OE-BevSeg: An Object Informed and Environment Aware Multimodal Framework for Bird’s-eye-view Vehicle Semantic Segmentation
Abstract
Bird’s-eye-view (BEV) semantic segmentation is becoming crucial in autonomous driving systems. It realizes ego-vehicle surrounding environment perception by projecting 2D multi-view images into 3D world space. Recently, BEV segmentation has made notable progress, attributed to better view transformation modules, larger image encoders, or more temporal information. However, there are still two issues: 1) a lack of effective understanding and enhancement of BEV space features, particularly in accurately capturing long-distance environmental features and 2) recognizing fine details of target objects. To address these issues, we propose OE-BevSeg, an end-to-end multimodal framework that enhances BEV segmentation performance through global environment-aware perception and local target object enhancement. OE-BevSeg employs an environment-aware BEV compressor. Based on prior knowledge about the main composition of the BEV surrounding environment varying with the increase of distance intervals, long-sequence global modeling is utilized to improve the model’s understanding and perception of the environment. From the perspective of enriching target object information in segmentation results, we introduce the center-informed object enhancement module, using centerness information to supervise and guide the segmentation head, thereby enhancing segmentation performance from a local enhancement perspective. Additionally, we designed a multimodal fusion branch that integrates multi-view RGB image features with radar/LiDAR features, achieving significant performance improvements. Extensive experiments show that, whether in camera-only or multimodal fusion BEV segmentation tasks, our approach achieves state-of-the-art results by a large margin on the nuScenes dataset for vehicle segmentation, demonstrating superior applicability in the field of autonomous driving. Our code will be released at https://github.com/SunJ1025/OE-BevSeg.
Index Terms:
BEV semantic segmentation, environment perception, centerness information, autonomous driving.
I Introduction
Recent years, BEV perception has played an increasingly important role in the field of autonomous driving [1, 2, 3, 4]. Almost all mainstream autonomous driving systems, robotics, etc., have adopted the BEV paradigm for 3D space perception. Due to the low cost of cameras, converting perspective view (PV) to BEV view [5, 6, 7, 8] using multiple cameras has attracted extensive attention. As a pixel-level classification algorithm, semantic segmentation [9, 10, 11] predicts high-precision semantic perception labels for autonomous vehicles. BEV semantic segmentation’s powerful representation of the surrounding environment provides rich contextual and geometric information for autonomous driving planning and decision. Meanwhile, the BEV space facilitates multi-modal fusion by merging data from different sensors (e.g., cameras, radar, LiDAR) into a unified space. BEVFusion[12] proposes a method for fusing RGB images and LiDAR data. It employs two parallel networks to separately extract image features and point cloud features, and finally performs fusion in the BEV space. BEVFusion [12] has demonstrated that incorporating LiDAR data can significantly enhance the accuracy and robustness of 3D object detection in autonomous driving. In this work, inspired by [10], we integrate radar/LiDAR information by simply rasterizing the radar/LiDAR data and combining it with camera features. Experimental results demonstrate that the utilization of radar or LiDAR significantly enhances the performance BEV segmentation by a large margin.
Generally speaking, BEV perception algorithms consist of three important fundamental components, which are PV image encoder, perspective transformation module, and decoder. Most pipelines mainly focus on improving these three aspects. Specifically, this involves handle the view discrepancy between the surrounding environment and a fixed-size BEV space, with the aim of achieving pixel-level semantic segmentation of different vehicle targets.
Existing methods typically involve designing a distinctive viewpoint transformation module between the camera image space and the BEV space. Early methods are mainly geometric projection-based approaches. Inverse perspective mapping (IPM) [13] is a representative algorithm among them, which requires using the camera’s intrinsic and extrinsic parameters or camera pose for transformation. However, this method is based on the assumption that the ground is flat and is sensitive to vehicle motion. Deep learning-based methods, such as Multi-Layer Perceptron (MLP) and Transformer [14], have demonstrated improved robustness. In this work, we do not use the computationally expensive Multi-scale Deformable Attention [15]. Instead, we employ a simple bilinear sampling strategy [10] to achieve efficient perspective transformation.
However, after completing the perspective transformation from PV to BEV, directly feeding the BEV features into the decoder for simple upsampling does not fully exploit the potential of the BEV feature. This approach may lose pivotal cues in the BEV space, resulting in less robust performance in some challenging scenarios. BEVDet [16] proposed a BEV encoder to further encodes the BEV feature. They utilized the residual structure of ResNet to perceive scale, direction, and velocity within the BEV space. UIF-BEV [17] introduced camera underlying information to achieve interaction between temporal and spatial data in the BEV space. OCBEV[18] utilizes high-confidence locations as decoder queries, adding heatmap supervision to the BEV feature. The above methods further process the BEV feature using convolutional networks or transformer architectures, leading to improved segmentation performance. However, they lack consideration of the long-distance hierarchical environment of the BEV space. In recent advancements in semantic segmentation, Mamba [19] architecture has improved the computational efficiency of the SSM model [20], demonstrating excellent performance in long-sequence modeling and global information dependency.
In this paper, we present OE-BevSeg, which adopts the classic Encoder-Decoder structure and introduces a fusion branch to fuse RGB image and point cloud data. We optimize the network from two aspects: environmental perception and target object enhancement. From the perspective of environmental perception, we introduce Mamba into BEV semantic segmentation. Unlike existing models, our method leverages Mamba’s efficient long-sequence modeling capability, achieving linear computational complexity while maintaining global enviroment awareness. Compared to Transformers of similar scale, Mamba has five times the throughput [19].
We explored the environmental characteristics of BEV space and proposed that the urban environmental elements in BEV space can be divided into three hierarchical stages as the distance from the ego-vehicle increases: road, buildings, and sky. Based on this, we proposed an improved Mamba scan mechanism. Inspired by [18], in addition to environment-aware perception, object-centric modeling is key to BEV segmentation. Therefore, we fully utilized centerness information [5] to enrich target area information, enhancing the model’s robustness in challenging scenarios.
In summary, our contributions are as follows:
-
•
We present an end-to-end multimodal framework for the BEV vehicle semantic segmentation. To the best of our knowledge, this is the first work to specifically design Mamba global modeling for the BEV segmentation.
-
•
We propose the Environment-aware BEV Compressor, which leverages Mamba’s global receptive field to enhance BEV feature’s ability to perceive and understand the long-distance surrounding environment.
-
•
We improve Mamba’s scanning mechanism in BEV space. Based on the enviroment prior knowledge, we propose a Bi-Surround Scan approach that prioritizes the modeling of relevant hierarchical environmental components, enabling model to capture the spatial relationships of BEV features and enhance the model’s environment perception capability, thereby better distinguishing between foreground and background.
-
•
From an object-centric modeling perspective, we propose the Center-Informed Object Enhancement module, which uses centerness information to supervise and guide the segmentation head. Spatial attention and multi-view deformable cross-attention are used to enhance the model’s focus on local target object areas, enriching the segmentation results with target object-related information.

II Related work
This paper contributes to the state-of-the-art BEV semantic segmentation algorithm. In this section, we will introduce related works on bird’s-eye-view (BEV) semantic segmentation algorithms, including camera-only methods and multimodal approaches. Specifically, we will review State Space-related models, which are introduced into the BEV segmentation field for the first time in this work.
II-A BEV Segmentation in Intelligent Traffic Systems.
In recent years, bird’s eye view (BEV) perception algorithms have made a significant contribution in the fields of intelligent transportation and autonomous driving. BEV semantic segmentation is critical as it provides essential local maps in today’s intelligent traffic systems, where perception is prioritized over High-definition (HD) mapping.
Camerea-based BEV Perception Methods. VPN [21] is one of the pioneering approaches in cross-view semantic segmentation. It introduced the View Parsing Network in simulated 3D environments, utilizing multiple MLP layers to regress the transformation matrix from PV to BEV. Based on VPN, PON [22] introduced a semantic Bayesian occupancy grid to establish map relationships across multiple frames. It also utilized a feature pyramid to extract multi-resolution features. CVT [7] is a Transformer-based method that utilizes cross-attention to perform the conversion from PV space to BEV space. BEVFormer [6] and BEVSegFormer [23] leverage deformable attention in a DETR-style [15] approach to enhance view transformation and feature representation. BEVFormer makes full use of spatiotemporal information by introducing a spatial cross-attention and temporal self-attention to aggregate spatial and temporal features. BEVSegFormer, by contrast, focuses on flexibly handling BEV segmentation tasks under arbitrary (single or multiple) cameras without requiring intrinsic and extrinsic camera parameters.
Multimodal Perception Methods. Cameras and radars are two of the most common sensors in the field of autonomous driving. Radar point cloud features typically contain information that complements camera data. Fishing Net [24] employs the same MLP as VPN for view conversion and extends BEV segmentation through posterior multimodal fusion using radar and LiDAR features. CRN [25] utilizes a well-designed multimodal fusion module and proposes a two-stage fusion method, which employs deformable attention to integrate camera and radar data effectively. In contrast to CRN, simpleBEV [10] proposes a lifting method that does not rely on depth estimation. It highlights that batch size and input resolution significantly impact BEV segmentation performance. The study also demonstrates that using a simple method to concatenate camera and rasterized radar data can effectively enhance segmentation performance.
II-B Developement of State Space Model.
State Space Model (SSM) have shown promising performance in long sequence modeling for its linear-time inference, parallelizable training, and robust performance. Unlike CNNs and Transformers, State Space Model (SSM) is inspired by traditional control theory, which maps input sequences to state representations. Structured State Space for Sequences (S4) [20] effectively handles discretized data by utilizing the zero-order hold method. The use of Highest Polynomial Powered Operator (HiPPO) [26] initialization significantly enhances the long-range modeling capabilities of the S4 model. However, S4 cannot adaptively adjust based on the input, meaning it cannot selectively focus on important parts of the input. Mamba incorporates selective information processing, enabling dynamic handling of input data. This allows the model to selectively remember or ignore different parts of the input, thereby improving the utilization of historical information.
Recent works, VMamba [27] and Vim [28], introduce the Mamba model to computer vision tasks. VMamba proposes a Cross-Scan Module to conduct selective scan in four different directions, which allows the model to maintain a global receptive field while achieving linear computational complexity. Vim introduces a Bidirectional SSM that performs global modeling in both forward and backward directions. [29, 30, 31], demonstrate the effectiveness of the Mamba model in medical and remote sensing image segmentation. Inspired by these works, we introduce Mamba into BEV semantic segmentation task to enhance the model’s global perception capabilities to the long-distance surrounding enviroments of the BEV space.
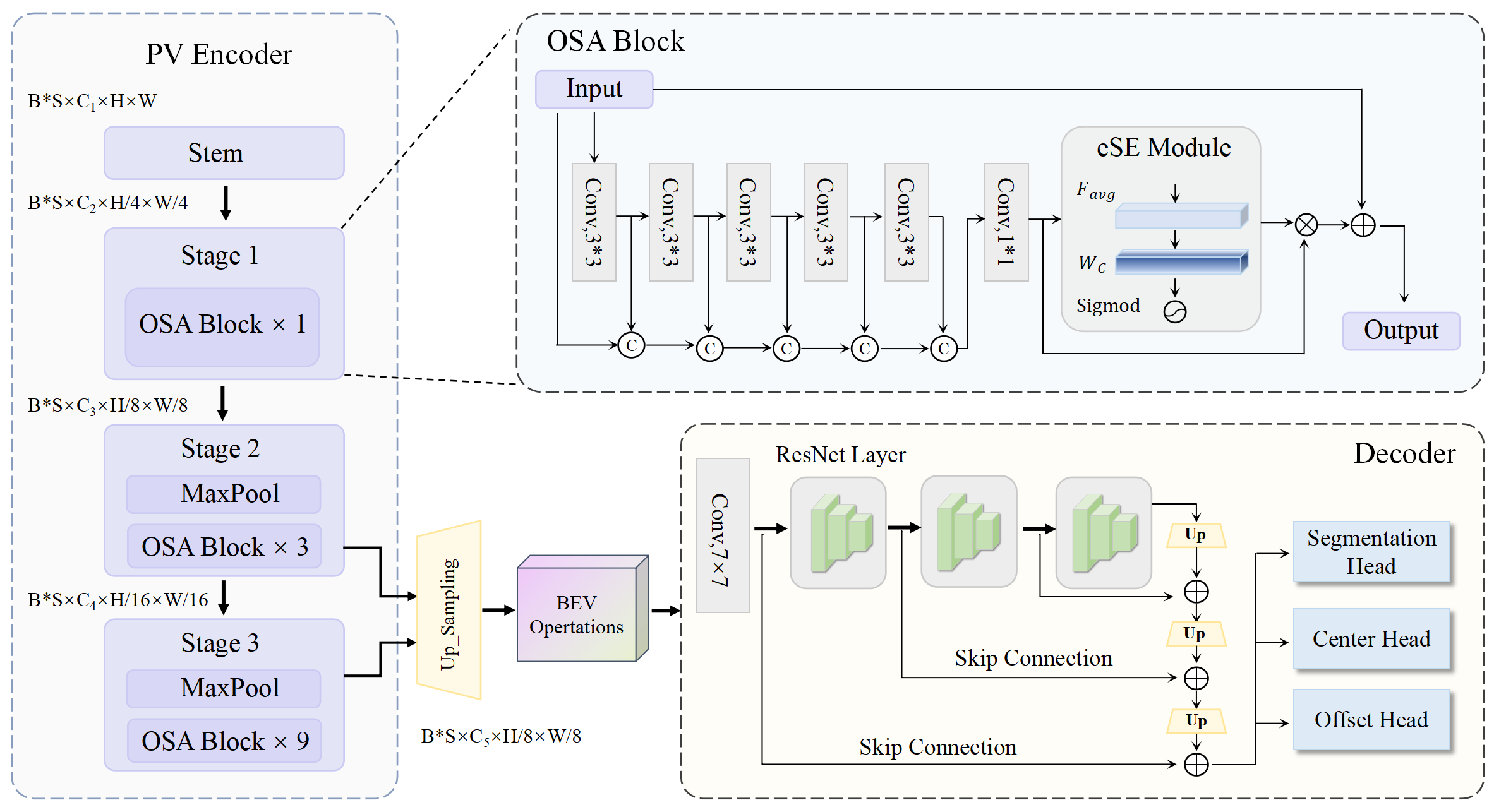
III Methodology
In this work, we propose the OE-BEVSeg model, which adopts an Encoder-Decoder framework and introduces a fusion branch to integrate radar/LiDAR and RGB PV features, achieving multimodal segmentation. We utilize a simple, parameter-free BEV perspective transformation module to obtain 3D voxels through bilinear sampling. Our BEV segmentation network is optimized from two perspectives: environment perception and target object enhancement. From the perspective of environment perception, we propose the Environment-aware BEV Compressor: (1) For the BEV features aggregated from surround-view, we utilize the long-range modeling capability of the Mamba to obtain global perception features. (2) Using prior knowledge, we design a bi-surround scan method based on the characteristics of BEV perception to enhance the model’s understanding of BEV space, thereby acquiring more robust BEV features. From the target object perspective, we propose the Center-Informed Object Enhancement module: (1) In the PV space, we use the centerness predicted by the center head as a query, leveraging multi-view deformable cross-attention to enhance the model’s ability to predict the centerness of the target object. (2) In the BEV space, we apply a spatial cross attention mechanism to the center feature to improve the focus on the object center region in the segmentation results.
III-A Problem Definition and Overview
In autonomous driving task, BEV perception involve segmenting by projecting the vehicle’s surrounding environment into a bird’s-eye view. As illustrated in Fig.2, the inputs typically consist of images from multiple cameras and radar point cloud , where and denote the number of cameras and the channels of the radar data, respectively. , , are used to represent the left-right, up-down, and front-back axes, respectively. After the PV sapce feature is extracted by the encoder, it is lifted to 3D space by a parameter free bilinear sampling method[10]. Then is aggregated to get the BEV feature , where is the dimension of the PV sapce feature. The 3D perception range represented by is in the and axes, with a corresponding resolution of . The up/down span of is set to , with a resolution of 8. The fusion of multimodal features and is achieved in BEV space to obtain the fused features . In this paper, we propose the Environment-aware BEV Compressor (EBC) and Center-Informed Object Enhancement (CIOE) modules to enhance the model’s environment perception ability and enrich the detail target object information. Finally, the Decoder performs upsampling and includes a multi-task head designed for segmentation and predicting centerness and offsets, which outputs the final segmentation mask .
III-B Overall Architecture
The overall architecture of our proposed OE-BevSeg illustrated in Fig.3. To capture rich contextual information, we utilized a large backbone VOVNetV2 followed by [32] as the encoder for PV perspective images, and the first three layers of a small backbone ResNet18 [33] for upsampling. The input image first passes through the stem, generating features with width and height of the . represent the batchsize, camera number, input channel. The stem is composed of three layers of convolutions with strides of and . The input channels of each stage . OSA block number of each stage . The One-Shot Aggregation (OSA) block employs the principle of dense interaction, aggregating the outputs of all previous layers in one step at the end to capture rich multi-scale texture information. The eSE Module is a crucial component of the OSA block, similar to the SENet [34] structure, which can further enhance segmentation performance. The eSE Module can be represented as follows:
| (1) |
| (2) |
Where represents average pooling, denotes fully connected layer, and refers to the hsigmod operation, which specifically consists of ReLU6. represents learnable channel weights, and indicates element-wise multiplication. and represent the input features and output features of the OSA block, respectively.
In the Decoder part, we use simple ResNet layers , along with bilinear upsampling and cross-layer skip connections to map the features to the output mask. By utilizing this layer-by-layer summative skip connection method, more multi-scale detail information is preserved during the upsampling process. The upsampling process can be summarized in the following equation:
| (3) |
where denotes the feature after upsampling in , and denotes the skip connection feature map in . Upsampling starts at the and proceeds sequentially forward, ultimately generating an upsampled feature map .

III-C Environment-aware BEV Compressor
Bird’s-Eye View (BEV) features encapsulate extensive environmental semantics, which significantly influences a model’s ability to differentiate between foreground and background elements. Previous research lacks further processing of BEV features after completing the perspective transformation. Inspired by the powerful long sequences modeling and computationally efficient State Space Model (SSM), we employed the recently prominent Mamba to model the global context of the environment in the BEV space.
With full consideration of the characteristics of the BEV perspective, we find that as the distance from the ego-vehicle increases, the surrounding environment sampled by the BEV features will change significantly. Specifically, at the closest distance to the ego-vehicle, such as , the main component of the environment is the road surface. At a further distance of , the main component of the environment is usually buildings. At , the main component in the environment from multiple camera views should be the sky-related elements. Experiments in distance-phase segmentation [17, 7] have also demonstrated this point, the segmentation results vary significantly at different distances from the ego-vehicle. Therefore, if only global features are learned while ignoring the characteristics of the driving environment, the model cannot effectively understand and perceive the BEV space. Based on the aforementioned prior knowledge, we have improved Mamba by proposing the Bi-Surround Scan mechanism to serialize the BEV features, enhancing the model’s environment-aware capabilities.
State Space Model (SSM). State Space Model originates from control theory and represents a method of mathematically describing a problem using the minimal number of variables that fully describe the linear time-invariant system, i.e., . In continuous time , the current hidden state is calculated using the previous hidden state and the current input . is the prediction of . Specifically, the model can be represented by the following ordinary differential equations:
| (4) |
| (5) |
Where is the evolution parameter, , and are the weighting parameters.
Discretization of SSM. The above SSMs cannot handle discrete data. To be applicable in deep learning, the SSMs of the continuous system need to be discretized. Structured State Space for Sequences (S4) achieves the discretization of SSMs using the zero-order hold technique, as shown in Eqn.(6)-(8):
| (6) |
| (7) |
| (8) |
| (9) |
| (10) |
However, the parameters of , , and in S4 cannot adaptively change based on different inputs, which limits the ability to effectively select important information. Mamba introduces a selection mechanism to enhance adaptability to different inputs and more effectively utilize previous information.
Bi-Surround Scan mechanism
Existing studies explore new scan methods suitable for specific tasks, such as cross-scan [27] and backward scan [28] to improve Mamba’s image understanding capability. Inspired by the BEV space’s surround sampling strategy and the typical urban environment’s main components based on distance intervals, we designed a bidirectional surround scan mechanism (Bi-Surround Scan) to improve Mamba’s adaptability in processing BEV features.
In this paper, the resolution of the BEV space is . The BEV features are divided into patches in the and axes, resulting in patch embeddings. As shown in Fig.4, according to the distance intervals from the ego-vehicle, we divided the BEV feature into three parts:, corresponding to the distances of . These three parts are hierarchically correspond to the road surface, buildings, and sky elements. Simply learning the global contextual information through serialization ignores this prior information. Therefore, based on the forward scan, we propose the forward surround scan and backward surround scan. These methods prioritize the modeling of environment-related components, allowing Mamba to learn hierarchical environmental features. The detailed process is illustrated in Algo.1. Given the BEV feature and the Surround-Scan Mamba block with three distinct scan branches, , , and . is employed as the activation function, and serves as the gating mechanism for the outputs , , . Finally, is obtained through skip connections.
III-D Center-Informed Object Enhancement
Inspired by object-centric modeling [18], we introduced a center head that uses vehicle instance centerness as supervisory information, and designed a corresponding center loss based on L2 distance. In addition to the loss function, we explicitly utilized centerness information in both PV and BEV space to enhance and improve the output of the segmentation head. As shown in Fig.5, we take the output of ConvBlock after Decoder and before center head in BEV space as center feature . Taking Center Feature as input, we use spatial attention [34] to obtain the center masks based on the
vehicle centerness. The entire process can be represented as follows:
| (11) |
Where and represent max pooling and average pooling, respectively. ⓒ denotes concatenation along the channel dimension, and is the Sigmoid operation.
In the PV space, we introduce Multi-view deformable cross attention based on the deformable attention in the BEVFormer [6]. Whereas in our framework, we replace the predefined queries with confidence heatmap output by the center head , Where represents batch size, and are left-right and front-back axes of BEV space, respectively, and denotes the number of channels in the confidence heatmap. The multi-view features are used as the key and value , where is the PV feature from the view. is the number of all camera views. for positional embeddings. Multi-view image features can be represented as , which we combine into a single vector . For center queries, . The specific formula is expressed as follows:
| (12) |
| (13) |
| (14) |
Through multi-view deformable cross attention , inquires about the vehicle centerness information from the multi-view image features , which enables the model to focus more on the spatial regions where vehicles are located in the image, thereby better distinguishing between foreground and background. The specific formula can be expressed as follows:
| (15) |

III-E Loss Function
Our OE-BevSeg includes a multi-task prediction head. In addition to the segmentation head, we introduce auxiliary task heads to predict vehicle instance centerness and offset. The centerness indicates the probability of finding the vehicle center [35], which is represented by the 2D Gaussian distribution and ranges from zero to one. The offset head output is a vector field, which points to the center of the instance.
The segmentation head uses the cross-entropy loss function, the center head is supervised using the loss, and the offset head uses the loss. To balance multi-task learning, we employ learnable weights based on uncertainty [36] to balance the three loss functions. The specific formulae are as follows:
| (16) |
| (17) |
| (18) |
| (19) |
Where represents the total number of pixels, and is the probability of predicting the pixel as a vehicle. , and are the learnable uncertainty weights corresponding to the respective loss functions.
IV EXPERIMENT
IV-A Dataset
In this study, we conducted extensive experiments on the challenging nuScenes [37] urban scenes dataset to demonstrate the effectiveness of our OE-BEVSeg in large-scale autonomous driving scenarios. All data were collected using 6 cameras, 1 LiDAR, and 5 radar sensors, and then sampled at a well-synchronized frequency of 2Hz for the keyframes. The data were collected from 1,000 complex driving scenarios in Boston and Singapore, with 850 scenarios used for training and 150 for testing. There are 28,130 samples in the training set, while the validation set comprises 6,019 samples. We conducted research on BEV segmentation specifically for vehicle objects and performed experiments combining radar/LiDAR multimodal data. The ”vehicle” superclass consists of eight categories, i.e., bicycle, bus, car, construction vehicle, emergency vehicle, motorcycle, trailer, and truck. We use the intersection-over-union (IOU) as evaluation metric.
| Method | Public Year | Backb. | Lifting | Temp. | Modalities | Batchsize | Resolution | IOU |
| FISHING[24] | CVPR’2020 | EN-b4 | MLP | RGB | - | 192320 | 30.0 | |
| Lift, Splat[38] | ECCV’2020 | EN-b0 | Depth splat | RGB | 4 | 128352 | 32.1 | |
| FIERY[5] | CVPR’2021 | EN-b4 | Depth splat | RGB | 12 | 224480 | 35.8 | |
| RGB+time | 12 | 224480 | 38.2 | |||||
| CVT[7] | CVPR’2022 | EN-b4 | Attention | RGB | 16 | 224448 | 36.0 | |
| TIIM[39] | ICRA’2022 | RN-50 | Ray attn. | RGB | 8 | 900 1600 | 38.9 | |
| RGB+time | 8 | 9001600 | 41.3 | |||||
| BEVFormer[6] | ECCV’2022 | RN-101 | Def. Attn. | RGB | 1 | 9001600 | 44.4 | |
| RGB+time | 1 | 9001600 | 46.7 | |||||
| FedBEVT[40] | T-IV-2023 | Trans. | Attention | RGB | 4 | - | 35.4 | |
| BAEFormer[41] | CVPR’2023 | EN-b4 | Attention | RGB | 16 | 224480 | 41.0 | |
| PETRV2[42] | ICCV’2023 | V2-99 | Attention | RGB | 1 | 9001600 | 46.3 | |
| SimpleBEV[10] | ICRA’2023 | RN-101 | Bilinear | RGB | 40 | 448800 | 47.4 | |
| UIF-BEV[17] | T-IV-2024 | Trans. | Attention | RGB+time | 4 | 224448 | 36.0 | |
| PointBEV[43] | CVPR’2024 | RN-50 | Bilinear | RGB | 28 | 448 × 800 | 47.0 | |
| EN-b4 | RGB | 28 | 448800 | 47.6 | ||||
| EN-b4 | RGB+time | 28 | 448800 | 48.7 | ||||
| Ours | OURS | V2Res-Net | Bilinear | RGB | 85 | 448800 | 52.6 | |
| Ours | OURS | V2Res-Net | Bilinear | RGB+Radar | 85 | 448800 | 58.0 | |
| Ours | OURS | V2Res-Net | Bilinear | RGB+LiDAR | 85 | 448800 | 65.3 |
IV-B Implementation Details
For the experimental implementation, We used the PyTorch framework and trained on four 40 GB NVIDIA A100 GPUs for a total of 20,000 iterations. The height and width of the input surround-view images are 448 and 800, respectively. The learning rate was set to 5e-4, using the Adam-W optimizer and the one-cycle learning rate schedule [44]. The resolution of the BEV space is , with a channel dimension of 128, corresponding to a perception range of . The encoder of our OE-BevSeg network adopts the first three stages of VOVNetV2, and the decoder uses the first three layers of ResNet18 as the backbone. Following the report of [10], a larger batch size yields superior results. With limited GPU memory, we accumulate the forward and backward over 5 iterations before performing a parameter update during training. This approach leads to more stable gradient updates and better model performance. Without increasing memory usage, we achieved training with a batch size of 40.
IV-C State-of-the-art comparison
We compared our approach with other competitive algorithms for BEV segmentation, including recent most advanced methods such as PETRv2[42], SimpleBEV [10], and PointBEV [43]. To ensure fair comparison, we also listed the viewpoint lift methods, whether temporal information was used, and the resolution used during training for each algorithm. As shown in Table I, our OE-BEVSeg demonstrates superior performance. Compared to SimpleBEV, which uses the same perspective transformation method and resolution, our method outperforms by in IOU under camera-only conditions. Additionally, compared to the latest PointBEV, which utilizes temporal information, we achieve a improvement in IOU. Compared to TIIM, BEVFormer and PETRv2, which use the original image resolution of , our method significantly outperforms these high-resolution training and testing algorithms even when the input is at resolution. Specifically, our method surpasses PETRv2 by in IOU. This substantial improvement in BEV segmentation performance demonstrates the effectiveness of our approach. Additionally, Table I illustrates the superiority of our multi-modal branches. By fusing radar data, our method further improves IOU by compared to the camera-only approach. When integrating LiDAR data, the IOU reaches , exceeding the camera-only approach by a large margin about .
| Method | Metric | |||||
| EBC Block | CIOE Block | Without Flitering | Visibility Filtering | |||
| Normal Scan | Surround Scan | BEV Enhance | PV Enhance | Params(M) | IOU | IOU |
| 62.27 | 43.68 | 50.53 | ||||
| 68.94 | 44.26 | 51.33 | ||||
| 69.23 | 44.34 | 51.64 | ||||
| 69.69 | 44.40 | 51.75 | ||||
| 69.98 | 44.37 | 52.10 | ||||
| 80.37 | 44.98 | 52.65 | ||||
IV-D Ablation Studies
In this section, we conduct extensive ablation studies on the core ingredients proposed in this paper: the EBC Block and CIOE Block, the combination of loss functions, different image resolutions, the combination of different modal data, and different vehicle perception distances.
| Vehicle seg. IoU (↑) | Metric | ||
| CE loss | Center loss | Offset loss | IOU(↑) |
| 47.42 | |||
| 46.93 | |||
| 48.04 | |||
| Vehicle seg. IoU (↑) | Input Shape | ||
| Method | Backb. | 224480 | 448800 |
| FIERY[5] | EN-b4 | 39.8 | - |
| CVT[7] | EN-b4 | 36.0 | 37.7 |
| LaRa [45] | EN-b4 | 38.9 | - |
| BEVFormer [6] | RN-50 | 42.0 | 45.5 |
| BAEFormer [41] | EN-b4 | 38.9 | 41.0 |
| SimpleBEV [10] | RN-50 | 43.0 | 46.6 |
| PointBEV[43] | RN-50 | 44.1 | 47.7 |
| EN-b4 | 44.7 | 48.7 | |
| OE-BEVSeg (Ours) | V2Res-Net | 47.6 | 52.6 |
| Vehicle. seg. IoU (↑) | Modalities | ||||
| Method | Radar | Lidar | RGB | IOU(↑) | |
| FISHING[24] | 30.0 | ||||
| Lift, Splat[38] | 32.1 | ||||
| SimpleBEV[10] | 47.4 | ||||
| OE-BEVSeg (Ours) | 52.6 | ||||
IV-D1 Effectiveness of EBC block
The Environment-aware BEV Compressor is our proposed global long-distance environment awareness module based on Mamba. Specifically, we designed a surround scan mechanism. As shown in Table II, we conducted ablation experiments on the normal scan and surround scan methods. The visibility filtering means that if a car is not visible from any camera viewpoint, we discard it. Without filtering means all annotated vehicles are considered. It can be observed that with the use of the visibility filter, the introduction of the EBC module increases the IOU by compared to the baseline. Without filtering, the increase is . When we use both normal scan and surround scan and use visibility filter, the IOU improvement is .
| Method | Modalities | Visibility Filtering | Without Flitering | ||||||
| Vehicle Perception Range | Vehicle Perception Range | ||||||||
| 0-20m | 20-35m | 35-50m | 0-50m | 0-20m | 20-35m | 35-50m | 0-50m | ||
| SimpleBEV | C | 65.7 | 44.9 | 27.3 | 47.4 | 62.0 | 38.6 | 22.5 | 40.8 |
| C+R | 70.1 | 53.6 | 39.1 | 55.5 | 66.1 | 45.4 | 31.4 | 47.6 | |
| OE-BEVSeg (Ours) | C | 70.6 | 51.0 | 32.9 | 52.6 | 66.2 | 42.9 | 26.8 | 44.9 |
| C+R | 72.8 | 56.8 | 40.6 | 58.0 | 68.4 | 47.1 | 32.5 | 49.1 | |
| C+L | 78.3 | 64.9 | 48.7 | 65.3 | 73.7 | 54.2 | 38.5 | 55.4 | |




IV-D2 Effectiveness of CIOE block
The center-informed object enhancement is proposed to better explicitly utilize vehicle instance centerness, enhancing and enriching the detail information of the target object in the segmentation results, and effectively distinguishing between the foreground and background. As shown in Table II, we achieve different levels of improvement by enhancing the BEV space and PV space using the CIOE block. Additionally, the experimental results demonstrate that using both the CIOE block and the EBC block yields the greatest benefits. After adding the CIOE block to the network, the model’s IOU improved by . Using both the CIOE block and the EBC block together, compared to the backbone, resultes in a IOU improvement.
IV-D3 Effectiveness of loss functions
In this paper, we propose a multi-task prediction head corresponding to three different losses: the cross-entropy loss function, center loss, and offset loss. As shown in Table III, at the beginning of our experiments, we performed ablation studies on the loss functions based on the baseline. It can be seen that introducing center loss on top of the cross-entropy loss function achieved better results than the offset loss. When we used all three losses simultaneously, the IOU reached a maximum of . This also demonstrates the effectiveness of our approach to enhancing target object information using vehicle centerness.
IV-D4 Ablation experiments with image resolution
The input image resolution has a significant impact on segmentation tasks, with larger resolutions generally yielding better segmentation results. In Table IV, we compared advanced models using two image resolutions: and . These models include CVT, BEVFormer, SimpleBEV, and PointBeV. The experimental results demonstrate that our OE-BevSeg achieved the best IOU regardless of whether a larger or smaller image resolution was used. Furthermore, OE-BevSeg outperformed other algorithms by a greater margin at higher resolutions. When the resolution was , the IOU exceeded that of SimpleBEV by and PointBEV by . These results confirm the importance of high-resolution images for BEV segmentation tasks and also demonstrate the robustness of our method to different resolution inputs.
IV-D5 Effectiveness of multimodal fusion
In this paper, we employed a multi-modal fusion branch to integrate multi-view RGB images with radar/LiDAR data, significantly enhancing the performance of BEV segmentation. As shown in Table V, we conducted comparative experiments with advanced BEV semantic segmentation algorithms that also use multi-modal data. The inclusion of additional auxiliary modal data resulted in substantial performance improvements across these algorithms. Compared to the best-performing SimpleBEV, our method achieved the highest IOU of when fusing radar data, surpassing SimpleBEV by . When fusing LiDAR data, our method also achieved the highest IOU of , surpassing SimpleBEV by . The fusion of LiDAR data demonstrated better potential performance compared to radar data. Our OE-BevSeg showing a improvement when using radar data in the fusion branch, and a substantial improvement when using LiDAR data.
IV-D6 Ablation experiments with vehicle perception distance
As shown in Table VI, we evaluated the model’s performance as the distance from the ego vehicle increases. We divided vehicle perception into three ranges: , , and , and also assessed the overall segmentation performance in . We conducted relevant ablation experiments under both visibility filtering and without filtering conditions. As depicted in Fig.6, it is clear that as the distance intervals increase, the model’s performance gradually declines. This also validates the feasibility of using the hierarchical environmental composition in the BEV space as prior knowledge. Our model demonstrated superior performance, surpassing SimpleBEV in every distance interval. Notably, in the challenging long-distance segmentation (), our OE-BevSeg outperformed SimpleBEV by under the without filtering condition and by under the visibility filtering condition.
IV-E Qualitative Results
As shown in Fig.7, we visualized the BEV vehicle segmentation results and selected some challenging scenarios, such as rainy, occlusion, and night. Our OE-BevSeg achieved segmentation results closest to the ground truth, even in these difficult scenarios. The blue mask represents vehicles, the red annotations indicate negative results, and the green annotations indicate good results. It can be seen that OE-BevSeg provides better segmentation details. Compared to SimpleBEV, we reduce the number of true negative samples in night and occlusion scenarios, as well as the number of false negative samples in rainy scenarios. The fusion of multi-modal information, such as radar and LiDAR, enriches the segmentation details, better delineating vehicle contours. Multi-modal information provides valuable cues for measuring scene structure, enhancing the BEV segmentation performance.
To more intuitively demonstrate the benefits of centerness in enhancing object detail information, as shown in Fig.8, we visualized the BEV feature and center feature using heatmaps based on the V2Res-Net baseline. We can observe a clear distinction between the visualization of the BEV and center feature. The BEV feature focuses more on global perception but lacks sufficient attention to the target object. In contrast, the center feature focuses more on the vehicle area, showing higher activation values. Therefore, utilizing centerness to supervise and guide the segmentation head enables the model to better distinguish between the foreground and background.
Fig.9 shows the heatmap visualizations of the BEV features from the decoder of different models. It can be seen that in challenging scenarios, our OE-BevSeg can effectively focus on the vehicle object regions and better understand the environment, demonstrating improved differentiation between relevant areas with target objects and irrelevant areas without targets. This indicates that our model not only achieves better perception and understanding of the BEV long-distance environment but also enriches the information of target objects, thereby achieving superior vehicle segmentation performance.
V Conclusion
In this work, an innovative end-to-end multimodal framework is designed to address two shortcomings in current BEV semantic segmentation methods, particularly in capturing long-distance environmental features and recognizing fine details of target objects. We have proposed two novel techniques, i.e., environment-aware BEV compressor and center-informed object enhancement. By leveraging long-sequence global modeling based on prior knowledge about the BEV surrounding environment, the model’s long-distance environmental perception and understanding are significantly improved. Furthermore, from a local enhancement perspective, the instance centerness information is utilized to enrich detail target object information. Extensive experiments conducted on the nuScenes dataset demonstrate that our approach achieves state-of-the-art results in both camera-only and multimodal fusion BEV vehicle semantic segmentation tasks. In future work, we aim to explore enhancing the computational efficiency of the BEV segmentation algorithm while maintaining high accuracy, enabling better application in autonomous driving scenarios.
References
- [1] S. Teng, X. Hu, P. Deng, B. Li, Y. Li, Y. Ai, D. Yang, L. Li, Z. Xuanyuan, F. Zhu et al., “Motion planning for autonomous driving: The state of the art and future perspectives,” IEEE Transactions on Intelligent Vehicles, vol. 8, no. 6, pp. 3692–3711, 2023.
- [2] L. He, S. Jiang, X. Liang, N. Wang, and S. Song, “Diff-net: Image feature difference based high-definition map change detection for autonomous driving,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 2635–2641.
- [3] L. He, L. Li, W. Sun, Z. Han, Y. Liu, S. Zheng, J. Wang, and K. Li, “Neural radiance field in autonomous driving: A survey,” arXiv preprint arXiv:2404.13816, 2024.
- [4] Z. Han, J. Wang, Z. Xu, S. Yang, L. He, S. Xu, J. Wang, and K. Li, “4d millimeter-wave radar in autonomous driving: A survey,” arXiv preprint arXiv:2306.04242, 2023.
- [5] A. Hu, Z. Murez, N. Mohan, S. Dudas, J. Hawke, V. Badrinarayanan, R. Cipolla, and A. Kendall, “Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 273–15 282.
- [6] Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y. Qiao, and J. Dai, “Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” in European conference on computer vision. Springer, 2022, pp. 1–18.
- [7] B. Zhou and P. Krähenbühl, “Cross-view transformers for real-time map-view semantic segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 13 760–13 769.
- [8] H. Xu, X. Zhang, J. He, Z. Geng, C. Pang, and Y. Yu, “Surround-view water surface bev segmentation for autonomous surface vehicles: Dataset, baseline and hybrid-bev network,” IEEE Transactions on Intelligent Vehicles, 2024.
- [9] J. Sun, J. Shen, X. Wang, Z. Mao, and J. Ren, “Bi-unet: A dual stream network for real-time highway surface segmentation,” IEEE Transactions on Intelligent Vehicles, vol. 8, no. 2, pp. 1549–1563, 2022.
- [10] A. W. Harley, Z. Fang, J. Li, R. Ambrus, and K. Fragkiadaki, “Simple-bev: What really matters for multi-sensor bev perception?” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 2759–2765.
- [11] J. Liu, Z. Cao, J. Yang, X. Liu, Y. Yang, and Z. Qu, “Bird’s-eye-view semantic segmentation with two-stream compact depth transformation and feature rectification,” IEEE Transactions on Intelligent Vehicles, vol. 8, no. 11, pp. 4546–4558, 2023.
- [12] Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. L. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” in 2023 IEEE international conference on robotics and automation (ICRA). IEEE, 2023, pp. 2774–2781.
- [13] M. Bertozz, A. Broggi, and A. Fascioli, “Stereo inverse perspective mapping: theory and applications,” Image and vision computing, vol. 16, no. 8, pp. 585–590, 1998.
- [14] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [15] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,” arXiv preprint arXiv:2010.04159, 2020.
- [16] J. Huang, G. Huang, Z. Zhu, Y. Ye, and D. Du, “Bevdet: High-performance multi-camera 3d object detection in bird-eye-view,” arXiv preprint arXiv:2112.11790, 2021.
- [17] Y. Ren, L. Wang, M. Li, H. Jiang, C. Lin, H. Yu, and Z. Cui, “Uif-bev: An underlying information fusion framework for bird’s-eye-view semantic segmentation,” IEEE Transactions on Intelligent Vehicles, 2024.
- [18] Z. Qi, J. Wang, X. Wu, and H. Zhao, “Ocbev: Object-centric bev transformer for multi-view 3d object detection,” in 2024 International Conference on 3D Vision (3DV). IEEE, 2024, pp. 1188–1197.
- [19] A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” arXiv preprint arXiv:2312.00752, 2023.
- [20] A. Gu, K. Goel, and C. Ré, “Efficiently modeling long sequences with structured state spaces,” arXiv preprint arXiv:2111.00396, 2021.
- [21] B. Pan, J. Sun, H. Y. T. Leung, A. Andonian, and B. Zhou, “Cross-view semantic segmentation for sensing surroundings,” IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 4867–4873, 2020.
- [22] T. Roddick and R. Cipolla, “Predicting semantic map representations from images using pyramid occupancy networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 138–11 147.
- [23] L. Peng, Z. Chen, Z. Fu, P. Liang, and E. Cheng, “Bevsegformer: Bird’s eye view semantic segmentation from arbitrary camera rigs,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 5935–5943.
- [24] N. Hendy, C. Sloan, F. Tian, P. Duan, N. Charchut, Y. Xie, C. Wang, and J. Philbin, “Fishing net: Future inference of semantic heatmaps in grids,” arXiv preprint arXiv:2006.09917, 2020.
- [25] Y. Kim, J. Shin, S. Kim, I.-J. Lee, J. W. Choi, and D. Kum, “Crn: Camera radar net for accurate, robust, efficient 3d perception,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17 615–17 626.
- [26] A. Gu, T. Dao, S. Ermon, A. Rudra, and C. Ré, “Hippo: Recurrent memory with optimal polynomial projections,” Advances in neural information processing systems, vol. 33, pp. 1474–1487, 2020.
- [27] Y. Liu, Y. Tian, Y. Zhao, H. Yu, L. Xie, Y. Wang, Q. Ye, and Y. Liu, “Vmamba: Visual state space model,” arXiv preprint arXiv:2401.10166, 2024.
- [28] L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,” arXiv preprint arXiv:2401.09417, 2024.
- [29] S. Zhao, H. Chen, X. Zhang, P. Xiao, L. Bai, and W. Ouyang, “Rs-mamba for large remote sensing image dense prediction,” arXiv preprint arXiv:2404.02668, 2024.
- [30] J. Ma, F. Li, and B. Wang, “U-mamba: Enhancing long-range dependency for biomedical image segmentation,” arXiv preprint arXiv:2401.04722, 2024.
- [31] Z. Xing, T. Ye, Y. Yang, G. Liu, and L. Zhu, “Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation,” arXiv preprint arXiv:2401.13560, 2024.
- [32] Y. Lee, J.-w. Hwang, S. Lee, Y. Bae, and J. Park, “An energy and gpu-computation efficient backbone network for real-time object detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2019, pp. 0–0.
- [33] K. He, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,” in Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14. Springer, 2016, pp. 630–645.
- [34] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141.
- [35] T. Wang, X. Zhu, J. Pang, and D. Lin, “Fcos3d: Fully convolutional one-stage monocular 3d object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 913–922.
- [36] A. Kendall, Y. Gal, and R. Cipolla, “Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7482–7491.
- [37] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” arXiv preprint arXiv:1903.11027, 2019.
- [38] J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16. Springer, 2020, pp. 194–210.
- [39] A. Saha, O. Mendez, C. Russell, and R. Bowden, “Translating images into maps,” in 2022 International conference on robotics and automation (ICRA). IEEE, 2022, pp. 9200–9206.
- [40] R. Song, R. Xu, A. Festag, J. Ma, and A. Knoll, “Fedbevt: Federated learning bird’s eye view perception transformer in road traffic systems,” IEEE Transactions on Intelligent Vehicles, 2023.
- [41] C. Pan, Y. He, J. Peng, Q. Zhang, W. Sui, and Z. Zhang, “Baeformer: Bi-directional and early interaction transformers for bird’s eye view semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9590–9599.
- [42] Y. Liu, J. Yan, F. Jia, S. Li, A. Gao, T. Wang, and X. Zhang, “Petrv2: A unified framework for 3d perception from multi-camera images,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3262–3272.
- [43] L. Chambon, E. Zablocki, M. Chen, F. Bartoccioni, P. Pérez, and M. Cord, “Pointbev: A sparse approach for bev predictions,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 195–15 204.
- [44] L. N. Smith and N. Topin, “Super-convergence: Very fast training of neural networks using large learning rates,” in Artificial intelligence and machine learning for multi-domain operations applications, vol. 11006. SPIE, 2019, pp. 369–386.
- [45] F. Bartoccioni, É. Zablocki, A. Bursuc, P. Pérez, M. Cord, and K. Alahari, “Lara: Latents and rays for multi-camera bird’s-eye-view semantic segmentation,” in Conference on Robot Learning. PMLR, 2023, pp. 1663–1672.