Omni 3D: BEOL-Compatible 3D Logic with
Omnipresent Power, Signal, and Clock
Abstract
This paper presents Omni 3D — a 3D-stacked device architecture that is naturally enabled by back-end-of-line (BEOL)-compatible transistors. Omni 3D arbitrarily interleaves metal layers for both signal/power with FETs in 3D (i.e., nFETs and pFETs are stacked in 3D). Thus, signal/power routing layers have fine-grained, all-sided access to the FET active regions maximizing 3D standard cell design flexibility. This is in sharp contrast to approaches such as back-side power delivery networks (BSPDNs), complementary FETs (CFETs), and stacked FETs. Importantly, the routing flexibility of Omni 3D is enabled by double-side routing and an interleaved metal (IM) layer for inter- and intra-cell routing, respectively. In this work, we explore Omni 3D variants (e.g., both with and without the IM layer) and optimize these variants using a virtual-source BEOL-FET compact model. We establish a physical design flow that efficiently utilizes the double-side routing in Omni 3D and perform a thorough design-technology-co-optimization (DTCO) of Omni 3D device architecture on several design points. From our design flow, we project improvement in the energy-delay product and reduction in area compared to the state-of-the-art CFETs with BSPDNs.
BEOL-compatible logic, backside routing, 3-track standard cell, design technology co-optimization (DTCO).
1 Introduction
Ultra-dense 3D integration of logic and memory (with 3D vertical connectivity ) promises significant improvements in computing energy efficiency and throughput, particularly for today’s challenging abundant-data applications [2]. Today, we can realize such ultra-dense 3D systems using monolithic 3D integration of back-end-of-line (BEOL)-compatible logic and memory technologies (that are fabricated at temperatures to prevent damage to upper BEOL metal interconnect layers). BEOL-compatible logic has been experimentally demonstrated using low-dimensional field-effect transistors (FETs), such as MoS2 FETs and carbon nanotube FETs (CNFETs) [3, 4, 5]. Multiple gate geometries (e.g., back-gated, top-gated, and gate-all-around [6, 7, 8, 9]) have been extensively studied for BEOL-compatible logic. However, device architectures that co-optimize 3D arrangement of BEOL-compatible FETs alongside metal connections have not been sufficiently explored.
Conversely, silicon (Si) device architectures have continuously evolved and have been key in technology node scaling. Innovations such as nanosheets [10], forksheets [11], and buried power rails (BPR) [12] have been proposed to enhance area efficiency, while back-side contacts (BSC) [13, 14] and vertical-horizontal-vertical (VHV) structures [15] have been introduced to improve drive strength and intra-cell connectivity, respectively. Beyond such innovations, complementary FET (CFET) architectures (that stack pFETs and nFETs in 3D) provide another avenue for continued Si transistor scaling [16, 17, 18]; a few CFET alternatives have also been presented, however with relaxed design rules [19, 20].
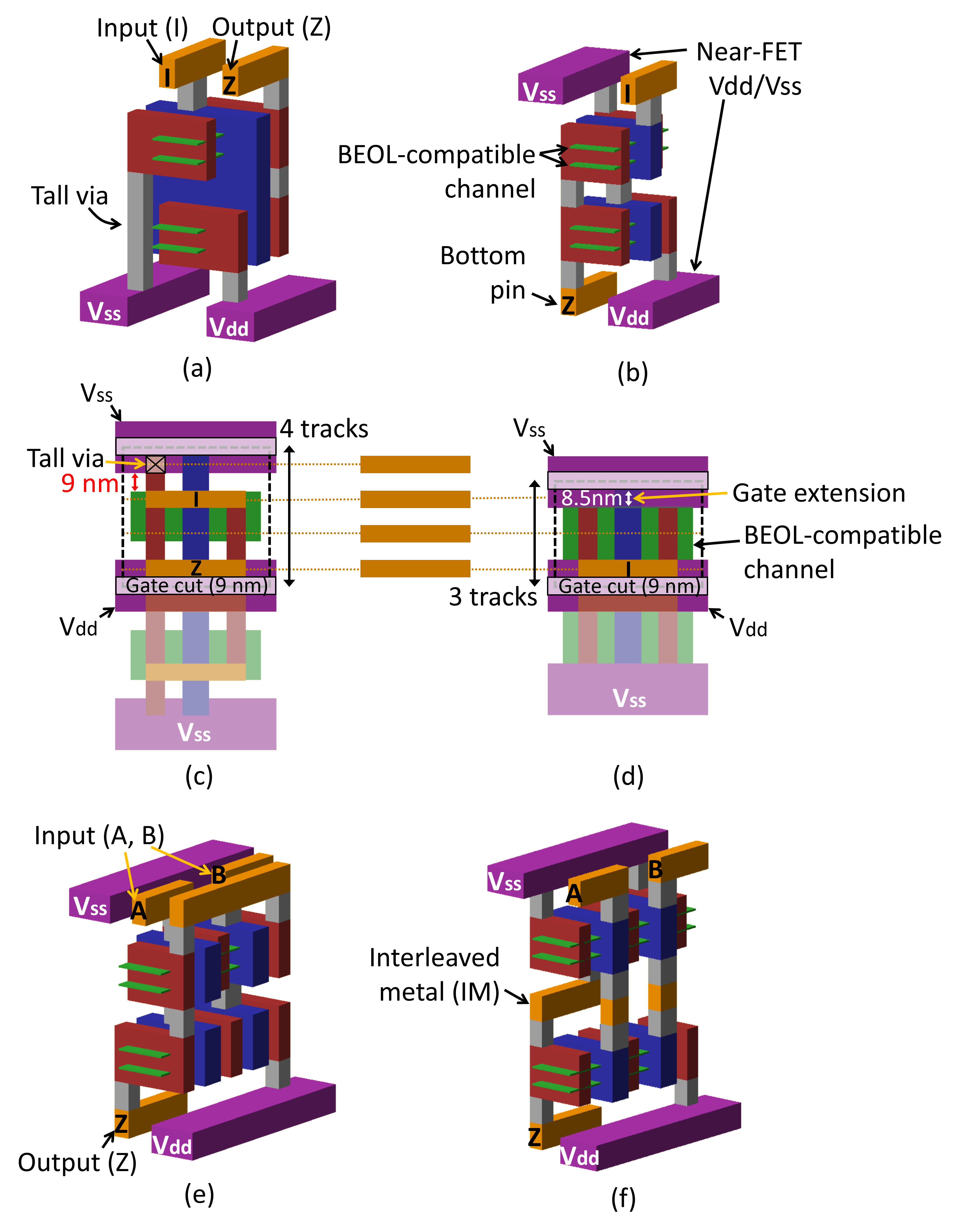
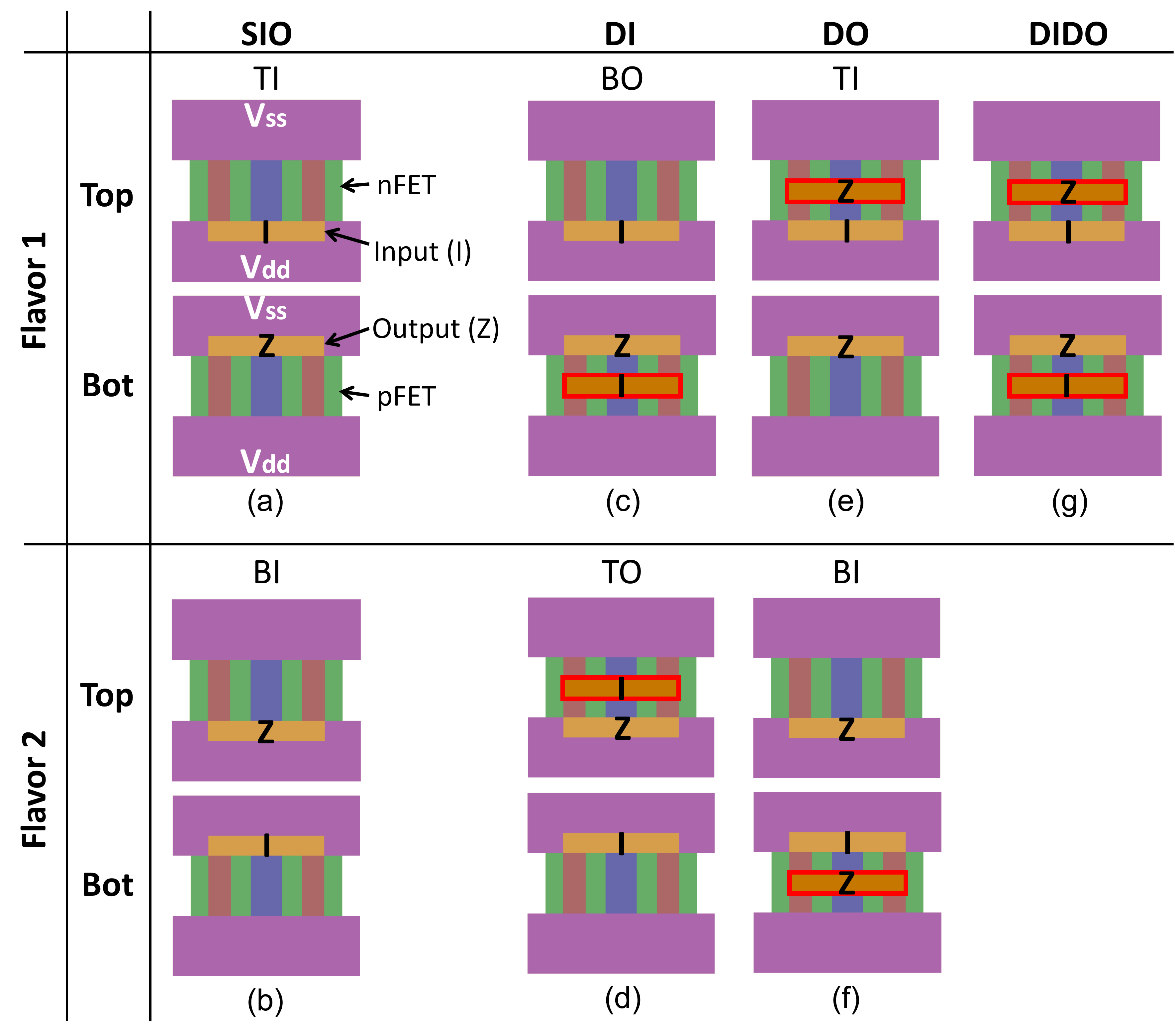
Recognizing the importance of device architecture, Omni 3D has been proposed as a dedicated solution for BEOL-compatible logic [1]. In contrast to CFETs in Fig. 1 (a), Omni 3D’s architecture (Fig. 1 (b)) is enabled by the following novelties: (1) One of the power rails is lifted above the upper FET to eliminate tall vias that limit the channel width in CFETs (Fig. 1 (c)). This enables Omni 3D -track cell heights (Fig. 1 (d)) that maintain comparable drive strength of -track CFETs. (2) Signal pins are defined on both the top and bottom sides as input (I) and output (Z) for double-side routing (See Fig. 1 (b)). (3) Interleaved metal (IM) between nFET and pFET is introduced to provide extra intra-cell routing tracks. For example, Fig. 1 (e) and (f) shows how IM improves the routing for the parallel connection of nFETs in NOR2. Prior work has shown how a combination of these advances allows Omni 3D to achieve energy-delay product (EDP) benefits in block-level designs (e.g., simple RISC-V cores) compared to CFET [1].
| Design parameters | CFET | Omni 3D | Reference |
| Contacted gate pitch (nm) | 42 | [13, 21] | |
| Gate length (nm) | 14, 15, 16, 17 | [22] | |
| Gate-to-S/D space (nm) | 5, 7, 9 | [22] | |
| Gate cut (nm) | 9 | [13] | |
| Gate extension (nm) | 8.5 | [13, 21] | |
| S/D extension (nm) | 0 | [21] | |
| S/D-to-via space (nm) | 9 | NA | [23] |
| S/D-to-BPR space (nm) | 3 | NA | [13] |
| M1 pitch/width (nm) | 18/9 | [13] | |
| # nanosheets | 1, 2, 3, 4 | [22] | |
| (V) | 0.45, 0.5, 0.55, 0.6, 0.65, 0.7 | [22] | |
Beyond the prior work on Omni 3D, we accomplish three key advances:
-
•
Device model: While the prior work employed a predictive model from an existing Si CFET literature [21], here we use a calibrated BEOL CNFET model. CNFETs are chosen as an example BEOL-compatible technology as: (1) CNFETs have large projected EDP benefits over Si transistors at advanced technology node [22], (2) BEOL-integration of complementary CNFETs is already achieved within industrial Si fabs and foundries [24], and (3) complex BEOL circuits and systems have been demonstrated using CNFETs (a RISC-V core, the largest BEOL-compatible logic tapeout to date [25]).
-
•
Device architecture: Prior work showed a comparison of one Omni 3D option over several CFETs. However, in this work, we explore multiple Omni 3D variants by including/excluding IM and configuring pin access patterns to further optimize Omni 3D routing.
-
•
Physical design: The past work on Omni 3D evaluated a small benchmark (a design with gates), due to the lack of a dedicated physical design flow (requiring manual customization of Omni 3D layouts). In contrast, we have now established a new Omni 3D physical design flow, integrated with commercial EDA tools supporting designs of various complexities (here, we show designs with gates) through cell grouping and flipping algorithms, avoiding redundant routing and balancing metal usage on both sides.
The remainder of this paper consists as follows: We optimize device layout in Section 2 and explore impact of IM and pin access patterns at standard cell level in Section 3. Section 4 explains physical design challenges with existing commercial tools and their solutions. In Section 5, Omni 3D is assessed and analyzed in comparison to CFET for three different logic cores. We summarize our work and discuss future opportunities in Section 6.
2 Design Technology Co-Optimization (DTCO)
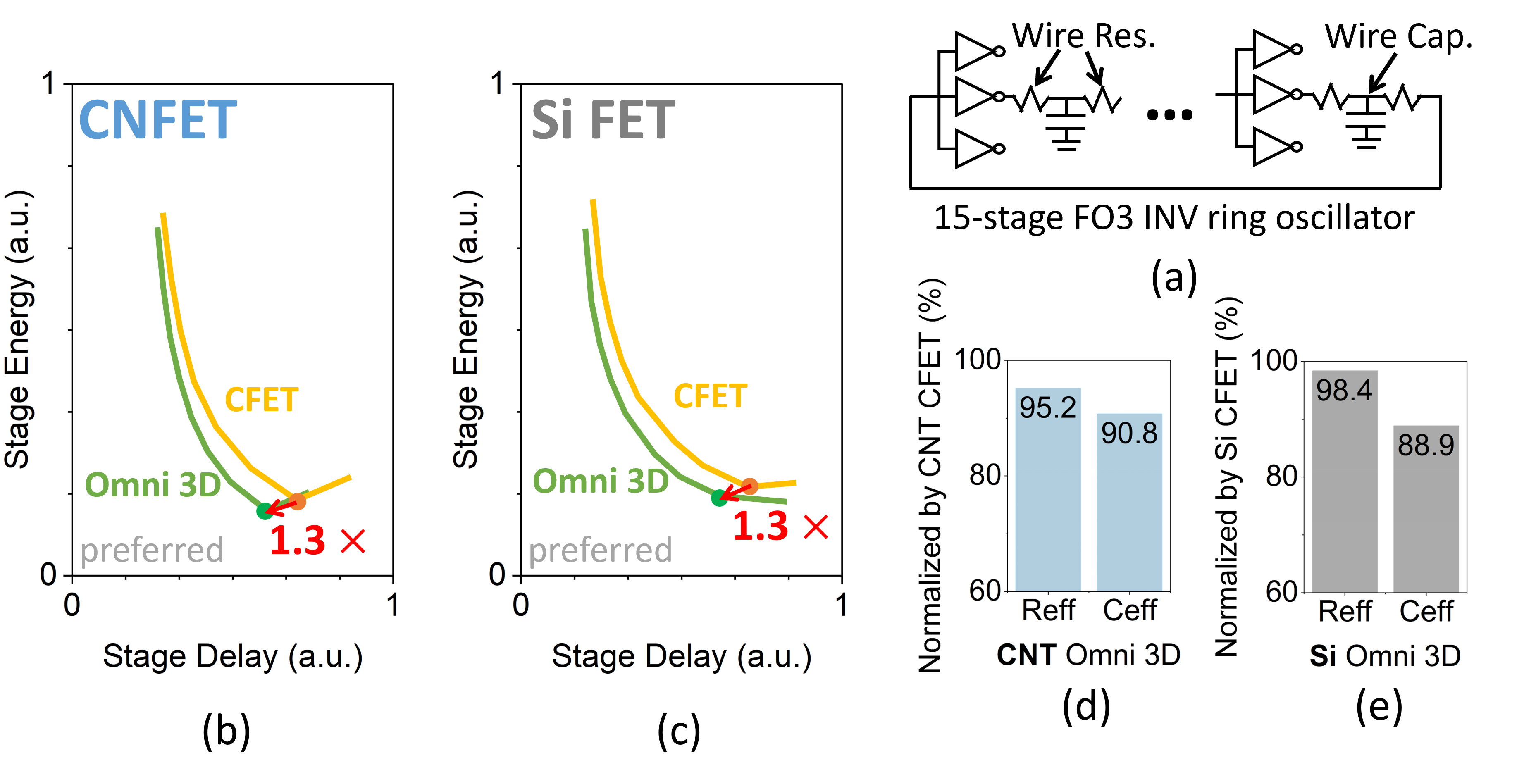
Device layouts vary with design parameters (e.g., gate length, gate-to-source/drain (S/D) space, and # nanosheets), which impact EDP [22]. Our DTCO framework determines the best sets of design parameters for Omni 3D and CFET. We use a hardware-calibrated [26] and theoretically-refined [22] virtual-source CNFET model. A ring oscillator (RO) circuit with 15-stage minimum size INVs, fan-out 3 (FO3), and interconnect (Fig. 2 (a)) is employed as a benchmark [27]. We explore a design space in Table 1 targeting a sub- technology node. Cell parasitics of 3D layouts are extracted with GTS Cell Designer [28]. Before of every RO simulation, threshold voltages are re-targeted to set the leakage current of both nFET and pFET to /FET. Among combinations for each CFET and Omni 3D design, those with contact length less than and those that cannot meet leakage current constraints by threshold adjustment are dropped from the set of feasible design points [22].
We show the single stage RO energy vs. delay pareto curves for Omni 3D with CNFET channel in Fig. 2 (b). Minimum-EDP design points for CFET and Omni 3D are highlighted. Both design points have gate length of , gate-to-S/D space of , one nanosheet, and of . Omni 3D achieves EDP benefits over CFET. Energy and delay are respectively improved by and .
Similar () EDP benefits were reported with Si FETs [1] as shown in Fig. 2 (c). However, the benefits stem from different reasons. Energy () and delay () benefits in Omni 3D can be decomposed into improvements in effective capacitance () and effective resistance (). and improvements for Omni 3D with CNFETs and Si FETs (compared to respective CFET architectures) are shown in Fig. 2 (d) and (e). The widened channel in Omni 3D impacts the effective width more for CNFETs due to its thinner thickness ( vs. of Si FET), further reducing . However, the benefits to from track height reduction are diminished because CNFET’s longer gate-to-S/D space ( vs. of Si FET) lessens the corresponding capacitance fraction. Structural differences between Si FETs and CNFETs have minimal contribution to the EDP benefits.
3 Omni 3D Variants
We discuss two independent variations of the Omni 3D standard cell library: (1) IM inclusion/exclusion and (2) different configurations of input & output pin within a cell.
3.1 Impact of IM
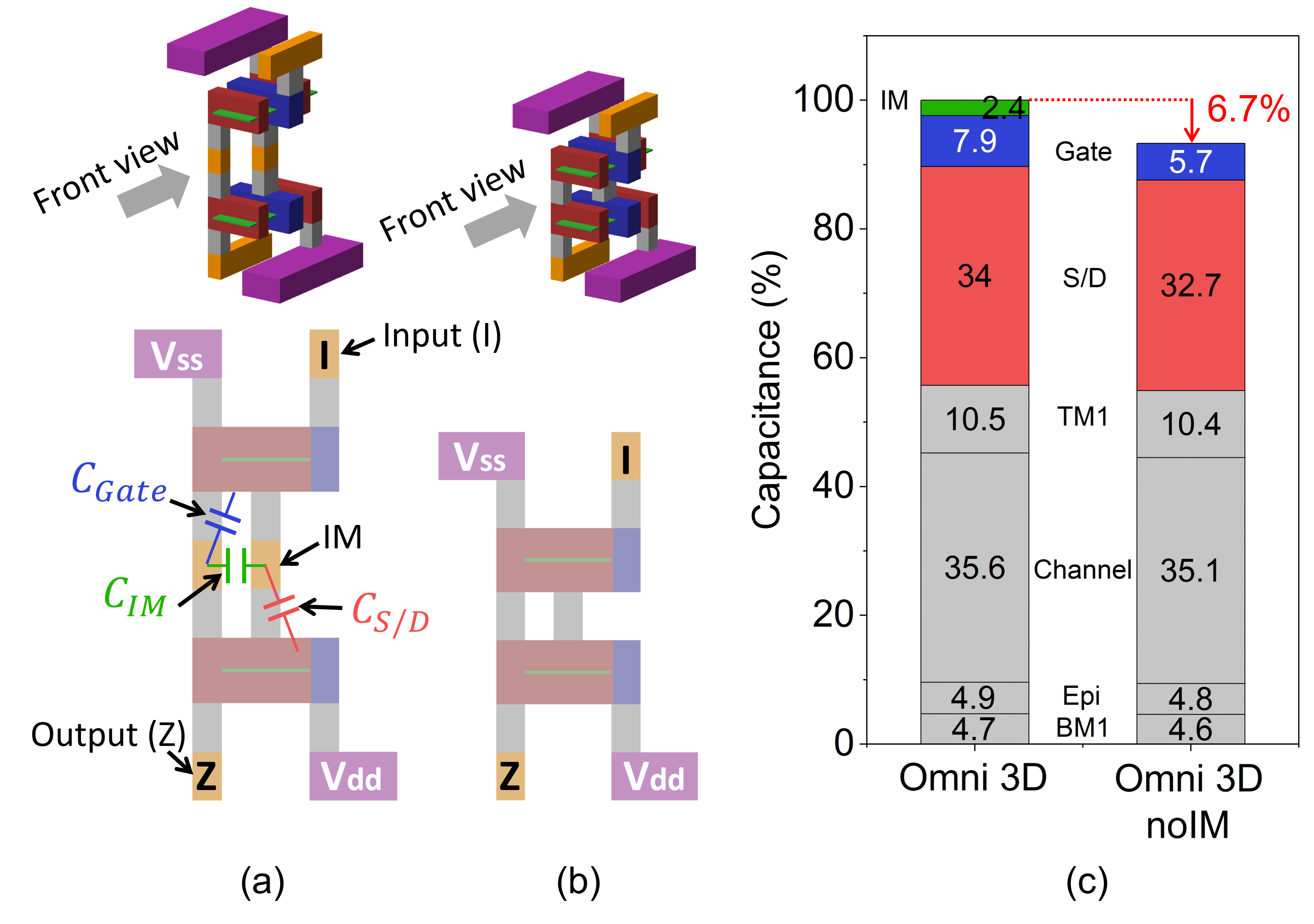
IM provides design flexibility with additional intra-cell routing tracks. However, these routing tracks may introduce extra parasitic capacitance. For example, INVs of Omni 3D and Omni 3D without IM (noIM) are illustrated in Fig. 3 (a) and (b), respectively; eliminating IM also removes the via below. Fig. 3 (c) shows input capacitance reduction by in noIM. More specifically, IM to the other IM, gate, and S/D capacitance are shrunk. This savings is valid for cells (e.g., INV and BUF) which uses IM as only another via stack.
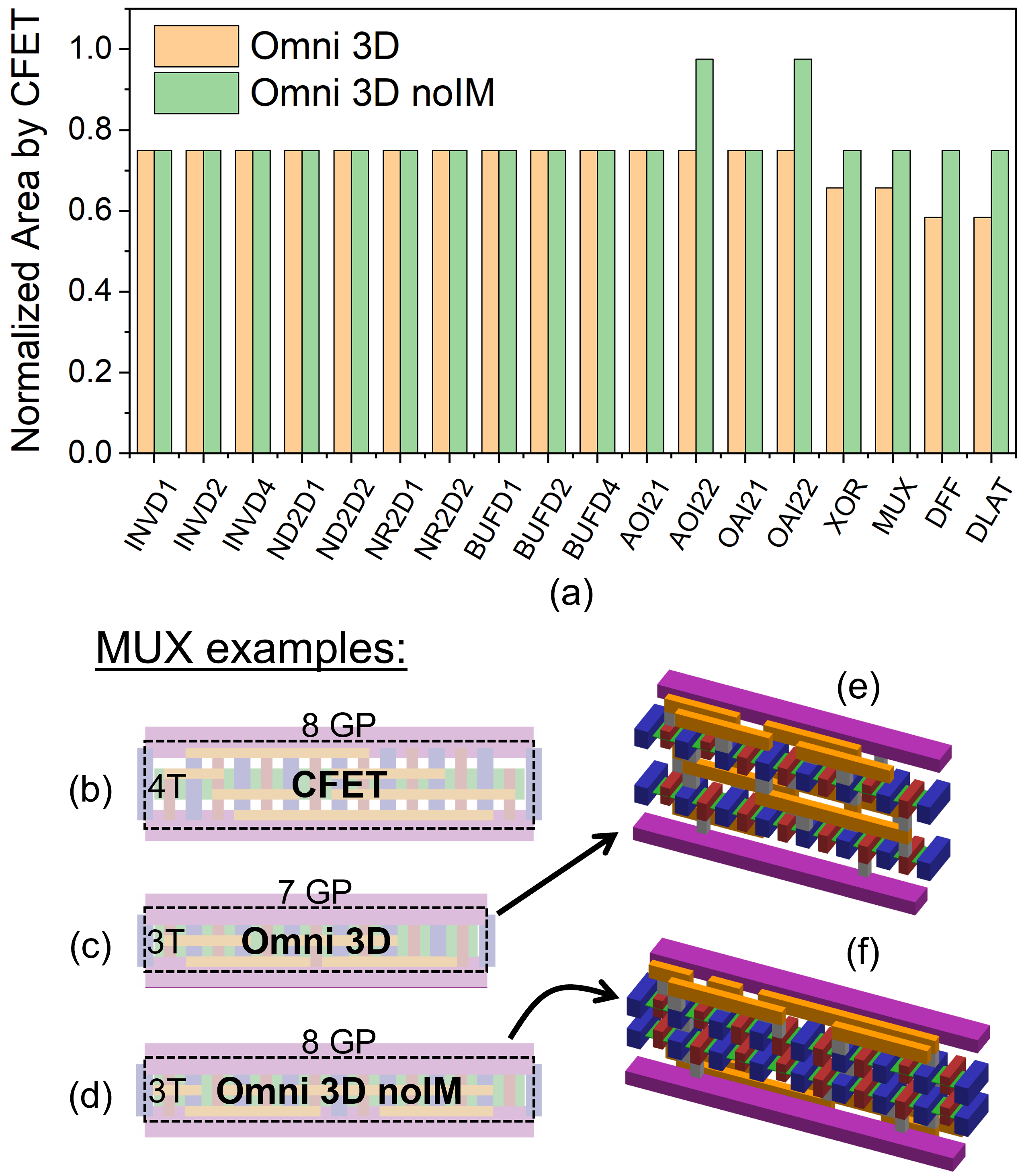
However, the design impact of IM on complex cells is different from INV/BUFs. We implement standard cells for Omni 3D, Omni 3D noIM, and CFET. Fig. 4 shows the area benefits of two Omni 3D variants over CFET and the impact of IM to the benefits. The majority of cells save area by cell height reduction, from tracks to tracks. Complex cells which demand heavy intra-cell routing (e.g., DFF, XOR, MUX) leverage extra three intra-cell routing tracks in the IM layer to further reduce cell area by shortening cell width in Omni 3D (orange in Fig. 4 (a), See MUX examples in (c) vs. (b)). In contrast, noIM only achieves cell height reduction (green in Fig. 4 (a), See (d) vs. (b)). This is because noIM has the same number of intra-cell routing metal tracks (two each on top and bottom) as CFET (four on top). IM usage for more compact Omni 3D MUX design is shown in Fig. 4 (e) vs. (f).
AOI22 and OAI22 have notable area overhead in Omni 3D noIM. One side of the Omni 3D noIM has only two routing tracks, which are fully occupied by the pins of such a many-input cell, leaving no room for intra-cell routing. Cell width of noIM must therefore be extended to facilitate the necessary intra-cell routing on that side while Omni 3D achieves the routing on the IM layer and avoids cell width extension.
3.2 Pin Access Pattern
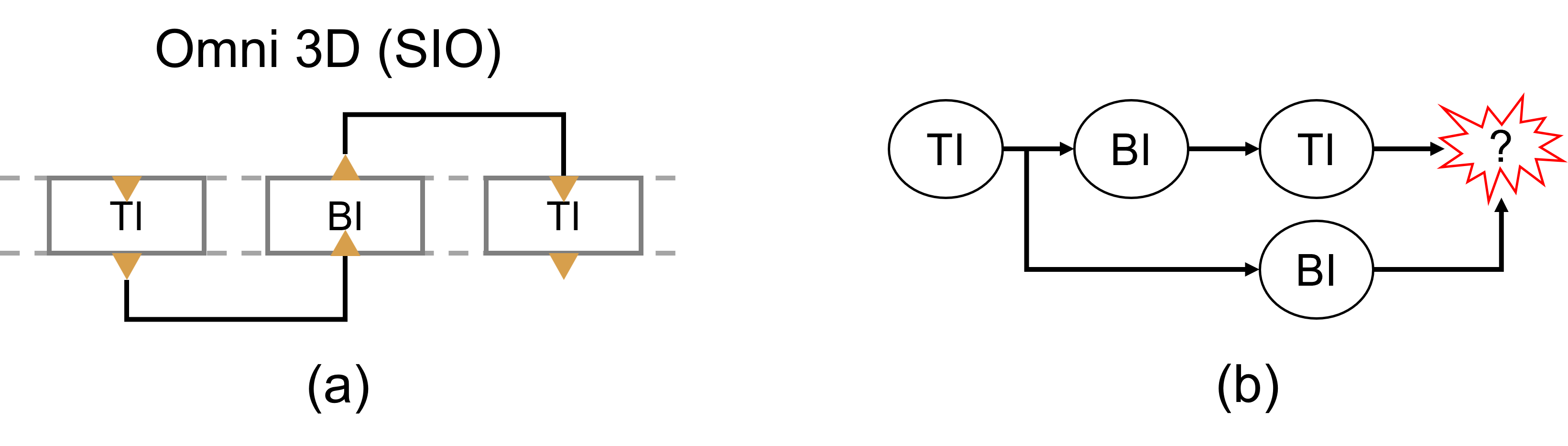
Input and output pin access configurations affect double-side signal routing. Omni 3D with a single-side input and output (SIO) needs two flavors for routing: a top-in (TI) cell and a bottom-in (BI) cell. Fig. 5 (a) depicts a chain of INV cells alternating between TI and BI to opimize routing. However, an arbitrary netlist can easily create a conflict due to multiple fan-in cells (in red) as exemplified in Fig. 5 (b). Thus, such a sequential dependency restricts routing.
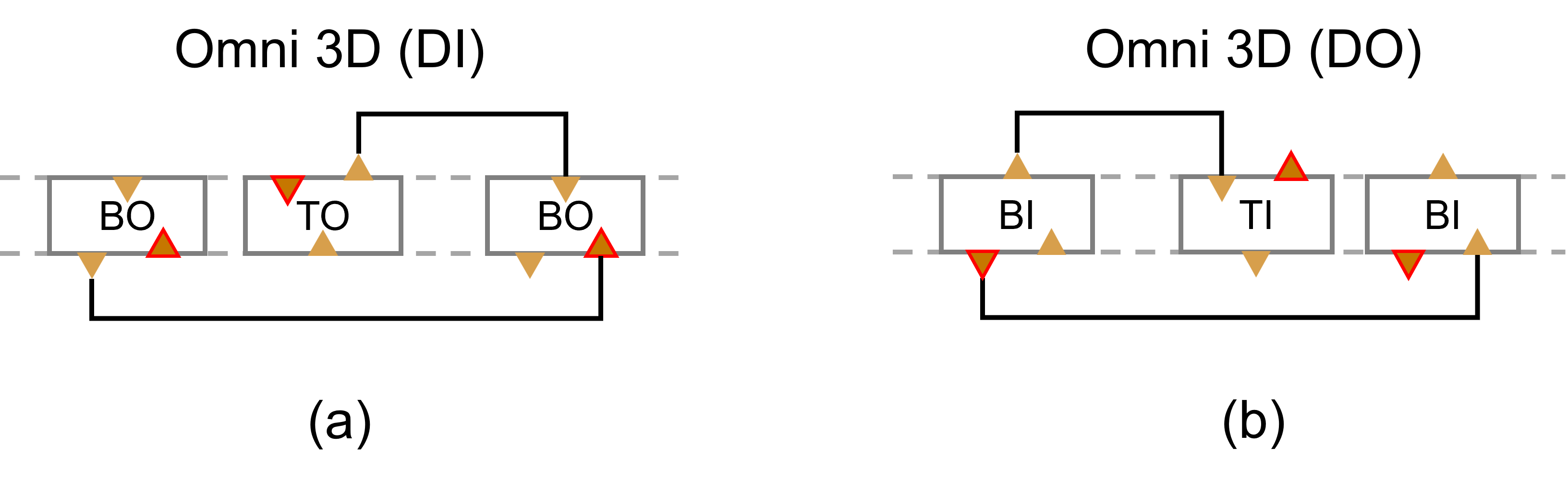
Enabling variants of Omni 3D relieve this sequential dependency. One is a double-side input (DI) cell which features duplicated input pins on both sides, and another is double-side output (DO) cell that is characterized by duplicated output pins on both sides. By adding an input pin to the bottom of and an output pin to the top of Fig. 6 (a), respectively, bottom-out (BO) DI (Fig. 6 (c)) and TI DO (Fig. 6 (e)) are formed. From the other flavor of SIO, the corresponding top-out (TO) DI and BI DO are produced (See Fig. 6 (b), (d), and (f)). Any DI cells can be routed by both BO and TO DI drivers as illustrated in Fig. 7 (a), and any DO drivers can route both TI and BI DO cells that follow as presented in Fig. 7 (b). While double-side input and double-side output (DIDO) variants (Fig. 6 (g)) simplify the cell library, it results in excessively many pins on both sides.

3.3 Discussion
We evaluated all four variants of Omni 3D with the same DTCO framework in Section 2, and the minimum-EDP design points are shown in Fig. 8. All variants have similar s, of CFET , because their channel widths are equal. Even though DO and DI both adds a pin to one side, the impact on turns out to be different. While adding an extra output pin increases input and output capacitance by and , respectively, adding an extra input pin raises input and output capacitance by and , respectively. In terms of total cell parasitic capacitance, their difference is less than which is diluted by the interconnect capacitance of RO. However, DO and DI showed and penalties, respectively, compared to SIO. This is because the input capacitance driven at the end of the interconnect has a greater impact on delay than the output capacitance driven in the beginning of the interconnect. Additionally, DIDO has more as the sum of DI and DO increases by . NoIM results in a reduction. Its area benefits in complex cells, however, can only be assessed at the block level.
More importantly, DO always adds only one pin to SIO while DI, in the case of a multi-input cell, needs to place multiple pins which may demand extra design area to ensure intra-cell routing. Considering both benefit and compact design, we choose DO as our optimal Omni 3D for block implementations.
4 Physical Design Enablement
4.1 PDK Preparation
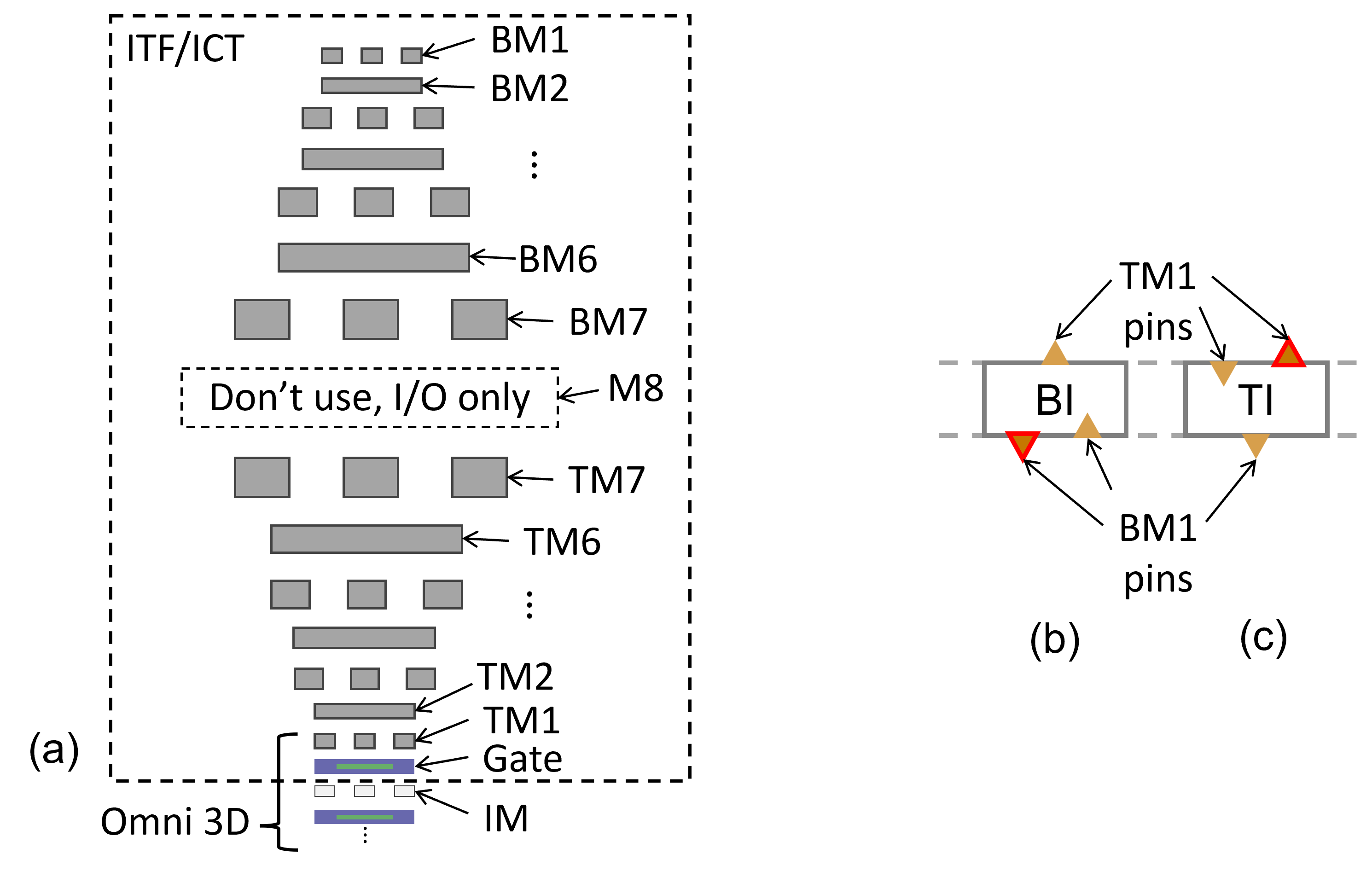
Two key changes in the process development kit (PDK) required to enable double-side routing with commercial EDA tools are: (1) An interconnect technology file (ITF/ICT) and (2) a standard cell layout exchange format (LEF) file. Existing parasitic extraction tools which generate the interconnect RC database (QRC techfile/TLUPlus) only support metal stacks on top of the substrate. Thus, we define bottom-side metal (BM) on top of top-side metal (TM) in reverse order as illustrated in Fig. 9 (a). One extra intermediate layer between TM and BM (i.e., M8) allows block I/O access on both sides but prohibits signal and clock routing to avoid a shortcut between TM7 to BM7. Such a shortcut would imply a vertical path penetrating the whole metal stack. We use predicted technology node metal/via pitches, resistances, and capacitance [29, 30].
Fig. 9 (b) presents pin definitions of BI DO INV in the LEF file. An input pin and output pin on bottom are in BM1, and the other output pin on top is in TM1; vice versa for TI DO INV in Fig. 9 (c). Pins with BM1 and TM1 are routed through BM2 BM7 and TM2 TM7, respectively. Consistently, and power rails of each cell are defined on BM1 and TM1, respectively, in the LEF file.
Omni 3D has a split PDN, with on the bottom side and on the top side. We constructed a mirrored PDN on both sides mimicking tight-pitch PDNs known to meet IR drop requirements [31, 32]. This is equivalent to a conventional top-side PDN with densities of and for the lowest and highest routing metal layers, respectively. The split PDN may create inductive loops in the power grid; optimizing the power grid for minimum inductance falls beyond the scope of our study.
4.2 Efficient Double-Side Routing
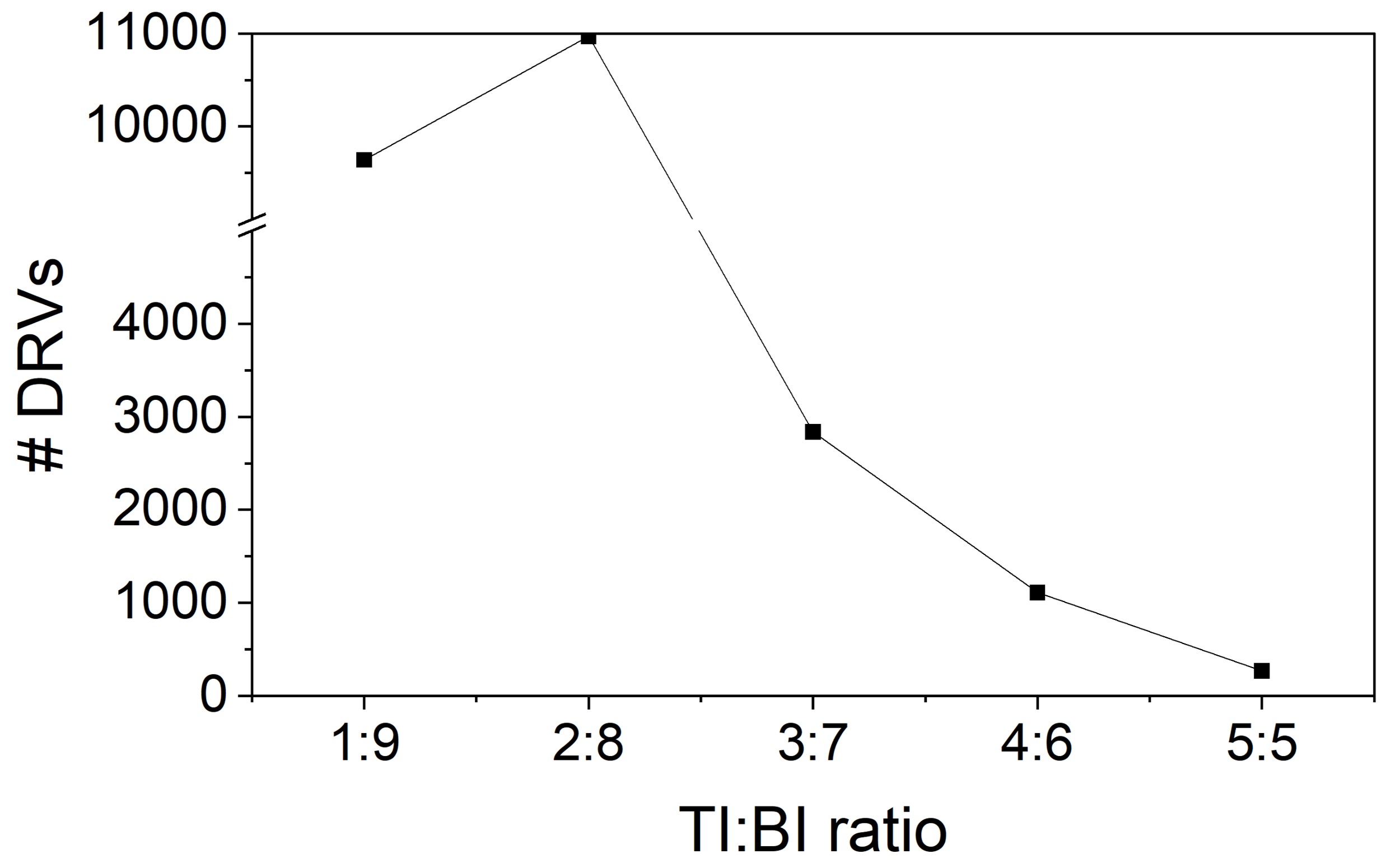
Traditional logic synthesis does not anticipate the Omni 3D physical design requirements in three ways. First, the netlist is synthesized to only considering power and delay, and the flavor (i.e., TI or BI) of a cell is arbitrarily determined. Taking the AES256 design as an example, the ratio of TI to BI is :. Using the resulting netlist would both diminish the value of Omni 3D as well as cause significant congestion. This issue can be addressed by balancing the TI and BI cell ratio after synthesis. Fig. 10 shows a decreasing trend of design rule violations (DRVs) as the TI:BI balance improves.
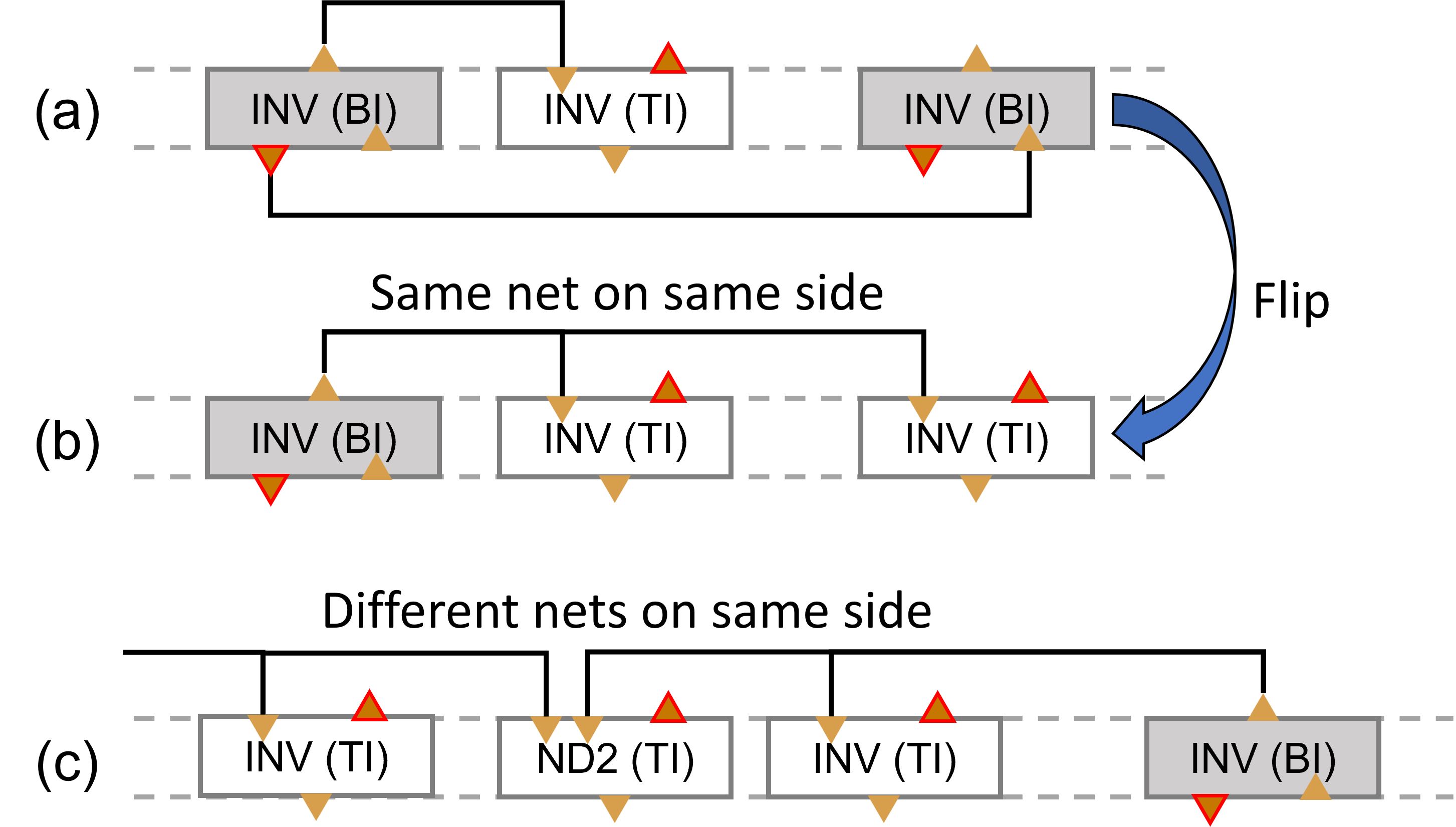
Another aspect is that a logical net can be mapped to two different physical nets as shown in Fig. 11 (a). If an INV (BI) drives two different flavor INVs, a logical net is split into two sides to access the corresponding input pins. However, if either of the load cells is flipped to the other flavor as depicted in Fig. 11 (b), the two physical nets are united on one side eliminating redundant metal usage. Lastly, if two logical nets share a multi-input cell (e.g., ND2 in Fig. 11 (c)), they need to be assigned on the same side. This means that simply balancing the TI and BI cell ratio without considering these characteristics also induces unnecessary routing congestion. In AES256 with simple TI:BI cell count balancing, DRVs remained at the even ratio.
To accommodate the Omni 3D physical design requirements for efficient double-side routing, we modify a netlist after logic synthesis by following Algo. 1. We first identify nets that need to be on the same side and accordingly cluster the relevant cells to be the same flavor. Depth-first search is used to find the cells to cluster. In detail, we start with putting a cell in into an empty cluster. In the function , we obtain the cell’s fan-in nets which must be on the same side, and then list out the sibling cells which are the fan-out cells of those nets. A sibling cell is added to the cluster by a recursive call of the function , increasing the search depth. Depth drilling ends when no sibling cells are found or the cell of interest is already clustered.
The clusters are then assigned to either a TI or BI flavor, targeting an even ratio of TI to BI. For simplicity, we sort the clusters in descending order by size and assign them alternatively to TI and BI flavors until the number of TI cells exceeds half of the total cell count. Large clusters are thus distributed evenly, with any remaining clusters assigned to BI.
4.3 Design Implementation Flow
We use the foundation flow [33] with three extra steps. (1) The cell clustering and assignment in Section 4.2 are performed after synthesis, and the updated netlists are loaded by the placer, with the placer using cell clusters for its seed placement. (2) Existing clock tree synthesis (CTS) inserts arbitrary flavors of buffers only considering delay and power, which leads to the clock tree using the prohibited layer (M8). After CTS, therefore, we flip the flavors of clock buffers whose fan-in nets employ M8. (3) Upon completion of detailed routing, we also flip the flavors of buffers in data paths to address potential detoured routes — nets that violate maximum transition time — by the arbitrary-flavor buffer insertion.
5 Assessment
| CFET | Omni 3D | Omni 3D noIM | |||||||||||||||||
| Design | Rocket | LDPC | AES | Rocket | LDPC | AES | Rocket | LDPC | AES | ||||||||||
| EDP | |||||||||||||||||||
| Energy | |||||||||||||||||||
| Delay | |||||||||||||||||||
| Core Area | |||||||||||||||||||
| # Cells (K) | 35 | 56 | 419 | 37 | 50 | 413 | 38 | 56 | 416 | ||||||||||
| Top metal | Signal/Clock | TM2 - TM5 | TM2 - TM7 | TM2 - TM5 | TM2 - TM7 | TM2 - TM5 | TM2 - TM7 | ||||||||||||
| Power | - | - |
|
|
|
|
|||||||||||||
| Bottom metal | Signal/Clock | - | - | BM2 - BM5 | BM2 - BM7 | BM2 - BM5 | BM2 - BM7 | ||||||||||||
| Power |
|
|
|
|
|
||||||||||||||
We implemented three open-source designs, a processor (Rocket) [34], ECC core (LDPC), and crypto core (AES256) [35] with CFETs, Omni 3D, and noIM libraries; CFETs use BSPDNs. Each design was implemented and simulated with various target clock periods to obtain the minimum-EDP design point; sweep ranges were , , with interval for Rocket, LDPC, and AES256, respectively. For technology assessment purposes, we take the average slack and clock skew of top critical paths rather than just the top critical path to avoid oultier distortions [31]. An achieved delay was calculated by subtracting the slack from the targeted clock period. Designs with # DRVs , slack , and clock skew are considered as valid implementations. Setting up area-hungry design specifications, final cell densities of Rocket, LDPC, and AES256 spanned , , and , respectively.
5.1 Results
In a relaxed target clock period region, as the target decreases, design achieves lower delay without significant impact on energy consumption. Therefore, the EDP trends of AES256 using CFETs and Omni 3D in Fig. 12 (a) are linear until ; empty symbols are invalid designs but are included to show the trend. The EDP gap between the two libraries is similar to one shown in RO ( EDP benefits in Omni 3D). However, after , CFETs started to include substantially more drivers to attain the target clock period and routing accordingly became more convoluted. However, Omni 3D still had enough routing capabilities. This difference allows delay benefits in Omni 3D physical design over RO. In the comparison of minimum-EDP designs, Omni 3D earned EDP and area benefits over CFETs simultaneously. Post-PnR layouts of AES256 are in Fig. 12 (b)(d). An even spatial division for the top and bottom side routing is achieved for Omni 3D.
The EDP and area benefits for the all three designs compared to CFETs are summarized in Table 2. Rocket has a small gate count () which can be routed up to TM5 in CFETs, so Omni 3D used up to TM5 and down to BM5. EDP and area benefits of Omni 3D are, respectively, and on average. Energy benefits are capped by while delay benefits vary depending on the congestion level of designs. noIM achieved the same EDP benefits on average while its area was saved by only due to the cell-level area penalties appeared in Fig. 4 (a).
5.2 Analysis and Observations
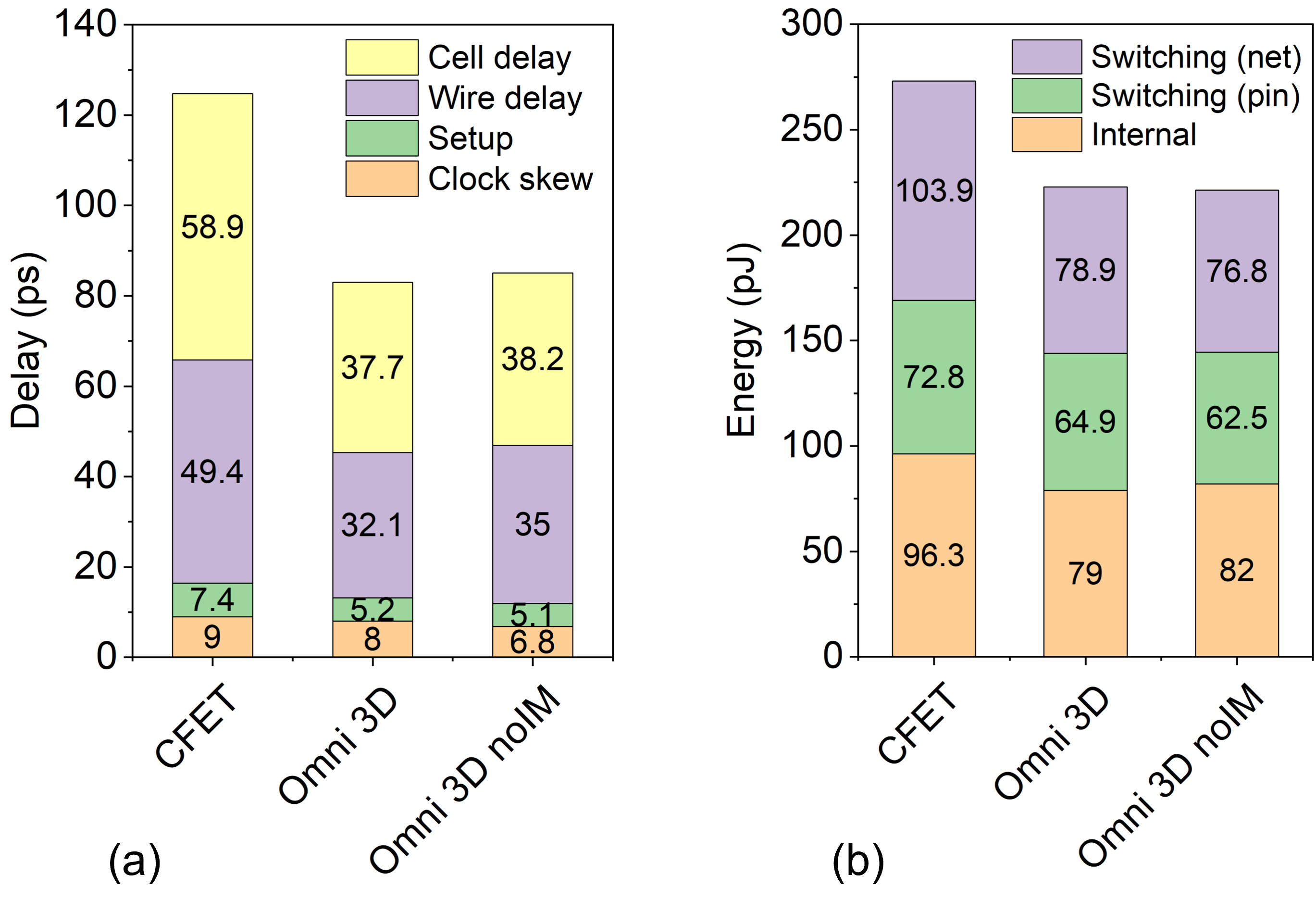
We analyze the delay, energy, and area benefits in detail taking AES256 as an example, comparing Omni 3D to CFET and then to noIM.
Delay: Fig. 13 (a) shows the delay breakdown of the top critical paths of each library. The achieved delay is composed of cell delay, wire delay, setup time of the flip-flop, and clock skew. Before comparison, one notable observation for CFETs is that the wire delay, constituting of the total delay, approached that of the cell delay (). This is attributed to the significant cell resistance improvement of using CNFETs. By introducing Omni 3D, routing congestion was relaxed, hence both wire and driver delays were reduced by and , respectively. noIM showed negligible difference in cell delay from Omni 3D and a penalty in wire delay, due to core area increase.
Energy: Energy breakdown is in Fig. 13 (b). With a default logic switching rate, leakage energy is about ; dynamic energy is decomposed into switching energies and internal energies. Internal energy is estimated from internal power, and switching energy of pins and nets are estimated from switching power in proportion to their capacitances. While cell count is comparable ( lower in Omni 3D compared to CFET), cell energy — sum of pin switching and internal energy — is lower by due to the compact cell design of Omni 3D. More importantly, net switching energy decreased by in Omni 3D even though the total wire length is only shorter. We attribute the extra net switching energy savings to changes in the wire length distributions across layers (see Fig. 14). M2 of Omni 3D in total is more used than in CFET, but TM2 and BM2 are physically located on two different layers. Thus, metal density of Omni 3D in each layer, which contributes to both ground and coupling capacitance, is reduced.
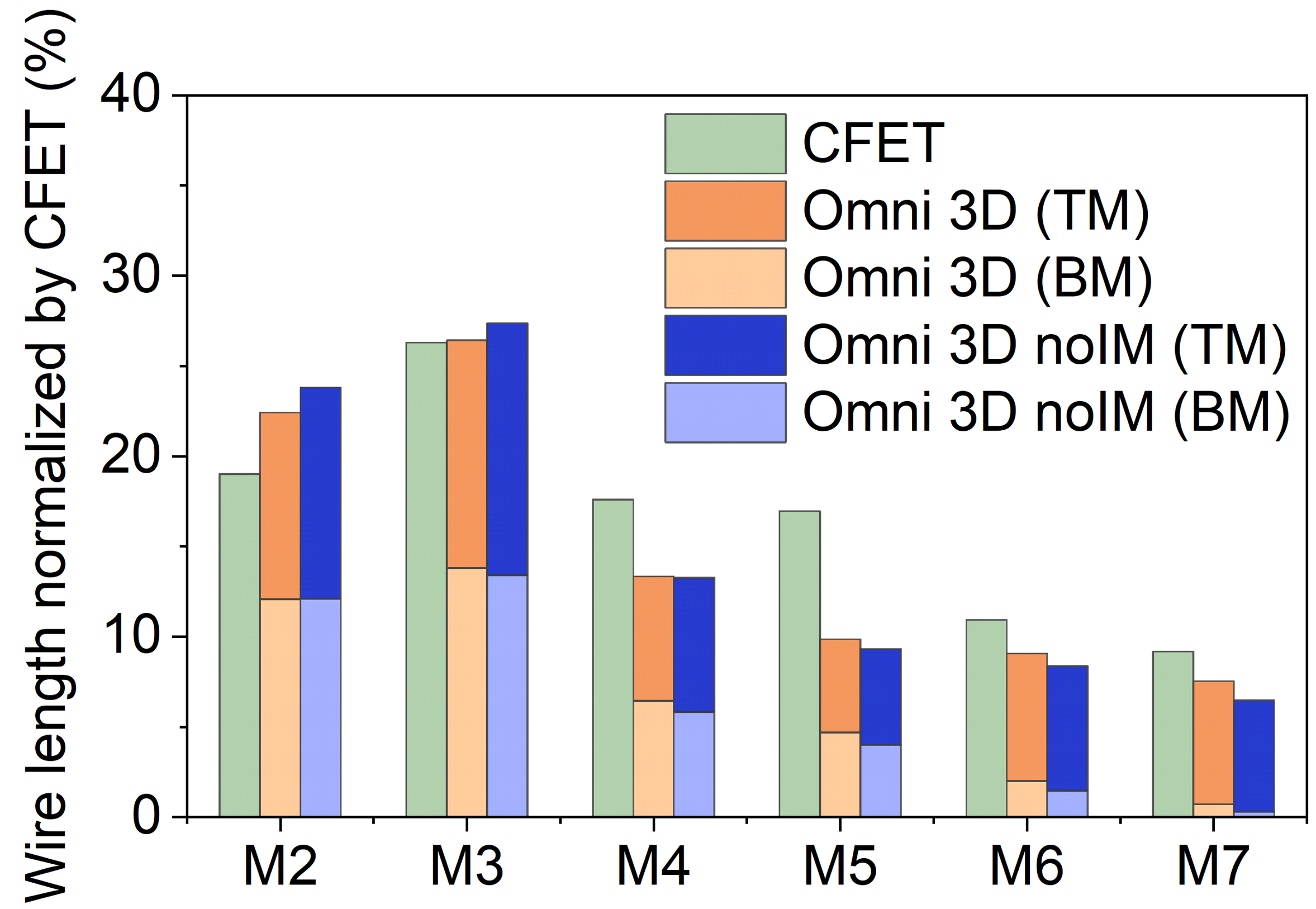
We observed that intensive use of lower metal layers (M2 and M3) in Omni 3D reduces upper layer metal (M4 and M5) utilization in Fig. 14. Considering the area of CFET over Omni 3D, and that both M2 and M3 are similar lengths indicates that Omni 3D relies more on lower metal layers; in other words, CFET is congested in M2 and M3, so some paths are detoured through M4 and M5. noIM has less than difference to Omni 3D in total wire length, and its distribution is only slightly different.
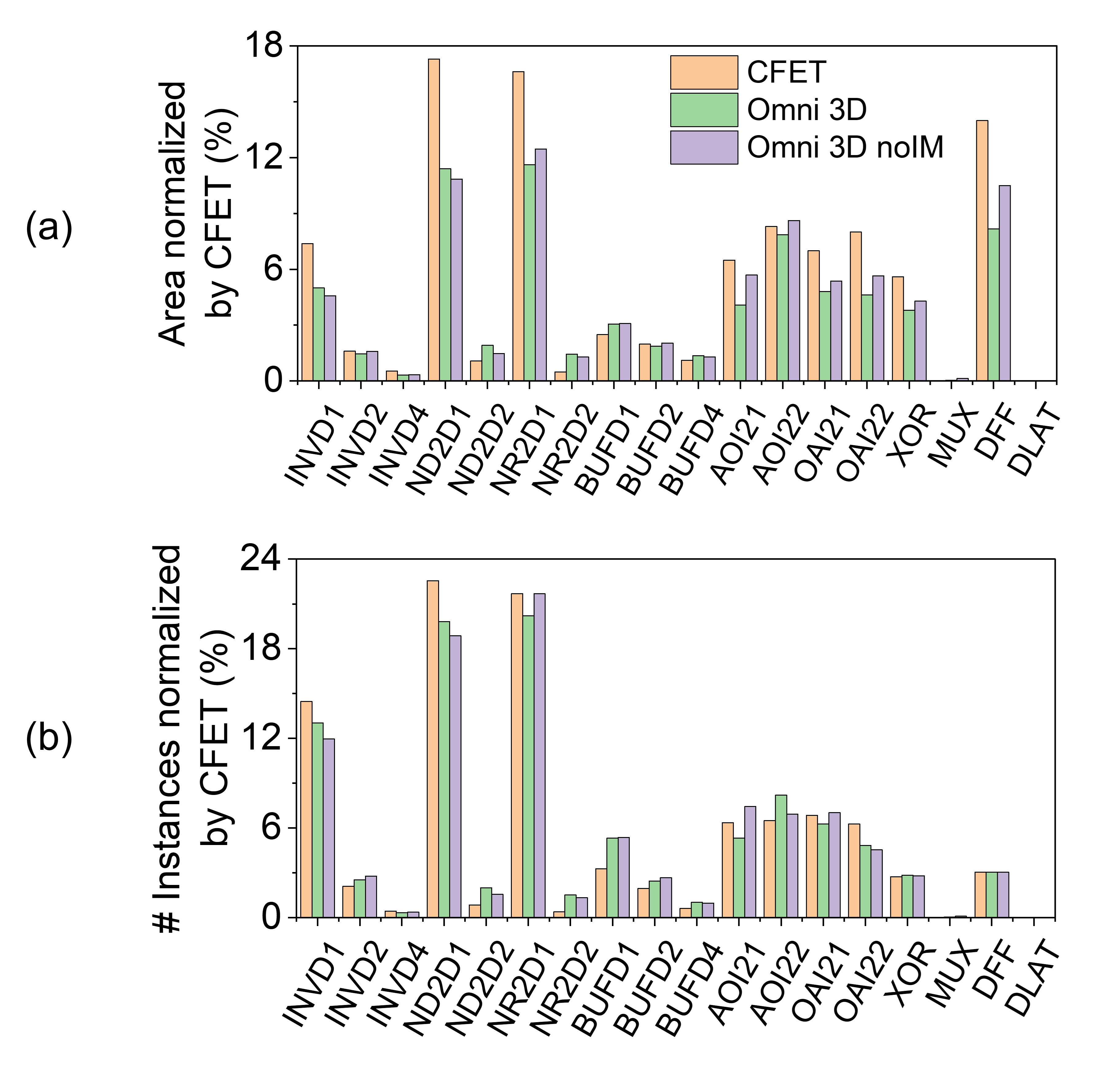
Area: To understand the area benefits in Omni 3D over CFET, area occupied by each cell in AES256 is normalized by the CFET AES256 total area in Fig 15 (a). CFET bars indicate the area contributions of individual cell. INVD1, ND2D1, NR2D1, and DFF have significant area contributions. Accordingly, area benefits of Omni 3D mainly comes from these cells. Note that while INV, ND, and NR provide only area benefit, area benefit of DFF is reflected in its large area savings contribution (). Some other cells (e.g., BUFD1) occupy similar or more area compared to CFET because their cell count increases as presented in Fig. 15 (b).
Fig. 15 (a) shows that DFF area benefits in Omni 3D are decreased in the noIM case vs. IM (due to additional routing flexibility in IM). Another notable impact of IM is that AOI and OAI distributions shift. Due to area-inefficient design of AOI22 and OAI22, their counts are lowered in Omni 3D noIM desgin points compared to Omni 3D designs, and instead, the counts of AOI21 and OAI21 increased to synthesize the same functions. Due to cell-level area increase in a few cells (e.g., DFF, AOI22, and OAI22), AES256 area benefit of noIM was cut to .
6 Conclusion
In this work, we investigate Omni 3D device architecture with a BEOL-compatible channel and physical design for efficient double-side routing. Omni 3D (DO) with IM showed the highest EDP () and area () benefits compared to CFETs with BSPDNs. noIM, with a lesser area benefit of can serve as an alternative option if IM is not preferred for device stability, fabrication, or cost issues.
Future work should address the EDA challenges of multi-tier logic for 3D systems and explore their design trade-offs systematically. Critical path-aware cell clustering and side assignment further improve delay. A remaining metal usage imbalance between sides (Fig. 14 M6 and M7), due to naïve metal layer assignments, warrants further investigation. Additionally, multi-tier Omni 3D, with its full tier-to-tier routing capabilities needs to be evaluated against traditional face-to-face or face-to-back 3D logic that relies on single-side routing and TSVs.
Acknowledgment
We thank SystemX Alliance for the support on this research.
References
- [1] T. Srimani et al., “N3XT 3D Technology Foundations and Their Lab-to-Fab: Omni 3D Logic, Logic+ Memory Ultra-Dense 3D, 3D Thermal Scaffolding,” in IEEE IEDM, 2023, pp. 1–4.
- [2] M. M. S. Aly et al., “The N3XT approach to energy-efficient abundant-data computing,” Proceedings of the IEEE, vol. 107, no. 1, pp. 19–48, 2018.
- [3] S.-K. Su et al., “Perspective on low-dimensional channel materials for extremely scaled CMOS,” in IEEE Symp. on VLSI Tech., 2022, pp. 403–404.
- [4] Y.-Y. Chung et al., “First Demonstration of GAA Monolayer-MoS 2 Nanosheet nFET with 410A m ID 1V VD at 40nm gate length,” in IEEE IEDM, 2022, pp. 34–5.
- [5] G. Pitner et al., “Building high performance transistors on carbon nanotube channel,” in IEEE Symp. on VLSI Tech., 2023, pp. 1–2.
- [6] ——, “Sub-0.5 nm interfacial dielectric enables superior electrostatics: 65 mV/dec top-gated carbon nanotube FETs at 15 nm gate length,” in IEEE IEDM, 2020, pp. 3–5.
- [7] S. Li et al., “High-performance and low parasitic capacitance CNT MOSFET: 1.2 mA/m at V DS of 0.75 V by self-aligned doping in sub-20 nm spacer,” in IEEE IEDM, 2023, pp. 1–4.
- [8] N. Safron et al., “High Performance Transistor of Aligned Carbon Nanotubes in a Nanosheet Structure,” in IEEE Symp. on VLSI Tech., 2024, pp. 1–2.
- [9] C. Gilardi et al., “Barrier Booster for Remote Extension Doping and its DTCO for 1D & 2D FETs,” in IEEE IEDM, 2023, pp. 1–4.
- [10] N. Loubet et al., “Stacked nanosheet gate-all-around transistor to enable scaling beyond FinFET,” in IEEE Symp. on VLSI Tech., 2017, pp. T230–T231.
- [11] P. Weckx et al., “Novel forksheet device architecture as ultimate logic scaling device towards 2nm,” in IEEE IEDM, 2019, pp. 36–5.
- [12] A. Gupta et al., “Buried power rail integration with FinFETs for ultimate CMOS scaling,” IEEE Trans. on Electron Devices, vol. 67, no. 12, pp. 5349–5354, 2020.
- [13] S. Yang et al., “PPA and scaling potential of backside power options in N2 and A14 nanosheet technology,” in IEEE Symp. on VLSI Tech., 2023, pp. 1–2.
- [14] M. Kobrinsky et al., “Novel cell architectures with back-side transistor contacts for scaling and performance,” in IEEE Symp. on VLSI Tech., 2023, pp. 1–2.
- [15] V. Vega-Gonzalez et al., “Semi-damascene integration of a 2-layer MOL VHV scaling booster to enable 4-track standard cells,” in IEEE IEDM, 2022, pp. 23–2.
- [16] M. Radosavljević et al., “Demonstration of a Stacked CMOS Inverter at 60nm Gate Pitch with Power Via and Direct Backside Device Contacts,” in IEEE IEDM, 2023, pp. 1–4.
- [17] S. Liao et al., “Complementary Field-Effect Transistor (CFET) Demonstration at 48nm Gate Pitch for Future Logic Technology Scaling,” in IEEE IEDM, 2023, pp. 1–4.
- [18] J. Park et al., “First demonstration of 3-dimensional stacked FET with top/bottom source-drain isolation and stacked n/p metal gate,” in IEEE IEDM, 2023, pp. 1–4.
- [19] H. Lu et al., “First Experimental Demonstration of Self-aligned Flip FET (FFET): a Breakthrough Stacked Transistor Technology with 2.5T Design, Dual-side Active and Interconnects,” in IEEE Symp. on VLSI Tech., 2024, pp. 1–2.
- [20] L.-C. Huang et al., “Optimization of CFET Standard Cell Using Double-Cell-Height Structure,” in International VLSI Symp. on Technology, Systems and Applications, 2024, pp. 1–3.
- [21] P. Schuddinck et al., “PPAC of sheet-based CFET configurations for 4 track design with 16nm metal pitch,” in IEEE Symp. on VLSI Tech., 2022, pp. 365–366.
- [22] C. Gilardi et al., “Extended scale length theory targeting low-dimensional FETs for carbon nanotube FET digital logic design-technology co-optimization,” in IEEE IEDM, 2021, pp. 27–3.
- [23] S. M. Y. Sherazi et al., “CFET standard-cell design down to 3Track height for node 3nm and below,” in Design-Process-Technology Co-optimization for Manufacturability XIII. SPIE, 2019, pp. 16–27.
- [24] T. Srimani et al., “Foundry monolithic 3D BEOL transistor+ memory stack: Iso-performance and Iso-footprint BEOL carbon nanotube FET+ RRAM vs. FEOL silicon FET+ RRAM,” in IEEE Symp. on VLSI Tech., 2023, pp. 1–2.
- [25] G. Hills et al., “Modern microprocessor built from complementary carbon nanotube transistors,” Nature, vol. 572, no. 7771, pp. 595–602, 2019.
- [26] C.-S. Lee et al., “A compact virtual-source model for carbon nanotube FETs in the sub-10-nm regime—Part II: Extrinsic elements, performance assessment, and design optimization,” IEEE Trans. on Electron Devices, vol. 62, no. 9, pp. 3070–3078, 2015.
- [27] A. Farokhnejad et al., “Evaluation of BEOL scaling boosters for sub-2nm using enhanced-RO analysis,” in IEEE International Interconnect Technology Conference, 2022, pp. 136–138.
- [28] GTS Cell Designer 2023.9, Global TCAD Solutions, 2024.
- [29] V. Huang et al., “A Comprehensive Modeling Platform for Interconnect Technologies,” IEEE Trans. on Electron Devices, vol. 70, no. 5, pp. 2594–2599, 2023.
- [30] IEEE International Roadmap for Devices and Systems, “International roadmap for devices and systems 2022 edition,” Tech. Rep., 2022. [Online]. Available: https://irds.ieee.org/editions/2022
- [31] S. Choi et al., “PROBE3. 0: A Systematic Framework for Design-Technology Pathfinding with Improved Design Enablement,” IEEE Trans. on CAD of Integrated Circuits and Systems, 2023.
- [32] G. Sisto et al., “Block-level evaluation and optimization of backside PDN for high-performance computing at the A14 node,” in IEEE Symp. on VLSI Tech., 2023, pp. 1–2.
- [33] A. Carsello et al., “mflowgen: A modular flow generator and ecosystem for community-driven physical design,” in Proceedings of the 59th ACM/IEEE Design Automation Conference, 2022, pp. 1339–1342.
- [34] K. Asanovic et al., “The rocket chip generator,” University of California, Berkeley, Tech. Rep. UCB/EECS-2016-17, vol. 4, pp. 6–2, 2016.
- [35] OpenCores, https://www.opencores.org, accessed: 2024-07-08.