Off-Policy Actor-Critic with Emphatic Weightings
Abstract
A variety of theoretically-sound policy gradient algorithms exist for the on-policy setting due to the policy gradient theorem, which provides a simplified form for the gradient. The off-policy setting, however, has been less clear due to the existence of multiple objectives and the lack of an explicit off-policy policy gradient theorem. In this work, we unify these objectives into one off-policy objective, and provide a policy gradient theorem for this unified objective. The derivation involves emphatic weightings and interest functions. We show multiple strategies to approximate the gradients, in an algorithm called Actor Critic with Emphatic weightings (ACE). We prove in a counterexample that previous (semi-gradient) off-policy actor-critic methods—particularly Off-Policy Actor-Critic (OffPAC) and Deterministic Policy Gradient (DPG)—converge to the wrong solution whereas ACE finds the optimal solution. We also highlight why these semi-gradient approaches can still perform well in practice, suggesting strategies for variance reduction in ACE. We empirically study several variants of ACE on two classic control environments and an image-based environment designed to illustrate the tradeoffs made by each gradient approximation. We find that by approximating the emphatic weightings directly, ACE performs as well as or better than OffPAC in all settings tested.
Keywords: off-policy learning, policy gradient, actor-critic, reinforcement learning
1 Introduction
Policy gradient methods are a general class of algorithms for learning optimal policies for both the on and off-policy settings. In policy gradient methods, a parameterized policy is improved using gradient ascent (Williams, 1992), with seminal work in actor-critic algorithms (Witten, 1977; Barto et al., 1983) and many techniques since proposed to reduce variance of the estimates of this gradient (Konda and Tsitsiklis, 2000; Weaver and Tao, 2001; Greensmith et al., 2004; Peters et al., 2005; Bhatnagar et al., 2007, 2009; Grondman et al., 2012; Gu et al., 2017b). These algorithms rely on a fundamental theoretical result: the policy gradient theorem. This theorem (Sutton et al., 1999a; Marbach and Tsitsiklis, 2001) simplifies estimation of the gradient, which would otherwise require difficult-to-estimate gradients with respect to the stationary distribution of the policy and potentially of the action-values.
These gradients can be sampled on-policy or off-policy. On-policy methods are limited to learning about the agent’s current policy: the policy must be executed to obtain a sample of the gradient. Conversely, in off-policy learning the agent can learn about many policies that are different from the policy being executed. Sampling these gradients is most straightforward in the on-policy setting, and so most policy gradient methods are on-policy.
Off-policy methods, however, are critical in an online setting, where an agent generates a single stream of interaction with its environment. Off-policy methods can learn from data generated by older versions of a policy, known as experience replay, a critical factor in the recent success of deep reinforcement learning (Lin, 1992; Mnih et al., 2015; Schaul et al., 2016). They also enable learning from other forms of suboptimal data, including data generated by human demonstration, non-learning controllers, and even random behaviour. Off-policy methods also enable learning about the optimal policy while executing an exploratory policy (Watkins and Dayan, 1992), thereby addressing the exploration-exploitation tradeoff. Finally, off-policy methods allow an agent to learn about many different policies at once, forming the basis for a predictive understanding of an agent’s environment (Sutton et al., 2011; White, 2015) and enabling the learning of options (Sutton et al., 1999b; Precup, 2000; Klissarov and Precup, 2021). With options, an agent can determine optimal (short) behaviours from its current state.
Off-policy policy gradient methods have been developed, particularly in recent years where the need for data efficiency and decorrelated samples in deep reinforcement learning require the use of experience replay and so off-policy learning. This work began with the Off-Policy Actor-Critic algorithm (OffPAC) (Degris et al., 2012a), where an off-policy policy gradient theorem was provided that parallels the on-policy policy gradient theorem, but only for tabular policy representations.111See B. Errata in Degris et al. (2012b) that the theorem only applies to tabular policy representations. This motivated further development, including a recent actor-critic algorithm proven to converge when the critic uses linear function approximation (Maei, 2018), as well as several methods using the approximate off-policy gradient such as Deterministic Policy Gradient (DPG) (Silver et al., 2014; Lillicrap et al., 2015), Actor-Critic with Experience Replay (ACER) (Wang et al., 2016), and Interpolated Policy Gradient (IPG) (Gu et al., 2017a). However, it remained an open question whether the foundational theorem that underlies these algorithms can be generalized beyond tabular representations.
This question was resolved with the development of an off-policy policy gradient theorem, for general policy parametrization (Imani et al., 2018). The key insight is that the gradient can be simplified if the gradient in each state is weighted with an emphatic weighting. This result, combined with previous methods for incrementally estimating emphatic weightings (Yu, 2015; Sutton et al., 2016), allowed for the design of a new off-policy actor-critic algorithm, called Actor-Critic with Emphatic Weightings (ACE). Afterwards, an algorithm was proposed that directly estimates the emphatic weightings using a gradient temporal difference update, with an associated proof of convergence using the standard two-timescale analysis (Zhang et al., 2020).
However, ACE and the underlying off-policy policy gradient theorem do not obviously resolve the dilemma of computing the off-policy gradient, because ACE—and previously OffPAC—were introduced under what is called the excursions objective. This objective weights states by the visitation distribution of the behaviour policy. This is sensible in the parallel off-policy setting, where many policies are learned in parallel from one stream of experience. The agent reasons about the outcomes of those policies when taking excursions from its current behaviour. In the episodic setting, however, weighting the states by the visitation distribution of the behaviour policy is not appropriate. Instead, an ideal episodic objective should be weighted by the start-state distribution, and this objective should be optimized from off-policy data without changing this weighting.
Potentially because of this mismatch, most recent methods have pursued strategies that directly correct state-weightings,222A notable exception is an approach that uses a nonparametric Bellman equation—essentially using nonparametric estimates of the environment model (Tosatto et al., 2020). This approach allows direct estimation of the gradient by taking derivatives through this nonparametric Bellman equation. to obtain gradients of either the episodic objective (Liu et al., 2020b) or a finite-horizon objective (Kallus and Uehara, 2020). This approach involves estimating the distribution of state visitation under the behaviour policy and the discounted state visitation under the target policy to obtain an importance sampling ratio to reweight the updates. One disadvantage to this approach is that the state visitation distribution must be estimated, and these estimates can be extremely biased—both by the initialization and by the limitations of the parametric function class used for the estimates.
In this work, we revisit estimating the off-policy gradient with emphatic weightings. First, we propose a unifying objective for the episodic setting and the excursions objective. This objective facilitates the design of a single, unifying off-policy algorithm pertinent to both settings. Then, we extend the off-policy policy gradient theorem both to this objective and to objectives that incorporate entropy regularization. We further show that the on-policy episodic objective can also be seen as a special case, through the use of interest functions to specify interest in the set of start states. We then highlight the difference to previous off-policy approaches including OffPAC and DPG, which use a biased gradient that we call the semi-gradient because it omits a component of the gradient. We prove that in a simple three state counterexample, with two states aliased, the stationary point under semi-gradients is suboptimal, unlike ACE which converges to the optimal solution.
Though such state-aliasing is not pathological, it does seem to contradict the success of methods built on OffPAC in the literature. We show that, under a condition called the strong growth condition (Schmidt and Roux, 2013), which is obtained if there is sufficient representational capacity, the semi-gradient solution is equivalent to that of ACE. Further, we highlight that even outside this setting, in some cases the semi-gradient can be seen as using the sound update underlying ACE, but with a different state weighting. These two insights help explain why OffPAC has been surprisingly effective and suggest promising directions for a lower-variance version of ACE.
Finally, we discuss several improvements to the algorithm, including using direct estimates of the emphatic weightings to reduce variance, incorporating experience replay, and balancing between the higher-variance full gradient update and the lower-variance semi-gradient update. We empirically investigate variants of ACE in several benchmark environments, and find that those with direct estimates of the emphatic weighting consistently perform as well as or better than OffPAC.
Remark on Contributions: This paper builds on our conference paper (Imani et al., 2018). The conference paper presented a policy gradient theorem for one off-policy objective function, and a counterexample showing that OffPAC and DPG can converge to the wrong solution, with experiments limited to the simple three-state counterexample.
An important limitation of that work is that it only applies to the excursions objective, which does not obviously relate to the standard policy gradient objective. Further, the work primarily investigated the true gradient, and did not provide much insight into how to practically use the algorithm. This paper builds on the conference paper in several substantive ways.
-
1.
We first clarify the confusion surrounding objectives by providing a more general objective that includes both the standard objective and the excursions objective. We provide all the derivations for this more general objective (their Theorems 1 and 2 and Proposition 1, which are our Theorems 2 and 3 and Proposition 6). The result is nearly identical, but reiterated with the more general definition, and slightly different terminology. We also highlight that we can recover a sound on-policy algorithm using interest functions.
-
2.
We prove that the semi-gradient from OffPAC has suboptimal solutions on the counterexample. The conference paper only showed this empirically. To obtain this result, we needed to extend the derivation to include entropy regularization, so that the optimal policy is stochastic and its parameters are bounded. Then we proved that the stationary points for OffPAC on the counterexample do not include the optimal point.
-
3.
We provide insight into why semi-gradient methods can perform well, by showing that in some cases the weighting does not affect the solution and that locally we can characterize the semi-gradient as a gradient update with a different state weighting.
-
4.
We provide several algorithmic improvements to ACE, particularly by directly estimating the emphatic weightings to give a lower variance update. In our experiments, this algorithm outperforms or performs comparably to all others, including OffPAC.
-
5.
We conduct a more thorough empirical investigation of ACE in more settings, including two classic benchmarks and a new partially-observable image-based domain. The experiments are aimed at deeply investigating the role of different components, including (a) the objective used for learning versus evaluation, (b) the algorithm for estimating the emphatic weightings, and (c) the algorithm used for the critic.
2 Problem Formulation
Throughout the paper, we use bolded symbols to represent vectors and matrices, and uppercase italicized symbols to represent random variables. We consider a Markov decision process (, , P, ), where denotes the set of states, denotes the set of actions, P denotes the one-step state transition dynamics, and denotes the transition-based reward function. At each timestep , the agent selects an action according to its behaviour policy , where . The environment responds by transitioning into a new state according to P, and emits a scalar reward .
The discounted sum of future rewards given actions are selected according to some target policy is called the return, and defined as:
| (1) | ||||
We use transition-based discounting , as it facilitates specifying different tasks (termination) on top of the same MDP (White, 2017). This generality is useful in our setting, where we may be interested in learning multiple (option) policies, off-policy. The state value function for and is defined as
| (2) |
where under discrete states and actions this corresponds to
and under continuous states and actions this corresponds to
When possible, we will opt for the more generic expectation notation, to address both the finite and continuous cases.
In off-policy control, the agent’s goal is to learn a target policy while following the behaviour policy . The target policy is a differentiable function of a weight vector . The goal of the agent is to learn a policy that maximizes total reward. Depending on the setting, however, this goal is specified with different objectives, as we discuss in the next section.
Throughout, we assume that the limiting distribution under exists, where
| (3) |
and P is the probability—or density—that when starting in state and executing . Similarly, denotes the limiting distribution333This term is sometimes overloaded to mean the discounted state visitation starting from a single start state : . This overloading comes from the definition given in the original policy gradient theorem (Sutton et al., 1999a). We only use it to mean state visitation (limiting distribution). of states under . Note that this limiting distribution exists in either the episodic or continuing settings (White, 2017; Huang, 2020). One way to see this is that in the episodic setting under transition-based discounting, there are no explicit terminal states. Rather, the agent transitions between the state right before termination, back to a start state, as it would for a continuing problem. The transition-based discount truncates returns, to specify that the goal of the agent from each state is to maximize return for the episode.
3 The Weighted-Excursions Objective for Off-Policy Control
In this section we introduce the weighted-excursions objective that unifies two objectives commonly considered in off-policy control. The objective encompasses the standard on-policy episodic objective as well as the excursions objective that allows option policies to be learned off-policy with different termination conditions. Throughout, we will define both the finite state and continuous state versions.
The standard episodic objective is
| (4) |
where is the start state distribution. This objective can be optimized in either the on-policy or off-policy settings, with different updates to account for the fact that data is gathered according to in the off-policy setting.
Another objective that has been considered in the off-policy setting is the excursions objective (Degris et al., 2012b)
| (5) |
where the state weighting is determined by the behaviour policy’s limiting state distribution . This objective assumes that the target policy will be executed as an excursion from the current behaviour—or that the agent will use the target policy in planning under the current state visitation. In the options framework (Sutton et al., 1999b), for example, the agent learns the optimal policies for a variety of different options, each with different termination conditions. The behaviour policy itself could be learning in a continuing environment, even though the objective for the option policy is episodic, in that it has termination conditions.
The excursions objective, however, is not necessarily appropriate for learning an alternative optimal policy. For example, consider an episodic setting where a reasonable behaviour policy is currently being used, and we would like to learn an improved policy. The improved policy will be executed from the set of start states, not from the visitation distribution under the behaviour policy. In this setting, we would like to optimize the standard episodic objective, using off-policy data generated by the current behaviour policy.
These two settings can be unified by considering the weighted-excursions objective
| (6) |
where the weighting represents the interest in a state (Sutton et al., 2016). This objective reduces to the episodic (start-state) formulation by setting . This choice is not just hypothetical; we will show how our algorithm designed for the excursions objective can also be used for the start-state formulation by using an easy-to-compute setting of the interest for each . This generalization goes beyond unifying the previous two objectives, and also naturally allows us to reweight states based on their importance for the target policy. For example, when learning an option, the interest function could be set to 1 in states from which the policy will be executed (i.e., the initiation set), and zero elsewhere.
More generally, we could consider the generic objective for any state weighting . Then the weighted-excursions objective is simply an instance of this more generic objective, with . The reason that we opt for the weighted-excursions objective is because it is sufficiently general to incorporate our two settings of interest but sufficiently restricted to facilitate development of a practical off-policy algorithm. In fact, the idea of interest comes from the same work on emphatic weightings (Sutton et al., 2016) on which we build our algorithm. This work also provides insight into how to easily incorporate such interest functions in the off-policy setting.
Remark: In this work, we focus on episodic objectives—those with termination—but it is worthwhile to contrast this to the objective used for continuing problems. For continuing problems, there is a compelling case for the average reward objective
| (7) |
for . Optimizing is equivalent to optimizing for a constant (Sutton and Barto, 2018). Intuitively, the agent seeks to maximize state values while shifting its state distribution towards high-valued states.
A sharp distinction has been previously made between alternative life objectives and excursions objectives in policy evaluation (Patterson et al., 2022). In that work, alternative life objectives use the state-weighting that specifies: learn the best value function as if data had been gathered under the target policy . Such a weighting is obtained by using prior corrections—namely reweighting entire trajectories with products of importance sampling ratios (Precup et al., 2000; Meuleau et al., 2000)—or estimating (Hallak and Mannor, 2017; Liu et al., 2018; Gelada and Bellemare, 2019). The excursions objective, on the other hand, uses a weighting of . This distinction is not clearly relevant to control. Instead, typically on-policy average reward algorithms are developed for the continuing objective—which has weighting . The few off-policy algorithms designed for the continuing, average reward setting directly estimate and (Liu et al., 2019). The episodic objective for control does not include , and so is different from the alternative life objective in policy evaluation.
In the remainder of this paper we develop an algorithm for optimizing the weighted-excursions objective in Equation (6) from off-policy data.
4 An Off-Policy Policy Gradient Theorem using Emphatic Weightings
In this section, we introduce the off-policy policy gradient theorem for the discrete and continuous settings as well as for deterministic policies. We additionally compare this gradient to the gradient underlying OffPAC, and provide a generalized gradient that interpolates between this gradient—called the semi-gradient—and the true gradient.
4.1 The Off-Policy Policy Gradient Theorem
The policy gradient theorem with function approximation in the on-policy setting was a seminal result (Sutton et al., 1999a, Theorem 1). The first attempt to extend the policy gradient theorem to the off-policy excursion objective was limited to the setting where the policy is tabular (Degris et al., 2012b, Theorem 2).444Note that the statement in the paper is stronger, but in an errata published by the authors, they highlight an error in the proof. Consequently, the result is only correct for the tabular setting. In this section, we show that the policy gradient theorem does hold in the off-policy setting for the weighted excursions objective, for arbitrary smooth policy parametrizations. The resulting gradient resembles the standard policy gradient, but with emphatic weightings to reweight the states.
Definition 1 (Emphatic Weighting)
The emphatic weighting for a behaviour policy and target policy can be recursively defined as
| (8) |
where the distribution over from next state is under P and .
Under finite states and actions, this expectation is . Under continuous states and actions, it is . If a deterministic policy is used, then it is .
Notice that these emphatic weightings involve states leading into ; bootstrapping is back-in-time, rather than forward. The emphatic weighting reflects the relative importance of a state , based on its own interest and weighting—the first term —as well as the discounted importance of states that lead into . For value estimation, this is sensible because it reflects how much the agent bootstraps off of the values in , and hence how much it relies on accurate estimates in . For policy gradients, we have a related role: the importance of a state is due both to its own value, as well as how much other states that lead into it depend on the value obtained from that state.
Theorem 2 (Off-Policy Policy Gradient Theorem)
For finite states and actions,
| (9) |
where
| (10) |
is the gradient for a given state, rewritten using the log-likelihood ratio. For continuous states, and either continuous or discrete actions,
| (9 for continuous states) |
Proof We first start with the finite state setting. The proof relies on the vector form of the emphatic weighting
where the vector has entries and is the matrix with entries . First notice that
Therefore, to compute the gradient of , we need to compute the gradient of the value function with respect to the policy parameters. A recursive form of the gradient of the value function can be derived, as we show below. Before starting, for simplicity of notation we will use
where . Now let us compute the gradient of the value function:
| (11) | ||||
We can simplify this more easily using vector form. Let be the matrix of gradients (with respect to the policy parameters ) of for each state , and the matrix where each row corresponding to state is the vector . Then
| (12) |
Therefore, we obtain
The proof is similar for the continuous case; we include it in Appendix B.
We additionally prove the deterministic policy gradient objective, for a deterministic policy, . The objective remains the same, but the space of possible policies is constrained, resulting in a slightly different gradient.
Theorem 3 (Deterministic Off-policy Policy Gradient Theorem)
| (13) |
where
The proof is presented in Appendix A.
4.2 Connection to OffPAC and the Semi-gradient
The off-policy policy gradient above contrasts with the one used by OffPAC
| (14) |
The only difference is in the state weighting . This small difference, however, is key for getting the correct gradient. In fact, the OffPAC gradient can be considered a semi-gradient, because it drops a part of the gradient when using the product rule:
The second term with is not obviously easy to compute, because it requires reasoning about how changes to the policy parameters affect the action-values. OffPAC opted to drop this term, and justify why this approximation was acceptable. The resulting semi-gradient has proven to be surprisingly effective, though we provide several examples in this work where it performs poorly.
Note that using this correct weighting is only critical due to state aliasing. If the policy representation is tabular, for example, the weighting on the gradients does not affect the asymptotic solution as long as it is non-zero.555Note that the weighting on the gradients could still affect the rate of convergence (Laroche and Tachet des Combes, 2021). The gradient if and only if , because the gradient vector has an independent entry for each state. Therefore, even if the state weighting in the gradient is changed to some other weighting , then we still get . This is the reason that the semi-gradient underlying OffPAC converges to a stationary point of this objective in the tabular setting. More generally, for any sufficiently powerful function approximator that can obtain for all states, this result holds. In optimization, this property has been termed the strong growth condition (Schmidt and Roux, 2013). We state this simple result for the irrelevance of the weighting formally in the following proposition, both to highlight it and because to the best of our knowledge it has not been formally stated.
Proposition 4 (Irrelevance of Weighting under the Strong Growth Condition)
If for all states, then is a stationary point under any state weighting .
This result states that with a function approximator that can perfectly maximize value in each state, the choice of state weighting in the gradient computation is not relevant. Both the off-policy gradient with emphatic weighting, and the semi-gradient with weighting , can converge to this stationary point.
Alternatively, we can consider the more generic emphatic weighting that lets us sweep between the gradient and the semi-gradient. The emphatic weightings were introduced for temporal difference (TD) learning with eligibility traces (Mahmood et al., 2015). The weightings depend on the eligibility trace parameter, . For , the weightings effectively become 1 everywhere—implicitly resulting in state weightings of —because there is no bootstrapping. For , the weightings are exactly as defined above.
Definition 5 (Generalized Emphatic Weighting)
For , the generalized emphatic weighting for a behaviour policy and target policy is defined as
| (15) |
For , .
Note that in the original work, was called the follow-on weighting, and the emphatic weighting. Because is a strict generalization of , we simply call an emphatic weighting as well.666Note that the original emphatic weightings (Sutton et al., 2016) use . This is because their emphatic weightings are designed to balance bias introduced from using for estimating value functions: larger means the emphatic weighting plays less of a role. For this setting, we want larger to correspond to the full emphatic weighting (the unbiased emphatic weighting), and smaller to correspond to a more biased estimate, to better match the typical meaning of such trace parameters.
The parameter can be interpreted as trading off bias and variance in the emphatic weightings. Notice that for , and assuming an interest of 1 everywhere, we get that . Such a choice would give exactly the semi-gradient weighting. As we increase , we interpolate between the semi-gradient and the full gradient. For , we get and so we have the full gradient. For , therefore, we obtain a biased gradient estimate, but the emphatic weightings themselves are easy to estimate—they are myopic estimates of interest—which could significantly reduce variance when estimating the gradient. Selecting between 0 and 1 could provide a reasonable balance, obtaining a nearly unbiased gradient to enable convergence to a valid stationary point but potentially reducing some variability when estimating the emphatic weighting. We will develop our algorithm for the general emphatic weighting, as this will give us more flexibility in the weighting, and will also allow us to incorporate OffPAC as one extreme (biased) version of the approach.
4.3 Summary
In this section we proved the off-policy policy gradient theorem for the weighted-excursions objective, for both stochastic (Theorem 2) and deterministic (Theorem 3) policies. These gradients are similar to the standard policy gradient, but with states weighted by emphatic weightings. We contrasted this to OffPAC, the (unsound) algorithm on which many off-policy policy gradient algorithms are built, highlighting that the only distinction is in this state weighting. We argued that this state weighting does not always affect the solution (Proposition 4), potentially partially explaining why OffPAC often performs well—especially in deep RL with large neural networks. Finally, we show how we can use generalized emphatic weightings, with a parameter (Definition 5), that allows us to interpolate between the sound, but harder-to-estimate emphatic weighting (at ) and the unsound, but easy-to-obtain weighting used in OffPAC (at ).
5 Actor-Critic with Emphatic Weightings
In this section, we develop an incremental actor-critic algorithm with emphatic weightings that uses the above off-policy policy gradient theorem. To perform a gradient ascent update on the policy parameters, the goal is to obtain a sample of the gradient in Equation 9. As discussed above, the only difference to the semi-gradient used by OffPAC, in Equation 14, is in the weighting of the states: the true gradient uses and the semi-gradient uses . Therefore, we can use standard solutions developed for other actor-critic algorithms to obtain a sample of . The key difficulty is in estimating to reweight this gradient.
5.1 Sampling the Gradient from a State
Before addressing this key difficulty, we provide a brief reminder on how to obtain a sample of , with more details in Appendix C. The simplest approach to compute the gradient for a given state is to use what is sometimes called the all-actions gradient . To avoid summing over all actions, we instead obtain an unbiased sample of the gradient under the action taken by the behaviour policy : where the importance sampling ratio corrects the distribution over actions. The estimated gradient has more variance when we only use a sampled action rather than all actions. The standard strategy to reduce this variance is to subtract a baseline, such as an estimate of the value function . The resulting update is
In practice, it is difficult to obtain to compute this gradient exactly. Instead, we obtain (a likely biased) sample of the advantage, . An unbiased but high variance estimate uses a sample of the return from , and uses . Then . On the other extreme, we can directly approximate the action-values, . In-between, we can use -step returns, or -returns, to balance between using observed rewards and value estimates. In this work, we opt for the simplest choice: with .
Finally, we need to estimate the values themselves. Any value approximation algorithm can be used to estimate , such as TD, gradient TD or even emphatic TD. Given we already compute the emphasis weighting, it is straightforward to use emphatic TD. We investigate both a gradient TD critic and an emphatic TD critic in the experiments.
5.2 Estimating the Gradient with Emphatic Weightings
The previous section outlined how to sample the gradient for a given state. We now need to ensure that these updates across states are weighted by the emphatic weighting. Intuitively, if we could estimate and for all , then we could simply premultiply the update with . However, estimating the state distribution is nontrivial, and actually unnecessary. In this section, we first explain how to obtain a Monte Carlo estimate of this pre-multiplier, and then how to directly estimate it with function approximation.
5.2.1 An Unbiased Estimate of the Gradient with Emphatic Weightings
We can rely on the original work introducing the emphatic weightings to obtain a Monte Carlo estimate with the update
| (16) |
where and is the interest observed in , with . Putting this together with the previous section, the gradient can be sampled by (1) sampling states according to , (2) taking actions according to , (3) obtaining an estimate of the advantage , and then (4) weighting the update with , to get
Note that the all-actions gradient update with this emphatic weighting would be
but as before we will assume that we use one sampled action. We prove that our update is an unbiased estimate of the gradient for a fixed policy in Proposition 6. We assume access to an unbiased estimate of the advantage for this result, though in practice is likely to have some bias due to using approximate values.
Proposition 6
For a fixed policy , with the conditions on the MDP from (Yu, 2015) and assuming unbiased , namely that ,
Proof Emphatic traces have been shown to provide an unbiased estimate of the true emphatic weighting for policy evaluation in Emphatic TD. We use the emphatic weighting differently, but can rely on the proof from (Sutton et al., 2016) to ensure that (a) . Note also that, given , the next action does not impact the expectation: (b) . Using these equalities, we obtain
where the last line follows from the fact that
5.2.2 A Biased Estimate of the Gradient with Emphatic Weightings
For a fixed policy, the emphatic trace provides an unbiased way to reweight the gradient. However, this is no longer true when the target policy is updated online in an actor-critic algorithm like ACE; the emphatic trace will contain importance sampling ratios for older versions of the policy. If the target policy changes substantially during the learning process—as one would hope—the older importance sampling ratios could bias the emphatic trace’s estimates. On the other hand, a constant discount rate would give exponentially less weight to older importance sampling ratios in the emphatic trace, potentially mitigating the bias. We empirically investigate the impact of this type of bias in section 9.3.
As a Monte Carlo estimator of the emphatic weightings, the emphatic trace can also yield high-variance estimates. Furthermore, the product of importance sampling ratios in the emphatic trace can lead to even higher-variance estimates, which can slow learning (Precup et al., 2001; Liu et al., 2020a; Ghiassian et al., 2018). As such, several algorithms have been proposed that use parametrized functions to estimate the factors required for reweighting the updates (Hallak and Mannor, 2017; Gelada and Bellemare, 2019; Liu et al., 2018; Zhang et al., 2019). We can similarly approximate the emphatic weighting directly.
For our setting, this involves estimating . Because is a function of , we directly approximate by learning a parametrized function and use it in place of to compute . Notice that the resulting , and so . Because we sample , weighting the update with an estimate of is effectively an importance sampling ratio that ensures the updates are weighted according to .
The direct approximation relies on the recursive equation for the emphatic weighting that allows for a temporal-difference update. Unlike the usual TD update, this update bootstraps off the estimate from the previous step rather than the next step, because the emphatic weightings accumulate interest back in time, leading into the state. Recall the recursive equation
This equation is a Bellman equation, that specifies the emphatic values for state in terms of the immediate interest and the states leading into . We approximate , rather than . The recursive formula for an that equals is
where is a sample of this target, as we show in the next proposition.
Proposition 7
Under the conditions stated by Sutton et al. (2016),
Proof The proof follows the strategy showing the unbiasedness of in Sutton et al. (2016).
The utility of this result is that it provides a way to sample the target for this Bellman equation.
The following is a sample update whose target is equal to the above in expectation, when sampling :
| (17) |
where is a step-size. The update aims to minimize the difference between the current estimate of the emphatic weightings and the target, using a standard semi-gradient TD update. We could alternatively use a gradient TD (Sutton et al., 2009; Sutton and Barto, 2018) update
| (18) |
where the auxiliary function provides an estimate of using a regression update.
Once we use an approximation to the emphatic weighting, we may introduce bias into the gradient estimate. As an extreme case, imagine the function is restricted to predict the same value for all states. Using these estimates means replacing in the actor updates with a constant factor that can be subsumed in the step-size and therefore following the semi-gradient updates in Equation 14. However, the advantage is that these lower-variance estimates do not have to be computed online, unlike . The function can be trained by sampling transitions from a replay buffer (Lin, 1993; Mnih et al., 2015) and applying the update in Equation 17.
5.3 Summary
In this section, we showed how to operationalize the off-policy policy gradient theorem, by discussing how to sample the gradient. The gradient involves a standard actor-critic update from a state , but additionally weighted by the emphatic weighting . We leverage existing results for sampling the emphatic weighting in Section 5.2.1, and proved that using this unbiased emphatic weighting in our update results in an unbiased update (Proposition 6). These sampled emphatic weightings, however, can be high variance and become biased if the policy changes on each step. We develop a parameterized estimator in Section 5.2.2, by developing a recursive formula for in Proposition 7. Though a similar form was used to show unbiasedness of a sampled weighting in the original work on emphasis (Sutton et al., 2016), they did not recognize nor leverage this recursive form to develop a TD algorithm to learn a parameterized estimator. We need this , instead of directly estimating , because states are sampled , so weighting by would be incorrect.
6 Incorporating Entropy Regularization
In this section, we discuss how to extend the off-policy policy gradient theorem to incorporate entropy regularization. We focus on discrete states and actions in the main body, and include results for continuous states and actions in the appendix. Entropy regularization is commonly used with policy gradient methods, as it encodes a preference for more stochasticity in the policy. Recall that at each state, the policy induces a probability distribution over actions whose entropy is defined as
This value captures the stochasticity in the policy. A uniform random policy will maximize entropy, while the entropy of a nearly deterministic policy will be a large negative value.
Entropy regularization is believed to promote exploration, improve the loss surface, and promote faster convergence rates. For exploration, entropy regularization can help make the policy more stochastic and diversify the set of states and actions that the agent learns about (Williams and Peng, 1991; Haarnoja et al., 2018). To find a good policy, the agent needs accurate estimates of values of different actions in different parts of the state space. A greedy policy only takes actions that are deemed optimal at the current point which results in learning only about a limited number of trajectories. Entropy regularization has also shown to help policy optimization by modifying the landscape. The resulting objective is smoother, which allows the use of larger step-sizes and also reduces the chance of getting stuck in bad local maxima (Ahmed et al., 2019).
Finally, the use of entropy regularization facilitates convergence analysis to stationary points. Mei et al. (2020) showed that entropy regularization can ensure existence of stationary points and also improve the rate of convergence in tabular policy optimization. The idea is similar to convex optimization, where regularization makes the loss function strongly convex and improves the convergence rate from sublinear to linear. In Appendix E, we extend the proof of existence of a stationary point for entropy regularized policy optimization to state aggregation. Therefore, in addition to extending our algorithm to allow for entropy regularization, we also use this extension to formally prove a counterexample for the semi-gradient updates.
Extending the results to entropy regularization is relatively straightforward, as it relies on the already developed machinery of soft action-values that include entropy in the rewards. Entropy regularization augments each reward with a sample of the entropy at the current state so that the return is modified to
where is a parameter that controls the amount of regularization. Entropy regularized state values and action values can be defined as (Geist et al., 2019)
Here, for entropy . The entropy-regularized objective function simply uses these entropy regularized values,
| (19) |
The off-policy policy gradient theorem can be extended to the entropy regularized objective. The result looks a little different, because the relationship between the soft values and soft action-values is a little different than in the unregularized setting. Notice that is not included in the first reward for , because this first action is given—not random—and entropy is an expectation over all actions. Further, can be arbitrarily large, though the entropy itself remains nicely bounded. For this reason, we do not define the soft action-values to be , as we typically would for the unregularized setting. Nonetheless, deriving the policy gradient theorem for these soft action-values uses exactly the same steps. Further, we do recover the unregularized formulation when .
Theorem 8 (Off-policy Policy Gradient Theorem for Entropy Regularization)
The proof is in Appendix D, as is the extension to continuous states, continuous actions, and other regularizers.
This theorem shows that we can use a similar update as in the unregularized setting, simply by adding . Given the true soft action-values , an update with an unbiased sample of the gradient is
In practice, we subtract a baseline and use an estimate of the advantage , by only directly estimating the soft values . The 1-step return sample is again the TD error, but with entropy regularization added to the rewards: .
7 Formulating Episodic Problems as a Special Case
The goal in an episodic problem is to maximize the expected episodic return. Mismatch between the algorithm’s objective and this goal, even in the on-policy setting, can lead the agent to suboptimal policies (Thomas, 2014; Nota and Thomas, 2020). This section describes how we can use the interest function to maximize the right objective.
The objective function in Equation 4 that weights state values by the start state distribution is equal to expected episodic return. With limited function approximation resources this weighting matters. If the parametrized function is incapable of representing a policy that maximizes all state values, the agent has to settle for lower values in some states to maximize the values of more important ones. For example, if the weighting is , the agent may incorrectly prioritize states that appear less often at the start of an episode and more frequently at other points in the behaviour policy’s trajectories, and fail to optimize the episode return.
The interest function in Equation 6 allows us to focus the parametrized function’s resources on states of interest. Recall that we assume that the agent observes interest in state , with . So far, we have not used the additional flexibility that the interest itself can be random, but for this unification we will use this property. If we could set then the objective function would correspond to the episodic objective. However, neither nor is available to the agent, and we would like to avoid estimating those distributions.
Fortunately, we can show that if the signal is set to one at the beginning of an episode and set to zero thereafter, its expectation in the limit of time will be proportional to the correct ratio. Under transition-based discounting, the agent is informed that an episode has begun whenever it receives a discount factor of zero: namely, that the transition resulted in termination. Therefore, we can obtain this result by allowing for the interest to be a function of the whole transition.
Proposition 9
If the signal is set to
| (20) |
then its expected value under the behaviour policy is
Proof
where we used the fact that and .
The constant term is the same for all states, . It simply reflects the probability of termination under the behaviour policy. This constant term does not change the relative ordering between policies, since all weight is still on the start states. Therefore, the resulting objective is equivalent to the episodic objective.
We can relate the resulting update to the on-policy and off-policy updates used for the episodic setting. In the on-policy setting, if we use the interest function given by Equation 20 and a constant discount factor during the episode, then the update reduces to the unbiased episodic actor-critic algorithm of Sutton and Barto (2018), originally proposed by Thomas (2014).
Sutton et al. (1999a) proved the policy gradient theorem for the episodic setting
where is the probability of going from a start state to state in steps under , the weighting in the gradient is the discounted state visit distribution, and the agent should discount updates that occur later in the episode to account for this weighting. An algorithm that does not discount later updates—and thus samples according to —results in a biased update.
To fix this problem, Thomas (2014) proposed the unbiased actor-critic algorithm with the updates rules
Since is initialized to and updated after the update to , will be during the first weight update, and will decay by each timestep thereafter.
The on-policy ACE update rule with and is
Because on the first time step and is initialized to , will be on the first weight update and will decay by each time step thereafter. From this inspection it is clear that the ACE update reduces to the unbiased actor-critic update in the on-policy episodic setting. The final ACE algorithm with all the discussed techniques is in Algorithm 1.
8 Stationary Points under the Semi-gradient and Gradient Updates
In this section, we provide more insight into the difference between the stationary points of the weighted excursions objective—obtained using the true gradient in Equation 9—versus those obtain with the semi-gradient update underlying OffPAC, in Equation 14. We first provide a counterexample showing that all the stationary points for the semi-gradient have poor performance. In fact, initializing at the optimal solution, and then updating with the semi-gradient, moves the solution away to one of these highly suboptimal stationary points. We then discuss that the semi-gradient update can actually be seen as a full gradient update, albeit with a different implicit state weighting. This connection illuminates why the semi-gradient does so poorly on the counterexample, but also potentially sheds light on why OffPAC has generally performed reasonably in practice.
8.1 A Counter-example for the Semi-Gradient Update
Recall that, in the derivation of the policy gradient theorem, the product rule breaks down the gradient of the value function into the two terms shown in Equation 11. The policy gradient theorem in OffPAC only considers the first term, i.e. the gradient of the policy given a fixed value function. The approximated gradient is
The approximation above weights the states by the behaviour policy’s state distribution instead of emphatic weightings.
To see the difference between these weightings, consider the MDP in Figure 1(a). For the actor, has a feature vector , and the feature vector for both and is . This aliased representation forces the actor to take a similar action in and . The behaviour policy takes actions and with probabilities and in all non-terminal states, so that , , and will have probabilities , , and under . The target policy is initialized to take and with probabilities and in all non-terminal states, which is close to optimal.
We trained two actors on this MDP, one with semi-gradient updates and one with gradient updates. The actors are initialized to the target policy above and the updates use exact values rather than critic estimates. States and actions are sampled from the behaviour policy. As shown in Figures 1(b) and 1(c), while both methods start close to the highest attainable value of the objective function (that of a deterministic policy that takes everywhere), semi-gradient updates move the actor towards a suboptimal policy and reduce the objective function along the way. Gradient updates, however, increase the probability of taking in all states and increase the value of the objective function.



The problem with semi-gradient updates boils down to the weighting. In an expected semi-gradient update, each state tries to increase the probability of the action with the highest action-value. There will be a conflict between the aliased states and because their highest-valued actions differ. If the states are weighted by in the expected update, will appear insignificant to the actor, and the update will increase the probability of in the aliased states. The ratio between and is not enough to counterbalance this weighting.
However, has an importance that the semi-gradient update overlooks. Taking a suboptimal action at will also reduce , and after many updates the actor will gradually prefer to take in . Eventually, the target policy will be to take at all states, which has a lower value under the objective function than the initial target policy. This experiment highlights why the weight of a state should depend not only on its own share of , but also on its predecessors. The behaviour policy’s state distribution is not the proper deciding factor in the competition between and , even when optimizing the excursions objective.
Proposition 10 formalizes the problem with semi-gradient updates by showing that, under any , semi-gradient updates will not converge to a stationary point of the objective function in the counterexample. The requirement is only needed to ensure existence of a stationary point; this result holds for arbitrarily close to zero. The proof is presented in Appendix E.
Proposition 10
For any where in the three-state counterexample, semi-gradient updates do not converge to a stationary point of the objective function.
8.2 The Semi-Gradient as a True Gradient with a Different Weighting
In this section, we show that the semi-gradient can locally be seen as a gradient update, with a different state weighting in the objective. Locally for the current weights with corresponding policy , that state weighting is , with objective . The resulting may not be a distribution. In fact, it may not even be positive! If it is negative, the objective tells the agent to minimize the value for that state. This is precisely what occurs in the above counterexample.
First, to see why this is the implicit state weighting, notice that for the semi-gradient update to be a gradient update, the weighting used in the update has to correspond to an emphatic weighting for some state weighting in the objective. In other words, where . This requirement implies that . Therefore, by using the weighting in the expected gradient, the semi-gradient update locally around can be seen as a gradient update on . This weighting actually changes as changes. In fact, we know that the semi-gradient update cannot be seen as the gradient of a fixed objective function, from our counterexample for OffPAC and the result for the on-policy setting showing that omitting the discount factor results in an update that is not a gradient (Nota and Thomas, 2020). However, even if this interpretation is only valid locally at each update, such a negative weighting can be problematic.
We can compute the implicit weighting , in our counter-example. Let and . Then we know that , and . Further, we know that and
The implicit for the semi-gradient update, locally around this , has where and so and
Using and , we get that
If , then ; if , then ; and if then both are zero. In our counterexample, we set , making the update move away from increasing the value in , namely preferring to increase the value in and decrease the value in . The iterative updates maintain the condition , even as the policy changes—which changes —so the implicit weighting systematically causes convergence to a suboptimal policy.
We note that the implicit weighting is independent of the representation. However, we know that the semi-gradient update converges to a stationary point of the excursions objective for the tabular setting. This might seem odd, given that the implicit weighting is negative for a state in this counterexample. However, this is not contradictory. Recall in Section 2 we discussed that in the tabular setting, the condition for the stationary point is that the gradient must be zero at every state, independently. Summing up zeros, even when weighting those zeros with a negative weighting, still results in zero.
There has been other work that has noted that optimizing under a different state weighting can still be effective. Proposition 6 of Ghosh et al. (2020) shows that a lower bound can be optimized, using data generated under the behaviour policy. The action-values of the behaviour policy is used, and only the log likelihood terms of the target policy are differentiated. This lower bound, however, is only an approximation to the true objective. Our result differs, in that it highlights that equivalent solutions can be obtained, even under different state weightings.
This view suggests a direction to reduce variance in the ACE updates: consider appropriate implicit weightings , that allow for low variance emphatic updates. One potentially promising approach is to only consider emphatic weightings a small number of steps back-in-time. Another is to err on the side of smaller in the emphatic trace in ACE, knowing that the implicit weighting may remain reasonable for a broad range of .
9 Experiments: Studying Properties of ACE
In this section we investigate key properties of the ACE algorithm empirically.777Code is available at: https://github.com/gravesec/actor-critic-with-emphatic-weightings. Specifically, we study the effects of the trade-off parameter and the choice of estimator for the emphatic weightings on the learned policy, as these choices are central to the ACE algorithm. First, we revisit the simple counterexample from Section 8.1 to examine how the trade-off parameter can affect the learned policy. Next, we illustrate some issues with using the emphatic trace in the ACE algorithm by testing it on a modified version of the counterexample. We then move to two classic control environments to study the two estimators discussed in Section 5.2 and their effects on the learned policy. Finally, we test several variants of ACE on a challenging environment designed to illustrate the issues associated with both estimators. Please see Table 1 in Appendix F for a description of each of the algorithms compared.
9.1 The Impact of the Trade-Off Parameter
The parameter can be interpreted as trading off bias and variance. For , the bias can be significant, as shown in the previous section. A natural question to ask is how the bias changes as ranges from 0 to 1.
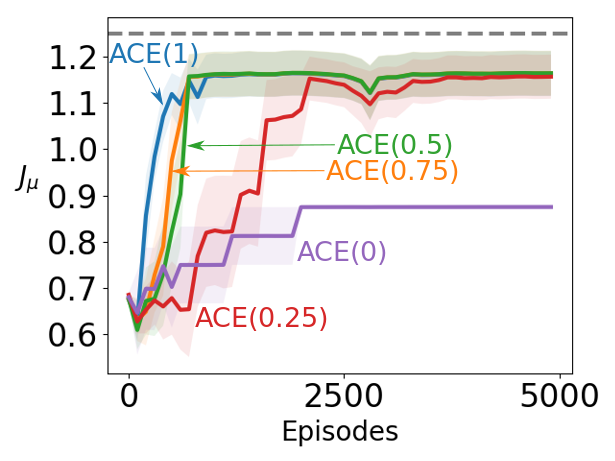
To answer this question, we repeated the experiment in Section 8.1, but this time with taking values in and the actor’s step-size taking values in , with the best-performing step-size (by total area under the learning curve, averaged over 30 runs) for each value of used in Figures 2(b) and 2(c). To highlight the rate of learning, the actor’s policy was initialized to take each action with equal probability. The results are displayed in Figure 2 with shaded regions depicting standard error.
Figure 2(a) shows the performance of ACE with each value of over the range of step-sizes tested. ACE performed well for a range of step-sizes, and even small values of significantly improved over (OffPAC). However, the performance of ACE with was more sensitive to the choice of step-size, with performance decreasing as the step-size grew large, while the performance of was lower overall but remained steady with larger step-sizes.
Figure 2(b) plots the learning curves for ACE with each value of . For (OffPAC), the algorithm decreased the objective function during learning to get to a suboptimal fixed point, while always improved the objective function relative to the starting point. For a surprisingly small choice of , the actor converged to the optimal solution, and even produced a much more reasonable solution than .
Figure 2(c) shows the probability of taking the optimal action in the aliased states. The optimal policy is to take in the aliased states with probability 1. ACE with (OffPAC) quickly converged to the suboptimal solution of choosing the best action for instead of . Even with just a bit higher than 0, convergence is to a more reasonable solution, choosing the optimal action the majority of the time.



To determine whether the parameter has similar effects when ACE is used with a learned critic, we repeated the previous experiment but this time using value estimates from a critic trained with GTD() (Maei, 2011). We checked all combinations of the following critic step-sizes: , the following critic trace decay rates: , and the following actor step-sizes: , and used the best-performing combination (by area under the learning curve) for each value of in Figures 3(b) and 3(c). We averaged the results over 10 runs, and plotted the standard error as shaded regions. Figure 3 shows that, as before, even relatively small values of can achieve close to the optimal solution. However, (OffPAC) still finds a suboptimal policy. Overall, the outcomes are similar to the previous experiment, although noisier due to the use of a learned critic rather than the true value function.


So far we have only considered ACE with a discrete action policy parameterization. However, an appealing property of actor-critic algorithms is their ability to naturally handle continuous action spaces. To determine if the findings above generalize to continuous action policy parameterizations, we created an environment similar to Figure 1(a), but with one continuous unbounded action. Taking action with value at will result in a transition to with probability and a transition to with probability , where denotes the logistic sigmoid function. For all actions from , the reward is zero. From and , the agent can only transition to the terminal state, with reward and respectively. The behaviour policy takes actions drawn from a Gaussian distribution with mean and variance .
Because the environment has continuous actions, we can include both stochastic and deterministic policies, and so can include DPG in the comparison. DPG is built on the semi-gradient, like OffPAC (Silver et al., 2014). We include True-DPG with Emphatic weightings (True-DPGE), which uses the true emphatic weightings rather than estimated ones to avoid the issue of estimating the emphatic weightings for a deterministic target policy, and focus the investigation on whether DPG converges to a suboptimal solution in this setting. Estimation of the emphatic weightings for a deterministic target policy is left for future work. The stochastic actor in ACE has a linear output unit and a softplus output unit to represent the mean and the standard deviation of a Gaussian distribution. All actors are initialized with zero weights.
Figure 4 summarizes the results. The first observation is that DPG demonstrates suboptimal behaviour similar to OffPAC. As training goes on, DPG prefers to take positive actions in all states, because is updated more often. This problem goes away in True-DPGE. The emphatic weightings emphasize updates in and, thus, the actor gradually prefers negative actions and surpasses DPG in performance. Similarly, True-ACE learns to take negative actions but, being a stochastic policy, it cannot achieve True-DPGE’s performance on this domain. ACE with different values, however, cannot outperform DPG, and this result suggests that an alternative to importance sampling ratios is needed to effectively extend ACE to continuous actions.



9.2 Challenges in Estimating the Emphatic Weightings
Up to this point we have been using the emphatic trace originally proposed by Sutton et al. (2016) to estimate the emphatic weightings. As discussed in Section 5, there can be multiple sources of inaccuracy from using this Monte Carlo estimate in an actor-critic framework.
However, it is unclear how the issues affecting the emphatic trace manifest in practice, and hence whether introducing a parametrized function to directly estimate the emphatic weightings is worth the added bias—especially if the representation is poor. To study the effects of this choice of estimator on the ACE algorithm, we conducted a series of experiments starting with a modified version of the counterexample in Figure 1(a), moving to two classic control environments, and ending with a challenging environment designed to illustrate the issues associated with both estimators.

The first environment, shown in Figure 5, is an extended version of the counterexample with two long chains before the aliased states. Like the original counterexample, the behaviour policy takes with probability and with probability in all non-terminal states, and the interest is set to for all states. Each state is represented by a unique feature vector except states and , which are aliased and appear the same to the actor. The addition of the new states makes trajectories considerably longer, which may exacerbate the issues with the emphatic trace.
We repeated the experiment from Figure 2 on the long counterexample. The following actor step-sizes were tested: , with the best-performing value (by total area under the learning curve, averaged over 10 runs) for each value of used in Figures 6(b) and 6(c). The actor was again initialized to take each action with equal probability, and the true state values were again used in the updates in order to isolate the effects of the emphatic trace.
We also trained an actor called True-ACE that uses the true emphatic weightings for the current target policy and behaviour policy, computed at each timestep. The performance of True-ACE is included here for the sake of comparison, as computing the exact emphatic weightings is not generally possible in an unknown environment.
The results in Figure 6 show that, even though performance improves as is increased, there is a significant gap between ACE with and True-ACE. Unlike Figure 2, the methods have more difficulty reaching the optimal solution, although ACE with larger does still find a significantly better solution than . Additionally, values of greater than result in high-variance estimates of the emphatic weightings, which lead to more variable performance, as shown by the larger shaded regions representing standard error. These results overall show the inaccuracies pointed out in Section 5 indeed disturb the updates in long trajectories.



9.3 Estimating the Emphatic Weightings in Classic Control Environments
The results of the previous experiments suggest that using the emphatic trace to estimate the emphatic weightings can significantly impact the performance of ACE. To better understand how the issues with the emphatic trace affect the learning process beyond our counterexample, we tested several variants of ACE on off-policy versions of two classic control environments: Puddle World (Degris et al., 2012b) and Mountain Car (Moore, 1990).
As an off-policy Monte Carlo estimator of the emphatic weightings, the emphatic trace can yield extremely high-variance estimates which can interfere with learning (Ghiassian et al., 2018). To see how the variance of the emphatic trace affects ACE, we tested a variant called ACE-direct that uses the one-step temporal-difference update from Section 5.2.2 to estimate the emphatic weightings. Temporal-difference methods often have lower variance than Monte Carlo methods—at the cost of introducing bias—which makes using a TD-style update to estimate the emphatic weightings an appealing alternative to the emphatic trace (Sutton and Barto, 2018).
As discussed in Section 5.2.2, the emphatic trace can also be biased when used in an actor-critic algorithm where the target policy is changing. To determine how detrimental this bias is to the performance of ACE, we tested a variant called ACE-ideal where all importance sampling ratios in the emphatic trace are re-computed at each time step using the current target policy, yielding an unbiased Monte Carlo estimate of the emphatic weighting for the current state. ACE-ideal is not a practical algorithm, as the computation and memory required grow with the number of time steps, but it allows us to isolate the effects of the bias introduced by using the emphatic trace with a changing target policy.
Other baselines for comparison included OffPAC, and ACE using the emphatic trace (referred to as ACE-trace). To determine the effects of different choices of critic, we included versions of each algorithm using an ETD critic (Sutton et al., 2016) and a TDRC critic (Ghiassian et al., 2020). We also included versions of each algorithm using the uniform interest function (i.e., for all time steps), as well as the episodic interest function from Section 7—with the exception of OffPAC. OffPAC scales policy updates using only the interest for the current time step, which when combined with the episodic interest function leads to a single policy update on the first time step followed by no updates thereafter.
To get a clear picture of the performance of each algorithm, we conducted a grid search on the free parameters of each algorithm. For the step size parameter of the actor, critic, and the direct estimator of emphatic weightings, we tested values of the form where ranged from 0 to 15. For the trace decay rate of the critic, we tested values of the form where ranged from 0 to 6. The discount factor was .95. We sought to establish the performance of each variant for , as they all reduce to OffPAC when .
Each combination of parameters for each algorithm was run on 5 different trajectories generated by a fixed behaviour policy interacting with the environment for 100,000 time steps. The learned policies were saved every 1,000 time steps and evaluated 50 times using both the episodic and excursions objective functions from Section 3. For the episodic objective function, the policies were evaluated by creating 50 different instances of the environment and executing the target policy from the starting state until termination or 1000 time steps had elapsed. The excursions objective function was evaluated similarly, but with the environment’s starting state drawn from the behaviour policy’s steady state distribution, chosen by running the behaviour policy for 50,000 time steps and saving every thousandth state. The results were averaged, and the best-performing combinations (by area under the learning curve for the appropriate objective function) were re-run on enough different trajectories to reduce the standard error to an acceptable level (100 runs for Puddle World, 30 runs for Mountain Car). The initial parameter sweep was intended to find good parameter settings for each method at a reasonable computational cost, and not necessarily the absolute best performance.
9.3.1 Puddle World
The Puddle World environment is a 2-dimensional continuous gridworld containing a start location, goal location, and puddles through which it is costly to move. While it first appeared in Boyan and Moore (1995), we use the version from Degris et al. (2012b) that includes an additional puddle near the goal state which makes the task more difficult.888Please see Degris et al. (2012b) for a picture of the Puddle World environment. The behaviour policy took the North, East, South, and West actions with probabilities .45, .45, .05, and .05 respectively. The observations were tile coded with a fairly low-resolution tile coder (4 tilings of tiles plus a bias unit) to generate feature vectors with a large degree of generalization.
Figure 7 presents the results for the Puddle World environment. The left-hand column shows learning curves, while the right-hand column contains sensitivity analyses for the actor’s step size. The first four plots (figures 7(a), 7(b), 7(c), and 7(d)) show results when using ETD as the critic, while the last four plots (figures 7(e), 7(f), 7(g), and 7(h)) show results for a TDRC critic. The first and third rows show results using the excursions objective function, and the second and fourth rows show results for the episodic objective function.







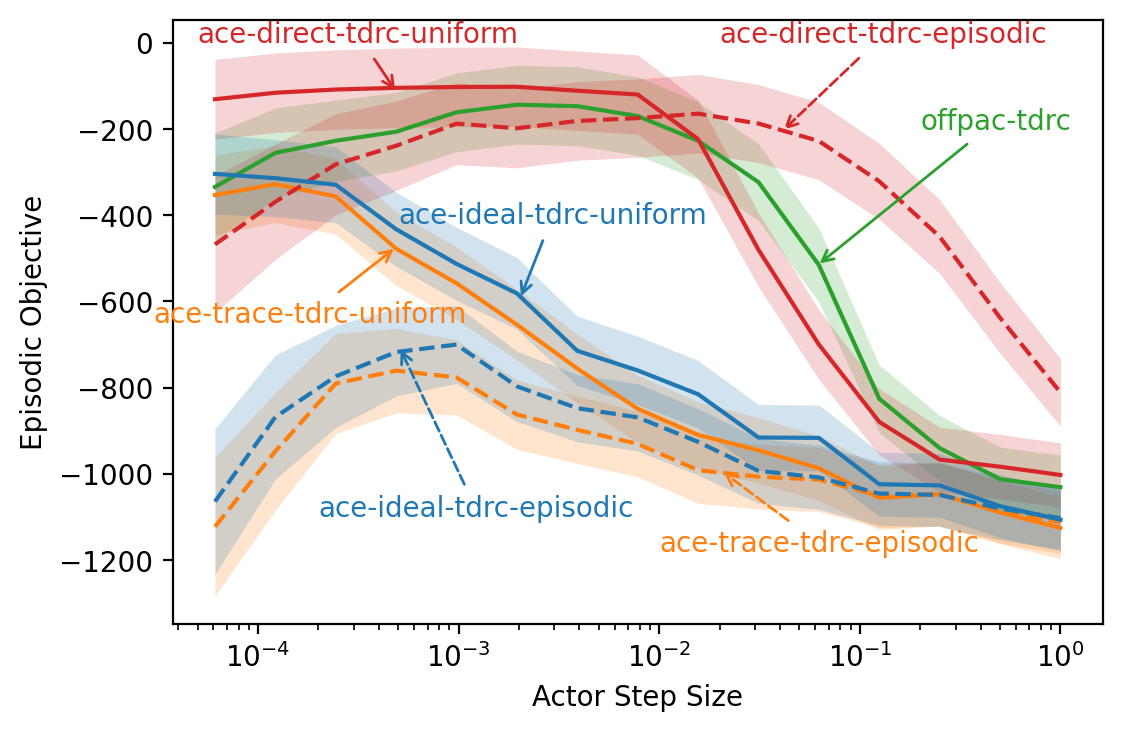
Comparing the performance of each algorithm under the excursions and episodic objective function, we can see that the algorithms all performed better in the excursions setting than the episodic setting. This is due to the excursions setting being easier than the episodic setting for the classic control problems in this section. In the excursions setting, the agent starts from the behaviour policy’s state distribution, which in the problems studied is closer to the goal state than the start state. This is not necessarily true for all problems, however, and in general there is no strict ordering of objectives in terms of difficulty.
ACE variants that used the episodic interest function (dashed lines) generally performed much worse than their counterparts using the uniform interest function (solid lines), with the exception of ACE-direct. This is consistent with the discussion in Section 7 of Thomas (2014)—although they deal with the on-policy case—which states scaling policy updates by an accumulating product of discount factors hurts the sample efficiency of the algorithm. However, the off-policy case can exacerbate this issue as the accumulating product includes both discount factors and importance sampling ratios. The fact that the direct method of estimating emphatic weightings allowed ACE to perform well when using the episodic interest function is intriguing and merits further study.
The choice of critic affected the performance of the algorithms to differing degrees. Replacing an ETD critic with a TDRC critic improved the performance of each of the algorithms, with episodic performance showing the greatest improvement (compare figures 7(c) and 7(g)), perhaps due to the excursions objective being easier for this environment as previously mentioned. ACE-direct with uniform interest performed well regardless of the choice of critic, but improved substantially in the episodic setting when using a TDRC critic. Using a TDRC critic instead of an ETD critic also improved the sensitivity of the algorithms to the actor’s step size, allowing a slightly wider range of step sizes to perform well for most methods (compare Figure 7(b) to 7(f), and Figure 7(d) to 7(h)).
When comparing ACE-trace (orange) to ACE-ideal (blue)—where the emphatic trace’s importance sampling ratios were computed using the current policy, resulting in an unbiased Monte Carlo estimate of the emphatic weightings—we can see that correcting the bias introduced by using the emphatic trace with a changing policy did not improve performance significantly in all but one situation. The one exception was when performance was evaluated with the excursions objective function (figures 7(a) and 7(e)). When using an ETD critic (Figure 7(a)), ACE-ideal outperformed ACE-trace early in learning before deteriorating to a similar level of performance by the end of the experiment. Conversely, ACE-ideal outperformed ACE-trace throughout the experiment when using a TDRC critic (Figure 7(e)), although the difference was barely significant. In all other situations, the performance of ACE-ideal was not significantly different from the performance of ACE-trace.
Overall, ACE-direct performed better than or equal to ACE-trace, ACE-ideal, and OffPAC across all combinations of critic, interest function, and objective function. However, it diverged for some actor step sizes when used with an ETD critic (figures 7(b) and 7(d)). This could be due to the use of a semi-gradient update rule (analogous to off-policy TD(0) which is not guaranteed to converge when used with function approximation) for the direct method of estimating emphatic weightings. To resolve this issue, one could use the gradient-based update rule in equation 18 of Section 5.2.2. We chose to use the semi-gradient update to keep both the explanation and experiments simple, as there were already a large number of concepts and algorithmic parameters involved.
9.3.2 Off-policy Mountain Car
In the original Mountain Car environment, the agent attempts to drive an underpowered car out of a valley (Moore, 1990).999Please see Degris et al. (2012b) for a picture of the Mountain Car environment. In the off-policy version, the agent learns from experience generated by a fixed behaviour policy, in this case the uniform random policy. The observations were tile coded using 8 tilings of tiles plus a bias unit. ACE-ideal was omitted from the Mountain Car experiments due to computational constraints; the uniform random behaviour policy rarely completed an episode, which resulted in extremely long trajectories that prevented ACE-ideal from running in a reasonable amount of time.
Figure 8 contains the results for the Off-policy Mountain Car environment. The left-hand column shows learning curves, while the right-hand column shows sensitivity analyses for the actor’s step size. The first four plots (figures 8(a), 8(b), 8(c), and 8(d)) show results when using ETD as the critic, while the last four plots (figures 8(e), 8(f), 8(g), and 8(h)) show results for a TDRC critic. The first and third rows show results using the excursions objective function, and the second and fourth rows show results for the episodic objective function.








Across all choices of critic and objective function, algorithms trained using the episodic interest function (dashed lines) performed much worse than their counterparts trained using the uniform interest function (solid lines). This finding is consistent with the results from Puddle World, although much more pronounced. In this specific experiment, the extremely long trajectories generated by the uniform random behaviour policy caused the emphatic trace (and hence the policy updates) of the algorithms that used episodic interest to quickly shrink to the point of irrelevance, whereas in the Puddle World experiment the behaviour policy encounters the goal state more often, limiting trajectory length and shrinking the updates more slowly. Nevertheless, using the direct method to estimate the emphatic weightings allowed ACE to improve the performance of the policy in some cases, whereas using the emphatic trace prevented the policy from meaningfully improving.
Again, the choice of critic played a role in the performance of all the algorithms to varying degrees. Using a TDRC critic instead of an ETD critic improved the performance of each of the algorithms, with OffPAC seeing the greatest improvement, followed by ACE-trace. ACE-direct again performed well regardless of the choice of critic. Using a TDRC critic improved the sensitivity of each of the algorithms to the actor’s step size, allowing a wider range of step sizes to perform well (compare figures 8(b) and 8(f), and 8(d) and 8(h)).
Comparing ACE-direct (red) to ACE-trace (orange) reveals several advantages of using the direct method to estimate the emphatic weightings. The direct method allowed ACE to learn faster, with less variance, and find a better-performing target policy by the end of the experiment, regardless of the choice of critic or objective function used for evaluation. In addition, the direct method allowed a wider range of actor step sizes to perform well, with performance increasing and decreasing more smoothly and predictably than when using the emphatic trace. Finally, the choice of critic had little effect on the performance of ACE-direct, whereas ACE-trace performed better with a TDRC critic than with an ETD critic. Overall, ACE with the direct method performed better than or equal to OffPAC (green) and ACE-trace for all critics and objective functions, but was less sensitive to the actor step size and choice of critic than OffPAC.
9.4 The Virtual Office Environment
The classic control environments considered in the previous section are well-known environments for testing general off-policy algorithms, but were not designed to probe the weaknesses of the specific algorithms being studied. Hence, both semi-gradient updates and the direct method of estimating emphatic weightings perform well, and the tradeoffs made in the design of each algorithm are not obvious. In this section, we introduce an environment designed to highlight issues with both semi-gradient updates and the direct method of estimating emphatic weightings.
The environment is based on Dung et al. (2007)’s Virtual Office, a grid world consisting of a hallway and two cubicles that are identical except for the goal locations. To illustrate the problem with semi-gradient updates, two key properties of the counterexample from Section 8.1 must be incorporated: the optimal actions in the two identical rooms must be different, and the behaviour policy must visit the suboptimal room more often. To accomplish the first goal, we introduced hidden goal states in the north-east and south-east corners of the two rooms, and assigned rewards of 1 and 0 respectively to the goal states of the north-east room and rewards of 0 and .5 respectively to the goal states of the south-east room. To encourage the behaviour policy to visit the suboptimal room (i.e., the south-east room) more often, we fixed the starting state to the left-most, middle-most state and used a behaviour policy that favoured the South and East actions, taking the North, East, South, and West actions with probabilities .2, .4, .3, and .1 respectively.
While Dung et al. (2007)’s Virtual Office contains some partial observability in the form of the two identical rooms, to fully illustrate the tradeoff made by the Markov assumption used in the derivation of the direct method, we limited the agent’s observations to a grid in front of the agent. The RGB colour values of each square in the agent’s view were used as observations, with the agent unable to see through walls or perceive the goal states.
The final environment was implemented using Minigrid (Chevalier-Boisvert et al., 2018), and is depicted in Figure 9. The agent (red triangle) must navigate to one of the terminal states (the north-east and south-east squares of the green rooms) to obtain the associated reward. The agent observes the RGB colour values of the grid of squares in front of it (the lighter blue squares), and selects the North, East, South, or West action in response.
For this experiment we followed the methodology detailed in the previous section, with minor changes. First, we restricted the critic trace decay rate to be 0, as eligibility traces can alleviate some of the issues caused by partial observability (Loch and Singh, 1998). Second, we ran each combination of parameters for 30 runs of 200,000 time steps each. The learned policies were saved every 5,000 time steps and evaluated 50 times using both the episodic and excursions objective functions. The best-performing parameter settings were then re-run 100 times and averaged.

Figure 10 contains the results of our experiment on the Virtual Office environment. The left-hand column shows learning curves, while the right-hand column shows sensitivity analyses for the actor’s step size. The first four plots (figures 10(a), 10(b), 10(c), and 10(d)) show results when using ETD as the critic, while the last four plots (figures 10(e), 10(f), 10(g), and 10(h)) show results for a TDRC critic. The first and third rows show results for the excursions objective function, and the second and fourth rows show the episodic objective function.
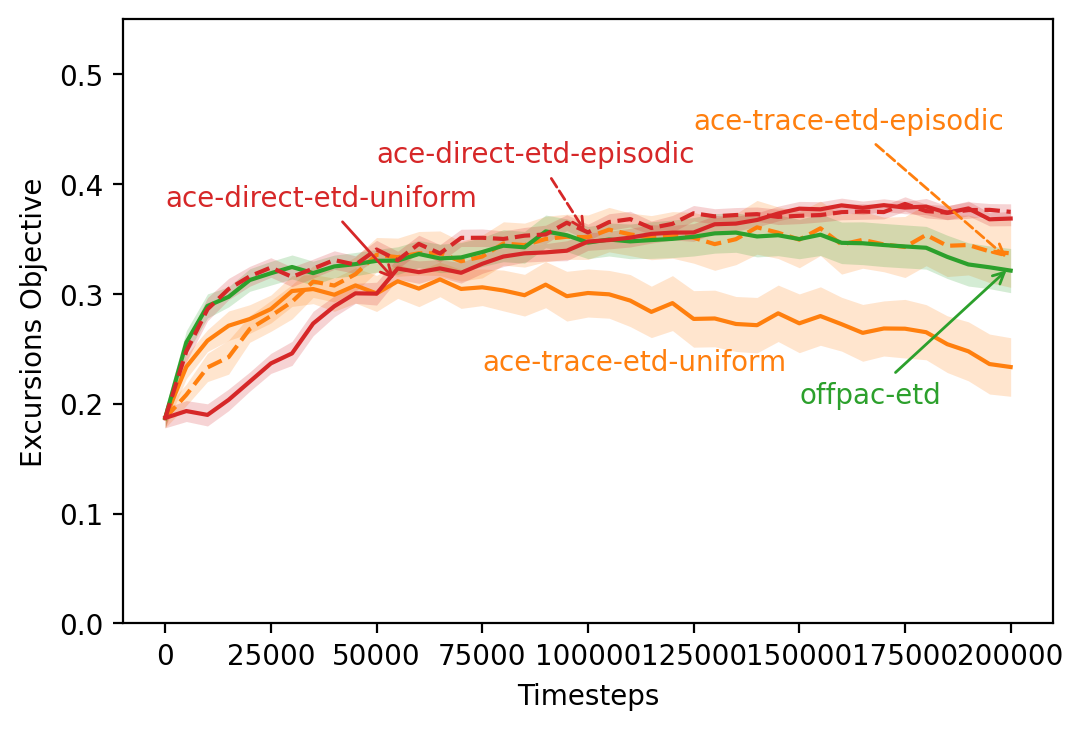







Interestingly, algorithms that used the episodic interest function (dashed lines) performed better than or equal to their counterparts that used the uniform interest function (solid lines) for all combinations of objective function and critic, unlike the previous experiments on Mountain Car and Puddle World. In addition, the algorithms that used the episodic interest function worked well for a larger range of step sizes, making it easier to find a value that performs well. This could be due to the partially observable nature of the environment; many of the agent’s observations are similar, which could cause the emphatic weightings with a uniform interest function to quickly become very large, necessitating a very small step size to compensate.
As in the previous experiments, the choice of critic played an important role in the performance of all the algorithms, although this time with mixed results. Using a TDRC critic instead of an ETD critic improved the performance of OffPAC and ACE-direct with uniform interest, but had very little impact on ACE-trace with uniform interest and ACE-direct with episodic interest, and actually reduced the performance of ACE-trace with episodic interest (compare figures 10(a) and 10(e), and 10(c) and 10(g)). Similarly, using a TDRC critic had mixed effects on the sensitivity of each of the algorithms to the actor’s step size. It allowed a wider range of step sizes to perform well for some algorithms, but also led to a narrower range of well-performing step sizes for some algorithms (compare figures 10(b) and 10(f), and 10(d) and 10(h)).
ACE-direct with the episodic interest function performed better than or equal to the other methods across most combinations of critic and objective function, with the possible exception of the episodic objective function. With a TDRC critic, OffPAC learned more quickly than the other methods before eventually being surpassed by both ACE-direct variants. However, OffPAC was able to close the gap near the end of the experiment, with the final learned policy of OffPAC performing comparably to the ACE-direct variants. With an ETD critic, ACE-trace with episodic interest performed surprisingly well, with the final policy possibly outperforming ACE-direct with episodic interest. However, the variance of the policy learned by ACE-trace was much larger than the other methods, rendering the difference in performance not statistically significant. Conversely, ACE-direct with episodic interest learned a low-variance policy on each of the settings tested, performing as well as or better than the other algorithms.
9.5 Summary
In this section we investigated several key properties of the ACE algorithm empirically. First we studied how the parameter trades off bias and variance in the counterexample from Section 8.1 and a continuous action version, finding that even small values of (i.e., closer to semi-gradient updates) greatly improved the quality of the final learned policy, both when using the true value function and when using a learned critic.
Next we tested the ability of the emphatic trace to accurately estimate the emphatic weightings on an extended version of the counterexample, showing that while higher values of improved performance, a significant gap remained between ACE with and ACE with the true emphatic weightings.
Then we moved to two classic control domains and tested several variants of ACE to determine how the choice of estimator for the emphatic weightings (and associated bias and variance properties) and the choice of critic affects the learning process. We found that the emphatic trace’s extreme variance greatly reduced the performance of ACE—with its bias playing somewhat less of a role—and replacing the emphatic trace with the direct method from Section 5.2.2 resulted in ACE performing as well as or better than the other variants. The TDRC critic was the better critic overall, but ACE with the direct method of estimating emphatic weightings was insensitive to the choice of critic and performed well regardless of whether ETD or TDRC was used.
Finally, we compared the performance of several variants of ACE on a new environment designed to highlight the weaknesses of each of the variants, finding that the episodic variant of ACE with the direct method of estimating emphatic weightings performed as well as or better than the other variants in almost all the situations tested, suggesting it should be the default method of estimating the emphatic weightings.
10 Conclusion
In this paper we introduced a generalized objective for learning policies and proved the off-policy policy gradient theorem using emphatic weightings. Using this theorem, we derived an off-policy actor-critic algorithm that follows the gradient of the objective function, as opposed to previous methods like OffPAC and DPG that follow an approximate semi-gradient. We designed a simple MDP to highlight that stationary points for semi-gradients can be highly suboptimal, with semi-gradient updates moving away from the optimal solution. We also show, though, that the semi-gradient methods can produce reasonable solutions, either because of sufficiently rich policy parameterizations or because in some cases they can be seen as using the true gradient update with a different state weighting.
We leverage these insights to improve the practicality of the method empirically. We design Actor-Critic with Emphatic Weightings (ACE) to have a tuneable parameter that sweeps between the full gradient (at ) and the semi-gradient (at ), often obtaining the best performance with a relatively small but non-zero (typically ). We additionally reduce variance by directly estimating emphatic weightings with function approximation rather than using the emphatic trace. Empirically, the direct method of estimating the emphatic weightings performed better than the emphatic trace across all objective functions and environments tested. In addition, ACE with the direct method was less sensitive to the actor step size and choice of critic than OffPAC. Overall, ACE with the direct method performed better than or equal to OffPAC in all situations, suggesting that incorporating (low-variance) state reweightings might be a reasonable direction for future policy gradient methods.
Acknowledgments and Disclosure of Funding
We gratefully acknowledge funding from the Natural Sciences and Engineering Research Council of Canada (NSERC), the Canada CIFAR AI Chair program, and the Alberta Machine Intelligence Institute (Amii). This research was enabled in part by support provided by SciNet and the Digital Research Alliance of Canada.
Appendix A Proof of Deterministic Off-Policy Policy Gradient Theorem
A.1 Assumptions
We make the following assumptions on the MDP:
Assumption 1
and their derivatives are continuous in all variables .
Assumption 2
is a compact set in , and is a compact set in .
Assumption 3
The policy and discount are such that the inverse kernel of exists, where .
A.2 Proof of Theorem 3
Proof We start by deriving a recursive form for the gradient of the value function with respect to the policy parameters:
| (21) |
where in Equation 21 we used the Leibniz integral rule to switch the order of integration and differentiation. We proceed with the derivation using the product rule:
| (22) |
For simplicity of notation, we will write Equation 22 as
| (23) |
since is a function of and for a fixed deterministic policy. Then we can write as an integral transform using the delta function:
| (24) |
Plugging Equation 24 into the left-hand side of Equation 23, we obtain:
| (25) |
where is the inverse kernel of . Now, using the continuous version of the weighted excursions objective defined in Equation 6, we have:
| (26) |
where in Equation 26 we used Fubini’s theorem to switch the order of integration.
Now, we convert the recursive definition of emphatic weightings for deterministic policies over continuous state-action spaces into a non-recursive form. Recall the definition:
| (27) |
Again, we can write as an integral transform using the delta function:
| (28) |
Plugging Equation 28 into the left-hand side of Equation 27, we obtain:
| (29) |
where is again the inverse kernel of . Plugging Equation 29 into Equation 26 yields
Appendix B Continuous State Off-Policy Policy Gradient Theorem
Given the Deterministic Off-Policy Policy Gradient Theorem in Appendix A, we can now provide a proof for the continuous-state version of the Off-Policy Policy Gradient Theorem provided in Theorem 2.
Proof The gradient of the objective in the continuous-states case is
| (30) |
Therefore, again to compute the gradient of we need to compute the gradient of the value function with respect to the policy parameters. A recursive form of the gradient of the value function can be derived, as we show below. Before starting, for simplicity of notation, we will again use
where . Now let us compute the gradient of the value function:
| (31) |
For simplicity of notation we will write Equation 31 as
| (32) |
where . Again, as in the deterministic off-policy policy gradient theorem, we can write as an integral transform using the delta function:
| (33) |
Plugging Equation 33 into the left-hand side of Equation 32, we obtain:
| (34) |
Plugging this gradient from Equation 34 back into Equation 30, we obtain
| (35) | ||||
| (36) | ||||
where in Equation 35 we used Fubini’s theorem to switch the order of integration, and in Equation 36 we use the non-recursive version of emphasis as shown in Equation 29.
Appendix C Standard Approaches for Sampling the Gradient from a State
In this section we overview the standard approach to sample the gradient from a given state, that is used in both ACE and OffPAC. This section reiterates known results, but is included here for completeness.
C.1 Sampling the Gradient for a Given State
For a given state, we can use the same strategies to sample the gradient as OffPAC, and many other actor-critic algorithms. We can use the log-likelihood approach, and incorporate baselines. For continuous actions, we can also use other strategies like the reparameterization trick. For concreteness, we explicitly explain how we sample this gradient here, using a value baseline and the log-likelihood approach, but emphasize that this can be replaced with other choices.
Under finite states, the simplest approach to compute the gradient for a given state is to use what is sometimes called the all-actions gradient
If there are many actions or if the action space is continuous, this gradient is not an appropriate choice. Instead, we can obtain a sample estimate of this gradient using the log-likelihood trick:
which follows from the fact that the derivative of is . Above we called this log likelihood form . Now we can use one action sampled according to to obtain an unbiased estimate of the all-actions gradient. In the off-policy setting, however, we do not use to select actions. So, additionally, we can incorporate importance sampling to adjust for the fact that the actions are taken according to behaviour policy :
We can obtain an unbiased sample of the gradient by sampling an action and using .
The estimated gradient has more variance when we only use a sampled action rather than all actions. The standard strategy to reduce this variance is to subtract a baseline. The baseline is a function of state, such as an estimate of the value function , with modified update
It is straightforward to show that the expected value of this update is the same, i.e. that
Note that this is not the minimal variance baseline (Dick, 2015), but it nonetheless is one of the most commonly chosen in practice due to its efficacy and simplicity.
C.2 Estimating the Advantage
In practice, it is difficult to obtain to compute this gradient exactly. Instead, we obtain (a likely biased) sample of the advantage, . An unbiased but high variance estimate uses a sample of the return from , and uses . Then . On the other extreme, we can directly approximate the action-values, . In-between, we can use -step returns, or -returns, to balance between using observed rewards and value estimates.
The simplest choice is to use a 1-step return: is used as an approximation of . The value function is typically called the critic, and plays both the role of estimating the return as well as that of a baseline. The advantage is set to , which is simply the TD error.
More generally, however, we can also use multi-step returns. For an -step return, with data sampled on-policy, with as short-hand for the product of discounts, we would use
With off-policy data, we would need to incorporate importance sampling ratios
where . For sufficiently large , we recover the sampled return and so obtain an unbiased—but likely high-variance—estimate of the advantage. An interim likely provides a reasonable choice between bias and variance, between with a direct estimation of , and large that gives an unbiased sample of the return.
We can also average across multiple , and obtain -returns (Sutton and Barto, 2018). For larger , more weight is put on the -step returns with larger , and for we once again recover an unbiased sample of the return. Such an approach was used in OffPAC, which requires storing traces of gradients of policy parameters (see Algorithm 1 in Degris et al., 2012b). Note that this -return is used for the policy update. The update to the value estimate (critic) itself can use a different , as it stores a separate trace for the gradient of the value function. The update with eligibility traces is only sound under linear function approximation for the values and linear function approximation for action-preferences. In this work, therefore, we opt for the simplest choice: with .
Finally, we need to estimate the values themselves. Any value approximation algorithm can be used to estimate , such as TD, gradient TD or even emphatic TD. Given we already compute the emphasis weighting, it is straightforward to use emphatic TD. We investigate both a gradient TD critic and an emphatic TD critic in the experiments.
Appendix D Proof of Theorem 8
D.1 Entropy-regularized OPPG theorem with discrete states and actions
Proof The proof for this theorem is mostly similar to the one for Theorem 2. First, since the interest function does not depend on the parameters,
Recall that . We define the following notation which helps with the recursive expression of the gradient:
where . The gradient of the entropy regularized value function is then
| (37) | ||||
So the gradient of the regularized value function can be written in vector form similar to the unregularized version. Let be the matrix of gradients of for each state ; and the matrix where each row corresponds to state in the vector . Then
| (38) | ||||
Therefore, we obtain
We can further simplify this gradient by explicitly computing the gradient of the negative of the entropy:
where the last line follows from the fact that .
This form looks a bit different than the (on-policy) policy gradient update given by (Geist et al., 2019, Theorem 6). We can actually get a similar form by rewriting the inner term above. For a specific , using chain rule on the entropy we obtain
D.2 Regularized OPPG theorem with continuous states and actions
Theorem 11
Proof We extend the result from the previous section to the continuous state and action setting using a similar strategy to the one we used in Appendix B to extend Theorem 2 to the continuous state setting. In addition, we opt for a generic regularizer , which slightly modifies the definition of the regularized value functions to be
We use the following notation to simplify the derivation:
Starting with the continuous objective function from equation (6) and using the Leibniz integral rule to differentiate under the integral (which applies because we assumed the state space is a compact set in Assumption 2 from Appendix A.1):
| (39) |
Next, we find a recursive expression for the gradient of the regularized value function:
where in the last step we used Fubini’s Theorem to switch the order of integrals (which we can do because the absolute value of the integral is finite due to Assumptions 1 and 2). Again we will use the shorthand to simplify the derivation. Next we write as the integral transform
plug it into the previous equation, and solve to get
where is the inverse kernel of . Then plugging the above into Equation (39), interchanging integrals using Fubini’s theorem, and simplifying gives
Appendix E Proof of Proposition 10
This section proves Proposition 10. First, a result by Mei et al. (2020) for tabular domains is extended to state aggregation and transition dependent discounting (which includes the three-state counterexample) to show that entropy-regularized policy gradient converges to a point where the gradient is zero. Then, it is shown that such point is not a stationary point for semi-gradient updates.
E.1 Entropy-regularized PG under State Aggregation
We assume the policy is a softmax policy and additionally specifically characterize the gradient under state aggregation. This specific characterization facilitates showing that the solution to the objective lies on the interior of the simplex, and so that a stationary point exists.
We define as the set of state that share their representation with including itself. We additionally defined the set of representative states, one for each bin in the aggregation. For example, in the three-state counterexample and . We simply need to choose one state in each aliased set, giving .
For a parameter set , the policy is a softmax transform defined as follows. For a state with representative state , i.e., , we have
| (40) |
Using again the three-state counterexample, has four components: and specify the policy for , and and specify the policy for both and since these two states are aliased.
The softmax policy has a simple well-known gradient, which we can explicitly write for state-aggregation in the following lemma for easy reference in later proofs.
Lemma 12
Assume the policy uses a softmax distribution, as in Equation 40. For any state , for any ,
| (41) |
and, across all actions, this can be compactly written as
Proof For explicit step to obtain this derivation, notice first that
and so
If , then
where the last step follows from the fact that under state aggregation. If , then
The gradient ascent update using the entropy-regularized objective is
| (42) |
for stepsize . For an appropriately small stepsize , this will converge to a stationary point if one exists, and otherwise move to a point on the simplex, where for an action in state . The standard condition on is that for Lipschitz constant of , which is a common assumption for policy gradient methods. In the next section, we show that this update converges to a stationary on the interior of the policy simplex.
We provide one more result, that is useful for this characterization. Lemma 13 breaks down the gradient into its components. Mei et al. (2020), in their Lemma 10, proved this result for entropy regularized policy gradients, assuming tabular policies in the on-policy setting. We extend it to state aggregation, with our off-policy gradient. Their presentation has an extra term . This discrepancy is just a difference in notation. In our formulation, entropy regularized action values are defined to contain the entropy term so that the connection between the regularized and unregularized policy gradient is clearer.
Lemma 13
For each state and action
E.2 Existence of stationary points for the entropy-regularized PG objective
We are now ready to prove that a stationary point exists for . Mei et al. (2020) (Lemma 17) proved that, under tabular representation and softmax parameterization, entropy regularized policy gradient updates converge to a point where the gradient is zero. We extend their proof to state aggregation and transition-dependent discounting. We additionally avoid assuming that the rewards are non-negative.
Assumption 4 (Lipschitz continuity)
is Lipschitz continuous with Lipschitz constant .
Assumption 5 (Bounded reward)
.
Assumption 6 (Bounded expected sum of future discounting)
There exists such that for any , . This assumption is satisfied if is proper, or if after a bounded number of steps .
We first prove that the state values are bounded and show that the action-values are lower bounded by the scaled log of the probabilities. We use this to show the main result in Proposition 15.
Proof First notice that for any distribution over actions
where is the number of actions. The inequality follows from the fact that the uniform distribution has the highest entropy. We use this inequality to bound , which is the entropy of . Using this bound on entropy, and the facts that the entropy is nonnegative and for all , we obtain
Finally, we can lower bound the advantage function, using and
giving
Proposition 15
Proof Let be the trajectory of parameters under the gradient ascent update, where . This trajectory either converges to finite that provides a policy on the interior of the policy simplex, or it pushes the weights for a subset of actions to infinity to converge to a point on the simplex, where certain actions have zero probability. The gradient is only zero for the solution on the interior, and so to prove the result we simply need to show that this process converges to the interior. We show this is true for every parameter in the vector , where and .
Define and as the sets of actions with zero and nonzero probability under . We use a proof by contradiction to show that for any as long as . Suppose there exist and such that . Note that for all . We know that and as . Therefore there exists such that for all and
According to Lemma 13, for all
| (43) |
So is non-decreasing after , because we only add this non-negative gradient to . This means that is lower bounded by a constant :
Next, we bound . Notice that the sum of gradient components over all actions at a state is zero:
| (44) |
Because
we get that for all ,
where the last line follows from Equation E.2. This means that is non-increasing after . For , we know that there exists some constant that lower bounds for all . Otherwise, would not have non-zero probability under . Therefore, non-increasing cannot be due to some approaching while others approach . Instead, each must also be bounded above. This means there exists some such that for every .
For all , we also know that there exists such that for all . Otherwise, if approaches infinity, then would not be in . Putting this together with the above, and knowing there is at least one ,
Finally, this gives
Taking the limit as , this lower bound remains positive, implying that , which is a contradiction.
Therefore, no such can exist and so for all . Since the policy converges to the interior of the probability simplex and the objective function is Lipschitz continuous, the gradient has to be zero at the point of convergence (Mei et al., 2020) (Lemma 17).
E.3 Proof for Three-State Counterexample
In the previous section, we showed that a stationary point for the entropy-regularized PG objective exists. We now show that in the three-state counterexample that such a point is not a stationary point under semi-gradient updates.
Lemma 16
A point with zero gradient is not a stationary point under semi-gradient updates in the three-state counterexample.
Proof Suppose is a point with zero gradient, i.e.:
Every component of the gradient vector is zero, thus
Since taking any action from or results in termination, the following holds for and any action :
States and have the same representation, meaning that and . So
For simplicity of notation, define
letting us write the above as
Similarly, the semi-gradient update to becomes
We show that, even though is a stationary point under the true gradient update, this semi-gradient under is not zero. Notice first that
Therefore,
| (45) | ||||
The second factor is nonzero due to softmax parametrization. It therefore suffices to show that the first term is not zero.
In each episode in the counterexample, regardless of the policy, the agent spends one step in and one step in either or . Therefore
Unfolding the emphatic weightings gives
Plugging these values into results in
Therefore,
and we get that
As long as , the semi-gradient is not zero. For example, as in Section 8.1, we can choose . Now we show that for a stationary point under the true gradient.
Let us first write the partial derivative w.r.t. the first parameter given that :
For this derivative to be zero, must be zero.
Recall that and . Then
| (46) |
because . For small values of , should be close to to make a stationary point.
Now let us write the partial derivative w.r.t. , again assuming and by noting that and are aliased:
Making the partial derivative zero requires either , , or the contents of the brackets to be zero. The first two are incompatible with the requirement for making Equation 46 zero so we will continue with the third one. Note that
and the factor in the brackets becomes
Making this zero is also at odds with the requirement for Equation 46. To see why, let’s consider both conditions, where we use to simplify notation.
The first equation requires . The second equation requires . These two equations intersect when , but otherwise do not equal each other, meaning we cannot satisfy both of these criteria. Therefore, for any , a stationary point under the true gradient cannot have and thus cannot be a stationary point under semi-gradient.
This counterexample shows one environment where the sets of stationary points under the true gradient is disjoint from the set of stationary points under the semi-gradient.
Appendix F Descriptions of Algorithms in Section 9
| ACE() | Actor-Critic with Emphatic weightings. interpolates between semi-gradient updates () and gradient updates (). |
|---|---|
| OffPAC | Off-Policy Actor-Critic (Degris et al., 2012b). Equivalent to ACE(). |
| GTD() | Gradient Temporal-Difference learning (Sutton et al., 2009). is the decay rate of the eligibility trace vector. |
| ETD() | Emphatic Temporal-Difference learning (Sutton et al., 2016). is the decay rate of the eligibility trace vector. |
| TDRC() | Temporal-Difference learning with Regularized Corrections (Ghiassian et al., 2020; Patterson et al., 2022). is the decay rate of the eligibility trace vector. |
| DPG | Deterministic Policy Gradient (Silver et al., 2014). Uses a deterministic policy parameterization and semi-gradient updates. |
| True-DPGE | A version of DPG using true gradient updates (i.e., scaling the update by the true emphatic weightings). |
| True-ACE | A version of ACE using the true emphatic weightings. |
| ACE-direct | A version of ACE that uses the direct method from Section 5.2.2 to estimate the emphatic weightings. |
| ACE-trace | A version of ACE that uses the emphatic trace from Sutton et al. (2016) to estimate the emphatic weightings. |
| ACE-ideal | A version of ACE that re-computes the emphatic trace on each time step using the current policy to remove the influence of old versions of the policy. |
References
- Ahmed et al. (2019) Zafarali Ahmed, Nicolas Le Roux, Mohammad Norouzi, and Dale Schuurmans. Understanding the impact of entropy on policy optimization. In International Conference on Machine Learning, 2019.
- Barto et al. (1983) Andrew G. Barto, Richard S. Sutton, and Charles W. Anderson. Neuronlike adaptive elements that can solve difficult learning control problems. IEEE Transactions on Systems, Man, and Cybernetics, (5), 1983.
- Bhatnagar et al. (2007) Shalabh Bhatnagar, Richard S. Sutton, Mohammad Ghavamzadeh, and Mark Lee. Incremental natural actor–critic algorithms. In Conference on Neural Information Processing Systems, 2007.
- Bhatnagar et al. (2009) Shalabh Bhatnagar, Richard S. Sutton, Mohammad Ghavamzadeh, and Mark Lee. Natural actor–critic algorithms. Automatica, 45(11), 2009.
- Boyan and Moore (1995) Justin Boyan and Andrew W. Moore. Generalization in reinforcement learning: Safely approximating the value function. Conference on Neural Information Processing Systems, pages 369–376, 1995.
- Brockman et al. (2016) Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. OpenAI Gym. arXiv preprint arXiv:1606.01540, 2016.
- Chevalier-Boisvert et al. (2018) Maxime Chevalier-Boisvert, Lucas Willems, and Suman Pal. Minimalistic gridworld environment for OpenAI Gym. https://github.com/maximecb/gym-minigrid, 2018.
- Degris et al. (2012a) Thomas Degris, Patrick M. Pilarski, and Richard S. Sutton. Model–free reinforcement learning with continuous action in practice. In American Control Conference, 2012a.
- Degris et al. (2012b) Thomas Degris, Martha White, and Richard S. Sutton. Off–policy actor–critic. In International Conference on Machine Learning, 2012b.
- Dick (2015) Travis B. Dick. Policy gradient reinforcement learning without regret. Master’s thesis, University of Alberta, 2015.
- Dung et al. (2007) Le Tien Dung, Takashi Komeda, and Motoki Takagi. Reinforcement learning in non-Markovian environments using automatic discovery of subgoals. In Society of Instrument and Control Engineers Annual Conference, pages 2601–2605. IEEE, 2007.
- et al. (2020) Charles R. Harris et al. Array programming with NumPy. Nature, 585(7825):357–362, September 2020. doi: 10.1038/s41586-020-2649-2. URL https://doi.org/10.1038/s41586-020-2649-2.
- Geist et al. (2019) Matthieu Geist, Bruno Scherrer, and Olivier Pietquin. A theory of regularized markov decision processes. In International Conference on Machine Learning, pages 2160–2169, 2019.
- Gelada and Bellemare (2019) Carles Gelada and Marc G. Bellemare. Off-policy deep reinforcement learning by bootstrapping the covariate shift. In AAAI Conference on Artificial Intelligence, volume 33, 2019.
- Ghiassian et al. (2018) Sina Ghiassian, Andrew Patterson, Martha White, Richard S. Sutton, and Adam White. Online off-policy prediction. arXiv:1811.02597, 2018.
- Ghiassian et al. (2020) Sina Ghiassian, Andrew Patterson, Shivam Garg, Dhawal Gupta, Adam White, and Martha White. Gradient temporal-difference learning with regularized corrections. In International Conference on Machine Learning, pages 3524–3534. PMLR, 2020.
- Ghosh et al. (2020) Dibya Ghosh, Marlos C. Machado, and Nicolas Le Roux. An operator view of policy gradient methods. In Conference on Neural Information Processing Systems, 2020.
- Greensmith et al. (2004) Evan Greensmith, Peter L. Bartlett, and Jonathan Baxter. Variance reduction techniques for gradient estimates in reinforcement learning. The Journal of Machine Learning Research, 5, 2004.
- Grondman et al. (2012) Ivo Grondman, Lucian Busoniu, Gabriel A.D. Lopes, and Robert Babuska. A survey of actor–critic reinforcement learning: Standard and natural policy gradients. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 42(6), 2012.
- Gu et al. (2017a) Shixiang Gu, Tim Lillicrap, Richard E. Turner, Zoubin Ghahramani, Bernhard Schölkopf, and Sergey Levine. Interpolated policy gradient: Merging on–policy and off–policy gradient estimation for deep reinforcement learning. In Conference on Neural Information Processing Systems, 2017a.
- Gu et al. (2017b) Shixiang Gu, Timothy Lillicrap, Zoubin Ghahramani, Richard E. Turner, and Sergey Levine. Q–prop: Sample–efficient policy gradient with an off–policy critic. In International Conference on Learning Representations, 2017b.
- Haarnoja et al. (2018) Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International Conference on Machine Learning, 2018.
- Hallak and Mannor (2017) Assaf Hallak and Shie Mannor. Consistent on-line off-policy evaluation. In International Conference on Machine Learning, volume 70, 2017.
- Huang (2020) Bojun Huang. Steady state analysis of episodic reinforcement learning. In Conference on Neural Information Processing Systems, 2020.
- Imani et al. (2018) Ehsan Imani, Eric Graves, and Martha White. An off–policy policy gradient theorem using emphatic weightings. In Conference on Neural Information Processing Systems, 2018.
- Kallus and Uehara (2020) Nathan Kallus and Masatoshi Uehara. Statistically efficient off–policy policy gradients. In International Conference on Machine Learning, 2020.
- Kirsch (2017) Andreas Kirsch. Mdp environments for the OpenAI Gym. Technical report, 2017. URL https://arxiv.org/abs/1709.09069.
- Klissarov and Precup (2021) Martin Klissarov and Doina Precup. Flexible option learning. Conference on Neural Information Processing Systems, pages 4632–4646, 2021.
- Konda and Tsitsiklis (2000) Vijay R. Konda and John N. Tsitsiklis. Actor–critic algorithms. In Conference on Neural Information Processing Systems, 2000.
- Laroche and Tachet des Combes (2021) Romain Laroche and Remi Tachet des Combes. Dr jekyll & mr hyde: the strange case of off-policy policy updates. Conference on Neural Information Processing Systems, 2021.
- Lillicrap et al. (2015) Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. In International Conference on Learning Representations, 2015.
- Lin (1992) Long-Ji Lin. Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine learning, 8(3-4), 1992.
- Lin (1993) Long-Ji Lin. Reinforcement learning for robots using neural networks. Technical report, Carnegie-Mellon University, 1993.
- Liu et al. (2018) Qiang Liu, Lihong Li, Ziyang Tang, and Dengyong Zhou. Breaking the curse of horizon: Infinite-horizon off-policy estimation. In Conference on Neural Information Processing Systems, 2018.
- Liu et al. (2019) Yao Liu, Adith Swaminathan, Alekh Agarwal, and Emma Brunskill. Off-policy policy gradient with stationary distribution correction. In Conference on Uncertainty in Artificial Intelligence, 2019.
- Liu et al. (2020a) Yao Liu, Pierre-Luc Bacon, and Emma Brunskill. Understanding the curse of horizon in off-policy evaluation via conditional importance sampling. In International Conference on Machine Learning, pages 6184–6193. PMLR, 2020a.
- Liu et al. (2020b) Yao Liu, Adith Swaminathan, Alekh Agarwal, and Emma Brunskill. Off–policy policy gradient with stationary distribution correction. In Conference on Uncertainty in Artificial Intelligence, 2020b.
- Loch and Singh (1998) John Loch and Satinder P. Singh. Using eligibility traces to find the best memoryless policy in partially observable Markov decision processes. In International Conference on Machine Learning, pages 323–331, 1998.
- Maei (2011) Hamid Maei. Gradient Temporal–Difference Learning Algorithms. PhD thesis, University of Alberta, 2011.
- Maei (2018) Hamid Reza Maei. Convergent actor–critic algorithms under off-policy training and function approximation. arXiv:1802.07842, 2018.
- Mahmood et al. (2015) A. Rupam Mahmood, Huizhen Yu, Martha White, and Richard S. Sutton. Emphatic temporal-difference learning. arXiv:1507.01569, 2015.
- Marbach and Tsitsiklis (2001) Peter Marbach and John N. Tsitsiklis. Simulation–based optimization of Markov reward processes. IEEE Transactions on Automatic Control, 46(2), 2001.
- Mei et al. (2020) Jincheng Mei, Chenjun Xiao, Csaba Szepesvari, and Dale Schuurmans. On the global convergence rates of softmax policy gradient methods. In International Conference on Machine Learning, 2020.
- Meuleau et al. (2000) Nicolas Meuleau, Leonid Peshkin, Leslie P. Kaelbling, and Kee-Eung Kim. Off–policy policy search. Technical report, MIT Artificial Intelligence Laboratory, 2000.
- Mnih et al. (2015) Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, et al. Human–level control through deep reinforcement learning. Nature, 518(7540), 2015.
- Moore (1990) Andrew William Moore. Efficient memory-based learning for robot control. PhD thesis, University of Cambridge, 1990.
- Nota and Thomas (2020) Chris Nota and Philip S. Thomas. Is the policy gradient a gradient? In International Conference on Autonomous Agents and Multiagent Systems, 2020.
- Patterson et al. (2022) Andrew Patterson, Adam White, and Martha White. A generalized projected bellman error for off-policy value estimation in reinforcement learning. The Journal of Machine Learning Research, 2022.
- Peters et al. (2005) Jan Peters, Sethu Vijayakumar, and Stefan Schaal. Natural actor-critic. In European Conference on Machine Learning, 2005.
- Precup (2000) Doina Precup. Temporal Abstraction In Reinforcement Learning. PhD thesis, University of Massachusetts Amherst, 2000.
- Precup et al. (2000) Doina Precup, Richard S. Sutton, and Satinder P. Singh. Eligibility Traces for Off–Policy Policy Evaluation. In International Conference on Machine Learning, 2000.
- Precup et al. (2001) Doina Precup, Richard S. Sutton, and Sanjoy Dasgupta. Off–policy temporal–difference learning with function approximation. International Conference on Machine Learning, 2001.
- Schaul et al. (2016) Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay. In International Conference on Learning Representations, 2016.
- Schmidt and Roux (2013) Mark Schmidt and Nicolas Le Roux. Fast convergence of stochastic gradient descent under a strong growth condition. arXiv:1308.6370, 2013.
- Silver et al. (2014) David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin Riedmiller. Deterministic policy gradient algorithms. In International Conference on Machine Learning, 2014.
- Sutton and Barto (2018) Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. 2nd edition, 2018.
- Sutton et al. (1999a) Richard S. Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. In Conference on Neural Information Processing Systems, 1999a.
- Sutton et al. (1999b) Richard S. Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial intelligence, 112(1-2), 1999b.
- Sutton et al. (2009) Richard S. Sutton, Hamid Reza Maei, Doina Precup, Shalabh Bhatnagar, David Silver, Csaba Szepesvári, and Eric Wiewiora. Fast gradient-descent methods for temporal–difference learning with linear function approximation. In International Conference on Machine Learning, 2009.
- Sutton et al. (2011) Richard S. Sutton, Joseph Modayil, Michael Delp, Thomas Degris, Patrick M. Pilarski, Adam White, and Doina Precup. Horde: A scalable real–time architecture for learning knowledge from unsupervised sensorimotor interaction. In International Conference on Autonomous Agents and MultiAgent Systems, 2011.
- Sutton et al. (2016) Richard S. Sutton, A. Rupam Mahmood, and Martha White. An emphatic approach to the problem of off–policy temporal–difference learning. The Journal of Machine Learning Research, 17, 2016.
- Thomas (2014) Philip Thomas. Bias in natural actor–critic algorithms. In International Conference on Machine Learning, 2014.
- Tosatto et al. (2020) Samuele Tosatto, Joao Carvalho, Hany Abdulsamad, and Jan Peters. A nonparametric off–policy policy gradient. In International Conference on Artificial Intelligence and Statistics, 2020.
- Wang et al. (2016) Ziyu Wang, Victor Bapst, Nicolas Heess, Volodymyr Mnih, Rémi Munos, Koray Kavukcuoglu, and Nando de Freitas. Sample efficient actor–critic with experience replay. In International Conference on Learning Representations, 2016.
- Watkins and Dayan (1992) Christopher J.C.H. Watkins and Peter Dayan. Q–learning. Machine Learning, 8(3-4), 1992.
- Weaver and Tao (2001) Lex Weaver and Nigel Tao. The optimal reward baseline for gradient–based reinforcement learning. In Conference on Uncertainty in Artificial Intelligence, 2001.
- White (2015) Adam White. Developing A Predictive Approach To Knowledge. PhD thesis, University of Alberta, 2015.
- White (2017) Martha White. Unifying task specification in reinforcement learning. In International Conference on Machine Learning, 2017.
- Williams (1992) Ronald J. Williams. Simple statistical gradient–following algorithms for connectionist reinforcement learning. Machine Learning, 8, 1992.
- Williams and Peng (1991) Ronald J. Williams and Jing Peng. Function optimization using connectionist reinforcement learning algorithms. Connection Science, 3(3), 1991.
- Witten (1977) Ian H. Witten. An adaptive optimal controller for discrete–time Markov environments. Information and Control, 34(4), 1977.
- Yu (2015) Huizhen Yu. On convergence of emphatic temporal–difference learning. In Conference on Learning Theory, 2015.
- Zhang et al. (2019) Shangtong Zhang, Wendelin Boehmer, and Shimon Whiteson. Generalized off-policy actor-critic. In Conference on Neural Information Processing Systems, 2019.
- Zhang et al. (2020) Shangtong Zhang, Bo Liu, Hengshuai Yao, and Shimon Whiteson. Provably convergent two–timescale off-policy actor–critic with function approximation. In International Conference on Machine Learning, 2020.