Occam Learning Meets Synthesis Through Unification
Abstract.
The generalizability of PBE solvers is the key to the empirical synthesis performance. Despite the importance of generalizability, related studies on PBE solvers are still limited. In theory, few existing solvers provide theoretical guarantees on generalizability, and in practice, there is a lack of PBE solvers with satisfactory generalizability on important domains such as conditional linear integer arithmetic (CLIA). In this paper, we adopt a concept from the computational learning theory, Occam learning, and perform a comprehensive study on the framework of synthesis through unification (STUN), a state-of-the-art framework for synthesizing programs with nested if-then-else operators. We prove that Eusolver, a state-of-the-art STUN solver, does not satisfy the condition of Occam learning, and then we design a novel STUN solver, PolyGen, of which the generalizability is theoretically guaranteed by Occam learning. We evaluate PolyGen on the domains of CLIA and demonstrate that PolyGen significantly outperforms two state-of-the-art PBE solvers on CLIA, Eusolver and Euphony, on both generalizability and efficiency.
1. Introduction
In the past decades, oracle-guided inductive program synthesis (OGIS) (Jha and Seshia, 2017) receives much attention. In each iteration of OGIS, an oracle provides input-output examples to an inductive program synthesizer, or programming-by-example (PBE) synthesizer (Shaw et al., 1975), and the PBE synthesizer generates a program based on the examples. There are two typical types of OGIS problems. In the first type, the oracle can verify whether the synthesized program is correct, and provides a counter-example if the program is incorrect. Many applications under the counter-example guided inductive synthesis (CEGIS) framework (Solar-Lezama et al., 2006) fall into this type. In the second type, the oracle cannot verify the correctness of the synthesized program but can provide a set of input-output examples. This includes the applications where the oracle is a black-box program, such as binary programs (Zhai et al., 2016), and applications where the program is too complex to verify its correctness, e.g., the task involves system calls or complex loops, such as program repair, second-order execution, and deobfuscation (Mechtaev et al., 2015a; Mechtaev et al., 2018; David et al., 2020; Blazytko et al., 2017; Jha et al., 2010).
In both types of problems, the generalizability of the PBE solver is the key to synthesis performance. In the first type, generalizability significantly affects the efficiency: the fewer examples the solver needs to synthesize a correct program, the fewer CEGIS iterations the synthesis requires, and thus the faster the synthesis would be. In the second type, the generalizability of the PBE solver decides the correctness of the whole OGIS system.
Despite the importance of generalizability, the studies on the generalizability of the existing PBE solvers are still limited. On the theoretical side, as far as we are aware, no existing PBE solver provides theoretical guarantees on generalizability. On the practical side, the generalizability of the existing PBE solvers is not satisfactory. As our evaluation will demonstrate later, on a synthesis task for solving the maximum segment sum problem, Eusolver (Alur et al., 2017), a state-of-the-art PBE solver, uses examples to find the correct program, while our solver uses only .
In this paper, we propose a novel PBE solver, PolyGen, that provides a theoretical guarantee on generalizability by construction. We adopt a concept from the computational learning theory, Occam learning (Blumer et al., 1987), and prove that PolyGen is an Occam solver, i.e., a PBE solver that satisfies the condition of Occam learning. A PBE solver is an Occam solver if, for any possible target program consistent with the given examples, the size of the synthesized program is guaranteed to be polynomial to the target program and sub-linear to the number of provided examples with a high probability. In other words, an Occam solver would prefer smaller programs to larger programs and thus follows the principle of Occam’s Razor. In theory, Blumer et al. (1987) have proved that, given any expected accuracy, the number of examples needed by an Occam solver to guarantee the accuracy is bounded by a polynomial on the size of the target program. In practice, Occam learning has exhibited good generalizability in different domains (Kearns and Li, 1988; Kearns and Schapire, 1994; Angluin and Laird, 1987; Natarajan, 1993; Aldous and Vazirani, 1995).
PolyGen follows the synthesis through unification (STUN) (Alur et al., 2015) framework. STUN is a framework for synthesizing nested if-then-else programs, and the solvers based on STUN such as Eusolver (Alur et al., 2017) and Euphony (Lee et al., 2018) achieve the state-of-the-art results on many important benchmarks, e.g., the CLIA track in the SyGuS competition. A typical STUN solver consists of a term solver and a unifier. First the term solver synthesizes a set of if-terms, each being correct for a different subset of the input space, and then the unifier synthesizes if-conditions that combine the terms with if-then-else into a correct program for the whole input space.
We first analyze a state-of-the-art STUN solver, Eusolver (Alur et al., 2017), and prove that Eusolver is not an Occam solver. Then we proceed to design PolyGen. A key challenge to design an Occam solver is to scale up while satisfying the condition of Occam learning. For example, a trivial approach to ensuring Occam learning is to enumerate programs from small to large, and returns the first program consistent with the examples. However, this approach only scales to small programs. To ensure scalability, we divide the synthesis task into subtasks each synthesizing a subpart of the program, and propagate the condition of Occam learning into a sufficient set of conditions, where each condition is defined on a subtask. Roughly, these conditions require that each subtask synthesizes either a small program or a set of programs whose total size is small. Then, we find efficient synthesis algorithms that meet the respective conditions for each subtask.
We instantiate PolyGen on the domains of conditional linear integer arithmetic (CLIA), and evaluate PolyGen against Esolver (Alur et al., 2013), the best known PBE solver on CLIA that always synthesizes the smallest valid program, Eusolver (Alur et al., 2017) and Euphony (Lee et al., 2018), two state-of-the-art PBE solvers on CLIA. Our evaluation is conducted on benchmarks collected from the dataset of SyGuS-Comp (Alur et al., 2019) and an application of synthesizing divide-and-conquer algorithms (Farzan and Nicolet, 2017). Besides, our evaluation considers two major oracle models in OGIS, corresponding to the applications where (1) the oracle can provide a counter-example for a given program, and (2) the oracle can only generate the correct output for a given input. Our evaluation results show that:
-
•
Comparing with Esolver, PolyGen achieves almost the same generalizability while solving 9.55 times more benchmarks than Esolver.
-
•
Comparing with Eusolver and Euphony, on efficiency, PolyGen solves 43.08%-79.63% more benchmarks with 7.02 - 15.07 speed-ups. Besides, on generalizability, Eusolver and Euphony requires 1.12 - 2.42 examples comparing with PolyGen on those jointly solved benchmarks. This ratio raises to at least 2.39 - 3.33 when all benchmarks are considered.
To sum up, this paper makes the following contributions:
-
•
We adopt the concept of Occam learning to the domain of PBE, prove that Eusolver is not an Occam solver, and provide a sufficient set of conditions for individual components in the STUN framework to form an Occam solver (Section 5).
- •
- •
2. Related Work
Generalizability of PBE Solvers. Generalizability is known to be important for PBE solvers, and there have been different approaches proposed to improve generalizability.
Guided by the principle of Occam’s Razor, a major line of previous work converts the PBE task into an optimization problem by requiring the solver to find the simplest program (Liang et al., 2010; Gulwani, 2011; Raychev et al., 2016; Mechtaev et al., 2015b). This method has been evaluated to be effective in different domains, such as user-interacting PBE systems (Gulwani, 2011) and program repair (Mechtaev et al., 2015b). However, the usage of this method is limited by efficiency, as in theory, requiring the optimality of the solution would greatly increase the difficulty of a problem. For many important domains, there is still a lack of an efficient enough PBE solver which implementing this method. For example, on the domains of CLIA, our evaluation shows that Eusolver, a state-of-the-art PBE solver, solves times more benchmarks than Esolver (Alur et al., 2013), the known best PBE solver on CLIA that guarantees to return the simplest program.
Comparing with these previous work, though our paper is also based on the principle of Occam’s Razor, we relax the constraint on the PBE solver by adopting the concept of Occam Learning (Blumer et al., 1987) from computational learning theory. Occam learning allows the solver to return a program that is at most polynomially worse than the optimal and still has theoretical guarantees on generalizability. While designing an Occam solver, we have more space to improve the efficiency than designing a solver optimizing the size. In this way, we successfully implement a PBE solver on CLIA that performs well on both efficiency and generalizability.
Another line of work uses learned models to guide the synthesis procedure, and thus focuses on only probable programs (Balog et al., 2017; Kalyan et al., 2018; Ji et al., 2020; Singh and Gulwani, 2015; Chen et al., 2019; Menon et al., 2013; Devlin et al., 2017; Lee et al., 2018). However, the efficiency of these approaches depends on domain knowledge. For example, Kalyan et al. (2018) use input-output examples to predict the structure of the target program on the string manipulation domain: The effectiveness of their model relies on the structural information provided by strings and thus is unavailable on those unstructured domains, such as CLIA. In our evaluation, we evaluate a state-of-the-art PBE solver based on learned models, namely Euphony (Lee et al., 2018), and the result shows that its effectiveness is limited on CLIA.
Analysis on the generalizability. Analyzing the generalizability of learning algorithms is an important problem in machine learning and has been studied for decades. The probably approximately correct (PAC) learnability (Valiant, 1984) is a widely used framework for analyzing generalizability. When discussing PAC learnability of a learning task, the goal is to find a learning algorithm that (1) runs in polynomial time, (2) requires only a polynomial number of examples to achieve any requirement on the accuracy. On the synthesis side, there has been a line of previous work on the PAC learnability of logic programs (Cohen, 1995a, b; Dzeroski et al., 1992). Besides, some approaches use the framework of PAC learnability to analyze the number of examples required by some specific algorithm (Lau et al., 2003; Drews et al., 2019).
In this paper, we seek a theoretical model that can compare the generalizability of different PBE solvers. At this time, the requirement on the generalizability provided by PAC learnability is too loose: According to the general bound provided by Blumer et al. (1987), when the program space is finite, this condition is satisfied by any valid PBE solver. Therefore, we adopt another concept, Occam Learning, from computational learning theory. Comparing with PAC learnability, Occam learning (1) has a higher requirement on generalizability, as shown by Blumer et al. (1987), and (2) can reflect some empirical results in program synthesis, such as a PBE solver that always returns the simplest program should have better generalizability than an arbitrary PBE solver. To our knowledge, we are the first to introduce Occam Learning into program synthesis.
Synthesizing CLIA Programs. As mentioned in the introduction, our approach is implemented in the CLIA domain. CLIA is an important domain for program synthesis, as CLIA programs widely exist in real-world projects and can express complex behaviors by using nested if-then-else operators. There have been many applications of CLIA synthesizers, such as program repair (Mechtaev et al., 2015b; Le et al., 2017), automated parallelization (Farzan and Nicolet, 2017; Morita et al., 2007). On CLIA, PBE solvers are usually built on the STUN framework (Alur et al., 2015), which firstly synthesizes a set of if-terms by a term solver, and then unifies them into a program by a unifier. There are two state-of-the-art PBE solvers:
-
•
Eusolver (Alur et al., 2017), which is comprised of an enumerative term solver and a unifier based on a decision-tree learning algorithm.
-
•
Euphony (Lee et al., 2018), which uses structural probability to guide the synthesis of Eusolver.
PolyGen also follows the STUN framework. We evaluate PolyGen against these two solvers in Section 9. The result shows that PolyGen outperforms them on both efficiency and generalizability.
Outside PBE, there are other techniques proposed for synthesizing CLIA programs:
-
•
DryadSynth (Huang et al., 2020) reconciles enumerative and deductive synthesis techniques. As DryadSynth requires a logic specificaion, it is not suitable for PBE tasks.
-
•
CVC4 (Reynolds et al., 2019) synthesizes programs from unsatisfiability proofs given by theory solvers. Though CVC4 is runnable on PBE tasks, it seldom generalizes from examples. We test CVC4 on a simple task where the target is to synthesize a program that returns the maximal value among three inputs. After requiring random examples, the error rate of the program synthesized by CVC4 on a random input is still larger than . In contrast, PolyGen requires only examples on average to synthesize a completely correct program.
3. Motivating Example and Approach Overview
In this section, we introduce the basic idea of our approach via a motivating example adopted from benchmark mpg_ite2.sl in the SyGuS competition. The target program is shown as the following, where are three integer inputs.
We assume that there are input-output examples provided to the PBE solver. Table 1 lists these examples, where tuple in column represents an input where are set to respectively, and the if-term in column Term represents the executed branch on each example.
| ID | Term | ID | Term | ID | Term | ||||||
3.1. Eusolver
In this paper, we focus on designing an Occam solver for PBE tasks. As mentioned before, an Occam solver should synthesize programs whose size is polynomial to the size of the target program and sub-linear to the number of provided examples with high probability. Since the target program is unknown, an Occam solver should satisfy this requirement when the target program is the smallest valid program (programs consistent with the given input-output examples), and thus prefer smaller programs to larger programs.
We first show that Eusolver (Alur et al., 2017) may return unnecessarily large programs and thus is unlikely to be an Occam solver. We shall formally prove that Eusolver is not an Occam solver in Section 5.3. Eusolver follows the STUN framework and provides a term solver and an unifier. The term solver is responsible for synthesizing a term set that jointly covers all the given examples. In our example, one valid term set is . A unifier is responsible for synthesizing a set of conditions to unify the term set into a program with nested if-then-else operators. In our example, the conditions are .
Similar to Occam learning, Eusolver also tries to return small programs. To achieve this, Eusolver enumerates the terms and the conditions from small to large, and then tries to combine the enumerated terms and conditions into a complete program. Though this approach controls the sizes of individual terms and conditions, it fails to control the number of the terms and the conditions, and thus may lead to unnecessarily large programs.
The term solver of Eusolver enumerates the terms from small to large, and includes a term in the term set when the set of examples covered by this term (i.e., the term is correct on these examples) is different from all smaller terms. The term set is complete when all examples are covered. As a result, this strategy may unnecessarily include many small terms, each covering only a few examples. In our motivating example, if constants such as are available, will return set instead of . Though such terms are small, the number of the terms grows with the number of examples.
The unifier of Eusolver builds a decision tree using the ID3 algorithms. Here the terms are considered as labels, the enumerated if-conditions are considered as conditions, and a term is a valid label for an example if it covers the example. However, ID3 is designed for fuzzy classification problems, uses information gain to select conditions, and may select conditions that negatively contribute to program synthesis. For example, will have good information gain for this example. In the original sets the three labels , and are evenly distributed. Predicate divides the examples into two sets where the distribution become uneven: in one set 50% of the examples are labelled with , and in the other set only 20% of the examples are labelled . However, in both sets the three labels still exist, and we still have to find conditions to distinguish them. As a result, selecting roughly doubles the size of the synthesized program.
3.2. PolyGen
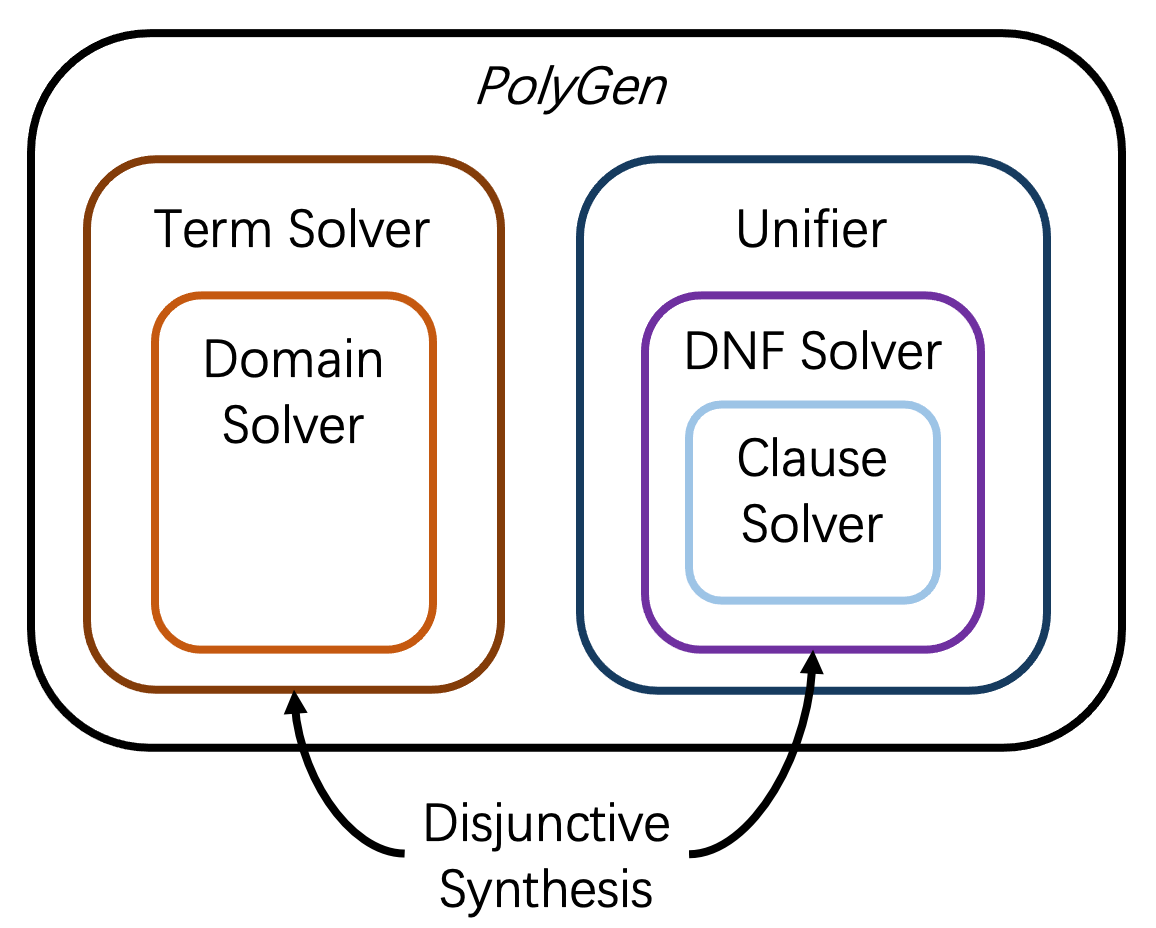

To synthesize small programs, PolyGen controls not only the size of individual terms and conditions but also the number of conditions and terms. The structure of PolyGen is shown as Figure 1(a). As we can see in the figure, PolyGen is built of a set of sub-solvers, each responsible for synthesizing part of the program. Figure 1(b) lists a program PolyGen synthesizes, and the colored rectangles show the parts of the program synthesized by the sub-solver with the same color. In the following we shall illustrate how PolyGen works.
3.2.1. Term Solver
To control the number of terms, the term solver of PolyGen iterates a threshold on the number of terms, and tries to synthesize a term set whose size is equal to or smaller than this threshold. The threshold starts with a small number, and increases by a constant in each iteration. The process terminates if any iteration successfully synthesizes a term set. In each iteration, PolyGen uses a randomized procedure to synthesize a term set. If a term set exists under a threshold, the probability that the term solver fails to synthesize a term set is bound by a constant . Let us assume that a term set exists within the first iterated threshold. After iterations, the probability of failing to synthesize reduces to , and the possible number of terms is only increased by . In other words, the number of the synthesized terms is guaranteed to be small with high probability.
Now we explain how we implement the randomized procedure to obtain a term set with a bounded failure probability. We assume there is a domain solver that synthesizes a term based on a set of examples, and the domain solver is also an Occam solver. For illustration, let us assume currently the threshold for the number of terms is 3, and in our example there exists at least one term set under this threshold. The term solver first samples many subsets of the examples and invoke the domain solver to synthesize a term for each subset. If any subset is covered by a term in , the domain solver will have a chance to synthesize the term. For example, if and are sampled, the domain solver has a chance to synthesize because of the generalizability of the Occam solver. As a result, if we sample enough subsets, we can synthesize a term in with any small bounded failure rate. Then for any successfully synthesized subsets, we repeat this procedure to synthesize terms for the remaining examples. For example, when is synthesized, the procedure continues with examples . The procedure ends when no example remains. Since in each turn the probability of failing to find a term in is bounded, the total probability of failing to find the term set is bounded. Please note the sizes of synthesized terms are guaranteed to be small as the domain solver is an Occam solver.
In the domain of CLIA, the if-terms are all linear integer expressions, and the domain solver can be implemented by finding the simplest valid term via linear integer programming, as we shall show in Section 8.
3.2.2. Unifier
To control the number of conditions, instead of synthesizing a decision tree, the unifier of PolyGen synthesizes decision list (Rivest, 1987). In a decision list, each condition distinguishes one term from the rest of the terms. Figure 1(b) shows the program synthesized by PolyGen on examples , which is semantically equivalent to the target program . The number of conditions is equal to the number of terms minus one, and thus is bounded.
However, the conditions in a decision list may become larger and thus cannot be synthesized using an enumerative algorithm. To efficiently synthesize small conditions to distinguish the terms, we notice that the conditions are in the disjunctive normal forms (DNF) in the initial definition of decision lists, where a DNF is the disjunction of clauses, a clause is the conjunction of literals, and a literal is a predicate in the grammar or its negation. Then we design three sub-solvers for different parts of the conditions. The clause solver synthesizes clauses from the literals, where the literals are enumerated by size in the same way as Eusolver. The DNF solver synthesizes a DNF formula based on the clause solver. Finally, the unifier synthesizes all the conditions based on the DNF solver.
Given a set of terms, the unifier create a synthesis subtask for each term , where the synthesized program has to return true on example inputs covered by (positive examples) and return false on the remaining example inputs (negative examples). For example, when synthesizing the condition for , are positive examples and are negative examples. Here are already covered by . Then the unifier invokes the DNF solver to solve these tasks. The conditions synthesized are guaranteed to be small if the DNF solver guarantees to return small conditions.
Before getting into the DNF solver, let us discuss the clause solver first. Given a set of literals, a set of input-output examples where the output is Boolean, the clause solver returns a clause, i.e., the conjunction of a subset of literals satisfying all examples. The clause solver reduces this problem into weighted set covering, and uses a standard approximation algorithm (Chvátal, 1979) to solve it. As will be formally proved later, the clause solver is an Occam solver.
Based on the clause solver, we build the DNF solver. The DNF solver synthesizes a set of clauses, where all clauses should return false for each negative example, and at least one clause should return true for each positive example. We notice this synthesis problem has the same form as the term solver: given a set of examples (in this case, a set of positive examples) and an Occam solver (in this case, the clause solver), we need to synthesize a set of programs (in this case, a set of clauses) to cover these examples. Therefore, the DNF solver uses the same algorithm as the term solver, and we uniformly refer this algorithm as disjunctive synthesis. Since the disjunctive synthesis algorithm guarantees the returned program set is small in terms of both the sizes of individual programs and the number of total programs, the DNF solver guarantees to return a condition of small size.
4. Occam Learning
4.1. Preliminaries: Programming by Example
The problem of programming-by-example (PBE) is usually discussed above an underlying domain , where represent a program space, an input space, and an output space respectively, is an oracle function that associates a program and an input with an output in , denoted as . The domain limits the ranges of possibly used programs and concerned inputs and provides the semantics of these programs.
For simplicity, we make two assumptions on the domain: (1) There is a universal oracle function for any domains; (2) The output space is always induced by the program space , the input space , and the oracle function , i.e., . In the remainder of this paper, we abbreviate a domain as a pair of a program space and an input space. We shall use notation to represent a family of domains, and thus discuss general properties of domains.
PBE (Shaw et al., 1975) is a subproblem of program synthesis where the solver is required to learn a program from a set of given input-output examples. As this paper focuses on the generalizability of PBE solvers, we assume that there is at least a program satisfying all given examples: The problem of determining whether there is a valid program is another domain of program synthesis, namely unrealizability (Hu et al., 2020; Kim et al., 2021), and is out of the scope of our paper.
Definition 4.1 (Programming by Example).
Given a domain , a PBE task is a sequence of input-output examples. Define as the set of PBE tasks where there is at least one program satisfying all examples. PBE solver is a function that takes a PBE task as the input, and returns a program satisfying all given examples, i.e., .
4.2. Occam Learning and Occam Solver
In computational learning theory, Occam Learning (Blumer et al., 1987) is proposed to explain the effectiveness of the principle of Occam’s Razor. In PBE, an Occam solver guarantees that the size of the synthesized program is at most polynomially larger than the size of the target program.
Definition 4.2 (Occam Solver111The original definition of Occam solvers is only for deterministic algorithms. Here we extend its definition to random algorithms. We compare these two definitions in Appendix A.).
For constants , PBE solver is an -Occam solver on a family of domains if there exist constants such that for any program domain , for any target program , for any input set , for any error rate :
where size(p) is the length of the binary representation of program , is defined as the PBE task corresponding to target program and inputs .
We assume the program domain is defined by a context-free grammar. At this time, a program can be represented by its left-most derivation and can be encoded as a sequence of grammar rules.
Definition 4.3.
The size of program is defined as , where is the number of grammar rules used to derive , and is the number of different grammar rules.
Example 4.4.
When only input variable , operator and constants are available in the grammar, is defined as . When there are input variables, constants and different operators available, is defined as .
The size provides a logarithmic upper bound on the number of programs no larger than .
Lemma 4.5.
For any domain , , .
Blumer et al. (1987) analysizes Occam solvers under the probably approximately correct (PAC) learnability framework, and proves that the generalizability of Occam solvers is always guaranteed.
Theorem 4.6.
Let be an -Occam solver on domain . Then there exist constants such that for any , for any distribution over and any target program :
where represents the error rate of program when the input distribution is and the target program is , i.e., .
Due to space limit, we move all proofs to Appendix B.
When and are fixed, Theorem 4.6 implies that an Occam solver can find a program similar to the target with only examples. Such a bound matches the principle of Occam’s Razor, as it increases monotonically when the size of the target program increases.
The class of Occam solvers can reflect the practical generalizability of PBE solvers. Let us take two primitive solvers and as an example. For any PBE task , let be the set of programs that are consistent with examples in :
-
•
is the most trivial synthesizer that has no guarantee on the quality of the result: It just uniformly returns a program from : .
-
•
regards a PBE task as an optimization problem, and always returns the syntactically smallest program in : .
In practice, it is usually believed that has better generalizability than . We prove that the class of Occam solvers can discover this advantage, as is an Occam solver but is not.
Theorem 4.7.
Let be the family of all possible domains. Then is an -Occam solver on , and is not an Occam solver on .
5. Synthesis Through Unification
5.1. Preliminaries: Synthesis through Unification
The framework of synthesis through unification (STUN) focuses on synthesis tasks for programs with nested if-then-else operators. Formally, STUN assumes that the program space can be decomposed into two subspaces, for if-conditions and if-terms respectively.
Definition 5.1.
A program space is a conditional program space if and only if there exist two program spaces and such that is the smallest set of programs such that:
We use pair to denote a conditional program space derived from term space and condition space . Besides, we call a domain conditional if the program space in is conditional.
A STUN solver synthesizes programs in two steps:
-
(1)
A term solver is invoked to synthesize a set of programs such that for any example, there is always a consistent program in .
-
(2)
A unifier is invoked to synthesize a valid program from conditional program space .
In this paper, we only consider the specialized version of the STUN framework on PBE tasks.
Definition 5.2 (Term Solver).
Given conditional domain , term solver returns a set of terms covering all examples in a given PBE task, where denotes the power set of :
Definition 5.3 (Unifier).
Given a conditional domain , a unifier is a function such that for any set of terms , is a valid PBE solver for .
A STUN solver consists of a term solver and a unifier . Given a PBE task , the solver returns as the synthesis result. Alur et al. (2015) proves that such a combination is complete when the conditional domain is if-closed. For other domains, STUN can be extended to be complete by backtracking to the term solver when the unifier fails (Alur et al., 2015, 2017).
Definition 5.4 (If-Closed).
A conditional domain is if-closed if:
Please note that any conditional domain with equality is if-closed, as can be constructed by testing the equality between the outputs of and . In the rest of the paper, we assume the conditional program space is if-closed, and use to denote a family of if-closed domains.
Eusolver (Alur et al., 2017) is a state-of-the-art solver following the STUN framework. It takes efficiency and generalizability as its design purposes, and makes a trade-off between them.
The term solver in Eusolver is motivated by . enumerates terms in in the increasing order of the size. For each term , if there is no smaller term that performs the same with on examples, will be included in the result. returns when the result is enough to cover all examples.
The unifier in Eusolver regards nested if-then-else operators as a decision tree, and uses ID3 (Quinlan, 1986), a standard decision-tree learning algorithm, to unify the terms. learns a decision tree recursively: In each recursion, it first tries to use a term to cover all remaining examples. If there is no such term, will heuristically pick up a condition from as the if-condition. According to the semantics of , the examples will be divided into two parts, which will be used to synthesize the then-branch and the else-branch respectively.
5.2. Generalizability of STUN
In this section, we study the generalizability of the STUN framework. To start, we extend the concept of Occam solvers to term solvers and unifiers: For an Occam term solver, there should be a polynomial bound on the total size of synthesized terms, and for an Occam unifier, the induced PBE solver should always be an Occam solver for any possible term set. These definitions will be used to guide our design of PolyGen later.
Definition 5.5.
For constants , term solver is an -Occam term solver on if there exist constants such that for any domain , for any target program , for any input set , for any error rate :
where is the total size of terms in term set , i.e., .
Definition 5.6.
For constants , unfier solver is an -Occam unifier on if there exist constants such that for any domain , for any term set , for any target program , for any input set , for any error rate :
In Definition 5.6, besides the size of the target program, the bound also refers to the total size of . Such relaxation allows the unifier to use more examples when a large term set is provided.
Based on the above definitions, we prove that under some conditions, an STUN solver comprised of an Occam term solver and an Occam unifier is also an Occam solver.
Theorem 5.7.
Let be a family of if-closed conditional domains, be an -Occam term solver on , be an -Occam unifier where . Then the STUN solver comprised of and is an -Occam solver.
5.3. Generalizability of Eusolver
In this section, we analyze the generalizability of Eusolver and prove that Eusolver is not an Occam solver. We start from the term solver . As enumerates terms in the increasing order of the size, guarantees that all synthesized terms are small. However, the main problem of is that it does not control the total number of synthesized terms. Therefore, the total size of the term set returned by can be extremely large, as shown in Example 5.8.
Example 5.8.
Consider the following term space , input space and target program :
As is the largest term in , on any input in , there is always a smaller term that performs the same as , where is a constant equal to . Therefore, whatever the PBE task is, always returns a subset of and never enumerates to the target program .
When all inputs in are included in the PBE task, the term set synthesized by is always . At this time, the total size of is , the number of examples is and the size of the target program is . Clearly, there are no and such that . Therefore, is not an Occam term solver.
Moreover, at this time, the program synthesized by Eusolver must utilize all terms in , and thus its size is no smaller than . So Eusolver is not an Occam solver as well.
The following fact comes from Example 5.8 immediately.
Theorem 5.9.
is not an Occam term solver on , and Eusolver is not an Occam solver on , where is the family of all if-closed conditional domains.
The generalizability of is related to the underlying decision-tree learning algorithm ID3. Hancock et al. (1995) proves that there is no polynomial-time algorithm for learning decision trees that generalizes within a polynomial number of examples unless , where represents the class of polynomial-time random algorithms with one-side error. Combining with Theorem 4.6, we obtain the following lemma, which implies that is unlikely to be an Occam unifier.
Theorem 5.10.
There is no polynomial-time Occam unifier on unless .
These results indicate that (1) Eusolver itself is not an Occam solver, and (2) if we would like to design an Occam solver following Theorem 5.7, neither nor can be reused.
6. Term Solver
6.1. Overview
For an Occam term solver, the total size of returned terms should be bounded. Therefore, a term solver must be an Occam solver if (1) the number of returned terms is bounded, and (2) the maximal size of returned terms is bounded.
Lemma 6.1.
For constants where , term solver is an -Occam solver on if there exist constants such that for any conditional domain , any target program , and any input set :
-
(1)
With a high probability, the size of terms returned by is bounded by .
-
(2)
With a high probability, the number of terms returned by is bounded by .
In Lemma 6.1, the first condition has a form similar to the guarantee provided by an Occam solver. Motivated by this point, we design as a meta-solver that takes an Occam solver on the term space as an input. To solve a term finding task, firstly decomposes it into several standard PBE tasks and then invokes to synthesize terms with bounded sizes.
One challenge is that, in a term finding task, different examples correspond to different target terms, i.e., if-terms used in the target program. To find a target term using , should pick up enough examples that correspond to the same target term. To do so, we utilize the fact that there must be a target term that covers a considerable portion of all examples, as shown in Lemma 6.2.
Lemma 6.2.
Let be a PBE task, and let be a set of terms that covers all examples in , i.e., . There is always a term such that:
Given a term finding task where is the set of target terms, let be the term that covers the most examples. According to Lemma 6.2, if we randomly select examples from , term will be consistent with all selected examples with a probability of at least . Therefore, repeatedly invokes on a small set of random examples drawn from : When the generalizability of is guaranteed on term space , the number of examples and the number of turns are large enough, would find a term semantically similar with with a high probability.
For the second condition, assumes that there is an upper bound , and searches among term sets with at most terms. If the search process guarantees to find a valid term set with a high probability when is larger than a small bound, which is polynomial to the size of the target program and sub-linear to the number of examples, the second condition of Lemma 6.2 can be satisfied by iteratively trying all possible .
6.2. Algorithm
The pseudo-code of is shown as Algorithm 1. is configured by a domain solver , which is used to synthesize terms, and a constant , which is used to configure bounds used in . We assume that can discover the case where there is no valid solution, and returns at this time.
The algorithm of is comprised of three parts. The first part implements the random sampling discussed previously, as function GetCandidatePrograms() (abbreviated as Get()). Get() takes four inputs: examples is a set of input-output examples, is an upper bound on the number of terms, is the number of examples provided to and is an upper bound on the size of terms. Guided by Lemma 6.2, Get() returns a set of programs that covers at least portion of examples. The body of Get() is a repeated sampling process (Line 3). In each turn, examples are sampled (Line 4), and solver is invoked to synthesize a program from these sampled examples (Line 5). Get() collects all valid results (Line 7) and returns them to Search() (Line 10).
Note that Get() only considers those programs of which the sizes are at most (Line 6). This bound comes from the definition of Occam solvers (Definition 4.2): When all examples provided to corresponds to the same target term and the size of this term is at most , with a high probability, the term found by will be no larger than . However, in other cases, the selected examples may happen to correspond to some other unwanted terms: At this time, the term found by may be much larger than the target term. Therefore, sets a limitation on the size and rejects those programs that are too large. This bound can be safely replaced by any function that is polynomial to and sub-linear to without affecting to be an Occam term solver.
The second part implements the backtracking as function Search() (Lines 11-18). Given a set of examples examples and size limit , Search() searches for a set of at most terms that covers all examples. Search() invokes function Get() to obtain a set of possible terms (Line 14), and then recursively tries each of them until a valid term set is found (Lines 15-16).
The third part of selects proper values for and iteratively (Lines 19-29). In each turn, considers the case where the number of target terms and their sizes are all and select proper values for and in the following ways:
-
•
By Theorem 4.6, when the size of the target term is , requires examples to guarantee the accuracy. Therefore, sets the upper bound of to .
-
•
Also by Theorem 4.6, when is set to , the term syntehsized by may still differ with the target term on a constant portion of inputs. As a result, may use times more terms to cover all examples in . Therefore, sets the upper bound of to .
As the time cost of Get() and Search() grows rapidly when and increases, tries all values of and from small to large (Lines 22-27), instead of directly using the largest possible and . The iteration ends immediately when a valid term set is found (Line 25).
6.3. Properties of
In this section, we discuss the properties of . As a meta solver, guarantees to be an Occam term solver when is an Occam solver on the term space.
Theorem 6.3.
is an -Occam solver on is an -Occam term solver on for any , where is defined as .
Then, we discuss the time cost of . With a high probability, invokes Search() only polynomial times, but the time cost of Search() may not be polynomial. By Algorithm 1, an invocation of Search() of depth on the recursion tree samples times. In the worst case, successfully synthesizes programs for all these samples, and the results are all different. At this time, Search() will recurse into different branches. Therefore, for each , domain solver will be invoked times in the worst case.
However, in practice, is usually much faster than the worst-case because:
-
•
The domain solver usually fails when the random examples correspond to different target terms, as the expressive ability of term domain is usually limited.
-
•
For those incorrect terms that happen to be synthesized, they seldom satisfy the requirement on the size and the number of covered examples (Line 6 in Algorithm 1).
In the best case where Get() never returns a term that is not used by the target program, will be invoked at most times: Such a bound is much smaller than the worst case.
7. Unifier
7.1. Overview
unifies terms into a decision list, a structure proposed by Rivest (1987) for compactly representing decision procedures. unifies a term set into the following form:
where belong to , the disjuctive normal form comprised of conditions in . is defined together with another two sets and , where the set of literals includes conditions in and their negations, the set of clauses includes the conjunctions of subsets of , and the set of DNF formulas includes disjunctions of subsets of .
We use notation to denote the set of decision lists where if-terms and if-conditions are from and respectively. In the following lemma, we show that is a suitable normal from for designing an Occam unifier, because for any program in , there is always a semantically equivalent program in with a close size.
Lemma 7.1.
For any conditional domain and any program , there exists a program such that (1) is semantically equivalent to on , and (2) .
decomposes the unification task into PBE tasks for respectively. Algorithm 3 shows the framework of , which synthesizes conditions in order (Lines 2-7). For each term and each remaining example , there are three possible cases:
-
•
If is not consistent with , the value of if-condition must be False on input (Line 3).
-
•
If is the only program in that is consistent with , the value of must be True on input (Line 4).
-
•
Otherwise, the value of does not matter, as is not the last choice. Therefore, ignores this example: If the synthesized is false on input , will be left to subsequent terms.
In this way, obtains a PBE task for , and it invokes a DNF solver to solve it (Line 5). Then, excludes all examples covered by (Line 6) and moves to the next term. At last, unifies all terms and conditions into a complete program (Lines 8-11).
Just like , unifier is an Occam unifier when is an Occam solver on .
Lemma 7.2.
is an -Occam solver on is an -Occam unifier on for any , where is defined as .
is a deterministic Occam solver on is a Occam unifier on .
By Lemma 7.2, the only problem remaining is to design an Occam solver for . We shall gradually build such a condition solver in the following two subsections.
7.2. Condition Synthesis for Clauses
For the sake of simplicity, we start by introducing some useful notations:
-
•
We regard a DNF formula as a set of clauses and regard a clause as a set of literals. We use notation and to represent their corresponding program respectively.
-
•
For an input space and a condition , we use and to denote the set of inputs where is evaluated to true and false respectively.
-
•
For a PBE task , we use , and to denote the inputs of examples, positive examples and negative examples in respectively, i.e.:
For a PBE task on domain , a valid condition should satisfy the following two conditions: (1) takes true on all positive examples in , i.e., ; (2) takes false on all negative examples in , i.e., . In this section, we build solver for the subproblem where the target condition is assumed to be a single clause.
The pseudo-code of is shown as Algorithm 3. starts with the first condition of valid clauses: . By the semantics of operator and, for any clause and any literal , must be a subset of . Therefore, only those literals that covers all positive examples can be used in the result. collects all these literals as clause (Line 8). Then the subsets of are exactly those clauses satisfying the first condition.
The remaining task is to find a subset of that satisfies the second condition, i.e., . Meanwhile, to make an Occam solver, the size of should be as small as possible. This problem is an instance of weighted set covering: needs to select some sets from to cover . This problem is known to be difficult: Moshkovitz (2011) proves that for any , there is no polynomial-time algorithm that always finds a solution at most times wrose than the optimal, unless , where is in our case.
In our implementation, we use a standard greedy algorithm for weighted set covering, which runs in polynomial time and always finds a solution at most times worse than the optimal (Lines 1-7). maintains set remNeg, representing the set of negative examples that have not been covered yet (Line 3). In each turn, selects the literal which covers the most uncovered negative examples in each unit of size (Line 5) and includes into the result (Line 6).
The size of the clause found by is bounded, as shown in Lemma 7.3. Therefore, is an Occam solver, as shown in Corollary 7.4. The time complexity of is polynomial to and , and thus is efficient when is not large.
Lemma 7.3.
Given condition space and PBE task , let be the smallest valid clause and be the clause found by . Then .
Corollary 7.4.
For any , is an -Occam solver on all possible clause domains.
7.3. Condition Synthesis for Disjunctive Normal Forms
In this section, we implement an Occam solver for disjunctive normal forms. By the semantics of operator or, we could obtain a lemma that is similar with Lemma 6.2 in form.
Lemma 7.5.
Let be a PBE task and be a DNF formula satisfying all examples in , then:
-
•
All clauses in must be false on all negative examples in , i.e., .
-
•
There exists a clause in that is true on at least portion of positive examples in , i.e., .
By this lemma, can be implemented similarly as by regarding as the domain solver, as shown in Algorithm 4. Comparing with the counterpart in , there are two main differences:
-
•
GetPossibleClause() finds a set of clauses that are evaluated to false on all negative examples, and are evaluated to true on at least portion of positive examples (Line 5). Correspondingly, only covered positive examples are excluded in each recursion (Line 6).
-
•
For the efficiency of , iteratively selects a parameter (Line 13). In each iteration, only those literals with size at most are available (Line 15).
Our implementation of GetPossibleClause() (abbreviated as Get()) optimizes the sampling algorithm in by opening the box of clause solver . By Algorithm 3, synthesizes clauses in two steps. It firstly finds a set of all usable literals and then simplifies it greedily. To synthesize a usable clause, set should satisfy all negative examples and at least portion of positive examples. We find the number of different satisfying this condition is usually small in practice. Therefore, Get() tries to find all possible , and simplifies them using function SimplifyClause().
Given an input space and a set of literals , define relation on clause space as , i.e., represents the relation of semantically equivalence on input space . Under relation , is divided into equivalent classes. We denote the class corresponding to clause as . It is easy to show that each class contains a globally largest clause that is the union of all its elements, i.e., . Then, we introduce the concept of representative clauses to denote the set of all possible generated by .
Definition 7.6 (Representative Clauses).
Given an input space , a size limit , and a set of literals , representative set includes all clause satisfying: (1) is the largest clause in , (2) takes true on at least portion of the inputs, i.e., .
According to this definition, is the set of possible when the PBE task is , the size limit is and the set of available literals is . Our implementation of Get() is shown as Algorithm 5. Get() maintains set result which is equal to for some hidden literal set . Initially, is empty and thus result includes only an empty clause, i.e., true (Line 1). Get() considers all literals in order (Lines 2-9). In each turn, a new literal is inserted to and thus result is updated correspondingly (Lines 3-8). At last, result is equal to , and thus Get() simplies and returns all valid clauses in result (Line 10).
We prove that is an Occam solver, as shown in Lemma 7.7. Combining with Lemma 7.2, is also an Occam unifier, as shown in Theorem 7.8.
Lemma 7.7.
For any , is a -Occam solver on .
Theorem 7.8.
For any , is a -Occam unifier on .
Finally, we prove that PolyGen is an Occam solver by combining Theorem 7.8, Theorem 6.3 and Theorem 5.7, as shown in Theorem 7.9.
Theorem 7.9.
is an -Occam solver on with PolyGen is an - Occam solver on for any .
Note that the bound in Theorem 7.9 is loose in practice, as it considers all corner cases for the sake of preciseness. For example, while analyzing solver , we consider the case where both the number of clauses and the size of the clauses are linear to the size of the target condition : At this time, there must be clauses of which the size is , and clauses of which the size is . Such an if-condition is seldom used in practice.
8. Implementation
We instantiate our approach PolyGen on the domains of conditional linear integer arithmetic (CLIA). Our implementation is in C++, and is available at https://github.com/jiry17/PolyGen.
Our implementation supports the family of CLIA domains defined in the evaluation of the study on Eusolver (Alur et al., 2017). where different domains only differ in the number of inputs. Concretely, given the number of inputs , a domain is defined as follows.
-
•
Term space contains all linear integer expressions of input variables .
-
•
Condition space contains all arithmetic comparisons between linear expressions and their boolean expressions, i.e., is the smallest set satisfying the following eqaution.
By Definition 5.4, is an if-closed conditional domain.
-
•
Input space contains integer assignments to input variables. For simplicity, we assume contains all assignments in a bounded range: .
To implement and , we set parameters and as . Besides, by Theorem 7.9, an Occam solver on is required to instantiate PolyGen on . We implement as an optimized solver that always synthesizes the smallest valid program. Concretely, given PBE task , synthesizes by solving the following optimization problem with respect to :
This problem is an instance of integer linear programming (ILP), and solves it by invoking Gurobi (Gurobi Optimization, 2021), a state-of-the-art solver for ILP. Clearly, is an -Occam solver, and thus by Theorem 7.9, PolyGen is an Occam solver on .
9. Evaluation
To evaluate PolyGen, we report several experiments to answer the following research questions:
-
•
RQ1: How does PolyGen compare against existing PBE solvers?
-
•
RQ2: How do term solver and unifier affect the performance of PolyGen?
9.1. Experimental Setup
Baseline Solvers. We compare PolyGen with three PBE solvers, Esolver (Alur et al., 2013), Eusolver (Alur et al., 2017), and Euphony (Lee et al., 2018), which represent the state-of-the-art of three different methods on improving generalizability:
-
(1)
The first method is guided by the principle of Occam’s Razor, which guarantees to synthesize the smallest valid program. On CLIA, ESolver is the best-known solver following this method, which enumerates programs in the increasing order of size, and prunes off useless programs via a strategy namely observational equivalence.
-
(2)
The second method combines the first method with efficient synthesis techniques heuristically, and thus makes a trade-off between generalizability and efficiency. Among them, Eusolver combines the principle of Occam’s Razor with the STUN framework by requiring the term solver to enumerate terms in the increasing order of size.
-
(3)
The third method uses a learned model to guide the synthesis. In this category, Euphony is the state-of-the-art among solvers available on CLIA. Euphony is based on Eusolver and uses a model based on structural probability to guide the search of Eusolver.
Oracle Models. Our evaluation follows the framework of OGIS (Jha and Seshia, 2017). We consider two different models of oracles, which cover major usages of PBE solvers in practice.
-
(1)
In model , the oracle can verify whether a program is correct, and can provide a counter-example if the program is incorrect. To synthesize from these oracles, the framework of counter-example guided inductive synthesis (CEGIS) (Solar-Lezama et al., 2006) is usually used.
Given an oracle in and a PBE solver , we run CEGIS with solver to synthesize a program from . We measure the generalizability of on as the number of examples finally used by to synthesize a correct program, which is equal to the number of CEGIS turns, and we measure the efficiency of as the total time cost of the CEGIS framework.
-
(2)
In model , the oracle cannot verify the correctness of a program but can provide a set of input-output examples. At this time, a program is usually synthesized by (1) invoking the oracle to generate as many examples as possible under some limits on resource, and then (2) invoking a PBE solver to synthesize a program from these examples.
To evaluate the performance of a PBE solver on an oracle in , we assume that there is a corresponding oracle in that could verify whether the synthesized program is completely correct for . We run in a similar way as CEGIS: starting from an empty set of examples, in each turn, we run on all existing examples. If the synthesis result is verified to be incorrect by , we request a new example from and then start a new turn. We measure the generalizability of on as the total number of used examples. Because the PBE solver is usually invoked only once in practice, we measure the efficiency of as the time cost of the last invocation.
Benchmark. Our evaluation is conducted on a dataset of benchmarks. For each benchmark, two different oracles and are provided, which correspond to models and respectively. The programs are synthesized in a domain of CLIA as stated in Section 8. consists of two parts, and , each obtained from an existing dataset.
Dataset . The first dataset consists of 82 benchmarks collected from the general track222There is also a CLIA track in SyGuS-Comp. We use the dataset of the general track here because (1) all benchmarks in the CLIA track are included in the general track, (2) the general track includes additional benchmarks that are collected from a varies of domains and can also be solved by programs in the CLIA syntax. in SyGuS-Comp (Alur et al., 2019), where each benchmark is provided with a logic specification .
To implement two oracles, we apply the algorithm used in Eusolver (Alur et al., 2017), which could (1) get the correct output for a given input, (2) get a counter-example for an incorrect result:
-
•
Oracle . Given a candidate program , firstly verifies the correctness of via an SMT solver, and invokes to generate a counter-example if is incorrect.
-
•
Oracle . randomly selects an input and invokes to complete it into an example.
is applicable only for special specifications, namely point-wise: specification is point-wise if it only relates an input point to its output. Therefore, we filter out those benchmarks where the specification is not point-wise, and those benchmarks that cannot be solved by a CLIA program.
Dataset . The second dataset consists of 18 tasks for synthesizing a combinator in a divide-and-conquer algorithm collected by Farzan and Nicolet (2017). The synthesized program can be converted to a divide-and-conquer algorithm using ParSynt (Farzan and Nicolet, 2017).
For example, the following specifies a task for synthesizing a combintor in the divde-and-conquer algorithm for the maximum segment sum (mss) problem.
| (1) |
where represents the list concatenation of lists , mps represents the maximum prefix sum of a list and mts represents the maximum suffix sum of a list. In this case, a valid combinator can be obtained from equation .
We choose this dataset because of the following reasons.
-
(1)
It is a typical application scenario for the oracle model . On the one hand, it is difficult to verify the correctness of a program, as the specification involves complex list operation that is difficult to model in SMT-Lib. On the other hand, it is easy to collect input-output examples for the combinator, as all inputs and the output are generated by some executable function, as shown in Equation 1.
-
(2)
if-then-else operators are frequently used in the combinator, as there are usually many possible cases when merging two halves. For example, the combinator for mss deals with cases, corresponds to if-terms and respectively.
-
(3)
Synthesizing the combinator directly is difficult, as it can be rather complex in practice. ParSynt can successfully synthesize the combinator only when a program sketch is provided.
Though it is difficult to verify the correctness of the synthesized program against the specification involving complex list operations, it is not difficult to verify the equivalence of two CLIA programs. The original dataset provides ground truth program for each task, and thus we can still implement the two oracles.
-
•
Given a candidate program , uses an SMT solver to verify whether and is semantically equivalent on the input space.
-
•
randomly selects an input and runs to get the corresponding output.
Configurations. All of the following experiments are conducted on Intel Core i7-8700 3.2GHz 6-Core Processor with 48GB of RAM. We use Z3 (de Moura and Bjørner, 2008) as the underlying SMT solver for oracles in model , and generate random inputs for oracles in model by setting each input variable to a random integer according to a uniform distribution over .
For each execution, we set the time limit as seconds, the memory limit as GB, and the example number limit as . Besides, as both PolyGen and oracles in model have randomness, we repeat all related executions times and consider the average performance only.
9.2. Exp1: Comparison of Approaches (RQ1)
Procedure. For each oracle model, we compare PolyGen with ESolver, Eusolver and Euphony on all benchmarks in . Among them, the experiment setting for Euphony is slightly different from others, as Euphony requires a labeled training set. We run Euphony in two steps:
-
•
First, for those benchmarks in where the target program is not explicitly provided, we label them using the program synthesized by PolyGen.
-
•
Second, we run Euphony using 3-fold cross-validation. We divide the dataset into three subsets. On each subset, we run Euphony with the model learned from the other two subsets. One delicate point is that contains benchmarks that are almost the same except the number of input variables. We put these benchmarks in the same subset and thus avoid data leaks.
Results. The results are summarized in Table 2 while more details are drawn as Figure 2. To compare the generalizability, in each comparison, for each benchmark solved by both PolyGen and the baseline solver, we record the ratio of the number of examples used by the baseline solver to the number of examples used by PolyGen. The geometric mean of these ratios is listed in column #Example. Similarly, to compare the efficiency, in each comparison, we record the ratio of the time cost of the baseline solver to the time cost of PolyGen for those benchmarks solved by both solvers and list the geometric mean of these ratios in column Time Cost.
| Model | |||||||
|---|---|---|---|---|---|---|---|
| Solver | #Solved | #Example | Time Cost | #Solved | #Example | #Example | Time Cost |
| PolyGen | |||||||
| Esolver | |||||||
| Eusolver | |||||||
| Euphony | |||||||
Comparing with Esolver, the generalizability of PolyGen is almost the same as ESolver on both oracle models. Recall that the theory of Occam learning used by PolyGen is only an approximation of the principle used by Esolver: Occam learning relaxes the requirement from finding the smallest valid program to finding a valid program with a bounded size. The experimental result shows that such an approximation does not affect the generalizability too much in practice. Meanwhile, benefiting from the relaxed requirement on the size provided by Occam Learning, PolyGen performs significantly better on efficiency: PolyGen solves more than times benchmarks comparing with Esolver, with a significant speed-up on those commonly solved benchmarks.

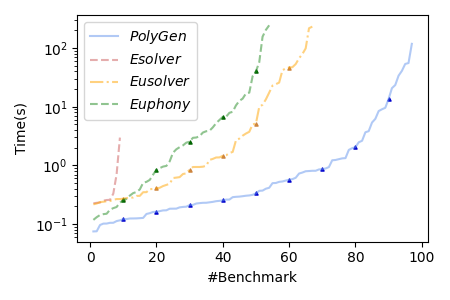






Comparing with Eusolver and Euphony, PolyGen performs significantly better on both generalizability and efficiency. The expreimental result on the generalizability is consistent with our theoretical analysis, as PolyGen is an Occam solver but Eusolver, Euphony are not. Comparing with , the advantage of PolyGen on oracle model seems less attractive. The reason is that on , the cost of distinguishing an incorrect program increases, and thus the effect of synthesis algorithms is weakened. For example, in benchmark qm_neg_1.sl, it is hard to distinguish between the target program is and a wrong program with a slightly different if-condition in model , as the probability for a random input to distinguish them is smaller than when the input is in the range .
Please note that the comparison in Column #Example suffers from a survivorship bias: On a large number of cases that PolyGen solves while Eusolver or Euphony does not, PolyGen is likely to have better generalizability. To validate this point, we perform an extra experiment on model . We iteratively rerun Eusolver and Euphony on those benchmarks where PolyGen solves but Eusolver or Euphony does not. Starting from only random example, we invoke Eusolver or Euphony with an enlarged time-limit of 30 minutes. If the solver synthesizes an incorrect program, we record the current number of examples as a lower bound of the generalizability, and then continue to the next iteration by doubling the number of examples. The iteration stops when Eusolver or Euphony successfully synthesizes a correct program or times out. After adding these lower bounds, the geometric mean of the ratios between the lower bounds and the number of examples used by PolyGen is reported in column #Example of Table 2. The result justifies the existence of the survivorship bias as the ratios increase from to . Please note that the new experiment still favors to Eusolver and Euphony because (1) the iteration only provides a coarse lower bound on the number of required examples, (2) the survivorship bias still exists as Eusolver and Euphony still time out on 27 and 28 out of 93 benchmarks, respectively.
In terms of efficiency, PolyGen solves almost all benchmarks in on both oracle models. We investigate those benchmarks where PolyGen times out, and conclude two major reasons:
-
•
As the time cost of grows quickly when the number of if-terms increases, PolyGen may time out when a large term set is used. For example, PolyGen fails in finding a valid term set for array_serach_15.sl as this benchmark requires different if-terms.
-
•
As consider conditions in the increasing order of the size, PolyGen may time out when a large condition is used. For example, PolyGen times out on mpg_example3.sl which uses if-condition . This defect can be improved by combining PolyGen with techniques on feature synthesis (Padhi and Millstein, 2017).
At last, a noteworthy result is that Euphony performs even worse than Eusolver in our evaluation, implying that the model used in Euphony plays a negative role. One possible reason is that the target programs in our dataset are diverse and are not easily predictable with a simple probabilistic model considering only the dependency between program elements.
9.3. Exp2: Comparison of the Term Solver and the Unifier (RQ2)
Procedure. In this experiment, we test how and affect the performance of PolyGen.
Here, we implement two weakened solvers and : replaces term solver with the term solver used in Eusolver, and replaces unifier with the unifier used in Eusolver. For each oracle model, we run these solvers on all benchmarks in .
| Model | ||||||
|---|---|---|---|---|---|---|
| Solver | #Solved | #Example | Time Cost | #Solved | #Example | Time Cost |
| PolyGen | ||||||
As shown in Table 3, the unifier improves a lot on both efficiency and generalizability. In contrast, majorly contributes to the efficiency, as the generalizability of PolyGen changes little when is replaced. The reason is that the number of examples required by the unifier usually dominates the number of examples required by the term solver, because an example for synthesizing if-conditions, where the output type is Boolean, provides much less information than an example for synthesizing if-terms, where the output is an integer.
10. Conclusion
In this paper, we adopt a concept from computational learning theory, Occam Learning, to study the generalizability of the STUN framework. On the theoretical side, we provide a sufficient set of conditions for individual components in STUN to form an Occam solver and prove that Eusolver, a state-of-the-art STUN solver, is not an Occam solver. Besides, we design an Occam solver PolyGen for the STUN framework. On the practical side, we instantiate PolyGen on the domains of CLIA and evaluate it against state-of-the-art PBE solvers on 100 benchmarks and 2 common oracle models. The evaluation shows that (1) PolyGen significantly outperforms existing STUN solvers on both efficiency and generalizability, and (2) PolyGen keeps almost the same generalizability with those solvers that always synthesize the smallest program, but achieves significantly better efficiency.
References
- (1)
- Aldous and Vazirani (1995) David J. Aldous and Umesh V. Vazirani. 1995. A Markovian Extension of Valiant’s Learning Model. Inf. Comput. 117, 2 (1995), 181–186. https://doi.org/10.1006/inco.1995.1037
- Alur et al. (2013) Rajeev Alur, Rastislav Bodík, Garvit Juniwal, Milo M. K. Martin, Mukund Raghothaman, Sanjit A. Seshia, Rishabh Singh, Armando Solar-Lezama, Emina Torlak, and Abhishek Udupa. 2013. Syntax-guided synthesis. In Formal Methods in Computer-Aided Design, FMCAD 2013, Portland, OR, USA, October 20-23, 2013. 1–8. http://ieeexplore.ieee.org/document/6679385/
- Alur et al. (2015) Rajeev Alur, Pavol Cerný, and Arjun Radhakrishna. 2015. Synthesis Through Unification. In Computer Aided Verification - 27th International Conference, CAV 2015, San Francisco, CA, USA, July 18-24, 2015, Proceedings, Part II. 163–179. https://doi.org/10.1007/978-3-319-21668-3_10
- Alur et al. (2019) Rajeev Alur, Dana Fisman, Saswat Padhi, Rishabh Singh, and Abhishek Udupa. 2019. SyGuS-Comp 2018: Results and Analysis. CoRR abs/1904.07146 (2019). arXiv:1904.07146 http://arxiv.org/abs/1904.07146
- Alur et al. (2017) Rajeev Alur, Arjun Radhakrishna, and Abhishek Udupa. 2017. Scaling Enumerative Program Synthesis via Divide and Conquer. In Tools and Algorithms for the Construction and Analysis of Systems - 23rd International Conference, TACAS 2017, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2017, Uppsala, Sweden, April 22-29, 2017, Proceedings, Part I. 319–336. https://doi.org/10.1007/978-3-662-54577-5_18
- Angluin and Laird (1987) Dana Angluin and Philip D. Laird. 1987. Learning From Noisy Examples. Mach. Learn. 2, 4 (1987), 343–370. https://doi.org/10.1007/BF00116829
- Balog et al. (2017) Matej Balog, Alexander L. Gaunt, Marc Brockschmidt, Sebastian Nowozin, and Daniel Tarlow. 2017. DeepCoder: Learning to Write Programs. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. https://openreview.net/forum?id=ByldLrqlx
- Blazytko et al. (2017) Tim Blazytko, Moritz Contag, Cornelius Aschermann, and Thorsten Holz. 2017. Syntia: Synthesizing the Semantics of Obfuscated Code. In 26th USENIX Security Symposium, USENIX Security 2017, Vancouver, BC, Canada, August 16-18, 2017. 643–659. https://www.usenix.org/conference/usenixsecurity17/technical-sessions/presentation/blazytko
- Blumer et al. (1987) Anselm Blumer, Andrzej Ehrenfeucht, David Haussler, and Manfred K. Warmuth. 1987. Occam’s Razor. Inf. Process. Lett. 24, 6 (1987), 377–380. https://doi.org/10.1016/0020-0190(87)90114-1
- Chen et al. (2019) Yanju Chen, Ruben Martins, and Yu Feng. 2019. Maximal multi-layer specification synthesis. In Proceedings of the ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT FSE 2019, Tallinn, Estonia, August 26-30, 2019. 602–612. https://doi.org/10.1145/3338906.3338951
- Chvátal (1979) Vasek Chvátal. 1979. A Greedy Heuristic for the Set-Covering Problem. Math. Oper. Res. 4, 3 (1979), 233–235. https://doi.org/10.1287/moor.4.3.233
- Cohen (1995a) William W. Cohen. 1995a. Pac-Learning Recursive Logic Programs: Efficient Algorithms. J. Artif. Intell. Res. 2 (1995), 501–539. https://doi.org/10.1613/jair.97
- Cohen (1995b) William W. Cohen. 1995b. Pac-learning Recursive Logic Programs: Negative Results. J. Artif. Intell. Res. 2 (1995), 541–573. https://doi.org/10.1613/jair.1917
- David et al. (2020) Robin David, Luigi Coniglio, and Mariano Ceccato. 2020. QSynth-A Program Synthesis based Approach for Binary Code Deobfuscation. In BAR 2020 Workshop.
- de Moura and Bjørner (2008) Leonardo Mendonça de Moura and Nikolaj Bjørner. 2008. Z3: An Efficient SMT Solver. In Tools and Algorithms for the Construction and Analysis of Systems, 14th International Conference, TACAS 2008, Held as Part of the Joint European Conferences on Theory and Practice of Software, ETAPS 2008, Budapest, Hungary, March 29-April 6, 2008. Proceedings. 337–340. https://doi.org/10.1007/978-3-540-78800-3_24
- Devlin et al. (2017) Jacob Devlin, Jonathan Uesato, Surya Bhupatiraju, Rishabh Singh, Abdel-rahman Mohamed, and Pushmeet Kohli. 2017. RobustFill: Neural Program Learning under Noisy I/O. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017. 990–998. http://proceedings.mlr.press/v70/devlin17a.html
- Drews et al. (2019) Samuel Drews, Aws Albarghouthi, and Loris D’Antoni. 2019. Efficient Synthesis with Probabilistic Constraints. In Computer Aided Verification - 31st International Conference, CAV 2019, New York City, NY, USA, July 15-18, 2019, Proceedings, Part I. 278–296. https://doi.org/10.1007/978-3-030-25540-4_15
- Dzeroski et al. (1992) Saso Dzeroski, Stephen Muggleton, and Stuart J. Russell. 1992. PAC-Learnability of Determinate Logic Programs. In Proceedings of the Fifth Annual ACM Conference on Computational Learning Theory, COLT 1992, Pittsburgh, PA, USA, July 27-29, 1992. 128–135. https://doi.org/10.1145/130385.130399
- Ernst et al. (2001) Michael D. Ernst, Jake Cockrell, William G. Griswold, and David Notkin. 2001. Dynamically Discovering Likely Program Invariants to Support Program Evolution. IEEE Trans. Software Eng. 27, 2 (2001), 99–123. https://doi.org/10.1109/32.908957
- Farzan and Nicolet (2017) Azadeh Farzan and Victor Nicolet. 2017. Synthesis of divide and conquer parallelism for loops. In Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2017, Barcelona, Spain, June 18-23, 2017. 540–555. https://doi.org/10.1145/3062341.3062355
- Gulwani (2011) Sumit Gulwani. 2011. Automating string processing in spreadsheets using input-output examples. In Proceedings of the 38th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 2011, Austin, TX, USA, January 26-28, 2011. 317–330. https://doi.org/10.1145/1926385.1926423
- Gurobi Optimization (2021) LLC Gurobi Optimization. 2021. Gurobi Optimizer Reference Manual. http://www.gurobi.com
- Hancock et al. (1995) Thomas R. Hancock, Tao Jiang, Ming Li, and John Tromp. 1995. Lower Bounds on Learning Decision Lists and Trees (Extended Abstract). In STACS 95, 12th Annual Symposium on Theoretical Aspects of Computer Science, Munich, Germany, March 2-4, 1995, Proceedings. 527–538. https://doi.org/10.1007/3-540-59042-0_102
- Hu et al. (2020) Qinheping Hu, John Cyphert, Loris D’Antoni, and Thomas W. Reps. 2020. Exact and approximate methods for proving unrealizability of syntax-guided synthesis problems. In Proceedings of the 41st ACM SIGPLAN International Conference on Programming Language Design and Implementation, PLDI 2020, London, UK, June 15-20, 2020. 1128–1142. https://doi.org/10.1145/3385412.3385979
- Huang et al. (2020) Kangjing Huang, Xiaokang Qiu, Peiyuan Shen, and Yanjun Wang. 2020. Reconciling enumerative and deductive program synthesis. In Proceedings of the 41st ACM SIGPLAN International Conference on Programming Language Design and Implementation, PLDI 2020, London, UK, June 15-20, 2020. 1159–1174. https://doi.org/10.1145/3385412.3386027
- Jha et al. (2010) Susmit Jha, Sumit Gulwani, Sanjit A Seshia, and Ashish Tiwari. 2010. Oracle-guided component-based program synthesis. In Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering-Volume 1. ACM, 215–224.
- Jha and Seshia (2017) Susmit Jha and Sanjit A. Seshia. 2017. A theory of formal synthesis via inductive learning. Acta Informatica 54, 7 (2017), 693–726. https://doi.org/10.1007/s00236-017-0294-5
- Ji et al. (2020) Ruyi Ji, Yican Sun, Yingfei Xiong, and Zhenjiang Hu. 2020. Guiding dynamic programing via structural probability for accelerating programming by example. Proc. ACM Program. Lang. 4, OOPSLA (2020), 224:1–224:29. https://doi.org/10.1145/3428292
- Kalyan et al. (2018) Ashwin Kalyan, Abhishek Mohta, Oleksandr Polozov, Dhruv Batra, Prateek Jain, and Sumit Gulwani. 2018. Neural-Guided Deductive Search for Real-Time Program Synthesis from Examples. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. https://openreview.net/forum?id=rywDjg-RW
- Kearns and Li (1988) Michael J. Kearns and Ming Li. 1988. Learning in the Presence of Malicious Errors (Extended Abstract). In Proceedings of the 20th Annual ACM Symposium on Theory of Computing, May 2-4, 1988, Chicago, Illinois, USA. 267–280. https://doi.org/10.1145/62212.62238
- Kearns and Schapire (1994) Michael J. Kearns and Robert E. Schapire. 1994. Efficient Distribution-Free Learning of Probabilistic Concepts. J. Comput. Syst. Sci. 48, 3 (1994), 464–497. https://doi.org/10.1016/S0022-0000(05)80062-5
- Kim et al. (2021) Jinwoo Kim, Qinheping Hu, Loris D’Antoni, and Thomas W. Reps. 2021. Semantics-guided synthesis. Proc. ACM Program. Lang. 5, POPL (2021), 1–32. https://doi.org/10.1145/3434311
- Lau et al. (2003) Tessa A. Lau, Steven A. Wolfman, Pedro M. Domingos, and Daniel S. Weld. 2003. Programming by Demonstration Using Version Space Algebra. Mach. Learn. 53, 1-2 (2003), 111–156. https://doi.org/10.1023/A:1025671410623
- Le et al. (2017) Xuan-Bach D. Le, Duc-Hiep Chu, David Lo, Claire Le Goues, and Willem Visser. 2017. S3: syntax- and semantic-guided repair synthesis via programming by examples. In ESEC/FSE. 593–604. https://doi.org/10.1145/3106237.3106309
- Lee et al. (2018) Woosuk Lee, Kihong Heo, Rajeev Alur, and Mayur Naik. 2018. Accelerating search-based program synthesis using learned probabilistic models. In Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2018, Philadelphia, PA, USA, June 18-22, 2018. 436–449. https://doi.org/10.1145/3192366.3192410
- Liang et al. (2010) Percy Liang, Michael I. Jordan, and Dan Klein. 2010. Learning Programs: A Hierarchical Bayesian Approach. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), June 21-24, 2010, Haifa, Israel. 639–646. https://icml.cc/Conferences/2010/papers/568.pdf
- Mechtaev et al. (2018) Sergey Mechtaev, Alberto Griggio, Alessandro Cimatti, and Abhik Roychoudhury. 2018. Symbolic execution with existential second-order constraints. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM, 389–399.
- Mechtaev et al. (2015a) Sergey Mechtaev, Jooyong Yi, and Abhik Roychoudhury. 2015a. DirectFix: Looking for Simple Program Repairs. In ICSE. 448–458. https://doi.org/10.1109/ICSE.2015.63
- Mechtaev et al. (2015b) Sergey Mechtaev, Jooyong Yi, and Abhik Roychoudhury. 2015b. DirectFix: Looking for Simple Program Repairs. In 37th IEEE/ACM International Conference on Software Engineering, ICSE 2015, Florence, Italy, May 16-24, 2015, Volume 1. 448–458. https://doi.org/10.1109/ICSE.2015.63
- Menon et al. (2013) Aditya Krishna Menon, Omer Tamuz, Sumit Gulwani, Butler W. Lampson, and Adam Kalai. 2013. A Machine Learning Framework for Programming by Example. In Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16-21 June 2013. 187–195. http://proceedings.mlr.press/v28/menon13.html
- Morita et al. (2007) Kazutaka Morita, Akimasa Morihata, Kiminori Matsuzaki, Zhenjiang Hu, and Masato Takeichi. 2007. Automatic inversion generates divide-and-conquer parallel programs. In Proceedings of the ACM SIGPLAN 2007 Conference on Programming Language Design and Implementation, San Diego, California, USA, June 10-13, 2007. 146–155. https://doi.org/10.1145/1250734.1250752
- Moshkovitz (2011) Dana Moshkovitz. 2011. The Projection Games Conjecture and The NP-Hardness of ln n-Approximating Set-Cover. Electron. Colloquium Comput. Complex. 18 (2011), 112. http://eccc.hpi-web.de/report/2011/112
- Natarajan (1993) B. K. Natarajan. 1993. Occam’s Razor for Functions. In Proceedings of the Sixth Annual ACM Conference on Computational Learning Theory, COLT 1993, Santa Cruz, CA, USA, July 26-28, 1993. 370–376. https://doi.org/10.1145/168304.168380
- Padhi and Millstein (2017) Saswat Padhi and Todd D. Millstein. 2017. Data-Driven Loop Invariant Inference with Automatic Feature Synthesis. CoRR abs/1707.02029 (2017). arXiv:1707.02029 http://arxiv.org/abs/1707.02029
- Quinlan (1986) J. Ross Quinlan. 1986. Induction of Decision Trees. Mach. Learn. 1, 1 (1986), 81–106. https://doi.org/10.1023/A:1022643204877
- Raychev et al. (2016) Veselin Raychev, Pavol Bielik, Martin T. Vechev, and Andreas Krause. 2016. Learning programs from noisy data. In Proceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 2016, St. Petersburg, FL, USA, January 20 - 22, 2016. 761–774. https://doi.org/10.1145/2837614.2837671
- Reynolds et al. (2019) Andrew Reynolds, Haniel Barbosa, Andres Nötzli, Clark W. Barrett, and Cesare Tinelli. 2019. cvc4sy: Smart and Fast Term Enumeration for Syntax-Guided Synthesis. In Computer Aided Verification - 31st International Conference, CAV 2019, New York City, NY, USA, July 15-18, 2019, Proceedings, Part II. 74–83. https://doi.org/10.1007/978-3-030-25543-5_5
- Rivest (1987) Ronald L. Rivest. 1987. Learning Decision Lists. Mach. Learn. 2, 3 (1987), 229–246. https://doi.org/10.1007/BF00058680
- Shaw et al. (1975) David E. Shaw, William R. Swartout, and C. Cordell Green. 1975. Inferring LISP Programs From Examples. In Advance Papers of the Fourth International Joint Conference on Artificial Intelligence, Tbilisi, Georgia, USSR, September 3-8, 1975. 260–267. http://ijcai.org/Proceedings/75/Papers/037.pdf
- Singh and Gulwani (2015) Rishabh Singh and Sumit Gulwani. 2015. Predicting a Correct Program in Programming by Example. In Computer Aided Verification - 27th International Conference, CAV 2015, San Francisco, CA, USA, July 18-24, 2015, Proceedings, Part I. 398–414. https://doi.org/10.1007/978-3-319-21690-4_23
- Solar-Lezama et al. (2006) Armando Solar-Lezama, Liviu Tancau, Rastislav Bodík, Sanjit A. Seshia, and Vijay A. Saraswat. 2006. Combinatorial sketching for finite programs. In Proceedings of the 12th International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS 2006, San Jose, CA, USA, October 21-25, 2006. 404–415. https://doi.org/10.1145/1168857.1168907
- Valiant (1984) Leslie G. Valiant. 1984. A Theory of the Learnable. Commun. ACM 27, 11 (1984), 1134–1142. https://doi.org/10.1145/1968.1972
- Zhai et al. (2016) Juan Zhai, Jianjun Huang, Shiqing Ma, Xiangyu Zhang, Lin Tan, Jianhua Zhao, and Feng Qin. 2016. Automatic model generation from documentation for Java API functions. In ICSE. 380–391.
Appendix A Appendix: Occam Learning
In this section, we compare the difference between the original definition of Occam Learning provided by Blumer et al. (1987) and the extended definition used in this paper (Definition 4.2).
Definition A.1 (Original Definition of Occam Learning).
Let be the concept classes containing target concepts and hypotheses respectively. Then, for constants and , a learning algorithm is an -Occam algorithm for using iff, given a set of samples labeled according to a concept , outputs a hypothesis such that:
-
•
is consistent with on , i.e., .
-
•
.
where is the maximum length of any sample , and are the lengths of the binary representations of concept and hypothesis respectively.
Definition A.2 (Definition 4.2).
For constants , PBE solver is an -Occam solver on a family of domains if there exist constants such that for any program domain , for any target program , for any input set , for any error rate :
where size is the length of the binary representation of program , is defined as the PBE task corresponding to target program and inputs .
To adopt the concept Occam Learning to our paper, we firstly replace terms in Definition A.1 with their counterparts in programming by example:
-
•
The classes of concepts and hypotheses both correspond to the program space .
-
•
The learner corresponds to a PBE solver .
-
•
The target concept , samples , the set of labeled samples and the learned hypothesis correspond to the target program , the set of inputs , the PBE task and the synthesized program respectively.
Second, for simplicity, we assume that the range of an input variable is finite and bounded, and thus ignore the cost of expressing samples, i.e., variable in Definition A.1. When the range of an input variable is bounded, a sample can be expressed using bits, where is the number of input variables, and thus can be bounded by . Therefore, at this time, removing from the upper bound would not affect the class of Occam algorithms (solvers), though the concrete values of constants and may be changed.
Third, we extend Definition A.1 to support randomness by introduing error rate . In Definition A.2, a random PBE solver is allowed to returned a program larger than the upper bound, but the probability should be bounded. In Definition A.2, factor is introduced to limit the size of the returned programs concentrate to the original polynomial bound, and thus we could prove a theoretical guarantee on the generalizability of a random Occam solver that is similar with the guarantee for deterministic Occam solvers.
Theorem A.3 (Theorem 4.6).
Let be an -Occam solver on domain . Then there exist constants such that for any , for any distribution over and for any target program :
where represents the error rate of program when the input distribution is and the target program is , i.e., .
Proof.
By Definition A.2, there exists constants such that:
| (2) |
Let be the set of programs sastisfying that the size is no larger than . By Lemma 4.5, we have an upper bound on :
Let be the event where returns a program outside . Then by Equation 2, . Besides, let be the set of program in satisfying . Then:
Therefore, we obtain the following inequality on :
where is a large enough constant and . ∎
Appendix B Appendix: Proofs
In this section, we complete the proofs of the theorems in our paper.
Lemma B.1 (Lemma 4.5).
For any domain , , .
Proof.
Let be the number of grammar rules used to derive program , be the set of available grammar rules, and be the size of . Let be an arbitrary rule in .
Let be the set of all program satisfying . Define function as , where is the leftmost derivation of program p’, and repeats for times. Clearly, is an injection, i.e., .
Therefore, . ∎
Theorem B.2 (Theorem 4.7).
Let be the family of all possible domains. Then is an -Occam solver on , and is not an Occam solver on .
Proof.
We start with . Let be the target program and be the program synthesized by . By the definition of , . Therefore, is an -Occam solver.
For , suppose that all programs in the program space satisfy all given examples, and the target program is the smallest program in the program space. Let be the program synthesized by . Then, by the definition of , follows a uniform distribution on the program space. Therefore, can be arbitrarily larger than , and is not an Occam solver. ∎
Theorem B.3 (Theorem 5.7).
Let be a family of if-closed conditional domains, be an -Occam term solver on , be an -Occam unifier where . Then the STUN solver comprised of and is an -Occam solver.
Proof.
Let be the target program, and be the term set synthesized by . By the definition of an Occam term solver, there exists constants and such that:
We construct the following function that converts a term into the program space of the unifier :
By the definition of , , where is the number of grammar rules, is a large enough constant.
can be extend to the whole program space where is the program replacing all terms used in with . Clearly, is no larger than .
Let be the program synthesized by . As is a valid program for the unifier , by the definition of an Occam unifier, there exists constants and such that:
For any , by taking , we obtain the following inequality:
where is a large enough constant and .
Therefore, the STUN solver comprised of and is an -Occam solver. ∎
Theorem B.4 (Theorem 5.9).
is not an Occam term solver on , and Eusolver is not an Occam solver on , where is the family of all if-closed conditional domains.
Proof.
This theorem is directly from Example 5.8. ∎
Theorem B.5 (Theorem 5.10).
There is no polynomial-time Occam unifier on unless .
Proof.
Suppose there is a polynomial-time Occam unifier . Given a decision tree learning problem with different tests and data labeled with different labels. We construct a conditional program domain where:
-
•
Input space contains different inputs, corresponding to data .
-
•
Term space contains different constants , corresponding to different labels.
-
•
Condition space contains different conditions , where correspond to different tests. If the test result of the th test on data is true, will be defined as true. Otherwise, will be defined as false.
Because , is an if-closed domain.
Let be a PBE task where is the index of the label corresponding to data , and let be the program synthesized by for PBE task and term set . We remove the usages of condition false in by replacing program () with its else-branch . Suppose be the resulting program. Clearly, the size of is no larger than and can be mapped back into a decision tree.
So far, we construct a polynomial-time learning algorithm for decision trees based on . By Theorem 4.6, this construction implies that the class of decision trees is PAC learnable. Combining with the fact that the class of decision trees is not PAC learnable unless (Hancock et al., 1995), we know there is no polynomial-time Occam unifier unless . ∎
Lemma B.6 (Lemma 6.1).
For constants where , term solver is an -Occam solver on if there exist constants such that for any conditional domain , any target program , and any input set :
-
(1)
With a high probability, the size of terms returned by is bounded by .
-
(2)
With a high probability, the number of terms returned by is bounded by .
Proof.
Let be the synthesized term set. For any , with a probability of at least :
Because , with a probability of at least :
where is a large enough constant. Therefore, is a -Occam solver. ∎
Lemma B.7 (Lemma 6.2).
Let be a PBE task, and let be a set of terms that covers all examples in , i.e., . There is always a term such that:
Proof.
Let be the terms in , and be the number of examples covered by term , i.e., . As covers all examples in , must be at least . Therefore, we have . ∎
Theorem B.8 (Theorem 6.3).
is an -Occam solver on is an -Occam term solver on for any , where is defined as .
Proof.
Let be the value of variable (Line 19 in Algorithm 1) when terminates. Let be the target program, be the terms used by , be the term set synthesized by , and be the number of examples, i.e., . By Algorithm 1, the total size of is bounded by :
where is a constant larger than and is a large enough constant.
Let be a large enough constant, be any constant larger than , be any constant larger than . Suppose , , . We denote an invocation Search() valid if the following three random events happens:
-
•
: There is at least one valid sampling round, where a sampling round is valid if covers all sampled examples, and is the target term in that covers the most examples in .
-
•
: , where is the term synthesized in the first valid sampling round.
-
•
: covers at least a half of those examples covered by in , i.e.,
Consider a recursion chain of function Search() with examples , where recurses into by including in the result, i.e., .
-
•
Claim: When all these invocations are valid, is at most .
-
•
Proof: By the definition of , . Then by the definition of , we have . Therefore, .
Because , such a recursion chain is allowed. Therefore, we only need to consider the probability for all invocations to be valid:
-
•
. As is the target term that covers the most examples, the probability for a random example to be in Covered(, T’) is at least . Therefore, the probability for a sampling round to be valid is :
The last two inequalities hold when constant is large enough.
-
•
. As is an -Occam solver, there exists constants such that:
Therefore, with a probability at least , we have:
The last inequality holds when constant is large enough.
-
•
. Let be the input space that contains all inputs in Covered(), and be a uniform distribution on . As is an -Occam solver, by Theorem 4.6, happens with a probability of at least if the following inequality holds:
where is a fixed constant. Clearly, when is large enough, this inequality always holds.
Let be the random event that the th invocation in is valid, and be the random event that all events in are valid. Then:
Therefore, when is larger than , in each iteration, returns with a probability at least . Therefore, for any :
where and are large enough constants. Note that is an arbitrary constant larger than , and are arbitrary constants larger than . Therefore, is an -Occam term solver for any . ∎
Lemma B.9 ( Lemma 7.1).
For any conditional domain and program , there is a program s.t. (1) is semantically equivalent to on , and (2) .
Proof.
Let be the set of terms used in . Without loss of generality, assume the structure of is as the following:
For each if-term in , we define its tree path as a sequence , where represents the if-conditions corresponding to this term from the top down, and represents the if-branches taken by this term ( represent the then-branch and the else-branch respectively). Let be a function mapping a path to a condition, which is defined as the following:
We construct the condition from the original program . Let be the set of paths corresponding to all usages of term . Then we construct the corresponding condition as .
Clearly, is semantically equivalent to on the input space . Besides, are all DNF formulas, and thus . Let be all if-conditions used in , and be the numbers of terms used in the then-branch and the else-branch of respectively. Then, can be calculated in the following way:
-
•
The total size of if-conditions is at most:
where is the number of grammar rules.
-
•
The total size of if-operators is , the total size of if-terms is .
Therefore, we have the following inequality:
where because each if-condition corresponds to an occurrence of itself and an if-then-else operator: Both of them contributes to by at least . ∎
Lemma B.10 (Lemma 7.2).
is an -Occam solver on is an -Occam unifier on for any , where is defined as .
is a deterministic -Occam solver on is a -Occam unifier on .
Proof.
Let be the term set and be the target program. Let be the if-conditions for in the same way as the proof of Lemma 7.1. Specially, if term is not used in , is defined as false. Let . By the construction of , we have (1) , and (2) never overlap, i.e., .
Let be the set of examples that are satisfied by term and are not satisfied by any term in . By Algorithm 3, the set of positive examples provided to synthesize must be a subset of . As may not satisfy all positive examples in , we construct conditions instead:
where are the clauses used in condition , i.e., . Clearly, is still a DNF formula, and satisfies all examples in . Therefore, is always a target condition for the PBE task corresponding to . As in , each clause in condition occurs at most times, each time with a comparison . Therefore, .
Let be the condition synthesized by . Let be any constant in . For simplicity, we abbreviate as . When is an -Occam solver, there exist constants such that:
Therefore, with a probability of at least :
where and are large enough constants, and is a constant larger than . Let be the program synthesized by . Then . Therefore, when is an -Occam solver, must be a unifier for any .
When is a deterministic -Occam solver, there exists constant such that:
At this time, we have the following bound on the total size of conditions .
where is a large enough constant. Therefore, at this time, is a -Occam unifier. ∎
Lemma B.11 (Lemma 7.3).
Given condition space and PBE task , let be the smallest valid clause and be the clause found by . Then .
Proof.
Let be the set of available literals, and be the set of literals satisfying all positive examples in . Then, and must be subsets of .
By Algorithm 3, while applying the greedily algorithm for set covering, we set the cost of a literal as its size. Therefore, by the approximation ratio of this algorithm, we have:
By this inequality, we have:
∎
Corollary B.12 (Corollary 7.4).
For any , is an -Occam solver on all possible clause domains.
Proof.
For any conditional space and PBE task , let be the target clause and be the clause synthesized by . By Lemma 7.3, we have:
where is a large enough constant and is a constant in . Therefore, for any , is an -Occam solver. ∎
Lemma B.13 (Lemma 7.5).
Let be a PBE task and be a DNF formula satisfying all examples in :
-
•
All clauses in must be false on all negative examples in , i.e., .
-
•
There exists a clause in that is true on at least portion of positive examples in , i.e., .
Proof.
By the semantics of operator or, the first condition is obtained directly. Let be the clauses in , and be the number of positive examples covered by each clause, i.e., . By the semantics of opeartor or, we know each positive example must be covered by at least one clause. Therefore:
In this way, the second condition is obtained. ∎
Lemma B.14 (Lemma 7.7).
For any , is a -Occam solver on .
Proof.
Let be the value of variable (Line 10 in Algorithm 4) when terminates. Let be the target DNF formula. When , and the initial value of is also , we make the following claim:
-
•
Claim: In invocation Search(), let be the set of clauses in satisfying . If , there must be a clause such that .
-
•
Proof: Let be the clause in that covers the most positive examples. Clearly, . As , the largest clause in must be in , and thus this clause is found by Get().
Let be the clause simplified from the largest clause in . By Lemma 7.3, .
By this claim, we obtain that in an iteration where , Search() can always find a set of clauses. So, there are at most clauses in the DNF formula synthesized by , and the size of each clause is at most . Therefore, the size of the synthesized DNF formula is , which directly implies that is a -Occam solver for any .
∎
Theorem B.15 (Theorem 7.8).
For any , is a -Occam unifier on .
Theorem B.16 (Theorem 7.9).
is an -Occam solver on with PolyGen is an -Occam solver on for any .