On progressive sharpening, flat minima and generalisation
Abstract
We present a new approach to understanding the relationship between loss curvature and input-output model behaviour in deep learning. Specifically, we use existing empirical analyses of the spectrum of deep network loss Hessians to ground an ansatz tying together the loss Hessian and the input-output Jacobian over training samples during the training of deep neural networks. We then prove a series of theoretical results which quantify the degree to which the input-output Jacobian of a model approximates its Lipschitz norm over a data distribution, and deduce a novel generalisation bound in terms of the empirical Jacobian. We use our ansatz, together with our theoretical results, to give a new account of the recently observed progressive sharpening phenomenon, as well as the generalisation properties of flat minima. Experimental evidence is provided to validate our claims.
1 Introduction
In this paper, we attempt to clarify how the curvature of the loss landscape of a deep neural network is related to the input-output behaviour of the model. Via a single mechanism, our Ansatz 3.1, we offer new explanations of both the as-yet unexplained progressive sharpening phenomenon Cohen et al. [2021] observed in the training of deep neural networks, and the long-speculative relationship between loss curvature and generalisation Hochreiter and Schmidhuber [1997], Keskar et al. [2017], Chaudhari et al. [2017], Foret et al. [2021].
The mechanism we propose in Ansatz 3.1 to mediate the relationship between loss curvature and input-output model behaviour is the input-output Jacobian of the model over the training sample, which is already understood to play a role in determining generalisation Drucker and Le Cun [1992], Bartlett et al. [2017], Neyshabur et al. [2017], Hoffman et al. [2019], Bubeck and Sellke [2021], Gouk et al. [2021], Novak et al. [2018], Ma and Ying [2021]. Our proposal is based on empirical observations made of the eigenspectrum of the Hessian of deep neural networks Papyan [2018, 2019], Ghorbani et al. [2019], whose outliers can be attributed to a summand of the Hessian known as the Gauss-Newton matrix. Crucially, the Gauss-Newton matrix is second-order only in the cost function, and solely first-order in the network layers.
The Gauss-Newton matrix is a Gram matrix (i.e. a product for some matrix ), and its conjugate , closely related to the tangent kernel identified in Jacot et al. [2018], has the same nonzero eigenvalues. Expanding reveals that it is determined in part by composite input-output layer Jacobians. Thus, insofar as the outlying Hessian eigenvalues are determined by those of the Gauss-Newton matrix, and insofar as input-output layer Jacobians determine the spectrum of the Gauss-Newton matrix via its isospectrality to its conjugate, one expects the largest singular values of the loss Hessian to be closely related to those of the model’s input-output Jacobian.
Our contributions in this paper are as follows.
-
1.
Based on previous empirical work identifying outlying loss Hessian eigenvalues with those of the Gauss-Newton matrix, we propose an ansatz: that under certain conditions, the largest eigenvalues of the loss Hessian control the growth of the largest singular values of the model’s input-output Jacobian. We focus in particular on the largest eigenvalue of the Hessian (the sharpness) and the largest singular value of the Jacobian (its spectral norm, which we abbreviate to simply norm in what follows).
-
2.
In Section 4 we provide theorems which quantify the extent to which the maximum input-output Jacobian spectral norm of a model over a training set will approximate the Lipschitz norm of the model over the underlying data distribution during training for datasets of practical relevance, including those generated by a generative adversarial network (GAN) or implicit neural function.
-
3.
In Section 5, we provide a theorem which gives a data-dependent, high probability lower bound on the empirical Jacobian norm of a model that grows during any effective training procedure. We combine this result with Ansatz 3.1 to give a new account of progressive sharpening, which enables us to change the severity of sharpening by scaling inputs and outputs. We report on classification experiments that validate our account.
-
4.
In Section 6, we provide a novel bound on the generalisation gap of the model in terms of the empirical Jacobian norm. Synthesising this result with Ansatz 3.1, we argue that low loss curvature implies good generalisation only insofar as low loss curvature implies small empirical Jacobian norm. We report on experiments measuring the effect of hyperparameters such as learning rate and batch size on loss sharpness, Jacobian norm and generalisation, revealing the validity of our explanation. Finally, we present the results of experiments measuring the loss sharpness, Jacobian norm and generalisation gap of networks trained with a variety of regularisation measures, revealing in all cases the superior correlation of Jacobian norm and generalisation when compared with loss sharpness, whether or not the regularisation technique targets loss sharpness.
2 Related work
Flatness, Jacobians and generalisation: The position that flatter minima generalise better dates back to Hochreiter and Schmidhuber [1997]. It has since become a staple concept in the toolbox of deep learning practitioners Keskar et al. [2017], Chaudhari et al. [2017], Foret et al. [2021], Chen et al. [2020], with its incorporation into training schemes yielding state-of-the-art performance in many tasks. Its effectiveness has motivated the study of the effect that learning hyperparameters such as learning rate and batch size have on the sharpness of minima to which the algorithm will converge Wu et al. [2018], Zhu et al. [2019], Mulayoff et al. [2021]. The hypothesis has received substantial criticism. In Dinh et al. [2017] it is shown that flatness is not necessary for good generalisation in ReLU models, since such models are invariant to scaling symmetries of the parameters which arbitrarily sharpen their loss landscapes. This observation has motivated the consideration of scale-invariant measures of loss sharpness Lyu et al. [2022], Jang et al. [2022]. In Granziol [2020], the sufficiency of loss flatness for good generalisation is disputed by showing that models trained with the cross-entropy cost generalise better with weight decay than without, despite the former ending up in sharper minima. Sufficiency of flatness for generalisation is further challenged for Gaussian-activated networks on regression tasks in Ramasinghe et al. [2023].
Relatively little work has looked into the mechanism underlying the relationship between loss curvature and generalisation. PAC-Bayes bounds Dziugaite and Roy [2017], Foret et al. [2021], F. He and T. Liu and D. Tao [2019] provide some theoretical support for the hypothesis that loss flatness is sufficient for good generalisation, however this hypothesis, taken unconditionally, is known to be false empirically Granziol [2020], Ramasinghe et al. [2023]. The same is true of Petzka et al. [2021], which cleverly bounds the generalisation gap by a rescaled loss Hessian trace. Despite advocating for the empirical Jacobian as the link between loss curvature and generalisation as we do, the insightful papers Ma and Ying [2021], Gamba et al. [2023] consider the relationship only at a critical point of the square cost, and in particular cannot offer explanations for progressive sharpening or the generalisation benefits of training with an only an initially large learning rate that is gradually decayed, as our account can. Lee et al. [2023] advocates empirically for the parameter-output Jacobian of the model as the mediating link between loss sharpness and generalisation, but provide no theoretical indication for why this should be the case. We provide evidence in Appendix D indicating that our proposal may be able to fill this gap in Lee et al. [2023].
Finally, we note that among other generalisation studies in the literature, ours is most closely related to Ma and Ying [2021] which exploits properties of the data distribution to prove a generalisation bound. Our bound is also related to Bartlett et al. [2017], Bubeck and Sellke [2021], Muthukumar and Sulam [2023], which recognise sensitivity to input perturbations as key to generalisation. Like Wei and Ma [2019], our work in addition formalises the intuitive idea that the empirical Jacobian norm regulates generalisation Drucker and Le Cun [1992], Hoffman et al. [2019], Novak et al. [2018]. Further study of our ansatz in relation to the edge of stability phenomenon Cohen et al. [2021] may be of utility to algorithmic stability approaches to generalisation Bousquet and Elisseeff [2002], Hardt et al. [2016], Charles and Papailiopoulos [2018], Kuzborskij and Lampert [2018], Bassily et al. [2020].
Progressive sharpening and edge of stability: The effect of learning rate on loss sharpness has been understood to some extent for several years Wu et al. [2018]. In Cohen et al. [2021], this relationship was attended to for deep networks with a rigorous empirical study which showed that, after an initial period of sharpness increase during training called progressive sharpening, the sharpness increase halted at around and oscillated there while loss continued to decrease non-monotonically, a phase called edge of stability. These phenomena show that the typical assumptions made in theoretical work, namely that the learning rate is always smaller than twice the reciprocal of the sharpness Allen-Zhu et al. [2019], Du et al. [2019a, b], MacDonald et al. [2022], do not hold in practice. Significant work has since been conducted to understand these phenomena Lyu et al. [2022], Lee and Jang [2023], Arora et al. [2022], Wang et al. [2022], Zhu et al. [2023], Ahn et al. [2022], with Damian et al. [2023] showing in particular that edge of stability is a universal phenomenon arising from a third-order stabilising effect that must be taken into account when the sharpness grows above . In contrast, progressive sharpening is not universal; it is primarily observed only in genuinely deep neural networks. Although it has been correlated to growth in the norm of the output layer Wang et al. [2022], the cause of progressive sharpening has so far remained mysterious. The mechanism we propose is the first account of which we are aware for a cause of progressive sharpening.
3 Background and paper outline
3.1 Outliers in the spectrum
We follow the formal framework introduced in MacDonald et al. [2022], which allows us to treat all neural network layers on a common footing. Specifically, we consider a multilayer parameterised system (the layers), with a data matrix consisting of data vectors in . We denote by the associated parameter-function map defined by
| (1) |
Given a convex cost function and a target matrix , we consider the associated loss
| (2) |
where is defined by .
Using the chain rule and the product rule, one observes that the Hessian of admits the decomposition
| (3) |
The first of these terms, often called the Gauss-Newton matrix, is positive-semidefinite by convexity of . It has been demonstrated empirically in a vast number of practical settings that the largest, outlying eigenvalues of the Hessian throughout training correlate closely with those of the Gauss-Newton matrix Papyan [2018, 2019], Cohen et al. [2021]. In attempting to understand the relationship between loss sharpness and model behaviour, therefore, empirical evidence invites us to devote special attention to the Gauss-Newton matrix. In what follows we assume based on this evidence that the outlying eigenvalues of the Gauss-Newton matrix determine those of the loss Hessian.
3.2 The Gauss-Newton matrix and input-output Jacobians
Letting denote the square root , we see that the Gauss-Newton matrix has the same nonzero eigenvalues as its conjugate matrix , which is closely related to the tangent kernel identified in Jacot et al. [2018]. Letting and denote the input-output and parameter derivatives of a layer respectively, one sees that
| (4) |
is a sum of positive-semidefinite matrices. Each summand is determined in large part by the composites of input-output layer Jacobians. Note, however, that the input-output Jacobian of the first layer does not appear; only its parameter derivative does.
It is clear then that insofar as the largest eigenvalues of the Hessian are determined by the Gauss-Newton matrix, these eigenvalues are determined in part by the input-output Jacobians of all layers following the first. We judge the following ansatz to be intuitively clear from careful consideration of Equation (4).
Ansatz 3.1.
Under certain conditions, an increase in the magnitude of the input-output Jacobian of a deep neural network will cause an increase in the loss sharpness. Conversely, a decrease in the sharpness will cause a decrease in the magnitude of the input-output Jacobian.
Note that Ma and Ying [2021], Gamba et al. [2023] already contain a rigorous proofs of Ansatz 3.1 under special conditions: namely at critical points of the square cost. This restricted setting is not sufficient for our purposes. To understand the relationship between loss curvature and model behaviour adequately, we must invoke Ansatz 3.1 throughout training and most frequently with the cross-entropy cost function, where Ma and Ying [2021], Gamba et al. [2023] do not apply.
Importantly, we make no claim that Ansatz 3.1 holds unconditionally. Generally, the relationship proposed in Ansatz 3.1 is necessarily mediated by the following factors present in Equation (4): (1) the square root of the second derivative of the cost function; (2) the presence of the parameter derivatives ; (3) the complete absence of the Jacobian of the first layer. These mediating factors prevent a simple upper bound of input-output Jacobian by loss Hessian, and we spent a significant amount of time and computational power exposing the importance of these mediating factors empirically (Figure 2, Appendix C). In all cases where Ansatz 3.1 appears not to apply, we are able to account for its inadequacy in terms of these mediating factors using Equation (4) and further measurements. Moreover, we are able to to explain all known exceptions to the “rules" of the superior generalisation of flat minima Granziol [2020], Ramasinghe et al. [2023] and of progressive sharpening Cohen et al. [2021] as consequences of unusual behaviour in these mediating factors. Ours is the only account we are aware of for these phenomena which can make this claim.
4 General theory
All of what follows is motivated by the following idea: the Lipschitz norm of a differentiable function is upper-bounded by the supremum, over the relevant data distribution, of the spectral norm of its Jacobian. Intuitively, this supremum will itself be approximated by the maximum Jacobian norm over a finite sample of points from the distribution, which by Ansatz 3.1 can be expected to relate to the loss Hessian of the model. It is this intuition we seek to formalise and, and whose practical relevance we seek to justify, in this section.
In what follows, we will use to denote the positive real numbers. We will use to denote a probability measure on , whose support we assume to be a metric space with metric inherited from . Given a Lipschitz function , we use to denote the Lipschitz norm of . Note the dual meaning of : when is vector-valued, it refers to the Euclidean norm, while when is operator-valued (e.g., when is a Jacobian), refers to the spectral norm. We will frequently invoke pointwise evaluation of the derivative of Lipschitz functions, and in doing so always rely on the fact that our evaluations are probabilistic and Lipschitz functions are differentiable almost everywhere. We will use to denote the closed Euclidean ball of radius centered . Finally, given a locally bounded (but not necessarily continuous) function and a compact set , we define the local variation of over by
| (5) |
Thus, for instance, if is Lipschitz and is a ball of radius , then . All proofs are deferred to the appendix.
We begin by specifying the data distributions with which we will be concerned.
Definition 4.1.
Let be a function such that for each , the function is decreasing and vanishes as . We say that a distribution is -good if for every and , with probability at least over i.i.d. samples from , one has .
A similar assumption on the data distribution is adopted in Ma and Ying [2021], however no proof is given in Ma and Ying [2021] that such an assumption is characteristic of data distributions of practical interest. Our first theorem, derived from [Reznikov and Saff, 2016, Theorem 2.1], is that many data distributions of practical interest in deep learning are indeed examples of Definition 4.1.
Theorem 4.2.
Suppose that is the normalised Riemannian volume measure of a compact, connected, embedded, -dimensional submanifold of Euclidean space (possibly with boundary and corners). Then there exists , with , such that is -good.
In particular, the uniform distribution on the unit hypercube in is -good with
| (6) |
and, for and sufficiently large, the uniform distribution on the -dimensional unit hypersphere is -good with
| (7) |
Moreover, if is any -good distribution, then the pushforward of by any Lipschitz function is -good.
Theorem 4.2 says in particular that the distribution generated by any GAN whose latent space is the uniform distribution on a hypercube or on a sphere is an example of a good distribution, as is any distribution generated by an implicit neural function Sitzmann et al. [2020]. Since a high dimensional isotropic Gaussian is close to a uniform distribution on a sphere, which is good by Theorem 4.2, we believe it likely that our theory can be strengthened to include Gaussian distributions, however we have not attempted to prove this and leave it to future work.
Our next theorem formalises our intuition that the maximum Jacobian is an approximate upper bound on the Lipschitz constant of a model throughout training. Its proof is implicit in the proofs of both of our following theorems which characterise progressive sharpening and generalisation in terms of the empirical Jacobian norm.
Theorem 4.3.
Suppose that is -good, and let and . Then with probability at least over i.i.d. samples from , for any Lipschitz function , one has:
| (8) |
5 Progressive sharpening
In this section we give our account of progressive sharpening. We will assume that training of a model is undertaken using a cost function , whose global minimum we assume to be zero, and for which we assume that there is such that for all . This is clearly always the case for the square cost; by Pinsker’s inequality, it also holds for the Kullback-Leibler divergence on softmax outputs, and hence also for the cross-entropy cost provided one subtracts label entropy.
Theorem 5.1.
Suppose that is -good, and let and . Let be a target function and fix a real number . Then with probability at least over i.i.d. samples drawn from , for any Lipschitz function satisfying for all , one has
| (9) |
Progressive sharpening: Theorem 4.3 tells us that any training procedure that reduces the loss over all data points will thus also increase the sample-maximum Jacobian norm from a low starting point. Invoking Ansatz 3.1, this increase in the sample-maximum Jacobian norm can be expected to cause a corresponding increase in the magnitude of the loss Hessian (see Appendix A.1): progressive sharpening.
Theorem 5.1 thus tells us that sharpening can be made more or less severe by scaling the distances between target values: indeed this is what we observe (Figure 1, see also Appendix B.1). One might also expect that for non-batch-normalised networks, scaling the inputs closer together would increase sharpening too. However, this is not the case, due to the mediating factors in Ansatz 3.1. Specifically, while it is true that such scaling increases the growth rate of the Jacobian norm, this increase in Jacobian norm does not necessarily increase sharpening, since it coincides with a decrease in the magnitude of the parameter derivatives, which are key factors in relating the model Jacobian to the loss Hessian (see Appendix C.2).
Edge of stability: Although the edge of stability mechanism explicated in Damian et al. [2023] can be expected to put some downward pressure on the model Jacobian, due to the presence of the mediating factors discussed following Ansatz 3.1 it need not cause the Jacobian to plateau in the same way that loss sharpness does. Nonetheless, this downward pressure on Jacobian is important: it is to this that we attribute the better generalisation of models trained with large learning rate, even if that learning rate is decayed towards the end of training. We validate this empirically in the next section and Appendix D.
Wide networks and linear models: It has been observed empirically that wide networks exhibit less severe sharpening, and linear (kernel) models exhibit none at all Cohen et al. [2021]. It might be thought, since these models nonetheless must increase in Jacobian norm during training by Theorem 5.1, that such models are therefore counterexamples to our explanation. They are in fact consistent: Theorem 5.1 only implies sharpening insofar as Ansatz 3.1 holds. Importantly, since the Jacobian of the first linear layer does not appear in Equation (4), an increase in the input-output Jacobian norm of a linear (kernel) model will not cause an increase in sharpness according to Ansatz 3.1. The same is true of wide networks, which approximate kernel models increasingly well as width is sent to infinity Lee et al. [2019]; thus wide networks will also be expected to sharpen less severely during training, as has been observed empirically.



6 Flat minima and generalisation
We argue in this section that loss flatness implies good generalisation only via encouraging smaller Jacobian norm, through Ansatz 3.1. Indeed, our final theorem, whose proof is inspired by that of [Ma and Ying, 2021, Theorem 6], assures us rigorously that on models that fit training data, sufficiently small empirical Jacobian norm and sufficiently large sample size suffice to guarantee good generalisation, as has long been suspected in the literature Drucker and Le Cun [1992].
Theorem 6.1.
Let be -good and let be a target function, which we assume to be Lipschitz. Let and let . Then with probability at least over all i.i.d. samples from , any Lipschitz function which coincides with on , satisfies:
| (10) |
Our proof of Theorem 6.1 is similar to that of [Ma and Ying, 2021, Theorem 6]. Our bound is an improvement on that of Ma and Ying [2021] in having better decay in . Additionally, in bounding in terms of the empirical Jacobian norm at convergence instead of training hyperparameters at convergence, our bound is sensitive to implicit Jacobian regularisation throughout training in a way that the bound of Ma and Ying [2021] is not. Our bound is thus in principle sensitive to the superior generalisation of networks trained with an initially high learning rate that is gradually decayed to a small learning rate (such networks experience more implicit Jacobian regularisation at the edge of stability), over networks trained with a small learning rate from initialisation. In contrast, the bound of Ma and Ying [2021] is not sensitive to this distinction.
Like [Ma and Ying, 2021, Theorem 6], however, our bound exhibits inferior decay in , where is the intrinsic dimension of the data distribution, when compared with the more common rates in the literature. The reason for this is that all bounds of which we are aware in the literature, with the exception of [Ma and Ying, 2021, Theorem 6], derive from consideration of hypothesis complexity, rather than data complexity as we and Ma and Ying [2021] consider. Although the method we adopt implies this worse decay in , our method has the advantage of not needing to invoke the large hypothesis complexity terms, such as Rademacher complexity and KL-divergence, that make bounds based on such terms so loose when applied to deep learning Zhang et al. [2017]. Moreover, since standard datasets in deep learning are intrinsically low dimensional Miyato et al. [2018], the rate in our bounds can still be expected to be nontrivial in practice.
In what follows we present experimental results measuring the generalisation gap (absolute value of train loss minus test loss), sharpness and Jacobian norm at the end of training with varying degrees of various regularisation techniques. Our results confirm that while loss sharpness is neither necessary nor sufficient for good generalisation, empirical Jacobian norm consistently correlates better with generalisation than does sharpness for all regularisation measures we studied. Moreover, whenever loss sharpness does correlate with generalisation, this correlation tends to go hand-in-hand with smaller Jacobian norm, as predicted by Ansatz 3.1. Note that the Jacobians we plot were all computed in evaluation mode, meaning all BN layers had their statistics fixed: that the relationship with the train mode loss Hessian can still be expected to hold is justified in Appendix A.1.

Cross-entropy and weight decay: It was observed in Granziol [2020] that when training with the cross-entropy cost, networks trained with weight decay generalised better than those trained without, despite converging to sharper minima. We confirm this observation in Figure 2. Using Ansatz 3.1 and Theorem 6.1, we are able to provide a new explanation for this fact. For the cross-entropy cost, both terms and appearing in the Hessian (Equation (3)) vanish at infinity in parameter space. By preventing convergence of the parameter vector to infinity in parameter space, weight-decay therefore encourages convergence to a sharper minimum than would otherwise be the case. However, since the Frobenius norm of a matrix is an upper bound on the spectral norm, weight decay also implicitly regularises the Jacobian of the model, leading to better generalisation by Theorem 6.1.
Since training with weight decay is the norm in practice, and since any correlations between vanishing Hessian and generalisation will likely be unreliable, we used weight decay in all of what follows.
Learning rate and batch size: It is commonly understood that larger learning rates and smaller batch sizes serve to encourage convergence to flatter minima Keskar et al. [2017], Wu et al. [2018]. By Theorem 6.1 and Ansatz 3.1, such hyperparameter choice can be expected to lead to better generalisation. We report on experiments testing this idea in Figures 3, 4 (ResNet18 on CIFAR10) and Appendix B.2 (ResNet18 and VGG11 on CIFAR10 and CIFAR100). The results are mostly consistent with expectations, with the exception of Jacobian norm being reduced with larger batch size at the highest learning rate while generalisation gap increases. The phenomenon appears to be data-agnostic (the same occurs with ResNet18 on CIFAR100), but architecture-dependent (we do not observe this problem with VGG11 on either CIFAR10 or CIFAR100). This is not necessarily inconsistent with Theorem 6.1, which allows for the empirical Jacobian norm to be a poor estimator of the Lipschitz constant of the model via the local variation in the model’s Jacobian. Our results indicate that this local variation term is increased during (impractical) large batch training of skip-connected architectures using a constant high learning rate.








Other regularisation techniques: We also test to see the extent that other common regularisation techniques, including label smoothing, data augmentation, mixup Zhang et al. [2018] and sharpness-aware minimisation (SAM) Foret et al. [2021] regularise Hessian and Jacobian to result in better generalisation. We find that while Jacobian norm is regularised at least initially across all techniques, only in SAM is sharpness regularised. This validates our proposal that Jacobian norm is a key mediating factor between sharpness and generalisation, as well as the position of Dinh et al. [2017] that flatness is not necessary for good generalisation. Note that at least some of the gradual increase in Jacobian norm for mixup and data augmentation as the -axis parameter is increased is to be expected due to our measurement scheme: see the caption in Figure 5. See Appendix B.3 for experimental details and similar results for VGG11 and CIFAR100.

7 Discussion
One limitation of our work is that Ansatz 3.1 is not mathematically rigorous. A close theoretical analysis would ideally provide rigorous conditions under which one can upper bound the model Jacobian norm in terms of loss sharpness throughout training. These conditions would need to be compatible with the empirical counterexmaples we give in Figure 2 and Appendix C.
A second limitation of our work is that we do not numerically evaluate our generalisation bound. Numerical evaluation of the bound would require both an estimate of the Lipschitz constant of a GAN which has generated the data, as well as the local variation of the Jacobian of the model defined in Equation (5). While existing techniques may be able to aid the first of these Fazlyab et al. [2019], we are unaware of any work studying the second, which is outside the scope of this paper. We leave this important evaluation to future work.
8 Conclusion
We proposed a new relationship between the loss Hessian of a deep neural network and the input-output Jacobian of the model. We proved several theorems allowing us to leverage this relationship in providing new explanations for progressive sharpening and the link between loss geometry and generalisation. An experimental study was conducted which validates our proposal.
References
- Cohen et al. [2021] J. Cohen, S. Kaur, Y. Li, J. Zico Kolter, and A. Talwalkar. Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability. In ICLR, 2021.
- Hochreiter and Schmidhuber [1997] S. Hochreiter and J. Schmidhuber. Flat minima. Neural Computation, 9(1):1–42, 1997.
- Keskar et al. [2017] N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, P. Tak, and P. Tang. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. In ICLR, 2017.
- Chaudhari et al. [2017] P. Chaudhari, A. Choromanska, S. Soatto, Y. LeCun, C. Baldassi, C. Borgs, J. Chayes, L. Sagun, and R. Zecchina. Entropy-SGD: Biasing Gradient Descent into Wide Valleys. In ICLR, 2017.
- Foret et al. [2021] P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur. Sharpness-Aware Minimization for Efficiently Improving Generalization. In ICLR, 2021.
- Drucker and Le Cun [1992] Harris Drucker and Yann Le Cun. Improving generalization performance using double backpropagation. IEEE Transactions on Neural Networks, 3(6):991–997, 1992.
- Bartlett et al. [2017] P. Bartlett, D. J. Foster, and M. Telgarsky. Spectrally-normalized margin bounds for neural networks. In NeurIPS, 2017.
- Neyshabur et al. [2017] B. Neyshabur, S. Bhojanapalli, D. Mcallester, and N. Srebro. Exploring Generalization in Deep Learning. In NeurIPS, 2017.
- Hoffman et al. [2019] J. Hoffman, D. A. Roberts, and S. Yaida. Robust Learning with Jacobian Regularization. arXiv:1908.02729, 2019.
- Bubeck and Sellke [2021] S. Bubeck and M. Sellke. A Universal Law of Robustness via Isoperimetry . In NeurIPS, 2021.
- Gouk et al. [2021] H. Gouk, E. Frank, B. Pfahringer, and M. J. Cree. Regularisation of neural networks by enforcing Lipschitz continuity. Machine Learning, 110:393–416, 2021.
- Novak et al. [2018] Roman Novak, Yasaman Bahri, Daniel A Abolafia, Jeffrey Pennington, and Jascha Sohl-Dickstein. Sensitivity and generalization in neural networks: an empirical study. In International Conference on Learning Representations, 2018.
- Ma and Ying [2021] C. Ma and L. Ying. On linear stability of sgd and input-smoothness of neural networks. NeurIPS, 2021.
- Papyan [2018] V. Papyan. The Full Spectrum of Deepnet Hessians at Scale: Dynamics with SGD Training and Sample Size. arXiv:1811.07062, 2018.
- Papyan [2019] V. Papyan. Measurements of three-level hierarchical structure in the outliers in the spectrum of deepnet hessians. In ICML, 2019.
- Ghorbani et al. [2019] B. Ghorbani, S. Krishnan, and Y. Xiao. An Investigation into Neural Net Optimization via Hessian Eigenvalue Density. In ICML, 2019.
- Jacot et al. [2018] A. Jacot, F. Gabriel, and C. Hongler. Neural Tangent Kernel: Convergence and Generalization in Neural Networks. In NeurIPS, pages 8571–8580, 2018.
- Chen et al. [2020] X. Chen, C.-J. Hsieh, and B. Gong. When Vision Transformers Outperform ResNets without Pre-training or Strong Data Augmentations. In ICLR, 2020.
- Wu et al. [2018] L. Wu, C. Ma, and W. E. How SGD Selects the Global Minima in Over-parameterized Learning: A Dynamical Stability Perspective. In NeurIPS, 2018.
- Zhu et al. [2019] Z. Zhu, J. Wu, B. Yu, L. Wu, and J. Ma. The Anisotropic Noise in Stochastic Gradient Descent: Its Behavior of Escaping from Sharp Minima and Regularization Effects. In ICML, 2019.
- Mulayoff et al. [2021] R. Mulayoff, T. Michaeli, and D. Soudry. The Implicit Bias of Minima Stability: A View from Function Space. In NeurIPS, 2021.
- Dinh et al. [2017] L. Dinh, R. Pascanu, S. Bengio, and Y. Bengio. Sharp minima can generalize for deep nets. In ICML, pages 1019 –1028, 2017.
- Lyu et al. [2022] K. Lyu, Z. Li, and S. Arora. Understanding the Generalization Benefit of Normalization Layers: Sharpness Reduction. In NeurIPS, 2022.
- Jang et al. [2022] C. Jang, S. Lee, F. Park, and Y.-K. Noh. A reparametrization-invariant sharpness measure based on information geometry. In NeurIPS, 2022.
- Granziol [2020] D. Granziol. Flatness is a False Friend. arXiv:2006.09091, 2020.
- Ramasinghe et al. [2023] S. Ramasinghe, L. E. MacDonald, M. Farazi, H. Saratchandran, and S. Lucey. How much does Initialization Affect Generalization? In ICML, 2023.
- Dziugaite and Roy [2017] G. K. Dziugaite and D. M. Roy. Computing Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters than Training Data. In UAI, 2017.
- F. He and T. Liu and D. Tao [2019] F. He and T. Liu and D. Tao. Control Batch Size and Learning Rate to Generalize Well: Theoretical and Empirical Evidence . In NeurIPS, 2019.
- Petzka et al. [2021] Henning Petzka, Michael Kamp, Linara Adilova, Cristian Sminchisescu, and Mario Boley. Relative flatness and generalization. Advances in Neural Information Processing Systems, 34:18420–18432, 2021.
- Gamba et al. [2023] M. Gamba, H. Azizpour, and M. Bjorkman. On the lipschitz constant of deep networks and double descent. arXiv:2301.12309, 2023.
- Lee et al. [2023] S. Lee, J. Park, and J. Lee. Implicit jacobian regularization weighted with impurity of probability output. ICML, 2023.
- Muthukumar and Sulam [2023] R. Muthukumar and J. Sulam. Sparsity-aware generalization theory for deep neural networks. PMLR, 195:1–31, 2023.
- Wei and Ma [2019] C. Wei and T. Ma. Data-dependent sample complexity of deep neural networks via lipschitz augmentation. NeurIPS, 2019.
- Bousquet and Elisseeff [2002] O. Bousquet and A. Elisseeff. Stability and Generalization. Journal of Machine Learning Research, 2:499–526, 2002.
- Hardt et al. [2016] M. Hardt, B. Recht, and Y. Singer. Train faster, generalize better: Stability of stochastic gradient descent. In ICML, 2016.
- Charles and Papailiopoulos [2018] Z. Charles and D. Papailiopoulos. Stability and Generalization of Learning Algorithms that Converge to Global Optima. In ICML, 2018.
- Kuzborskij and Lampert [2018] I. Kuzborskij and C. H. Lampert. Data-Dependent Stability of Stochastic Gradient Descent. In ICML, 2018.
- Bassily et al. [2020] R. Bassily, V. Feldman, C. Guzmán, and K. Talwar. Stability of Stochastic Gradient Descent on Nonsmooth Convex Losses. In NeurIPS, 2020.
- Allen-Zhu et al. [2019] Z. Allen-Zhu, Y. Li, and Z. Song. A Convergence Theory for Deep Learning via Over-Parameterization. In ICML, pages 242–252, 2019.
- Du et al. [2019a] S. S. Du, X. Zhai, B. Poczos, and A. Singh. Gradient Descent Provably Optimizes Over-parameterized Neural Networks. In ICLR, 2019a.
- Du et al. [2019b] S. S. Du, J. Lee, H. Li, L. Wang, and X. Zhai. Gradient Descent Finds Global Minima of Deep Neural Networks. In ICML, pages 1675–1685, 2019b.
- MacDonald et al. [2022] L. E. MacDonald, H. Saratchandran, J. Valmadre, and S. Lucey. A global analysis of global optimisation. arXiv:2210.05371, 2022.
- Lee and Jang [2023] S. Lee and C. Jang. A new characterization of the edge of stability based on a sharpness measure aware of batch gradient distribution. In ICLR, 2023.
- Arora et al. [2022] S. Arora, Z. Li, and A. Panigrahi. Understanding Gradient Descent on Edge of Stability in Deep Learning. In ICML, 2022.
- Wang et al. [2022] Z. Wang, Z. Li, and J. Li. Analyzing Sharpness along GD Trajectory: Progressive Sharpening and Edge of Stability. In NeurIPS, 2022.
- Zhu et al. [2023] X. Zhu, Z. Wang, X. Wang, M. Zhou, and R. Ge. Understanding Edge-of-Stability Training Dynamics with a Minimalist Example. In ICLR, 2023.
- Ahn et al. [2022] K. Ahn, J. Zhang, and S. Sra. Understanding the unstable convergence of gradient descent. In ICML, 2022.
- Damian et al. [2023] A. Damian, E. Nichani, and J. Lee. Self-Stabilization: The Implicit Bias of Gradient Descent at the Edge of Stability. In ICLR, 2023.
- Reznikov and Saff [2016] A. Reznikov and E. B. Saff. The covering radius of randomly distributed points on a manifold. International Mathematics Research Notices, 2016(19):6065–6094, 2016.
- Sitzmann et al. [2020] V. Sitzmann, J. Martel, A. Bergman, D. Lindell, and G. Wetzstein. Implicit neural representations with periodic activation functions. In NeurIPS, 2020.
- Lee et al. [2019] J. Lee, L. Xiao, S. Schoenholtz, Y. Bahri, R. Novak, J. Sohl-Dickstein, and J. Pennington. Wide neural networks of any depth evolve as linear models under gradient descent. NeurIPS, 2019.
- Zhang et al. [2017] C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals. Understanding deep learning requires rethinking generalization. In ICLR, 2017.
- Miyato et al. [2018] T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida. Spectral Normalization for Generative Adversarial Networks. In ICML, 2018.
- Zhang et al. [2018] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz. mixup: Beyond Empirical Risk Minimization . In ICLR, 2018.
- Fazlyab et al. [2019] M. Fazlyab, A. Robey, H. Hassani, M. Morari, and G. Pappas. Efficient and accurate estimation of lipschitz constants for deep neural networks. NeurIPS, 2019.
- Li [2011] S. Li. Concise formulas for the area and volume of a hyperspherical cap. Asian Journal of Mathematics and Statistics, 4(1):66–70, 2011.
Computational resources: Exploratory experiments were conducted using a desktop machine with two Nvidia RTX A6000 GPUs. The extended experimental results in the appendix were obtained on a shared HPC system, where a total of 3500 GPU hours were used across the lifetime of the project (Nvidia A100 GPUs).
Appendix A Proofs
Here we give proofs of the theorems stated in the main body of the paper. To prove our first theorem, Theorem 4.2, we require the following differential-geometric lemma.
Lemma A.1.
Let be any compact, embedded, -dimensional submanifold of , possibly with boundary and corners. Equip with the Riemannian structure inherited from this embedding and let be the normalised volume measure of induced by its Riemannian structure. Then there exists and such that
for all and , where denotes the closed Euclidean ball around of radius .
Proof.
Since the Riemannian structure on is inherited from its embedding into , the embedding is bi-Lipschitz and hence there exists a constant such that
for all , where denotes the geodesic distance induced on by the Riemannian structure. It follows that for all , one has , where is the closed geodesic ball of radius about . Hence
| (11) |
and it remains only to lower-bound for sufficiently small. This we achieve by considering the geometry of .
Given , let be the Riemannian exponential map and let denote the zero tangent vector. Recall that the injectivity radius of is the largest number for which the restriction of to the -ball about zero in is a diffeomorphism onto its image for all . The injectivity radius exists and is strictly positive by compactness of . Let be any number that is strictly smaller than .
Let us now fix . Since is a radial isometry, it maps onto for any . Let denote the standard Euclidean volume element in and the volume form on . Since is a diffeomorphism, there exists a nonvanishing, smooth function on for which . Letting denote the minimum of , we then have
| (12) |
Here is the usual scaling factor one sees in the volume of a Euclidean -ball. Using compactness of , we define and . It then follows from the estimates (11) and (12) that
for all and as claimed. ∎
Proof of Theorem 4.2.
The proof we give is derived from [Reznikov and Saff, 2016, Theorem 2.1], however we wish to be more precise with our constants than is the case in Reznikov and Saff [2016]. We thus give a full proof here.
First, using the fact that satisfies the hypotheses of Lemma A.1, fix and for which for all , and define . This function will play a key role in the proof.
Now fix , let be a set of i.i.d. points sampled from , and let denote the covering radius of . Suppose that for some real number , and let be any maximal set of points in whose distinct pairwise distances are all bounded below by . Then we can find such that . Indeed, by hypothesis on , there exists such that . There also exists such that , since otherwise we could add to and contradict the maximality of . One then has , so that does not intersect .
It has thus been shown that
| (13) |
Since for all , is an upper bound on the probability that a randomly selected will not lie within of a given . Letting denote the cardinality of , the independence of the therefore permits an upper bound
| (14) |
The cardinality of can be further bounded via
| (15) |
so that one has
| (16) |
Using the invertibility of , one now sets , with . The McLaurin series for with reveals that
| (17) |
so that the bound becomes
| (18) |
Substituting yields
| (19) |
from which the general claim follows.
The result is specialised to the unit hypercube simply by observing that in this case, one can take
| (20) |
which is the volume of the intersection of the ball of radius , centered at a corner, with the cube.
For the unit hypersphere , fix and consider the Euclidean ball centered at . It is clear that the intersection is a geodesic for the inherited Riemannian metric on . In particular, for , is a hyperspherical cap. Elementary trigonometry shows that the angle subtended by the line connecting to and the line connecting any point on the boundary of to is given by . It then follows from [Li, 2011, p. 67] and the elementary trigonometric identity that one has
where
is the regularised incomplete beta function and is the volume of the unit -sphere. For any one has , thus one has the estimate
Now, fixing and assuming , we therefore have
We can then use in defining as in Equation (19) provided only that the assumption is satisfied. Setting , this requirement reduces to having sufficiently large that .
For the final result, when pushing forward a good distribution by a Lipschitz function, the stated result follows from the Lipschitz identity. ∎
Proof of Theorem 4.3.
Fix and . By -goodness of the data distribution, with probability at least over i.i.d. samples , the balls cover . For notational convenience, denote by simply . Conditioning on the event that the cover , one has
The result follows. ∎
Proof of Theorem 5.1.
Recall that by hypothesis on , one has for all in the domain of . Thus, since for all , we therefore have
| (21) |
for all . That is, for each , is contained in the -ball centred on the target value .
Since the smallest distance between any two and is realised when these points lie on the straight line between and , one has the lower bound
| (22) |
for all . Invoking the Lipschitz identity, and using the fact that for with probability zero, then gives
| (23) |
Conditioning now on the event that , which occurs with probability at least by -goodness of , and invoking Theorem 4.3 together with the subadditivity of the component-wise maximum function, gives the result. ∎
Proof of Theorem 6.1.
Fix and . Since is -good, with probability at least over i.i.d. samples , for each there exists such that . Conditioning on this event and fixing with corresponding nearby , the triangle inequality applies to yield
| (24) |
which gives
| (25) |
after applying the Lipschitz identities and invoking the hypothesis that and agree on training data. The proof of Theorem 4.3 now applies to show that, conditioned on this same event, one has
| (26) |
Taking the -expectation of both sides yields the result. ∎
A.1 A note on Jacobian computations
In our experiments, the Jacobian norm and sharpnesss are estimated using the power method and the Hessian/Jacobian-vector product functions in PyTorch. Recalling that we use to denote the set of data matrices, consisting of a batch of data column vectors concatenated together, there are two different kinds of functions whose Jacobians we would like to compute. The first of these are functions defined columnwise by some other map : that is
| (27) |
where lower indices index columns so that for all . In this case, flattening (columns first) shows that is just a block-diagonal matrix, whose block is . Hence . For a network in evaluation mode, every layer Jacobian is of this form.
On the other hand, for a network in train mode (as is the case when evaluating the Hessian of the loss), batch normalisation (BN) layers do not have this form. BN layers in train mode are nonlinear transformations defined by
| (28) |
where and denote mean and variance computed across the column index (again we omit the parameters as they are not essential to the discussion). The skeptical reader would rightly question whether the Jacobian of BN in train mode (to which Equation (4) applies) is sufficiently close to the Jacobian of BN in evaluation mode (to which Theorem 6.1 applies) for Ansatz 3.1 to be valid for BN networks. Our next and final theorem says that for sufficiently large datasets, this is not a problem.
Theorem A.2.
Let and denote a batch normalisation layer in train and evaluation mode respectively. Given a data matrix , assume the coordinates of are . Then .
Proof of Theorem A.2.
Given a data matrix , let its row-wise mean and variance, thought of as constant vectors, be denoted by and . The evaluation mode BN map is simply an affine transformation, with Jacobian coordinates given by
| (29) |
By [MacDonald et al., 2022, Lemma 8.3], the train mode BN map can be thought of as the composite , where are defined by
| (30) |
and
| (31) |
respectively. Here denotes the matrix of 1s, and denotes the vector of row-wise norms of .
As in [MacDonald et al., 2022, Lemma 8.3], one has
| (32) |
for any data matrix . Thus, invoking the chain rule and simplifying, we therefore get
| (33) |
Since the components are by hypothesis, the result follows. ∎
Appendix B Additional experimental results and details
B.1 Progressive sharpening
We trained ResNet18 and VGG11 (superficially modifying https://github.com/kuangliu/pytorch-cifar/blob/master/models/resnet.py and https://github.com/chengyangfu/pytorch-vgg-cifar10/blob/master/vgg.py respectively, with VGG11 in addition having its dropout layers removed, but BN layers retained) with full batch gradient descent on CIFAR10 with learning rates , and , using label smoothings of , and . The models with no label smoothing were trained to 99 percent accuracy, and the number of iterations required to do this were then used as the number of iterations to train the models using nonzero label smoothing. Sharpness and Jacobian norm were computed every 5, 10, or 20 iterations depending on the number of iterations required for convergence of the non-label-smoothed model. Five trials were conducted in each case, with mean and standard deviation plotted. Line style indicates degree of label smoothing.
The dataset was standardised so that each vector component is centered, with unit standard deviation. Full batch gradient descent was approximated by averaging the gradients over 10 “ghost batches” of size 5000 each, as in Cohen et al. [2021]. This is justified with BN networks by Theorem A.2. The Jacobian norm we plot is for the Jacobian of the softmaxed model, as required by our derivation of Equation (9). The sharpness and Jacobian norms were estimated using a randomly chosen subset of 2500 data points. In all cases, the smoother labels are associated with less severe increase in Jacobian and sharpness during training, as predicted by Equation (9). Refer to fullbatch.py in the supplementary material for the code we used to run these experiments.










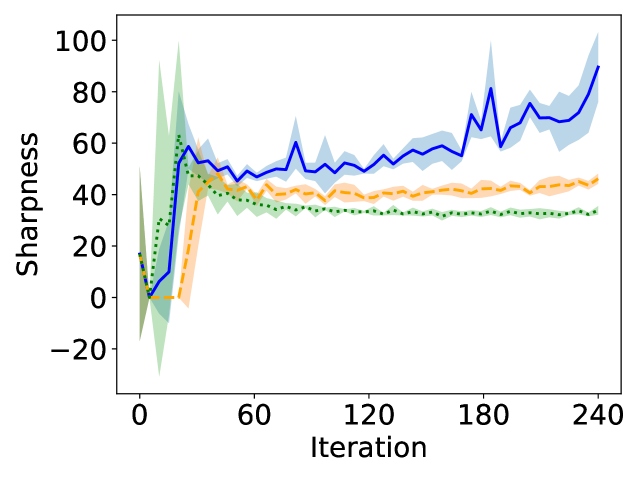







B.2 Batch size and learning rate
We trained a VGG11 and ResNet18 (superficially modifying https://github.com/chengyangfu/pytorch-vgg-cifar10/blob/master/vgg.py and https://github.com/kuangliu/pytorch-cifar/blob/master/models/resnet.py respectively, additionally removing dropout and retaining BN in the VGG11) on CIFAR10 and CIFAR100 at constant learning rates 0.1, 0.01, and 0.001, with batch sizes of 64, 128, 256, 512 and 1024. The data were normalised by their RGB-channelwise mean and standard deviation, computed across all pixel coordinates and all elements of the training set. Five trials of each were conducted. Training loss on the full data set was computed every 100 iterations, and training was terminated when the average of the most recent 10 such losses was smaller than 0.01 for CIFAR10 and 0.02 for CIFAR100. Weight decay regularisation of 0.0001 was used throughout. Refer to batch_lr.py in the supplementary material.
At the termination of training, training loss and test loss were computed, with estimates of the Jacobian norm and sharpness computed using a randomly selected subset of size 2000 from the training set. The same seed was used to generate the parameters for a given trail as was used to generate the random subset of the training set.
We see that, on the whole, the claim that smaller batch sizes and larger learning rates lead to flatter minima and better generalisation is supported by our experiments, with Jacobian norm in particular being well-correlated to generalisation gap as anticipated by Theorem 6.1 and Ansatz 3.1. As noted in the main body of the paper, the notable exception to this is ResNet models trained with the largest learning rate, where Jacobian norm appears to underestimate the Lipschitz constant of the model and hence the generalisation gap. We speculate that this is due to large learning rate training of skip connected models leading to larger Jacobian Lipschitz constant, making the Jacobian norm a poorer estimate of the Lipschitz constant of the model and hence of generalisation (Theorems 4.3 and 6.1).









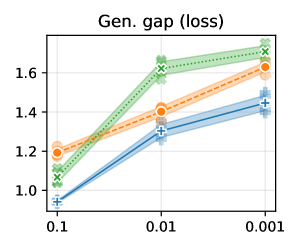











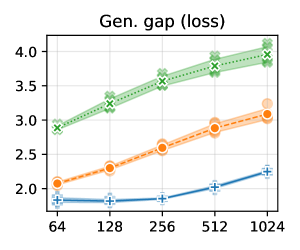










B.3 Extended practical results
Here we provide the experimental details and additional experimental results for Section 6. In addition to the generalisation gap, sharpness, and (input-output) Jacobian norm, these plots include the operator norm of the Gauss-Newton matrix, the loss on the training set, and the accuracy on the validation set. Note that the figures in this section present the final metrics at the conclusion of training as a function of the regularisation parameter, and hence progressive sharpening (as a function of time) will not be observed directly. Rather, the purpose is to examine the impact of different regularisation strategies on the Hessian and model Jacobian.
In all cases, the model Jacobian is correlated with the generalisation gap, whereas the Hessian is often uncorrelated. Moreover, the norm of the Gauss-Newton matrix is (almost) always very similar to that of Hessian, in line with previous empirical observation Papyan [2018, 2019], Cohen et al. [2021]. The results support the arguments that (i) the model Jacobian is strongly related to the generalisation gap and (ii) while the Hessian is connected to the model Jacobian, and forcing the Hessian to be sufficiently small likewise appears to force the Jacobian to be smaller (see the SAM plots), the Hessian is also influenced by other factors and can be large even without the Jacobian being large (see other plots). All of these phenomena are consistent with our ansatz.
The figures in this section present results for {CIFAR10, CIFAR100} {VGG11, ResNet18} {batch-norm, no batch-norm}. Line colour and style denote different initial learning rates. The models were trained for 90 epochs with a minibatch size of 128 examples using Polyak momentum of 0.9. The learning rate was decayed by a factor of 10 after 50 and 80 epochs. Models were trained using the softmax cross-entropy loss with weight decay of 0.0005. (If weight decay were disabled, we would often observe the Hessian to collapse to zero as the training loss went to zero, due to the vanishing second gradient of the cost function in this region [Cohen et al., 2021, Appendix C]. This would make the correlation between sharpness and generalisation gap even worse.) Refer to train_jax.py and slurm/launch_wd_sweep.sh for the default configuration and experiment configuration, respectively.
For each regularisation strategy, the degree of regularisation is parametrised as follows. Label smoothing considers smoothed labels with . Mixup takes a convex combination of two examples . The coefficient is drawn from a symmetric beta distribution with , which corresponds to a Bernoulli distribution when and a uniform distribution when . Data augmentation modifies the inputs with probability ; the image transforms which we adopt are the standard choices for CIFAR (four-pixel padding, random crop, random horizontal flip). Sharpness Aware Minimisation (SAM) restricts the distance between the current parameter vector and that which is used to compute the update, which simplifies to SGD when .
For all results presented in this section, the loss and generalisation gap were computed using “clean” training examples; that is, without mixup or data augmentation in the respective experiments (despite this requiring an additional evaluation of the model for each step). The Hessian, Gauss-Newton and input-output Jacobian norms were similarly computed using a random batch of 1000 clean training examples. The losses and matrix norms in this section similarly exclude weight decay. Label smoothing was interpreted as a modification of the loss function rather than the training distribution, and therefore was included in the calculation of the losses and matrix norms. Batch-norm layers were used in “train mode” (statistical moments computed from batch) for the Hessian and Gauss-Newton matrix, and in “eval mode” (statistical moments are constants) for the Jacobian matrix, although this difference was observed to have negligible effect on the Jacobian norm.
B.3.1 CIFAR10




B.3.2 CIFAR100




Appendix C On mediating factors in the ansatz
In this section we provide classification and regression experiments to show that the relationship between loss curvature and input-output Jacobians is not always simple. Recall again Equation (4):
| (34) |
Due to the presence of the parameter derivatives and the square root of the Hessian of the cost function, as well as the absence of the first layer Jacobian in Equation (4), it is not always true that the magnitude of the Hessian and that of the model’s input-output Jacobian are correlated.
C.1 The cost function
We trained a VGG11, again using https://github.com/chengyangfu/pytorch-vgg-cifar10/blob/master/vgg.py with drouput layers removed and BN layers retained, on CIFAR10 using SGD with a batch size of 128, using differing degrees of label smoothing. Data was standardised so that each RGB channel has zero mean and unit standard deviation over all pixel coordinates and training samples. In Figure 28 we plot the sharpness and Jacobian norm every five iterations in the first epoch, observing exactly the same relationship between label smoothing, Jacobian norm and sharpness as predicted in Section 5. Refer to vgg_sgd.py in the supplementary material for the code to run these experiments.



Zooming out, however, to the full training run over 90 epochs, Figure 29 shows that the Hessian ultimately behaves markedly differently.



The reason for this is that the norm of the network output grows to infinity in the unsmoothed case (Figure 29), and this growth in output corresponds to a vanishing of the term [Cohen et al., 2021, Appendix C] corresponding to the cross-entropy cost in Equation (4). Note that this growth is also to blame for the eventual collapse of the norm of the Jacobian of the softmaxed model, since the derivative of softmax vanishes at infinity also. This vanishing of the Jacobian should not be interpreted as saying that the Lipschitz constant of the model has collapsed (since if this were the case the model would not be able to fit the data), but rather that the maximum Jacobian norm over training samples has ceased to be a good approximation of the Lipschitz constant of the model, due to the Jacobian itself having a large Lipschitz constant (Theorem 4.3).
C.2 The parameter derivatives
Recall Theorem 5.1. We have already shown that decreasing the distance between labels decreases the severity of Jacobian growth, and, in line with Ansatz 3.1, also reduces the severity of progressive sharpening. It seems that one could also manipulate this severity by increasing the distance between input data points, for instance by scaling all data by a constant. We test this training simple, fully-connected, three layer networks, of width 200, with gradient descent on the first 5000 data points of CIFAR10. The data is standardised to have componentwise zero mean and unit standard deviation (measured across the whole dataset). The networks are initialised using the uniform distribution on the interval with endpoints (default PyTorch initialisation) and trained with a learning rate of for 300 iterations using the cross-entropy cost. Both ReLU and tanh activations are considered. Refer to small_network.py in the supplementary material for the code we used to run these experiments.
We scale the inputs by factors of 0.5, 1.0 and 1.5, bringing the data closer together at 0.5 and further apart at 1.5. From Theorem 5.1, we anticipate the Jacobian growth to go from most to least severe on these scalings respectively, with sharpness growth behaving similarly according to Ansatz 3.1. Surprisingly, we find that while Jacobian growth is more severe for the smaller scalings, the sharpness growth is less.
The reason for this is the effect of data scaling on the parameter derivatives in Equation (4). It is easily computed (cf. MacDonald et al. [2022]) that the parameter derivative is simply determined by the matrix of features from the previous layer. In the experimental settings we examined, these matrices are larger for the larger scaling values, which pushes the sharpness upwards despite Jacobian norm being smaller. Figures 30 and 31 show this phenomenon on ReLU and tanh activated networks respectively.








C.3 The absence of the first layer Jacobian
We replicate the experiments of Section 8 in Ramasinghe et al. [2023], where it is demonstrated that flatness of minimum is not correlated with model smoothness in a simple regression task, and point to a possible explanation of this within our theory.
In detail, a four layer MLP with either Gaussian or ReLU activations is trained to regress 8 points in . Each network is trained from a high frequency initialisation (obtained from default PyTorch initialisation on the Gaussian network, and by pretraining on for the ReLU network) to yield a non-smooth fit of the target data, and a low frequency initialisation (a wide Gaussian distribution for the Gaussian-activated network, and the default PyTorch initialisation for the ReLU network) to achieve a smooth fit of the data (see Figure 32). Refer to coordinate_network.py in the supplementary material for the code we used to run this experiment.




The models were trained with gradient descent using a learning rate of and momentum of 0.9, for 10000 epochs for the Gaussian networks and 100000 epochs for the ReLU networks. The pretraining for the high frequency ReLU initialisation was achieved using Adam with a learning rate of and default PyTorch settings.
| Gaussian activated network | ||
|---|---|---|
| Norm | High freq. | Low freq. |
| Jacobian norm | ||
| sharpness | ||
| First layer weight norm | ||
| ReLU activated network | ||
|---|---|---|
| Norm | High freq. | Low freq. |
| Jacobian norm | ||
| sharpness | ||
| First layer weight norm | ||
Tables 1 and 2 record the means and standard deviations of loss Hessian and Jacobian norms of the Gaussian and ReLU networks over 10 trials. As in Ramasinghe et al. [2023], we find that while the smoothly interpolating ReLU models on average land in flatter minima than the non-smoothly interpolating models, the opposite is true for the Gaussian networks.
Keeping in mind that the high variances in these numbers make it difficult to come to a conclusion about the trend, we propose a possible explanation for why the Gaussian activated networks do not appear to behave according to Ansatz 3.1. From Equation (4), the Hessian cannot be expected to relate to the Jacobian of the first layer. Note now the discrepancy between the first layer weight norms in the low frequency versus high frequency fits with the Gaussian networks, which does not occur for the ReLU networks. We believe this to be the cause of the larger Hessian for the low-frequency Gaussian models: with such a small weight matrix in the first layer, all higher layers must be relied upon to fit the data, making their Jacobians higher than they would otherwise need to be. These larger Jacobians would then push the Hessian magnitude higher by Equation (4).
Appendix D Relationship to the parameter-output Jacobian
In Lee et al. [2023], the parameter-output Jacobian is advocated as the mediating link between loss sharpness and generalisation. Extensive experiments are provided to support this claim. In particular, it is shown that regularising by the Frobenius norm of the parameter-output Jacobian during training is sufficient to alleviate the poor generalisation of (toy) networks trained using a small learning rate. However, no theoretical reasons are given for why the parameter-output Jacobian should be related to generalisation.
We expect that our Theorem 6.1 could provide the theoretical link missing in Lee et al. [2023]. Indeed, the term in brackets in our Equation (4) is precisely the Gram matrix of the parameter-output Jacobian. Thus, our Ansatz 3.1 states that regularisation of the parameter-output Jacobian will also regularise the input-output Jacobian. If this is true, then we should see similar improvements in network performance when training with a small learning rate using an input-output Jacobian regulariser to those seen in Lee et al. [2023] when training with the parameter-output Jacobian regulariser. Moreover, one should see that these improvements are correlated to input-output Jacobian norm in all cases. Figure 33 demonstrates that this is indeed the case, using the same settings on data and models as were used for the regulariser experiments in Section 6.

