[2]\fnmWei \surHuang
1]\orgnameCSIRO Space and Astronomy, \orgaddress\street26 Dick Perry Ave, \cityKensington, \postcode6151, \stateWA, \countryAustralia
[2]\orgnameRIKEN AIP, \cityTokyo, \countryJapan
On the Convergence Analysis of Over-Parameterized Variational Autoencoders: A Neural Tangent Kernel Perspective
Abstract
Variational Auto-Encoders (VAEs) have emerged as powerful probabilistic models for generative tasks. However, their convergence properties have not been rigorously proven. The challenge of proving convergence is inherently difficult due to the highly non-convex nature of the training objective and the implementation of a Stochastic Neural Network (SNN) within VAE architectures. This paper addresses these challenges by characterizing the optimization trajectory of SNNs utilized in VAEs through the lens of Neural Tangent Kernel (NTK) techniques. These techniques govern the optimization and generalization behaviors of ultra-wide neural networks. We provide a mathematical proof of VAE convergence under mild assumptions, thus advancing the theoretical understanding of VAE optimization dynamics. Furthermore, we establish a novel connection between the optimization problem faced by over-parameterized SNNs and the Kernel Ridge Regression (KRR) problem. Our findings not only contribute to the theoretical foundation of VAEs but also open new avenues for investigating the optimization of generative models using advanced kernel methods. Our theoretical claims are verified by experimental simulations.
keywords:
Variational Auto-encoder, Stochastic Neural Network, Neural Tangent Kernel1 Introduction
Variational Autoencoders (VAEs) [1] have garnered significant interest and have been applied across a diverse array of applications, ranging from image generation and style transfer [2, 3, 4] to natural language processing [5]. VAEs aim to learn a compressed yet structured latent representation of input data by maximizing the Evidence Lower BOund (ELBO), thereby facilitating the reconstruction of the original data. Unlike traditional autoencoders [6, 7], VAEs focus on learning the distribution of latent codes, enabling the generation of new samples from this distribution. The dimensionality of the latent space is dictated by data complexity, model objectives, and task-specific needs, ranging from a few to several thousand dimensions. Larger latent spaces can encode more information and provide better disentanglement learning [8, 9, 10], a finding that our experiments also support (see Figures 3 and 4). Concurrently, there is an intuitive belief that a larger latent space may pose challenges to training, such as issues with non-convergence or slow convergence rates.
On the other hand, despite the widespread application of VAEs, our theoretical understanding of the training dynamics remains limited. Investigating the optimization of Deep VAEs theoretically is notoriously challenging, as training deep neural networks involves non-convex optimization of a high-dimensional objective function. The complexity of this optimization problem is further exacerbated by the incorporation of stochastic neural networks (SNNs) in VAEs, which introduces additional stochasticity into the training process. Several studies have attempted to shed light on this problem from different perspectives. For instance, He et al. [11] conducted an empirical investigation of the learning dynamics of deep VAEs to study the posterior collapse. Lucas et al. [12] presented a simple and intuitive analysis of linear VAEs to explain the same collapse. Moreover, Koehler et al. [13] analyzed the training dynamics, offering insights into implicit bias convergence for linear VAEs. However, much of the existing research either leans heavily on empirical simulations or centers around linear VAEs, leaving the broader success of VAEs insufficiently explained.
To address concerns about the convergence in high-dimensional latent spaces in VAEs, in this work, we introduce a novel convergence analysis for VAE training dynamics, specifically when an over-parameterized stochastic neural network serves as its model. While the convergence properties of deterministic neural networks have been extensively explored [14, 15, 16, 17, 18, 19, 20, 21, 22], the convergence behavior of SNNs in VAE remains less understood. Our approach leverages non-asymptotic analysis of dynamical systems, allowing us to examine the behavior of over-parameterized VAEs during training. We demonstrate that the convergence outcome aligns with solving a kernel ridge regression under certain mild assumptions. To our knowledge, this is the first rigorous analysis of the convergence behavior of over-parameterized VAEs. We further validate our theoretical insights through experiments on various image generation tasks. In summary, our key contributions are as follows:
-
•
We establish a non-asymptotic convergence analysis for over-parameterized SNNs. Specifically, we investigate the convergence rate of the optimization algorithm used to train the VAE.
-
•
We link the optimization of over-parameterized SNNs with kernel ridge regression, shedding light on the regularization effects of the KL penalty in VAEs.
-
•
Theoretically, we prove that VAEs with high-dimensional latent spaces can converge, providing a theoretical foundation for employing large latent spaces in VAEs to capture more information.
2 Related Work
Convergence Analysis of Over-parameterized Neural Networks
The convergence analysis of over-parameterized neural networks (NNs) has become an important topic in deep learning research. In a seminal paper, Jacot et al. [14] showed that the optimization behavior of infinitely-wide NNs can be described using a kernel function called neural tangent Kerenl (NTK). This kernel simplifies the optimization dynamics into a linear system that is more tractable. The NTK provides a way to explicitly characterize the dynamics of the neural network during training and to analyze its convergence behavior [23, 24]. Additionally, a series of studies [16, 17, 25, 26, 15, 20] have presented convergence results of over-parameterized networks through a non-asymptotic lens. Furthermore, the Rademacher complexity analysis characterized the generalization ability of trained over-parameterized NNs on unseen data [27, 26]. In addition, NTK has been widely applied to different deep network structures, aiding in understanding their optimization dynamics. This includes convolutional networks [25], orthogonally initialized NN [18], graph neural networks [28], active learning [29], transformer [30], neural architecture search [31], and GAN [32].
Among existing studies of training dynamics of over-parameterized networks, the works of [33, 34, 35, 36] are the most aligned with our research. Nguyen et al. [33] explored the gradient dynamics of over-parameterized auto-encoders (AE) and provided a rigorous proof for the linear convergence of gradient descent in the context of AEs. However, their techniques cannot be directly applied to variational auto-encoders (VAEs) because of the additional randomness introduced by stochastic neural networks. In a separate study, Liu et al. [34] examined the predictive variance of stochastic neural networks. They demonstrated that as the width of an optimized stochastic neural network approaches infinity, its predictive variance on the training set diminishes to zero. While their work sheds light on the behavior of stochastic neural networks in the infinite-width limit, they have not shown the convergence of infinitely-wide neural networks, which is one of the most desirable perspectives of studying a NN. Two other notable studies [35, 36] approached SNNs within the PAC-Bayes framework, leveraging the NTK. However, the SNN structure in our VAE research differs from the PAC-Bayes framework, particularly in how stochasticity is introduced in the latent layer.
Theoretical study of VAEs
While VAEs have been successfully applied in various domains, their theoretical properties are still not fully understood. Several recent works have attempted to provide a theoretical understanding of VAEs. For instance, recent works by [37, 38, 39] refereed to information theory, deriving variational bounds on the mutual information between the input and the latent variable and the objective function. One work by Lucas et al. [12] provided an intuitive explanation for the posterior collapse phenomenon in VAEs. They analyze linear VAEs and show that the posterior collapse can be attributed to the low-rank structure of the encoder. In addition, Kumar et al. [40] presented an approximation of VAE objective function consisting of deterministic auto-encoding objective plus analytic regularizers that depend on the Hessian or Jacobian of the decoding model. Nakagawa et al. [41] provided a quantitative understanding of the VAE property through the differential-geometric and information-theoretic interpretations of VAE. Moreover, [42, 43, 44] are not around the optimization dynamics but they study problems of optimization landscape. In contrast, our work studies the training dynamics of over-parameterized VAEs with the non-linear activation, emphasizing the challenges on the non-linear activation and the complicated optimization behavior.
3 Problem Setup and Preliminary
3.1 Notation
In this work, we adopt a standard notation to represent vectors, matrices, and scalars. Specifically, we use bold-faced letters for vectors and matrices and non-bold letters for scalars. To denote the Euclidean norm of a vector or the spectral norm of a matrix, we use the notation . The Frobenius norm of a matrix is represented by . We use the notation to represent the set of integers from 1 to . Besides, we represent a matrix as a set of row vectors, i.e., , where with is a column vector of the matrix. Finally, we denote the least eigenvalue of a matrix by , which is equivalent to .
3.2 Variational Auto-encoder
A Variational auto-encoder (VAE) [1], as a directed probabilistic graphical model (DPGM), is designed to learn a latent variable model. Its primary objective is to maximize the log-likelihood of the training data via variational inference, where is the number of training samples. The VAE introduces a distribution to approximate the intractable true posterior , where are neural network parameters that can be learned in the encoder. Then, the decoder takes as input to generate as a reconstruction for .
The common training objective of the VAE is to maximize the Evidence Lower Bound (ELBO), given by:
| (1) |
where , and and represent the parameters in encoder and decoder, respectively. The first term in the ELBO measures the reconstruction loss between the generated and the original . The second term represents the Kullback-Leibler (KL) divergence between the approximate posterior and the prior , where is often chosen to be an isotropic multivariate Gaussian distribution.
3.3 Stochastic Neural Network and Objective Function

Consider a stochastic neural network (SNN) , where is the input dimension. In the context of this work, our SNN is defined as follows:
| (2) |
where is the encoded representation derived from the input , are weight matrices employed to construct the latent Gaussian representation. Here represents the width of the network, indicating the number of neurons, is the non-linear activation function, is the decoder representation function, and is the linear weight matrix utilized in the final layer. A visual representation of the SNN under study is depicted in Figure 1.
In the construction of the latent representation, we employ the re-parametrization trick, a technique that allows for the backpropagation of gradients through random nodes. In particular, the latent variable can be expressed as:
| (3) |
where and represent the mean and variance weights, respectively. Besides, is a random variable drawn from a standard normal distribution.
Given the structure of the SNN, our objective function considered in this work is defined as:
| (4) |
where , and is the latent representation for input at time . Besides, is an adjustable hyperparameter that balances latent channel capacity and independence constraints with reconstruction accuracy [45]. The first term is called the reconstruction loss. In this study, we utilize the mean squared error as our reconstruction loss, following seminal theoretical works [35, 17, 27, 26]. The second term is a Kullback–Leibler (KL) divergence, where prior distribution is the Gaussian distribution of latent variable at initialization, and the posterior is the distribution of latent variable after training, . It’s worth noting that our KL is tailored to align with our theoretical analysis for constructing kernel ridge regression.
To optimize the objective function given by (4), we adopt a gradient descent rule:
| (5) |
where is the learning rate. Note that while the weights in the encoder and decoder remain fixed, we specifically optimize the mean weights , variance weights , and the weights in the final layer . This optimization strategy is primarily adopted for the sake of theoretical simplicity. It’s worth noting that this choice does not compromise or alter our final conclusions.
4 Theoretical Results
In this section, we present our primary theoretical findings related to the optimization of the VAE’s objective function. We start from the essential definitions and assumptions, later the convergence will be established. Finally, we prove the kernel ridge regression result through over-parameterization.
4.1 Definition and Assumptions
For the purpose of our optimization analysis, we introduce the concept of the neural tangent kernel for a stochastic neural network:
Definition 1 (Stochastic Neural Tangent Kernel).
The tangent kernels associated with output function at weights are defined as,
| (6) |
and denote the index of input samples while represent the index of output functions. Furthermore, the NTK for the entire network is defined as .
A few remarks on Definition 1 are in order. Unlike standard (deterministic) neural networks, the VAE comprises two sets of parameters in the latent layer, namely, and . Due to the reparameterization trick, gradient descent is executed on each of these parameters independently. Consequently, we observe two distinct tangent kernels corresponding to each parameter set. Secondly, The scenario with multiple outputs in variational autoencoder networks presents added complexity compared to networks with a single output [16, 26]. Given that the output dimension of the stochastic neural network is , the neural tangent kernel is a matrix of size . As we delve deeper in the subsequent sections, it will become evident that the non-diagonal NTK across the output index is zero, and the diagonal NTK remains consistent across the output index. This uniformity allows us to employ Kronecker products, facilitating the derivation of NTKs.
Next, we impose some technical conditions on the activation function, which is stated as follows:
Assumption 4.1 (Continuous and Partial Derivative Continuous).
The activation function and its partial derivative are continuous in .
This assumption ensures that we can interchange the operations of integration and differentiation over the activation function. Subsequently, we present technical conditions on both the activation function and the decoder representation function:
Assumption 4.2 (-Lipschitz and -Smooth).
There exist constants and such that for any :
These conditions are important in demonstrating the stability of the training process within the framework of the NTK.
4.2 Optimization analysis
For the sake of simplification, we focus on the optimization of the stochastic neural network as described in (2), emphasizing solely on the reconstruction loss. This means we are setting aside the KL divergence term for the time being. Additionally, given that we’re adopting a squared loss without KL divergence, the objective function (4) reduces to:
| (7) |
Then the gradient flow dynamics of output function are governed by:
| (8) |
Equation (8) implies that the dynamics of output function are governed by the neural tangent kernels. Furthermore, as we will show later, the neural tangent kernels will stay constant during the training process in the infinite-width limit. In this way, Equation (8) reduces to an ordinary differential equation (ODE):
| (9) |
where we define the neural tangent kernel of an infinitely-wide SNN by:
| (10) |
To demonstrate the convergence result induced by Equation (9), we perform an in-depth concentration analysis. This analysis focuses on the convergence of stochastic neural networks in a non-asymptotic manner, i.e., with a large but finite width. We present our main result in the following theorem:
Theorem 1.
Assume the lowest eigenvalue of the limiting NTK is greater than zero, i.e., and for . Suppose the network’s width , then with probability at least over the random initialization we have,
| (11) |
4.3 Regularization effect of KL divergence
By Theorem 1, we establish the global convergence of stochastic neural networks with a large width in VAE. Building on this foundation, we further consider full objective function (4) which incorporates an additional KL divergence term.
After a detailed calculation of the KL divergence for two Gaussian distributions, we simplify our analysis by making certain assumptions. Specifically, we assume that remains constant and select a prior such that the objective function (4) is transformed to:
| (12) |
Building on this, we further analyze the regularization effect of the KL term when training VAEs and present our findings in the subsequent theorem:
Theorem 2.
Suppose and the objective function follows the form (12). When we only optimize the mean weight , for any test input with probability at least over the random initialization, we have
| (13) |
where is the residual error term and is upper bounded by with and .
The proof of Theorem 2 will be given in the Appendix. Note that the error term is bounded by the difference between the output function of the finite network and the infinitely-wide network. This difference is further decomposed into the initial difference and the difference during training. The latter can be bounded by , where comes from the input and results from the integration over the training time. Besides, the necessity of fixing the variance weight in Theorem 2 arises because we are seeking a closed-form solution under the NTK regime. Theorem 2 reveals the regularization effect of the KL divergence on the convergence of over-parameterized VAEs and makes a connection between solution of training a VAE and kernel ridge regression.
5 Proof Sketch
In this section, we outline the approach used to establish the convergence results for VAEs and provide proofs for Theorem 1 and Theorem 2. Our first step involves demonstrating that the NTKs, in the infinite-width limit, converge to deterministic kernels:
Lemma 1.
Consider a stochastic network of the form (2), with the initialization of , , and . Then the tangent kernels at initialization before training in the infinite-width limit follow the expression:
| (14) | ||||
where and we define:
Proof of Lemma 1.
We first rewrite the expression for the stochastic neural network as follows:
Then the derivative of output function for with respect to the parameters , and for can be expressed as:
where we have interchanged integration and differentiation over activation by Assumption 4.2, and . We then calculate each NTK at initialization, i.e. :
(1) The neural tangent kernel .
where we define and . For all pairs of , is the average of i.i.d. random variables. Because is i.i.d., we know that . Therefore, we have
As a result, we conclude the proof:
(2) Similarly, the neural tangent kernel :
(3) The neural tangent kernel .
Again, this neural tangent kernel is the average of i.i.d. random variables. Therefore we have . ∎
Lemma 1 establishes that the NTKs converge to deterministic kernels in the infinite-width limit. We then study the behavior of tangent kernels with ultra-wide condition, namely at initialization. The following lemma demonstrates that if is large, then , , and have a lower bound on smallest eigenvalue with high probability.
Lemma 2 (NTK at initialization).
If , while , , and are initialized by the form in Lemma 1, then with probability at least over the initialization of weights, we have,
| (15) | ||||
Proof of Lemma 2.
The proof is by the standard concentration bound. By Lemma 1 we have shown that each neural tangent kernel is a sum of i.i.d. random variables. Then by Hoeffding’s inequality for sub-Gaussian variable, we know that
holds with probability at least . Because NTK matrix is of size , we then apply a union bound over all and . By setting , we obtain that
There by matrix perturbation theory we have,
Similarly, applying the above argument to and can yield the same result without much revision. Thus, by Hoeffding’s inequality and union bound over matrix size, we know that the following inequalities hold with probability at least ,
Finally, by the triangle inequality, we arrive at:
On the other hand, we can achieve the lower bound by triangle inequality:
We finalize the proof by setting . ∎
Lemma 2 completes the first step of our proof strategy, which states that if the width is large enough, then the neural tangent kernel of SNN at initialization before training is close to the limiting kernel and is positive definite.
However, a challenge arises due to the time-dependent nature of NTKs. These matrices evolve during the gradient descent training process. To account for this problem, we build a lemma stating that if the weights during training are close to their initialization, then the NTKs during training are close to the deterministic kernel . Moreover, these NTKs will maintain a lower bound on their smallest eigenvalue, throughout the gradient descent training:
Lemma 3.
Suppose that , and at initialization that , , , and for . If the weights at a training step satisfy: , , and , where , , and are constants, then with probability at least over the random initialization, we have
| (16) |
Proof.
(1) We first analyze :
Now we bound the distance between and through the following inequality:
where is because of triangle inequality, and (b) is because of the assumptions that as well as -Lipschitz and -Smooth of activations and . In particular, we have used the following inequalities:
Summing over all entries of the matrix, we can bound the perturbation:
Finally, due to the condition that and , we have,
(2) Similarly, we have:
(3) Finally,
With all the inequalities at hand, we conclude the proof:
∎
Lemma 3 demonstrates that if the change of weight is bounded, then the tangent kernel matrix is close to its expectation. The next lemma will show that the changes of weights during training are bounded when the NTK is close to the limiting NTK:
Lemma 4.
Suppose for , then,
| (17) |
Proof of Lemma 4.
The dynamics of loss can be calculated,
Integrating the differential function, the loss can be bounded as follows:
which implies the linear convergence rate of the stochastic neural network. Then the gradient flow for is as follows,
Integrating the gradient, we have:
Similarly, we have:
∎
Lemma 4 states that once the least eigenvalue of NTK during training are bounded, the change of weight will be bounded (evidenced by empirical simulation shown in Figure 2). By employing a proof by contradiction, combined with the results from Lemma, we can deduce that during training the NTKs of the SNN remain close to the deterministic kernel, provided the neural network is sufficiently wide. In a conclusion, with all the lemmas at hand, we arrive at the final Theorem 1 by the following lemma:
Lemma 5.
If , , and , then for all , ; Besides, the loss follows:
Proof of Lemma 5.
The proof is a standard contradiction. Suppose the conclusion does not hold at time , which implies that there exists , , then by Lemma 3 we know there exists such that . However, this is contradictory to Lemma 4.
To finalize the proof, we bound :
Finally, , , and result in which completes the proof. ∎
Finally, we give the detailed proof of Theorem 2, which is based on the linearization of the output function with respect to the weight space.
Proof of Theorem 2.
Our proof first establishes the result of kernel ridge regression in the infinite-width limit, then bounds the perturbation on the network’s prediction. The output function can be expressed as,
where , and . It is known that the objective function with KL divergence follows:
We then calculate the gradient flow dynamics for mean weight:
which is an ordinary differential equation. It is easy to see that the solution is,
where . Plugging the result into the linearized output function, we have,
For an arbitrary test data , we have,
when we take the time to be infinity,
| (18) |
The next step is to show the difference between finite-width neural network and infinitely-wide network:
where with and . Note the expression in Equation (18) can be rewritten as and the solution to this equation can be further written as the result of applying gradient flow on the following kernel ridge regression problem
with initialization . We use to denote this parameter at time trained by gradient flow and be the predictor for at time . With these notations, we rewrite
where we have used the fact that the initial prediction is .
We thus can analyze the difference between the SNN predictor and infinite-width SNN predictor via this integral form as follows:
For the second term , recall that by Lemma 3. Besides, we know that . Therefore, we can bound:
As a result, we have . To bound , we have
As a result, we have . Lastly, we put things together and get
∎
6 Experiments
In this section, we provide empirical evidence to support our theoretical analysis concerning the training dynamics of over-parameterized stochastic neural networks, which are optimized using VAE training objectives. Our experimental results, derived from training on the MNIST dataset, corroborate our theoretical predictions. In addition, we report our observation that VAEs with larger latent spaces are capable of learning more information, which substantiates the rationale behind our theoretical examination of the convergence properties of over-parameterized VAEs.
6.1 Theoretical verification
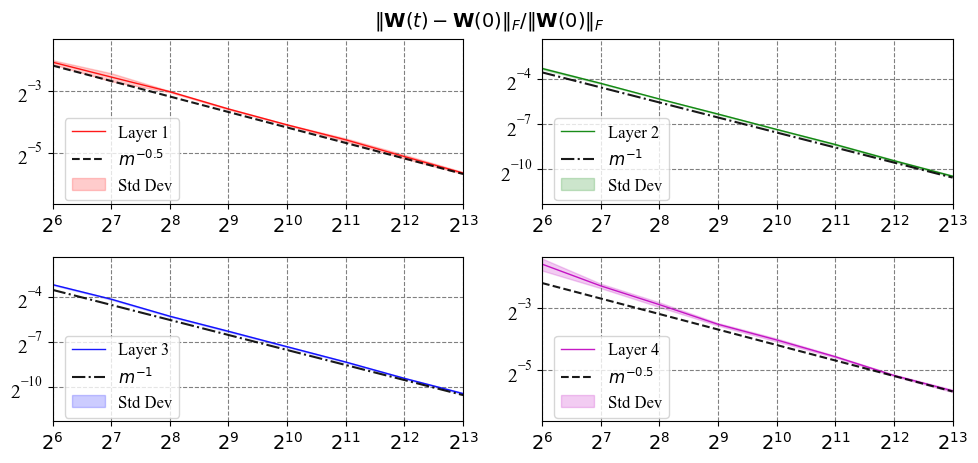
To empirically validate our lemmas, we employ a three-hidden-layer fully connected network, guided by the training objective function as presented in Equation (4). The network parameters are initialized using the Neural Tangent Kernel (NTK) parameterization, in line with Equation (2). For training, we adopt the ordinary mean-squared error (MSE) as the reconstruction loss and employ full-batch gradient descent with a consistent learning rate of 1 on a subset of the MNIST dataset containing 128 samples and 10 classes. We measure the change in weights of each layer, denoted by , after performing steps of gradient descent updates from random initialization. Figure 2 displays the results for each layer. We only measure the change in weight for the latent layer (). Our observations show that the relative Frobenius norm changes in the Encoder and Decoder scales as , while the hidden layers’ weights scale as . This result confirms that the weights of SNN do not move too much during training, and further confirms the correctness of our theoretical claim (Lemma 4). Notably, a similar convergence rate for weight changes in deterministic neural networks was observed in [23]. To empirically validate our lemmas, we employ a three-hidden-layer Tanh fully connected network, guided by the training objective function as presented in Equation (4). The network parameters are initialized using the Neural Tangent Kernel (NTK) parameterization, in line with Equation (2). For training, we adopt the ordinary mean-squared error (MSE) as the reconstruction loss and employ full-batch gradient descent with a consistent learning rate of 1 on a subset of the MNIST dataset containing 128 samples and 10 classes. We measure the change in weights of each layer, denoted by , after performing steps of gradient descent updates from random initialization. Figure 2 displays the results for each layer. We only measure the change in weight for the latent layer (). Our observations show that the relative Frobenius norm changes in the Encoder and Decoder scales as , while the hidden layers’ weights scale as . This result confirms that the weights of SNN do not move too much during training, and further confirms the correctness of our theoretical claim (Lemma 4). Notably, a similar convergence rate for weight changes in deterministic neural networks was observed in [23].
6.2 Large latent space can learn more



In this subsection, we report our experimental observations, aligning with numerous prior studies [8, 9]. We observed that larger latent spaces are capable of capturing more information, as evidenced by higher disentanglement scores and the emergence of additional features not discernible in models with narrower VAE configurations.
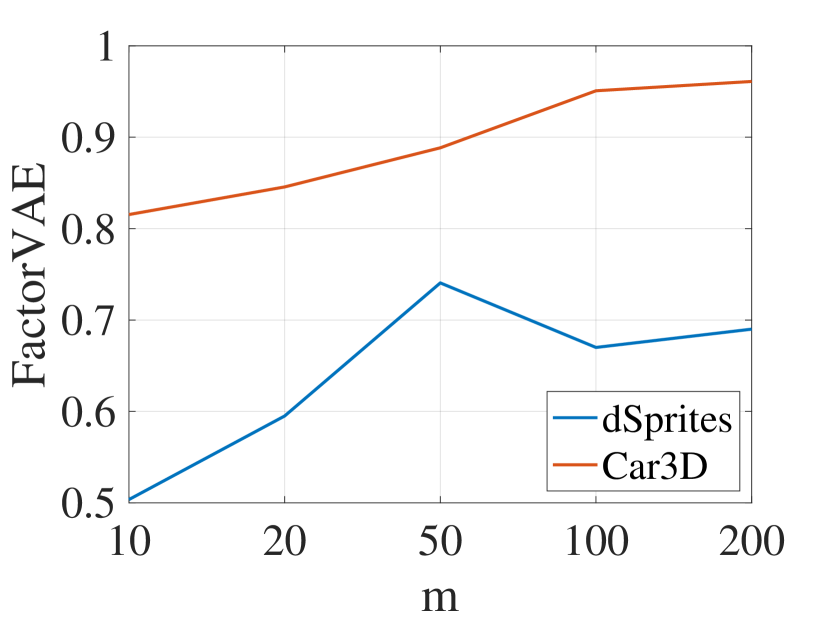
Adopting the experimental setup utilized in Beta-VAE[45], we explored the effects of varying latent space dimensions. Our experiments were conducted on the dSprites[45] and Cars3D datasets[46]. As shown in Figure 3, the width of the latent space, denoted by , is varied across [10,20,50,100,200]. We assessed the performance using a suite of disentanglement score metrics, including the BetaVAE, -VAE metric [45], Mutual Information Gap (MIG) [47], Separated Attribute Predictability (SAP) score [48], and Factor-VAE metric [49]. Our findings indicate that larger latent spaces lead to higher disentanglement scores, with the exception of a less pronounced improvement when employing the BetaVAE metric on the Cars3D dataset. These results corroborate the hypothesis that a larger latent space is capable of capturing more information.

Furthermore, in our experiments with the CelebA [50] datasets, we observed that a larger latent space can reveal additional features not detected in smaller latent space VAEs. As illustrated in Figure 4, on the CelebA dataset, a VAE with a latent space of 256 dimensions uncovered new image attributes such as emotion, eye style, and hairstyle, which were not identified by a VAE with a latent space of just 10 dimensions. These findings confirm that VAEs with larger latent spaces are capable of detecting additional features not observable in narrower VAE configurations.
These observations validate the intuitive notion that VAEs with larger latent spaces exhibit superior disentanglement performance. This underlines our initial motivation for investigating over-parameterized VAEs, as opposed to conventional VAEs, to leverage the benefits of increased latent dimensionality.
7 Conclusion
In this work, we have established the convergence of over-parameterized VAEs using the neural tangent kernel techniques. Additionally, we have demonstrated that the expected output function trained with the full objective function and KL divergence converges to the kernel ridge regression, confirming the regularization effect of the additional KL divergence. The theoretical insights presented in this paper pave the way for analyzing stochastic neural networks within other paradigms, such as deep Bayesian networks. Our empirical evaluations corroborate that the theoretical predictions are consistent with real-world training dynamics. Furthermore, through experimental investigations on real datasets, we have highlighted the training efficiency of over-parameterized VAEs, as suggested by our theoretical findings.
References
- \bibcommenthead
- Kingma and Welling [2013] Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
- Radford et al. [2015] Radford, A., Metz, L., Chintala, S.: Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434 (2015)
- Van Den Oord and Vinyals [2017] Van Den Oord, A., Vinyals, O.: Neural discrete representation learning. In: Advances in Neural Information Processing Systems, pp. 6306–6315 (2017)
- Wang et al. [2022] Wang, L., Huang, W., Zhang, M., Pan, S., Chang, X., Su, S.W.: Pruning graph neural networks by evaluating edge properties. Knowledge-Based Systems 256, 109847 (2022)
- Bowman et al. [2015] Bowman, S.R., Vilnis, L., Vinyals, O., Dai, A.M., Jozefowicz, R., Bengio, S.: Generating sentences from a continuous space. arXiv preprint arXiv:1511.06349 (2015)
- Ng et al. [2011] Ng, A., et al.: Sparse autoencoder. CS294A Lecture notes 72(2011), 1–19 (2011)
- Tschannen et al. [2018] Tschannen, M., Bachem, O., Lucic, M.: Recent advances in autoencoder-based representation learning. arXiv preprint arXiv:1812.05069 (2018)
- Song et al. [2019] Song, T., Sun, J., Chen, B., Peng, W., Song, J.: Latent space expanded variational autoencoder for sentence generation. IEEE Access 7, 144618–144627 (2019)
- Lim et al. [2020] Lim, K.-L., Jiang, X., Yi, C.: Deep clustering with variational autoencoder. IEEE Signal Processing Letters 27, 231–235 (2020)
- Zhang et al. [2022] Zhang, M., Wang, L., Campos, D., Huang, W., Guo, C., Yang, B.: Weighted mutual learning with diversity-driven model compression. Advances in Neural Information Processing Systems 35, 11520–11533 (2022)
- He et al. [2019] He, J., Spokoyny, D., Neubig, G., Berg-Kirkpatrick, T.: Lagging inference networks and posterior collapse in variational autoencoders. arXiv preprint arXiv:1901.05534 (2019)
- Lucas et al. [2019] Lucas, J., Tucker, G., Grosse, R.B., Norouzi, M.: Don’t blame the ELBO! a linear VAE perspective on posterior collapse. Advances in Neural Information Processing Systems 32 (2019)
- Koehler et al. [2021] Koehler, F., Mehta, V., Risteski, A., Zhou, C.: Variational autoencoders in the presence of low-dimensional data: landscape and implicit bias. arXiv preprint arXiv:2112.06868 (2021)
- Jacot et al. [2018] Jacot, A., Gabriel, F., Hongler, C.: Neural tangent kernel: Convergence and generalization in neural networks. arXiv preprint arXiv:1806.07572 (2018)
- Allen-Zhu et al. [2019] Allen-Zhu, Z., Li, Y., Song, Z.: A convergence theory for deep learning via over-parameterization. In: International Conference on Machine Learning, pp. 242–252 (2019). PMLR
- Du et al. [2018] Du, S.S., Zhai, X., Poczos, B., Singh, A.: Gradient descent provably optimizes over-parameterized neural networks. arXiv preprint arXiv:1810.02054 (2018)
- Du et al. [2019] Du, S., Lee, J., Li, H., Wang, L., Zhai, X.: Gradient descent finds global minima of deep neural networks. In: International Conference on Machine Learning, pp. 1675–1685 (2019). PMLR
- Huang et al. [2020] Huang, W., Du, W., Da Xu, R.Y.: On the neural tangent kernel of deep networks with orthogonal initialization. arXiv preprint arXiv:2004.05867 (2020)
- Huang et al. [2021] Huang, W., Li, Y., Du, W., Da Xu, R.Y., Yin, J., Chen, L., Zhang, M.: Towards deepening graph neural networks: A gntk-based optimization perspective. arXiv preprint arXiv:2103.03113 (2021)
- Zou et al. [2020] Zou, D., Cao, Y., Zhou, D., Gu, Q.: Gradient descent optimizes over-parameterized deep relu networks. Machine Learning 109(3), 467–492 (2020)
- Chen et al. [2021] Chen, Y., Huang, W., Nguyen, L., Weng, T.-W.: On the equivalence between neural network and support vector machine. Advances in Neural Information Processing Systems 34 (2021)
- Chen et al. [2019] Chen, Z., Cao, Y., Zou, D., Gu, Q.: How much over-parameterization is sufficient to learn deep relu networks? arXiv preprint arXiv:1911.12360 (2019)
- Lee et al. [2019] Lee, J., Xiao, L., Schoenholz, S., Bahri, Y., Novak, R., Sohl-Dickstein, J., Pennington, J.: Wide neural networks of any depth evolve as linear models under gradient descent. Advances in neural information processing systems 32 (2019)
- Yang [2019] Yang, G.: Scaling limits of wide neural networks with weight sharing: Gaussian process behavior, gradient independence, and neural tangent kernel derivation. arXiv preprint arXiv:1902.04760 (2019)
- Arora et al. [2019a] Arora, S., Du, S.S., Hu, W., Li, Z., Salakhutdinov, R., Wang, R.: On exact computation with an infinitely wide neural net. arXiv preprint arXiv:1904.11955 (2019)
- Arora et al. [2019b] Arora, S., Du, S., Hu, W., Li, Z., Wang, R.: Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks. In: International Conference on Machine Learning, pp. 322–332 (2019). PMLR
- Cao and Gu [2019] Cao, Y., Gu, Q.: Generalization bounds of stochastic gradient descent for wide and deep neural networks. Advances in Neural Information Processing Systems 32, 10836–10846 (2019)
- Du et al. [2019] Du, S.S., Hou, K., Salakhutdinov, R.R., Poczos, B., Wang, R., Xu, K.: Graph neural tangent kernel: Fusing graph neural networks with graph kernels. Advances in Neural Information Processing Systems 32, 5723–5733 (2019)
- Wang et al. [2022] Wang, H., Huang, W., Wu, Z., Tong, H., Margenot, A.J., He, J.: Deep active learning by leveraging training dynamics. Advances in Neural Information Processing Systems 35, 25171–25184 (2022)
- Hron et al. [2020] Hron, J., Bahri, Y., Sohl-Dickstein, J., Novak, R.: Infinite attention: Nngp and ntk for deep attention networks. In: International Conference on Machine Learning, pp. 4376–4386 (2020). PMLR
- Chen et al. [2022] Chen, W., Huang, W., Gong, X., Hanin, B., Wang, Z.: Deep architecture connectivity matters for its convergence: A fine-grained analysis. Advances in neural information processing systems 35, 35298–35312 (2022)
- Franceschi et al. [2022] Franceschi, J.-Y., De Bézenac, E., Ayed, I., Chen, M., Lamprier, S., Gallinari, P.: A neural tangent kernel perspective of gans. In: International Conference on Machine Learning, pp. 6660–6704 (2022). PMLR
- Nguyen et al. [2021] Nguyen, T.V., Wong, R.K., Hegde, C.: Benefits of jointly training autoencoders: An improved neural tangent kernel analysis. IEEE Transactions on Information Theory 67(7), 4669–4692 (2021)
- Ziyin et al. [2022] Ziyin, L., Zhang, H., Meng, X., Lu, Y., Xing, E., Ueda, M.: Stochastic neural networks with infinite width are deterministic. arXiv preprint arXiv:2201.12724 (2022)
- Huang et al. [2023] Huang, W., Liu, C., Chen, Y., Da Xu, R.Y., Zhang, M., Weng, T.-W.: Analyzing deep pac-bayesian learning with neural tangent kernel: Convergence, analytic generalization bound, and efficient hyperparameter selection. Transactions on Machine Learning Research (2023)
- Clerico et al. [2023] Clerico, E., Deligiannidis, G., Doucet, A.: Wide stochastic networks: Gaussian limit and pac-bayesian training. In: International Conference on Algorithmic Learning Theory, pp. 447–470 (2023). PMLR
- Alemi et al. [2018] Alemi, A., Poole, B., Fischer, I., Dillon, J., Saurous, R.A., Murphy, K.: Fixing a broken elbo. In: International Conference on Machine Learning, pp. 159–168 (2018). PMLR
- Dai and Wipf [2019] Dai, B., Wipf, D.: Diagnosing and enhancing vae models. arXiv preprint arXiv:1903.05789 (2019)
- Rolinek et al. [2019] Rolinek, M., Zietlow, D., Martius, G.: Variational autoencoders pursue pca directions (by accident). In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12406–12415 (2019)
- Kumar and Poole [2020] Kumar, A., Poole, B.: On implicit regularization in beta-vae. In: International Conference on Machine Learning, pp. 5480–5490 (2020). PMLR
- Nakagawa et al. [2021] Nakagawa, A., Kato, K., Suzuki, T.: Quantitative understanding of vae as a non-linearly scaled isometric embedding. In: International Conference on Machine Learning, pp. 7916–7926 (2021). PMLR
- Wipf [2023] Wipf, D.: Marginalization is not marginal: No bad vae local minima when learning optimal sparse representations (2023)
- Dai et al. [2021] Dai, B., Wenliang, L., Wipf, D.: On the value of infinite gradients in variational autoencoder models. Advances in Neural Information Processing Systems 34, 7180–7192 (2021)
- Dai et al. [2020] Dai, B., Wang, Z., Wipf, D.: The usual suspects? reassessing blame for vae posterior collapse. In: International Conference on Machine Learning, pp. 2313–2322 (2020). PMLR
- Higgins et al. [2016] Higgins, I., Matthey, L., Pal, A., Burgess, C., Glorot, X., Botvinick, M., Mohamed, S., Lerchner, A.: beta-vae: Learning basic visual concepts with a constrained variational framework (2016)
- Reed et al. [2015] Reed, S.E., Zhang, Y., Zhang, Y., Lee, H.: Deep visual analogy-making. Advances in neural information processing systems 28 (2015)
- [47] Chen, R.T., Li, X., Grosse, R., Duvenaud, D.: Isolating sources of disentanglement in vaes. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems, vol. 2615, p. 2625
- Kumar et al. [2017] Kumar, A., Sattigeri, P., Balakrishnan, A.: Variational inference of disentangled latent concepts from unlabeled observations. arXiv preprint arXiv:1711.00848 (2017)
- Kim and Mnih [2018] Kim, H., Mnih, A.: Disentangling by factorising. In: International Conference on Machine Learning, pp. 2649–2658 (2018). PMLR
- Liu et al. [2015] Liu, Z., Luo, P., Wang, X., Tang, X.: Deep learning face attributes in the wild. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 3730–3738 (2015)