On encounter rates in star clusters
Abstract
Close encounters between stars in star forming regions are important as they can perturb or destroy protoplanetary discs, young planetary systems, and stellar multiple systems. We simulate simple, viralised, equal-mass -body star clusters and find that both the rate and total number of encounters between stars varies by factors of several in statistically identical clusters due to the stochastic/chaotic details of orbits and stellar dynamics. Encounters tend to rapidly ‘saturate’ in the core of a cluster, with stars there each having many encounters, while more distant stars have none. However, we find that the fraction of stars that have had at least one encounter within a particular distance grows in the same way (scaling with crossing time and half-mass radius) in all clusters, and we present a new (empirical) way of estimating the fraction of stars that have had at least one encounter at a particular distance.
1 Introduction
Young stars are commonly found with circumstellar discs (e.g. Hillenbrand et al., 1998; Lada et al., 2000; Haisch et al., 2000, 2001), and these discs are thought to be where planet formation occurs. Since most stars are formed in relatively dense environments (e.g. Lada & Lada, 2003), it is possible for the discs, and the on going planet formation process within, to be affected by close encounters between stars.
Simulations have shown that the effect of tidal perturbation from a stellar fly-by can range from slightly changing the density distribution in the disc to truncating or even destroying it (e.g. Clarke & Pringle, 1993; Cuello et al., 2022), depending on how close the encounter is. This dynamical truncation, as well as photoevaporation (e.g. Concha-Ramírez et al., 2022), and face-on accretion (Wijnen et al., 2017), can significantly affect the population of young stars with discs in the early stages of star formation. Perturbations can also trigger disc instabilities (e.g. Thies et al., 2005, 2010) and may determine the population of planets forming in the disc (Ndugu et al., 2022). Another interesting effect of encounters on the disc is the misalignment between the rotational planes of the disc and the host star due to a non-coplanar encounter (e.g. Heller, 1993; Larwood, 1997). Encounters may alter already formed planetary systems, changing orbits (e.g. Breslau & Pfalzner, 2019), or disrupting them (e.g. Parker & Quanz, 2012). And encounters can similarly alter or destroy multiple stellar systems (e.g. Goodwin, 2010; Reipurth et al., 2014).
Young stars with masses M☉ typically have discs with radii of a few hundreds of au (e.g. Andrews & Williams, 2007). For the discs of those stars to be significantly perturbed in encounters, the periastron distance between the encountering stars needs to be less than au. Therefore, to understand how important encounters are in affecting discs/planet formation, a key question is how many young stars have encounters within au?
There are two approaches one might take to finding the rates and numbers of encounters in some star cluster of interest. The first is to perform -body simulations of a variety of similar systems which is time consuming and computationally expensive (e.g. Parker & Quanz, 2012; Craig & Krumholz, 2013), the second would be to have some (ideally analytic) estimate to quickly get at least a ‘feel’ for the expected values.
In this paper, we examine the encounter rate in a number of -body simulations of bound star clusters. We show that encounter rates can vary by up to an order of magnitude between statistically identical clusters, but the fraction of stars that have had an encounter remains statistically the same. We present an empirical way of estimating the fraction of stars in a cluster that have had at least one encounter within a particular distance.
2 The encounter rate
The number of encounters per unit time () for a star seems like it should depend on several factors: the encounter distance of interest, some average number density of stars, and the typical velocity of stars. The velocity of stars will affect the encounter rate by both changing how often stars encounter other stars, and also changing how effective gravitational focusing is.
2.1 The standard method
The most common method of calculating encounter times is based on the fundamental assumptions that a star is travelling through an effectively infinite, uniform density medium at a constant speed (see e.g. the derivation in Binney & Tremaine, 2008, note that these assumptions are perfectly adequate if one is interested in e.g. the Galactic disc).
The encounter rate for any individual star is typically given by
| (1) |
where is the number density of the stars, is the velocity dispersion, is the closest distance during the encounter, is the gravitational constant, and is the typical mass of the stars (Binney & Tremaine, 2008). The second term in the brackets is associated with the gravitational focusing effect which deflects the trajectories and decreases the distance of closest approach for slow encounters or encounters between more massive stars.
For an ensemble of stars (e.g. a cluster), it seems reasonable to assume that the total encounter rate (total number of encounters per unit time, ) scales with the total number of stars. Since each encounter involves two stars, the encounter rate should scale with , i.e. .
In convenient units where is in au, in km s-1, in pc-3, and in M☉, the encounter rate in a cluster of stars is then
| (2) |
Therefore, it would seem that to calculate the rate of encounters, , at a particular distance of interest, , in an ensemble of stars, the correct values of (a) number density, , and (b) velocity dispersion, , are required. If there is a distribution of stellar masses, an appropriate value for must be taken.
While various assumptions that go into this simple calculation are clearly wrong for star clusters (e.g. moving through an effectively infinite uniform density medium at a constant speed) one might think that some simple variation on this approach might work (e.g. taking some appropriate average speed and density). However, we will show that this approach in star clusters gives an often wrong, and an always misleading, ‘answer’.
2.2 What do we want to know?
It is important to clarify what we want to know about encounters in a cluster. In most cases, what we would like is an estimate of what fraction of stars have had a close encounter as this tells us the relative levels of disc/planetary system/multiple system perturbation/destruction. It is important to remember that this is not what an estimate of an encounter rate gives without a further assumption of how the encounters are distributed between stars.
As an example let us take a cluster that we shall examine in detail later: an , M☉, equal-mass (so M☉) virialised Plummer sphere cluster with half-mass radius pc. If we want to know the number of stars that have had an encounter within, e.g. au, we can calculate that Myr-1 by taking the values for the velocity dispersion and half-mass density of this cluster and putting them into equation (2).
If we assume this encounter rate estimate is correct, to calculate how many stars have had an encounter after some time we need to make a further assumption that encounters are random so that after Myr there will be 50 stars that have had an encounter, and after Myr stars (ie. per cent) will have had an encounter. (One could be somewhat more sophisticated and estimate as the encounter fraction starts to approach unity how many stars have had zero, one, two etc. encounters.)
In assuming encounters are random, this calculation ignores that encounters are much more likely to occur in the core, and that after a few crossing times some stars in the core are likely to have had multiple encounters, while those in the halo may have had none. Indeed, when stated like this, this approach does seem extremely naive and it would be surprising if it gave the correct answer.
3 Simulations
We investigate encounter rates in clusters by performing -body simulations in which we can record individual encounters, the stars involved, and their distances of closest approach. The simulations we report here are of the simplest bound systems: virialised Plummer spheres of equal-mass stars.
We simulate and virialised Plummer spheres (Plummer, 1911) initialised by the method described in Aarseth et al. (1974) with initial half-mass radii of , and pc. Simulations are run only with equal-mass stars so that we can ignore any complicating effects of mass spectra.
The number of stars (), the stellar mass (), the initial half-mass radius (), and the label of simulated clusters are shown in Table 1. Clusters with pc are truncated at pc, those with pc are truncated at 5 pc, and pc clusters are truncated at 7 pc so that they have approximately the same relative sizes.
| Cluster IDs | (M☉) | (pc) | (Myr) | |
|---|---|---|---|---|
| N3SMR050-A to J | 1.0 | |||
| N3SMR075-A to J | 1.9 | |||
| N3SMR100-A to J | 3.1 | |||
| N6SMR050-A to J | 0.74 |
All simulations are run for Myr using our own -body code. The code uses a forth-order Hermite scheme (Makino & Aarseth, 1992) as the integrator. We keep the energy error well below by employing an adaptive timestep, i.e. using equation (7) from Makino & Aarseth (1992) with parameter for clusters and for clusters. We also use block timestepping for runs to speed up the calculations.
The separation between any pair of stars is monitored at every timestep. Once two stars are closer to each other than au, whether they are bound or unbound, they are considered as having close encounter. During this period, the closest separation is recorded and taken as the encounter distance once the stars move away from each other beyond au. In binaries multiple ‘encounters’ will occur, if the separation stays below au this is only counted as one ‘encounter’. This is to prevent hard binaries inflating the close encounter rate, however as we discuss below hard binaries form extremely rarely in our simulations.
Simulations are run with a gravitational softening length of au to avoid collisions or computationally expensive very close encounters. This is only of importance for the details of extremely close encounters at au which is much closer than the vast majority of encounters and at a distance that would completely disrupt discs or planetary systems.
3.1 Number density and velocity dispersion
It would seem reasonable to assume that encounter rates and fractions should depend in some way on both number density and velocity dispersion. Below we go into some detail on how the number density and velocity dispersion of a cluster might be quantified. This is important to show that the encounter rates we measure in simulations disagree with simple calculations because the assumptions that underlie them are wrong for clusters, rather than that we are using the ‘wrong’ values for number density or velocity dispersion, or not accounting for how they change with time. A reader happy to take our word for this can skip the details below.
3.1.1 Number density
The derivation of equation (2) assumes that stars are uniformly distributed and so is constant in time and space. This is a reasonable assumption for e.g. encounters in the Galactic disc, but not for encounters in a cluster (or any region where the number density varies on short length-scales).
There are a number of ways one could quantify some average number density, and they can result in very different values for the estimated encounter rate.
The first average number density we use is simply calculated from the half-mass radius of the cluster ():
| (3) |
The second average number density is the mean number density defined by
| (4) |
where and are the number density and the probability density function of the distance of stars from the centre of mass of the cluster (). In practice, we can approximate the integral by
| (5) |
where and are the size and the number of bins of stellar distances from the centre of mass of the cluster.
Theoretically, the probability density function is defined as , where is the probability of finding stars at distance between and from the centre of mass of the cluster. But practically, the value of in equation (5) may be obtained from
| (6) |
where is the number of stars in the -bin and is the number of stars in the cluster. The number density in equation (5) is related to via
| (7) |
where is a spherical volume element containing stars. Substituting equations (6) and (7) in (5) gives
| (8) |
The half-mass number density is often used as it is simple to calculate, the more complex mean number density has the advantage of including information on the full density distribution of the cluster. We also note here that the half-mass radius is often used as a characteristic radius as it remains roughly constant over the long-term evolution of a cluster (Aarseth et al., 1974), however the half-mass radius does fluctuate, especially at early times and so even the half-mass density changes (sometimes by factors of several).
3.1.2 Velocity dispersion
The velocity dispersion () in equation (1) and (2) comes from the assumption that the velocity distribution of the stars in the cluster is Maxwellian. From the Maxwell-Boltzmann distribution, the velocity dispersion is related to the mode of the distribution () by . The mode can simply be determined by constructing the velocity histogram and then fitting it with a polynomial regression to find the position of the peak.
It should be noted that this way of finding the velocity dispersion is only possible when all (3D) velocities are well known. In any observation the value of is either ‘guessed’ by assuming virial equilibrium, or observed in either 1D (radial velocities) or 2D (proper motions) with usually quite significant errors and biases (e.g. binary inflation, see Cottaar et al. (2012)).
3.1.3 Time-averaging
There are two ways to calculate the number density and velocity dispersion to use in equation (2). One is to take the values of or calculated instantaneously at the end of the simulation, the other is to take a time average.
In a simulation it is possible to calculate full 3D time-averaged values for various quantities. However, to estimate encounter rates in an observed region or for a single snapshot only the current values for any quantity can be calculated, and even they might be uncertain/guesstimated (e.g. no velocity data is available and only 2D positions).
For later reference, Table 2 shows the initial, time-averaged and final (i.e. those at 10 Myr) values of , , and for all simulations.
4 Results
In our simulations we follow all encounters at distances of au. We record when the encounter occurred, which two stars were involved, and the distance of closest approach. This allows us to find the encounter rate within a particular distance (i.e. what equation (2) attempts to estimate), and the number of stars that have had such an encounter – something equation (2) cannot tell us without further assumptions, but is often what we wish to know.
4.1 Comparing an and an cluster
We start by comparing encounter rates at various distances in two clusters with and equal-mass stars. Both are initially virialised Plummer Spheres with pc, with stars each of mass M☉.
Figure 1 shows the cumulative number of encounters over Myr in the (top panel) and (bottom panel) clusters. In each panel the lines from bottom-to-top are the cumulative numbers of encounters at (orange), (green), (magenta), and (blue) au respectively. At the top left of each sub-figure are three numbers for each of the encounter distances: the first is the actual encounter rate (Myr-1) as found in the simulation, the next two are time-averaged estimates that we will return to later, but note for now that all three numbers are often quite different. The two simulations shown are N3SMR050-A (top) and N6SMR050-A (bottom).
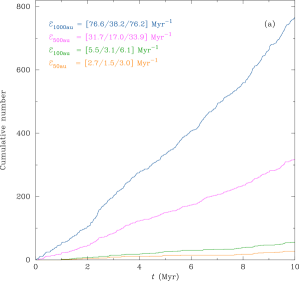
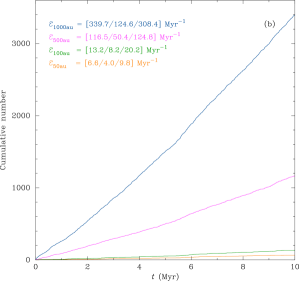
Figure 1 shows a number of features one might expect.
-
1.
The total number of encounters grows roughly linearly with time (in these two clusters at least).
-
2.
The number of encounters at different distances scales very roughly with (e.g. for after Myr there have been encounters at au, and at au).
-
3.
Increasing both (and therefore also ) by a factor of two results in about times more encounters (e.g. when , and when at au).
The second and third numbers in the top left are the estimates of encounter rate as calculated from equation (2) using the time-averaged values of the half-mass number density () and the mean number density () respectively.
In both cases using under-estimates the number of encounters by a factor of . Using seems better, often giving a reasonable estimate (but sometimes being off by a factor of ). So at a first glance at just these two simulations one might consider that using often provides a reasonable estimate of the encounter rate in a cluster.
However, we have only compared two simulations which just happened to be those labelled A in our ensembles. As we show below, when we look at the whole ensemble the picture becomes much more complicated, and this emphasises the importance of looking at ensembles of simulations when dealing with -body systems.
| Cluster | (km s-1) | (pc-3) | (pc-3) | at kau (Myr-1) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ini. | Avg. | End | Ini. | Avg. | End | Ini. | Avg. | End | ||||
| N3SMR050-A | ||||||||||||
| N3SMR050-B | ||||||||||||
| N3SMR050-C | ||||||||||||
| N3SMR050-D | ||||||||||||
| N3SMR050-E | ||||||||||||
| N3SMR050-F | ||||||||||||
| N3SMR050-G | ||||||||||||
| N3SMR050-H | ||||||||||||
| N3SMR050-I | ||||||||||||
| N3SMR050-J | ||||||||||||
| N3SMR050-A..J | ||||||||||||
4.2 An ensemble of statistically identical clusters
We now consider all ten clusters in our equal-mass stars, and a half-mass radius of pc ensemble. The only difference between these clusters is the random number seed used to generate the initial positions and velocities. Therefore one would expect that the encounter rates in each would be similar - and ideally be close to an analytic estimate.
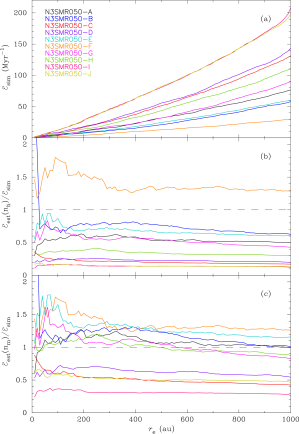
The top panel of Fig. 2 shows the final encounter rates () for each of our identical clusters measured after Myr from to au.111The exact values of encounter rates at separations of less than a few au may be affected by our softening, but a close encounter did happen, we just might not be able to trust the distance of closest approach too precisely. The simulation shown in the top panel of Fig. 1 is A which is the black line towards the middle-bottom of all the lines.
The most important thing to note about the top panel of Fig. 2 is the total encounter rates after 10 Myr varies very significantly between clusters with a difference of almost an order of magnitude. There appears to be no ‘typical’ clusters and some outliers – just a seemingly random spread in encounter rates between clusters that are initially statistically identical.
Interestingly, all of the curves in the top panel of Fig. 2 follow a distribution that goes roughly as suggesting that the distribution of encounter distances is what would be expected for unbound encounters. However, the distribution can slightly deviate from , often due to three-body encounters between a single star and a binary (which has formed during the simulation). These encounters can cause an increase in the encounter rate at au, as can be most obviously seen in cluster I (dark red line at the top of the figure).
The other panels of Fig. 2 show the difference between the analytically estimated encounter rates and the actual encounter rates for each cluster. In the middle panel the half-mass density () is used for the estimate, and in the bottom panel it is the mean number density (). A good match to the analytic estimate is the black dashed line at a ratio of unity.
Using the half-mass density never gives a good estimate, and can be wrong by an order of magnitude. Using the mean density is slightly better - three or four clusters stay reasonably close to unity, but most clusters are always wrong by factors of several.
One obvious explanation would be that different clusters have changed significantly (some expanding and some contracting?).
In Table 2 we give the initial, time averaged and final values of , , and for all ten clusters, as well as the final cumulative encounter rate. The averages and variance of each quantity over all the clusters are given in the bottom line.
The velocity dispersions () are very similar between all clusters, but measures of density can change significantly over time with quite different time averaged and final values, and between different measures (half mass or mean).
However, these variations do not seem to correlate with the vastly different encounter rates. The last three columns show the encounter rates estimated with and and then the actual encounter rates from the simulations. Only once (cluster F) does get close to predicting the actual encounter rate. Estimates using are reasonable for 5/10 of the clusters, but very wrong for 5/10. We think this was seen by Craig & Krumholz (2013) who note that their simulations had far more encounters than one might expect, but substructure complicated their analysis.
What is particularly interesting is that there is no systematic change in encounters rates with any measure of density or how they evolve. Cluster F has the lowest final mean density (484 pc-1) and the lowest encounter rate (30 Myr-1), but cluster I has the second lowest final mean density (531 pc-1), but the highest encounter rate (208 Myr-1). Clusters B and E have almost the same encounter rate, but final mean densities that are different by a factor of over two (735 and 1813 pc-1).
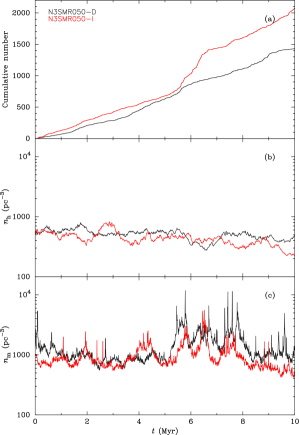
One might think that maybe there was some extreme deviation in density at some point in time that the time averaged densities do not properly include, however this is not the case. In Fig. 3 we show the numbers of encounters with au (top panel), half-mass density (middle panel), and mean density (lower panel) for clusters D and I (cf. Fig. 1).
Cluster D (black line) shows a relatively linear increase in encounter numbers to end with encounters within 10 Myr. Cluster I (red line) is similar to cluster D until a period between 6–7 Myr when the encounter rate increases significantly.
There is no reason to think that the increased encounter rate in cluster I is due to density variations however. The middle panel shows that both cluster’s half-mass densities are very similar, and both fairly constant and declining slightly. The bottom panel shows more variation in the mean densities with short-lived fluctuations of factors of a few, but both clusters show this behaviour, and, if anything, cluster D has higher densities. There are fluctuations in the mean density of cluster I around when the encounter rate increases significantly, but there are others when it does not.
Examination of the data shows that the large numbers of encounters in cluster I at 6–7 Myr is due to a few pairs of stars having multiple self-encounters in weakly bound pairs (cf. Moeckel & Clarke, 2011).
In all the ensembles of statistically identical clusters we have run we find no systematic relationship between any measure of cluster density and encounter rates (apart from occasionally in just a few of the clusters, but these could be chance given that many fluctuations do not correlate).
4.2.1 Binaries
All our simulations start with no binaries. An interesting question is how many binaries can form, and how they might alter the evolution.
Soft binaries are extremely easy to form (see Moeckel & Clarke, 2011), and can inflate the encounter rate. Any wide binary with periastron below 1000au and apastron above 1000au will be included as multiple encounters - however such binaries are extremely soft and short lived in our simulations (this was seen in cluster I).
Hard binaries, however, are much more difficult to form. The soft binaries we find are very weakly bound and can appear due to fluctuations in the global potential. However, to form a hard, long-lived, binary system requires a three-body encounter as the third body is needed to carry-away the excess energy (see Goodman & Hut, 1993). A back-of-the-envelope calculation suggests hard binary formation should be rare in our clusters, and an examination of the simulations finds only a few hard binaries have managed to form (one every few simulations, and never more than one in a simulation).
4.3 The number of stars having had an encounter
We clearly see that the total number of encounters between stars at any particular distance can be different by maybe an order of magnitude in initially statistically identical clusters, in a way that cannot be explained by density fluctuations.
The encounter rates we have shown in Fig. 2 and Table 2 are the number of times two stars come closer together than a particular distance. However, this measure does not include information on if a particular star, or a particular pair of stars, have had multiple encounters.
Star clusters have a density distribution with a high density core and increasingly lower density as one moves outwards, and a Plummer profile is a reasonable approximation to young, bound clusters.
Within this density distribution stars can have a variety of orbits (which can change after encounters). Some stars will spend a significant amount of their time in the high density core, some will spend most of their time in the low density halo, and various combinations in between (orbits can be radial or circular etc. and can change over time).
This means that each individual star will have a unique encounter history. Those that spend a lot of time in the core may have multiple encounters, while those in the halo may have none. In addition (as seen above), some stars may get into loosely bound multiples (cf. Moeckel & Clarke, 2011) and potentially have numerous self-encounters which can inflate the encounter rate significantly (see above).
| Cluster | |||||
|---|---|---|---|---|---|
| N3SMR050-A | |||||
| N3SMR050-B | |||||
| N3SMR050-C | |||||
| N3SMR050-D | |||||
| N3SMR050-E | |||||
| N3SMR050-F | |||||
| N3SMR050-G | |||||
| N3SMR050-H | |||||
| N3SMR050-I | |||||
| N3SMR050-J | |||||
| N3SMR050-A..J |
Despite the large variation in encounter rates, When we measure the encounter fraction in each of our ten clusters we find that this value is statistically the same. In Table 3 we show the number () and fraction () of stars in each of the ten statistically identical clusters from Fig. 2 and Table 2 that have had an encounter within 1000 au after 10 Myr. This number is between 143 and 170 () – statistically consistent with being the same number, and a little over half the stars in the cluster at .
This tells us that in all clusters in this ensemble the same fraction of stars are having very different numbers of encounters.
We can also examine other ensembles of statistically identical clusters and we find that the encounter fraction in different clusters in the same ensemble is statistically the same.
The mean and variances of encounter fractions for each ensemble are given in Table 4, but to summarise for au: for clusters with pc, the encounter fraction is ; for clusters with pc, the encounter fraction is ; and for clusters with pc, the encounter fraction is .
We do not present the data here in detail, but the same is true for different encounter distances: ie. the encounter fraction is lower when the distance is e.g. 500au, but the encounter fraction is statistically the same within each ensemble. (It is difficult to say anything about extremely close encounters as we are into small- statistics.)
That the encounter fraction is constant is extremely interesting, as the most useful measure of encounters is often how many stars have had at least one encounter closer than a particular distance over a particular timescale.
4.3.1 Encounter fractions in different clusters
As we saw above, within an ensemble of statistically identical clusters the fraction of stars that have at least one encounter within 1000 au within 10 Myr is statistically the same, but it is different between different ensembles.

| Cluster | |||||
|---|---|---|---|---|---|
| N3SMR050-A..J | |||||
| N3SMR075-A..J | |||||
| N3SMR100-A..J | |||||
| N6SMR050-A..J |
The top panel of Fig. 4 shows how the encounter fraction, increases with (absolute) time for all of our ensembles. The blue line and shaded region which shows the variance at the top are for the clusters with pc. The red line and shaded region are for the clusters with pc. The purple line and shaded region are for the clusters with pc. And at the bottom the green line and shaded region are for the clusters with pc.
As can be seen, in each case the encounter fraction within ensembles evolves in the same general way - rising rapidly and then flattening - but different ensembles seem to evolve at different rates.
That encounters occur at different rates in these different ensembles should not be a surprise as each of the clusters have a different internal dynamical timescale set by their crossing time. In the middle panel of Fig. 4 we show the encounter fractions by crossing time, rather than by physical time, and the differences between the different ensembles becomes less pronounced. That the (green) clusters with pc have had the fewest encounters is clearly to a large extent because these clusters are dynamically much younger.
However, it is clearly not just dynamical age that is important as the lines are still somewhat different. The reason for this is that the cluster size plays a role. In all of these simulations we are counting encounters within au which is a more significant fraction of the distances between stars in an pc cluster than in an pc cluster. So, we would expect the encounter timescale to also be sensitive to the relative impact parameter .
In the bottom panel of Fig. 4, we plot encounter fraction against an ‘encounter crossing time’, , defined as
| (9) |
Now in the bottom panel we appear to have found a timescale on which all clusters show extremely similar behaviour. For encounters within au there is a sharp rise in in the first to a point where roughly a third of all stars have had an encounter. It then takes another for the next third of stars to have an encounter.
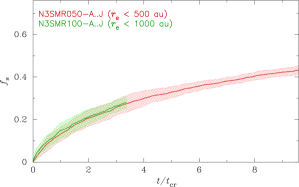
To test the scaling with , in Fig. 5 we compare encounters within au in an pc cluster (red) with encounters within au in an pc cluster (green). Here is the same in both clusters (half the encounter distance, but half the half-mass radius), therefore we would expect the growth of the different encounter fractions with just the crossing time to be the same, which they are as is clear in the figure.
Note that there are various subtleties at play such as different velocity dispersions causing the effect of gravitational focusing to be different, and we are dealing with small- stochastic systems. But overall, the overlap between evolution between different clusters within ensembles and very different ensembles is impressive when scaled by crossing time and relative encounter cross section.
4.3.2 An empirical relationship
The bottom panel of Fig. 4 provides a way of getting a rough estimate of the encounter fraction of stars, , at a particular encounter distance, , after some time, , in any cluster if one knows the crossing time, and half-mass radius, . Then from equation (9) one can calculate , and so .
It is worth pointing-out that the curve in the bottom panel looks like it should have a fairly simple function that would provide a fit. However, we have struggled to find a simple ( or parameter) function that fits (the problem is that the initial rise is much steeper than e.g. an exponential will fit). Therefore we would suggest simply reading-off the value of from the bottom panel of Fig. 4 for whatever value of .
We stress that this is a rough estimate, however, as rough-and-ready as this may be, it will still almost certainly provide a much better feeling for how many stars have had an encounter than any attempt to use equation (2), and then to extrapolate to an encounter fraction.
4.3.3 An example
We can take a roughly Orion Nebula-like cluster with M☉, , a half-mass radius pc, and age Myr and attempt to estimate what fraction of stars have had an encounter at au. For such a cluster, pc-3, and assuming virial equilibrium km s-1, and so Myr.
From equation (9) if au, then Myr. Therefore this cluster has an ‘encounter age’ of . From the bottom panel of Fig. 4 this would suggest around per cent of stars will have had an encounter within au.
If we use equation (2), we find Myr-1. For an age of Myr this suggests encounters among the stars. An extremely naive extrapolation might suggest that therefore all stars had an encounter within au. One can be a little more sophisticated and assume that encounters are random which finds that per cent of stars will have had an encounter (as each one of the encounters involves two stars, even if they are random most stars will have been involved in one). Even if the value of encounters in Myr happened, by luck, to be right, the extension of this encounter number to the number of stars involved in encounters is certainly not random.
5 Conclusions
We have performed -body simulations of small star clusters to investigate stellar encounters with separations au. This is the regime in which discs, planetary systems, and multiple stellar systems can be significantly perturbed or destroyed.
We find that the encounter rates vary by up to an order of magnitude between statistically identical clusters. However, we find that the fraction of stars that have had an encounter is statistically the same within statistically identical clusters.
The fraction of stars that have had an encounter increases rapidly at early dynamical times before flattening significantly once stars in orbits particularly susceptible to encounters have had at least one encounter. This depends on both the dynamical timescale of the cluster (), and the relative impact parameter .
We find a consistent, and reasonably tight, relationship between the fraction of stars that have had an encounter and a modified crossing time .
The relationship we have found has a seemingly solid physical basis, but no detailed theoretical underpinning (we are working on this). However, it provides a simple way of extracting an estimate of the encounter fraction for a particular cluster of a particular age from a figure. While this is empirical, it almost certainly provides a much better estimate of the true encounter fraction than any attempt to apply standard theory.
References
- Aarseth et al. (1974) Aarseth, S. J., Henon, M., & Wielen, R. 1974, A&A, 37, 183
- Andrews & Williams (2007) Andrews, S. M., & Williams, J. P. 2007, ApJ, 659, 705, doi: 10.1086/511741
- Binney & Tremaine (2008) Binney, J., & Tremaine, S. 2008, Galactic Dynamics: Second Edition (Princeton University Press)
- Breslau & Pfalzner (2019) Breslau, A., & Pfalzner, S. 2019, A&A, 621, A101, doi: 10.1051/0004-6361/201833729
- Clarke & Pringle (1993) Clarke, C. J., & Pringle, J. E. 1993, MNRAS, 261, 190, doi: 10.1093/mnras/261.1.190
- Concha-Ramírez et al. (2022) Concha-Ramírez, F., Wilhelm, M. J. C., & Zwart, S. P. 2022, MNRAS, doi: 10.1093/mnras/stac1733
- Cottaar et al. (2012) Cottaar, M., Meyer, M. R., & Parker, R. J. 2012, A&A, 547, A35, doi: 10.1051/0004-6361/201219673
- Craig & Krumholz (2013) Craig, J., & Krumholz, M. R. 2013, ApJ, 769, 150, doi: 10.1088/0004-637X/769/2/150
- Cuello et al. (2022) Cuello, N., Ménard, F., & Price, D. J. 2022, arXiv e-prints, arXiv:2207.09752. https://arxiv.org/abs/2207.09752
- Goodman & Hut (1993) Goodman, J., & Hut, P. 1993, ApJ, 403, 271, doi: 10.1086/172200
- Goodwin (2010) Goodwin, S. P. 2010, Philosophical Transactions of the Royal Society of London Series A, 368, 851, doi: 10.1098/rsta.2009.0254
- Haisch et al. (2000) Haisch, Jr., K. E., Lada, E. A., & Lada, C. J. 2000, AJ, 120, 1396, doi: 10.1086/301521
- Haisch et al. (2001) —. 2001, ApJ, 553, L153, doi: 10.1086/320685
- Heller (1993) Heller, C. H. 1993, ApJ, 408, 337, doi: 10.1086/172591
- Hillenbrand et al. (1998) Hillenbrand, L. A., Strom, S. E., Calvet, N., et al. 1998, AJ, 116, 1816, doi: 10.1086/300536
- Lada & Lada (2003) Lada, C. J., & Lada, E. A. 2003, ARA&A, 41, 57, doi: 10.1146/annurev.astro.41.011802.094844
- Lada et al. (2000) Lada, C. J., Muench, A. A., Haisch, Jr., K. E., et al. 2000, AJ, 120, 3162, doi: 10.1086/316848
- Larwood (1997) Larwood, J. D. 1997, MNRAS, 290, 490, doi: 10.1093/mnras/290.3.490
- Makino & Aarseth (1992) Makino, J., & Aarseth, S. J. 1992, PASJ, 44, 141
- Moeckel & Clarke (2011) Moeckel, N., & Clarke, C. J. 2011, MNRAS, 415, 1179, doi: 10.1111/j.1365-2966.2011.18731.x
- Ndugu et al. (2022) Ndugu, N., Abedigamba, O. P., & Andama, G. 2022, MNRAS, 512, 861, doi: 10.1093/mnras/stac569
- Parker & Quanz (2012) Parker, R. J., & Quanz, S. P. 2012, MNRAS, 419, 2448, doi: 10.1111/j.1365-2966.2011.19911.x
- Plummer (1911) Plummer, H. C. 1911, MNRAS, 71, 460, doi: 10.1093/mnras/71.5.460
- Reipurth et al. (2014) Reipurth, B., Clarke, C. J., Boss, A. P., et al. 2014, in Protostars and Planets VI, ed. H. Beuther, R. S. Klessen, C. P. Dullemond, & T. Henning, 267, doi: 10.2458/azu_uapress_9780816531240-ch012
- Thies et al. (2010) Thies, I., Kroupa, P., Goodwin, S. P., Stamatellos, D., & Whitworth, A. P. 2010, ApJ, 717, 577, doi: 10.1088/0004-637X/717/1/577
- Thies et al. (2005) Thies, I., Kroupa, P., & Theis, C. 2005, MNRAS, 364, 961, doi: 10.1111/j.1365-2966.2005.09644.x
- Wijnen et al. (2017) Wijnen, T. P. G., Pols, O. R., Pelupessy, F. I., & Portegies Zwart, S. 2017, A&A, 604, A91, doi: 10.1051/0004-6361/201731072