Data Repository. Life expectancy and healthy life expectancy, 2016. URL https://apps.who.int/gho/data/view.main.SDG2016LEXREGv?lang=en.
- Repository (1997) StatLib Repository. California housing, 1997. URL https://www.dcc.fc.up.pt/~ltorgo/Regression/cal_housing.html.
- Robbins and Monro (1951) Herbert Robbins and Sutton Monro. A stochastic approximation method. The Annals of Mathematical Statistics, 22(3):400–407, 1951.
- Safran and Shamir (2020) Itay Safran and Ohad Shamir. How good is sgd with random shuffling? In Conference on Learning Theory, pages 3250–3284. PMLR, 2020.
- Sankararaman et al. (2020) Karthik Abinav Sankararaman, Soham De, Zheng Xu, W Ronny Huang, and Tom Goldstein. The impact of neural network overparameterization on gradient confusion and stochastic gradient descent. In International conference on machine learning, pages 8469–8479. PMLR, 2020.
- Schmidt and Roux (2013) Mark Schmidt and Nicolas Le Roux. Fast convergence of stochastic gradient descent under a strong growth condition, 2013.
- Shamir and Zhang (2013) Ohad Shamir and Tong Zhang. Stochastic gradient descent for non-smooth optimization: Convergence results and optimal averaging schemes. In Sanjoy Dasgupta and David McAllester, editors, Proceedings of the 30th International Conference on Machine Learning, volume 28 of Proceedings of Machine Learning Research, pages 71–79, Atlanta, Georgia, USA, 17–19 Jun 2013. PMLR. URL https://proceedings.mlr.press/v28/shamir13.html.
- Soudry et al. (2018) Daniel Soudry, Elad Hoffer, Mor Shpigel Nacson, Suriya Gunasekar, and Nathan Srebro. The implicit bias of gradient descent on separable data. J. Mach. Learn. Res., 19(1):2822–2878, January 2018. ISSN 1532-4435.
- Tran et al. (2021) Trang H Tran, Lam M Nguyen, and Quoc Tran-Dinh. SMG: A shuffling gradient-based method with momentum. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 10379–10389. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/tran21b.html.
- Tran et al. (2022) Trang H Tran, Katya Scheinberg, and Lam M Nguyen. Nesterov accelerated shuffling gradient method for convex optimization. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors, Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 21703–21732. PMLR, 17–23 Jul 2022. URL https://proceedings.mlr.press/v162/tran22a.html.
- Vaswani et al. (2019) Sharan Vaswani, Francis Bach, and Mark Schmidt. Fast and faster convergence of sgd for over-parameterized models and an accelerated perceptron. In Kamalika Chaudhuri and Masashi Sugiyama, editors, Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 89 of Proceedings of Machine Learning Research, pages 1195–1204. PMLR, 16–18 Apr 2019. URL https://proceedings.mlr.press/v89/vaswani19a.html.
- Zhou et al. (2019) Yi Zhou, Junjie Yang, Huishuai Zhang, Yingbin Liang, and Vahid Tarokh. Sgd converges to global minimum in deep learning via star-convex path. arXiv preprint arXiv:1901.00451, 2019.
- Zou and Gu (2019) Difan Zou and Quanquan Gu. An improved analysis of training over-parameterized deep neural networks. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett, editors, Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 2053–2062, 2019.
- Zou et al. (2018) Difan Zou, Yuan Cao, Dongruo Zhou, and Quanquan Gu. Stochastic gradient descent optimizes over-parameterized deep relu networks, 2018.
On the Convergence to a Global Solution
of Shuffling-Type Gradient Algorithms
Supplementary Material, NeurIPS 2023
Appendix A Theoretical settings: Proof of Theorem 1
A.1 Proof of Theorem 1
Proof.
Let us use the notation . We consider an architecture with be the vectorized weight and consists of a final bias layer :
where and are some inner architecture, which can be chosen arbitrarily.
Firstly, we compute the gradient of with respect to . For , we have
| (18) |
The last equality follows since for every and for . In other words, it is the identity matrix.
Let us denote that and . We prove the following statement for :
for every and
We begin with the first inequality:
Now let us prove the PL condition for each function , i.e., there exists a constant such that:
Recall the squared loss that and . We can see that the constant satisfies the following inequality for every :
where the last inequality follows since .
The PL condition for directly implies the second inequality. The last inequality follows from the facts that and . Hence, Theorem 1 is proved.
∎
Appendix B Preliminary results for SGD Shuffling Algorithm
In this section, we present the preliminary results for Algorithm 1. Firstly, from the choice of learning rate and the update in Algorithm 1, for , we have
| (19) |
Hence,
| (20) |
Next, we refer to a Lemma in [Nguyen et al., 2021] to bound the updates of shuffling SGD algorithms.
Lemma 3 (Lemma 5 in Nguyen et al. [2021]).
Now considering the term , we get that
We further have
| (23) |
Appendix C Main results: Proofs of Lemma 4, Lemma 2, Theorem 2, and Corollary 1
C.1 Proof of Lemma 4
Lemma 4.
Proof.
We start with Assumption 5. Using the inequality , we have for and :
This statement is equivalent to
| (26) |
C.2 Proof of Lemma 2
C.3 Proof of Theorem 2
C.4 Proof of Corollary 1
Proof.
Choose , we have
Note that and , we get that . We continue from the statement of Theorem 2 and the choice :
with
Let and choose . Then the number of iterations is
to guarantee
Hence, the total complexity (number of individual gradient computations needed to reach accuracy) is .
If we further assume that :
and the complexity is . ∎