On Generating Lagrangian Cuts for Two-Stage Stochastic Integer Programs
)
Abstract
We investigate new methods for generating Lagrangian cuts to solve two-stage stochastic integer programs. Lagrangian cuts can be added to a Benders reformulation, and are derived from solving single scenario integer programming subproblems identical to those used in the nonanticipative Lagrangian dual of a stochastic integer program. While Lagrangian cuts have the potential to significantly strengthen the Benders relaxation, generating Lagrangian cuts can be computationally demanding. We investigate new techniques for generating Lagrangian cuts with the goal of obtaining methods that provide significant improvements to the Benders relaxation quickly. Computational results demonstrate that our proposed method improves the Benders relaxation significantly faster than previous methods for generating Lagrangian cuts and, when used within a branch-and-cut algorithm, significantly reduces the size of the search tree for three classes of test problems.
1 Introduction
We study methods for solving two-stage stochastic integer programs (SIPs) with general mixed-integer first-stage and second-stage variables. Two-stage stochastic programs are used to model problems with uncertain data, where a decision maker first decides the values of first-stage decision variables, then observes the values of the uncertain data, and finally decides the values of second-stage decision variables. The objective is to minimize the sum of the first-stage cost and the expected value of the second-stage cost, where the expected value is taken with respect to the distribution of the uncertain data. Each realization of the uncertain data is called a scenario. Assuming the uncertainty is modeled with a finite set of scenarios , a two-stage SIP can be formulated as follows:
| (1) |
where , and for each , denotes the probability of scenario and is the recourse function of scenario defined as
| (2) |
Here and denote the integrality restrictions on some or all variables of and , respectively. Sign restrictions and variable bounds, if present, are assumed to be included in the constraints or . Matrices and vectors are the realization of the uncertain data associated with scenario . We do not assume relatively complete recourse, i.e., it is possible that the recourse problem (2) is infeasible for some and satisfying , in which case by convention.
Two-stage SIPs can also be written in the extensive form:
| (3) | ||||
| s.t. | ||||
From this perspective, SIPs are essentially large-scale mixed-integer programs (MIPs) with special block structure. Directly solving (3) as a MIP can be difficult when is large. Therefore, significant research has been devoted to the study of decomposition methods for solving SIP problems. Benders decomposition [1, 2] and dual decomposition [3] are the two most commonly used decomposition methods for solving SIPs. In Benders decomposition, the second-stage variables are projected out from the Benders master model and linear programming (LP) relaxations of scenario subproblems are solved to add cuts in the master model. In dual decomposition, a copy of the first-stage variables is created for each scenario and constraints are added to require the copies to be equal to each other. A Lagrangian relaxation is then formed by relaxing these so-called nonanticipativity constraints. Solving the corresponding Lagrangian dual problem requires solving single-scenario MIPs to provide function values and supergradients of the Lagrangian relaxation. A more detailed description of dual decomposition for SIPs is given in Section 2.2. Usually dual decomposition generates a much stronger bound than Benders decomposition but the bound takes much longer to compute. Rahmaniani et al. [4] proposed Benders dual decomposition (BDD) in which Lagrangian cuts generated by solving single-scenario MIPs identical to the subproblems in dual decomposition are added to the Benders formulation to strengthen the relaxation. Similarly, Li and Grossmann [5] develop a Benders-like decomposition algorithm implementing both Benders cuts and Lagrangian cuts for solving convex mixed 0-1 nonlinear stochastic programs. While representing an interesting hybrid between the Benders and dual decomposition approaches, the time spent generating the Lagrangian cuts remains a limitation in these approaches. In this paper, we extend this line of work by investigating methods to generate Lagrangian cuts more efficiently.
This work more broadly contributes to the significant research investigating the use of cutting planes to strengthen the Benders model. Laporte and Louveaux [6] propose integer L-shaped cuts for SIPs with pure binary first-stage variables. Sen and Higle [7] and Sen and Sherali [8] apply disjunctive programming techniques to convexify the second-stage problems for SIPs with pure binary first-stage variables. Ntaimo [9] investigates the use of Fenchel cuts added to strengthen the subproblem relaxations. Gade et al. [10] and Zhang and Küçükyavuz [11] demonstrate how Gomory cuts can be used within a Benders decomposition method for solving SIPs with pure integer first-stage and second-stage variables, leading to a finitely convergent algorithm. Qi and Sen [12] use cuts valid for multi-term disjunctions introduced in [13] to derive an algorithm for SIPs with mixed-integer recourse. van der Laan and Romeijnders [14] propose a new class of cuts, scaled cuts, which integrates previously generated Lagrangian cuts into a cut-generation model, again leading to a finitely convergent cutting-plane method for SIPs with mixed-integer recourse. Bodur et al. [15] compare the strength of split cuts derived in the Benders master problem space to those added in the scenario LP relaxation space. Zou et al. [16] propose strengthened Benders cuts and Lagrangian cuts to solve pure binary multistage SIPs.
There are also other approaches for solving SIPs that do not rely on a Benders model. Lulli and Sen [17] develop a column generation based algorithm for solving multistage SIPs. Lubin et al. [18] apply proximal bundle methods to parallelize the dual decomposition algorithm. Boland et al. [19] and Guo et al. [20] investigate the use of progressive hedging to calculate the Lagrangian dual bound. Kim and Dandurand [21] propose a new branching method for dual decomposition of SIPs. Kim et al. [22] apply asynchronous trust-region methods to solve the Lagrangian dual used in dual decomposition.
The goal of this paper is to develop an effective way of generating Lagrangian cuts to add to a Benders model. The main contributions of our work are summarized as follows.
- 1.
-
2.
We propose methods for accelerating the generation of Lagrangian cuts, including solving the cut generation problem in a restricted subspace, and using a MIP approximation to identify a promising restricted subspace. Numerical results indicate that these approaches lead to significantly faster bound improvement from Lagrangian cuts.
-
3.
We conduct an extensive numerical study on three classes of two-stage SIPs. We compare the impact of different strategies for generating Lagrangian cuts. Computational results are also given for using our method within branch-and-cut as an exact solution method. We find that this method has potential to outperform both a pure Benders approach and a pure dual decomposition approach.
Finally, we note that while we focus on new techniques for generating Lagrangian cuts for use in solving two-stage SIPs, these techniques can be directly applied to multi-stage SIPs by integrating them within the stochastic dual dynamic integer programming (SDDIP) algorithm in [16].
2 Preliminaries
2.1 Branch-and-Cut Based Methods
Problem (1) can be reformulated as the following Benders model:
| (4) |
where for each , contains the first-stage constraints and the epigraph of , i.e.,
| (5) |
In a typical approach to solve (4), each recourse function is replaced by a cutting-plane underestimate which creates a relaxation and is dynamically updated. In each iteration, an approximate problem defined by the current underestimate is solved to obtain a candidate solution and then a cut generation problem is solved to update the cutting plane approximation if necessary. This process is repeated until no cuts are identified.
We review two types of valid inequalities for . The first collection of cuts are Benders cuts [1, 2]. Benders cuts are generated based on the LP relaxation of the problem (2) defining . Given a candidate solution , the LP relaxation of the recourse problem is solved:
| (6) |
Let be an optimal dual solution of problem (6). Based on LP duality, the following Benders cut is valid for :
| (7) |
If the SIP has continuous recourse, i.e., , then (7) is tight at , i.e., The cutting-plane model is often constructed by iteratively adding Benders cuts until the lower bound converges to the LP relaxation bound. Benders cuts are sufficient to provide convergence for solving SIPs with continuous recourse [24].
Another useful family of cuts is the integer L-shaped cuts introduced in [6]. These cuts are valid only when the first-stage variables are binary, i.e., , but can be applied even when the second-stage includes integer decision variables. In this case, given and a value such that for all feasible , the following integer L-shaped cut is a valid inequality for :
| (8) |
A standard branch-and-cut algorithm using Benders cuts and integer L-shaped cuts is described in Appendix. The branch-and-cut algorithm can be implemented using a lazy constraint callback in modern MIP solvers, which allows the addition of Benders or integer L-shaped cuts when the solver encounters a solution with (i.e., satisfies any integrality constraints) but for which for some . These two classes of cuts are sufficient to guarantee convergence for SIPs with continuous recourse or pure binary first-stage variables. However, the efficiency of the algorithm depends significantly on the strength of the cutting-plane models ’s. Given poor relaxations of the recourse functions, the branch-and-bound search may end up exploring a huge number of nodes, resulting in a long solution time. As discussed in Section 1 many methods have been proposed to strengthen the model in order to accelerate the algorithm.
We note that the validity of Lagrangian cuts does not require either continuous recourse or pure binary first-stage variables. However, outside of those settings, additional cuts or a specialized branching scheme would be required to obtain a convergent algorithm. We refer the reader to, e.g., [25, 12, 14, 11] for examples of methods that can be used to obtain a finitely convergent algorithm in other settings. Lagrangian cuts could potentially be added to enhance any of these approaches.
2.2 Dual Decomposition
In dual decomposition [3], a copy of the first-stage variables is created for each scenario which yields a reformulation of (1):
Lagrangian relaxation is applied to the nonanticipativity constraints in this formulation with multipliers for , which gives the following Lagrangian relaxation problem:
| (9) | ||||
| s.t. |
where for each . Throughout this paper we assume that is nonempty for each
The nonanticipative Lagrangian dual problem is defined as . Note that constraint is implicitly enforced in since when . Under this condition, the variables in (9) can be eliminated, and hence (9) can be solved by solving a separate optimization for each scenario . The nonanticipative Lagrangian dual problem
is a convex program which gives a lower bound on the optimal value of (1). The following theorem provides a primal characterization of the bound .
Theorem 1 (Carøe and Schultz [3]).
The following equality holds:
Empirical evidence (e.g., [26, 27]) shows that the Lagrangian dual bound is often a tight lower bound on the optimal objective value of (2). Such a bound can be used in a branch and bound algorithm and to generate feasible solutions using heuristics (see, e.g., [3, 21]). However, the Lagrangian dual problem can be hard to solve due to its large size (with variables) and the difficulty of solving MIP subproblems to evaluate and obtain supergradients of at a point .
2.3 Benders Dual Decomposition
The BDD algorithm [4] is a version of Benders decomposition that uses strengthened Benders cuts and Lagrangian cuts to tighten the Benders model. In particular, they solve two types of scenario MIPs to generate optimality and feasibility cuts for :
-
1.
Given any , let be an optimal solution of
Then the following Lagrangian optimality cut is valid for :
(10) -
2.
Given any , let be an optimal solution of
Then the following Lagrangian feasibility cut is valid for :
(11)
The BDD algorithm generates both types of Lagrangian cuts by heuristically solving a Lagrangian cut generation problem. Numerical results from [4] show that Lagrangian cuts are able to close significant gap at the root node for a variety of SIP problems. Our goal in this work is to provide new methods for quickly finding strong Lagrangian cuts.
3 Selection and Normalization of Lagrangian Cuts
We begin by introducing an alternative view of the Lagrangian cuts (10) and (11) which leads to a different cut generation formulation. Let be defined as
| (12) |
for . According to (12), for any , the following inequality is valid for set defined in (5):
| (13) |
We next demonstrate that the set of all cuts of the form (13) is equivalent to set of Lagrangian cuts (10) and (11), and therefore we refer to cuts of the form (13) as Lagrangian cuts. For any , let denote the set defined by all cuts (13) with coefficients restricted on , i.e.,
Proposition 2.
Let be a neighborhood of the origin and let . Define . Then .
Proof.
We first show that . Let . We show that satisfies (10) and (11) for all . Let , and choose and large enough such that , and thus satisfies (13) using these values for . Multiplying inequality (13) with by gives
where is as defined in (10) and where we have used the observation that the function is positively homogeneous. Subtracting from both sides yields that satisfies (10). On the other hand, inequality (13) with implies
Multiplying both sides by and subtracting from both sides gives inequality (11). Since can be arbitrary, it implies .
Since Proposition 2 holds for any neighborhood of the origin, it allows flexibility to choose a normalization on the Lagrangian cut coefficients when generating cuts. We discuss the choice of such a normalization in Section 4.
Let denote the bound we obtain after adding all Lagrangian cuts, i.e.,
Since is positively homogeneous and the set defined by an inequality is invariant to any positive scaling of the inequality, we also have
for any such that is a neighborhood of the origin. Rahmaniani et al. [4] showed that for , adding all Lagrangian cuts of the form (10) and feasibility cuts (11) yields a Benders master problem with optimal objective value equal to . This is not true in general when . However, Li and Grossmann [5] showed that . We show in the following theorem that this is an equality, i.e., . Since according to Theorem 1 when , this result generalizes the result in [4].
Theorem 3.
The equality holds.
Proof.
Although has been shown in [5], we show both directions for completeness.
On the one hand, let and . Then there exists such that and . Then by definition of , we have
for all , which implies that .
On the other hand, let and . Since is a polyhedron, which is convex and closed, there exists a hyperplane strictly separating from . In other words, there exists and such that . Note that we have in this case since if . Then
i.e., violates the Lagrangian cut . Therefore, . ∎
We next consider the problem of separating a point from using Lagrangian cuts. Given a candidate solution and a convex and compact , the problem of separating from can be formulated as the following bounded convex optimization problem
| (14) |
Problem (14) can be solved by bundle methods given an oracle for evaluating the function value and a supergradient of . The function value and a supergradient of can be evaluated at any by solving the single-scenario MIP (12). Let be an optimal solution of (12). Then we have and is a supergradient of at .
Although (14) is a convex optimization problem, the requirement to solve a potentially large number of MIP problems of the form (12) to evaluate function values and supergradients of to find a single Lagrangian cut can make the use of such cuts computationally prohibitive. Numerical results in [16] indicate that although Lagrangian cuts can significantly improve the LP relaxation bound for many SIP problems, the use of exact separation of Lagrangian cuts does not improve overall solution time. In an attempt to reduce the time required to separate Lagrangian cuts, Rahmaniani et al. [4] applied an inner approximation heuristic. In the next section, we propose an alternative approach for generating Lagrangian cuts more quickly.
4 Restricted Separation of Lagrangian Cuts
Observe that given any , evaluating gives a valid inequality (13). By picking properly, we show in the following proposition that a small number of Lagrangian cuts is sufficient to give the perfect information bound [29] defined as
Although the perfect information bound can computed by solving a separate subproblem for each scenario, it is often better than the LP relaxation bound because each subproblem is a MIP.
Proposition 4.
The following equality holds:
| (15) |
Proof.
We first show the “” direction. It follows by observing that if satisfies for all , then
| (16) | ||||
The inequality (15) follows from the fact that the first inequality in (16) must hold at equality for all optimal solutions of (15). This is because if for some , we can obtain a feasible solution with a lower objective value by decreasing the value of . ∎
From this example, we see that Lagrangian cuts with can already yield the perfect information bound. One interpretation of this example is that useful Lagrangian cuts can be obtained even when searching in a heavily constrained set of coefficients, which motivates our study of restricted separation of Lagrangian cuts.
4.1 General Framework
We propose solving the following restricted version of (14) to search for a Lagrangian cut that separates a solution :
| (17) |
where can be any convex compact subset of , which is not necessarily defined by a neighborhood of the origin.
While setting to be a neighborhood of the origin would give an exact separation of Lagrangian cuts, our proposal is to use a more restricted definition of with the goal of obtaining a separation problem that can be solved faster. As one might expect, the strength of the cut generated from (17) will heavily depend on the choice of . We propose to define to be the span of a small set of vectors. Specifically, we require
for some , where are chosen vectors. If span , then this approach reduces to exact separation. However, for smaller , we expect a trade-off between computation time and strength of cuts. A natural possibility for the vectors , which we explore in Section 4.3, is to use the coefficients of Benders cuts derived from the LP relaxations.
4.2 Solution of (17)
We present a basic cutting-plane algorithm for solving (17) in Algorithm 1. The classical cutting-plane method used in the algorithm can be replaced by other bundle methods, e.g., the level method [30]. Within the solution process of (17), the function is approximated by an upper bounding cutting-plane model defined by
| (18) |
for , where is a finite subset of . In our implementation, for each scenario , all feasible first-stage solutions obtained from evaluating and the corresponding feasible second-stage costs are added into . Specifically, each time we solve (12) for some , we collect all optimal and sub-optimal solutions from the solver and store the first-stage solution and the corresponding feasible second-stage cost . To guarantee finite convergence, we assume that at least one of the optimal solutions obtained when solving (12) is an extreme point of . Note that even though we may solve problem (17) associated with different and , the previous remains a valid overestimate of . Therefore, whenever we need to solve (12) with some new and , we use the currently stored to initialize . In our implementation, to avoid unboundedness of , is initialized by the perfect information solution , where .
While Algorithm 1 is for the most part a standard cutting-plane algorithm, an important detail is the stopping condition which uses a relative tolerance . Convergence of Algorithm 1 follows standard arguments for a cutting-plane algorithm. Specifically, because the set of extreme-point optimal solutions from (12) is finite, there will eventually be an iteration where the optimal solution obtained when solving (12) is already contained in the set . When that occurs, after updating it will hold that . At that point it either holds that UB or UB-LB UB and the algorithm terminates. If the optimal value of (17) is positive, then UB will be strictly positive throughout the algorithm. In that case Algorithm 1 returns a violating Lagrangian cut with cut violation LB. The value of controls the trade-off between the strength of the cut and the running time. On the other hand, if the optimal value of (17) is non-positive, then we can terminate as soon as UB, since in this case we are assured a violated cut will not be found.
We next demonstrate that even when using it is possible to attain the full strength of the Lagrangian cuts for a given set when applying them repeatedly within a cutting-plane algorithm for solving a relaxation of problem (4). To make this result concrete, we state such a cutting-plane algorithm in Algorithm 2. At each iteration , we approximate the true objective function by the cutting-plane model:
where represents the Benders cuts and Lagrangian cuts associated with scenario that have been added to the master relaxation up to iteration . At iteration , a master problem based on the current cutting-plane model is solved and generates candidate solution . For each scenario , the restricted Lagrangian cut separation problem (17) is solved using Algorithm 1 with restricted to be a (typically low-dimensional) set . The cutting-plane model is then updated by adding the violated Lagrangian cuts (if any) for each scenario.
We show in the next theorem that if we search on a static compact and keep adding Lagrangian cuts by solving (17) to a relative tolerance with , the algorithm will converge to a solution that satisfies all the restricted Lagrangian cuts.
Theorem 5.
In Algorithm 2, let be a compact set independent of , and assume that at each iteration of Algorithm 2, for each scenario , a Lagrangian cut (if a violated one exists) is generated by solving (17) to relative tolerance with . Then for each scenario , every accumulation point of the sequence satisfies .
Proof.
Note that is a piecewise linear concave function. Therefore, is Lipschitz continuous. Assume is any fixed subsequence of that converges to a point . Assume for contradiction that
Since is bounded, there exists such that
This implies that for all ,
where the second “” follows from . Let denote the multiplier associated with the Lagrangian cut added at iteration . For any ,
since the Lagrangian cut associated with was added before iteration . On the other hand,
Since the sequence is bounded and function is Lipschitz continuous, there exists such that for all . This contradicts with the fact that is bounded. ∎
In practice, we allow to change with iteration , but Theorem 5 provides motivation for solving (17) to a relative tolerance. In Section 5.2.1, we present results of experiments demonstrating that for at least one problem class, using much larger than 0 can lead to significantly faster improvement in the lower bound obtained when using Lagrangian cuts. When allowing to change with iteration , Theorem 5 no longer applies. Instead, in this setting we follow common practice and terminate the cut-generation process after no more cuts are found, or when it is detected that the progress in increasing the lower bound has significantly slowed (see Section 5.3 for an example stopping condition).
4.3 Choice of
The primary difference between the exact separation (14) and the proposed restricted separation problem (17) is the restriction constraint . Ideally, we would like to choose so that (17) is easy to solve, in particular avoiding evaluating the function too many times, while also yielding a cut (13) that has a similar strength compared with the Lagrangian cut corresponding to the optimal solution of (14). Our proposal that aims to satisfy these properties is to define to be the span of past Benders cuts with some normalization. Specifically, we propose
| (19) |
Here and are both predetermined parameters, and are the coefficients of the last Benders cuts corresponding to scenario . The choice of is important. The motivation for this choice is that the combination of cut coefficients from the LP relaxation could give a good approximation of the tangent of the supporting hyperplanes of at an (near-)optimal solution. The normalization used here is similar to the one proposed for the selection of Benders cuts in [23].
Different normalization leads to different cuts. Our second proposal is to use
| (20) |
which replaces in (19) by . This normalization may tend to lead to solutions with sparse . An advantage of this normalization is that it leads to a MIP approximation for optimally choosing ’s from a set of candidate vectors, which we discuss next.
Let be a given (potentially large) collection of coefficient vectors for a scenario . We construct a MIP model for selecting a subset of these vectors of size at most , to then use in (20). Specifically, we introduce a binary variable for each , where indicates we select as one of the vectors to use in (20). Using these decision variables, the problem of selecting a subset of at most vectors that maximizes the normalized violation can be formulated as the following mixed-integer nonlinear program:
| (21) | |||||
| s.t. | (22) | ||||
| (23) | |||||
| (24) | |||||
| (25) | |||||
| (26) | |||||
| (27) | |||||
The objective and constraints (22) and (23) match the formulation (20), whereas constraint (25) limits the number of selected vectors to at most , and (24) enforces that if a vector is not selected then the weight on that vector must be zero. This problem is computationally challenging due to the implicit function . However, if we replace by its current cutting-plane approximation , then the problem can be solved as a MIP. Specifically, the MIP approximation of (21)-(27) is given by:
| (28) | ||||||
| s.t. | ||||||
After solving this approximation, we choose the vectors to be the vectors with . Given this basis, we then solve (17) with defined in (20) to generate Lagrangian cuts. The basis size in this case can be strictly smaller than . Observe that the optimal value of (28) gives an upper bound of (21)-(27). Therefore, if the optimal objective value of (28) is small, this would indicate we would not be able to generate a highly violated Lagrangian cut for this scenario, and hence we can skip this scenario for generating Lagrangian cuts.
5 Computational Study
We report our results from a computational study investigating different variants of our proposed methods for generating Lagrangian cuts and also comparing these to existing approaches. In Section 5.2 we investigate the bound closed over time by just adding cuts to the LP relaxation. In Section 5.3 we investigate the impact of using our cut-generation strategy to solve our test instances to optimality within a simple branch-and-cut algorithm.
We conduct our study on three test problems. The first two test problems are standard SIP problems that can be found in literature: the stochastic server location problem (SSLP, binary first-stage and mixed-integer second-stage) introduced in [31], and the stochastic network interdiction problem (SNIP, binary first-stage and continuous second-stage) in [32]. We also create a variant of the stochastic server location problem (SSLPV) that has mixed-binary first-stage variables and continuous second-stage varaibles. Our test set includes 24 SSLP instances with 20-50 first-stage variables, 2000-2100 second-stage variables, and 50-200 scenarios. The SSLPV test instances are the same as for SSLP, except the number of first-stage variable is doubled, with half of them being continuous. We use 20 instances of the SNIP problem having 320 first-stage variables, 2586 second-stage variables, and 456 scenarios. More details of the test problems and instances can be found in Appendix.
We consider in total six implementations of Lagrangian cuts:
- 1.
-
2.
BDD: BDD3 from [4]. This algorithm uses a multiphase implementation that first generates Benders cuts and strengthened Benders cuts, and then generates Lagrangian cuts based on a regularized inner approximation for separation.
-
3.
Exact: Exact separation of Lagrangian cuts of the form (17) with .
- 4.
- 5.
- 6.
5.1 Implementation Details
All experiments are run on a Windows laptop with 16GB RAM and an Intel Core i7-7660U processor running at 2.5GHz. All LPs, MIPs and convex quadratic programs (QPs) are solved using the optimization solver Gurobi 8.1.1 for SNIP and SSLP instances, and are solved using Gurobi 9.0.3 for SSLPV instances.
In Algorithm 1, we also terminate if the upper bound is small enough () or two consecutive multipliers are too close to each other (infinity norm of the difference ). A computational issue that can occur when solving (17) is that if we obtain a solution with (or very small), the solution of of (12) does not provide information about since the coefficients associated with the variables are equal zero. In that case, if we store the “optimal” second-stage cost and use it together with to define a cut in the cutting-plane model (18), this second-stage cost value can be very far away from and lead to a very loose cut. So in our implementation, when is small (), after finding from solving (12), we reevaluate by solving the scenario subproblem (2) with fixed and use this value as .
For adding Benders cuts in Algorithm 2, the initialization of is obtained by one iteration of Benders cuts. Specifically, to avoid unboundedness, we solve to obtain a candidate solution and add the corresponding Benders cuts for all scenarios. As described in Algorithm 2, lines 2-2, Benders cuts from the LP relaxation are added using the classical cutting-plane method [33]. This implementation was used for the SNIP test problem. For the SSLP test problem we found this phase took too long to converge, so the phase of adding Benders cuts as described in lines 2-2 was replaced by the level method [30]. Benders cuts are only added if the violation is at least . We store the coefficients of all Benders cuts that have been added to the master problem. For each , we define in the definitions of Rstr1 and Rstr2 based on the coefficients of the Benders cuts that have been most recently found by the algorithm for scenario .
We use Algorithm 1 for solving the separation problem, with one exception. When doing exact separation of Lagrangian cuts (i.e., without constraining to be low-dimensional set) we implement a level method for solving (17), because in that case we found Algorithm 1 converged too slowly. Based on preliminary experiments, the normalization coefficient in (19) or (20) is set to be 1 for tests on SSLP and SSLPV instances, and 0.1 for tests on SNIP instances.
In all SSLP, SSLPV, and SNIP instances the set is integral and we have relatively complete recourse. Therefore, no feasibility cuts are necessary. Only Lagrangian cuts with are added in our tests.
For the BDD tests, we follow the implementation of [4] and set the regularization coefficient as for SSLP and SSLPV instances and as for SNIP instances. These values are chosen based on preliminary experiments as producing the best improvement in bound over time.
5.2 LP Relaxation Results
We first compare results obtained from different implementations of Lagrangian cuts on our test problems and study the impact of different parameters in the algorithm. The stopping condition of Algorithm 2 for all root node experiments is that either the algorithm hits the one-hour time limit or there is no cut that can be found by the algorithm (with a relative tolerance).
To compare the overall performance of the methods visually across many test instances, we present results in the form of a -gap-closed profile. Given a set of problem instances and a set of cut generation methods , let denote the largest gap closed by any of the methods (compared with the LP bound) in for instance . The -gap-closed profile is defined with respect to certain threshold . Given the value of , we define as the earliest time of closing the gap by at least for problem with method . If method did not close a gap at least before termination, we define . The -gap-closed profile is a figure representing the cumulative growth (distribution function) of the -gap-closed ratio ’s over time where
In this paper, is either the set of all SSLP test instances, all SNIP test instances or all SSLPV instances, and is the set of all methods with all parameters we have tested. Therefore, for each instance , is defined to be the largest gap we have been able to close with Lagrangian cuts. We set parameter equal to either or for summarizing the information regarding time needed for obtaining what we refer to as a “reasonably good bound” () or a “strong bound” ().
To illustrate the behavior of these algorithms we also present the lower bound obtained over time using different cut generation schemes on some individual instances.
5.2.1 Relative Gap Tolerance








We first examine the impact of varying the relative gap tolerance . Experiments are run with parameter being and , respectively. A small value (e.g., ) means solving (17) to near optimality, which may generate strong cuts but can be time-consuming to generate each cut. Using large values might sacrifice some strength of the cut in an iteration for an earlier termination.
For different values, in Figure 1, we compare the bounds obtained by Exact over time. As the trend is quite similar for instances within the same problem class, we only report the convergence profiles for one SSLP instance (sslp1_20_100_200) and one SSLPV instance (sslp1_20_100_200_var). For the SNIP instances, which have many more first-stage variables, Exact often cannot finish one iteration of separation within an hour, so we put the convergence profile of Exact for one SNIP instance in Appendix. For the SSLP and SSLPV instances, a large value tends to close the gap faster than a small value. Plots providing the same comparison for Rstr1 with are provided in Appendix. For Rstr1, a large value helps improve the bound efficiently for SSLP and SSLPV instances while the choice of has little impact on the performance of the SNIP instances.
To summarize the impact of over the full set of test instances, we plot the -gap-closed profile and -gap-closed profile with different values for SSLP and SNIP instances in Figures 2 and 3. We omit the gap-closed profiles for the SSLPV instances since they are similar to those for the SSLP instances. The gap-closed profiles for SNIP instances with Exact are omitted as no useful bound is obtained by Exact for any of the SNIP instances. For the SSLP and SSLPV instances, it is preferable to use a large value as both a reasonable bound ( gap closed) and a strong bound ( gap closed) are obtained earlier when is large. For the SNIP instances, there is less clear preference although small values perform slightly better. This is because the time spent on each iteration of separation does not vary too much by changing the value for the SNIP instances.
Conclusion. Depending on the problem, the choice of can have either a mild or big impact. But we find a relatively large , e.g., , has a stable performance on our instance classes.
5.2.2 Basis Size
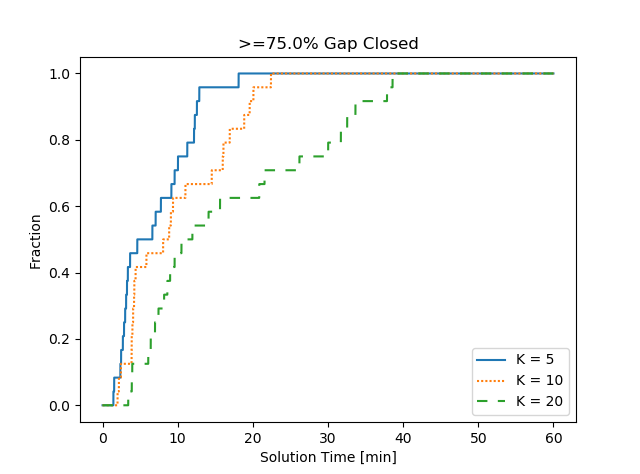







We next investigate the impact of the choice of the basis size in Rstr1, Rstr2 and RstrMIP. In Figures 4 and 5 we plot the -gap-closed profiles and the -gap-closed profiles with different values for SSLP and SNIP instances, respectively. The results for SSLPV instances are omitted as they are similar to the results for SSLP instances. Plots showing the evolution of the lower bound obtained using Rstr1, Rstr2 and RstrMIP with different values on an example SNIP instance, an example SSLP instance and an example SSLPV instance are given in Appendix.
As seen in Figures 4 and 5, the trends are quite different for different problem classes when applying Rstr1. For SSLP and SSLPV instances, smaller performs better for obtaining a reasonably good bound faster since the restricted separation is much easier to solve when is small. However, for SNIP instances seems to dominate and . We believe this is because the time to generate a cut is not significantly impacted by for the SNIP instances, but gives much stronger cuts for closing the gap. Comparing Rstr1 and Rstr2, Rstr2 appears to be less sensitive to in terms of obtaining a reasonably good bound for SSLP instances. On the other hand, the performance of Rstr2 is almost identical to the performance of Rstr1 for SNIP instances. For SSLP and SSLPV instances with Rstr1 or Rstr2, we find that larger often leads to longer solution time for obtaining a reasonable bound while small () is incapable of getting a strong bound. We observe that RstrMIP is fairly robust to the choice of the basis size . One particular reason is that the constraint in (28) is often loose in early stages of the algorithm for relatively large ’s as the constraint tends to select a sparse and thus a sparse . For the same instance, different basis sizes result in very close bounds at the end of the run.
Conclusion. The basis size yields a trade-off between the strength of cuts and computation time. We find the optimal choice of for Rstr1 depends on the instance. Slightly larger () often works better for Rstr2 while the performance of RstrMIP is much more robust to the choice of .
5.2.3 Comparison between Methods






We present results obtained by strengthened Benders cut (StrBen), the Benders dual decomposition (BDD) and different variants of our restricted Lagrangian cut separation (Exact, Rstr1, Rstr2 and RstrMIP). For all variants of restricted Lagrangian cut separation, we choose relative gap tolerance . For basis sizes, we set for Rstr1, Rstr2 and RstrMIP. We plot -gap-closed profiles and -gap-closed profiles for these methods in Figure 6.
Apparently, RstrMIP has the best performance on SSLP instances in terms of the gap closed over time. On SSLPV instances, the performances of Rstr2 and RstrMIP are similar while much better than other methods. On SNIP instances, the performance of Rstr1, Rstr2 and RstrMIP are almost identical while RstrMIP is much more robust in the choice of as observed in Section 5.2.2. The curves for BDD are flat on the bottom plots of Figure 6 as BDD fails to close 75% of the gap for all SNIP instances. Convergence profiles for BDD on one SSLP instance, one SSLPV instance and one SNIP instance can be found in Appendix.
Conclusion. RstrMIP has the best overall performance and in particular is more robust to the choice of .
5.2.4 Integrality gaps
In Table 1, we report statistics (minimum, maximum and average) of the LP integrality gap and the integrality gap obtained after 60 minutes of Lagrangian cut generation by RstrMIP with for each problem class. The integrality gaps are calculated as (LB)/, where LB is the lower bound obtained from the Benders model before or after adding the generated Lagrangian cuts. The results show that RstrMIP closes the vast majority of the gap to the optimal value. Since the resulting bound closely approximates the optimal value, and the exact Lagrangian dual must lie between this bound and the optimal value, these results imply that, on these test instances, our method approximates the optimal value of the Lagrangian dual, and that the Lagrangian dual approximates the optimal value. We emphasize, however, that this experiment is just to illustrate the potential for this method to close a majority of the gap when given enough time – we recommend using an early stopping condition to stop the cut generation process earlier when it is detected that the bound improvement has slowed significantly.
| Gap after RstrMIP | |||||||
|---|---|---|---|---|---|---|---|
| LP gap (%) | cuts (%) | ||||||
| Class | min | max | average | min | max | average | |
| SSLP | 32.9 | 58.0 | 44.4 | 0.0 | 3.6 | 0.7 | |
| SSLPV | 18.2 | 27.8 | 23.8 | 0.0 | 2.1 | 0.8 | |
| SNIP | 22.1 | 34.2 | 28.0 | 0.8 | 5.9 | 3.0 | |
5.3 Tests for Solving to Optimality
Finally, we study the use of our approach for generating Lagrangian cuts within a branch-and-cut method to solve SIPs to optimality, where Benders cuts and integer L-shaped cuts are added using Gurobi lazy constraint callback when a new solution satisfying the integrality constraints is found. We refer to this method as LBC. We consider only RstrMIP with and as the implementation of Lagrangian cuts. To reduce the time spent on Lagrangian cut generation at the root node, an early termination rule is applied. We stop generating Lagrangian cuts if the gap closed in the last 5 iterations is less than 1% of the total gap closed so far. For comparison, we also experiment with Benders cuts integrated with branch-and-cut (BBC – Algorithm 3 in Appendix) and the DSP solver [34] on the same instances. A two-hour time limit is set for these experiments. Gurobi heuristics are turned off for the branch-and-cut master problem to avoid the bug in Gurobi 8.1.1 that the MIP solution generated by Gurobi heuristics sometimes cannot trigger the callback. (This bug is supposed to be fixed in Gurobi 9.1.)
| On instances | On instances | |||||
| LBC | BBC | DSP | LBC | BBC | DSP | |
| # solved | 12/12 | 0/12 | 12/12 | 12/12 | 0/12 | 7/12 |
| Avg soln time | 1496 | 1259 | 4348 | |||
| Avg gap (%) | 0.0 | 18.1 | — | 0.0 | 27.0 | — |
| Avg B&C time | 25 | — | 163 | — | ||
| Avg # nodes | 775 | 13808 | — | 1411 | 3954 | — |
We present the results obtained by LBC, BBC and DSP on SSLP instances in Table 2. We report the number of instances at sample size or each algorithm solved within the time limit (‘# solved’), the total average solution time of each algorithm (‘Avg soln time’) including time to generate cuts if relevant, the average ending optimality gap (‘Avg gap (%)’), average time spent solving the problem with branch-and-cut not including the initial cut generation time (‘Avg B&C time’), and the average number of branch-and-bound nodes explored (‘Avg # nodes’). The ending optimality gap of a method on an instance is calculated as where UB and LB are the upper and lower bounds obtained from the method when the time limit was reached.
All SSLP instances are solved to optimality by LBC within the two-hour time limit with at most a few thousand nodes explored. On the other hand, none of the SSLP instances are solved by BBC before hitting the time limit, leaving a relatively large optimality gap. SSLP instances are hard to solve by BBC since neither Benders cuts or integer L-shaped cuts are strong enough to cut off infeasible points efficiently in the case when second-stage variables are discrete. Comparing with DSP, LBC solves more SSLP instances than DSP withinin the time limit. The performance of LBC is relatively stable compared with DSP in the sense that LBC scales well as increases. The efficiency of DSP heavily depends on the strength of the nonanticipative dual bound. For all instances where DSP outperforms LBC on solution time, no branching is needed for closing the dual gap. We observe that LBC spends most of the solution time on generating Lagrangian cuts for SSLP instances. The branch-and-cut time required after generating Lagrangian cuts is very small.
| On instances | On instances | |||||
| LBC | BBC | DSP | LBC | BBC | DSP | |
| # solved | 11/12 | 0/12 | 3/12 | 7/12 | 0/12 | 2/12 |
| Avg soln time | — | — | ||||
| Avg gap (%) | 0.1 | 18.4 | — | 0.3 | 20.8 | — |
| Avg B&C time | — | — | ||||
| Avg # nodes | — | — | ||||
In Table 3, we report results obtained by these methods for the SSLPV instances. We do not report the average solution time of DSP because for many of the SSLPV instances DSP fails at a very early stage by outputting an infeasible solution. Even though the performances of our approaches at the root node is similar for SSLPV as SSLP, we find the SSLPV instances are far more difficult to solve to optimality than the SSLP instances. As with the SSLP instances, BBC is unable to solve any of the SSLPV instances because the Benders cuts are not strong enough. Within the two-hour time limit, only a small fraction of the SSLPV instances can be solved by DSP correctly. On the other hand, LBC solves the majority of the SSLPV instances, and the ending optimality gaps are small for those unsolved instances, showing its capability and stability in dealing with different problem classes.
| LBC | BBC | DSP | |
| # solved | 20/20 | 20/20 | 0/20 |
| Avg soln time | 2333 | 163 | |
| Avg gap (%) | 0.0 | 0.0 | — |
| Avg B&C time | 71 | 116 | — |
| Avg # nodes | 1231 | 3348 | — |
| LBC | BBC | |
| # solved | 20/20 | 9/20 |
| Avg soln time | 2385 | |
| Avg gap (%) | 0.0 | 2.9 |
| Avg B&C time | 71 | |
| Avg # nodes | 4236 |
In Table 4 we report results using these methods to solve the SNIP instances. We observe that no SNIP instance can be solved within two hours by DSP. This is because solving the nonanticipative dual problem of SNIP instances is not completed in two hours. BBC solves the SNIP instances faster than LBC as the time spent on cut generation at the root node is much shorter and the Benders cuts, when combined with Gurobi’s presolve and cut generation procedures are sufficient for keeping the number of nodes small.
To better understand the impact of the Lagrangian cuts vs. Benders cuts on their own, we also report results obtained by LBC and BBC with Gurobi presolve and cuts disabled in Table 5. We see that Gurobi presolve and cuts are quite essential for solving SNIP instances when using only Benders cuts. In this case, BBC is unable to solve many of the instances within the time limit. This is because Gurobi presolve and cuts significantly improve the LP bounds for BBC. LBC still solves all SNIP instances, demonstrating the strength of the Lagrangian cuts generated.
6 Conclusion
We derive a new method for generating Lagrangian cuts to add to a Benders formulation of a two-stage SIP. Extensive numerical experiments on three SIP problem classes indicate that the proposed method can improve the bound more quickly than alternative methods for using Lagrangian cuts. When incorporating the proposed method within a simple branch-and-cut algorithm for solving the problems to optimality we find that our method is able to solve one problem class within a time limit that is is not solved by the open-source solver DSP, and performs modestly better on the other problem classes.
A direction of future work is to explore the integration of our techniques for generating Lagrangian cuts with the use of other classes of cuts for two-stage SIPs, and also for multi-stage SIPs via the SDDIP algorithm proposed by [16]
Appendix
A Branch-and-Cut Algorithm
A standard branch-and-cut algorithm for solving two-stage SIPs with either continuous recourse or pure binary first-stage variables is described in Algorithm 3. The algorithm starts with the approximations of uses it to create an LP initial LP relaxation of problem (4) represented by the root node which is added to the list of candidate nodes . In our case, the approximations are constructed by Benders cuts and Lagrangian cuts. Within each iteration, the algorithm picks a node from and solves the corresponding LP which is a relaxation of problem (4) with the addition of the constraints adding from branching, and generates a candidate solution . If does not satisfy the integrality constraints (), the algorithm creates two new subproblems (nodes) by subdividing the feasible solutions to that node. The subproblems are created by choosing an integer decision variable having , and adding the constraint in one of the subproblems and adding the constraint in the other subproblem. If satisfies the integrality constraints (), the algorithm evaluates for all . If any violated Benders cuts and integer L-shaped cuts are identified, these are used to update , and the relaxation at that node is then solved again. This process of searching for and adding cuts if violated when can be implemented using the “Lazy constraint callback” in commercial solvers. If no violated Benders or integer L-shaped cuts are identified, then the current solution is feasible and thus the upper bound and best known solution (the incumbent ) is updated. The algorithm terminates when there are no more nodes to explore in the candidate list .
Test Problems
The SSLP problem
The SSLP problem [31] is a two-stage SIP with pure binary first-stage and mixed-binary second-stage variables. In this problem, the decision maker has to choose from sites to allocate servers with some cost in the first stage. Then in the second stage, the availability of each client would be observed and every available client must be served at some site. The first-stage variables are denoted by with if and only if a server is located at site . The second-stage variables are denoted by and where if and only if client is served at site in scenario and is the amount of resource shortage at at site in scenario . Allocating a server costs at site . Each allocated server can provide up to units of resource. Client uses units of resource and generates revenue if served at site . Each unit of resource shortage at site incurs a penalty . The client availability in scenario is represented by with if and only if client is present in scenario . The extensive formulation of the problem is as follows:
| s.t. | |||||
All SSLP instances are generated with and . For each size , three instances are generated with . For each SSLP instance, the data are generated as:
-
•
, .
-
•
Uniform(), .
-
•
Uniform(), , .
-
•
, .
-
•
.
-
•
Bernoulli(), , .
All SSLP instances are named of the form sslp___ where denotes the number of sites, denotes number of clients, is the number of scenarios and is the instance number.
The SSLPV problem
The SSLPV problem is a variant of the SSLP problem that has mixed-binary first-stage and pure continuous second-stage variables. There are two main differences between SSLP and SSLPV. First, in the SSLPV problem, in addition to choosing which sites to “open” for servers, the decision maker also has an option to add more servers than the “base number” if the site is open. Second, in the second stage, we allow the clients’ demands to be partly met by the servers, and only unmet shortage will be penalized. Thus, in this problem the recourse problem is a linear program. We assume that if a site is selected (binary decision) it has base capacity of (independent of ), and installing this has cost . In addition, it is possible to install any fraction of an additional units of capacity at site , with total cost if the total new capacity is installed and the cost reduced proportionallly if a fraction is installed. The variable representing the amount of additional server capacity added at site is denoted by a continuous variable . The extensive formulation of the problem is as follows:
| s.t. | |||||
Each SSLPV instance corresponds to a SSLP instance. In all SSLPV instances, we set , , and for each site , we set , , where and and are the data from the SSLP instance. The other data is the same as the data of the SSLP instances. All SSLP instances are named of the form sslp____var where denotes the number of sites, denotes number of clients, is the number of scenarios and is the instance number.
The SNIP problem
The SNIP problem [32] is a two-stage SIP with pure binary first-stage and continuous second-stage variables. In this problem the defender interdicts arcs on a directed network by installing sensors in the first stage to maximize the probability of finding an attacker. Then in the second stage, the origin and destination of the attacker are observed and the attacker chooses the maximum reliability path from its origin to its destination. Let and denote the node set and the arc set of the network and let denote the set of interdictable arcs. The first-stage variables are denoted by with if and only if the defender installs a sensor on arc . The scenarios define the possible origin/destination combinations of the attacker, with representing the origin and representing the destination of the attacker for each scenario . The second-stage variables are denoted by where denotes the maximum probability of reaching destination undetected from node in scenario . The budget for installing sensors is , and the cost of installing a sensor on arc is for each arc . For each arc , the probability of traveling on arc undetected is if the arc is not interdicted, or if the arc is interdicted. Finally, let denote the maximum probability of reaching the destination undetected from node when no sensors are installed. The extensive formulation of the problem is as follows:
| s.t. | |||||
All of the SNIP instances we used in this paper are from [32]. We consider instances with snipno = 3, and budget . All instances have 320 first-stage binary variables, 2586 second-stage continuous variables per scenario and 456 scenarios.
Some Convergence Profiles
Figures 8 - 11 present the evolution of the progress in the lower bound over time on one representative example SSLP instance and one representative example SNIP instance using various cut generation approaches and parameters.





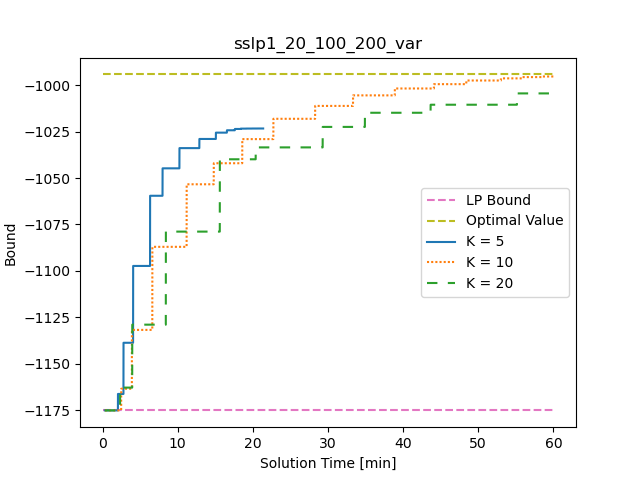







From Figure 11 we see that for the example SSLP instance, BDD does not make much progress in the first 10 minutes, but then makes steady improvement. The shift occurs when BDD switches from its initial phase of generating only strengthened Benders cuts to the second phase of heuristically generating Lagrangain cuts. In the initial phase BDD the strengthened Benders cuts are not strong enough to substantially improve the bound after the first iteration, so that significant bound progress only occurs again after switching to the second phase. We experimented with making this transition quicker (or even skipping it altogether) but we found that this led to poor performance of BDD. It appears that the first phase is important for building an inner approximation that is used for separation of Lagrangian cuts in the next phase. The convergence profiles of BDD on the SNIP instance and the SSLPV instance clearly show its slow convergence relative to all variations of our proposed restricted Lagrangian cut generation approach.
References
- [1] J. F. Benders, “Partitioning procedures for solving mixed-variables programming problems,” Numerische Mathematik, vol. 4, pp. 238–252, 1962.
- [2] R. M. Van Slyke and R. Wets, “L-shaped linear programs with applications to optimal control and stochastic programming,” SIAM Journal on Applied Mathematics, vol. 17, no. 4, pp. 638–663, 1969.
- [3] C. C. Carøe and R. Schultz, “Dual decomposition in stochastic integer programming,” Operations Research Letters, vol. 24, no. 1-2, pp. 37–45, 1999.
- [4] R. Rahmaniani, S. Ahmed, T. G. Crainic, M. Gendreau, and W. Rei, “The Benders dual decomposition method,” Operations Research, vol. 68, pp. 878–895, 2020.
- [5] C. Li and I. E. Grossmann, “An improved l-shaped method for two-stage convex 0–1 mixed integer nonlinear stochastic programs,” Computers & Chemical Engineering, vol. 112, pp. 165–179, 2018.
- [6] G. Laporte and F. V. Louveaux, “The integer l-shaped method for stochastic integer programs with complete recourse,” Operations research letters, vol. 13, no. 3, pp. 133–142, 1993.
- [7] S. Sen and J. L. Higle, “The c 3 theorem and a d 2 algorithm for large scale stochastic mixed-integer programming: Set convexification,” Mathematical Programming, vol. 104, no. 1, pp. 1–20, 2005.
- [8] S. Sen and H. D. Sherali, “Decomposition with branch-and-cut approaches for two-stage stochastic mixed-integer programming,” Mathematical Programming, vol. 106, no. 2, pp. 203–223, 2006.
- [9] L. Ntaimo, “Fenchel decomposition for stochastic mixed-integer programming,” Journal of Global Optimization, vol. 55, no. 1, pp. 141–163, 2013.
- [10] D. Gade, S. Küçükyavuz, and S. Sen, “Decomposition algorithms with parametric gomory cuts for two-stage stochastic integer programs,” Mathematical Programming, vol. 144, no. 1-2, pp. 39–64, 2014.
- [11] M. Zhang and S. Küçükyavuz, “Finitely convergent decomposition algorithms for two-stage stochastic pure integer programs,” SIAM Journal on Optimization, vol. 24, no. 4, pp. 1933–1951, 2014.
- [12] Y. Qi and S. Sen, “The ancestral benders’ cutting plane algorithm with multi-term disjunctions for mixed-integer recourse decisions in stochastic programming,” Mathematical Programming, vol. 161, no. 1-2, pp. 193–235, 2017.
- [13] B. Chen, S. Küçükyavuz, and S. Sen, “Finite disjunctive programming characterizations for general mixed-integer linear programs,” Operations Research, vol. 59, no. 1, pp. 202–210, 2011.
- [14] N. van der Laan and W. Romeijnders, “A converging benders’ decomposition algorithm for two-stage mixed-integer recourse models,” 2020. http://www.optimization-online.org/DB_HTML/2020/12/8165.html.
- [15] M. Bodur, S. Dash, O. Günlük, and J. Luedtke, “Strengthened benders cuts for stochastic integer programs with continuous recourse,” INFORMS Journal on Computing, vol. 29, no. 1, pp. 77–91, 2017.
- [16] J. Zou, S. Ahmed, and X. A. Sun, “Stochastic dual dynamic integer programming,” Mathematical Programming, vol. 175, no. 1-2, pp. 461–502, 2019.
- [17] G. Lulli and S. Sen, “A branch-and-price algorithm for multistage stochastic integer programming with application to stochastic batch-sizing problems,” Management Science, vol. 50, no. 6, pp. 786–796, 2004.
- [18] M. Lubin, K. Martin, C. G. Petra, and B. Sandıkçı, “On parallelizing dual decomposition in stochastic integer programming,” Operations Research Letters, vol. 41, no. 3, pp. 252–258, 2013.
- [19] N. Boland, J. Christiansen, B. Dandurand, A. Eberhard, J. Linderoth, J. Luedtke, and F. Oliveira, “Combining progressive hedging with a frank–wolfe method to compute lagrangian dual bounds in stochastic mixed-integer programming,” SIAM Journal on Optimization, vol. 28, no. 2, pp. 1312–1336, 2018.
- [20] G. Guo, G. Hackebeil, S. M. Ryan, J.-P. Watson, and D. L. Woodruff, “Integration of progressive hedging and dual decomposition in stochastic integer programs,” Operations Research Letters, vol. 43, no. 3, pp. 311 – 316, 2015.
- [21] K. Kim and B. Dandurand, “Scalable branching on dual decomposition of stochastic mixed-integer programming problems.” Preprint on webpage at http://www.optimization-online.org/DB_HTML/2018/10/6867.html, 2018.
- [22] K. Kim, C. G. Petra, and V. M. Zavala, “An asynchronous bundle-trust-region method for dual decomposition of stochastic mixed-integer programming,” SIAM Journal on Optimization, vol. 29, no. 1, pp. 318–342, 2019.
- [23] M. Fischetti, D. Salvagnin, and A. Zanette, “A note on the selection of benders’ cuts,” Mathematical Programming, vol. 124, no. 1-2, pp. 175–182, 2010.
- [24] P. Kall, S. W. Wallace, and P. Kall, Stochastic programming. Springer, 1994.
- [25] S. Ahmed, M. Tawarmalani, and N. V. Sahinidis, “A finite branch-and-bound algorithm for two-stage stochastic integer programs,” Mathematical Programming, vol. 100, no. 2, pp. 355–377, 2004.
- [26] P. Schütz, A. Tomasgard, and S. Ahmed, “Supply chain design under uncertainty using sample average approximation and dual decomposition,” European Journal of Operational Research, vol. 199, no. 2, pp. 409–419, 2009.
- [27] S. Solak, J.-P. B. Clarke, E. L. Johnson, and E. R. Barnes, “Optimization of r&d project portfolios under endogenous uncertainty,” European Journal of Operational Research, vol. 207, no. 1, pp. 420–433, 2010.
- [28] R. T. Rockafellar, Convex analysis, vol. 36. Princeton university press, 1970.
- [29] M. Avriel and A. Williams, “The value of information and stochastic programming,” Operations Research, vol. 18, no. 5, pp. 947–954, 1970.
- [30] C. Lemaréchal, A. Nemirovskii, and Y. Nesterov, “New variants of bundle methods,” Mathematical programming, vol. 69, no. 1-3, pp. 111–147, 1995.
- [31] L. Ntaimo and S. Sen, “The million-variable “march” for stochastic combinatorial optimization,” Journal of Global Optimization, vol. 32, no. 3, pp. 385–400, 2005.
- [32] F. Pan and D. P. Morton, “Minimizing a stochastic maximum-reliability path,” Networks: An International Journal, vol. 52, no. 3, pp. 111–119, 2008.
- [33] J. E. Kelley, Jr, “The cutting-plane method for solving convex programs,” Journal of the society for Industrial and Applied Mathematics, vol. 8, no. 4, pp. 703–712, 1960.
- [34] K. Kim and V. M. Zavala, “Algorithmic innovations and software for the dual decomposition method applied to stochastic mixed-integer programs,” Mathematical Programming Computation, vol. 10, no. 2, pp. 225–266, 2018.